Enabling Precise Identification and Citabilityof Dynamic Data. Recommendations of the RDA Working Group on Data Citation
|
|
|
- Merilyn Daniel
- 6 years ago
- Views:
Transcription
1 Enabling Precise Identification and Citabilityof Dynamic Data Recommendations of the RDA Working Group on Data Citation Andreas Rauber Vienna University of Technology Favoritenstr. 9-11/ Vienna, Austria
2 Outline Why should we want to cite data? What are the challenges in data identification and citation? How should we do it, according to the RDA WG? Who is doing it so far, and how? Summary
3 Why to cite data? Data is the basis for almost everything - escience, digital humanities, - Industry Driving policies, society, Why should we cite data? - Prevent scientific misconduct ( extrinsic )? Pa

4 Prevent Scientific Misconduct On average: ~ 2% of scientists admitted they had "fabricated" (made up), "falsified" or "altered" data to "improve the outcome" at least once. 34% admitted to other questionable research practices including "failing to present data that contradict one's own previous research" and "dropping observations or data points from analyses based on a gut feeling that they were inaccurate." 14% knew someone who had fabricated, falsified or altered data. Up to 72% knew someone who had committed other questionable research practices. Source: Pa
5 Prevent Scientific Misconduct On average: ~ 2% of scientists admitted they had "fabricated" (made up), "falsified" or "altered" data to "improve the outcome" at least once. 34% admitted to other questionable research practices including "failing to present data that contradict one's own previous research" and "dropping observations or data points from analyses based on a gut feeling that they were inaccurate." 14% knew someone who had fabricated, falsified or altered data. Up to 72% knew someone who had committed other questionable research practices. Source: Pa
6 Why to cite data? Data is the basis for almost everything - escience, digital humanities, - Industry Driving policies, society, Why should we cite data? - Prevent scientific misconduct ( extrinsic )? - Give credit ( altruistic )? Pa
7 Giving credit Prime motivator for sharing data Shared data gets cited more frequently Citations are the currency of science Pa
8 Giving credit Prime motivator for sharing data Shared data gets cited more frequently Citations are the currency of science Pa
9 Why to cite data? Data is the basis for almost everything - escience, digital humanities, - Industry Driving policies, society, Why should we cite data? - Prevent Scientific misconduct ( extrinsic )? - Give credit ( altruistic )? - Show solid basis ( egoistic )? Pa
10 Citing to give credit Why do we cite papers? ( related work ) Fundamental basis for own work foundation! No need to prove - it s been done! Speed-up the process, efficiency Basis for discourse, scientific work, Pa
11 Why to cite data? Data is the basis for almost everything - escience, digital humanities, - Industry Driving policies, society, Why should we cite data? - Prevent Scientific misconduct ( extrinsic )? - Give credit ( altruistic )? - Show solid basis ( egoistic )? - Enable reproducibility, re-use (extrinsic + altruistic + egoistic)? Pa
12 Reproducibility Reproducibility is core to the scientific method Focus not on misconduct but on complexity and the will to produce good work Should be easy - Get the code, compile, run, - Why is it difficult? Pa

13 Challenges in Reproducibility



14 Challenges in Reproducibility Excursion: Scientific Processes



15 Challenges in Reproducibility Excursion: scientific processes set1_freq440hz_am11.0hz set1_freq440hz_am12.0hz set1_freq440hz_am05.5hz Java Matlab




16 Challenges in Reproducibility Excursion: Scientific Processes Bug? Psychoacoustic transformation tables? Forgetting a transformation? Different implementation of filters? Limited accuracy of calculation? Difference in FFT implementation?...?


17 Challenges in Reproducibility Workflows Taverna

18 Challenges in Reproducibility
19 Challenges in Reproducibility Large scale quantitative analysis Obtain workflows from MyExperiments.org - March 2015: almost WFs (approx /year) - Focus on Taverna 2 WFs: WFs - Published by authors should be better quality Try to re-execute the workflows - Record data on the reasons for failure along Analyse the most common reasons for failures
20 Challenges in Reproducibility Re-Execution results Majority of workflows fails Only 23.6 % are successfully executed - No analysis yet on correctness of results Rudolf Mayer, Andreas Rauber, A Quantitative Study on the Re-executability of Publicly Shared Scientific Workflows, 11th IEEE Intl. Conference on e-science, 2015.
21 Challenges in Reproducibility 613 papers in 8 ACM conferences Process - download paper and classify - search for a link to code (paper, web, twice) - download code - build and execute Christian Collberg and Todd Proebsting. Repeatability in Computer Systems Research, CACM 59(3):
22 Reproducibility solved! (?) Provide source code, parameters, data, Wrap it up in a container/virtual machine, LXC Why do we want reproducibility? Which levels or reproducibility are there? What do we gain by different levels of reproducibility? A simple re-run is usually not enough otherwise, video would be sufficient.
23 Types of Reproducibility The PRIMAD Model 1 : which attributes can we prime? - Data Parameters Input data - Platform - Implementation - Method - Research Objective - Actors What do we gain by priming one or the other? [1] Juliana Freire, Norbert Fuhr, and Andreas Rauber. Reproducibility of Data-Oriented Experiments in escience. Dagstuhl Reports, 6(1), 2016.

24 Types of Reproducibility and Gains
25 Reproducibility Papers Aim for reproducibility: for one s own sake and as Chairs of conference tracks, editor, reviewer, supervisor, - Review of reproducibility of submitted work (material provided) - Encouraging reproducibility studies - (Messages to stakeholders in Dagstuhl Report) Consistency of results, not identity! Reproducibility studies and papers - Not just re-running code / a virtual machine - When is a reproducibility paper worth the effort / worth being published?
26 Challenges in Reproducibility Peer Review and Verification Peer review is an established process - Focused on publications mainly - Hardly any data quality reviews - Even less reproducibility studies Reproducing or replicating experiments is not considered original research - No recognition - No money - A lot of work Encourage reproducibility studies Needed beyond science!

27 Challenges in Reproducibility In a nutshell and another aspect of reproducibility: Source: xkcd
28 Why to cite data? Data is the basis for almost everything - escience, digital humanities, - Industry Driving policies, society, Why should we cite data? - Prevent Scientific misconduct ( extrinsic )? - Give credit ( altruistic )? - Show solid basis ( egoistic )? - Enable reproducibility, re-use (extrinsic + altruistic + egoistic)? - Because it s what you do if you do good work, speeding up the process of scientific discovery, efficiency! ( intrinsic ) Pa
29 Why to cite data? It s what you do! Lots of benefits - Makes live easier because you can build on a solid foundation - Speeds up the process because you can re-use existing stuff - Helps avoiding / detecting mistakes, improves quality, comparability - Reuse increases citations, visibility ( currency ) But: - To achieve this it must be easy, straightforward, automatic - Citing Papers is easy - what about data? (more about this later first: we should just do it ) Pa
30 Joint Declaration of Data Citation Principles 8 Principles created by the Data Citation Synthesis Group The Data Citation Principles cover purpose, function and attributes of citations Goal: Encourage communities to develop practices and tools that embody uniform data citation principles Page 30

31 Joint Declaration of Data Citation Principles Page 31
32 Joint Declaration of Data Citation Principles (cont d) 1) Importance Data should be considered legitimate, citable products of research. Data citations should be accorded the same importance as publications. 2) Credit and Attribution Data citations should facilitate giving credit and normative and legal attribution to all contributors to the data. Page 32
33 Joint Declaration of Data Citation Principles (cont d) 3) Evidence Whenever and wherever a claim relies upon data, the corresponding data should be cited. 4) Unique Identification A data citation should include a persistent method for identification that is machine actionable, globally unique, and widely used by a community. Page 33
34 Joint Declaration of Data Citation Principles (cont d) 5) Access Data citations should facilitate access to the data themselves and to such associated metadata, documentation, code, and other materials, as are necessary for both humans and machines to make informed use of the referenced data. 6) Persistence Unique identifiers, and metadata describing the data, and its disposition, should persist - even beyond the lifespan of the data they describe. Page 34
35 Joint Declaration of Data Citation Principles (cont d) 7) Specificity and Verifiability Data citations should facilitate identification of, access to, and verification of the specific data that support a claim. Citations or citation metadata should include information about provenance and fixity sufficient to facilitate verifying that the specific time slice, version and/or granular portion of data retrieved subsequently is the same as was originally cited. Page 35
36 Joint Declaration of Data Citation Principles (cont d) 8) Interoperability and flexibility Data citation methods should be sufficiently flexible to accommodate the variant practices among communities, but should not differ so much that they compromise interoperability of data citation practices across communities. Page 36
37 Glossary Joint Declaration of Data Citation Principles (cont d)

38 Benefits of Citation Identification Documentation Context Impact Transparency Reproducibility Reuse Pa
39 Outline Why should we want to cite data? What are the challenges in data identification and citation? How should we do it, according to the RDA WG? Who is doing it so far, and how? Summary
40 Why to cite data? It s what you do! Lots of benefits - Makes live easier because you can build on a solid foundation - Speeds up the process because you can re-use existing stuff - Helps avoiding / detecting mistakes, improves quality - Reuse increases citations, visibility, currency But: - To achieve this it must be easy, straightforward, automatic - Citing Papers is easy - what about data? (more about this later first: we should just do it ) Pa

41 How to cite data? Referencing research papers is well established Pa


42 Example: Web Page Download Example: Web-page download 42

43 Example: Web Page Download 43
44 Example: Web Page Download 44

45 Example: Sharing Platform Example: Data sharing platforms 45
46 Example: Sharing Platform Example: Data sharing platforms 46

47 Example: Sharing Platform 47

48 Subset Citation in Papers Example: Subsets of data Khosravi, Hossein, and Ehsanollah Kabir. "Introducing a very large dataset of handwritten Farsi digits and a study on their varieties." Pattern Recognition Letters (2007):

49 Subset Citation in Papers Example: Subsets of data 49

50 Subset Citation in Papers Example: Subsets of data Khosravi, Hossein, and Ehsanollah Kabir. "Introducing a very large dataset of handwritten Farsi digits and a study on their varieties." Pattern Recognition Letters (2007):
51 Motivation Research data is fundamental for science/industry/ - Data serves as input for workflows and experiments - Data is the source for graphs and visualisations in publications - Decisions are based on data Data is needed for Reproducibility - Repeat experiments - Verify / compare results Need to provide specific data set - Service for data repositories Source: open.wien.gv.at 1. Put data in data repository, 2. Assign PID (DOI, Ark, URI, ) 3. Make is accessible done!?
52 Identification of Dynamic Data Usually, datasets have to be static - Fixed set of data, no changes: no corrections to errors, no new data being added But: (research) data is dynamic - Adding new data, correcting errors, enhancing data quality, - Changes sometimes highly dynamic, at irregular intervals Current approaches - Identifying entire data stream, without any versioning - Using accessed at date - Artificial versioning by identifying batches of data (e.g. annual), aggregating changes into releases (time-delayed!) Would like to identify precisely the data as it existed at a specific point in time
53 Granularity of Subsets What about the granularity of data to be identified? - Enormous amounts of CSV data - Researchers use specific subsets of data - Need to identify precisely the subset used Current approaches - Storing a copy of subset as used in study -> scalability - Citing entire dataset, providing textual description of subset -> imprecise (ambiguity) - Storing list of record identifiers in subset -> scalability, not for arbitrary subsets (e.g. when not entire record selected) Would like to be able to identify precisely the subset of (dynamic) data used in a process
54 Data Citation Requirements Dynamic data - corrections, additions, Arbitrary subsets of data (granularity) - rows/columns, time sequences, - from single number to the entire set Stable across technology changes - e.g. migration to new database Machine-actionable - not just machine-readable, definitely not just human-readable and interpretable Scalable to very large / highly dynamic datasets - But: should also work for small and/or static datasets!
 Source: http://www.phdcomics.com/comics.php?")
55 What we do NOT want Common approaches to data management (from PhD Comics: A Story Told in File Names, ) Source:
56 Outline Why should we want to cite data? What are the challenges in data identification and citation? How should we do it, according to the RDA WG? Who is doing it so far, and how? Summary
57 RDA WG Data Citation Research Data Alliance WG on Data Citation: Making Dynamic Data Citeable March 2014 September Concentrating on the problems of large, dynamic (changing) datasets Final version presented Sep 2015 at P7 in Paris, France Endorsed September 2016 at P8 in Denver, CO Since then: supporting adopters
58 We have RDA WGDC - Solution Data & some means of access ( query )
59 Dynamic Data Citation We have: Data + Means-of-access Dynamic Data Citation: Cite (dynamic) data dynamically via query!
60 Dynamic Data Citation We have: Data + Means-of-access Dynamic Data Citation: Cite (dynamic) data dynamically via query! Steps: 1. Data versioned (history, with time-stamps)
61 Dynamic Data Citation We have: Data + Means-of-access Dynamic Data Citation: Cite (dynamic) data dynamically via query! Steps: 1. Data versioned (history, with time-stamps) Researcher creates working-set via some interface:
62 Dynamic Data Citation We have: Data + Means-of-access Dynamic Data Citation: Cite (dynamic) data dynamically via query! Steps: 1. Data versioned (history, with time-stamps) Researcher creates working-set via some interface: 2. Access store & assign PID to QUERY, enhanced with Time-stamping for re-execution against versioned DB Re-writing for normalization, unique-sort, mapping to history Hashing result-set: verifying identity/correctness leading to landing page S. Pröll, A. Rauber. Scalable Data Citation in Dynamic Large Databases: Model and Reference Implementation. In IEEE Intl. Conf. on Big Data 2013 (IEEE BigData2013),
63 Data Citation Deployment Researcher uses workbench to identify subset of data Upon executing selection ( download ) user gets Data (package, access API, ) PID (e.g. DOI) (Query is time-stamped and stored) Hash value computed over the data for local storage Recommended citation text (e.g. BibTeX) PID resolves to landing page Provides detailed metadata, link to parent data set, subset, Option to retrieve original data OR current version OR changes Upon activating PID associated with a data citation Query is re-executed against time-stamped and versioned DB Results as above are returned Query store aggregates data usage
64 Data Citation Deployment Researcher Note: queryuses stringworkbench provides excellent to identify subset of data Upon provenance executing information selection on ( download ) the data set! user gets Data (package, access API, ) PID (e.g. DOI) (Query is time-stamped and stored) Hash value computed over the data for local storage Recommended citation text (e.g. BibTeX) PID resolves to landing page Provides detailed metadata, link to parent data set, subset, Option to retrieve original data OR current version OR changes Upon activating PID associated with a data citation Query is re-executed against time-stamped and versioned DB Results as above are returned Query store aggregates data usage
65 Data Citation Deployment Researcher Note: queryuses stringworkbench provides excellent to identify subset of data Upon provenance executing information selection on ( download ) the data set! user gets Data (package, access API, ) PID (e.g. DOI) (Query is time-stamped and stored) Hash value computed over the data for local storage This is an important advantage over traditional approaches relying on, e.g. storing a list of identifiers/db dump!!! Recommended citation text (e.g. BibTeX) PID resolves to landing page Provides detailed metadata, link to parent data set, subset, Option to retrieve original data OR current version OR changes Upon activating PID associated with a data citation Query is re-executed against time-stamped and versioned DB Results as above are returned Query store aggregates data usage
66 Data Citation Deployment Researcher Note: queryuses stringworkbench provides excellent to identify subset of data Upon provenance executing information selection on ( download ) the data set! user gets Data (package, access API, ) PID (e.g. DOI) (Query is time-stamped and stored) Hash value computed over the data for local storage Recommended citation text (e.g. BibTeX) This is an important advantage over traditional approaches relying on, e.g. storing a list of identifiers/db dump!!! PID resolves to Identify landing which pageparts of the data are used. Provides detailed If data metadata, changes, link to identify parent data which set, queries subset, (studies) are affected Upon activating PID associated with a data citation Query is re-executed against time-stamped and versioned DB Results as above are returned Query store aggregates data usage Option to retrieve original data OR current version OR changes
67 Data Citation Output 14 Recommendations grouped into 4 phases: - Preparing data and query store - Persistently identifying specific data sets - Resolving PIDs - Upon modifications to the data infrastructure 2-page flyer More detailed report: Bulletin of IEEE TCDL TCDL-DC-2016_paper_1.pdf
68 Data Citation Recommendations Preparing Data & Query Store - R1 Data Versioning - R2 Timestamping - R3 Query Store When Data should be persisted - R4 Query Uniqueness - R5 Stable Sorting - R6 Result Set Verification - R7 Query Timestamping - R8 Query PID - R9 Store Query - R10 Citation Text When Resolving a PID - R11 Landing Page - R12 Machine Actionability Upon Modifications to the Data Infrastructure - R13 Technology Migration - R14 Migration Verification
69 R1: Data Versioning Apply versioning to ensure earlier states of the data can be retrieved Versioning allows tracing the changes (static data: no changes principle still applies) No in-place updates or deletes - Mark record as deleted, re-insert new record instead of update - Keep old versions only way to be able to go back Do we really need to keep everything? - ( changes that were never read never existed ) Src: Pa
70 R2: Data Timestamping Ensure that operations on data are timestamped, i.e. any additions, deletions are marked with a timestamp Timestamping is closely related to versioning Granularity depends on - Change frequency / tracking requirements Per individual operation Batch-operations Grouped in-between read accesses ( changes that were never read do not matter ) - System (data storage, databases) e.g. FAT 2 seconds, NTFS 100 ns, EXT4 1 ns Pa
71 R1 & R2: Versioning / Timestamping Note: R1 & R2 are already pretty much standard in many (RDBMS-) research databases Different ways to implement, depending on - data type / data structure: RDBMS, CSV, XML, LOD, - data volume - amount and type of changes - number of APIs, flexibility to change them Distributed settings: - synchronized clocks, or: - each node keeps individual, local time time-stamps for distributed queries based on local times Pa
72 R1 & R2: Versioning / Timestamping Implementation options for e.g. relational DBs: History Table - Utilizes full history table - Also inserts reflected in history table - Doubles storage space, no API adaptions Integrated - Extend original tables by temporal metadata - Expand primary key by timestamp/version column - Minimal storage footprint, changes to all APIs Hybrid - Utilize history table for deleted record versions with metadata - Original table reflects latest version only - Minimal storage footprint, some API change, expensive query re-writes Solution to be adopted depends on trade-off - Storage Demand - Query Complexity - Software/API adaption Page 72
73 R3: Query Store Provide means for storing queries and the associated metadata in order to re-execute them. Approach is based upon queries. - Therefore we need to preserve the queries Original and re-written (R4, R5), potentially migrated (R13) - Query parameters and system settings - Execution metadata - Hash keys (multiple, if re-written) (R4, R6) - Persistent identifier(s) (R8) - Citation text (R10) Comparatively small, even for high query volumes Pa
74 R4: Query Uniqueness Re-write the query to a normalized form so that identical queries can be detected. Compute checksum of the normalized query to efficiently detect identical queries Detecting identical queries can be challenging - Query semantics can be expressed in different ways - Different queries can deliver identical results - Interfaces can be used for maintaining a stable query structure Best effort, no perfect solution Usually not a problem if queries generated via standardized interfaces, e.g. workbench optional! Worst case: two PIDs for semantically equivalent queries Pa
75 R4: Query Uniqueness Query re-writing needed to - Standardization/Normalization of query to help with identifying semantically identical queries upper/lower case spelling, sorting of filter parameters, - Re-write to adapt to versioning approach chosen (versioning in operational tables, separate history table, ), e.g. identify last change to result set touched upon (i.e. select including elements marked deleted, check most recent timestamp, to determine correct PID assignment) - Add timestamp to any select statement in query - Apply unique sort to any table touched upon in query prior to query to ensure unique sort (see R5) 75




76 R4: Query Uniqueness Normalizing queries to detect identical queries - WHERE clause sorted - Calculate query string hash - Identify semantically identical queries - non-identical queries: columns in different order 76


77 R4: Query Uniqueness Adapt query to history table 77
78 R5: Stable Sorting Ensure that the sorting of the records in the data set is unambiguous and reproducible The sequence of the results in the result set may not be fixed, but data processing results may depend on sequence - Many databases are set based - The storage system may use non-deterministic features If this needs to be addressed, apply default sort (on id) prior to any user-defined sort Optional! Pa
79 R6: Result Set Verification Compute fixity information (also referred to as checksum or hash key) of the query result set to enable verification of the correctness of a result upon re-execution. Correctness: - No record has changed within a data subset - All records which have been in the original data set are also in the re-generated data set Compute a hash key - Allows to compare the completeness of results - For extremely large result sets: potentially limit hash input data, e.g. only row headers + record id s Pa
80 R7: Query Timestamping Assign a timestamp to the query based on the last update to the entire database (or the last update to the selection of data affected by the query or the query execution time). Allows to map the execution of a query to a state of the database - Execution time: default solution, simple, potentially privacy concerns? - Last global update: simple, recommended - Last update to affected subset: complex to implement All equivalent in functionality! (transparent to user) Pa
81 R8: Query PID Assign a new PID to the query if either the query is new or if the result set returned from an earlier identical query is different due to changes in the data. Otherwise, return the existing PID of the earlier query to the user. Existing PID: Identical query (semantics) with identical result set, i.e. no change to any element touched upon by query since first processing of the query New PID: whenever query semantics is not absolutely identical (irrespective of result set being potentially identical!) Pa
82 Note: R8: Query PID - Identical result set alone does not mean that the query semantics is identical - Will assign different PIDs to capture query semantics - Need to normalize query to allow comparison Process: - Re-write query to adapt to versioning system, stable sorting, - Determine query hash - Execute user query and determine result set hash - Check query store for queries with identical query hash If found, check for identical result set hash 82
83 R9: Store the Query Store query and metadata (e.g. PID, original and normalised query, query and result set checksum, timestamp, superset PID, data set description, and other) in the query store. - Query store is central infrastructure - Stores query details for long term - Provides information even when the data should be gone - Responsible for re-execution - Holds data for landing pages - Stores sensitive information Pa
84 R10: Create Citation Texts Generate citation texts in the format prevalent in the designated community for lowering the barrier for citing and sharing the data. Include the PID in the citation text snippet. Researchers are lazy /efficient - Support citing by allow them to copy and paste citations for data - Citations contain text including PIDs and timestamps - Adapted for each community 2 PIDs! - Superset: the database and it s holder (repository, data center) - Subset: based on the query - Accumulate credits for subset and (dynamic) data collection/holder
85 R10: Automated Citation Texts Can be created automatically - relatively simple for relational - more complex for hierarchical/xml Learning to Cite: - Gianmaria Silvello. Learning to Cite Framework: How to Automatically Construct Citations for Hierarchical Data. Journal of the Association for Information Science and Technology (JASIST), Volume 68 issue 6, pp , June


86 R10: Automated Citation Texts EAD: Encoded Archival Description Slides with permission by G. Silvello
87 R10: Automated Citation Texts A human-readable citation: Slides with permission by G. Silvello

88 R10: Automated Citation Texts A human-readable citation: Slides with permission by G. Silvello
89 R10: Automated Citation Texts A machine-readable citation: - Conjunction of XML paths Slides with permission by G. Silvello
90 R10: Automated Citation Texts Mapping machine-readable to human-readable: Slides with permission by G. Silvello
91 R10: Automated Citation Texts Learning citation models Slides with permission by G. Silvello
92 R11: Landing Page Make the PIDs resolve to a human readable landing page that provides the data (via query re-execution) and metadata, including a link to the superset (PID of the data source) and citation text snippet. - Data sets and subsets uniquely identifiable by their PID, which resolves to a human readable landing page. - Landing page reachable by a unique URL, presented in a Web browser - Not all information needs to be provided on landing page (e.g. query strings frequently not relevant / potential security threat) Pa
93 R12: Machine Actionability Provide an API / machine actionable landing page to access metadata and data via query re-execution. - Experiments are increasingly automated - Machines most likely to consume data citations - Allows machines to resolve PIDs, access metadata and data - Note: does NOT imply full / automatic access to data! Authentication Load analysis - Handshake, content negotiation, - Allows automatic meta-studies, monitoring, Pa
94 R13: Technology Migration When data is migrated to a new representation (e.g. new database system, a new schema or a completely different technology), migrate also the queries and associated fixity information. - Technology evolves and data may be moved to a new technology stack - Query languages change Migration required - Migrate data and the queries (both are with the data center!) - Adapt versioning, re-compute query hash-keys - Maybe decide to keep original queries in the provenace trace Note: such data migrations constitute major projects, usually happen rarely require all APIs to be adapted, Pa
95 R14: Migration Verification Verify successful data and query migration, ensuring that queries can be re-executed correctly. Sanity check: After migration is done, verify that the data can still be retrieved correctly Use query and result set hashes in the query store to verify results If hash function is incompatible/cannot be computed on new system as hash input data sequence cannot be obtained, pairwise comparison of subset elements - May constitute new PID / data subset in this case, as subsequent processes will not be able to use it as input if result set presentation has changed, breaks processes Pa
96 RDA Recommendations - Summary Building blocks of supporting dynamic data citation: - Uniquely identifiable data records - Versioned data, marking changes as insertion/deletion - Time stamps of data insertion / deletions - Query language for constructing subsets Add modules: - Persistent query store: queries and the timestamp (either: <when issued> or <of last change to data>) - Query rewriting module - PID assignment for queries that enables access Stable across data source migrations (e.g. diff. DBMS), scalable, machine-actionable Page 96
97 Benefits RDA Recommendations - Summary - Allows identifying, retrieving and citing the precise data subset with minimal storage overhead by only storing the versioned data and the queries used for extracting it - Allows retrieving the data both as it existed at a given point in time as well as the current view on it, by re-executing the same query with the stored or current timestamp - It allows to cite even an empty set! - The query stored for identifying data subsets provides valuable provenance data - Query store collects information on data usage, offering a basis for data management decisions - Metadata such as checksums support the verification of the correctness and authenticity of data sets retrieved - The same principles work for all types of data Pa
98 RDA Recommendations - Summary Some considerations and questions - May data be deleted? Yes, of course, given appropriate policies. Queries may then not be re-executable against the original timestamp anymore - Does the system need to store every query? No, only data sets that should be persisted for citation and later re-use need to be stored. - Can I obtain only the most recent data set? Queries can be re-executed with the original timestamp or with the current timestamp or any other timestamp desired. - Which PID system should be used? Any PID system can, in principle, be applied according to the institutional policy. Pa
99 Outline Why should we want to cite data? What are the challenges in data identification and citation? How should we do it, according to the RDA WG? Who is doing it so far, and how? Summary
100 Pilots / Adopters Several adopters - Different types of data, different settings, - CSV & SQL reference implementation (SBA/TUW) Pilots: - Biomedical BigData Sharing, Electronic Health Records (Center for Biomedical Informatics, Washington Univ. in St. Louis) - Marine Research Data Biological & Chemical Oceanography Data Management Office (BCO-DMO) - Vermont Monitoring Cooperative: Forest Ecosystem Monitoring - ARGO Boy Network, British Oceanographic Data Centre (BODC) - Virtual Atomic and Molecular Data Centre (VAMDC) - UK Riverflow Riverflow Archive, Centre for Ecology and Hydrology
101 Pilots / Adopters Series of Webinars presenting implementations - Recordings, slides, supporting papers - webconference/webconference-data-citation-wg.html - Implementing of the RDA Data Citation Recommendations by the Climate Change Centre Austria (CCCA) for a repository of NetCDF files - Implementing the RDA Data Citation Recommendations for Long-Tail Research Data / CSV files - Implementing the RDA Data Citation Recommendations in the Distributed Infrastructure of the Virtual and Atomic Molecular Data Center (VAMDC) - Implementation of Dynamic Data Citation at the Vermont Monitoring Cooperative - Adoption of the RDA Data Citation of Evolving Data Recommendation to Electronic Health Records
102 Reference Implementation for CSV Data (and SQL) Stefan Pröll, SBA Christoph Meixner, TU Wien
103 Large Scale Research Settings RDA recommendations implemented in data infrastructures Required adaptions - Introduce versioning, if not already in place - Capture sub-setting process (queries) - Implement dedicated query store to store queries - A bit of additional functionality (query re-writing, hash functions, ) Done!? - Big data, database driven - Well-defined interfaces - Trained experts available - Complex, only for professional research infrastructures? Slide by Stefan Pröll

104 Long Tail Research Data Big data, well organized, often used and cited Data set size Amount of data sets Less well organized, Dark data non-standardised no dedicated infrastructure Slide by Stefan Pröll
105 Prototype Implementations Solution for small-scale data - CSV files, no expensive infrastructure, low overhead 2 Reference implementations : Git based Prototypes: widely used versioning system - A) Using separate folders - B) Using branches MySQL based Prototype: - C) Migrates CSV data into relational database Data backend responsible for versioning data sets Subsets are created with scripts or queries via API or Web Interface Transparent to user: always CSV Slide by Stefan Pröll
106 Git-Based Reference Implementation Git Implementation 1 Upload CSV files to Git repository (versioning) Subsets created via scripting language (e.g. R) Select rows/columns, sort, returns CSV + metadata file Metadata file with script parameters stored in Git (Scripts stored in Git as well) PID assigned to metadata file Use Git to retrieve proper data set version and re-execute script on retrieved file Slide by Stefan Pröll
107 Git-Based Reference Implementation Git Implementation 2 Addresses issues - common commit history, branching data Using Git branching model: Orphaned branches for queries and data - Keeps commit history clean - Allows merging of data files Web interface for queries (CSV2JDBC) Use commit hash for identification - Assigned PID hashed with SHA1 - Use hash of PID as filename (ensure permissible characters) Slide by Stefan Pröll
108 Git-Based Reference Implementation Prototype: Step 1: Select a CSV file in the repository Step 2: Create a subset with a SQL query (on CSV data) Slide by Stefan Pröll Step 3: Store the query script and metadata Step 4: Re-Execute!
109 MySQL-Based Reference Implementation MySQL Prototype Data upload - User uploads a CSV file into the system Data migration from CSV file into RDBMS - Generate table structure - Add metadata columns (versioning) - Add indices (performance) Dynamic data - Insert, update and delete records - Events are recorded with a timestamp Subset creation - User selects columns, filters and sorts records in web interface - System traces the selection process - Exports CSV Slide by Stefan Pröll Barrymieny
110 MySQL-Based Reference Implementation Source at Github: Videos: Login: Upload: Subset: Resolver: Update: Slide by Stefan Pröll
111 CSV Reference Implementations Stefan Pröll, Christoph Meixner, Andreas Rauber Precise Data Identification Services for Long Tail Research Data. Proceedings of the intl. Conference on Preservation of Digital Objects (ipres2016), Oct , Bern, Switzerland. Source at Github: RDA-WGDC-CSV-Data-Citation-Prototype Videos: Login: Upload: Subset: Resolver: Update: Slide by Stefan Pröll
112 WG Data Citation Pilot WUSTL Cynthia Hudson Vitale, Leslie McIntosh, Snehil Gupta Washington University in St.Luis
113 Biomedical Adoption Project Goals Implement RDA Data Citation WG recommendation to local Washington U i2b2 Engage other i2b2 community adoptees Contribute source code back to i2b2 community Repository Slides Bibliography Slide by Leslie McIntosh
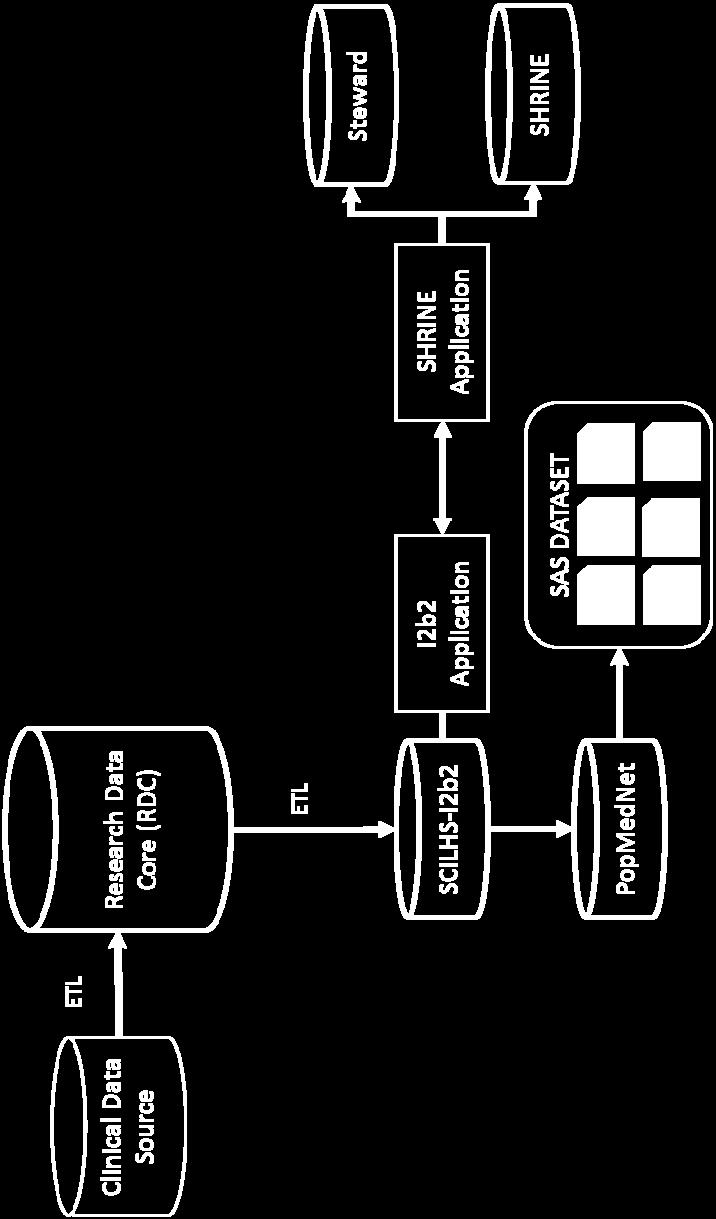

114 RDA-MacArthur Grant Focus Data Broker Researchers Slide by Leslie McIntosh
115 R1 and R2 Implementation 1 2 triggers RDC.hist_table* 3 c1 c2 c3 sys_period RDC.table c1 c2 c3 sys_period PostgreSQL Extension temporal_tables *stores history of data changes Slide by Leslie McIntosh
116 Return on Investment (ROI) - Estimated 20 hours to complete 1 study $150/hr (unsubsidized) $3000 per study 115 research studies per year 14 replication studies Slide by Leslie McIntosh
117 CBMI Research Reproducibility Resources Repository Slides Bibliography epro Slide by Leslie McIntosh
118 From RDA Data Citation Recommendations to new paradigms for citing data from VAMDC C.M. Zwölf and VAMDC Consortium
119 The Virtual Atomic and Molecular Data Centre Astrophysics Health and clinical sciences Plasma sciences VAMDC Single and unique access to heterogeneous A+M Databases Lighting technologies Atmospheric Physics Federates 29 heterogeneous databases The V of VAMDC stands for Virtual in the sense that the e infrastructure does not contain data. The infrastructure is a wrapping for exposing in a unified way a set of heterogeneous databases. The consortium is politically organized around a Memorandum of understanding (15 international members have signed the MoU, 1 November 2014) High quality scientific data come from different Physical/Chemical Communities Fusion technologies Environmental sciences Provides data producers with a large dissemination platform Slide by Carlo Maria Zwölf Remove bottleneck between dataproducers and wide body of users
120 VAMDC Infrastructure Technical Architecture Resource registered into Registry Layer Asks for available resources Existing Independent A+M database VAMDC wrapping layer VAMDC Node Standard Layer Accept queries submitted in standard grammar Results formatted into standard XML file (XSAMS) VAMDC Clients (dispatch query on all the registered resources) Portal SpecView SpectCol Unique A+M query Set of standard files VAMDC is agnostic about the local data storage strategy on each node. Each node implements the access/query/result protocols. There is no central management system. Decisions about technical evolutions are made by consensus in Consortium. It is both technical and political challenging to implement the WG recommendations. Slide by Carlo Maria Zwölf
121 Let us implement the recommendation!! Implementation will be an overlay to the standard / output layer, thus independent from any specific data-node Tagging versions of data Two layers mechanisms 1 Fine grained granularity: Evolution of XSAMS output standard for tracking data modifications 2 Coarse grained granularity: At each data modification to a given data node, the version of the Data-Node changes With the second mechanism we know that something changed : in other words, we know that the result of an identical query may be different from one version to the other. The detail of which data changed is accessible using the first mechanisms. Slide by Carlo Maria Zwölf
122 Let us implement the recommendation!! Implementation will be an overlay to the standard / output layer, thus independent from any specific data-node Tagging versions of data Query Store Two layers mechanisms 1 Fine grained granularity: Evolution of XSAMS output standard for tracking data modifications 2 Coarse grained granularity: At each data modification to a given data node, the version of the Data-Node changes With the second mechanism we know that something changed : in other words, we know that the result of an identical query may be different from one version to the other. The detail of which data changed is accessible using the first mechanisms Slide by Carlo Maria Zwölf Is built over the versioning of Data Is plugged over the existing VAMDC data-extraction mechanisms Due to the distributed VAMDC architecture, the Query Store architecture is similar to a log-service
123 Data-Versioning: Overview of the fine grained mechanisms This approach has several advantages: It solves the data tagging granularity problem It is independent from what is considered a dataset The new files are compliant with old libraries & processing programs We add a new feature, an overlay to the existing structure We induce a structuration, without changing the structure New model for datasets citation and extraction reproducibility in VAMDC, C.M. Zwölf, N. Moreau, M.-L. Dubernet, J. Mol. Spectrosc. (2016), Arxiv version: Slide by Carlo Maria Zwölf
124 Let us focus on the query store: Sketching the functioning From the final user point of view: Data extraction procedure VAMDC portal (query interface) Query VAMDC infrastructur e Computed response VAMD portal (result part) Access to the output data file Digital Unique Identifier associated to the current extraction Use DOI in papers Manage queries (with authorisation/ authentication) Group arbitrary set of queries (with related DUI) and assign them a DOI to use in publications The original query Date & time where query was processed Version of the infrastructure when the query was processed List of publications needed for answering the query When supported (by the VAMDC federated DB): retrieve the output data-file as it was computed (query re-execution) Query Metadata Resolves Landing Page Query Store Slide by Carlo Maria Zwölf
125 Let us focus on the query store: The difficulty we have to cope with: Handle a query store in a distributed environment (RDA did not design it for these configurations) Integrate the query store with the existing VAMDC infrastructure The implementation of the query store is the goal of a jointly collaboration between VAMDC and RDA-Europe Development started during spring 2016 Final product released during 2017 Collaboration with Elsevier for embedding the VAMDC query store into the pages displaying the digital version of papers. Designing technical solution for Paper / data linking at the paper submission (for authors) Paper / data linking at the paper display (for readers) Slide by Carlo Maria Zwölf
126 Climate Change Centre Austria (CCCA) Chris Schubert
127 CCCA Climate Change Centre Austria Climate research network for sustained, high-quality Austrian climate research. 28 members (11 universities, 13 non-univ. institutions, 4 supporting members) Structure: Coordination Office (Vienna, BOKU), Service Centre (Univ. Graz), Data Centre (ZAMG, Vienna) Service available at Slide by Chris Schubert
128 Slide by Chris Schubert CCCA

129 Slide by Chris Schubert CCCA

130 Slide by Chris Schubert CCCA
131 CCCA NetCDF Files: Slide by Chris Schubert
132 Slide by Chris Schubert CCCA

133 CCCA Slide by Chris Schubert

134 Slide by Chris Schubert CCCA

135 UK Riverflow Archive Matthew Fry
136 UK National River Flow Archive Curation and dissemination of regulatory river flow data for research and other access Data used for significant research outputs, and a large number of citations annually Updated annually but also regular revision of entire flow series through time (e.g. stations resurveyed) Internal auditing, but history is not Open Stations exposed to users Slides by Matthew Frey
137 UK National River Flow Archive ORACLE Relational database Time series and metadata tables ~20M daily flow records, + monthly / daily catchment rainfall series Metadata (station history, owners, catchment soils / geology, etc.) Total size of ~5GB Time series tables automatically audited, - But reconstruction is complex Users generally download simple files But public API is in development / R-NRFA package is out there Fortunately all access is via single codeset Slides by Matthew Frey
138 Our data citation requirements Cannot currently cite whole dataset Allow citation a subset of the data, as it was at the time Fit with current workflow / update schedule, and requirements for reproducibility Fit with current (file download) and future (API) user practices Resilient to gradual or fundamental changes in technologies used Allow tracking of citations in publications Slides by Matthew Frey
139 Options for versioning / citation Regulate queries: - limitations on service provided Enable any query to be timestamped / cited / reproducible: - does not readily allow verification (e.g. checksum) of queries (R7), or storage of queries (R9) Manage which queries can be citable: - limitation on publishing workflow? Slides by Matthew Frey
140 Versioning / citation solution Automated archiving of entire database version controlled scripts defining tables, creating / populating archived tables (largely complete) Fits in with data workflow public / dev versions this only works because we have irregular / occasional updates Simplification of the data model (complete) API development (being undertaken independently of dynamic citation requirements): - allows subsetting of dataset in a number of ways initially simply - need to implement versioning (started) to ensure will cope with changes to data structures Fit to dynamic data citation recommendations? - Largely - Need to address mechanism for users to request / create citable version of a query Resource required: estimated ~2 person months Slides by Matthew Frey
141 Outline Why should we want to cite data? What are the challenges in data identification and citation? How should we do it, according to the RDA WG? Who is doing it so far, and how? Summary
142 Summary Data citation essential for solid and efficient science (but not just for science!) It is more than just giving credit Human-readable and machine-actionable RDA recommendations - Time-stamp and version data if it is evolving - Provide PIDs to arbitrary subsets via selection mechanism ( query ) (rather than statically assigned PIDs to pre-defined subsets) 2 PIDs: - for evolving intellectual object - for precise, static subset
143 Benefits Retrieval of precise subset with low storage overhead Subset as cited or as it is now (including e.g. corrections) Query provides provenance information Query store supports analysis of data usage Fixity information (hash/checksum) supports verification Same principles applicable across all settings - Small and large data - Static and dynamic data - Any subset (including empty set!) - Different data representations (RDBMS, CSV, XML, LOD, ) Relatively straight-forward to implement
144 Interested in implementing? If you have a dataset / are operating a data center that - has dynamic data and / or - allows researchers to select subsets of this data for studies and would like to support precise identification / citability Let us know! - Join RDA WGDC: - Support for adoption pilots - Cooperate on implementing and deploying recommendations Collecting feedback, identifying potential issues,
145 Thank you! Thanks!
Implementing the RDA Data Citation Recommendations for Long Tail Research Data. Stefan Pröll
 Implementing the RDA Data Citation Recommendations for Long Tail Research Data Stefan Pröll Overview 2 Introduction Recap of the WGDC Recommendations Long Tail Research Data SQL Prototype Git Prototype
Implementing the RDA Data Citation Recommendations for Long Tail Research Data Stefan Pröll Overview 2 Introduction Recap of the WGDC Recommendations Long Tail Research Data SQL Prototype Git Prototype
Implementing the RDA data citation recommendations in the distributed Infrastructure of the Virtual Atomic and Molecular Data Centre
 Implementing the RDA data citation recommendations in the distributed Infrastructure of the Virtual Atomic and Molecular Data Centre C.M. Zwölf, N. Moreau and VAMDC consortium The Virtual Atomic and Molecular
Implementing the RDA data citation recommendations in the distributed Infrastructure of the Virtual Atomic and Molecular Data Centre C.M. Zwölf, N. Moreau and VAMDC consortium The Virtual Atomic and Molecular
Approaches to Making Dynamic Data Citeable Recommendations of the RDA Working Group Andreas Rauber
 Approaches to Making Dynamic Data Citeable Recommendations of the RDA Working Group Andreas Rauber Vienna University of Technology rauber@ifs.tuwien.ac.at http://www.ifs.tuwien.ac.at/~andi Outline Joint
Approaches to Making Dynamic Data Citeable Recommendations of the RDA Working Group Andreas Rauber Vienna University of Technology rauber@ifs.tuwien.ac.at http://www.ifs.tuwien.ac.at/~andi Outline Joint
Data Citation Working Group P7 March 2 nd 2016, Tokyo
 Data Citation Working Group Mtg @ P7 March 2 nd 2016, Tokyo Agenda 2 11:00 - Welcome and Intro 11:10 Recommendations: Re-cap, Flyer, Report 11:30 - Recommendations Q&A 11:45 - Adoption activities 12:15
Data Citation Working Group Mtg @ P7 March 2 nd 2016, Tokyo Agenda 2 11:00 - Welcome and Intro 11:10 Recommendations: Re-cap, Flyer, Report 11:30 - Recommendations Q&A 11:45 - Adoption activities 12:15
State of the Art in Data Citation
 State of the Art in Data Citation Ruth Duerr This work is licensed under a Creative Commons Attribution v4.0 License. Overview Citing data in publications is a re-emerging practice that: Encourages reproducibility
State of the Art in Data Citation Ruth Duerr This work is licensed under a Creative Commons Attribution v4.0 License. Overview Citing data in publications is a re-emerging practice that: Encourages reproducibility
Adoption of Data Citation Outcomes by BCO-DMO
 Adoption of Data Citation Outcomes by BCO-DMO Cynthia Chandler, Adam Shepherd, David Bassendine Biological and Chemical Oceanography Data Management Office Woods Hole Oceanographic Institution and Blue
Adoption of Data Citation Outcomes by BCO-DMO Cynthia Chandler, Adam Shepherd, David Bassendine Biological and Chemical Oceanography Data Management Office Woods Hole Oceanographic Institution and Blue
Scalable Data Citation in Dynamic, Large Databases: Model and Reference Implementation
 Scalable Data Citation in Dynamic, Large Databases: Model and Reference Implementation Stefan Pröll SBA Research Vienna, Austria sproell@sba-research.org Andreas Rauber Technical University of Vienna Vienna,
Scalable Data Citation in Dynamic, Large Databases: Model and Reference Implementation Stefan Pröll SBA Research Vienna, Austria sproell@sba-research.org Andreas Rauber Technical University of Vienna Vienna,
Indiana University Research Technology and the Research Data Alliance
 Indiana University Research Technology and the Research Data Alliance Rob Quick Manager High Throughput Computing Operations Officer - OSG and SWAMP Board Member - RDA Organizational Assembly RDA Mission
Indiana University Research Technology and the Research Data Alliance Rob Quick Manager High Throughput Computing Operations Officer - OSG and SWAMP Board Member - RDA Organizational Assembly RDA Mission
Reproducible Workflows Biomedical Research. P Berlin, Germany
 Reproducible Workflows Biomedical Research P11 2018 Berlin, Germany Contributors Leslie McIntosh Research Data Alliance, U.S., Executive Director Oya Beyan Aachen University, Germany Anthony Juehne RDA,
Reproducible Workflows Biomedical Research P11 2018 Berlin, Germany Contributors Leslie McIntosh Research Data Alliance, U.S., Executive Director Oya Beyan Aachen University, Germany Anthony Juehne RDA,
DOI for Astronomical Data Centers: ESO. Hainaut, Bordelon, Grothkopf, Fourniol, Micol, Retzlaff, Sterzik, Stoehr [ESO] Enke, Riebe [AIP]
![DOI for Astronomical Data Centers: ESO. Hainaut, Bordelon, Grothkopf, Fourniol, Micol, Retzlaff, Sterzik, Stoehr [ESO] Enke, Riebe [AIP]](/thumbs/92/110506144.jpg "DOI for Astronomical Data Centers: ESO. Hainaut, Bordelon, Grothkopf, Fourniol, Micol, Retzlaff, Sterzik, Stoehr [ESO] Enke, Riebe [AIP]") DOI for Astronomical Data Centers: ESO Hainaut, Bordelon, Grothkopf, Fourniol, Micol, Retzlaff, Sterzik, Stoehr [ESO] Enke, Riebe [AIP] DOI for Astronomical Data Centers: ESO Hainaut, Bordelon, Grothkopf,
DOI for Astronomical Data Centers: ESO Hainaut, Bordelon, Grothkopf, Fourniol, Micol, Retzlaff, Sterzik, Stoehr [ESO] Enke, Riebe [AIP] DOI for Astronomical Data Centers: ESO Hainaut, Bordelon, Grothkopf,
State of the Art in Ethno/ Scientific Data Management
 State of the Art in Ethno/ Scientific Data Management Ruth Duerr This work is licensed under a Creative Commons Attribution v4.0 License. Overview Data management layers Data lifecycle Levels of data Citation
State of the Art in Ethno/ Scientific Data Management Ruth Duerr This work is licensed under a Creative Commons Attribution v4.0 License. Overview Data management layers Data lifecycle Levels of data Citation
Services to Make Sense of Data. Patricia Cruse, Executive Director, DataCite Council of Science Editors San Diego May 2017
 Services to Make Sense of Data Patricia Cruse, Executive Director, DataCite Council of Science Editors San Diego May 2017 How many journals make data sharing a requirement of publication? https://jordproject.wordpress.com/2013/07/05/going-back-to-basics-reusing-data/
Services to Make Sense of Data Patricia Cruse, Executive Director, DataCite Council of Science Editors San Diego May 2017 How many journals make data sharing a requirement of publication? https://jordproject.wordpress.com/2013/07/05/going-back-to-basics-reusing-data/
Enabling Open Science: Data Discoverability, Access and Use. Jo McEntyre Head of Literature Services
 Enabling Open Science: Data Discoverability, Access and Use Jo McEntyre Head of Literature Services www.ebi.ac.uk About EMBL-EBI Part of the European Molecular Biology Laboratory International, non-profit
Enabling Open Science: Data Discoverability, Access and Use Jo McEntyre Head of Literature Services www.ebi.ac.uk About EMBL-EBI Part of the European Molecular Biology Laboratory International, non-profit
DOIs for Research Data
 DOIs for Research Data Open Science Days 2017, 16.-17. Oktober 2017, Berlin Britta Dreyer, Technische Informationsbibliothek (TIB) http://orcid.org/0000-0002-0687-5460 Scope 1. DataCite Services 2. Data
DOIs for Research Data Open Science Days 2017, 16.-17. Oktober 2017, Berlin Britta Dreyer, Technische Informationsbibliothek (TIB) http://orcid.org/0000-0002-0687-5460 Scope 1. DataCite Services 2. Data
Persistent identifiers, long-term access and the DiVA preservation strategy
 Persistent identifiers, long-term access and the DiVA preservation strategy Eva Müller Electronic Publishing Centre Uppsala University Library, http://publications.uu.se/epcentre/ 1 Outline DiVA project
Persistent identifiers, long-term access and the DiVA preservation strategy Eva Müller Electronic Publishing Centre Uppsala University Library, http://publications.uu.se/epcentre/ 1 Outline DiVA project
Persistent Identifier the data publishing perspective. Sünje Dallmeier-Tiessen, CERN 1
 Persistent Identifier the data publishing perspective Sünje Dallmeier-Tiessen, CERN 1 Agenda Data Publishing Specific Data Publishing Needs THOR Latest Examples/Solutions Publishing Centerpiece of research
Persistent Identifier the data publishing perspective Sünje Dallmeier-Tiessen, CERN 1 Agenda Data Publishing Specific Data Publishing Needs THOR Latest Examples/Solutions Publishing Centerpiece of research
Institutional Repository using DSpace. Yatrik Patel Scientist D (CS)
") Institutional Repository using DSpace Yatrik Patel Scientist D (CS) yatrik@inflibnet.ac.in What is Institutional Repository? Institutional repositories [are]... digital collections capturing and preserving
Institutional Repository using DSpace Yatrik Patel Scientist D (CS) yatrik@inflibnet.ac.in What is Institutional Repository? Institutional repositories [are]... digital collections capturing and preserving
Data Replication: Automated move and copy of data. PRACE Advanced Training Course on Data Staging and Data Movement Helsinki, September 10 th 2013
 Data Replication: Automated move and copy of data PRACE Advanced Training Course on Data Staging and Data Movement Helsinki, September 10 th 2013 Claudio Cacciari c.cacciari@cineca.it Outline The issue
Data Replication: Automated move and copy of data PRACE Advanced Training Course on Data Staging and Data Movement Helsinki, September 10 th 2013 Claudio Cacciari c.cacciari@cineca.it Outline The issue
SHARING YOUR RESEARCH DATA VIA
 SHARING YOUR RESEARCH DATA VIA SCHOLARBANK@NUS MEET OUR TEAM Gerrie Kow Head, Scholarly Communication NUS Libraries gerrie@nus.edu.sg Estella Ye Research Data Management Librarian NUS Libraries estella.ye@nus.edu.sg
SHARING YOUR RESEARCH DATA VIA SCHOLARBANK@NUS MEET OUR TEAM Gerrie Kow Head, Scholarly Communication NUS Libraries gerrie@nus.edu.sg Estella Ye Research Data Management Librarian NUS Libraries estella.ye@nus.edu.sg
EUDAT. A European Collaborative Data Infrastructure. Daan Broeder The Language Archive MPI for Psycholinguistics CLARIN, DASISH, EUDAT
 EUDAT A European Collaborative Data Infrastructure Daan Broeder The Language Archive MPI for Psycholinguistics CLARIN, DASISH, EUDAT OpenAire Interoperability Workshop Braga, Feb. 8, 2013 EUDAT Key facts
EUDAT A European Collaborative Data Infrastructure Daan Broeder The Language Archive MPI for Psycholinguistics CLARIN, DASISH, EUDAT OpenAire Interoperability Workshop Braga, Feb. 8, 2013 EUDAT Key facts
Science Europe Consultation on Research Data Management
 Science Europe Consultation on Research Data Management Consultation available until 30 April 2018 at http://scieur.org/rdm-consultation Introduction Science Europe and the Netherlands Organisation for
Science Europe Consultation on Research Data Management Consultation available until 30 April 2018 at http://scieur.org/rdm-consultation Introduction Science Europe and the Netherlands Organisation for
FREYA Connected Open Identifiers for Discovery, Access and Use of Research Resources
 FREYA Connected Open Identifiers for Discovery, Access and Use of Research Resources Brian Matthews Data Science and Technology Group Scientific Computing Department STFC Persistent Identifiers Long-lasting
FREYA Connected Open Identifiers for Discovery, Access and Use of Research Resources Brian Matthews Data Science and Technology Group Scientific Computing Department STFC Persistent Identifiers Long-lasting
National Data Sharing and Accessibility Policy-2012 (NDSAP-2012)
") National Data Sharing and Accessibility Policy-2012 (NDSAP-2012) Department of Science & Technology Ministry of science & Technology Government of India Government of India Ministry of Science & Technology
National Data Sharing and Accessibility Policy-2012 (NDSAP-2012) Department of Science & Technology Ministry of science & Technology Government of India Government of India Ministry of Science & Technology
Medici for Digital Cultural Heritage Libraries. George Tsouloupas, PhD The LinkSCEEM Project
 Medici for Digital Cultural Heritage Libraries George Tsouloupas, PhD The LinkSCEEM Project Overview of Digital Libraries A Digital Library: "An informal definition of a digital library is a managed collection
Medici for Digital Cultural Heritage Libraries George Tsouloupas, PhD The LinkSCEEM Project Overview of Digital Libraries A Digital Library: "An informal definition of a digital library is a managed collection
Writing a Data Management Plan A guide for the perplexed
 March 29, 2012 Writing a Data Management Plan A guide for the perplexed Agenda Rationale and Motivations for Data Management Plans Data and data structures Metadata and provenance Provisions for privacy,
March 29, 2012 Writing a Data Management Plan A guide for the perplexed Agenda Rationale and Motivations for Data Management Plans Data and data structures Metadata and provenance Provisions for privacy,
Data Citation and Scholarship
 University of California, Los Angeles From the SelectedWorks of Christine L. Borgman August 25, 2015 Data Citation and Scholarship Christine L Borgman, University of California, Los Angeles Available at:
University of California, Los Angeles From the SelectedWorks of Christine L. Borgman August 25, 2015 Data Citation and Scholarship Christine L Borgman, University of California, Los Angeles Available at:
User Scripting April 14, 2018
 April 14, 2018 Copyright 2013, 2018, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and
April 14, 2018 Copyright 2013, 2018, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and
Fusion Registry 9 SDMX Data and Metadata Management System
 Registry 9 Data and Management System Registry 9 is a complete and fully integrated statistical data and metadata management system using. Whether you require a metadata repository supporting a highperformance
Registry 9 Data and Management System Registry 9 is a complete and fully integrated statistical data and metadata management system using. Whether you require a metadata repository supporting a highperformance
PERSISTENT IDENTIFIERS FOR THE UK: SOCIAL AND ECONOMIC DATA
 PERSISTENT IDENTIFIERS FOR THE UK: SOCIAL AND ECONOMIC DATA MATTHEW WOOLLARD.. ECONOMIC AND SOCIAL DATA SERVICE UNIVERSITY OF ESSEX... METADATA AND PERSISTENT IDENTIFIERS FOR SOCIAL AND ECONOMIC DATA,
PERSISTENT IDENTIFIERS FOR THE UK: SOCIAL AND ECONOMIC DATA MATTHEW WOOLLARD.. ECONOMIC AND SOCIAL DATA SERVICE UNIVERSITY OF ESSEX... METADATA AND PERSISTENT IDENTIFIERS FOR SOCIAL AND ECONOMIC DATA,
EUDAT B2FIND A Cross-Discipline Metadata Service and Discovery Portal
 EUDAT B2FIND A Cross-Discipline Metadata Service and Discovery Portal Heinrich Widmann, DKRZ DI4R 2016, Krakow, 28 September 2016 www.eudat.eu EUDAT receives funding from the European Union's Horizon 2020
EUDAT B2FIND A Cross-Discipline Metadata Service and Discovery Portal Heinrich Widmann, DKRZ DI4R 2016, Krakow, 28 September 2016 www.eudat.eu EUDAT receives funding from the European Union's Horizon 2020
Cancer Waiting Times. Getting Started with Beta Testing. Beta Testing period: 01 February May Copyright 2018 NHS Digital
 Getting Started with Beta Testing Beta Testing period: 01 February 2018 03 May 2018 Copyright 2018 NHS Digital Document management Revision History Version Date Summary of Changes 0.1 23/03/2018 Initial
Getting Started with Beta Testing Beta Testing period: 01 February 2018 03 May 2018 Copyright 2018 NHS Digital Document management Revision History Version Date Summary of Changes 0.1 23/03/2018 Initial
EUDAT- Towards a Global Collaborative Data Infrastructure
 EUDAT- Towards a Global Collaborative Data Infrastructure FOT-Net Data Stakeholder Meeting Brussels, 8 March 2016 Yann Le Franc, PhD e-science Data Factory, France CEO and founder EUDAT receives funding
EUDAT- Towards a Global Collaborative Data Infrastructure FOT-Net Data Stakeholder Meeting Brussels, 8 March 2016 Yann Le Franc, PhD e-science Data Factory, France CEO and founder EUDAT receives funding
ISMTE Best Practices Around Data for Journals, and How to Follow Them" Brooks Hanson Director, Publications, AGU
 ISMTE Best Practices Around Data for Journals, and How to Follow Them" Brooks Hanson Director, Publications, AGU bhanson@agu.org 1 Recent Alignment by Publishers, Repositories, and Funders Around Data
ISMTE Best Practices Around Data for Journals, and How to Follow Them" Brooks Hanson Director, Publications, AGU bhanson@agu.org 1 Recent Alignment by Publishers, Repositories, and Funders Around Data
From Open Data to Data- Intensive Science through CERIF
 From Open Data to Data- Intensive Science through CERIF Keith G Jeffery a, Anne Asserson b, Nikos Houssos c, Valerie Brasse d, Brigitte Jörg e a Keith G Jeffery Consultants, Shrivenham, SN6 8AH, U, b University
From Open Data to Data- Intensive Science through CERIF Keith G Jeffery a, Anne Asserson b, Nikos Houssos c, Valerie Brasse d, Brigitte Jörg e a Keith G Jeffery Consultants, Shrivenham, SN6 8AH, U, b University
A Data Citation Roadmap for Scholarly Data Repositories
 A Data Citation Roadmap for Scholarly Data Repositories Tim Clark (Harvard Medical School & Massachusetts General Hospital) Martin Fenner (DataCite) Mercè Crosas (Institute for Quantiative Social Science,
A Data Citation Roadmap for Scholarly Data Repositories Tim Clark (Harvard Medical School & Massachusetts General Hospital) Martin Fenner (DataCite) Mercè Crosas (Institute for Quantiative Social Science,
EUDAT Common data infrastructure
 EUDAT Common data infrastructure Giuseppe Fiameni SuperComputing Applications and Innovation CINECA Italy Peter Wittenburg Max Planck Institute for Psycholinguistics Nijmegen, Netherlands some major characteristics
EUDAT Common data infrastructure Giuseppe Fiameni SuperComputing Applications and Innovation CINECA Italy Peter Wittenburg Max Planck Institute for Psycholinguistics Nijmegen, Netherlands some major characteristics
Long-term preservation for INSPIRE: a metadata framework and geo-portal implementation
 Long-term preservation for INSPIRE: a metadata framework and geo-portal implementation INSPIRE 2010, KRAKOW Dr. Arif Shaon, Dr. Andrew Woolf (e-science, Science and Technology Facilities Council, UK) 3
Long-term preservation for INSPIRE: a metadata framework and geo-portal implementation INSPIRE 2010, KRAKOW Dr. Arif Shaon, Dr. Andrew Woolf (e-science, Science and Technology Facilities Council, UK) 3
DataONE: Open Persistent Access to Earth Observational Data
 Open Persistent Access to al Robert J. Sandusky, UIC University of Illinois at Chicago The Net Partners Update: ONE and the Conservancy December 14, 2009 Outline NSF s Net Program ONE Introduction Motivating
Open Persistent Access to al Robert J. Sandusky, UIC University of Illinois at Chicago The Net Partners Update: ONE and the Conservancy December 14, 2009 Outline NSF s Net Program ONE Introduction Motivating
Cheshire 3 Framework White Paper: Implementing Support for Digital Repositories in a Data Grid Environment
 Cheshire 3 Framework White Paper: Implementing Support for Digital Repositories in a Data Grid Environment Paul Watry Univ. of Liverpool, NaCTeM pwatry@liverpool.ac.uk Ray Larson Univ. of California, Berkeley
Cheshire 3 Framework White Paper: Implementing Support for Digital Repositories in a Data Grid Environment Paul Watry Univ. of Liverpool, NaCTeM pwatry@liverpool.ac.uk Ray Larson Univ. of California, Berkeley
The Materials Data Facility
 The Materials Data Facility Ben Blaiszik (blaiszik@uchicago.edu), Kyle Chard (chard@uchicago.edu) Ian Foster (foster@uchicago.edu) materialsdatafacility.org What is MDF? We aim to make it simple for materials
The Materials Data Facility Ben Blaiszik (blaiszik@uchicago.edu), Kyle Chard (chard@uchicago.edu) Ian Foster (foster@uchicago.edu) materialsdatafacility.org What is MDF? We aim to make it simple for materials
FAIR-aligned Scientific Repositories: Essential Infrastructure for Open and FAIR Data
 FAIR-aligned Scientific Repositories: Essential Infrastructure for Open and FAIR Data GeoDaRRs: What is the existing landscape and what gaps exist in that landscape for data producers and users? 7 August
FAIR-aligned Scientific Repositories: Essential Infrastructure for Open and FAIR Data GeoDaRRs: What is the existing landscape and what gaps exist in that landscape for data producers and users? 7 August
Persistent Identifiers
 Persistent Identifiers Adam Carter (EUDAT/EPCC) 0000-0001-9544-9211 including content originally created by Tobias Weigel (DKNZ) and Larry Lannom (CNRI) Why PIDs? What are PIDs? How to use PIDs What I
Persistent Identifiers Adam Carter (EUDAT/EPCC) 0000-0001-9544-9211 including content originally created by Tobias Weigel (DKNZ) and Larry Lannom (CNRI) Why PIDs? What are PIDs? How to use PIDs What I
LIBER Webinar: A Data Citation Roadmap for Scholarly Data Repositories
 LIBER Webinar: A Data Citation Roadmap for Scholarly Data Repositories Martin Fenner (DataCite) Mercè Crosas (Institute for Quantiative Social Science, Harvard University) May 15, 2017 2014 Joint Declaration
LIBER Webinar: A Data Citation Roadmap for Scholarly Data Repositories Martin Fenner (DataCite) Mercè Crosas (Institute for Quantiative Social Science, Harvard University) May 15, 2017 2014 Joint Declaration
Access Control for Shared Resources
 Access Control for Shared Resources Erik Wilde and Nick Nabholz Computer Engineering and Networks Laboratory (TIK) Swiss Federal Institute of Technology (ETH Zürich) Abstract Access control for shared
Access Control for Shared Resources Erik Wilde and Nick Nabholz Computer Engineering and Networks Laboratory (TIK) Swiss Federal Institute of Technology (ETH Zürich) Abstract Access control for shared
Design & Manage Persistent URIs
 Training Module 2.3 OPEN DATA SUPPORT Design & Manage Persistent URIs PwC firms help organisations and individuals create the value they re looking for. We re a network of firms in 158 countries with close
Training Module 2.3 OPEN DATA SUPPORT Design & Manage Persistent URIs PwC firms help organisations and individuals create the value they re looking for. We re a network of firms in 158 countries with close
Inge Van Nieuwerburgh OpenAIRE NOAD Belgium. Tools&Services. OpenAIRE EUDAT. can be reused under the CC BY license
 Inge Van Nieuwerburgh OpenAIRE NOAD Belgium Tools&Services OpenAIRE EUDAT can be reused under the CC BY license Open Access Infrastructure for Research in Europe www.openaire.eu Research Data Services,
Inge Van Nieuwerburgh OpenAIRE NOAD Belgium Tools&Services OpenAIRE EUDAT can be reused under the CC BY license Open Access Infrastructure for Research in Europe www.openaire.eu Research Data Services,
Enabling Seamless Sharing of Data among Organizations Using the DaaS Model in a Cloud
 Enabling Seamless Sharing of Data among Organizations Using the DaaS Model in a Cloud Addis Mulugeta Ethiopian Sugar Corporation, Addis Ababa, Ethiopia addismul@gmail.com Abrehet Mohammed Omer Department
Enabling Seamless Sharing of Data among Organizations Using the DaaS Model in a Cloud Addis Mulugeta Ethiopian Sugar Corporation, Addis Ababa, Ethiopia addismul@gmail.com Abrehet Mohammed Omer Department
Data Curation Profile Human Genomics
 Data Curation Profile Human Genomics Profile Author Profile Author Institution Name Contact J. Carlson N. Brown Purdue University J. Carlson, jrcarlso@purdue.edu Date of Creation October 27, 2009 Date
Data Curation Profile Human Genomics Profile Author Profile Author Institution Name Contact J. Carlson N. Brown Purdue University J. Carlson, jrcarlso@purdue.edu Date of Creation October 27, 2009 Date
Horizon 2020 and the Open Research Data pilot. Sarah Jones Digital Curation Centre, Glasgow
 Horizon 2020 and the Open Research Data pilot Sarah Jones Digital Curation Centre, Glasgow sarah.jones@glasgow.ac.uk Twitter: @sjdcc Data Management Plan (DMP) workshop, e-infrastructures Austria, Vienna,
Horizon 2020 and the Open Research Data pilot Sarah Jones Digital Curation Centre, Glasgow sarah.jones@glasgow.ac.uk Twitter: @sjdcc Data Management Plan (DMP) workshop, e-infrastructures Austria, Vienna,
Archiving and Maintaining Curated Databases
 Archiving and Maintaining Curated Databases Heiko Müller University of Edinburgh, UK hmueller@inf.ed.ac.uk Abstract Curated databases represent a substantial amount of effort by a dedicated group of people
Archiving and Maintaining Curated Databases Heiko Müller University of Edinburgh, UK hmueller@inf.ed.ac.uk Abstract Curated databases represent a substantial amount of effort by a dedicated group of people
Reproducibility and FAIR Data in the Earth and Space Sciences
 Reproducibility and FAIR Data in the Earth and Space Sciences December 2017 Brooks Hanson Sr. VP, Publications, American Geophysical Union bhanson@agu.org Earth and Space Science is Essential for Society
Reproducibility and FAIR Data in the Earth and Space Sciences December 2017 Brooks Hanson Sr. VP, Publications, American Geophysical Union bhanson@agu.org Earth and Space Science is Essential for Society
Newly-Created, Work-in-Progress (WIP), Approval Cycle, Approved or Copied-from-Previously-Approved, Work-in-Progress (WIP), Approval Cycle, Approved
, Approval Cycle, Approved or Copied-from-Previously-Approved, Work-in-Progress (WIP), Approval Cycle, Approved") A New Approach to Enterprise Data Organization A Cuboid Enterprises are generally overwhelmed with data, making the ability to store, process, analyze, interpret, consume, and act upon that data a primary
A New Approach to Enterprise Data Organization A Cuboid Enterprises are generally overwhelmed with data, making the ability to store, process, analyze, interpret, consume, and act upon that data a primary
Data Curation Profile Plant Genetics / Corn Breeding
 Profile Author Author s Institution Contact Researcher(s) Interviewed Researcher s Institution Katherine Chiang Cornell University Library ksc3@cornell.edu Withheld Cornell University Date of Creation
Profile Author Author s Institution Contact Researcher(s) Interviewed Researcher s Institution Katherine Chiang Cornell University Library ksc3@cornell.edu Withheld Cornell University Date of Creation
Making Sense of Data: What You Need to know about Persistent Identifiers, Best Practices, and Funder Requirements
 Making Sense of Data: What You Need to know about Persistent Identifiers, Best Practices, and Funder Requirements Council of Science Editors May 23, 2017 Shelley Stall, MBA, CDMP, EDME AGU Assistant Director,
Making Sense of Data: What You Need to know about Persistent Identifiers, Best Practices, and Funder Requirements Council of Science Editors May 23, 2017 Shelley Stall, MBA, CDMP, EDME AGU Assistant Director,
re3data.org - Making research data repositories visible and discoverable
 re3data.org - Making research data repositories visible and discoverable Robert Ulrich, Karlsruhe Institute of Technology Hans-Jürgen Goebelbecker, Karlsruhe Institute of Technology Frank Scholze, Karlsruhe
re3data.org - Making research data repositories visible and discoverable Robert Ulrich, Karlsruhe Institute of Technology Hans-Jürgen Goebelbecker, Karlsruhe Institute of Technology Frank Scholze, Karlsruhe
DIGITAL STEWARDSHIP SUPPLEMENTARY INFORMATION FORM
 OMB No. 3137 0071, Exp. Date: 09/30/2015 DIGITAL STEWARDSHIP SUPPLEMENTARY INFORMATION FORM Introduction: IMLS is committed to expanding public access to IMLS-funded research, data and other digital products:
OMB No. 3137 0071, Exp. Date: 09/30/2015 DIGITAL STEWARDSHIP SUPPLEMENTARY INFORMATION FORM Introduction: IMLS is committed to expanding public access to IMLS-funded research, data and other digital products:
Welcome to the Pure International Conference. Jill Lindmeier HR, Brand and Event Manager Oct 31, 2018
 0 Welcome to the Pure International Conference Jill Lindmeier HR, Brand and Event Manager Oct 31, 2018 1 Mendeley Data Use Synergies with Pure to Showcase Additional Research Outputs Nikhil Joshi Solutions
0 Welcome to the Pure International Conference Jill Lindmeier HR, Brand and Event Manager Oct 31, 2018 1 Mendeley Data Use Synergies with Pure to Showcase Additional Research Outputs Nikhil Joshi Solutions
Roy Lowry, Gwen Moncoiffe and Adam Leadbetter (BODC) Cathy Norton and Lisa Raymond (MBLWHOI Library) Ed Urban (SCOR) Peter Pissierssens (IODE Project
 Cathy Norton and Lisa Raymond (MBLWHOI Library) Ed Urban (SCOR) Peter Pissierssens (IODE Project") Roy Lowry, Gwen Moncoiffe and Adam Leadbetter (BODC) Cathy Norton and Lisa Raymond (MBLWHOI Library) Ed Urban (SCOR) Peter Pissierssens (IODE Project Office) Linda Pikula (IODE GEMIM/NOAA Library) Data
Roy Lowry, Gwen Moncoiffe and Adam Leadbetter (BODC) Cathy Norton and Lisa Raymond (MBLWHOI Library) Ed Urban (SCOR) Peter Pissierssens (IODE Project Office) Linda Pikula (IODE GEMIM/NOAA Library) Data
Microsoft SharePoint Server 2013 Plan, Configure & Manage
 Microsoft SharePoint Server 2013 Plan, Configure & Manage Course 20331-20332B 5 Days Instructor-led, Hands on Course Information This five day instructor-led course omits the overlap and redundancy that
Microsoft SharePoint Server 2013 Plan, Configure & Manage Course 20331-20332B 5 Days Instructor-led, Hands on Course Information This five day instructor-led course omits the overlap and redundancy that
COMPUTER AND INFORMATION SCIENCE JENA DB. Group Abhishek Kumar Harshvardhan Singh Abhisek Mohanty Suhas Tumkur Chandrashekhara
 JENA DB Group - 10 Abhishek Kumar Harshvardhan Singh Abhisek Mohanty Suhas Tumkur Chandrashekhara OUTLINE Introduction Data Model Query Language Implementation Features Applications Introduction Open Source
JENA DB Group - 10 Abhishek Kumar Harshvardhan Singh Abhisek Mohanty Suhas Tumkur Chandrashekhara OUTLINE Introduction Data Model Query Language Implementation Features Applications Introduction Open Source
For Attribution: Developing Data Attribution and Citation Practices and Standards
 For Attribution: Developing Data Attribution and Citation Practices and Standards Board on Research Data and Information Policy and Global Affairs Division National Research Council in collaboration with
For Attribution: Developing Data Attribution and Citation Practices and Standards Board on Research Data and Information Policy and Global Affairs Division National Research Council in collaboration with
Research Data Repository Interoperability Primer
 Research Data Repository Interoperability Primer The Research Data Repository Interoperability Working Group will establish standards for interoperability between different research data repository platforms
Research Data Repository Interoperability Primer The Research Data Repository Interoperability Working Group will establish standards for interoperability between different research data repository platforms
ISO Self-Assessment at the British Library. Caylin Smith Repository
 ISO 16363 Self-Assessment at the British Library Caylin Smith Repository Manager caylin.smith@bl.uk @caylinssmith Outline Digital Preservation at the British Library The Library s Digital Collections Achieving
ISO 16363 Self-Assessment at the British Library Caylin Smith Repository Manager caylin.smith@bl.uk @caylinssmith Outline Digital Preservation at the British Library The Library s Digital Collections Achieving
CODE AND DATA MANAGEMENT. Toni Rosati Lynn Yarmey
 CODE AND DATA MANAGEMENT Toni Rosati Lynn Yarmey Data Management is Important! Because Reproducibility is the foundation of science Journals are starting to require data deposit You want to get credit
CODE AND DATA MANAGEMENT Toni Rosati Lynn Yarmey Data Management is Important! Because Reproducibility is the foundation of science Journals are starting to require data deposit You want to get credit
Cian Kinsella CEO, Digiprove
 Cian Kinsella CEO, Digiprove cian.kinsella@digiprove.com Malaga 7 th June 2013 Been developing software since 1972 Commercial and Freelance Co-founder of 3 Software Product Companies Have had many different
Cian Kinsella CEO, Digiprove cian.kinsella@digiprove.com Malaga 7 th June 2013 Been developing software since 1972 Commercial and Freelance Co-founder of 3 Software Product Companies Have had many different
Database Developers Forum APEX
 Database Developers Forum APEX 20.05.2014 Antonio Romero Marin, Aurelien Fernandes, Jose Rolland Lopez De Coca, Nikolay Tsvetkov, Zereyakob Makonnen, Zory Zaharieva BE-CO Contents Introduction to the Controls
Database Developers Forum APEX 20.05.2014 Antonio Romero Marin, Aurelien Fernandes, Jose Rolland Lopez De Coca, Nikolay Tsvetkov, Zereyakob Makonnen, Zory Zaharieva BE-CO Contents Introduction to the Controls
European Platform on Rare Diseases Registration
 The European Commission s science and knowledge service Joint Research Centre European Platform on Rare Diseases Registration Simona Martin Agnieszka Kinsner-Ovaskainen Monica Lanzoni Andri Papadopoulou
The European Commission s science and knowledge service Joint Research Centre European Platform on Rare Diseases Registration Simona Martin Agnieszka Kinsner-Ovaskainen Monica Lanzoni Andri Papadopoulou
NETWRIX GROUP POLICY CHANGE REPORTER
 NETWRIX GROUP POLICY CHANGE REPORTER ADMINISTRATOR S GUIDE Product Version: 7.2 November 2012. Legal Notice The information in this publication is furnished for information use only, and does not constitute
NETWRIX GROUP POLICY CHANGE REPORTER ADMINISTRATOR S GUIDE Product Version: 7.2 November 2012. Legal Notice The information in this publication is furnished for information use only, and does not constitute
EUDAT-B2FIND A FAIR and Interdisciplinary Discovery Portal for Research Data
 EUDAT-B2FIND A FAIR and Interdisciplinary Discovery Portal for Research Data Heinrich Widmann, DKRZ Claudia Martens, DKRZ Open Science Days, Berlin, 17 October 2017 www.eudat.eu EUDAT receives funding
EUDAT-B2FIND A FAIR and Interdisciplinary Discovery Portal for Research Data Heinrich Widmann, DKRZ Claudia Martens, DKRZ Open Science Days, Berlin, 17 October 2017 www.eudat.eu EUDAT receives funding
MPEG-21: The 21st Century Multimedia Framework
 MPEG-21: The 21st Century Multimedia Framework Jan Bormans, Jean Gelissen, and Andrew Perkis IEEE Signal Processing Magazine, March 2003 Outline Context and motivation of MPEG-21 An overview of MPEG-21
MPEG-21: The 21st Century Multimedia Framework Jan Bormans, Jean Gelissen, and Andrew Perkis IEEE Signal Processing Magazine, March 2003 Outline Context and motivation of MPEG-21 An overview of MPEG-21
Data publication and discovery with Globus
 Data publication and discovery with Globus Questions and comments to outreach@globus.org The Globus data publication and discovery services make it easy for institutions and projects to establish collections,
Data publication and discovery with Globus Questions and comments to outreach@globus.org The Globus data publication and discovery services make it easy for institutions and projects to establish collections,
McAfee Security Management Center
 Data Sheet McAfee Security Management Center Unified management for next-generation devices Key advantages: Single pane of glass across the management lifecycle for McAfee next generation devices. Scalability
Data Sheet McAfee Security Management Center Unified management for next-generation devices Key advantages: Single pane of glass across the management lifecycle for McAfee next generation devices. Scalability
EUDAT. Towards a pan-european Collaborative Data Infrastructure
 EUDAT Towards a pan-european Collaborative Data Infrastructure Damien Lecarpentier CSC-IT Center for Science, Finland CESSDA workshop Tampere, 5 October 2012 EUDAT Towards a pan-european Collaborative
EUDAT Towards a pan-european Collaborative Data Infrastructure Damien Lecarpentier CSC-IT Center for Science, Finland CESSDA workshop Tampere, 5 October 2012 EUDAT Towards a pan-european Collaborative
An overview of the OAIS and Representation Information
 An overview of the OAIS and Representation Information JORUM, DCC and JISC Forum Long-term Curation and Preservation of Learning Objects February 9 th 2006 University of Glasgow Manjula Patel UKOLN and
An overview of the OAIS and Representation Information JORUM, DCC and JISC Forum Long-term Curation and Preservation of Learning Objects February 9 th 2006 University of Glasgow Manjula Patel UKOLN and
Product Data Sheet: TimeBase
 Product Data Sheet: Time Series Database is a high performance event-oriented time-series database engine and messaging middleware. is designed explicitly for very fast population and retrieval of massive
Product Data Sheet: Time Series Database is a high performance event-oriented time-series database engine and messaging middleware. is designed explicitly for very fast population and retrieval of massive
Slide 1 & 2 Technical issues Slide 3 Technical expertise (continued...)
") Technical issues 1 Slide 1 & 2 Technical issues There are a wide variety of technical issues related to starting up an IR. I m not a technical expert, so I m going to cover most of these in a fairly superficial
Technical issues 1 Slide 1 & 2 Technical issues There are a wide variety of technical issues related to starting up an IR. I m not a technical expert, so I m going to cover most of these in a fairly superficial
EUDAT - Open Data Services for Research
 EUDAT - Open Data Services for Research Johannes Reetz EUDAT operations Max Planck Computing & Data Centre Science Operations Workshop 2015 ESO, Garching 24-27th November 2015 EUDAT receives funding from
EUDAT - Open Data Services for Research Johannes Reetz EUDAT operations Max Planck Computing & Data Centre Science Operations Workshop 2015 ESO, Garching 24-27th November 2015 EUDAT receives funding from
Data Discovery - Introduction
 Data Discovery - Introduction Why (benefits of reusing data) How EUDAT's services help with this (in general) Adam Carter In days gone by: Design an experiment Getting Your Data Conduct the experiment
Data Discovery - Introduction Why (benefits of reusing data) How EUDAT's services help with this (in general) Adam Carter In days gone by: Design an experiment Getting Your Data Conduct the experiment
Data Management Plans. Sarah Jones Digital Curation Centre, Glasgow
 Data Management Plans Sarah Jones Digital Curation Centre, Glasgow sarah.jones@glasgow.ac.uk Twitter: @sjdcc Data Management Plan (DMP) workshop, e-infrastructures Austria, Vienna, 17 November 2016 What
Data Management Plans Sarah Jones Digital Curation Centre, Glasgow sarah.jones@glasgow.ac.uk Twitter: @sjdcc Data Management Plan (DMP) workshop, e-infrastructures Austria, Vienna, 17 November 2016 What
Metadata Models for Experimental Science Data Management
 Metadata Models for Experimental Science Data Management Brian Matthews Facilities Programme Manager Scientific Computing Department, STFC Co-Chair RDA Photon and Neutron Science Interest Group Task lead,
Metadata Models for Experimental Science Data Management Brian Matthews Facilities Programme Manager Scientific Computing Department, STFC Co-Chair RDA Photon and Neutron Science Interest Group Task lead,
Developing the ERS Collaboration Framework
 1 Developing the ERS Collaboration Framework Patrick J. Martin, Ph.D. BAE Systems Technology Solutions patrick.j.martin@baesystems.com 10-26-2016 2 ERS Development Challenges Resilient System A system
1 Developing the ERS Collaboration Framework Patrick J. Martin, Ph.D. BAE Systems Technology Solutions patrick.j.martin@baesystems.com 10-26-2016 2 ERS Development Challenges Resilient System A system
Metadata for Data Discovery: The NERC Data Catalogue Service. Steve Donegan
 Metadata for Data Discovery: The NERC Data Catalogue Service Steve Donegan Introduction NERC, Science and Data Centres NERC Discovery Metadata The Data Catalogue Service NERC Data Services Case study:
Metadata for Data Discovery: The NERC Data Catalogue Service Steve Donegan Introduction NERC, Science and Data Centres NERC Discovery Metadata The Data Catalogue Service NERC Data Services Case study:
PID System for eresearch
 the European Persistant Identifier Gesellschaft für wissenschaftliche Datenverarbeitung mbh Göttingen Am Fassberg, 37077 Göttingen ulrich.schwardmann@gwdg.de IZA/Gesis/RatSWD-WS Persistent Identifiers
the European Persistant Identifier Gesellschaft für wissenschaftliche Datenverarbeitung mbh Göttingen Am Fassberg, 37077 Göttingen ulrich.schwardmann@gwdg.de IZA/Gesis/RatSWD-WS Persistent Identifiers
TEXT MINING: THE NEXT DATA FRONTIER
 TEXT MINING: THE NEXT DATA FRONTIER An Infrastructural Approach Dr. Petr Knoth CORE (core.ac.uk) Knowledge Media institute, The Open University United Kingdom 2 OpenMinTeD Establish an open and sustainable
TEXT MINING: THE NEXT DATA FRONTIER An Infrastructural Approach Dr. Petr Knoth CORE (core.ac.uk) Knowledge Media institute, The Open University United Kingdom 2 OpenMinTeD Establish an open and sustainable
Globus Platform Services for Data Publication. Greg Nawrocki University of Chicago & Argonne National Lab GeoDaRRS August 7, 2018
 Globus Platform Services for Data Publication Greg Nawrocki greg@globus.org University of Chicago & Argonne National Lab GeoDaRRS August 7, 2018 Outline Globus Overview Globus Data Publication v1 Lessons
Globus Platform Services for Data Publication Greg Nawrocki greg@globus.org University of Chicago & Argonne National Lab GeoDaRRS August 7, 2018 Outline Globus Overview Globus Data Publication v1 Lessons
B2SAFE metadata management
 B2SAFE metadata management version 1.2 by Claudio Cacciari, Robert Verkerk, Adil Hasan, Elena Erastova Introduction The B2SAFE service provides a set of functions for long term bit stream data preservation:
B2SAFE metadata management version 1.2 by Claudio Cacciari, Robert Verkerk, Adil Hasan, Elena Erastova Introduction The B2SAFE service provides a set of functions for long term bit stream data preservation:
Europeana Core Service Platform
 Europeana Core Service Platform DELIVERABLE D7.1: Strategic Development Plan, Architectural Planning Revision Final Date of submission 30 October 2015 Author(s) Marcin Werla, PSNC Pavel Kats, Europeana
Europeana Core Service Platform DELIVERABLE D7.1: Strategic Development Plan, Architectural Planning Revision Final Date of submission 30 October 2015 Author(s) Marcin Werla, PSNC Pavel Kats, Europeana
The OAIS Reference Model: current implementations
 The OAIS Reference Model: current implementations Michael Day, UKOLN, University of Bath m.day@ukoln.ac.uk Chinese-European Workshop on Digital Preservation, Beijing, China, 14-16 July 2004 Presentation
The OAIS Reference Model: current implementations Michael Day, UKOLN, University of Bath m.day@ukoln.ac.uk Chinese-European Workshop on Digital Preservation, Beijing, China, 14-16 July 2004 Presentation
THE NATIONAL DATA SERVICE(S) & NDS CONSORTIUM A Call to Action for Accelerating Discovery Through Data Services we can Build Ed Seidel
 & NDS CONSORTIUM A Call to Action for Accelerating Discovery Through Data Services we can Build Ed Seidel") THE NATIONAL DATA SERVICE(S) & NDS CONSORTIUM A Call to Action for Accelerating Discovery Through Data Services we can Build Ed Seidel National Center for Supercomputing Applications University of Illinois
THE NATIONAL DATA SERVICE(S) & NDS CONSORTIUM A Call to Action for Accelerating Discovery Through Data Services we can Build Ed Seidel National Center for Supercomputing Applications University of Illinois
CoE CENTRE of EXCELLENCE ON DATA WAREHOUSING
 in partnership with Overall handbook to set up a S-DWH CoE: Deliverable: 4.6 Version: 3.1 Date: 3 November 2017 CoE CENTRE of EXCELLENCE ON DATA WAREHOUSING Handbook to set up a S-DWH 1 version 2.1 / 4
in partnership with Overall handbook to set up a S-DWH CoE: Deliverable: 4.6 Version: 3.1 Date: 3 November 2017 CoE CENTRE of EXCELLENCE ON DATA WAREHOUSING Handbook to set up a S-DWH 1 version 2.1 / 4
The Virtual Observatory and the IVOA
 The Virtual Observatory and the IVOA The Virtual Observatory Emergence of the Virtual Observatory concept by 2000 Concerns about the data avalanche, with in mind in particular very large surveys such as
The Virtual Observatory and the IVOA The Virtual Observatory Emergence of the Virtual Observatory concept by 2000 Concerns about the data avalanche, with in mind in particular very large surveys such as
Big Data infrastructure and tools in libraries
 Line Pouchard, PhD Purdue University Libraries Research Data Group Big Data infrastructure and tools in libraries 08/10/2016 DATA IN LIBRARIES: THE BIG PICTURE IFLA/ UNIVERSITY OF CHICAGO BIG DATA: A VERY
Line Pouchard, PhD Purdue University Libraries Research Data Group Big Data infrastructure and tools in libraries 08/10/2016 DATA IN LIBRARIES: THE BIG PICTURE IFLA/ UNIVERSITY OF CHICAGO BIG DATA: A VERY
Automated Testing of Tableau Dashboards
 Kinesis Technical Whitepapers April 2018 Kinesis CI Automated Testing of Tableau Dashboards Abstract Companies make business critical decisions every day, based on data from their business intelligence
Kinesis Technical Whitepapers April 2018 Kinesis CI Automated Testing of Tableau Dashboards Abstract Companies make business critical decisions every day, based on data from their business intelligence
Its All About The Metadata
 Best Practices Exchange 2013 Its All About The Metadata Mark Evans - Digital Archiving Practice Manager 11/13/2013 Agenda Why Metadata is important Metadata landscape A flexible approach Case study - KDLA
Best Practices Exchange 2013 Its All About The Metadata Mark Evans - Digital Archiving Practice Manager 11/13/2013 Agenda Why Metadata is important Metadata landscape A flexible approach Case study - KDLA
Introduction to K2View Fabric
 Introduction to K2View Fabric 1 Introduction to K2View Fabric Overview In every industry, the amount of data being created and consumed on a daily basis is growing exponentially. Enterprises are struggling
Introduction to K2View Fabric 1 Introduction to K2View Fabric Overview In every industry, the amount of data being created and consumed on a daily basis is growing exponentially. Enterprises are struggling
Trust and Certification: the case for Trustworthy Digital Repositories. RDA Europe webinar, 14 February 2017 Ingrid Dillo, DANS, The Netherlands
 Trust and Certification: the case for Trustworthy Digital Repositories RDA Europe webinar, 14 February 2017 Ingrid Dillo, DANS, The Netherlands Perhaps the biggest challenge in sharing data is trust: how
Trust and Certification: the case for Trustworthy Digital Repositories RDA Europe webinar, 14 February 2017 Ingrid Dillo, DANS, The Netherlands Perhaps the biggest challenge in sharing data is trust: how
Introduction to INSPIRE. Network Services
 Introduction to INSPIRE. Network Services European Commission Joint Research Centre Institute for Environment and Sustainability Digital Earth and Reference Data Unit www.jrc.ec.europa.eu Serving society
Introduction to INSPIRE. Network Services European Commission Joint Research Centre Institute for Environment and Sustainability Digital Earth and Reference Data Unit www.jrc.ec.europa.eu Serving society
Andrea Sciabà CERN, Switzerland
 Frascati Physics Series Vol. VVVVVV (xxxx), pp. 000-000 XX Conference Location, Date-start - Date-end, Year THE LHC COMPUTING GRID Andrea Sciabà CERN, Switzerland Abstract The LHC experiments will start
Frascati Physics Series Vol. VVVVVV (xxxx), pp. 000-000 XX Conference Location, Date-start - Date-end, Year THE LHC COMPUTING GRID Andrea Sciabà CERN, Switzerland Abstract The LHC experiments will start
9 Reasons To Use a Binary Repository for Front-End Development with Bower
 9 Reasons To Use a Binary Repository for Front-End Development with Bower White Paper Introduction The availability of packages for front-end web development has somewhat lagged behind back-end systems.
9 Reasons To Use a Binary Repository for Front-End Development with Bower White Paper Introduction The availability of packages for front-end web development has somewhat lagged behind back-end systems.
Data Curation Handbook Steps
 Data Curation Handbook Steps By Lisa R. Johnston Preliminary Step 0: Establish Your Data Curation Service: Repository data curation services should be sustained through appropriate staffing and business
Data Curation Handbook Steps By Lisa R. Johnston Preliminary Step 0: Establish Your Data Curation Service: Repository data curation services should be sustained through appropriate staffing and business