Big Data Analytics at OSC
|
|
|
- Julie Garrison
- 5 years ago
- Views:
Transcription
1 Big Data Analytics at OSC 04/05/2018 SUG Shameema Oottikkal Data Application Engineer Ohio SuperComputer Center 1
2 Data Analytics at OSC Introduction: Data Analytical nodes OSC Ondemand Applications: R Spark Hadoop Howto: Rstudio on Ondemand Spark on Ondemand 2

3 Data Analytical nodes Owens data analytics environment is comprised of 16 nodes, each with 48 CPU cores, 1.5TB of RAM and 24TB of local disk. Storage Options: $HOME: 500GB Backed up daily Permanent storage Local disk:$tmpdir 1.5TB or 24TB Not backed up Temporary storage /fs/scratch: 1200TB Not backed up Temporary storage /fs/project: Upon request 1-5TB Backed up daily 1-3 years 3
4 OSC OnDemand ondemand.osc.edu 1: User Interface Web based Usable from computers, tablets, smartphones Zero installation Single point of entry User needs three things ondemand.osc.edu OSC Username OSC Password Connected to all resources at OSC 2: Interactive Services File Access Job Management Visualization Apps Desktop access Single-click apps (Abaqus, Ansys, Comsol, Paraview) Terminal Access Tutorial available at osc.edu/ondemand 4

5 5
6 6
7 Data Analytical Applications Python: A popular general-purpose, high-level programming language with numerous mathematical and scientific packages available for data analytics R: A programming language for statistical and machine learning applications with very strong graphical capabilities MATLAB: A full featured data analysis toolkit with many advanced algorithms readily available Spark and Hadoop: Big data Frameworks based on distributed storage Intel Compilers: Compilers for generating optimized code for Intel CPUs. Intel MKL: The Math Kernel Library provides optimized subroutines for common computation tasks such as matrix-matrix calculations. Statistical software: Octave, Stata, FFTW, ScaLAPACK, MINPACK, sprng2 7
8 Batch Usage R and Rstudio R is a language and environment for statistical computing and graphics. R provides a wide variety of statistical and graphical techniques and is highly extensible. 8
9 Rstudio on Ondemand 9
10 10
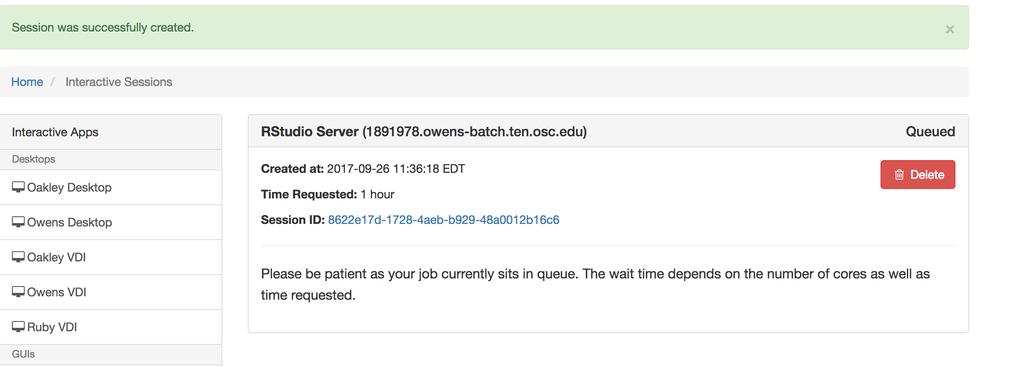
11 11
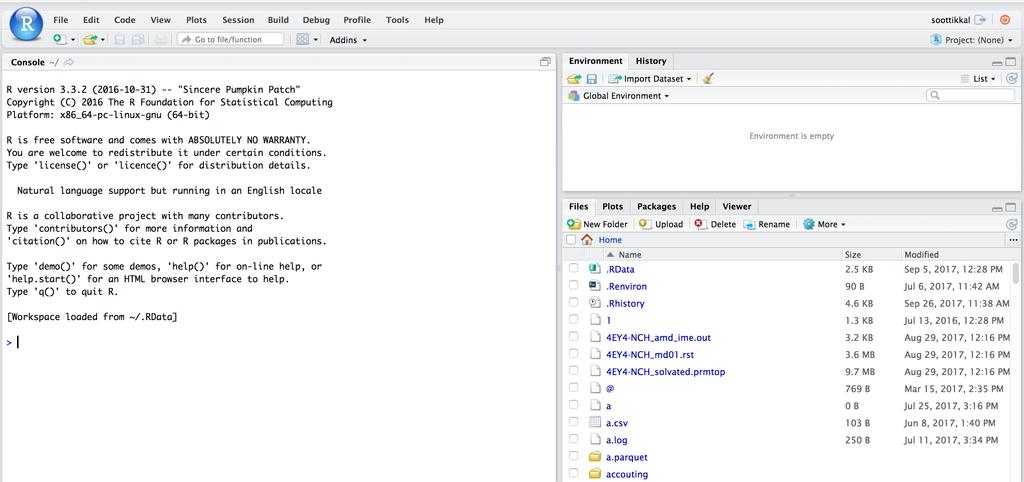
12 12


13 Apache Spark Apache Spark is an open source cluster computing framework originally developed in the AMPLab at University of California, Berkeley but was later donated to the Apache Software Foundation where it remains today. In contrast to Hadoop's disk-based analytics paradigm, Spark has multi-stage in-memory analytics. 13

14 Spark workflow Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program (called the driver program). Requires cluster managers which allocate resources across applications. Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application. Next, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks to the executors to run. 14
15 RDD- Resilient Distributed Datasets RDD (Resilient Distributed Dataset) is the main logical data unit in Spark. They are Distributed and partitioned Stored in memory Immutable Partitions recomputed on failure RDD- Transformations and Actions Transformations are executed on demand. That means they are computed lazily. Eg: filter, join, sort Actions return final results of RDD computations. Actions triggers execution using lineage graph to load the data into original RDD, carry out all intermediate transformations and return final results to Driver program or write it out to file system. Eg: collect(), count(), take() 15

16 RDD Operations 16
 3. Action on RDD >>> lineswithspark.count() # Number of items in this RDD 12 4. Combining Transformation and Actions >>> data.filter(lambda line: \"Spark\" in line).count() # How many lines contain \"Spark\"?")
17 Interactive Analysis with the Spark Shell $SPARK_HOME/bin/pyspark # Opens SparkContext 1. Create a RDD >>> data = sc.textfile("readme.md") 2. Transformation of RDD >>>lineswithspark = data.filter(lambda line: "Spark" in line) 3. Action on RDD >>> lineswithspark.count() # Number of items in this RDD Combining Transformation and Actions >>> data.filter(lambda line: "Spark" in line).count() # How many lines contain "Spark"? 12 17
18 Spark documentation at OSC 18
19 Choose Jupyter+Spark app from the Interactive Apps option. 19
20 20
21 21
22 22
23 You will see a file called pyspark_tutorials.ipynb. Please check on the file and click on duplicate to make a copy of the file. You will see a new file pyspark_tutorials-copy1.ipynb is created. Double-click on the pyspark_tutorials-copy1.ipynb file will launch Jupyter interface for Spark to proceed with the tutorials. 23

24 24
25 Running Spark interactively in batch 25
26 Running Spark non-interactively 26
27 1. Create an App in python: stati.py from pyspark import SparkContext import urllib f = urllib.urlretrieve (" data_file = "./kddcup.data.gz" sc = SparkContext(appName="Stati") raw_data = sc.textfile(data_file) import numpy as np def parse_interaction(line): line_split = line.split(",") symbolic_indexes = [1,2,3,41] clean_line_split=[item for i, item in enumerate(line_split) if i not in symbolic_indexes] return np.array([float(x) for x in clean_line_split]) vector_data=raw_data.map(parse_interaction) Running Spark using PBS script from pyspark.mllib.stat import Statistics from math import sqrt summary = Statistics.colStats(vector_data) print ("Duration Statistics:") print (" Mean %f" % (round(summary.mean()[0],3))) print ("St. deviation : %f"%(round(sqrt(summary.variance()[0]),3))) print (" Max value: %f"%(round(summary.max()[0],3))) print (" Min value: %f"%(round(summary.min()[0],3))) 27
28 2. Create a PBS script: stati.pbs #PBS -N spark-statistics #PBS -l nodes=18:ppn=28 #PBS -l walltime=00:10:00 module load spark/2.0.0 cp stati.py $TMPDIR cd $TMPDIR pbs-spark-submit stati.py > stati.log cp * $PBS_O_WORKDIR 3. Run Spark job qsub stati.pbs 4. Output: stati.log sync from spark://n0381.ten.osc.edu:7077 starting org.apache.spark.deploy.master.master, logging to /nfs/15/soottikkal/spark/kdd/spark-soottikkalorg.apache.spark.deploy.master.master-1-n0381.ten.osc.edu.out failed to launch org.apache.spark.deploy.master.master: full log in /nfs/15/soottikkal/spark/kdd/spark-soottikkal-org.apache.spark.deploy.master.master-1-n0381.ten.osc.edu.out Duration Statistics: Mean St. deviation : Max value: Min value: Total value count: Number of non-zero values: SPARK_MASTER=spark://n0381.ten.osc.edu:
29 CASE STUDY Data mining of historical jobs records of OSC s clusters Aim: To understand client utilizations of OSC recourses. Data: Historical records of every Job that ran on any OSC clusters that includes information's such as number of nodes, software, CPU time and timestamp. DATA on MYSQL DB Data till 2016 Newer Data Import to Spark Import to Spark Save as parquet file Append to parquet file Reload to Spark Analysis 29
 df.")
.count().show() #Which software is used most? df.")
 #who uses gaussian software most? df.")
30 #importing data Pyspark code for data analysis df=sqlcontext.read.parquet( pbsacct/jobs.parquet") df.show(5) #Which types of queue is mostly used df.select("jobid", queue").groupby("queue").count().show() #Which software is used most? df.select("jobid","sw_app").groupby ("sw_app").count().sort(col("count").desc()).show() #who uses gaussian software most? df.registertemptable( Jobs ) sqlcontext.sql(" SELECT username FROM Jobs WHERE sw_app='gaussian " ).show() 30



31 Results Statistics MYSQL SPARK Job vs CPU 1 hour 5 sec CPU vs Account 1.25 hour Walltime vs user 5 sec 1.40 hour 5 sec 31

32 Running Hadoop at OSC A Hadoop cluster can be launched within the HPC environment, but managed by the PBS job scheduler using Myhadoop framework developed by San Diego Supercomputer Center. (Please see 32
33 Using Hadoop: Sample PBS Script 33
34 Using Hadoop: Sample PBS Script 34
35 Upcoming Events XSEDE Big Data workshop May 1-2; 11-5 p.m.; Ohio Supercomputer Center, 1224 Kinnear Road. OSC Big Data workshop June 6th; p.m.; Ohio Supercomputer Center, 1224 Kinnear Road. 35
36 Thank you! Questions or comments: General questions about OSC service: 36
Big Data Analytics with Hadoop and Spark at OSC
 Big Data Analytics with Hadoop and Spark at OSC 09/28/2017 SUG Shameema Oottikkal Data Application Engineer Ohio SuperComputer Center email:soottikkal@osc.edu 1 Data Analytics at OSC Introduction: Data
Big Data Analytics with Hadoop and Spark at OSC 09/28/2017 SUG Shameema Oottikkal Data Application Engineer Ohio SuperComputer Center email:soottikkal@osc.edu 1 Data Analytics at OSC Introduction: Data
SUG Breakout Session: OSC OnDemand App Development
 SUG Breakout Session: OSC OnDemand App Development Basil Mohamed Gohar Web and Interface Applications Manager Eric Franz Senior Engineer & Technical Lead This work is supported by the National Science
SUG Breakout Session: OSC OnDemand App Development Basil Mohamed Gohar Web and Interface Applications Manager Eric Franz Senior Engineer & Technical Lead This work is supported by the National Science
Processing of big data with Apache Spark
 Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Processing of big data with Apache Spark JavaSkop 18 Aleksandar Donevski AGENDA What is Apache Spark? Spark vs Hadoop MapReduce Application Requirements Example Architecture Application Challenges 2 WHAT
Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context
 1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
1 Apache Spark is a fast and general-purpose engine for large-scale data processing Spark aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes
Spark Overview. Professor Sasu Tarkoma.
 Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
Spark Overview 2015 Professor Sasu Tarkoma www.cs.helsinki.fi Apache Spark Spark is a general-purpose computing framework for iterative tasks API is provided for Java, Scala and Python The model is based
MapReduce, Hadoop and Spark. Bompotas Agorakis
 MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
MapReduce, Hadoop and Spark Bompotas Agorakis Big Data Processing Most of the computations are conceptually straightforward on a single machine but the volume of data is HUGE Need to use many (1.000s)
Cloud Computing & Visualization
 Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Cloud Computing & Visualization Workflows Distributed Computation with Spark Data Warehousing with Redshift Visualization with Tableau #FIUSCIS School of Computing & Information Sciences, Florida International
Beyond MapReduce: Apache Spark Antonino Virgillito
 Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
Beyond MapReduce: Apache Spark Antonino Virgillito 1 Why Spark? Most of Machine Learning Algorithms are iterative because each iteration can improve the results With Disk based approach each iteration
DATA SCIENCE USING SPARK: AN INTRODUCTION
 DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
DATA SCIENCE USING SPARK: AN INTRODUCTION TOPICS COVERED Introduction to Spark Getting Started with Spark Programming in Spark Data Science with Spark What next? 2 DATA SCIENCE PROCESS Exploratory Data
Introduction to HPC Resources and Linux
 Introduction to HPC Resources and Linux Burak Himmetoglu Enterprise Technology Services & Center for Scientific Computing e-mail: bhimmetoglu@ucsb.edu Paul Weakliem California Nanosystems Institute & Center
Introduction to HPC Resources and Linux Burak Himmetoglu Enterprise Technology Services & Center for Scientific Computing e-mail: bhimmetoglu@ucsb.edu Paul Weakliem California Nanosystems Institute & Center
Computing Services to Accelerate Research and Innovation
 Computing Services to Accelerate Research and Innovation Kate Cahill Education & Training Specialist Updated: 9/6/2107 Slide 1 Outline https://www.osc.edu/ What is OSC? HPC Concepts Hardware Overview Data
Computing Services to Accelerate Research and Innovation Kate Cahill Education & Training Specialist Updated: 9/6/2107 Slide 1 Outline https://www.osc.edu/ What is OSC? HPC Concepts Hardware Overview Data
Cerebro Quick Start Guide
 Cerebro Quick Start Guide Overview of the system Cerebro consists of a total of 64 Ivy Bridge processors E5-4650 v2 with 10 cores each, 14 TB of memory and 24 TB of local disk. Table 1 shows the hardware
Cerebro Quick Start Guide Overview of the system Cerebro consists of a total of 64 Ivy Bridge processors E5-4650 v2 with 10 cores each, 14 TB of memory and 24 TB of local disk. Table 1 shows the hardware
Big Data Infrastructures & Technologies
 Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
Big Data Infrastructures & Technologies Spark and MLLIB OVERVIEW OF SPARK What is Spark? Fast and expressive cluster computing system interoperable with Apache Hadoop Improves efficiency through: In-memory
2/26/2017. Originally developed at the University of California - Berkeley's AMPLab
 Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
Apache is a fast and general engine for large-scale data processing aims at achieving the following goals in the Big data context Generality: diverse workloads, operators, job sizes Low latency: sub-second
An Introduction to Apache Spark
 An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Apache Spark Anastasios Skarlatidis @anskarl Software Engineer/Researcher IIT, NCSR "Demokritos" Outline Part I: Getting to know Spark Part II: Basic programming Part III: Spark under
An Introduction to Big Data Analysis using Spark
 An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
An Introduction to Big Data Analysis using Spark Mohamad Jaber American University of Beirut - Faculty of Arts & Sciences - Department of Computer Science May 17, 2017 Mohamad Jaber (AUB) Spark May 17,
Apache Spark Internals
 Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
Apache Spark Internals Pietro Michiardi Eurecom Pietro Michiardi (Eurecom) Apache Spark Internals 1 / 80 Acknowledgments & Sources Sources Research papers: https://spark.apache.org/research.html Presentations:
Before We Start. Sign in hpcxx account slips Windows Users: Download PuTTY. Google PuTTY First result Save putty.exe to Desktop
 Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Big data systems 12/8/17
 Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
Big data systems 12/8/17 Today Basic architecture Two levels of scheduling Spark overview Basic architecture Cluster Manager Cluster Cluster Manager 64GB RAM 32 cores 64GB RAM 32 cores 64GB RAM 32 cores
CSE 444: Database Internals. Lecture 23 Spark
 CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
CSE 444: Database Internals Lecture 23 Spark References Spark is an open source system from Berkeley Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Data-intensive computing systems
 Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Data-intensive computing systems University of Verona Computer Science Department Damiano Carra Acknowledgements q Credits Part of the course material is based on slides provided by the following authors
Computing with the Moore Cluster
 Computing with the Moore Cluster Edward Walter An overview of data management and job processing in the Moore compute cluster. Overview Getting access to the cluster Data management Submitting jobs (MPI
Computing with the Moore Cluster Edward Walter An overview of data management and job processing in the Moore compute cluster. Overview Getting access to the cluster Data management Submitting jobs (MPI
Using the IBM Opteron 1350 at OSC. October 19-20, 2010
 Using the IBM Opteron 1350 at OSC October 19-20, 2010 Table of Contents Hardware Overview The Linux Operating System User Environment and Storage 2 Hardware Overview Hardware introduction Login node configuration
Using the IBM Opteron 1350 at OSC October 19-20, 2010 Table of Contents Hardware Overview The Linux Operating System User Environment and Storage 2 Hardware Overview Hardware introduction Login node configuration
Spark, Shark and Spark Streaming Introduction
 Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Spark, Shark and Spark Streaming Introduction Tushar Kale tusharkale@in.ibm.com June 2015 This Talk Introduction to Shark, Spark and Spark Streaming Architecture Deployment Methodology Performance References
Introduction to GALILEO
 Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Maurizio Cremonesi m.cremonesi@cineca.it
Introduction to GALILEO Parallel & production environment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Maurizio Cremonesi m.cremonesi@cineca.it
Introduction to Apache Spark. Patrick Wendell - Databricks
 Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Introduction to Apache Spark Patrick Wendell - Databricks What is Spark? Fast and Expressive Cluster Computing Engine Compatible with Apache Hadoop Efficient General execution graphs In-memory storage
Cloud Computing 3. CSCI 4850/5850 High-Performance Computing Spring 2018
 Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Cloud Computing 3 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning
Outline. CS-562 Introduction to data analysis using Apache Spark
 Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Outline Data flow vs. traditional network programming What is Apache Spark? Core things of Apache Spark RDD CS-562 Introduction to data analysis using Apache Spark Instructor: Vassilis Christophides T.A.:
Turning Relational Database Tables into Spark Data Sources
 Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Turning Relational Database Tables into Spark Data Sources Kuassi Mensah Jean de Lavarene Director Product Mgmt Director Development Server Technologies October 04, 2017 3 Safe Harbor Statement The following
Specialist ICT Learning
 Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
Specialist ICT Learning APPLIED DATA SCIENCE AND BIG DATA ANALYTICS GTBD7 Course Description This intensive training course provides theoretical and technical aspects of Data Science and Business Analytics.
An Introduction to Apache Spark
 An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
An Introduction to Apache Spark 1 History Developed in 2009 at UC Berkeley AMPLab. Open sourced in 2010. Spark becomes one of the largest big-data projects with more 400 contributors in 50+ organizations
Analytic Cloud with. Shelly Garion. IBM Research -- Haifa IBM Corporation
 Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Analytic Cloud with Shelly Garion IBM Research -- Haifa 2014 IBM Corporation Why Spark? Apache Spark is a fast and general open-source cluster computing engine for big data processing Speed: Spark is capable
Pyspark standalone code
 COSC 6339 Big Data Analytics Introduction to Spark (II) Edgar Gabriel Spring 2017 Pyspark standalone code from pyspark import SparkConf, SparkContext from operator import add conf = SparkConf() conf.setappname(
COSC 6339 Big Data Analytics Introduction to Spark (II) Edgar Gabriel Spring 2017 Pyspark standalone code from pyspark import SparkConf, SparkContext from operator import add conf = SparkConf() conf.setappname(
Big Data Analytics with Apache Spark. Nastaran Fatemi
 Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
Big Data Analytics with Apache Spark Nastaran Fatemi Apache Spark Throughout this part of the course we will use the Apache Spark framework for distributed data-parallel programming. Spark implements a
Principal Software Engineer Red Hat Emerging Technology June 24, 2015
 USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
USING APACHE SPARK FOR ANALYTICS IN THE CLOUD William C. Benton Principal Software Engineer Red Hat Emerging Technology June 24, 2015 ABOUT ME Distributed systems and data science in Red Hat's Emerging
MLI - An API for Distributed Machine Learning. Sarang Dev
 MLI - An API for Distributed Machine Learning Sarang Dev MLI - API Simplify the development of high-performance, scalable, distributed algorithms. Targets common ML problems related to data loading, feature
MLI - An API for Distributed Machine Learning Sarang Dev MLI - API Simplify the development of high-performance, scalable, distributed algorithms. Targets common ML problems related to data loading, feature
Applied Spark. From Concepts to Bitcoin Analytics. Andrew F.
 Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
Applied Spark From Concepts to Bitcoin Analytics Andrew F. Hart ahart@apache.org @andrewfhart My Day Job CTO, Pogoseat Upgrade technology for live events 3/28/16 QCON-SP Andrew Hart 2 Additionally Member,
COSC 6339 Big Data Analytics. Introduction to Spark. Edgar Gabriel Fall What is SPARK?
 COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
COSC 6339 Big Data Analytics Introduction to Spark Edgar Gabriel Fall 2018 What is SPARK? In-Memory Cluster Computing for Big Data Applications Fixes the weaknesses of MapReduce Iterative applications
Workshop Set up. Workshop website: Workshop project set up account at my.osc.edu PZS0724 Nq7sRoNrWnFuLtBm
 Workshop Set up Workshop website: https://khill42.github.io/osc_introhpc/ Workshop project set up account at my.osc.edu PZS0724 Nq7sRoNrWnFuLtBm If you already have an OSC account, sign in to my.osc.edu
Workshop Set up Workshop website: https://khill42.github.io/osc_introhpc/ Workshop project set up account at my.osc.edu PZS0724 Nq7sRoNrWnFuLtBm If you already have an OSC account, sign in to my.osc.edu
2/26/2017. RDDs. RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is used to run an application
are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is used to run an application
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Running Jobs, Submission Scripts, Modules
 9/17/15 Running Jobs, Submission Scripts, Modules 16,384 cores total of about 21,000 cores today Infiniband interconnect >3PB fast, high-availability, storage GPGPUs Large memory nodes (512GB to 1TB of
9/17/15 Running Jobs, Submission Scripts, Modules 16,384 cores total of about 21,000 cores today Infiniband interconnect >3PB fast, high-availability, storage GPGPUs Large memory nodes (512GB to 1TB of
Introduction to High Performance Computing at the Ohio Supercomputer Center
 Introduction to High Performance Computing at the Ohio Supercomputer Center Dr. Judy Gardiner Spring 2014 Slide 1 Outline Overview What is OSC? HPC Concepts Hardware Overview Resource Grants and Accounts
Introduction to High Performance Computing at the Ohio Supercomputer Center Dr. Judy Gardiner Spring 2014 Slide 1 Outline Overview What is OSC? HPC Concepts Hardware Overview Resource Grants and Accounts
Oracle Big Data Fundamentals Ed 2
 Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
Oracle University Contact Us: 1.800.529.0165 Oracle Big Data Fundamentals Ed 2 Duration: 5 Days What you will learn In the Oracle Big Data Fundamentals course, you learn about big data, the technologies
08/04/2018. RDDs. RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application contains
are the primary abstraction in Spark are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application contains
Outline 10/13/2015. Computing Services to Accelerate Research and Innovation
 Computing Services to Accelerate Research and Innovation Dr. Judy Gardiner Autumn 2015 Slide 1 Outline Overview What is OSC? HPC Concepts Hardware Overview Resource Grants and Accounts at OSC How to use
Computing Services to Accelerate Research and Innovation Dr. Judy Gardiner Autumn 2015 Slide 1 Outline Overview What is OSC? HPC Concepts Hardware Overview Resource Grants and Accounts at OSC How to use
CS/Math 471: Intro. to Scientific Computing
 CS/Math 471: Intro. to Scientific Computing Getting Started with High Performance Computing Matthew Fricke, PhD Center for Advanced Research Computing Table of contents 1. The Center for Advanced Research
CS/Math 471: Intro. to Scientific Computing Getting Started with High Performance Computing Matthew Fricke, PhD Center for Advanced Research Computing Table of contents 1. The Center for Advanced Research
RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters
 1 RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application
1 RDDs are the primary abstraction in Spark RDDs are distributed collections of objects spread across the nodes of a clusters They are split in partitions Each node of the cluster that is running an application
Spark Streaming. Guido Salvaneschi
 Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Spark Streaming Guido Salvaneschi 1 Spark Streaming Framework for large scale stream processing Scales to 100s of nodes Can achieve second scale latencies Integrates with Spark s batch and interactive
Apache Spark 2 X Cookbook Cloud Ready Recipes For Analytics And Data Science
 Apache Spark 2 X Cookbook Cloud Ready Recipes For Analytics And Data Science We have made it easy for you to find a PDF Ebooks without any digging. And by having access to our ebooks online or by storing
Apache Spark 2 X Cookbook Cloud Ready Recipes For Analytics And Data Science We have made it easy for you to find a PDF Ebooks without any digging. And by having access to our ebooks online or by storing
Scalable Tools - Part I Introduction to Scalable Tools
 Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
Scalable Tools - Part I Introduction to Scalable Tools Adisak Sukul, Ph.D., Lecturer, Department of Computer Science, adisak@iastate.edu http://web.cs.iastate.edu/~adisak/mbds2018/ Scalable Tools session
HPC DOCUMENTATION. 3. Node Names and IP addresses:- Node details with respect to their individual IP addresses are given below:-
 HPC DOCUMENTATION 1. Hardware Resource :- Our HPC consists of Blade chassis with 5 blade servers and one GPU rack server. a.total available cores for computing: - 96 cores. b.cores reserved and dedicated
HPC DOCUMENTATION 1. Hardware Resource :- Our HPC consists of Blade chassis with 5 blade servers and one GPU rack server. a.total available cores for computing: - 96 cores. b.cores reserved and dedicated
Page 1. Goals for Today" Background of Cloud Computing" Sources Driving Big Data" CS162 Operating Systems and Systems Programming Lecture 24
 Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Goals for Today" CS162 Operating Systems and Systems Programming Lecture 24 Capstone: Cloud Computing" Distributed systems Cloud Computing programming paradigms Cloud Computing OS December 2, 2013 Anthony
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Streaming vs. batch processing
 COSC 6339 Big Data Analytics Introduction to Spark (III) 2 nd homework assignment Edgar Gabriel Fall 2018 Streaming vs. batch processing Batch processing: Execution of a compute job without manual intervention
COSC 6339 Big Data Analytics Introduction to Spark (III) 2 nd homework assignment Edgar Gabriel Fall 2018 Streaming vs. batch processing Batch processing: Execution of a compute job without manual intervention
Using Sapelo2 Cluster at the GACRC
 Using Sapelo2 Cluster at the GACRC New User Training Workshop Georgia Advanced Computing Resource Center (GACRC) EITS/University of Georgia Zhuofei Hou zhuofei@uga.edu 1 Outline GACRC Sapelo2 Cluster Diagram
Using Sapelo2 Cluster at the GACRC New User Training Workshop Georgia Advanced Computing Resource Center (GACRC) EITS/University of Georgia Zhuofei Hou zhuofei@uga.edu 1 Outline GACRC Sapelo2 Cluster Diagram
Introduction to PICO Parallel & Production Enviroment
 Introduction to PICO Parallel & Production Enviroment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Nicola Spallanzani n.spallanzani@cineca.it
Introduction to PICO Parallel & Production Enviroment Mirko Cestari m.cestari@cineca.it Alessandro Marani a.marani@cineca.it Domenico Guida d.guida@cineca.it Nicola Spallanzani n.spallanzani@cineca.it
Quick Guide for the Torque Cluster Manager
 Quick Guide for the Torque Cluster Manager Introduction: One of the main purposes of the Aries Cluster is to accommodate especially long-running programs. Users who run long jobs (which take hours or days
Quick Guide for the Torque Cluster Manager Introduction: One of the main purposes of the Aries Cluster is to accommodate especially long-running programs. Users who run long jobs (which take hours or days
NERSC. National Energy Research Scientific Computing Center
 NERSC National Energy Research Scientific Computing Center Established 1974, first unclassified supercomputer center Original mission: to enable computational science as a complement to magnetically controlled
NERSC National Energy Research Scientific Computing Center Established 1974, first unclassified supercomputer center Original mission: to enable computational science as a complement to magnetically controlled
Cloud, Big Data & Linear Algebra
 Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Cloud, Big Data & Linear Algebra Shelly Garion IBM Research -- Haifa 2014 IBM Corporation What is Big Data? 2 Global Data Volume in Exabytes What is Big Data? 2005 2012 2017 3 Global Data Volume in Exabytes
Reactive App using Actor model & Apache Spark. Rahul Kumar Software
 Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Reactive App using Actor model & Apache Spark Rahul Kumar Software Developer @rahul_kumar_aws About Sigmoid We build realtime & big data systems. OUR CUSTOMERS Agenda Big Data - Intro Distributed Application
Computing Services to Accelerate Research and Innovation. An introduction to OSC services, hardware, and environment
 Computing Services to Accelerate Research and Innovation An introduction to OSC services, hardware, and environment Kate Cahill Education & Training Specialist OSC is here to empower your research. Outline
Computing Services to Accelerate Research and Innovation An introduction to OSC services, hardware, and environment Kate Cahill Education & Training Specialist OSC is here to empower your research. Outline
Agenda. Spark Platform Spark Core Spark Extensions Using Apache Spark
 Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Agenda Spark Platform Spark Core Spark Extensions Using Apache Spark About me Vitalii Bondarenko Data Platform Competency Manager Eleks www.eleks.com 20 years in software development 9+ years of developing
Chapter 4: Apache Spark
 Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Chapter 4: Apache Spark Lecture Notes Winter semester 2016 / 2017 Ludwig-Maximilians-University Munich PD Dr. Matthias Renz 2015, Based on lectures by Donald Kossmann (ETH Zürich), as well as Jure Leskovec,
Jupyter and Spark on Mesos: Best Practices. June 21 st, 2017
 Jupyter and Spark on Mesos: Best Practices June 2 st, 207 Agenda About me What is Spark & Jupyter Demo How Spark+Mesos+Jupyter work together Experience Q & A About me Graduated from EE @ Tsinghua Univ.
Jupyter and Spark on Mesos: Best Practices June 2 st, 207 Agenda About me What is Spark & Jupyter Demo How Spark+Mesos+Jupyter work together Experience Q & A About me Graduated from EE @ Tsinghua Univ.
Altus Data Engineering
 Altus Data Engineering Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
Altus Data Engineering Important Notice 2010-2018 Cloudera, Inc. All rights reserved. Cloudera, the Cloudera logo, and any other product or service names or slogans contained in this document are trademarks
A Tutorial on Apache Spark
 A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
A Tutorial on Apache Spark A Practical Perspective By Harold Mitchell The Goal Learning Outcomes The Goal Learning Outcomes NOTE: The setup, installation, and examples assume Windows user Learn the following:
Discretized Streams. An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters
 Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Discretized Streams An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica UC BERKELEY Motivation Many important
Hadoop 2.x Core: YARN, Tez, and Spark. Hortonworks Inc All Rights Reserved
 Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
Hadoop 2.x Core: YARN, Tez, and Spark YARN Hadoop Machine Types top-of-rack switches core switch client machines have client-side software used to access a cluster to process data master nodes run Hadoop
An exceedingly high-level overview of ambient noise processing with Spark and Hadoop
 IRIS: USArray Short Course in Bloomington, Indian Special focus: Oklahoma Wavefields An exceedingly high-level overview of ambient noise processing with Spark and Hadoop Presented by Rob Mellors but based
IRIS: USArray Short Course in Bloomington, Indian Special focus: Oklahoma Wavefields An exceedingly high-level overview of ambient noise processing with Spark and Hadoop Presented by Rob Mellors but based
THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION
 Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
Apache Spark Lorenzo Di Gaetano THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION What is Apache Spark? A general purpose framework for big data processing It interfaces
ICS-ACI System Basics
 ICS-ACI System Basics Adam W. Lavely, Ph.D. Fall 2017 Slides available: goo.gl/ss9itf awl5173 ICS@PSU 1 Contents 1 Overview 2 HPC Overview 3 Getting Started on ACI 4 Moving On awl5173 ICS@PSU 2 Contents
ICS-ACI System Basics Adam W. Lavely, Ph.D. Fall 2017 Slides available: goo.gl/ss9itf awl5173 ICS@PSU 1 Contents 1 Overview 2 HPC Overview 3 Getting Started on ACI 4 Moving On awl5173 ICS@PSU 2 Contents
Distributed Systems. 22. Spark. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Distributed Systems 22. Spark Paul Krzyzanowski Rutgers University Fall 2016 November 26, 2016 2015-2016 Paul Krzyzanowski 1 Apache Spark Goal: generalize MapReduce Similar shard-and-gather approach to
Prototyping Data Intensive Apps: TrendingTopics.org
 Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
Prototyping Data Intensive Apps: TrendingTopics.org Pete Skomoroch Research Scientist at LinkedIn Consultant at Data Wrangling @peteskomoroch 09/29/09 1 Talk Outline TrendingTopics Overview Wikipedia Page
Announcements. Reading Material. Map Reduce. The Map-Reduce Framework 10/3/17. Big Data. CompSci 516: Database Systems
 Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Announcements CompSci 516 Database Systems Lecture 12 - and Spark Practice midterm posted on sakai First prepare and then attempt! Midterm next Wednesday 10/11 in class Closed book/notes, no electronic
Our new HPC-Cluster An overview
 Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Our new HPC-Cluster An overview Christian Hagen Universität Regensburg Regensburg, 15.05.2009 Outline 1 Layout 2 Hardware 3 Software 4 Getting an account 5 Compiling 6 Queueing system 7 Parallelization
Massive Online Analysis - Storm,Spark
 Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
Massive Online Analysis - Storm,Spark presentation by R. Kishore Kumar Research Scholar Department of Computer Science & Engineering Indian Institute of Technology, Kharagpur Kharagpur-721302, India (R
UAntwerpen, 24 June 2016
 Tier-1b Info Session UAntwerpen, 24 June 2016 VSC HPC environment Tier - 0 47 PF Tier -1 623 TF Tier -2 510 Tf 16,240 CPU cores 128/256 GB memory/node IB EDR interconnect Tier -3 HOPPER/TURING STEVIN THINKING/CEREBRO
Tier-1b Info Session UAntwerpen, 24 June 2016 VSC HPC environment Tier - 0 47 PF Tier -1 623 TF Tier -2 510 Tf 16,240 CPU cores 128/256 GB memory/node IB EDR interconnect Tier -3 HOPPER/TURING STEVIN THINKING/CEREBRO
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info
 We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
We are ready to serve Latest Testing Trends, Are you ready to learn?? New Batches Info START DATE : TIMINGS : DURATION : TYPE OF BATCH : FEE : FACULTY NAME : LAB TIMINGS : PH NO: 9963799240, 040-40025423
Blended Learning Outline: Cloudera Data Analyst Training (171219a)
") Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Blended Learning Outline: Cloudera Data Analyst Training (171219a) Cloudera Univeristy s data analyst training course will teach you to apply traditional data analytics and business intelligence skills
Jialin Liu, Evan Racah, Quincey Koziol, Richard Shane Canon, Alex Gittens, Lisa Gerhardt, Suren Byna, Mike F. Ringenburg, Prabhat
 H5Spark H5Spark: Bridging the I/O Gap between Spark and Scien9fic Data Formats on HPC Systems Jialin Liu, Evan Racah, Quincey Koziol, Richard Shane Canon, Alex Gittens, Lisa Gerhardt, Suren Byna, Mike
H5Spark H5Spark: Bridging the I/O Gap between Spark and Scien9fic Data Formats on HPC Systems Jialin Liu, Evan Racah, Quincey Koziol, Richard Shane Canon, Alex Gittens, Lisa Gerhardt, Suren Byna, Mike
Getting started with the CEES Grid
 Getting started with the CEES Grid October, 2013 CEES HPC Manager: Dennis Michael, dennis@stanford.edu, 723-2014, Mitchell Building room 415. Please see our web site at http://cees.stanford.edu. Account
Getting started with the CEES Grid October, 2013 CEES HPC Manager: Dennis Michael, dennis@stanford.edu, 723-2014, Mitchell Building room 415. Please see our web site at http://cees.stanford.edu. Account
PACE. Instructional Cluster Environment (ICE) Orientation. Mehmet (Memo) Belgin, PhD Research Scientist, PACE
 Orientation. Mehmet (Memo) Belgin, PhD Research Scientist, PACE") PACE Instructional Cluster Environment (ICE) Orientation Mehmet (Memo) Belgin, PhD www.pace.gatech.edu Research Scientist, PACE What is PACE A Partnership for an Advanced Computing Environment Provides
PACE Instructional Cluster Environment (ICE) Orientation Mehmet (Memo) Belgin, PhD www.pace.gatech.edu Research Scientist, PACE What is PACE A Partnership for an Advanced Computing Environment Provides
Our Workshop Environment
 Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Our Environment Today Your laptops or workstations: only used for portal access Bridges
Our Workshop Environment John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Our Environment Today Your laptops or workstations: only used for portal access Bridges
/ Cloud Computing. Recitation 13 April 12 th 2016
 15-319 / 15-619 Cloud Computing Recitation 13 April 12 th 2016 Overview Last week s reflection Project 4.1 Quiz 11 Budget issues Tagging, 15619Project This week s schedule Unit 5 - Modules 21 Project 4.2
15-319 / 15-619 Cloud Computing Recitation 13 April 12 th 2016 Overview Last week s reflection Project 4.1 Quiz 11 Budget issues Tagging, 15619Project This week s schedule Unit 5 - Modules 21 Project 4.2
MapReduce Spark. Some slides are adapted from those of Jeff Dean and Matei Zaharia
 MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
MapReduce Spark Some slides are adapted from those of Jeff Dean and Matei Zaharia What have we learnt so far? Distributed storage systems consistency semantics protocols for fault tolerance Paxos, Raft,
Fast, Interactive, Language-Integrated Cluster Computing
 Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Spark Fast, Interactive, Language-Integrated Cluster Computing Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael Franklin, Scott Shenker, Ion Stoica www.spark-project.org
Supercomputing environment TMA4280 Introduction to Supercomputing
 Supercomputing environment TMA4280 Introduction to Supercomputing NTNU, IMF February 21. 2018 1 Supercomputing environment Supercomputers use UNIX-type operating systems. Predominantly Linux. Using a shell
Supercomputing environment TMA4280 Introduction to Supercomputing NTNU, IMF February 21. 2018 1 Supercomputing environment Supercomputers use UNIX-type operating systems. Predominantly Linux. Using a shell
microsoft
 70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
70-775.microsoft Number: 70-775 Passing Score: 800 Time Limit: 120 min Exam A QUESTION 1 Note: This question is part of a series of questions that present the same scenario. Each question in the series
OPERATING SYSTEM. PREPARED BY : DHAVAL R. PATEL Page 1. Q.1 Explain Memory
 Q.1 Explain Memory Data Storage in storage device like CD, HDD, DVD, Pen drive etc, is called memory. The device which storage data is called storage device. E.g. hard disk, floppy etc. There are two types
Q.1 Explain Memory Data Storage in storage device like CD, HDD, DVD, Pen drive etc, is called memory. The device which storage data is called storage device. E.g. hard disk, floppy etc. There are two types
Apache Flink: Distributed Stream Data Processing
 Apache Flink: Distributed Stream Data Processing K.M.J. Jacobs CERN, Geneva, Switzerland 1 Introduction The amount of data is growing significantly over the past few years. Therefore, the need for distributed
Apache Flink: Distributed Stream Data Processing K.M.J. Jacobs CERN, Geneva, Switzerland 1 Introduction The amount of data is growing significantly over the past few years. Therefore, the need for distributed
Sherlock for IBIIS. William Law Stanford Research Computing
 Sherlock for IBIIS William Law Stanford Research Computing Overview How we can help System overview Tech specs Signing on Batch submission Software environment Interactive jobs Next steps We are here to
Sherlock for IBIIS William Law Stanford Research Computing Overview How we can help System overview Tech specs Signing on Batch submission Software environment Interactive jobs Next steps We are here to
Big Data processing: a framework suitable for Economists and Statisticians
 Big Data processing: a framework suitable for Economists and Statisticians Giuseppe Bruno 1, D. Condello 1 and A. Luciani 1 1 Economics and statistics Directorate, Bank of Italy; Economic Research in High
Big Data processing: a framework suitable for Economists and Statisticians Giuseppe Bruno 1, D. Condello 1 and A. Luciani 1 1 Economics and statistics Directorate, Bank of Italy; Economic Research in High
PBS Pro Documentation
 Introduction Most jobs will require greater resources than are available on individual nodes. All jobs must be scheduled via the batch job system. The batch job system in use is PBS Pro. Jobs are submitted
Introduction Most jobs will require greater resources than are available on individual nodes. All jobs must be scheduled via the batch job system. The batch job system in use is PBS Pro. Jobs are submitted
PBS Pro and Ansys Examples
 PBS Pro and Ansys Examples Introduction This document contains a number of different types of examples of using Ansys on the HPC, listed below. 1. Single-node Ansys Job 2. Single-node CFX Job 3. Single-node
PBS Pro and Ansys Examples Introduction This document contains a number of different types of examples of using Ansys on the HPC, listed below. 1. Single-node Ansys Job 2. Single-node CFX Job 3. Single-node
 About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
About Codefrux While the current trends around the world are based on the internet, mobile and its applications, we try to make the most out of it. As for us, we are a well established IT professionals
TDDE31/732A54 - Big Data Analytics Lab compendium
 TDDE31/732A54 - Big Data Analytics Lab compendium For relational databases lab, please refer to http://www.ida.liu.se/~732a54/lab/rdb/index.en.shtml. Description and Aim In the lab exercises you will work
TDDE31/732A54 - Big Data Analytics Lab compendium For relational databases lab, please refer to http://www.ida.liu.se/~732a54/lab/rdb/index.en.shtml. Description and Aim In the lab exercises you will work
UF Research Computing: Overview and Running STATA
 UF : Overview and Running STATA www.rc.ufl.edu Mission Improve opportunities for research and scholarship Improve competitiveness in securing external funding Matt Gitzendanner magitz@ufl.edu Provide high-performance
UF : Overview and Running STATA www.rc.ufl.edu Mission Improve opportunities for research and scholarship Improve competitiveness in securing external funding Matt Gitzendanner magitz@ufl.edu Provide high-performance
732A54 - Big Data Analytics Lab compendium
 Description and Aim 732A54 - Big Data Analytics Lab compendium (Spark and Spark SQL) In the lab exercises you will work with the historical meteorological data from the Swedish Meteorological and Hydrological
Description and Aim 732A54 - Big Data Analytics Lab compendium (Spark and Spark SQL) In the lab exercises you will work with the historical meteorological data from the Swedish Meteorological and Hydrological