Lecture 9: More ILP. Today: limits of ILP, case studies, boosting ILP (Sections )
|
|
|
- Bryan Grant
- 5 years ago
- Views:
Transcription
1 Lecture 9: More ILP Today: limits of ILP, case studies, boosting ILP (Sections ) 1
2 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target prediction Perfect memory disambiguation Perfect instruction and data caches Single-cycle latencies for all ALUs Infinite ROB size (window of in-flight instructions) No limit on number of instructions in each pipeline stage The last instruction may be scheduled in the first cycle What is the only constraint in this processor? 2
3 ILP Limits The perfect processor: Infinite registers (no WAW or WAR hazards) Perfect branch direction and target prediction Perfect memory disambiguation Perfect instruction and data caches Single-cycle latencies for all ALUs Infinite ROB size (window of in-flight instructions) No limit on number of instructions in each pipeline stage The last instruction may be scheduled in the first cycle The only constraint is a true dependence (register or memory RAW hazards) (with value prediction, how would the perfect processor behave?) 3

4 Infinite Window Size and Issue Rate 4
5 Effect of Window Size Window size is effected by register file/rob size, branch mispredict rate, fetch bandwidth, etc. We will use a window size of 2K instrs and a max issue rate of 64 for subsequent experiments 5


6 Imperfect Branch Prediction Note: no branch mispredict penalty; branch mispredict restricts window size Assume a large tournament predictor for subsequent experiments 6
 256 int and fp registers for subsequent experiments 7")
7 Effect of Name Dependences More registers fewer WAR and WAW constraints (usually register file size goes hand in hand with in-flight window size) 256 int and fp registers for subsequent experiments 7
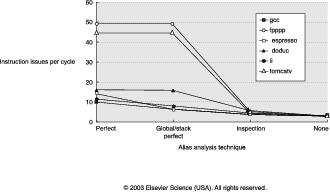
8 Memory Dependences 8
9 Limits of ILP Summary Int programs are more limited by branches, memory disambiguation, etc., while FP programs are limited most by window size We have not yet examined the effect of branch mispredict penalty and imperfect caching All of the studied factors have relatively comparable influence on CPI: window/register size, branch prediction, memory disambiguation Can we do better? Yes: better compilers, value prediction, memory dependence prediction, multi-path execution 9
10 Pentium III (P6 Microarchitecture) Case Study 14-stage pipeline: 8 for fetch/decode/dispatch, 3+ for o-o-o, 3 for commit branch mispredict penalty of cycles Out-of-order execution with a 40-entry ROB (40 temporary or virtual registers) and 20 reservation stations Each x86 instruction gets converted into RISC-like micro-ops on average, one CISC instr 1.37 micro-ops Three instructions in each pipeline stage 3 instructions can simultaneously leave the pipeline ideal CPµI = 0.33 ideal CPI =
11 Branch Prediction 512-entry global two-level branch predictor and 512-entry BTB 20% combined mispredict rate For every instruction committed, 0.2 instructions on the mispredicted path are also executed (wasted power!) Mispredict penalty is cycles 11
 average CPI = 1.15 (Int) and 2.")
12 CPI Performance Owing to stalls, the processor can fall behind (no instructions are committed for 55% of all cycles), but then recover with multi-instruction commits (31% of all cycles) average CPI = 1.15 (Int) and 2.0 (FP) Overlap of different stalls CPI is not the sum of individual stalls IPC is also an attractive metric 12
13 Alternative Designs Tomasulo s algorithm When an instruction is decoded and dispatched, it is assigned to a reservation station The reservation station has an ALU and space for storing operands ready operands are copied from the register file into the reservation station If an operand is not ready, the reservation station keeps track of which reservation station will produce it this is a form of register renaming Instructions are dispatched in order (dispatch stalls if a reservation station is not available), instructions begin execution out-of-order 13
14 Tomasulo s Algorithm Instr Fetch R1 RS3 R1 RS3 R1 RS4 Decode & Issue Stall if no functional unit available Register File Common Data Bus in1 in2 in1 in2 in1 in2 in1 in2 ALU ALU ALU ALU Instrs read register operands immediately (avoids WAR), wait for results produced by other ALUs (more names), and then execute, the earlier write to R1 never happens (avoids WAW) 14
15 Improving Performance What is the best strategy for improving performance? Take a single design and keep pipelining Increase capacity: use a larger branch predictor, larger cache, larger ROB/register file Increase bandwidth: more instructions fetched/ decoded/issued/committed per cycle 15
16 Deep Pipelining If instructions are independent, deep pipelining allows an instruction to leave the pipeline sooner If instructions are dependent, the gap between them (in nanoseconds) widens there is an optimal pipeline depth Some structures are hard to pipeline register files Pipelining can increase bypassing complexity 16
17 Capacity/Bandwidth Even if we design a 6-wide processor, most units go under-utilized (average IPC of 2.0!) hence, increased bandwidth is not going to buy much Higher capacity (being able to examine 500 speculative instructions) can increase the chances of finding work and boost IPC what is the big bottleneck? Higher capacity (and higher bandwidth) increases the complexity of each structure and its access time for example, access times: 32KB cache in 1 cycle, 128KB cache in 2 cycles 17
18 Future Microprocessors By increasing branch predictor, window size, number of ALUs, pipeline stages, IPC and clock speed can improve however, this is a case of diminishing returns! For example, with a window size of 400 and with 10 ALUs, we are likely to find fewer than four instructions to issue every cycle under-utilization, wasted work, low throughput per watt consumed Hence, a more cost-effective solution: build four simple processors in the same area each processor executes a different thread high thread throughput, but probably poorer single application performance 18
19 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling processor area, single thread performance barely improves Strategies for thread-level parallelism: multiple threads share the same large processor reduces under-utilization, efficient resource allocation Simultaneous Multi-Threading (SMT) each thread executes on its own mini processor simple design, low interference between threads Chip Multi-Processing (CMP) 19
20 Title Bullet 20
Lecture 8: Instruction Fetch, ILP Limits. Today: advanced branch prediction, limits of ILP (Sections , )
") Lecture 8: Instruction Fetch, ILP Limits Today: advanced branch prediction, limits of ILP (Sections 3.4-3.5, 3.8-3.14) 1 1-Bit Prediction For each branch, keep track of what happened last time and use
Lecture 8: Instruction Fetch, ILP Limits Today: advanced branch prediction, limits of ILP (Sections 3.4-3.5, 3.8-3.14) 1 1-Bit Prediction For each branch, keep track of what happened last time and use
250P: Computer Systems Architecture. Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019
 Anton Burtsev February, 2019") 250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
250P: Computer Systems Architecture Lecture 9: Out-of-order execution (continued) Anton Burtsev February, 2019 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction and instr
Lecture 8: Branch Prediction, Dynamic ILP. Topics: static speculation and branch prediction (Sections )
") Lecture 8: Branch Prediction, Dynamic ILP Topics: static speculation and branch prediction (Sections 2.3-2.6) 1 Correlating Predictors Basic branch prediction: maintain a 2-bit saturating counter for each
Lecture 8: Branch Prediction, Dynamic ILP Topics: static speculation and branch prediction (Sections 2.3-2.6) 1 Correlating Predictors Basic branch prediction: maintain a 2-bit saturating counter for each
Lecture 9: Dynamic ILP. Topics: out-of-order processors (Sections )
") Lecture 9: Dynamic ILP Topics: out-of-order processors (Sections 2.3-2.6) 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB) Branch prediction and instr fetch R1 R1+R2 R2 R1+R3 BEQZ R2 R3
Lecture 9: Dynamic ILP Topics: out-of-order processors (Sections 2.3-2.6) 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB) Branch prediction and instr fetch R1 R1+R2 R2 R1+R3 BEQZ R2 R3
CSE 820 Graduate Computer Architecture. week 6 Instruction Level Parallelism. Review from Last Time #1
 CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
CSE 820 Graduate Computer Architecture week 6 Instruction Level Parallelism Based on slides by David Patterson Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level
NOW Handout Page 1. Review from Last Time #1. CSE 820 Graduate Computer Architecture. Lec 8 Instruction Level Parallelism. Outline
 CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
CSE 820 Graduate Computer Architecture Lec 8 Instruction Level Parallelism Based on slides by David Patterson Review Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Handout 2 ILP: Part B
 Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Handout 2 ILP: Part B Review from Last Time #1 Leverage Implicit Parallelism for Performance: Instruction Level Parallelism Loop unrolling by compiler to increase ILP Branch prediction to increase ILP
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation 1 Branch Prediction Basic 2-bit predictor: For each branch: Predict taken or not
Instruction Level Parallelism
 Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Instruction Level Parallelism Software View of Computer Architecture COMP2 Godfrey van der Linden 200-0-0 Introduction Definition of Instruction Level Parallelism(ILP) Pipelining Hazards & Solutions Dynamic
Multiple Instruction Issue and Hardware Based Speculation
 Multiple Instruction Issue and Hardware Based Speculation Soner Önder Michigan Technological University, Houghton MI www.cs.mtu.edu/~soner Hardware Based Speculation Exploiting more ILP requires that we
Multiple Instruction Issue and Hardware Based Speculation Soner Önder Michigan Technological University, Houghton MI www.cs.mtu.edu/~soner Hardware Based Speculation Exploiting more ILP requires that we
LIMITS OF ILP. B649 Parallel Architectures and Programming
 LIMITS OF ILP B649 Parallel Architectures and Programming A Perfect Processor Register renaming infinite number of registers hence, avoids all WAW and WAR hazards Branch prediction perfect prediction Jump
LIMITS OF ILP B649 Parallel Architectures and Programming A Perfect Processor Register renaming infinite number of registers hence, avoids all WAW and WAR hazards Branch prediction perfect prediction Jump
EITF20: Computer Architecture Part3.2.1: Pipeline - 3
 EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
EITF20: Computer Architecture Part3.2.1: Pipeline - 3 Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration Dynamic scheduling - Tomasulo Superscalar, VLIW Speculation ILP limitations What we have done
Lecture 11: Out-of-order Processors. Topics: more ooo design details, timing, load-store queue
 Lecture 11: Out-of-order Processors Topics: more ooo design details, timing, load-store queue 1 Problem 0 Show the renamed version of the following code: Assume that you have 36 physical registers and
Lecture 11: Out-of-order Processors Topics: more ooo design details, timing, load-store queue 1 Problem 0 Show the renamed version of the following code: Assume that you have 36 physical registers and
ECE 505 Computer Architecture
 ECE 505 Computer Architecture Pipelining 2 Berk Sunar and Thomas Eisenbarth Review 5 stages of RISC IF ID EX MEM WB Ideal speedup of pipelining = Pipeline depth (N) Practically Implementation problems
ECE 505 Computer Architecture Pipelining 2 Berk Sunar and Thomas Eisenbarth Review 5 stages of RISC IF ID EX MEM WB Ideal speedup of pipelining = Pipeline depth (N) Practically Implementation problems
Lecture: Out-of-order Processors. Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ
 Lecture: Out-of-order Processors Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB)
Lecture: Out-of-order Processors Topics: out-of-order implementations with issue queue, register renaming, and reorder buffer, timing, LSQ 1 An Out-of-Order Processor Implementation Reorder Buffer (ROB)
Reorder Buffer Implementation (Pentium Pro) Reorder Buffer Implementation (Pentium Pro)
 Reorder Buffer Implementation (Pentium Pro)") Reorder Buffer Implementation (Pentium Pro) Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers) physical register file that is the same size as the architectural registers
Reorder Buffer Implementation (Pentium Pro) Hardware data structures retirement register file (RRF) (~ IBM 360/91 physical registers) physical register file that is the same size as the architectural registers
Instruction Level Parallelism (ILP)
") 1 / 26 Instruction Level Parallelism (ILP) ILP: The simultaneous execution of multiple instructions from a program. While pipelining is a form of ILP, the general application of ILP goes much further into
1 / 26 Instruction Level Parallelism (ILP) ILP: The simultaneous execution of multiple instructions from a program. While pipelining is a form of ILP, the general application of ILP goes much further into
5008: Computer Architecture
 5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
5008: Computer Architecture Chapter 2 Instruction-Level Parallelism and Its Exploitation CA Lecture05 - ILP (cwliu@twins.ee.nctu.edu.tw) 05-1 Review from Last Lecture Instruction Level Parallelism Leverage
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism. In-Cheol Park Dept. of EE, KAIST
 Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Chapter 4. Advanced Pipelining and Instruction-Level Parallelism In-Cheol Park Dept. of EE, KAIST Instruction-level parallelism Loop unrolling Dependence Data/ name / control dependence Loop level parallelism
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
The Processor: Instruction-Level Parallelism
 The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
The Processor: Instruction-Level Parallelism Computer Organization Architectures for Embedded Computing Tuesday 21 October 14 Many slides adapted from: Computer Organization and Design, Patterson & Hennessy
Ti Parallel Computing PIPELINING. Michał Roziecki, Tomáš Cipr
 Ti5317000 Parallel Computing PIPELINING Michał Roziecki, Tomáš Cipr 2005-2006 Introduction to pipelining What is this What is pipelining? Pipelining is an implementation technique in which multiple instructions
Ti5317000 Parallel Computing PIPELINING Michał Roziecki, Tomáš Cipr 2005-2006 Introduction to pipelining What is this What is pipelining? Pipelining is an implementation technique in which multiple instructions
CPI < 1? How? What if dynamic branch prediction is wrong? Multiple issue processors: Speculative Tomasulo Processor
 1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
1 CPI < 1? How? From Single-Issue to: AKS Scalar Processors Multiple issue processors: VLIW (Very Long Instruction Word) Superscalar processors No ISA Support Needed ISA Support Needed 2 What if dynamic
Lecture: SMT, Cache Hierarchies. Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1)
") Lecture: SMT, Cache Hierarchies Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized
Lecture: SMT, Cache Hierarchies Topics: SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized
Instruction-Level Parallelism and Its Exploitation
 Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 2 Instruction-Level Parallelism and Its Exploitation 1 Overview Instruction level parallelism Dynamic Scheduling Techniques es Scoreboarding Tomasulo s s Algorithm Reducing Branch Cost with Dynamic
Chapter 06: Instruction Pipelining and Parallel Processing
 Chapter 06: Instruction Pipelining and Parallel Processing Lesson 09: Superscalar Processors and Parallel Computer Systems Objective To understand parallel pipelines and multiple execution units Instruction
Chapter 06: Instruction Pipelining and Parallel Processing Lesson 09: Superscalar Processors and Parallel Computer Systems Objective To understand parallel pipelines and multiple execution units Instruction
Multiple Instruction Issue. Superscalars
 Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
Multiple Instruction Issue Multiple instructions issued each cycle better performance increase instruction throughput decrease in CPI (below 1) greater hardware complexity, potentially longer wire lengths
CMSC411 Fall 2013 Midterm 2 Solutions
 CMSC411 Fall 2013 Midterm 2 Solutions 1. (12 pts) Memory hierarchy a. (6 pts) Suppose we have a virtual memory of size 64 GB, or 2 36 bytes, where pages are 16 KB (2 14 bytes) each, and the machine has
CMSC411 Fall 2013 Midterm 2 Solutions 1. (12 pts) Memory hierarchy a. (6 pts) Suppose we have a virtual memory of size 64 GB, or 2 36 bytes, where pages are 16 KB (2 14 bytes) each, and the machine has
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
Computer Architecture A Quantitative Approach, Fifth Edition. Chapter 3. Instruction-Level Parallelism and Its Exploitation
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 3 Instruction-Level Parallelism and Its Exploitation Introduction Pipelining become universal technique in 1985 Overlaps execution of
Lecture 11: SMT and Caching Basics. Today: SMT, cache access basics (Sections 3.5, 5.1)
") Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Lecture 11: SMT and Caching Basics Today: SMT, cache access basics (Sections 3.5, 5.1) 1 Thread-Level Parallelism Motivation: a single thread leaves a processor under-utilized for most of the time by doubling
Chapter 03. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 03 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 3.3 Comparison of 2-bit predictors. A noncorrelating predictor for 4096 bits is first, followed
Chapter 03 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 3.3 Comparison of 2-bit predictors. A noncorrelating predictor for 4096 bits is first, followed
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1
 CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - CPI < 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
EN164: Design of Computing Systems Lecture 24: Processor / ILP 5
 EN164: Design of Computing Systems Lecture 24: Processor / ILP 5 Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
EN164: Design of Computing Systems Lecture 24: Processor / ILP 5 Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Lecture: Out-of-order Processors
 Lecture: Out-of-order Processors Topics: branch predictor wrap-up, a basic out-of-order processor with issue queue, register renaming, and reorder buffer 1 Amdahl s Law Architecture design is very bottleneck-driven
Lecture: Out-of-order Processors Topics: branch predictor wrap-up, a basic out-of-order processor with issue queue, register renaming, and reorder buffer 1 Amdahl s Law Architecture design is very bottleneck-driven
Hardware-based Speculation
 Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
Hardware-based Speculation Hardware-based Speculation To exploit instruction-level parallelism, maintaining control dependences becomes an increasing burden. For a processor executing multiple instructions
CS433 Homework 2 (Chapter 3)
") CS433 Homework 2 (Chapter 3) Assigned on 9/19/2017 Due in class on 10/5/2017 Instructions: 1. Please write your name and NetID clearly on the first page. 2. Refer to the course fact sheet for policies
CS433 Homework 2 (Chapter 3) Assigned on 9/19/2017 Due in class on 10/5/2017 Instructions: 1. Please write your name and NetID clearly on the first page. 2. Refer to the course fact sheet for policies
Lecture: SMT, Cache Hierarchies. Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.
 Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 0 Consider the following LSQ and when operands are
Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 0 Consider the following LSQ and when operands are
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
EECC551 - Shaaban. 1 GHz? to???? GHz CPI > (?)
") Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Evolution of Processor Performance So far we examined static & dynamic techniques to improve the performance of single-issue (scalar) pipelined CPU designs including: static & dynamic scheduling, static
Lecture: SMT, Cache Hierarchies. Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.
 Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 1 Consider the following LSQ and when operands are
Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics and innovations (Sections B.1-B.3, 2.1) 1 Problem 1 Consider the following LSQ and when operands are
EE382A Lecture 7: Dynamic Scheduling. Department of Electrical Engineering Stanford University
 EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 7-1 Announcements Project proposal due on Wed 10/14 2-3 pages submitted
EE382A Lecture 7: Dynamic Scheduling Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 7-1 Announcements Project proposal due on Wed 10/14 2-3 pages submitted
CPI IPC. 1 - One At Best 1 - One At best. Multiple issue processors: VLIW (Very Long Instruction Word) Speculative Tomasulo Processor
 Speculative Tomasulo Processor") Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Single-Issue Processor (AKA Scalar Processor) CPI IPC 1 - One At Best 1 - One At best 1 From Single-Issue to: AKS Scalar Processors CPI < 1? How? Multiple issue processors: VLIW (Very Long Instruction
Getting CPI under 1: Outline
 CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
CMSC 411 Computer Systems Architecture Lecture 12 Instruction Level Parallelism 5 (Improving CPI) Getting CPI under 1: Outline More ILP VLIW branch target buffer return address predictor superscalar more
Advanced Computer Architecture
 Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Advanced Computer Architecture Chapter 1 Introduction into the Sequential and Pipeline Instruction Execution Martin Milata What is a Processors Architecture Instruction Set Architecture (ISA) Describes
Dynamic Scheduling. CSE471 Susan Eggers 1
 Dynamic Scheduling Why go out of style? expensive hardware for the time (actually, still is, relatively) register files grew so less register pressure early RISCs had lower CPIs Why come back? higher chip
Dynamic Scheduling Why go out of style? expensive hardware for the time (actually, still is, relatively) register files grew so less register pressure early RISCs had lower CPIs Why come back? higher chip
Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.
 Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.") Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Instruction-Level Parallelism and its Exploitation: PART 2 Hardware-based speculation (2.6) Multiple-issue plus static scheduling = VLIW (2.7) Multiple-issue, dynamic scheduling, and speculation (2.8)
Computer Systems Architecture
 Computer Systems Architecture Lecture 12 Mahadevan Gomathisankaran March 4, 2010 03/04/2010 Lecture 12 CSCE 4610/5610 1 Discussion: Assignment 2 03/04/2010 Lecture 12 CSCE 4610/5610 2 Increasing Fetch
Computer Systems Architecture Lecture 12 Mahadevan Gomathisankaran March 4, 2010 03/04/2010 Lecture 12 CSCE 4610/5610 1 Discussion: Assignment 2 03/04/2010 Lecture 12 CSCE 4610/5610 2 Increasing Fetch
Computer Architecture 计算机体系结构. Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
Computer Architecture 计算机体系结构 Lecture 4. Instruction-Level Parallelism II 第四讲 指令级并行 II Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review Hazards (data/name/control) RAW, WAR, WAW hazards Different types
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Lecture 16: Core Design. Today: basics of implementing a correct ooo core: register renaming, commit, LSQ, issue queue
 Lecture 16: Core Design Today: basics of implementing a correct ooo core: register renaming, commit, LSQ, issue queue 1 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction
Lecture 16: Core Design Today: basics of implementing a correct ooo core: register renaming, commit, LSQ, issue queue 1 The Alpha 21264 Out-of-Order Implementation Reorder Buffer (ROB) Branch prediction
Real Processors. Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University
 Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
Real Processors Lecture for CPSC 5155 Edward Bosworth, Ph.D. Computer Science Department Columbus State University Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel
Superscalar Organization
 Superscalar Organization Nima Honarmand Instruction-Level Parallelism (ILP) Recall: Parallelism is the number of independent tasks available ILP is a measure of inter-dependencies between insns. Average
Superscalar Organization Nima Honarmand Instruction-Level Parallelism (ILP) Recall: Parallelism is the number of independent tasks available ILP is a measure of inter-dependencies between insns. Average
CPE 631 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Lecture 10: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenković, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Tomasulo
Advanced d Instruction Level Parallelism. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Advanced d Instruction ti Level Parallelism Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu ILP Instruction-Level Parallelism (ILP) Pipelining:
Superscalar Processors
 Superscalar Processors Superscalar Processor Multiple Independent Instruction Pipelines; each with multiple stages Instruction-Level Parallelism determine dependencies between nearby instructions o input
Superscalar Processors Superscalar Processor Multiple Independent Instruction Pipelines; each with multiple stages Instruction-Level Parallelism determine dependencies between nearby instructions o input
Page # CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Michela Taufer
 Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design
 EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
EN164: Design of Computing Systems Topic 06.b: Superscalar Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 1) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3) Hardware Speculation and Precise
CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions
 CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis6627 Powerpoint Lecture Notes from John Hennessy
CISC 662 Graduate Computer Architecture Lecture 11 - Hardware Speculation Branch Predictions Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis6627 Powerpoint Lecture Notes from John Hennessy
Portland State University ECE 587/687. The Microarchitecture of Superscalar Processors
 Portland State University ECE 587/687 The Microarchitecture of Superscalar Processors Copyright by Alaa Alameldeen and Haitham Akkary 2011 Program Representation An application is written as a program,
Portland State University ECE 587/687 The Microarchitecture of Superscalar Processors Copyright by Alaa Alameldeen and Haitham Akkary 2011 Program Representation An application is written as a program,
Static vs. Dynamic Scheduling
 Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
Static vs. Dynamic Scheduling Dynamic Scheduling Fast Requires complex hardware More power consumption May result in a slower clock Static Scheduling Done in S/W (compiler) Maybe not as fast Simpler processor
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects
 Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
Announcements UG4 Honours project selection: Talk to Vijay or Boris if interested in computer architecture projects Inf3 Computer Architecture - 2017-2018 1 Last time: Tomasulo s Algorithm Inf3 Computer
Instruction Level Parallelism
 Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Instruction Level Parallelism The potential overlap among instruction execution is called Instruction Level Parallelism (ILP) since instructions can be executed in parallel. There are mainly two approaches
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 5)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 5) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3, 3.9, and Appendix C) Hardware
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 5) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3, 3.9, and Appendix C) Hardware
Architectural Performance. Superscalar Processing. 740 October 31, i486 Pipeline. Pipeline Stage Details. Page 1
 Superscalar Processing 740 October 31, 2012 Evolution of Intel Processor Pipelines 486, Pentium, Pentium Pro Superscalar Processor Design Speculative Execution Register Renaming Branch Prediction Architectural
Superscalar Processing 740 October 31, 2012 Evolution of Intel Processor Pipelines 486, Pentium, Pentium Pro Superscalar Processor Design Speculative Execution Register Renaming Branch Prediction Architectural
CS 152, Spring 2011 Section 8
 CS 152, Spring 2011 Section 8 Christopher Celio University of California, Berkeley Agenda Grades Upcoming Quiz 3 What it covers OOO processors VLIW Branch Prediction Intel Core 2 Duo (Penryn) Vs. NVidia
CS 152, Spring 2011 Section 8 Christopher Celio University of California, Berkeley Agenda Grades Upcoming Quiz 3 What it covers OOO processors VLIW Branch Prediction Intel Core 2 Duo (Penryn) Vs. NVidia
Lecture: SMT, Cache Hierarchies. Topics: memory dependence wrap-up, SMT processors, cache access basics (Sections B.1-B.3, 2.1)
") Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics (Sections B.1-B.3, 2.1) 1 Problem 3 Consider the following LSQ and when operands are available. Estimate
Lecture: SMT, Cache Hierarchies Topics: memory dependence wrap-up, SMT processors, cache access basics (Sections B.1-B.3, 2.1) 1 Problem 3 Consider the following LSQ and when operands are available. Estimate
CPE 631 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation
 Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
Lecture 11: Instruction Level Parallelism and Its Dynamic Exploitation Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Outline Instruction
ECE 341. Lecture # 15
 ECE 341 Lecture # 15 Instructor: Zeshan Chishti zeshan@ece.pdx.edu November 19, 2014 Portland State University Pipelining Structural Hazards Pipeline Performance Lecture Topics Effects of Stalls and Penalties
ECE 341 Lecture # 15 Instructor: Zeshan Chishti zeshan@ece.pdx.edu November 19, 2014 Portland State University Pipelining Structural Hazards Pipeline Performance Lecture Topics Effects of Stalls and Penalties
CS 2410 Mid term (fall 2015) Indicate which of the following statements is true and which is false.
 Indicate which of the following statements is true and which is false.") CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
CS 2410 Mid term (fall 2015) Name: Question 1 (10 points) Indicate which of the following statements is true and which is false. (1) SMT architectures reduces the thread context switch time by saving in
EECC551 Exam Review 4 questions out of 6 questions
 EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
EECC551 Exam Review 4 questions out of 6 questions (Must answer first 2 questions and 2 from remaining 4) Instruction Dependencies and graphs In-order Floating Point/Multicycle Pipelining (quiz 2) Improving
Chapter 4 The Processor 1. Chapter 4D. The Processor
 Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Chapter 4 The Processor 1 Chapter 4D The Processor Chapter 4 The Processor 2 Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline
Page 1. CISC 662 Graduate Computer Architecture. Lecture 8 - ILP 1. Pipeline CPI. Pipeline CPI (I) Pipeline CPI (II) Michela Taufer
 Pipeline CPI (II) Michela Taufer") CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
CISC 662 Graduate Computer Architecture Lecture 8 - ILP 1 Michela Taufer Pipeline CPI http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson
ESE 545 Computer Architecture Instruction-Level Parallelism (ILP): Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW
: Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW") Computer Architecture ESE 545 Computer Architecture Instruction-Level Parallelism (ILP): Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW 1 Review from Last Lecture Leverage Implicit
Computer Architecture ESE 545 Computer Architecture Instruction-Level Parallelism (ILP): Speculation, Reorder Buffer, Exceptions, Superscalar Processors, VLIW 1 Review from Last Lecture Leverage Implicit
Processor (IV) - advanced ILP. Hwansoo Han
 - advanced ILP. Hwansoo Han") Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
Processor (IV) - advanced ILP Hwansoo Han Instruction-Level Parallelism (ILP) Pipelining: executing multiple instructions in parallel To increase ILP Deeper pipeline Less work per stage shorter clock cycle
E0-243: Computer Architecture
 E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
E0-243: Computer Architecture L1 ILP Processors RG:E0243:L1-ILP Processors 1 ILP Architectures Superscalar Architecture VLIW Architecture EPIC, Subword Parallelism, RG:E0243:L1-ILP Processors 2 Motivation
CIS 662: Midterm. 16 cycles, 6 stalls
 CIS 662: Midterm Name: Points: /100 First read all the questions carefully and note how many points each question carries and how difficult it is. You have 1 hour 15 minutes. Plan your time accordingly.
CIS 662: Midterm Name: Points: /100 First read all the questions carefully and note how many points each question carries and how difficult it is. You have 1 hour 15 minutes. Plan your time accordingly.
Chapter 3 & Appendix C Part B: ILP and Its Exploitation
 CS359: Computer Architecture Chapter 3 & Appendix C Part B: ILP and Its Exploitation Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 3.1 Concepts and
CS359: Computer Architecture Chapter 3 & Appendix C Part B: ILP and Its Exploitation Yanyan Shen Department of Computer Science and Engineering Shanghai Jiao Tong University 1 Outline 3.1 Concepts and
Superscalar Processors Ch 14
 Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processing (5) Superscalar Processors Ch 14. New dependency for superscalar case? (8) Output Dependency?
 Superscalar Processors Ch 14. New dependency for superscalar case? (8) Output Dependency?") Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
Superscalar Processors Ch 14 Limitations, Hazards Instruction Issue Policy Register Renaming Branch Prediction PowerPC, Pentium 4 1 Superscalar Processing (5) Basic idea: more than one instruction completion
EEC 581 Computer Architecture. Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW)
") 1 EEC 581 Computer Architecture Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University Overview
1 EEC 581 Computer Architecture Instruction Level Parallelism (3.6 Hardware-based Speculation and 3.7 Static Scheduling/VLIW) Chansu Yu Electrical and Computer Engineering Cleveland State University Overview
Advanced Computer Architecture
 Advanced Computer Architecture 1 L E C T U R E 4: D A T A S T R E A M S I N S T R U C T I O N E X E C U T I O N I N S T R U C T I O N C O M P L E T I O N & R E T I R E M E N T D A T A F L O W & R E G I
Advanced Computer Architecture 1 L E C T U R E 4: D A T A S T R E A M S I N S T R U C T I O N E X E C U T I O N I N S T R U C T I O N C O M P L E T I O N & R E T I R E M E N T D A T A F L O W & R E G I
Page 1. Recall from Pipelining Review. Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: Ideas to Reduce Stalls
 CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
CS252 Graduate Computer Architecture Recall from Pipelining Review Lecture 16: Instruction Level Parallelism and Dynamic Execution #1: March 16, 2001 Prof. David A. Patterson Computer Science 252 Spring
In embedded systems there is a trade off between performance and power consumption. Using ILP saves power and leads to DECREASING clock frequency.
 Lesson 1 Course Notes Review of Computer Architecture Embedded Systems ideal: low power, low cost, high performance Overview of VLIW and ILP What is ILP? It can be seen in: Superscalar In Order Processors
Lesson 1 Course Notes Review of Computer Architecture Embedded Systems ideal: low power, low cost, high performance Overview of VLIW and ILP What is ILP? It can be seen in: Superscalar In Order Processors
Tomasulo s Algorithm
 Tomasulo s Algorithm Architecture to increase ILP Removes WAR and WAW dependencies during issue WAR and WAW Name Dependencies Artifact of using the same storage location (variable name) Can be avoided
Tomasulo s Algorithm Architecture to increase ILP Removes WAR and WAW dependencies during issue WAR and WAW Name Dependencies Artifact of using the same storage location (variable name) Can be avoided
ILP: Instruction Level Parallelism
 ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
ILP: Instruction Level Parallelism Tassadaq Hussain Riphah International University Barcelona Supercomputing Center Universitat Politècnica de Catalunya Introduction Introduction Pipelining become universal
ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)
 Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5)") Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Instruction-Level Parallelism and its Exploitation: PART 1 ILP concepts (2.1) Basic compiler techniques (2.2) Reducing branch costs with prediction (2.3) Dynamic scheduling (2.4 and 2.5) Project and Case
Chapter 7. Digital Design and Computer Architecture, 2 nd Edition. David Money Harris and Sarah L. Harris. Chapter 7 <1>
 Chapter 7 Digital Design and Computer Architecture, 2 nd Edition David Money Harris and Sarah L. Harris Chapter 7 Chapter 7 :: Topics Introduction (done) Performance Analysis (done) Single-Cycle Processor
Chapter 7 Digital Design and Computer Architecture, 2 nd Edition David Money Harris and Sarah L. Harris Chapter 7 Chapter 7 :: Topics Introduction (done) Performance Analysis (done) Single-Cycle Processor
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
Chapter 3: Instruction Level Parallelism (ILP) and its exploitation. Types of dependences
 and its exploitation. Types of dependences") Chapter 3: Instruction Level Parallelism (ILP) and its exploitation Pipeline CPI = Ideal pipeline CPI + stalls due to hazards invisible to programmer (unlike process level parallelism) ILP: overlap execution
Chapter 3: Instruction Level Parallelism (ILP) and its exploitation Pipeline CPI = Ideal pipeline CPI + stalls due to hazards invisible to programmer (unlike process level parallelism) ILP: overlap execution
CS 252 Graduate Computer Architecture. Lecture 4: Instruction-Level Parallelism
 CS 252 Graduate Computer Architecture Lecture 4: Instruction-Level Parallelism Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://wwweecsberkeleyedu/~krste
CS 252 Graduate Computer Architecture Lecture 4: Instruction-Level Parallelism Krste Asanovic Electrical Engineering and Computer Sciences University of California, Berkeley http://wwweecsberkeleyedu/~krste
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Final Review Shuai Wang Department of Computer Science and Technology Nanjing University Computer Architecture Computer architecture, like other architecture, is the art
Computer Architecture Spring 2016 Final Review Shuai Wang Department of Computer Science and Technology Nanjing University Computer Architecture Computer architecture, like other architecture, is the art
RECAP. B649 Parallel Architectures and Programming
 RECAP B649 Parallel Architectures and Programming RECAP 2 Recap ILP Exploiting ILP Dynamic scheduling Thread-level Parallelism Memory Hierarchy Other topics through student presentations Virtual Machines
RECAP B649 Parallel Architectures and Programming RECAP 2 Recap ILP Exploiting ILP Dynamic scheduling Thread-level Parallelism Memory Hierarchy Other topics through student presentations Virtual Machines
Multithreaded Processors. Department of Electrical Engineering Stanford University
 Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
Lecture 12: Multithreaded Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 12-1 The Big Picture Previous lectures: Core design for single-thread
CS433 Homework 2 (Chapter 3)
") CS Homework 2 (Chapter ) Assigned on 9/19/2017 Due in class on 10/5/2017 Instructions: 1. Please write your name and NetID clearly on the first page. 2. Refer to the course fact sheet for policies on collaboration..
CS Homework 2 (Chapter ) Assigned on 9/19/2017 Due in class on 10/5/2017 Instructions: 1. Please write your name and NetID clearly on the first page. 2. Refer to the course fact sheet for policies on collaboration..
Exploitation of instruction level parallelism
 Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Exploitation of instruction level parallelism Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering
Complex Pipelines and Branch Prediction
 Complex Pipelines and Branch Prediction Daniel Sanchez Computer Science & Artificial Intelligence Lab M.I.T. L22-1 Processor Performance Time Program Instructions Program Cycles Instruction CPI Time Cycle
Complex Pipelines and Branch Prediction Daniel Sanchez Computer Science & Artificial Intelligence Lab M.I.T. L22-1 Processor Performance Time Program Instructions Program Cycles Instruction CPI Time Cycle