CS560 Lecture Parallel Architecture 1
|
|
|
- Amy Sullivan
- 5 years ago
- Views:
Transcription


1 Parallel Architecture Announcements The RamCT merge is done! Please repost introductions. Manaf s office hours HW0 is due tomorrow night, please try RamCT submission HW1 has been posted Today Isoefficiency Levels of parallelism in architecture and programming models Leveraging the memory hierarchy Understanding performance limits Machine balance Roofline model Performance analysis logistics for this semester CS560 Lecture Parallel Architecture 1 Recall Parallel Performance Metrics Speedup exec time for efficient serial computation on problem size N exectime for parallel version of computation on problem size N with P processors speedup is the serial exec time divided by the parallel exec time Efficiency efficiency is the percentage of all the processing power that is being used CS560 Lecture Parallel Architecture 2
2 Isoefficiency Main idea Keep the parallel efficiency the same and increase the problem size. The isoefficiency function indicates how much the problem size needs to increase as processors are added. N A[i] Example i=0 Summation is a reduction Serial execution time T S (N) =O(N) Parallel execution time needs to include communication time and idle time, or parallel overhead T (N,P) =O(N/P + log 2 (P )) Isoefficiency function indicates how the problem size must increase as a function of the number of processors to maintain the same efficiency. N = P lg P CS560 Lecture Parallel Architecture 3 Parallel Architectures Parallelism Many processing units (floating point and integer units, processors) Places to store data (memory, cache) Various ways the processors are connected to the memory. No real winner parallel architecture, so variety in programming models. Tradeoffs between portable code and efficient code. Goal of automation tools (e.g., compilers) is to find the sweet spots CS560 Lecture Parallel Architecture 4
3 Levels of Parallelism in Architectures Instruction Level Parallelism Pipeline parallelism superscalar VLIW (very long instruction word) Vector processing units Shared Memory Parallelism: multiple processors connected to same memory usually with cache coherency Multicore machines like veges Node of the cray Shared memory for a thread block in a GPU and global memory in GPU Distributed Memory Parallelism: multiple processors each with own memory connected with an interconnect Between nodes of the cray Clusters CS560 Lecture Parallel Architecture 5 Levels of Parallelism in Programming Models Instruction Level Parallelism Mostly handled by the compiler Loop unrolling MMX, SSE, and AVX Shared Memory Parallelism OpenMP Threads: pthreads, Java threads, Cilk, TBB Distributed Memory Parallelism MPI PGAS languages Co-array Fortran, Unified Parallel C, Titanium, New languages with concept of places/locales X10 Chapel CS560 Lecture Parallel Architecture 6
4 Memory Hierarchy What? There is an ever growing hierarchy of caches that lie between main memory and the processing unit. Eg, L1 cache, L2 cache, L3 cache In parallel machines the hierarchy causes non-uniform memory access (NUMA) due to subsets of cores sharing caches. Why? It takes cycles to access main memory directly. Caches (SRAM-based memory) are fast but expensive and therefore not that large. CS560 Lecture Parallel Architecture 7 An Example Memory Hierarchy (HI'!!"#$%!&$' EFG'&!"#$%!&$',589'<5&9$'&!%&#!B!9' C&54'()'*+*,!'.4+88!&;' C+$%!&;' *5$%8#!&' =!&'>6%!' (+&"!&;''' $85<!&;'' *,!+=!&'' =!&'>6%!' (KI' (JI' (DI' ()I' ()'*+*,!' '-./012' (D'*+*,!' -./012' 1+#3'4!45&6' -7/012' "5*+8'$!*539+&6'$%5&+"!' -85*+8'9#$:$2' ()'*+*,!',589$'*+*,!'8#3!$'&!%&#!B!9' C&54'(D'*+*,!' (D'*+*,!',589$'*+*,!'8#3!$' &!%&#!B!9'C&54'4+#3'4!45&6' 1+#3'4!45&6',589$'9#$:'>85*:$' &!%&#!B!9'C&54'85*+8'9#$:$' (5*+8'9#$:$',589'@8!$' &!%&#!B!9'C&54'9#$:$'53' &!45%!'3!%<5&:'$!&B!&$' (LI'!!45%!'$!*539+&6'$%5&+"!' -%+=!$;'9#$%&#>?%!9'@8!'$6$%!4$;'A!>'$!&B!&$2' Source:
5 Examples of Caching in the Hierarchy E+*,!'M6=!' A,+%'#$'E+*,!9N' A,!&!'#$'#%'E+*,!9N' (+%!3*6'-*6*8!$2' L-O);G6(5)'9%&5) ).IV)>9%() *).9F107(%) 2"3) 4&&%(55)6%$,57$89,5) +,-./01)2"3) *) #$%&'$%() "<)>$>/() "H)>$>/() D0%6B$7)E(F9%G) 3BC(%)>$>/() A(6'9%?);BC(%) >$>/() 3%9'5(%)>$>/() :(;)>$>/() NL-;G6(5);79>?) NL-;G6(5);79>?) I$%65)9J)K7(5) I$%65)9J)K7(5) +,-./01)"<) +,S+C-./01)"H) E$0,)F(F9%G) E$0,)F(F9%G) "9>$7)&05?) "9>$7)&05?)!(F96()5(%Q(%)&05?5) <) <*) <**) <**) <*=***=***) <*=***=***) <=***=***=***) #$%&'$%() #$%&'$%() #$%&'$%()U)+R) W05?)>$>/()) W05?)5(>69%5) W05?)>9,6%977(%) <**=***) W05?)K%F'$%() +R) 4TRSATR)>70(,6) :(;);%9'5(%) :(;)1%9PG) 5(%Q(%) Source: Harpertown Architecture (veges in department) //commands! setenv PATH /s/bach/e/proj/rtrt/software/bin:$path! lstopo --output-format pdf > lstopo-out.pdf! CS560 Lecture Parallel Architecture 10

 HT 64-Magny-Cours 1 NUMA processor =")

 1.")

6 Cray Architecture XT6m Compute Node Architecture 6MB L3 Cache HT3 HT3 HT3 6MB L3 Cache HT3 6MB L3 Cache HT3 6MB L3 Cache To Interconnect Each compute node contains 2 processors (2 sockets) HT 64-Magny-Cours 1 NUMA processor = 6 cores 4 NUMA processors per compute node 24 cores per compute node 4 NUMA processors per compute blade 32 GB RAM (shared) / compute node = TB total RAM (ECC DDR3 SDRAM) 1.33 GB RAM / core Source: 11 NVIDIA Tesla (bananas, coconuts, apples, and oranges) Source: 12
7 Data Reuse and Data Locality Definitions Temporal reuse is when the same memory location is read more than once. Spatial reuse is when more than one memory location mapped to the same cache line are used. Temporal and spatial data locality occurs when those reuses occur before the cache line is kicked out of cache. Matrix Multiply Example <Draw pictures in class> for (i=0; i<n; i++) {! for (j=0; j<n; j++) {! C[i][j] = 0;! for (k=0; k<n; k++) {! C[i][j] += A[j][k] * B[k][j]; } } }! Sparse Matrix Vector Example <Draw pictures in class> for (j=0; j<n; j++) { Y[i] = 0; }! for (i=0; i<nnz; i++) {! Y[row[i]] += val[i]*x[col[i]];! } CS560 Lecture Parallel Architecture 13 Arithmetic Intensity and Machine Balance Arithmetic Intensity Ratio of arithmetic operations to memory operations within a computation/loop. Machine Balance Ratio of peak floating point ops per cycle to sustained memory ops per cycle. Number of floating point operations that can be performed during the time for an average memory access. Why? If the arithmetic intensity doesn t match the machine balance then the computation will be memory bound. If there is data reuse then it might be possible to store data in scalars (i.e. registers) and raise the arithmetic intensity. CS560 Lecture Parallel Architecture 14
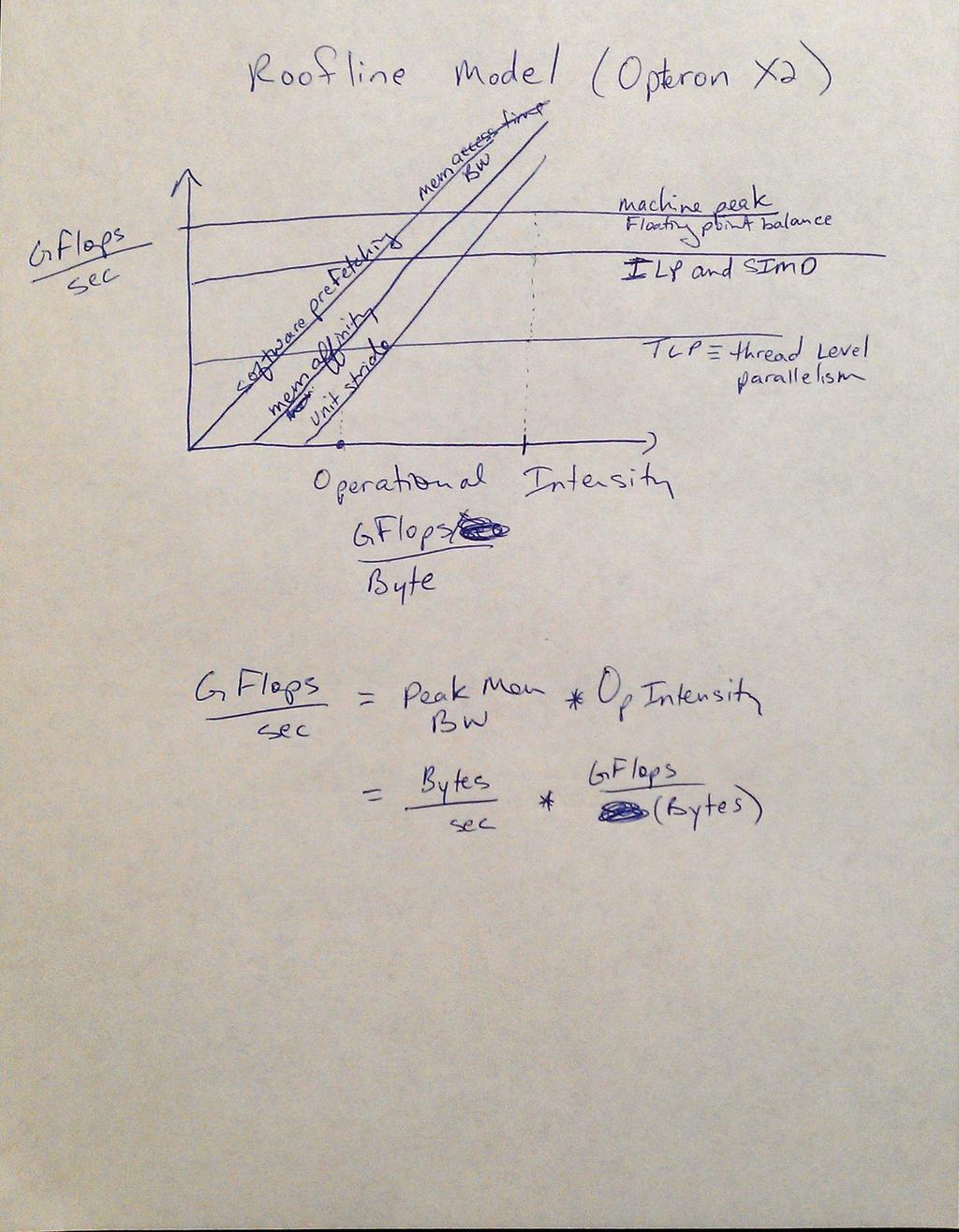
8 Roofline Model (Will be using this in HW2) Roofline: An Insightful Visual Performance Model for Multicore Architecture By Sam Williams, Andrew Waterman, and David Patterson ACM Communications, April 2009, Vol 52, No 4. Operational Intensity: Operations per byte of DRAM traffic. Roofline graph per machine FLOPS/sec versus operational intensity Horizontal line for the peak floating point performance (compute bound) Diagonal line for the measured peak memory performance (memory bound) Placing ceilings to represent how performance optimizations can help Improve ILP and apply SIMD (computation bound) Balance floating point operation mix (computation bound) Unit stride accesses (memory bound) Memory affinity (memory bound) CS560 Lecture Parallel Architecture 15 Logistics of Performance Analysis Multiple observations are necessary Execution time will not be the same for every run: other users, slightly different cache alignments, etc. Need to plot the execution time average of 5-10 observations with bars for standard deviation. Is 5-10 enough? Performance Issues for specific architectures Throughout the semester post programming techniques that improve performance on the veges, cray, and tesla machines. CS560 Lecture Parallel Architecture 16
9 Concepts Isoefficiency Levels of Parallelism in Arch and Programming Languages ILP, shared memory, distributed memory Loop unrolling, SSE and AVX instructions, do all loops, SPMD, message passing Memory Hierarchy NUMA Data reuse and data locality Programming constructs to manage data locality? Performance limits Machine balance Roofline model (how to draw the graph) operational intensity Programming techniques to break through ceilings CS560 Lecture Parallel Architecture 17 Next Time Reading Berkeley View Homework HW0 is due Wednesday 1/25/12 HW1 is due Wednesday 2/1/12 Lecture Scientific Applications of Interest CS560 Lecture Parallel Architecture 18

10

11
12
Roofline Model (Will be using this in HW2)
") Parallel Architecture Announcements HW0 is due Friday night, thank you for those who have already submitted HW1 is due Wednesday night Today Computing operational intensity Dwarves and Motifs Stencil computation
Parallel Architecture Announcements HW0 is due Friday night, thank you for those who have already submitted HW1 is due Wednesday night Today Computing operational intensity Dwarves and Motifs Stencil computation
SCIENTIFIC COMPUTING FOR ENGINEERS PERFORMANCE MODELING
 2/20/13 CS 594: SCIENTIFIC COMPUTING FOR ENGINEERS PERFORMANCE MODELING Heike McCraw mccraw@icl.utk.edu 1. Basic Essentials OUTLINE Abstract architecture model Communication, Computation, and Locality
2/20/13 CS 594: SCIENTIFIC COMPUTING FOR ENGINEERS PERFORMANCE MODELING Heike McCraw mccraw@icl.utk.edu 1. Basic Essentials OUTLINE Abstract architecture model Communication, Computation, and Locality
Chapter 6. Parallel Processors from Client to Cloud. Copyright 2014 Elsevier Inc. All rights reserved.
 Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
Lecture 2. Memory locality optimizations Address space organization
 Lecture 2 Memory locality optimizations Address space organization Announcements Office hours in EBU3B Room 3244 Mondays 3.00 to 4.00pm; Thurs 2:00pm-3:30pm Partners XSED Portal accounts Log in to Lilliput
Lecture 2 Memory locality optimizations Address space organization Announcements Office hours in EBU3B Room 3244 Mondays 3.00 to 4.00pm; Thurs 2:00pm-3:30pm Partners XSED Portal accounts Log in to Lilliput
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 207/8 A.J.Proença The Roofline Performance Model (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 207/8 AJProença, Advanced Architectures,
Advanced Architectures Master Informatics Eng. 207/8 A.J.Proença The Roofline Performance Model (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 207/8 AJProença, Advanced Architectures,
Instructor: Leopold Grinberg
 Part 1 : Roofline Model Instructor: Leopold Grinberg IBM, T.J. Watson Research Center, USA e-mail: leopoldgrinberg@us.ibm.com 1 ICSC 2014, Shanghai, China The Roofline Model DATA CALCULATIONS (+, -, /,
Part 1 : Roofline Model Instructor: Leopold Grinberg IBM, T.J. Watson Research Center, USA e-mail: leopoldgrinberg@us.ibm.com 1 ICSC 2014, Shanghai, China The Roofline Model DATA CALCULATIONS (+, -, /,
Tools and techniques for optimization and debugging. Fabio Affinito October 2015
 Tools and techniques for optimization and debugging Fabio Affinito October 2015 Fundamentals of computer architecture Serial architectures Introducing the CPU It s a complex, modular object, made of different
Tools and techniques for optimization and debugging Fabio Affinito October 2015 Fundamentals of computer architecture Serial architectures Introducing the CPU It s a complex, modular object, made of different
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
Tools and techniques for optimization and debugging. Andrew Emerson, Fabio Affinito November 2017
 Tools and techniques for optimization and debugging Andrew Emerson, Fabio Affinito November 2017 Fundamentals of computer architecture Serial architectures Introducing the CPU It s a complex, modular object,
Tools and techniques for optimization and debugging Andrew Emerson, Fabio Affinito November 2017 Fundamentals of computer architecture Serial architectures Introducing the CPU It s a complex, modular object,
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Advanced Parallel Programming I
 Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Advanced Parallel Programming I Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2016 22.09.2016 1 Levels of Parallelism RISC Software GmbH Johannes Kepler University
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
The Art of Parallel Processing
 The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
The Art of Parallel Processing Ahmad Siavashi April 2017 The Software Crisis As long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
CSE 160 Lecture 10. Instruction level parallelism (ILP) Vectorization
 Vectorization") CSE 160 Lecture 10 Instruction level parallelism (ILP) Vectorization Announcements Quiz on Friday Signup for Friday labs sessions in APM 2013 Scott B. Baden / CSE 160 / Winter 2013 2 Particle simulation
CSE 160 Lecture 10 Instruction level parallelism (ILP) Vectorization Announcements Quiz on Friday Signup for Friday labs sessions in APM 2013 Scott B. Baden / CSE 160 / Winter 2013 2 Particle simulation
Evaluation of sparse LU factorization and triangular solution on multicore architectures. X. Sherry Li
 Evaluation of sparse LU factorization and triangular solution on multicore architectures X. Sherry Li Lawrence Berkeley National Laboratory ParLab, April 29, 28 Acknowledgement: John Shalf, LBNL Rich Vuduc,
Evaluation of sparse LU factorization and triangular solution on multicore architectures X. Sherry Li Lawrence Berkeley National Laboratory ParLab, April 29, 28 Acknowledgement: John Shalf, LBNL Rich Vuduc,
Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature. Intel Software Developer Conference London, 2017
 Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature Intel Software Developer Conference London, 2017 Agenda Vectorization is becoming more and more important What is
Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature Intel Software Developer Conference London, 2017 Agenda Vectorization is becoming more and more important What is
CS4230 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/28/12. Homework 1: Parallel Programming Basics
 CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
CS4230 Parallel Programming Lecture 3: Introduction to Parallel Architectures Mary Hall August 28, 2012 Homework 1: Parallel Programming Basics Due before class, Thursday, August 30 Turn in electronically
BOPS, Not FLOPS! A New Metric, Measuring Tool, and Roofline Performance Model For Datacenter Computing. Chen Zheng ICT,CAS
 BOPS, Not FLOPS! A New Metric, Measuring Tool, and Roofline Performance Model For Datacenter Computing Chen Zheng ICT,CAS Data Center Computing (DC ) HPC only takes 20% market share Big Data, AI, Internet
BOPS, Not FLOPS! A New Metric, Measuring Tool, and Roofline Performance Model For Datacenter Computing Chen Zheng ICT,CAS Data Center Computing (DC ) HPC only takes 20% market share Big Data, AI, Internet
CS560 Lecture Parallelism Review 1
 Prelude CS560 Lecture Parallelism Review 1 Parallelism Review Announcements The readings marked Read: are required. The readings marked Other resources: are NOT required reading but more for your reference.
Prelude CS560 Lecture Parallelism Review 1 Parallelism Review Announcements The readings marked Read: are required. The readings marked Other resources: are NOT required reading but more for your reference.
Modern CPU Architectures
 Modern CPU Architectures Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2014 16.04.2014 1 Motivation for Parallelism I CPU History RISC Software GmbH Johannes
Modern CPU Architectures Alexander Leutgeb, RISC Software GmbH RISC Software GmbH Johannes Kepler University Linz 2014 16.04.2014 1 Motivation for Parallelism I CPU History RISC Software GmbH Johannes
Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature
 Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature Intel Software Developer Conference Frankfurt, 2017 Klaus-Dieter Oertel, Intel Agenda Intel Advisor for vectorization
Visualizing and Finding Optimization Opportunities with Intel Advisor Roofline feature Intel Software Developer Conference Frankfurt, 2017 Klaus-Dieter Oertel, Intel Agenda Intel Advisor for vectorization
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
COMP Parallel Computing. SMM (1) Memory Hierarchies and Shared Memory
 Memory Hierarchies and Shared Memory") COMP 633 - Parallel Computing Lecture 6 September 6, 2018 SMM (1) Memory Hierarchies and Shared Memory 1 Topics Memory systems organization caches and the memory hierarchy influence of the memory hierarchy
COMP 633 - Parallel Computing Lecture 6 September 6, 2018 SMM (1) Memory Hierarchies and Shared Memory 1 Topics Memory systems organization caches and the memory hierarchy influence of the memory hierarchy
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Memory Systems IRAM. Principle of IRAM
 Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
Memory Systems 165 other devices of the module will be in the Standby state (which is the primary state of all RDRAM devices) or another state with low-power consumption. The RDRAM devices provide several
Introduction to tuning on many core platforms. Gilles Gouaillardet RIST
 Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
KNL tools. Dr. Fabio Baruffa
 KNL tools Dr. Fabio Baruffa fabio.baruffa@lrz.de 2 Which tool do I use? A roadmap to optimization We will focus on tools developed by Intel, available to users of the LRZ systems. Again, we will skip the
KNL tools Dr. Fabio Baruffa fabio.baruffa@lrz.de 2 Which tool do I use? A roadmap to optimization We will focus on tools developed by Intel, available to users of the LRZ systems. Again, we will skip the
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #11 2/21/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline Midterm 1:
EE/CSCI 451: Parallel and Distributed Computation Lecture #11 2/21/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline Midterm 1:
A General Discussion on! Parallelism!
 Lecture 2! A General Discussion on! Parallelism! John Cavazos! Dept of Computer & Information Sciences! University of Delaware! www.cis.udel.edu/~cavazos/cisc879! Lecture 2: Overview Flynn s Taxonomy of
Lecture 2! A General Discussion on! Parallelism! John Cavazos! Dept of Computer & Information Sciences! University of Delaware! www.cis.udel.edu/~cavazos/cisc879! Lecture 2: Overview Flynn s Taxonomy of
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Objective. We will study software systems that permit applications programs to exploit the power of modern high-performance computers.
 CS 612 Software Design for High-performance Architectures 1 computers. CS 412 is desirable but not high-performance essential. Course Organization Lecturer:Paul Stodghill, stodghil@cs.cornell.edu, Rhodes
CS 612 Software Design for High-performance Architectures 1 computers. CS 412 is desirable but not high-performance essential. Course Organization Lecturer:Paul Stodghill, stodghil@cs.cornell.edu, Rhodes
Lecture 2: Single processor architecture and memory
 Lecture 2: Single processor architecture and memory David Bindel 30 Aug 2011 Teaser What will this plot look like? for n = 100:10:1000 tic; A = []; for i = 1:n A(i,i) = 1; end times(n) = toc; end ns =
Lecture 2: Single processor architecture and memory David Bindel 30 Aug 2011 Teaser What will this plot look like? for n = 100:10:1000 tic; A = []; for i = 1:n A(i,i) = 1; end times(n) = toc; end ns =
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort
 Rob van Nieuwpoort") PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
PARALLEL PROGRAMMING MANY-CORE COMPUTING: INTRO (1/5) Rob van Nieuwpoort rob@cs.vu.nl Schedule 2 1. Introduction, performance metrics & analysis 2. Many-core hardware 3. Cuda class 1: basics 4. Cuda class
Parallelism. CS6787 Lecture 8 Fall 2017
 Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Parallelism CS6787 Lecture 8 Fall 2017 So far We ve been talking about algorithms We ve been talking about ways to optimize their parameters But we haven t talked about the underlying hardware How does
Uniprocessor Optimizations. Idealized Uniprocessor Model
 Uniprocessor Optimizations Arvind Krishnamurthy Fall 2004 Idealized Uniprocessor Model Processor names bytes, words, etc. in its address space These represent integers, floats, pointers, arrays, etc. Exist
Uniprocessor Optimizations Arvind Krishnamurthy Fall 2004 Idealized Uniprocessor Model Processor names bytes, words, etc. in its address space These represent integers, floats, pointers, arrays, etc. Exist
UC Berkeley CS61C : Machine Structures
 inst.eecs.berkeley.edu/~cs61c UC Berkeley CS61C : Machine Structures Lecture 39 Intra-machine Parallelism 2010-04-30!!!Head TA Scott Beamer!!!www.cs.berkeley.edu/~sbeamer Old-Fashioned Mud-Slinging with
inst.eecs.berkeley.edu/~cs61c UC Berkeley CS61C : Machine Structures Lecture 39 Intra-machine Parallelism 2010-04-30!!!Head TA Scott Beamer!!!www.cs.berkeley.edu/~sbeamer Old-Fashioned Mud-Slinging with
45-year CPU Evolution: 1 Law -2 Equations
 4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
4004 8086 PowerPC 601 Pentium 4 Prescott 1971 1978 1992 45-year CPU Evolution: 1 Law -2 Equations Daniel Etiemble LRI Université Paris Sud 2004 Xeon X7560 Power9 Nvidia Pascal 2010 2017 2016 Are there
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. Sources. What is Computer Architecture?
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
Lecture 4. Instruction Level Parallelism Vectorization, SSE Optimizing for the memory hierarchy
 Lecture 4 Instruction Level Parallelism Vectorization, SSE Optimizing for the memory hierarchy Partners? Announcements Scott B. Baden / CSE 160 / Winter 2011 2 Today s lecture Why multicore? Instruction
Lecture 4 Instruction Level Parallelism Vectorization, SSE Optimizing for the memory hierarchy Partners? Announcements Scott B. Baden / CSE 160 / Winter 2011 2 Today s lecture Why multicore? Instruction
Case study: OpenMP-parallel sparse matrix-vector multiplication
 Case study: OpenMP-parallel sparse matrix-vector multiplication A simple (but sometimes not-so-simple) example for bandwidth-bound code and saturation effects in memory Sparse matrix-vector multiply (spmvm)
Case study: OpenMP-parallel sparse matrix-vector multiplication A simple (but sometimes not-so-simple) example for bandwidth-bound code and saturation effects in memory Sparse matrix-vector multiply (spmvm)
Memory Hierarchy. Computer Systems Organization (Spring 2017) CSCI-UA 201, Section 3. Instructor: Joanna Klukowska
 CSCI-UA 201, Section 3. Instructor: Joanna Klukowska") Memory Hierarchy Computer Systems Organization (Spring 2017) CSCI-UA 201, Section 3 Instructor: Joanna Klukowska Slides adapted from Randal E. Bryant and David R. O Hallaron (CMU) Mohamed Zahran (NYU)
Memory Hierarchy Computer Systems Organization (Spring 2017) CSCI-UA 201, Section 3 Instructor: Joanna Klukowska Slides adapted from Randal E. Bryant and David R. O Hallaron (CMU) Mohamed Zahran (NYU)
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Memory Hierarchy. Cache Memory Organization and Access. General Cache Concept. Example Memory Hierarchy Smaller, faster,
 Memory Hierarchy Computer Systems Organization (Spring 2017) CSCI-UA 201, Section 3 Cache Memory Organization and Access Instructor: Joanna Klukowska Slides adapted from Randal E. Bryant and David R. O
Memory Hierarchy Computer Systems Organization (Spring 2017) CSCI-UA 201, Section 3 Cache Memory Organization and Access Instructor: Joanna Klukowska Slides adapted from Randal E. Bryant and David R. O
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #7 2/5/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
EE/CSCI 451: Parallel and Distributed Computation Lecture #7 2/5/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
Fourier-Motzkin and Farkas Questions (HW10)
") Automating Scheduling Logistics Final report for project due this Friday, 5/4/12 Quiz 4 due this Monday, 5/7/12 Poster session Thursday May 10 from 2-4pm Distance students need to contact me to set up
Automating Scheduling Logistics Final report for project due this Friday, 5/4/12 Quiz 4 due this Monday, 5/7/12 Poster session Thursday May 10 from 2-4pm Distance students need to contact me to set up
High-Performance Parallel Computing
 High-Performance Parallel Computing P. (Saday) Sadayappan Rupesh Nasre Course Overview Emphasis on algorithm development and programming issues for high performance No assumed background in computer architecture;
High-Performance Parallel Computing P. (Saday) Sadayappan Rupesh Nasre Course Overview Emphasis on algorithm development and programming issues for high performance No assumed background in computer architecture;
Administration. Prerequisites. Meeting times. CS 380C: Advanced Topics in Compilers
 Administration CS 380C: Advanced Topics in Compilers Instructor: eshav Pingali Professor (CS, ICES) Office: POB 4.126A Email: pingali@cs.utexas.edu TA: TBD Graduate student (CS) Office: Email: Meeting
Administration CS 380C: Advanced Topics in Compilers Instructor: eshav Pingali Professor (CS, ICES) Office: POB 4.126A Email: pingali@cs.utexas.edu TA: TBD Graduate student (CS) Office: Email: Meeting
Chapter 7. Multicores, Multiprocessors, and Clusters
 Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Chapter 7 Multicores, Multiprocessors, and Clusters Introduction Goal: connecting multiple computers to get higher performance Multiprocessors Scalability, availability, power efficiency Job-level (process-level)
Memory access patterns. 5KK73 Cedric Nugteren
 Memory access patterns 5KK73 Cedric Nugteren Today s topics 1. The importance of memory access patterns a. Vectorisation and access patterns b. Strided accesses on GPUs c. Data re-use on GPUs and FPGA
Memory access patterns 5KK73 Cedric Nugteren Today s topics 1. The importance of memory access patterns a. Vectorisation and access patterns b. Strided accesses on GPUs c. Data re-use on GPUs and FPGA
CS4961 Parallel Programming. Lecture 3: Introduction to Parallel Architectures 8/30/11. Administrative UPDATE. Mary Hall August 30, 2011
 CS4961 Parallel Programming Lecture 3: Introduction to Parallel Architectures Administrative UPDATE Nikhil office hours: - Monday, 2-3 PM, MEB 3115 Desk #12 - Lab hours on Tuesday afternoons during programming
CS4961 Parallel Programming Lecture 3: Introduction to Parallel Architectures Administrative UPDATE Nikhil office hours: - Monday, 2-3 PM, MEB 3115 Desk #12 - Lab hours on Tuesday afternoons during programming
How to Write Fast Numerical Code
 How to Write Fast Numerical Code Lecture: Memory hierarchy, locality, caches Instructor: Markus Püschel TA: Alen Stojanov, Georg Ofenbeck, Gagandeep Singh Organization Temporal and spatial locality Memory
How to Write Fast Numerical Code Lecture: Memory hierarchy, locality, caches Instructor: Markus Püschel TA: Alen Stojanov, Georg Ofenbeck, Gagandeep Singh Organization Temporal and spatial locality Memory
Introduction II. Overview
 Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
This Unit: Putting It All Together. CIS 501 Computer Architecture. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
This Unit: Putting It All Together CIS 501 Computer Architecture Unit 12: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital Circuits
Basics of Performance Engineering
 ERLANGEN REGIONAL COMPUTING CENTER Basics of Performance Engineering J. Treibig HiPerCH 3, 23./24.03.2015 Why hardware should not be exposed Such an approach is not portable Hardware issues frequently
ERLANGEN REGIONAL COMPUTING CENTER Basics of Performance Engineering J. Treibig HiPerCH 3, 23./24.03.2015 Why hardware should not be exposed Such an approach is not portable Hardware issues frequently
Submission instructions (read carefully): SS17 / Assignment 4 Instructor: Markus Püschel. ETH Zurich
: SS17 / Assignment 4 Instructor: Markus Püschel. ETH Zurich") 263-2300-00: How To Write Fast Numerical Code Assignment 4: 120 points Due Date: Th, April 13th, 17:00 http://www.inf.ethz.ch/personal/markusp/teaching/263-2300-eth-spring17/course.html Questions: fastcode@lists.inf.ethz.ch
263-2300-00: How To Write Fast Numerical Code Assignment 4: 120 points Due Date: Th, April 13th, 17:00 http://www.inf.ethz.ch/personal/markusp/teaching/263-2300-eth-spring17/course.html Questions: fastcode@lists.inf.ethz.ch
211: Computer Architecture Summer 2016
 211: Computer Architecture Summer 2016 Liu Liu Topic: Assembly Programming Storage - Assembly Programming: Recap - Call-chain - Factorial - Storage: - RAM - Caching - Direct - Mapping Rutgers University
211: Computer Architecture Summer 2016 Liu Liu Topic: Assembly Programming Storage - Assembly Programming: Recap - Call-chain - Factorial - Storage: - RAM - Caching - Direct - Mapping Rutgers University
Memory Hierarchy. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Memory Hierarchy Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Time (ns) The CPU-Memory Gap The gap widens between DRAM, disk, and CPU speeds
Memory Hierarchy Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Time (ns) The CPU-Memory Gap The gap widens between DRAM, disk, and CPU speeds
Trends and Challenges in Multicore Programming
 Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Trends and Challenges in Multicore Programming Eva Burrows Bergen Language Design Laboratory (BLDL) Department of Informatics, University of Bergen Bergen, March 17, 2010 Outline The Roadmap of Multicores
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
This Unit: Putting It All Together. CIS 371 Computer Organization and Design. What is Computer Architecture? Sources
 This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
This Unit: Putting It All Together CIS 371 Computer Organization and Design Unit 15: Putting It All Together: Anatomy of the XBox 360 Game Console Application OS Compiler Firmware CPU I/O Memory Digital
Joe Hummel, PhD. Microsoft MVP Visual C++ Technical Staff: Pluralsight, LLC Professor: U. of Illinois, Chicago.
 Joe Hummel, PhD Microsoft MVP Visual C++ Technical Staff: Pluralsight, LLC Professor: U. of Illinois, Chicago email: joe@joehummel.net stuff: http://www.joehummel.net/downloads.html Async programming:
Joe Hummel, PhD Microsoft MVP Visual C++ Technical Staff: Pluralsight, LLC Professor: U. of Illinois, Chicago email: joe@joehummel.net stuff: http://www.joehummel.net/downloads.html Async programming:
Lecture 16 Optimizing for the memory hierarchy
 Lecture 16 Optimizing for the memory hierarchy A4 has been released Announcements Using SSE intrinsics, you can speed up your code by nearly a factor of 2 Scott B. Baden / CSE 160 / Wi '16 2 Today s lecture
Lecture 16 Optimizing for the memory hierarchy A4 has been released Announcements Using SSE intrinsics, you can speed up your code by nearly a factor of 2 Scott B. Baden / CSE 160 / Wi '16 2 Today s lecture
Lect. 2: Types of Parallelism
 Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
CS4961 Parallel Programming. Lecture 7: Introduction to SIMD 09/14/2010. Homework 2, Due Friday, Sept. 10, 11:59 PM. Mary Hall September 14, 2010
 Parallel Programming Lecture 7: Introduction to SIMD Mary Hall September 14, 2010 Homework 2, Due Friday, Sept. 10, 11:59 PM To submit your homework: - Submit a PDF file - Use the handin program on the
Parallel Programming Lecture 7: Introduction to SIMD Mary Hall September 14, 2010 Homework 2, Due Friday, Sept. 10, 11:59 PM To submit your homework: - Submit a PDF file - Use the handin program on the
Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication. Steve Rennich Nvidia Developer Technology - Compute
 Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication Steve Rennich Nvidia Developer Technology - Compute Block Sparse Matrix Vector Multiplication Sparse Matrix-Vector Multiplication
Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication Steve Rennich Nvidia Developer Technology - Compute Block Sparse Matrix Vector Multiplication Sparse Matrix-Vector Multiplication
SE-292 High Performance Computing. Memory Hierarchy. R. Govindarajan Memory Hierarchy
 SE-292 High Performance Computing Memory Hierarchy R. Govindarajan govind@serc Memory Hierarchy 2 1 Memory Organization Memory hierarchy CPU registers few in number (typically 16/32/128) subcycle access
SE-292 High Performance Computing Memory Hierarchy R. Govindarajan govind@serc Memory Hierarchy 2 1 Memory Organization Memory hierarchy CPU registers few in number (typically 16/32/128) subcycle access
UC Berkeley CS61C : Machine Structures
 inst.eecs.berkeley.edu/~cs61c Review! UC Berkeley CS61C : Machine Structures Lecture 28 Intra-machine Parallelism Parallelism is necessary for performance! It looks like itʼs It is the future of computing!
inst.eecs.berkeley.edu/~cs61c Review! UC Berkeley CS61C : Machine Structures Lecture 28 Intra-machine Parallelism Parallelism is necessary for performance! It looks like itʼs It is the future of computing!
Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console
 Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Computer Architecture Unit 11: Putting it All Together: Anatomy of the XBox 360 Game Console Slides originally developed by Milo Martin & Amir Roth at University of Pennsylvania! Computer Architecture
Kirill Rogozhin. Intel
 Kirill Rogozhin Intel From Old HPC principle to modern performance model Old HPC principles: 1. Balance principle (e.g. Kung 1986) hw and software parameters altogether 2. Compute Density, intensity, machine
Kirill Rogozhin Intel From Old HPC principle to modern performance model Old HPC principles: 1. Balance principle (e.g. Kung 1986) hw and software parameters altogether 2. Compute Density, intensity, machine
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Lecture 3: Intro to parallel machines and models
 Lecture 3: Intro to parallel machines and models David Bindel 1 Sep 2011 Logistics Remember: http://www.cs.cornell.edu/~bindel/class/cs5220-f11/ http://www.piazza.com/cornell/cs5220 Note: the entire class
Lecture 3: Intro to parallel machines and models David Bindel 1 Sep 2011 Logistics Remember: http://www.cs.cornell.edu/~bindel/class/cs5220-f11/ http://www.piazza.com/cornell/cs5220 Note: the entire class
Overview. CS 472 Concurrent & Parallel Programming University of Evansville
 Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Overview CS 472 Concurrent & Parallel Programming University of Evansville Selection of slides from CIS 410/510 Introduction to Parallel Computing Department of Computer and Information Science, University
Lecture 12: Instruction Execution and Pipelining. William Gropp
 Lecture 12: Instruction Execution and Pipelining William Gropp www.cs.illinois.edu/~wgropp Yet More To Consider in Understanding Performance We have implicitly assumed that an operation takes one clock
Lecture 12: Instruction Execution and Pipelining William Gropp www.cs.illinois.edu/~wgropp Yet More To Consider in Understanding Performance We have implicitly assumed that an operation takes one clock
Vector an ordered series of scalar quantities a one-dimensional array. Vector Quantity Data Data Data Data Data Data Data Data
 Vector Processors A vector processor is a pipelined processor with special instructions designed to keep the (floating point) execution unit pipeline(s) full. These special instructions are vector instructions.
Vector Processors A vector processor is a pipelined processor with special instructions designed to keep the (floating point) execution unit pipeline(s) full. These special instructions are vector instructions.
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Intel profiling tools and roofline model. Dr. Luigi Iapichino
 Intel profiling tools and roofline model Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimization (and to the next hour) We will focus on tools developed
Intel profiling tools and roofline model Dr. Luigi Iapichino luigi.iapichino@lrz.de Which tool do I use in my project? A roadmap to optimization (and to the next hour) We will focus on tools developed
How to Write Fast Numerical Code Spring 2012 Lecture 13. Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato
 How to Write Fast Numerical Code Spring 2012 Lecture 13 Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato ATLAS Mflop/s Compile Execute Measure Detect Hardware Parameters L1Size NR MulAdd
How to Write Fast Numerical Code Spring 2012 Lecture 13 Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato ATLAS Mflop/s Compile Execute Measure Detect Hardware Parameters L1Size NR MulAdd
PCOPP Uni-Processor Optimization- Features of Memory Hierarchy. Uni-Processor Optimization Features of Memory Hierarchy
 PCOPP-2002 Day 1 Classroom Lecture Uni-Processor Optimization- Features of Memory Hierarchy 1 The Hierarchical Memory Features and Performance Issues Lecture Outline Following Topics will be discussed
PCOPP-2002 Day 1 Classroom Lecture Uni-Processor Optimization- Features of Memory Hierarchy 1 The Hierarchical Memory Features and Performance Issues Lecture Outline Following Topics will be discussed
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
AMath 483/583 Lecture 11
 AMath 483/583 Lecture 11 Outline: Computer architecture Cache considerations Fortran optimization Reading: S. Goedecker and A. Hoisie, Performance Optimization of Numerically Intensive Codes, SIAM, 2001.
AMath 483/583 Lecture 11 Outline: Computer architecture Cache considerations Fortran optimization Reading: S. Goedecker and A. Hoisie, Performance Optimization of Numerically Intensive Codes, SIAM, 2001.
AMath 483/583 Lecture 11. Notes: Notes: Comments on Homework. Notes: AMath 483/583 Lecture 11
 AMath 483/583 Lecture 11 Outline: Computer architecture Cache considerations Fortran optimization Reading: S. Goedecker and A. Hoisie, Performance Optimization of Numerically Intensive Codes, SIAM, 2001.
AMath 483/583 Lecture 11 Outline: Computer architecture Cache considerations Fortran optimization Reading: S. Goedecker and A. Hoisie, Performance Optimization of Numerically Intensive Codes, SIAM, 2001.
Lecture 12. Memory Design & Caches, part 2. Christos Kozyrakis Stanford University
 Lecture 12 Memory Design & Caches, part 2 Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee108b 1 Announcements HW3 is due today PA2 is available on-line today Part 1 is due on 2/27
Lecture 12 Memory Design & Caches, part 2 Christos Kozyrakis Stanford University http://eeclass.stanford.edu/ee108b 1 Announcements HW3 is due today PA2 is available on-line today Part 1 is due on 2/27
An Auto-Tuning Framework for Parallel Multicore Stencil Computations
 Software Engineering Seminar Sebastian Hafen An Auto-Tuning Framework for Parallel Multicore Stencil Computations Shoaib Kamil, Cy Chan, Leonid Oliker, John Shalf, Samuel Williams 1 Stencils What is a
Software Engineering Seminar Sebastian Hafen An Auto-Tuning Framework for Parallel Multicore Stencil Computations Shoaib Kamil, Cy Chan, Leonid Oliker, John Shalf, Samuel Williams 1 Stencils What is a
Day 6: Optimization on Parallel Intel Architectures
 Day 6: Optimization on Parallel Intel Architectures Lecture day 6 Ryo Asai Colfax International colfaxresearch.com April 2017 colfaxresearch.com/ Welcome Colfax International, 2013 2017 Disclaimer 2 While
Day 6: Optimization on Parallel Intel Architectures Lecture day 6 Ryo Asai Colfax International colfaxresearch.com April 2017 colfaxresearch.com/ Welcome Colfax International, 2013 2017 Disclaimer 2 While
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
EE282 Computer Architecture. Lecture 1: What is Computer Architecture?
 EE282 Computer Architecture Lecture : What is Computer Architecture? September 27, 200 Marc Tremblay Computer Systems Laboratory Stanford University marctrem@csl.stanford.edu Goals Understand how computer
EE282 Computer Architecture Lecture : What is Computer Architecture? September 27, 200 Marc Tremblay Computer Systems Laboratory Stanford University marctrem@csl.stanford.edu Goals Understand how computer
Munara Tolubaeva Technical Consulting Engineer. 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries.
 Munara Tolubaeva Technical Consulting Engineer 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries. notices and disclaimers Intel technologies features and benefits depend
Munara Tolubaeva Technical Consulting Engineer 3D XPoint is a trademark of Intel Corporation in the U.S. and/or other countries. notices and disclaimers Intel technologies features and benefits depend
Carlo Cavazzoni, HPC department, CINECA
 Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Introduction to Shared memory architectures Carlo Cavazzoni, HPC department, CINECA Modern Parallel Architectures Two basic architectural scheme: Distributed Memory Shared Memory Now most computers have
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
A Crash Course in Compilers for Parallel Computing. Mary Hall Fall, L2: Transforms, Reuse, Locality
 A Crash Course in Compilers for Parallel Computing Mary Hall Fall, 2008 1 Overview of Crash Course L1: Data Dependence Analysis and Parallelization (Oct. 30) L2 & L3: Loop Reordering Transformations, Reuse
A Crash Course in Compilers for Parallel Computing Mary Hall Fall, 2008 1 Overview of Crash Course L1: Data Dependence Analysis and Parallelization (Oct. 30) L2 & L3: Loop Reordering Transformations, Reuse
DEPARTMENT OF ELECTRONICS & COMMUNICATION ENGINEERING QUESTION BANK
 DEPARTMENT OF ELECTRONICS & COMMUNICATION ENGINEERING QUESTION BANK SUBJECT : CS6303 / COMPUTER ARCHITECTURE SEM / YEAR : VI / III year B.E. Unit I OVERVIEW AND INSTRUCTIONS Part A Q.No Questions BT Level
DEPARTMENT OF ELECTRONICS & COMMUNICATION ENGINEERING QUESTION BANK SUBJECT : CS6303 / COMPUTER ARCHITECTURE SEM / YEAR : VI / III year B.E. Unit I OVERVIEW AND INSTRUCTIONS Part A Q.No Questions BT Level