Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics
|
|
|
- Baldric Booth
- 5 years ago
- Views:
Transcription
 Graduate Institute of Physics, National Taiwan University Leung Ce")
1 Adaptive-Mesh-Refinement Hydrodynamic GPU Computation in Astrophysics H. Y. Schive ( 薛熙于 ) Graduate Institute of Physics, National Taiwan University Leung Center for Cosmology and Particle Astrophysics (LeCosPA) T. Chiueh ( 闕志鴻 ), Y. C. Tsai ( 蔡御之 ) Graduate Institute of Physics, National Taiwan University Leung Center for Cosmology and Particle Astrophysics (LeCosPA) Workshop on GPU Supercomputing (1/16/2009)


2 GPU Applications From the smallest scale (QCD, Quantum Spin System) to the largest scale (Astrophysics & Cosmology)
3 Outline Introduction GraCCA (Graphic-Card Cluster for Astrophysics) system and previous work AMR Hydrodynamics + Self-Gravity Simulation in GPUs Conclusion and Future Work
4 Introduction : GPU vs. CPU Faster, Faster, Faster!!! GPU : low clock rate, multi-processors GTX GHz, 240 processors 30 multiprocessors : each has 16 KB fast shared memory ~ 933 GFLOPS CPU : high clock rate, few processors Intel Core 2 Quad Q GHz, quad-core ~ 40 GFLOPS 23 times faster
5 Programming interface : CUDA (Compute Unified Device Architecture) GPU multithreaded coprocessor to CPU Execute thousands of threads in parallel All threads execute the same kernel Kernel Thread (1) Thread (2)... Thread (N) Processor (1) Processor (2)... Processor (128) GPU
6 GraCCA Graphic-Card Cluster for Astrophysics
7 Architecture 18 nodes, 36 GPUs Theoretical performance : 518.4*36 = 18.7 TFLOPS Network : gigabit Ethernet Hardwares in each node Hardware Model Amount Graphic Card NVIDIA GeForce 8800 GTX 2 Motherboard Gigabyte GA-M59SLI S5 1 CPU AMD Athlon 64 X Power Supply Thermaltake Toughpower 750W 1 RAM DDR GB RAM 4 Hard Disk Seagate 80G SATAII 1
8 Architecture Gigabit Network Switch 1 Gigabit Network Card PC Memory (DDR2-667, 2 GB) PCI-Express x16 CPU PCI-Express x16 Node 18 GPU Memory GPU Memory (GDDR3, 768 MB) (GDDR3, 768 MB) G80 GPU G80 GPU Graphic Card 1 Graphic Card 2 Node 1






9 Photos of GraCCA Multi-node Single-node
10 Previous Work : Parallel Direct N-body Simulation ~ Schive et al., NewA 13, 418. Speed (GFLOPS) 1.E+04 1.E+03 1.E x speed-up over a single CPU Ngpu = 1 Ngpu = 2 Ngpu = 4 Ngpu = 8 Ngpu = 16 Ngpu = 32 for N = 1024k : Single GPU : 257 GFLOPS 32 GPUs : 6.62 TFLOPS 1.E+01 1.E+03 1.E+04 1.E+05 1.E+06 1.E+07 N
11 Core Collapse in Globular Cluster Initial condition : Plummer s model It took about one month for the N=64k case One of a few groups having the computation capability for simulating the core collapse for N=64k 14 N = 64K N = 32K 12 log( Core Density ) N = 16K N = 8K Scaled N body time
12 AMR Hydrodynamics Simulation in GPUs
13 PDE in Hydrodynamics Conservation laws of mass, momentum, and energy ρ t ( ρ t ( E) t + ( r v) ρ r v) + ( ρ = 0 rr vv + P) = r + ( v( E+ P)) = ρ ρ φ r v φ ρ: density v : velocity P : pressure ψ: potential E : energy density
14 Adaptive-Mesh-Refinement Boring Region : flat, empty, low error coarse mesh Interesting Region : high density, high contrast, high error fine mesh
15 Example : Sedov-Taylor Blast Wave Density spherical shock compression ratio ~ refine levels ( )

16 Sedov-Taylor Blast Wave Density
17 Basic Scheme 2 nd -order TVD scheme for the fluid solver SOR method for the Poisson solver Hierarchical oct-tree data-structure Basic unit : patch ( fixed number of grids ) Patch in level 0 (2*2 grids) Patch in level 1 (2*2 grids) Patch in level 2 (2*2 grids)
18 GPU Acceleration Two main tasks in the AMR program: 1. Patch construction : decision making, interpolation, complex data-structure, data assignment ~ complicated, but time-saving CPU 2. 3-D hydrodynamics + Poisson solver : ~ straightforward, but time-consuming GPU feed with hundreds of patches simultaneously
19 Parallel Evaluation of Multi- Patches in a Single GPU Multiprocessor (1) Multiprocessor (2) 1 Multiprocessor (3)... Multiprocessor (16) GPU
20 Concurrent Execution in CPU and GPU Preparing data for the GPU fluid solver (data copy, interpolation ) is also very time-consuming!! Hide this preparing time by the asynchronous execution in GPU time CPU Prepare patch 2 Prepare patch 3 GPU Evaluate patch 1 Evaluate patch 2
21 Concurrent Memory Copy and Kernel Execution The bandwidth between CPU and GPU is only 4 GB/s just not high enough!!! Hide this data-transferring time by the concurrent memory copy (between CPU and GPU ) and execution in GPU time 16x PCI-E Transfer patch 2 Transfer patch 3 GPU Evaluate patch 1 Evaluate patch 2
22 Performance (hydrodynamics only) Single GPU vs. single CPU (64 3, 128 3, 256 3, ) x speed-up speed-up ratio simulation size
23 Poisson Solver in GPU Successive Over-Relaxation method (SOR) Given the boundary condition, the SOR method will iteratively approach the solution of the Poisson equation The patch with 8 3 grids can be perfectly fit into the shared memory of GPU (16 KB per multiprocessor in the GeForce 8800 GTX) only need to transfer data between global memory and shared memory before and after the iteration loop more iterations, higher performance
24 Performance of the SOR in GPU Single GPU vs. single CPU 17.5x speed-up for iterations ~ speed-up ratio iteration
25 Multi-GPUs Each CPU and GPU handle a sub-domain Exchanging data by MPI CPU 0 GPU 0 CPU 2 GPU 2 Data-transfer (gigabit-network) CPU 1 GPU 1 CPU 3 GPU 3
26 Network Bandwidth The computation is highly improved, but the communication is NOT!! Gigabit Ethernet bandwidth ~ only 128 MB/s We must minimize the amount of data to be transferred!!! possible direction for data transfer
27 Performance (multi GPUs) 512^3 run : 8 GPUs vs. 8 CPUs: 10.0x speed-up 1024^3 run : 8 GPUs vs. 8 CPUs: 9.5x speed-up speed-up ratio ^3 run Measured Ideal number of GPUs
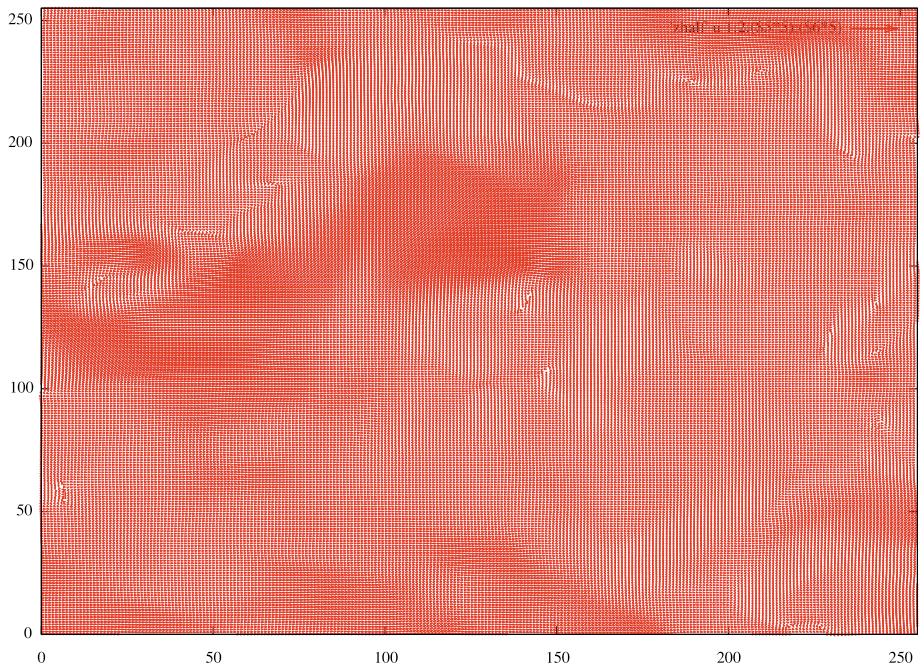
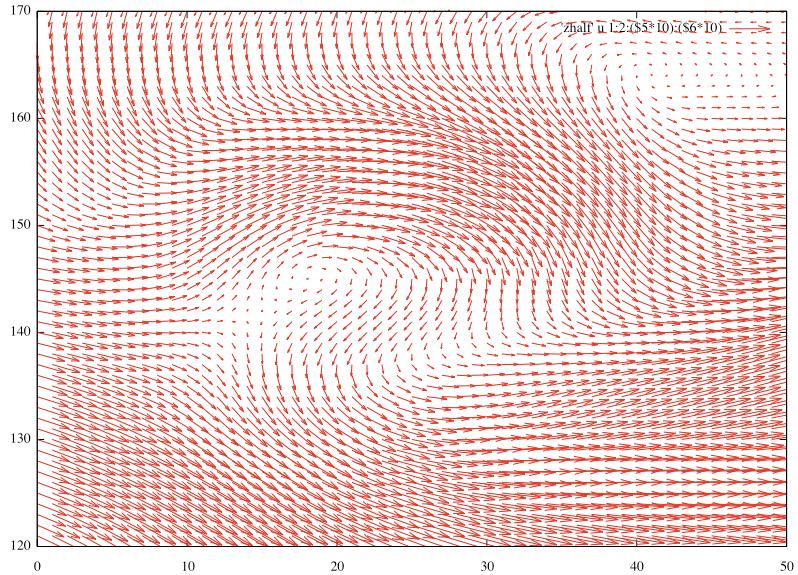
28 Demo : Kelvin-Helmholtz Instability
29 Performance in the state-of-art GPU Performance in the GTX 280 GPU Hydrodynamics solver : 1192 ms 638 ms Poisson solver : 336 ms 154 ms The performance is further improved by a factor of 2 But the speed-up ratio of an upgraded GPU over an upgraded CPU is about the same
30 Conclusion and Future Work Parallel GPUs-accelerated AMR hydrodynamics program 1 GPU vs. 1 CPU : 12.3x speed-up 8 GPUs vs. 8 CPUs : 10.0x speed-up GPU-accelerated Poisson solver in GPU 17.5x speed-up for 40 iterations Future work Complete the Poisson solver Dark matter particles Load balance MHD Optimization in the latest GPU (GTX 280, Tesla S1070)
GAMER : a GPU-accelerated Adaptive-MEsh-Refinement Code for Astrophysics GPU 與自適性網格於天文模擬之應用與效能
 GAMER : a GPU-accelerated Adaptive-MEsh-Refinement Code for Astrophysics GPU 與自適性網格於天文模擬之應用與效能 Hsi-Yu Schive ( 薛熙于 ), Tzihong Chiueh ( 闕志鴻 ), Yu-Chih Tsai ( 蔡御之 ), Ui-Han Zhang ( 張瑋瀚 ) Graduate Institute
GAMER : a GPU-accelerated Adaptive-MEsh-Refinement Code for Astrophysics GPU 與自適性網格於天文模擬之應用與效能 Hsi-Yu Schive ( 薛熙于 ), Tzihong Chiueh ( 闕志鴻 ), Yu-Chih Tsai ( 蔡御之 ), Ui-Han Zhang ( 張瑋瀚 ) Graduate Institute
RAMSES on the GPU: An OpenACC-Based Approach
 RAMSES on the GPU: An OpenACC-Based Approach Claudio Gheller (ETHZ-CSCS) Giacomo Rosilho de Souza (EPFL Lausanne) Romain Teyssier (University of Zurich) Markus Wetzstein (ETHZ-CSCS) PRACE-2IP project EU
RAMSES on the GPU: An OpenACC-Based Approach Claudio Gheller (ETHZ-CSCS) Giacomo Rosilho de Souza (EPFL Lausanne) Romain Teyssier (University of Zurich) Markus Wetzstein (ETHZ-CSCS) PRACE-2IP project EU
Adaptive Mesh Astrophysical Fluid Simulations on GPU. San Jose 10/2/2009 Peng Wang, NVIDIA
 Adaptive Mesh Astrophysical Fluid Simulations on GPU San Jose 10/2/2009 Peng Wang, NVIDIA Overview Astrophysical motivation & the Enzo code Finite volume method and adaptive mesh refinement (AMR) CUDA
Adaptive Mesh Astrophysical Fluid Simulations on GPU San Jose 10/2/2009 Peng Wang, NVIDIA Overview Astrophysical motivation & the Enzo code Finite volume method and adaptive mesh refinement (AMR) CUDA
N-Body Simulation using CUDA. CSE 633 Fall 2010 Project by Suraj Alungal Balchand Advisor: Dr. Russ Miller State University of New York at Buffalo
 N-Body Simulation using CUDA CSE 633 Fall 2010 Project by Suraj Alungal Balchand Advisor: Dr. Russ Miller State University of New York at Buffalo Project plan Develop a program to simulate gravitational
N-Body Simulation using CUDA CSE 633 Fall 2010 Project by Suraj Alungal Balchand Advisor: Dr. Russ Miller State University of New York at Buffalo Project plan Develop a program to simulate gravitational
General Purpose GPU Computing in Partial Wave Analysis
 JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
JLAB at 12 GeV - INT General Purpose GPU Computing in Partial Wave Analysis Hrayr Matevosyan - NTC, Indiana University November 18/2009 COmputationAL Challenges IN PWA Rapid Increase in Available Data
Software and Performance Engineering for numerical codes on GPU clusters
 Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Software and Performance Engineering for numerical codes on GPU clusters H. Köstler International Workshop of GPU Solutions to Multiscale Problems in Science and Engineering Harbin, China 28.7.2010 2 3
Numerical Algorithms on Multi-GPU Architectures
 Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
Numerical Algorithms on Multi-GPU Architectures Dr.-Ing. Harald Köstler 2 nd International Workshops on Advances in Computational Mechanics Yokohama, Japan 30.3.2010 2 3 Contents Motivation: Applications
arxiv: v1 [cs.ms] 8 Aug 2018
![arxiv: v1 [cs.ms] 8 Aug 2018](/thumbs/83/87599411.jpg "arxiv: v1 [cs.ms] 8 Aug 2018") ACCELERATING WAVE-PROPAGATION ALGORITHMS WITH ADAPTIVE MESH REFINEMENT USING THE GRAPHICS PROCESSING UNIT (GPU) XINSHENG QIN, RANDALL LEVEQUE, AND MICHAEL MOTLEY arxiv:1808.02638v1 [cs.ms] 8 Aug 2018 Abstract.
ACCELERATING WAVE-PROPAGATION ALGORITHMS WITH ADAPTIVE MESH REFINEMENT USING THE GRAPHICS PROCESSING UNIT (GPU) XINSHENG QIN, RANDALL LEVEQUE, AND MICHAEL MOTLEY arxiv:1808.02638v1 [cs.ms] 8 Aug 2018 Abstract.
NVIDIA GTX200: TeraFLOPS Visual Computing. August 26, 2008 John Tynefield
 NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
NVIDIA GTX200: TeraFLOPS Visual Computing August 26, 2008 John Tynefield 2 Outline Execution Model Architecture Demo 3 Execution Model 4 Software Architecture Applications DX10 OpenGL OpenCL CUDA C Host
Large scale Imaging on Current Many- Core Platforms
 Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Large scale Imaging on Current Many- Core Platforms SIAM Conf. on Imaging Science 2012 May 20, 2012 Dr. Harald Köstler Chair for System Simulation Friedrich-Alexander-Universität Erlangen-Nürnberg, Erlangen,
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters
 Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
GPGPUs in HPC. VILLE TIMONEN Åbo Akademi University CSC
 GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
GPGPUs in HPC VILLE TIMONEN Åbo Akademi University 2.11.2010 @ CSC Content Background How do GPUs pull off higher throughput Typical architecture Current situation & the future GPGPU languages A tale of
Two-Phase flows on massively parallel multi-gpu clusters
 Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
Two-Phase flows on massively parallel multi-gpu clusters Peter Zaspel Michael Griebel Institute for Numerical Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Workshop Programming of Heterogeneous
J. Blair Perot. Ali Khajeh-Saeed. Software Engineer CD-adapco. Mechanical Engineering UMASS, Amherst
 Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
Ali Khajeh-Saeed Software Engineer CD-adapco J. Blair Perot Mechanical Engineering UMASS, Amherst Supercomputers Optimization Stream Benchmark Stag++ (3D Incompressible Flow Code) Matrix Multiply Function
PREPARING AN AMR LIBRARY FOR SUMMIT. Max Katz March 29, 2018
 PREPARING AN AMR LIBRARY FOR SUMMIT Max Katz March 29, 2018 CORAL: SIERRA AND SUMMIT NVIDIA Volta fueling supercomputers IBM Power 9 + NVIDIA Volta V100 Sierra (LLNL): 4 GPUs/node, ~4300 nodes Summit (ORNL):
PREPARING AN AMR LIBRARY FOR SUMMIT Max Katz March 29, 2018 CORAL: SIERRA AND SUMMIT NVIDIA Volta fueling supercomputers IBM Power 9 + NVIDIA Volta V100 Sierra (LLNL): 4 GPUs/node, ~4300 nodes Summit (ORNL):
Center for Computational Science
 Center for Computational Science Toward GPU-accelerated meshfree fluids simulation using the fast multipole method Lorena A Barba Boston University Department of Mechanical Engineering with: Felipe Cruz,
Center for Computational Science Toward GPU-accelerated meshfree fluids simulation using the fast multipole method Lorena A Barba Boston University Department of Mechanical Engineering with: Felipe Cruz,
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs
 High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
High-Order Finite-Element Earthquake Modeling on very Large Clusters of CPUs or GPUs Gordon Erlebacher Department of Scientific Computing Sept. 28, 2012 with Dimitri Komatitsch (Pau,France) David Michea
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters
 Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
Flux Vector Splitting Methods for the Euler Equations on 3D Unstructured Meshes for CPU/GPU Clusters Manfred Liebmann Technische Universität München Chair of Optimal Control Center for Mathematical Sciences,
High Performance Computing with Accelerators
 High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
High Performance Computing with Accelerators Volodymyr Kindratenko Innovative Systems Laboratory @ NCSA Institute for Advanced Computing Applications and Technologies (IACAT) National Center for Supercomputing
Accelerating CFD with Graphics Hardware
 Accelerating CFD with Graphics Hardware Graham Pullan (Whittle Laboratory, Cambridge University) 16 March 2009 Today Motivation CPUs and GPUs Programming NVIDIA GPUs with CUDA Application to turbomachinery
Accelerating CFD with Graphics Hardware Graham Pullan (Whittle Laboratory, Cambridge University) 16 March 2009 Today Motivation CPUs and GPUs Programming NVIDIA GPUs with CUDA Application to turbomachinery
Fluent User Services Center
 Solver Settings 5-1 Using the Solver Setting Solver Parameters Convergence Definition Monitoring Stability Accelerating Convergence Accuracy Grid Independence Adaption Appendix: Background Finite Volume
Solver Settings 5-1 Using the Solver Setting Solver Parameters Convergence Definition Monitoring Stability Accelerating Convergence Accuracy Grid Independence Adaption Appendix: Background Finite Volume
Study and implementation of computational methods for Differential Equations in heterogeneous systems. Asimina Vouronikoy - Eleni Zisiou
 Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
Study and implementation of computational methods for Differential Equations in heterogeneous systems Asimina Vouronikoy - Eleni Zisiou Outline Introduction Review of related work Cyclic Reduction Algorithm
CUDA Experiences: Over-Optimization and Future HPC
 CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
CUDA Experiences: Over-Optimization and Future HPC Carl Pearson 1, Simon Garcia De Gonzalo 2 Ph.D. candidates, Electrical and Computer Engineering 1 / Computer Science 2, University of Illinois Urbana-Champaign
Finite Element Integration and Assembly on Modern Multi and Many-core Processors
 Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Finite Element Integration and Assembly on Modern Multi and Many-core Processors Krzysztof Banaś, Jan Bielański, Kazimierz Chłoń AGH University of Science and Technology, Mickiewicza 30, 30-059 Kraków,
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions
 Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
Data Partitioning on Heterogeneous Multicore and Multi-GPU systems Using Functional Performance Models of Data-Parallel Applictions Ziming Zhong Vladimir Rychkov Alexey Lastovetsky Heterogeneous Computing
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
Master Educational Program Information technology in applications Mathematical computations with GPUs GPU architecture Alexey A. Romanenko arom@ccfit.nsu.ru Novosibirsk State University GPU Graphical Processing
DIFFERENTIAL. Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka
 USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
USE OF FOR Tomáš Oberhuber, Atsushi Suzuki, Jan Vacata, Vítězslav Žabka Faculty of Nuclear Sciences and Physical Engineering Czech Technical University in Prague Mini workshop on advanced numerical methods
CSE 591: GPU Programming. Introduction. Entertainment Graphics: Virtual Realism for the Masses. Computer games need to have: Klaus Mueller
 Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Entertainment Graphics: Virtual Realism for the Masses CSE 591: GPU Programming Introduction Computer games need to have: realistic appearance of characters and objects believable and creative shading,
Accelerating image registration on GPUs
 Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Accelerating image registration on GPUs Harald Köstler, Sunil Ramgopal Tatavarty SIAM Conference on Imaging Science (IS10) 13.4.2010 Contents Motivation: Image registration with FAIR GPU Programming Combining
Graphic-card cluster for astrophysics (GraCCA) Performance tests
 Performance tests") Available online at www.sciencedirect.com ew Astronomy 13 (2008) 418 435 www.elsevier.com/locate/newast Graphic-card cluster for astrophysics (GraCCA) Performance tests Hsi-Yu Schive *, Chia-Hung Chien,
Available online at www.sciencedirect.com ew Astronomy 13 (2008) 418 435 www.elsevier.com/locate/newast Graphic-card cluster for astrophysics (GraCCA) Performance tests Hsi-Yu Schive *, Chia-Hung Chien,
Fast Tridiagonal Solvers on GPU
 Fast Tridiagonal Solvers on GPU Yao Zhang John Owens UC Davis Jonathan Cohen NVIDIA GPU Technology Conference 2009 Outline Introduction Algorithms Design algorithms for GPU architecture Performance Bottleneck-based
Fast Tridiagonal Solvers on GPU Yao Zhang John Owens UC Davis Jonathan Cohen NVIDIA GPU Technology Conference 2009 Outline Introduction Algorithms Design algorithms for GPU architecture Performance Bottleneck-based
Computing on GPU Clusters
 Computing on GPU Clusters Robert Strzodka (MPII), Dominik Göddeke G (TUDo( TUDo), Dominik Behr (AMD) Conference on Parallel Processing and Applied Mathematics Wroclaw, Poland, September 13-16, 16, 2009
Computing on GPU Clusters Robert Strzodka (MPII), Dominik Göddeke G (TUDo( TUDo), Dominik Behr (AMD) Conference on Parallel Processing and Applied Mathematics Wroclaw, Poland, September 13-16, 16, 2009
CME 213 S PRING Eric Darve
 CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
CME 213 S PRING 2017 Eric Darve Summary of previous lectures Pthreads: low-level multi-threaded programming OpenMP: simplified interface based on #pragma, adapted to scientific computing OpenMP for and
Gradient Free Design of Microfluidic Structures on a GPU Cluster
 Gradient Free Design of Microfluidic Structures on a GPU Cluster Austen Duffy - Florida State University SIAM Conference on Computational Science and Engineering March 2, 2011 Acknowledgements This work
Gradient Free Design of Microfluidic Structures on a GPU Cluster Austen Duffy - Florida State University SIAM Conference on Computational Science and Engineering March 2, 2011 Acknowledgements This work
SEASHORE / SARUMAN. Short Read Matching using GPU Programming. Tobias Jakobi
 SEASHORE SARUMAN Summary 1 / 24 SEASHORE / SARUMAN Short Read Matching using GPU Programming Tobias Jakobi Center for Biotechnology (CeBiTec) Bioinformatics Resource Facility (BRF) Bielefeld University
SEASHORE SARUMAN Summary 1 / 24 SEASHORE / SARUMAN Short Read Matching using GPU Programming Tobias Jakobi Center for Biotechnology (CeBiTec) Bioinformatics Resource Facility (BRF) Bielefeld University
Asynchronous OpenCL/MPI numerical simulations of conservation laws
 Asynchronous OpenCL/MPI numerical simulations of conservation laws Philippe HELLUY 1,3, Thomas STRUB 2. 1 IRMA, Université de Strasbourg, 2 AxesSim, 3 Inria Tonus, France IWOCL 2015, Stanford Conservation
Asynchronous OpenCL/MPI numerical simulations of conservation laws Philippe HELLUY 1,3, Thomas STRUB 2. 1 IRMA, Université de Strasbourg, 2 AxesSim, 3 Inria Tonus, France IWOCL 2015, Stanford Conservation
A TALENTED CPU-TO-GPU MEMORY MAPPING TECHNIQUE
 A TALENTED CPU-TO-GPU MEMORY MAPPING TECHNIQUE Abu Asaduzzaman, Deepthi Gummadi, and Chok M. Yip Department of Electrical Engineering and Computer Science Wichita State University Wichita, Kansas, USA
A TALENTED CPU-TO-GPU MEMORY MAPPING TECHNIQUE Abu Asaduzzaman, Deepthi Gummadi, and Chok M. Yip Department of Electrical Engineering and Computer Science Wichita State University Wichita, Kansas, USA
Parallel Algorithms: Adaptive Mesh Refinement (AMR) method and its implementation
 method and its implementation") Parallel Algorithms: Adaptive Mesh Refinement (AMR) method and its implementation Massimiliano Guarrasi m.guarrasi@cineca.it Super Computing Applications and Innovation Department AMR - Introduction Solving
Parallel Algorithms: Adaptive Mesh Refinement (AMR) method and its implementation Massimiliano Guarrasi m.guarrasi@cineca.it Super Computing Applications and Innovation Department AMR - Introduction Solving
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster
 Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
Performance Analysis of Memory Transfers and GEMM Subroutines on NVIDIA TESLA GPU Cluster Veerendra Allada, Troy Benjegerdes Electrical and Computer Engineering, Ames Laboratory Iowa State University &
AREPO: a moving-mesh code for cosmological hydrodynamical simulations
 AREPO: a moving-mesh code for cosmological hydrodynamical simulations E pur si muove: Galiliean-invariant cosmological hydrodynamical simulations on a moving mesh Springel, 2010 arxiv:0901.4107 Rubens
AREPO: a moving-mesh code for cosmological hydrodynamical simulations E pur si muove: Galiliean-invariant cosmological hydrodynamical simulations on a moving mesh Springel, 2010 arxiv:0901.4107 Rubens
Performance potential for simulating spin models on GPU
 Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
Performance potential for simulating spin models on GPU Martin Weigel Institut für Physik, Johannes-Gutenberg-Universität Mainz, Germany 11th International NTZ-Workshop on New Developments in Computational
Acknowledgements. Prof. Dan Negrut Prof. Darryl Thelen Prof. Michael Zinn. SBEL Colleagues: Hammad Mazar, Toby Heyn, Manoj Kumar
 Philipp Hahn Acknowledgements Prof. Dan Negrut Prof. Darryl Thelen Prof. Michael Zinn SBEL Colleagues: Hammad Mazar, Toby Heyn, Manoj Kumar 2 Outline Motivation Lumped Mass Model Model properties Simulation
Philipp Hahn Acknowledgements Prof. Dan Negrut Prof. Darryl Thelen Prof. Michael Zinn SBEL Colleagues: Hammad Mazar, Toby Heyn, Manoj Kumar 2 Outline Motivation Lumped Mass Model Model properties Simulation
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation
 Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
Multi-GPU Scaling of Direct Sparse Linear System Solver for Finite-Difference Frequency-Domain Photonic Simulation 1 Cheng-Han Du* I-Hsin Chung** Weichung Wang* * I n s t i t u t e o f A p p l i e d M
General Plasma Physics
 Present and Future Computational Requirements General Plasma Physics Center for Integrated Computation and Analysis of Reconnection and Turbulence () Kai Germaschewski, Homa Karimabadi Amitava Bhattacharjee,
Present and Future Computational Requirements General Plasma Physics Center for Integrated Computation and Analysis of Reconnection and Turbulence () Kai Germaschewski, Homa Karimabadi Amitava Bhattacharjee,
Splotch: High Performance Visualization using MPI, OpenMP and CUDA
 Splotch: High Performance Visualization using MPI, OpenMP and CUDA Klaus Dolag (Munich University Observatory) Martin Reinecke (MPA, Garching) Claudio Gheller (CSCS, Switzerland), Marzia Rivi (CINECA,
Splotch: High Performance Visualization using MPI, OpenMP and CUDA Klaus Dolag (Munich University Observatory) Martin Reinecke (MPA, Garching) Claudio Gheller (CSCS, Switzerland), Marzia Rivi (CINECA,
arxiv: v1 [physics.comp-ph] 4 Nov 2013
![arxiv: v1 [physics.comp-ph] 4 Nov 2013](/thumbs/74/70979601.jpg "arxiv: v1 [physics.comp-ph] 4 Nov 2013") arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
arxiv:1311.0590v1 [physics.comp-ph] 4 Nov 2013 Performance of Kepler GTX Titan GPUs and Xeon Phi System, Weonjong Lee, and Jeonghwan Pak Lattice Gauge Theory Research Center, CTP, and FPRD, Department
Introduction CPS343. Spring Parallel and High Performance Computing. CPS343 (Parallel and HPC) Introduction Spring / 29
 Introduction Spring / 29") Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
Introduction CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction Spring 2018 1 / 29 Outline 1 Preface Course Details Course Requirements 2 Background Definitions
On the Comparative Performance of Parallel Algorithms on Small GPU/CUDA Clusters
 1 On the Comparative Performance of Parallel Algorithms on Small GPU/CUDA Clusters N. P. Karunadasa & D. N. Ranasinghe University of Colombo School of Computing, Sri Lanka nishantha@opensource.lk, dnr@ucsc.cmb.ac.lk
1 On the Comparative Performance of Parallel Algorithms on Small GPU/CUDA Clusters N. P. Karunadasa & D. N. Ranasinghe University of Colombo School of Computing, Sri Lanka nishantha@opensource.lk, dnr@ucsc.cmb.ac.lk
Applications of Berkeley s Dwarfs on Nvidia GPUs
 Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
Applications of Berkeley s Dwarfs on Nvidia GPUs Seminar: Topics in High-Performance and Scientific Computing Team N2: Yang Zhang, Haiqing Wang 05.02.2015 Overview CUDA The Dwarfs Dynamic Programming Sparse
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability 1 History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA)
") NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
NVIDIA s Compute Unified Device Architecture (CUDA) Mike Bailey mjb@cs.oregonstate.edu Reaching the Promised Land NVIDIA GPUs CUDA Knights Corner Speed Intel CPUs General Programmability History of GPU
When MPPDB Meets GPU:
 When MPPDB Meets GPU: An Extendible Framework for Acceleration Laura Chen, Le Cai, Yongyan Wang Background: Heterogeneous Computing Hardware Trend stops growing with Moore s Law Fast development of GPU
When MPPDB Meets GPU: An Extendible Framework for Acceleration Laura Chen, Le Cai, Yongyan Wang Background: Heterogeneous Computing Hardware Trend stops growing with Moore s Law Fast development of GPU
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE)
") GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
GPU ACCELERATION OF WSMP (WATSON SPARSE MATRIX PACKAGE) NATALIA GIMELSHEIN ANSHUL GUPTA STEVE RENNICH SEID KORIC NVIDIA IBM NVIDIA NCSA WATSON SPARSE MATRIX PACKAGE (WSMP) Cholesky, LDL T, LU factorization
Introduction to GPU hardware and to CUDA
 Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
Introduction to GPU hardware and to CUDA Philip Blakely Laboratory for Scientific Computing, University of Cambridge Philip Blakely (LSC) GPU introduction 1 / 35 Course outline Introduction to GPU hardware
GPUs and GPGPUs. Greg Blanton John T. Lubia
 GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
GPUs and GPGPUs Greg Blanton John T. Lubia PROCESSOR ARCHITECTURAL ROADMAP Design CPU Optimized for sequential performance ILP increasingly difficult to extract from instruction stream Control hardware
3D ADI Method for Fluid Simulation on Multiple GPUs. Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA
 3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
3D ADI Method for Fluid Simulation on Multiple GPUs Nikolai Sakharnykh, NVIDIA Nikolay Markovskiy, NVIDIA Introduction Fluid simulation using direct numerical methods Gives the most accurate result Requires
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
Paralization on GPU using CUDA An Introduction
 Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
Paralization on GPU using CUDA An Introduction Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction to GPU 2 Introduction to CUDA Graphics Processing
CSE 591/392: GPU Programming. Introduction. Klaus Mueller. Computer Science Department Stony Brook University
 CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
CSE 591/392: GPU Programming Introduction Klaus Mueller Computer Science Department Stony Brook University First: A Big Word of Thanks! to the millions of computer game enthusiasts worldwide Who demand
Optimizing Multiple GPU FDTD Simulations in CUDA
 Center of Applied Electromagnetic Systems Research (CAESR) Optimizing Multiple GPU FDTD Simulations in CUDA Matthew J. Inman mjinman@olemiss.edu Atef Z. Elsherbeni Center For Applied Electromagnetics Systems
Center of Applied Electromagnetic Systems Research (CAESR) Optimizing Multiple GPU FDTD Simulations in CUDA Matthew J. Inman mjinman@olemiss.edu Atef Z. Elsherbeni Center For Applied Electromagnetics Systems
Lagrangian methods and Smoothed Particle Hydrodynamics (SPH) Computation in Astrophysics Seminar (Spring 2006) L. J. Dursi
 Computation in Astrophysics Seminar (Spring 2006) L. J. Dursi") Lagrangian methods and Smoothed Particle Hydrodynamics (SPH) Eulerian Grid Methods The methods covered so far in this course use an Eulerian grid: Prescribed coordinates In `lab frame' Fluid elements flow
Lagrangian methods and Smoothed Particle Hydrodynamics (SPH) Eulerian Grid Methods The methods covered so far in this course use an Eulerian grid: Prescribed coordinates In `lab frame' Fluid elements flow
Accelerating GPU computation through mixed-precision methods. Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University
 Accelerating GPU computation through mixed-precision methods Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University Outline Motivation Truncated Precision using CUDA Solving Linear
Accelerating GPU computation through mixed-precision methods Michael Clark Harvard-Smithsonian Center for Astrophysics Harvard University Outline Motivation Truncated Precision using CUDA Solving Linear
Parallel Direct Simulation Monte Carlo Computation Using CUDA on GPUs
 Parallel Direct Simulation Monte Carlo Computation Using CUDA on GPUs C.-C. Su a, C.-W. Hsieh b, M. R. Smith b, M. C. Jermy c and J.-S. Wu a a Department of Mechanical Engineering, National Chiao Tung
Parallel Direct Simulation Monte Carlo Computation Using CUDA on GPUs C.-C. Su a, C.-W. Hsieh b, M. R. Smith b, M. C. Jermy c and J.-S. Wu a a Department of Mechanical Engineering, National Chiao Tung
Intermediate Parallel Programming & Cluster Computing
 High Performance Computing Modernization Program (HPCMP) Summer 2011 Puerto Rico Workshop on Intermediate Parallel Programming & Cluster Computing in conjunction with the National Computational Science
High Performance Computing Modernization Program (HPCMP) Summer 2011 Puerto Rico Workshop on Intermediate Parallel Programming & Cluster Computing in conjunction with the National Computational Science
Heterogeneous Multi-Computer System A New Platform for Multi-Paradigm Scientific Simulation
 Heterogeneous Multi-Computer System A New Platform for Multi-Paradigm Scientific Simulation Taisuke Boku, Hajime Susa, Masayuki Umemura, Akira Ukawa Center for Computational Physics, University of Tsukuba
Heterogeneous Multi-Computer System A New Platform for Multi-Paradigm Scientific Simulation Taisuke Boku, Hajime Susa, Masayuki Umemura, Akira Ukawa Center for Computational Physics, University of Tsukuba
GPU Accelerated Solvers for ODEs Describing Cardiac Membrane Equations
 GPU Accelerated Solvers for ODEs Describing Cardiac Membrane Equations Fred Lionetti @ CSE Andrew McCulloch @ Bioeng Scott Baden @ CSE University of California, San Diego What is heart modeling? Bioengineer
GPU Accelerated Solvers for ODEs Describing Cardiac Membrane Equations Fred Lionetti @ CSE Andrew McCulloch @ Bioeng Scott Baden @ CSE University of California, San Diego What is heart modeling? Bioengineer
CSCI 402: Computer Architectures. Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI.
 Fengguang Song Department of Computer & Information Science IUPUI.") CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
CSCI 402: Computer Architectures Parallel Processors (2) Fengguang Song Department of Computer & Information Science IUPUI 6.6 - End Today s Contents GPU Cluster and its network topology The Roofline performance
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators
 On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
On Level Scheduling for Incomplete LU Factorization Preconditioners on Accelerators Karl Rupp, Barry Smith rupp@mcs.anl.gov Mathematics and Computer Science Division Argonne National Laboratory FEMTEC
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Using GPUs to compute the multilevel summation of electrostatic forces
 Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
Using GPUs to compute the multilevel summation of electrostatic forces David J. Hardy Theoretical and Computational Biophysics Group Beckman Institute for Advanced Science and Technology University of
CRAY XK6 REDEFINING SUPERCOMPUTING. - Sanjana Rakhecha - Nishad Nerurkar
 CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
CRAY XK6 REDEFINING SUPERCOMPUTING - Sanjana Rakhecha - Nishad Nerurkar CONTENTS Introduction History Specifications Cray XK6 Architecture Performance Industry acceptance and applications Summary INTRODUCTION
Experiences with ENZO on the Intel R Many Integrated Core (Intel MIC) Architecture
 Architecture") Experiences with ENZO on the Intel R Many Integrated Core (Intel MIC) Architecture 1 Introduction Robert Harkness National Institute for Computational Sciences Oak Ridge National Laboratory The National
Experiences with ENZO on the Intel R Many Integrated Core (Intel MIC) Architecture 1 Introduction Robert Harkness National Institute for Computational Sciences Oak Ridge National Laboratory The National
GPU Architecture. Alan Gray EPCC The University of Edinburgh
 GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
GPU Architecture Alan Gray EPCC The University of Edinburgh Outline Why do we want/need accelerators such as GPUs? Architectural reasons for accelerator performance advantages Latest GPU Products From
Particle-in-Cell Simulations on Modern Computing Platforms. Viktor K. Decyk and Tajendra V. Singh UCLA
 Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Particle-in-Cell Simulations on Modern Computing Platforms Viktor K. Decyk and Tajendra V. Singh UCLA Outline of Presentation Abstraction of future computer hardware PIC on GPUs OpenCL and Cuda Fortran
Shallow Water Simulations on Graphics Hardware
 Shallow Water Simulations on Graphics Hardware Ph.D. Thesis Presentation 2014-06-27 Martin Lilleeng Sætra Outline Introduction Parallel Computing and the GPU Simulating Shallow Water Flow Topics of Thesis
Shallow Water Simulations on Graphics Hardware Ph.D. Thesis Presentation 2014-06-27 Martin Lilleeng Sætra Outline Introduction Parallel Computing and the GPU Simulating Shallow Water Flow Topics of Thesis
arxiv: v1 [physics.ins-det] 11 Jul 2015
![arxiv: v1 [physics.ins-det] 11 Jul 2015](/thumbs/90/102656934.jpg "arxiv: v1 [physics.ins-det] 11 Jul 2015") GPGPU for track finding in High Energy Physics arxiv:7.374v [physics.ins-det] Jul 5 L Rinaldi, M Belgiovine, R Di Sipio, A Gabrielli, M Negrini, F Semeria, A Sidoti, S A Tupputi 3, M Villa Bologna University
GPGPU for track finding in High Energy Physics arxiv:7.374v [physics.ins-det] Jul 5 L Rinaldi, M Belgiovine, R Di Sipio, A Gabrielli, M Negrini, F Semeria, A Sidoti, S A Tupputi 3, M Villa Bologna University
Advanced CUDA Optimizing to Get 20x Performance. Brent Oster
 Advanced CUDA Optimizing to Get 20x Performance Brent Oster Outline Motivation for optimizing in CUDA Demo performance increases Tesla 10-series architecture details Optimization case studies Particle
Advanced CUDA Optimizing to Get 20x Performance Brent Oster Outline Motivation for optimizing in CUDA Demo performance increases Tesla 10-series architecture details Optimization case studies Particle
Reconstruction of Trees from Laser Scan Data and further Simulation Topics
 Reconstruction of Trees from Laser Scan Data and further Simulation Topics Helmholtz-Research Center, Munich Daniel Ritter http://www10.informatik.uni-erlangen.de Overview 1. Introduction of the Chair
Reconstruction of Trees from Laser Scan Data and further Simulation Topics Helmholtz-Research Center, Munich Daniel Ritter http://www10.informatik.uni-erlangen.de Overview 1. Introduction of the Chair
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
GPU Programming. Lecture 1: Introduction. Miaoqing Huang University of Arkansas 1 / 27
 1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
1 / 27 GPU Programming Lecture 1: Introduction Miaoqing Huang University of Arkansas 2 / 27 Outline Course Introduction GPUs as Parallel Computers Trend and Design Philosophies Programming and Execution
International Supercomputing Conference 2009
 International Supercomputing Conference 2009 Implementation of a Lattice-Boltzmann-Method for Numerical Fluid Mechanics Using the nvidia CUDA Technology E. Riegel, T. Indinger, N.A. Adams Technische Universität
International Supercomputing Conference 2009 Implementation of a Lattice-Boltzmann-Method for Numerical Fluid Mechanics Using the nvidia CUDA Technology E. Riegel, T. Indinger, N.A. Adams Technische Universität
A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids
 A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids Patrice Castonguay and Antony Jameson Aerospace Computing Lab, Stanford University GTC Asia, Beijing, China December 15 th, 2011
A Scalable GPU-Based Compressible Fluid Flow Solver for Unstructured Grids Patrice Castonguay and Antony Jameson Aerospace Computing Lab, Stanford University GTC Asia, Beijing, China December 15 th, 2011
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Multicore Hardware and Parallelism
 Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Multicore Hardware and Parallelism Minsoo Ryu Department of Computer Science and Engineering 2 1 Advent of Multicore Hardware 2 Multicore Processors 3 Amdahl s Law 4 Parallelism in Hardware 5 Q & A 2 3
Towards real-time prediction of Tsunami impact effects on nearshore infrastructure
 Towards real-time prediction of Tsunami impact effects on nearshore infrastructure Manfred Krafczyk & Jonas Tölke Inst. for Computational Modeling in Civil Engineering http://www.cab.bau.tu-bs.de 24.04.2007
Towards real-time prediction of Tsunami impact effects on nearshore infrastructure Manfred Krafczyk & Jonas Tölke Inst. for Computational Modeling in Civil Engineering http://www.cab.bau.tu-bs.de 24.04.2007
NVidia s GPU Microarchitectures. By Stephen Lucas and Gerald Kotas
 NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
NVidia s GPU Microarchitectures By Stephen Lucas and Gerald Kotas Intro Discussion Points - Difference between CPU and GPU - Use s of GPUS - Brie f History - Te sla Archite cture - Fermi Architecture -
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016
 ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
ACCELERATING CFD AND RESERVOIR SIMULATIONS WITH ALGEBRAIC MULTI GRID Chris Gottbrath, Nov 2016 Challenges What is Algebraic Multi-Grid (AMG)? AGENDA Why use AMG? When to use AMG? NVIDIA AmgX Results 2
Adaptive Mesh Refinement
 Aleander Knebe, Universidad Autonoma de Madrid Adaptive Mesh Refinement AMR codes Poisson s equation ΔΦ( ) = 4πGρ( ) Poisson s equation F ( ) = m Φ( ) ΔΦ( ) = 4πGρ( ) particle approach F ( Gm i ) = i m
Aleander Knebe, Universidad Autonoma de Madrid Adaptive Mesh Refinement AMR codes Poisson s equation ΔΦ( ) = 4πGρ( ) Poisson s equation F ( ) = m Φ( ) ΔΦ( ) = 4πGρ( ) particle approach F ( Gm i ) = i m
Analysis and Visualization Algorithms in VMD
 1 Analysis and Visualization Algorithms in VMD David Hardy Research/~dhardy/ NAIS: State-of-the-Art Algorithms for Molecular Dynamics (Presenting the work of John Stone.) VMD Visual Molecular Dynamics
1 Analysis and Visualization Algorithms in VMD David Hardy Research/~dhardy/ NAIS: State-of-the-Art Algorithms for Molecular Dynamics (Presenting the work of John Stone.) VMD Visual Molecular Dynamics
T6: Position-Based Simulation Methods in Computer Graphics. Jan Bender Miles Macklin Matthias Müller
 T6: Position-Based Simulation Methods in Computer Graphics Jan Bender Miles Macklin Matthias Müller Jan Bender Organizer Professor at the Visual Computing Institute at Aachen University Research topics
T6: Position-Based Simulation Methods in Computer Graphics Jan Bender Miles Macklin Matthias Müller Jan Bender Organizer Professor at the Visual Computing Institute at Aachen University Research topics
X-TRACT: software for simulation and reconstruction of X-ray phase-contrast CT
 X-TRACT: software for simulation and reconstruction of X-ray phase-contrast CT T.E.Gureyev, Ya.I.Nesterets, S.C.Mayo, A.W.Stevenson, D.M.Paganin, G.R.Myers and S.W.Wilkins CSIRO Materials Science and Engineering
X-TRACT: software for simulation and reconstruction of X-ray phase-contrast CT T.E.Gureyev, Ya.I.Nesterets, S.C.Mayo, A.W.Stevenson, D.M.Paganin, G.R.Myers and S.W.Wilkins CSIRO Materials Science and Engineering
Scalability of Processing on GPUs
 Scalability of Processing on GPUs Keith Kelley, CS6260 Final Project Report April 7, 2009 Research description: I wanted to figure out how useful General Purpose GPU computing (GPGPU) is for speeding up
Scalability of Processing on GPUs Keith Kelley, CS6260 Final Project Report April 7, 2009 Research description: I wanted to figure out how useful General Purpose GPU computing (GPGPU) is for speeding up
Advances of parallel computing. Kirill Bogachev May 2016
 Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Advances of parallel computing Kirill Bogachev May 2016 Demands in Simulations Field development relies more and more on static and dynamic modeling of the reservoirs that has come a long way from being
Computational Fluid Dynamics (CFD) using Graphics Processing Units
 using Graphics Processing Units") Computational Fluid Dynamics (CFD) using Graphics Processing Units Aaron F. Shinn Mechanical Science and Engineering Dept., UIUC Accelerators for Science and Engineering Applications: GPUs and Multicores
Computational Fluid Dynamics (CFD) using Graphics Processing Units Aaron F. Shinn Mechanical Science and Engineering Dept., UIUC Accelerators for Science and Engineering Applications: GPUs and Multicores
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System
 The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
The Uintah Framework: A Unified Heterogeneous Task Scheduling and Runtime System Alan Humphrey, Qingyu Meng, Martin Berzins Scientific Computing and Imaging Institute & University of Utah I. Uintah Overview
By : Veenus A V, Associate GM & Lead NeST-NVIDIA Center for GPU computing, Trivandrum, India Office: NeST/SFO Technologies, San Jose, CA,
 By : Veenus A V, Associate GM & Lead NeST-NVIDIA Center for GPU computing, Trivandrum, India Office: NeST/SFO Technologies, San Jose, CA, www.nestsoftware.com veenusav @ gmail. com Sri Buddha Do not simply
By : Veenus A V, Associate GM & Lead NeST-NVIDIA Center for GPU computing, Trivandrum, India Office: NeST/SFO Technologies, San Jose, CA, www.nestsoftware.com veenusav @ gmail. com Sri Buddha Do not simply
CUDA Optimizations WS Intelligent Robotics Seminar. Universität Hamburg WS Intelligent Robotics Seminar Praveen Kulkarni
 CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
CUDA Optimizations WS 2014-15 Intelligent Robotics Seminar 1 Table of content 1 Background information 2 Optimizations 3 Summary 2 Table of content 1 Background information 2 Optimizations 3 Summary 3
High Performance Computing (HPC) Introduction
 Introduction") High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
High Performance Computing (HPC) Introduction Ontario Summer School on High Performance Computing Scott Northrup SciNet HPC Consortium Compute Canada June 25th, 2012 Outline 1 HPC Overview 2 Parallel Computing
Experts in Application Acceleration Synective Labs AB
 Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
Experts in Application Acceleration 1 2009 Synective Labs AB Magnus Peterson Synective Labs Synective Labs quick facts Expert company within software acceleration Based in Sweden with offices in Gothenburg
Simulating Shallow Water on GPUs Programming of Heterogeneous Systems in Physics
 Simulating Shallow Water on GPUs Programming of Heterogeneous Systems in Physics Martin Pfeiffer (m.pfeiffer@uni-jena.de) Friedrich Schiller University Jena 06.10.2011 Simulating Shallow Water on GPUs
Simulating Shallow Water on GPUs Programming of Heterogeneous Systems in Physics Martin Pfeiffer (m.pfeiffer@uni-jena.de) Friedrich Schiller University Jena 06.10.2011 Simulating Shallow Water on GPUs