Data mining, 4 cu Lecture 8:
|
|
|
- Justin Dalton
- 6 years ago
- Views:
Transcription

1 Data mining, 4 cu Lecture 8: Graph mining Spring 2010 Lecturer: Juho Rousu Teaching assistant: Taru Itäpelto
2 Frequent Subgraph Mining Extend association rule mining to finding frequent subgraphs Useful for Web Mining, computational chemistry, bioinformatics, spatial data sets, etc
3 Graphs in Applications Application Graphs used to analyze Vertices Edges Web mining Web browsing patterns Web pages Hyperlinks between pages Computational chemistry Structure of chemical compounds Atoms Bonds Networking Internet routing Server computers Interconnection between servers Bioinformatics Gene/protein interaction Genes/proteins Regulatory relations, physical binding
4 Graphs and subgraphs A graph G = (V,E) is composed of vertices (nodes) V and a set of edges E. In labeled graphs, vertices, edges or both can have labels describing them and differentiating them from each other Graph G =(V,E ) is a subgraph of G = (V,E) if V is a subset of V and E is a subset of E
5 Induced subgraph Graph G =(V,E ) is an induced subgraph of G = (V,E) if V is a subset of V, E contains all edges in E that have both ends in the set V The number of induced subgraphs is typically significantly less than the number of general subgraphs in induced subgraph E is determined by G and V
 Graph is undirected if edges have no orientation (u,v) and (v,u) denote the same object We concentrate in undirected")
6 Directed and undirected graphs Graph is directed if the edges are oriented (denoted by arrowhead), i.e. edge (u,v) is different object from edge (v,u) Graph is undirected if edges have no orientation (u,v) and (v,u) denote the same object We concentrate in undirected graphs
7 Connected and disconnected graphs Graph G = (V,E) is connected, if there is a path between any two nodes in V Otherwise the graph is disconnected A connected component is a maximal connected subgraph of a graph below, {1,2,3,4}, {5,8,6} and {7} with the connecting edges We concentrate in connected graphs
8 Support of a subgraph Given a collection of graphs G, the support of subgraph g is defined as the fraction of all graphs that contain g as its subgraph
9 Frequent subgraph mining: Definition Given a set of graphs G and a support threshold minsup, the goal is to find all subgraphs g with support s(g) at least minsup
10 Brute-force method? Generate all connected subgraphs, count the supports, and prune Problem: exponential number of subgraphs Considerably higher number of subgraphs than itemsets, given the same items (=node labels) An item can appear only once in an itemset but many times in a subgraph Given a fixed set of nodes, edges can be organized and labeled in many ways to create a set of different subgraphs Also more subgraphs than subsequences
11 Using itemset Apriori for subgraph mining One approach to mine subgraphs efficiently is to transform the graph dataset into a transaction database Each combination of vertex label edge label vertex label is defined as an item The width of the transaction is the number of edges in the graph
12 Using itemset Apriori for subgraph mining Problem: Multiple edges will be mapped into one item if they have the same label combination loss of information How to convert a frequent itemset into a frequent subgraph? Which of the edges in the original graph to choose Subgraph structure will be ambiquous
13 Note: Representing Transactions as Graphs The other direction, mapping transactions to graphs does not lose information Each transaction is a clique (fully connected subgraph) of items, an itemset is a subset of the clique So frequent subgraph mining can solve frequent itemset mining (in principle), but not vice versa
14 Apriori-like approach for frequent subgraph mining Try to follow the usual Apriori scheme: 1. Find frequent 1-subgraphs 2. Repeat until no more frequent subgraphs are found; 1. Candidate generation - Use frequent (k-1)-subgraphs to generate candidate k-subgraph 2. Candidate pruning - Prune candidate subgraphs that contain infrequent (k-1)-subgraphs 3. Support counting - Count the support of each remaining candidate 4. Eliminate candidate k-subgraphs that are infrequent Details much more complicated, try to touch the main issues in the following
15 Example
16 Candidate generation Goal: is to merge a pair of k-1-subgraphs to create a k- subgraph First need to define k: Number of vertices: merge two subgraphs that have k-1 vertices Number of edges: merge two subgraphs that have k-1 edges How to avoid generating the same subgraph many times Require that the k-1 subgraphs share a common k-2 subgraph, called a core
17 Candidate Generation: difference to itemset mining In Apriori: Merging two frequent k-itemsets will produce a candidate (k +1)-itemset In frequent subgraph mining Merging two frequent k-subgraphs will in general produce more than one candidate (k+1)-subgraph
18 Candidate generation via vertex growing Generate a candidate by merging two subgraphs (G1, G2) that have a common core (subgraph of k-2 vertices) plus 1 extra vertex each A set of candidates will be generated that differ by one edge (d,e) and its label: G3 below is the candidate without the edge (d,e)
19 Adjacency matrix representation The vertex-growing approach can be viewed in terms of combining adjacency matrices of the subgraphs In our adjacency matrix representation Rows and columns correspond to nodes - non-zero cells along a row (column) correspond to neighbors Cells correspond to edges - cell contains edge label (or zero if no edge)
20 Vertex Growing and adjacency matrices Vertex growing takes two adjacency matrices that differ in the last row, and creates and augmented matrix by adding the last row and last column of the second matrix to the first matrix.
21 Multiplicity of Candidates in vertex growing A separate candidate is generated for each possible label of the edge (d,e)
22 Candidate Generation via Edge Growing Edge growing approach inserts a new edge to an existing frequent subgraph Number of vertices not necessarily increased Criterion for merging is topological equivalence of the core
23 Topological equivalence All vertices in G1 are topologically equivalent: no matter where we add an edge, the resulting graph will have the same topology G2 contains two pairs of topologically equivalent vertices v1 & v4, v2 & v3: adding an edge to v1 or v4 will give one topology, adding an edge to v2 or v3 will give another topology G3 contains no topologically equivalent vertices: any choice of a vertex will lead to a different topology
24 Multiplicity of Candidates in Edge growing Edge growing approach creates multiple candidates of three different kinds Case 1: topologically equivalent vertices (e) can be mapped to a single vertex or a pair of vertices
25 Multiplicity of Candidates in Edge growing Case 2: Core contains topologically equivalent vertices All symmetric orientations of the core generate potentially a different candidate
26 Multiplicity of Candidates in Edge growing Case 3: Core multiplicity Depending on how we select the core, we get different candidates
27 Candidate pruning Given a candidate k-subgraph, we need to check whether all the k-1-subgraphs are frequent Approach: Successively remove one edge from the k-subgraph If the resulting k-1 subgraph is connected check whether it is frequent If not, remove the k-subgraph from the candidates Checking whether a k-1-subgraph is contained in the list of frequent k-1-subgraphs is not easy Requires solving graph isomorphism problem, i.e. checking whether two graphs are topoplogically equivalent
28 Hardness of graph matching Subgraph isomorphism: Determining if a graph G contains another graph G as its subgraph is known as the subgraph isomorphism problem One of the classical NP-hard problems, so no polynomial-time algorithm likely to exist Needed in identification of the common core and support counting Graph isomorphism: Determining if two graphs are topologically equivalent is the graph isomorphism problem Complexity is not known, but no polynomial-time algorithm known Needed: in candidate generation step, to determine whether a candidate has been generated and candidate pruning step, to check whether its (k-1)-subgraphs are frequent
29 Redundancy in the Adjacency Matrix Representation The same graph can be represented in many ways
30 Graph Isomorphism Use canonical labeling to handle isomorphism Map each graph into an ordered string representation (known as its code) such that two isomorphic graphs will be mapped to the same canonical encoding Example: - Lexicographically largest adjacency matrix String: Canonical:
31 Support counting Given a candidate k-subgraph, we need to check its support in out set of graphs Basic approach is to solve the subgraph isomorphism for each graph in the database More efficient is to store the graphs that contain k-1 subgraphs in list of graph IDs ( TID sets ) intersect the lists of graph IDs of the k-1 subgraphs that generated the current graph, and only compute the subgraph isomorphism between the k- subgraph and the graphs that are contained in the intersection

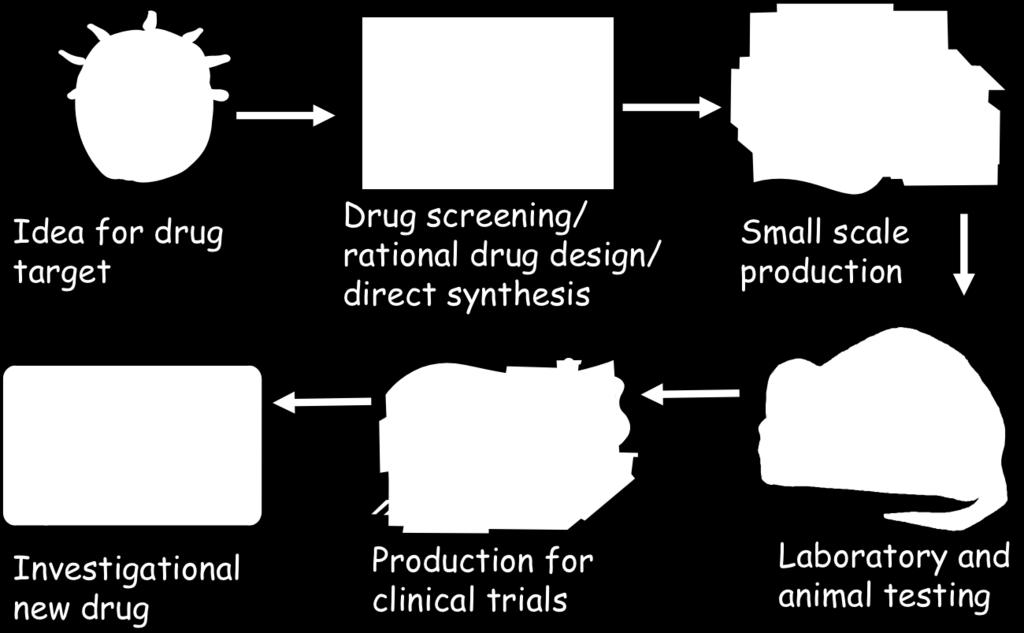
32 Graph mining application: Drug Discovery
33 Graph Classification Approach Graph Databases Discover Frequent Select Discriminating 1 2 Sub-graphs Features 3 Transform Graphs in Feature Representation Learn a Classification Model 4
34 Chemical Compound Datasets Predictive Toxicology Challenge (PTC) Predicting toxicity (carcinogenicity) of compounds. Bio assays on four kinds of rodents 4 Classification Problems -- Approx 400 chemical compounds. DTP AIDS Antiviral Screen (AIDS) Predicting anti-hiv activity of compounds. Assay to measure protection of human cells against HIV infection. 3 Classification problems -- Approx 40,000 chemical compounds. Anthrax Predicting binding ability of compounds with the anthrax toxin. Expensive molecular dynamics simulation Collaboration with Dr. Frank Lebeda, USAMRIID Approx 35,000 chemical compounds
35 Most Discriminating Subbgraphs (a) On Toxicology (PTC) Dataset (b) On AIDS Dataset (c) On Anthrax Dataset
36 Graph Mining - Motivation, Algorithms and Applications (2 cp) Special course during the intensive period Preliminary dates: May 2010 Teacher: Professor Ehud Gudes, Ben-Gurion University of the Negev Beer-Sheva, Israel Coordinator: Greger Lindén Place: Department of Computer Science, Exactum Building. Gustaf Hällströmin katu 2b Enroll at
gspan: Graph-Based Substructure Pattern Mining
 University of Illinois at Urbana-Champaign February 3, 2017 Agenda What motivated the development of gspan? Technical Preliminaries Exploring the gspan algorithm Experimental Performance Evaluation Introduction
University of Illinois at Urbana-Champaign February 3, 2017 Agenda What motivated the development of gspan? Technical Preliminaries Exploring the gspan algorithm Experimental Performance Evaluation Introduction
Apriori Algorithm. 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke
 Apriori Algorithm For a given set of transactions, the main aim of Association Rule Mining is to find rules that will predict the occurrence of an item based on the occurrences of the other items in the
Apriori Algorithm For a given set of transactions, the main aim of Association Rule Mining is to find rules that will predict the occurrence of an item based on the occurrences of the other items in the
2. Discovery of Association Rules
 2. Discovery of Association Rules Part I Motivation: market basket data Basic notions: association rule, frequency and confidence Problem of association rule mining (Sub)problem of frequent set mining
2. Discovery of Association Rules Part I Motivation: market basket data Basic notions: association rule, frequency and confidence Problem of association rule mining (Sub)problem of frequent set mining
Data Structures. Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali Association Rules: Basic Concepts and Application
 Data Structures Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali 2009-2010 Association Rules: Basic Concepts and Application 1. Association rules: Given a set of transactions, find
Data Structures Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali 2009-2010 Association Rules: Basic Concepts and Application 1. Association rules: Given a set of transactions, find
Frequent Pattern Mining. Based on: Introduction to Data Mining by Tan, Steinbach, Kumar
 Frequent Pattern Mining Based on: Introduction to Data Mining by Tan, Steinbach, Kumar Item sets A New Type of Data Some notation: All possible items: Database: T is a bag of transactions Transaction transaction
Frequent Pattern Mining Based on: Introduction to Data Mining by Tan, Steinbach, Kumar Item sets A New Type of Data Some notation: All possible items: Database: T is a bag of transactions Transaction transaction
Discovering Frequent Geometric Subgraphs
 Discovering Frequent Geometric Subgraphs Michihiro Kuramochi and George Karypis Department of Computer Science/Army HPC Research Center University of Minnesota 4-192 EE/CS Building, 200 Union St SE Minneapolis,
Discovering Frequent Geometric Subgraphs Michihiro Kuramochi and George Karypis Department of Computer Science/Army HPC Research Center University of Minnesota 4-192 EE/CS Building, 200 Union St SE Minneapolis,
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R,
 Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R, statistics foundations 5 Introduction to D3, visual analytics
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R, statistics foundations 5 Introduction to D3, visual analytics
Introduction to Graph Theory
 Introduction to Graph Theory Tandy Warnow January 20, 2017 Graphs Tandy Warnow Graphs A graph G = (V, E) is an object that contains a vertex set V and an edge set E. We also write V (G) to denote the vertex
Introduction to Graph Theory Tandy Warnow January 20, 2017 Graphs Tandy Warnow Graphs A graph G = (V, E) is an object that contains a vertex set V and an edge set E. We also write V (G) to denote the vertex
Data Mining in Bioinformatics Day 5: Frequent Subgraph Mining
 Data Mining in Bioinformatics Day 5: Frequent Subgraph Mining Chloé-Agathe Azencott & Karsten Borgwardt February 18 to March 1, 2013 Machine Learning & Computational Biology Research Group Max Planck Institutes
Data Mining in Bioinformatics Day 5: Frequent Subgraph Mining Chloé-Agathe Azencott & Karsten Borgwardt February 18 to March 1, 2013 Machine Learning & Computational Biology Research Group Max Planck Institutes
Subgraph Isomorphism. Artem Maksov, Yong Li, Reese Butler 03/04/2015
 Subgraph Isomorphism Artem Maksov, Yong Li, Reese Butler 03/04/2015 Similar Graphs The two graphs below look different but are structurally the same. Definition What is Graph Isomorphism? An isomorphism
Subgraph Isomorphism Artem Maksov, Yong Li, Reese Butler 03/04/2015 Similar Graphs The two graphs below look different but are structurally the same. Definition What is Graph Isomorphism? An isomorphism
Chapters 11 and 13, Graph Data Mining
 CSI 4352, Introduction to Data Mining Chapters 11 and 13, Graph Data Mining Young-Rae Cho Associate Professor Department of Computer Science Balor Universit Graph Representation Graph An ordered pair GV,E
CSI 4352, Introduction to Data Mining Chapters 11 and 13, Graph Data Mining Young-Rae Cho Associate Professor Department of Computer Science Balor Universit Graph Representation Graph An ordered pair GV,E
Mining Minimal Contrast Subgraph Patterns
 Mining Minimal Contrast Subgraph Patterns Roger Ming Hieng Ting James Bailey Abstract In this paper, we introduce a new type of contrast pattern, the minimal contrast subgraph. It is able to capture structural
Mining Minimal Contrast Subgraph Patterns Roger Ming Hieng Ting James Bailey Abstract In this paper, we introduce a new type of contrast pattern, the minimal contrast subgraph. It is able to capture structural
BIL694-Lecture 1: Introduction to Graphs
 BIL694-Lecture 1: Introduction to Graphs Lecturer: Lale Özkahya Resources for the presentation: http://www.math.ucsd.edu/ gptesler/184a/calendar.html http://www.inf.ed.ac.uk/teaching/courses/dmmr/ Outline
BIL694-Lecture 1: Introduction to Graphs Lecturer: Lale Özkahya Resources for the presentation: http://www.math.ucsd.edu/ gptesler/184a/calendar.html http://www.inf.ed.ac.uk/teaching/courses/dmmr/ Outline
Data mining, 4 cu Lecture 6:
 582364 Data mining, 4 cu Lecture 6: Quantitative association rules Multi-level association rules Spring 2010 Lecturer: Juho Rousu Teaching assistant: Taru Itäpelto Data mining, Spring 2010 (Slides adapted
582364 Data mining, 4 cu Lecture 6: Quantitative association rules Multi-level association rules Spring 2010 Lecturer: Juho Rousu Teaching assistant: Taru Itäpelto Data mining, Spring 2010 (Slides adapted
Data Mining in Bioinformatics Day 5: Graph Mining
 Data Mining in Bioinformatics Day 5: Graph Mining Karsten Borgwardt February 25 to March 10 Bioinformatics Group MPIs Tübingen from Borgwardt and Yan, KDD 2008 tutorial Graph Mining and Graph Kernels,
Data Mining in Bioinformatics Day 5: Graph Mining Karsten Borgwardt February 25 to March 10 Bioinformatics Group MPIs Tübingen from Borgwardt and Yan, KDD 2008 tutorial Graph Mining and Graph Kernels,
Association Pattern Mining. Lijun Zhang
 Association Pattern Mining Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction The Frequent Pattern Mining Model Association Rule Generation Framework Frequent Itemset Mining Algorithms
Association Pattern Mining Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction The Frequent Pattern Mining Model Association Rule Generation Framework Frequent Itemset Mining Algorithms
Computer Algebra Investigation of Known Primitive Triangle-Free Strongly Regular Graphs
 Computer Algebra Investigation of Known Primitive Triangle-Free Strongly Regular Graphs Matan Ziv-Av (Jointly with Mikhail Klin) Ben-Gurion University of the Negev SCSS 2013 RISC, JKU July 5, 2013 Ziv-Av
Computer Algebra Investigation of Known Primitive Triangle-Free Strongly Regular Graphs Matan Ziv-Av (Jointly with Mikhail Klin) Ben-Gurion University of the Negev SCSS 2013 RISC, JKU July 5, 2013 Ziv-Av
Data Mining in Bioinformatics Day 3: Graph Mining
 Graph Mining and Graph Kernels Data Mining in Bioinformatics Day 3: Graph Mining Karsten Borgwardt & Chloé-Agathe Azencott February 6 to February 17, 2012 Machine Learning and Computational Biology Research
Graph Mining and Graph Kernels Data Mining in Bioinformatics Day 3: Graph Mining Karsten Borgwardt & Chloé-Agathe Azencott February 6 to February 17, 2012 Machine Learning and Computational Biology Research
Treewidth and graph minors
 Treewidth and graph minors Lectures 9 and 10, December 29, 2011, January 5, 2012 We shall touch upon the theory of Graph Minors by Robertson and Seymour. This theory gives a very general condition under
Treewidth and graph minors Lectures 9 and 10, December 29, 2011, January 5, 2012 We shall touch upon the theory of Graph Minors by Robertson and Seymour. This theory gives a very general condition under
A Roadmap to an Enhanced Graph Based Data mining Approach for Multi-Relational Data mining
 A Roadmap to an Enhanced Graph Based Data mining Approach for Multi-Relational Data mining D.Kavinya 1 Student, Department of CSE, K.S.Rangasamy College of Technology, Tiruchengode, Tamil Nadu, India 1
A Roadmap to an Enhanced Graph Based Data mining Approach for Multi-Relational Data mining D.Kavinya 1 Student, Department of CSE, K.S.Rangasamy College of Technology, Tiruchengode, Tamil Nadu, India 1
Mining frequent Closed Graph Pattern
 Mining frequent Closed Graph Pattern Seminar aus maschninellem Lernen Referent: Yingting Fan 5.November Fachbereich 21 Institut Knowledge Engineering Prof. Fürnkranz 1 Outline Motivation and introduction
Mining frequent Closed Graph Pattern Seminar aus maschninellem Lernen Referent: Yingting Fan 5.November Fachbereich 21 Institut Knowledge Engineering Prof. Fürnkranz 1 Outline Motivation and introduction
CARPENTER Find Closed Patterns in Long Biological Datasets. Biological Datasets. Overview. Biological Datasets. Zhiyu Wang
 CARPENTER Find Closed Patterns in Long Biological Datasets Zhiyu Wang Biological Datasets Gene expression Consists of large number of genes Knowledge Discovery and Data Mining Dr. Osmar Zaiane Department
CARPENTER Find Closed Patterns in Long Biological Datasets Zhiyu Wang Biological Datasets Gene expression Consists of large number of genes Knowledge Discovery and Data Mining Dr. Osmar Zaiane Department
Chapter 4: Association analysis:
 Chapter 4: Association analysis: 4.1 Introduction: Many business enterprises accumulate large quantities of data from their day-to-day operations, huge amounts of customer purchase data are collected daily
Chapter 4: Association analysis: 4.1 Introduction: Many business enterprises accumulate large quantities of data from their day-to-day operations, huge amounts of customer purchase data are collected daily
Using a Hash-Based Method for Apriori-Based Graph Mining
 Using a Hash-Based Method for Apriori-Based Graph Mining Phu Chien Nguyen, Takashi Washio, Kouzou Ohara, and Hiroshi Motoda The Institute of Scientific and Industrial Research, Osaka University 8-1 Mihogaoka,
Using a Hash-Based Method for Apriori-Based Graph Mining Phu Chien Nguyen, Takashi Washio, Kouzou Ohara, and Hiroshi Motoda The Institute of Scientific and Industrial Research, Osaka University 8-1 Mihogaoka,
motifs In the context of networks, the term motif may refer to di erent notions. Subgraph motifs Coloured motifs { }
 motifs In the context of networks, the term motif may refer to di erent notions. Subgraph motifs Coloured motifs G M { } 2 subgraph motifs 3 motifs Find interesting patterns in a network. 4 motifs Find
motifs In the context of networks, the term motif may refer to di erent notions. Subgraph motifs Coloured motifs G M { } 2 subgraph motifs 3 motifs Find interesting patterns in a network. 4 motifs Find
Subsea: An efficient heuristic algorithm for subgraph isomorphism
 Subsea: An efficient heuristic algorithm for subgraph isomorphism V. Lipets, N. Vanetik, E. Gudes Dept. of Computer Science, Ben-Gurion University { lipets, orlovn, ehud } @cs.bgu.ac.il Abstract We present
Subsea: An efficient heuristic algorithm for subgraph isomorphism V. Lipets, N. Vanetik, E. Gudes Dept. of Computer Science, Ben-Gurion University { lipets, orlovn, ehud } @cs.bgu.ac.il Abstract We present
Introduction III. Graphs. Motivations I. Introduction IV
 Introduction I Graphs Computer Science & Engineering 235: Discrete Mathematics Christopher M. Bourke cbourke@cse.unl.edu Graph theory was introduced in the 18th century by Leonhard Euler via the Königsberg
Introduction I Graphs Computer Science & Engineering 235: Discrete Mathematics Christopher M. Bourke cbourke@cse.unl.edu Graph theory was introduced in the 18th century by Leonhard Euler via the Königsberg
Chapter 6: Association Rules
 Chapter 6: Association Rules Association rule mining Proposed by Agrawal et al in 1993. It is an important data mining model. Transaction data (no time-dependent) Assume all data are categorical. No good
Chapter 6: Association Rules Association rule mining Proposed by Agrawal et al in 1993. It is an important data mining model. Transaction data (no time-dependent) Assume all data are categorical. No good
CS473-Algorithms I. Lecture 13-A. Graphs. Cevdet Aykanat - Bilkent University Computer Engineering Department
 CS473-Algorithms I Lecture 3-A Graphs Graphs A directed graph (or digraph) G is a pair (V, E), where V is a finite set, and E is a binary relation on V The set V: Vertex set of G The set E: Edge set of
CS473-Algorithms I Lecture 3-A Graphs Graphs A directed graph (or digraph) G is a pair (V, E), where V is a finite set, and E is a binary relation on V The set V: Vertex set of G The set E: Edge set of
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data: Part I Instructor: Yizhou Sun yzsun@ccs.neu.edu November 12, 2013 Announcement Homework 4 will be out tonight Due on 12/2 Next class will be canceled
CS6220: DATA MINING TECHNIQUES Mining Graph/Network Data: Part I Instructor: Yizhou Sun yzsun@ccs.neu.edu November 12, 2013 Announcement Homework 4 will be out tonight Due on 12/2 Next class will be canceled
Graphs: Introduction. Ali Shokoufandeh, Department of Computer Science, Drexel University
 Graphs: Introduction Ali Shokoufandeh, Department of Computer Science, Drexel University Overview of this talk Introduction: Notations and Definitions Graphs and Modeling Algorithmic Graph Theory and Combinatorial
Graphs: Introduction Ali Shokoufandeh, Department of Computer Science, Drexel University Overview of this talk Introduction: Notations and Definitions Graphs and Modeling Algorithmic Graph Theory and Combinatorial
Math 776 Graph Theory Lecture Note 1 Basic concepts
 Math 776 Graph Theory Lecture Note 1 Basic concepts Lectured by Lincoln Lu Transcribed by Lincoln Lu Graph theory was founded by the great Swiss mathematician Leonhard Euler (1707-178) after he solved
Math 776 Graph Theory Lecture Note 1 Basic concepts Lectured by Lincoln Lu Transcribed by Lincoln Lu Graph theory was founded by the great Swiss mathematician Leonhard Euler (1707-178) after he solved
Interestingness Measurements
 Interestingness Measurements Objective measures Two popular measurements: support and confidence Subjective measures [Silberschatz & Tuzhilin, KDD95] A rule (pattern) is interesting if it is unexpected
Interestingness Measurements Objective measures Two popular measurements: support and confidence Subjective measures [Silberschatz & Tuzhilin, KDD95] A rule (pattern) is interesting if it is unexpected
Association Rule Mining. Entscheidungsunterstützungssysteme
 Association Rule Mining Entscheidungsunterstützungssysteme Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set
Association Rule Mining Entscheidungsunterstützungssysteme Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set
Graph Theory: Introduction
 Graph Theory: Introduction Pallab Dasgupta, Professor, Dept. of Computer Sc. and Engineering, IIT Kharagpur pallab@cse.iitkgp.ernet.in Resources Copies of slides available at: http://www.facweb.iitkgp.ernet.in/~pallab
Graph Theory: Introduction Pallab Dasgupta, Professor, Dept. of Computer Sc. and Engineering, IIT Kharagpur pallab@cse.iitkgp.ernet.in Resources Copies of slides available at: http://www.facweb.iitkgp.ernet.in/~pallab
Matching Algorithms. Proof. If a bipartite graph has a perfect matching, then it is easy to see that the right hand side is a necessary condition.
 18.433 Combinatorial Optimization Matching Algorithms September 9,14,16 Lecturer: Santosh Vempala Given a graph G = (V, E), a matching M is a set of edges with the property that no two of the edges have
18.433 Combinatorial Optimization Matching Algorithms September 9,14,16 Lecturer: Santosh Vempala Given a graph G = (V, E), a matching M is a set of edges with the property that no two of the edges have
Chapter 7: Frequent Itemsets and Association Rules
 Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2011/12 VII.1-1 Chapter VII: Frequent Itemsets and Association
Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2011/12 VII.1-1 Chapter VII: Frequent Itemsets and Association
An Apriori-Based Algorithm for Mining Frequent Substructures from Graph Data
 An Apriori-Based Algorithm for Mining Frequent Substructures from Graph Data Akihiro Inokuchi, Takashi Washio, and Hiroshi Motoda I.S.I.R., Osaka University 8-1, Mihogaoka, Ibarakishi, Osaka, 567-0047,
An Apriori-Based Algorithm for Mining Frequent Substructures from Graph Data Akihiro Inokuchi, Takashi Washio, and Hiroshi Motoda I.S.I.R., Osaka University 8-1, Mihogaoka, Ibarakishi, Osaka, 567-0047,
Big Data Management and NoSQL Databases
 NDBI040 Big Data Management and NoSQL Databases Lecture 10. Graph databases Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Graph Databases Basic
NDBI040 Big Data Management and NoSQL Databases Lecture 10. Graph databases Doc. RNDr. Irena Holubova, Ph.D. holubova@ksi.mff.cuni.cz http://www.ksi.mff.cuni.cz/~holubova/ndbi040/ Graph Databases Basic
Nesnelerin İnternetinde Veri Analizi
 Bölüm 4. Frequent Patterns in Data Streams w3.gazi.edu.tr/~suatozdemir What Is Pattern Discovery? What are patterns? Patterns: A set of items, subsequences, or substructures that occur frequently together
Bölüm 4. Frequent Patterns in Data Streams w3.gazi.edu.tr/~suatozdemir What Is Pattern Discovery? What are patterns? Patterns: A set of items, subsequences, or substructures that occur frequently together
Frequent Itemsets Melange
 Frequent Itemsets Melange Sebastien Siva Data Mining Motivation and objectives Finding all frequent itemsets in a dataset using the traditional Apriori approach is too computationally expensive for datasets
Frequent Itemsets Melange Sebastien Siva Data Mining Motivation and objectives Finding all frequent itemsets in a dataset using the traditional Apriori approach is too computationally expensive for datasets
Graph Mining and Social Network Analysis
 Graph Mining and Social Network Analysis Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References q Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann
Graph Mining and Social Network Analysis Data Mining and Text Mining (UIC 583 @ Politecnico di Milano) References q Jiawei Han and Micheline Kamber, "Data Mining: Concepts and Techniques", The Morgan Kaufmann
Chapter 6: Basic Concepts: Association Rules. Basic Concepts: Frequent Patterns. (absolute) support, or, support. (relative) support, s, is the
 support, or, support. (relative) support, s, is the") Chapter 6: What Is Frequent ent Pattern Analysis? Frequent pattern: a pattern (a set of items, subsequences, substructures, etc) that occurs frequently in a data set frequent itemsets and association rule
Chapter 6: What Is Frequent ent Pattern Analysis? Frequent pattern: a pattern (a set of items, subsequences, substructures, etc) that occurs frequently in a data set frequent itemsets and association rule
Learning decomposable models with a bounded clique size
 Learning decomposable models with a bounded clique size Achievements 2014-2016 Aritz Pérez Basque Center for Applied Mathematics Bilbao, March, 2016 Outline 1 Motivation and background 2 The problem 3
Learning decomposable models with a bounded clique size Achievements 2014-2016 Aritz Pérez Basque Center for Applied Mathematics Bilbao, March, 2016 Outline 1 Motivation and background 2 The problem 3
KNIME Enalos+ Molecular Descriptor nodes
 KNIME Enalos+ Molecular Descriptor nodes A Brief Tutorial Novamechanics Ltd Contact: info@novamechanics.com Version 1, June 2017 Table of Contents Introduction... 1 Step 1-Workbench overview... 1 Step
KNIME Enalos+ Molecular Descriptor nodes A Brief Tutorial Novamechanics Ltd Contact: info@novamechanics.com Version 1, June 2017 Table of Contents Introduction... 1 Step 1-Workbench overview... 1 Step
Clustering Part 4 DBSCAN
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
EMPIRICAL COMPARISON OF GRAPH CLASSIFICATION AND REGRESSION ALGORITHMS. By NIKHIL S. KETKAR
 EMPIRICAL COMPARISON OF GRAPH CLASSIFICATION AND REGRESSION ALGORITHMS By NIKHIL S. KETKAR A dissertation submitted in partial fulfillment of the requirements for the degree of DOCTORATE OF PHILOSOPHY
EMPIRICAL COMPARISON OF GRAPH CLASSIFICATION AND REGRESSION ALGORITHMS By NIKHIL S. KETKAR A dissertation submitted in partial fulfillment of the requirements for the degree of DOCTORATE OF PHILOSOPHY
A Novel method for Frequent Pattern Mining
 A Novel method for Frequent Pattern Mining K.Rajeswari #1, Dr.V.Vaithiyanathan *2 # Associate Professor, PCCOE & Ph.D Research Scholar SASTRA University, Tanjore, India 1 raji.pccoe@gmail.com * Associate
A Novel method for Frequent Pattern Mining K.Rajeswari #1, Dr.V.Vaithiyanathan *2 # Associate Professor, PCCOE & Ph.D Research Scholar SASTRA University, Tanjore, India 1 raji.pccoe@gmail.com * Associate
Chapter 7: Frequent Itemsets and Association Rules
 Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2013/14 VII.1&2 1 Motivational Example Assume you run an on-line
Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2013/14 VII.1&2 1 Motivational Example Assume you run an on-line
A Technical Analysis of Market Basket by using Association Rule Mining and Apriori Algorithm
 A Technical Analysis of Market Basket by using Association Rule Mining and Apriori Algorithm S.Pradeepkumar*, Mrs.C.Grace Padma** M.Phil Research Scholar, Department of Computer Science, RVS College of
A Technical Analysis of Market Basket by using Association Rule Mining and Apriori Algorithm S.Pradeepkumar*, Mrs.C.Grace Padma** M.Phil Research Scholar, Department of Computer Science, RVS College of
Vertical decomposition of a lattice using clique separators
 Vertical decomposition of a lattice using clique separators Anne Berry, Romain Pogorelcnik, Alain Sigayret LIMOS UMR CNRS 6158 Ensemble Scientifique des Cézeaux Université Blaise Pascal, F-63 173 Aubière,
Vertical decomposition of a lattice using clique separators Anne Berry, Romain Pogorelcnik, Alain Sigayret LIMOS UMR CNRS 6158 Ensemble Scientifique des Cézeaux Université Blaise Pascal, F-63 173 Aubière,
Graphs. Data Structures and Algorithms CSE 373 SU 18 BEN JONES 1
 Graphs Data Structures and Algorithms CSE 373 SU 18 BEN JONES 1 Warmup Discuss with your neighbors: Come up with as many kinds of relational data as you can (data that can be represented with a graph).
Graphs Data Structures and Algorithms CSE 373 SU 18 BEN JONES 1 Warmup Discuss with your neighbors: Come up with as many kinds of relational data as you can (data that can be represented with a graph).
A mining method for tracking changes in temporal association rules from an encoded database
 A mining method for tracking changes in temporal association rules from an encoded database Chelliah Balasubramanian *, Karuppaswamy Duraiswamy ** K.S.Rangasamy College of Technology, Tiruchengode, Tamil
A mining method for tracking changes in temporal association rules from an encoded database Chelliah Balasubramanian *, Karuppaswamy Duraiswamy ** K.S.Rangasamy College of Technology, Tiruchengode, Tamil
Course Introduction / Review of Fundamentals of Graph Theory
 Course Introduction / Review of Fundamentals of Graph Theory Hiroki Sayama sayama@binghamton.edu Rise of Network Science (From Barabasi 2010) 2 Network models Many discrete parts involved Classic mean-field
Course Introduction / Review of Fundamentals of Graph Theory Hiroki Sayama sayama@binghamton.edu Rise of Network Science (From Barabasi 2010) 2 Network models Many discrete parts involved Classic mean-field
Introduction to Parallel & Distributed Computing Parallel Graph Algorithms
 Introduction to Parallel & Distributed Computing Parallel Graph Algorithms Lecture 16, Spring 2014 Instructor: 罗国杰 gluo@pku.edu.cn In This Lecture Parallel formulations of some important and fundamental
Introduction to Parallel & Distributed Computing Parallel Graph Algorithms Lecture 16, Spring 2014 Instructor: 罗国杰 gluo@pku.edu.cn In This Lecture Parallel formulations of some important and fundamental
Epilog: Further Topics
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases SS 2016 Epilog: Further Topics Lecture: Prof. Dr. Thomas
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Knowledge Discovery in Databases SS 2016 Epilog: Further Topics Lecture: Prof. Dr. Thomas
Parallelization of Graph Isomorphism using OpenMP
 Parallelization of Graph Isomorphism using OpenMP Vijaya Balpande Research Scholar GHRCE, Nagpur Priyadarshini J L College of Engineering, Nagpur ABSTRACT Advancement in computer architecture leads to
Parallelization of Graph Isomorphism using OpenMP Vijaya Balpande Research Scholar GHRCE, Nagpur Priyadarshini J L College of Engineering, Nagpur ABSTRACT Advancement in computer architecture leads to
Lecture notes for April 6, 2005
 Lecture notes for April 6, 2005 Mining Association Rules The goal of association rule finding is to extract correlation relationships in the large datasets of items. Many businesses are interested in extracting
Lecture notes for April 6, 2005 Mining Association Rules The goal of association rule finding is to extract correlation relationships in the large datasets of items. Many businesses are interested in extracting
Extraction of Frequent Subgraph from Graph Database
 Extraction of Frequent Subgraph from Graph Database Sakshi S. Mandke, Sheetal S. Sonawane Deparment of Computer Engineering Pune Institute of Computer Engineering, Pune, India. sakshi.mandke@cumminscollege.in;
Extraction of Frequent Subgraph from Graph Database Sakshi S. Mandke, Sheetal S. Sonawane Deparment of Computer Engineering Pune Institute of Computer Engineering, Pune, India. sakshi.mandke@cumminscollege.in;
CMTreeMiner: Mining Both Closed and Maximal Frequent Subtrees
 MTreeMiner: Mining oth losed and Maximal Frequent Subtrees Yun hi, Yirong Yang, Yi Xia, and Richard R. Muntz University of alifornia, Los ngeles, 90095, US {ychi,yyr,xiayi,muntz}@cs.ucla.edu bstract. Tree
MTreeMiner: Mining oth losed and Maximal Frequent Subtrees Yun hi, Yirong Yang, Yi Xia, and Richard R. Muntz University of alifornia, Los ngeles, 90095, US {ychi,yyr,xiayi,muntz}@cs.ucla.edu bstract. Tree
Graph Indexing: A Frequent Structure-based Approach
 Graph Indexing: A Frequent Structure-based Approach Xifeng Yan Philip S. Yu Jiawei Han Department of omputer Science University of Illinois at Urbana-hampaign {xyan, hanj}@cs.uiuc.edu IBM T. J. Watson
Graph Indexing: A Frequent Structure-based Approach Xifeng Yan Philip S. Yu Jiawei Han Department of omputer Science University of Illinois at Urbana-hampaign {xyan, hanj}@cs.uiuc.edu IBM T. J. Watson
Graph Algorithms Using Depth First Search
 Graph Algorithms Using Depth First Search Analysis of Algorithms Week 8, Lecture 1 Prepared by John Reif, Ph.D. Distinguished Professor of Computer Science Duke University Graph Algorithms Using Depth
Graph Algorithms Using Depth First Search Analysis of Algorithms Week 8, Lecture 1 Prepared by John Reif, Ph.D. Distinguished Professor of Computer Science Duke University Graph Algorithms Using Depth
AC-Close: Efficiently Mining Approximate Closed Itemsets by Core Pattern Recovery
 : Efficiently Mining Approximate Closed Itemsets by Core Pattern Recovery Hong Cheng Philip S. Yu Jiawei Han University of Illinois at Urbana-Champaign IBM T. J. Watson Research Center {hcheng3, hanj}@cs.uiuc.edu,
: Efficiently Mining Approximate Closed Itemsets by Core Pattern Recovery Hong Cheng Philip S. Yu Jiawei Han University of Illinois at Urbana-Champaign IBM T. J. Watson Research Center {hcheng3, hanj}@cs.uiuc.edu,
Data Mining Concepts
 Data Mining Concepts Outline Data Mining Data Warehousing Knowledge Discovery in Databases (KDD) Goals of Data Mining and Knowledge Discovery Association Rules Additional Data Mining Algorithms Sequential
Data Mining Concepts Outline Data Mining Data Warehousing Knowledge Discovery in Databases (KDD) Goals of Data Mining and Knowledge Discovery Association Rules Additional Data Mining Algorithms Sequential
Frequent Pattern Mining
 Frequent Pattern Mining How Many Words Is a Picture Worth? E. Aiden and J-B Michel: Uncharted. Reverhead Books, 2013 Jian Pei: CMPT 741/459 Frequent Pattern Mining (1) 2 Burnt or Burned? E. Aiden and J-B
Frequent Pattern Mining How Many Words Is a Picture Worth? E. Aiden and J-B Michel: Uncharted. Reverhead Books, 2013 Jian Pei: CMPT 741/459 Frequent Pattern Mining (1) 2 Burnt or Burned? E. Aiden and J-B
GADDI: Distance Index based Subgraph Matching in Biological Networks
 GADDI: Distance Index based Subgraph Matching in Biological Networks Shijie Zhang, Shirong Li, and Jiong Yang Dept. of Electrical Engineering and Computer Science Case Western Reserve University 10900
GADDI: Distance Index based Subgraph Matching in Biological Networks Shijie Zhang, Shirong Li, and Jiong Yang Dept. of Electrical Engineering and Computer Science Case Western Reserve University 10900
Paths. Path is a sequence of edges that begins at a vertex of a graph and travels from vertex to vertex along edges of the graph.
 Paths Path is a sequence of edges that begins at a vertex of a graph and travels from vertex to vertex along edges of the graph. Formal Definition of a Path (Undirected) Let n be a nonnegative integer
Paths Path is a sequence of edges that begins at a vertex of a graph and travels from vertex to vertex along edges of the graph. Formal Definition of a Path (Undirected) Let n be a nonnegative integer
Let G = (V, E) be a graph. If u, v V, then u is adjacent to v if {u, v} E. We also use the notation u v to denote that u is adjacent to v.
 be a graph. If u, v V, then u is adjacent to v if {u, v} E. We also use the notation u v to denote that u is adjacent to v.") Graph Adjacent Endpoint of an edge Incident Neighbors of a vertex Degree of a vertex Theorem Graph relation Order of a graph Size of a graph Maximum and minimum degree Let G = (V, E) be a graph. If u,
Graph Adjacent Endpoint of an edge Incident Neighbors of a vertex Degree of a vertex Theorem Graph relation Order of a graph Size of a graph Maximum and minimum degree Let G = (V, E) be a graph. If u,
Performance of general graph isomorphism algorithms Sara Voss Coe College, Cedar Rapids, IA
 Performance of general graph isomorphism algorithms Sara Voss Coe College, Cedar Rapids, IA I. Problem and Motivation Graphs are commonly used to provide structural and/or relational descriptions. A node
Performance of general graph isomorphism algorithms Sara Voss Coe College, Cedar Rapids, IA I. Problem and Motivation Graphs are commonly used to provide structural and/or relational descriptions. A node
Association Analysis: Basic Concepts and Algorithms
 5 Association Analysis: Basic Concepts and Algorithms Many business enterprises accumulate large quantities of data from their dayto-day operations. For example, huge amounts of customer purchase data
5 Association Analysis: Basic Concepts and Algorithms Many business enterprises accumulate large quantities of data from their dayto-day operations. For example, huge amounts of customer purchase data
BCB 713 Module Spring 2011
 Association Rule Mining COMP 790-90 Seminar BCB 713 Module Spring 2011 The UNIVERSITY of NORTH CAROLINA at CHAPEL HILL Outline What is association rule mining? Methods for association rule mining Extensions
Association Rule Mining COMP 790-90 Seminar BCB 713 Module Spring 2011 The UNIVERSITY of NORTH CAROLINA at CHAPEL HILL Outline What is association rule mining? Methods for association rule mining Extensions
University of Florida CISE department Gator Engineering. Clustering Part 4
 Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
Clustering Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville DBSCAN DBSCAN is a density based clustering algorithm Density = number of
CSE 634/590 Data mining Extra Credit: Classification by Association rules: Example Problem. Muhammad Asiful Islam, SBID:
 CSE 634/590 Data mining Extra Credit: Classification by Association rules: Example Problem Muhammad Asiful Islam, SBID: 106506983 Original Data Outlook Humidity Wind PlayTenis Sunny High Weak No Sunny
CSE 634/590 Data mining Extra Credit: Classification by Association rules: Example Problem Muhammad Asiful Islam, SBID: 106506983 Original Data Outlook Humidity Wind PlayTenis Sunny High Weak No Sunny
Mining Association Rules in Large Databases
 Mining Association Rules in Large Databases Association rules Given a set of transactions D, find rules that will predict the occurrence of an item (or a set of items) based on the occurrences of other
Mining Association Rules in Large Databases Association rules Given a set of transactions D, find rules that will predict the occurrence of an item (or a set of items) based on the occurrences of other
Community Detection. Community
 Community Detection Community In social sciences: Community is formed by individuals such that those within a group interact with each other more frequently than with those outside the group a.k.a. group,
Community Detection Community In social sciences: Community is formed by individuals such that those within a group interact with each other more frequently than with those outside the group a.k.a. group,
Graphs. Edges may be directed (from u to v) or undirected. Undirected edge eqvt to pair of directed edges
 or undirected. Undirected edge eqvt to pair of directed edges") (p 186) Graphs G = (V,E) Graphs set V of vertices, each with a unique name Note: book calls vertices as nodes set E of edges between vertices, each encoded as tuple of 2 vertices as in (u,v) Edges may
(p 186) Graphs G = (V,E) Graphs set V of vertices, each with a unique name Note: book calls vertices as nodes set E of edges between vertices, each encoded as tuple of 2 vertices as in (u,v) Edges may
V8 Molecular decomposition of graphs
 V8 Molecular decomposition of graphs - Most cellular processes result from a cascade of events mediated by proteins that act in a cooperative manner. - Protein complexes can share components: proteins
V8 Molecular decomposition of graphs - Most cellular processes result from a cascade of events mediated by proteins that act in a cooperative manner. - Protein complexes can share components: proteins
A Performance Analysis on Maximal Common Subgraph Algorithms
 A Performance Analysis on Maximal Common Subgraph Algorithms Ruud Welling University of Twente P.O. Box 217, 7500AE Enschede The Netherlands r.h.a.welling@student.utwente.nl ABSTRACT Graphs can be used
A Performance Analysis on Maximal Common Subgraph Algorithms Ruud Welling University of Twente P.O. Box 217, 7500AE Enschede The Netherlands r.h.a.welling@student.utwente.nl ABSTRACT Graphs can be used
Mining Complex Patterns
 Mining Complex Data COMP 790-90 Seminar Spring 0 The UNIVERSITY of NORTH CAROLINA at CHAPEL HILL Mining Complex Patterns Common Pattern Mining Tasks: Itemsets (transactional, unordered data) Sequences
Mining Complex Data COMP 790-90 Seminar Spring 0 The UNIVERSITY of NORTH CAROLINA at CHAPEL HILL Mining Complex Patterns Common Pattern Mining Tasks: Itemsets (transactional, unordered data) Sequences
CLOSET+:Searching for the Best Strategies for Mining Frequent Closed Itemsets
 CLOSET+:Searching for the Best Strategies for Mining Frequent Closed Itemsets Jianyong Wang, Jiawei Han, Jian Pei Presentation by: Nasimeh Asgarian Department of Computing Science University of Alberta
CLOSET+:Searching for the Best Strategies for Mining Frequent Closed Itemsets Jianyong Wang, Jiawei Han, Jian Pei Presentation by: Nasimeh Asgarian Department of Computing Science University of Alberta
Approximation slides 1. An optimal polynomial algorithm for the Vertex Cover and matching in Bipartite graphs
 Approximation slides 1 An optimal polynomial algorithm for the Vertex Cover and matching in Bipartite graphs Approximation slides 2 Linear independence A collection of row vectors {v T i } are independent
Approximation slides 1 An optimal polynomial algorithm for the Vertex Cover and matching in Bipartite graphs Approximation slides 2 Linear independence A collection of row vectors {v T i } are independent
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 1/8/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 Supermarket shelf
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 1/8/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 Supermarket shelf
Pattern Mining in Frequent Dynamic Subgraphs
 Pattern Mining in Frequent Dynamic Subgraphs Karsten M. Borgwardt, Hans-Peter Kriegel, Peter Wackersreuther Institute of Computer Science Ludwig-Maximilians-Universität Munich, Germany kb kriegel wackersr@dbs.ifi.lmu.de
Pattern Mining in Frequent Dynamic Subgraphs Karsten M. Borgwardt, Hans-Peter Kriegel, Peter Wackersreuther Institute of Computer Science Ludwig-Maximilians-Universität Munich, Germany kb kriegel wackersr@dbs.ifi.lmu.de
On the Relationships between Zero Forcing Numbers and Certain Graph Coverings
 On the Relationships between Zero Forcing Numbers and Certain Graph Coverings Fatemeh Alinaghipour Taklimi, Shaun Fallat 1,, Karen Meagher 2 Department of Mathematics and Statistics, University of Regina,
On the Relationships between Zero Forcing Numbers and Certain Graph Coverings Fatemeh Alinaghipour Taklimi, Shaun Fallat 1,, Karen Meagher 2 Department of Mathematics and Statistics, University of Regina,
Graph Based Approach for Finding Frequent Itemsets to Discover Association Rules
 Graph Based Approach for Finding Frequent Itemsets to Discover Association Rules Manju Department of Computer Engg. CDL Govt. Polytechnic Education Society Nathusari Chopta, Sirsa Abstract The discovery
Graph Based Approach for Finding Frequent Itemsets to Discover Association Rules Manju Department of Computer Engg. CDL Govt. Polytechnic Education Society Nathusari Chopta, Sirsa Abstract The discovery
A Fast Algorithm for Data Mining. Aarathi Raghu Advisor: Dr. Chris Pollett Committee members: Dr. Mark Stamp, Dr. T.Y.Lin
 A Fast Algorithm for Data Mining Aarathi Raghu Advisor: Dr. Chris Pollett Committee members: Dr. Mark Stamp, Dr. T.Y.Lin Our Work Interested in finding closed frequent itemsets in large databases Large
A Fast Algorithm for Data Mining Aarathi Raghu Advisor: Dr. Chris Pollett Committee members: Dr. Mark Stamp, Dr. T.Y.Lin Our Work Interested in finding closed frequent itemsets in large databases Large
Optimization using Ant Colony Algorithm
 Optimization using Ant Colony Algorithm Er. Priya Batta 1, Er. Geetika Sharmai 2, Er. Deepshikha 3 1Faculty, Department of Computer Science, Chandigarh University,Gharaun,Mohali,Punjab 2Faculty, Department
Optimization using Ant Colony Algorithm Er. Priya Batta 1, Er. Geetika Sharmai 2, Er. Deepshikha 3 1Faculty, Department of Computer Science, Chandigarh University,Gharaun,Mohali,Punjab 2Faculty, Department
Graph Theory S 1 I 2 I 1 S 2 I 1 I 2
 Graph Theory S I I S S I I S Graphs Definition A graph G is a pair consisting of a vertex set V (G), and an edge set E(G) ( ) V (G). x and y are the endpoints of edge e = {x, y}. They are called adjacent
Graph Theory S I I S S I I S Graphs Definition A graph G is a pair consisting of a vertex set V (G), and an edge set E(G) ( ) V (G). x and y are the endpoints of edge e = {x, y}. They are called adjacent
Efficient Subgraph Matching by Postponing Cartesian Products
 Efficient Subgraph Matching by Postponing Cartesian Products Computer Science and Engineering Lijun Chang Lijun.Chang@unsw.edu.au The University of New South Wales, Australia Joint work with Fei Bi, Xuemin
Efficient Subgraph Matching by Postponing Cartesian Products Computer Science and Engineering Lijun Chang Lijun.Chang@unsw.edu.au The University of New South Wales, Australia Joint work with Fei Bi, Xuemin
Survey on Graph Query Processing on Graph Database. Presented by FAN Zhe
 Survey on Graph Query Processing on Graph Database Presented by FA Zhe utline Introduction of Graph and Graph Database. Background of Subgraph Isomorphism. Background of Subgraph Query Processing. Background
Survey on Graph Query Processing on Graph Database Presented by FA Zhe utline Introduction of Graph and Graph Database. Background of Subgraph Isomorphism. Background of Subgraph Query Processing. Background
Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science Algorithms For Inference Fall 2014
 Suggested Reading: Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms For Inference Fall 2014 Probabilistic Modelling and Reasoning: The Junction
Suggested Reading: Massachusetts Institute of Technology Department of Electrical Engineering and Computer Science 6.438 Algorithms For Inference Fall 2014 Probabilistic Modelling and Reasoning: The Junction
Bipartite Roots of Graphs
 Bipartite Roots of Graphs Lap Chi Lau Department of Computer Science University of Toronto Graph H is a root of graph G if there exists a positive integer k such that x and y are adjacent in G if and only
Bipartite Roots of Graphs Lap Chi Lau Department of Computer Science University of Toronto Graph H is a root of graph G if there exists a positive integer k such that x and y are adjacent in G if and only
Graph Theory. Probabilistic Graphical Models. L. Enrique Sucar, INAOE. Definitions. Types of Graphs. Trajectories and Circuits.
 Theory Probabilistic ical Models L. Enrique Sucar, INAOE and (INAOE) 1 / 32 Outline and 1 2 3 4 5 6 7 8 and 9 (INAOE) 2 / 32 A graph provides a compact way to represent binary relations between a set of
Theory Probabilistic ical Models L. Enrique Sucar, INAOE and (INAOE) 1 / 32 Outline and 1 2 3 4 5 6 7 8 and 9 (INAOE) 2 / 32 A graph provides a compact way to represent binary relations between a set of
CS 534: Computer Vision Segmentation II Graph Cuts and Image Segmentation
 CS 534: Computer Vision Segmentation II Graph Cuts and Image Segmentation Spring 2005 Ahmed Elgammal Dept of Computer Science CS 534 Segmentation II - 1 Outlines What is Graph cuts Graph-based clustering
CS 534: Computer Vision Segmentation II Graph Cuts and Image Segmentation Spring 2005 Ahmed Elgammal Dept of Computer Science CS 534 Segmentation II - 1 Outlines What is Graph cuts Graph-based clustering
9 About Intersection Graphs
 9 About Intersection Graphs Since this lecture we focus on selected detailed topics in Graph theory that are close to your teacher s heart... The first selected topic is that of intersection graphs, i.e.
9 About Intersection Graphs Since this lecture we focus on selected detailed topics in Graph theory that are close to your teacher s heart... The first selected topic is that of intersection graphs, i.e.
Computability Theory
 CS:4330 Theory of Computation Spring 2018 Computability Theory Other NP-Complete Problems Haniel Barbosa Readings for this lecture Chapter 7 of [Sipser 1996], 3rd edition. Sections 7.4 and 7.5. The 3SAT
CS:4330 Theory of Computation Spring 2018 Computability Theory Other NP-Complete Problems Haniel Barbosa Readings for this lecture Chapter 7 of [Sipser 1996], 3rd edition. Sections 7.4 and 7.5. The 3SAT
Graph Theory Review. January 30, Network Science Analytics Graph Theory Review 1
 Graph Theory Review Gonzalo Mateos Dept. of ECE and Goergen Institute for Data Science University of Rochester gmateosb@ece.rochester.edu http://www.ece.rochester.edu/~gmateosb/ January 30, 2018 Network
Graph Theory Review Gonzalo Mateos Dept. of ECE and Goergen Institute for Data Science University of Rochester gmateosb@ece.rochester.edu http://www.ece.rochester.edu/~gmateosb/ January 30, 2018 Network
Graph-based Learning. Larry Holder Computer Science and Engineering University of Texas at Arlington
 Graph-based Learning Larry Holder Computer Science and Engineering University of Texas at Arlingt 1 Graph-based Learning Multi-relatial data mining and learning SUBDUE graph-based relatial learner Discovery
Graph-based Learning Larry Holder Computer Science and Engineering University of Texas at Arlingt 1 Graph-based Learning Multi-relatial data mining and learning SUBDUE graph-based relatial learner Discovery
An Apriori-like algorithm for Extracting Fuzzy Association Rules between Keyphrases in Text Documents
 An Apriori-lie algorithm for Extracting Fuzzy Association Rules between Keyphrases in Text Documents Guy Danon Department of Information Systems Engineering Ben-Gurion University of the Negev Beer-Sheva
An Apriori-lie algorithm for Extracting Fuzzy Association Rules between Keyphrases in Text Documents Guy Danon Department of Information Systems Engineering Ben-Gurion University of the Negev Beer-Sheva
Chapter 28. Outline. Definitions of Data Mining. Data Mining Concepts
 Chapter 28 Data Mining Concepts Outline Data Mining Data Warehousing Knowledge Discovery in Databases (KDD) Goals of Data Mining and Knowledge Discovery Association Rules Additional Data Mining Algorithms
Chapter 28 Data Mining Concepts Outline Data Mining Data Warehousing Knowledge Discovery in Databases (KDD) Goals of Data Mining and Knowledge Discovery Association Rules Additional Data Mining Algorithms