High Performance Computing on GPUs using NVIDIA CUDA
|
|
|
- Oswald Harris
- 6 years ago
- Views:
Transcription
1 High Performance Computing on GPUs using NVIDIA CUDA Slides include some material from GPGPU tutorial at SIGGRAPH2007: 1
2 Outline Motivation Stream programming Simplified HW and SW model Simple GPU programming example Increasing stream granularity Using shared memory Matrix multiplication Improving performance Some real life example 2
3 Disclaimer This lecture will discuss GPUs from the Parallel Computing perspective since I am NOT an expert in graphics hardware 3
4 4
5 Why GPUs-II 5
6 Is it a miracle? NO! Architectural solution prefers parallelism over single thread performance! Example problem I have 100 apples to eat 1) high performance computing objective: optimize the time of eating one apple 2) high throughput computing objective: optimize the time of eating all apples The 1 st option has been exhausted!!! Performance = parallel hardware + scalable parallel program! 6
7 Why not in CPUs? Not applicable to general purpose computing Complex programming model Still immature Platform is a moving target Vendor-dependent architectures Incompatible architectural changes from generation to generation Programming model is vendor dependent NVIDIA CUDA AMD(ATI) Close To Metal (CTM) INTEL ( LARRABEE) nobody knows 7
8 Simple stream programming model 8
9 Generic GPU hardware/software model Massively parallel processor: many concurrently running threads (thousands) Threads access global GPU memory Each thread has limited number of private registers Caching: two options Not cached (latency hidden through time-slicing) Cached with unknown cache organization, but optimized for 2D spatial locality Single Program Multiple Data (SPMD) model The same program, called kernel, is executed on the different data 9
10 How we design an algorithm Problem: compute product of two vectors A[10000] and B[10000] and store it in C[10000] Think data-parallel: same set of operations (kernel) applied to multiple data chunks apply fine grain parallelization (caution here! - see in a few slides) Thread creation is cheap The more threads the better Idea: one thread multiplies 2 numbers 10
11 How we implement an algorithm CPU 1.Allocate three arrays in GPU memory 2.Copy data CPU -> GPU 3.Invoke kernel with threads, pass ptrs to the arrays from the step 1. 4.Wait until complete and copy data GPU->CPU GPU Get my threadid C[threadId]=A[threadId]*B[threadId] 11
12 Any performance estimates? Performance criterion - GFLOP/s Key issue: memory or CPU bound? We can fully utilize GPUs only if the data can be made available in the ALUs on time!!! Otherwise at most the number of operations which can be performed on the available data. Arithmetic intensity: number of FLOPs per memory access Performance= min[membw*a,gpu HW] For example: A=1/3, GPU HW=345GFLOP/s, MemBW=22GFloat/s: Performance= ~7GFLOP/s ~2% utilization!!! 12
13 Enhanced model 13
14 Generic model - limitations Best used for streaming-like workloads Embarrassingly parallel: running algorithm on multiple data Low data reuse High number of operations per memory access (arithmetic intensity) to allow latency hiding Low speedups otherwise Memory bound applications benefit from higher memory bandwidth, but result in low GPU utilization 14

15 NVIDIA CUDA extension: Fast on-chip memory Adopted from CUDA programming guide 15
16 Changed programming model Low latency/high bandwidth memory shared between threads in one thread block (up to 512 threads). 16K 16K 16K Programming model: stream of thread blocks Challenge: optimal structuring of computations to take advantage of fast memory 16
17 Thread block Scheduling of threads in a TB Warp: thread in one warp are executed concurrently ( well... Half-warp in lock-step, half-warps are swapped Warps MAY be executed concurrently. Otherwise according to the thread ID in the warp Thread communication in a TB Shared memory TB-wide synchronization (barrier) 17
18 Multiple thread blocks Thread blocks are completely independent No scheduling guarantees Communication problematic Atomic memory instructions available Synchronization is dangerous: may bring to deadlock if not enough hardware Better think of thread blocks as a STREAM 18
19 Breaking the stream hardware abstraction Processors are split into groups Each group (multiprocessor -MP) has fast memory and set of registers shared among all processors NVIDIA GTX8800: thread processors per MP, shared memory size: 16KB, B registers, 16 MPs per video card Thread block is scheduled on a SINGLE MP, why? 19
20 Thread blocks and MP Different thread blocks may be scheduled (via preemption) on the same MP to allow better utilization and global memory latency hiding PROBLEM: shared memory and register file should be large enough to allow preemption! Determining the best block size is kerneldependent! More threads per block less blocks can be scheduled may lead to lower throughput Fewer threads per block more blocks, but less registers/shared memory per block 20
21 Matrix multiplication example Product of two NxN matrices Streaming approach Each thread computes single value of the output Is it any good??? No! Arithmetic Intensity =(2N-1)/(2N+1) => Max performance: 22GFLOP/s (instead of 345!!!) Why? O(N) data reuse is NOT utilized Optimally: Arithmetic intensity= (2N-1)/(2N/N +1)=O(N) => CPU bound!!!!! 21
")
22 Better approach (borrowed from Mark Harris slides) 22
23 Generalized approach to shared memory Think of it as a distributed user-managed cache When regular access pattern - better to have implicit cache management In matrix product we know implicitly that the access is sequential Less trivial for irregular access pattern -> implement REAL cache logic interleaved into the kernel devise cache tag, handle misses, tag collisions, etc, analyze it just like regular cache Sorry guys, self reference here: Efficient sum-product computation on GPUs 23
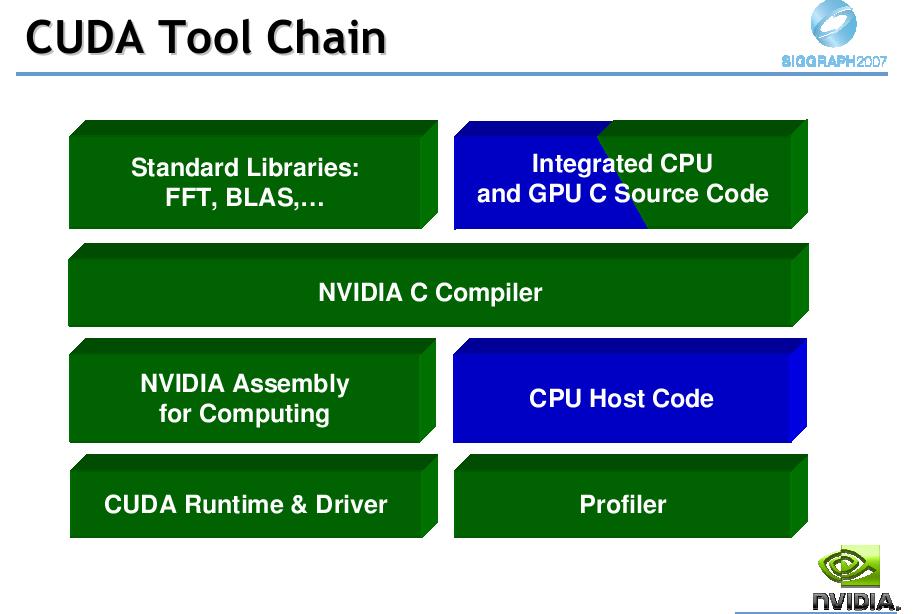
24 CUDA 24
25 CUDA at glance Compiler Handles language extensions Compiles GPU code into HW-independent intermediate code (read PTX and NVCC spec to know more) Runtime GPU memory management/transfer, CPU->GPU control, etc...supports emulation mode for debugging NO PROFILER YET (expecting soon) Driver JIT compilation and optimizations, mapping onto graphics pipeline, (sign NDA to know more.). Watchdog problem for kernels over 5 seconds (not on LINUX without X!!) HW support (only in new GPUs) 25
26 Sample code walkthrough: from NVIDIA User guide (see 26
27 Few performance guidelines Check SIGGRAPH tutorial for more Algorithm: data parallel + structure to use shared memory (exploit the data reuse!) Estimate upper bounds! Coherent memory accesses! Use many threads Unroll loops! Use fast version of integer operations or avoid them altogether Minimize synchronization where possible Optimize TB size where possible. (occupancy: # warps per MP as a possible measure) in conjunction with register and shared memory use Know to use constant and texture memory Avoid divergence of a single warp Minimize CPU<-> GPU memory transfers 27
28 Real life application: genetic linkage analysis Used to find disease provoking genes Can be very demanding Our research: map computations onto inference in Bayesian networks One approach: parallelize to use thousands of computers worldwide (see Superlink-online ) Another approach: parallelize to take advantage of GPUs 28
29 Method Parallelize sum-product computations Generalization of matrix chain product More challenging data access pattern Shared memory as a user-managed cache Explicit caching mechanism is implemented 29
30 Results Performance comparison: NVIDIA GTX8800 <- >Single core of Intel Dual Core 2, 3GHz, 2M L2 Speedup up to ~60 on synthetic benchmarks ( 57GFLOPs peak vs. ~0.9GFLOP peak) Speedup up to on real Bayesian networks Speedup up to 700(!) if log scale used for better precision More on this: see my home page 30
31 Conclusion GPUs are great for HPC CUDA rocks! Short learning curve Easy to build proof of concepts GPUs seem to be the next many-cores architecture See The Landscape of Parallel Computing Research: A View from Berkeley Go and try it! 31
32 Resources CUDA 32
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Computer Architecture
 Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Jens Teubner Computer Architecture Summer 2017 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2017 Jens Teubner Computer Architecture Summer 2017 34 Part II Graphics
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
CUDA. Schedule API. Language extensions. nvcc. Function type qualifiers (1) CUDA compiler to handle the standard C extensions.
 CUDA compiler to handle the standard C extensions.") Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
Schedule CUDA Digging further into the programming manual Application Programming Interface (API) text only part, sorry Image utilities (simple CUDA examples) Performace considerations Matrix multiplication
CS GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8. Markus Hadwiger, KAUST
 CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
CS 380 - GPU and GPGPU Programming Lecture 8+9: GPU Architecture 7+8 Markus Hadwiger, KAUST Reading Assignment #5 (until March 12) Read (required): Programming Massively Parallel Processors book, Chapter
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v7.0 March 2015 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL
 TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
TUNING CUDA APPLICATIONS FOR MAXWELL DA-07173-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Maxwell Tuning Guide... 1 1.1. NVIDIA Maxwell Compute Architecture... 1 1.2. CUDA Best Practices...2
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Programming Model
 CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA Xing Zeng, Dongyue Mou Introduction Example Pro & Contra Trend Introduction Example Pro & Contra Trend Introduction What is CUDA? - Compute Unified Device Architecture. - A powerful parallel programming
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Scientific Computing on GPUs: GPU Architecture Overview
 Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Scientific Computing on GPUs: GPU Architecture Overview Dominik Göddeke, Jakub Kurzak, Jan-Philipp Weiß, André Heidekrüger and Tim Schröder PPAM 2011 Tutorial Toruń, Poland, September 11 http://gpgpu.org/ppam11
Multi Agent Navigation on GPU. Avi Bleiweiss
 Multi Agent Navigation on GPU Avi Bleiweiss Reasoning Explicit Implicit Script, storytelling State machine, serial Compute intensive Fits SIMT architecture well Navigation planning Collision avoidance
Multi Agent Navigation on GPU Avi Bleiweiss Reasoning Explicit Implicit Script, storytelling State machine, serial Compute intensive Fits SIMT architecture well Navigation planning Collision avoidance
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPU Computing: Development and Analysis. Part 1. Anton Wijs Muhammad Osama. Marieke Huisman Sebastiaan Joosten
 GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
GPU Computing: Development and Analysis Part 1 Anton Wijs Muhammad Osama Marieke Huisman Sebastiaan Joosten NLeSC GPU Course Rob van Nieuwpoort & Ben van Werkhoven Who are we? Anton Wijs Assistant professor,
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
From Shader Code to a Teraflop: How GPU Shader Cores Work. Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian)
") From Shader Code to a Teraflop: How GPU Shader Cores Work Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian) 1 This talk Three major ideas that make GPU processing cores run fast Closer look at real
From Shader Code to a Teraflop: How GPU Shader Cores Work Jonathan Ragan- Kelley (Slides by Kayvon Fatahalian) 1 This talk Three major ideas that make GPU processing cores run fast Closer look at real
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Optimizing Parallel Reduction in CUDA. Mark Harris NVIDIA Developer Technology
 Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Optimizing Parallel Reduction in CUDA Mark Harris NVIDIA Developer Technology Parallel Reduction Common and important data parallel primitive Easy to implement in CUDA Harder to get it right Serves as
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Graphics Processor Acceleration and YOU
 Graphics Processor Acceleration and YOU James Phillips Research/gpu/ Goals of Lecture After this talk the audience will: Understand how GPUs differ from CPUs Understand the limits of GPU acceleration Have
Graphics Processor Acceleration and YOU James Phillips Research/gpu/ Goals of Lecture After this talk the audience will: Understand how GPUs differ from CPUs Understand the limits of GPU acceleration Have
Real-Time Rendering Architectures
 Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
Real-Time Rendering Architectures Mike Houston, AMD Part 1: throughput processing Three key concepts behind how modern GPU processing cores run code Knowing these concepts will help you: 1. Understand
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
From Shader Code to a Teraflop: How Shader Cores Work
 From Shader Code to a Teraflop: How Shader Cores Work Kayvon Fatahalian Stanford University This talk 1. Three major ideas that make GPU processing cores run fast 2. Closer look at real GPU designs NVIDIA
From Shader Code to a Teraflop: How Shader Cores Work Kayvon Fatahalian Stanford University This talk 1. Three major ideas that make GPU processing cores run fast 2. Closer look at real GPU designs NVIDIA
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
Improving Performance of Machine Learning Workloads
 Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
Improving Performance of Machine Learning Workloads Dong Li Parallel Architecture, System, and Algorithm Lab Electrical Engineering and Computer Science School of Engineering University of California,
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CUDA Performance Optimization. Patrick Legresley
 CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
CUDA Performance Optimization Patrick Legresley Optimizations Kernel optimizations Maximizing global memory throughput Efficient use of shared memory Minimizing divergent warps Intrinsic instructions Optimizations
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Introduction to CUDA
 Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
Introduction to CUDA Overview HW computational power Graphics API vs. CUDA CUDA glossary Memory model, HW implementation, execution Performance guidelines CUDA compiler C/C++ Language extensions Limitations
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
GPGPU. Peter Laurens 1st-year PhD Student, NSC
 GPGPU Peter Laurens 1st-year PhD Student, NSC Presentation Overview 1. What is it? 2. What can it do for me? 3. How can I get it to do that? 4. What s the catch? 5. What s the future? What is it? Introducing
GPGPU Peter Laurens 1st-year PhD Student, NSC Presentation Overview 1. What is it? 2. What can it do for me? 3. How can I get it to do that? 4. What s the catch? 5. What s the future? What is it? Introducing
Warps and Reduction Algorithms
 Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
Warps and Reduction Algorithms 1 more on Thread Execution block partitioning into warps single-instruction, multiple-thread, and divergence 2 Parallel Reduction Algorithms computing the sum or the maximum
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
high performance medical reconstruction using stream programming paradigms
 high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Analysis Report. Number of Multiprocessors 3 Multiprocessor Clock Rate Concurrent Kernel Max IPC 6 Threads per Warp 32 Global Memory Bandwidth
 Analysis Report v3 Duration 932.612 µs Grid Size [ 1024,1,1 ] Block Size [ 1024,1,1 ] Registers/Thread 32 Shared Memory/Block 28 KiB Shared Memory Requested 64 KiB Shared Memory Executed 64 KiB Shared
Analysis Report v3 Duration 932.612 µs Grid Size [ 1024,1,1 ] Block Size [ 1024,1,1 ] Registers/Thread 32 Shared Memory/Block 28 KiB Shared Memory Requested 64 KiB Shared Memory Executed 64 KiB Shared
Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow
 Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
Tesla GPU Computing A Revolution in High Performance Computing
 Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
Tesla GPU Computing A Revolution in High Performance Computing Gernot Ziegler, Developer Technology (Compute) (Material by Thomas Bradley) Agenda Tesla GPU Computing CUDA Fermi What is GPU Computing? Introduction
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Introduction to GPU programming with CUDA
 Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
Introduction to GPU programming with CUDA Dr. Juan C Zuniga University of Saskatchewan, WestGrid UBC Summer School, Vancouver. June 12th, 2018 Outline 1 Overview of GPU computing a. what is a GPU? b. GPU
QR Decomposition on GPUs
 QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
QR Decomposition QR Algorithms Block Householder QR Andrew Kerr* 1 Dan Campbell 1 Mark Richards 2 1 Georgia Tech Research Institute 2 School of Electrical and Computer Engineering Georgia Institute of
Parallel Systems Course: Chapter IV. GPU Programming. Jan Lemeire Dept. ETRO November 6th 2008
 Parallel Systems Course: Chapter IV GPU Programming Jan Lemeire Dept. ETRO November 6th 2008 GPU Message-passing Programming with Parallel CUDAMessagepassing Parallel Processing Processing Overview 1.
Parallel Systems Course: Chapter IV GPU Programming Jan Lemeire Dept. ETRO November 6th 2008 GPU Message-passing Programming with Parallel CUDAMessagepassing Parallel Processing Processing Overview 1.
S WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS. Jakob Progsch, Mathias Wagner GTC 2018
 S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
S8630 - WHAT THE PROFILER IS TELLING YOU: OPTIMIZING GPU KERNELS Jakob Progsch, Mathias Wagner GTC 2018 1. Know your hardware BEFORE YOU START What are the target machines, how many nodes? Machine-specific
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms. Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli
 High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
High performance 2D Discrete Fourier Transform on Heterogeneous Platforms Shrenik Lad, IIIT Hyderabad Advisor : Dr. Kishore Kothapalli Motivation Fourier Transform widely used in Physics, Astronomy, Engineering
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA
 Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
Fundamental Optimizations in CUDA Peng Wang, Developer Technology, NVIDIA Optimization Overview GPU architecture Kernel optimization Memory optimization Latency optimization Instruction optimization CPU-GPU
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer
 CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
CUDA Optimization: Memory Bandwidth Limited Kernels CUDA Webinar Tim C. Schroeder, HPC Developer Technology Engineer Outline We ll be focussing on optimizing global memory throughput on Fermi-class GPUs
From Brook to CUDA. GPU Technology Conference
 From Brook to CUDA GPU Technology Conference A 50 Second Tutorial on GPU Programming by Ian Buck Adding two vectors in C is pretty easy for (i=0; i
From Brook to CUDA GPU Technology Conference A 50 Second Tutorial on GPU Programming by Ian Buck Adding two vectors in C is pretty easy for (i=0; i
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Multiprocessor Support
 CSC 256/456: Operating Systems Multiprocessor Support John Criswell University of Rochester 1 Outline Multiprocessor hardware Types of multi-processor workloads Operating system issues Where to run the
CSC 256/456: Operating Systems Multiprocessor Support John Criswell University of Rochester 1 Outline Multiprocessor hardware Types of multi-processor workloads Operating system issues Where to run the
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Optimization solutions for the segmented sum algorithmic function
 Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
Optimization solutions for the segmented sum algorithmic function ALEXANDRU PÎRJAN Department of Informatics, Statistics and Mathematics Romanian-American University 1B, Expozitiei Blvd., district 1, code
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
Comparing Memory Systems for Chip Multiprocessors
 Comparing Memory Systems for Chip Multiprocessors Jacob Leverich Hideho Arakida, Alex Solomatnikov, Amin Firoozshahian, Mark Horowitz, Christos Kozyrakis Computer Systems Laboratory Stanford University
Comparing Memory Systems for Chip Multiprocessors Jacob Leverich Hideho Arakida, Alex Solomatnikov, Amin Firoozshahian, Mark Horowitz, Christos Kozyrakis Computer Systems Laboratory Stanford University
Why GPUs? Robert Strzodka (MPII), Dominik Göddeke G. TUDo), Dominik Behr (AMD)
, Dominik Göddeke G. TUDo), Dominik Behr (AMD)") Why GPUs? Robert Strzodka (MPII), Dominik Göddeke G (TUDo( TUDo), Dominik Behr (AMD) Conference on Parallel Processing and Applied Mathematics Wroclaw, Poland, September 13-16, 16, 2009 www.gpgpu.org/ppam2009
Why GPUs? Robert Strzodka (MPII), Dominik Göddeke G (TUDo( TUDo), Dominik Behr (AMD) Conference on Parallel Processing and Applied Mathematics Wroclaw, Poland, September 13-16, 16, 2009 www.gpgpu.org/ppam2009
Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency
 Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency Yijie Huangfu and Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University {huangfuy2,wzhang4}@vcu.edu
Profiling-Based L1 Data Cache Bypassing to Improve GPU Performance and Energy Efficiency Yijie Huangfu and Wei Zhang Department of Electrical and Computer Engineering Virginia Commonwealth University {huangfuy2,wzhang4}@vcu.edu
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
Practical Introduction to CUDA and GPU
 Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Practical Introduction to CUDA and GPU Charlie Tang Centre for Theoretical Neuroscience October 9, 2009 Overview CUDA - stands for Compute Unified Device Architecture Introduced Nov. 2006, a parallel computing
Lecture 1: Introduction and Computational Thinking
 PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
PASI Summer School Advanced Algorithmic Techniques for GPUs Lecture 1: Introduction and Computational Thinking 1 Course Objective To master the most commonly used algorithm techniques and computational
Applications of Berkeley s Dwarfs on Nvidia GPUs
 Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Introduction to Parallel Computing with CUDA. Oswald Haan
 Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Introduction to Parallel Computing with CUDA Oswald Haan ohaan@gwdg.de Schedule Introduction to Parallel Computing with CUDA Using CUDA CUDA Application Examples Using Multiple GPUs CUDA Application Libraries
Parallel Programming on Larrabee. Tim Foley Intel Corp
 Parallel Programming on Larrabee Tim Foley Intel Corp Motivation This morning we talked about abstractions A mental model for GPU architectures Parallel programming models Particular tools and APIs This
Parallel Programming on Larrabee Tim Foley Intel Corp Motivation This morning we talked about abstractions A mental model for GPU architectures Parallel programming models Particular tools and APIs This
Design of Digital Circuits Lecture 21: GPUs. Prof. Onur Mutlu ETH Zurich Spring May 2017
 Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
Design of Digital Circuits Lecture 21: GPUs Prof. Onur Mutlu ETH Zurich Spring 2017 12 May 2017 Agenda for Today & Next Few Lectures Single-cycle Microarchitectures Multi-cycle and Microprogrammed Microarchitectures
A Detailed GPU Cache Model Based on Reuse Distance Theory
 A Detailed GPU Cache Model Based on Reuse Distance Theory Cedric Nugteren, Gert-Jan van den Braak, Henk Corporaal Eindhoven University of Technology (Netherlands) Henri Bal Vrije Universiteit Amsterdam
A Detailed GPU Cache Model Based on Reuse Distance Theory Cedric Nugteren, Gert-Jan van den Braak, Henk Corporaal Eindhoven University of Technology (Netherlands) Henri Bal Vrije Universiteit Amsterdam
ECE 574 Cluster Computing Lecture 15
 ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
ECE 574 Cluster Computing Lecture 15 Vince Weaver http://web.eece.maine.edu/~vweaver vincent.weaver@maine.edu 30 March 2017 HW#7 (MPI) posted. Project topics due. Update on the PAPI paper Announcements
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Performance potential for simulating spin models on GPU
 Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Data parallel algorithms, algorithmic building blocks, precision vs. accuracy
 Data parallel algorithms, algorithmic building blocks, precision vs. accuracy Robert Strzodka Architecture of Computing Systems GPGPU and CUDA Tutorials Dresden, Germany, February 25 2008 2 Overview Parallel
Data parallel algorithms, algorithmic building blocks, precision vs. accuracy Robert Strzodka Architecture of Computing Systems GPGPU and CUDA Tutorials Dresden, Germany, February 25 2008 2 Overview Parallel
Lecture 15: Introduction to GPU programming. Lecture 15: Introduction to GPU programming p. 1
 Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Lecture 15: Introduction to GPU programming Lecture 15: Introduction to GPU programming p. 1 Overview Hardware features of GPGPU Principles of GPU programming A good reference: David B. Kirk and Wen-mei
Programmable Graphics Hardware (GPU) A Primer
 A Primer") Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Programmable Graphics Hardware (GPU) A Primer Klaus Mueller Stony Brook University Computer Science Department Parallel Computing Explained video Parallel Computing Explained Any questions? Parallelism
Parallel Programming Multicore systems
 FYS3240 PC-based instrumentation and microcontrollers Parallel Programming Multicore systems Spring 2011 Lecture #9 Bekkeng, 4.4.2011 Introduction Until recently, innovations in processor technology have
FYS3240 PC-based instrumentation and microcontrollers Parallel Programming Multicore systems Spring 2011 Lecture #9 Bekkeng, 4.4.2011 Introduction Until recently, innovations in processor technology have
Introduction to GPU computing
 Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
Introduction to GPU computing Nagasaki Advanced Computing Center Nagasaki, Japan The GPU evolution The Graphic Processing Unit (GPU) is a processor that was specialized for processing graphics. The GPU
4.10 Historical Perspective and References
 334 Chapter Four Data-Level Parallelism in Vector, SIMD, and GPU Architectures 4.10 Historical Perspective and References Section L.6 (available online) features a discussion on the Illiac IV (a representative
334 Chapter Four Data-Level Parallelism in Vector, SIMD, and GPU Architectures 4.10 Historical Perspective and References Section L.6 (available online) features a discussion on the Illiac IV (a representative
Lecture 7: The Programmable GPU Core. Kayvon Fatahalian CMU : Graphics and Imaging Architectures (Fall 2011)
") Lecture 7: The Programmable GPU Core Kayvon Fatahalian CMU 15-869: Graphics and Imaging Architectures (Fall 2011) Today A brief history of GPU programmability Throughput processing core 101 A detailed
Lecture 7: The Programmable GPU Core Kayvon Fatahalian CMU 15-869: Graphics and Imaging Architectures (Fall 2011) Today A brief history of GPU programmability Throughput processing core 101 A detailed
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 207/8 A.J.Proença The Roofline Performance Model (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 207/8 AJProença, Advanced Architectures,
Advanced Architectures Master Informatics Eng. 207/8 A.J.Proença The Roofline Performance Model (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 207/8 AJProença, Advanced Architectures,
CUDA (Compute Unified Device Architecture)
") CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CUDA (Compute Unified Device Architecture) Mike Bailey History of GPU Performance vs. CPU Performance GFLOPS Source: NVIDIA G80 = GeForce 8800 GTX G71 = GeForce 7900 GTX G70 = GeForce 7800 GTX NV40 = GeForce
CS377P Programming for Performance GPU Programming - II
 CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
CS377P Programming for Performance GPU Programming - II Sreepathi Pai UTCS November 11, 2015 Outline 1 GPU Occupancy 2 Divergence 3 Costs 4 Cooperation to reduce costs 5 Scheduling Regular Work Outline
How to Optimize Geometric Multigrid Methods on GPUs
 How to Optimize Geometric Multigrid Methods on GPUs Markus Stürmer, Harald Köstler, Ulrich Rüde System Simulation Group University Erlangen March 31st 2011 at Copper Schedule motivation imaging in gradient
How to Optimize Geometric Multigrid Methods on GPUs Markus Stürmer, Harald Köstler, Ulrich Rüde System Simulation Group University Erlangen March 31st 2011 at Copper Schedule motivation imaging in gradient
GPU Architecture. Robert Strzodka (MPII), Dominik Göddeke G. TUDo), Dominik Behr (AMD)
, Dominik Göddeke G. TUDo), Dominik Behr (AMD)") GPU Architecture Robert Strzodka (MPII), Dominik Göddeke G (TUDo( TUDo), Dominik Behr (AMD) Conference on Parallel Processing and Applied Mathematics Wroclaw, Poland, September 13-16, 16, 2009 www.gpgpu.org/ppam2009
GPU Architecture Robert Strzodka (MPII), Dominik Göddeke G (TUDo( TUDo), Dominik Behr (AMD) Conference on Parallel Processing and Applied Mathematics Wroclaw, Poland, September 13-16, 16, 2009 www.gpgpu.org/ppam2009
Profiling of Data-Parallel Processors
 Profiling of Data-Parallel Processors Daniel Kruck 09/02/2014 09/02/2014 Profiling Daniel Kruck 1 / 41 Outline 1 Motivation 2 Background - GPUs 3 Profiler NVIDIA Tools Lynx 4 Optimizations 5 Conclusion
Profiling of Data-Parallel Processors Daniel Kruck 09/02/2014 09/02/2014 Profiling Daniel Kruck 1 / 41 Outline 1 Motivation 2 Background - GPUs 3 Profiler NVIDIA Tools Lynx 4 Optimizations 5 Conclusion