The Processor. Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut. CSE3666: Introduction to Computer Architecture
|
|
|
- Thomasina Manning
- 6 years ago
- Views:
Transcription
1 The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture
2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware Two MIPS implementations A simplified version A more realistic pipelined version Simple subset, shows most aspects Memory reference: lw, sw Arithmetic/logical: add, sub, and, or, slt Control transfer: beq, j
3 Instruction Execution PC instruction memory, fetch instruction Register numbers register file, read registers Depending on instruction class Use ALU to calculate Arithmetic result Memory address for load/store Branch target address Access data memory for load/store PC target address or PC + 4
4 CPU Overview

5 Multiplexers Can t just join wires together Use multiplexers


6 Control Chapter 4 The Processor 6
7 Logic Design Basics Information encoded in binary Low voltage = 0, High voltage = 1 One wire per bit Multi-bit data encoded on multi-wire buses Combinational element Operate on data Output is a function of input State (sequential) elements Store information
8 Combinational Elements AND-gate Y = A & B Adder Y = A + B A B + Y A B I0 I1 M u x S Y Multiplexer Y = S? I1 : I0 Y Arithmetic/Logic Unit Y = F(A, B) A ALU Y B F Chapter 4 The Processor 8
9 Sequential Elements Register: stores data in a circuit Uses a clock signal to determine when to update the stored value Edge-triggered: update when Clk changes from 0 to 1 D Clk Q Clk D Q
10 Sequential Elements Register with write control Only updates on clock edge when write control input is 1 Used when stored value is required later Clk D Write Clk Q Write D Q


11 Clocking Methodology Combinational logic transforms data during clock cycles Between clock edges Input from state elements, output to state element Longest delay determines clock period
12 Building a Datapath Datapath Elements that process data and addresses in the CPU Registers, ALUs, mux s, memories, We will build a MIPS datapath incrementally Refining the overview design

13 Instruction Fetch 32-bit register Increment by 4 for next instruction

14 R-Format Instructions Read two register operands Perform arithmetic/logical operation Write register result

15 Load/Store Instructions Read register operands Calculate address using 16-bit offset Use ALU, but sign-extend offset Load: Read memory and update register Store: Write register value to memory
16 Branch Instructions Read register operands Compare operands Use ALU, subtract and check Zero output Calculate target address Sign-extend displacement Shift left 2 places (word displacement) Add to PC + 4 Already calculated by instruction fetch


17 Branch Instructions Just re-routes wires Sign-bit wire replicated
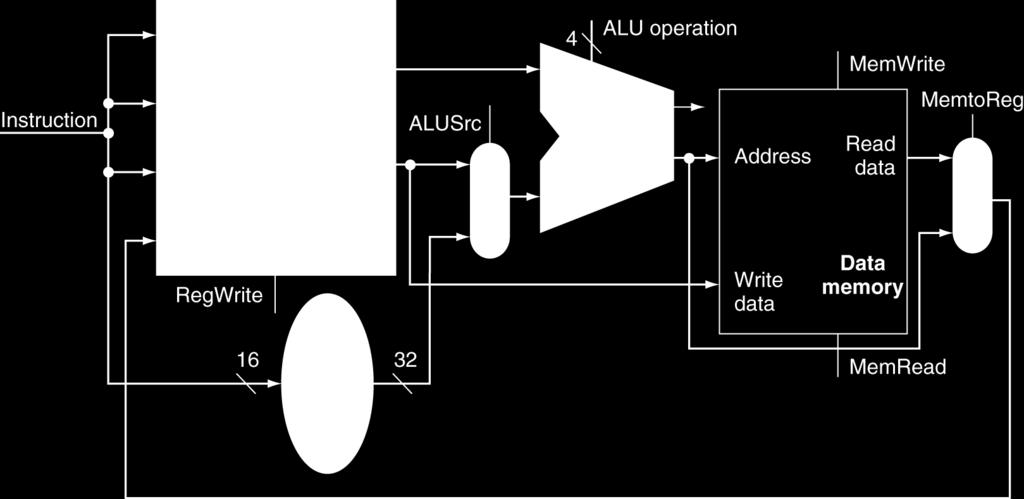
18 R-Type/Load/Store Datapath
19 Composing the Elements First-cut data path does an instruction in one clock cycle Each datapath element can only do one function at a time Hence, we need separate instruction and data memories Use multiplexers where alternate data sources are used for different instructions

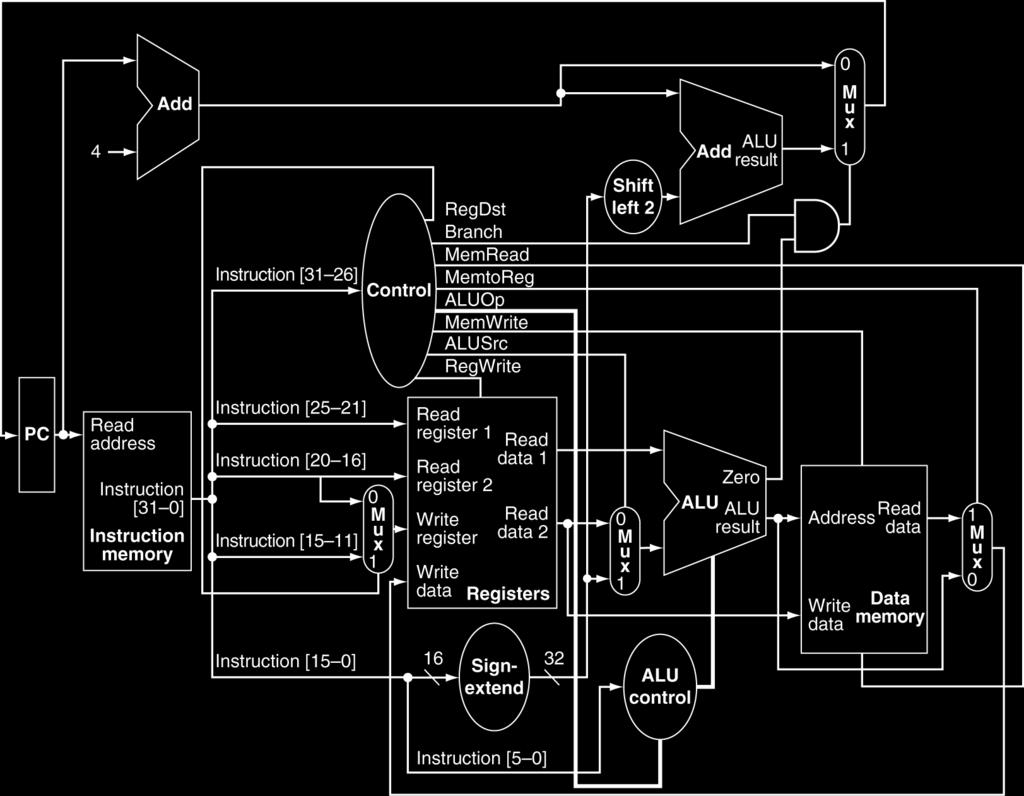
20 Full Datapath
21 ALU Control ALU used for Load/Store: F = add Branch: F = subtract R-type: F depends on funct field ALU control Function 0000 AND 0001 OR 0010 add 0110 subtract 0111 set-on-less-than 1100 NOR
22 ALU Control Assume 2-bit ALUOp derived from opcode Combinational logic derives ALU control opcode ALUOp Operation funct ALU function ALU control lw 00 load word XXXXXX add 0010 sw 00 store word XXXXXX add 0010 beq 01 branch equal XXXXXX subtract 0110 R-type 10 add add 0010 subtract subtract 0110 AND AND 0000 OR OR 0001 set-on-less-than set-on-less-than 0111
23 The Main Control Unit Control signals derived from instruction R-type Load/ Store Branch 0 rs rt rd shamt funct 31:26 25:21 20:16 15:11 10:6 5:0 35 or 43 rs rt address 31:26 25:21 20:16 15:0 4 rs rt address 31:26 25:21 20:16 15:0 opcode always read read, except for load write for R- type and load sign-extend and add
24 Datapath With Control Chapter 4 The Processor 24
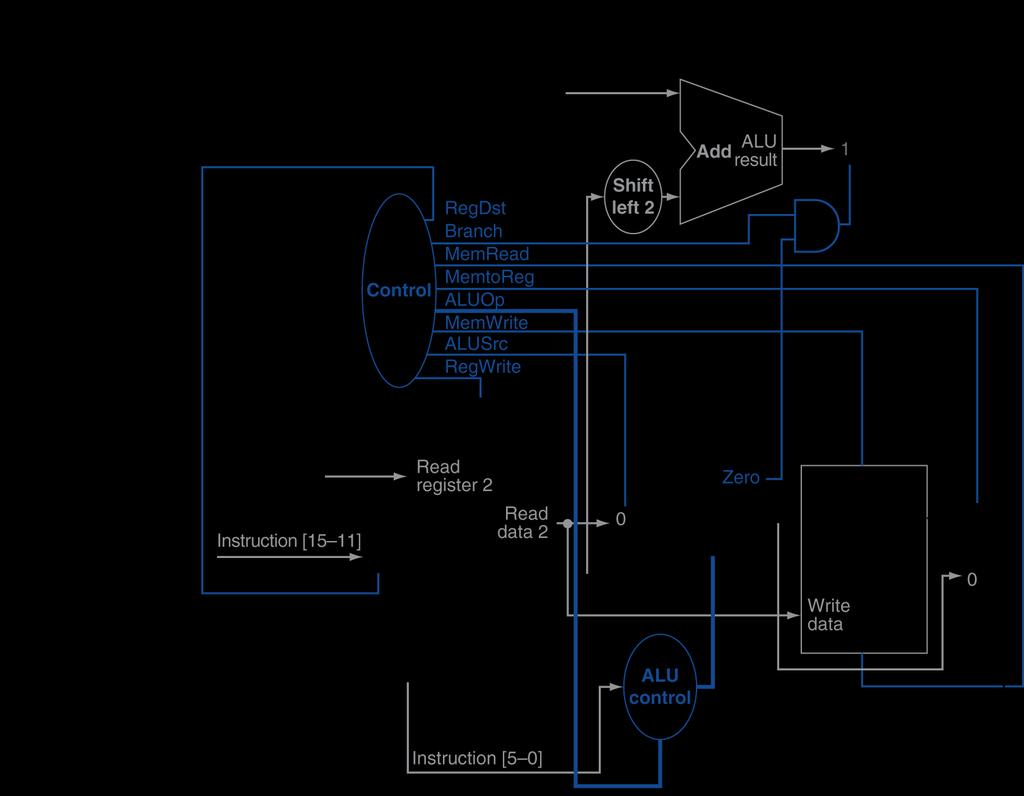
25 R-Type Instruction
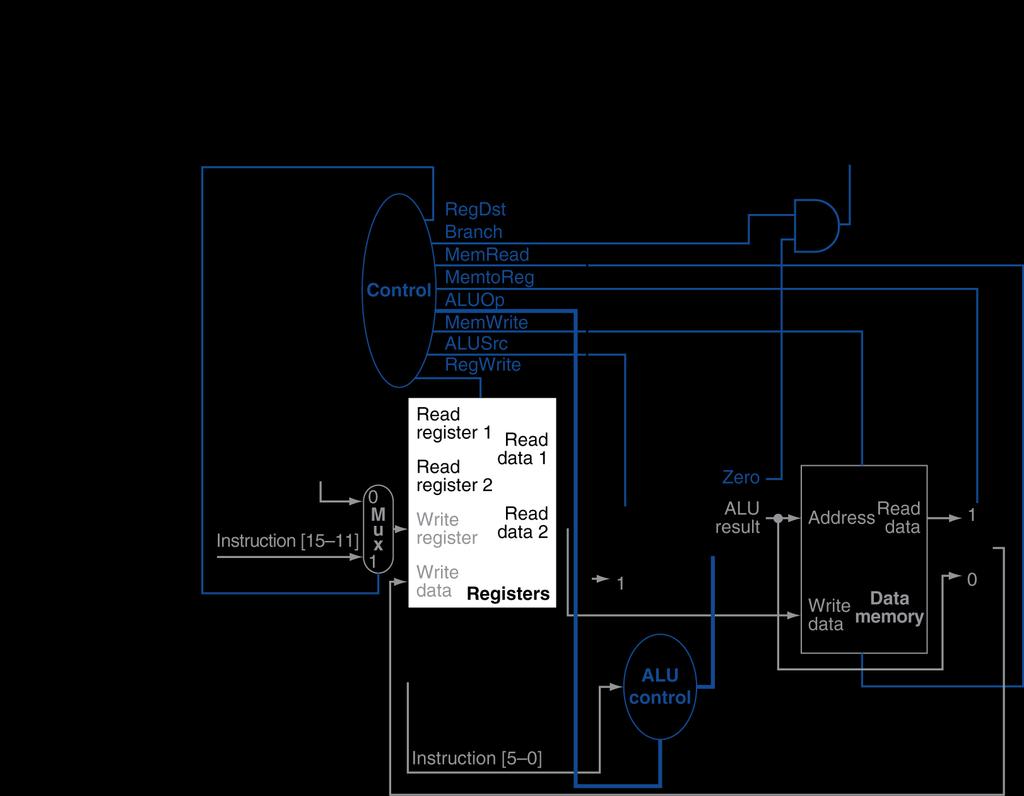
26 Load Instruction
27 Branch-on-Equal Instruction
28 Implementing Jumps Jump 2 address 31:26 25:0 Jump uses word address Update PC with concatenation of Top 4 bits of old PC 26-bit jump address 00 Need an extra control signal decoded from opcode


29 Datapath With Jumps Added
30 Five stages in MIPS instruction execution 1. IF: Instruction fetch from memory 2. ID: Instruction decode & register read 3. EX: Execute operation or calculate address 4. MEM: Access memory operand 5. WB: Write result back to register
31 Performance Assume time for stages is 100ps for register read or write 200ps for other stages Instr Instr fetch Register read ALU op Memory access Register write Total time lw 200ps 100 ps 200ps 200ps 100 ps 800ps sw 200ps 100 ps 200ps 200ps 700ps R-format 200ps 100 ps 200ps 100 ps 600ps beq 200ps 100 ps 200ps 500ps
32 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not feasible to vary period for different instructions Violates design principle Making the common case fast We will improve performance by pipelining

33 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup = 2n/0.5n = number of stages
34 MIPS Pipeline Five stages, one step per stage 1. IF: Instruction fetch from memory 2. ID: Instruction decode & register read 3. EX: Execute operation or calculate address 4. MEM: Access memory operand 5. WB: Write result back to register
 Pipelined (Tc= 200ps)")
35 Pipeline Performance Single-cycle (Tc= 800ps) Pipelined (Tc= 200ps)
36 Pipeline Speedup If all stages are balanced i.e., all take the same time Time _ Between _ Instructions pipelined Time _ Between _ Instructions Number _ of _ stages nonpipelined If not balanced, speedup is less Speedup due to increased throughput Latency (time for each instruction) does not decrease
37 Pipelining and ISA Design MIPS ISA designed for pipelining All instructions are 32-bits Easier to fetch and decode in one cycle c.f. x86: 1- to 17-byte instructions Few and regular instruction formats Can decode and read registers in one step Load/store addressing Can calculate address in 3 rd stage, access memory in 4 th stage Alignment of memory operands Memory access takes only one cycle
38 Hazards Situations that prevent starting the next instruction in the next cycle Structural hazards A required resource is busy Data hazard Need to wait for previous instruction to complete its data read/write Control hazard Deciding on control action depends on previous instruction

39 MIPS Pipelined Datapath MEM Right-to-left flow leads to hazards WB


40 Pipeline Registers State registers between each pipeline stage to isolate them Hold information produced in previous cycles
41 PC MIPS Pipeline Datapath Additions/Mods IF:IFetch ID:Dec EX:Execute MEM: MemAccess WB: WriteBack IF/ID ID/EX EX/MEM Add 4 Instruction Memory Read Address Read Addr 1 Register Read Read Addr 2 Data 1 File Write Addr Write Data Read Data 2 Shift left 2 Add ALU Address Write Data Data Memory Read Data MEM/WB Sign 16 Extend 32 System Clock

42 Pipelined Control Control signals derived from instruction As in single-cycle implementation All control signals can be determined during decode And held in the state registers
43 PC MIPS Pipeline Control Path Modifications PCSrc ID/EX EX/MEM IF/ID Control 4 Instruction Memory Read Address Add RegWrite Read Addr 1 Register Read Read Addr 2 Data 1 File Write Addr Write Data Read Data 2 Sign 16 Extend 32 Shift left 2 ALUSrc Add ALU ALU cntrl ALUOp Branch Address Write Data Data Memory Read Data MemRead MEM/WB MemtoReg RegDst
44 Pipeline Control IF Stage: read Instr Memory (always asserted) and write PC (on System Clock) ID Stage: no optional control signals to set Reg Dst EX Stage MEM Stage WB Stage ALU Op1 ALU Op0 ALU Src Brch Mem Read Mem Write Reg Write Mem toreg R lw sw X X beq X X
45 Graphically Representing MIPS Pipeline ALU IM Reg DM Reg Can help with answering questions like: How many cycles does it take to execute this code? What is the ALU doing during cycle 4? Is there a hazard, why does it occur, and how can it be fixed?
46 Pipelined Execution Time (clock cycles) I n s t r. O r d e r Inst 0 Inst 1 Inst 2 Inst 3 ALU IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg ALU IM Reg DM Reg Once the pipeline is full, one instruction is completed every cycle, so CPI = 1 Inst 4 Time to fill the pipeline ALU IM Reg DM Reg
47 Pipeline Operation Cycle-by-cycle flow of instructions through the pipelined datapath Single-clock-cycle pipeline diagram Shows pipeline usage in a single cycle Highlight resources used Multi-clock-cycle diagram Graph of operation over time

48 Multi-Cycle Pipeline Diagram Form showing resource usage

49 Multi-Cycle Pipeline Diagram Traditional form

50 Single-Cycle Pipeline Diagram State of pipeline in a given cycle
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware 4.1 Introduction We will examine two MIPS implementations
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware 4.1 Introduction We will examine two MIPS implementations
Processor (I) - datapath & control. Hwansoo Han
 - datapath & control. Hwansoo Han") Processor (I) - datapath & control Hwansoo Han Introduction CPU performance factors Instruction count - Determined by ISA and compiler CPI and Cycle time - Determined by CPU hardware We will examine two
Processor (I) - datapath & control Hwansoo Han Introduction CPU performance factors Instruction count - Determined by ISA and compiler CPI and Cycle time - Determined by CPU hardware We will examine two
Chapter 4 The Processor 1. Chapter 4A. The Processor
 Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4 The Processor 1 Chapter 4A The Processor Chapter 4 The Processor 2 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Chapter 4. Instruction Execution. Introduction. CPU Overview. Multiplexers. Chapter 4 The Processor 1. The Processor.
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
The Processor: Datapath and Control. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 The Processor: Datapath and Control Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Introduction CPU performance factors Instruction count Determined
The Processor: Datapath and Control Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Introduction CPU performance factors Instruction count Determined
The Processor (1) Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University") The Processor (1) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
The Processor (1) Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu EEE3050: Theory on Computer Architectures, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
COMPUTER ORGANIZATION AND DESIGN. The Hardware/Software Interface. Chapter 4. The Processor: A Based on P&H
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: A Based on P&H Introduction We will examine two MIPS implementations A simplified version A more realistic pipelined
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: A Based on P&H Introduction We will examine two MIPS implementations A simplified version A more realistic pipelined
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4. The Processor Designing the datapath
 Chapter 4 The Processor Designing the datapath Introduction CPU performance determined by Instruction Count Clock Cycles per Instruction (CPI) and Cycle time Determined by Instruction Set Architecure (ISA)
Chapter 4 The Processor Designing the datapath Introduction CPU performance determined by Instruction Count Clock Cycles per Instruction (CPI) and Cycle time Determined by Instruction Set Architecure (ISA)
Chapter 4. The Processor. Instruction count Determined by ISA and compiler. We will examine two MIPS implementations
 Chapter 4 The Processor Part I Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations
Chapter 4 The Processor Part I Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
COMPUTER ORGANIZATION AND DESIGN 5 Edition th The Hardware/Software Interface Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined
Systems Architecture
 Systems Architecture Lecture 15: A Simple Implementation of MIPS Jeremy R. Johnson Anatole D. Ruslanov William M. Mongan Some or all figures from Computer Organization and Design: The Hardware/Software
Systems Architecture Lecture 15: A Simple Implementation of MIPS Jeremy R. Johnson Anatole D. Ruslanov William M. Mongan Some or all figures from Computer Organization and Design: The Hardware/Software
Chapter 4. The Processor. Computer Architecture and IC Design Lab
 Chapter 4 The Processor Introduction CPU performance factors CPI Clock Cycle Time Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS
Chapter 4 The Processor Introduction CPU performance factors CPI Clock Cycle Time Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1
 Chapter 4.1") Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 14: One Cycle MIPs Datapath Adapted from Computer Organization and Design, Patterson & Hennessy, UCB R-Format Instructions Read two register operands Perform
ECE232: Hardware Organization and Design Lecture 14: One Cycle MIPs Datapath Adapted from Computer Organization and Design, Patterson & Hennessy, UCB R-Format Instructions Read two register operands Perform
COMPUTER ORGANIZATION AND DESIGN
 ARM COMPUTER ORGANIZATION AND DESIGN Edition The Hardware/Software Interface Chapter 4 The Processor Modified and extended by R.J. Leduc - 2016 To understand this chapter, you will need to understand some
ARM COMPUTER ORGANIZATION AND DESIGN Edition The Hardware/Software Interface Chapter 4 The Processor Modified and extended by R.J. Leduc - 2016 To understand this chapter, you will need to understand some
Introduction. Datapath Basics
 Introduction CPU performance factors - Instruction count; determined by ISA and compiler - CPI and Cycle time; determined by CPU hardware 1 We will examine a simplified MIPS implementation in this course
Introduction CPU performance factors - Instruction count; determined by ISA and compiler - CPI and Cycle time; determined by CPU hardware 1 We will examine a simplified MIPS implementation in this course
The MIPS Processor Datapath
 The MIPS Processor Datapath Module Outline MIPS datapath implementation Register File, Instruction memory, Data memory Instruction interpretation and execution. Combinational control Assignment: Datapath
The MIPS Processor Datapath Module Outline MIPS datapath implementation Register File, Instruction memory, Data memory Instruction interpretation and execution. Combinational control Assignment: Datapath
3/12/2014. Single Cycle (Review) CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?
 CSE 2021: Computer Organization. Single Cycle with Jump. Multi-Cycle Implementation. Why Multi-Cycle?") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10b CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan 2 Single Cycle with Jump Multi-Cycle Implementation Instruction:
ECE260: Fundamentals of Computer Engineering
 Datapath for a Simplified Processor James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Introduction
Datapath for a Simplified Processor James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania Based on Computer Organization and Design, 5th Edition by Patterson & Hennessy Introduction
COMP2611: Computer Organization. The Pipelined Processor
 COMP2611: Computer Organization The 1 2 Background 2 High-Performance Processors 3 Two techniques for designing high-performance processors by exploiting parallelism: Multiprocessing: parallelism among
COMP2611: Computer Organization The 1 2 Background 2 High-Performance Processors 3 Two techniques for designing high-performance processors by exploiting parallelism: Multiprocessing: parallelism among
LECTURE 3: THE PROCESSOR
 LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
LECTURE 3: THE PROCESSOR Abridged version of Patterson & Hennessy (2013):Ch.4 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU
TDT4255 Computer Design. Lecture 4. Magnus Jahre. TDT4255 Computer Design
 1 TDT4255 Computer Design Lecture 4 Magnus Jahre 2 Outline Chapter 4.1 to 4.4 A Multi-cycle Processor Appendix D 3 Chapter 4 The Processor Acknowledgement: Slides are adapted from Morgan Kaufmann companion
1 TDT4255 Computer Design Lecture 4 Magnus Jahre 2 Outline Chapter 4.1 to 4.4 A Multi-cycle Processor Appendix D 3 Chapter 4 The Processor Acknowledgement: Slides are adapted from Morgan Kaufmann companion
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Computer Organization and Structure Bing-Yu Chen National Taiwan University The Processor Logic Design Conventions Building a Datapath A Simple Implementation Scheme An Overview of Pipelining Pipelined
Full Datapath. CSCI 402: Computer Architectures. The Processor (2) 3/21/19. Fengguang Song Department of Computer & Information Science IUPUI
 3/21/19. Fengguang Song Department of Computer & Information Science IUPUI") CSCI 42: Computer Architectures The Processor (2) Fengguang Song Department of Computer & Information Science IUPUI Full Datapath Branch Target Instruction Fetch Immediate 4 Today s Contents We have looked
CSCI 42: Computer Architectures The Processor (2) Fengguang Song Department of Computer & Information Science IUPUI Full Datapath Branch Target Instruction Fetch Immediate 4 Today s Contents We have looked
Introduction. Chapter 4. Instruction Execution. CPU Overview. University of the District of Columbia 30 September, Chapter 4 The Processor 1
 Chapter 4 The Processor Introduction CPU performance factors Instruction count etermined by IS and compiler CPI and Cycle time etermined by CPU hardware We will examine two MIPS implementations simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count etermined by IS and compiler CPI and Cycle time etermined by CPU hardware We will examine two MIPS implementations simplified
Pipelining Analogy. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop: Speedup = 8/3.5 = 2.3.
 Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup =2n/05n+15 2n/0.5n 1.5 4 = number of stages 4.5 An Overview
ELEC 5200/6200 Computer Architecture and Design Spring 2017 Lecture 4: Datapath and Control
 ELEC 52/62 Computer Architecture and Design Spring 217 Lecture 4: Datapath and Control Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University, Auburn, AL 36849
ELEC 52/62 Computer Architecture and Design Spring 217 Lecture 4: Datapath and Control Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University, Auburn, AL 36849
LECTURE 5. Single-Cycle Datapath and Control
 LECTURE 5 Single-Cycle Datapath and Control PROCESSORS In lecture 1, we reminded ourselves that the datapath and control are the two components that come together to be collectively known as the processor.
LECTURE 5 Single-Cycle Datapath and Control PROCESSORS In lecture 1, we reminded ourselves that the datapath and control are the two components that come together to be collectively known as the processor.
Lecture Topics. Announcements. Today: Single-Cycle Processors (P&H ) Next: continued. Milestone #3 (due 2/9) Milestone #4 (due 2/23)
 Next: continued. Milestone #3 (due 2/9) Milestone #4 (due 2/23)") Lecture Topics Today: Single-Cycle Processors (P&H 4.1-4.4) Next: continued 1 Announcements Milestone #3 (due 2/9) Milestone #4 (due 2/23) Exam #1 (Wednesday, 2/15) 2 1 Exam #1 Wednesday, 2/15 (3:00-4:20
Lecture Topics Today: Single-Cycle Processors (P&H 4.1-4.4) Next: continued 1 Announcements Milestone #3 (due 2/9) Milestone #4 (due 2/23) Exam #1 (Wednesday, 2/15) 2 1 Exam #1 Wednesday, 2/15 (3:00-4:20
Chapter 4. The Processor
 Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Chapter 4 The Processor 1 Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A
Determined by ISA and compiler. We will examine two MIPS implementations. A simplified version A more realistic pipelined version
 MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
MIPS Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
CPE 335 Computer Organization. Basic MIPS Architecture Part I
 CPE 335 Computer Organization Basic MIPS Architecture Part I Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s8/index.html CPE232 Basic MIPS Architecture
CPE 335 Computer Organization Basic MIPS Architecture Part I Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s8/index.html CPE232 Basic MIPS Architecture
CSCI 402: Computer Architectures. Fengguang Song Department of Computer & Information Science IUPUI. Today s Content
 3/6/8 CSCI 42: Computer Architectures The Processor (2) Fengguang Song Department of Computer & Information Science IUPUI Today s Content We have looked at how to design a Data Path. 4.4, 4.5 We will design
3/6/8 CSCI 42: Computer Architectures The Processor (2) Fengguang Song Department of Computer & Information Science IUPUI Today s Content We have looked at how to design a Data Path. 4.4, 4.5 We will design
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Processor (II) - pipelining. Hwansoo Han
 - pipelining. Hwansoo Han") Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Processor (II) - pipelining Hwansoo Han Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 =2.3 Non-stop: 2n/0.5n + 1.5 4 = number
Inf2C - Computer Systems Lecture Processor Design Single Cycle
 Inf2C - Computer Systems Lecture 10-11 Processor Design Single Cycle Boris Grot School of Informatics University of Edinburgh Previous lectures Combinational circuits Combinations of gates (INV, AND, OR,
Inf2C - Computer Systems Lecture 10-11 Processor Design Single Cycle Boris Grot School of Informatics University of Edinburgh Previous lectures Combinational circuits Combinations of gates (INV, AND, OR,
ECS 154B Computer Architecture II Spring 2009
 ECS 154B Computer Architecture II Spring 2009 Pipelining Datapath and Control 6.2-6.3 Partially adapted from slides by Mary Jane Irwin, Penn State And Kurtis Kredo, UCD Pipelined CPU Break execution into
ECS 154B Computer Architecture II Spring 2009 Pipelining Datapath and Control 6.2-6.3 Partially adapted from slides by Mary Jane Irwin, Penn State And Kurtis Kredo, UCD Pipelined CPU Break execution into
CPE 335 Computer Organization. Basic MIPS Pipelining Part I
 CPE 335 Computer Organization Basic MIPS Pipelining Part I Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s08/index.html CPE232 Basic MIPS Pipelining
CPE 335 Computer Organization Basic MIPS Pipelining Part I Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s08/index.html CPE232 Basic MIPS Pipelining
Pipelining. CSC Friday, November 6, 2015
 Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Pipelining CSC 211.01 Friday, November 6, 2015 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory register file ALU data memory register file Not
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
ECE331: Hardware Organization and Design
 ECE331: Hardware Organization and Design Lecture 35: Final Exam Review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Material from Earlier in the Semester Throughput and latency
ECE331: Hardware Organization and Design Lecture 35: Final Exam Review Adapted from Computer Organization and Design, Patterson & Hennessy, UCB Material from Earlier in the Semester Throughput and latency
Single Cycle Datapath
 Single Cycle atapath Lecture notes from MKP, H. H. Lee and S. Yalamanchili Section 4.-4.4 Appendices B.7, B.8, B.,.2 Practice Problems:, 4, 6, 9 ing (2) Introduction We will examine two MIPS implementations
Single Cycle atapath Lecture notes from MKP, H. H. Lee and S. Yalamanchili Section 4.-4.4 Appendices B.7, B.8, B.,.2 Practice Problems:, 4, 6, 9 ing (2) Introduction We will examine two MIPS implementations
Single Cycle Datapath
 Single Cycle atapath Lecture notes from MKP, H. H. Lee and S. Yalamanchili Section 4.1-4.4 Appendices B.3, B.7, B.8, B.11,.2 ing Note: Appendices A-E in the hardcopy text correspond to chapters 7-11 in
Single Cycle atapath Lecture notes from MKP, H. H. Lee and S. Yalamanchili Section 4.1-4.4 Appendices B.3, B.7, B.8, B.11,.2 ing Note: Appendices A-E in the hardcopy text correspond to chapters 7-11 in
Lecture 7 Pipelining. Peng Liu.
 Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Chapter 4. The Processor
 Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
Chapter 4 The Processor 4.1 Introduction Introduction CPU performance factors Instruction count CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations Determined by ISA
ENGN1640: Design of Computing Systems Topic 04: Single-Cycle Processor Design
 ENGN64: Design of Computing Systems Topic 4: Single-Cycle Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN64: Design of Computing Systems Topic 4: Single-Cycle Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
CO Computer Architecture and Programming Languages CAPL. Lecture 18 & 19
 CO2-3224 Computer Architecture and Programming Languages CAPL Lecture 8 & 9 Dr. Kinga Lipskoch Fall 27 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be
CO2-3224 Computer Architecture and Programming Languages CAPL Lecture 8 & 9 Dr. Kinga Lipskoch Fall 27 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be
EIE/ENE 334 Microprocessors
 EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
EIE/ENE 334 Microprocessors Lecture 6: The Processor Week #06/07 : Dejwoot KHAWPARISUTH Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2009, Elsevier (MK) http://webstaff.kmutt.ac.th/~dejwoot.kha/
Computer Architecture. Lecture 6.1: Fundamentals of
 CS3350B Computer Architecture Winter 2015 Lecture 6.1: Fundamentals of Instructional Level Parallelism Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and
CS3350B Computer Architecture Winter 2015 Lecture 6.1: Fundamentals of Instructional Level Parallelism Marc Moreno Maza www.csd.uwo.ca/courses/cs3350b [Adapted from lectures on Computer Organization and
Computer Architecture Computer Science & Engineering. Chapter 4. The Processor BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Computer Architecture Computer Science & Engineering Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware
Lecture 4: Review of MIPS. Instruction formats, impl. of control and datapath, pipelined impl.
 Lecture 4: Review of MIPS Instruction formats, impl. of control and datapath, pipelined impl. 1 MIPS Instruction Types Data transfer: Load and store Integer arithmetic/logic Floating point arithmetic Control
Lecture 4: Review of MIPS Instruction formats, impl. of control and datapath, pipelined impl. 1 MIPS Instruction Types Data transfer: Load and store Integer arithmetic/logic Floating point arithmetic Control
EECS150 - Digital Design Lecture 10- CPU Microarchitecture. Processor Microarchitecture Introduction
 EECS150 - Digital Design Lecture 10- CPU Microarchitecture Feb 18, 2010 John Wawrzynek Spring 2010 EECS150 - Lec10-cpu Page 1 Processor Microarchitecture Introduction Microarchitecture: how to implement
EECS150 - Digital Design Lecture 10- CPU Microarchitecture Feb 18, 2010 John Wawrzynek Spring 2010 EECS150 - Lec10-cpu Page 1 Processor Microarchitecture Introduction Microarchitecture: how to implement
Review: Abstract Implementation View
 Review: Abstract Implementation View Split memory (Harvard) model - single cycle operation Simplified to contain only the instructions: memory-reference instructions: lw, sw arithmetic-logical instructions:
Review: Abstract Implementation View Split memory (Harvard) model - single cycle operation Simplified to contain only the instructions: memory-reference instructions: lw, sw arithmetic-logical instructions:
COMP303 - Computer Architecture Lecture 8. Designing a Single Cycle Datapath
 COMP33 - Computer Architecture Lecture 8 Designing a Single Cycle Datapath The Big Picture The Five Classic Components of a Computer Processor Input Control Memory Datapath Output The Big Picture: The
COMP33 - Computer Architecture Lecture 8 Designing a Single Cycle Datapath The Big Picture The Five Classic Components of a Computer Processor Input Control Memory Datapath Output The Big Picture: The
MIPS Pipelining. Computer Organization Architectures for Embedded Computing. Wednesday 8 October 14
 MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
MIPS Pipelining Computer Organization Architectures for Embedded Computing Wednesday 8 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy 4th Edition, 2011, MK
Mark Redekopp and Gandhi Puvvada, All rights reserved. EE 357 Unit 15. Single-Cycle CPU Datapath and Control
 EE 37 Unit Single-Cycle CPU path and Control CPU Organization Scope We will build a CPU to implement our subset of the MIPS ISA Memory Reference Instructions: Load Word (LW) Store Word (SW) Arithmetic
EE 37 Unit Single-Cycle CPU path and Control CPU Organization Scope We will build a CPU to implement our subset of the MIPS ISA Memory Reference Instructions: Load Word (LW) Store Word (SW) Arithmetic
ECE260: Fundamentals of Computer Engineering
 ECE260: Fundamentals of Computer Engineering Pipelined Datapath and Control James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania ECE260: Fundamentals of Computer Engineering
ECE260: Fundamentals of Computer Engineering Pipelined Datapath and Control James Moscola Dept. of Engineering & Computer Science York College of Pennsylvania ECE260: Fundamentals of Computer Engineering
CENG 3420 Lecture 06: Datapath
 CENG 342 Lecture 6: Datapath Bei Yu byu@cse.cuhk.edu.hk CENG342 L6. Spring 27 The Processor: Datapath & Control q We're ready to look at an implementation of the MIPS q Simplified to contain only: memory-reference
CENG 342 Lecture 6: Datapath Bei Yu byu@cse.cuhk.edu.hk CENG342 L6. Spring 27 The Processor: Datapath & Control q We're ready to look at an implementation of the MIPS q Simplified to contain only: memory-reference
CENG 3420 Computer Organization and Design. Lecture 06: MIPS Processor - I. Bei Yu
 CENG 342 Computer Organization and Design Lecture 6: MIPS Processor - I Bei Yu CEG342 L6. Spring 26 The Processor: Datapath & Control q We're ready to look at an implementation of the MIPS q Simplified
CENG 342 Computer Organization and Design Lecture 6: MIPS Processor - I Bei Yu CEG342 L6. Spring 26 The Processor: Datapath & Control q We're ready to look at an implementation of the MIPS q Simplified
Full Datapath. Chapter 4 The Processor 2
 Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
Pipelining Full Datapath Chapter 4 The Processor 2 Datapath With Control Chapter 4 The Processor 3 Performance Issues Longest delay determines clock period Critical path: load instruction Instruction memory
EECS150 - Digital Design Lecture 9- CPU Microarchitecture. Watson: Jeopardy-playing Computer
 EECS150 - Digital Design Lecture 9- CPU Microarchitecture Feb 15, 2011 John Wawrzynek Spring 2011 EECS150 - Lec09-cpu Page 1 Watson: Jeopardy-playing Computer Watson is made up of a cluster of ninety IBM
EECS150 - Digital Design Lecture 9- CPU Microarchitecture Feb 15, 2011 John Wawrzynek Spring 2011 EECS150 - Lec09-cpu Page 1 Watson: Jeopardy-playing Computer Watson is made up of a cluster of ninety IBM
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3. Emil Sekerinski, McMaster University, Fall Term 2015/16
 4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
4. The Processor Computer Architecture COMP SCI 2GA3 / SFWR ENG 2GA3 Emil Sekerinski, McMaster University, Fall Term 2015/16 Instruction Execution Consider simplified MIPS: lw/sw rt, offset(rs) add/sub/and/or/slt
CPU Organization (Design)
") ISA Requirements CPU Organization (Design) Datapath Design: Capabilities & performance characteristics of principal Functional Units (FUs) needed by ISA instructions (e.g., Registers, ALU, Shifters, Logic
ISA Requirements CPU Organization (Design) Datapath Design: Capabilities & performance characteristics of principal Functional Units (FUs) needed by ISA instructions (e.g., Registers, ALU, Shifters, Logic
Chapter 5: The Processor: Datapath and Control
 Chapter 5: The Processor: Datapath and Control Overview Logic Design Conventions Building a Datapath and Control Unit Different Implementations of MIPS instruction set A simple implementation of a processor
Chapter 5: The Processor: Datapath and Control Overview Logic Design Conventions Building a Datapath and Control Unit Different Implementations of MIPS instruction set A simple implementation of a processor
Chapter 4. The Processor
 Chapter 4 The Processor Recall. ISA? Instruction Fetch Instruction Decode Operand Fetch Execute Result Store Next Instruction Instruction Format or Encoding how is it decoded? Location of operands and
Chapter 4 The Processor Recall. ISA? Instruction Fetch Instruction Decode Operand Fetch Execute Result Store Next Instruction Instruction Format or Encoding how is it decoded? Location of operands and
The Processor: Datapath & Control
 Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture The Processor: Datapath & Control Processor Design Step 3 Assemble Datapath Meeting Requirements Build the
Orange Coast College Business Division Computer Science Department CS 116- Computer Architecture The Processor: Datapath & Control Processor Design Step 3 Assemble Datapath Meeting Requirements Build the
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining
 Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
Computer and Information Sciences College / Computer Science Department Enhancing Performance with Pipelining Single-Cycle Design Problems Assuming fixed-period clock every instruction datapath uses one
CC 311- Computer Architecture. The Processor - Control
 CC 311- Computer Architecture The Processor - Control Control Unit Functions: Instruction code Control Unit Control Signals Select operations to be performed (ALU, read/write, etc.) Control data flow (multiplexor
CC 311- Computer Architecture The Processor - Control Control Unit Functions: Instruction code Control Unit Control Signals Select operations to be performed (ALU, read/write, etc.) Control data flow (multiplexor
Department of Computer and IT Engineering University of Kurdistan. Computer Architecture Pipelining. By: Dr. Alireza Abdollahpouri
 Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
Department of Computer and IT Engineering University of Kurdistan Computer Architecture Pipelining By: Dr. Alireza Abdollahpouri Pipelined MIPS processor Any instruction set can be implemented in many
CPE 335. Basic MIPS Architecture Part II
 CPE 335 Computer Organization Basic MIPS Architecture Part II Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s08/index.html CPE232 Basic MIPS Architecture
CPE 335 Computer Organization Basic MIPS Architecture Part II Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s08/index.html CPE232 Basic MIPS Architecture
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor? Chapter 4 The Processor 2 Introduction We will learn How the ISA determines many aspects
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor? Chapter 4 The Processor 2 Introduction We will learn How the ISA determines many aspects
COSC 6385 Computer Architecture - Pipelining
 COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
COSC 6385 Computer Architecture - Pipelining Fall 2006 Some of the slides are based on a lecture by David Culler, Instruction Set Architecture Relevant features for distinguishing ISA s Internal storage
Topic #6. Processor Design
 Topic #6 Processor Design Major Goals! To present the single-cycle implementation and to develop the student's understanding of combinational and clocked sequential circuits and the relationship between
Topic #6 Processor Design Major Goals! To present the single-cycle implementation and to develop the student's understanding of combinational and clocked sequential circuits and the relationship between
Lecture 6 Datapath and Controller
 Lecture 6 Datapath and Controller Peng Liu liupeng@zju.edu.cn Windows Editor and Word Processing UltraEdit, EditPlus Gvim Linux or Mac IOS Emacs vi or vim Word Processing(Windows, Linux, and Mac IOS) LaTex
Lecture 6 Datapath and Controller Peng Liu liupeng@zju.edu.cn Windows Editor and Word Processing UltraEdit, EditPlus Gvim Linux or Mac IOS Emacs vi or vim Word Processing(Windows, Linux, and Mac IOS) LaTex
CENG 3420 Lecture 06: Pipeline
 CENG 3420 Lecture 06: Pipeline Bei Yu byu@cse.cuhk.edu.hk CENG3420 L06.1 Spring 2019 Outline q Pipeline Motivations q Pipeline Hazards q Exceptions q Background: Flip-Flop Control Signals CENG3420 L06.2
CENG 3420 Lecture 06: Pipeline Bei Yu byu@cse.cuhk.edu.hk CENG3420 L06.1 Spring 2019 Outline q Pipeline Motivations q Pipeline Hazards q Exceptions q Background: Flip-Flop Control Signals CENG3420 L06.2
Computer Organization and Structure
 Computer Organization and Structure 1. Assuming the following repeating pattern (e.g., in a loop) of branch outcomes: Branch outcomes a. T, T, NT, T b. T, T, T, NT, NT Homework #4 Due: 2014/12/9 a. What
Computer Organization and Structure 1. Assuming the following repeating pattern (e.g., in a loop) of branch outcomes: Branch outcomes a. T, T, NT, T b. T, T, T, NT, NT Homework #4 Due: 2014/12/9 a. What
RISC Processor Design
 RISC Processor Design Single Cycle Implementation - MIPS Virendra Singh Indian Institute of Science Bangalore virendra@computer.org Lecture 13 SE-273: Processor Design Feb 07, 2011 SE-273@SERC 1 Courtesy:
RISC Processor Design Single Cycle Implementation - MIPS Virendra Singh Indian Institute of Science Bangalore virendra@computer.org Lecture 13 SE-273: Processor Design Feb 07, 2011 SE-273@SERC 1 Courtesy:
CSEN 601: Computer System Architecture Summer 2014
 CSEN 601: Computer System Architecture Summer 2014 Practice Assignment 5 Solutions Exercise 5-1: (Midterm Spring 2013) a. What are the values of the control signals (except ALUOp) for each of the following
CSEN 601: Computer System Architecture Summer 2014 Practice Assignment 5 Solutions Exercise 5-1: (Midterm Spring 2013) a. What are the values of the control signals (except ALUOp) for each of the following
Systems Architecture I
 Systems Architecture I Topics A Simple Implementation of MIPS * A Multicycle Implementation of MIPS ** *This lecture was derived from material in the text (sec. 5.1-5.3). **This lecture was derived from
Systems Architecture I Topics A Simple Implementation of MIPS * A Multicycle Implementation of MIPS ** *This lecture was derived from material in the text (sec. 5.1-5.3). **This lecture was derived from
Chapter 4. The Processor. Jiang Jiang
 Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
Chapter 4 The Processor Jiang Jiang jiangjiang@ic.sjtu.edu.cn [Adapted from Computer Organization and Design, 4 th Edition, Patterson & Hennessy, 2008, MK] Chapter 4 The Processor 2 Introduction CPU performance
Major CPU Design Steps
 Datapath Major CPU Design Steps. Analyze instruction set operations using independent RTN ISA => RTN => datapath requirements. This provides the the required datapath components and how they are connected
Datapath Major CPU Design Steps. Analyze instruction set operations using independent RTN ISA => RTN => datapath requirements. This provides the the required datapath components and how they are connected
The Big Picture: Where are We Now? EEM 486: Computer Architecture. Lecture 3. Designing a Single Cycle Datapath
 The Big Picture: Where are We Now? EEM 486: Computer Architecture Lecture 3 The Five Classic Components of a Computer Processor Input Control Memory Designing a Single Cycle path path Output Today s Topic:
The Big Picture: Where are We Now? EEM 486: Computer Architecture Lecture 3 The Five Classic Components of a Computer Processor Input Control Memory Designing a Single Cycle path path Output Today s Topic:
Instruction word R0 R1 R2 R3 R4 R5 R6 R8 R12 R31
 4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
4.16 Exercises 419 Exercise 4.11 In this exercise we examine in detail how an instruction is executed in a single-cycle datapath. Problems in this exercise refer to a clock cycle in which the processor
Lecture 10: Simple Data Path
 Lecture 10: Simple Data Path Course so far Performance comparisons Amdahl s law ISA function & principles What do bits mean? Computer math Today Take QUIZ 6 over P&H.1-, before 11:59pm today How do computers
Lecture 10: Simple Data Path Course so far Performance comparisons Amdahl s law ISA function & principles What do bits mean? Computer math Today Take QUIZ 6 over P&H.1-, before 11:59pm today How do computers
Pipeline design. Mehran Rezaei
 Pipeline design Mehran Rezaei How Can We Improve the Performance? Exec Time = IC * CPI * CCT Optimization IC CPI CCT Source Level * Compiler * * ISA * * Organization * * Technology * With Pipelining We
Pipeline design Mehran Rezaei How Can We Improve the Performance? Exec Time = IC * CPI * CCT Optimization IC CPI CCT Source Level * Compiler * * ISA * * Organization * * Technology * With Pipelining We
Design of Digital Circuits 2017 Srdjan Capkun Onur Mutlu (Guest starring: Frank K. Gürkaynak and Aanjhan Ranganathan)
") Microarchitecture Design of Digital Circuits 27 Srdjan Capkun Onur Mutlu (Guest starring: Frank K. Gürkaynak and Aanjhan Ranganathan) http://www.syssec.ethz.ch/education/digitaltechnik_7 Adapted from Digital
Microarchitecture Design of Digital Circuits 27 Srdjan Capkun Onur Mutlu (Guest starring: Frank K. Gürkaynak and Aanjhan Ranganathan) http://www.syssec.ethz.ch/education/digitaltechnik_7 Adapted from Digital
Lecture 9. Pipeline Hazards. Christos Kozyrakis Stanford University
 Lecture 9 Pipeline Hazards Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee18b 1 Announcements PA-1 is due today Electronic submission Lab2 is due on Tuesday 2/13 th Quiz1 grades will
Lecture 9 Pipeline Hazards Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee18b 1 Announcements PA-1 is due today Electronic submission Lab2 is due on Tuesday 2/13 th Quiz1 grades will
CSEE 3827: Fundamentals of Computer Systems
 CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
CSEE 3827: Fundamentals of Computer Systems Lecture 21 and 22 April 22 and 27, 2009 martha@cs.columbia.edu Amdahl s Law Be aware when optimizing... T = improved Taffected improvement factor + T unaffected
The overall datapath for RT, lw,sw beq instrucution
 Designing The Main Control Unit: Remember the three instruction classes {R-type, Memory, Branch}: a) R-type : Op rs rt rd shamt funct 1.src 2.src dest. 31-26 25-21 20-16 15-11 10-6 5-0 a) Memory : Op rs
Designing The Main Control Unit: Remember the three instruction classes {R-type, Memory, Branch}: a) R-type : Op rs rt rd shamt funct 1.src 2.src dest. 31-26 25-21 20-16 15-11 10-6 5-0 a) Memory : Op rs
CS/COE0447: Computer Organization
 CS/COE0447: Computer Organization and Assembly Language Datapath and Control Sangyeun Cho Dept. of Computer Science A simple MIPS We will design a simple MIPS processor that supports a small instruction
CS/COE0447: Computer Organization and Assembly Language Datapath and Control Sangyeun Cho Dept. of Computer Science A simple MIPS We will design a simple MIPS processor that supports a small instruction
CS/COE0447: Computer Organization
 A simple MIPS CS/COE447: Computer Organization and Assembly Language Datapath and Control Sangyeun Cho Dept. of Computer Science We will design a simple MIPS processor that supports a small instruction
A simple MIPS CS/COE447: Computer Organization and Assembly Language Datapath and Control Sangyeun Cho Dept. of Computer Science We will design a simple MIPS processor that supports a small instruction
Improving Performance: Pipelining
 Improving Performance: Pipelining Memory General registers Memory ID EXE MEM WB Instruction Fetch (includes PC increment) ID Instruction Decode + fetching values from general purpose registers EXE EXEcute
Improving Performance: Pipelining Memory General registers Memory ID EXE MEM WB Instruction Fetch (includes PC increment) ID Instruction Decode + fetching values from general purpose registers EXE EXEcute