Impala. A Modern, Open Source SQL Engine for Hadoop. Yogesh Chockalingam
|
|
|
- Darren Blake Young
- 5 years ago
- Views:
Transcription


1 Impala A Modern, Open Source SQL Engine for Hadoop Yogesh Chockalingam
2 Agenda Introduction Architecture Front End Back End Evaluation Comparison with Spark SQL
3 Introduction
4



5
6 Why not use Hive or HBase? Hive is a data warehousing tool built on top of Hadoop and uses Hive Query Language(HQL) for querying data stored in a Hadoop cluster. HQL automatically translates queries into MapReduce jobs. Hive doesn t support transactions. HBase is a NoSQL database that runs on top of HDFS that provides real-time read/write access.
7 Impala General purpose SQL query engine: Works across analytical and transactional workloads High performance: Execution engine written in C++ Runs directly within Hadoop Does not use MapReduce MPP database support: Multi-user workloads
8 Creating tables CREATE TABLE T (...) PARTITIONED BY (day int, month int) LOCATION '<hdfs-path>' STORED AS PARQUET; For a partitioned table, data is placed in subdirectories whose paths reflect the partition columns' values. For example, for day 17, month 2 of table T, all data files would be located in <root>/day=17/month=2/
9 Metadata Table metadata including the table definition, column names, data types, schema etc. are stored in HCatalog.
10 INSERT / UPDATE / DELETE The user can add data to a table simply by copying/moving data files into the directory! Does NOT support UPDATE and DELETE. Limitation of HDFS, as it does not support an in-place update. Recompute the values and replace the data in the partitions. COMPUTE STATS <table> after inserts. Those statistics will subsequently be used during query optimization.
11 Architecture
12 I: Impala Daemon Impala daemon service is dually responsible for: 1. Accepting queries from client processes and orchestrating their execution across the cluster. In this role it s called the query coordinator. 2. Executing individual query fragments on behalf of other Impala daemons. The Impala daemons are in constant communication with the statestore, to confirm which nodes are healthy and can accept new work. They also receive broadcast messages from the catalog daemon via the statestore, to keep track of metadata changes. Catalog Statestore Impala Daemon
13 II: Statestore Daemon Handles cluster membership information. Periodically sends two kinds of messages to Impala daemons: Topic update: The new changes made since the last topic update message Keepalive: A heartbeat mechanism If an Impala daemon goes offline, the statestore informs all the other Impala daemons so that future queries can avoid making requests to the unreachable node.
14 III: Catalog Daemon Impala's catalog service serves catalog metadata to Impala daemons via the statestore broadcast mechanism, and executes DDL operations on behalf of Impala daemons. The catalog service pulls information from Hive Metastore and aggregates that information into an Impala-compatible catalog structure. This structure is then passed on to the statestore daemon which communicates with the Impala daemons.

15 1. Request arrives from client via Thrift API SQL App ODBC SQL request Hive Metastore HDFS NN Statestore Impala Daemon Impala Daemon Impala Daemon

16 2. Planner turns request into collections of plan fragments. Coordinator initiates execution on remote Impala daemons. SQL App ODBC Hive Metastore HDFS NN Statestore

17 3. Intermediate results are streamed between Impala daemons. Query results are streamed back to client. SQL App ODBC Hive Metastore HDFS NN Statestore Query Results Query Planner Query Coordinator Query Executor HDFS DN HBase
18 Front-End
19 Query Plans The Impala frontend is responsible for compiling SQL text into query plans executable by the Impala backends. The query compilation process proceeds as follows: Query parsing Semantic analysis Query planning/optimization Query planning 1. Single node planning 2. Plan parallelization and fragmentation
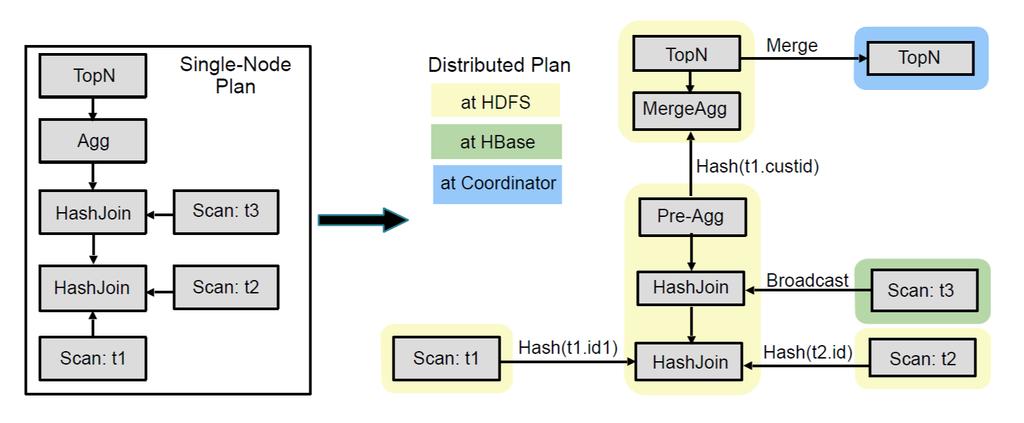
20 Query Planning: Single Node In the first phase, the parse tree is translated into a non-executable single-node plan tree. E.g. Query joining two HDFS tables (t1, t2) and one HBase table (t3) followed by an aggregation and order by with limit (top-n). SELECT t1.custid, SUM(t2.revenue) AS revenue FROM LargeHdfsTable t1 JOIN LargeHdfsTable t2 ON (t1.id1 = t2.id) JOIN SmallHbaseTable t3 ON (t1.id2 = t3.id) WHERE t3.category = 'Online' GROUP BY t1.custid ORDER BY revenue DESC LIMIT 10; Agg HashJoin HashJoin Scan: t3 Scan: t2 Scan: t1
21 Query Planning: Distributed Nodes The second planning phase takes the single-node plan as input and produces a distributed execution plan. Goal: To minimize data movement Maximize scan locality as remote reads are considerably slower than local ones. Cost--based decision based on column stats/estimated cost of data transfers Decide parallel join strategy: Broadcast Join: Join is collocated with left-hand side input; right--hand side table is broadcast to each node executing join. Preferred for small right-hand side input. Partitioned Join: Both tables are hash-partitioned on join columns. Preferred for large joins.
22
23 Back-End
24 Executing the Query Impala's backend receives query fragments from the front-end and is responsible for their execution. High performance: Written in C++ for minimal execution overhead Internal in-memory tuple format puts fixed-width data at fixed offsets Uses intrinsic/special CPU instructions for tasks like text parsing and CRC computation. Runtime code generation for big loops

25 Runtime Code Generation Impala uses runtime code generation to produce query-specific versions of functions that are critical to performance. For example, to convert every record to Impala s in-memory tuple format: Known at query compile time: # of tuples in a batch, tuple layout, column types, etc. Generate at compile time: unrolled loop that inlines all function calls, dead code elimination and minimizes branches. Code generated using LLVM
26 Evaluation

27 Comparison of query response times on single-user runs.

28 Comparison of query response times and throughput on multi-user runs.

29 Comparison of the performance of Impala and a commercial analytic RDBMS.
30 Comparison with Spark SQL
31 Impala is faster than Spark SQL as it is an engine designed especially for the mission of interactive SQL over HDFS, and it has architecture concepts that helps it achieve that. For example the Impala always-on daemons are up and waiting for queries 24/7 something that is not part of Spark SQL.
32 Thank you!
Impala Intro. MingLi xunzhang
 Impala Intro MingLi xunzhang Overview MPP SQL Query Engine for Hadoop Environment Designed for great performance BI Connected(ODBC/JDBC, Kerberos, LDAP, ANSI SQL) Hadoop Components HDFS, HBase, Metastore,
Impala Intro MingLi xunzhang Overview MPP SQL Query Engine for Hadoop Environment Designed for great performance BI Connected(ODBC/JDBC, Kerberos, LDAP, ANSI SQL) Hadoop Components HDFS, HBase, Metastore,
April Copyright 2013 Cloudera Inc. All rights reserved.
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and thevirtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here 2013-11-12 Copyright 2013 Cloudera
Cloudera Impala Headline Goes Here
 Cloudera Impala Headline Goes Here JusAn Erickson Senior Product Manager Speaker Name or Subhead Goes Here February 2013 DO NOT USE PUBLICLY PRIOR TO 10/23/12 Agenda Intro to Impala Architectural Overview
Cloudera Impala Headline Goes Here JusAn Erickson Senior Product Manager Speaker Name or Subhead Goes Here February 2013 DO NOT USE PUBLICLY PRIOR TO 10/23/12 Agenda Intro to Impala Architectural Overview
Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018
: Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018") Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018 K. Zhang (pic source: mapr.com/blog) Copyright BUDT 2016 758 Where
Lecture 7 (03/12, 03/14): Hive and Impala Decisions, Operations & Information Technologies Robert H. Smith School of Business Spring, 2018 K. Zhang (pic source: mapr.com/blog) Copyright BUDT 2016 758 Where
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop. Course Duration: 25 days (60 hours duration). Bigdata Fundamentals. Day1: (2hours)
. Bigdata Fundamentals. Day1: (2hours)") Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Bigdata Fundamentals Day1: (2hours) 1. Understanding BigData. a. What is Big Data? b. Big-Data characteristics. c. Challenges with the traditional Data Base Systems and Distributed Systems. 2. Distributions:
Configuring and Deploying Hadoop Cluster Deployment Templates
 Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Configuring and Deploying Hadoop Cluster Deployment Templates This chapter contains the following sections: Hadoop Cluster Profile Templates, on page 1 Creating a Hadoop Cluster Profile Template, on page
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
Big Data com Hadoop. VIII Sessão - SQL Bahia. Impala, Hive e Spark. Diógenes Pires 03/03/2018
 Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI)
") CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
CERTIFICATE IN SOFTWARE DEVELOPMENT LIFE CYCLE IN BIG DATA AND BUSINESS INTELLIGENCE (SDLC-BD & BI) The Certificate in Software Development Life Cycle in BIGDATA, Business Intelligence and Tableau program
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Big Data Technology Ecosystem. Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara
 Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Big Data Technology Ecosystem Mark Burnette Pentaho Director Sales Engineering, Hitachi Vantara Agenda End-to-End Data Delivery Platform Ecosystem of Data Technologies Mapping an End-to-End Solution Case
Apache Hive for Oracle DBAs. Luís Marques
 Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Apache Hive for Oracle DBAs Luís Marques About me Oracle ACE Alumnus Long time open source supporter Founder of Redglue (www.redglue.eu) works for @redgluept as Lead Data Architect @drune After this talk,
Hive and Shark. Amir H. Payberah. Amirkabir University of Technology (Tehran Polytechnic)
") Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Hive and Shark Amir H. Payberah amir@sics.se Amirkabir University of Technology (Tehran Polytechnic) Amir H. Payberah (Tehran Polytechnic) Hive and Shark 1393/8/19 1 / 45 Motivation MapReduce is hard to
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
BIG DATA COURSE CONTENT
 BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
BIG DATA COURSE CONTENT [I] Get Started with Big Data Microsoft Professional Orientation: Big Data Duration: 12 hrs Course Content: Introduction Course Introduction Data Fundamentals Introduction to Data
The Hadoop Ecosystem. EECS 4415 Big Data Systems. Tilemachos Pechlivanoglou
 The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
The Hadoop Ecosystem EECS 4415 Big Data Systems Tilemachos Pechlivanoglou tipech@eecs.yorku.ca A lot of tools designed to work with Hadoop 2 HDFS, MapReduce Hadoop Distributed File System Core Hadoop component
Big Data Analytics using Apache Hadoop and Spark with Scala
 Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Big Data Analytics using Apache Hadoop and Spark with Scala Training Highlights : 80% of the training is with Practical Demo (On Custom Cloudera and Ubuntu Machines) 20% Theory Portion will be important
Hive SQL over Hadoop
 Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Hive SQL over Hadoop Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction Apache Hive is a high-level abstraction on top of MapReduce Uses
Apache HAWQ (incubating)
") HADOOP NATIVE SQL What is HAWQ? Apache HAWQ (incubating) Is an elastic parallel processing SQL engine that runs native in Apache Hadoop to directly access data for advanced analytics. Why HAWQ? Hadoop
HADOOP NATIVE SQL What is HAWQ? Apache HAWQ (incubating) Is an elastic parallel processing SQL engine that runs native in Apache Hadoop to directly access data for advanced analytics. Why HAWQ? Hadoop
Big Data Syllabus. Understanding big data and Hadoop. Limitations and Solutions of existing Data Analytics Architecture
 Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Big Data Syllabus Hadoop YARN Setup Programming in YARN framework j Understanding big data and Hadoop Big Data Limitations and Solutions of existing Data Analytics Architecture Hadoop Features Hadoop Ecosystem
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
Exam Questions
 Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) https://www.2passeasy.com/dumps/70-775/ NEW QUESTION 1 You are implementing a batch processing solution by using Azure
Cloudera Impala User Guide
 Cloudera Impala User Guide Important Notice (c) 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, and any other product or service names or slogans contained in
Cloudera Impala User Guide Important Notice (c) 2010-2015 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, Cloudera Impala, and any other product or service names or slogans contained in
exam. Microsoft Perform Data Engineering on Microsoft Azure HDInsight. Version 1.0
 70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
70-775.exam Number: 70-775 Passing Score: 800 Time Limit: 120 min File Version: 1.0 Microsoft 70-775 Perform Data Engineering on Microsoft Azure HDInsight Version 1.0 Exam A QUESTION 1 You use YARN to
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
SQT03 Big Data and Hadoop with Azure HDInsight Andrew Brust. Senior Director, Technical Product Marketing and Evangelism
 Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Big Data and Hadoop with Azure HDInsight Andrew Brust Senior Director, Technical Product Marketing and Evangelism Datameer Level: Intermediate Meet Andrew Senior Director, Technical Product Marketing and
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Microsoft. Exam Questions Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo
 Version:Demo") Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 You have an Azure HDInsight cluster. You need to store data in a file format that
Microsoft Exam Questions 70-775 Perform Data Engineering on Microsoft Azure HDInsight (beta) Version:Demo NEW QUESTION 1 You have an Azure HDInsight cluster. You need to store data in a file format that
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Security and Performance advances with Oracle Big Data SQL
 Security and Performance advances with Oracle Big Data SQL Jean-Pierre Dijcks Oracle Redwood Shores, CA, USA Key Words SQL, Oracle, Database, Analytics, Object Store, Files, Big Data, Big Data SQL, Hadoop,
Security and Performance advances with Oracle Big Data SQL Jean-Pierre Dijcks Oracle Redwood Shores, CA, USA Key Words SQL, Oracle, Database, Analytics, Object Store, Files, Big Data, Big Data SQL, Hadoop,
CIS 601 Graduate Seminar. Dr. Sunnie S. Chung Dhruv Patel ( ) Kalpesh Sharma ( )
 Kalpesh Sharma ( )") Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
Guide: CIS 601 Graduate Seminar Presented By: Dr. Sunnie S. Chung Dhruv Patel (2652790) Kalpesh Sharma (2660576) Introduction Background Parallel Data Warehouse (PDW) Hive MongoDB Client-side Shared SQL
HDInsight > Hadoop. October 12, 2017
 HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Couchbase Architecture Couchbase Inc. 1
 Couchbase Architecture 2015 Couchbase Inc. 1 $whoami Laurent Doguin Couchbase Developer Advocate @ldoguin laurent.doguin@couchbase.com 2015 Couchbase Inc. 2 2 Big Data = Operational + Analytic (NoSQL +
Couchbase Architecture 2015 Couchbase Inc. 1 $whoami Laurent Doguin Couchbase Developer Advocate @ldoguin laurent.doguin@couchbase.com 2015 Couchbase Inc. 2 2 Big Data = Operational + Analytic (NoSQL +
Big Data Architect.
 Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
Big Data Architect www.austech.edu.au WHAT IS BIG DATA ARCHITECT? A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData
 Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData ` Ronen Ovadya, Ofir Manor, JethroData About JethroData Founded 2012 Raised funding from Pitango in 2013 Engineering in Israel,
Interactive SQL-on-Hadoop from Impala to Hive/Tez to Spark SQL to JethroData ` Ronen Ovadya, Ofir Manor, JethroData About JethroData Founded 2012 Raised funding from Pitango in 2013 Engineering in Israel,
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Copyright 2012, Oracle and/or its affiliates. All rights reserved.
 1 Big Data Connectors: High Performance Integration for Hadoop and Oracle Database Melli Annamalai Sue Mavris Rob Abbott 2 Program Agenda Big Data Connectors: Brief Overview Connecting Hadoop with Oracle
1 Big Data Connectors: High Performance Integration for Hadoop and Oracle Database Melli Annamalai Sue Mavris Rob Abbott 2 Program Agenda Big Data Connectors: Brief Overview Connecting Hadoop with Oracle
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Workload Experience Manager
 Workload Experience Manager Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are
Workload Experience Manager Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Sempala. Interactive SPARQL Query Processing on Hadoop
 Sempala Interactive SPARQL Query Processing on Hadoop Alexander Schätzle, Martin Przyjaciel-Zablocki, Antony Neu, Georg Lausen University of Freiburg, Germany ISWC 2014 - Riva del Garda, Italy Motivation
Sempala Interactive SPARQL Query Processing on Hadoop Alexander Schätzle, Martin Przyjaciel-Zablocki, Antony Neu, Georg Lausen University of Freiburg, Germany ISWC 2014 - Riva del Garda, Italy Motivation
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
HAWQ: A Massively Parallel Processing SQL Engine in Hadoop
 HAWQ: A Massively Parallel Processing SQL Engine in Hadoop Lei Chang, Zhanwei Wang, Tao Ma, Lirong Jian, Lili Ma, Alon Goldshuv Luke Lonergan, Jeffrey Cohen, Caleb Welton, Gavin Sherry, Milind Bhandarkar
HAWQ: A Massively Parallel Processing SQL Engine in Hadoop Lei Chang, Zhanwei Wang, Tao Ma, Lirong Jian, Lili Ma, Alon Goldshuv Luke Lonergan, Jeffrey Cohen, Caleb Welton, Gavin Sherry, Milind Bhandarkar
1 Big Data Hadoop. 1. Introduction About this Course About Big Data Course Logistics Introductions
 Big Data Hadoop Architect Online Training (Big Data Hadoop + Apache Spark & Scala+ MongoDB Developer And Administrator + Apache Cassandra + Impala Training + Apache Kafka + Apache Storm) 1 Big Data Hadoop
Big Data Hadoop Architect Online Training (Big Data Hadoop + Apache Spark & Scala+ MongoDB Developer And Administrator + Apache Cassandra + Impala Training + Apache Kafka + Apache Storm) 1 Big Data Hadoop
Cloudera Kudu Introduction
 Cloudera Kudu Introduction Zbigniew Baranowski Based on: http://slideshare.net/cloudera/kudu-new-hadoop-storage-for-fast-analytics-onfast-data What is KUDU? New storage engine for structured data (tables)
Cloudera Kudu Introduction Zbigniew Baranowski Based on: http://slideshare.net/cloudera/kudu-new-hadoop-storage-for-fast-analytics-onfast-data What is KUDU? New storage engine for structured data (tables)
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Overview. : Cloudera Data Analyst Training. Course Outline :: Cloudera Data Analyst Training::
 Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Module Title Duration : Cloudera Data Analyst Training : 4 days Overview Take your knowledge to the next level Cloudera University s four-day data analyst training course will teach you to apply traditional
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Practical Big Data Processing An Overview of Apache Flink
 Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
Practical Big Data Processing An Overview of Apache Flink Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de With slides from Volker Markl and data artisans 1 2013
Shark: SQL and Rich Analytics at Scale. Michael Xueyuan Han Ronny Hajoon Ko
 Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Shark: SQL and Rich Analytics at Scale Michael Xueyuan Han Ronny Hajoon Ko What Are The Problems? Data volumes are expanding dramatically Why Is It Hard? Needs to scale out Managing hundreds of machines
Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09. Presented by: Daniel Isaacs
 Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09 Presented by: Daniel Isaacs It all starts with cluster computing. MapReduce Why
Andrew Pavlo, Erik Paulson, Alexander Rasin, Daniel Abadi, David DeWitt, Samuel Madden, and Michael Stonebraker SIGMOD'09 Presented by: Daniel Isaacs It all starts with cluster computing. MapReduce Why
Gain Insights From Unstructured Data Using Pivotal HD. Copyright 2013 EMC Corporation. All rights reserved.
 Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
Gain Insights From Unstructured Data Using Pivotal HD 1 Traditional Enterprise Analytics Process 2 The Fundamental Paradigm Shift Internet age and exploding data growth Enterprises leverage new data sources
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Data Architectures in Azure for Analytics & Big Data
 Data Architectures in for Analytics & Big Data October 20, 2018 Melissa Coates Solution Architect, BlueGranite Microsoft Data Platform MVP Blog: www.sqlchick.com Twitter: @sqlchick Data Architecture A
Data Architectures in for Analytics & Big Data October 20, 2018 Melissa Coates Solution Architect, BlueGranite Microsoft Data Platform MVP Blog: www.sqlchick.com Twitter: @sqlchick Data Architecture A
Swimming in the Data Lake. Presented by Warner Chaves Moderated by Sander Stad
 Swimming in the Data Lake Presented by Warner Chaves Moderated by Sander Stad Thank You microsoft.com hortonworks.com aws.amazon.com red-gate.com Empower users with new insights through familiar tools
Swimming in the Data Lake Presented by Warner Chaves Moderated by Sander Stad Thank You microsoft.com hortonworks.com aws.amazon.com red-gate.com Empower users with new insights through familiar tools
Oracle Big Data SQL. Release 3.2. Rich SQL Processing on All Data
 Oracle Big Data SQL Release 3.2 The unprecedented explosion in data that can be made useful to enterprises from the Internet of Things, to the social streams of global customer bases has created a tremendous
Oracle Big Data SQL Release 3.2 The unprecedented explosion in data that can be made useful to enterprises from the Internet of Things, to the social streams of global customer bases has created a tremendous
YARN: A Resource Manager for Analytic Platform Tsuyoshi Ozawa
 YARN: A Resource Manager for Analytic Platform Tsuyoshi Ozawa ozawa.tsuyoshi@lab.ntt.co.jp ozawa@apache.org About me Tsuyoshi Ozawa Research Engineer @ NTT Twitter: @oza_x86_64 Over 150 reviews in 2015
YARN: A Resource Manager for Analytic Platform Tsuyoshi Ozawa ozawa.tsuyoshi@lab.ntt.co.jp ozawa@apache.org About me Tsuyoshi Ozawa Research Engineer @ NTT Twitter: @oza_x86_64 Over 150 reviews in 2015
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation)
 (Development, Administration & REAL TIME Projects Implementation)") HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
HADOOP COURSE CONTENT (HADOOP-1.X, 2.X & 3.X) (Development, Administration & REAL TIME Projects Implementation) Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big
Time Series Storage with Apache Kudu (incubating)
") Time Series Storage with Apache Kudu (incubating) Dan Burkert (Committer) dan@cloudera.com @danburkert Tweet about this talk: @getkudu or #kudu 1 Time Series machine metrics event logs sensor telemetry
Time Series Storage with Apache Kudu (incubating) Dan Burkert (Committer) dan@cloudera.com @danburkert Tweet about this talk: @getkudu or #kudu 1 Time Series machine metrics event logs sensor telemetry
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG
 BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
BIG DATA ANALYTICS USING HADOOP TOOLS APACHE HIVE VS APACHE PIG Prof R.Angelin Preethi #1 and Prof J.Elavarasi *2 # Department of Computer Science, Kamban College of Arts and Science for Women, TamilNadu,
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Hadoop is supplemented by an ecosystem of open source projects IBM Corporation. How to Analyze Large Data Sets in Hadoop
 Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Hadoop Open Source Projects Hadoop is supplemented by an ecosystem of open source projects Oozie 25 How to Analyze Large Data Sets in Hadoop Although the Hadoop framework is implemented in Java, MapReduce
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Question: 1 You need to place the results of a PigLatin script into an HDFS output directory. What is the correct syntax in Apache Pig?
 Volume: 72 Questions Question: 1 You need to place the results of a PigLatin script into an HDFS output directory. What is the correct syntax in Apache Pig? A. update hdfs set D as./output ; B. store D
Volume: 72 Questions Question: 1 You need to place the results of a PigLatin script into an HDFS output directory. What is the correct syntax in Apache Pig? A. update hdfs set D as./output ; B. store D
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture
 Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Delving Deep into Hadoop Course Contents Introduction to Hadoop and Architecture Hadoop 1.0 Architecture Introduction to Hadoop & Big Data Hadoop Evolution Hadoop Architecture Networking Concepts Use cases
Oracle Big Data. A NA LYT ICS A ND MA NAG E MENT.
 Oracle Big Data. A NALYTICS A ND MANAG E MENT. Oracle Big Data: Redundância. Compatível com ecossistema Hadoop, HIVE, HBASE, SPARK. Integração com Cloudera Manager. Possibilidade de Utilização da Linguagem
Oracle Big Data. A NALYTICS A ND MANAG E MENT. Oracle Big Data: Redundância. Compatível com ecossistema Hadoop, HIVE, HBASE, SPARK. Integração com Cloudera Manager. Possibilidade de Utilização da Linguagem
4th National Conference on Electrical, Electronics and Computer Engineering (NCEECE 2015)
") 4th National Conference on Electrical, Electronics and Computer Engineering (NCEECE 2015) Benchmark Testing for Transwarp Inceptor A big data analysis system based on in-memory computing Mingang Chen1,2,a,
4th National Conference on Electrical, Electronics and Computer Engineering (NCEECE 2015) Benchmark Testing for Transwarp Inceptor A big data analysis system based on in-memory computing Mingang Chen1,2,a,
Oracle Big Data Connectors
 Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Oracle Big Data Connectors Oracle Big Data Connectors is a software suite that integrates processing in Apache Hadoop distributions with operations in Oracle Database. It enables the use of Hadoop to process
Hadoop. Introduction to BIGDATA and HADOOP
 Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Hadoop Introduction to BIGDATA and HADOOP What is Big Data? What is Hadoop? Relation between Big Data and Hadoop What is the need of going ahead with Hadoop? Scenarios to apt Hadoop Technology in REAL
Do-It-Yourself 1. Oracle Big Data Appliance 2X Faster than
 Oracle Big Data Appliance 2X Faster than Do-It-Yourself 1 Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such
Oracle Big Data Appliance 2X Faster than Do-It-Yourself 1 Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such
Hadoop course content
 course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
course content COURSE DETAILS 1. In-detail explanation on the concepts of HDFS & MapReduce frameworks 2. What is 2.X Architecture & How to set up Cluster 3. How to write complex MapReduce Programs 4. In-detail
The Evolution of Big Data Platforms and Data Science
 IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
Introduction to Hive Cloudera, Inc.
 Introduction to Hive Outline Motivation Overview Data Model Working with Hive Wrap up & Conclusions Background Started at Facebook Data was collected by nightly cron jobs into Oracle DB ETL via hand-coded
Introduction to Hive Outline Motivation Overview Data Model Working with Hive Wrap up & Conclusions Background Started at Facebook Data was collected by nightly cron jobs into Oracle DB ETL via hand-coded
Apache Flink Big Data Stream Processing
 Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de XLDB 11.10.2017 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2017
Apache Flink Big Data Stream Processing Tilmann Rabl Berlin Big Data Center www.dima.tu-berlin.de bbdc.berlin rabl@tu-berlin.de XLDB 11.10.2017 1 2013 Berlin Big Data Center All Rights Reserved DIMA 2017
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
MapR Enterprise Hadoop
 2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
2014 MapR Technologies 2014 MapR Technologies 1 MapR Enterprise Hadoop Top Ranked Cloud Leaders 500+ Customers 2014 MapR Technologies 2 Key MapR Advantage Partners Business Services APPLICATIONS & OS ANALYTICS
Going beyond MapReduce
 Going beyond MapReduce MapReduce provides a simple abstraction to write distributed programs running on large-scale systems on large amounts of data MapReduce is not suitable for everyone MapReduce abstraction
Going beyond MapReduce MapReduce provides a simple abstraction to write distributed programs running on large-scale systems on large amounts of data MapReduce is not suitable for everyone MapReduce abstraction
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Oracle Big Data SQL High Performance Data Virtualization Explained
 Keywords: Oracle Big Data SQL High Performance Data Virtualization Explained Jean-Pierre Dijcks Oracle Redwood City, CA, USA Big Data SQL, SQL, Big Data, Hadoop, NoSQL Databases, Relational Databases,
Keywords: Oracle Big Data SQL High Performance Data Virtualization Explained Jean-Pierre Dijcks Oracle Redwood City, CA, USA Big Data SQL, SQL, Big Data, Hadoop, NoSQL Databases, Relational Databases,
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin. Presented by: Suhua Wei Yong Yu
 CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
CIS 601 Graduate Seminar Presentation Introduction to MapReduce --Mechanism and Applicatoin Presented by: Suhua Wei Yong Yu Papers: MapReduce: Simplified Data Processing on Large Clusters 1 --Jeffrey Dean
A comparative analysis of state-of-the-art SQL-on-Hadoop systems for interactive analytics
 A comparative analysis of state-of-the-art SQL-on-Hadoop systems for interactive analytics Ashish Tapdiya Vanderbilt University Email: ashish.tapdiya@vanderbilt.edu Daniel Fabbri Vanderbilt University
A comparative analysis of state-of-the-art SQL-on-Hadoop systems for interactive analytics Ashish Tapdiya Vanderbilt University Email: ashish.tapdiya@vanderbilt.edu Daniel Fabbri Vanderbilt University
Databricks, an Introduction
 Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
What is Gluent? The Gluent Data Platform
 What is Gluent? The Gluent Data Platform The Gluent Data Platform provides a transparent data virtualization layer between traditional databases and modern data storage platforms, such as Hadoop, in the
What is Gluent? The Gluent Data Platform The Gluent Data Platform provides a transparent data virtualization layer between traditional databases and modern data storage platforms, such as Hadoop, in the
Oracle Big Data Fundamentals Ed 2
 Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Processing big data with modern applications: Hadoop as DWH backend at Pro7. Dr. Kathrin Spreyer Big data engineer
 Processing big data with modern applications: Hadoop as DWH backend at Pro7 Dr. Kathrin Spreyer Big data engineer GridKa School Karlsruhe, 02.09.2014 Outline 1. Relational DWH 2. Data integration with
Processing big data with modern applications: Hadoop as DWH backend at Pro7 Dr. Kathrin Spreyer Big data engineer GridKa School Karlsruhe, 02.09.2014 Outline 1. Relational DWH 2. Data integration with
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Insight Case Studies. Tuning the Beloved DB-Engines. Presented By Nithya Koka and Michael Arnold
 Insight Case Studies Tuning the Beloved DB-Engines Presented By Nithya Koka and Michael Arnold Who is Nithya Koka? Senior Hadoop Administrator Project Lead Client Engagement On-Call Engineer Cluster Ninja
Insight Case Studies Tuning the Beloved DB-Engines Presented By Nithya Koka and Michael Arnold Who is Nithya Koka? Senior Hadoop Administrator Project Lead Client Engagement On-Call Engineer Cluster Ninja
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet
 In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
In-memory data pipeline and warehouse at scale using Spark, Spark SQL, Tachyon and Parquet Ema Iancuta iorhian@gmail.com Radu Chilom radu.chilom@gmail.com Big data analytics / machine learning 6+ years
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Shark: SQL and Rich Analytics at Scale. Yash Thakkar ( ) Deeksha Singh ( )
 Deeksha Singh ( )") Shark: SQL and Rich Analytics at Scale Yash Thakkar (2642764) Deeksha Singh (2641679) RDDs as foundation for relational processing in Shark: Resilient Distributed Datasets (RDDs): RDDs can be written at
Shark: SQL and Rich Analytics at Scale Yash Thakkar (2642764) Deeksha Singh (2641679) RDDs as foundation for relational processing in Shark: Resilient Distributed Datasets (RDDs): RDDs can be written at
Approaching the Petabyte Analytic Database: What I learned
 Disclaimer This document is for informational purposes only and is subject to change at any time without notice. The information in this document is proprietary to Actian and no part of this document may
Disclaimer This document is for informational purposes only and is subject to change at any time without notice. The information in this document is proprietary to Actian and no part of this document may
Apache Hadoop.Next What it takes and what it means
 Apache Hadoop.Next What it takes and what it means Arun C. Murthy Founder & Architect, Hortonworks @acmurthy (@hortonworks) Page 1 Hello! I m Arun Founder/Architect at Hortonworks Inc. Lead, Map-Reduce
Apache Hadoop.Next What it takes and what it means Arun C. Murthy Founder & Architect, Hortonworks @acmurthy (@hortonworks) Page 1 Hello! I m Arun Founder/Architect at Hortonworks Inc. Lead, Map-Reduce