Parallel Computing with MATLAB on Discovery Cluster
|
|
|
- Julius Garrison
- 5 years ago
- Views:
Transcription

1 Parallel Computing with MATLAB on Discovery Cluster Northeastern University Research Computing: Nilay K Roy, MS Computer Science, Ph.D Computational Physics
2 Lets look at the Discovery Cluster Matlab environment Setting queues and no of cores Running matlab interactively Running matlab in batch

3
4
5
6

7
8
9
10

11
12
13

14

15
16
17 PARFOR tic s = ; parfor i = 1:s s = s + 1; end toc tic s = ; for i = 1:s s = s + 1; end toc
18 Now for some computation and profiling runs PARPOOL (replaced by MATLABPOOL command in R2013b) example batch run SPMD example batch run
19 First a profiler run lets do this on pmode start local 4 cluster Parallel Command Window (pmode) starts P>> R1 = rand(16, codistributor()) P>> R2 = rand(16, codistributor()) P>> mpiprofile on P>> P = R1*R2 P>> mpiprofile off P>> mpiprofile viewer


20

21 GPU RUNS with Matlab
22 Over 100 operations (e.g. fft, ifft, eig) are now available as built-in MATLAB functions that can be executed directly on the GPU by providing an input argument of the type GPUArray GPU-enabled functions are overloaded

23

24

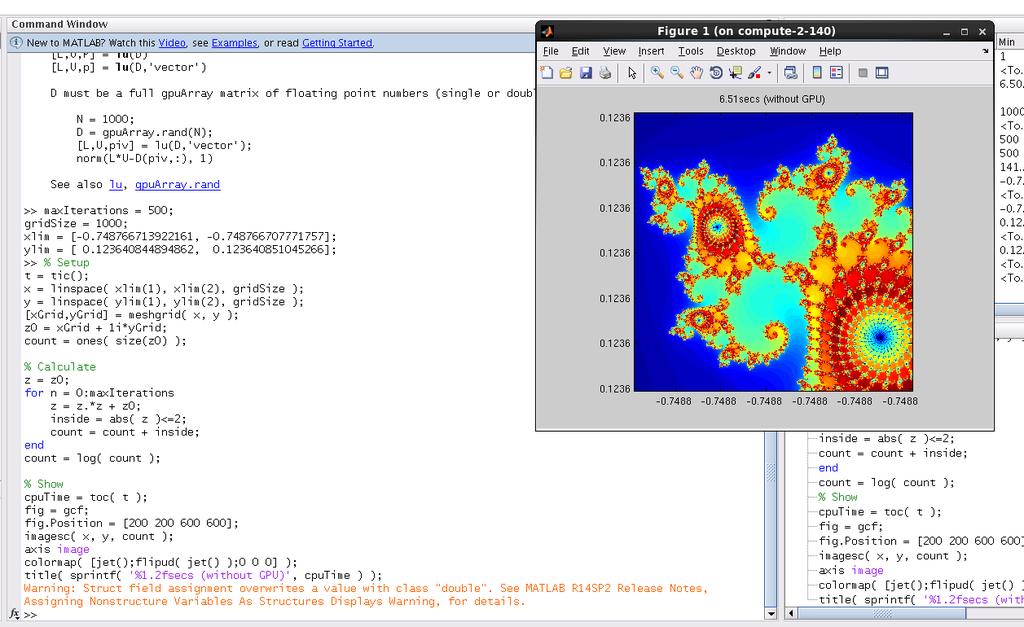
25
26

27
, we make one call to a parallelized GPU operation that performs the whole")
28 Elementwise operation For GPU array inputs, the function used with arrayfun gets compiled into native GPU code Using arrayfun means that instead of many thousands of calls to separate GPU-optimized operations (at least 6 per iteration), we make one call to a parallelized GPU operation that performs the whole calculation
 One GPU thread is required for location in the Mandelbrot Set, with the threads grouped into blocks The kernel indicates how big a thread-block")
29 CUDA and Matlab CUDA/C++ implementation of the element processing algorithm needs to hand written manually compiled using nvidia's NVCC compiler to produce the assembly-level ptx file (.ptx stands for "Parallel Thread execution language") One GPU thread is required for location in the Mandelbrot Set, with the threads grouped into blocks The kernel indicates how big a thread-block is, and in the code below we use this to calculate the number of thread-blocks required This then becomes the GridSize We will look at this shortly Lets look at a simple handwritten cuda two vector addition
30

31
32 pctdemos]$ cat paralleldemo_gpu_mandelbrot.m maxiterations = 500; gridsize = 1000; xlim = [ , ]; ylim = [ , ]; % Setup t = tic(); x = linspace( xlim(1), xlim(2), gridsize ); y = linspace( ylim(1), ylim(2), gridsize ); [xgrid,ygrid] = meshgrid( x, y ); z0 = xgrid + 1i*yGrid; count = ones( size(z0) ); % Calculate z = z0; for n = 0:maxIterations z = z.*z + z0; inside = abs( z )<=2; count = count + inside; end count = log( count ); % Show cputime = toc( t ); set( gcf, 'Position', [ ] ); imagesc( x, y, count ); axis image colormap( [jet();flipud( jet() );0 0 0] ); title( sprintf( '%1.2fsecs (without GPU)', cputime ) ); %% Using gpuarray % When MATLAB encounters data on the GPU, calculations with that data are % performed on the GPU. The class % <matlab:doc('gpuarray') gpuarray > provides % GPU versions of many functions that you can use to create data arrays, % including the % <matlab:doc('gpuarray.linspace') linspace >, % <matlab:doc('gpuarray.logspace') logspace >, and % <matlab:doc('gpuarray.meshgrid') meshgrid > functions % needed here. Similarly, the count array is initialized directly on the % GPU using the function % <matlab:doc('gpuarray.ones') gpuarray.ones >. % % With these changes to the data initialization the calculations will now % be performed on the GPU: % Setup t = tic(); x = gpuarray.linspace( xlim(1), xlim(2), gridsize ); y = gpuarray.linspace( ylim(1), ylim(2), gridsize ); [xgrid,ygrid] = meshgrid( x, y ); z0 = complex( xgrid, ygrid ); count = gpuarray.ones( size(z0) ); % Calculate z = z0; for n = 0:maxIterations z = z.*z + z0; inside = abs( z )<=2; count = count + inside; end count = log( count ); % Show count = gather( count ); % Fetch the data back from the GPU naivegputime = toc( t ); imagesc( x, y, count ) axis image title( sprintf( '%1.3fsecs (naive GPU) = %1.1fx faster',... naivegputime, cputime/naivegputime ) ) %% Element-wise Operation % Noting that the algorithm is operating equally on every element of the % input, we can place the code in a helper function and call it using % <matlab:doc('gpuarray.arrayfun') arrayfun >. For GPU array % inputs, the function used with arrayfun gets compiled into native GPU % code. In this case we placed the loop in % <matlab:edit('pctdemo_processmandelbrotelement.m') % pctdemo_processmandelbrotelement.m >: % % function count = pctdemo_processmandelbrotelement(x0,y0,maxiterations) % z0 = complex(x0,y0); % z = z0; % count = 1; % while (count <= maxiterations) && (abs(z) <= 2) % count = count + 1; % z = z*z + z0; % end % count = log(count); % % Note that an early abort has been introduced because this function % processes only a single element. For most views of the Mandelbrot Set a % significant number of elements stop very early and this can save a lot of % processing. The for loop has also been replaced by a while loop % because they are usually more efficient. This function makes no mention % of the GPU and uses no GPU-specific features - it is standard MATLAB % code.
33 % Using arrayfun means that instead of many thousands of calls to % separate GPU-optimized operations (at least 6 per iteration), we make one % call to a parallelized GPU operation that performs the whole calculation. % This significantly reduces overhead. % Setup t = tic(); x = gpuarray.linspace( xlim(1), xlim(2), gridsize ); y = gpuarray.linspace( ylim(1), ylim(2), gridsize ); [xgrid,ygrid] = meshgrid( x, y ); % Calculate count = xgrid, ygrid, maxiterations ); % Show count = gather( count ); % Fetch the data back from the GPU gpuarrayfuntime = toc( t ); imagesc( x, y, count ) axis image title( sprintf( '%1.3fsecs (GPU arrayfun) = %1.1fx faster',... gpuarrayfuntime, cputime/gpuarrayfuntime ) ); %% Working with CUDA % <matlab:doc('parallel.gpu.cudakernel') parallel.gpu.cudakernel > % % A CUDA/C++ % in <matlab:edit('pctdemo_processmandelbrotelement.cu') % pctdemo_processmandelbrotelement.cu > % pctdemo_processmandelbrotelement.ptx (.ptx stands for "Parallel % Thread execution language") % % % device % unsigned int doiterations( double const realpart0, % double const imagpart0, % unsigned int const maxiters ) { % // Initialize: z = z0 % double realpart = realpart0; % double imagpart = imagpart0; % unsigned int count = 0; % // Loop until escape % while ( ( count <= maxiters ) % && ((realpart*realpart + imagpart*imagpart) <= 4.0) ) { % ++count; % // Update: z = z*z + z0; % double const oldrealpart = realpart; % realpart = realpart*realpart - imagpart*imagpart + realpart0; % imagpart = 2.0*oldRealPart*imagPart + imagpart0; % } % return count; % } % One GPU thread is required for location in the Mandelbrot Set, with the % threads grouped into blocks. The kernel indicates how big a thread-block % is, and in the code below we use this to calculate the number of % thread-blocks required. This then becomes the GridSize. % Load the kernel cudafilename = 'pctdemo_processmandelbrotelement.cu'; ptxfilename = ['pctdemo_processmandelbrotelement.',paralle l.gpu.ptxext]; kernel = parallel.gpu.cudakernel( ptxfilename, cudafilename ); % Setup t = tic(); x = gpuarray.linspace( xlim(1), xlim(2), gridsize ); y = gpuarray.linspace( ylim(1), ylim(2), gridsize ); [xgrid,ygrid] = meshgrid( x, y ); % Make sure we have sufficient blocks to cover all of the locations numelements = numel( xgrid ); kernel.threadblocksize = [kernel.maxthreadsperblock,1,1]; kernel.gridsize = [ceil(numelements/kernel.maxthreadsperblock),1]; % Call the kernel count = gpuarray.zeros( size(xgrid) ); count = feval( kernel, count, xgrid, ygrid, maxiterations, numelements ); % Show count = gather( count ); % Fetch the data back from the GPU gpucudakerneltime = toc( t ); imagesc( x, y, count ) axis image title( sprintf( '%1.3fsecs (GPU CUDAKernel) = %1.1fx faster',... gpucudakerneltime, cputime/gpucudakerneltime ) ); [nilay.roy@compute pctdemos]$
![MAP REDUCE and LARGE DATA SETS mapreduce reads a chunk of data from the input datastore [data,info] = read(ds) -> calls the map function to work on chunk map function receives the chunk of data,](/docs-images/80/82078924/images/34-0.jpg "organizes it or performs a precursory calculation ->then uses the add and addmulti functions to add key-value pairs to an intermediate data storage object called a KeyValueStore - The number of calls")
34 MAP REDUCE and LARGE DATA SETS mapreduce reads a chunk of data from the input datastore [data,info] = read(ds) -> calls the map function to work on chunk map function receives the chunk of data, organizes it or performs a precursory calculation ->then uses the add and addmulti functions to add key-value pairs to an intermediate data storage object called a KeyValueStore - The number of calls to the map function by mapreduce is equal to the number of chunks in the input datastore after the map function works on all of the chunks of data in the datastore, mapreduce groups all of the values in the intermediate KeyValueStore object by unique key mapreduce calls the reduce function once for each unique key added by the map function -> each unique key can have many associated values mapreduce passes the values to the reduce function as a ValueIterator object (used to iterate over the values) ValueIterator object for each unique key contains all the associated values for that key reduce function uses the hasnext and getnext functions to iterate through the values in the ValueIterator object one at a time after aggregating the intermediate results from the map function, the reduce function adds final key-value pairs to the output using the add and addmulti functions order of the keys in the output is the same as the order in which the reduce function adds them to the final KeyValueStore object - mapreduce does not explicitly sort the output. Note: reduce function writes the final key-value pairs to a final KeyValueStore object - from this object, mapreduce pulls the key-value pairs into the output datastore, which is a KeyValueDatastore object by default
35 Matlab mapreduce can also be run on HADOOP hdfs file system M2M Translator Matlab has their own but one can create ones own Coding in Java Beyond scope of this talk.
36
MATLAB Distributed Computing Server (MDCS) Training
 Training") MATLAB Distributed Computing Server (MDCS) Training Artemis HPC Integration and Parallel Computing with MATLAB Dr Hayim Dar hayim.dar@sydney.edu.au Dr Nathaniel Butterworth nathaniel.butterworth@sydney.edu.au
MATLAB Distributed Computing Server (MDCS) Training Artemis HPC Integration and Parallel Computing with MATLAB Dr Hayim Dar hayim.dar@sydney.edu.au Dr Nathaniel Butterworth nathaniel.butterworth@sydney.edu.au
Parallel Computing with MATLAB
 Parallel Computing with MATLAB CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University
Parallel Computing with MATLAB CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University
Getting Started with MATLAB Francesca Perino
 Getting Started with MATLAB Francesca Perino francesca.perino@mathworks.it 2014 The MathWorks, Inc. 1 Agenda MATLAB Intro Importazione ed esportazione Programmazione in MATLAB Tecniche per la velocizzazione
Getting Started with MATLAB Francesca Perino francesca.perino@mathworks.it 2014 The MathWorks, Inc. 1 Agenda MATLAB Intro Importazione ed esportazione Programmazione in MATLAB Tecniche per la velocizzazione
Parallel and Distributed Computing with MATLAB The MathWorks, Inc. 1
 Parallel and Distributed Computing with MATLAB 2018 The MathWorks, Inc. 1 Practical Application of Parallel Computing Why parallel computing? Need faster insight on more complex problems with larger datasets
Parallel and Distributed Computing with MATLAB 2018 The MathWorks, Inc. 1 Practical Application of Parallel Computing Why parallel computing? Need faster insight on more complex problems with larger datasets
Mit MATLAB auf der Überholspur Methoden zur Beschleunigung von MATLAB Anwendungen
 Mit MATLAB auf der Überholspur Methoden zur Beschleunigung von MATLAB Anwendungen Frank Graeber Application Engineering MathWorks Germany 2013 The MathWorks, Inc. 1 Speed up the serial code within core
Mit MATLAB auf der Überholspur Methoden zur Beschleunigung von MATLAB Anwendungen Frank Graeber Application Engineering MathWorks Germany 2013 The MathWorks, Inc. 1 Speed up the serial code within core
Adaptive Algorithms and Parallel Computing
 Adaptive Algorithms and Parallel Computing Multicore and Multimachine Computing with MATLAB Academic year 2016-2017 Simone Scardapane Content of the Lecture Main points: Parallelizing loops with the par-for
Adaptive Algorithms and Parallel Computing Multicore and Multimachine Computing with MATLAB Academic year 2016-2017 Simone Scardapane Content of the Lecture Main points: Parallelizing loops with the par-for
Parallel Computing with MATLAB
 Parallel Computing with MATLAB Jos Martin Principal Architect, Parallel Computing Tools jos.martin@mathworks.co.uk 1 2013 The MathWorks, Inc. www.matlabexpo.com Code used in this presentation can be found
Parallel Computing with MATLAB Jos Martin Principal Architect, Parallel Computing Tools jos.martin@mathworks.co.uk 1 2013 The MathWorks, Inc. www.matlabexpo.com Code used in this presentation can be found
Parallel Computing with MATLAB
 Parallel Computing with MATLAB Jos Martin Principal Architect, Parallel Computing Tools jos.martin@mathworks.co.uk 2015 The MathWorks, Inc. 1 Overview Scene setting Task Parallel (par*) Why doesn t it
Parallel Computing with MATLAB Jos Martin Principal Architect, Parallel Computing Tools jos.martin@mathworks.co.uk 2015 The MathWorks, Inc. 1 Overview Scene setting Task Parallel (par*) Why doesn t it
Parallel and Distributed Computing with MATLAB Gerardo Hernández Manager, Application Engineer
 Parallel and Distributed Computing with MATLAB Gerardo Hernández Manager, Application Engineer 2018 The MathWorks, Inc. 1 Practical Application of Parallel Computing Why parallel computing? Need faster
Parallel and Distributed Computing with MATLAB Gerardo Hernández Manager, Application Engineer 2018 The MathWorks, Inc. 1 Practical Application of Parallel Computing Why parallel computing? Need faster
Adaptive Algorithms and Parallel Computing
 Adaptive Algorithms and Parallel Computing Multicore and Multimachine Computing with MATLAB (Part 1) Academic year 2014-2015 Simone Scardapane Content of the Lecture Main points: Parallelizing loops with
Adaptive Algorithms and Parallel Computing Multicore and Multimachine Computing with MATLAB (Part 1) Academic year 2014-2015 Simone Scardapane Content of the Lecture Main points: Parallelizing loops with
Speeding up MATLAB Applications Sean de Wolski Application Engineer
 Speeding up MATLAB Applications Sean de Wolski Application Engineer 2014 The MathWorks, Inc. 1 Non-rigid Displacement Vector Fields 2 Agenda Leveraging the power of vector and matrix operations Addressing
Speeding up MATLAB Applications Sean de Wolski Application Engineer 2014 The MathWorks, Inc. 1 Non-rigid Displacement Vector Fields 2 Agenda Leveraging the power of vector and matrix operations Addressing
INTRODUCTION TO MATLAB PARALLEL COMPUTING TOOLBOX. Kadin Tseng Boston University Scientific Computing and Visualization
 INTRODUCTION TO MATLAB PARALLEL COMPUTING TOOLBOX Kadin Tseng Boston University Scientific Computing and Visualization MATLAB Parallel Computing Toolbox 2 The Parallel Computing Toolbox is a MATLAB tool
INTRODUCTION TO MATLAB PARALLEL COMPUTING TOOLBOX Kadin Tseng Boston University Scientific Computing and Visualization MATLAB Parallel Computing Toolbox 2 The Parallel Computing Toolbox is a MATLAB tool
Daniel D. Warner. May 31, Introduction to Parallel Matlab. Daniel D. Warner. Introduction. Matlab s 5-fold way. Basic Matlab Example
 to May 31, 2010 What is Matlab? Matlab is... an Integrated Development Environment for solving numerical problems in computational science. a collection of state-of-the-art algorithms for scientific computing
to May 31, 2010 What is Matlab? Matlab is... an Integrated Development Environment for solving numerical problems in computational science. a collection of state-of-the-art algorithms for scientific computing
GPU-Accelerated Beat Detection for Dancing Monkeys
 GPU-Accelerated Beat Detection for Dancing Monkeys Philip Peng University of Pennsylvania Yanjie Feng University of Pennsylvania Abstract In music-based rhythm games, the game system needs to create patterns
GPU-Accelerated Beat Detection for Dancing Monkeys Philip Peng University of Pennsylvania Yanjie Feng University of Pennsylvania Abstract In music-based rhythm games, the game system needs to create patterns
Information for Candidates. Test Format
 Information for Candidates Test Format The MathWorks Certified MATLAB Professional (MCMP) exam consists of two sections: 25 multiplechoice questions and 8 performance-based problems. MATLAB access is not
Information for Candidates Test Format The MathWorks Certified MATLAB Professional (MCMP) exam consists of two sections: 25 multiplechoice questions and 8 performance-based problems. MATLAB access is not
Matlab: Parallel Computing Toolbox
 Matlab: Parallel Computing Toolbox Shuxia Zhang University of Mineesota e-mail: szhang@msi.umn.edu or help@msi.umn.edu Tel: 612-624-8858 (direct), 612-626-0802(help) Outline Introduction - Matlab PCT How
Matlab: Parallel Computing Toolbox Shuxia Zhang University of Mineesota e-mail: szhang@msi.umn.edu or help@msi.umn.edu Tel: 612-624-8858 (direct), 612-626-0802(help) Outline Introduction - Matlab PCT How
MATLAB: The challenges involved in providing a high-level language on a GPU
 MATLAB: The challenges involved in providing a high-level language on a GPU Jos Martin jos.martin@mathworks.co.uk 2013 The MathWorks, Inc. 1 Agenda Why did we introduce GPU support? What did we do? What
MATLAB: The challenges involved in providing a high-level language on a GPU Jos Martin jos.martin@mathworks.co.uk 2013 The MathWorks, Inc. 1 Agenda Why did we introduce GPU support? What did we do? What
High Performance and GPU Computing in MATLAB
 High Performance and GPU Computing in MATLAB Jan Houška houska@humusoft.cz http://www.humusoft.cz 1 About HUMUSOFT Company: Humusoft s.r.o. Founded: 1990 Number of employees: 18 Location: Praha 8, Pobřežní
High Performance and GPU Computing in MATLAB Jan Houška houska@humusoft.cz http://www.humusoft.cz 1 About HUMUSOFT Company: Humusoft s.r.o. Founded: 1990 Number of employees: 18 Location: Praha 8, Pobřežní
Process Big Data in MATLAB Using MapReduce
 Process Big Data in MATLAB Using MapReduce This example shows how to use the datastore and mapreduce functions to process a large amount of file-based data. The MapReduce algorithm is a mainstay of many
Process Big Data in MATLAB Using MapReduce This example shows how to use the datastore and mapreduce functions to process a large amount of file-based data. The MapReduce algorithm is a mainstay of many
Introduction to Matlab/Octave
 Introduction to Matlab/Octave February 28, 2014 This document is designed as a quick introduction for those of you who have never used the Matlab/Octave language, as well as those of you who have used
Introduction to Matlab/Octave February 28, 2014 This document is designed as a quick introduction for those of you who have never used the Matlab/Octave language, as well as those of you who have used
Modeling a 4G LTE System in MATLAB
 Modeling a 4G LTE System in MATLAB Part 2: Simulation acceleration Houman Zarrinkoub PhD. Signal Processing Product Manager MathWorks houmanz@mathworks.com 2011 The MathWorks, Inc. 1 Why simulation acceleration?
Modeling a 4G LTE System in MATLAB Part 2: Simulation acceleration Houman Zarrinkoub PhD. Signal Processing Product Manager MathWorks houmanz@mathworks.com 2011 The MathWorks, Inc. 1 Why simulation acceleration?
Working with Large Sets of Images in MATLAB Just Got Easier Avi Nehemiah
 Working with Large Sets of Images in MATLAB Just Got Easier Avi Nehemiah 2015 The MathWorks, Inc. 1 Challenges Posed by Large Sets of Images 1. How do I import several thousand images into MATLAB? 2. Can
Working with Large Sets of Images in MATLAB Just Got Easier Avi Nehemiah 2015 The MathWorks, Inc. 1 Challenges Posed by Large Sets of Images 1. How do I import several thousand images into MATLAB? 2. Can
Multicore Computer, GPU 및 Cluster 환경에서의 MATLAB Parallel Computing 기능
 Multicore Computer, GPU 및 Cluster 환경에서의 MATLAB Parallel Computing 기능 성호현 MathWorks Korea 2012 The MathWorks, Inc. 1 A Question to Consider Do you want to speed up your algorithms? If so Do you have a multi-core
Multicore Computer, GPU 및 Cluster 환경에서의 MATLAB Parallel Computing 기능 성호현 MathWorks Korea 2012 The MathWorks, Inc. 1 A Question to Consider Do you want to speed up your algorithms? If so Do you have a multi-core
Technical Report TR
 Technical Report TR-2012-03 Parallel Ray Tracing Simulations with MATLAB for Dynamic Lens Systems Nicolai Wengert and Dan Negrut August 10, 2012 Abstract Ray tracing simulations are required for investigating
Technical Report TR-2012-03 Parallel Ray Tracing Simulations with MATLAB for Dynamic Lens Systems Nicolai Wengert and Dan Negrut August 10, 2012 Abstract Ray tracing simulations are required for investigating
Di Zhao Ohio State University MVAPICH User Group (MUG) Meeting, August , Columbus Ohio
 Meeting, August , Columbus Ohio") Di Zhao zhao.1029@osu.edu Ohio State University MVAPICH User Group (MUG) Meeting, August 26-27 2013, Columbus Ohio Nvidia Kepler K20X Intel Xeon Phi 7120 Launch Date November 2012 Q2 2013 Processor Per-processor
Di Zhao zhao.1029@osu.edu Ohio State University MVAPICH User Group (MUG) Meeting, August 26-27 2013, Columbus Ohio Nvidia Kepler K20X Intel Xeon Phi 7120 Launch Date November 2012 Q2 2013 Processor Per-processor
Accelerating System Simulations
 Accelerating System Simulations 김용정부장 Senior Applications Engineer 2013 The MathWorks, Inc. 1 Why simulation acceleration? From algorithm exploration to system design Size and complexity of models increases
Accelerating System Simulations 김용정부장 Senior Applications Engineer 2013 The MathWorks, Inc. 1 Why simulation acceleration? From algorithm exploration to system design Size and complexity of models increases
Data Analytics with MATLAB
 Data Analytics with MATLAB Tackling the Challenges of Big Data Adrienne James, PhD MathWorks 7 th October 2014 2014 The MathWorks, Inc. 1 Big Data in Industry ENERGY Asset Optimization FINANCE Market Risk,
Data Analytics with MATLAB Tackling the Challenges of Big Data Adrienne James, PhD MathWorks 7 th October 2014 2014 The MathWorks, Inc. 1 Big Data in Industry ENERGY Asset Optimization FINANCE Market Risk,
MATLAB Distributed Computing Server Release Notes
 MATLAB Distributed Computing Server Release Notes How to Contact MathWorks www.mathworks.com Web comp.soft-sys.matlab Newsgroup www.mathworks.com/contact_ts.html Technical Support suggest@mathworks.com
MATLAB Distributed Computing Server Release Notes How to Contact MathWorks www.mathworks.com Web comp.soft-sys.matlab Newsgroup www.mathworks.com/contact_ts.html Technical Support suggest@mathworks.com
Deep learning in MATLAB From Concept to CUDA Code
 Deep learning in MATLAB From Concept to CUDA Code Roy Fahn Applications Engineer Systematics royf@systematics.co.il 03-7660111 Ram Kokku Principal Engineer MathWorks ram.kokku@mathworks.com 2017 The MathWorks,
Deep learning in MATLAB From Concept to CUDA Code Roy Fahn Applications Engineer Systematics royf@systematics.co.il 03-7660111 Ram Kokku Principal Engineer MathWorks ram.kokku@mathworks.com 2017 The MathWorks,
Performance Analysis of Matlab Code and PCT
 p. 1/45 Performance Analysis of Matlab Code and PCT Xiaoxu Guan High Performance Computing, LSU March 21, 2018 1 tic; 2 nsize = 10000; 3 for k = 1:nsize 4 B(k) = sum( A(:,k) ); 5 6 toc; p. 2/45 Overview
p. 1/45 Performance Analysis of Matlab Code and PCT Xiaoxu Guan High Performance Computing, LSU March 21, 2018 1 tic; 2 nsize = 10000; 3 for k = 1:nsize 4 B(k) = sum( A(:,k) ); 5 6 toc; p. 2/45 Overview
Data Analytics with MATLAB. Tackling the Challenges of Big Data
 Data Analytics with MATLAB Tackling the Challenges of Big Data How big is big? What characterises big data? Any collection of data sets so large and complex that it becomes difficult to process using traditional
Data Analytics with MATLAB Tackling the Challenges of Big Data How big is big? What characterises big data? Any collection of data sets so large and complex that it becomes difficult to process using traditional
Big Data con MATLAB. Lucas García The MathWorks, Inc. 1
 Big Data con MATLAB Lucas García 2015 The MathWorks, Inc. 1 Agenda Introduction Remote Arrays in MATLAB Tall Arrays for Big Data Scaling up Summary 2 Architecture of an analytics system Data from instruments
Big Data con MATLAB Lucas García 2015 The MathWorks, Inc. 1 Agenda Introduction Remote Arrays in MATLAB Tall Arrays for Big Data Scaling up Summary 2 Architecture of an analytics system Data from instruments
Parallel Computing with MATLAB
 Parallel Computing with MATLAB Jemmy Hu SHARCNET HPC Consultant University of Waterloo May 24, 2012 https://www.sharcnet.ca/~jemmyhu/tutorials/uwo_2012 Content MATLAB: UWO site license on goblin MATLAB:
Parallel Computing with MATLAB Jemmy Hu SHARCNET HPC Consultant University of Waterloo May 24, 2012 https://www.sharcnet.ca/~jemmyhu/tutorials/uwo_2012 Content MATLAB: UWO site license on goblin MATLAB:
Using Parallel Computing Toolbox to accelerate the Video and Image Processing Speed. Develop parallel code interactively
 Using Parallel Computing Toolbox to accelerate the Video and Image Processing Speed Presenter: Claire Chuang TeraSoft Inc. Agenda Develop parallel code interactively parallel applications for faster processing
Using Parallel Computing Toolbox to accelerate the Video and Image Processing Speed Presenter: Claire Chuang TeraSoft Inc. Agenda Develop parallel code interactively parallel applications for faster processing
HPC Middle East. KFUPM HPC Workshop April Mohamed Mekias HPC Solutions Consultant. Introduction to CUDA programming
 KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
KFUPM HPC Workshop April 29-30 2015 Mohamed Mekias HPC Solutions Consultant Introduction to CUDA programming 1 Agenda GPU Architecture Overview Tools of the Trade Introduction to CUDA C Patterns of Parallel
Modeling and Simulating Social Systems with MATLAB
 Modeling and Simulating Social Systems with MATLAB Lecture 6 Optimization and Parallelization Olivia Woolley, Tobias Kuhn, Dario Biasini, Dirk Helbing Chair of Sociology, in particular of Modeling and
Modeling and Simulating Social Systems with MATLAB Lecture 6 Optimization and Parallelization Olivia Woolley, Tobias Kuhn, Dario Biasini, Dirk Helbing Chair of Sociology, in particular of Modeling and
Mit MATLAB auf der Überholspur Methoden zur Beschleunigung von MATLAB Anwendungen
 Mit MATLAB auf der Überholspur Methoden zur Beschleunigung von MATLAB Anwendungen Michael Glaßer Application Engineering MathWorks Germany 2014 The MathWorks, Inc. 1 Key Takeaways 1. Speed up your serial
Mit MATLAB auf der Überholspur Methoden zur Beschleunigung von MATLAB Anwendungen Michael Glaßer Application Engineering MathWorks Germany 2014 The MathWorks, Inc. 1 Key Takeaways 1. Speed up your serial
Chapter 3 Parallel Software
 Chapter 3 Parallel Software Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
Chapter 3 Parallel Software Part I. Preliminaries Chapter 1. What Is Parallel Computing? Chapter 2. Parallel Hardware Chapter 3. Parallel Software Chapter 4. Parallel Applications Chapter 5. Supercomputers
We are IntechOpen, the world s leading publisher of Open Access books Built by scientists, for scientists. International authors and editors
 We are IntechOpen, the world s leading publisher of Open Access books Built by scientists, for scientists 4,000 116,000 120M Open access books available International authors and editors Downloads Our
We are IntechOpen, the world s leading publisher of Open Access books Built by scientists, for scientists 4,000 116,000 120M Open access books available International authors and editors Downloads Our
Parallel Programming in MATLAB on BioHPC
 Parallel Programming in MATLAB on BioHPC [web] [email] portal.biohpc.swmed.edu biohpc-help@utsouthwestern.edu 1 Updated for 2017-05-17 What is MATLAB High level language and development environment for:
Parallel Programming in MATLAB on BioHPC [web] [email] portal.biohpc.swmed.edu biohpc-help@utsouthwestern.edu 1 Updated for 2017-05-17 What is MATLAB High level language and development environment for:
GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS
 CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
CIS 601 - Graduate Seminar Presentation 1 GPU ACCELERATED DATABASE MANAGEMENT SYSTEMS PRESENTED BY HARINATH AMASA CSU ID: 2697292 What we will talk about.. Current problems GPU What are GPU Databases GPU
Supporting Data Parallelism in Matcloud: Final Report
 Supporting Data Parallelism in Matcloud: Final Report Yongpeng Zhang, Xing Wu 1 Overview Matcloud is an on-line service to run Matlab-like script on client s web browser. Internally it is accelerated by
Supporting Data Parallelism in Matcloud: Final Report Yongpeng Zhang, Xing Wu 1 Overview Matcloud is an on-line service to run Matlab-like script on client s web browser. Internally it is accelerated by
MATLAB on BioHPC. portal.biohpc.swmed.edu Updated for
 MATLAB on BioHPC [web] [email] portal.biohpc.swmed.edu biohpc-help@utsouthwestern.edu 1 Updated for 2015-06-17 What is MATLAB High level language and development environment for: - Algorithm and application
MATLAB on BioHPC [web] [email] portal.biohpc.swmed.edu biohpc-help@utsouthwestern.edu 1 Updated for 2015-06-17 What is MATLAB High level language and development environment for: - Algorithm and application
Tackling Big Data Using MATLAB
 Tackling Big Data Using MATLAB Alka Nair Application Engineer 2015 The MathWorks, Inc. 1 Building Machine Learning Models with Big Data Access Preprocess, Exploration & Model Development Scale up & Integrate
Tackling Big Data Using MATLAB Alka Nair Application Engineer 2015 The MathWorks, Inc. 1 Building Machine Learning Models with Big Data Access Preprocess, Exploration & Model Development Scale up & Integrate
Implementation of the finite-difference method for solving Maxwell`s equations in MATLAB language on a GPU
 Implementation of the finite-difference method for solving Maxwell`s equations in MATLAB language on a GPU 1 1 Samara National Research University, Moskovskoe Shosse 34, Samara, Russia, 443086 Abstract.
Implementation of the finite-difference method for solving Maxwell`s equations in MATLAB language on a GPU 1 1 Samara National Research University, Moskovskoe Shosse 34, Samara, Russia, 443086 Abstract.
Blocks, Grids, and Shared Memory
 Blocks, Grids, and Shared Memory GPU Course, Fall 2012 Last week: ax+b Homework Threads, Blocks, Grids CUDA threads are organized into blocks Threads operate in SIMD(ish) manner -- each executing same
Blocks, Grids, and Shared Memory GPU Course, Fall 2012 Last week: ax+b Homework Threads, Blocks, Grids CUDA threads are organized into blocks Threads operate in SIMD(ish) manner -- each executing same
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
NVIDIA CUDA. Fermi Compatibility Guide for CUDA Applications. Version 1.1
 NVIDIA CUDA Fermi Compatibility Guide for CUDA Applications Version 1.1 4/19/2010 Table of Contents Software Requirements... 1 What Is This Document?... 1 1.1 Application Compatibility on Fermi... 1 1.2
NVIDIA CUDA Fermi Compatibility Guide for CUDA Applications Version 1.1 4/19/2010 Table of Contents Software Requirements... 1 What Is This Document?... 1 1.1 Application Compatibility on Fermi... 1 1.2
The Evolution of Big Data Platforms and Data Science
 IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
MATLAB AND PARALLEL COMPUTING
 Image Processing & Communication, vol. 17, no. 4, pp. 207-216 DOI: 10.2478/v10248-012-0048-5 207 MATLAB AND PARALLEL COMPUTING MAGDALENA SZYMCZYK, PIOTR SZYMCZYK AGH University of Science and Technology,
Image Processing & Communication, vol. 17, no. 4, pp. 207-216 DOI: 10.2478/v10248-012-0048-5 207 MATLAB AND PARALLEL COMPUTING MAGDALENA SZYMCZYK, PIOTR SZYMCZYK AGH University of Science and Technology,
Lecture 3: MATLAB advanced use cases
 Lecture 3: MATLAB advanced use cases Efficient programming in MATLAB Juha Kuortti and Heikki Apiola February 17, 2018 Aalto University juha.kuortti@aalto.fi Before we begin On this lecture, we will mostly
Lecture 3: MATLAB advanced use cases Efficient programming in MATLAB Juha Kuortti and Heikki Apiola February 17, 2018 Aalto University juha.kuortti@aalto.fi Before we begin On this lecture, we will mostly
CUDA Architecture & Programming Model
 CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
CUDA Architecture & Programming Model Course on Multi-core Architectures & Programming Oliver Taubmann May 9, 2012 Outline Introduction Architecture Generation Fermi A Brief Look Back At Tesla What s New
Parallel MATLAB at VT
 Parallel MATLAB at VT Gene Cliff (AOE/ICAM - ecliff@vt.edu ) James McClure (ARC/ICAM - mcclurej@vt.edu) Justin Krometis (ARC/ICAM - jkrometis@vt.edu) 11:00am - 11:50am, Thursday, 25 September 2014... NLI...
Parallel MATLAB at VT Gene Cliff (AOE/ICAM - ecliff@vt.edu ) James McClure (ARC/ICAM - mcclurej@vt.edu) Justin Krometis (ARC/ICAM - jkrometis@vt.edu) 11:00am - 11:50am, Thursday, 25 September 2014... NLI...
GPU Programming. Maciej Halber
 GPU Programming Maciej Halber Aim Give basic introduction to CUDA C How to write kernels Memory transfer Talk about general parallel computing concepts Memory communication patterns Talk about efficiency
GPU Programming Maciej Halber Aim Give basic introduction to CUDA C How to write kernels Memory transfer Talk about general parallel computing concepts Memory communication patterns Talk about efficiency
Matlab for Engineers
 Matlab for Engineers Alistair Johnson 31st May 2012 Centre for Doctoral Training in Healthcare Innovation Institute of Biomedical Engineering Department of Engineering Science University of Oxford Supported
Matlab for Engineers Alistair Johnson 31st May 2012 Centre for Doctoral Training in Healthcare Innovation Institute of Biomedical Engineering Department of Engineering Science University of Oxford Supported
CANDIDATE INFORMATION
 CANDIDATE INFORMATION PREPARING FOR YOUR EXAM OBJECTIVES TESTED MathWorks training courses provide coverage across these objectives as well as exercises if additional learning and practice are necessary.
CANDIDATE INFORMATION PREPARING FOR YOUR EXAM OBJECTIVES TESTED MathWorks training courses provide coverage across these objectives as well as exercises if additional learning and practice are necessary.
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Parallel Programming in MATLAB on BioHPC
 Parallel Programming in MATLAB on BioHPC [web] [email] portal.biohpc.swmed.edu biohpc-help@utsouthwestern.edu 1 Updated for 2018-03-21 What is MATLAB High level language and development environment for:
Parallel Programming in MATLAB on BioHPC [web] [email] portal.biohpc.swmed.edu biohpc-help@utsouthwestern.edu 1 Updated for 2018-03-21 What is MATLAB High level language and development environment for:
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav
 CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
CUDA PROGRAMMING MODEL Chaithanya Gadiyam Swapnil S Jadhav CMPE655 - Multiple Processor Systems Fall 2015 Rochester Institute of Technology Contents What is GPGPU? What s the need? CUDA-Capable GPU Architecture
Introduction to Matlab
 Introduction to Matlab Stefan Güttel September 22, 2017 Contents 1 Introduction 2 2 Matrices and Arrays 2 3 Expressions 3 4 Basic Linear Algebra commands 4 5 Graphics 5 6 Programming Scripts 6 7 Functions
Introduction to Matlab Stefan Güttel September 22, 2017 Contents 1 Introduction 2 2 Matrices and Arrays 2 3 Expressions 3 4 Basic Linear Algebra commands 4 5 Graphics 5 6 Programming Scripts 6 7 Functions
USING INLINE PTX ASSEMBLY IN CUDA
 USING INLINE PTX ASSEMBLY IN CUDA DA-05713-001_v03 April 2011 Application Note DOCUMENT CHANGE HISTORY DA-05713-001_v03 Version Date Authors Description of Change 01 February 14, 2011 CUDA Initial release
USING INLINE PTX ASSEMBLY IN CUDA DA-05713-001_v03 April 2011 Application Note DOCUMENT CHANGE HISTORY DA-05713-001_v03 Version Date Authors Description of Change 01 February 14, 2011 CUDA Initial release
Distributing Computation to Large GPU Clusters
 Distributing Computation to Large GPU Clusters What is this about? DiCE: Software library for writing applications scaling to many GPUs and CPUs in a cluster What is this about? DiCE: Software library
Distributing Computation to Large GPU Clusters What is this about? DiCE: Software library for writing applications scaling to many GPUs and CPUs in a cluster What is this about? DiCE: Software library
[ NOTICE ] YOU HAVE TO INSTALL ALL FILES PREVIOUSLY, BECAUSE A INSTALLATION TIME IS TOO LONG.
![[ NOTICE ] YOU HAVE TO INSTALL ALL FILES PREVIOUSLY, BECAUSE A INSTALLATION TIME IS TOO LONG.](/thumbs/96/128486115.jpg "[ NOTICE ] YOU HAVE TO INSTALL ALL FILES PREVIOUSLY, BECAUSE A INSTALLATION TIME IS TOO LONG.") [ NOTICE ] YOU HAVE TO INSTALL ALL FILES PREVIOUSLY, BECAUSE A INSTALLATION TIME IS TOO LONG. Setting up Development Environment 1. O/S Platform is Windows. 2. Install the latest NVIDIA Driver. 11) 3.
[ NOTICE ] YOU HAVE TO INSTALL ALL FILES PREVIOUSLY, BECAUSE A INSTALLATION TIME IS TOO LONG. Setting up Development Environment 1. O/S Platform is Windows. 2. Install the latest NVIDIA Driver. 11) 3.
Calcul intensif et Stockage de Masse. CÉCI/CISM HPC training sessions Use of Matlab on the clusters
 Calcul intensif et Stockage de Masse CÉCI/ HPC training sessions Use of Matlab on the clusters Typical usage... Interactive Batch Type in and get an answer Submit job and fetch results Sequential Parallel
Calcul intensif et Stockage de Masse CÉCI/ HPC training sessions Use of Matlab on the clusters Typical usage... Interactive Batch Type in and get an answer Submit job and fetch results Sequential Parallel
CS/EE 217 GPU Architecture and Parallel Programming. Lecture 10. Reduction Trees
 CS/EE 217 GPU Architecture and Parallel Programming Lecture 10 Reduction Trees David Kirk/NVIDIA and Wen-mei W. Hwu University of Illinois, 2007-2012 1 Objective To master Reduction Trees, arguably the
CS/EE 217 GPU Architecture and Parallel Programming Lecture 10 Reduction Trees David Kirk/NVIDIA and Wen-mei W. Hwu University of Illinois, 2007-2012 1 Objective To master Reduction Trees, arguably the
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction. Francesco Rossi University of Bologna and INFN
 CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
CUDA and GPU Performance Tuning Fundamentals: A hands-on introduction Francesco Rossi University of Bologna and INFN * Using this terminology since you ve already heard of SIMD and SPMD at this school
Compiling CUDA and Other Languages for GPUs. Vinod Grover and Yuan Lin
 Compiling CUDA and Other Languages for GPUs Vinod Grover and Yuan Lin Agenda Vision Compiler Architecture Scenarios SDK Components Roadmap Deep Dive SDK Samples Demos Vision Build a platform for GPU computing
Compiling CUDA and Other Languages for GPUs Vinod Grover and Yuan Lin Agenda Vision Compiler Architecture Scenarios SDK Components Roadmap Deep Dive SDK Samples Demos Vision Build a platform for GPU computing
Calcul intensif et Stockage de Masse. CÉCI/CISM HPC training sessions
 Calcul intensif et Stockage de Masse CÉCI/ HPC training sessions Calcul intensif et Stockage de Masse Parallel Matlab on the cluster /CÉCI Training session www.uclouvain.be/cism www.ceci-hpc.be November
Calcul intensif et Stockage de Masse CÉCI/ HPC training sessions Calcul intensif et Stockage de Masse Parallel Matlab on the cluster /CÉCI Training session www.uclouvain.be/cism www.ceci-hpc.be November
Parallel Programming Models. Parallel Programming Models. Threads Model. Implementations 3/24/2014. Shared Memory Model (without threads)
") Parallel Programming Models Parallel Programming Models Shared Memory (without threads) Threads Distributed Memory / Message Passing Data Parallel Hybrid Single Program Multiple Data (SPMD) Multiple Program
Parallel Programming Models Parallel Programming Models Shared Memory (without threads) Threads Distributed Memory / Message Passing Data Parallel Hybrid Single Program Multiple Data (SPMD) Multiple Program
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture
 An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
An Introduction to GPGPU Pro g ra m m ing - CUDA Arc hitec ture Rafia Inam Mälardalen Real-Time Research Centre Mälardalen University, Västerås, Sweden http://www.mrtc.mdh.se rafia.inam@mdh.se CONTENTS
Jason Yalim. Here we perform a few tasks to ensure a clean working environment for our script.
 Table of Contents Initialization... 1 Part One -- Computation... 1 Part Two -- Plotting... 5 Part Three -- Plotting Incorrectly... 7 Part Four -- Showing Output Adjacent to Code... 8 Part Five -- Creating
Table of Contents Initialization... 1 Part One -- Computation... 1 Part Two -- Plotting... 5 Part Three -- Plotting Incorrectly... 7 Part Four -- Showing Output Adjacent to Code... 8 Part Five -- Creating
Spring 2010 Instructor: Michele Merler.
 Spring 2010 Instructor: Michele Merler http://www1.cs.columbia.edu/~mmerler/comsw3101-2.html MATLAB does not use explicit type initialization like other languages Just assign some value to a variable name,
Spring 2010 Instructor: Michele Merler http://www1.cs.columbia.edu/~mmerler/comsw3101-2.html MATLAB does not use explicit type initialization like other languages Just assign some value to a variable name,
Modern Processor Architectures. L25: Modern Compiler Design
 Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Modern Processor Architectures L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant minimising the number of instructions
Lab 1 Part 1: Introduction to CUDA
 Lab 1 Part 1: Introduction to CUDA Code tarball: lab1.tgz In this hands-on lab, you will learn to use CUDA to program a GPU. The lab can be conducted on the SSSU Fermi Blade (M2050) or NCSA Forge using
Lab 1 Part 1: Introduction to CUDA Code tarball: lab1.tgz In this hands-on lab, you will learn to use CUDA to program a GPU. The lab can be conducted on the SSSU Fermi Blade (M2050) or NCSA Forge using
Column-Oriented Database Systems. Liliya Rudko University of Helsinki
 Column-Oriented Database Systems Liliya Rudko University of Helsinki 2 Contents 1. Introduction 2. Storage engines 2.1 Evolutionary Column-Oriented Storage (ECOS) 2.2 HYRISE 3. Database management systems
Column-Oriented Database Systems Liliya Rudko University of Helsinki 2 Contents 1. Introduction 2. Storage engines 2.1 Evolutionary Column-Oriented Storage (ECOS) 2.2 HYRISE 3. Database management systems
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS
 CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
CS 179: GPU Computing LECTURE 4: GPU MEMORY SYSTEMS 1 Last time Each block is assigned to and executed on a single streaming multiprocessor (SM). Threads execute in groups of 32 called warps. Threads in
Dr. Chuck Cartledge. 4 Feb. 2015
 CS-495/595 Hadoop (part 1) Lecture #3 Dr. Chuck Cartledge 4 Feb. 2015 1/23 Table of contents I 1 Miscellanea 2 Assignment 3 The Book 4 Chapter 1 5 Chapter 2 7 Break 8 Assignment #2 9 Conclusion 10 References
CS-495/595 Hadoop (part 1) Lecture #3 Dr. Chuck Cartledge 4 Feb. 2015 1/23 Table of contents I 1 Miscellanea 2 Assignment 3 The Book 4 Chapter 1 5 Chapter 2 7 Break 8 Assignment #2 9 Conclusion 10 References
Designing a Domain-specific Language to Simulate Particles. dan bailey
 Designing a Domain-specific Language to Simulate Particles dan bailey Double Negative Largest Visual Effects studio in Europe Offices in London and Singapore Large and growing R & D team Squirt Fluid Solver
Designing a Domain-specific Language to Simulate Particles dan bailey Double Negative Largest Visual Effects studio in Europe Offices in London and Singapore Large and growing R & D team Squirt Fluid Solver
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
CUDA programming. CUDA requirements. CUDA Querying. CUDA Querying. A CUDA-capable GPU (NVIDIA) NVIDIA driver A CUDA SDK
 NVIDIA driver A CUDA SDK") CUDA programming Bedrich Benes, Ph.D. Purdue University Department of Computer Graphics CUDA requirements A CUDA-capable GPU (NVIDIA) NVIDIA driver A CUDA SDK Standard C compiler http://www.nvidia.com/cuda
CUDA programming Bedrich Benes, Ph.D. Purdue University Department of Computer Graphics CUDA requirements A CUDA-capable GPU (NVIDIA) NVIDIA driver A CUDA SDK Standard C compiler http://www.nvidia.com/cuda
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
INLINE PTX ASSEMBLY IN CUDA
 INLINE PTX ASSEMBLY IN CUDA SP-04456-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Using...1 1.1. Assembler (ASM) Statements...1 1.1.1. Parameters...1 1.1.2. Constraints...3 1.2. Pitfalls...
INLINE PTX ASSEMBLY IN CUDA SP-04456-001_v6.5 August 2014 Application Note TABLE OF CONTENTS Chapter 1. Using...1 1.1. Assembler (ASM) Statements...1 1.1.1. Parameters...1 1.1.2. Constraints...3 1.2. Pitfalls...
CS1114 Section 8: The Fourier Transform March 13th, 2013
 CS1114 Section 8: The Fourier Transform March 13th, 2013 http://xkcd.com/26 Today you will learn about an extremely useful tool in image processing called the Fourier transform, and along the way get more
CS1114 Section 8: The Fourier Transform March 13th, 2013 http://xkcd.com/26 Today you will learn about an extremely useful tool in image processing called the Fourier transform, and along the way get more
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management
 X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
X10 specific Optimization of CPU GPU Data transfer with Pinned Memory Management Hideyuki Shamoto, Tatsuhiro Chiba, Mikio Takeuchi Tokyo Institute of Technology IBM Research Tokyo Programming for large
BIG DATA: Data Analytics with MATLAB Christophe POUILLOT Senior Consultant MathWorks
 BIG DATA: Data Analytics with MATLAB Christophe POUILLOT Senior Consultant MathWorks christophe.pouillot@mathworks.fr 2014 The MathWorks, Inc. 1 Definition of Big Data Data so large and complex that it
BIG DATA: Data Analytics with MATLAB Christophe POUILLOT Senior Consultant MathWorks christophe.pouillot@mathworks.fr 2014 The MathWorks, Inc. 1 Definition of Big Data Data so large and complex that it
CUDA Development Using NVIDIA Nsight, Eclipse Edition. David Goodwin
 CUDA Development Using NVIDIA Nsight, Eclipse Edition David Goodwin NVIDIA Nsight Eclipse Edition CUDA Integrated Development Environment Project Management Edit Build Debug Profile SC'12 2 Powered By
CUDA Development Using NVIDIA Nsight, Eclipse Edition David Goodwin NVIDIA Nsight Eclipse Edition CUDA Integrated Development Environment Project Management Edit Build Debug Profile SC'12 2 Powered By
2015 The MathWorks, Inc. 1
 2015 The MathWorks, Inc. 1 What s New in Release 2015a and 2014b Young Joon Lee Principal Application Engineer 2015 The MathWorks, Inc. 2 Agenda New Features Graphics and Data Design Performance Design
2015 The MathWorks, Inc. 1 What s New in Release 2015a and 2014b Young Joon Lee Principal Application Engineer 2015 The MathWorks, Inc. 2 Agenda New Features Graphics and Data Design Performance Design
Optimizing CUDA for GPU Architecture. CSInParallel Project
 Optimizing CUDA for GPU Architecture CSInParallel Project August 13, 2014 CONTENTS 1 CUDA Architecture 2 1.1 Physical Architecture........................................... 2 1.2 Virtual Architecture...........................................
Optimizing CUDA for GPU Architecture CSInParallel Project August 13, 2014 CONTENTS 1 CUDA Architecture 2 1.1 Physical Architecture........................................... 2 1.2 Virtual Architecture...........................................
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
INTRODUCTION TO MATLAB PARALLEL COMPUTING TOOLBOX
 INTRODUCTION TO MATLAB PARALLEL COMPUTING TOOLBOX Keith Ma ---------------------------------------- keithma@bu.edu Research Computing Services ----------- help@rcs.bu.edu Boston University ----------------------------------------------------
INTRODUCTION TO MATLAB PARALLEL COMPUTING TOOLBOX Keith Ma ---------------------------------------- keithma@bu.edu Research Computing Services ----------- help@rcs.bu.edu Boston University ----------------------------------------------------
Evolution of Big Data Facebook. Architecture Summit, Shenzhen, August 2012 Ashish Thusoo
 Evolution of Big Data Architectures@ Facebook Architecture Summit, Shenzhen, August 2012 Ashish Thusoo About Me Currently Co-founder/CEO of Qubole Ran the Data Infrastructure Team at Facebook till 2011
Evolution of Big Data Architectures@ Facebook Architecture Summit, Shenzhen, August 2012 Ashish Thusoo About Me Currently Co-founder/CEO of Qubole Ran the Data Infrastructure Team at Facebook till 2011
Batch Processing Basic architecture
 Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
Batch Processing Basic architecture in big data systems COS 518: Distributed Systems Lecture 10 Andrew Or, Mike Freedman 2 1 2 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores 3
MapReduce & HyperDex. Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University
 MapReduce & HyperDex Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University 1 Distributing Processing Mantra Scale out, not up. Assume failures are common. Move processing to the data. Process
MapReduce & HyperDex Kathleen Durant PhD Lecture 21 CS 3200 Northeastern University 1 Distributing Processing Mantra Scale out, not up. Assume failures are common. Move processing to the data. Process
MATLAB Basics. Configure a MATLAB Package 6/7/2017. Stanley Liang, PhD York University. Get a MATLAB Student License on Matworks
 MATLAB Basics Stanley Liang, PhD York University Configure a MATLAB Package Get a MATLAB Student License on Matworks Visit MathWorks at https://www.mathworks.com/ It is recommended signing up with a student
MATLAB Basics Stanley Liang, PhD York University Configure a MATLAB Package Get a MATLAB Student License on Matworks Visit MathWorks at https://www.mathworks.com/ It is recommended signing up with a student
Distributed Systems. 22. Spark. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design
 L25: Modern Compiler Design") Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Modern Processor Architectures (A compiler writer s perspective) L25: Modern Compiler Design The 1960s - 1970s Instructions took multiple cycles Only one instruction in flight at once Optimisation meant
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Dynamic Cuda with F# HPC GPU & F# Meetup. March 19. San Jose, California
 Dynamic Cuda with F# HPC GPU & F# Meetup March 19 San Jose, California Dr. Daniel Egloff daniel.egloff@quantalea.net +41 44 520 01 17 +41 79 430 03 61 About Us! Software development and consulting company!
Dynamic Cuda with F# HPC GPU & F# Meetup March 19 San Jose, California Dr. Daniel Egloff daniel.egloff@quantalea.net +41 44 520 01 17 +41 79 430 03 61 About Us! Software development and consulting company!