Association Rules. Juliana Freire. Modified from Jeff Ullman, Jure Lescovek, Bing Liu, Jiawei Han
|
|
|
- Marcia Boyd
- 6 years ago
- Views:
Transcription
1 Association Rules Juliana Freire Modified from Jeff Ullman, Jure Lescovek, Bing Liu, Jiawei Han
2 Association Rules: Some History Bar code technology allowed retailers to collect massive volumes of sales data Basket data: transaction date, set of items bought Leverage information for marketing How to design coupons? How to organize shelves? Data is very large and stored in tertiary storage Current (as of 1993) database systems do not provide necessary functionality for a user interested in taking advantage of this information 2
3 Association Rules: Some History The birth of data mining! Agrawal et al. (SIGMOD 1993) introduced the problem Mining a large collection of basket data to discover association rules Many papers followed 3
4 Association Rules: Some History Any feeling of deja vu? GPS technology, massive volumes of Web data, user crowds, has allowed <government, companies, > to collect massive volumes of data Leverage information for marketing, to improve citizens lives, etc The birth of Big data! 4

5 Association Rules: Impact 5

6 Association Rules: Impact 6
7 Association Rule Discovery Supermarket shelf management: Goal: Identify items that are bought together by sufficiently many customers the frequent itemsets Items that co-occur more frequently than would be expected were the items bought independently Bread + milk is not surprising Hot dogs + mustard is not surprising either, but supermarkets can do clever marketing: hot dogs on sale and increase the price of mustard 7

8 Association Rule Discovery Supermarket shelf management: Goal: Identify items that are bought together by sufficiently many customers the frequent itemsets Approach: Process the sales data collected with barcode scanners to find dependencies among items A classic rule: If one buys diaper and milk, then she is likely to buy beer Don t be surprised if you find six-packs next to diapers!
9 The Market-Basket Model A large set of items, e.g., things sold in a supermarket I = {i 1, i 2,, i m } A much larger set of baskets/ transactions, e.g., the things one customer buys on one day t a set of items, and t I. Transaction Database T: a set of An average Walmart stores sells 120,000 items; Walmart processes 1M transaction every hour transactions T = {t 1, t 2,, t n }.
10 Market-Baskets and Associations A many-many mapping (association) between two kinds of objects. Identify connections among items, not baskets. E.g., 90% of transactions that purchase bread and butter also purchase milk The technology focuses on common events, not rare events ( long tail ) Why is this required for bricks and mortar but not for online retailers? 10
11 Applications Market Baskets Items = products; baskets = sets of products someone bought in one trip to the store. Real market baskets: Chain stores keep TBs of data about what customers buy together Tells how typical customers navigate stores, lets them position tempting items Place items close to each other, e.g., printer + laptop Place items far apart customer is likely to find/buy something interesting on the way Suggests tie-in tricks, e.g., run sale on diapers and raise the price of beer High support needed, or no $$ s Only useful if many buy diapers & beer. Amazon s people who bought X also bought Y 12
12 Applications Plagiarism Baskets = sentences; items = documents containing those sentences. Items that appear together too often could represent plagiarism. I love NYC {d1, d3, d5} The subway is slow {d1, d3} Notice items do not have to be in baskets. 13
13 Applications Drugs/Side Effects Baskets = patients; Items = drugs & side-effects Has been used to detect combinations of drugs that result in particular side-effects But requires extension: Absence of an item needs to be observed as well as presence 14
14 Applications Related Concepts Baskets = Web pages; items = words. Unusual words appearing together in a large number of documents, e.g., Brad and Angelina, may indicate an interesting relationship. 15
15 Association Rules: Approach Given a set of baskets, discover association rules People who bought {a,b,c} tend to buy {d,e} 2-step approach Find frequent itemsets Generate association rules 16
16 Why Is Frequent Pattern Mining Important? Finding inherent regularities in data: Discloses an intrinsic and important property of data sets Forms the foundation for many essential data mining tasks Association, correlation, and causality analysis Sequential, structural (e.g., sub-graph) patterns Pattern analysis in spatiotemporal, multimedia, timeseries, and stream data Cluster analysis: frequent pattern-based clustering
17 Scale of the Problem WalMart sells 120,000 items and can store billions of baskets. The Web has billions of words and many billions of pages. A big data problem! 18
18 Outline Define: Frequent itemsets Association rules: confidence, support, interestingness Algorithms for finding frequent itemsets 19
19 Frequent Itemsets Simplest question: find sets of items that appear frequently in the baskets. Support for itemset I = the number of baskets containing all items in I. Often expressed as a fraction of the total number of baskets Given a support threshold s, sets of items that appear in at least s baskets are called frequent itemsets. Support of {Beer, Bread} = 2 Support of {Coke, Milk} =? 20
20 Example: Frequent Itemsets Items={milk, coke, pepsi, beer, juice}. Support = 3 baskets. B 1 = {m, c, b} B 2 = {m, p, j} B 3 = {m, b} B 4 = {c, j} B 5 = {m, p, b} B 6 = {m, c, b, j} B 7 = {c, b, j} B 8 = {b, c} Frequent itemsets: {m}-5, {c}-5, {b}-4, {j}-4, {p}-2 How many doubletons can be frequent?, {b,c}, {c,j} {m,b} {m,p} {j,p} 21
21 The Market-Basket Model A transaction t contains X, a set of items (itemset) in I, if X t. An itemset is a set of items. E.g., X = {milk, bread, cereal} is an itemset. A k-itemset is an itemset with k items. E.g., {milk, bread, cereal} is a 3-itemset An association rule is an implication of the form: X Y, where X, Y I, and X Y = 22
22 Association Rules If-then rules about the contents of baskets. {i 1, i 2,,i k } j means: if a basket contains all of i 1,,i k then it is likely to contain j. Confidence of this association rule is the probability of j given i 1,,i k. 23
23 Example: Confidence B 1 = {m, c, b} B 2 = {m, p, j} B 3 = {m, b} B 4 = {c, j} B 5 = {m, p, b} B 6 = {m, c, b, j} B 7 = {c, b, j} B 8 = {b, c} An association rule: {m, b} c. Confidence = 2/4 = 50%. 24
24 Interesting Association Rules Not all high-confidence rules are interesting The rule Xà Milk may have high confidence for many itemsets X, because milk is purchased very often (independent of X) and the confidence will be very high Interest of an association rule Ià j is the difference between its confidence and the fraction of baskets that contain j Interest (Ià j) = conf(ià j) Pr[j] Interesting rules are those with high positive or negative interest values For uninteresting rules, the fraction of baskets containing j will be the same as the fraction of the subset baskets including {I,j}. So confidence will be high, but interest low 25
25 Example: Confidence and Interest B 1 = {m, c, b} B 2 = {m, p, j} B 3 = {m, b} B 4 = {c, j} B 5 = {m, p, b} B 6 = {m, c, b, j} B 7 = {c, b, j} B 8 = {b, c} An association rule: {m, b} c. Confidence = 2/4 = 50%. Interest ({m,b}à c) = Confidence ({m,b}à c) Pr[c] = 0.5 5/8 = 1/8 --- not very interesting Item c appears in 5/8 of the baskets 26
26 Example: Confidence and Interest {diapers} à beer The fraction of diaper-buyers that buy beer is significantly greater than the fraction of all customers that buy beer interest({diapers}à beer) = (support({diapers,beer})/support({diapers})) (support({beer})/num_baskets) {coke} à pepsi Negative interest people who buy coke are unlikely to also buy pepsi interest({coke}à pepsi) = (support({coke,pepsi})/support({coke})) (support({pepsi})/num_baskets) 27
27 Finding Association Rules Goal: Find all rules that satisfy the user-specified minimum support (minsup) and minimum confidence (minconf). Support >= s and confidence >=c For brick-and-mortar marketing: support of 1% is reasonably high confidence of 50% is adequate, otherwise rule has little practical effect Key Features Completeness: find all rules. Mining with data on hard disk (not in memory) 29
28 Mining Association Rules Two steps: 1) Find all itemsets I that have minimum support (frequent itemsets, also called large itemsets). 2) Rule generation: Use frequent itemsets to generate rules. For every subset A of I, generate rule A à I-A If I is frequent, then so is A Perform a single pass to compute the rule confidence Conf(A,Bà C,D) = supp(a,b,c,d)/supp(a,b) Can generate bigger rules from smaller ones Output rules above confidence threshold The hard part! 30
29 Example conf(ià j) = supp(i,j)/supp(i) B1 ={m,c,b} B2 = {m,p,j} B3 ={m,c,b,n} B4 = {c,j} B5 ={m,p,b} B6 = {m,c,b,j} B7 ={c,b,j} B8 = {b,c} Min support s = 3, confidence = ) Frequent itemsets {m} 5; {c} 6; {b} 6; {n} 1; {p} 2; {j} 4 {m,c} 3; {m,b} 4; {m,n} 1; ; {b,c} 5; {c,j} 3; {m,c,b} 3 2) Generate rules mà c: c=3/5 mà b: c=4/5 bà m: c=4/6 bà c: c=5/6 b,c à m: c=3/5 b,m à c: c=3/4 31
30 Computing Itemsets Back to finding frequent itemsets Typically, data is kept in flat files rather than in a database system: Stored on disk Stored basket-by-basket Baskets are small but we have many baskets and many items Expand baskets into pairs, triples, etc. as you read baskets Use k nested loops to generate all sets of size k Note: We want to find frequent itemsets. To find them, we have to count them. To count them, we have to generate them. Item Item Item Item Item Item Item Item Item Item Item Item Etc. Items are positive integers, and boundaries between baskets are 1. B1 B2 B3 32
31 Computing Itemsets Cost of mining is the number of disk I/Os Disk access costs: Seek time (milliseconds) Rotational latency (milliseconds) Transfer rate (100 MB/sec) RAM (nanoseconds): factor of 10 6 faster than disk In practice, association-rule algorithms read data in passes We measure the cost by the number of passes over the data Main memory bottleneck: As we read the baskets, we need to count the pairs, triples, The number of different things we can count is limited by main memory Swapping counts in/out is a disaster. Why? 33
32 Finding Frequent Pairs This is the hardest problem! Often, frequent pairs are common, frequent triples are rare The probability of being frequent drops with size We always need to generate all the itemsets But we would only like to count/keep track of those itemsets that in the end turn out to be frequent 34
33 Naïve Algorithm Read file once, counting in main memory the occurrences of each pair From each basket of n items, generate its n(n-1)/2 pairs using two nested loops Problem: fails if n 2 exceeds main memory 120K (Walmart); 10B (Web pages) 35
34 Example: Counting Pairs Suppose 10 5 items at Walmart Suppose counts are 4-byte integers. Number of pairs of items: 10 5 (10 5-1)/2 = 5*10 9 (approximately). Number of bytes: 4*5*10 9 = 2*10 10 (20 gigabytes) of main memory needed. 36
35 Details of Main-Memory Counting Two approaches: 1. Count all pairs, using a triangular matrix. requires only 4 bytes/pair. Note: always assume integers are 4 bytes. 2. Keep a table of triples [i, j, c] = the count of the pair of items {i, j } is c. requires 12 bytes, but only for those pairs with count > 0. 37
36 Comparing Approaches 4 per pair 12 per occurring pair Method (1) Method (2) 38
37 Triangular-Matrix Approach n = total number or items Requires table of size O(n) to convert item names to consecutive integers. Count {i, j } only if i < j. Keep pairs in the order {1,2}, {1,3},, {1,n }, {2,3}, {2,4},, {2,n }, {3,4},, {3,n }, {n -1,n }. Pair {i,j} is at position (i-1)(n-i/2) + j i Total number of pairs n(n-1)/2; total bytes 2n 2 39
38 Triangular-Matrix Approach 1,2 1,3 1,4 1,5 2,3 2,4 2,5 3,4 3,5 4,5 Pair {i, j} is at position (i 1)(n i/2) + j i {1,2}: = 1 {1,3} = = 2 {1,4} = = 3 {1,5} = = 4 {2,3} = (2-1)*(5-2/2) + 3 2= 5 {2,4} = (2-1)*(5-2/2) + 4 2= 6 {2,5} = (2-1)*(5-2/2) +5-2= 7 {3,4} = (3-1)*(5-3/2) +4-2= 8 40
39 Details of Approach #2 Total bytes used is about 12p, where p is the number of pairs that actually occur. [i, j, count] 3 integers are needed 12 bytes Save space by not storing triples for pairs with count=0 Beats triangular matrix if at most 1/3 of possible pairs actually occur Because it uses 3 times more memory per pair then matrix May require extra space for retrieval structure, e.g., a hash table. h(i,j) à count 41
40 A-Priori Algorithm (1) A two-pass approach called a-priori limits the need for main memory. Key idea: monotonicity If a set of items appears at least s times, so does every subset. The downward closure property of frequent patterns Any subset of a frequent itemset must be frequent If {beer, diaper, nuts} is frequent, so is {beer, diaper} i.e., every transaction having {beer, diaper, nuts} also contains {beer, diaper} Contrapositive for pairs: if item i does not appear in s baskets, then no pair including i can appear in s baskets. 42
41 A-Priori Algorithm (2) Candidate generation-and-test approach Apriori pruning principle: If there is any itemset which is infrequent, its superset should not be generated/tested! (Agrawal & 94, Mannila, et KDD 94) 43
42 Max-Patterns A long pattern contains a combinatorial number of subpatterns, e.g., {a 1,, a 100 } contains ( 1001 ) + ( 1002 ) + + ( ) = = 1.27*10 30 sub-patterns! Solution: Compact the output by mining max-patterns instead An itemset X is a max-pattern if X is frequent and there exists no frequent super-pattern Y כ X (proposed by SIGMOD 98) 45
43 Compacting the Output Maximal Frequent itemsets: no immediate superset is frequent Count Maximal ( A 4 No B 5 No C 3 No AB 4 Yes AC 2 No BC 3 Yes ABC 2 No S=3 BC is also frequent Frequent and its only superset ABC is not frequent 46
44 A-Priori Algorithm (3) Pass 1: Read baskets and count in main memory the occurrences of each item. Requires only memory proportional to #items n. Items that appear at least s times are the frequent items. Typical s=1% -- many singletons will be infrequent Pass 2: Read baskets again and count in main memory only those pairs both of which were found in Pass 1 to be frequent. Requires memory proportional to square of frequent items only (for counts) 2m 2 instead of 2n 2 Plus a list of the frequent items (so you know what must be counted). 52
45 The Apriori Algorithm An Example Sup Itemset sup Database TDB min = 2 {A} 2 L Tid Items C 1 1 {B} 3 10 A, C, D 20 B, C, E 30 A, B, C, E 40 B, E 1 st scan {C} 3 {D} 1 {E} 3 C 2 C 2 {A, B} 1 L 2 Itemset sup 2 nd scan {A, C} 2 {B, C} 2 {B, E} 3 {C, E} 2 Itemset sup {A, C} 2 {A, E} 1 {B, C} 2 {B, E} 3 {C, E} 2 Itemset sup {A} 2 {B} 3 {C} 3 {E} 3 Itemset {A, B} {A, C} {A, E} {B, C} {B, E} {C, E} C Itemset 3 3 rd scan L 3 {B, C, E} Itemset sup {B, C, E} 2 53


46 The Apriori Algorithm An Example Sup Itemset sup Database TDB min = 2 {A} 2 L Tid Items C 1 1 {B} 3 10 A, C, D 20 B, C, E 1 st {C} 3 Should scan we count: {D} 1 ABC 30 A, B, C, E {E} 3 ACE 40 B, E C 2 C 2 {A, B} 1 L 2 Itemset sup 2 nd scan {A, C} 2 {B, C} 2 {B, E} 3 {C, E} 2 Itemset sup {A, C} 2 {A, E} 1 {B, C} 2 {B, E} 3 {C, E} 2 Itemset sup {A} 2 {B} 3 {C} 3 {E} 3 Itemset {A, B} {A, C} {A, E} {B, C} {B, E} {C, E} C Itemset 3 3 rd scan L 3 {B, C, E} Itemset sup {B, C, E} 2 54

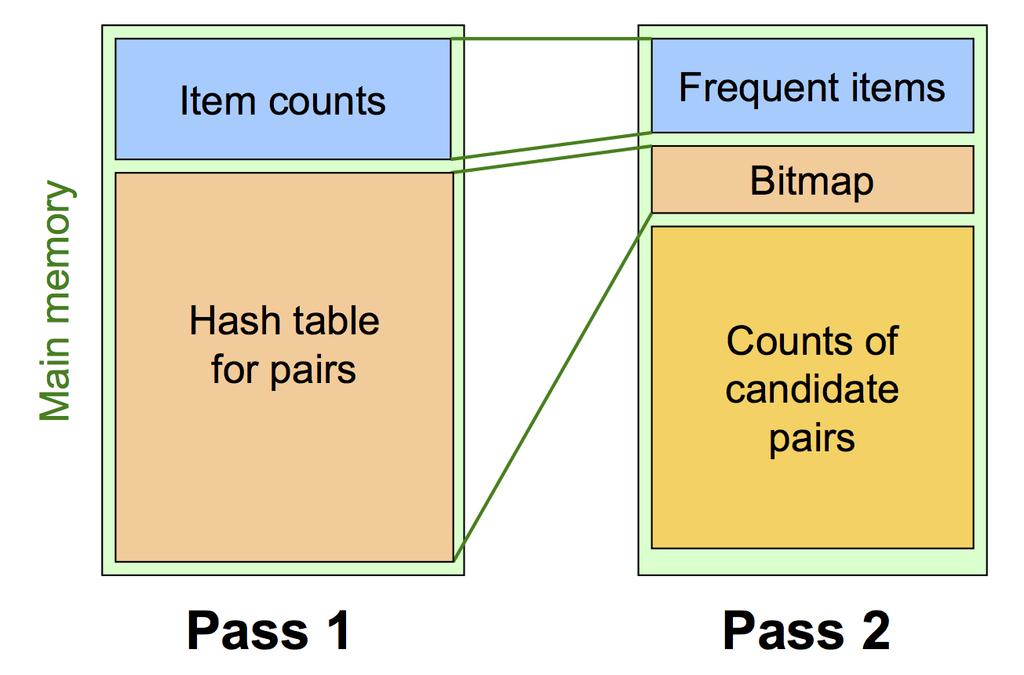
47 Main-Memory Picture of A-Priori n Item counts Frequent items m < n Counts of pairs of frequent items Pass 1 Pass 2 55
48 Detail for A-Priori You can use the triangular matrix method with m = number of frequent items. May save space compared with storing triples. Item counts Frequent items Old item #s Trick: re-number frequent items 1,2, and keep a table relating new numbers to original item numbers. Main memory Counts of pairs of Counts frequent of pairs items of frequent items Pass 1 Pass 2 56
49 Frequent Triples, Etc. For each k, we construct two sets of k tuples (sets of size k ): C k = candidate k -sets = those that might be frequent sets (support > s ) based on information from the pass for k 1. L k = the set of truly frequent k -sets. 57
50 Frequent Triples, Etc. All items Count the items All pairs of items from L 1 Count the pairs To be explained C 1 Filter L 1 Construct C 2 Filter L 2 Construct C 3 First pass Second pass Frequent items Frequent pairs 58
51 How to Generate Candidates? Suppose the items in L k-1 are listed in an order Step 1: self-joining L k-1 insert into C k select p.item 1, p.item 2,, p.item k-1, q.item k-1 from L k-1 p, L k-1 q where p.item 1 =q.item 1,, p.item k-2 =q.item k-2, p.item k-1 < q.item k-1 Step 2: pruning use A-Priori property! forall itemsets c in C k do forall (k-1)-subsets s of c do if (s is not in L k-1 ) then delete c from C k {A,C} {B,C} {B,E} {C,E} à {A,B,C} {A,C,E} {B,C,E} X X sup=2 59
52 A-Priori for All Frequent Itemsets One pass for each k. Needs room in main memory to count each candidate k -set. For typical market-basket data and reasonable support (e.g., 1%), k = 2 requires the most memory. 60
53 A-Priori for All Frequent Itemsets Many possible extensions: Lower the support s as itemset gets bigger Association rules with intervals: For example: Men over 65 have 2 cars Association rules when items are in a taxonomy Bread, Butter FruitJam BakedGoods, MilkProduct PreservedGoods 63
54 Improvements to A-Priori 65 Modified Slides by Jeff Ullman
55 Association Rules: Not enough memory Counting for candidates C2 requires a lot of memory -- O(n 2 ) Can we do better? 1. PCY: In pass 1, there is a lot of memory left, leverage that to help with pass 2 Maintain a hash table with as many buckets as fit in memory Keep count for each bucket into which pairs of items are hashed Just the count, not the pairs! 2. Multistage improves PCY 66
56 Aside: Hash-Based Filtering Simple problem: Given a set S of one billion strings of length 10. E.g., allowed addresses, not spam Need to scan a larger file F of strings and output those that are in S. I.e., filter spam Main memory available = 1GB = 10 9 bytes So I can t afford to store S in memory need 10 * 4 * 10 9 bytes 67
57 Solution Create a bit array of 8 billion bits initially all 0 s. Use up the 1GB! Choose a hash function h with range [0, 8*10 9 ), and hash each member of S to one of the bits, which is then set to 1. Filter the file F by hashing each string and outputting only those that hash to a 1. For more details, see Mining Data Streams chapter, in Mining of Massive Datasets 68
58 Solution (cont.) File F Filter To output; may be in S. h(s1), h(s2),, h(sn) = h False positives are possible Drop; surely not in S. 69
59 Solution (cont.) If a string is in S, it surely hashes to a 1, so it always gets through. Can repeat with another hash function and bit array to reduce the false positives. Each filter step costs one pass through the remaining file F and reduces the fraction of false positives. Repeat passes until few false positives. Either accept some errors, or check the remaining strings. e.g., divide surviving F into chunks that fit in memory and make a pass though S for each. 71
60 PCY Algorithm An Application of for each basket: Hash-Filtering for each item in basket: add 1 to item s count; for each pair of items: hash pair to a bucket add 1 to the count for that bucket 1. Pairs of items need to be generated from the input file; they are not present in the file. 2. We are not just interested in the presence of a pair, but we need to see whether it is present at least s (support) times. 79
61 PCY Algorithm A bucket contains a frequent pair if its count is at least the support threshold. If a bucket contains a frequent pair, the bucket is surely frequent Even without any frequent pair, a bucket can be frequent. We cannot use the hash to eliminate any member of this bucket If a bucket is not frequent, no pair that hashes to that bucket could possibly be a frequent pair. Pairs that hash to this bucket can be eliminated as candidates On Pass 2, we only count pairs that hash to frequent buckets. 80

62 Main-Memory: PCY 81
63 PCY Algorithm Before Pass 1 Organize Space to count each item. Main Memory One (typically) 4-byte integer per item. Use the rest of the space for as many integers, representing buckets, as we can. 82
64 PCY Algorithm Pass 1 FOR (each basket) { } FOR (each item in the basket) add 1 to item s count; FOR (each pair of items) { } hash the pair to a bucket; add 1 to the count for that bucket 83
65 PCY Algorithm Between Passes Replace the buckets by a bit-vector: 1 means the bucket is frequent; 0 means it is not. 4-byte integers are replaced by bits, so the bit-vector requires 1/32 of memory. Also, decide which items are frequent and list them for the second pass. 85
66 PCY Algorithm Pass 2 Count all pairs {i, j } that meet the conditions for being a candidate pair: 1. Both i and j are frequent items. 2. The pair {i, j }, hashes to a bucket number whose bit in the bit vector is 1. Both conditions are necessary for the pair to have a chance of being frequent. 86
67 Main-Memory: PCY 87
68 Memory Details Buckets require a few bytes each. Note: we don t have to count past s. # buckets is O(main-memory size). On second pass, a table of (item, item, count) triples is essential Pairs of frequent items that PCY avoids counting are placed randomly in the matrix can t compact the matrix Thus, hash table must eliminate 2/3 of the candidate pairs for PCY to beat a-priori. 88
69 Refinement: Multistage Algorithm Further reduce the number of candidates to be counted Remember: memory is the bottleneck Still need to generate all itemsets Uses several successive hash tables --- reduce the number of false positives Requires more than two passes Key idea: After Pass 1 of PCY, rehash only those pairs that qualify for Pass 2 of PCY. i and j are frequent, and {i,j} hashes to a frequent bucket from Pass 1 On middle pass, fewer pairs contribute to buckets, so fewer false positives frequent buckets with no frequent pair. Requires 3 passes over the data 90

70 Multistage Picture 91
71 Multistage Pass 3 Count only those pairs {i, j } that satisfy these candidate pair conditions: 1. Both i and j are frequent items. 2. Using the first hash function, the pair hashes to a bucket whose bit in the first bit-vector is Using the second hash function, the pair hashes to a bucket whose bit in the second bit-vector is 1. 92
72 Important Points 1. The two hash functions have to be independent. 2. We need to check both hashes on the third pass. If not, we would wind up counting pairs of frequent items that hashed first to an infrequent bucket but happened to hash second to a frequent bucket. 93
73 Multihash Key idea: use several independent hash tables on the first pass. 94

74 Multihash Picture 95
75 Multihash Key idea: use several independent hash tables on the first pass. Risk: halving the number of buckets doubles the average count. We have to be sure most buckets will still not reach count s. If so, we can get a benefit like multistage, but in only 2 passes. 96
76 Extensions Either multistage or multihash can use more than two hash functions. In multistage, there is a point of diminishing returns, since the bit-vectors eventually consume all of main memory. For multihash, the bit-vectors occupy exactly what one PCY bitmap does, but too many hash functions makes all counts > s. 97
77 All (Or Most) Frequent Itemsets In < 2 Passes A-Priori, PCY, etc., take k passes to find frequent itemsets of size k. Other techniques use 2 or fewer passes for all sizes: Random sampling SON (Savasere, Omiecinski, and Navathe) Toivonen (see texbook) 98
78 Random Sampling Take a random sample of the market baskets. Run a-priori or one of its improvements (for sets of all sizes, not just pairs) in main memory, so you don t pay for disk I/O each time you increase the size of itemsets. Be sure you leave enough space for counts. Use as your support threshold a suitable, scaled-back number. E.g., if your sample is 1/100 of the baskets, use s /100 as your support threshold instead of s. Copy of sample baskets Space for counts 99
79 Random Sampling: Option Optionally, verify that your guesses are truly frequent in the entire data set by a second pass (avoid false positives). But you don t catch sets frequent in the whole but not in the sample (false negatives). Smaller threshold, e.g., s /125, helps catch more truly frequent itemsets. But requires more space. 100
80 Partition: Scan Database Only Twice Any itemset that is potentially frequent in DB must be frequent in at least one of the partitions of DB Scan 1: partition database and find local frequent patterns Scan 2: consolidate global frequent patterns A. Savasere, E. Omiecinski, and S. Navathe. An efficient algorithm for mining association in large databases. In VLDB
81 SON Algorithm (1) Repeatedly read small subsets of the baskets into main memory and perform the first pass of the simple algorithm on each subset. This is not sampling but processing the entire file in memorysized chunks An itemset becomes a candidate if it is found to be frequent in any one or more subsets of the baskets. 102
82 SON Algorithm (2) Take the union of all frequent itemsets found in one or more chunks these are the candidate itemsets On a second pass, count all the candidate itemsets and determine which are frequent in the entire set. Key monotonicity idea: an itemset cannot be frequent in the entire set of baskets unless it is frequent in at least one subset. 103
83 SON Algorithm Distributed Version This idea lends itself to distributed data mining. If baskets are distributed among many nodes, compute frequent itemsets at each node, then distribute the candidates from each node. Finally, accumulate the counts of all candidates. 104
84 SON Mapreduce Map 1:lower support -- support =s * p Each mapper gets a fraction p of input Output: (FrequentItemset,1) Reduce 1: reducer is assigned a set of itemsets Output: itemsets that appear 1 or more times Map2: all candidates and portion of input file Count occurrences of candidates in file Output: (CandidateSet, support) Reduce 2: sum support values for CandidateSet 105
85 Mining Various Kinds of Association Rules Mining multilevel association Miming multidimensional association Mining quantitative association Mining interesting correlation patterns 117 See Data Mining: Concepts and Techniques, by Han and Kamber
86 Mining Multiple-Level Association Rules Items often form hierarchies Flexible support settings Items at the lower level are expected to have lower support Exploration of shared multi-level mining (Agrawal & 95, Han & 95) uniform support Level 1 min_sup = 5% Milk [support = 10%] reduced support Level 1 min_sup = 5% Level 2 min_sup = 5% 2% Milk [support = 6%] Skim Milk [support = 4%] Level 2 min_sup = 3% 118
87 Mining Multi-Dimensional Association Single-dimensional rules: buys(x, milk ) buys(x, bread ) Multi-dimensional rules: 2 dimensions or predicates Inter-dimension assoc. rules (no repeated predicates) age(x, ) occupation(x, student ) buys(x, coke ) Hybrid-dimension assoc. rules (repeated predicates) age(x, ) buys(x, popcorn ) buys(x, coke ) Categorical Attributes: finite number of possible values, no ordering among values data cube approach Quantitative Attributes: numeric, implicit ordering among values discretization, clustering, and gradient approaches 119
88 From Associations to Correlations play basketball eat cereal [40%, 66.7%] is misleading The overall % of students eating cereal is 75% > 66.7%. Rules is only an estimate of the conditional probability of eat cereal given play basketball play basketball not eat cereal [20%, 33.3%] is more accurate, although with lower support and confidence Measure of dependent/correlated events: lift lift = P( A B) P( A) P( B) Basketball Not basketball Sum (row) Cereal Not cereal Sum(col.) / 5000 lift( B, C) = = / 5000*3750 / 5000 B is negatively correlated with C 120 lift(b, C) = 1000 / / 5000 *1250 / 5000 =1.33 B is correlated with not C
89 Summary - 1 Market-basket model: useful for different applications use your imagination! Products and transactions: item placement, sales strategies, etc Sentences and documents: plagiarism Patients and drugs/side effects: drug combinations that result in particular side effects Frequent itemsets and association rules The bottleneck: counting pairs Triangular matrices: save space by mapping a matrix into a 1- dimensional array Triples: if fewer than 1/3 of pairs actually occur in baskets, triples are more efficient than triangular matrices 121
90 Summary - 2 Monotonicity of frequent itemsetsà allow for efficient algorithms No need to count all itemsets! A-priory algorithm: find all pairs in 2 passes Additional passes for bigger sets PCY algorithm: leverages spare main memory in first pass to reduce the number of pairs that need to be counted Multistage: multiple passes to hash pairs to different hash tables Multihash: use multiple hash tables in the first pass Randomized: user random samples instead of the full data set: may result in false positive and negatives SON algorithm: improvement over randomized divide and conquer 122
High dim. data. Graph data. Infinite data. Machine learning. Apps. Locality sensitive hashing. Filtering data streams.
 http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Network Analysis
http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Network Analysis
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 1/8/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 Supermarket shelf
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 1/8/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 Supermarket shelf
Big Data Analytics CSCI 4030
 Supermarket shelf management Market-basket model: Goal: Identify items that are bought together by sufficiently many customers Approach: Process the sales data collected with barcode scanners to find dependencies
Supermarket shelf management Market-basket model: Goal: Identify items that are bought together by sufficiently many customers Approach: Process the sales data collected with barcode scanners to find dependencies
We will be releasing HW1 today It is due in 2 weeks (1/25 at 23:59pm) The homework is long
 The homework is long") 1/21/18 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 1 We will be releasing HW1 today It is due in 2 weeks (1/25 at 23:59pm) The homework is long Requires proving theorems
1/21/18 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 1 We will be releasing HW1 today It is due in 2 weeks (1/25 at 23:59pm) The homework is long Requires proving theorems
Introduction to Data Mining
 Introduction to Data Mining Lecture #13: Frequent Itemsets-2 Seoul National University 1 In This Lecture Efficient Algorithms for Finding Frequent Itemsets A-Priori PCY 2-Pass algorithm: Random Sampling,
Introduction to Data Mining Lecture #13: Frequent Itemsets-2 Seoul National University 1 In This Lecture Efficient Algorithms for Finding Frequent Itemsets A-Priori PCY 2-Pass algorithm: Random Sampling,
Jeffrey D. Ullman Stanford University
 Jeffrey D. Ullman Stanford University A large set of items, e.g., things sold in a supermarket. A large set of baskets, each of which is a small set of the items, e.g., the things one customer buys on
Jeffrey D. Ullman Stanford University A large set of items, e.g., things sold in a supermarket. A large set of baskets, each of which is a small set of the items, e.g., the things one customer buys on
Association Rules. CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University. Slides adapted from lectures by Jeff Ullman
 Association Rules CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University Slides adapted from lectures by Jeff Ullman A large set of items e.g., things sold in a supermarket A large set
Association Rules CS345a: Data Mining Jure Leskovec and Anand Rajaraman Stanford University Slides adapted from lectures by Jeff Ullman A large set of items e.g., things sold in a supermarket A large set
Data Mining: Concepts and Techniques. Chapter 5. SS Chung. April 5, 2013 Data Mining: Concepts and Techniques 1
 Data Mining: Concepts and Techniques Chapter 5 SS Chung April 5, 2013 Data Mining: Concepts and Techniques 1 Chapter 5: Mining Frequent Patterns, Association and Correlations Basic concepts and a road
Data Mining: Concepts and Techniques Chapter 5 SS Chung April 5, 2013 Data Mining: Concepts and Techniques 1 Chapter 5: Mining Frequent Patterns, Association and Correlations Basic concepts and a road
Roadmap. PCY Algorithm
 1 Roadmap Frequent Patterns A-Priori Algorithm Improvements to A-Priori Park-Chen-Yu Algorithm Multistage Algorithm Approximate Algorithms Compacting Results Data Mining for Knowledge Management 50 PCY
1 Roadmap Frequent Patterns A-Priori Algorithm Improvements to A-Priori Park-Chen-Yu Algorithm Multistage Algorithm Approximate Algorithms Compacting Results Data Mining for Knowledge Management 50 PCY
Improvements to A-Priori. Bloom Filters Park-Chen-Yu Algorithm Multistage Algorithm Approximate Algorithms Compacting Results
 Improvements to A-Priori Bloom Filters Park-Chen-Yu Algorithm Multistage Algorithm Approximate Algorithms Compacting Results 1 Aside: Hash-Based Filtering Simple problem: I have a set S of one billion
Improvements to A-Priori Bloom Filters Park-Chen-Yu Algorithm Multistage Algorithm Approximate Algorithms Compacting Results 1 Aside: Hash-Based Filtering Simple problem: I have a set S of one billion
Frequent Item Sets & Association Rules
 Frequent Item Sets & Association Rules V. CHRISTOPHIDES vassilis.christophides@inria.fr https://who.rocq.inria.fr/vassilis.christophides/big/ Ecole CentraleSupélec 1 Some History Bar code technology allowed
Frequent Item Sets & Association Rules V. CHRISTOPHIDES vassilis.christophides@inria.fr https://who.rocq.inria.fr/vassilis.christophides/big/ Ecole CentraleSupélec 1 Some History Bar code technology allowed
Hash-Based Improvements to A-Priori. Park-Chen-Yu Algorithm Multistage Algorithm Approximate Algorithms
 Hash-Based Improvements to A-Priori Park-Chen-Yu Algorithm Multistage Algorithm Approximate Algorithms 1 PCY Algorithm 1 Hash-based improvement to A-Priori. During Pass 1 of A-priori, most memory is idle.
Hash-Based Improvements to A-Priori Park-Chen-Yu Algorithm Multistage Algorithm Approximate Algorithms 1 PCY Algorithm 1 Hash-based improvement to A-Priori. During Pass 1 of A-priori, most memory is idle.
ANU MLSS 2010: Data Mining. Part 2: Association rule mining
 ANU MLSS 2010: Data Mining Part 2: Association rule mining Lecture outline What is association mining? Market basket analysis and association rule examples Basic concepts and formalism Basic rule measurements
ANU MLSS 2010: Data Mining Part 2: Association rule mining Lecture outline What is association mining? Market basket analysis and association rule examples Basic concepts and formalism Basic rule measurements
Chapter 4: Mining Frequent Patterns, Associations and Correlations
 Chapter 4: Mining Frequent Patterns, Associations and Correlations 4.1 Basic Concepts 4.2 Frequent Itemset Mining Methods 4.3 Which Patterns Are Interesting? Pattern Evaluation Methods 4.4 Summary Frequent
Chapter 4: Mining Frequent Patterns, Associations and Correlations 4.1 Basic Concepts 4.2 Frequent Itemset Mining Methods 4.3 Which Patterns Are Interesting? Pattern Evaluation Methods 4.4 Summary Frequent
Chapter 6: Basic Concepts: Association Rules. Basic Concepts: Frequent Patterns. (absolute) support, or, support. (relative) support, s, is the
 support, or, support. (relative) support, s, is the") Chapter 6: What Is Frequent ent Pattern Analysis? Frequent pattern: a pattern (a set of items, subsequences, substructures, etc) that occurs frequently in a data set frequent itemsets and association rule
Chapter 6: What Is Frequent ent Pattern Analysis? Frequent pattern: a pattern (a set of items, subsequences, substructures, etc) that occurs frequently in a data set frequent itemsets and association rule
Association rules. Marco Saerens (UCL), with Christine Decaestecker (ULB)
, with Christine Decaestecker (ULB)") Association rules Marco Saerens (UCL), with Christine Decaestecker (ULB) 1 Slides references Many slides and figures have been adapted from the slides associated to the following books: Alpaydin (2004),
Association rules Marco Saerens (UCL), with Christine Decaestecker (ULB) 1 Slides references Many slides and figures have been adapted from the slides associated to the following books: Alpaydin (2004),
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R,
 Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R, statistics foundations 5 Introduction to D3, visual analytics
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R, statistics foundations 5 Introduction to D3, visual analytics
Association Rule Mining. Entscheidungsunterstützungssysteme
 Association Rule Mining Entscheidungsunterstützungssysteme Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set
Association Rule Mining Entscheidungsunterstützungssysteme Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set
Frequent Pattern Mining
 Frequent Pattern Mining How Many Words Is a Picture Worth? E. Aiden and J-B Michel: Uncharted. Reverhead Books, 2013 Jian Pei: CMPT 741/459 Frequent Pattern Mining (1) 2 Burnt or Burned? E. Aiden and J-B
Frequent Pattern Mining How Many Words Is a Picture Worth? E. Aiden and J-B Michel: Uncharted. Reverhead Books, 2013 Jian Pei: CMPT 741/459 Frequent Pattern Mining (1) 2 Burnt or Burned? E. Aiden and J-B
BCB 713 Module Spring 2011
 Association Rule Mining COMP 790-90 Seminar BCB 713 Module Spring 2011 The UNIVERSITY of NORTH CAROLINA at CHAPEL HILL Outline What is association rule mining? Methods for association rule mining Extensions
Association Rule Mining COMP 790-90 Seminar BCB 713 Module Spring 2011 The UNIVERSITY of NORTH CAROLINA at CHAPEL HILL Outline What is association rule mining? Methods for association rule mining Extensions
Frequent Pattern Mining S L I D E S B Y : S H R E E J A S W A L
 Frequent Pattern Mining S L I D E S B Y : S H R E E J A S W A L Topics to be covered Market Basket Analysis, Frequent Itemsets, Closed Itemsets, and Association Rules; Frequent Pattern Mining, Efficient
Frequent Pattern Mining S L I D E S B Y : S H R E E J A S W A L Topics to be covered Market Basket Analysis, Frequent Itemsets, Closed Itemsets, and Association Rules; Frequent Pattern Mining, Efficient
signicantly higher than it would be if items were placed at random into baskets. For example, we
 2 Association Rules and Frequent Itemsets The market-basket problem assumes we have some large number of items, e.g., \bread," \milk." Customers ll their market baskets with some subset of the items, and
2 Association Rules and Frequent Itemsets The market-basket problem assumes we have some large number of items, e.g., \bread," \milk." Customers ll their market baskets with some subset of the items, and
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 6
 Chapter 6") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2017 Han, Kamber & Pei. All
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2017 Han, Kamber & Pei. All
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 16: Association Rules Jan-Willem van de Meent (credit: Yijun Zhao, Yi Wang, Tan et al., Leskovec et al.) Apriori: Summary All items Count
Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 16: Association Rules Jan-Willem van de Meent (credit: Yijun Zhao, Yi Wang, Tan et al., Leskovec et al.) Apriori: Summary All items Count
Association Rules. Berlin Chen References:
 Association Rules Berlin Chen 2005 References: 1. Data Mining: Concepts, Models, Methods and Algorithms, Chapter 8 2. Data Mining: Concepts and Techniques, Chapter 6 Association Rules: Basic Concepts A
Association Rules Berlin Chen 2005 References: 1. Data Mining: Concepts, Models, Methods and Algorithms, Chapter 8 2. Data Mining: Concepts and Techniques, Chapter 6 Association Rules: Basic Concepts A
CS570 Introduction to Data Mining
 CS570 Introduction to Data Mining Frequent Pattern Mining and Association Analysis Cengiz Gunay Partial slide credits: Li Xiong, Jiawei Han and Micheline Kamber George Kollios 1 Mining Frequent Patterns,
CS570 Introduction to Data Mining Frequent Pattern Mining and Association Analysis Cengiz Gunay Partial slide credits: Li Xiong, Jiawei Han and Micheline Kamber George Kollios 1 Mining Frequent Patterns,
Basic Concepts: Association Rules. What Is Frequent Pattern Analysis? COMP 465: Data Mining Mining Frequent Patterns, Associations and Correlations
 What Is Frequent Pattern Analysis? COMP 465: Data Mining Mining Frequent Patterns, Associations and Correlations Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and
What Is Frequent Pattern Analysis? COMP 465: Data Mining Mining Frequent Patterns, Associations and Correlations Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and
Chapter 4 Data Mining A Short Introduction
 Chapter 4 Data Mining A Short Introduction Data Mining - 1 1 Today's Question 1. Data Mining Overview 2. Association Rule Mining 3. Clustering 4. Classification Data Mining - 2 2 1. Data Mining Overview
Chapter 4 Data Mining A Short Introduction Data Mining - 1 1 Today's Question 1. Data Mining Overview 2. Association Rule Mining 3. Clustering 4. Classification Data Mining - 2 2 1. Data Mining Overview
Apriori Algorithm. 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke
 Apriori Algorithm For a given set of transactions, the main aim of Association Rule Mining is to find rules that will predict the occurrence of an item based on the occurrences of the other items in the
Apriori Algorithm For a given set of transactions, the main aim of Association Rule Mining is to find rules that will predict the occurrence of an item based on the occurrences of the other items in the
Interestingness Measurements
 Interestingness Measurements Objective measures Two popular measurements: support and confidence Subjective measures [Silberschatz & Tuzhilin, KDD95] A rule (pattern) is interesting if it is unexpected
Interestingness Measurements Objective measures Two popular measurements: support and confidence Subjective measures [Silberschatz & Tuzhilin, KDD95] A rule (pattern) is interesting if it is unexpected
Interestingness Measurements
 Interestingness Measurements Objective measures Two popular measurements: support and confidence Subjective measures [Silberschatz & Tuzhilin, KDD95] A rule (pattern) is interesting if it is unexpected
Interestingness Measurements Objective measures Two popular measurements: support and confidence Subjective measures [Silberschatz & Tuzhilin, KDD95] A rule (pattern) is interesting if it is unexpected
Frequent Itemsets. Chapter 6
 Chapter 6 Frequent Itemsets We turn in this chapter to one of the major families of techniques for characterizing data: the discovery of frequent itemsets. This problem is often viewed as the discovery
Chapter 6 Frequent Itemsets We turn in this chapter to one of the major families of techniques for characterizing data: the discovery of frequent itemsets. This problem is often viewed as the discovery
Mining Association Rules in Large Databases
 Mining Association Rules in Large Databases Vladimir Estivill-Castro School of Computing and Information Technology With contributions fromj. Han 1 Association Rule Mining A typical example is market basket
Mining Association Rules in Large Databases Vladimir Estivill-Castro School of Computing and Information Technology With contributions fromj. Han 1 Association Rule Mining A typical example is market basket
Product presentations can be more intelligently planned
 Association Rules Lecture /DMBI/IKI8303T/MTI/UI Yudho Giri Sucahyo, Ph.D, CISA (yudho@cs.ui.ac.id) Faculty of Computer Science, Objectives Introduction What is Association Mining? Mining Association Rules
Association Rules Lecture /DMBI/IKI8303T/MTI/UI Yudho Giri Sucahyo, Ph.D, CISA (yudho@cs.ui.ac.id) Faculty of Computer Science, Objectives Introduction What is Association Mining? Mining Association Rules
Nesnelerin İnternetinde Veri Analizi
 Bölüm 4. Frequent Patterns in Data Streams w3.gazi.edu.tr/~suatozdemir What Is Pattern Discovery? What are patterns? Patterns: A set of items, subsequences, or substructures that occur frequently together
Bölüm 4. Frequent Patterns in Data Streams w3.gazi.edu.tr/~suatozdemir What Is Pattern Discovery? What are patterns? Patterns: A set of items, subsequences, or substructures that occur frequently together
Association Rules. A. Bellaachia Page: 1
 Association Rules 1. Objectives... 2 2. Definitions... 2 3. Type of Association Rules... 7 4. Frequent Itemset generation... 9 5. Apriori Algorithm: Mining Single-Dimension Boolean AR 13 5.1. Join Step:...
Association Rules 1. Objectives... 2 2. Definitions... 2 3. Type of Association Rules... 7 4. Frequent Itemset generation... 9 5. Apriori Algorithm: Mining Single-Dimension Boolean AR 13 5.1. Join Step:...
Thanks to the advances of data processing technologies, a lot of data can be collected and stored in databases efficiently New challenges: with a
 Data Mining and Information Retrieval Introduction to Data Mining Why Data Mining? Thanks to the advances of data processing technologies, a lot of data can be collected and stored in databases efficiently
Data Mining and Information Retrieval Introduction to Data Mining Why Data Mining? Thanks to the advances of data processing technologies, a lot of data can be collected and stored in databases efficiently
2 CONTENTS
 Contents 5 Mining Frequent Patterns, Associations, and Correlations 3 5.1 Basic Concepts and a Road Map..................................... 3 5.1.1 Market Basket Analysis: A Motivating Example........................
Contents 5 Mining Frequent Patterns, Associations, and Correlations 3 5.1 Basic Concepts and a Road Map..................................... 3 5.1.1 Market Basket Analysis: A Motivating Example........................
Mining Association Rules in Large Databases
 Mining Association Rules in Large Databases Association rules Given a set of transactions D, find rules that will predict the occurrence of an item (or a set of items) based on the occurrences of other
Mining Association Rules in Large Databases Association rules Given a set of transactions D, find rules that will predict the occurrence of an item (or a set of items) based on the occurrences of other
Market baskets Frequent itemsets FP growth. Data mining. Frequent itemset Association&decision rule mining. University of Szeged.
 Frequent itemset Association&decision rule mining University of Szeged What frequent itemsets could be used for? Features/observations frequently co-occurring in some database can gain us useful insights
Frequent itemset Association&decision rule mining University of Szeged What frequent itemsets could be used for? Features/observations frequently co-occurring in some database can gain us useful insights
Data Structures. Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali Association Rules: Basic Concepts and Application
 Data Structures Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali 2009-2010 Association Rules: Basic Concepts and Application 1. Association rules: Given a set of transactions, find
Data Structures Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali 2009-2010 Association Rules: Basic Concepts and Application 1. Association rules: Given a set of transactions, find
What Is Data Mining? CMPT 354: Database I -- Data Mining 2
 Data Mining What Is Data Mining? Mining data mining knowledge Data mining is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data CMPT
Data Mining What Is Data Mining? Mining data mining knowledge Data mining is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data CMPT
Frequent Pattern Mining. Based on: Introduction to Data Mining by Tan, Steinbach, Kumar
 Frequent Pattern Mining Based on: Introduction to Data Mining by Tan, Steinbach, Kumar Item sets A New Type of Data Some notation: All possible items: Database: T is a bag of transactions Transaction transaction
Frequent Pattern Mining Based on: Introduction to Data Mining by Tan, Steinbach, Kumar Item sets A New Type of Data Some notation: All possible items: Database: T is a bag of transactions Transaction transaction
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
Association Rules Apriori Algorithm
 Association Rules Apriori Algorithm Market basket analysis n Market basket analysis might tell a retailer that customers often purchase shampoo and conditioner n Putting both items on promotion at the
Association Rules Apriori Algorithm Market basket analysis n Market basket analysis might tell a retailer that customers often purchase shampoo and conditioner n Putting both items on promotion at the
Frequent Pattern Mining
 Frequent Pattern Mining...3 Frequent Pattern Mining Frequent Patterns The Apriori Algorithm The FP-growth Algorithm Sequential Pattern Mining Summary 44 / 193 Netflix Prize Frequent Pattern Mining Frequent
Frequent Pattern Mining...3 Frequent Pattern Mining Frequent Patterns The Apriori Algorithm The FP-growth Algorithm Sequential Pattern Mining Summary 44 / 193 Netflix Prize Frequent Pattern Mining Frequent
Association Pattern Mining. Lijun Zhang
 Association Pattern Mining Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction The Frequent Pattern Mining Model Association Rule Generation Framework Frequent Itemset Mining Algorithms
Association Pattern Mining Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction The Frequent Pattern Mining Model Association Rule Generation Framework Frequent Itemset Mining Algorithms
Association Analysis. CSE 352 Lecture Notes. Professor Anita Wasilewska
 Association Analysis CSE 352 Lecture Notes Professor Anita Wasilewska Association Rules Mining An Introduction This is an intuitive (more or less ) introduction It contains explanation of the main ideas:
Association Analysis CSE 352 Lecture Notes Professor Anita Wasilewska Association Rules Mining An Introduction This is an intuitive (more or less ) introduction It contains explanation of the main ideas:
CMPUT 391 Database Management Systems. Data Mining. Textbook: Chapter (without 17.10)
") CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University 10/19/2017 Slides adapted from Prof. Jiawei Han @UIUC, Prof.
CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University 10/19/2017 Slides adapted from Prof. Jiawei Han @UIUC, Prof.
Roadmap DB Sys. Design & Impl. Association rules - outline. Citations. Association rules - idea. Association rules - idea.
 15-721 DB Sys. Design & Impl. Association Rules Christos Faloutsos www.cs.cmu.edu/~christos Roadmap 1) Roots: System R and Ingres... 7) Data Analysis - data mining datacubes and OLAP classifiers association
15-721 DB Sys. Design & Impl. Association Rules Christos Faloutsos www.cs.cmu.edu/~christos Roadmap 1) Roots: System R and Ingres... 7) Data Analysis - data mining datacubes and OLAP classifiers association
Which Null-Invariant Measure Is Better? Which Null-Invariant Measure Is Better?
 Which Null-Invariant Measure Is Better? D 1 is m,c positively correlated, many null transactions D 2 is m,c positively correlated, little null transactions D 3 is m,c negatively correlated, many null transactions
Which Null-Invariant Measure Is Better? D 1 is m,c positively correlated, many null transactions D 2 is m,c positively correlated, little null transactions D 3 is m,c negatively correlated, many null transactions
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
Fundamental Data Mining Algorithms
 2018 EE448, Big Data Mining, Lecture 3 Fundamental Data Mining Algorithms Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html REVIEW What is Data
2018 EE448, Big Data Mining, Lecture 3 Fundamental Data Mining Algorithms Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html REVIEW What is Data
Chapter 4: Association analysis:
 Chapter 4: Association analysis: 4.1 Introduction: Many business enterprises accumulate large quantities of data from their day-to-day operations, huge amounts of customer purchase data are collected daily
Chapter 4: Association analysis: 4.1 Introduction: Many business enterprises accumulate large quantities of data from their day-to-day operations, huge amounts of customer purchase data are collected daily
Discovering interesting rules from financial data
 Discovering interesting rules from financial data Przemysław Sołdacki Institute of Computer Science Warsaw University of Technology Ul. Andersa 13, 00-159 Warszawa Tel: +48 609129896 email: psoldack@ii.pw.edu.pl
Discovering interesting rules from financial data Przemysław Sołdacki Institute of Computer Science Warsaw University of Technology Ul. Andersa 13, 00-159 Warszawa Tel: +48 609129896 email: psoldack@ii.pw.edu.pl
Advance Association Analysis
 Advance Association Analysis 1 Minimum Support Threshold 3 Effect of Support Distribution Many real data sets have skewed support distribution Support distribution of a retail data set 4 Effect of Support
Advance Association Analysis 1 Minimum Support Threshold 3 Effect of Support Distribution Many real data sets have skewed support distribution Support distribution of a retail data set 4 Effect of Support
CompSci 516 Data Intensive Computing Systems
 CompSci 516 Data Intensive Computing Systems Lecture 20 Data Mining and Mining Association Rules Instructor: Sudeepa Roy CompSci 516: Data Intensive Computing Systems 1 Reading Material Optional Reading:
CompSci 516 Data Intensive Computing Systems Lecture 20 Data Mining and Mining Association Rules Instructor: Sudeepa Roy CompSci 516: Data Intensive Computing Systems 1 Reading Material Optional Reading:
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 7
 Chapter 7") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 7 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2017 Han and Kamber & Pei.
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 7 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2017 Han and Kamber & Pei.
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 6
 Chapter 6") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2016 Han, Kamber & Pei. All
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2016 Han, Kamber & Pei. All
Association Rules Apriori Algorithm
 Association Rules Apriori Algorithm Market basket analysis n Market basket analysis might tell a retailer that customers often purchase shampoo and conditioner n Putting both items on promotion at the
Association Rules Apriori Algorithm Market basket analysis n Market basket analysis might tell a retailer that customers often purchase shampoo and conditioner n Putting both items on promotion at the
Efficient Remining of Generalized Multi-supported Association Rules under Support Update
 Efficient Remining of Generalized Multi-supported Association Rules under Support Update WEN-YANG LIN 1 and MING-CHENG TSENG 1 Dept. of Information Management, Institute of Information Engineering I-Shou
Efficient Remining of Generalized Multi-supported Association Rules under Support Update WEN-YANG LIN 1 and MING-CHENG TSENG 1 Dept. of Information Management, Institute of Information Engineering I-Shou
Chapter 7: Frequent Itemsets and Association Rules
 Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2013/14 VII.1&2 1 Motivational Example Assume you run an on-line
Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2013/14 VII.1&2 1 Motivational Example Assume you run an on-line
Association mining rules
 Association mining rules Given a data set, find the items in data that are associated with each other. Association is measured as frequency of occurrence in the same context. Purchasing one product when
Association mining rules Given a data set, find the items in data that are associated with each other. Association is measured as frequency of occurrence in the same context. Purchasing one product when
Performance and Scalability: Apriori Implementa6on
 Performance and Scalability: Apriori Implementa6on Apriori R. Agrawal and R. Srikant. Fast algorithms for mining associa6on rules. VLDB, 487 499, 1994 Reducing Number of Comparisons Candidate coun6ng:
Performance and Scalability: Apriori Implementa6on Apriori R. Agrawal and R. Srikant. Fast algorithms for mining associa6on rules. VLDB, 487 499, 1994 Reducing Number of Comparisons Candidate coun6ng:
Association Rule Mining (ARM) Komate AMPHAWAN
 Komate AMPHAWAN") Association Rule Mining (ARM) Komate AMPHAWAN 1 J-O-K-E???? 2 What can be inferred? I purchase diapers I purchase a new car I purchase OTC cough (ไอ) medicine I purchase a prescription medication (ใบส
Association Rule Mining (ARM) Komate AMPHAWAN 1 J-O-K-E???? 2 What can be inferred? I purchase diapers I purchase a new car I purchase OTC cough (ไอ) medicine I purchase a prescription medication (ใบส
Pattern Mining. Knowledge Discovery and Data Mining 1. Roman Kern KTI, TU Graz. Roman Kern (KTI, TU Graz) Pattern Mining / 42
 Pattern Mining / 42") Pattern Mining Knowledge Discovery and Data Mining 1 Roman Kern KTI, TU Graz 2016-01-14 Roman Kern (KTI, TU Graz) Pattern Mining 2016-01-14 1 / 42 Outline 1 Introduction 2 Apriori Algorithm 3 FP-Growth
Pattern Mining Knowledge Discovery and Data Mining 1 Roman Kern KTI, TU Graz 2016-01-14 Roman Kern (KTI, TU Graz) Pattern Mining 2016-01-14 1 / 42 Outline 1 Introduction 2 Apriori Algorithm 3 FP-Growth
Decision Support Systems
 Decision Support Systems 2011/2012 Week 6. Lecture 11 HELLO DATA MINING! THE PLAN: MINING FREQUENT PATTERNS (Classes 11-13) Homework 5 CLUSTER ANALYSIS (Classes 14-16) Homework 6 SUPERVISED LEARNING (Classes
Decision Support Systems 2011/2012 Week 6. Lecture 11 HELLO DATA MINING! THE PLAN: MINING FREQUENT PATTERNS (Classes 11-13) Homework 5 CLUSTER ANALYSIS (Classes 14-16) Homework 6 SUPERVISED LEARNING (Classes
Association Rule Discovery
 Association Rule Discovery Association Rules describe frequent co-occurences in sets an item set is a subset A of all possible items I Example Problems: Which products are frequently bought together by
Association Rule Discovery Association Rules describe frequent co-occurences in sets an item set is a subset A of all possible items I Example Problems: Which products are frequently bought together by
Association Rule Discovery
 Association Rule Discovery Association Rules describe frequent co-occurences in sets an itemset is a subset A of all possible items I Example Problems: Which products are frequently bought together by
Association Rule Discovery Association Rules describe frequent co-occurences in sets an itemset is a subset A of all possible items I Example Problems: Which products are frequently bought together by
Scalable Frequent Itemset Mining Methods
 Scalable Frequent Itemset Mining Methods The Downward Closure Property of Frequent Patterns The Apriori Algorithm Extensions or Improvements of Apriori Mining Frequent Patterns by Exploring Vertical Data
Scalable Frequent Itemset Mining Methods The Downward Closure Property of Frequent Patterns The Apriori Algorithm Extensions or Improvements of Apriori Mining Frequent Patterns by Exploring Vertical Data
Supervised and Unsupervised Learning (II)
") Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Supervised and Unsupervised Learning (II) Yong Zheng Center for Web Intelligence DePaul University, Chicago IPD 346 - Data Science for Business Program DePaul University, Chicago, USA Intro: Supervised
Data Mining Part 3. Associations Rules
 Data Mining Part 3. Associations Rules 3.2 Efficient Frequent Itemset Mining Methods Fall 2009 Instructor: Dr. Masoud Yaghini Outline Apriori Algorithm Generating Association Rules from Frequent Itemsets
Data Mining Part 3. Associations Rules 3.2 Efficient Frequent Itemset Mining Methods Fall 2009 Instructor: Dr. Masoud Yaghini Outline Apriori Algorithm Generating Association Rules from Frequent Itemsets
Model for Load Balancing on Processors in Parallel Mining of Frequent Itemsets
 American Journal of Applied Sciences 2 (5): 926-931, 2005 ISSN 1546-9239 Science Publications, 2005 Model for Load Balancing on Processors in Parallel Mining of Frequent Itemsets 1 Ravindra Patel, 2 S.S.
American Journal of Applied Sciences 2 (5): 926-931, 2005 ISSN 1546-9239 Science Publications, 2005 Model for Load Balancing on Processors in Parallel Mining of Frequent Itemsets 1 Ravindra Patel, 2 S.S.
Chapter 6: Association Rules
 Chapter 6: Association Rules Association rule mining Proposed by Agrawal et al in 1993. It is an important data mining model. Transaction data (no time-dependent) Assume all data are categorical. No good
Chapter 6: Association Rules Association rule mining Proposed by Agrawal et al in 1993. It is an important data mining model. Transaction data (no time-dependent) Assume all data are categorical. No good
Lecture notes for April 6, 2005
 Lecture notes for April 6, 2005 Mining Association Rules The goal of association rule finding is to extract correlation relationships in the large datasets of items. Many businesses are interested in extracting
Lecture notes for April 6, 2005 Mining Association Rules The goal of association rule finding is to extract correlation relationships in the large datasets of items. Many businesses are interested in extracting
Production rule is an important element in the expert system. By interview with
 2 Literature review Production rule is an important element in the expert system By interview with the domain experts, we can induce the rules and store them in a truth maintenance system An assumption-based
2 Literature review Production rule is an important element in the expert system By interview with the domain experts, we can induce the rules and store them in a truth maintenance system An assumption-based
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 6
 Chapter 6") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2011 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2011 Han, Kamber & Pei. All rights
Jarek Szlichta Acknowledgments: Jiawei Han, Micheline Kamber and Jian Pei, Data Mining - Concepts and Techniques
 Jarek Szlichta http://data.science.uoit.ca/ Acknowledgments: Jiawei Han, Micheline Kamber and Jian Pei, Data Mining - Concepts and Techniques Frequent Itemset Mining Methods Apriori Which Patterns Are
Jarek Szlichta http://data.science.uoit.ca/ Acknowledgments: Jiawei Han, Micheline Kamber and Jian Pei, Data Mining - Concepts and Techniques Frequent Itemset Mining Methods Apriori Which Patterns Are
Association Rules and
 Association Rules and Sequential Patterns Road Map Frequent itemsets and rules Apriori algorithm FP-Growth Data formats Class association rules Sequential patterns. GSP algorithm 2 Objectives Association
Association Rules and Sequential Patterns Road Map Frequent itemsets and rules Apriori algorithm FP-Growth Data formats Class association rules Sequential patterns. GSP algorithm 2 Objectives Association
Data Mining Algorithms
 Algorithms Fall 2017 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Looking for patterns in data Machine
Algorithms Fall 2017 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Looking for patterns in data Machine
An Evolutionary Algorithm for Mining Association Rules Using Boolean Approach
 An Evolutionary Algorithm for Mining Association Rules Using Boolean Approach ABSTRACT G.Ravi Kumar 1 Dr.G.A. Ramachandra 2 G.Sunitha 3 1. Research Scholar, Department of Computer Science &Technology,
An Evolutionary Algorithm for Mining Association Rules Using Boolean Approach ABSTRACT G.Ravi Kumar 1 Dr.G.A. Ramachandra 2 G.Sunitha 3 1. Research Scholar, Department of Computer Science &Technology,
Road Map. Objectives. Objectives. Frequent itemsets and rules. Items and transactions. Association Rules and Sequential Patterns
 Road Map Association Rules and Sequential Patterns Frequent itemsets and rules Apriori algorithm FP-Growth Data formats Class association rules Sequential patterns. GSP algorithm 2 Objectives Association
Road Map Association Rules and Sequential Patterns Frequent itemsets and rules Apriori algorithm FP-Growth Data formats Class association rules Sequential patterns. GSP algorithm 2 Objectives Association
Machine Learning: Symbolische Ansätze
 Machine Learning: Symbolische Ansätze Unsupervised Learning Clustering Association Rules V2.0 WS 10/11 J. Fürnkranz Different Learning Scenarios Supervised Learning A teacher provides the value for the
Machine Learning: Symbolische Ansätze Unsupervised Learning Clustering Association Rules V2.0 WS 10/11 J. Fürnkranz Different Learning Scenarios Supervised Learning A teacher provides the value for the
Improved Frequent Pattern Mining Algorithm with Indexing
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 16, Issue 6, Ver. VII (Nov Dec. 2014), PP 73-78 Improved Frequent Pattern Mining Algorithm with Indexing Prof.
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 16, Issue 6, Ver. VII (Nov Dec. 2014), PP 73-78 Improved Frequent Pattern Mining Algorithm with Indexing Prof.
Association Rules Outline
 Association Rules Outline Goal: Provide an overview of basic Association Rule mining techniques Association Rules Problem Overview Large/Frequent itemsets Association Rules Algorithms Apriori Sampling
Association Rules Outline Goal: Provide an overview of basic Association Rule mining techniques Association Rules Problem Overview Large/Frequent itemsets Association Rules Algorithms Apriori Sampling
CS 6093 Lecture 7 Spring 2011 Basic Data Mining. Cong Yu 03/21/2011
 CS 6093 Lecture 7 Spring 2011 Basic Data Mining Cong Yu 03/21/2011 Announcements No regular office hour next Monday (March 28 th ) Office hour next week will be on Tuesday through Thursday by appointment
CS 6093 Lecture 7 Spring 2011 Basic Data Mining Cong Yu 03/21/2011 Announcements No regular office hour next Monday (March 28 th ) Office hour next week will be on Tuesday through Thursday by appointment
Finding Similar Sets. Applications Shingling Minhashing Locality-Sensitive Hashing
 Finding Similar Sets Applications Shingling Minhashing Locality-Sensitive Hashing Goals Many Web-mining problems can be expressed as finding similar sets:. Pages with similar words, e.g., for classification
Finding Similar Sets Applications Shingling Minhashing Locality-Sensitive Hashing Goals Many Web-mining problems can be expressed as finding similar sets:. Pages with similar words, e.g., for classification
Chapter 7: Frequent Itemsets and Association Rules
 Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2011/12 VII.1-1 Chapter VII: Frequent Itemsets and Association
Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2011/12 VII.1-1 Chapter VII: Frequent Itemsets and Association
PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets
 2011 Fourth International Symposium on Parallel Architectures, Algorithms and Programming PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets Tao Xiao Chunfeng Yuan Yihua Huang Department
2011 Fourth International Symposium on Parallel Architectures, Algorithms and Programming PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets Tao Xiao Chunfeng Yuan Yihua Huang Department
Data Mining Clustering
 Data Mining Clustering Jingpeng Li 1 of 34 Supervised Learning F(x): true function (usually not known) D: training sample (x, F(x)) 57,M,195,0,125,95,39,25,0,1,0,0,0,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,0,0 0
Data Mining Clustering Jingpeng Li 1 of 34 Supervised Learning F(x): true function (usually not known) D: training sample (x, F(x)) 57,M,195,0,125,95,39,25,0,1,0,0,0,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,0,0 0
Carnegie Mellon Univ. Dept. of Computer Science /615 DB Applications. Data mining - detailed outline. Problem
 Faloutsos & Pavlo 15415/615 Carnegie Mellon Univ. Dept. of Computer Science 15415/615 DB Applications Lecture # 24: Data Warehousing / Data Mining (R&G, ch 25 and 26) Data mining detailed outline Problem
Faloutsos & Pavlo 15415/615 Carnegie Mellon Univ. Dept. of Computer Science 15415/615 DB Applications Lecture # 24: Data Warehousing / Data Mining (R&G, ch 25 and 26) Data mining detailed outline Problem
D Data Mining: Concepts and and Tech Techniques
 Data Mining: Concepts and Techniques (3 rd ed.) Chapter 5 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2009 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 5 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2009 Han, Kamber & Pei. All rights
CompSci 516 Data Intensive Computing Systems
 CompSci 516 Data Intensive Computing Systems Lecture 25 Data Mining and Mining Association Rules Instructor: Sudeepa Roy Due CS, Spring 2016 CompSci 516: Data Intensive Computing Systems 1 Announcements
CompSci 516 Data Intensive Computing Systems Lecture 25 Data Mining and Mining Association Rules Instructor: Sudeepa Roy Due CS, Spring 2016 CompSci 516: Data Intensive Computing Systems 1 Announcements
A Taxonomy of Classical Frequent Item set Mining Algorithms
 A Taxonomy of Classical Frequent Item set Mining Algorithms Bharat Gupta and Deepak Garg Abstract These instructions Frequent itemsets mining is one of the most important and crucial part in today s world
A Taxonomy of Classical Frequent Item set Mining Algorithms Bharat Gupta and Deepak Garg Abstract These instructions Frequent itemsets mining is one of the most important and crucial part in today s world
2. Discovery of Association Rules
 2. Discovery of Association Rules Part I Motivation: market basket data Basic notions: association rule, frequency and confidence Problem of association rule mining (Sub)problem of frequent set mining
2. Discovery of Association Rules Part I Motivation: market basket data Basic notions: association rule, frequency and confidence Problem of association rule mining (Sub)problem of frequent set mining
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING Set Data: Frequent Pattern Mining Instructor: Yizhou Sun yzsun@cs.ucla.edu November 22, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification
CS145: INTRODUCTION TO DATA MINING Set Data: Frequent Pattern Mining Instructor: Yizhou Sun yzsun@cs.ucla.edu November 22, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification
Data mining - detailed outline. Carnegie Mellon Univ. Dept. of Computer Science /615 DB Applications. Problem.
 Faloutsos & Pavlo 15415/615 Carnegie Mellon Univ. Dept. of Computer Science 15415/615 DB Applications Data Warehousing / Data Mining (R&G, ch 25 and 26) C. Faloutsos and A. Pavlo Data mining detailed outline
Faloutsos & Pavlo 15415/615 Carnegie Mellon Univ. Dept. of Computer Science 15415/615 DB Applications Data Warehousing / Data Mining (R&G, ch 25 and 26) C. Faloutsos and A. Pavlo Data mining detailed outline
1. Interpret single-dimensional Boolean association rules from transactional databases
 1 STARTSTUDING.COM 1. Interpret single-dimensional Boolean association rules from transactional databases Association rule mining: Finding frequent patterns, associations, correlations, or causal structures
1 STARTSTUDING.COM 1. Interpret single-dimensional Boolean association rules from transactional databases Association rule mining: Finding frequent patterns, associations, correlations, or causal structures
CSE 5243 INTRO. TO DATA MINING
 CSE 53 INTRO. TO DATA MINING Locality Sensitive Hashing (LSH) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan Parthasarathy @OSU MMDS Secs. 3.-3.. Slides
CSE 53 INTRO. TO DATA MINING Locality Sensitive Hashing (LSH) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan Parthasarathy @OSU MMDS Secs. 3.-3.. Slides