Lecturer: William W.Y. Hsu. Programming Languages
|
|
|
- Corey Thornton
- 6 years ago
- Views:
Transcription
1 Lecturer: William W.Y. Hsu Programming Languages
2 Chapter 2 - Programming Language Syntax
3 3 Scanning The main task of scanning is to identify tokens.
4 4 Pseudo-Code Scanner We skip any initial white spaces We read the next character If it is a / we look at the next character if that is a * we have a comment; we skip forward through the terminating */ otherwise we return a / and reuse the look-ahead If it is one of the one-character tokens ([],;=+- etc.) we return that token...
5 5 Pseudo-Code Scanner We could just turn this into real code and use that as the scanner, and that would be fine for small programs. However, for larger programs that must be correct a more formal approach is more appropriate.
6 6 Lexical Analysis Lexical analyzer: reads input characters and produces a sequence of tokens as output (nexttoken()). Trying to understand each element in a program. Token: a group of characters having a collective meaning. const pi = ; Token 1: (const, -) Token 2: (identifier, pi ) Token 3: (=, -) Token 4: (realnumber, ) Token 5: (;, -)
7 7 Interaction of Lexical Analyzer with Parser Source program Lexical analyzer token Nexttoken() parser symbol table
8 8 Terminology Some terminology: Token: a group of characters having a collective meaning. A lexeme is a particular instant of a token. E.g. token: identifier, lexeme: pi, etc. pattern: the rule describing how a token can be formed. E.g: identifier: ([a-z] [A-Z]) ([a-z] [A-Z] [0-9])* Lexical analyzer does not have to be an individual phase. Having a separate phase simplifies the design and improves the efficiency and portability.
9 9 Lexical Analysis Issues Two issues in lexical analysis. How to specify tokens (patterns)? How to recognize the tokens given a token specification (how to implement the nexttoken() routine)? How to specify tokens: All the basic elements in a language must be tokens so that they can be recognized. main() { int i, j; for (i=0; i<50; I++) { printf( I = %d, i); } } There are not many types of tokens in a typical programming language: constant, identifier, reserved word, operator and misc. symbol.
10 10 Tokens Type of tokens in C++: Constants: char constants: a string constants: I=%d int constants: 50 float point constants: Identifiers: i, j, counter, Reserved words: main, int, for, Operators: +, =, ++, /, Misc symbols: (, ), {, }, Tokens are specified by regular expressions.
11 11 Regular Expressions (RE) A RE consist of: A character (e.g., 0, 1,...) The empty string (i.e., ε ) Two REs next to each other (e.g., unsiged_integer digit ) to denote concatenation. Two REs separated by next to each other (e.g., unsiged_integer digit ) to denote one RE or the other. An RE followed by * (called the Kleene star) to denote zero or more iterations of the RE. Parentheses (in order to avoid ambiguity).
12 12 Regular Expressions (RE) Definitions alphabet : a finite set of symbols. E.g. {a, b, c} A string over an alphabet is a finite sequence of symbols drawn from that alphabet (sometimes a string is also called a sentence or a word). A language is a set of strings over an alphabet. Operation on languages (a set): union of L and M, LL MM = {ss ss in LL or ss in MM} concatenation of L and M, LLMM = {ssss ss in LL and tt in MM} Kleene closure of L, LL = ii=0 LL ii Positive closure of L, LL + = ii=1 LL ii Example: L={aa, bb, cc}, M = {abc}
13 13 Formal Definition of Regular Expressions Given an alphabet Σ εε is a regular expression that denote {εε}, the set that contains the empty string. For each aa Σ, aa is a regular expression denote {aa}, the set containing the string aa. rr and ss are regular expressions denoting the language (set) LL(rr) and LL(ss). Then (rr) (ss) is a regular expression denoting LL(rr) LL(ss) (rr)(ss) is a regular expression denoting LL(rr)LL(ss) rr is a regular expression denoting LL rr Regular expression is defined together with the language it denotes.
14 14 Regular Expressions Numerical literals in Pascal may be generated by the following:
15 15 Regular Expressions A RE is NEVER defined in terms of itself! Thus, REs cannot define recursive statements. The set of tokens that can be recognized by regular expressions is called a regular set.
16 16 Example Let = {aa, bb} aa bb (aa bb)(aa bb) aa aa bb aa aa bb We assume that * has the highest precedence and is left associative. Concatenation has second highest precedence and is left associative and has the lowest precedence and is left associative aa bb cc = aa bb cc
17 17 Regular Definition Gives names to regular expressions to construct more complicate regular expressions. dd 1 rr 1 dd 2 rr 2 dd nn rr nn Example: llllllllllll AA BB CC ZZ aa bb. zz dddddddddd iiiiiiiiiiiiiiiiiiii llllllllllll(llllllllllll dddddddddd) Cannot use recursive definitions dddddddddddd dddddddddd dddddddddddd dddddddddd
18 18 Regular Expression for Tokens in C++ Constants: char constants: any_char string constants: I=%d [^ ]* not quite right. int constants: digit (digit)* float point constants 50.0 digit (digit)*. digit (digit) * Identifiers: letter (letter digit _ ) * Reserved words: m a i n for main Operators: + for +, and + + for ++ Misc symbols: ( for (
19 19 Regular Expression for Tokens in C++ A signed number in C++: e e e E-010 NNNNNN dddddddddd dddddddddd NNNNNNNNNNNN (+ εε) (NNNNNN NNNNNN. NNNNNN) (εε (ee EE)(+ εε)nnnnnn )
20 20 Two Issues in Lexical Analysis Specifying tokens (regular expression). Identifying tokens specified by regular expression. How do we do this?
21 21 How to Recognize Tokens Specified by Regular Expressions? A recognizer for a language is a program that takes a string xx as input and answers yes if xx is a sentence of the language and no otherwise. In the context of lexical analysis, given a string and a regular expression, a recognizer of the language specified by the regular expression answer yes if the string is in the language. How to recognize regular expression int? i n t error All other characters
22 22 How to Recognize Tokens Specified by Regular Expressions? How to recognize regular expression int for? i n t f o r A regular expression can be compiled into a recognizer (automatically) by constructing a finite automata which can be deterministic or non-deterministic.

23 23 Deterministic finite automaton (DFA) Every regular set can be defined by using deterministic finite automaton (DFA). DFAs are turning machines that have a finite number of states and deterministically move between states. For example, the DFA for 0*10*1(0 1)* is S: Start state End state (Double Circle) Intermediate state
24 24 Constructing DFAs A DFA can be constructed from a RE via two steps. 1. Construct a nondeterministic finite automaton (NFA) from the RE. 2. Construct a DFA from the NFA. 3. Minimize the DFA
.")
25 25 What is an NFA? An NFA is similar to a DFA, except that state transitions are nondeterministic. This nondeterminism is encapsulated via the epsilon transition (written as ε). The ε transitions imply that either transition can be taken with any (or no) input. This stands for: 0 1
26 26 Non-deterministic Finite Automata (NFA) A non-deterministic finite automata (NFA) is a mathematical model that consists of: a 5-tuple (QQ, Σ, δδ, qq 0, FF) a set of states QQ a set of input symbols Σ a transition δδ function that maps state-symbol pairs to sets of states. A state qq 0 that is distinguished as the start (initial) state A set of states FF distinguished as accepting (final) states. An NFA accepts an input string xx if and only if there is some path in the transition graph from the start state to some accepting state (after consuming xx).
27 27 Finite State Machines = Regular Expression Recognizers relop < <= <> > >= = start < id letter ( letter digit ) * = > 5 6 = > other 3 4 * return(relop, LE) return(relop, NE) return(relop, LT) return(relop, EQ) = 7 return(relop, GE) other 8 * return(relop, GT) letter or digit start 9 letter other 10 11* return(gettoken(), install_id())
28 28 Non-deterministic Finite Automata (NFA) An NFA is non-deterministic in that (1) same character can label two or more transitions out of one state (2) empty string can label transitions. For example, here is an NFA that recognizes the language? a a b b b An NFA can easily implemented using a transition table, which can be used in the language recognizer. State a b 0 {0, 1} {0} 1 - {2} 2 - {3}

29 29 The Four RE Rules and NFA Rule 1--Base case: a S a

30 30 The Four RE Rules and NFA Rule 2--Concatenation: AB S a S b S a b

31 31 The Four RE Rules and NFA Rule 3--Alternation: a b S a S b S ϵ ϵ a b ϵ ϵ
32 32 The Four RE Rules and NFA Rule 4--Kleene Closure: a* ϵ S ϵ a ϵ ϵ
33 33 Constructing a DFA From an NFA Construct the DFA by collapsing the states of an NFA. Three steps 1. Identify set of states that can be reached from the start state via epsilon-transitions and make this one state. 2. For a given DFA state (which is a set of NFA states) consider each possible input and combine the resulting NFA states into one DFA state. 3. Repeat Step 2 until all states have been added.


34 34 An Example: 0 (1*) 00*
35 35 Minimize via Partitioning First, partition states into final and non-final. Second, determine the effect of the state transition based on what partition the transition goes to. Third, create new partition for those states that have different transitions. Fourth, repeat.
36 36 Minimize via Partitioning

37 37 Minimize via Partitioning
38 38 Another Example of Minimization Consider the following DFA. Accepting states are red. Non-accepting states are blue. Are any states really the same?
39 39 Another Example S 2 and S 7 are really the same: Both Final states Both go to S 6 under input b. Both go to S 3 under an a. S 0 and S 5 really the same. Why? We say each pair is equivalent. Are there any other equivalent states? We can merge equivalent states into 1 state.
40 40 Partitioning Algorithm First step: Divide the set of states into final and non-final states. a b S 0 S 1 S 4 S 1 S 5 S 2 S 3 S 3 S 3 S 4 S 1 S 4 S 5 S 1 S 4 S 6 S 3 S 7 S 2 S 3 S 6 S 7 S 3 S 6
41 41 Partitioning Algorithm Next step: See if states in each partition each go to the same partition. S 1 & S 6 are different from the rest of the states in Partition I (but like each other). We will move them to a new partition. a b S 0 S 1 (I) S 4 (I) S 1 S 5 (I) S 2 (II) S 3 S 3 (I) S 3 (I) S 4 S 1 (I) S 4 (I) S 5 S 1 (I) S 4 (I) S 6 S 3 (I) S 7 (II) S 2 S 3 (I) S 6 (I) S 7 S 3 (I) S 6 (I)
42 42 Partitioning Algorithm New partitions are created. States are updated to match their new partition. a b S 0 S 1 (III) S 4 (I) S 3 S 3 (I) S 3 (I) S 4 S 1 (III) S 4 (I) S 5 S 1 (III) S 4 (I) S 1 S 5 (I) S 2 (II) S 6 S 3 (I) S 7 (II) S 2 S 3 (I) S 6 (III) S 7 S 3 (I) S 6 (III)
43 43 Partitioning Algorithm Repeat the process. See if states in each partition each go to the same partition. In Partition I, S 3 goes to a different partition from S 0, S 5 and S 4. Move S 3 to its own partition. States S 2, S 6, and S 7 changes respectively. a b S 0 S 1 (III) S 4 (I) S 4 S 1 (III) S 4 (I) S 5 S 1 (III) S 4 (I) S 3 S 3 (IV) S 3 (IV) S 1 S 5 (I) S 2 (II) S 6 S 3 (IV) S 7 (II) S 2 S 3 (IV) S 6 (III) S 7 S 3 (IV) S 6 (III)
44 44 Partitioning Algorithm Now S 6 goes to a different partition on an a from S 1. S 6 gets its own partition. We now have 5 partitions. Note changes in S 2 and S 7. All states within each of the 5 partitions are identical. We can call the states I, II III, IV and V. a b S 0 S 1 (III) S 4 (I) S 4 S 1 (III) S 4 (I) S 5 S 1 (III) S 4 (I) S 3 S 3 (IV) S 3 (IV) S 1 S 5 (I) S 2 (II) S 6 S 3 (IV) S 7 (II) S 2 S 3 (IV) S 6 (V) S 7 S 3 (IV) S 6 (V)
45 45 Partitioning Algorithm a b I III I II IV V III I II IV IV IV V IV II
46 46 Scanning Recall scanner is responsible for Tokenizing source. Removing comments. Dealing with pragmas (i.e., significant comments). Saving text of identifiers, numbers, strings. Saving source locations (file, line, column) for error messages.
47 #pragma GCC ivdep #pragma GCC ivdep 47 Pragmas Pragmas are comments that provide direction for the compiler. #pragma omp parallel for #pragma GCC ivdep For example, Variable x is used a lot, keep it in memory if possible. These are handled by the parser since this makes the grammar much simpler.
48 48 Scanning Suppose we are building an ad-hoc (hand-written) scanner for Pascal: We read the characters one at a time with look-ahead. If it is one of the one-character tokens { ( ) [ ] < >, ; = + - etc } we announce that token. If it is a., we look at the next character. If that is a dot, we announce. Otherwise, we announce. and reuse the look-ahead.
49 49 Scanning If it is a <, we look at the next character.. If that is a = we announce <=. Otherwise, we announce < and reuse the look-ahead, etc. If it is a letter, we keep reading letters and digits and maybe underscores until we can't anymore. Then we check to see if it is a reserve word. If it is a digit, we keep reading until we find a non-digit. If that is not a. we announce an integer. Otherwise, we keep looking for a real number. If the character after the. is not a digit we announce an integer and reuse the. and the look-ahead.
50 50 Scanning Pictorial representation of a scanner for calculator tokens, in the form of a finite automaton
51 51 Scanning This is a deterministic finite automaton (DFA) Lex, scangen, etc. build these things automatically from a set of regular expressions. Specifically, they construct a machine that accepts the language identifier int const real const comment symbol...
52 52 Scanning We run the machine over and over to get one token after another. Nearly universal rule: Always take the longest possible token from the input thus foobar is foobar and never f or foo or foob more to the point, is a real const and never 3,., and Regular expressions "generate" a regular language; DFAs "recognize" it.
53 53 Scanning Scanners tend to be built three ways: Ad-hoc. Semi-mechanical pure DFA. (usually realized as nested case statements) Table-driven DFA. Ad-hoc generally yields the fastest, most compact code by doing lots of special-purpose things, though good automatically-generated scanners come very close.
54 54 Scanning Writing a pure DFA as a set of nested case statements is a surprisingly useful programming technique. Though it's often easier to use perl, awk, sed. For details see Figure Table-driven DFA is what lex and scangen produce lex (flex) in the form of C code. Scangen in the form of numeric tables and a separate driver. (for details see Figure 2.12)
55 55 Scanning Note that the rule about longest-possible tokens means you return only when the next character can't be used to continue the current token. The next character will generally need to be saved for the next token. In some cases, you may need to peek at more than one character of look-ahead in order to know whether to proceed. In Pascal, for example, when you have a 3 and you a see a dot: Do you proceed (in hopes of getting 3.14, a real number)? or Do you stop (in fear of getting 3..5, an array range)? It is possible to maintain a DFA for keywords, but the number of states would be even larger! So, they are handled as exceptions to the rule.
56 56 Scanning In messier cases, you may not be able to get by with any fixed amount of look-ahead. In Fortran, for example, we have DO 5 I = 1,25 loop DO 5 I = 1.25 assignment Here, we need to remember we were in a potentially final state, and save enough information that we can back up to it, if we get stuck later.
57 57 Parsing The main task of parsing is to identify the syntax.
58 58 Context-Free Grammars Context-Free Grammars (CFGs) are similar to REs except that they can handle recursion. expr id number - expr ( expr ) expr op expr op + - * / Each rule is called a production. One of the nonterminals, usually the first one, is called the start symbol, and it defines the construct defined by the grammar. Non-terminals are symbols that are defined by the CFG and can appear on both the left and right side of.
59 59 Backus-Naur Form The notation for context-free grammars (CFG) is sometimes called Backus-Naur Form (BNF) A CFG consists of A set of terminals T. A set of non-terminals N. A start symbol S (a non-terminal). A set of productions.
60 60 Extended Backus-Naur Form Extended BNF includes the Kleene star, parentheses, and the Kleene Plus (+), which stands for one or more iterations. id_list id (, id )* id_list id id_list id_list, id
61 61 Derivation A derivation is a series of replacement operations that derive a string of terminals from the start symbol. Derivation of slope * x + intercept expr expr op expr expr op id expr + id expr op expr + id expr op id + id expr * id + id id * id + id (slope) * (x) + (intercept) denotes derived from. This derivation replaces the rightmost nonterminal. Derivations with this behavior are called (rightmost or canonical derivation.
 + intercept This is a rightmost")
62 62 Parse Tree A parse tree is the graphical representation of the derivation. This parse tree constructs the formula: (slope*x) + intercept This is a rightmost derivation.
 which is not equal to slope*x + intercept This is a")
63 63 Parse Tree (Ambiguous) This grammar, is ambiguous and can construct the following parse tree. This parse tree constructs the formula slope*(x+intercept) which is not equal to slope*x + intercept This is a leftmost derivation.
64 64 Disambiguating Grammar The problem with our original grammar was that we did not fully express the grammatical structure (i.e., associativity and precedence). To create an unambiguous grammar, we need to fully specify the grammar. expr term expr add_op term term factor term mult_op factor factor id number - factor ( expr ) add_op + - mult_op * /
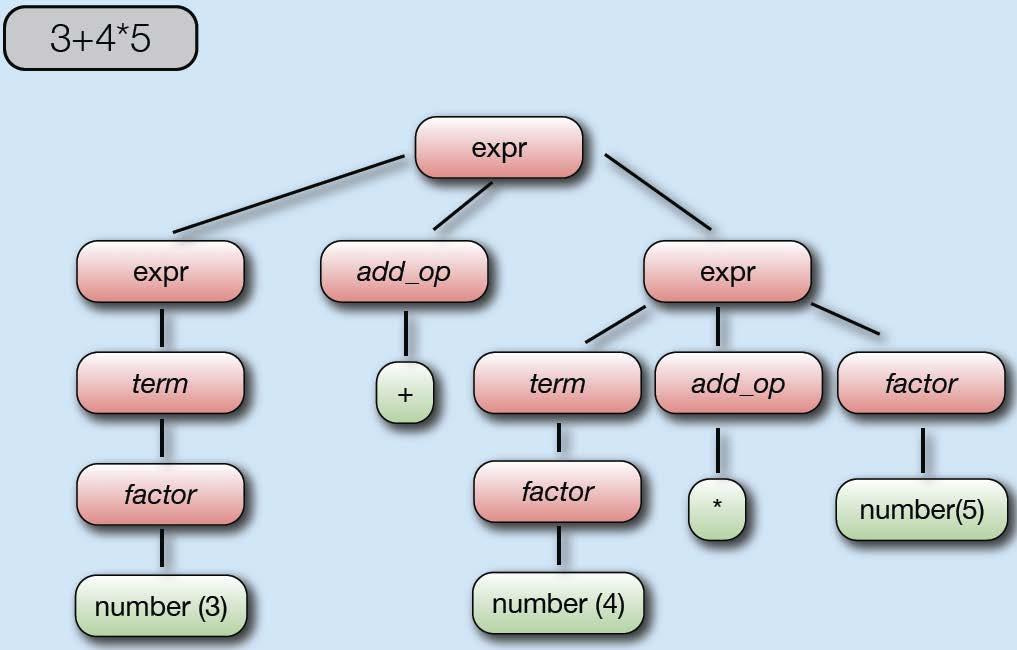
65 65
66 66


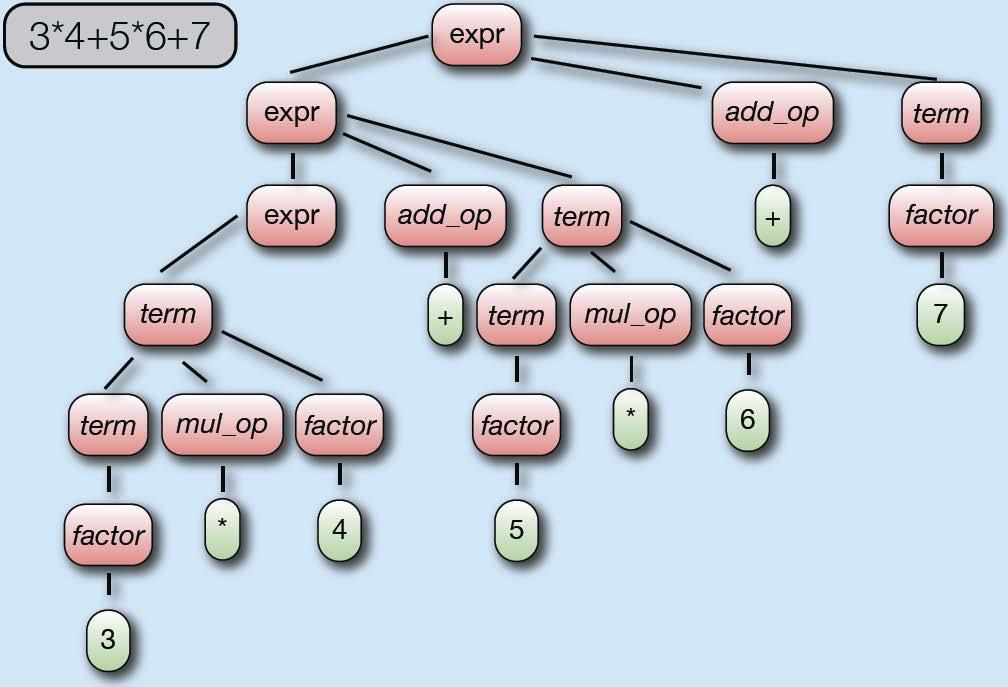
67 67 Compare 3+4 and 3*4
68 68 Compare 3+4 and 3*4 How can you derive these trees by examining one character at a time? In order to derive these trees, the first character that we need to examine is the math symbol. To parse these sentences, we need to search through them to find the math symbols. Then we need to sort out the multiplication from the addition.
69 69 Parsing By analogy to RE and DFAs, a context-free grammar (CFG) is a generator for a context-free language (CFL). A parser is a language recognizer. There is an infinite number of grammars for every context-free language. Not all grammars are created equal.
70 70 Parsing It turns out that for any CFG we can create a parser that runs in O(n^3) time. There are two well-known parsing algorithms that permit this Early's algorithm Cooke-Younger-Kasami (CYK) algorithm O(n^3) time is clearly unacceptable for a parser in a compiler - too slow.
71 71 Parsing There are two types of grammars that can be parsed in linear time, i.e., O(n). LL: Left-to-right, Left-most derivation LR: Left-to-right, Right-most derivation LL parsers are also called 'top-down', or 'predictive' parsers & LR parsers are also called 'bottom-up', or 'shift-reduce' parsers. There are several important sub-classes of LR parsers SLR LALR We won't be going into detail on the differences between them.
72 72 Parsing Every LL(1) grammar is also LR(1), though right recursion in production tends to require very deep stacks and complicates semantic analysis. Every CFL that can be parsed deterministically has an SLR(1) grammar (which is LR(1)). Every deterministic CFL with the prefix property (no valid string is a prefix of another valid string) has an LR(0) grammar.
73 73 Top-down LL parsers are top-down, i.e., they identify the nonterminals first and terminals second. LL grammars are grammars that can be parsed by an LL parser. Suppose for the following grammar: id_list id id_list_tail id_list_tail,id id_list_tail id_list_tail ; We want to parse: A, B, C;


74 74 Top-down LL parsers are predictive because they predict the next state. After id(a) is discovered, the next state is predicted as id_list_tail. Notice that token are placed in the tree from the leftmost to rightmost.
75 75 Bottom-up LR parsers are bottom-up, i.e., they discover they terminals first and non-terminals second. LR grammars are grammars that can be parsed by an LR parser. All LL grammars are LR grammars but not vice versa. Suppose for the following grammar: id_list id id_list_tail id_list_tail,id id_list_tail id_list_tail ; We want to parse: A, B, C;

76 76 Bottom-up

77 77 Bottom-up LR parsers are called shift parsers because they shift the states. Notice that tokens are added to the tree from the rightmost to the left-most.
78 78 Bottom-up Some times you LL and LR parsers written as LL(n) and LR(n) to denote the parser needs to look ahead n tokens. The problem with this grammar is that it can require an arbitrarily large number of terminals to be shifted before placing them into the tree.
79 79 A Better Bottom-up Grammar This grammar limits the number of suspended non-terminals. id_list id_list_prefix ; id_list_prefix id_list_prefix, id id_list_prefix id However, it cannot be parsed by LL (top-down) parser. Since when the parser discovers an id it does not know the number of id_list_prefixs.


80 80 A Better Bottom-up Grammar Both of these are valid break downs, but we don t know which one. Therefore, is NOT a valid LL grammar, but it is a valid LR grammar.
81 81 LL(1) Grammar program stmt_list $$ stmt_list stmt stmt_list ε stmt id:= expr read id read expr expr term term_tail term_tail add_op term term_tail ε term factor factor_tail factor_tail mult_op factor factor_tail ε factor (expr) id literal add_op + - mult_op * /
82 82 LL(1) Grammar This grammar (for the calculator) unlike the previous calculator grammar is an LL grammar, because when an id is encountered we know exactly where it belongs. Like the bottom-up grammar, this one captures associativity and precedence, but most people don't find it as pretty For one thing, the operands of a given operator aren't in a RHS together! The simplicity of the parsing algorithm makes up for this weakness. How do we parse a string with this grammar? Build the parse tree incrementally. Try parsing c := 2*A+B
83 83 LL Parsing Example (average program) read A read B sum := A + B write sum write sum / 2 We start at the top and predict needed productions on the basis of the current left-most non-terminal in the tree and the current input token.
84 84 LL Parsing Parse tree for the average program (Figure 2.17)
85 85 LL Parsing Table-driven LL parsing: you have a big loop in which you repeatedly look up an action in a two-dimensional table based on current leftmost non-terminal and current input token. The actions are: 1. Match a terminal. 2. Predict a production. 3. Announce a syntax error.
86 86 LL Parsing LL(1) parse table for parsing for calculator language
87 87 LL Parsing initial stack program read A read.. predict (1) stmt_list $$ read A read.. predict (2) stmt stmt_list $$ read A read.. predict (5) read id stmt_list $$ read A read.. match read id stmt_list $$ A read B sum.. match id stmt_list $$ read B sum :=.. predict (2) stmt stmt_list $$ read B sum :=.. predict (5) read id stmt_list $$ read B sum :=.. match read id stmt_list $$ B sum := A + B.. match id stmt_list $$ sum := A + B.. predict (2) stmt stmt_list $$ sum := A + B.. predict (4) id := expr stmt_list $$ sum := A + B.. match id := expr stmt_list $$ := A + B write.. match := expr stmt_list $$ A + B write.. predict (7) term term stmt_list $$ A + B write.. predict (10) factor factor term stmt_list $$ A + B write.. predict (14) id factor term stmt_list $$ A + B write.. match id factor term stmt_list $$ + B write sum.. predict (12) term stmt_list $$ + B write sum.. predict (8) addop term term stmt_list $$ + B write sum..
88 88 LL Parsing To keep track of the left-most non-terminal, you push the asyet-unseen portions of productions onto a stack. For details see Figure 2.20 The key thing to keep in mind is that the stack contains all the stuff you expect to see between now and the end of the program. What you predict you will see.
89 89 LL Parsing Problems trying to make a grammar LL(1) Left recursion Example: id_list id id_list, id equivalently id_list id id_list_tail id_list_tail, id id_list_tail ε We can get rid of all left recursion mechanically in any grammar.
90 LL Parsing Problems trying to make a grammar LL(1) Common prefixes: another thing that LL parsers can't handle Solved by "left-factoring Example: stmt id := expr id ( arg_list ) equivalently stmt id id_stmt_tail id_stmt_tail := expr ( arg_list) We can eliminate left-factor mechanically.
91 LL Parsing Note that eliminating left recursion and common prefixes does NOT make a grammar LL. There are infinitely many non-ll LANGUAGES, and the mechanical transformations work on them just fine. The few that arise in practice, however, can generally be handled with kludges.
92 LL Parsing Problems trying to make a grammar LL(1) The"dangling else" problem prevents grammars from being LL(1) (or in fact LL(k) for any k). The following natural grammar fragment is ambiguous (Pascal): stmt if cond then_clause else_clause other_stuff then_clause then stmt else_clause else stmt epsilon
93 LL Parsing The less natural grammar fragment can be parsed bottom-up but not top-down: stmt balanced_stmt unbalanced_stmt balanced_stmt if cond then balanced_stmt else balanced_stmt other_stuff unbalanced_stmt if cond then stmt if cond then balanced_stmt else unbalanced_stmt
94 LL Parsing The usual approach, whether top-down OR bottom-up, is to use the ambiguous grammar together with a disambiguating rule that says: else goes with the closest then or More generally, the first of two possible productions is the one to predict (or reduce).
95 LL Parsing Better yet, languages (since Pascal) generally employ explicit end-markers, which eliminate this problem. In Modula-2, for example, one says: if A = B then if C = D then E := F end else G := H end Ada says 'end if'; other languages say 'fi.
96 LL Parsing One problem with end markers is that they tend to bunch up. In Pascal you say: if A = B then else if A = C then else if A = D then else if A = E then else...; With end markers this becomes: if A = B then else if A = C then else if A = D then else if A = E then else...; end; end; end; end;
97 97 Recursive Descent & LL Parse Table There are two ways to build an LL parse table: Recursive Descent, which is a recursive program with case statements that correspond to each one-to-one to nonterminals. LL Parse Table, which consist of an iterative driver program and a table that contains all of the nonterminals.
98 98 LL(1) Grammar Revisited program stmt_list $$ stmt_list stmt stmt_list ε stmt id:= expr read id read expr expr term term_tail term_tail add_op term term_tail ε term factor factor_tail factor_tail mult_op factor factor_tail ε factor (expr) id literal add_op + - mult_op * /
99 99 Recursive Descent procedure program() case in_tok of id, read, write, $$: stmt_list() match($$) else return error procedure stmt_list() case in_tok of id, read, write: stmt(); stmt_list(); $$: skip else return error procedure stmt() case in_tok of id: match(id); match(:=); expr() read: match(read); match(id) write: match(write); expr() else return error procedure match(expec) if in_tok = expec consume in_tok else return error
100 100 Recursive Descent in_tok is a global variable that is the current token. consume changes in_tok to the next token. The question is how do we label the case statements?
101 101 First, Follow, and Predict Three functions allow us to label the branches FIRST(a): The terminals (and ε) that can be the first tokens of the non-terminal symbol a. FOLLOW(A): The terminals that can follow the terminal or nonterminal symbol A. PREDICT(A a): The terminals that can be the first tokens as a result of the production A a.
102 102 LL Parsing The algorithm to build predict sets is tedious (for a "real" sized grammar), but relatively simple: It consists of three stages: (1) compute FIRST sets for symbols (2) compute FOLLOW sets for non-terminals (this requires computing FIRST sets for some strings) (3) compute predict sets or table for all productions
103 103 First Set Rules 1. If X is a terminal then First(X) is just X! 2. If there is a Production X ε then add ε to first(x). 3. If there is a Production X Y1Y2..Yk then add first(y1y2..yk) to first(x). 4. First(Y1Y2..Yk) is either: 1. First(Y1) (if First(Y1) doesn't contain ε) 2. OR (if First(Y1) does contain ε) then First (Y1Y2..Yk) is everything in First(Y1) <except for ε > as well as everything in First(Y2..Yk) 3. If First(Y1) First(Y2)..First(Yk) all contain ε then add ε to First(Y1Y2..Yk) as well.
104 104 An Example Grammar E TE E +TE ε T FT T *FT ε F (E) F id Non-Terminals E E T T F First set
105 105 An Example Grammar E TE E +TE E ε T FT T *FT T ε F (E) F id Non-Terminals First set E E ε T T ε F Applying Rule 2.
106 106 An Example Grammar E TE E +TE T FT T *FT Non-Terminals First set E E ε, + T T ε, * F F (E) F id Applying Rule 3.
107 107 An Example Grammar E TE T FT Non-Terminals First set E E ε, + T T ε, * F id, ( F (E) F id Applying Rule 3.
108 108 An Example Grammar E TE T FT Non-Terminals First set E E ε, + T id, ( T ε, * F id, ( Applying Rule 3.
109 109 An Example Grammar E TE Applying Rule 3, nothing more changes and we are done! Non-Terminals First set E id, ( E ε, + T id, ( T ε, * F id, ( + + ε ε * * ( ( ) ) id id
110 110 Follow Set Rules 1. First put $ (the end of input marker) in Follow(S) (S is the start symbol). 2. If there is a production A abb, (where a can be a whole string) then everything in FIRST(b) except for ε is placed in FOLLOW(B). 3. If there is a production A ab, then everything in FOLLOW(A) is in FOLLOW(B). 4. If there is a production A abb, where FIRST(b) contains ε, then everything in FOLLOW(A) is in FOLLOW(B).
111 111 An Example Grammar E TE E +TE ε T FT T *FT ε F (E) F id Non-Terminals Follow set E $ E T T F The first thing we do is Add $ to the start Symbol 'E'.
112 112 An Example Grammar E TE E +TE E ε T FT T *FT T ε F (E) F id Non-Terminals Follow set E $ E T + T F Apply rule 2 to E' +TE. This says that everything in First(E ) except for ε should be in Follow(T).
113 113 An Example Grammar E TE E +TE E ε T FT T *FT T ε F (E) F id Non-Terminals Follow set E $ E $ T + T F Apply rule 3 to E TE. This says that we should add everything in Follow(E) into Follow(E ).
114 114 An Example Grammar E TE E +TE E ε T FT T *FT T ε F (E) F id Non-Terminals Follow set E $ E $ T + T + F Apply rule 3 to T FT. This says that we should add everything in Follow(T) into Follow(T ).
115 115 An Example Grammar E TE E +TE E ε T FT T *FT T ε F (E) F id Non-Terminals Follow set E $ E $ T + T + F * Apply rule 2 to T *FT. This says that everything in First(T ) except for ε should be in Follow(F).
116 116 An Example Grammar E TE E +TE E ε T FT T *FT T ε F (E) F id Non-Terminals Follow set E $, ) E $ T + T + F * Apply rule 2 to F (E). This says that everything in First(')') should be in Follow(E).
117 117 An Example Grammar E TE E +TE E ε T FT T *FT T ε F (E) F id Non-Terminals Follow set E $, ) E $, ) T + T + F * Apply rule 3 to E TE. This says that we should add everything in Follow(E) into Follow(E ).
118 Apply rule 4 to E +TE. This says that we should add everything in Follow(E ) into Follow(T) (because First(E ) contains ε. 118 An Example Grammar E TE E +TE E ε T FT T *FT T ε F (E) F id Non-Terminals E $, ) E $, ) Follow set T +, $, ) T + F *
119 119 An Example Grammar E TE E +TE E ε T FT T *FT T ε F (E) F id Non-Terminals Follow set E $, ) E $, ) T +, $, ) T +, $, ) F * Apply rule 3 to T FT. This says that we should add everything in Follow(T) into Follow(T ).
120 120 An Example Grammar E TE E +TE E ε T FT T *FT T ε F (E) F id Non-Terminals Follow set E $, ) E $, ) T +, $, ) T +, $, ) F *, +, $, ) Apply rule 4 to T *FT. This says that we should add everything in Follow(T') into Follow(F).
121 Predict (A X 1... X m ) == (FIRST (X 1... X m ) - {ε}) (if X 1,..., X m * ε then FOLLOW (A) ELSE NULL) 121 Predict Set E TE E +TE E ε T FT T *FT T ε F (E) F id Expression E TE E +TE + Predict set (, id E ε $, ) T FT T *FT * (, id T ε +, $, ) F (E) ( F id id
122 122 LL Parsing program stmt_list $$ stmt_list stmt stmt_list ε stmt id:= expr read id read expr expr term term_tail term_tail add_op term term_tail ε term factor factor_tail factor_tail mult_op factor factor_tail ε factor (expr) id literal add_op + - mult_op * / FIRST(program) = {id, read, write, $$} FOLLOW(program) = {ε} PREDICT(program stmt_list $$) = {id, read, write, $$} FOLLOW(id) = {+,*,/,),:=,id,read, write,$$} FIRST(factor_tail) = { *, /, ε} FOLLOW(factor_tail) ={+,-,),id,read,write,$$} PREDICT(factor_tail m_op factor factor_tail) = {*,/} PREDICT(factor_tail ε) = {+,-,),id,read, write, $$}

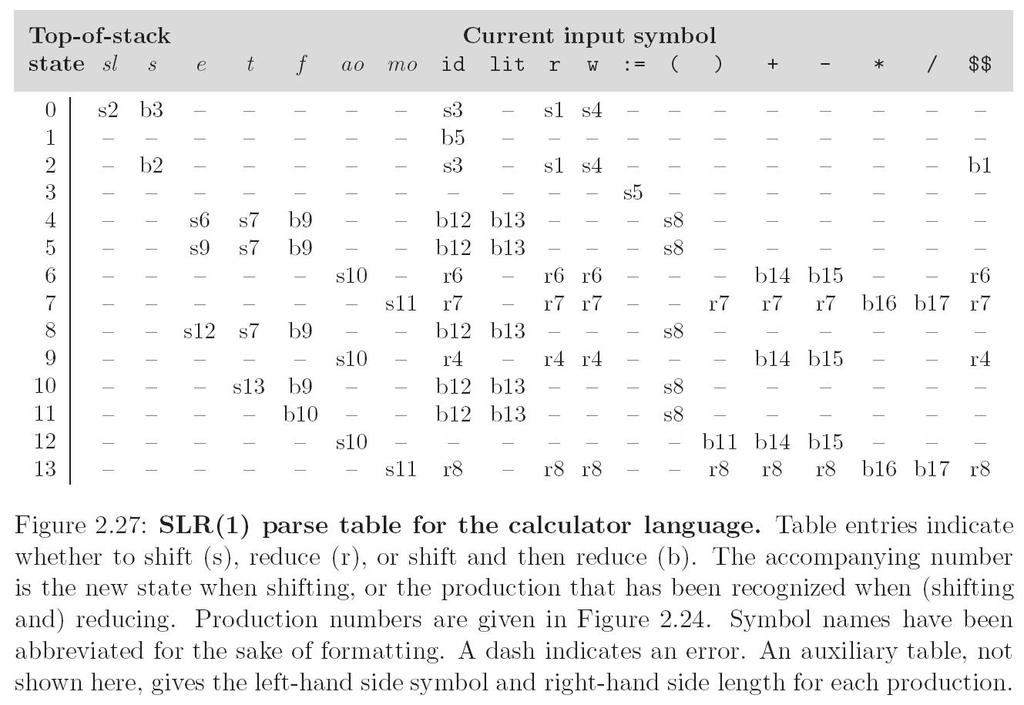
123 123 LL Parsing LL(1) parse table for parsing for calculator language
124 124 LL Parsing It is conventional in general discussions of grammars to use: Lower case letters near the beginning of the alphabet for terminals. Lower case letters near the end of the alphabet for strings of terminals. Upper case letters near the beginning of the alphabet for non-terminals. Upper case letters near the end of the alphabet for arbitrary symbols. Greek letters for arbitrary strings of symbols.
125 125 LL Parsing Algorithm First/Follow/Predict: FIRST(α) == {a : α * a β} (if α =>* ε THEN {ε} ELSE NULL) FOLLOW(A) == {a : S + α A a β} (if S * α A THEN {ε} ELSE NULL) Predict (A X 1... X m ) == (FIRST (X 1... X m ) - {ε}) (if X 1,..., X m * ε then FOLLOW (A) ELSE NULL) A good demonstration site:
126 LL Parsing 126
127 127
128 128 LL Parsing If any token belongs to the predict set of more than one production with the same LHS, then the grammar is not LL(1). A conflict can arise because: The same token can begin more than one RHS. It can begin one RHS and can also appear after the LHS in some valid program, and one possible RHS is ε..
129 129 LR Parsing LR parsers are almost always table-driven: Like a table-driven LL parser, an LR parser uses a big loop in which it repeatedly inspects a two-dimensional table to find out what action to take. Unlike the LL parser, however, the LR driver has non-trivial state (like a DFA), and the table is indexed by current input token and current state. The stack contains a record of what has been seen SO FAR (NOT what is expected).
130 130 LR Parsing A scanner is a DFA. It can be specified with a state diagram. An LL or LR parser is a PDA, Early's & CYK algorithms do NOT use PDAs. A PDA can be specified with a state diagram and a stack The state diagram looks just like a DFA state diagram, except the arcs are labeled with <input symbol, top-of-stack symbol> pairs, and in addition to moving to a new state the PDA has the option of pushing or popping a finite number of symbols onto/off the stack.
131 131 LR Parsing An LL(1) PDA has only one state! Actually two; it needs a second one to accept with, but that's all (it's pretty simple). All the arcs are self loops; the only difference between them is the choice of whether to push or pop. The final state is reached by a transition that sees EOF on the input and the stack.
132 132 LR Parsing An SLR/LALR/LR PDA has multiple states it is a "recognizer," not a "predictor" it builds a parse tree from the bottom up the states keep track of which productions we might be in the middle The parsing of the Characteristic Finite State Machine (CFSM) is based on Shift Reduce
133 133 LR Parsing To illustrate LR parsing, consider the grammar (Figure 2.24, Page 73): program stmt list $$$ stmt_list stmt_list stmt stmt stmt id := expr read id write expr expr term expr add op term term factor term mult_op factor factor ( expr ) id number add_op + - mult_op * / term factor term mult_op factor factor ( expr ) id number add op + - mult op * /
134 134 LR Parsing This grammar is SLR(1), a particularly nice class of bottomup grammar: It isn't exactly what we saw originally. We've eliminated the epsilon production to simplify the presentation. For details on the table driven SLR(1) parsing please note the following slides.
135 LR Parsing 135
136 136
137 137
138 138 LR Parsing SLR parsing is based on: Shift Reduce Shift & Reduce (for optimization).
Syntax. Syntax. We will study three levels of syntax Lexical Defines the rules for tokens: literals, identifiers, etc.
 Syntax Syntax Syntax defines what is grammatically valid in a programming language Set of grammatical rules E.g. in English, a sentence cannot begin with a period Must be formal and exact or there will
Syntax Syntax Syntax defines what is grammatically valid in a programming language Set of grammatical rules E.g. in English, a sentence cannot begin with a period Must be formal and exact or there will
Chapter 2 :: Programming Language Syntax
 Chapter 2 :: Programming Language Syntax Michael L. Scott kkman@sangji.ac.kr, 2015 1 Regular Expressions A regular expression is one of the following: A character The empty string, denoted by Two regular
Chapter 2 :: Programming Language Syntax Michael L. Scott kkman@sangji.ac.kr, 2015 1 Regular Expressions A regular expression is one of the following: A character The empty string, denoted by Two regular
programming languages need to be precise a regular expression is one of the following: tokens are the building blocks of programs
 Chapter 2 :: Programming Language Syntax Programming Language Pragmatics Michael L. Scott Introduction programming languages need to be precise natural languages less so both form (syntax) and meaning
Chapter 2 :: Programming Language Syntax Programming Language Pragmatics Michael L. Scott Introduction programming languages need to be precise natural languages less so both form (syntax) and meaning
COP4020 Programming Languages. Syntax Prof. Robert van Engelen
 COP4020 Programming Languages Syntax Prof. Robert van Engelen Overview Tokens and regular expressions Syntax and context-free grammars Grammar derivations More about parse trees Top-down and bottom-up
COP4020 Programming Languages Syntax Prof. Robert van Engelen Overview Tokens and regular expressions Syntax and context-free grammars Grammar derivations More about parse trees Top-down and bottom-up
COP4020 Programming Languages. Syntax Prof. Robert van Engelen
 COP4020 Programming Languages Syntax Prof. Robert van Engelen Overview n Tokens and regular expressions n Syntax and context-free grammars n Grammar derivations n More about parse trees n Top-down and
COP4020 Programming Languages Syntax Prof. Robert van Engelen Overview n Tokens and regular expressions n Syntax and context-free grammars n Grammar derivations n More about parse trees n Top-down and
Chapter 2 - Programming Language Syntax. September 20, 2017
 Chapter 2 - Programming Language Syntax September 20, 2017 Specifying Syntax: Regular expressions and context-free grammars Regular expressions are formed by the use of three mechanisms Concatenation Alternation
Chapter 2 - Programming Language Syntax September 20, 2017 Specifying Syntax: Regular expressions and context-free grammars Regular expressions are formed by the use of three mechanisms Concatenation Alternation
Syntax Analysis. COMP 524: Programming Language Concepts Björn B. Brandenburg. The University of North Carolina at Chapel Hill
 Syntax Analysis Björn B. Brandenburg The University of North Carolina at Chapel Hill Based on slides and notes by S. Olivier, A. Block, N. Fisher, F. Hernandez-Campos, and D. Stotts. The Big Picture Character
Syntax Analysis Björn B. Brandenburg The University of North Carolina at Chapel Hill Based on slides and notes by S. Olivier, A. Block, N. Fisher, F. Hernandez-Campos, and D. Stotts. The Big Picture Character
Syntax Analysis. The Big Picture. The Big Picture. COMP 524: Programming Languages Srinivas Krishnan January 25, 2011
 Syntax Analysis COMP 524: Programming Languages Srinivas Krishnan January 25, 2011 Based in part on slides and notes by Bjoern Brandenburg, S. Olivier and A. Block. 1 The Big Picture Character Stream Token
Syntax Analysis COMP 524: Programming Languages Srinivas Krishnan January 25, 2011 Based in part on slides and notes by Bjoern Brandenburg, S. Olivier and A. Block. 1 The Big Picture Character Stream Token
Parsing. Roadmap. > Context-free grammars > Derivations and precedence > Top-down parsing > Left-recursion > Look-ahead > Table-driven parsing
 Roadmap > Context-free grammars > Derivations and precedence > Top-down parsing > Left-recursion > Look-ahead > Table-driven parsing The role of the parser > performs context-free syntax analysis > guides
Roadmap > Context-free grammars > Derivations and precedence > Top-down parsing > Left-recursion > Look-ahead > Table-driven parsing The role of the parser > performs context-free syntax analysis > guides
Programming Languages (CS 550) Lecture 4 Summary Scanner and Parser Generators. Jeremy R. Johnson
 Lecture 4 Summary Scanner and Parser Generators. Jeremy R. Johnson") Programming Languages (CS 550) Lecture 4 Summary Scanner and Parser Generators Jeremy R. Johnson 1 Theme We have now seen how to describe syntax using regular expressions and grammars and how to create
Programming Languages (CS 550) Lecture 4 Summary Scanner and Parser Generators Jeremy R. Johnson 1 Theme We have now seen how to describe syntax using regular expressions and grammars and how to create
Wednesday, September 9, 15. Parsers
 Parsers What is a parser A parser has two jobs: 1) Determine whether a string (program) is valid (think: grammatically correct) 2) Determine the structure of a program (think: diagramming a sentence) Agenda
Parsers What is a parser A parser has two jobs: 1) Determine whether a string (program) is valid (think: grammatically correct) 2) Determine the structure of a program (think: diagramming a sentence) Agenda
Parsers. What is a parser. Languages. Agenda. Terminology. Languages. A parser has two jobs:
 What is a parser Parsers A parser has two jobs: 1) Determine whether a string (program) is valid (think: grammatically correct) 2) Determine the structure of a program (think: diagramming a sentence) Agenda
What is a parser Parsers A parser has two jobs: 1) Determine whether a string (program) is valid (think: grammatically correct) 2) Determine the structure of a program (think: diagramming a sentence) Agenda
Monday, September 13, Parsers
 Parsers Agenda Terminology LL(1) Parsers Overview of LR Parsing Terminology Grammar G = (Vt, Vn, S, P) Vt is the set of terminals Vn is the set of non-terminals S is the start symbol P is the set of productions
Parsers Agenda Terminology LL(1) Parsers Overview of LR Parsing Terminology Grammar G = (Vt, Vn, S, P) Vt is the set of terminals Vn is the set of non-terminals S is the start symbol P is the set of productions
3. Parsing. Oscar Nierstrasz
 3. Parsing Oscar Nierstrasz Thanks to Jens Palsberg and Tony Hosking for their kind permission to reuse and adapt the CS132 and CS502 lecture notes. http://www.cs.ucla.edu/~palsberg/ http://www.cs.purdue.edu/homes/hosking/
3. Parsing Oscar Nierstrasz Thanks to Jens Palsberg and Tony Hosking for their kind permission to reuse and adapt the CS132 and CS502 lecture notes. http://www.cs.ucla.edu/~palsberg/ http://www.cs.purdue.edu/homes/hosking/
Lexical and Syntax Analysis (2)
") Lexical and Syntax Analysis (2) In Text: Chapter 4 N. Meng, F. Poursardar Motivating Example Consider the grammar S -> cad A -> ab a Input string: w = cad How to build a parse tree top-down? 2 Recursive-Descent
Lexical and Syntax Analysis (2) In Text: Chapter 4 N. Meng, F. Poursardar Motivating Example Consider the grammar S -> cad A -> ab a Input string: w = cad How to build a parse tree top-down? 2 Recursive-Descent
Revisit the example. Transformed DFA 10/1/16 A B C D E. Start
 Revisit the example ε 0 ε 1 Start ε a ε 2 3 ε b ε 4 5 ε a b b 6 7 8 9 10 ε-closure(0)={0, 1, 2, 4, 7} = A Trans(A, a) = {1, 2, 3, 4, 6, 7, 8} = B Trans(A, b) = {1, 2, 4, 5, 6, 7} = C Trans(B, a) = {1,
Revisit the example ε 0 ε 1 Start ε a ε 2 3 ε b ε 4 5 ε a b b 6 7 8 9 10 ε-closure(0)={0, 1, 2, 4, 7} = A Trans(A, a) = {1, 2, 3, 4, 6, 7, 8} = B Trans(A, b) = {1, 2, 4, 5, 6, 7} = C Trans(B, a) = {1,
Part 5 Program Analysis Principles and Techniques
 1 Part 5 Program Analysis Principles and Techniques Front end 2 source code scanner tokens parser il errors Responsibilities: Recognize legal programs Report errors Produce il Preliminary storage map Shape
1 Part 5 Program Analysis Principles and Techniques Front end 2 source code scanner tokens parser il errors Responsibilities: Recognize legal programs Report errors Produce il Preliminary storage map Shape
Parsers. Xiaokang Qiu Purdue University. August 31, 2018 ECE 468
 Parsers Xiaokang Qiu Purdue University ECE 468 August 31, 2018 What is a parser A parser has two jobs: 1) Determine whether a string (program) is valid (think: grammatically correct) 2) Determine the structure
Parsers Xiaokang Qiu Purdue University ECE 468 August 31, 2018 What is a parser A parser has two jobs: 1) Determine whether a string (program) is valid (think: grammatically correct) 2) Determine the structure
CS 315 Programming Languages Syntax. Parser. (Alternatively hand-built) (Alternatively hand-built)
 (Alternatively hand-built)") Programming languages must be precise Remember instructions This is unlike natural languages CS 315 Programming Languages Syntax Precision is required for syntax think of this as the format of the language
Programming languages must be precise Remember instructions This is unlike natural languages CS 315 Programming Languages Syntax Precision is required for syntax think of this as the format of the language
Wednesday, August 31, Parsers
 Parsers How do we combine tokens? Combine tokens ( words in a language) to form programs ( sentences in a language) Not all combinations of tokens are correct programs (not all sentences are grammatically
Parsers How do we combine tokens? Combine tokens ( words in a language) to form programs ( sentences in a language) Not all combinations of tokens are correct programs (not all sentences are grammatically
Compilers. Yannis Smaragdakis, U. Athens (original slides by Sam
 Compilers Parsing Yannis Smaragdakis, U. Athens (original slides by Sam Guyer@Tufts) Next step text chars Lexical analyzer tokens Parser IR Errors Parsing: Organize tokens into sentences Do tokens conform
Compilers Parsing Yannis Smaragdakis, U. Athens (original slides by Sam Guyer@Tufts) Next step text chars Lexical analyzer tokens Parser IR Errors Parsing: Organize tokens into sentences Do tokens conform
Lecture 3: Lexical Analysis
 Lecture 3: Lexical Analysis COMP 524 Programming Language Concepts tephen Olivier January 2, 29 Based on notes by A. Block, N. Fisher, F. Hernandez-Campos, J. Prins and D. totts Goal of Lecture Character
Lecture 3: Lexical Analysis COMP 524 Programming Language Concepts tephen Olivier January 2, 29 Based on notes by A. Block, N. Fisher, F. Hernandez-Campos, J. Prins and D. totts Goal of Lecture Character
CS 403: Scanning and Parsing
 CS 403: Scanning and Parsing Stefan D. Bruda Fall 2017 THE COMPILATION PROCESS Character stream Scanner (lexical analysis) Token stream Parser (syntax analysis) Parse tree Semantic analysis Abstract syntax
CS 403: Scanning and Parsing Stefan D. Bruda Fall 2017 THE COMPILATION PROCESS Character stream Scanner (lexical analysis) Token stream Parser (syntax analysis) Parse tree Semantic analysis Abstract syntax
CS Lecture 2. The Front End. Lecture 2 Lexical Analysis
 CS 1622 Lecture 2 Lexical Analysis CS 1622 Lecture 2 1 Lecture 2 Review of last lecture and finish up overview The first compiler phase: lexical analysis Reading: Chapter 2 in text (by 1/18) CS 1622 Lecture
CS 1622 Lecture 2 Lexical Analysis CS 1622 Lecture 2 1 Lecture 2 Review of last lecture and finish up overview The first compiler phase: lexical analysis Reading: Chapter 2 in text (by 1/18) CS 1622 Lecture
THE COMPILATION PROCESS EXAMPLE OF TOKENS AND ATTRIBUTES
 THE COMPILATION PROCESS Character stream CS 403: Scanning and Parsing Stefan D. Bruda Fall 207 Token stream Parse tree Abstract syntax tree Modified intermediate form Target language Modified target language
THE COMPILATION PROCESS Character stream CS 403: Scanning and Parsing Stefan D. Bruda Fall 207 Token stream Parse tree Abstract syntax tree Modified intermediate form Target language Modified target language
Chapter 3. Describing Syntax and Semantics ISBN
 Chapter 3 Describing Syntax and Semantics ISBN 0-321-49362-1 Chapter 3 Topics Introduction The General Problem of Describing Syntax Formal Methods of Describing Syntax Copyright 2009 Addison-Wesley. All
Chapter 3 Describing Syntax and Semantics ISBN 0-321-49362-1 Chapter 3 Topics Introduction The General Problem of Describing Syntax Formal Methods of Describing Syntax Copyright 2009 Addison-Wesley. All
Note that for recursive descent to work, if A ::= B1 B2 is a grammar rule we need First k (B1) disjoint from First k (B2).
 disjoint from First k (B2).") LL(k) Grammars We need a bunch of terminology. For any terminal string a we write First k (a) is the prefix of a of length k (or all of a if its length is less than k) For any string g of terminal and
LL(k) Grammars We need a bunch of terminology. For any terminal string a we write First k (a) is the prefix of a of length k (or all of a if its length is less than k) For any string g of terminal and
Compiler Construction: Parsing
 Compiler Construction: Parsing Mandar Mitra Indian Statistical Institute M. Mitra (ISI) Parsing 1 / 33 Context-free grammars. Reference: Section 4.2 Formal way of specifying rules about the structure/syntax
Compiler Construction: Parsing Mandar Mitra Indian Statistical Institute M. Mitra (ISI) Parsing 1 / 33 Context-free grammars. Reference: Section 4.2 Formal way of specifying rules about the structure/syntax
UNIT -2 LEXICAL ANALYSIS
 OVER VIEW OF LEXICAL ANALYSIS UNIT -2 LEXICAL ANALYSIS o To identify the tokens we need some method of describing the possible tokens that can appear in the input stream. For this purpose we introduce
OVER VIEW OF LEXICAL ANALYSIS UNIT -2 LEXICAL ANALYSIS o To identify the tokens we need some method of describing the possible tokens that can appear in the input stream. For this purpose we introduce
CMSC 330: Organization of Programming Languages
 CMSC 330: Organization of Programming Languages Context Free Grammars and Parsing 1 Recall: Architecture of Compilers, Interpreters Source Parser Static Analyzer Intermediate Representation Front End Back
CMSC 330: Organization of Programming Languages Context Free Grammars and Parsing 1 Recall: Architecture of Compilers, Interpreters Source Parser Static Analyzer Intermediate Representation Front End Back
Languages and Compilers
 Principles of Software Engineering and Operational Systems Languages and Compilers SDAGE: Level I 2012-13 3. Formal Languages, Grammars and Automata Dr Valery Adzhiev vadzhiev@bournemouth.ac.uk Office:
Principles of Software Engineering and Operational Systems Languages and Compilers SDAGE: Level I 2012-13 3. Formal Languages, Grammars and Automata Dr Valery Adzhiev vadzhiev@bournemouth.ac.uk Office:
Syntactic Analysis. Top-Down Parsing
 Syntactic Analysis Top-Down Parsing Copyright 2017, Pedro C. Diniz, all rights reserved. Students enrolled in Compilers class at University of Southern California (USC) have explicit permission to make
Syntactic Analysis Top-Down Parsing Copyright 2017, Pedro C. Diniz, all rights reserved. Students enrolled in Compilers class at University of Southern California (USC) have explicit permission to make
Context-free grammars
 Context-free grammars Section 4.2 Formal way of specifying rules about the structure/syntax of a program terminals - tokens non-terminals - represent higher-level structures of a program start symbol,
Context-free grammars Section 4.2 Formal way of specifying rules about the structure/syntax of a program terminals - tokens non-terminals - represent higher-level structures of a program start symbol,
Languages and Compilers
 Principles of Software Engineering and Operational Systems Languages and Compilers SDAGE: Level I 2012-13 4. Lexical Analysis (Scanning) Dr Valery Adzhiev vadzhiev@bournemouth.ac.uk Office: TA-121 For
Principles of Software Engineering and Operational Systems Languages and Compilers SDAGE: Level I 2012-13 4. Lexical Analysis (Scanning) Dr Valery Adzhiev vadzhiev@bournemouth.ac.uk Office: TA-121 For
CSE 130 Programming Language Principles & Paradigms Lecture # 5. Chapter 4 Lexical and Syntax Analysis
 Chapter 4 Lexical and Syntax Analysis Introduction - Language implementation systems must analyze source code, regardless of the specific implementation approach - Nearly all syntax analysis is based on
Chapter 4 Lexical and Syntax Analysis Introduction - Language implementation systems must analyze source code, regardless of the specific implementation approach - Nearly all syntax analysis is based on
COMP-421 Compiler Design. Presented by Dr Ioanna Dionysiou
 COMP-421 Compiler Design Presented by Dr Ioanna Dionysiou Administrative! [ALSU03] Chapter 3 - Lexical Analysis Sections 3.1-3.4, 3.6-3.7! Reading for next time [ALSU03] Chapter 3 Copyright (c) 2010 Ioanna
COMP-421 Compiler Design Presented by Dr Ioanna Dionysiou Administrative! [ALSU03] Chapter 3 - Lexical Analysis Sections 3.1-3.4, 3.6-3.7! Reading for next time [ALSU03] Chapter 3 Copyright (c) 2010 Ioanna
 SYNTAX ANALYSIS 1. Define parser. Hierarchical analysis is one in which the tokens are grouped hierarchically into nested collections with collective meaning. Also termed as Parsing. 2. Mention the basic
SYNTAX ANALYSIS 1. Define parser. Hierarchical analysis is one in which the tokens are grouped hierarchically into nested collections with collective meaning. Also termed as Parsing. 2. Mention the basic
Lexical Analysis (ASU Ch 3, Fig 3.1)
") Lexical Analysis (ASU Ch 3, Fig 3.1) Implementation by hand automatically ((F)Lex) Lex generates a finite automaton recogniser uses regular expressions Tasks remove white space (ws) display source program
Lexical Analysis (ASU Ch 3, Fig 3.1) Implementation by hand automatically ((F)Lex) Lex generates a finite automaton recogniser uses regular expressions Tasks remove white space (ws) display source program
Top down vs. bottom up parsing
 Parsing A grammar describes the strings that are syntactically legal A recogniser simply accepts or rejects strings A generator produces sentences in the language described by the grammar A parser constructs
Parsing A grammar describes the strings that are syntactically legal A recogniser simply accepts or rejects strings A generator produces sentences in the language described by the grammar A parser constructs
Chapter 4. Lexical and Syntax Analysis
 Chapter 4 Lexical and Syntax Analysis Chapter 4 Topics Introduction Lexical Analysis The Parsing Problem Recursive-Descent Parsing Bottom-Up Parsing Copyright 2012 Addison-Wesley. All rights reserved.
Chapter 4 Lexical and Syntax Analysis Chapter 4 Topics Introduction Lexical Analysis The Parsing Problem Recursive-Descent Parsing Bottom-Up Parsing Copyright 2012 Addison-Wesley. All rights reserved.
Table-Driven Parsing
 Table-Driven Parsing It is possible to build a non-recursive predictive parser by maintaining a stack explicitly, rather than implicitly via recursive calls [1] The non-recursive parser looks up the production
Table-Driven Parsing It is possible to build a non-recursive predictive parser by maintaining a stack explicitly, rather than implicitly via recursive calls [1] The non-recursive parser looks up the production
Regular Expressions. Agenda for Today. Grammar for a Tiny Language. Programming Language Specifications
 Agenda for Today Regular Expressions CSE 413, Autumn 2005 Programming Languages Basic concepts of formal grammars Regular expressions Lexical specification of programming languages Using finite automata
Agenda for Today Regular Expressions CSE 413, Autumn 2005 Programming Languages Basic concepts of formal grammars Regular expressions Lexical specification of programming languages Using finite automata
CA Compiler Construction
 CA4003 - Compiler Construction David Sinclair A top-down parser starts with the root of the parse tree, labelled with the goal symbol of the grammar, and repeats the following steps until the fringe of
CA4003 - Compiler Construction David Sinclair A top-down parser starts with the root of the parse tree, labelled with the goal symbol of the grammar, and repeats the following steps until the fringe of
Syntax Analysis. Martin Sulzmann. Martin Sulzmann Syntax Analysis 1 / 38
 Syntax Analysis Martin Sulzmann Martin Sulzmann Syntax Analysis 1 / 38 Syntax Analysis Objective Recognize individual tokens as sentences of a language (beyond regular languages). Example 1 (OK) Program
Syntax Analysis Martin Sulzmann Martin Sulzmann Syntax Analysis 1 / 38 Syntax Analysis Objective Recognize individual tokens as sentences of a language (beyond regular languages). Example 1 (OK) Program
Chapter 4. Lexical and Syntax Analysis. Topics. Compilation. Language Implementation. Issues in Lexical and Syntax Analysis.
 Topics Chapter 4 Lexical and Syntax Analysis Introduction Lexical Analysis Syntax Analysis Recursive -Descent Parsing Bottom-Up parsing 2 Language Implementation Compilation There are three possible approaches
Topics Chapter 4 Lexical and Syntax Analysis Introduction Lexical Analysis Syntax Analysis Recursive -Descent Parsing Bottom-Up parsing 2 Language Implementation Compilation There are three possible approaches
Compiler Construction 2016/2017 Syntax Analysis
 Compiler Construction 2016/2017 Syntax Analysis Peter Thiemann November 2, 2016 Outline 1 Syntax Analysis Recursive top-down parsing Nonrecursive top-down parsing Bottom-up parsing Syntax Analysis tokens
Compiler Construction 2016/2017 Syntax Analysis Peter Thiemann November 2, 2016 Outline 1 Syntax Analysis Recursive top-down parsing Nonrecursive top-down parsing Bottom-up parsing Syntax Analysis tokens
Programming Language Syntax and Analysis
 Programming Language Syntax and Analysis 2017 Kwangman Ko (http://compiler.sangji.ac.kr, kkman@sangji.ac.kr) Dept. of Computer Engineering, Sangji University Introduction Syntax the form or structure of
Programming Language Syntax and Analysis 2017 Kwangman Ko (http://compiler.sangji.ac.kr, kkman@sangji.ac.kr) Dept. of Computer Engineering, Sangji University Introduction Syntax the form or structure of
Lexical Analysis - 1. A. Overview A.a) Role of Lexical Analyzer
 Role of Lexical Analyzer") CMPSC 470 Lecture 02 Topics: Regular Expression Transition Diagram Lexical Analyzer Implementation A. Overview A.a) Role of Lexical Analyzer Lexical Analysis - 1 Lexical analyzer does: read input character
CMPSC 470 Lecture 02 Topics: Regular Expression Transition Diagram Lexical Analyzer Implementation A. Overview A.a) Role of Lexical Analyzer Lexical Analysis - 1 Lexical analyzer does: read input character
MIT Specifying Languages with Regular Expressions and Context-Free Grammars
 MIT 6.035 Specifying Languages with Regular essions and Context-Free Grammars Martin Rinard Laboratory for Computer Science Massachusetts Institute of Technology Language Definition Problem How to precisely
MIT 6.035 Specifying Languages with Regular essions and Context-Free Grammars Martin Rinard Laboratory for Computer Science Massachusetts Institute of Technology Language Definition Problem How to precisely
Where We Are. CMSC 330: Organization of Programming Languages. This Lecture. Programming Languages. Motivation for Grammars
 CMSC 330: Organization of Programming Languages Context Free Grammars Where We Are Programming languages Ruby OCaml Implementing programming languages Scanner Uses regular expressions Finite automata Parser
CMSC 330: Organization of Programming Languages Context Free Grammars Where We Are Programming languages Ruby OCaml Implementing programming languages Scanner Uses regular expressions Finite automata Parser
Architecture of Compilers, Interpreters. CMSC 330: Organization of Programming Languages. Front End Scanner and Parser. Implementing the Front End
 Architecture of Compilers, Interpreters : Organization of Programming Languages ource Analyzer Optimizer Code Generator Context Free Grammars Intermediate Representation Front End Back End Compiler / Interpreter
Architecture of Compilers, Interpreters : Organization of Programming Languages ource Analyzer Optimizer Code Generator Context Free Grammars Intermediate Representation Front End Back End Compiler / Interpreter
CMSC 330: Organization of Programming Languages. Architecture of Compilers, Interpreters
 : Organization of Programming Languages Context Free Grammars 1 Architecture of Compilers, Interpreters Source Scanner Parser Static Analyzer Intermediate Representation Front End Back End Compiler / Interpreter
: Organization of Programming Languages Context Free Grammars 1 Architecture of Compilers, Interpreters Source Scanner Parser Static Analyzer Intermediate Representation Front End Back End Compiler / Interpreter
Syntax Analysis/Parsing. Context-free grammars (CFG s) Context-free grammars vs. Regular Expressions. BNF description of PL/0 syntax
 Context-free grammars vs. Regular Expressions. BNF description of PL/0 syntax") Susan Eggers 1 CSE 401 Syntax Analysis/Parsing Context-free grammars (CFG s) Purpose: determine if tokens have the right form for the language (right syntactic structure) stream of tokens abstract syntax
Susan Eggers 1 CSE 401 Syntax Analysis/Parsing Context-free grammars (CFG s) Purpose: determine if tokens have the right form for the language (right syntactic structure) stream of tokens abstract syntax
 WWW.STUDENTSFOCUS.COM UNIT -3 SYNTAX ANALYSIS 3.1 ROLE OF THE PARSER Parser obtains a string of tokens from the lexical analyzer and verifies that it can be generated by the language for the source program.
WWW.STUDENTSFOCUS.COM UNIT -3 SYNTAX ANALYSIS 3.1 ROLE OF THE PARSER Parser obtains a string of tokens from the lexical analyzer and verifies that it can be generated by the language for the source program.
VIVA QUESTIONS WITH ANSWERS
 VIVA QUESTIONS WITH ANSWERS 1. What is a compiler? A compiler is a program that reads a program written in one language the source language and translates it into an equivalent program in another language-the
VIVA QUESTIONS WITH ANSWERS 1. What is a compiler? A compiler is a program that reads a program written in one language the source language and translates it into an equivalent program in another language-the
4. Lexical and Syntax Analysis
 4. Lexical and Syntax Analysis 4.1 Introduction Language implementation systems must analyze source code, regardless of the specific implementation approach Nearly all syntax analysis is based on a formal
4. Lexical and Syntax Analysis 4.1 Introduction Language implementation systems must analyze source code, regardless of the specific implementation approach Nearly all syntax analysis is based on a formal
Top-Down Parsing and Intro to Bottom-Up Parsing. Lecture 7
 Top-Down Parsing and Intro to Bottom-Up Parsing Lecture 7 1 Predictive Parsers Like recursive-descent but parser can predict which production to use Predictive parsers are never wrong Always able to guess
Top-Down Parsing and Intro to Bottom-Up Parsing Lecture 7 1 Predictive Parsers Like recursive-descent but parser can predict which production to use Predictive parsers are never wrong Always able to guess
Zhizheng Zhang. Southeast University
 Zhizheng Zhang Southeast University 2016/10/5 Lexical Analysis 1 1. The Role of Lexical Analyzer 2016/10/5 Lexical Analysis 2 2016/10/5 Lexical Analysis 3 Example. position = initial + rate * 60 2016/10/5
Zhizheng Zhang Southeast University 2016/10/5 Lexical Analysis 1 1. The Role of Lexical Analyzer 2016/10/5 Lexical Analysis 2 2016/10/5 Lexical Analysis 3 Example. position = initial + rate * 60 2016/10/5
MIT Specifying Languages with Regular Expressions and Context-Free Grammars. Martin Rinard Massachusetts Institute of Technology
 MIT 6.035 Specifying Languages with Regular essions and Context-Free Grammars Martin Rinard Massachusetts Institute of Technology Language Definition Problem How to precisely define language Layered structure
MIT 6.035 Specifying Languages with Regular essions and Context-Free Grammars Martin Rinard Massachusetts Institute of Technology Language Definition Problem How to precisely define language Layered structure
Formal Languages and Compilers Lecture VI: Lexical Analysis
 Formal Languages and Compilers Lecture VI: Lexical Analysis Free University of Bozen-Bolzano Faculty of Computer Science POS Building, Room: 2.03 artale@inf.unibz.it http://www.inf.unibz.it/ artale/ Formal
Formal Languages and Compilers Lecture VI: Lexical Analysis Free University of Bozen-Bolzano Faculty of Computer Science POS Building, Room: 2.03 artale@inf.unibz.it http://www.inf.unibz.it/ artale/ Formal
4. Lexical and Syntax Analysis
 4. Lexical and Syntax Analysis 4.1 Introduction Language implementation systems must analyze source code, regardless of the specific implementation approach Nearly all syntax analysis is based on a formal
4. Lexical and Syntax Analysis 4.1 Introduction Language implementation systems must analyze source code, regardless of the specific implementation approach Nearly all syntax analysis is based on a formal
Parsing. source code. while (k<=n) {sum = sum+k; k=k+1;}
 {sum = sum+k; k=k+1;}") Compiler Construction Grammars Parsing source code scanner tokens regular expressions lexical analysis Lennart Andersson parser context free grammar Revision 2012 01 23 2012 parse tree AST builder (implicit)
Compiler Construction Grammars Parsing source code scanner tokens regular expressions lexical analysis Lennart Andersson parser context free grammar Revision 2012 01 23 2012 parse tree AST builder (implicit)
Chapter 3: Lexing and Parsing
 Chapter 3: Lexing and Parsing Aarne Ranta Slides for the book Implementing Programming Languages. An Introduction to Compilers and Interpreters, College Publications, 2012. Lexing and Parsing* Deeper understanding
Chapter 3: Lexing and Parsing Aarne Ranta Slides for the book Implementing Programming Languages. An Introduction to Compilers and Interpreters, College Publications, 2012. Lexing and Parsing* Deeper understanding
CMSC 330: Organization of Programming Languages
 CMSC 330: Organization of Programming Languages Context Free Grammars 1 Architecture of Compilers, Interpreters Source Analyzer Optimizer Code Generator Abstract Syntax Tree Front End Back End Compiler
CMSC 330: Organization of Programming Languages Context Free Grammars 1 Architecture of Compilers, Interpreters Source Analyzer Optimizer Code Generator Abstract Syntax Tree Front End Back End Compiler
Formal Languages and Grammars. Chapter 2: Sections 2.1 and 2.2
 Formal Languages and Grammars Chapter 2: Sections 2.1 and 2.2 Formal Languages Basis for the design and implementation of programming languages Alphabet: finite set Σ of symbols String: finite sequence
Formal Languages and Grammars Chapter 2: Sections 2.1 and 2.2 Formal Languages Basis for the design and implementation of programming languages Alphabet: finite set Σ of symbols String: finite sequence
Lecture 4: Syntax Specification
 The University of North Carolina at Chapel Hill Spring 2002 Lecture 4: Syntax Specification Jan 16 1 Phases of Compilation 2 1 Syntax Analysis Syntax: Webster s definition: 1 a : the way in which linguistic
The University of North Carolina at Chapel Hill Spring 2002 Lecture 4: Syntax Specification Jan 16 1 Phases of Compilation 2 1 Syntax Analysis Syntax: Webster s definition: 1 a : the way in which linguistic
Compiler course. Chapter 3 Lexical Analysis
 Compiler course Chapter 3 Lexical Analysis 1 A. A. Pourhaji Kazem, Spring 2009 Outline Role of lexical analyzer Specification of tokens Recognition of tokens Lexical analyzer generator Finite automata
Compiler course Chapter 3 Lexical Analysis 1 A. A. Pourhaji Kazem, Spring 2009 Outline Role of lexical analyzer Specification of tokens Recognition of tokens Lexical analyzer generator Finite automata
Lexical and Syntax Analysis
 Lexical and Syntax Analysis In Text: Chapter 4 N. Meng, F. Poursardar Lexical and Syntactic Analysis Two steps to discover the syntactic structure of a program Lexical analysis (Scanner): to read the input
Lexical and Syntax Analysis In Text: Chapter 4 N. Meng, F. Poursardar Lexical and Syntactic Analysis Two steps to discover the syntactic structure of a program Lexical analysis (Scanner): to read the input
Top-Down Parsing and Intro to Bottom-Up Parsing. Lecture 7
 Top-Down Parsing and Intro to Bottom-Up Parsing Lecture 7 1 Predictive Parsers Like recursive-descent but parser can predict which production to use Predictive parsers are never wrong Always able to guess
Top-Down Parsing and Intro to Bottom-Up Parsing Lecture 7 1 Predictive Parsers Like recursive-descent but parser can predict which production to use Predictive parsers are never wrong Always able to guess
Chapter 3 Lexical Analysis
 Chapter 3 Lexical Analysis Outline Role of lexical analyzer Specification of tokens Recognition of tokens Lexical analyzer generator Finite automata Design of lexical analyzer generator The role of lexical
Chapter 3 Lexical Analysis Outline Role of lexical analyzer Specification of tokens Recognition of tokens Lexical analyzer generator Finite automata Design of lexical analyzer generator The role of lexical
Section A. A grammar that produces more than one parse tree for some sentences is said to be ambiguous.
 Section A 1. What do you meant by parser and its types? A parser for grammar G is a program that takes as input a string w and produces as output either a parse tree for w, if w is a sentence of G, or
Section A 1. What do you meant by parser and its types? A parser for grammar G is a program that takes as input a string w and produces as output either a parse tree for w, if w is a sentence of G, or
Context-free grammars (CFG s)
") Syntax Analysis/Parsing Purpose: determine if tokens have the right form for the language (right syntactic structure) stream of tokens abstract syntax tree (AST) AST: captures hierarchical structure of
Syntax Analysis/Parsing Purpose: determine if tokens have the right form for the language (right syntactic structure) stream of tokens abstract syntax tree (AST) AST: captures hierarchical structure of
Lexical Analysis. Introduction
 Lexical Analysis Introduction Copyright 2015, Pedro C. Diniz, all rights reserved. Students enrolled in the Compilers class at the University of Southern California have explicit permission to make copies
Lexical Analysis Introduction Copyright 2015, Pedro C. Diniz, all rights reserved. Students enrolled in the Compilers class at the University of Southern California have explicit permission to make copies
Lexical Analysis. Dragon Book Chapter 3 Formal Languages Regular Expressions Finite Automata Theory Lexical Analysis using Automata
 Lexical Analysis Dragon Book Chapter 3 Formal Languages Regular Expressions Finite Automata Theory Lexical Analysis using Automata Phase Ordering of Front-Ends Lexical analysis (lexer) Break input string
Lexical Analysis Dragon Book Chapter 3 Formal Languages Regular Expressions Finite Automata Theory Lexical Analysis using Automata Phase Ordering of Front-Ends Lexical analysis (lexer) Break input string
CMSC 330: Organization of Programming Languages
 CMSC 330: Organization of Programming Languages Context Free Grammars 1 Architecture of Compilers, Interpreters Source Analyzer Optimizer Code Generator Abstract Syntax Tree Front End Back End Compiler
CMSC 330: Organization of Programming Languages Context Free Grammars 1 Architecture of Compilers, Interpreters Source Analyzer Optimizer Code Generator Abstract Syntax Tree Front End Back End Compiler
8 Parsing. Parsing. Top Down Parsing Methods. Parsing complexity. Top down vs. bottom up parsing. Top down vs. bottom up parsing
 8 Parsing Parsing A grammar describes syntactically legal strings in a language A recogniser simply accepts or rejects strings A generator produces strings A parser constructs a parse tree for a string
8 Parsing Parsing A grammar describes syntactically legal strings in a language A recogniser simply accepts or rejects strings A generator produces strings A parser constructs a parse tree for a string
Introduction to parsers
 Syntax Analysis Introduction to parsers Context-free grammars Push-down automata Top-down parsing LL grammars and parsers Bottom-up parsing LR grammars and parsers Bison/Yacc - parser generators Error
Syntax Analysis Introduction to parsers Context-free grammars Push-down automata Top-down parsing LL grammars and parsers Bottom-up parsing LR grammars and parsers Bison/Yacc - parser generators Error
Bottom-up parsing. Bottom-Up Parsing. Recall. Goal: For a grammar G, withstartsymbols, any string α such that S α is called a sentential form
 Bottom-up parsing Bottom-up parsing Recall Goal: For a grammar G, withstartsymbols, any string α such that S α is called a sentential form If α V t,thenα is called a sentence in L(G) Otherwise it is just
Bottom-up parsing Bottom-up parsing Recall Goal: For a grammar G, withstartsymbols, any string α such that S α is called a sentential form If α V t,thenα is called a sentence in L(G) Otherwise it is just
CS1622. Today. A Recursive Descent Parser. Preliminaries. Lecture 9 Parsing (4)
") CS1622 Lecture 9 Parsing (4) CS 1622 Lecture 9 1 Today Example of a recursive descent parser Predictive & LL(1) parsers Building parse tables CS 1622 Lecture 9 2 A Recursive Descent Parser. Preliminaries
CS1622 Lecture 9 Parsing (4) CS 1622 Lecture 9 1 Today Example of a recursive descent parser Predictive & LL(1) parsers Building parse tables CS 1622 Lecture 9 2 A Recursive Descent Parser. Preliminaries
Parsing. Note by Baris Aktemur: Our slides are adapted from Cooper and Torczon s slides that they prepared for COMP 412 at Rice.
 Parsing Note by Baris Aktemur: Our slides are adapted from Cooper and Torczon s slides that they prepared for COMP 412 at Rice. Copyright 2010, Keith D. Cooper & Linda Torczon, all rights reserved. Students
Parsing Note by Baris Aktemur: Our slides are adapted from Cooper and Torczon s slides that they prepared for COMP 412 at Rice. Copyright 2010, Keith D. Cooper & Linda Torczon, all rights reserved. Students
Lexical Analyzer Scanner
 Lexical Analyzer Scanner ASU Textbook Chapter 3.1, 3.3, 3.4, 3.6, 3.7, 3.5 Tsan-sheng Hsu tshsu@iis.sinica.edu.tw http://www.iis.sinica.edu.tw/~tshsu 1 Main tasks Read the input characters and produce
Lexical Analyzer Scanner ASU Textbook Chapter 3.1, 3.3, 3.4, 3.6, 3.7, 3.5 Tsan-sheng Hsu tshsu@iis.sinica.edu.tw http://www.iis.sinica.edu.tw/~tshsu 1 Main tasks Read the input characters and produce
PART 3 - SYNTAX ANALYSIS. F. Wotawa TU Graz) Compiler Construction Summer term / 309
 Compiler Construction Summer term / 309") PART 3 - SYNTAX ANALYSIS F. Wotawa (IST @ TU Graz) Compiler Construction Summer term 2016 64 / 309 Goals Definition of the syntax of a programming language using context free grammars Methods for parsing
PART 3 - SYNTAX ANALYSIS F. Wotawa (IST @ TU Graz) Compiler Construction Summer term 2016 64 / 309 Goals Definition of the syntax of a programming language using context free grammars Methods for parsing
Concepts Introduced in Chapter 4
 Concepts Introduced in Chapter 4 Grammars Context-Free Grammars Derivations and Parse Trees Ambiguity, Precedence, and Associativity Top Down Parsing Recursive Descent, LL Bottom Up Parsing SLR, LR, LALR
Concepts Introduced in Chapter 4 Grammars Context-Free Grammars Derivations and Parse Trees Ambiguity, Precedence, and Associativity Top Down Parsing Recursive Descent, LL Bottom Up Parsing SLR, LR, LALR
LR Parsing Techniques
 LR Parsing Techniques Introduction Bottom-Up Parsing LR Parsing as Handle Pruning Shift-Reduce Parser LR(k) Parsing Model Parsing Table Construction: SLR, LR, LALR 1 Bottom-UP Parsing A bottom-up parser
LR Parsing Techniques Introduction Bottom-Up Parsing LR Parsing as Handle Pruning Shift-Reduce Parser LR(k) Parsing Model Parsing Table Construction: SLR, LR, LALR 1 Bottom-UP Parsing A bottom-up parser
EDAN65: Compilers, Lecture 06 A LR parsing. Görel Hedin Revised:
 EDAN65: Compilers, Lecture 06 A LR parsing Görel Hedin Revised: 2017-09-11 This lecture Regular expressions Context-free grammar Attribute grammar Lexical analyzer (scanner) Syntactic analyzer (parser)
EDAN65: Compilers, Lecture 06 A LR parsing Görel Hedin Revised: 2017-09-11 This lecture Regular expressions Context-free grammar Attribute grammar Lexical analyzer (scanner) Syntactic analyzer (parser)
Week 2: Syntax Specification, Grammars
 CS320 Principles of Programming Languages Week 2: Syntax Specification, Grammars Jingke Li Portland State University Fall 2017 PSU CS320 Fall 17 Week 2: Syntax Specification, Grammars 1/ 62 Words and Sentences
CS320 Principles of Programming Languages Week 2: Syntax Specification, Grammars Jingke Li Portland State University Fall 2017 PSU CS320 Fall 17 Week 2: Syntax Specification, Grammars 1/ 62 Words and Sentences
Syntax Analysis Part I
 Syntax Analysis Part I Chapter 4: Context-Free Grammars Slides adapted from : Robert van Engelen, Florida State University Position of a Parser in the Compiler Model Source Program Lexical Analyzer Token,
Syntax Analysis Part I Chapter 4: Context-Free Grammars Slides adapted from : Robert van Engelen, Florida State University Position of a Parser in the Compiler Model Source Program Lexical Analyzer Token,
Lexical and Syntax Analysis. Top-Down Parsing
 Lexical and Syntax Analysis Top-Down Parsing Easy for humans to write and understand String of characters Lexemes identified String of tokens Easy for programs to transform Data structure Syntax A syntax
Lexical and Syntax Analysis Top-Down Parsing Easy for humans to write and understand String of characters Lexemes identified String of tokens Easy for programs to transform Data structure Syntax A syntax
Lexical Analyzer Scanner
 Lexical Analyzer Scanner ASU Textbook Chapter 3.1, 3.3, 3.4, 3.6, 3.7, 3.5 Tsan-sheng Hsu tshsu@iis.sinica.edu.tw http://www.iis.sinica.edu.tw/~tshsu 1 Main tasks Read the input characters and produce
Lexical Analyzer Scanner ASU Textbook Chapter 3.1, 3.3, 3.4, 3.6, 3.7, 3.5 Tsan-sheng Hsu tshsu@iis.sinica.edu.tw http://www.iis.sinica.edu.tw/~tshsu 1 Main tasks Read the input characters and produce
General Overview of Compiler
 General Overview of Compiler Compiler: - It is a complex program by which we convert any high level programming language (source code) into machine readable code. Interpreter: - It performs the same task
General Overview of Compiler Compiler: - It is a complex program by which we convert any high level programming language (source code) into machine readable code. Interpreter: - It performs the same task
Introduction to Parsing. Comp 412
 COMP 412 FALL 2010 Introduction to Parsing Comp 412 Copyright 2010, Keith D. Cooper & Linda Torczon, all rights reserved. Students enrolled in Comp 412 at Rice University have explicit permission to make
COMP 412 FALL 2010 Introduction to Parsing Comp 412 Copyright 2010, Keith D. Cooper & Linda Torczon, all rights reserved. Students enrolled in Comp 412 at Rice University have explicit permission to make
Syntax Analysis. Amitabha Sanyal. (www.cse.iitb.ac.in/ as) Department of Computer Science and Engineering, Indian Institute of Technology, Bombay
 Department of Computer Science and Engineering, Indian Institute of Technology, Bombay") Syntax Analysis (www.cse.iitb.ac.in/ as) Department of Computer Science and Engineering, Indian Institute of Technology, Bombay September 2007 College of Engineering, Pune Syntax Analysis: 2/124 Syntax
Syntax Analysis (www.cse.iitb.ac.in/ as) Department of Computer Science and Engineering, Indian Institute of Technology, Bombay September 2007 College of Engineering, Pune Syntax Analysis: 2/124 Syntax
3. Syntax Analysis. Andrea Polini. Formal Languages and Compilers Master in Computer Science University of Camerino
 3. Syntax Analysis Andrea Polini Formal Languages and Compilers Master in Computer Science University of Camerino (Formal Languages and Compilers) 3. Syntax Analysis CS@UNICAM 1 / 54 Syntax Analysis: the
3. Syntax Analysis Andrea Polini Formal Languages and Compilers Master in Computer Science University of Camerino (Formal Languages and Compilers) 3. Syntax Analysis CS@UNICAM 1 / 54 Syntax Analysis: the
CSEP 501 Compilers. Languages, Automata, Regular Expressions & Scanners Hal Perkins Winter /8/ Hal Perkins & UW CSE B-1
 CSEP 501 Compilers Languages, Automata, Regular Expressions & Scanners Hal Perkins Winter 2008 1/8/2008 2002-08 Hal Perkins & UW CSE B-1 Agenda Basic concepts of formal grammars (review) Regular expressions
CSEP 501 Compilers Languages, Automata, Regular Expressions & Scanners Hal Perkins Winter 2008 1/8/2008 2002-08 Hal Perkins & UW CSE B-1 Agenda Basic concepts of formal grammars (review) Regular expressions
CMSC 330: Organization of Programming Languages. Context Free Grammars
 CMSC 330: Organization of Programming Languages Context Free Grammars 1 Architecture of Compilers, Interpreters Source Analyzer Optimizer Code Generator Abstract Syntax Tree Front End Back End Compiler
CMSC 330: Organization of Programming Languages Context Free Grammars 1 Architecture of Compilers, Interpreters Source Analyzer Optimizer Code Generator Abstract Syntax Tree Front End Back End Compiler
Introduction to Lexical Analysis
 Introduction to Lexical Analysis Outline Informal sketch of lexical analysis Identifies tokens in input string Issues in lexical analysis Lookahead Ambiguities Specifying lexical analyzers (lexers) Regular
Introduction to Lexical Analysis Outline Informal sketch of lexical analysis Identifies tokens in input string Issues in lexical analysis Lookahead Ambiguities Specifying lexical analyzers (lexers) Regular
The analysis part breaks up the source program into constituent pieces and creates an intermediate representation of the source program.
 COMPILER DESIGN 1. What is a compiler? A compiler is a program that reads a program written in one language the source language and translates it into an equivalent program in another language-the target
COMPILER DESIGN 1. What is a compiler? A compiler is a program that reads a program written in one language the source language and translates it into an equivalent program in another language-the target
COMPILER DESIGN UNIT I LEXICAL ANALYSIS. Translator: It is a program that translates one language to another Language.
 UNIT I LEXICAL ANALYSIS Translator: It is a program that translates one language to another Language. Source Code Translator Target Code 1. INTRODUCTION TO LANGUAGE PROCESSING The Language Processing System
UNIT I LEXICAL ANALYSIS Translator: It is a program that translates one language to another Language. Source Code Translator Target Code 1. INTRODUCTION TO LANGUAGE PROCESSING The Language Processing System
CS 406/534 Compiler Construction Parsing Part I
 CS 406/534 Compiler Construction Parsing Part I Prof. Li Xu Dept. of Computer Science UMass Lowell Fall 2004 Part of the course lecture notes are based on Prof. Keith Cooper, Prof. Ken Kennedy and Dr.
CS 406/534 Compiler Construction Parsing Part I Prof. Li Xu Dept. of Computer Science UMass Lowell Fall 2004 Part of the course lecture notes are based on Prof. Keith Cooper, Prof. Ken Kennedy and Dr.
Languages, Automata, Regular Expressions & Scanners. Winter /8/ Hal Perkins & UW CSE B-1
 CSE 401 Compilers Languages, Automata, Regular Expressions & Scanners Hal Perkins Winter 2010 1/8/2010 2002-10 Hal Perkins & UW CSE B-1 Agenda Quick review of basic concepts of formal grammars Regular
CSE 401 Compilers Languages, Automata, Regular Expressions & Scanners Hal Perkins Winter 2010 1/8/2010 2002-10 Hal Perkins & UW CSE B-1 Agenda Quick review of basic concepts of formal grammars Regular