Parallel Computing: Parallel Architectures Jin, Hai
|
|
|
- Edward Golden
- 5 years ago
- Views:
Transcription
1 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology
2 Peripherals Computer Central Processing Unit Main Memory Computer System s Interconnection Communication lines Input Output 2
3 ! Microprocessor clock speeds have posted impressive gains over the past two decades (two to three orders of magnitude).! Higher levels of device integration have made available a large number of transistors.! How best to utilize these resources?! Conventionally, use these resources in multiple functional units and execute multiple instructions in the same cycle (ILP) " Pipelining " Superscalar 3
4 ! overlaps various stages of instruction execution to achieve performance F1 E1 F2 E2 F3 E I1 I2 I3 Time I1: I2: F1 E1 F2 E2 F: Fetch E: Execute I3: F3 E3 Time 4
5 ! Limitations:! The speed of a pipeline is eventually limited by the slowest stage. needs more stage, or very deep pipelines! However, in typical program traces, every 5-6th instruction is a conditional jump! - requires very accurate branch prediction.! The penalty of a misprediction grows with the depth of the pipeline, since a larger number of instructions will have to be flushed. 5
6 ! multiple redundant functional units within each CPU so that multiple instructions can executed on separate data items concurrently.! Early ones: two ALUs and a single FPU! modern ones: have more, e.g. the PowerPC 970 includes four ALUs and two FPUs, as ewll as two SIMD units. 6
7 ! The performance of the system as a whole will suffer if unable to keep all of the units fed with instructions.! Things affect the performance:! True Data Dependency: The result of one operation is an input to the next.! Resource Dependency: Two operations require the same resource.! Branch Dependency: Scheduling instructions across conditional branch statements cannot be done deterministically a-priori. 7
8 ! The scheduler - a piece of hardware looks at a large number of instructions in an instruction queue and selects appropriate number of instructions to execute concurrently based on these factors.! Very Long Instruction Word (VLIW) processors - rely on compile time analysis to identify and bundle together instructions that can be executed concurrently. 8
9 ! Limitations:! The degrees of intrinsic parallelism in the instruction stream, i.e. limited amount of instruction-level parallelism! The complexity and time cost of the dispatcher and associated dependency checking logic. 9
10 Power and Heat: Intel Embraces Multicore! May 17, 2004 Intel, the world's largest chip maker, publicly acknowledged that it had hit a ''thermal wall'' on its microprocessor line. As a result, the company is changing its product strategy and disbanding one of its most advanced design groups. Intel also said that it would abandon two advanced chip development projects Now, Intel is embarked on a course already adopted by some of its major rivals: obtaining more computing power by stamping multiple processors on a single chip rather than straining to increase the speed of a single processor Intel's decision to change course and embrace a ''dual core' processor structure shows the challenge of overcoming the effects of heat generated by the constant on-off movement of tiny switches in modern computers some analysts and former Intel designers said that Intel was coming to terms with escalating heat problems so severe they threatened to cause its chips to fracture at extreme temperatures New York Times, May 17,

11 Processor Memor y Processor Memor y Global Memory! Handful of processors each supporting ~1 hardware thread! On-chip memory near processors (cache, RAM, or both)! Shared global memory space (external DRAM) 11
12 ! Multicore! Single powerful thread per core! Thread parallel! Explicit communication! Explicit synchronization 12
13 ! PPE Power Processing Element! SPE Synergistic Processing Element! SPU Synergistic Processing Unit! LS Local Store! MFC Memory Flow Controller! EIB Element Interconnect Bus 13
14 Cell Processor the PPE! More-less a standard scalar processor! Access to the main memory through load and store instructions! Standard L1 and L2 caches! Capable of running scalar (not vectorized) code fast! Capable of running a standard operating system, e.g., Linux! Capable of executing IEEE floating point arithmetic (double and single precision) 14
15 Cell Processor the SPE! Completely a vector processor! Only executes code from the local memory! Only operates on data in the local memory! Accesses the maim memory and local memories of other SPEs only through DMA messages! Loads and stores only 128-bit vectors! Only operates on 128-bit vectors (scalar instructions are emulated in software)! Only supports a single thread with a register file of 128 vector registers at its disposal 15
16 Cell Processor Local Store! A fast local memory! Private memory of the SPU! 256 KB of static RAM! Loads and stores take only a few cycles! Supports only vector (128 b) loads and stores! DMA transfers to the main memory! DMA transfers to other Local Stores! No hardware coherency 16
!")
17 Cell: Vectorization! You need to vectorize as much as possible scalar operations are not supported (emulated in software)! Loads and stores load and store 4-element vectors! Arithmetic operations - operate on 4-element vectors 17

18 Cell: Vectorization! Shuffles, shifts and rotations allow to rearrange data within a vector! The SPU has two pipelines, one for arithmetics, one for shuffles / shifts / rotations / etc.! The SPU can complete in one cycle one floating point operation and one shuffle / shift / rotation 18

19 Cell: Dual-Issue! Two pipelines can issue / complete one instruction each in one cycle! Even pipeline! Arithmetics! Odd pipeline! Loads and stores! Shuffles, shifts, rotations 19
20 Cell Processor MFC! DMA engine! Moves data between the main memory and Local Store! Moves data between local stores! Messages do not block computation! Multiple messages at the same time 20
21 Cell Processor EIB! A fast internal bus! Connects all elements in the chip! Each SPE has bandwidth of 25.6 GB/s! The EIB has aggregate bandwidth of GB/s! The main memory has bandwidth of 25.6 GB/s! The main memory is organized in 16 banks (2 KB interleaved)! Maximum bandwidth achieved when transferring entire cache lines (aligned 128 B continuous blocks of data) 21

22 Cell: Communication! While the SPU is computing, the MFC can transfer data! Overlap computation and communication (double!buffering) 22
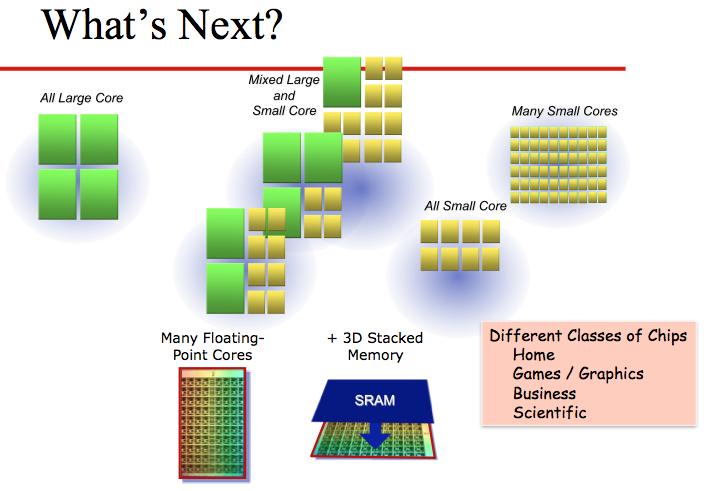
23 23
24 ! A GPU (Graphics Processing Unit) contains multiple cores that utilise hardware multithreading and SIMD.! All PCs have a GPU - the main chip inside a computer which calculates and generates the positioning of graphics on a computer screen.! Games typically renders s 60 fps! Screen resolution is typically 1600 x 1200 and each pixel is recalculated every frame! This corresponds to processing pps! GPUs are designed to make these operations fast 24

25 Obviously, this pattern of computation is common with many other applications 25
26 Flynn s Taxonomy Data stream Single Multiple Instruction stream Single Multiple SISD Uniprocessor MISD Rarely used SIMD Procesor arrays Pipelined vector processors MIMD Multiprocessors Multicomputers 26
27 Types of Parallelism 27
 28")
28 ! Single Instruction Multiple Data architecture! A single instruction can operate on multiple data elements in parallel! rely on the highly structured nature of the underlying computations " Data parallelism! widely applied in multimedia processing (e.g., graphics, image and video) 28
29 29
30 Stream Processing! A stream is a set of input and output data! Stream processing is a series of operations (kernel functions) applied for each element in a stream! Uniform streaming is most typical. One kernel at a time is applied to all elements of the stream! Single Instruction Multiple Data (SIMD) 30

31 Instruction-Based Processing! During processing, the data required for an instruction s execution is loaded into the cache, if not already present! Very flexible model, but has the disadvantage that the data-sequence is completely driven by the instruction sequence, yielding inefficient performance for uniform operations on large data blocks 31

32 Data Stream Processing! The processor is first configured by the instructions that need to be performed and in the next step a data-stream is processed! The execution can be distributed among several pipelines 32
33 ! The GPU (a set of multiprocessors) executes many thread blocks! Each thread block consists of many threads! Within thread block threads are grouped in warps! Each thread has:! Per-thread registers! Per-thread memory (in DRAM)! Each thread block has:! Per-thread-block shared memory! Global memory (DRAM) is accessible to all threads 33
34 ! SM Streaming Multiprocessor (more-less a core)! SP Streaming Processor ( scalar processor core ) (AKA thread processor )! Register file! Shared memory! Constant cache (read only for SM)! Texture cache (read only for SM) 34
35 ! Eight scalar processors (thread procs.) with one instruction issue logic (SIMD)! Long vector (32 threads = 1 warp)! Massively multithreaded (512 scalar hardware threads = 16 warps)! Huge register file (8192 scalar registers shared among all threads)! Can load and store data directly to and from the main memory! Can load and store data to and from shared memory 35
36 ! DRAM memory! Large latency (hundreds of cycles)! Large bandwidth (140 GB/s)! Maximum bandwidth requires coalescing (e.g. transferring of aligned 128 B blocks of data)! Organized in 6 to 8 partitions (256 B interleaved). Maximum bandwidth requires balanced accesses to all partitions. 36
37 ! A fast local memory! Private to a thread block! 16 KB of static RAM! Loads and stores take only a few cycles! Organized in 16 banks! Allows to load 16 elements (e.g. floats) simultaneously by 16 threads (half-warp) if there are no bank conflicts (e.g. 16 consecutive addresses). Otherwise access is serialized. 37
38 General-Purpose Computing on GPUs! Idea:! Potential for very high performance at low cost! Architecture well suited for certain kinds of parallel applications (data parallel)! Early challenges:! Architectures very customized to graphics problems (e.g., vertex and fragment processors)! Programmed using graphics-specific programming models or libraries! Recent trends:! Some convergence between commodity and GPUs and their associated parallel programming models 38
39 CUDA! Compute Unified Device Architecture, one of first to support heterogeneous architectures! Data-parallel programming interface to GPU! Data to be operated on is discretized into independent partition of memory! Each thread performs roughly same computation to different partition of data! When appropriate, easy to express and very efficient parallelization! Programmer expresses! Thread programs to be launched on GPU, and how to launch! Data organization and movement between host and GPU! Synchronization, memory management, 39

40 CUDA Software Stack 40

41 ! device = GPU = a set of multiprocessors! Multiprocessor = a set of processors & shared memory! Kernel = GPU program! Grid = array of thread blocks that execute a kernel! Thread block = group of SIMD threads that execute a kernel and can communicate via shared memory 41

42 CUDA Hardware Model 42

43 CUDA Memory Model Each thread can: Read/write per-thread registers Read/write per-thread local memory Read/write per-block shared memory Read/write per-grid global memory Read only per-grid constant memory Read only per-grid texture memory The host can read/write global, constant, and texture memory 43
44 CUDA Programming Model! The GPU is viewed as a compute device that:! is a coprocessor to the CPU or host! has its own device memory! runs many threads in parallel! Data-parallel portions of an application are executed on the device as kernels which run in parallel on many threads 44

45 CUDA Programming Model 45

46 Future Computer Systems 46

47 47
CS 426 Parallel Computing. Parallel Computing Platforms
 CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
CS 426 Parallel Computing Parallel Computing Platforms Ozcan Ozturk http://www.cs.bilkent.edu.tr/~ozturk/cs426/ Slides are adapted from ``Introduction to Parallel Computing'' Topic Overview Implicit Parallelism:
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 12
Computer Architecture
 Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Computer Architecture Slide Sets WS 2013/2014 Prof. Dr. Uwe Brinkschulte M.Sc. Benjamin Betting Part 10 Thread and Task Level Parallelism Computer Architecture Part 10 page 1 of 36 Prof. Dr. Uwe Brinkschulte,
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Portland State University ECE 588/688. Graphics Processors
 Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Portland State University ECE 588/688 Graphics Processors Copyright by Alaa Alameldeen 2018 Why Graphics Processors? Graphics programs have different characteristics from general purpose programs Highly
Introduction to Computing and Systems Architecture
 Introduction to Computing and Systems Architecture 1. Computability A task is computable if a sequence of instructions can be described which, when followed, will complete such a task. This says little
Introduction to Computing and Systems Architecture 1. Computability A task is computable if a sequence of instructions can be described which, when followed, will complete such a task. This says little
EE382N (20): Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin
: Computer Architecture - Parallelism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez. The University of Texas at Austin") EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
EE382 (20): Computer Architecture - ism and Locality Spring 2015 Lecture 09 GPUs (II) Mattan Erez The University of Texas at Austin 1 Recap 2 Streaming model 1. Use many slimmed down cores to run in parallel
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
The University of Texas at Austin
 EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
EE382N: Principles in Computer Architecture Parallelism and Locality Fall 2009 Lecture 24 Stream Processors Wrapup + Sony (/Toshiba/IBM) Cell Broadband Engine Mattan Erez The University of Texas at Austin
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
GRAPHICS PROCESSING UNITS
 GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
GRAPHICS PROCESSING UNITS Slides by: Pedro Tomás Additional reading: Computer Architecture: A Quantitative Approach, 5th edition, Chapter 4, John L. Hennessy and David A. Patterson, Morgan Kaufmann, 2011
Multi-Processors and GPU
 Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
Multi-Processors and GPU Philipp Koehn 7 December 2016 Predicted CPU Clock Speed 1 Clock speed 1971: 740 khz, 2016: 28.7 GHz Source: Horowitz "The Singularity is Near" (2005) Actual CPU Clock Speed 2 Clock
All About the Cell Processor
 All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
All About the Cell H. Peter Hofstee, Ph. D. IBM Systems and Technology Group SCEI/Sony Toshiba IBM Design Center Austin, Texas Acknowledgements Cell is the result of a deep partnership between SCEI/Sony,
Introduction to CELL B.E. and GPU Programming. Agenda
 Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Introduction to CELL B.E. and GPU Programming Department of Electrical & Computer Engineering Rutgers University Agenda Background CELL B.E. Architecture Overview CELL B.E. Programming Environment GPU
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline Fermi/Kepler Architecture Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
Fundamental CUDA Optimization. NVIDIA Corporation
 Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
Fundamental CUDA Optimization NVIDIA Corporation Outline! Fermi Architecture! Kernel optimizations! Launch configuration! Global memory throughput! Shared memory access! Instruction throughput / control
CSCI-GA Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs
: Architecture and Programming Lecture 2: Hardware Perspective of GPUs") CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com History of GPUs
CSCI-GA.3033-004 Graphics Processing Units (GPUs): Architecture and Programming Lecture 2: Hardware Perspective of GPUs Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com History of GPUs
Processor Performance and Parallelism Y. K. Malaiya
 Processor Performance and Parallelism Y. K. Malaiya Processor Execution time The time taken by a program to execute is the product of n Number of machine instructions executed n Number of clock cycles
Processor Performance and Parallelism Y. K. Malaiya Processor Execution time The time taken by a program to execute is the product of n Number of machine instructions executed n Number of clock cycles
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING UNIT-1
 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
IBM Cell Processor. Gilbert Hendry Mark Kretschmann
 IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
IBM Cell Processor Gilbert Hendry Mark Kretschmann Architectural components Architectural security Programming Models Compiler Applications Performance Power and Cost Conclusion Outline Cell Architecture:
high performance medical reconstruction using stream programming paradigms
 high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
high performance medical reconstruction using stream programming paradigms This Paper describes the implementation and results of CT reconstruction using Filtered Back Projection on various stream programming
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Spring 2011 Prof. Hyesoon Kim
 Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
Spring 2011 Prof. Hyesoon Kim PowerPC-base Core @3.2GHz 1 VMX vector unit per core 512KB L2 cache 7 x SPE @3.2GHz 7 x 128b 128 SIMD GPRs 7 x 256KB SRAM for SPE 1 of 8 SPEs reserved for redundancy total
RISC Processors and Parallel Processing. Section and 3.3.6
 RISC Processors and Parallel Processing Section 3.3.5 and 3.3.6 The Control Unit When a program is being executed it is actually the CPU receiving and executing a sequence of machine code instructions.
RISC Processors and Parallel Processing Section 3.3.5 and 3.3.6 The Control Unit When a program is being executed it is actually the CPU receiving and executing a sequence of machine code instructions.
Lect. 2: Types of Parallelism
 Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Lect. 2: Types of Parallelism Parallelism in Hardware (Uniprocessor) Parallelism in a Uniprocessor Pipelining Superscalar, VLIW etc. SIMD instructions, Vector processors, GPUs Multiprocessor Symmetric
Lecture 13: Memory Consistency. + a Course-So-Far Review. Parallel Computer Architecture and Programming CMU , Spring 2013
 Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Lecture 13: Memory Consistency + a Course-So-Far Review Parallel Computer Architecture and Programming Today: what you should know Understand the motivation for relaxed consistency models Understand the
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Parallel Processing. Computer Architecture. Computer Architecture. Outline. Multiple Processor Organization
 Computer Architecture Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Parallel Processing http://www.yildiz.edu.tr/~naydin 1 2 Outline Multiple Processor
Computer Architecture Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Parallel Processing http://www.yildiz.edu.tr/~naydin 1 2 Outline Multiple Processor
Master Program (Laurea Magistrale) in Computer Science and Networking. High Performance Computing Systems and Enabling Platforms.
 in Computer Science and Networking. High Performance Computing Systems and Enabling Platforms.") Master Program (Laurea Magistrale) in Computer Science and Networking High Performance Computing Systems and Enabling Platforms Marco Vanneschi Multithreading Contents Main features of explicit multithreading
Master Program (Laurea Magistrale) in Computer Science and Networking High Performance Computing Systems and Enabling Platforms Marco Vanneschi Multithreading Contents Main features of explicit multithreading
Antonio R. Miele Marco D. Santambrogio
 Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
Advanced Topics on Heterogeneous System Architectures GPU Politecnico di Milano Seminar Room A. Alario 18 November, 2015 Antonio R. Miele Marco D. Santambrogio Politecnico di Milano 2 Introduction First
CS8803SC Software and Hardware Cooperative Computing GPGPU. Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology
 CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
CS8803SC Software and Hardware Cooperative Computing GPGPU Prof. Hyesoon Kim School of Computer Science Georgia Institute of Technology Why GPU? A quiet revolution and potential build-up Calculation: 367
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
GPU Fundamentals Jeff Larkin November 14, 2016
 GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
GPU Fundamentals Jeff Larkin , November 4, 206 Who Am I? 2002 B.S. Computer Science Furman University 2005 M.S. Computer Science UT Knoxville 2002 Graduate Teaching Assistant 2005 Graduate
10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems
 1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface. 5 th. Edition. Chapter 6. Parallel Processors from Client to Cloud
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 6 Parallel Processors from Client to Cloud Introduction Goal: connecting multiple computers to get higher performance
CSCI-GA Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore
 CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
CSCI-GA.3033-012 Multicore Processors: Architecture & Programming Lecture 10: Heterogeneous Multicore Mohamed Zahran (aka Z) mzahran@cs.nyu.edu http://www.mzahran.com Status Quo Previously, CPU vendors
Introduction to parallel computing
 Introduction to parallel computing 2. Parallel Hardware Zhiao Shi (modifications by Will French) Advanced Computing Center for Education & Research Vanderbilt University Motherboard Processor https://sites.google.com/
Introduction to parallel computing 2. Parallel Hardware Zhiao Shi (modifications by Will French) Advanced Computing Center for Education & Research Vanderbilt University Motherboard Processor https://sites.google.com/
Outline Marquette University
 COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
COEN-4710 Computer Hardware Lecture 1 Computer Abstractions and Technology (Ch.1) Cristinel Ababei Department of Electrical and Computer Engineering Credits: Slides adapted primarily from presentations
High Performance Computing. University questions with solution
 High Performance Computing University questions with solution Q1) Explain the basic working principle of VLIW processor. (6 marks) The following points are basic working principle of VLIW processor. The
High Performance Computing University questions with solution Q1) Explain the basic working principle of VLIW processor. (6 marks) The following points are basic working principle of VLIW processor. The
CellSs Making it easier to program the Cell Broadband Engine processor
 Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Perez, Bellens, Badia, and Labarta CellSs Making it easier to program the Cell Broadband Engine processor Presented by: Mujahed Eleyat Outline Motivation Architecture of the cell processor Challenges of
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to Multicore architecture. Tao Zhang Oct. 21, 2010
 Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
Introduction to Multicore architecture Tao Zhang Oct. 21, 2010 Overview Part1: General multicore architecture Part2: GPU architecture Part1: General Multicore architecture Uniprocessor Performance (ECint)
CDA3101 Recitation Section 13
 CDA3101 Recitation Section 13 Storage + Bus + Multicore and some exam tips Hard Disks Traditional disk performance is limited by the moving parts. Some disk terms Disk Performance Platters - the surfaces
CDA3101 Recitation Section 13 Storage + Bus + Multicore and some exam tips Hard Disks Traditional disk performance is limited by the moving parts. Some disk terms Disk Performance Platters - the surfaces
Motivation for Parallelism. Motivation for Parallelism. ILP Example: Loop Unrolling. Types of Parallelism
 Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Motivation for Parallelism Motivation for Parallelism The speed of an application is determined by more than just processor speed. speed Disk speed Network speed... Multiprocessors typically improve the
Parallel Programming Principle and Practice. Lecture 9 Introduction to GPGPUs and CUDA Programming Model
 Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
Parallel Programming Principle and Practice Lecture 9 Introduction to GPGPUs and CUDA Programming Model Outline Introduction to GPGPUs and Cuda Programming Model The Cuda Thread Hierarchy / Memory Hierarchy
CUDA OPTIMIZATIONS ISC 2011 Tutorial
 CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
CUDA OPTIMIZATIONS ISC 2011 Tutorial Tim C. Schroeder, NVIDIA Corporation Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control
DEPARTMENT OF ELECTRONICS & COMMUNICATION ENGINEERING QUESTION BANK
 DEPARTMENT OF ELECTRONICS & COMMUNICATION ENGINEERING QUESTION BANK SUBJECT : CS6303 / COMPUTER ARCHITECTURE SEM / YEAR : VI / III year B.E. Unit I OVERVIEW AND INSTRUCTIONS Part A Q.No Questions BT Level
DEPARTMENT OF ELECTRONICS & COMMUNICATION ENGINEERING QUESTION BANK SUBJECT : CS6303 / COMPUTER ARCHITECTURE SEM / YEAR : VI / III year B.E. Unit I OVERVIEW AND INSTRUCTIONS Part A Q.No Questions BT Level
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Tesla Architecture, CUDA and Optimization Strategies
 Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Tesla Architecture, CUDA and Optimization Strategies Lan Shi, Li Yi & Liyuan Zhang Hauptseminar: Multicore Architectures and Programming Page 1 Outline Tesla Architecture & CUDA CUDA Programming Optimization
Lecture 1: Introduction
 Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
Contemporary Computer Architecture Instruction set architecture Lecture 1: Introduction CprE 581 Computer Systems Architecture, Fall 2016 Reading: Textbook, Ch. 1.1-1.7 Microarchitecture; examples: Pipeline
CS427 Multicore Architecture and Parallel Computing
 CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
CS427 Multicore Architecture and Parallel Computing Lecture 6 GPU Architecture Li Jiang 2014/10/9 1 GPU Scaling A quiet revolution and potential build-up Calculation: 936 GFLOPS vs. 102 GFLOPS Memory Bandwidth:
DHANALAKSHMI SRINIVASAN INSTITUTE OF RESEARCH AND TECHNOLOGY. Department of Computer science and engineering
 DHANALAKSHMI SRINIVASAN INSTITUTE OF RESEARCH AND TECHNOLOGY Department of Computer science and engineering Year :II year CS6303 COMPUTER ARCHITECTURE Question Bank UNIT-1OVERVIEW AND INSTRUCTIONS PART-B
DHANALAKSHMI SRINIVASAN INSTITUTE OF RESEARCH AND TECHNOLOGY Department of Computer science and engineering Year :II year CS6303 COMPUTER ARCHITECTURE Question Bank UNIT-1OVERVIEW AND INSTRUCTIONS PART-B
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References q This set of slides is mainly based on: " CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory " Slide of Applied
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
B. Tech. Project Second Stage Report on
 B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
B. Tech. Project Second Stage Report on GPU Based Active Contours Submitted by Sumit Shekhar (05007028) Under the guidance of Prof Subhasis Chaudhuri Table of Contents 1. Introduction... 1 1.1 Graphic
Roadrunner. By Diana Lleva Julissa Campos Justina Tandar
 Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
Roadrunner By Diana Lleva Julissa Campos Justina Tandar Overview Roadrunner background On-Chip Interconnect Number of Cores Memory Hierarchy Pipeline Organization Multithreading Organization Roadrunner
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Non-uniform memory access machine or (NUMA) is a system where the memory access time to any region of memory is not the same for all processors.
 is a system where the memory access time to any region of memory is not the same for all processors.") CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies
 Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Accelerating the Implicit Integration of Stiff Chemical Systems with Emerging Multi-core Technologies John C. Linford John Michalakes Manish Vachharajani Adrian Sandu IMAGe TOY 2009 Workshop 2 Virginia
Computer Systems Architecture I. CSE 560M Lecture 19 Prof. Patrick Crowley
 Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
Computer Systems Architecture I CSE 560M Lecture 19 Prof. Patrick Crowley Plan for Today Announcement No lecture next Wednesday (Thanksgiving holiday) Take Home Final Exam Available Dec 7 Due via email
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer parallelism Flynn s categories
 04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
Lecture 26: Parallel Processing. Spring 2018 Jason Tang
 Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
Original PlayStation: no vector processing or floating point support. Photorealism at the core of design strategy
 Competitors using generic parts Performance benefits to be had for custom design Original PlayStation: no vector processing or floating point support Geometry issues Photorealism at the core of design
Competitors using generic parts Performance benefits to be had for custom design Original PlayStation: no vector processing or floating point support Geometry issues Photorealism at the core of design
Issues in Multiprocessors
 Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores message passing explicit sends & receives Which execution model control parallel
Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores message passing explicit sends & receives Which execution model control parallel
Instruction Register. Instruction Decoder. Control Unit (Combinational Circuit) Control Signals (These signals go to register) The bus and the ALU
 Control Signals (These signals go to register) The bus and the ALU") Hardwired and Microprogrammed Control For each instruction, the control unit causes the CPU to execute a sequence of steps correctly. In reality, there must be control signals to assert lines on various
Hardwired and Microprogrammed Control For each instruction, the control unit causes the CPU to execute a sequence of steps correctly. In reality, there must be control signals to assert lines on various
GPU Programming. Lecture 1: Introduction. Miaoqing Huang University of Arkansas 1 / 27
 1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
Chapter 6. Parallel Processors from Client to Cloud. Copyright 2014 Elsevier Inc. All rights reserved.
 Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
Chapter 6 Parallel Processors from Client to Cloud FIGURE 6.1 Hardware/software categorization and examples of application perspective on concurrency versus hardware perspective on parallelism. 2 FIGURE
Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow
 Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Fundamental Optimizations (GTC 2010) Paulius Micikevicius NVIDIA Outline Kernel optimizations Launch configuration Global memory throughput Shared memory access Instruction throughput / control flow Optimization
Numerical Simulation on the GPU
 Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Numerical Simulation on the GPU Roadmap Part 1: GPU architecture and programming concepts Part 2: An introduction to GPU programming using CUDA Part 3: Numerical simulation techniques (grid and particle
Advanced d Processor Architecture. Computer Systems Laboratory Sungkyunkwan University
 Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
Advanced d Processor Architecture Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Modern Microprocessors More than just GHz CPU Clock Speed SPECint2000
CMSC 611: Advanced. Parallel Systems
 CMSC 611: Advanced Computer Architecture Parallel Systems Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems
CMSC 611: Advanced Computer Architecture Parallel Systems Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems
POLITECNICO DI MILANO. Advanced Topics on Heterogeneous System Architectures! Multiprocessors
 POLITECNICO DI MILANO Advanced Topics on Heterogeneous System Architectures! Multiprocessors Politecnico di Milano! SeminarRoom, Bld 20! 30 November, 2017! Antonio Miele! Marco Santambrogio! Politecnico
POLITECNICO DI MILANO Advanced Topics on Heterogeneous System Architectures! Multiprocessors Politecnico di Milano! SeminarRoom, Bld 20! 30 November, 2017! Antonio Miele! Marco Santambrogio! Politecnico
Parallel Architecture. Hwansoo Han
 Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
Parallel Architecture Hwansoo Han Performance Curve 2 Unicore Limitations Performance scaling stopped due to: Power Wire delay DRAM latency Limitation in ILP 3 Power Consumption (watts) 4 Wire Delay Range
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Parallel Computing Platforms
 Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
Parallel Computing Platforms Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu SSE3054: Multicore Systems, Spring 2017, Jinkyu Jeong (jinkyu@skku.edu)
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
Introduction to CUDA Algoritmi e Calcolo Parallelo. Daniele Loiacono
 Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Introduction to CUDA Algoritmi e Calcolo Parallelo References This set of slides is mainly based on: CUDA Technical Training, Dr. Antonino Tumeo, Pacific Northwest National Laboratory Slide of Applied
Threading Hardware in G80
 ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
ing Hardware in G80 1 Sources Slides by ECE 498 AL : Programming Massively Parallel Processors : Wen-Mei Hwu John Nickolls, NVIDIA 2 3D 3D API: API: OpenGL OpenGL or or Direct3D Direct3D GPU Command &
Chapter 04. Authors: John Hennessy & David Patterson. Copyright 2011, Elsevier Inc. All rights Reserved. 1
 Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
Chapter 04 Authors: John Hennessy & David Patterson Copyright 2011, Elsevier Inc. All rights Reserved. 1 Figure 4.1 Potential speedup via parallelism from MIMD, SIMD, and both MIMD and SIMD over time for
ASSEMBLY LANGUAGE MACHINE ORGANIZATION
 ASSEMBLY LANGUAGE MACHINE ORGANIZATION CHAPTER 3 1 Sub-topics The topic will cover: Microprocessor architecture CPU processing methods Pipelining Superscalar RISC Multiprocessing Instruction Cycle Instruction
ASSEMBLY LANGUAGE MACHINE ORGANIZATION CHAPTER 3 1 Sub-topics The topic will cover: Microprocessor architecture CPU processing methods Pipelining Superscalar RISC Multiprocessing Instruction Cycle Instruction
Latches. IT 3123 Hardware and Software Concepts. Registers. The Little Man has Registers. Data Registers. Program Counter
 IT 3123 Hardware and Software Concepts Notice: This session is being recorded. CPU and Memory June 11 Copyright 2005 by Bob Brown Latches Can store one bit of data Can be ganged together to store more
IT 3123 Hardware and Software Concepts Notice: This session is being recorded. CPU and Memory June 11 Copyright 2005 by Bob Brown Latches Can store one bit of data Can be ganged together to store more
CS 654 Computer Architecture Summary. Peter Kemper
 CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
CS 654 Computer Architecture Summary Peter Kemper Chapters in Hennessy & Patterson Ch 1: Fundamentals Ch 2: Instruction Level Parallelism Ch 3: Limits on ILP Ch 4: Multiprocessors & TLP Ap A: Pipelining
Introduction. CSCI 4850/5850 High-Performance Computing Spring 2018
 Introduction CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University What is Parallel
Introduction CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University What is Parallel
Parallel Computer Architectures. Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam
 Parallel Computer Architectures Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam Outline Flynn s Taxonomy Classification of Parallel Computers Based on Architectures Flynn s Taxonomy Based on notions of
Parallel Computer Architectures Lectured by: Phạm Trần Vũ Prepared by: Thoại Nam Outline Flynn s Taxonomy Classification of Parallel Computers Based on Architectures Flynn s Taxonomy Based on notions of
GPGPU LAB. Case study: Finite-Difference Time- Domain Method on CUDA
 GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
GPGPU LAB Case study: Finite-Difference Time- Domain Method on CUDA Ana Balevic IPVS 1 Finite-Difference Time-Domain Method Numerical computation of solutions to partial differential equations Explicit
Introducing Multi-core Computing / Hyperthreading
 Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Introducing Multi-core Computing / Hyperthreading Clock Frequency with Time 3/9/2017 2 Why multi-core/hyperthreading? Difficult to make single-core clock frequencies even higher Deeply pipelined circuits:
Multiprocessors - Flynn s Taxonomy (1966)
") Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Multiprocessors - Flynn s Taxonomy (1966) Single Instruction stream, Single Data stream (SISD) Conventional uniprocessor Although ILP is exploited Single Program Counter -> Single Instruction stream The
Copyright 2012, Elsevier Inc. All rights reserved.
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 1 Fundamentals of Quantitative Design and Analysis 1 Computer Technology Performance improvements: Improvements in semiconductor technology
Lecture 2: CUDA Programming
 CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
CS 515 Programming Language and Compilers I Lecture 2: CUDA Programming Zheng (Eddy) Zhang Rutgers University Fall 2017, 9/12/2017 Review: Programming in CUDA Let s look at a sequential program in C first:
Memory Architectures. Week 2, Lecture 1. Copyright 2009 by W. Feng. Based on material from Matthew Sottile.
 Week 2, Lecture 1 Copyright 2009 by W. Feng. Based on material from Matthew Sottile. Directory-Based Coherence Idea Maintain pointers instead of simple states with each cache block. Ingredients Data owners
Week 2, Lecture 1 Copyright 2009 by W. Feng. Based on material from Matthew Sottile. Directory-Based Coherence Idea Maintain pointers instead of simple states with each cache block. Ingredients Data owners
Massively Parallel Architectures
 Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Massively Parallel Architectures A Take on Cell Processor and GPU programming Joel Falcou - LRI joel.falcou@lri.fr Bat. 490 - Bureau 104 20 janvier 2009 Motivation The CELL processor Harder,Better,Faster,Stronger
Sony/Toshiba/IBM (STI) CELL Processor. Scientific Computing for Engineers: Spring 2008
 CELL Processor. Scientific Computing for Engineers: Spring 2008") Sony/Toshiba/IBM (STI) CELL Processor Scientific Computing for Engineers: Spring 2008 Nec Hercules Contra Plures Chip's performance is related to its cross section same area 2 performance (Pollack's Rule)
Sony/Toshiba/IBM (STI) CELL Processor Scientific Computing for Engineers: Spring 2008 Nec Hercules Contra Plures Chip's performance is related to its cross section same area 2 performance (Pollack's Rule)