HDFS: Hadoop Distributed File System. CIS 612 Sunnie Chung
|
|
|
- Jonas Gibson
- 5 years ago
- Views:
Transcription
1 HDFS: Hadoop Distributed File System CIS 612 Sunnie Chung
2 What is Big Data?? Bulk Amount Unstructured Introduction Lots of Applications which need to handle huge amount of data (in terms of 500+ TB per day) If a regular machine need to transmit 1TB of data through 4 channels : 43 Minutes. What if 500 TB?? SS Chung CIS 612 Lecture Notes 2
3 What is Hadoop? Framework for large-scale data processing Inspired by Google s Architecture: Google File System (GFS) and MapReduce Open-source Apache project Nutch search engine project Apache Incubator Written in Java and shell scripts SS Chung CIS 612 Lecture Notes 3
4 Hadoop Distributed File System (HDFS) Storage unit of Hadoop Relies on principles of Distributed File System. HDFS have a Master-Slave architecture Main Components: Name Node : Master Data Node : Slave 3+ replicas for each block Default Block Size : 128MB SS Chung CIS 612 Lecture Notes 4
5 H Hadoop Distributed File System (HDFS) Hadoop Distributed File System (HDFS) Runs entirely in userspace The file system is dynamically distributed across multiple computers Allows for nodes to be added or removed easily Highly scalable in a horizontal fashion Hadoop Development Platform Uses a MapReduce model for working with data Users can program in Java, C++, and other languages SS Chung CIS 612 Lecture Notes 5
6 Why should I use Hadoop? Fault-tolerant hardware is expensive Hadoop designed to run on commodity hardware Automatically handles data replication and deals with node failure Does all the hard work so you can focus on processing data SS Chung CIS 612 Lecture Notes 6
7 HDFS: Key Features Highly Fault Tolerant: Automatic Failure Recovery System High aggregate throughput for streaming large files Supports replication and locality features Designed to work with systems with vary large file (files with size in TB) and few in number. Provides streaming access to file system data. It is specifically good for write once read many kind of files (for example Log files). SS Chung CIS 612 Lecture Notes 7
8 Hadoop Distributed File System (HDFS) Can be built out of commodity hardware. HDFS doesn't need highly expensive storage devices Uses off the shelf hardware Rapid Elasticity Need more capacity, just assign some more nodes Scalable Can add or remove nodes with little effort or reconfiguration Resistant to Failure Individual node failure does not disrupt the system SS Chung CIS 612 Lecture Notes 8








9 Who uses Hadoop? SS Chung CIS 612 Lecture Notes 9
10 What features does Hadoop offer? API and implementation for working with MapReduce Infrastructure Job configuration and efficient scheduling Web-based monitoring of cluster stats Handles failures in computation and data nodes Distributed File System optimized for huge amounts of data SS Chung CIS 612 Lecture Notes 10
11 When should you choose Hadoop? Need to process a lot of unstructured data Processing needs are easily run in parallel Batch jobs are acceptable Access to lots of cheap commodity machines SS Chung CIS 612 Lecture Notes 11
12 When should you avoid Hadoop? Intense calculations with little or no data Processing cannot easily run in parallel Data is not self-contained Need interactive results SS Chung CIS 612 Lecture Notes 12
13 Hadoop Examples Hadoop would be a good choice for: Indexing log files Sorting vast amounts of data Image analysis Search engine optimization Analytics Hadoop would be a poor choice for: Calculating Pi to 1,000,000 digits Calculating Fibonacci sequences A general RDBMS replacement SS Chung CIS 612 Lecture Notes 13
14 Hadoop Distributed File System (HDFS) How does Hadoop work? Runs on top of multiple commodity systems A Hadoop cluster is composed of nodes One Master Node Many Slave Nodes Multiple nodes are used for storing data & processing data System abstracts the underlying hardware to users/software SS Chung CIS 612 Lecture Notes 14
15 How HDFS works: Split Data Data copied into HDFS is split into blocks Typical HDFS block size is 128 MB (VS 4 KB on UNIX File Systems) SS Chung CIS 612 Lecture Notes 15
16 How HDFS works: Replication Each block is replicated to multiple machines This allows for node failure without data loss Block #1 Data Node 1 Block #2 Block #2 Data Node 2 Block #3 Block #1 Data Node 3 Block #3 SS Chung CIS 612 Lecture Notes 16
17 HDFS Architecture
18 Hadoop Distributed File System (HDFS)p: HDFS HDFS Consists of data blocks Files are divided into data blocks HDFS is a multi-node system Name Node (Master) Single point of failure Data Node (Slave) Failure tolerant (Data replication) Default size if 64MB Default replication of blocks is 3 Blocks are spread out over Data Nodes SS Chung CIS 612 Lecture Notes 18
19 Hadoop Architecture Overview Client Job Tracker Task Tracker Task Tracker Data Node Data Node Name Node Data Node Data Node SS Chung CIS 612 Lecture Notes 19
20 Hadoop Components: Job Tracker Client Job Tracker Task Tracker Task Tracker Data Node Data Node Name Node Data Node Data Node Only one Job Tracker per cluster Receives job requests submitted by client Schedules and monitors jobs on task trackers SS Chung CIS 612 Lecture Notes 20
21 Hadoop Components: Name Node Data Node Task Tracker Data Node Client Job Tracker Name Node Task Tracker Data Node Data Node OneactiveNameNodepercluster Manages the file system namespace and metadata Singlepointoffailure:Goodplacetospendmoneyonhardware SS Chung CIS 612 Lecture Notes 21
22 Name Node Master of HDFS Maintains and Manages data on Data Nodes High reliability Machine (can be even RAID) Expensive Hardware Stores NO data; Just holds Metadata! Secondary Name Node: Reads from RAM of Name Node and stores it to hard disks periodically. Active & Passive Name Nodes from Gen2 Hadoop SS Chung CIS 612 Lecture Notes 22
23 Hadoop Components: Task Tracker Data Node Task Tracker Data Node Client Job Tracker Name Node Task Tracker Data Node Therearetypicallyalotoftasktrackers Responsible for executing operations Readsblocksofdatafromdatanodes Data Node SS Chung CIS 612 Lecture Notes 23
24 Hadoop Components: Data Node Data Node Task Tracker Data Node Client Job Tracker Name Node Task Tracker Data Node Data Node Therearetypicallyalotofdatanodes Datanodesmanagedatablocksandservethemtoclients Dataisreplicatedsofailureisnotaproblem SS Chung CIS 612 Lecture Notes 24
25 Data Nodes Slaves in HDFS Provides Data Storage Deployed on independent machines Responsible for serving Read/Write requests from Client. The data processing is done on Data Nodes. SS Chung CIS 612 Lecture Notes 25

26 HDFS Architecture SS Chung CIS 612 Lecture Notes 26
27 Hadoop Modes of Operation Hadoop supports three modes of operation: Standalone Pseudo-Distributed Fully-Distributed SS Chung CIS 612 Lecture Notes 27

28 HDFS Operation SS Chung CIS 612 Lecture Notes 28
29 HDFS Operation Client makes a Write request to Name Node Name Node responds with the information about on available data nodes and where data to be written. Client write the data to the addressed Data Node. Replicas for all blocks are automatically created by Data Pipeline. If Write fails, Data Node will notify the Client and get new location to write. If Write Completed Successfully, Acknowledgement is given to Client Non-Posted Write by Hadoop SS Chung CIS 612 Lecture Notes 29

30 HDFS: File Write SS Chung CIS 612 Lecture Notes 30

31 HDFS: File Read SS Chung CIS 612 Lecture Notes 31
32 Hadoop Hadoop: Development Hadoop PlatformStack User written code runs on system System appears to user as a single entity User does not need to worry about distributed system Many system can run on top of Hadoop Allows further abstraction from system SS Chung CIS 612 Lecture Notes 32
33 Hive and Hadoop: HBase are layers Hive on & top HBase of Hadoop HBase & Hive are applications Provide an interface to data on the HDFS Other programs or applications may use Hive or HBase as an intermediate layer ZooKeeper HBase SS Chung CIS 612 Lecture Notes 33
34 Hadoop: Hive Hive Data warehousing application SQL like commands (HiveQL) Not a traditional relational database Scales horizontally with ease Supports massive amounts of data* * Facebook has more than 15PB of information stored in it and imports 60TB each day (as of 2010) SS Chung CIS 612 Lecture Notes 34
35 Hadoop: HBase HBase No SQL Like language Uses custom Java API for working with data Modeled after Google s BigTable Random read/write operations allowed Multiple concurrent read/write operations allowed SS Chung CIS 612 Lecture Notes 35
36 Hadoop MapReduce Hadoop has it s own implementation of MapReduce Hadoop API: Tutorial: Custom Serialization Data Types Writable/Comparable Text vs String LongWritable vs long IntWritable vs int DoubleWritable vs double SS Chung CIS 612 Lecture Notes 36
37 Structure of a Hadoop Mapper (WordCount) SS Chung CIS 612 Lecture Notes 37
38 Structure of a Hadoop Reducer (WordCount) SS Chung CIS 612 Lecture Notes 38
39 Hadoop MapReduce Working with the Hadoop A quick overview of Hadoop commands bin/start-all.sh bin/stop-all.sh bin/hadoop fs put localsourcepath hdfsdestinationpath bin/hadoop fs get hdfssourcepath localdestinationpath bin/hadoop fs rmr foldertodelete bin/hadoop job kill job_id Running a Hadoop MR Program bin/hadoop jar jarfilename.jar programtorun parm1 parm2 SS Chung CIS 612 Lecture Notes 39
40 Useful Application Sites [1] [2] 10gen. Mongodb. [3] Apache. Cassandra. [4] Apache. Hadoop. [5] Apache. Hbase. [6] Apache, Hive. [7] Apache, Pig. [8] Zoo Keeper, SS Chung CIS 612 Lecture Notes 40
41 How MapReduce Works in Hadoop
42 Lifecycle of a MapReduce Job Map function Reduce function Run this program as a MapReduce job
43 Lifecycle of a MapReduce Job Map function Reduce function Run this program as a MapReduce job
44 Lifecycle of a MapReduce Job Time Input Splits Map Wave 1 Map Wave 2 Reduce Wave 1 Reduce Wave 2
45 Hadoop MR Job Interface: Input Format The Hadoop MapReduce framework spawns one map task for each InputSplit InputSplit: Input File is Split to Input Splits (Logical splits (usually 1 block), not Physically split chunks) Input Format::getInputSplits() The number of maps is usually driven by the total number of blocks (InputSplits) of the input files. 1 block size = 128 MB, 10 TB file configured with maps
46 Hadoop MR Job Interface: map() The framework then calls map(writablecomparable, Writable, OutputCollector, Reporter) for each key/value pair (line_num, line_string ) in the InputSplit for that task. Output pairs are collected with calls to OutputCollector.collect(WritableComparable,Writable).
47 Hadoop MR Job Interface: combiner() Optional combiner, via JobConf.setCombinerClass(Class) to perform local aggregation of the intermediate outputs of mapper
48 Hadoop MR Job Interface: Partitioner() Partitioner controls the partitioning of the keys of the intermediate map-outputs. The key (or a subset of the key) is used to derive the partition, typically by a hash function. The total number of partitions is the same as the number of reducers HashPartitioner is the default Partitioner of reduce tasks for the job
49 Hadoop MR Job Interface: reducer() Reducer has 3 primary phases: 1. Shuffle: 2. Sort 3. Reduce
50 Hadoop MR Job Interface: reducer() Shuffle Input to the Reducer is the sorted output of the mappers. In this phase the framework fetches the relevant partition of the output of all the mappers, via HTTP. Sort The framework groups Reducer inputs by keys (since different mappers may have output the same key) in this stage. The shuffle and sort phases occur simultaneously; while map-outputs are being fetched they are merged.
51 Hadoop MR Job Interface: reducer() Reduce The framework then calls reduce(writablecomparable, Iterator, OutputCollector, Reporter) method for each <key, (list of values)> pair in the grouped inputs. The output of the reduce task is typically written to the FileSystem via OutputCollector.collect(WritableComparable, Writable).
52 MR Job Parameters Map Parameters io.sort.mb Shuffle/Reduce Parameters io.sort.factor mapred.inmem.merge.threshold mapred.job.shuffle.merge.percent

53 Components in a Hadoop MR Workflow Next few slides are from:
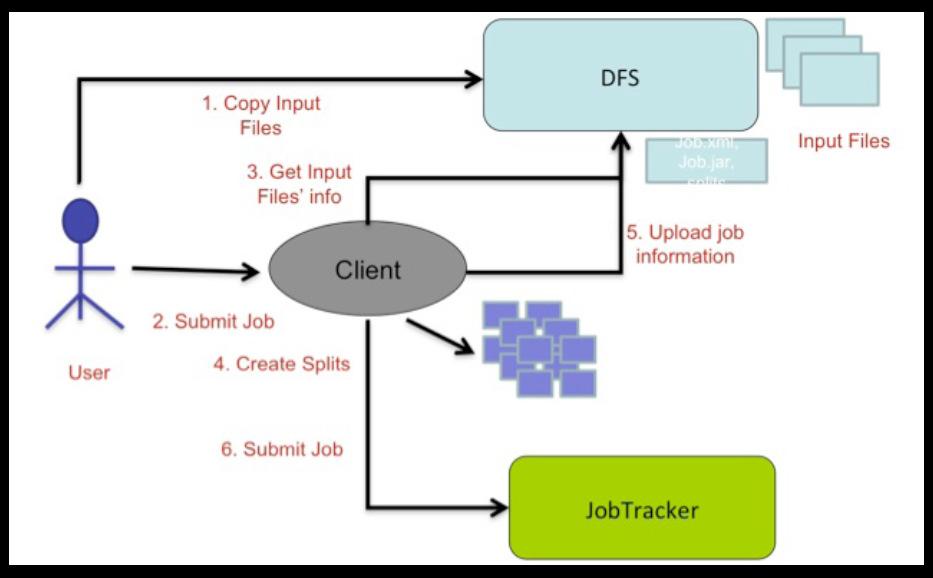
54 Job Submission
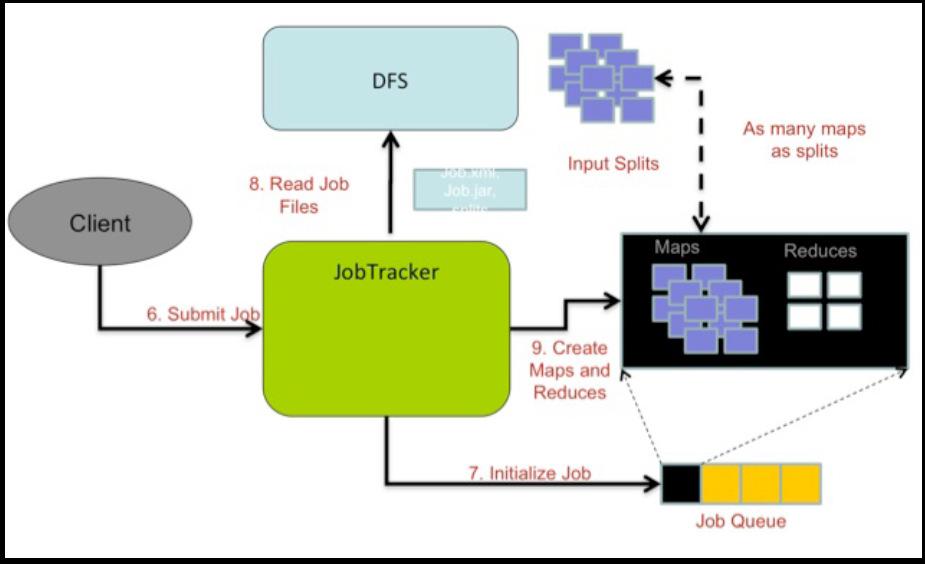
55 Initialization
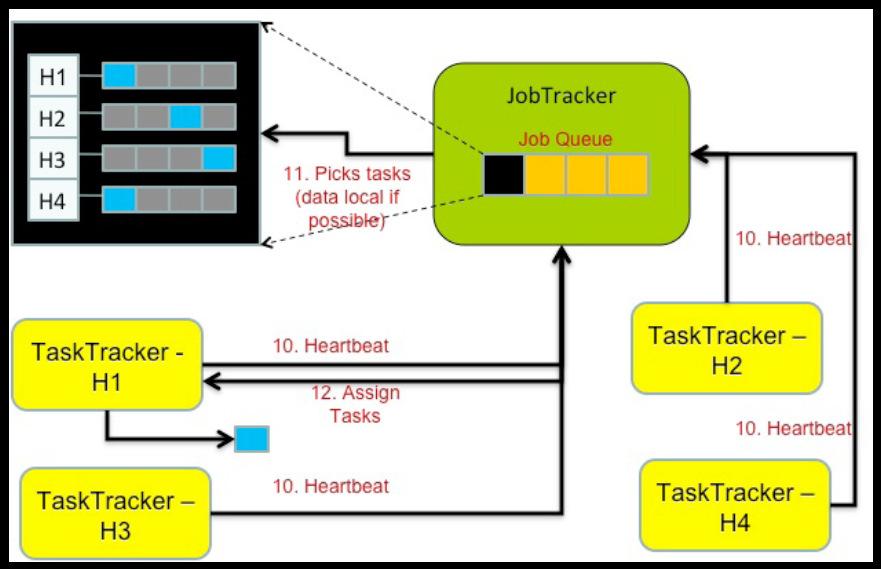
56 Scheduling
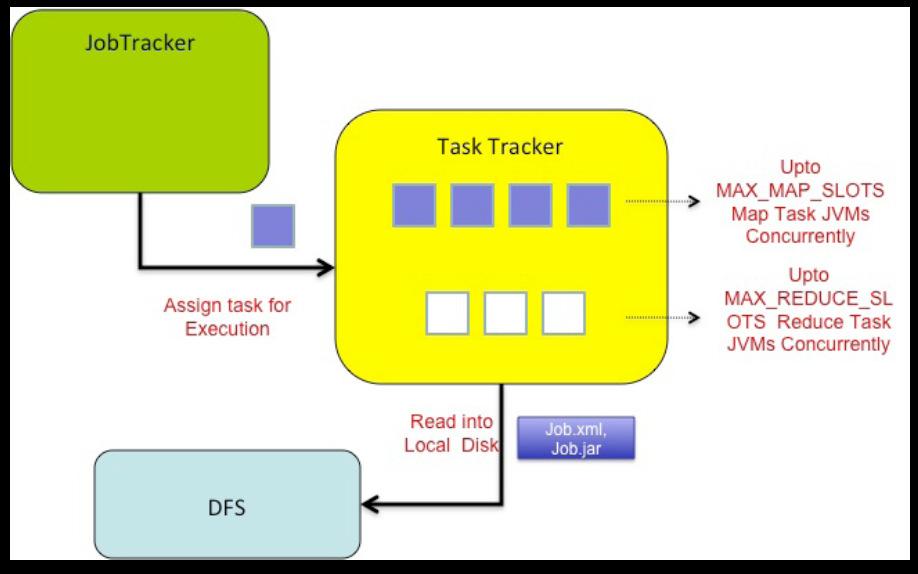
57 Execution
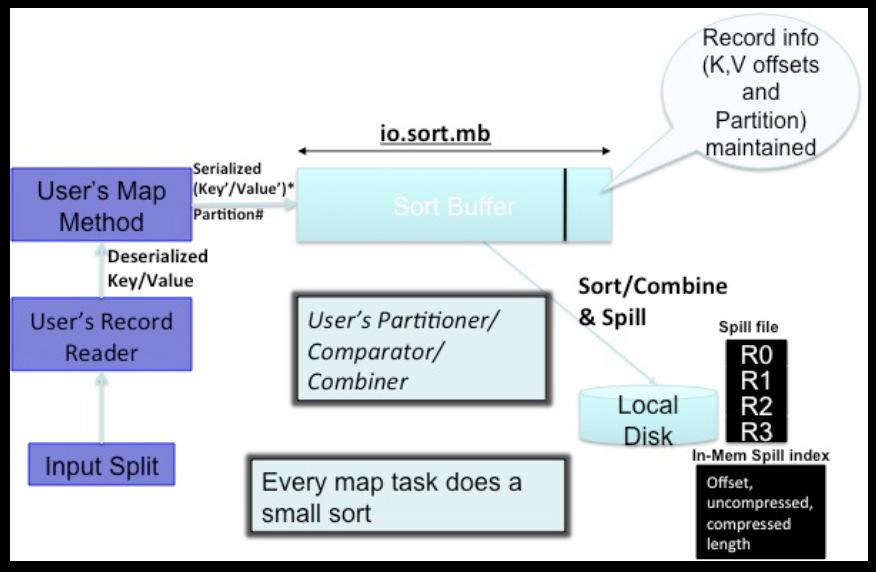
58 Map Task

59 Sort Buffer

60 Reduce Tasks
61 Quick Overview of Other Topics Dealing with failures Hadoop Distributed FileSystem (HDFS) Optimizing a MapReduce job
62 Dealing with Failures and Slow Tasks What to do when a task fails? Try again (retries possible because of idempotence) Try again somewhere else Report failure What about slow tasks: stragglers Run another version of the same task in parallel. Take results from the one that finishes first What are the pros and cons of this approach? Fault tolerance is of high priority in the MapReduce framework
63 HDFS Architecture
64 Lifecycle of a MapReduce Job Time Input Splits Map Wave 1 Map Wave 2 Reduce Wave 1 Reduce Wave 2 How are the number of splits, number of map and reduce tasks, memory allocation to tasks, etc., determined?

65 Job Configuration Parameters 190+ parameters in Hadoop Set manually or defaults are used

66 Hadoop Job Configuration Parameters Image source:
67 Tuning Hadoop Job Conf. Parameters Do their settings impact performance? What are ways to set these parameters? Defaults -- are they good enough? Best practices -- the best setting can depend on data, job, and cluster properties Automatic setting
68 Experimental Setting Hadoop cluster on 1 master + 16 workers Each node: 2GHz AMD processor, 1.8GB RAM, 30GB local disk Relatively ill-provisioned! Xen VM running Debian Linux Max 4 concurrent maps & 2 reduces Maximum map wave size = 16x4 = 64 Maximum reduce wave size = 16x2 = 32 Not all users can run large Hadoop clusters: Can Hadoop be made competitive in the node, multi GB to TB data size range?



69 Parameters Varied in Experiments



70 Hadoop 50GB TeraSort Varying number of reduce tasks, number of concurrent sorted streams for merging, and fraction of map-side sort buffer devoted to metadata storage
71 Hadoop 50GB TeraSort Varying number of reduce tasks for different values of the fraction of map-side sort buffer devoted to metadata storage (with io.sort.factor = 500)
72 Hadoop 50GB TeraSort Varying number of reduce tasks for different values of io.sort.factor (io.sort.record.percent = 0.05, default)
73 Hadoop 75GB TeraSort 1D projection for io.sort.factor=500
74 Automatic Optimization? (Not yet in Hadoop) Map Wave 1 Map Wave 2 Map Wave 3 Reduce Wave 1 Shuffle Reduce Wave 2 What if #reduces increased to 9? Map Wave 1 Map Wave 2 Map Wave 3 Reduce Wave 1 Reduce Wave 2 Reduce Wave 3
Hadoop. copyright 2011 Trainologic LTD
 Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Hadoop Hadoop is a framework for processing large amounts of data in a distributed manner. It can scale up to thousands of machines. It provides high-availability. Provides map-reduce functionality. Hides
Topics. Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples
 Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Hadoop Introduction 1 Topics Big Data Analytics What is and Why Hadoop? Comparison to other technologies Hadoop architecture Hadoop ecosystem Hadoop usage examples 2 Big Data Analytics What is Big Data?
Parallel Programming Principle and Practice. Lecture 10 Big Data Processing with MapReduce
 Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
Parallel Programming Principle and Practice Lecture 10 Big Data Processing with MapReduce Outline MapReduce Programming Model MapReduce Examples Hadoop 2 Incredible Things That Happen Every Minute On The
HADOOP FRAMEWORK FOR BIG DATA
 HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
HADOOP FRAMEWORK FOR BIG DATA Mr K. Srinivas Babu 1,Dr K. Rameshwaraiah 2 1 Research Scholar S V University, Tirupathi 2 Professor and Head NNRESGI, Hyderabad Abstract - Data has to be stored for further
Lecture 11 Hadoop & Spark
 Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Lecture 11 Hadoop & Spark Dr. Wilson Rivera ICOM 6025: High Performance Computing Electrical and Computer Engineering Department University of Puerto Rico Outline Distributed File Systems Hadoop Ecosystem
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2013/14
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2013/14 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Cluster File
Cloud Computing and Hadoop Distributed File System. UCSB CS170, Spring 2018
 Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Cloud Computing and Hadoop Distributed File System UCSB CS70, Spring 08 Cluster Computing Motivations Large-scale data processing on clusters Scan 000 TB on node @ 00 MB/s = days Scan on 000-node cluster
Hadoop An Overview. - Socrates CCDH
 Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Hadoop An Overview - Socrates CCDH What is Big Data? Volume Not Gigabyte. Terabyte, Petabyte, Exabyte, Zettabyte - Due to handheld gadgets,and HD format images and videos - In total data, 90% of them collected
Big Data Hadoop Developer Course Content. Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours
 Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Big Data Hadoop Developer Course Content Who is the target audience? Big Data Hadoop Developer - The Complete Course Course Duration: 45 Hours Complete beginners who want to learn Big Data Hadoop Professionals
Improving the MapReduce Big Data Processing Framework
 Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
Improving the MapReduce Big Data Processing Framework Gistau, Reza Akbarinia, Patrick Valduriez INRIA & LIRMM, Montpellier, France In collaboration with Divyakant Agrawal, UCSB Esther Pacitti, UM2, LIRMM
TITLE: PRE-REQUISITE THEORY. 1. Introduction to Hadoop. 2. Cluster. Implement sort algorithm and run it using HADOOP
 TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
TITLE: Implement sort algorithm and run it using HADOOP PRE-REQUISITE Preliminary knowledge of clusters and overview of Hadoop and its basic functionality. THEORY 1. Introduction to Hadoop The Apache Hadoop
Where We Are. Review: Parallel DBMS. Parallel DBMS. Introduction to Data Management CSE 344
 Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
Where We Are Introduction to Data Management CSE 344 Lecture 22: MapReduce We are talking about parallel query processing There exist two main types of engines: Parallel DBMSs (last lecture + quick review)
A BigData Tour HDFS, Ceph and MapReduce
 A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
A BigData Tour HDFS, Ceph and MapReduce These slides are possible thanks to these sources Jonathan Drusi - SCInet Toronto Hadoop Tutorial, Amir Payberah - Course in Data Intensive Computing SICS; Yahoo!
Introduction to Hadoop. Scott Seighman Systems Engineer Sun Microsystems
 Introduction to Hadoop Scott Seighman Systems Engineer Sun Microsystems 1 Agenda Identify the Problem Hadoop Overview Target Workloads Hadoop Architecture Major Components > HDFS > Map/Reduce Demo Resources
Introduction to Hadoop Scott Seighman Systems Engineer Sun Microsystems 1 Agenda Identify the Problem Hadoop Overview Target Workloads Hadoop Architecture Major Components > HDFS > Map/Reduce Demo Resources
MI-PDB, MIE-PDB: Advanced Database Systems
 MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
MI-PDB, MIE-PDB: Advanced Database Systems http://www.ksi.mff.cuni.cz/~svoboda/courses/2015-2-mie-pdb/ Lecture 10: MapReduce, Hadoop 26. 4. 2016 Lecturer: Martin Svoboda svoboda@ksi.mff.cuni.cz Author:
Chapter 5. The MapReduce Programming Model and Implementation
 Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Chapter 5. The MapReduce Programming Model and Implementation - Traditional computing: data-to-computing (send data to computing) * Data stored in separate repository * Data brought into system for computing
Data Clustering on the Parallel Hadoop MapReduce Model. Dimitrios Verraros
 Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Data Clustering on the Parallel Hadoop MapReduce Model Dimitrios Verraros Overview The purpose of this thesis is to implement and benchmark the performance of a parallel K- means clustering algorithm on
Introduction to BigData, Hadoop:-
 Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Introduction to BigData, Hadoop:- Big Data Introduction: Hadoop Introduction What is Hadoop? Why Hadoop? Hadoop History. Different types of Components in Hadoop? HDFS, MapReduce, PIG, Hive, SQOOP, HBASE,
Distributed File Systems II
 Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Distributed File Systems II To do q Very-large scale: Google FS, Hadoop FS, BigTable q Next time: Naming things GFS A radically new environment NFS, etc. Independence Small Scale Variety of workloads Cooperation
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
CA485 Ray Walshe Google File System
 Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Google File System Overview Google File System is scalable, distributed file system on inexpensive commodity hardware that provides: Fault Tolerance File system runs on hundreds or thousands of storage
Databases 2 (VU) ( / )
 ( / )") Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Databases 2 (VU) (706.711 / 707.030) MapReduce (Part 3) Mark Kröll ISDS, TU Graz Nov. 27, 2017 Mark Kröll (ISDS, TU Graz) MapReduce Nov. 27, 2017 1 / 42 Outline 1 Problems Suited for Map-Reduce 2 MapReduce:
Hadoop Map Reduce 10/17/2018 1
 Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
Hadoop Map Reduce 10/17/2018 1 MapReduce 2-in-1 A programming paradigm A query execution engine A kind of functional programming We focus on the MapReduce execution engine of Hadoop through YARN 10/17/2018
MapReduce. U of Toronto, 2014
 MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
MapReduce U of Toronto, 2014 http://www.google.org/flutrends/ca/ (2012) Average Searches Per Day: 5,134,000,000 2 Motivation Process lots of data Google processed about 24 petabytes of data per day in
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 9 MapReduce Prof. Li Jiang 2014/11/19 1 What is MapReduce Origin from Google, [OSDI 04] A simple programming model Functional model For large-scale
CS427 Multicore Architecture and Parallel Computing Lecture 9 MapReduce Prof. Li Jiang 2014/11/19 1 What is MapReduce Origin from Google, [OSDI 04] A simple programming model Functional model For large-scale
Introduction to MapReduce. Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng.
 Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Introduction to MapReduce Instructor: Dr. Weikuan Yu Computer Sci. & Software Eng. Before MapReduce Large scale data processing was difficult! Managing hundreds or thousands of processors Managing parallelization
Clustering Lecture 8: MapReduce
 Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Clustering Lecture 8: MapReduce Jing Gao SUNY Buffalo 1 Divide and Conquer Work Partition w 1 w 2 w 3 worker worker worker r 1 r 2 r 3 Result Combine 4 Distributed Grep Very big data Split data Split data
Innovatus Technologies
 HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
HADOOP 2.X BIGDATA ANALYTICS 1. Java Overview of Java Classes and Objects Garbage Collection and Modifiers Inheritance, Aggregation, Polymorphism Command line argument Abstract class and Interfaces String
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS
 PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
PLATFORM AND SOFTWARE AS A SERVICE THE MAPREDUCE PROGRAMMING MODEL AND IMPLEMENTATIONS By HAI JIN, SHADI IBRAHIM, LI QI, HAIJUN CAO, SONG WU and XUANHUA SHI Prepared by: Dr. Faramarz Safi Islamic Azad
Hadoop/MapReduce Computing Paradigm
 Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Hadoop/Reduce Computing Paradigm 1 Large-Scale Data Analytics Reduce computing paradigm (E.g., Hadoop) vs. Traditional database systems vs. Database Many enterprises are turning to Hadoop Especially applications
Map-Reduce. Marco Mura 2010 March, 31th
 Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Map-Reduce Marco Mura (mura@di.unipi.it) 2010 March, 31th This paper is a note from the 2009-2010 course Strumenti di programmazione per sistemi paralleli e distribuiti and it s based by the lessons of
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2012/13
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2012/13 MapReduce & Hadoop The new world of Big Data (programming model) Overview of this Lecture Module Background Google MapReduce
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Introduction to Hadoop and MapReduce
 Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
Introduction to Hadoop and MapReduce Antonino Virgillito THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Large-scale Computation Traditional solutions for computing large
50 Must Read Hadoop Interview Questions & Answers
 50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
50 Must Read Hadoop Interview Questions & Answers Whizlabs Dec 29th, 2017 Big Data Are you planning to land a job with big data and data analytics? Are you worried about cracking the Hadoop job interview?
What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed?
 Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
Simple to start What is the maximum file size you have dealt so far? Movies/Files/Streaming video that you have used? What have you observed? What is the maximum download speed you get? Simple computation
BigData and Map Reduce VITMAC03
 BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
BigData and Map Reduce VITMAC03 1 Motivation Process lots of data Google processed about 24 petabytes of data per day in 2009. A single machine cannot serve all the data You need a distributed system to
Distributed Systems 16. Distributed File Systems II
 Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Distributed Systems 16. Distributed File Systems II Paul Krzyzanowski pxk@cs.rutgers.edu 1 Review NFS RPC-based access AFS Long-term caching CODA Read/write replication & disconnected operation DFS AFS
Introduction to Map Reduce
 Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Introduction to Map Reduce 1 Map Reduce: Motivation We realized that most of our computations involved applying a map operation to each logical record in our input in order to compute a set of intermediate
Hadoop File System S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y 11/15/2017
 Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Hadoop File System 1 S L I D E S M O D I F I E D F R O M P R E S E N T A T I O N B Y B. R A M A M U R T H Y Moving Computation is Cheaper than Moving Data Motivation: Big Data! What is BigData? - Google
Big Data Programming: an Introduction. Spring 2015, X. Zhang Fordham Univ.
 Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Big Data Programming: an Introduction Spring 2015, X. Zhang Fordham Univ. Outline What the course is about? scope Introduction to big data programming Opportunity and challenge of big data Origin of Hadoop
Principles of Data Management. Lecture #16 (MapReduce & DFS for Big Data)
") Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Principles of Data Management Lecture #16 (MapReduce & DFS for Big Data) Instructor: Mike Carey mjcarey@ics.uci.edu Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Today s News Bulletin
Cloud Programming. Programming Environment Oct 29, 2015 Osamu Tatebe
 Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
Cloud Programming Programming Environment Oct 29, 2015 Osamu Tatebe Cloud Computing Only required amount of CPU and storage can be used anytime from anywhere via network Availability, throughput, reliability
CPSC 426/526. Cloud Computing. Ennan Zhai. Computer Science Department Yale University
 CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
CPSC 426/526 Cloud Computing Ennan Zhai Computer Science Department Yale University Recall: Lec-7 In the lec-7, I talked about: - P2P vs Enterprise control - Firewall - NATs - Software defined network
Cloud Computing CS
 Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Cloud Computing CS 15-319 Programming Models- Part III Lecture 6, Feb 1, 2012 Majd F. Sakr and Mohammad Hammoud 1 Today Last session Programming Models- Part II Today s session Programming Models Part
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Introduction to Data Management CSE 344 Lecture 24: MapReduce CSE 344 - Winter 215 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Due next Thursday evening Will send out reimbursement codes later
Advanced Data Management Technologies
 ADMT 2017/18 Unit 16 J. Gamper 1/53 Advanced Data Management Technologies Unit 16 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
ADMT 2017/18 Unit 16 J. Gamper 1/53 Advanced Data Management Technologies Unit 16 MapReduce J. Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Acknowledgements: Much of the information
A brief history on Hadoop
 Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
Hadoop Basics A brief history on Hadoop 2003 - Google launches project Nutch to handle billions of searches and indexing millions of web pages. Oct 2003 - Google releases papers with GFS (Google File System)
ΕΠΛ 602:Foundations of Internet Technologies. Cloud Computing
 ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
ΕΠΛ 602:Foundations of Internet Technologies Cloud Computing 1 Outline Bigtable(data component of cloud) Web search basedonch13of thewebdatabook 2 What is Cloud Computing? ACloudis an infrastructure, transparent
Data Analytics Job Guarantee Program
 Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Data Analytics Job Guarantee Program 1. INSTALLATION OF VMWARE 2. MYSQL DATABASE 3. CORE JAVA 1.1 Types of Variable 1.2 Types of Datatype 1.3 Types of Modifiers 1.4 Types of constructors 1.5 Introduction
Big Data Hadoop Course Content
 Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
Big Data Hadoop Course Content Topics covered in the training Introduction to Linux and Big Data Virtual Machine ( VM) Introduction/ Installation of VirtualBox and the Big Data VM Introduction to Linux
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Introduction to Data Management CSE 344
 Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
Introduction to Data Management CSE 344 Lecture 26: Parallel Databases and MapReduce CSE 344 - Winter 2013 1 HW8 MapReduce (Hadoop) w/ declarative language (Pig) Cluster will run in Amazon s cloud (AWS)
STATS Data Analysis using Python. Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns
 STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
STATS 700-002 Data Analysis using Python Lecture 7: the MapReduce framework Some slides adapted from C. Budak and R. Burns Unit 3: parallel processing and big data The next few lectures will focus on big
Big Data Analytics. Izabela Moise, Evangelos Pournaras, Dirk Helbing
 Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Big Data Analytics Izabela Moise, Evangelos Pournaras, Dirk Helbing Izabela Moise, Evangelos Pournaras, Dirk Helbing 1 Big Data "The world is crazy. But at least it s getting regular analysis." Izabela
Programming Models MapReduce
 Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
Programming Models MapReduce Majd Sakr, Garth Gibson, Greg Ganger, Raja Sambasivan 15-719/18-847b Advanced Cloud Computing Fall 2013 Sep 23, 2013 1 MapReduce In a Nutshell MapReduce incorporates two phases
CISC 7610 Lecture 2b The beginnings of NoSQL
 CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
CISC 7610 Lecture 2b The beginnings of NoSQL Topics: Big Data Google s infrastructure Hadoop: open google infrastructure Scaling through sharding CAP theorem Amazon s Dynamo 5 V s of big data Everyone
MapReduce and Hadoop
 Università degli Studi di Roma Tor Vergata MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference Big Data stack High-level Interfaces Data Processing
Università degli Studi di Roma Tor Vergata MapReduce and Hadoop Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference Big Data stack High-level Interfaces Data Processing
Certified Big Data Hadoop and Spark Scala Course Curriculum
 Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
Certified Big Data Hadoop and Spark Scala Course Curriculum The Certified Big Data Hadoop and Spark Scala course by DataFlair is a perfect blend of indepth theoretical knowledge and strong practical skills
TP1-2: Analyzing Hadoop Logs
 TP1-2: Analyzing Hadoop Logs Shadi Ibrahim January 26th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
TP1-2: Analyzing Hadoop Logs Shadi Ibrahim January 26th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
Certified Big Data and Hadoop Course Curriculum
 Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Certified Big Data and Hadoop Course Curriculum The Certified Big Data and Hadoop course by DataFlair is a perfect blend of in-depth theoretical knowledge and strong practical skills via implementation
Introduction to Hadoop. Owen O Malley Yahoo!, Grid Team
 Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Introduction to Hadoop Owen O Malley Yahoo!, Grid Team owen@yahoo-inc.com Who Am I? Yahoo! Architect on Hadoop Map/Reduce Design, review, and implement features in Hadoop Working on Hadoop full time since
Challenges for Data Driven Systems
 Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Challenges for Data Driven Systems Eiko Yoneki University of Cambridge Computer Laboratory Data Centric Systems and Networking Emergence of Big Data Shift of Communication Paradigm From end-to-end to data
Getting Started with Spark
 Getting Started with Spark Shadi Ibrahim March 30th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
Getting Started with Spark Shadi Ibrahim March 30th, 2017 MapReduce has emerged as a leading programming model for data-intensive computing. It was originally proposed by Google to simplify development
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Introduction to MapReduce. Adapted from Jimmy Lin (U. Maryland, USA)
") Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Introduction to MapReduce Adapted from Jimmy Lin (U. Maryland, USA) Motivation Overview Need for handling big data New programming paradigm Review of functional programming mapreduce uses this abstraction
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Introduction to Hadoop. High Availability Scaling Advantages and Challenges. Introduction to Big Data
 Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Introduction to Hadoop High Availability Scaling Advantages and Challenges Introduction to Big Data What is Big data Big Data opportunities Big Data Challenges Characteristics of Big data Introduction
Map Reduce. Yerevan.
 Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Map Reduce Erasmus+ @ Yerevan dacosta@irit.fr Divide and conquer at PaaS 100 % // Typical problem Iterate over a large number of records Extract something of interest from each Shuffle and sort intermediate
Hadoop Development Introduction
 Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Hadoop Development Introduction What is Bigdata? Evolution of Bigdata Types of Data and their Significance Need for Bigdata Analytics Why Bigdata with Hadoop? History of Hadoop Why Hadoop is in demand
Map Reduce Group Meeting
 Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
Map Reduce Group Meeting Yasmine Badr 10/07/2014 A lot of material in this presenta0on has been adopted from the original MapReduce paper in OSDI 2004 What is Map Reduce? Programming paradigm/model for
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
The amount of data increases every day Some numbers ( 2012):
:") 1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
1 The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect
2/26/2017. The amount of data increases every day Some numbers ( 2012):
:") The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
The amount of data increases every day Some numbers ( 2012): Data processed by Google every day: 100+ PB Data processed by Facebook every day: 10+ PB To analyze them, systems that scale with respect to
STORM AND LOW-LATENCY PROCESSING.
 STORM AND LOW-LATENCY PROCESSING Low latency processing Similar to data stream processing, but with a twist Data is streaming into the system (from a database, or a netk stream, or an HDFS file, or ) We
STORM AND LOW-LATENCY PROCESSING Low latency processing Similar to data stream processing, but with a twist Data is streaming into the system (from a database, or a netk stream, or an HDFS file, or ) We
Introduction to MapReduce
 732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
732A54 Big Data Analytics Introduction to MapReduce Christoph Kessler IDA, Linköping University Towards Parallel Processing of Big-Data Big Data too large to be read+processed in reasonable time by 1 server
Parallel Data Processing with Hadoop/MapReduce. CS140 Tao Yang, 2014
 Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Parallel Data Processing with Hadoop/MapReduce CS140 Tao Yang, 2014 Overview What is MapReduce? Example with word counting Parallel data processing with MapReduce Hadoop file system More application example
Outline. What is Big Data? Hadoop HDFS MapReduce Twitter Analytics and Hadoop
 Intro To Hadoop Bill Graham - @billgraham Data Systems Engineer, Analytics Infrastructure Info 290 - Analyzing Big Data With Twitter UC Berkeley Information School September 2012 This work is licensed
Intro To Hadoop Bill Graham - @billgraham Data Systems Engineer, Analytics Infrastructure Info 290 - Analyzing Big Data With Twitter UC Berkeley Information School September 2012 This work is licensed
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective
 ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
ECE 7650 Scalable and Secure Internet Services and Architecture ---- A Systems Perspective Part II: Data Center Software Architecture: Topic 1: Distributed File Systems GFS (The Google File System) 1 Filesystems
Announcements. Optional Reading. Distributed File System (DFS) MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm
 MapReduce Process. MapReduce. Database Systems CSE 414. HW5 is due tomorrow 11pm") Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
Announcements HW5 is due tomorrow 11pm Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create your AWS account before
CS 61C: Great Ideas in Computer Architecture. MapReduce
 CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
CS 61C: Great Ideas in Computer Architecture MapReduce Guest Lecturer: Justin Hsia 3/06/2013 Spring 2013 Lecture #18 1 Review of Last Lecture Performance latency and throughput Warehouse Scale Computing
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
High Performance Computing on MapReduce Programming Framework
 International Journal of Private Cloud Computing Environment and Management Vol. 2, No. 1, (2015), pp. 27-32 http://dx.doi.org/10.21742/ijpccem.2015.2.1.04 High Performance Computing on MapReduce Programming
International Journal of Private Cloud Computing Environment and Management Vol. 2, No. 1, (2015), pp. 27-32 http://dx.doi.org/10.21742/ijpccem.2015.2.1.04 High Performance Computing on MapReduce Programming
Distributed Filesystem
 Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
Distributed Filesystem 1 How do we get data to the workers? NAS Compute Nodes SAN 2 Distributing Code! Don t move data to workers move workers to the data! - Store data on the local disks of nodes in the
April Final Quiz COSC MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model.
 Explain briefly the main ideas and components of the MapReduce programming model.") 1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
1. MapReduce Programming a) Explain briefly the main ideas and components of the MapReduce programming model. MapReduce is a framework for processing big data which processes data in two phases, a Map
Introduction to MapReduce
 Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
Basics of Cloud Computing Lecture 4 Introduction to MapReduce Satish Srirama Some material adapted from slides by Jimmy Lin, Christophe Bisciglia, Aaron Kimball, & Sierra Michels-Slettvet, Google Distributed
EXTRACT DATA IN LARGE DATABASE WITH HADOOP
 International Journal of Advances in Engineering & Scientific Research (IJAESR) ISSN: 2349 3607 (Online), ISSN: 2349 4824 (Print) Download Full paper from : http://www.arseam.com/content/volume-1-issue-7-nov-2014-0
International Journal of Advances in Engineering & Scientific Research (IJAESR) ISSN: 2349 3607 (Online), ISSN: 2349 4824 (Print) Download Full paper from : http://www.arseam.com/content/volume-1-issue-7-nov-2014-0
International Journal of Advance Engineering and Research Development. A Study: Hadoop Framework
 Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Scientific Journal of Impact Factor (SJIF): e-issn (O): 2348- International Journal of Advance Engineering and Research Development Volume 3, Issue 2, February -2016 A Study: Hadoop Framework Devateja
Database Systems CSE 414
 Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Systems CSE 414 Lecture 19: MapReduce (Ch. 20.2) CSE 414 - Fall 2017 1 Announcements HW5 is due tomorrow 11pm HW6 is posted and due Nov. 27 11pm Section Thursday on setting up Spark on AWS Create
Database Applications (15-415)
") Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Database Applications (15-415) Hadoop Lecture 24, April 23, 2014 Mohammad Hammoud Today Last Session: NoSQL databases Today s Session: Hadoop = HDFS + MapReduce Announcements: Final Exam is on Sunday April
Microsoft Big Data and Hadoop
 Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Microsoft Big Data and Hadoop Lara Rubbelke @sqlgal Cindy Gross @sqlcindy 2 The world of data is changing The 4Vs of Big Data http://nosql.mypopescu.com/post/9621746531/a-definition-of-big-data 3 Common
Importing and Exporting Data Between Hadoop and MySQL
 Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Importing and Exporting Data Between Hadoop and MySQL + 1 About me Sarah Sproehnle Former MySQL instructor Joined Cloudera in March 2010 sarah@cloudera.com 2 What is Hadoop? An open-source framework for
Hadoop. Introduction / Overview
 Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
Hadoop Introduction / Overview Preface We will use these PowerPoint slides to guide us through our topic. Expect 15 minute segments of lecture Expect 1-4 hour lab segments Expect minimal pretty pictures
MapReduce-style data processing
 MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce-style data processing Software Languages Team University of Koblenz-Landau Ralf Lämmel and Andrei Varanovich Related meanings of MapReduce Functional programming with map & reduce An algorithmic
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Apache Hadoop.Next What it takes and what it means
 Apache Hadoop.Next What it takes and what it means Arun C. Murthy Founder & Architect, Hortonworks @acmurthy (@hortonworks) Page 1 Hello! I m Arun Founder/Architect at Hortonworks Inc. Lead, Map-Reduce
Apache Hadoop.Next What it takes and what it means Arun C. Murthy Founder & Architect, Hortonworks @acmurthy (@hortonworks) Page 1 Hello! I m Arun Founder/Architect at Hortonworks Inc. Lead, Map-Reduce
Shark: Hive (SQL) on Spark
 on Spark") Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Shark: Hive (SQL) on Spark Reynold Xin UC Berkeley AMP Camp Aug 21, 2012 UC BERKELEY SELECT page_name, SUM(page_views) views FROM wikistats GROUP BY page_name ORDER BY views DESC LIMIT 10; Stage 0: Map-Shuffle-Reduce
Expert Lecture plan proposal Hadoop& itsapplication
 Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Expert Lecture plan proposal Hadoop& itsapplication STARTING UP WITH BIG Introduction to BIG Data Use cases of Big Data The Big data core components Knowing the requirements, knowledge on Analyst job profile
Data Informatics. Seon Ho Kim, Ph.D.
 Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
Data Informatics Seon Ho Kim, Ph.D. seonkim@usc.edu HBase HBase is.. A distributed data store that can scale horizontally to 1,000s of commodity servers and petabytes of indexed storage. Designed to operate
A FRAMEWORK FOR AUTOMATIC OPTIMIZATION OF MAPREDUCE PROGRAMS BASED ON JOB PARAMETER CONFIGURATIONS PRAVEEN KUMAR LAKKIMSETTI
 A FRAMEWORK FOR AUTOMATIC OPTIMIZATION OF MAPREDUCE PROGRAMS BASED ON JOB PARAMETER CONFIGURATIONS By PRAVEEN KUMAR LAKKIMSETTI B. Tech., Vellore Institute of Technology University, 2009 A REPORT Submitted
A FRAMEWORK FOR AUTOMATIC OPTIMIZATION OF MAPREDUCE PROGRAMS BASED ON JOB PARAMETER CONFIGURATIONS By PRAVEEN KUMAR LAKKIMSETTI B. Tech., Vellore Institute of Technology University, 2009 A REPORT Submitted