HMEM and Lemaitre2: First bricks of the CÉCI s infrastructure
|
|
|
- Derek Evans
- 6 years ago
- Views:
Transcription
1 HMEM and Lemaitre2: First bricks of the CÉCI s infrastructure - CÉCI: What we want - Cluster HMEM - Cluster Lemaitre2 - Comparison - What next? - Support and training - Conclusions
 and high throughput and low latency interconnect (infiniband) Dedicated sites for")
2 CÉCI: What we want CÉCI: Consor*um des Equipements de Calcul Intensif en FWB (ULB, ULG, UMONS, FUNDP and UCL) supported by the F.R.S FNRS Infrastructures: Several sites with high performance parallel systems: Clusters with many nodes (many core) and high throughput and low latency interconnect (infiniband) Dedicated sites for specific needs: High memory systems > Large amount of memory per node > Large amount of memory per core Adapted planorm for very long processes (up to 30 days) GPU accelerators =>... Support and training: organized once a year for all the researchers in FWB User support available locally (close to researchers) HMEM Lemaitre2
: 12 cores 45 nm SOI L1 64 KB D + 64")

3 HMEM : the processor 50% UCL 50% CÉCI AMD Opteron 6100 series (Magny Cours): 12 cores 45 nm SOI L1 64 KB D + 64 KB I 512 KB (per core) L3 12 MB (per socket) 4 HT3 links 25.6 GB/s 4 channel DDR3 memory controller 34.15GB/s@1066 MHz
4 HMEM : the cluster 50% UCL 50% CÉCI 816 CPUs (Opteron GHz), IB QDR (40Gbps) 2 nodes 512 GB RAM, 7 nodes 256 GB et 8 nodes 128 GB 11 TB /home, 5 TB /workdir, 30 TB /scratch Infiniband QDR Working node... Working node... Working node... Working node 2 x 512 GB RAM, 3.2 TB /scratch 7 x 256 GB RAM, 1.7 TB /scratch 7 x 128 GB RAM, 1.7 TB /scratch GbE 1 x 128 GB RAM, 0.7 TB /scratch (UCL/ELIC) FHGFS: 30TB Sharing local disks of the WN



 L3 12 MB (per socket) 2 QPI links 25.")
5 Lemaitre2: the processor 100% CÉCI CISM Up to 32 GB/s DDR3 DDR3 DDR3 Ch0 Ch0 C0 C1 C2 C3 C4 C5 C0 C1 C2 C3 C4 C5 Ch1 Ch2 Ch1 L3 12MB L3 12MB QPI 25.6 GB/s 5520 Chipset Ch2 DDR3 DDR3 DDR3 Up to 32 GB/s CÉCI HMEM Lemaitre2 Comparison Next? Training Conclusions Intel Xeon 5600 series (Westmere EP): 6 cores 32 nm L1 32 KB D + 32 KB I 256 KB (per core) L3 12 MB (per socket) 2 QPI links 25.6 GB/s 3 channel DDR3 memory controller 32GB/s CECI Day 2012



6 Lemaitre2 : the cluster CISM CÉCI HMEM Lemaitre2 Comparison Next? Training Conclusions 112 nodes, 1344 cores (Intel Xeon X GHz), IB QDR (40Gbps) 4 GB/core 40 TB /home and 120 TB /scratch Server Server 12 disks GbE 12 disks Home: 40TB Access Infiniband QDR Mngmt Lemaitre2 Working node Server Server disks 12 disks Working node 12 disks 12 disks Scratch: Lustre: 120TB Working node CECI Day 2012
7 Comparison
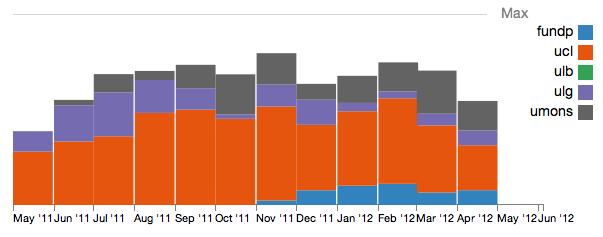
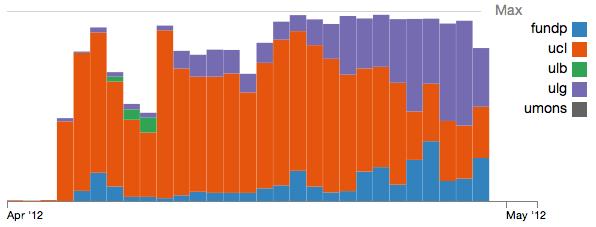
8 % Utilization

9 What next? 2012: Installajon of at UCL : New infrastructures at ULB, ULG, UMONS and FUNDP
10 Access Centralized Idenjficajon System: => Access to any cluster with the same login Same resource manager system everywhere (SLURM): => Same submission script everywhere CECI s infrastructures are in a restricted area => Access restricted to the idenjfied university networks

11 Training session organised by the CISM

12 Training session organised by the CISM Last session (October 2011)


13 Conclusions Two clusters, and Lemaitre2, have been installed and successfully shared into the Consorjum CECI. => Average usage already very high 2012: New infrastructures at ULB, ULG, FUNDP and UMONS. => Up to 6000 cores expected for 2013 Centralized idenjficajon system and use of the same resource manager system everywhere (SLURM) is organized once a year for researchers coming from all the universijes of the FWB. Support is provided locally. Maintaining such a high end infrastructures and providing user support and training require dedicated human resources. => Thanks to local administrators and FNRS logisjcians who make it possible.
14 Thanks
DELIVERABLE D5.5 Report on ICARUS visualization cluster installation. John BIDDISCOMBE (CSCS) Jerome SOUMAGNE (CSCS)
 Jerome SOUMAGNE (CSCS)") DELIVERABLE D5.5 Report on ICARUS visualization cluster installation John BIDDISCOMBE (CSCS) Jerome SOUMAGNE (CSCS) 02 May 2011 NextMuSE 2 Next generation Multi-mechanics Simulation Environment Cluster
DELIVERABLE D5.5 Report on ICARUS visualization cluster installation John BIDDISCOMBE (CSCS) Jerome SOUMAGNE (CSCS) 02 May 2011 NextMuSE 2 Next generation Multi-mechanics Simulation Environment Cluster
ANSYS Fluent 14 Performance Benchmark and Profiling. October 2012
 ANSYS Fluent 14 Performance Benchmark and Profiling October 2012 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information
ANSYS Fluent 14 Performance Benchmark and Profiling October 2012 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information
HPC Hardware Overview
 HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn
Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments
 Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments Torben Kling-Petersen, PhD Presenter s Name Principle Field Title andengineer Division HPC &Cloud LoB SunComputing Microsystems
Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments Torben Kling-Petersen, PhD Presenter s Name Principle Field Title andengineer Division HPC &Cloud LoB SunComputing Microsystems
HPC Capabilities at Research Intensive Universities
 HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
PODShell: Simplifying HPC in the Cloud Workflow
 PODShell: Simplifying HPC in the Cloud Workflow June 2011 Penguin provides Linux HPC Solutions Linux Systems Servers Workstations Cluster Management Software HPC as a Service - Penguin on Demand Professional
PODShell: Simplifying HPC in the Cloud Workflow June 2011 Penguin provides Linux HPC Solutions Linux Systems Servers Workstations Cluster Management Software HPC as a Service - Penguin on Demand Professional
Introduction to HPC at UCL
 Institut de calcul intensif et de stockage de masse Introduction to HPC at UCL Technical reminders and available equipment From algorithm to computer program: optimization and parallel code source code
Institut de calcul intensif et de stockage de masse Introduction to HPC at UCL Technical reminders and available equipment From algorithm to computer program: optimization and parallel code source code
Six-Core AMD Opteron Processor
 What s you should know about the Six-Core AMD Opteron Processor (Codenamed Istanbul ) Six-Core AMD Opteron Processor Versatility Six-Core Opteron processors offer an optimal mix of performance, energy
What s you should know about the Six-Core AMD Opteron Processor (Codenamed Istanbul ) Six-Core AMD Opteron Processor Versatility Six-Core Opteron processors offer an optimal mix of performance, energy
PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE SHEET) Supply and installation of High Performance Computing System
 (TECHNICAL SPECIFICATIONS & COMPLIANCE SHEET) Supply and installation of High Performance Computing System") INSTITUTE FOR PLASMA RESEARCH (An Autonomous Institute of Department of Atomic Energy, Government of India) Near Indira Bridge; Bhat; Gandhinagar-382428; India PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE
INSTITUTE FOR PLASMA RESEARCH (An Autonomous Institute of Department of Atomic Energy, Government of India) Near Indira Bridge; Bhat; Gandhinagar-382428; India PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE
Before We Start. Sign in hpcxx account slips Windows Users: Download PuTTY. Google PuTTY First result Save putty.exe to Desktop
 Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Before We Start Sign in hpcxx account slips Windows Users: Download PuTTY Google PuTTY First result Save putty.exe to Desktop Research Computing at Virginia Tech Advanced Research Computing Compute Resources
Feedback on BeeGFS. A Parallel File System for High Performance Computing
 Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
Feedback on BeeGFS A Parallel File System for High Performance Computing Philippe Dos Santos et Georges Raseev FR 2764 Fédération de Recherche LUmière MATière December 13 2016 LOGO CNRS LOGO IO December
Comet Virtualization Code & Design Sprint
 Comet Virtualization Code & Design Sprint SDSC September 23-24 Rick Wagner San Diego Supercomputer Center Meeting Goals Build personal connections between the IU and SDSC members of the Comet team working
Comet Virtualization Code & Design Sprint SDSC September 23-24 Rick Wagner San Diego Supercomputer Center Meeting Goals Build personal connections between the IU and SDSC members of the Comet team working
PlaFRIM. Technical presentation of the platform
 PlaFRIM Technical presentation of the platform 1-11/12/2018 Contents 2-11/12/2018 01. 02. 03. 04. 05. 06. 07. Overview Nodes description Networks Storage Evolutions How to acces PlaFRIM? Need Help? 01
PlaFRIM Technical presentation of the platform 1-11/12/2018 Contents 2-11/12/2018 01. 02. 03. 04. 05. 06. 07. Overview Nodes description Networks Storage Evolutions How to acces PlaFRIM? Need Help? 01
CPMD Performance Benchmark and Profiling. February 2014
 CPMD Performance Benchmark and Profiling February 2014 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
CPMD Performance Benchmark and Profiling February 2014 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
CP2K Performance Benchmark and Profiling. April 2011
 CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
Sugon TC6600 blade server
 Sugon TC6600 blade server The converged-architecture blade server The TC6600 is a new generation, multi-node and high density blade server with shared power, cooling, networking and management infrastructure
Sugon TC6600 blade server The converged-architecture blade server The TC6600 is a new generation, multi-node and high density blade server with shared power, cooling, networking and management infrastructure
Outline. March 5, 2012 CIRMMT - McGill University 2
 Outline CLUMEQ, Calcul Quebec and Compute Canada Research Support Objectives and Focal Points CLUMEQ Site at McGill ETS Key Specifications and Status CLUMEQ HPC Support Staff at McGill Getting Started
Outline CLUMEQ, Calcul Quebec and Compute Canada Research Support Objectives and Focal Points CLUMEQ Site at McGill ETS Key Specifications and Status CLUMEQ HPC Support Staff at McGill Getting Started
Demonstration Milestone for Parallel Directory Operations
 Demonstration Milestone for Parallel Directory Operations This milestone was submitted to the PAC for review on 2012-03-23. This document was signed off on 2012-04-06. Overview This document describes
Demonstration Milestone for Parallel Directory Operations This milestone was submitted to the PAC for review on 2012-03-23. This document was signed off on 2012-04-06. Overview This document describes
University at Buffalo Center for Computational Research
 University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
GPU Computing with Fornax. Dr. Christopher Harris
 GPU Computing with Fornax Dr. Christopher Harris ivec@uwa CAASTRO GPU Training Workshop 8-9 October 2012 Introducing the Historical GPU Graphics Processing Unit (GPU) n : A specialised electronic circuit
GPU Computing with Fornax Dr. Christopher Harris ivec@uwa CAASTRO GPU Training Workshop 8-9 October 2012 Introducing the Historical GPU Graphics Processing Unit (GPU) n : A specialised electronic circuit
The rcuda technology: an inexpensive way to improve the performance of GPU-based clusters Federico Silla
 The rcuda technology: an inexpensive way to improve the performance of -based clusters Federico Silla Technical University of Valencia Spain The scope of this talk Delft, April 2015 2/47 More flexible
The rcuda technology: an inexpensive way to improve the performance of -based clusters Federico Silla Technical University of Valencia Spain The scope of this talk Delft, April 2015 2/47 More flexible
MILC Performance Benchmark and Profiling. April 2013
 MILC Performance Benchmark and Profiling April 2013 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
MILC Performance Benchmark and Profiling April 2013 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects?
 Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects? N. S. Islam, X. Lu, M. W. Rahman, and D. K. Panda Network- Based Compu2ng Laboratory Department of Computer
Can Parallel Replication Benefit Hadoop Distributed File System for High Performance Interconnects? N. S. Islam, X. Lu, M. W. Rahman, and D. K. Panda Network- Based Compu2ng Laboratory Department of Computer
Datura The new HPC-Plant at Albert Einstein Institute
 Datura The new HPC-Plant at Albert Einstein Institute Nico Budewitz Max Planck Institue for Gravitational Physics, Germany Cluster Day, 2011 Outline 1 History HPC-Plants at AEI -2009 Peyote, Lagavulin,
Datura The new HPC-Plant at Albert Einstein Institute Nico Budewitz Max Planck Institue for Gravitational Physics, Germany Cluster Day, 2011 Outline 1 History HPC-Plants at AEI -2009 Peyote, Lagavulin,
The Impact of Inter-node Latency versus Intra-node Latency on HPC Applications The 23 rd IASTED International Conference on PDCS 2011
 The Impact of Inter-node Latency versus Intra-node Latency on HPC Applications The 23 rd IASTED International Conference on PDCS 2011 HPC Scale Working Group, Dec 2011 Gilad Shainer, Pak Lui, Tong Liu,
The Impact of Inter-node Latency versus Intra-node Latency on HPC Applications The 23 rd IASTED International Conference on PDCS 2011 HPC Scale Working Group, Dec 2011 Gilad Shainer, Pak Lui, Tong Liu,
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System X idataplex CINECA, Italy The site selection
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 11th CALL (T ier-0) Contributing sites and the corresponding computer systems for this call are: BSC, Spain IBM System X idataplex CINECA, Italy The site selection
Maximizing Memory Performance for ANSYS Simulations
 Maximizing Memory Performance for ANSYS Simulations By Alex Pickard, 2018-11-19 Memory or RAM is an important aspect of configuring computers for high performance computing (HPC) simulation work. The performance
Maximizing Memory Performance for ANSYS Simulations By Alex Pickard, 2018-11-19 Memory or RAM is an important aspect of configuring computers for high performance computing (HPC) simulation work. The performance
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0)
") TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 6 th CALL (Tier-0) Contributing sites and the corresponding computer systems for this call are: GCS@Jülich, Germany IBM Blue Gene/Q GENCI@CEA, France Bull Bullx
HA-PACS/TCA: Tightly Coupled Accelerators for Low-Latency Communication between GPUs
 HA-PACS/TCA: Tightly Coupled Accelerators for Low-Latency Communication between GPUs Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba,
HA-PACS/TCA: Tightly Coupled Accelerators for Low-Latency Communication between GPUs Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba,
Philippe Thierry Sr Staff Engineer Intel Corp.
 HPC@Intel Philippe Thierry Sr Staff Engineer Intel Corp. IBM, April 8, 2009 1 Agenda CPU update: roadmap, micro-μ and performance Solid State Disk Impact What s next Q & A Tick Tock Model Perenity market
HPC@Intel Philippe Thierry Sr Staff Engineer Intel Corp. IBM, April 8, 2009 1 Agenda CPU update: roadmap, micro-μ and performance Solid State Disk Impact What s next Q & A Tick Tock Model Perenity market
HPC 2 Informed by Industry
 HPC 2 Informed by Industry HPC User Forum October 2011 Merle Giles Private Sector Program & Economic Development mgiles@ncsa.illinois.edu National Center for Supercomputing Applications University of Illinois
HPC 2 Informed by Industry HPC User Forum October 2011 Merle Giles Private Sector Program & Economic Development mgiles@ncsa.illinois.edu National Center for Supercomputing Applications University of Illinois
The rcuda middleware and applications
 The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
The rcuda middleware and applications Will my application work with rcuda? rcuda currently provides binary compatibility with CUDA 5.0, virtualizing the entire Runtime API except for the graphics functions,
Architectures for Scalable Media Object Search
 Architectures for Scalable Media Object Search Dennis Sng Deputy Director & Principal Scientist NVIDIA GPU Technology Workshop 10 July 2014 ROSE LAB OVERVIEW 2 Large Database of Media Objects Next- Generation
Architectures for Scalable Media Object Search Dennis Sng Deputy Director & Principal Scientist NVIDIA GPU Technology Workshop 10 July 2014 ROSE LAB OVERVIEW 2 Large Database of Media Objects Next- Generation
Evaluating the Impact of RDMA on Storage I/O over InfiniBand
 Evaluating the Impact of RDMA on Storage I/O over InfiniBand J Liu, DK Panda and M Banikazemi Computer and Information Science IBM T J Watson Research Center The Ohio State University Presentation Outline
Evaluating the Impact of RDMA on Storage I/O over InfiniBand J Liu, DK Panda and M Banikazemi Computer and Information Science IBM T J Watson Research Center The Ohio State University Presentation Outline
LBRN - HPC systems : CCT, LSU
 LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
HPC Architectures. Types of resource currently in use
 HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
HPC Architectures Types of resource currently in use Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
MegaGauss (MGs) Cluster Design Overview
 Cluster Design Overview") MegaGauss (MGs) Cluster Design Overview NVIDIA Tesla (Fermi) S2070 Modules Based Solution Version 6 (Apr 27, 2010) Alexander S. Zaytsev p. 1 of 15: "Title" Front view: planar
MegaGauss (MGs) Cluster Design Overview NVIDIA Tesla (Fermi) S2070 Modules Based Solution Version 6 (Apr 27, 2010) Alexander S. Zaytsev p. 1 of 15: "Title" Front view: planar
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0)
") PRACE 16th Call Technical Guidelines for Applicants V1: published on 26/09/17 TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0) The contributing sites and the corresponding computer systems
PRACE 16th Call Technical Guidelines for Applicants V1: published on 26/09/17 TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 16 th CALL (T ier-0) The contributing sites and the corresponding computer systems
GROMACS Performance Benchmark and Profiling. September 2012
 GROMACS Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource
GROMACS Performance Benchmark and Profiling September 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science
 Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
Increasing the efficiency of your GPU-enabled cluster with rcuda. Federico Silla Technical University of Valencia Spain
 Increasing the efficiency of your -enabled cluster with rcuda Federico Silla Technical University of Valencia Spain Outline Why remote virtualization? How does rcuda work? The performance of the rcuda
Increasing the efficiency of your -enabled cluster with rcuda Federico Silla Technical University of Valencia Spain Outline Why remote virtualization? How does rcuda work? The performance of the rcuda
DEDICATED SERVERS WITH EBS
 DEDICATED WITH EBS TABLE OF CONTENTS WHY CHOOSE A DEDICATED SERVER? 3 DEDICATED WITH EBS 4 INTEL ATOM DEDICATED 5 AMD OPTERON DEDICATED 6 INTEL XEON DEDICATED 7 MANAGED SERVICES 8 SERVICE GUARANTEES 9
DEDICATED WITH EBS TABLE OF CONTENTS WHY CHOOSE A DEDICATED SERVER? 3 DEDICATED WITH EBS 4 INTEL ATOM DEDICATED 5 AMD OPTERON DEDICATED 6 INTEL XEON DEDICATED 7 MANAGED SERVICES 8 SERVICE GUARANTEES 9
SNAP Performance Benchmark and Profiling. April 2014
 SNAP Performance Benchmark and Profiling April 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox For more information on the supporting
SNAP Performance Benchmark and Profiling April 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: HP, Mellanox For more information on the supporting
The SHARED hosting plan is designed to meet the advanced hosting needs of businesses who are not yet ready to move on to a server solution.
 SHARED HOSTING @ RS.2000/- PER YEAR ( SSH ACCESS, MODSECURITY FIREWALL, DAILY BACKUPS, MEMCHACACHED, REDIS, VARNISH, NODE.JS, REMOTE MYSQL ACCESS, GEO IP LOCATION TOOL 5GB FREE VPN TRAFFIC,, 24/7/365 SUPPORT
SHARED HOSTING @ RS.2000/- PER YEAR ( SSH ACCESS, MODSECURITY FIREWALL, DAILY BACKUPS, MEMCHACACHED, REDIS, VARNISH, NODE.JS, REMOTE MYSQL ACCESS, GEO IP LOCATION TOOL 5GB FREE VPN TRAFFIC,, 24/7/365 SUPPORT
GROMACS (GPU) Performance Benchmark and Profiling. February 2016
 Performance Benchmark and Profiling. February 2016") GROMACS (GPU) Performance Benchmark and Profiling February 2016 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Mellanox, NVIDIA Compute
GROMACS (GPU) Performance Benchmark and Profiling February 2016 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Mellanox, NVIDIA Compute
ANSYS HPC Technology Leadership
 ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
ANSYS HPC Technology Leadership 1 ANSYS, Inc. November 14, Why ANSYS Users Need HPC Insight you can t get any other way It s all about getting better insight into product behavior quicker! HPC enables
LS-DYNA Performance Benchmark and Profiling. October 2017
 LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
FhGFS - Performance at the maximum
 FhGFS - Performance at the maximum http://www.fhgfs.com January 22, 2013 Contents 1. Introduction 2 2. Environment 2 3. Benchmark specifications and results 3 3.1. Multi-stream throughput................................
FhGFS - Performance at the maximum http://www.fhgfs.com January 22, 2013 Contents 1. Introduction 2 2. Environment 2 3. Benchmark specifications and results 3 3.1. Multi-stream throughput................................
AMBER 11 Performance Benchmark and Profiling. July 2011
 AMBER 11 Performance Benchmark and Profiling July 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
AMBER 11 Performance Benchmark and Profiling July 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
GPUs and Emerging Architectures
 GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
GPUs and Emerging Architectures Mike Giles mike.giles@maths.ox.ac.uk Mathematical Institute, Oxford University e-infrastructure South Consortium Oxford e-research Centre Emerging Architectures p. 1 CPUs
In the multi-core age, How do larger, faster and cheaper and more responsive memory sub-systems affect data management? Dhabaleswar K.
 In the multi-core age, How do larger, faster and cheaper and more responsive sub-systems affect data management? Panel at ADMS 211 Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory Department
In the multi-core age, How do larger, faster and cheaper and more responsive sub-systems affect data management? Panel at ADMS 211 Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory Department
Modern computer architecture. From multicore to petaflops
 Modern computer architecture From multicore to petaflops Motivation: Multi-ores where and why Introduction: Moore s law Intel Sandy Brige EP: 2.3 Billion nvidia FERMI: 3 Billion 1965: G. Moore claimed
Modern computer architecture From multicore to petaflops Motivation: Multi-ores where and why Introduction: Moore s law Intel Sandy Brige EP: 2.3 Billion nvidia FERMI: 3 Billion 1965: G. Moore claimed
(Detailed Terms, Technical Specifications, and Bidding Format) This section describes the main objective to be achieved through this procurement.
 This section describes the main objective to be achieved through this procurement.") ITEM:- Supply and Installation of Servers for Private Cloud Annexure Tender No: - 201601945 IIT Bombay is setting up a cloud to host important applications and data for a national project. The cloud is
ITEM:- Supply and Installation of Servers for Private Cloud Annexure Tender No: - 201601945 IIT Bombay is setting up a cloud to host important applications and data for a national project. The cloud is
Computer Science Section. Computational and Information Systems Laboratory National Center for Atmospheric Research
 Computer Science Section Computational and Information Systems Laboratory National Center for Atmospheric Research My work in the context of TDD/CSS/ReSET Polynya new research computing environment Polynya
Computer Science Section Computational and Information Systems Laboratory National Center for Atmospheric Research My work in the context of TDD/CSS/ReSET Polynya new research computing environment Polynya
LAMMPS-KOKKOS Performance Benchmark and Profiling. September 2015
 LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
Intel Workstation Technology
 Intel Workstation Technology Turning Imagination Into Reality November, 2008 1 Step up your Game Real Workstations Unleash your Potential 2 Yesterday s Super Computer Today s Workstation = = #1 Super Computer
Intel Workstation Technology Turning Imagination Into Reality November, 2008 1 Step up your Game Real Workstations Unleash your Potential 2 Yesterday s Super Computer Today s Workstation = = #1 Super Computer
HYCOM Performance Benchmark and Profiling
 HYCOM Performance Benchmark and Profiling Jan 2011 Acknowledgment: - The DoD High Performance Computing Modernization Program Note The following research was performed under the HPC Advisory Council activities
HYCOM Performance Benchmark and Profiling Jan 2011 Acknowledgment: - The DoD High Performance Computing Modernization Program Note The following research was performed under the HPC Advisory Council activities
NAMD Performance Benchmark and Profiling. January 2015
 NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
Scaling to Petaflop. Ola Torudbakken Distinguished Engineer. Sun Microsystems, Inc
 Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
OpenFOAM Performance Testing and Profiling. October 2017
 OpenFOAM Performance Testing and Profiling October 2017 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Huawei, Mellanox Compute resource - HPC
OpenFOAM Performance Testing and Profiling October 2017 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Huawei, Mellanox Compute resource - HPC
Altair RADIOSS Performance Benchmark and Profiling. May 2013
 Altair RADIOSS Performance Benchmark and Profiling May 2013 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Altair, AMD, Dell, Mellanox Compute
Altair RADIOSS Performance Benchmark and Profiling May 2013 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Altair, AMD, Dell, Mellanox Compute
2008 International ANSYS Conference
 2008 International ANSYS Conference Maximizing Productivity With InfiniBand-Based Clusters Gilad Shainer Director of Technical Marketing Mellanox Technologies 2008 ANSYS, Inc. All rights reserved. 1 ANSYS,
2008 International ANSYS Conference Maximizing Productivity With InfiniBand-Based Clusters Gilad Shainer Director of Technical Marketing Mellanox Technologies 2008 ANSYS, Inc. All rights reserved. 1 ANSYS,
Cray events. ! Cray User Group (CUG): ! Cray Technical Workshop Europe:
: ! Cray Technical Workshop Europe:") Cray events! Cray User Group (CUG):! When: May 16-19, 2005! Where: Albuquerque, New Mexico - USA! Registration: reserved to CUG members! Web site: http://www.cug.org! Cray Technical Workshop Europe:! When:
Cray events! Cray User Group (CUG):! When: May 16-19, 2005! Where: Albuquerque, New Mexico - USA! Registration: reserved to CUG members! Web site: http://www.cug.org! Cray Technical Workshop Europe:! When:
Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE
 Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE Hitoshi Sato *1, Shuichi Ihara *2, Satoshi Matsuoka *1 *1 Tokyo Institute
Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE Hitoshi Sato *1, Shuichi Ihara *2, Satoshi Matsuoka *1 *1 Tokyo Institute
CSCS HPC storage. Hussein N. Harake
 CSCS HPC storage Hussein N. Harake Points to Cover - XE6 External Storage (DDN SFA10K, SRP, QDR) - PCI-E SSD Technology - RamSan 620 Technology XE6 External Storage - Installed Q4 2010 - In Production
CSCS HPC storage Hussein N. Harake Points to Cover - XE6 External Storage (DDN SFA10K, SRP, QDR) - PCI-E SSD Technology - RamSan 620 Technology XE6 External Storage - Installed Q4 2010 - In Production
NAMD Performance Benchmark and Profiling. February 2012
 NAMD Performance Benchmark and Profiling February 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
NAMD Performance Benchmark and Profiling February 2012 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource -
C-Series Servers Meat and Tators
 C-Series Servers Meat and Tators Jimmy Ray Purser Chief Geek, TechWiseTV 2006 Cisco Systems, Inc. All rights reserved. 1 When it comes to Servers 2006 Cisco Systems, Inc. All rights reserved. 2 Unified
C-Series Servers Meat and Tators Jimmy Ray Purser Chief Geek, TechWiseTV 2006 Cisco Systems, Inc. All rights reserved. 1 When it comes to Servers 2006 Cisco Systems, Inc. All rights reserved. 2 Unified
Himeno Performance Benchmark and Profiling. December 2010
 Himeno Performance Benchmark and Profiling December 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource
Himeno Performance Benchmark and Profiling December 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource
Adaptive MPI Multirail Tuning for Non-Uniform Input/Output Access
 Adaptive MPI Multirail Tuning for Non-Uniform Input/Output Access S. Moreaud, B. Goglin and R. Namyst INRIA Runtime team-project University of Bordeaux, France Context Multicore architectures everywhere
Adaptive MPI Multirail Tuning for Non-Uniform Input/Output Access S. Moreaud, B. Goglin and R. Namyst INRIA Runtime team-project University of Bordeaux, France Context Multicore architectures everywhere
Choosing Resources Wisely Plamen Krastev Office: 38 Oxford, Room 117 FAS Research Computing
 Choosing Resources Wisely Plamen Krastev Office: 38 Oxford, Room 117 Email:plamenkrastev@fas.harvard.edu Objectives Inform you of available computational resources Help you choose appropriate computational
Choosing Resources Wisely Plamen Krastev Office: 38 Oxford, Room 117 Email:plamenkrastev@fas.harvard.edu Objectives Inform you of available computational resources Help you choose appropriate computational
HyperTransport Technology
 HyperTransport Technology in 2009 and Beyond Mike Uhler VP, Accelerated Computing, AMD President, HyperTransport Consortium February 11, 2009 Agenda AMD Roadmap Update Torrenza, Fusion, Stream Computing
HyperTransport Technology in 2009 and Beyond Mike Uhler VP, Accelerated Computing, AMD President, HyperTransport Consortium February 11, 2009 Agenda AMD Roadmap Update Torrenza, Fusion, Stream Computing
Erkenntnisse aus aktuellen Performance- Messungen mit LS-DYNA
 14. LS-DYNA Forum, Oktober 2016, Bamberg Erkenntnisse aus aktuellen Performance- Messungen mit LS-DYNA Eric Schnepf 1, Dr. Eckardt Kehl 1, Chih-Song Kuo 2, Dymitrios Kyranas 2 1 Fujitsu Technology Solutions
14. LS-DYNA Forum, Oktober 2016, Bamberg Erkenntnisse aus aktuellen Performance- Messungen mit LS-DYNA Eric Schnepf 1, Dr. Eckardt Kehl 1, Chih-Song Kuo 2, Dymitrios Kyranas 2 1 Fujitsu Technology Solutions
LS-DYNA Performance Benchmark and Profiling. October 2017
 LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
The AMD64 Technology for Server and Workstation. Dr. Ulrich Knechtel Enterprise Program Manager EMEA
 The AMD64 Technology for Server and Workstation Dr. Ulrich Knechtel Enterprise Program Manager EMEA Agenda Direct Connect Architecture AMD Opteron TM Processor Roadmap Competition OEM support The AMD64
The AMD64 Technology for Server and Workstation Dr. Ulrich Knechtel Enterprise Program Manager EMEA Agenda Direct Connect Architecture AMD Opteron TM Processor Roadmap Competition OEM support The AMD64
STAR-CCM+ Performance Benchmark and Profiling. July 2014
 STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
AcuSolve Performance Benchmark and Profiling. October 2011
 AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox, Altair Compute
AcuSolve Performance Benchmark and Profiling October 2011 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox, Altair Compute
WaveView. System Requirement V6. Reference: WST Page 1. WaveView System Requirements V6 WST
 WaveView System Requirement V6 Reference: WST-0125-01 www.wavestore.com Page 1 WaveView System Requirements V6 Copyright notice While every care has been taken to ensure the information contained within
WaveView System Requirement V6 Reference: WST-0125-01 www.wavestore.com Page 1 WaveView System Requirements V6 Copyright notice While every care has been taken to ensure the information contained within
Interconnection Network for Tightly Coupled Accelerators Architecture
 Interconnection Network for Tightly Coupled Accelerators Architecture Toshihiro Hanawa, Yuetsu Kodama, Taisuke Boku, Mitsuhisa Sato Center for Computational Sciences University of Tsukuba, Japan 1 What
Interconnection Network for Tightly Coupled Accelerators Architecture Toshihiro Hanawa, Yuetsu Kodama, Taisuke Boku, Mitsuhisa Sato Center for Computational Sciences University of Tsukuba, Japan 1 What
DESKTOP CONFIGURATION(without Monitor)
") DSK1 DESKTOP CONFIGURATION(without Monitor) Processor:Intel Core i3-6100 Processor (Dual Core, 3MB, 4T, 3.7GHz, 65W), Intel H110 Chipset, RAM: 4 GB DDR4-2133mhz, Hard Disk: 500 GB, Integrated Graphics,
DSK1 DESKTOP CONFIGURATION(without Monitor) Processor:Intel Core i3-6100 Processor (Dual Core, 3MB, 4T, 3.7GHz, 65W), Intel H110 Chipset, RAM: 4 GB DDR4-2133mhz, Hard Disk: 500 GB, Integrated Graphics,
rcuda: towards energy-efficiency in GPU computing by leveraging low-power processors and InfiniBand interconnects
 rcuda: towards energy-efficiency in computing by leveraging low-power processors and InfiniBand interconnects Federico Silla Technical University of Valencia Spain Joint research effort Outline Current
rcuda: towards energy-efficiency in computing by leveraging low-power processors and InfiniBand interconnects Federico Silla Technical University of Valencia Spain Joint research effort Outline Current
HPC Technology Update Challenges or Chances?
 HPC Technology Update Challenges or Chances? Swiss Distributed Computing Day Thomas Schoenemeyer, Technology Integration, CSCS 1 Move in Feb-April 2012 1500m2 16 MW Lake-water cooling PUE 1.2 New Datacenter
HPC Technology Update Challenges or Chances? Swiss Distributed Computing Day Thomas Schoenemeyer, Technology Integration, CSCS 1 Move in Feb-April 2012 1500m2 16 MW Lake-water cooling PUE 1.2 New Datacenter
Study. Dhabaleswar. K. Panda. The Ohio State University HPIDC '09
 RDMA over Ethernet - A Preliminary Study Hari Subramoni, Miao Luo, Ping Lai and Dhabaleswar. K. Panda Computer Science & Engineering Department The Ohio State University Introduction Problem Statement
RDMA over Ethernet - A Preliminary Study Hari Subramoni, Miao Luo, Ping Lai and Dhabaleswar. K. Panda Computer Science & Engineering Department The Ohio State University Introduction Problem Statement
Real Parallel Computers
 Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
Real Parallel Computers Modular data centers Background Information Recent trends in the marketplace of high performance computing Strohmaier, Dongarra, Meuer, Simon Parallel Computing 2005 Short history
ABySS Performance Benchmark and Profiling. May 2010
 ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA
 Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
John Fragalla TACC 'RANGER' INFINIBAND ARCHITECTURE WITH SUN TECHNOLOGY. Presenter s Name Title and Division Sun Microsystems
 TACC 'RANGER' INFINIBAND ARCHITECTURE WITH SUN TECHNOLOGY SUBTITLE WITH TWO LINES OF TEXT IF NECESSARY John Fragalla Presenter s Name Title and Division Sun Microsystems Principle Engineer High Performance
TACC 'RANGER' INFINIBAND ARCHITECTURE WITH SUN TECHNOLOGY SUBTITLE WITH TWO LINES OF TEXT IF NECESSARY John Fragalla Presenter s Name Title and Division Sun Microsystems Principle Engineer High Performance
Block Lanczos-Montgomery Method over Large Prime Fields with GPU Accelerated Dense Operations
 Block Lanczos-Montgomery Method over Large Prime Fields with GPU Accelerated Dense Operations D. Zheltkov, N. Zamarashkin INM RAS September 24, 2018 Scalability of Lanczos method Notations Matrix order
Block Lanczos-Montgomery Method over Large Prime Fields with GPU Accelerated Dense Operations D. Zheltkov, N. Zamarashkin INM RAS September 24, 2018 Scalability of Lanczos method Notations Matrix order
A Plugin-based Approach to Exploit RDMA Benefits for Apache and Enterprise HDFS
 A Plugin-based Approach to Exploit RDMA Benefits for Apache and Enterprise HDFS Adithya Bhat, Nusrat Islam, Xiaoyi Lu, Md. Wasi- ur- Rahman, Dip: Shankar, and Dhabaleswar K. (DK) Panda Network- Based Compu2ng
A Plugin-based Approach to Exploit RDMA Benefits for Apache and Enterprise HDFS Adithya Bhat, Nusrat Islam, Xiaoyi Lu, Md. Wasi- ur- Rahman, Dip: Shankar, and Dhabaleswar K. (DK) Panda Network- Based Compu2ng
OCTOPUS Performance Benchmark and Profiling. June 2015
 OCTOPUS Performance Benchmark and Profiling June 2015 2 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the
OCTOPUS Performance Benchmark and Profiling June 2015 2 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the
Overview of the Texas Advanced Computing Center. Bill Barth TACC September 12, 2011
 Overview of the Texas Advanced Computing Center Bill Barth TACC September 12, 2011 TACC Mission & Strategic Approach To enable discoveries that advance science and society through the application of advanced
Overview of the Texas Advanced Computing Center Bill Barth TACC September 12, 2011 TACC Mission & Strategic Approach To enable discoveries that advance science and society through the application of advanced
Mellanox Technologies Maximize Cluster Performance and Productivity. Gilad Shainer, October, 2007
 Mellanox Technologies Maximize Cluster Performance and Productivity Gilad Shainer, shainer@mellanox.com October, 27 Mellanox Technologies Hardware OEMs Servers And Blades Applications End-Users Enterprise
Mellanox Technologies Maximize Cluster Performance and Productivity Gilad Shainer, shainer@mellanox.com October, 27 Mellanox Technologies Hardware OEMs Servers And Blades Applications End-Users Enterprise
Sherlock for IBIIS. William Law Stanford Research Computing
 Sherlock for IBIIS William Law Stanford Research Computing Overview How we can help System overview Tech specs Signing on Batch submission Software environment Interactive jobs Next steps We are here to
Sherlock for IBIIS William Law Stanford Research Computing Overview How we can help System overview Tech specs Signing on Batch submission Software environment Interactive jobs Next steps We are here to
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Quotations invited. 2. The supplied hardware should have 5 years comprehensive onsite warranty (24 x 7 call logging) from OEM directly.
 from OEM directly.") Enquiry No: IITK/ME/mkdas/2016/01 May 04, 2016 Quotations invited Sealed quotations are invited for the purchase of an HPC cluster with the specification outlined below. Technical as well as the commercial
Enquiry No: IITK/ME/mkdas/2016/01 May 04, 2016 Quotations invited Sealed quotations are invited for the purchase of an HPC cluster with the specification outlined below. Technical as well as the commercial
Longhorn Project TACC s XD Visualization Resource
 Longhorn Project TACC s XD Visualization Resource DOE Computer Graphics Forum April 14, 2010 Longhorn Visualization and Data Analysis In November 2008, NSF accepted proposals for the Extreme Digital Resources
Longhorn Project TACC s XD Visualization Resource DOE Computer Graphics Forum April 14, 2010 Longhorn Visualization and Data Analysis In November 2008, NSF accepted proposals for the Extreme Digital Resources
Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX
 Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX Inventing Internet TV Available in more than 190 countries 104+ million subscribers Lots of Streaming == Lots of Traffic
Scaling Internet TV Content Delivery ALEX GUTARIN DIRECTOR OF ENGINEERING, NETFLIX Inventing Internet TV Available in more than 190 countries 104+ million subscribers Lots of Streaming == Lots of Traffic
EMC ISILON X-SERIES. Specifications. EMC Isilon X210. EMC Isilon X410 ARCHITECTURE
 EMC ISILON X-SERIES EMC Isilon X210 The EMC Isilon X-Series, powered by the OneFS operating system, uses a highly versatile yet simple scale-out storage architecture to speed access to massive amounts
EMC ISILON X-SERIES EMC Isilon X210 The EMC Isilon X-Series, powered by the OneFS operating system, uses a highly versatile yet simple scale-out storage architecture to speed access to massive amounts
ISILON X-SERIES. Isilon X210. Isilon X410 ARCHITECTURE SPECIFICATION SHEET Dell Inc. or its subsidiaries.
 SPECIFICATION SHEET Isilon X410 Isilon X210 ISILON X-SERIES The Dell EMC Isilon X-Series, powered by the Isilon OneFS operating system, uses a highly versatile yet simple scale-out storage architecture
SPECIFICATION SHEET Isilon X410 Isilon X210 ISILON X-SERIES The Dell EMC Isilon X-Series, powered by the Isilon OneFS operating system, uses a highly versatile yet simple scale-out storage architecture
Tightly Coupled Accelerators Architecture
 Tightly Coupled Accelerators Architecture Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba, Japan 1 What is Tightly Coupled Accelerators
Tightly Coupled Accelerators Architecture Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba, Japan 1 What is Tightly Coupled Accelerators
EPYC VIDEO CUG 2018 MAY 2018
 AMD UPDATE CUG 2018 EPYC VIDEO CRAY AND AMD PAST SUCCESS IN HPC AMD IN TOP500 LIST 2002 TO 2011 2011 - AMD IN FASTEST MACHINES IN 11 COUNTRIES ZEN A FRESH APPROACH Designed from the Ground up for Optimal
AMD UPDATE CUG 2018 EPYC VIDEO CRAY AND AMD PAST SUCCESS IN HPC AMD IN TOP500 LIST 2002 TO 2011 2011 - AMD IN FASTEST MACHINES IN 11 COUNTRIES ZEN A FRESH APPROACH Designed from the Ground up for Optimal