Adapted from David Patterson s slides on graduate computer architecture
|
|
|
- Monica Booker
- 6 years ago
- Views:
Transcription


1 Mei Yang Adapted from David Patterson s slides on graduate computer architecture Introduction Ten Advanced Optimizations of Cache Performance Memory Technology and Optimizations Virtual Memory and Virtual Machines Crosscutting Issues Memory Hierarchies in ARM Cortex-A8 And Intel Core i7 Fallacies and Pitfalls 2 ECG 700 Fall12 1

2 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per bit than slower memory Solution: organize memory system into a hierarchy Entire addressable memory space available in largest, slowest memory Incrementally smaller and faster memories, each containing a subset of the memory below it, proceed in steps up toward the processor Temporal and spatial locality insures that nearly all references can be found in smaller memories Gives the allusion of a large, fast memory being presented to the processor 3 4 ECG 700 Fall12 2

3 5 Memory hierarchy design becomes more crucial with recent multi-core processors: Aggregate peak bandwidth grows with # cores: Intel Core i7 can generate two references per core per clock Four cores and 3.2 GHz clock 25.6 billion 64-bit data references/second billion 128-bit instruction references = GB/s! DRAM bandwidth is only 6% of this (25 GB/s) Requires: Multi-port, pipelined caches Two levels of cache per core Shared third-level cache on chip 6 ECG 700 Fall12 3
4 High-end microprocessors have >10 MB on-chip cache Consumes large amount of area and power budget Account for 25 ~ 50% of total power consumption Need consider both performance and power trade-off Performance in terms of average memory access time, determined by the cache access time, miss rate, and miss penalty 7 When a word is not found in the cache, a miss occurs: Fetch word from lower level in hierarchy, requiring a higher latency reference Lower level may be another cache or the main memory Also fetch the other words contained within the block Takes advantage of spatial locality Place block into cache in any location within its set, determined by address block address MOD number of sets 8 ECG 700 Fall12 4
5 n sets => n-way set associative Direct-mapped cache => one block per set Fully associative => one set Writing to cache: two strategies Write-through Immediately update lower levels of hierarchy Write-back Only update lower levels of hierarchy when an updated block is replaced Both strategies use write buffer to make writes asynchronous 9 Miss rate Fraction of cache access that result in a miss Causes of misses Compulsory First reference to a block Capacity Blocks discarded and later retrieved Conflict Program makes repeated references to multiple addresses from different blocks that map to the same location in the cache 10 ECG 700 Fall12 5

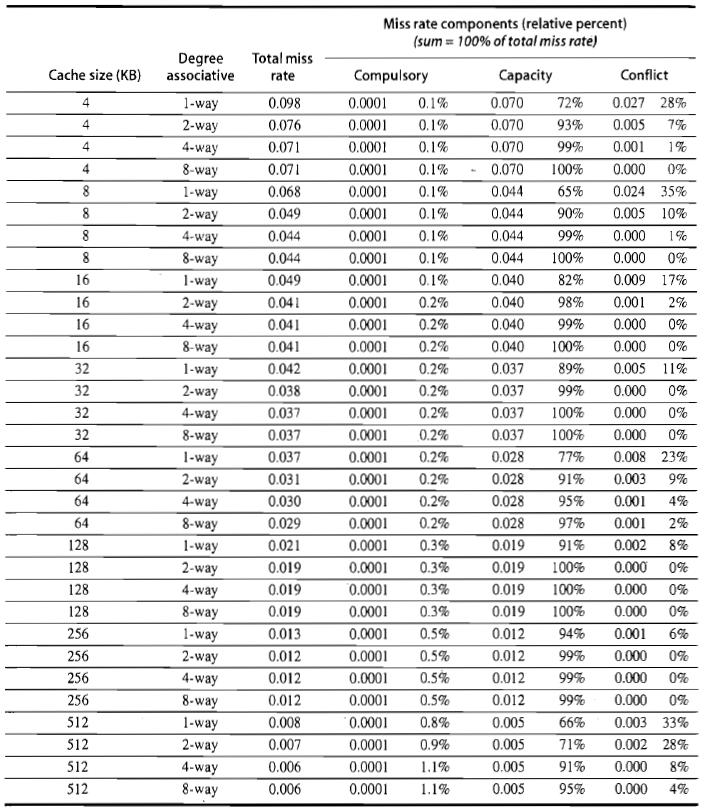
6 11 12 ECG 700 Fall12 6
7 Note that speculative and multithreaded processors may execute other instructions during a miss Reduces performance impact of misses ECG 700 Fall12 7

8 Six basic cache optimizations: Larger block size Reduces compulsory misses Increases capacity and conflict misses, increases miss penalty Larger total cache capacity to reduce miss rate Increases hit time, increases power consumption Higher associativity Reduces conflict misses Increases hit time, increases power consumption Higher number of cache levels Reduces overall memory access time Giving priority to read misses over writes Reduces miss penalty Avoiding address translation in cache indexing Reduces hit time 15 Access time vs. size and associativity 16 ECG 700 Fall12 8
9 What is the impact of two different cache organizations on the performance of a processor? Assume the CPI with a perfect cache is 1.6, the clock cycle time is 0.35ns, there are 1.4 mem refers/instruction, the size of both caches is 128KB, with block size 64 byes. One cache is direct mapped with miss rate of 2.1%. The other is two-way set associative with miss rate of 1.9% and 1.35 times stretching of cache clock cycle time. Assume the hit time is 1 clock cycle and the miss penalty is 65ns. Find the AMAT and the processor performance. AMAT = Hit time + Miss rate X Miss penalty AMAT_1-way = (0.021 x 65) = 1.72ns. AMAT_2-way = 0.35 x (0.019 x 65) = 1.71ns. CPU time = IC x (CPI + Misses/instruction x Miss penalty) x CC = IC x (CPI x CC + (Miss rate x Mem accesses / instruction x Miss penalty X CC) CPU time_1-way = IC x (1.6 x (0.021 x 1.4 x 65)) = 2.47 x IC CPU time_2-way = IC x (1.6 x 0.35 x (0.019 x 1.4 x 65)) = 2.49 x IC 17 Small and simple first level caches Critical timing path: addressing tag memory, then comparing tags, then selecting correct set Direct-mapped caches can overlap tag compare and transmission of data Lower associativity reduces power because fewer cache lines are accessed 18 ECG 700 Fall12 9

10 Energy per read vs. size and associativity 19 To improve hit time, predict the way to preset mux Mis-prediction gives longer hit time Prediction accuracy > 90% for two-way > 80% for four-way I-cache has better accuracy than D-cache First used on MIPS R10000 in mid-90s Used on ARM Cortex-A8 Extend to predict block as well Way selection Increases mis-prediction penalty 20 ECG 700 Fall12 10

11 Pipeline cache access to improve bandwidth Examples: Pentium: 1 cycle Pentium Pro Pentium III: 2 cycles Pentium 4 Core i7: 4 cycles Increases branch mis-prediction penalty Makes it easier to increase associativity 21 Allow hits before previous misses complete Hit under miss Hit under multiple miss L2 must support this In general, processors can hide L1 miss penalty but not L2 miss penalty 22 ECG 700 Fall12 11
12 What is more important for floating-point programs and integer programs: two-way set associativity or hit under one miss for the primary data caches? Assume the average miss rates for 32KB data caches: 5.2% and 4.9% for floating-point programs with a direct-mapped cache and a two-way set associative cache, respectively; 3.5% and 3.2% for integer programs with a direct-mapped cache and a two-way set associative cache, respectively. Assume the miss penalty to L2 is 10 cycles, and the L2 misses and penalty are the same. For floating-point programs, the average memory stall times are Miss rate DM x Miss penalty = 5.2% x 10 = 0.52 Miss rate 2-way x Miss penalty = 4.9% x 10 = 0.49 The cache latency for two-way associatitivy is 0.49/0.52=94% vs. directmapped cache, while the hit under miss reduces the latency to 87.5% For integer-point programs, the average memory stall times are Miss rate DM x Miss penalty = 3.5% x 10 = 0.35 Miss rate 2-way x Miss penalty = 3.2% x 10 = 0.32 The cache latency for two-way associatitivy is 0.32/0.35 or 91% for directmapped cache, while the hit under miss reduces the latency to 91% 23 Organize cache as independent banks to support simultaneous access ARM Cortex-A8 supports 1-4 banks for L2 Intel i7 supports 4 banks for L1 and 8 banks for L2 Interleave banks according to block address 24 ECG 700 Fall12 12

13 Critical word first Request missed word from memory first Send it to the processor as soon as it arrives Early restart Request words in normal order Send missed work to the processor as soon as it arrives Effectiveness of these strategies depends on block size and likelihood of another access to the portion of the block that has not yet been fetched 25 When storing to a block that is already pending in the write buffer, update write buffer Write merging reduces stalls due to full write buffer Do not apply to I/O addresses No write merging Write merging 26 ECG 700 Fall12 13


14 Loop Interchange Swap nested loops to access memory in sequential order Blocking Instead of accessing entire rows or columns, subdivide matrices into blocks Requires more memory accesses but improves locality of accesses ECG 700 Fall12 14

15 Fetch two blocks on miss (include next sequential block) Pentium 4 Pre-fetching 29 Insert prefetch instructions before data is needed Non-faulting: prefetch doesn t cause exceptions Register prefetch Loads data into register Cache prefetch Loads data into cache Combine with loop unrolling and software pipelining 30 ECG 700 Fall12 15
16 For the code below, determine the which accesses are likely to cause data cache misses. Next, insert prefetch instructions to reduce misses. Finally, calculate the number of prefetch instructions executed and the misses avoided by prefetching. Let s assume we have an 8KB direct-mapped data cache with 16- bye blocks, and it s the write-back cache that does write allocate. The elements of a and b are 8 bytes. There are 3 rows and 100 columns for a and 3 columns for b. for (i=0; i < 3; i=i+1) for (j=0; j<100; j=j+1) a[i][j] = b[j][0] * b[j+1][0]; Since a has 3 rows and 100 columns, its accesses will lead to 3x(100/2), or 150 misses. While b has 101 misses for accessing b[j+1][0]. So totally 251 misses. for (j=0; j < 100; j=j+1) { prefetch(b[j+7][0]); //b(j,0) for 7 iterations later prefetch(a[0][j+7]); //a(0,j) for 7 iterations later a[0][j] = b[j][0] * b[j+1][0]; }; for (i=0; i<3; i=i+1) for (j=0; j<100; j=j+1){ prefetch(a[i][j+7]); //a[i][j] for +7 iterations a[i][j] = b[j][0] * b[j+1][0]; } 31 7 misses for elements b[0][0] to b[6][0] in the first loop. 4 misses for elements a[0][0] to a[0][6] in the first loop. 4 misses for elements a[1][0] to a[1][6] in the second loop. 4 misses for elements a[2][0] to a[2][6] in the second loop. Totally 19 misses. Calculate the time saved in the previous example. Ignore instruction cache misses and assume there are no conflict or capacity misses in the data cache. Assume that prefetches can overlap with each other and with cache misses. The original loop takes 7 clock cycles per iteration, the first prefetch loop takes 9 clock cycles per iteration, and the second prefetch loop takes 8 clock cycles per iteration. A miss takes 100 clock cycles. Original doubly nested loop: 300 x x 100 = clock cycles Prefetch loop: 9 x x x 100 x x 100 = 4400 clock cycles The speedup of prefetch code to orignal loop: 27200/4400 = 6.2 times 32 ECG 700 Fall12 16

17 33 Performance metrics Latency is concern of cache Bandwidth is concern of multiprocessors and I/O Access time Time between read request and when desired word arrives Cycle time Minimum time between unrelated requests to memory DRAM used for main memory, SRAM used for cache 34 ECG 700 Fall12 17
18 SRAM Requires low power to retain bit Requires 6 transistors/bit DRAM Must be re-written after being read Must also be periodically refeshed Every ~ 8 ms Each row can be refreshed simultaneously One transistor/bit Address lines are multiplexed: Upper half of address: row access strobe (RAS) Lower half of address: column access strobe (CAS) 35 Internal organization 36 ECG 700 Fall12 18
19 Amdahl: Memory capacity should grow linearly with processor speed Unfortunately, memory capacity and speed has not kept pace with processors Some optimizations: Multiple accesses to same row Synchronous DRAM Added clock to DRAM interface Burst mode with critical word first Wider interfaces Double data rate (DDR) Multiple banks on each DRAM device ECG 700 Fall12 19
 Higher clock rates (266 MHz, 333 MHz, 400 MHz) DDR3 1.5 V 800 MHz DDR4 1-1.")
20 39 DDR: DDR2 Lower power (2.5 V -> 1.8 V) Higher clock rates (266 MHz, 333 MHz, 400 MHz) DDR3 1.5 V 800 MHz DDR V 1600 MHz GDDR5 is graphics memory based on DDR3 40 ECG 700 Fall12 20
21 Graphics memory: Achieve 2-5 X bandwidth per DRAM vs. DDR3 Wider interfaces (32 vs. 16 bit) Higher clock rate Possible because they are attached via soldering instead of socketted DIMM modules Reducing power in SDRAMs: Lower voltage Low power mode (ignores clock, continues to refresh) ECG 700 Fall12 21
22 Type of EEPROM Must be erased (in blocks) before being overwritten Non volatile Limited number of write cycles Cheaper than SDRAM, more expensive than disk Slower than SRAM, faster than disk 43 Memory is susceptible to cosmic rays Soft errors: dynamic errors Detected and fixed by error correcting codes (ECC) Hard errors: permanent errors Use sparse rows to replace defective rows Chipkill: a RAID-like error recovery technique 44 ECG 700 Fall12 22
23 Protection via virtual memory Keeps processes in their own memory space Role of architecture: Provide user mode and supervisor mode Protect certain aspects of CPU state Provide mechanisms for switching between user mode and supervisor mode Provide mechanisms to limit memory accesses Provide TLB to translate addresses 45 Supports isolation and security Sharing a computer among many unrelated users Enabled by raw speed of processors, making the overhead more acceptable Allows different ISAs and operating systems to be presented to user programs System Virtual Machines SVM software is called virtual machine monitor or hypervisor Individual virtual machines run under the monitor are called guest VMs 46 ECG 700 Fall12 23
24 Each guest OS maintains its own set of page tables VMM adds a level of memory between physical and virtual memory called real memory VMM maintains shadow page table that maps guest virtual addresses to physical addresses Requires VMM to detect guest s changes to its own page table Occurs naturally if accessing the page table pointer is a privileged operation 47 Coretex-A8 is a configurable core that supports ARMv7 ISA Issues two instructions per clock at clock rates up to 1GHz Can support two-level cache L1 (I & D): each 16KB or 32 KB as four-way set associative Optional L2: 128KB up to 1 MB as eight-way set associative Uses a pair of TLBs (I and D), each is fully associative with 32 entries and a variable page size (4KB, 16KB, 64KB, 1MB, and 16 MB) 48 ECG 700 Fall12 24

25 49 50 ECG 700 Fall12 25
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
LECTURE 5: MEMORY HIERARCHY DESIGN
 LECTURE 5: MEMORY HIERARCHY DESIGN Abridged version of Hennessy & Patterson (2012):Ch.2 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive
LECTURE 5: MEMORY HIERARCHY DESIGN Abridged version of Hennessy & Patterson (2012):Ch.2 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 2. Memory Hierarchy Design. Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems)
") EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
EI338: Computer Systems and Engineering (Computer Architecture & Operating Systems) Chentao Wu 吴晨涛 Associate Professor Dept. of Computer Science and Engineering Shanghai Jiao Tong University SEIEE Building
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design Edited by Mansour Al Zuair 1 Introduction Programmers want unlimited amounts of memory with low latency Fast
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design Edited by Mansour Al Zuair 1 Introduction Programmers want unlimited amounts of memory with low latency Fast
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2011/12 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2011/12 1 2
Memory Hierarchy Computing Systems & Performance MSc Informatics Eng. Memory Hierarchy (most slides are borrowed)
") Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
Computing Systems & Performance Memory Hierarchy MSc Informatics Eng. 2012/13 A.J.Proença Memory Hierarchy (most slides are borrowed) AJProença, Computer Systems & Performance, MEI, UMinho, 2012/13 1 2
COSC 6385 Computer Architecture - Memory Hierarchies (III)
") COSC 6385 Computer Architecture - Memory Hierarchies (III) Edgar Gabriel Spring 2014 Memory Technology Performance metrics Latency problems handled through caches Bandwidth main concern for main memory
COSC 6385 Computer Architecture - Memory Hierarchies (III) Edgar Gabriel Spring 2014 Memory Technology Performance metrics Latency problems handled through caches Bandwidth main concern for main memory
COSC 6385 Computer Architecture - Memory Hierarchies (II)
") COSC 6385 Computer Architecture - Memory Hierarchies (II) Edgar Gabriel Spring 2018 Types of cache misses Compulsory Misses: first access to a block cannot be in the cache (cold start misses) Capacity
COSC 6385 Computer Architecture - Memory Hierarchies (II) Edgar Gabriel Spring 2018 Types of cache misses Compulsory Misses: first access to a block cannot be in the cache (cold start misses) Capacity
CSE 502 Graduate Computer Architecture
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 CSE 502 Graduate Computer Architecture Lec 11-14 Advanced Memory Memory Hierarchy Design Larry Wittie Computer Science, StonyBrook
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 CSE 502 Graduate Computer Architecture Lec 11-14 Advanced Memory Memory Hierarchy Design Larry Wittie Computer Science, StonyBrook
The University of Adelaide, School of Computer Science 13 September 2018
 Computer Architecture A Quantitative Approach, Sixth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Computer Architecture A Quantitative Approach, Sixth Edition Chapter 2 Memory Hierarchy Design 1 Programmers want unlimited amounts of memory with low latency Fast memory technology is more expensive per
Memories. CPE480/CS480/EE480, Spring Hank Dietz.
 Memories CPE480/CS480/EE480, Spring 2018 Hank Dietz http://aggregate.org/ee480 What we want, what we have What we want: Unlimited memory space Fast, constant, access time (UMA: Uniform Memory Access) What
Memories CPE480/CS480/EE480, Spring 2018 Hank Dietz http://aggregate.org/ee480 What we want, what we have What we want: Unlimited memory space Fast, constant, access time (UMA: Uniform Memory Access) What
Memory Hierarchy Basics
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases
Introduction to cache memories
 Course on: Advanced Computer Architectures Introduction to cache memories Prof. Cristina Silvano Politecnico di Milano email: cristina.silvano@polimi.it 1 Summary Summary Main goal Spatial and temporal
Course on: Advanced Computer Architectures Introduction to cache memories Prof. Cristina Silvano Politecnico di Milano email: cristina.silvano@polimi.it 1 Summary Summary Main goal Spatial and temporal
Memory Hierarchy Basics. Ten Advanced Optimizations. Small and Simple
 Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases capacity and conflict misses, increases miss penalty Larger total cache capacity to reduce miss
Memory Hierarchy Basics Six basic cache optimizations: Larger block size Reduces compulsory misses Increases capacity and conflict misses, increases miss penalty Larger total cache capacity to reduce miss
LRU. Pseudo LRU A B C D E F G H A B C D E F G H H H C. Copyright 2012, Elsevier Inc. All rights reserved.
 LRU A list to keep track of the order of access to every block in the set. The least recently used block is replaced (if needed). How many bits we need for that? 27 Pseudo LRU A B C D E F G H A B C D E
LRU A list to keep track of the order of access to every block in the set. The least recently used block is replaced (if needed). How many bits we need for that? 27 Pseudo LRU A B C D E F G H A B C D E
MEMORY HIERARCHY DESIGN
 1 MEMORY HIERARCHY DESIGN Chapter 2 OUTLINE Introduction Basics of Memory Hierarchy Advanced Optimizations of Cache Memory Technology and Optimizations 2 READINGASSIGNMENT Important! 3 Read Appendix B
1 MEMORY HIERARCHY DESIGN Chapter 2 OUTLINE Introduction Basics of Memory Hierarchy Advanced Optimizations of Cache Memory Technology and Optimizations 2 READINGASSIGNMENT Important! 3 Read Appendix B
3Introduction. Memory Hierarchy. Chapter 2. Memory Hierarchy Design. Computer Architecture A Quantitative Approach, Fifth Edition
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 2 Memory Hierarchy Design 1 Introduction Programmers want unlimited amounts of memory with low latency Fast memory technology is more
,e-pg PATHSHALA- Computer Science Computer Architecture Module 25 Memory Hierarchy Design - Basics
 ,e-pg PATHSHALA- Computer Science Computer Architecture Module 25 Memory Hierarchy Design - Basics The objectives of this module are to discuss about the need for a hierarchical memory system and also
,e-pg PATHSHALA- Computer Science Computer Architecture Module 25 Memory Hierarchy Design - Basics The objectives of this module are to discuss about the need for a hierarchical memory system and also
Memory Hierarchy. Advanced Optimizations. Slides contents from:
 Memory Hierarchy Advanced Optimizations Slides contents from: Hennessy & Patterson, 5ed. Appendix B and Chapter 2. David Wentzlaff, ELE 475 Computer Architecture. MJT, High Performance Computing, NPTEL.
Memory Hierarchy Advanced Optimizations Slides contents from: Hennessy & Patterson, 5ed. Appendix B and Chapter 2. David Wentzlaff, ELE 475 Computer Architecture. MJT, High Performance Computing, NPTEL.
LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY
 LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY Abridged version of Patterson & Hennessy (2013):Ch.5 Principle of Locality Programs access a small proportion of their address space at any time Temporal
LECTURE 4: LARGE AND FAST: EXPLOITING MEMORY HIERARCHY Abridged version of Patterson & Hennessy (2013):Ch.5 Principle of Locality Programs access a small proportion of their address space at any time Temporal
Memory Technology. Chapter 5. Principle of Locality. Chapter 5 Large and Fast: Exploiting Memory Hierarchy 1
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 5 Large and Fast: Exploiting Memory Hierarchy 5 th Edition Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 5 Large and Fast: Exploiting Memory Hierarchy 5 th Edition Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic
Mainstream Computer System Components CPU Core 2 GHz GHz 4-way Superscaler (RISC or RISC-core (x86): Dynamic scheduling, Hardware speculation
: Dynamic scheduling, Hardware speculation") Mainstream Computer System Components CPU Core 2 GHz - 3.0 GHz 4-way Superscaler (RISC or RISC-core (x86): Dynamic scheduling, Hardware speculation One core or multi-core (2-4) per chip Multiple FP, integer
Mainstream Computer System Components CPU Core 2 GHz - 3.0 GHz 4-way Superscaler (RISC or RISC-core (x86): Dynamic scheduling, Hardware speculation One core or multi-core (2-4) per chip Multiple FP, integer
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address space at any time Temporal locality Items accessed recently are likely to
Mainstream Computer System Components
 Mainstream Computer System Components Double Date Rate (DDR) SDRAM One channel = 8 bytes = 64 bits wide Current DDR3 SDRAM Example: PC3-12800 (DDR3-1600) 200 MHz (internal base chip clock) 8-way interleaved
Mainstream Computer System Components Double Date Rate (DDR) SDRAM One channel = 8 bytes = 64 bits wide Current DDR3 SDRAM Example: PC3-12800 (DDR3-1600) 200 MHz (internal base chip clock) 8-way interleaved
CSEE W4824 Computer Architecture Fall 2012
 CSEE W4824 Computer Architecture Fall 2012 Lecture 8 Memory Hierarchy Design: Memory Technologies and the Basics of Caches Luca Carloni Department of Computer Science Columbia University in the City of
CSEE W4824 Computer Architecture Fall 2012 Lecture 8 Memory Hierarchy Design: Memory Technologies and the Basics of Caches Luca Carloni Department of Computer Science Columbia University in the City of
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
COSC 6385 Computer Architecture. - Memory Hierarchies (II)
") COSC 6385 Computer Architecture - Memory Hierarchies (II) Fall 2008 Cache Performance Avg. memory access time = Hit time + Miss rate x Miss penalty with Hit time: time to access a data item which is available
COSC 6385 Computer Architecture - Memory Hierarchies (II) Fall 2008 Cache Performance Avg. memory access time = Hit time + Miss rate x Miss penalty with Hit time: time to access a data item which is available
Chapter Seven. Memories: Review. Exploiting Memory Hierarchy CACHE MEMORY AND VIRTUAL MEMORY
 Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
Chapter Seven CACHE MEMORY AND VIRTUAL MEMORY 1 Memories: Review SRAM: value is stored on a pair of inverting gates very fast but takes up more space than DRAM (4 to 6 transistors) DRAM: value is stored
Computer Architecture Computer Science & Engineering. Chapter 5. Memory Hierachy BK TP.HCM
 Computer Architecture Computer Science & Engineering Chapter 5 Memory Hierachy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic
Computer Architecture Computer Science & Engineering Chapter 5 Memory Hierachy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic
Computer Organization and Structure. Bing-Yu Chen National Taiwan University
 Computer Organization and Structure Bing-Yu Chen National Taiwan University Large and Fast: Exploiting Memory Hierarchy The Basic of Caches Measuring & Improving Cache Performance Virtual Memory A Common
Computer Organization and Structure Bing-Yu Chen National Taiwan University Large and Fast: Exploiting Memory Hierarchy The Basic of Caches Measuring & Improving Cache Performance Virtual Memory A Common
Reducing Hit Times. Critical Influence on cycle-time or CPI. small is always faster and can be put on chip
 Reducing Hit Times Critical Influence on cycle-time or CPI Keep L1 small and simple small is always faster and can be put on chip interesting compromise is to keep the tags on chip and the block data off
Reducing Hit Times Critical Influence on cycle-time or CPI Keep L1 small and simple small is always faster and can be put on chip interesting compromise is to keep the tags on chip and the block data off
EN1640: Design of Computing Systems Topic 06: Memory System
 EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Advanced Computer Architecture- 06CS81-Memory Hierarchy Design
 Advanced Computer Architecture- 06CS81-Memory Hierarchy Design AMAT and Processor Performance AMAT = Average Memory Access Time Miss-oriented Approach to Memory Access CPIExec includes ALU and Memory instructions
Advanced Computer Architecture- 06CS81-Memory Hierarchy Design AMAT and Processor Performance AMAT = Average Memory Access Time Miss-oriented Approach to Memory Access CPIExec includes ALU and Memory instructions
Lecture 11. Virtual Memory Review: Memory Hierarchy
 Lecture 11 Virtual Memory Review: Memory Hierarchy 1 Administration Homework 4 -Due 12/21 HW 4 Use your favorite language to write a cache simulator. Input: address trace, cache size, block size, associativity
Lecture 11 Virtual Memory Review: Memory Hierarchy 1 Administration Homework 4 -Due 12/21 HW 4 Use your favorite language to write a cache simulator. Input: address trace, cache size, block size, associativity
CACHE MEMORIES ADVANCED COMPUTER ARCHITECTURES. Slides by: Pedro Tomás
 CACHE MEMORIES Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 2 and Appendix B, John L. Hennessy and David A. Patterson, Morgan Kaufmann,
CACHE MEMORIES Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 2 and Appendix B, John L. Hennessy and David A. Patterson, Morgan Kaufmann,
CSC 631: High-Performance Computer Architecture
 CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 9: Memory Part I CSC 631: High-Performance Computer Architecture 1 Introduction Programmers want unlimited amounts of memory with low
CSC 631: High-Performance Computer Architecture Spring 2017 Lecture 9: Memory Part I CSC 631: High-Performance Computer Architecture 1 Introduction Programmers want unlimited amounts of memory with low
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
CSE 431 Computer Architecture Fall Chapter 5A: Exploiting the Memory Hierarchy, Part 1
 CSE 431 Computer Architecture Fall 2008 Chapter 5A: Exploiting the Memory Hierarchy, Part 1 Mary Jane Irwin ( www.cse.psu.edu/~mji ) [Adapted from Computer Organization and Design, 4 th Edition, Patterson
CSE 431 Computer Architecture Fall 2008 Chapter 5A: Exploiting the Memory Hierarchy, Part 1 Mary Jane Irwin ( www.cse.psu.edu/~mji ) [Adapted from Computer Organization and Design, 4 th Edition, Patterson
CS222: Cache Performance Improvement
 CS222: Cache Performance Improvement Dr. A. Sahu Dept of Comp. Sc. & Engg. Indian Institute of Technology Guwahati Outline Eleven Advanced Cache Performance Optimization Prev: Reducing hit time & Increasing
CS222: Cache Performance Improvement Dr. A. Sahu Dept of Comp. Sc. & Engg. Indian Institute of Technology Guwahati Outline Eleven Advanced Cache Performance Optimization Prev: Reducing hit time & Increasing
Memory Hierarchy. Slides contents from:
 Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Advanced optimizations of cache performance ( 2.2)
") Advanced optimizations of cache performance ( 2.2) 30 1. Small and Simple Caches to reduce hit time Critical timing path: address tag memory, then compare tags, then select set Lower associativity Direct-mapped
Advanced optimizations of cache performance ( 2.2) 30 1. Small and Simple Caches to reduce hit time Critical timing path: address tag memory, then compare tags, then select set Lower associativity Direct-mapped
Lecture 20: Memory Hierarchy Main Memory and Enhancing its Performance. Grinch-Like Stuff
 Lecture 20: ory Hierarchy Main ory and Enhancing its Performance Professor Alvin R. Lebeck Computer Science 220 Fall 1999 HW #4 Due November 12 Projects Finish reading Chapter 5 Grinch-Like Stuff CPS 220
Lecture 20: ory Hierarchy Main ory and Enhancing its Performance Professor Alvin R. Lebeck Computer Science 220 Fall 1999 HW #4 Due November 12 Projects Finish reading Chapter 5 Grinch-Like Stuff CPS 220
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per
EITF20: Computer Architecture Part4.1.1: Cache - 2
 EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
CPU issues address (and data for write) Memory returns data (or acknowledgment for write)
 Memory returns data (or acknowledgment for write)") The Main Memory Unit CPU and memory unit interface Address Data Control CPU Memory CPU issues address (and data for write) Memory returns data (or acknowledgment for write) Memories: Design Objectives
The Main Memory Unit CPU and memory unit interface Address Data Control CPU Memory CPU issues address (and data for write) Memory returns data (or acknowledgment for write) Memories: Design Objectives
COSC 6385 Computer Architecture - Memory Hierarchy Design (III)
") COSC 6385 Computer Architecture - Memory Hierarchy Design (III) Fall 2006 Reducing cache miss penalty Five techniques Multilevel caches Critical word first and early restart Giving priority to read misses
COSC 6385 Computer Architecture - Memory Hierarchy Design (III) Fall 2006 Reducing cache miss penalty Five techniques Multilevel caches Critical word first and early restart Giving priority to read misses
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Memory technology and optimizations ( 2.3) Main Memory
 Main Memory") Memory technology and optimizations ( 2.3) 47 Main Memory Performance of Main Memory: Latency: affects Cache Miss Penalty» Access Time: time between request and word arrival» Cycle Time: minimum time between
Memory technology and optimizations ( 2.3) 47 Main Memory Performance of Main Memory: Latency: affects Cache Miss Penalty» Access Time: time between request and word arrival» Cycle Time: minimum time between
Chapter 5. Topics in Memory Hierachy. Computer Architectures. Tien-Fu Chen. National Chung Cheng Univ.
 Computer Architectures Chapter 5 Tien-Fu Chen National Chung Cheng Univ. Chap5-0 Topics in Memory Hierachy! Memory Hierachy Features: temporal & spatial locality Common: Faster -> more expensive -> smaller!
Computer Architectures Chapter 5 Tien-Fu Chen National Chung Cheng Univ. Chap5-0 Topics in Memory Hierachy! Memory Hierachy Features: temporal & spatial locality Common: Faster -> more expensive -> smaller!
V. Primary & Secondary Memory!
 V. Primary & Secondary Memory! Computer Architecture and Operating Systems & Operating Systems: 725G84 Ahmed Rezine 1 Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM)
V. Primary & Secondary Memory! Computer Architecture and Operating Systems & Operating Systems: 725G84 Ahmed Rezine 1 Memory Technology Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM)
Donn Morrison Department of Computer Science. TDT4255 Memory hierarchies
 TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
TDT4255 Lecture 10: Memory hierarchies Donn Morrison Department of Computer Science 2 Outline Chapter 5 - Memory hierarchies (5.1-5.5) Temporal and spacial locality Hits and misses Direct-mapped, set associative,
Lecture 18: Memory Hierarchy Main Memory and Enhancing its Performance Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 18: Memory Hierarchy Main Memory and Enhancing its Performance Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Review: Reducing Miss Penalty Summary Five techniques Read priority
Lecture 18: Memory Hierarchy Main Memory and Enhancing its Performance Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Review: Reducing Miss Penalty Summary Five techniques Read priority
Memory Hierarchies 2009 DAT105
 Memory Hierarchies Cache performance issues (5.1) Virtual memory (C.4) Cache performance improvement techniques (5.2) Hit-time improvement techniques Miss-rate improvement techniques Miss-penalty improvement
Memory Hierarchies Cache performance issues (5.1) Virtual memory (C.4) Cache performance improvement techniques (5.2) Hit-time improvement techniques Miss-rate improvement techniques Miss-penalty improvement
Memory Technology. Caches 1. Static RAM (SRAM) Dynamic RAM (DRAM) Magnetic disk. Ideal memory. 0.5ns 2.5ns, $2000 $5000 per GB
 Dynamic RAM (DRAM) Magnetic disk. Ideal memory. 0.5ns 2.5ns, $2000 $5000 per GB") Memory Technology Caches 1 Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per GB Ideal memory Average access time similar
Memory Technology Caches 1 Static RAM (SRAM) 0.5ns 2.5ns, $2000 $5000 per GB Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 5ms 20ms, $0.20 $2 per GB Ideal memory Average access time similar
Chapter-5 Memory Hierarchy Design
 Chapter-5 Memory Hierarchy Design Unlimited amount of fast memory - Economical solution is memory hierarchy - Locality - Cost performance Principle of locality - most programs do not access all code or
Chapter-5 Memory Hierarchy Design Unlimited amount of fast memory - Economical solution is memory hierarchy - Locality - Cost performance Principle of locality - most programs do not access all code or
Chapter 5 (Part II) Large and Fast: Exploiting Memory Hierarchy. Baback Izadi Division of Engineering Programs
 Large and Fast: Exploiting Memory Hierarchy. Baback Izadi Division of Engineering Programs") Chapter 5 (Part II) Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Virtual Machines Host computer emulates guest operating system and machine resources Improved isolation of multiple
Chapter 5 (Part II) Baback Izadi Division of Engineering Programs bai@engr.newpaltz.edu Virtual Machines Host computer emulates guest operating system and machine resources Improved isolation of multiple
Chapter 5 Memory Hierarchy Design. In-Cheol Park Dept. of EE, KAIST
 Chapter 5 Memory Hierarchy Design In-Cheol Park Dept. of EE, KAIST Why cache? Microprocessor performance increment: 55% per year Memory performance increment: 7% per year Principles of locality Spatial
Chapter 5 Memory Hierarchy Design In-Cheol Park Dept. of EE, KAIST Why cache? Microprocessor performance increment: 55% per year Memory performance increment: 7% per year Principles of locality Spatial
The Memory Hierarchy & Cache
 Removing The Ideal Memory Assumption: The Memory Hierarchy & Cache The impact of real memory on CPU Performance. Main memory basic properties: Memory Types: DRAM vs. SRAM The Motivation for The Memory
Removing The Ideal Memory Assumption: The Memory Hierarchy & Cache The impact of real memory on CPU Performance. Main memory basic properties: Memory Types: DRAM vs. SRAM The Motivation for The Memory
Textbook: Burdea and Coiffet, Virtual Reality Technology, 2 nd Edition, Wiley, Textbook web site:
 Textbook: Burdea and Coiffet, Virtual Reality Technology, 2 nd Edition, Wiley, 2003 Textbook web site: www.vrtechnology.org 1 Textbook web site: www.vrtechnology.org Laboratory Hardware 2 Topics 14:332:331
Textbook: Burdea and Coiffet, Virtual Reality Technology, 2 nd Edition, Wiley, 2003 Textbook web site: www.vrtechnology.org 1 Textbook web site: www.vrtechnology.org Laboratory Hardware 2 Topics 14:332:331
Computer System Components
 Computer System Components CPU Core 1 GHz - 3.2 GHz 4-way Superscaler RISC or RISC-core (x86): Deep Instruction Pipelines Dynamic scheduling Multiple FP, integer FUs Dynamic branch prediction Hardware
Computer System Components CPU Core 1 GHz - 3.2 GHz 4-way Superscaler RISC or RISC-core (x86): Deep Instruction Pipelines Dynamic scheduling Multiple FP, integer FUs Dynamic branch prediction Hardware
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Static RAM (SRAM) Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 0.5ns 2.5ns, $2000 $5000 per GB 5.1 Introduction Memory Technology 5ms
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Static RAM (SRAM) Dynamic RAM (DRAM) 50ns 70ns, $20 $75 per GB Magnetic disk 0.5ns 2.5ns, $2000 $5000 per GB 5.1 Introduction Memory Technology 5ms
EITF20: Computer Architecture Part 5.1.1: Virtual Memory
 EITF20: Computer Architecture Part 5.1.1: Virtual Memory Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache optimization Virtual memory Case study AMD Opteron Summary 2 Memory hierarchy 3 Cache
EITF20: Computer Architecture Part 5.1.1: Virtual Memory Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache optimization Virtual memory Case study AMD Opteron Summary 2 Memory hierarchy 3 Cache
Memory Hierarchy and Caches
 Memory Hierarchy and Caches COE 301 / ICS 233 Computer Organization Dr. Muhamed Mudawar College of Computer Sciences and Engineering King Fahd University of Petroleum and Minerals Presentation Outline
Memory Hierarchy and Caches COE 301 / ICS 233 Computer Organization Dr. Muhamed Mudawar College of Computer Sciences and Engineering King Fahd University of Petroleum and Minerals Presentation Outline
The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350):
:") The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350): Motivation for The Memory Hierarchy: { CPU/Memory Performance Gap The Principle Of Locality Cache $$$$$ Cache Basics:
The Memory Hierarchy & Cache Review of Memory Hierarchy & Cache Basics (from 350): Motivation for The Memory Hierarchy: { CPU/Memory Performance Gap The Principle Of Locality Cache $$$$$ Cache Basics:
Memory Hierarchy. Slides contents from:
 Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Memory Hierarchy Slides contents from: Hennessy & Patterson, 5ed Appendix B and Chapter 2 David Wentzlaff, ELE 475 Computer Architecture MJT, High Performance Computing, NPTEL Memory Performance Gap Memory
Case Study 1: Optimizing Cache Performance via Advanced Techniques
 6 Solutions to Case Studies and Exercises Chapter 2 Solutions Case Study 1: Optimizing Cache Performance via Advanced Techniques 2.1 a. Each element is 8B. Since a 64B cacheline has 8 elements, and each
6 Solutions to Case Studies and Exercises Chapter 2 Solutions Case Study 1: Optimizing Cache Performance via Advanced Techniques 2.1 a. Each element is 8B. Since a 64B cacheline has 8 elements, and each
COMPUTER ORGANIZATION AND DESIGN
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 5 Large and Fast: Exploiting Memory Hierarchy Principle of Locality Programs access a small proportion of their address
Chapter 2: Memory Hierarchy Design (Part 3) Introduction Caches Main Memory (Section 2.2) Virtual Memory (Section 2.4, Appendix B.4, B.
 Introduction Caches Main Memory (Section 2.2) Virtual Memory (Section 2.4, Appendix B.4, B.") Chapter 2: Memory Hierarchy Design (Part 3) Introduction Caches Main Memory (Section 2.2) Virtual Memory (Section 2.4, Appendix B.4, B.5) Memory Technologies Dynamic Random Access Memory (DRAM) Optimized
Chapter 2: Memory Hierarchy Design (Part 3) Introduction Caches Main Memory (Section 2.2) Virtual Memory (Section 2.4, Appendix B.4, B.5) Memory Technologies Dynamic Random Access Memory (DRAM) Optimized
ELEC 5200/6200 Computer Architecture and Design Spring 2017 Lecture 7: Memory Organization Part II
 ELEC 5200/6200 Computer Architecture and Design Spring 2017 Lecture 7: Organization Part II Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University, Auburn,
ELEC 5200/6200 Computer Architecture and Design Spring 2017 Lecture 7: Organization Part II Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University, Auburn,
Chapter 5B. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
Chapter 5B Large and Fast: Exploiting Memory Hierarchy One Transistor Dynamic RAM 1-T DRAM Cell word access transistor V REF TiN top electrode (V REF ) Ta 2 O 5 dielectric bit Storage capacitor (FET gate,
Memory. Lecture 22 CS301
 Memory Lecture 22 CS301 Administrative Daily Review of today s lecture w Due tomorrow (11/13) at 8am HW #8 due today at 5pm Program #2 due Friday, 11/16 at 11:59pm Test #2 Wednesday Pipelined Machine Fetch
Memory Lecture 22 CS301 Administrative Daily Review of today s lecture w Due tomorrow (11/13) at 8am HW #8 due today at 5pm Program #2 due Friday, 11/16 at 11:59pm Test #2 Wednesday Pipelined Machine Fetch
CS650 Computer Architecture. Lecture 9 Memory Hierarchy - Main Memory
 CS65 Computer Architecture Lecture 9 Memory Hierarchy - Main Memory Andrew Sohn Computer Science Department New Jersey Institute of Technology Lecture 9: Main Memory 9-/ /6/ A. Sohn Memory Cycle Time 5
CS65 Computer Architecture Lecture 9 Memory Hierarchy - Main Memory Andrew Sohn Computer Science Department New Jersey Institute of Technology Lecture 9: Main Memory 9-/ /6/ A. Sohn Memory Cycle Time 5
Advanced cache optimizations. ECE 154B Dmitri Strukov
 Advanced cache optimizations ECE 154B Dmitri Strukov Advanced Cache Optimization 1) Way prediction 2) Victim cache 3) Critical word first and early restart 4) Merging write buffer 5) Nonblocking cache
Advanced cache optimizations ECE 154B Dmitri Strukov Advanced Cache Optimization 1) Way prediction 2) Victim cache 3) Critical word first and early restart 4) Merging write buffer 5) Nonblocking cache
Chapter 5A. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
Chapter 5A Large and Fast: Exploiting Memory Hierarchy Memory Technology Static RAM (SRAM) Fast, expensive Dynamic RAM (DRAM) In between Magnetic disk Slow, inexpensive Ideal memory Access time of SRAM
CSE Memory Hierarchy Design Ch. 5 (Hennessy and Patterson)
") CSE 4201 Memory Hierarchy Design Ch. 5 (Hennessy and Patterson) Memory Hierarchy We need huge amount of cheap and fast memory Memory is either fast or cheap; never both. Do as politicians do: fake it Give
CSE 4201 Memory Hierarchy Design Ch. 5 (Hennessy and Patterson) Memory Hierarchy We need huge amount of cheap and fast memory Memory is either fast or cheap; never both. Do as politicians do: fake it Give
MEMORY HIERARCHY DESIGN. B649 Parallel Architectures and Programming
 MEMORY HIERARCHY DESIGN B649 Parallel Architectures and Programming Basic Optimizations Average memory access time = Hit time + Miss rate Miss penalty Larger block size to reduce miss rate Larger caches
MEMORY HIERARCHY DESIGN B649 Parallel Architectures and Programming Basic Optimizations Average memory access time = Hit time + Miss rate Miss penalty Larger block size to reduce miss rate Larger caches
Memory latency: Affects cache miss penalty. Measured by:
 Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
Computer Systems Architecture I. CSE 560M Lecture 18 Guest Lecturer: Shakir James
 Computer Systems Architecture I CSE 560M Lecture 18 Guest Lecturer: Shakir James Plan for Today Announcements No class meeting on Monday, meet in project groups Project demos < 2 weeks, Nov 23 rd Questions
Computer Systems Architecture I CSE 560M Lecture 18 Guest Lecturer: Shakir James Plan for Today Announcements No class meeting on Monday, meet in project groups Project demos < 2 weeks, Nov 23 rd Questions
The Memory Hierarchy. Cache, Main Memory, and Virtual Memory (Part 2)
") The Memory Hierarchy Cache, Main Memory, and Virtual Memory (Part 2) Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Cache Line Replacement The cache
The Memory Hierarchy Cache, Main Memory, and Virtual Memory (Part 2) Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Cache Line Replacement The cache
Multilevel Memories. Joel Emer Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
1 Multilevel Memories Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Based on the material prepared by Krste Asanovic and Arvind CPU-Memory Bottleneck 6.823
CS3350B Computer Architecture
 CS335B Computer Architecture Winter 25 Lecture 32: Exploiting Memory Hierarchy: How? Marc Moreno Maza wwwcsduwoca/courses/cs335b [Adapted from lectures on Computer Organization and Design, Patterson &
CS335B Computer Architecture Winter 25 Lecture 32: Exploiting Memory Hierarchy: How? Marc Moreno Maza wwwcsduwoca/courses/cs335b [Adapted from lectures on Computer Organization and Design, Patterson &
Outline. 1 Reiteration. 2 Cache performance optimization. 3 Bandwidth increase. 4 Reduce hit time. 5 Reduce miss penalty. 6 Reduce miss rate
 Outline Lecture 7: EITF20 Computer Architecture Anders Ardö EIT Electrical and Information Technology, Lund University November 21, 2012 A. Ardö, EIT Lecture 7: EITF20 Computer Architecture November 21,
Outline Lecture 7: EITF20 Computer Architecture Anders Ardö EIT Electrical and Information Technology, Lund University November 21, 2012 A. Ardö, EIT Lecture 7: EITF20 Computer Architecture November 21,
EITF20: Computer Architecture Part4.1.1: Cache - 2
 EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
EITF20: Computer Architecture Part4.1.1: Cache - 2 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Cache performance optimization Bandwidth increase Reduce hit time Reduce miss penalty Reduce miss
Cache Optimisation. sometime he thought that there must be a better way
 Cache sometime he thought that there must be a better way 2 Cache 1. Reduce miss rate a) Increase block size b) Increase cache size c) Higher associativity d) compiler optimisation e) Parallelism f) prefetching
Cache sometime he thought that there must be a better way 2 Cache 1. Reduce miss rate a) Increase block size b) Increase cache size c) Higher associativity d) compiler optimisation e) Parallelism f) prefetching
EN1640: Design of Computing Systems Topic 06: Memory System
 EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
EN164: Design of Computing Systems Topic 6: Memory System Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University Spring
Memory latency: Affects cache miss penalty. Measured by:
 Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row. Static RAM may be used for main memory
Name: 1. Caches a) The average memory access time (AMAT) can be modeled using the following formula: AMAT = Hit time + Miss rate * Miss penalty
 The average memory access time (AMAT) can be modeled using the following formula: AMAT = Hit time + Miss rate * Miss penalty") 1. Caches a) The average memory access time (AMAT) can be modeled using the following formula: ( 3 Pts) AMAT Hit time + Miss rate * Miss penalty Name and explain (briefly) one technique for each of the
1. Caches a) The average memory access time (AMAT) can be modeled using the following formula: ( 3 Pts) AMAT Hit time + Miss rate * Miss penalty Name and explain (briefly) one technique for each of the
Chapter 2 (cont) Instructor: Josep Torrellas CS433. Copyright Josep Torrellas 1999, 2001, 2002,
 Instructor: Josep Torrellas CS433. Copyright Josep Torrellas 1999, 2001, 2002,") Chapter 2 (cont) Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Improving Cache Performance Average mem access time = hit time + miss rate * miss penalty speed up
Chapter 2 (cont) Instructor: Josep Torrellas CS433 Copyright Josep Torrellas 1999, 2001, 2002, 2013 1 Improving Cache Performance Average mem access time = hit time + miss rate * miss penalty speed up
Main Memory. EECC551 - Shaaban. Memory latency: Affects cache miss penalty. Measured by:
 Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row (~every 8 msec). Static RAM may be
Main Memory Main memory generally utilizes Dynamic RAM (DRAM), which use a single transistor to store a bit, but require a periodic data refresh by reading every row (~every 8 msec). Static RAM may be
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface COEN-4710 Computer Hardware Lecture 7 Large and Fast: Exploiting Memory Hierarchy (Chapter 5) Cristinel Ababei Marquette University Department
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface COEN-4710 Computer Hardware Lecture 7 Large and Fast: Exploiting Memory Hierarchy (Chapter 5) Cristinel Ababei Marquette University Department
Caching Basics. Memory Hierarchies
 Caching Basics CS448 1 Memory Hierarchies Takes advantage of locality of reference principle Most programs do not access all code and data uniformly, but repeat for certain data choices spatial nearby
Caching Basics CS448 1 Memory Hierarchies Takes advantage of locality of reference principle Most programs do not access all code and data uniformly, but repeat for certain data choices spatial nearby
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science CPUtime = IC CPI Execution + Memory accesses Instruction
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science CPUtime = IC CPI Execution + Memory accesses Instruction
Chapter 5. Large and Fast: Exploiting Memory Hierarchy
 Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Chapter 5 Large and Fast: Exploiting Memory Hierarchy Processor-Memory Performance Gap 10000 µproc 55%/year (2X/1.5yr) Performance 1000 100 10 1 1980 1983 1986 1989 Moore s Law Processor-Memory Performance
Memory Hierarchies. Instructor: Dmitri A. Gusev. Fall Lecture 10, October 8, CS 502: Computers and Communications Technology
 Memory Hierarchies Instructor: Dmitri A. Gusev Fall 2007 CS 502: Computers and Communications Technology Lecture 10, October 8, 2007 Memories SRAM: value is stored on a pair of inverting gates very fast
Memory Hierarchies Instructor: Dmitri A. Gusev Fall 2007 CS 502: Computers and Communications Technology Lecture 10, October 8, 2007 Memories SRAM: value is stored on a pair of inverting gates very fast
CMSC 611: Advanced Computer Architecture. Cache and Memory
 CMSC 611: Advanced Computer Architecture Cache and Memory Classification of Cache Misses Compulsory The first access to a block is never in the cache. Also called cold start misses or first reference misses.
CMSC 611: Advanced Computer Architecture Cache and Memory Classification of Cache Misses Compulsory The first access to a block is never in the cache. Also called cold start misses or first reference misses.