Programming in CUDA. Malik M Khan
|
|
|
- Steven Crawford
- 6 years ago
- Views:
Transcription
1 Programming in CUDA October 21, 2010 Malik M Khan
2 Outline Reminder of CUDA Architecture Execution Model - Brief mention of control flow Heterogeneous Memory Hierarchy - Locality through data placement - Maximizing bandwidth through global memory coalescing - Avoiding memory bank conflicts Tiling and its Applicability to CUDA Code Generation - Example Matrix-Vector Multiplication This lecture includes slides provided by: Wen-mei Hwu (UIUC) and David Kirk (NVIDIA) see and Austin Robison (NVIDIA)
3 Reading David Kirk and Wen-mei Hwu manuscript (in progress) - CUDA 2.x Manual, particularly Chapters 2 and 4 (download from nvidia.com/cudazone) Nice series from Dr. Dobbs Journal by Rob Farber -
4 CUDA Programming Model: A Highly Multithreaded Coprocessor The GPU is viewed as a compute device that: - Is a coprocessor to the CPU or host - Has its own DRAM (device memory) - Runs many threads in parallel Data-parallel portions of an application are executed on the device as kernels which run in parallel on many threads Differences between GPU and CPU threads - GPU threads are extremely lightweight 11/05/09 - Very little creation overhead - GPU needs 1000s of threads for full efficiency - Multi-core CPU needs only a few
5 Batching: Grids and Blocks A kernel is executed as a grid of thread blocks - All threads share data memory space A thread block is a batch of threads that can cooperate with each other by: - Synchronizing their execution - For hazard-free shared memory accesses - Efficiently sharing data through a low latency shared memory Host Kernel 1 Kernel 2 Block (1, 1) Device Grid 1 Block (0, 0) Block (0, 1) Grid 2 Block (1, 0) Block (1, 1) Block (2, 0) Block (2, 1) Two threads from two different blocks cannot cooperate David Kirk/NVIDIA and Wen-mei W. Hwu, 2007 ECE 498AL, University of Illinois, Urbana-Champaign Courtesy: NDVIA (0, 0) (0, 1) (0, 2) (1, 0) (1, 1) (1, 2) (2, 0) (2, 1) (2, 2) (3, 0) (3, 1) (3, 2) (4, 0) (4, 1) (4, 2)
6 Block and IDs s and blocks have IDs Device Grid 1 - So each thread can decide what data to work on Block (0, 0) Block (1, 0) Block (2, 0) - Block ID: 1D or 2D (blockidx.x, blockidx.y) Block (0, 1) Block (1, 1) Block (2, 1) - ID: 1D, 2D, or 3D (threadidx.{x,y,z}) Block (1, 1) Simplifies memory addressing when processing multidimensional data - Image processing - Solving PDEs on volumes - (0, 0) (0, 1) (0, 2) (1, 0) (1, 1) (1, 2) (2, 0) (2, 1) (2, 2) (3, 0) (3, 1) (3, 2) (4, 0) (4, 1) (4, 2) Courtesy: NDVIA David Kirk/NVIDIA and Wen-mei W. Hwu, 2007 ECE 498AL, University of Illinois, Urbana-Champaign
7 David Kirk/NVIDIA and Wen-mei W. Hwu, 2007 ECE 498AL, University of Illinois, Urbana-Champaign Hardware Implementation: A Set of SIMD Multiprocessors A device has a set of multiprocessors Each multiprocessor is a set of 32-bit processors with a Single Instruction Multiple Data architecture - Shared instruction unit At each clock cycle, a multiprocessor executes the same instruction on a group of threads called a warp The number of threads in a warp is the warp size Device Multiprocessor N Multiprocessor 2 Multiprocessor 1 Processor 1 Processor 2 Processor M Instruction Unit
8 Hardware Execution Model I. SIMD Execution of warpsize=m threads (from single block) Result is a set of instruction streams roughly equal to # blocks in thread divided by warpsize Device Multiprocessor N Multiprocessor 2 Multiprocessor 1 II. Multithreaded Execution across different instruction streams within block Also possibly across different blocks if there are more blocks than SMs III. Each block mapped to single SM No direct interaction across SMs Register s Processor 1 Shared Memory Register s Processor 2 Register s Processor M Instruction Unit Constant Cache Texture Cache Device memory
9 A Very Simple Execution Model No branch prediction - Just evaluate branch targets and wait for resolution - But wait is only a small number of cycles No speculation - Only execute useful instructions
10 Terminology Divergent paths - Different threads within a warp take different control flow paths within a kernel function - N divergent paths in a warp? - An N-way divergent warp is serially issued over the N different paths using a hardware stack and per-thread predication logic to only write back results from the threads taking each divergent path. - Performance decreases by about a factor of N
11 Hardware Implementation: Memory Architecture The local, global, constant, and texture spaces are regions of device memory Each multiprocessor has: - A set of 32-bit registers per processor - On-chip shared memory - Where the shared memory space resides - A read-only constant cache - To speed up access to the constant memory space - A read-only texture cache - To speed up access to the texture memory space Device David Kirk/NVIDIA and Wen-mei W. Hwu, 2007 ECE 498AL, University of Illinois, Urbana-Champaign Multiprocessor N Multiprocessor 2 Multiprocessor 1 Registers Processor 1 Device memory Shared Memory Registers Processor 2 Registers Processor M Instruction Unit Constant Cache Texture Cache Global, constant, texture memories
12 Programmer s View: Memory Spaces Each thread can: - Read/write per-thread registers - Read/write per-thread local memory - Read/write per-block shared memory - Read/write per-grid global memory - Read only per-grid constant memory - Read only per-grid texture memory Grid Block (0, 0) Registers Shared Memory Registers Block (1, 0) Shared Memory Registers Registers (0, 0) (1, 0) (0, 0) (1, 0) Local Memory Local Memory Local Memory Local Memory The host can read/write global, constant, and texture memory Host David Kirk/NVIDIA and Wen-mei W. Hwu, 2007 ECE 498AL, University of Illinois, Urbana-Champaign Global Memory Constant Memory Texture Memory
13 Now Let s Look at Shared Memory Common Programming Pattern (5.1.2 of CUDA manual) - Load data into shared memory - Synchronize (if necessary) - Operate on data in shared memory - Synchronize (if necessary) - Write intermediate results to global memory - Repeat until done Shared memory Global memory Familiar concept?
14 Mechanics of Using Shared Memory shared type qualifier required Must be allocated from global/device function, or as extern Examples: extern shared float d_s_array[]; /* a form of dynamic allocation */ /* MEMSIZE is size of per-block */ /* shared memory*/ host void outercompute() { compute<<<gs,bs,memsize>>>(); } global void compute() { d_s_array[i] = ; } global void compute2() { shared float d_s_array[m]; } /* create or copy from global memory */ d_s_array[j] = ; /* write result back to global memory */ d_g_array[j] = d_s_array[j];
15 Bandwidth to Shared Memory: Parallel Memory Accesses Consider each thread accessing a different location in shared memory Bandwidth maximized if each one is able to proceed in parallel Hardware to support this - Banked memory: each bank can support an access on every memory cycle
16 Bank Addressing Examples No Bank Conflicts - Linear addressing stride == 1 No Bank Conflicts - Random 1:1 Permutation Bank 0 Bank 1 Bank 2 Bank 3 Bank 4 Bank 5 Bank 6 Bank Bank 0 Bank 1 Bank 2 Bank 3 Bank 4 Bank 5 Bank 6 Bank 7 15 Bank Bank 15 David Kirk/NVIDIA and Wen-mei W. Hwu, ECE 498AL, University of Illinois, Urbana-Champaign
17 Bank Addressing Examples 2-way Bank Conflicts - Linear addressing stride == 2 8-way Bank Conflicts - Linear addressing stride == Bank 0 Bank 1 Bank 2 Bank 3 Bank 4 Bank 5 Bank 6 Bank 7 Bank x8 x8 Bank 0 Bank 1 Bank 2 Bank 7 Bank 8 Bank 9 Bank 15 David Kirk/NVIDIA and Wen-mei W. Hwu,
18 How addresses map to banks on G80 Each bank has a bandwidth of 32 bits per clock cycle Successive 32-bit words are assigned to successive banks G80 has 16 banks - So bank = address % 16 - Same as the size of a half-warp - No bank conflicts between different half-warps, only within a single half-warp David Kirk/NVIDIA and Wen-mei W. Hwu, ECE 498AL, University of Illinois, Urbana-Champaign
19 Shared memory bank conflicts Shared memory is as fast as registers if there are no bank conflicts The fast case: - If all threads of a half-warp access different banks, there is no bank conflict - If all threads of a half-warp access the identical address, there is no bank conflict (broadcast) The slow case: - Bank Conflict: multiple threads in the same half-warp access the same bank - Must serialize the accesses - Cost = max # of simultaneous accesses to a single bank David Kirk/NVIDIA and Wen-mei W. Hwu, ECE 498AL, University of Illinois, Urbana-Champaign
20 Global Memory Accesses Each thread issues memory accesses to data types of varying sizes, perhaps as small as 1 byte entities Given an address to load or store, memory returns/updates segments of either 32 bytes, 64 bytes or 128 bytes Maximizing bandwidth: - Operate on an entire 128 byte segment for each memory transfer
21 Understanding Global Memory Accesses Memory protocol for compute capability 1.2* (CUDA Manual ) Start with memory request by smallest numbered thread. Find the memory segment that contains the address (32, 64 or 128 byte segment, depending on data type) Find other active threads requesting addresses within that segment and coalesce Reduce transaction size if possible Access memory and mark threads as inactive Repeat until all threads in half-warp are serviced *Includes Tesla and GTX platforms
22 David Kirk/NVIDIA and Wen-mei W. Hwu, ECE 498AL, University of Illinois, Urbana-Champaign Memory Layout of a Matrix in C Access direction in Kernel code M 0,0 M 0,1 M 1,0 M 1,1 M 2,0 M 3,0 M 2,1 M 3,1 M 0,2 M 1,2 M 2,2 M 3,2 M 0,3 M 1,3 M 2,3 M 3,3 M Time Period 1 T 1 T 2 T 3 T 4 Time Period 2 T 1 T 2 T 3 T 4 M 0,0 M 1,0 M 2,0 M 3,0 M 1,1 M 0,1 M 2,1 M 3,1 M 0,2 M 1,2 M 2,2 M 3,2 M 0,3 M 1,3 M 2,3 M 3,3
23 David Kirk/NVIDIA and Wen-mei W. Hwu, ECE 498AL, University of Illinois, Urbana-Champaign Memory Layout of a Matrix in C Access direction in Kernel code M 0,0 M 0,1 M 1,0 M 1,1 M 2,0 M 3,0 M 2,1 M 3,1 M 0,2 M 1,2 M 2,2 M 3,2 Time Period 2 M 0,3 M 1,3 M 2,3 M 3,3 T 1 T 2 T 3 T 4 Time Period 1 T 1 T 2 T 3 T 4 M M 0,0 M 1,0 M 2,0 M 3,0 M 1,1 M 0,1 M 2,1 M 3,1 M 0,2 M 1,2 M 2,2 M 3,2 M 0,3 M 1,3 M 2,3 M 3,3
24 Using Loop Transformations in GPU Code Generation Cod transformations Application Conventional Architectures GPU Tiling Manage reuse in limited storage Manage reuse in limited storage Partition parallel execution at 2 levels Data-copy Eliminate conflict misses in cache Copy data to specialized memory structures Permutation Unrolling Reorder loop structure to enable other optimizations Exposes fine-grain parallelism by replicating the loop body Reorder loop structure to enable other optimizations Exposes fine-grain parallelism by replicating the loop body

25 Tiling for Computation Mapping in GPUs I Tiles Mapped to blocks J
26 Matrix-Vector Multiply: A Naïve Strategy N = 1024 Sequential code* for (i = 0; i < N; i++) for (j = 0; j < N; j++) a[i] = a[i] + c[j][i] * b[j]; CUDA Kernel global GPU_MV(float* a, float* b, float** c){ int i= blockidx.x* threadidx.x; for (int j=0; j<n; j++) a[i] = a[i]+ c[j][i]* b[j] ; } Performance < 3.75GF < CUBLAS2.2 Host Code...copy data to device... dim3 dimgrid(n/512, 1); dim3 dimblock(512, 1); GPU_MV<<<dimGrid,dimBlock>>>(gpuA,gpuB,gpuC);...copy data back to host * Following CUBLAS notation for matrix vector multiplication which takes transposed matrix as input.
27 Decision Algorithm: Computational Decomposition Block Parallelism tile_by_index({ i }, {TI}, {l1_control="ii },{"ii","i", "j }) cudaize( block{ ii }, thread{} ) Parallelism cudaize( block{ ii }, thread{ i } )
 Registers Data Reuse inside thread Final Loop Order Cudaize Unrolling cudaize( block{ ii }, thread{ i } ) unroll to depth( 1")
28 Decision Algorithm: Data Staging Data Staging Shared Memory Data Reuse across threads tile_by_index({ j }, {TJ}, {l1_control= jj },{"ii", jj,"i", "j }) Registers Data Reuse inside thread Final Loop Order Cudaize Unrolling cudaize( block{ ii }, thread{ i } ) unroll to depth( 1 )
29 CUDA-CHiLL Recipe N = 1024 TI= TJ = 32 tile_by_index({ i, j }, {TI,TJ}, {l1_control="ii, l2_control= k },{"ii", jj,"i", "j }) normalize_index( i ) cudaize( mv_gpu, {a=n, b=n, c=n*n},{block={ ii }, thread={ i }}) copy_to_shared( tx, b, 1) copy_to_registers( jj, a ) unroll_to_depth(1)
30 Matrix-Vector Multiply: GPU Code Generated Code: with Computational decomposition only. global GPU_MV(float* a, float* b, float** c) { int bx = blockidx.x; int tx = threadidx.x; int i = 32*bx+tx; for (j = 0; j < N; j++) a[i] = a[i] + c[j][i] * b[j]; } Final MV Generated Code: with Data staged in shared memory & registers. global GPU_MV(float* a, float* b, float** c) { int bx = blockidx.x; int tx = threadidx.x; shared float bcpy[32]; float acpy = a[tx + 32 * bx]; for (jj = 0; jj < 32; jj++) { } bcpy[tx] = b[32 * jj + tx]; syncthreads(); //this loop is actually fully unrolled for (j = 32 * jj; j <= 32 * jj + 32; j++) acpy = acpy + c[j][32 * bx + tx] * bcpy [j]; syncthreads(); a[tx + 32 * bx] = acpy; } Performance always tops CUBLAS 2.2 & ~4x improvement on the naïve GPU kernel


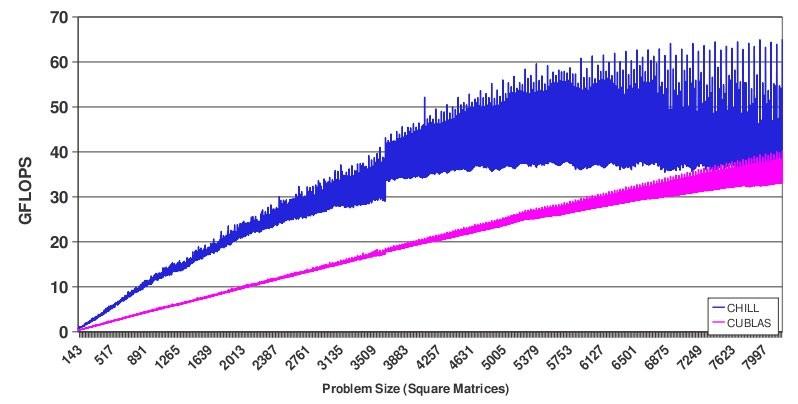


31 BLAS Library Kernel Optimization MV Results MM Results


32 Memory Copy and Stencil Optimization 2D Convolution Matrix Transpose
33 Summary of Lecture A deeper probe of performance issues - Execution model - Control flow - Heterogeneous memory hierarchy - Locality and bandwidth - Tiling for CUDA code generation - An example of Tiling Transformation with Matrix-Vector Multiplication.
L17: CUDA, cont. 11/3/10. Final Project Purpose: October 28, Next Wednesday, November 3. Example Projects
 L17: CUDA, cont. October 28, 2010 Final Project Purpose: - A chance to dig in deeper into a parallel programming model and explore concepts. - Present results to work on communication of technical ideas
L17: CUDA, cont. October 28, 2010 Final Project Purpose: - A chance to dig in deeper into a parallel programming model and explore concepts. - Present results to work on communication of technical ideas
L14: CUDA, cont. Execution Model and Memory Hierarchy"
 Programming Assignment 3, Due 11:59PM Nov. 7 L14: CUDA, cont. Execution Model and Hierarchy" October 27, 2011! Purpose: - Synthesize the concepts you have learned so far - Data parallelism, locality and
Programming Assignment 3, Due 11:59PM Nov. 7 L14: CUDA, cont. Execution Model and Hierarchy" October 27, 2011! Purpose: - Synthesize the concepts you have learned so far - Data parallelism, locality and
2/2/11. Administrative. L6: Memory Hierarchy Optimization IV, Bandwidth Optimization. Project Proposal (due 3/9) Faculty Project Suggestions
 Faculty Project Suggestions") Administrative L6: Memory Hierarchy Optimization IV, Bandwidth Optimization Next assignment available Goals of assignment: simple memory hierarchy management block-thread decomposition tradeoff Due Tuesday,
Administrative L6: Memory Hierarchy Optimization IV, Bandwidth Optimization Next assignment available Goals of assignment: simple memory hierarchy management block-thread decomposition tradeoff Due Tuesday,
1/25/12. Administrative
 Administrative L3: Memory Hierarchy Optimization I, Locality and Data Placement Next assignment due Friday, 5 PM Use handin program on CADE machines handin CS6235 lab1 TA: Preethi Kotari - Email:
Administrative L3: Memory Hierarchy Optimization I, Locality and Data Placement Next assignment due Friday, 5 PM Use handin program on CADE machines handin CS6235 lab1 TA: Preethi Kotari - Email:
Administrative Issues. L10: Dense Linear Algebra on GPUs. Triangular Solve (STRSM) Outline 2/25/11. Next assignment, linear algebra
 Outline 2/25/11. Next assignment, linear algebra") Administrative Issues L10: Dense Linear Algebra on GPUs Next assignment, linear algebra Handed out by Friday Due before spring break handin cs6963 lab 3 Outline Triangular solve assignment from
Administrative Issues L10: Dense Linear Algebra on GPUs Next assignment, linear algebra Handed out by Friday Due before spring break handin cs6963 lab 3 Outline Triangular solve assignment from
2/17/10. Administrative. L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies. Administrative, cont.
 Administrative L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies Next assignment on the website Description at end of class Due Wednesday, Feb. 17, 5PM Use handin program on
Administrative L7: Memory Hierarchy Optimization IV, Bandwidth Optimization and Case Studies Next assignment on the website Description at end of class Due Wednesday, Feb. 17, 5PM Use handin program on
L18: Introduction to CUDA
 L18: Introduction to CUDA November 5, 2009 Administrative Homework assignment 3 will be posted today (after class) Due, Thursday, November 5 before class - Use the handin program on the CADE machines -
L18: Introduction to CUDA November 5, 2009 Administrative Homework assignment 3 will be posted today (after class) Due, Thursday, November 5 before class - Use the handin program on the CADE machines -
Review for Midterm 3/28/11. Administrative. Parts of Exam. Midterm Exam Monday, April 4. Midterm. Design Review. Final projects
 Administrative Midterm - In class April 4, open notes - Review notes, readings and review lecture (before break) - Will post prior exams Design Review - Intermediate assessment of progress on project,
Administrative Midterm - In class April 4, open notes - Review notes, readings and review lecture (before break) - Will post prior exams Design Review - Intermediate assessment of progress on project,
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
CUDA programming model. N. Cardoso & P. Bicudo. Física Computacional (FC5)
") CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA programming model N. Cardoso & P. Bicudo Física Computacional (FC5) N. Cardoso & P. Bicudo CUDA programming model 1/23 Outline 1 CUDA qualifiers 2 CUDA Kernel Thread hierarchy Kernel, configuration
CUDA Memory Model. Monday, 21 February Some material David Kirk, NVIDIA and Wen-mei W. Hwu, (used with permission)
") CUDA Memory Model Some material David Kirk, NVIDIA and Wen-mei W. Hwu, 2007-2009 (used with permission) 1 G80 Implementation of CUDA Memories Each thread can: Grid Read/write per-thread registers Read/write
CUDA Memory Model Some material David Kirk, NVIDIA and Wen-mei W. Hwu, 2007-2009 (used with permission) 1 G80 Implementation of CUDA Memories Each thread can: Grid Read/write per-thread registers Read/write
Introduction to CUDA (1 of n*)
") Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Administrivia Introduction to CUDA (1 of n*) Patrick Cozzi University of Pennsylvania CIS 565 - Spring 2011 Paper presentation due Wednesday, 02/23 Topics first come, first serve Assignment 4 handed today
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Advanced Architectures Master Informatics Eng. 2018/19 A.J.Proença Data Parallelism 3 (GPU/CUDA, Neural Nets,...) (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 2018/19 1 The
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
L3: Data Partitioning and Memory Organization, Synchronization
 Outline More on CUDA L3: Data Partitioning and Organization, Synchronization January 21, 2009 1 First assignment, due Jan. 30 (later in lecture) Error checking mechanisms Synchronization More on data partitioning
Outline More on CUDA L3: Data Partitioning and Organization, Synchronization January 21, 2009 1 First assignment, due Jan. 30 (later in lecture) Error checking mechanisms Synchronization More on data partitioning
Introduction to CUDA (1 of n*)
") Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Agenda Introduction to CUDA (1 of n*) GPU architecture review CUDA First of two or three dedicated classes Joseph Kider University of Pennsylvania CIS 565 - Spring 2011 * Where n is 2 or 3 Acknowledgements
Introduction to GPU programming. Introduction to GPU programming p. 1/17
 Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Introduction to GPU programming Introduction to GPU programming p. 1/17 Introduction to GPU programming p. 2/17 Overview GPUs & computing Principles of CUDA programming One good reference: David B. Kirk
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Lecture 5. Performance Programming with CUDA
 Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
Lecture 5 Performance Programming with CUDA Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Today s lecture Matrix multiplication 2011 Scott B. Baden / CSE 262 / Spring 2011 3 Memory Hierarchy
GPU & High Performance Computing (by NVIDIA) CUDA. Compute Unified Device Architecture Florian Schornbaum
 CUDA. Compute Unified Device Architecture Florian Schornbaum") GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
GPU & High Performance Computing (by NVIDIA) CUDA Compute Unified Device Architecture 29.02.2008 Florian Schornbaum GPU Computing Performance In the last few years the GPU has evolved into an absolute
Code Optimizations for High Performance GPU Computing
 Code Optimizations for High Performance GPU Computing Yi Yang and Huiyang Zhou Department of Electrical and Computer Engineering North Carolina State University 1 Question to answer Given a task to accelerate
Code Optimizations for High Performance GPU Computing Yi Yang and Huiyang Zhou Department of Electrical and Computer Engineering North Carolina State University 1 Question to answer Given a task to accelerate
1/31/11. How to tell if results are correct. Assignment 2: Analyzing the Results. Targets of Memory Hierarchy Optimizations. Overview of Lecture
 Administrative L5: emory Hierarchy Optimization III, Data lacement, cont. and emory Bandwidth Optimizations ext assignment available ext four slides Goals of assignment: simple memory hierarchy management
Administrative L5: emory Hierarchy Optimization III, Data lacement, cont. and emory Bandwidth Optimizations ext assignment available ext four slides Goals of assignment: simple memory hierarchy management
Spring Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
Spring 2011 Prof. Hyesoon Kim 2 Warp is the basic unit of execution A group of threads (e.g. 32 threads for the Tesla GPU architecture) Warp Execution Inst 1 Inst 2 Inst 3 Sources ready T T T T One warp
CS/EE 217 GPU Architecture and Parallel Programming. Lecture 10. Reduction Trees
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 10 Reduction Trees David Kirk/NVIDIA and Wen-mei W. Hwu University of Illinois, 2007-2012 1 Objective To master Reduction Trees, arguably the
CS/EE 217 GPU Architecture and Parallel Programming Lecture 10 Reduction Trees David Kirk/NVIDIA and Wen-mei W. Hwu University of Illinois, 2007-2012 1 Objective To master Reduction Trees, arguably the
Module 2: Introduction to CUDA C
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Mattan Erez. The University of Texas at Austin
 EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
EE382V (17325): Principles in Computer Architecture Parallelism and Locality Fall 2007 Lecture 12 GPU Architecture (NVIDIA G80) Mattan Erez The University of Texas at Austin Outline 3D graphics recap and
Introduction to CUDA Programming
 Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Introduction to CUDA Programming Steve Lantz Cornell University Center for Advanced Computing October 30, 2013 Based on materials developed by CAC and TACC Outline Motivation for GPUs and CUDA Overview
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Data Parallel Execution Model
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
CS/EE 217 GPU Architecture and Parallel Programming Lecture 3: Kernel-Based Data Parallel Execution Model David Kirk/NVIDIA and Wen-mei Hwu, 2007-2013 Objective To understand the organization and scheduling
Lecture 7. Using Shared Memory Performance programming and the memory hierarchy
 Lecture 7 Using Shared Memory Performance programming and the memory hierarchy Announcements Scott B. Baden /CSE 260/ Winter 2014 2 Assignment #1 Blocking for cache will boost performance but a lot more
Lecture 7 Using Shared Memory Performance programming and the memory hierarchy Announcements Scott B. Baden /CSE 260/ Winter 2014 2 Assignment #1 Blocking for cache will boost performance but a lot more
HPC COMPUTING WITH CUDA AND TESLA HARDWARE. Timothy Lanfear, NVIDIA
 HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
HPC COMPUTING WITH CUDA AND TESLA HARDWARE Timothy Lanfear, NVIDIA WHAT IS GPU COMPUTING? What is GPU Computing? x86 PCIe bus GPU Computing with CPU + GPU Heterogeneous Computing Low Latency or High Throughput?
GPU Programming. Performance Considerations. Miaoqing Huang University of Arkansas Fall / 60
 1 / 60 GPU Programming Performance Considerations Miaoqing Huang University of Arkansas Fall 2013 2 / 60 Outline Control Flow Divergence Memory Coalescing Shared Memory Bank Conflicts Occupancy Loop Unrolling
1 / 60 GPU Programming Performance Considerations Miaoqing Huang University of Arkansas Fall 2013 2 / 60 Outline Control Flow Divergence Memory Coalescing Shared Memory Bank Conflicts Occupancy Loop Unrolling
Lecture 2: Introduction to CUDA C
 CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
CS/EE 217 GPU Architecture and Programming Lecture 2: Introduction to CUDA C David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2013 1 CUDA /OpenCL Execution Model Integrated host+device app C program Serial or
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC.
 David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
Module 3: CUDA Execution Model -I. Objective
 ECE 8823A GPU Architectures odule 3: CUDA Execution odel -I 1 Objective A more detailed look at kernel execution Data to thread assignment To understand the organization and scheduling of threads Resource
ECE 8823A GPU Architectures odule 3: CUDA Execution odel -I 1 Objective A more detailed look at kernel execution Data to thread assignment To understand the organization and scheduling of threads Resource
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Shared Memory. Table of Contents. Shared Memory Learning CUDA to Solve Scientific Problems. Objectives. Technical Issues Shared Memory.
 Table of Contents Shared Memory Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain miguel.cardenas@ciemat.es
Table of Contents Shared Memory Learning CUDA to Solve Scientific Problems. 1 Objectives Miguel Cárdenas Montes Centro de Investigaciones Energéticas Medioambientales y Tecnológicas, Madrid, Spain miguel.cardenas@ciemat.es
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CSE 160 Lecture 24. Graphical Processing Units
 CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
CSE 160 Lecture 24 Graphical Processing Units Announcements Next week we meet in 1202 on Monday 3/11 only On Weds 3/13 we have a 2 hour session Usual class time at the Rady school final exam review SDSC
Dense Linear Algebra. HPC - Algorithms and Applications
 Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
Dense Linear Algebra HPC - Algorithms and Applications Alexander Pöppl Technical University of Munich Chair of Scientific Computing November 6 th 2017 Last Tutorial CUDA Architecture thread hierarchy:
This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC.
 David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
David Kirk/NVIDIA and Wen-mei Hwu, 2006-2008 This is a draft chapter from an upcoming CUDA textbook by David Kirk from NVIDIA and Prof. Wen-mei Hwu from UIUC. Please send any comment to dkirk@nvidia.com
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose 10:30 AM Friday October 2, 2009 Joe Stam Optimization GPUs are very fast BUT Naïve programming can result in disappointing performance
CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012
 CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012 Overview 1. Memory Access Efficiency 2. CUDA Memory Types 3. Reducing Global Memory Traffic 4. Example: Matrix-Matrix
CUDA Memory Types All material not from online sources/textbook copyright Travis Desell, 2012 Overview 1. Memory Access Efficiency 2. CUDA Memory Types 3. Reducing Global Memory Traffic 4. Example: Matrix-Matrix
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Module 2: Introduction to CUDA C. Objective
 ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
ECE 8823A GPU Architectures Module 2: Introduction to CUDA C 1 Objective To understand the major elements of a CUDA program Introduce the basic constructs of the programming model Illustrate the preceding
Matrix Multiplication in CUDA. A case study
 Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
Matrix Multiplication in CUDA A case study 1 Matrix Multiplication: A Case Study Matrix multiplication illustrates many of the basic features of memory and thread management in CUDA Usage of thread/block
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
EE382N (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)
: Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III)") EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 18 GPUs (III) Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture
Lecture 7. Overlap Using Shared Memory Performance programming the memory hierarchy
 Lecture 7 Overlap Using Shared Memory Performance programming the memory hierarchy Announcements Mac Mini lab (APM 2402) Starts Tuesday Every Tues and Fri for the next 2 weeks Project proposals due on
Lecture 7 Overlap Using Shared Memory Performance programming the memory hierarchy Announcements Mac Mini lab (APM 2402) Starts Tuesday Every Tues and Fri for the next 2 weeks Project proposals due on
GPU programming. Dr. Bernhard Kainz
 GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
GPU programming Dr. Bernhard Kainz Overview About myself Motivation GPU hardware and system architecture GPU programming languages GPU programming paradigms Pitfalls and best practice Reduction and tiling
CS 677: Parallel Programming for Many-core Processors Lecture 6
 1 CS 677: Parallel Programming for Many-core Processors Lecture 6 Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Logistics Midterm: March 11
1 CS 677: Parallel Programming for Many-core Processors Lecture 6 Instructor: Philippos Mordohai Webpage: www.cs.stevens.edu/~mordohai E-mail: Philippos.Mordohai@stevens.edu Logistics Midterm: March 11
CS 179: GPU Computing. Recitation 2: Synchronization, Shared memory, Matrix Transpose
 CS 179: GPU Computing Recitation 2: Synchronization, Shared memory, Matrix Transpose Synchronization Ideal case for parallelism: no resources shared between threads no communication between threads Many
CS 179: GPU Computing Recitation 2: Synchronization, Shared memory, Matrix Transpose Synchronization Ideal case for parallelism: no resources shared between threads no communication between threads Many
Double-Precision Matrix Multiply on CUDA
 Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
Double-Precision Matrix Multiply on CUDA Parallel Computation (CSE 60), Assignment Andrew Conegliano (A5055) Matthias Springer (A995007) GID G--665 February, 0 Assumptions All matrices are square matrices
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture
 COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
COMP 605: Introduction to Parallel Computing Lecture : GPU Architecture Mary Thomas Department of Computer Science Computational Science Research Center (CSRC) San Diego State University (SDSU) Posted:
Lecture 6. Programming with Message Passing Message Passing Interface (MPI)
") Lecture 6 Programming with Message Passing Message Passing Interface (MPI) Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Finish CUDA Today s lecture Programming with message passing 2011
Lecture 6 Programming with Message Passing Message Passing Interface (MPI) Announcements 2011 Scott B. Baden / CSE 262 / Spring 2011 2 Finish CUDA Today s lecture Programming with message passing 2011
GPU Programming. Lecture 2: CUDA C Basics. Miaoqing Huang University of Arkansas 1 / 34
 1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
1 / 34 GPU Programming Lecture 2: CUDA C Basics Miaoqing Huang University of Arkansas 2 / 34 Outline Evolvements of NVIDIA GPU CUDA Basic Detailed Steps Device Memories and Data Transfer Kernel Functions
CSE 591: GPU Programming. Memories. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591: GPU Programming Memories Klaus Mueller Computer Science Department Stony Brook University Importance of Memory Access Efficiency Every loop iteration has two global memory accesses two floating
CSE 591: GPU Programming Memories Klaus Mueller Computer Science Department Stony Brook University Importance of Memory Access Efficiency Every loop iteration has two global memory accesses two floating
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
COSC 6374 Parallel Computations Introduction to CUDA
 COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
COSC 6374 Parallel Computations Introduction to CUDA Edgar Gabriel Fall 2014 Disclaimer Material for this lecture has been adopted based on various sources Matt Heavener, CS, State Univ. of NY at Buffalo
Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA
 Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA Shane Ryoo, Christopher I. Rodrigues, Sara S. Baghsorkhi, Sam S. Stone, David B. Kirk, and Wen-mei H. Hwu
Optimization Principles and Application Performance Evaluation of a Multithreaded GPU Using CUDA Shane Ryoo, Christopher I. Rodrigues, Sara S. Baghsorkhi, Sam S. Stone, David B. Kirk, and Wen-mei H. Hwu
G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G
 Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
Joined Advanced Student School (JASS) 2009 March 29 - April 7, 2009 St. Petersburg, Russia G P G P U : H I G H - P E R F O R M A N C E C O M P U T I N G Dmitry Puzyrev St. Petersburg State University Faculty
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Performance optimization with CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Performance optimization with CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide
Performance optimization with CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide
Device Memories and Matrix Multiplication
 Device Memories and Matrix Multiplication 1 Device Memories global, constant, and shared memories CUDA variable type qualifiers 2 Matrix Multiplication an application of tiling runningmatrixmul in the
Device Memories and Matrix Multiplication 1 Device Memories global, constant, and shared memories CUDA variable type qualifiers 2 Matrix Multiplication an application of tiling runningmatrixmul in the
Administrative. L8: Writing Correct Programs, cont. and Control Flow. Questions/comments from previous lectures. Outline 2/10/11
 Administrative L8 Writing Correct Programs, cont. and Control Flow Next assignment available Goals of assignment simple memory hierarchy management block-thread decomposition tradeoff Due Thursday, Feb.
Administrative L8 Writing Correct Programs, cont. and Control Flow Next assignment available Goals of assignment simple memory hierarchy management block-thread decomposition tradeoff Due Thursday, Feb.
EE382N (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 22 CUDA
: Computer Architecture - Parallelism and Locality Fall 2011 Lecture 22 CUDA") EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 22 CUDA Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture 22
EE382 (20): Computer Architecture - Parallelism and Locality Fall 2011 Lecture 22 CUDA Mattan Erez The University of Texas at Austin EE382: Principles of Computer Architecture, Fall 2011 -- Lecture 22
Reductions and Low-Level Performance Considerations CME343 / ME May David Tarjan NVIDIA Research
 Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
Reductions and Low-Level Performance Considerations CME343 / ME339 27 May 2011 David Tarjan [dtarjan@nvidia.com] NVIDIA Research REDUCTIONS Reduction! Reduce vector to a single value! Via an associative
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Slide credit: Slides adapted from David Kirk/NVIDIA and Wen-mei W. Hwu, DRAM Bandwidth
 Slide credit: Slides adapted from David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2016 DRAM Bandwidth MEMORY ACCESS PERFORMANCE Objective To learn that memory bandwidth is a first-order performance factor in
Slide credit: Slides adapted from David Kirk/NVIDIA and Wen-mei W. Hwu, 2007-2016 DRAM Bandwidth MEMORY ACCESS PERFORMANCE Objective To learn that memory bandwidth is a first-order performance factor in
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Convolution Soup: A case study in CUDA optimization. The Fairmont San Jose Joe Stam
 Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
Convolution Soup: A case study in CUDA optimization The Fairmont San Jose Joe Stam Optimization GPUs are very fast BUT Poor programming can lead to disappointing performance Squeaking out the most speed
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
ECE 408 / CS 483 Final Exam, Fall 2014
 ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
ECE 408 / CS 483 Final Exam, Fall 2014 Thursday 18 December 2014 8:00 to 11:00 Central Standard Time You may use any notes, books, papers, or other reference materials. In the interest of fair access across
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
ECE 8823: GPU Architectures. Objectives
 ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
ECE 8823: GPU Architectures Introduction 1 Objectives Distinguishing features of GPUs vs. CPUs Major drivers in the evolution of general purpose GPUs (GPGPUs) 2 1 Chapter 1 Chapter 2: 2.2, 2.3 Reading
CS/EE 217 Midterm. Question Possible Points Points Scored Total 100
 CS/EE 217 Midterm ANSWER ALL QUESTIONS TIME ALLOWED 60 MINUTES Question Possible Points Points Scored 1 24 2 32 3 20 4 24 Total 100 Question 1] [24 Points] Given a GPGPU with 14 streaming multiprocessor
CS/EE 217 Midterm ANSWER ALL QUESTIONS TIME ALLOWED 60 MINUTES Question Possible Points Points Scored 1 24 2 32 3 20 4 24 Total 100 Question 1] [24 Points] Given a GPGPU with 14 streaming multiprocessor
Josef Pelikán, Jan Horáček CGG MFF UK Praha
 GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
GPGPU and CUDA 2012-2018 Josef Pelikán, Jan Horáček CGG MFF UK Praha pepca@cgg.mff.cuni.cz http://cgg.mff.cuni.cz/~pepca/ 1 / 41 Content advances in hardware multi-core vs. many-core general computing
Lecture 1: Introduction and Computational Thinking
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
CUDA Lecture 2. Manfred Liebmann. Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17
 CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
CUDA Lecture 2 Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences, M17 manfred.liebmann@tum.de December 15, 2015 CUDA Programming Fundamentals CUDA
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
General Purpose GPU programming (GP-GPU) with Nvidia CUDA. Libby Shoop
 with Nvidia CUDA. Libby Shoop") General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates
General Purpose GPU programming (GP-GPU) with Nvidia CUDA Libby Shoop 3 What is (Historical) GPGPU? General Purpose computation using GPU and graphics API in applications other than 3D graphics GPU accelerates
Overview: Graphics Processing Units
 advent of GPUs GPU architecture Overview: Graphics Processing Units the NVIDIA Fermi processor the CUDA programming model simple example, threads organization, memory model case study: matrix multiply
advent of GPUs GPU architecture Overview: Graphics Processing Units the NVIDIA Fermi processor the CUDA programming model simple example, threads organization, memory model case study: matrix multiply
Introduction to GPU (Graphics Processing Unit) Architecture & Programming
 Architecture & Programming") Introduction to GU (Graphics rocessing Unit) Architecture & rogramming C240A. 2017 T. Yang ome of slides are from M. Hall of Utah C6235 Overview Hardware architecture rogramming model Example Historical
Introduction to GU (Graphics rocessing Unit) Architecture & rogramming C240A. 2017 T. Yang ome of slides are from M. Hall of Utah C6235 Overview Hardware architecture rogramming model Example Historical
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
CS 314 Principles of Programming Languages
 CS 314 Principles of Programming Languages Zheng Zhang Fall 2016 Dec 14 GPU Programming Rutgers University Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing computations
CS 314 Principles of Programming Languages Zheng Zhang Fall 2016 Dec 14 GPU Programming Rutgers University Programming with CUDA Compute Unified Device Architecture (CUDA) Mapping and managing computations
Introduction to GPGPU and GPU-architectures
 Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
Introduction to GPGPU and GPU-architectures Henk Corporaal Gert-Jan van den Braak http://www.es.ele.tue.nl/ Contents 1. What is a GPU 2. Programming a GPU 3. GPU thread scheduling 4. GPU performance bottlenecks
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
Nvidia G80 Architecture and CUDA Programming
 Nvidia G80 Architecture and CUDA Programming School of Electrical Engineering and Computer Science CUDA Programming Model: A Highly Multithreaded Coprocessor The GPU is viewed as a compute device that:
Nvidia G80 Architecture and CUDA Programming School of Electrical Engineering and Computer Science CUDA Programming Model: A Highly Multithreaded Coprocessor The GPU is viewed as a compute device that: