Deep Learning Frameworks with Spark and GPUs
|
|
|
- Millicent Wilkerson
- 6 years ago
- Views:
Transcription


1 Deep Learning Frameworks with Spark and GPUs
2 Abstract Spark is a powerful, scalable, real-time data analytics engine that is fast becoming the de facto hub for data science and big data. However, in parallel, GPU clusters is fast becoming the default way to quickly develop and train deep learning models. As data science teams and data savvy companies mature, they'll need to invest in both platforms if they intend to leverage both big data and artificial intelligence for competitive advantage. We'll discuss and show in action an examination of TensorflowOnSpark, CaffeOnSpark, DeepLearning4J, IBM's SystemML, and Intel's BigDL and distributed versions of various deep learning frameworks, namely TensorFlow, Caffe, and Torch.
3 The Deep Learning Landscape Frameworks - Tensorflow, MXNet, Caffe, Torch, Theano, etc Boutique Frameworks - TensorflowOnSpark, CaffeOnSpark Data Backends - File system, Amazon EFS, Spark, Hadoop, etc, etc. Cloud Ecosystems - AWS, GCP, IBM Cloud, etc, etc
 HDFS integration Data Scientist Workflow DataFrames SQL")
4 Pipelining w/ job chains or Spark Stre Why Spark Ecosystem Many Data sources Environments Applications Real-time data In-memory RDDs (resilient distributed data sets) HDFS integration Data Scientist Workflow DataFrames SQL APIs
5 Approaches to Deep Learning + Spark
6 Yahoo: CaffeOnSpark, TensorFlowOnSpark Designed to run on existing Spark and Hadoop clusters, and use existing Spark libraries like SparkSQL or Spark s MLlib machine learning libraries Should be noted that the Caffe and TensorFlow versions used by these lag the release version by about 4-6 weeks Source: Yahoo

7 Skymind.ai: DeepLearning4J Deeplearning4j is an open-source, distributed deep-learning library written for Java and Scala. DL4J can import neural net models from most major frameworks via Keras, including TensorFlow, Caffe, Torch and Theano. Keras is employed as Deeplearning4j's Python API. Source: deeplearning4j.org
8 IBM: SystemML Apache SystemML runs on top of Apache Spark, where it automatically scales your data, line by line, determining whether your code should be run on the driver or an Apache Spark cluster. Algorithm customizability via R-like and Python-like languages. Multiple execution modes, including Spark MLContext, Spark Batch, Hadoop Batch, Standalone, and JMLC. Automatic optimization based on data and cluster characteristics to ensure both efficiency and scalability. Limited set of algorithms supported so far Source: Niketan Panesar
 Source:")
9 Intel: BigDL Modeled after Torch, supports Scala and Python programs Scales out via Spark Leverages IBM MKL (Math Kernel Library) Source: MSDN

")
10 Google: TensorFlow Flexible, powerful deep learning framework that supports CPU, GPU, multi-gpu, and multi-server GPU with Tensorflow Distributed Keras support Strong ecosystem (we ll talk more about this) Source: Google
11 Why We Chose TensorFlow for Our Study


12 TensorFlow s Web Popularity We decided to focus on TensorFlow as it represent the majority the deep learning framework usage in the market right now. Source:

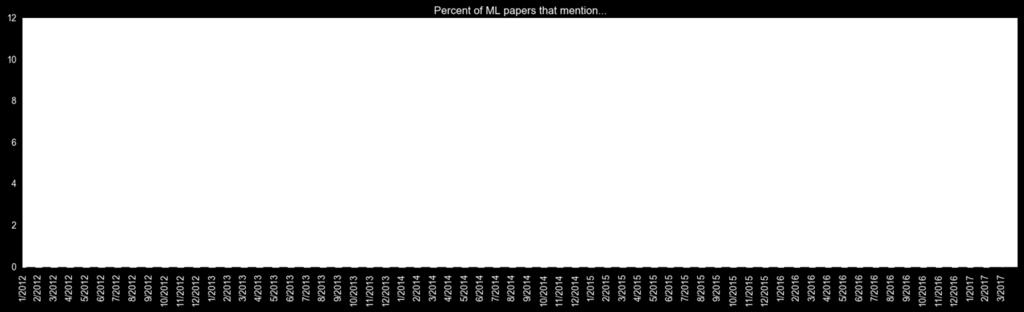
13 TensorFlow s Academic Popularity It is also worth noting that TensorFlow represents a large portion of what the research community is currently interested in. Source:
14 A Quick Case Study
15 Model and Benchmark Information Our model uses the following: Dataset: CIFAR10 Architecture: Pictured to the right Optimizer: Adam For benchmarking, we will consider: Images per second Time to 85% accuracy (averaged across 10 runs) All models run on p2 AWS instances Model Configurations: Single server - CPU Single server - GPU Single server - multi-gpu Multi server distributed TensorFlow Multi server TensorFlow on Spark Input 2 Convolution Module (64 depth) 2 Convolution Module (128 depth) 4 Convolution Module (256 depth) Fully Connected Layer (1024 depth) Fully Connected Layer (1024 depth) Output Layer (10 depth) 2 Convolution Module 3X3 Convolution 3X3 Convolution 2X2 (2) Max Pooling 4 Convolution Module 3X3 Convolution 3X3 Convolution 3X3 Convolution 3X3 Convolution 2X2 (2) Max Pooling
16 TensorFlow - Single Server CPU and GPU This is really well documented and the basis for why most of the frameworks were created. Using GPUs for deep learning creates high returns quickly. Managing dependencies for GPU-enabled deep learning frameworks can be tedious (cuda drivers, cuda versions, cudnn versions, framework versions). Bitfusion can help alleviate a lot of these issues with our AMIs and docker containers Performance CPU: Images per second ~ 40 Time to 85% accuracy ~ GPU: Images per second ~ 1420 Time to 85% accuracy ~ Note: CPU can be sped up on more CPU focused machines. When going from CPU to GPU, it can be hugely beneficial to explicitly put data tasks on CPU and number crunching (gradient calculations) on GPUs with tf.device().
17 TensorFlow - Single Server Multi-GPU Implementation Details For this example we used 3 GPUs on a single machine (p2.8xlarge) Performance Images per second ~ 3200 Time to 85% accuracy ~ Code Changes Need to write code to define device placement with tf.device() Write code to calculate gradients on each GPU and then calculates an average gradient for the update
18 Either a cluster manager needs to be set up or jobs need to be kicked off individually on workers and parameter servers Distributed TensorFlow Implementation Details For this example we used 1 parameter server and 3 worker servers. Performance Images per second ~ 2250 Time to 85% accuracy ~ We used EFS, but other shared file systems or native file systems could be used Code Changes Need to write code to define a parameter server and worker server Need to implement special session: tf.monitoredsession()
19 TensorFlow on Spark Implementation Details For this example we used 1 parameter server and 3 worker servers. Performance Images per second ~ 2450 Time to 85% accuracy ~ Requires data to be placed in HDFS Code Changes TensorFlow on Spark requires renaming a few TF variables from a vanilla distributed TF implementation. (tf.train.server() becomes TFNode.start_cluster_server(), etc.) Need to understand multiple utils for reading/writing to HDFS

20 Performance Summary It should be noted again that the CPU performance is on a p2.xlarge For this example, local communication through multi-gpu is much more efficient than distributed communication TensorFlow on Spark provided speedups in the distributed setting (most likely from RDMA) For each processing step the effective batch size is identical (125 images for single GPU/CPU and 42 for the 3 GPU and 3 server distributed)
21 When to Use What and Practical Considerations
22 Practical Considerations Size of Data If the size of the input data is especially large (large images for example) the entire model might not fit onto a single GPU If the number of records is prohibitively large a shared file system or database might be required If the number of records is large convergence can be sped up using multiple GPUs or distributed models Size of Model If the size of the network is larger than your GPU s memory, splitting the model across multi-gpus (model parallel)
23 Number of Updates Practical Considerations Continued If the number of updates and the size of the updates are considerable, multiple GPU configurations on a single server should be Hardware Configurations Network speeds play a crucial role in distributed model settings GPUs connected with RDMA over Infiniband have shown significant speedup over more basic grpc over ethernet
24 Use multiple channels simultaneously where applicable: PCIe, multiple IB ports grpc vs RDMA vs MPI grpc and MPI are possible transports for distributed TF, however: Continued grpc latency is us/msg due to userspace <-> kernel switches MPI latency is 1-3us/message due to OS bypass, but requires communications to be serialized to a single thread. Otherwise, us latency TensorFlow typically spawns ~100 threads making MPI suboptimal Our approach, powered by Bitfusion Core compute virtualization engine, is to use native IB verbs + RDMA for the primary transport 1-3 us per message across all threads of execution
25 Key Takeaways and Future Work Key Takeaways GPUs are almost always better Saturating GPUs locally should be a priority before going to a distributed setting If your data is already built on Spark TensorFlow on Spark provides an easy way to integrate If you want to get the most recent TensorFlow features, TFoS has a version release delay Future Work Use TensorFlow on Spark on our Dell Infiniband cluster
26 Questions?
Characterizing and Benchmarking Deep Learning Systems on Modern Data Center Architectures
 Characterizing and Benchmarking Deep Learning Systems on Modern Data Center Architectures Talk at Bench 2018 by Xiaoyi Lu The Ohio State University E-mail: luxi@cse.ohio-state.edu http://www.cse.ohio-state.edu/~luxi
Characterizing and Benchmarking Deep Learning Systems on Modern Data Center Architectures Talk at Bench 2018 by Xiaoyi Lu The Ohio State University E-mail: luxi@cse.ohio-state.edu http://www.cse.ohio-state.edu/~luxi
The Evolution of Big Data Platforms and Data Science
 IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
IBM Analytics The Evolution of Big Data Platforms and Data Science ECC Conference 2016 Brandon MacKenzie June 13, 2016 2016 IBM Corporation Hello, I m Brandon MacKenzie. I work at IBM. Data Science - Offering
Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda
 Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda 1 Motivation And Intro Programming Model Spark Data Transformation Model Construction Model Training Model Inference Execution Model Data Parallel Training
Pouya Kousha Fall 2018 CSE 5194 Prof. DK Panda 1 Motivation And Intro Programming Model Spark Data Transformation Model Construction Model Training Model Inference Execution Model Data Parallel Training
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems
 S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
S8765 Performance Optimization for Deep- Learning on the Latest POWER Systems Khoa Huynh Senior Technical Staff Member (STSM), IBM Jonathan Samn Software Engineer, IBM Evolving from compute systems to
WITH INTEL TECHNOLOGIES
 WITH INTEL TECHNOLOGIES Commitment Is to Enable The Best Democratize technologies Advance solutions Unleash innovations Intel Xeon Scalable Processor Family Delivers Ideal Enterprise Solutions NEW Intel
WITH INTEL TECHNOLOGIES Commitment Is to Enable The Best Democratize technologies Advance solutions Unleash innovations Intel Xeon Scalable Processor Family Delivers Ideal Enterprise Solutions NEW Intel
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
High-Performance Training for Deep Learning and Computer Vision HPC
 High-Performance Training for Deep Learning and Computer Vision HPC Panel at CVPR-ECV 18 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
High-Performance Training for Deep Learning and Computer Vision HPC Panel at CVPR-ECV 18 by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu http://www.cse.ohio-state.edu/~panda
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Onto Petaflops with Kubernetes
 Onto Petaflops with Kubernetes Vishnu Kannan Google Inc. vishh@google.com Key Takeaways Kubernetes can manage hardware accelerators at Scale Kubernetes provides a playground for ML ML journey with Kubernetes
Onto Petaflops with Kubernetes Vishnu Kannan Google Inc. vishh@google.com Key Takeaways Kubernetes can manage hardware accelerators at Scale Kubernetes provides a playground for ML ML journey with Kubernetes
NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS
 TECHNICAL OVERVIEW NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS A Guide to the Optimized Framework Containers on NVIDIA GPU Cloud Introduction Artificial intelligence is helping to solve some of the most
TECHNICAL OVERVIEW NVIDIA GPU CLOUD DEEP LEARNING FRAMEWORKS A Guide to the Optimized Framework Containers on NVIDIA GPU Cloud Introduction Artificial intelligence is helping to solve some of the most
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Scalable Tools - Part I Introduction to Scalable Tools
 Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Data Analytics and Machine Learning: From Node to Cluster
 Data Analytics and Machine Learning: From Node to Cluster Presented by Viswanath Puttagunta Ganesh Raju Understanding use cases to optimize on ARM Ecosystem Date BKK16-404B March 10th, 2016 Event Linaro
Data Analytics and Machine Learning: From Node to Cluster Presented by Viswanath Puttagunta Ganesh Raju Understanding use cases to optimize on ARM Ecosystem Date BKK16-404B March 10th, 2016 Event Linaro
Managing Deep Learning Workflows
 Managing Deep Learning Workflows Deep Learning on AWS Batch treske@amazon.de September 2017 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Business Understanding Data Understanding
Managing Deep Learning Workflows Deep Learning on AWS Batch treske@amazon.de September 2017 2017, Amazon Web Services, Inc. or its Affiliates. All rights reserved. Business Understanding Data Understanding
Why AI Frameworks Need (not only) RDMA?
 RDMA?") Why AI Frameworks Need (not only) RDMA? With Design and Implementation Experience of Networking Support on TensorFlow GDR, Apache MXNet, WeChat Amber, and Tencent Angel Bairen Yi (byi@connect.ust.hk) Jingrong
Why AI Frameworks Need (not only) RDMA? With Design and Implementation Experience of Networking Support on TensorFlow GDR, Apache MXNet, WeChat Amber, and Tencent Angel Bairen Yi (byi@connect.ust.hk) Jingrong
Machine Learning In A Snap. Thomas Parnell Research Staff Member IBM Research - Zurich
 Machine Learning In A Snap Thomas Parnell Research Staff Member IBM Research - Zurich What are GLMs? Ridge Regression Support Vector Machines Regression Generalized Linear Models Classification Lasso Regression
Machine Learning In A Snap Thomas Parnell Research Staff Member IBM Research - Zurich What are GLMs? Ridge Regression Support Vector Machines Regression Generalized Linear Models Classification Lasso Regression
TensorFlowOnSpark Scalable TensorFlow Learning on Spark Clusters Lee Yang, Andrew Feng Yahoo Big Data ML Platform Team
 TensorFlowOnSpark Scalable TensorFlow Learning on Spark Clusters Lee Yang, Andrew Feng Yahoo Big Data ML Platform Team What is TensorFlowOnSpark Why TensorFlowOnSpark at Yahoo? Major contributor to open-source
TensorFlowOnSpark Scalable TensorFlow Learning on Spark Clusters Lee Yang, Andrew Feng Yahoo Big Data ML Platform Team What is TensorFlowOnSpark Why TensorFlowOnSpark at Yahoo? Major contributor to open-source
Scaled Machine Learning at Matroid
 Scaled Machine Learning at Matroid Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Machine Learning Pipeline Learning Algorithm Replicate model Data Trained Model Serve Model Repeat entire pipeline Scaling
Scaled Machine Learning at Matroid Reza Zadeh @Reza_Zadeh http://reza-zadeh.com Machine Learning Pipeline Learning Algorithm Replicate model Data Trained Model Serve Model Repeat entire pipeline Scaling
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Review: The best frameworks for machine learning and deep learning
 Review: The best frameworks for machine learning and deep learning infoworld.com/article/3163525/analytics/review-the-best-frameworks-for-machine-learning-and-deep-learning.html By Martin Heller Over the
Review: The best frameworks for machine learning and deep learning infoworld.com/article/3163525/analytics/review-the-best-frameworks-for-machine-learning-and-deep-learning.html By Martin Heller Over the
NVIDIA DLI HANDS-ON TRAINING COURSE CATALOG
 NVIDIA DLI HANDS-ON TRAINING COURSE CATALOG Valid Through July 31, 2018 INTRODUCTION The NVIDIA Deep Learning Institute (DLI) trains developers, data scientists, and researchers on how to use artificial
NVIDIA DLI HANDS-ON TRAINING COURSE CATALOG Valid Through July 31, 2018 INTRODUCTION The NVIDIA Deep Learning Institute (DLI) trains developers, data scientists, and researchers on how to use artificial
Big Data. Big Data Analyst. Big Data Engineer. Big Data Architect
 Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Big Data Big Data Analyst INTRODUCTION TO BIG DATA ANALYTICS ANALYTICS PROCESSING TECHNIQUES DATA TRANSFORMATION & BATCH PROCESSING REAL TIME (STREAM) DATA PROCESSING Big Data Engineer BIG DATA FOUNDATION
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Python based Data Science on Cray Platforms Rob Vesse, Alex Heye, Mike Ringenburg - Cray Inc C O M P U T E S T O R E A N A L Y Z E
 Python based Data Science on Cray Platforms Rob Vesse, Alex Heye, Mike Ringenburg - Cray Inc Overview Supported Technologies Cray PE Python Support Shifter Urika-XC Anaconda Python Spark Intel BigDL machine
Python based Data Science on Cray Platforms Rob Vesse, Alex Heye, Mike Ringenburg - Cray Inc Overview Supported Technologies Cray PE Python Support Shifter Urika-XC Anaconda Python Spark Intel BigDL machine
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Backtesting with Spark
 Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Backtesting with Spark Patrick Angeles, Cloudera Sandy Ryza, Cloudera Rick Carlin, Intel Sheetal Parade, Intel 1 Traditional Grid Shared storage Storage and compute scale independently Bottleneck on I/O
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
A performance comparison of Deep Learning frameworks on KNL
 A performance comparison of Deep Learning frameworks on KNL R. Zanella, G. Fiameni, M. Rorro Middleware, Data Management - SCAI - CINECA IXPUG Bologna, March 5, 2018 Table of Contents 1. Problem description
A performance comparison of Deep Learning frameworks on KNL R. Zanella, G. Fiameni, M. Rorro Middleware, Data Management - SCAI - CINECA IXPUG Bologna, March 5, 2018 Table of Contents 1. Problem description
Accelerating Spark Workloads using GPUs
 Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Accelerating Spark Workloads using GPUs Rajesh Bordawekar, Minsik Cho, Wei Tan, Benjamin Herta, Vladimir Zolotov, Alexei Lvov, Liana Fong, and David Kung IBM T. J. Watson Research Center 1 Outline Spark
Efficient Communication Library for Large-Scale Deep Learning
 IBM Research AI Efficient Communication Library for Large-Scale Deep Learning Mar 26, 2018 Minsik Cho (minsikcho@us.ibm.com) Deep Learning changing Our Life Automotive/transportation Security/public safety
IBM Research AI Efficient Communication Library for Large-Scale Deep Learning Mar 26, 2018 Minsik Cho (minsikcho@us.ibm.com) Deep Learning changing Our Life Automotive/transportation Security/public safety
Big Data Meets HPC: Exploiting HPC Technologies for Accelerating Big Data Processing and Management
 Big Data Meets HPC: Exploiting HPC Technologies for Accelerating Big Data Processing and Management SigHPC BigData BoF (SC 17) by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu
Big Data Meets HPC: Exploiting HPC Technologies for Accelerating Big Data Processing and Management SigHPC BigData BoF (SC 17) by Dhabaleswar K. (DK) Panda The Ohio State University E-mail: panda@cse.ohio-state.edu
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Integrate MATLAB Analytics into Enterprise Applications
 Integrate Analytics into Enterprise Applications Aurélie Urbain MathWorks Consulting Services 2015 The MathWorks, Inc. 1 Data Analytics Workflow Data Acquisition Data Analytics Analytics Integration Business
Integrate Analytics into Enterprise Applications Aurélie Urbain MathWorks Consulting Services 2015 The MathWorks, Inc. 1 Data Analytics Workflow Data Acquisition Data Analytics Analytics Integration Business
CERN openlab & IBM Research Workshop Trip Report
 CERN openlab & IBM Research Workshop Trip Report Jakob Blomer, Javier Cervantes, Pere Mato, Radu Popescu 2018-12-03 Workshop Organization 1 full day at IBM Research Zürich ~25 participants from CERN ~10
CERN openlab & IBM Research Workshop Trip Report Jakob Blomer, Javier Cervantes, Pere Mato, Radu Popescu 2018-12-03 Workshop Organization 1 full day at IBM Research Zürich ~25 participants from CERN ~10
IBM Deep Learning Solutions
 IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
IBM Deep Learning Solutions Reference Architecture for Deep Learning on POWER8, P100, and NVLink October, 2016 How do you teach a computer to Perceive? 2 Deep Learning: teaching Siri to recognize a bicycle
Unifying Big Data Workloads in Apache Spark
 Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Unifying Big Data Workloads in Apache Spark Hossein Falaki @mhfalaki Outline What s Apache Spark Why Unification Evolution of Unification Apache Spark + Databricks Q & A What s Apache Spark What is Apache
Harp-DAAL for High Performance Big Data Computing
 Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
IBM Data Science Experience White paper. SparkR. Transforming R into a tool for big data analytics
 IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
IBM Data Science Experience White paper R Transforming R into a tool for big data analytics 2 R Executive summary This white paper introduces R, a package for the R statistical programming language that
Bare Metal Library. Abstractions for modern hardware Cyprien Noel
 Bare Metal Library Abstractions for modern hardware Cyprien Noel Plan 1. 2. 3. Modern Hardware? New challenges & opportunities Three use cases Current solutions Leveraging hardware Simple abstraction Myself
Bare Metal Library Abstractions for modern hardware Cyprien Noel Plan 1. 2. 3. Modern Hardware? New challenges & opportunities Three use cases Current solutions Leveraging hardware Simple abstraction Myself
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Apache Spark 2 X Cookbook Cloud Ready Recipes For Analytics And Data Science
 Apache Spark 2 X Cookbook Cloud Ready Recipes For Analytics And Data Science We have made it easy for you to find a PDF Ebooks without any digging. And by having access to our ebooks online or by storing
Apache Spark 2 X Cookbook Cloud Ready Recipes For Analytics And Data Science We have made it easy for you to find a PDF Ebooks without any digging. And by having access to our ebooks online or by storing
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Machine Learning for Large-Scale Data Analysis and Decision Making A. Distributed Machine Learning Week #9
 Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Distributed Machine Learning Week #9 Today Distributed computing for machine learning Background MapReduce/Hadoop & Spark Theory
Machine Learning for Large-Scale Data Analysis and Decision Making 80-629-17A Distributed Machine Learning Week #9 Today Distributed computing for machine learning Background MapReduce/Hadoop & Spark Theory
TensorFlow: A System for Learning-Scale Machine Learning. Google Brain
 TensorFlow: A System for Learning-Scale Machine Learning Google Brain The Problem Machine learning is everywhere This is in large part due to: 1. Invention of more sophisticated machine learning models
TensorFlow: A System for Learning-Scale Machine Learning Google Brain The Problem Machine learning is everywhere This is in large part due to: 1. Invention of more sophisticated machine learning models
SCALABLE DISTRIBUTED DEEP LEARNING
 SEOUL Oct.7, 2016 SCALABLE DISTRIBUTED DEEP LEARNING Han Hee Song, PhD Soft On Net 10/7/2016 BATCH PROCESSING FRAMEWORKS FOR DL Data parallelism provides efficient big data processing: data collecting,
SEOUL Oct.7, 2016 SCALABLE DISTRIBUTED DEEP LEARNING Han Hee Song, PhD Soft On Net 10/7/2016 BATCH PROCESSING FRAMEWORKS FOR DL Data parallelism provides efficient big data processing: data collecting,
Twitter data Analytics using Distributed Computing
 Twitter data Analytics using Distributed Computing Uma Narayanan Athrira Unnikrishnan Dr. Varghese Paul Dr. Shelbi Joseph Research Scholar M.tech Student Professor Assistant Professor Dept. of IT, SOE
Twitter data Analytics using Distributed Computing Uma Narayanan Athrira Unnikrishnan Dr. Varghese Paul Dr. Shelbi Joseph Research Scholar M.tech Student Professor Assistant Professor Dept. of IT, SOE
Contents PART I: CLOUD, BIG DATA, AND COGNITIVE COMPUTING 1
 Preface xiii PART I: CLOUD, BIG DATA, AND COGNITIVE COMPUTING 1 1 Princi ples of Cloud Computing Systems 3 1.1 Elastic Cloud Systems for Scalable Computing 3 1.1.1 Enabling Technologies for Cloud Computing
Preface xiii PART I: CLOUD, BIG DATA, AND COGNITIVE COMPUTING 1 1 Princi ples of Cloud Computing Systems 3 1.1 Elastic Cloud Systems for Scalable Computing 3 1.1.1 Enabling Technologies for Cloud Computing
CafeGPI. Single-Sided Communication for Scalable Deep Learning
 CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
CafeGPI Single-Sided Communication for Scalable Deep Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Deep Neural Networks
Sharing High-Performance Devices Across Multiple Virtual Machines
 Sharing High-Performance Devices Across Multiple Virtual Machines Preamble What does sharing devices across multiple virtual machines in our title mean? How is it different from virtual networking / NSX,
Sharing High-Performance Devices Across Multiple Virtual Machines Preamble What does sharing devices across multiple virtual machines in our title mean? How is it different from virtual networking / NSX,
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay Mellanox Technologies
 Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
Spark Over RDMA: Accelerate Big Data SC Asia 2018 Ido Shamay 1 Apache Spark - Intro Spark within the Big Data ecosystem Data Sources Data Acquisition / ETL Data Storage Data Analysis / ML Serving 3 Apache
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI
 NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
NVIDIA DGX SYSTEMS PURPOSE-BUILT FOR AI Overview Unparalleled Value Product Portfolio Software Platform From Desk to Data Center to Cloud Summary AI researchers depend on computing performance to gain
NVIDIA DEEP LEARNING INSTITUTE
 NVIDIA DEEP LEARNING INSTITUTE TRAINING CATALOG Valid Through July 31, 2018 INTRODUCTION The NVIDIA Deep Learning Institute (DLI) trains developers, data scientists, and researchers on how to use artificial
NVIDIA DEEP LEARNING INSTITUTE TRAINING CATALOG Valid Through July 31, 2018 INTRODUCTION The NVIDIA Deep Learning Institute (DLI) trains developers, data scientists, and researchers on how to use artificial
MATLAB. Senior Application Engineer The MathWorks Korea The MathWorks, Inc. 2
 1 Senior Application Engineer The MathWorks Korea 2017 The MathWorks, Inc. 2 Data Analytics Workflow Business Systems Smart Connected Systems Data Acquisition Engineering, Scientific, and Field Business
1 Senior Application Engineer The MathWorks Korea 2017 The MathWorks, Inc. 2 Data Analytics Workflow Business Systems Smart Connected Systems Data Acquisition Engineering, Scientific, and Field Business
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Democratizing Machine Learning on Kubernetes
 Democratizing Machine Learning on Kubernetes Joy Qiao, Senior Solution Architect - AI and Research Group, Microsoft Lachlan Evenson - Principal Program Manager AKS/ACS, Microsoft Who are we? The Data Scientist
Democratizing Machine Learning on Kubernetes Joy Qiao, Senior Solution Architect - AI and Research Group, Microsoft Lachlan Evenson - Principal Program Manager AKS/ACS, Microsoft Who are we? The Data Scientist
Deep Learning mit PowerAI - Ein Überblick
 Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
Stephen Lutz Deep Learning mit PowerAI - Open Group Master Certified IT Specialist Technical Sales IBM Cognitive Infrastructure IBM Germany Ein Überblick Stephen.Lutz@de.ibm.com What s that? and what s
Matrix Computations and " Neural Networks in Spark
 Matrix Computations and " Neural Networks in Spark Reza Zadeh Paper: http://arxiv.org/abs/1509.02256 Joint work with many folks on paper. @Reza_Zadeh http://reza-zadeh.com Training Neural Networks Datasets
Matrix Computations and " Neural Networks in Spark Reza Zadeh Paper: http://arxiv.org/abs/1509.02256 Joint work with many folks on paper. @Reza_Zadeh http://reza-zadeh.com Training Neural Networks Datasets
Asynchronous Stochastic Gradient Descent on GPU: Is It Really Better than CPU?
 Asynchronous Stochastic Gradient Descent on GPU: Is It Really Better than CPU? Florin Rusu Yujing Ma, Martin Torres (Ph.D. students) University of California Merced Machine Learning (ML) Boom Two SIGMOD
Asynchronous Stochastic Gradient Descent on GPU: Is It Really Better than CPU? Florin Rusu Yujing Ma, Martin Torres (Ph.D. students) University of California Merced Machine Learning (ML) Boom Two SIGMOD
Scaling Distributed Machine Learning
 Scaling Distributed Machine Learning with System and Algorithm Co-design Mu Li Thesis Defense CSD, CMU Feb 2nd, 2017 nx min w f i (w) Distributed systems i=1 Large scale optimization methods Large-scale
Scaling Distributed Machine Learning with System and Algorithm Co-design Mu Li Thesis Defense CSD, CMU Feb 2nd, 2017 nx min w f i (w) Distributed systems i=1 Large scale optimization methods Large-scale
Toward Scalable Deep Learning
 한국정보과학회 인공지능소사이어티 머신러닝연구회 두번째딥러닝워크샵 2015.10.16 Toward Scalable Deep Learning 윤성로 Electrical and Computer Engineering Seoul National University http://data.snu.ac.kr Breakthrough: Big Data + Machine Learning
한국정보과학회 인공지능소사이어티 머신러닝연구회 두번째딥러닝워크샵 2015.10.16 Toward Scalable Deep Learning 윤성로 Electrical and Computer Engineering Seoul National University http://data.snu.ac.kr Breakthrough: Big Data + Machine Learning
Keras: Handwritten Digit Recognition using MNIST Dataset
 Keras: Handwritten Digit Recognition using MNIST Dataset IIT PATNA January 31, 2018 1 / 30 OUTLINE 1 Keras: Introduction 2 Installing Keras 3 Keras: Building, Testing, Improving A Simple Network 2 / 30
Keras: Handwritten Digit Recognition using MNIST Dataset IIT PATNA January 31, 2018 1 / 30 OUTLINE 1 Keras: Introduction 2 Installing Keras 3 Keras: Building, Testing, Improving A Simple Network 2 / 30
Defense Data Generation in Distributed Deep Learning System Se-Yoon Oh / ADD-IDAR
 Defense Data Generation in Distributed Deep Learning System Se-Yoon Oh / 2017. 10. 31 syoh@add.re.kr Page 1/36 Overview 1. Introduction 2. Data Generation Synthesis 3. Distributed Deep Learning 4. Conclusions
Defense Data Generation in Distributed Deep Learning System Se-Yoon Oh / 2017. 10. 31 syoh@add.re.kr Page 1/36 Overview 1. Introduction 2. Data Generation Synthesis 3. Distributed Deep Learning 4. Conclusions
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop, Yarn and Beyond
 Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
Hadoop, Yarn and Beyond 1 B. R A M A M U R T H Y Overview We learned about Hadoop1.x or the core. Just like Java evolved, Java core, Java 1.X, Java 2.. So on, software and systems evolve, naturally.. Lets
Deep learning prevalence. first neuroscience department. Spiking Neuron Operant conditioning First 1 Billion transistor processor
 WELCOME TO Operant conditioning 1938 Spiking Neuron 1952 first neuroscience department 1964 Deep learning prevalence mid 2000s The Turing Machine 1936 Transistor 1947 First computer science department
WELCOME TO Operant conditioning 1938 Spiking Neuron 1952 first neuroscience department 1964 Deep learning prevalence mid 2000s The Turing Machine 1936 Transistor 1947 First computer science department
Khadija Souissi. Auf z Systems November IBM z Systems Mainframe Event 2016
 Khadija Souissi Auf z Systems 07. 08. November 2016 @ IBM z Systems Mainframe Event 2016 Acknowledgements Apache Spark, Spark, Apache, and the Spark logo are trademarks of The Apache Software Foundation.
Khadija Souissi Auf z Systems 07. 08. November 2016 @ IBM z Systems Mainframe Event 2016 Acknowledgements Apache Spark, Spark, Apache, and the Spark logo are trademarks of The Apache Software Foundation.
Scaling MATLAB. for Your Organisation and Beyond. Rory Adams The MathWorks, Inc. 1
 Scaling MATLAB for Your Organisation and Beyond Rory Adams 2015 The MathWorks, Inc. 1 MATLAB at Scale Front-end scaling Scale with increasing access requests Back-end scaling Scale with increasing computational
Scaling MATLAB for Your Organisation and Beyond Rory Adams 2015 The MathWorks, Inc. 1 MATLAB at Scale Front-end scaling Scale with increasing access requests Back-end scaling Scale with increasing computational
Deploying Machine Learning Models in Practice
 Deploying Machine Learning Models in Practice Nick Pentreath Principal Engineer @MLnick About @MLnick on Twitter & Github Principal Engineer, IBM CODAIT - Center for Open-Source Data & AI Technologies
Deploying Machine Learning Models in Practice Nick Pentreath Principal Engineer @MLnick About @MLnick on Twitter & Github Principal Engineer, IBM CODAIT - Center for Open-Source Data & AI Technologies
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Machine Learning With Python. Bin Chen Nov. 7, 2017 Research Computing Center
 Machine Learning With Python Bin Chen Nov. 7, 2017 Research Computing Center Outline Introduction to Machine Learning (ML) Introduction to Neural Network (NN) Introduction to Deep Learning NN Introduction
Machine Learning With Python Bin Chen Nov. 7, 2017 Research Computing Center Outline Introduction to Machine Learning (ML) Introduction to Neural Network (NN) Introduction to Deep Learning NN Introduction
Data Science and Open Source Software. Iraklis Varlamis Assistant Professor Harokopio University of Athens
 Data Science and Open Source Software Iraklis Varlamis Assistant Professor Harokopio University of Athens varlamis@hua.gr What is data science? 2 Why data science is important? More data (volume, variety,...)
Data Science and Open Source Software Iraklis Varlamis Assistant Professor Harokopio University of Athens varlamis@hua.gr What is data science? 2 Why data science is important? More data (volume, variety,...)
Integrate MATLAB Analytics into Enterprise Applications
 Integrate Analytics into Enterprise Applications Lyamine Hedjazi 2015 The MathWorks, Inc. 1 Data Analytics Workflow Preprocessing Data Business Systems Build Algorithms Smart Connected Systems Take Decisions
Integrate Analytics into Enterprise Applications Lyamine Hedjazi 2015 The MathWorks, Inc. 1 Data Analytics Workflow Preprocessing Data Business Systems Build Algorithms Smart Connected Systems Take Decisions
Deploying Deep Learning Networks to Embedded GPUs and CPUs
 Deploying Deep Learning Networks to Embedded GPUs and CPUs Rishu Gupta, PhD Senior Application Engineer, Computer Vision 2015 The MathWorks, Inc. 1 MATLAB Deep Learning Framework Access Data Design + Train
Deploying Deep Learning Networks to Embedded GPUs and CPUs Rishu Gupta, PhD Senior Application Engineer, Computer Vision 2015 The MathWorks, Inc. 1 MATLAB Deep Learning Framework Access Data Design + Train
Integrate MATLAB Analytics into Enterprise Applications
 Integrate Analytics into Enterprise Applications Dr. Roland Michaely 2015 The MathWorks, Inc. 1 Data Analytics Workflow Access and Explore Data Preprocess Data Develop Predictive Models Integrate Analytics
Integrate Analytics into Enterprise Applications Dr. Roland Michaely 2015 The MathWorks, Inc. 1 Data Analytics Workflow Access and Explore Data Preprocess Data Develop Predictive Models Integrate Analytics
Apache SystemML Declarative Machine Learning
 Apache Big Data Seville 2016 Apache SystemML Declarative Machine Learning Luciano Resende About Me Luciano Resende (lresende@apache.org) Architect and community liaison at Have been contributing to open
Apache Big Data Seville 2016 Apache SystemML Declarative Machine Learning Luciano Resende About Me Luciano Resende (lresende@apache.org) Architect and community liaison at Have been contributing to open
Embarquez votre Intelligence Artificielle (IA) sur CPU, GPU et FPGA
 sur CPU, GPU et FPGA") Embarquez votre Intelligence Artificielle (IA) sur CPU, GPU et FPGA Pierre Nowodzienski Engineer pierre.nowodzienski@mathworks.fr 2018 The MathWorks, Inc. 1 From Data to Business value Make decisions Get
Embarquez votre Intelligence Artificielle (IA) sur CPU, GPU et FPGA Pierre Nowodzienski Engineer pierre.nowodzienski@mathworks.fr 2018 The MathWorks, Inc. 1 From Data to Business value Make decisions Get
Application Acceleration Beyond Flash Storage
 Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Application Acceleration Beyond Flash Storage Session 303C Mellanox Technologies Flash Memory Summit July 2014 Accelerating Applications, Step-by-Step First Steps Make compute fast Moore s Law Make storage
Towards Scalable Machine Learning
 Towards Scalable Machine Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Fraunhofer Center Machnine Larning Outline I Introduction
Towards Scalable Machine Learning Janis Keuper itwm.fraunhofer.de/ml Competence Center High Performance Computing Fraunhofer ITWM, Kaiserslautern, Germany Fraunhofer Center Machnine Larning Outline I Introduction
Activator Library. Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success.
 Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
Focus on maximizing the value of your data, gain business insights, increase your team s productivity, and achieve success. ACTIVATORS Designed to give your team assistance when you need it most without
HPC and AI Solution Overview. Garima Kochhar HPC and AI Innovation Lab
 HPC and AI Solution Overview Garima Kochhar HPC and AI Innovation Lab 1 Dell EMC HPC and DL team charter Design, develop and integrate HPC and DL Heading systems Lorem ipsum dolor sit amet, consectetur
HPC and AI Solution Overview Garima Kochhar HPC and AI Innovation Lab 1 Dell EMC HPC and DL team charter Design, develop and integrate HPC and DL Heading systems Lorem ipsum dolor sit amet, consectetur
Machine Learning on VMware vsphere with NVIDIA GPUs
 Machine Learning on VMware vsphere with NVIDIA GPUs Uday Kurkure, Hari Sivaraman, Lan Vu GPU Technology Conference 2017 2016 VMware Inc. All rights reserved. Gartner Hype Cycle for Emerging Technology
Machine Learning on VMware vsphere with NVIDIA GPUs Uday Kurkure, Hari Sivaraman, Lan Vu GPU Technology Conference 2017 2016 VMware Inc. All rights reserved. Gartner Hype Cycle for Emerging Technology
Cloud Computing 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Programming Systems for Big Data
 Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Programming Systems for Big Data CS315B Lecture 17 Including material from Kunle Olukotun Prof. Aiken CS 315B Lecture 17 1 Big Data We ve focused on parallel programming for computational science There
Large-Scale GPU programming
 Large-Scale GPU programming Tim Kaldewey Research Staff Member Database Technologies IBM Almaden Research Center tkaldew@us.ibm.com Assistant Adjunct Professor Computer and Information Science Dept. University
Large-Scale GPU programming Tim Kaldewey Research Staff Member Database Technologies IBM Almaden Research Center tkaldew@us.ibm.com Assistant Adjunct Professor Computer and Information Science Dept. University
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Employing HPC DEEP-EST for HEP Data Analysis. Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN)
, Maria Girone (CERN)") Employing HPC DEEP-EST for HEP Data Analysis Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN) 1 Outline The DEEP-EST Project Goals and Motivation HEP Data Analysis on HPC with Apache Spark on HPC
Employing HPC DEEP-EST for HEP Data Analysis Viktor Khristenko (CERN, DEEP-EST), Maria Girone (CERN) 1 Outline The DEEP-EST Project Goals and Motivation HEP Data Analysis on HPC with Apache Spark on HPC
OPERATIONALIZING MACHINE LEARNING USING GPU ACCELERATED, IN-DATABASE ANALYTICS
 OPERATIONALIZING MACHINE LEARNING USING GPU ACCELERATED, IN-DATABASE ANALYTICS 1 Why GPUs? A Tale of Numbers 100x Performance Increase Infrastructure Cost Savings Performance 100x gains over traditional
OPERATIONALIZING MACHINE LEARNING USING GPU ACCELERATED, IN-DATABASE ANALYTICS 1 Why GPUs? A Tale of Numbers 100x Performance Increase Infrastructure Cost Savings Performance 100x gains over traditional
Data Processing at the Speed of 100 Gbps using Apache Crail. Patrick Stuedi IBM Research
 Data Processing at the Speed of 100 Gbps using Apache Crail Patrick Stuedi IBM Research The CRAIL Project: Overview Data Processing Framework (e.g., Spark, TensorFlow, λ Compute) Spark-IO FS Albis Streaming
Data Processing at the Speed of 100 Gbps using Apache Crail Patrick Stuedi IBM Research The CRAIL Project: Overview Data Processing Framework (e.g., Spark, TensorFlow, λ Compute) Spark-IO FS Albis Streaming
HPE Deep Learning Cookbook: Recipes to Run Deep Learning Workloads. Natalia Vassilieva, Sergey Serebryakov
 HPE Deep Learning Cookbook: Recipes to Run Deep Learning Workloads Natalia Vassilieva, Sergey Serebryakov Deep learning ecosystem today Software Hardware 2 HPE s portfolio for deep learning Government,
HPE Deep Learning Cookbook: Recipes to Run Deep Learning Workloads Natalia Vassilieva, Sergey Serebryakov Deep learning ecosystem today Software Hardware 2 HPE s portfolio for deep learning Government,
Embedded Technosolutions
 Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
Hadoop Big Data An Important technology in IT Sector Hadoop - Big Data Oerie 90% of the worlds data was generated in the last few years. Due to the advent of new technologies, devices, and communication
New Developments in Spark
 New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
New Developments in Spark And Rethinking APIs for Big Data Matei Zaharia and many others What is Spark? Unified computing engine for big data apps > Batch, streaming and interactive Collection of high-level
Applied Spark. From Concepts to Bitcoin Analytics. Andrew F.
 Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Hardware and Software. Fei-Fei Li & Justin Johnson & Serena Yeung. Lecture 6-1
 Lecture 6: Hardware and Software Lecture 6-1 Administrative Assignment 1 was due yesterday. Assignment 2 is out, due Wed May 1. Project proposal due Wed April 24. Project-only office hours leading up to
Lecture 6: Hardware and Software Lecture 6-1 Administrative Assignment 1 was due yesterday. Assignment 2 is out, due Wed May 1. Project proposal due Wed April 24. Project-only office hours leading up to
MapReduce review. Spark and distributed data processing. Who am I? Today s Talk. Reynold Xin
 Who am I? Reynold Xin Stanford CS347 Guest Lecture Spark and distributed data processing PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD), UC Berkeley AMPLab Reynold
Who am I? Reynold Xin Stanford CS347 Guest Lecture Spark and distributed data processing PMC member, Apache Spark Cofounder & Chief Architect, Databricks PhD on leave (ABD), UC Berkeley AMPLab Reynold