HPC Hardware Overview
|
|
|
- Harvey Lane
- 5 years ago
- Views:
Transcription
1 HPC Hardware Overview John Lockman III April 19, 2013 Texas Advanced Computing Center The University of Texas at Austin
2 Outline Lonestar Dell blade-based system InfiniBand ( QDR) Intel Processors Longhorn Dell blade-based system InfiniBand (QDR) Intel Processors Stampede Dell Infiniband (FDR) Intel Processors Ranch & Corral - Storage Systems
3 About this Talk As an applications programmer you may not care about hardware details, but We need to consider performance issues Better performance means faster turnaround and/or larger problems We will focus on the most relevant architecture characteristics Do not hesitate to ask questions as we go
4 High Performance Computing In our context, it refers to hardware and software tools dedicated to computationally intensive tasks Distinction between HPC center (throughput focused) and Data center (data focused) is becoming fuzzy High bandwidth, low latency Memory Network
5 Lonestar: Intel hexa-core system
6 Lonestar: Introduction Lonestar Cluster Configuration & Diagram Server Blades Dell PowerEdge M610 Blade (Intel Hexa-Core) Server Nodes Microprocessor Architecture Features Instruction Pipeline Speeds and Feeds Block Diagram Node Interconnect Hierarchy InfiniBand Switch and Adapters Performance

7 Lonestar Cluster Overview lonestar.tacc.utexas.edu
8 Lonestar Cluster Overview Hardware Components Characteristics Peak Performance 302 TFLOPS Nodes 2 Hexa-Core Xeon nodes / cores Memory 1333 MHz DDR3 DIMMS 24 GB/node, 45 TB total Shared Disk Lustre parallel file system 1 PB Local Disk SATA 146GB/node, 276 TB total Interconnect Infiniband 4 GB/sec P-2-P


9 Blade : Rack : System 1 node : 2 x 6 cores = 12 cores 1 chassis : 16 nodes = 192 cores 1 rack : 3 x 16 nodes = 576 cores 39⅓ racks : cores 3 chassis 16 blades
10 Lonestar login nodes Dell PowerEdge M610 Intel dual socket Xeon hexa-core 3.33GHz 24 GB DDR MHz DIMMS Intel QPI 5520 Chipset Dell 1200 PowerVault 15 TB HOME disk 1 GB user quota(5x)
11 Lonestar compute nodes 16 Blades / 10U chassis Dell PowerEdge M619 Dual socket Intel hexa-core Xeon 3.33 GHz(1.25x) 13.3 GFLOPS/core(1.25x) 64 KB L1 cache (independent) 12 MB L2 cache (unified) 24 GB DDR MHz DIMMS Intel QPI 5520 Chipset 2x QPI 6.4 GT/s 146 GB 10k RPM SAS-SATA local disk (/tmp)
12 Motherboard DDR DDR Hexa-core Xeon QPI Hexa-core Xeon 12 CPU Cores IOH I/O Hub DMI PCIe ICH I/O Controller

13 Intel Xeon 5600(Westmere) 32 KB L1 cache/core 256 KB L2 cache/core Shared 12 MB L3 cache Core 1 Core 2

14 Cluster Interconnect 16 independent 4 GB/s connections/chassis



15 Lonestar Parallel File Systems: Lustre &NFS 97 TB 1GB/ user Ethernet $HOME 226 TB 200GB/ user $WORK TB InfiniBand $SCRATCH Uses IP over IB
16 Longhorn: Intel Quad-core system
17 Longhorn: Introduction First NSF extreme Digital Visualization grant (XD Vis) Designed for scientific visualization and data analysis Very large memory per computational core Two NVIDIA Graphics cards per node Rendering performance 154 billion triangles/second
18 Longhorn Cluster Overview Hardware Components Characteristics Peak Performance (CPUs) 512 Intel Xeon E TFLOPS Peak Performance (GPUs, SP) System Memory 128 NVIDIA Quadroplex 2200 S4 DDR3-DIMMS 500 TFLOPS 48 GB/node (240 nodes) 144 GB/node (16 nodes) 13.5 TB total Graphics Memory 512 FX5800 x 4GB 2 TB Disk Lustre parallel file system 210 TB Interconnect QDR Infiniband 4 GB/sec P-2-P
19 Longhorn Large Mem nodes Dell R710 Intel dual socket quad-core Xeon 2.53GHz 144 GB DDR3 ( 18 GB/core ) Intel 5520 chipset NVIDIA Quadroplex 2200 S4 4 NVIDIA Quadro FX CUDA cores 4 GB Memory 102 GB/s Memory bandwidth
20 Longhorn standard nodes Dell R610 Dual socket Intel quad-core Xeon 2.53 GHz 48 GB DDR3 ( 6 GB/core ) Intel 5520 chipset NVIDIA Quadroplex 2200 S4 4 NVIDIA Quadro FX CUDA cores 4 GB Memory 102 GB/s Memory bandwidth
21 DDR3 DDR3 DDR3 DDR3 DDR3 DDR3 DDR3 DDR3 DDR3 Motherboard (R610/R710) Quad Core Intel Xeon 5500 Quad Core Intel Xeon 5500 DDR3 DDR3 DDR3 DDR3 DDR3 DDR3 DDR3 DDR3 DDR3 12 DIMM slots (R610) 18 DIMM slots (R710) Intel lanes PCI Express or 36 lines PCI Express 2.0






 2 20-lane QPI")
22 QPI 0 QPI 1 Cache Sizes in Intel Nehalem QPI 0 QPI 1 Memory Controller Memory Controller Core 1 Core 2 Core 3 Core 4 L3 8 MB L2 256 KB L1 32 KB Core 1 L2 256 KB L1 32 KB Core 2 L2 256 KB L1 32 KB Core 3 L2 256 KB L1 32 KB Core 4 Shared L3 Cache Total QPI bandwidth up to 25.6 GB/s (@ 3.2 GHz) 2 20-lane QPI links 4 quadrants (10 lanes each)
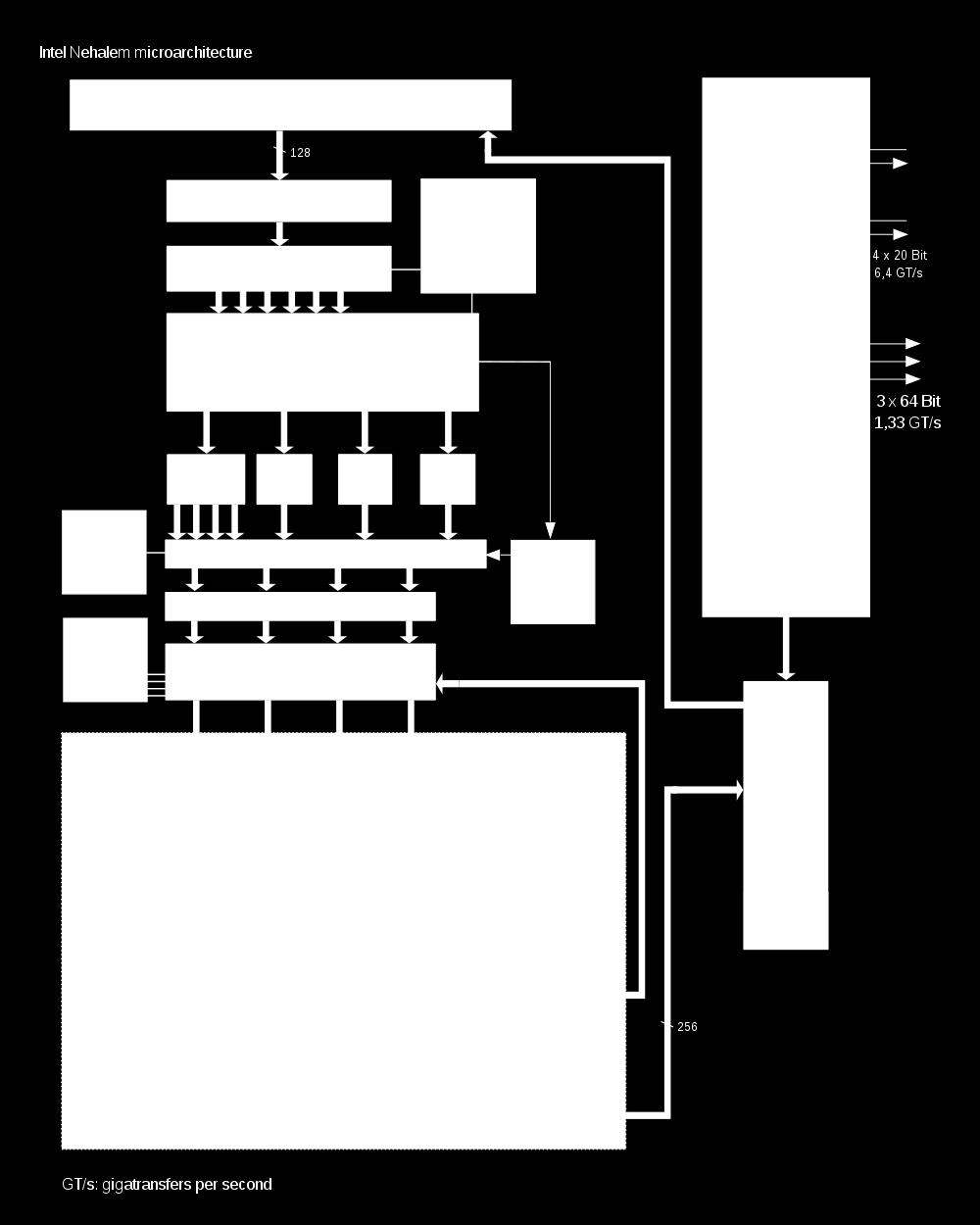
23 Nehalem μarchitecture
24 Stampede: Intel 8 core system

25 Stampede NSF : High Performance Computing System Acquisition: Enhancing the Petascale Computing Environment for Science and Engineering Enable sustained petascale computational and datadriven science and engineering and provide an innovative component
 is the innovative component High performance and low power per operation Highly")
26 Dell/Intel Partnership TACC Partnered with Dell and Intel to design Stampede Intel MIC (Intel Xeon Phi) is the innovative component High performance and low power per operation Highly programmable
27 Datacenter Expansion
28 Thermal Storage New Machine Room New Infrastructure


")



29 2x footprint, 2x power, 20x Capability (Stampede vs. Ranger) 1M gallons Thermal Storage 3,750 Tons 14KV in, 480V out 6.5MW ~3,000 GPM

30 Stampede consists of U cabinets.
31 Key Datacenter Features Thermal energy storage to reduce peak power consumption Hot aisle containment to boost efficiency Datacenter power increased to ~12MW Expand experiments in mineral oil cooling




32 Cooling and Electrical Infrastructure

33 Stampede debuted at #7 on the Top 500 Stampede Performance
34 Stampede Overview $27.5M acquisition 9+ petaflops (PF) peak performance 2+ PF Linux cluster 6400 Dell DCS C8220X nodes 2.7GHz Intel Xeon E5 (Sandy Bridge) 102,400 total cores 56Gb/s FDR Mellanox InfiniBand 7+ PF Intel Xeon Phi Coprocessor TACC has a special release: Intel Xeon Phi SE10P 14+ PB disk, 150GB/s 16 1TB shared memory nodes 128 NVIDIA Tesla K20 GPUs
35 Processor Specs Arch. Features Xeon E5 Xeon Phi SE10P Frequency 2.7GHz +turbo 1.0GHz +turbo Cores 8 61 HW threads/core 2 4 Vector size 256 bits 4 doubles 8 singles 512 bits 8 doubles 16 singles Instr. Pipeline Out of Order In Order Registers Caches L1:32KB L2:256KB L3:20MB L132KB L2:512KB Memory 2 GB/core 128 MB/core Sustained Memory BW 75 GB/s 170 GB/s Sustain Peak FLOPS 1 thread/core 2 threads/core Instruction Set x86 + AVX x86 + new vector instructions



36 MIC Details
37 What is a MIC Basic Design Ideas Leverage x86 architecture (CPU with many cores) X86 cores are simpler, but allow for more compute throughput Leverage existing x86 programming models Dedicate much of the silicon to floating point ops Cache coherent Increase floating-point throughput Implement as a separate device Strip expensive features (out-of-order execution, branch prediction, etc.) Widen SIMD registers for more throughput Fast (GDDR5) memory on card Runs a full Linux operating system (BusyBox)

38 MIC Architecture Many cores on the die L1 and L2 cache Bidirectional ring network Memory and PCIe connection
39 Stampede Login Nodes Component Technology 4 login nodes stampede.tacc.utexas.edu Processors Sockets per Node/Cores per Socket Motherboard Memory Per Node $HOME /tmp (2) E5-2680, 2.7 GHz 8 cores Dell R720, Intel QPI 600 Chipset 32GB DDR MHz Cache: 256KB/core L2: 20MB Global: Lustre, 5GB quota Local: Shared, 432GB SATA 10K rpm
40 Dell DCS C8220z Compute Node Component Sockets per Node/Cores per Socket Coprocessors/Cores Motherboard Memory Per Host Memory per Coprocessor Interconnect Processor-Processor Processor-Coprocessor PCI Express Processor PCI Express Coprocessor 250GB Disk Technology 2/8 Xeon E GHz (turbo, 3.5) 1/61 Xeon Phi SE10P 1.1GHz Dell C8220, Intel PQI, C610 Chipset 32GB 8x4GB 4 channels DDR3-1600MHz 8GB DDR5 QPI 8.0 GT/s PCI-e x40 lanes, Gen 3 x16 lanes, Gen 2 (extended) 7.5 RPM SATA








41 HCA Compute Node Configuration CPUs and MIC appear as separate HOSTS ( symmetric computing) Comm layer & Virtual IP Service For MIC PCIe
42 Stampede Filesystems Storage Class Size Architecture Features Local (each node) Login: 1TB Compute: 250GB Big Mem: 600 GB SATA SATA SATA 432GB mounted on /tmp 80GB mounted on /tmp 398GB mounted on /tmp Parallel 14PB Lustre 72 Dell R610 (OSS) 4 Dell R710 (MDS) Ranch (Tape Storage) 60PB SAM-FS 10GB/s connection through 4 GridFTP Servers
43 Stampede Filesystems $HOME Quota : 5GB, 150K files Filesystem is backed up $WORK Quota: 400GB, 3M files NOT backed up Use cdw to change to $WORK $SCRATCH No Quota Total size ~8.5PB NOT backed up Use cds to change to $SCRATCH Files older than 10 days are subject to purge policy /tmp Local disk ~80GB
44 Large Memory and Visualization Nodes 16 Large Memory Nodes 32 cores 1TB of memory Used for data-intense applications requiring disk caching and large memory methods 128 Visualization Nodes 16 cores NVIDIA Tesla K20 with 8GB GDDR5 memory
45 Storage Ranch Long term tape storage Corral 1 PB of spinning disk

46 Ranch Archival System Sun StorageTek Silo 10,000 - T1000B tapes 6,000 - T1000C tapes ~40 PB total capacity Used for long-term storage

47 6PB DataDirect Networks online disk storage 8 Dell 1950 servers 8 Dell 2950 servers 12 Dell R710 servers High Performance Parallel File System Multiple databases irods data management Replication to tape archive Multiple levels of access control Web and other data access available globally Corral
48 References
49 Lonestar Related References User Guide services.tacc.utexas.edu/index.php/lonestar-user-guide Developers
50 Longhorn Related References User Guide services.tacc.utexas.edu/index.php/longhorn-user-guide General Information Developers developer.intel.com/design/pentium4/manuals/index2.htm developer.nvidia.com/forums/index.php
51 Stampede Related References User Guide General Information on-phi-detail.html



52 John Lockman III For more information:
The Stampede is Coming Welcome to Stampede Introductory Training. Dan Stanzione Texas Advanced Computing Center
 The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming Welcome to Stampede Introductory Training Dan Stanzione Texas Advanced Computing Center dan@tacc.utexas.edu Thanks for Coming! Stampede is an exciting new system of incredible power.
The Stampede is Coming: A New Petascale Resource for the Open Science Community
 The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
The Stampede is Coming: A New Petascale Resource for the Open Science Community Jay Boisseau Texas Advanced Computing Center boisseau@tacc.utexas.edu Stampede: Solicitation US National Science Foundation
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing
 TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
TACC s Stampede Project: Intel MIC for Simulation and Data-Intensive Computing Jay Boisseau, Director April 17, 2012 TACC Vision & Strategy Provide the most powerful, capable computing technologies and
Managing Terascale Systems and Petascale Data Archives
 Managing Terascale Systems and Petascale Data Archives February 26, 2010 Tommy Minyard, Ph.D. Director of Advanced Computing Systems Motivation: What s all the high performance computing fuss about? It
Managing Terascale Systems and Petascale Data Archives February 26, 2010 Tommy Minyard, Ph.D. Director of Advanced Computing Systems Motivation: What s all the high performance computing fuss about? It
Introduction to Xeon Phi. Bill Barth January 11, 2013
 Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
Introduction to Xeon Phi Bill Barth January 11, 2013 What is it? Co-processor PCI Express card Stripped down Linux operating system Dense, simplified processor Many power-hungry operations removed Wider
A Unified Approach to Heterogeneous Architectures Using the Uintah Framework
 DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
DOE for funding the CSAFE project (97-10), DOE NETL, DOE NNSA NSF for funding via SDCI and PetaApps A Unified Approach to Heterogeneous Architectures Using the Uintah Framework Qingyu Meng, Alan Humphrey
Parallel Programming on Ranger and Stampede
 Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Parallel Programming on Ranger and Stampede Steve Lantz Senior Research Associate Cornell CAC Parallel Computing at TACC: Ranger to Stampede Transition December 11, 2012 What is Stampede? NSF-funded XSEDE
Overview of the Texas Advanced Computing Center. Bill Barth TACC September 12, 2011
 Overview of the Texas Advanced Computing Center Bill Barth TACC September 12, 2011 TACC Mission & Strategic Approach To enable discoveries that advance science and society through the application of advanced
Overview of the Texas Advanced Computing Center Bill Barth TACC September 12, 2011 TACC Mission & Strategic Approach To enable discoveries that advance science and society through the application of advanced
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Introduction to the Intel Xeon Phi on Stampede
 June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
June 10, 2014 Introduction to the Intel Xeon Phi on Stampede John Cazes Texas Advanced Computing Center Stampede - High Level Overview Base Cluster (Dell/Intel/Mellanox): Intel Sandy Bridge processors
Tutorial. Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers
 Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
Tutorial Preparing for Stampede: Programming Heterogeneous Many-Core Supercomputers Dan Stanzione, Lars Koesterke, Bill Barth, Kent Milfeld dan/lars/bbarth/milfeld@tacc.utexas.edu XSEDE 12 July 16, 2012
STAR-CCM+ Performance Benchmark and Profiling. July 2014
 STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
STAR-CCM+ Performance Benchmark and Profiling July 2014 Note The following research was performed under the HPC Advisory Council activities Participating vendors: CD-adapco, Intel, Dell, Mellanox Compute
John Fragalla TACC 'RANGER' INFINIBAND ARCHITECTURE WITH SUN TECHNOLOGY. Presenter s Name Title and Division Sun Microsystems
 TACC 'RANGER' INFINIBAND ARCHITECTURE WITH SUN TECHNOLOGY SUBTITLE WITH TWO LINES OF TEXT IF NECESSARY John Fragalla Presenter s Name Title and Division Sun Microsystems Principle Engineer High Performance
TACC 'RANGER' INFINIBAND ARCHITECTURE WITH SUN TECHNOLOGY SUBTITLE WITH TWO LINES OF TEXT IF NECESSARY John Fragalla Presenter s Name Title and Division Sun Microsystems Principle Engineer High Performance
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins
 Matt Kelly & Ryan Rawlins") Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Intel Many Integrated Core (MIC) Matt Kelly & Ryan Rawlins Outline History & Motivation Architecture Core architecture Network Topology Memory hierarchy Brief comparison to GPU & Tilera Programming Applications
Analyzing Performance and Power of Applications on GPUs with Dell 12G Platforms. Dr. Jeffrey Layton Enterprise Technologist HPC
 Analyzing Performance and Power of Applications on GPUs with Dell 12G Platforms Dr. Jeffrey Layton Enterprise Technologist HPC Why GPUs? GPUs have very high peak compute capability! 6-9X CPU Challenges
Analyzing Performance and Power of Applications on GPUs with Dell 12G Platforms Dr. Jeffrey Layton Enterprise Technologist HPC Why GPUs? GPUs have very high peak compute capability! 6-9X CPU Challenges
GROMACS (GPU) Performance Benchmark and Profiling. February 2016
 Performance Benchmark and Profiling. February 2016") GROMACS (GPU) Performance Benchmark and Profiling February 2016 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Mellanox, NVIDIA Compute
GROMACS (GPU) Performance Benchmark and Profiling February 2016 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Dell, Mellanox, NVIDIA Compute
Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments
 Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments Torben Kling-Petersen, PhD Presenter s Name Principle Field Title andengineer Division HPC &Cloud LoB SunComputing Microsystems
Sun Lustre Storage System Simplifying and Accelerating Lustre Deployments Torben Kling-Petersen, PhD Presenter s Name Principle Field Title andengineer Division HPC &Cloud LoB SunComputing Microsystems
1. ALMA Pipeline Cluster specification. 2. Compute processing node specification: $26K
 1. ALMA Pipeline Cluster specification The following document describes the recommended hardware for the Chilean based cluster for the ALMA pipeline and local post processing to support early science and
1. ALMA Pipeline Cluster specification The following document describes the recommended hardware for the Chilean based cluster for the ALMA pipeline and local post processing to support early science and
LAMMPS-KOKKOS Performance Benchmark and Profiling. September 2015
 LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
LAMMPS-KOKKOS Performance Benchmark and Profiling September 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox, NVIDIA
Accelerating HPC. (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing
 Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing") Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Accelerating HPC (Nash) Dr. Avinash Palaniswamy High Performance Computing Data Center Group Marketing SAAHPC, Knoxville, July 13, 2010 Legal Disclaimer Intel may make changes to specifications and product
Resources Current and Future Systems. Timothy H. Kaiser, Ph.D.
 Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Resources Current and Future Systems Timothy H. Kaiser, Ph.D. tkaiser@mines.edu 1 Most likely talk to be out of date History of Top 500 Issues with building bigger machines Current and near future academic
Philippe Thierry Sr Staff Engineer Intel Corp.
 HPC@Intel Philippe Thierry Sr Staff Engineer Intel Corp. IBM, April 8, 2009 1 Agenda CPU update: roadmap, micro-μ and performance Solid State Disk Impact What s next Q & A Tick Tock Model Perenity market
HPC@Intel Philippe Thierry Sr Staff Engineer Intel Corp. IBM, April 8, 2009 1 Agenda CPU update: roadmap, micro-μ and performance Solid State Disk Impact What s next Q & A Tick Tock Model Perenity market
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
Introduc)on to Xeon Phi ACES Aus)n, TX Dec. 04 2013 Kent Milfeld, Luke Wilson, John McCalpin, Lars Koesterke TACC What is it? Co- processor PCI Express card Stripped down Linux opera)ng system Dense, simplified
LBRN - HPC systems : CCT, LSU
 LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
LBRN - HPC systems : CCT, LSU HPC systems @ CCT & LSU LSU HPC Philip SuperMike-II SuperMIC LONI HPC Eric Qeenbee2 CCT HPC Delta LSU HPC Philip 3 Compute 32 Compute Two 2.93 GHz Quad Core Nehalem Xeon 64-bit
Introduc)on to Hyades
on to Hyades") Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
Introduc)on to Hyades Shawfeng Dong Department of Astronomy & Astrophysics, UCSSC Hyades 1 Hardware Architecture 2 Accessing Hyades 3 Compu)ng Environment 4 Compiling Codes 5 Running Jobs 6 Visualiza)on
HPC Capabilities at Research Intensive Universities
 HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
HPC Capabilities at Research Intensive Universities Purushotham (Puri) V. Bangalore Department of Computer and Information Sciences and UAB IT Research Computing UAB HPC Resources 24 nodes (192 cores)
LS-DYNA Performance Benchmark and Profiling. April 2015
 LS-DYNA Performance Benchmark and Profiling April 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
LS-DYNA Performance Benchmark and Profiling April 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
Power Systems AC922 Overview. Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017
 Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
Power Systems AC922 Overview Chris Mann IBM Distinguished Engineer Chief System Architect, Power HPC Systems December 11, 2017 IBM POWER HPC Platform Strategy High-performance computer and high-performance
An Introduction to the Intel Xeon Phi. Si Liu Feb 6, 2015
 Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
Training Agenda Session 1: Introduction 8:00 9:45 Session 2: Native: MIC stand-alone 10:00-11:45 Lunch break Session 3: Offload: MIC as coprocessor 1:00 2:45 Session 4: Symmetric: MPI 3:00 4:45 1 Last
n N c CIni.o ewsrg.au
 @NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
@NCInews NCI and Raijin National Computational Infrastructure 2 Our Partners General purpose, highly parallel processors High FLOPs/watt and FLOPs/$ Unit of execution Kernel Separate memory subsystem GPGPU
System Design of Kepler Based HPC Solutions. Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering.
 System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
System Design of Kepler Based HPC Solutions Saeed Iqbal, Shawn Gao and Kevin Tubbs HPC Global Solutions Engineering. Introduction The System Level View K20 GPU is a powerful parallel processor! K20 has
Preparing for Highly Parallel, Heterogeneous Coprocessing
 Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
Preparing for Highly Parallel, Heterogeneous Coprocessing Steve Lantz Senior Research Associate Cornell CAC Workshop: Parallel Computing on Ranger and Lonestar May 17, 2012 What Are We Talking About Here?
University at Buffalo Center for Computational Research
 University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
University at Buffalo Center for Computational Research The following is a short and long description of CCR Facilities for use in proposals, reports, and presentations. If desired, a letter of support
The Stampede Supercomputer
 The Stampede Supercomputer Niall Gaffney (Dan Stanzione, Karl Schulz, Bill Barth, Tommy Minyard) July 2013 Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872
The Stampede Supercomputer Niall Gaffney (Dan Stanzione, Karl Schulz, Bill Barth, Tommy Minyard) July 2013 Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872
Introduc)on to Xeon Phi
on to Xeon Phi") Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Introduc)on to Xeon Phi IXPUG 14 Lars Koesterke Acknowledgements Thanks/kudos to: Sponsor: National Science Foundation NSF Grant #OCI-1134872 Stampede Award, Enabling, Enhancing, and Extending Petascale
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA
 Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE SHEET) Supply and installation of High Performance Computing System
 (TECHNICAL SPECIFICATIONS & COMPLIANCE SHEET) Supply and installation of High Performance Computing System") INSTITUTE FOR PLASMA RESEARCH (An Autonomous Institute of Department of Atomic Energy, Government of India) Near Indira Bridge; Bhat; Gandhinagar-382428; India PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE
INSTITUTE FOR PLASMA RESEARCH (An Autonomous Institute of Department of Atomic Energy, Government of India) Near Indira Bridge; Bhat; Gandhinagar-382428; India PART-I (B) (TECHNICAL SPECIFICATIONS & COMPLIANCE
Overview of Tianhe-2
 Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
Overview of Tianhe-2 (MilkyWay-2) Supercomputer Yutong Lu School of Computer Science, National University of Defense Technology; State Key Laboratory of High Performance Computing, China ytlu@nudt.edu.cn
HP GTC Presentation May 2012
 HP GTC Presentation May 2012 Today s Agenda: HP s Purpose-Built SL Server Line Desktop GPU Computing Revolution with HP s Z Workstations Hyperscale the new frontier for HPC New HPC customer requirements
HP GTC Presentation May 2012 Today s Agenda: HP s Purpose-Built SL Server Line Desktop GPU Computing Revolution with HP s Z Workstations Hyperscale the new frontier for HPC New HPC customer requirements
NAMD Performance Benchmark and Profiling. January 2015
 NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
NAMD Performance Benchmark and Profiling January 2015 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute resource
Architecting High Performance Computing Systems for Fault Tolerance and Reliability
 Architecting High Performance Computing Systems for Fault Tolerance and Reliability Blake T. Gonzales HPC Computer Scientist Dell Advanced Systems Group blake_gonzales@dell.com Agenda HPC Fault Tolerance
Architecting High Performance Computing Systems for Fault Tolerance and Reliability Blake T. Gonzales HPC Computer Scientist Dell Advanced Systems Group blake_gonzales@dell.com Agenda HPC Fault Tolerance
Intel Knights Landing Hardware
 Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Intel Knights Landing Hardware TACC KNL Tutorial IXPUG Annual Meeting 2016 PRESENTED BY: John Cazes Lars Koesterke 1 Intel s Xeon Phi Architecture Leverages x86 architecture Simpler x86 cores, higher compute
Emerging Technologies for HPC Storage
 Emerging Technologies for HPC Storage Dr. Wolfgang Mertz CTO EMEA Unstructured Data Solutions June 2018 The very definition of HPC is expanding Blazing Fast Speed Accessibility and flexibility 2 Traditional
Emerging Technologies for HPC Storage Dr. Wolfgang Mertz CTO EMEA Unstructured Data Solutions June 2018 The very definition of HPC is expanding Blazing Fast Speed Accessibility and flexibility 2 Traditional
Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE
 Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE Hitoshi Sato *1, Shuichi Ihara *2, Satoshi Matsuoka *1 *1 Tokyo Institute
Lustre2.5 Performance Evaluation: Performance Improvements with Large I/O Patches, Metadata Improvements, and Metadata Scaling with DNE Hitoshi Sato *1, Shuichi Ihara *2, Satoshi Matsuoka *1 *1 Tokyo Institute
Intel Architecture for HPC
 Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Intel Architecture for HPC Georg Zitzlsberger georg.zitzlsberger@vsb.cz 1st of March 2018 Agenda Salomon Architectures Intel R Xeon R processors v3 (Haswell) Intel R Xeon Phi TM coprocessor (KNC) Ohter
Enabling Performance-per-Watt Gains in High-Performance Cluster Computing
 WHITE PAPER Appro Xtreme-X Supercomputer with the Intel Xeon Processor E5-2600 Product Family Enabling Performance-per-Watt Gains in High-Performance Cluster Computing Appro Xtreme-X Supercomputer with
WHITE PAPER Appro Xtreme-X Supercomputer with the Intel Xeon Processor E5-2600 Product Family Enabling Performance-per-Watt Gains in High-Performance Cluster Computing Appro Xtreme-X Supercomputer with
Data Sheet Fujitsu Server PRIMERGY CX250 S2 Dual Socket Server Node
 Data Sheet Fujitsu Server PRIMERGY CX250 S2 Dual Socket Server Node Data Sheet Fujitsu Server PRIMERGY CX250 S2 Dual Socket Server Node Datasheet for Red Hat certification Standard server node for PRIMERGY
Data Sheet Fujitsu Server PRIMERGY CX250 S2 Dual Socket Server Node Data Sheet Fujitsu Server PRIMERGY CX250 S2 Dual Socket Server Node Datasheet for Red Hat certification Standard server node for PRIMERGY
Leibniz Supercomputer Centre. Movie on YouTube
 SuperMUC @ Leibniz Supercomputer Centre Movie on YouTube Peak Performance Peak performance: 3 Peta Flops 3*10 15 Flops Mega 10 6 million Giga 10 9 billion Tera 10 12 trillion Peta 10 15 quadrillion Exa
SuperMUC @ Leibniz Supercomputer Centre Movie on YouTube Peak Performance Peak performance: 3 Peta Flops 3*10 15 Flops Mega 10 6 million Giga 10 9 billion Tera 10 12 trillion Peta 10 15 quadrillion Exa
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment. TOP500 Supercomputers, June 2014
 InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
InfiniBand Strengthens Leadership as the Interconnect Of Choice By Providing Best Return on Investment TOP500 Supercomputers, June 2014 TOP500 Performance Trends 38% CAGR 78% CAGR Explosive high-performance
HMEM and Lemaitre2: First bricks of the CÉCI s infrastructure
 HMEM and Lemaitre2: First bricks of the CÉCI s infrastructure - CÉCI: What we want - Cluster HMEM - Cluster Lemaitre2 - Comparison - What next? - Support and training - Conclusions CÉCI: What we want CÉCI:
HMEM and Lemaitre2: First bricks of the CÉCI s infrastructure - CÉCI: What we want - Cluster HMEM - Cluster Lemaitre2 - Comparison - What next? - Support and training - Conclusions CÉCI: What we want CÉCI:
Sugon TC6600 blade server
 Sugon TC6600 blade server The converged-architecture blade server The TC6600 is a new generation, multi-node and high density blade server with shared power, cooling, networking and management infrastructure
Sugon TC6600 blade server The converged-architecture blade server The TC6600 is a new generation, multi-node and high density blade server with shared power, cooling, networking and management infrastructure
Data Sheet FUJITSU Server PRIMERGY CX2550 M4 Dual Socket Server Node
 Data Sheet FUJITSU Server PRIMERGY CX2550 M4 Dual Socket Server Node Data Sheet FUJITSU Server PRIMERGY CX2550 M4 Dual Socket Server Node Cloud/HPC optimized server node for PRIMERGY CX400 M4 FUJITSU Server
Data Sheet FUJITSU Server PRIMERGY CX2550 M4 Dual Socket Server Node Data Sheet FUJITSU Server PRIMERGY CX2550 M4 Dual Socket Server Node Cloud/HPC optimized server node for PRIMERGY CX400 M4 FUJITSU Server
HPC Innovation Lab Update. Dell EMC HPC Community Meeting 3/28/2017
 HPC Innovation Lab Update Dell EMC HPC Community Meeting 3/28/2017 Dell EMC HPC Innovation Lab charter Design, develop and integrate Heading HPC systems Lorem ipsum Flexible reference dolor sit amet, architectures
HPC Innovation Lab Update Dell EMC HPC Community Meeting 3/28/2017 Dell EMC HPC Innovation Lab charter Design, develop and integrate Heading HPC systems Lorem ipsum Flexible reference dolor sit amet, architectures
DESCRIPTION GHz, 1.536TB shared memory RAM, and 20.48TB RAW internal storage teraflops About ScaleMP
 DESCRIPTION The Auburn University College of Engineering Computational Fluid Dynamics Cluster is built using Dell M1000E Blade Chassis Server Platform. The Cluster will consist of (4) M1000E Blade Chassis
DESCRIPTION The Auburn University College of Engineering Computational Fluid Dynamics Cluster is built using Dell M1000E Blade Chassis Server Platform. The Cluster will consist of (4) M1000E Blade Chassis
Fujitsu PRIMERGY BX920 S1 Dual-Socket Server
 Datasheet Fujitsu PRIMERGY BX920 S1 Dual-Socket Server Blade All-around server blade packing lots of computing power in small form factor. The PRIMERGY BX Blade Servers are the ideal choice for data center
Datasheet Fujitsu PRIMERGY BX920 S1 Dual-Socket Server Blade All-around server blade packing lots of computing power in small form factor. The PRIMERGY BX Blade Servers are the ideal choice for data center
Erkenntnisse aus aktuellen Performance- Messungen mit LS-DYNA
 14. LS-DYNA Forum, Oktober 2016, Bamberg Erkenntnisse aus aktuellen Performance- Messungen mit LS-DYNA Eric Schnepf 1, Dr. Eckardt Kehl 1, Chih-Song Kuo 2, Dymitrios Kyranas 2 1 Fujitsu Technology Solutions
14. LS-DYNA Forum, Oktober 2016, Bamberg Erkenntnisse aus aktuellen Performance- Messungen mit LS-DYNA Eric Schnepf 1, Dr. Eckardt Kehl 1, Chih-Song Kuo 2, Dymitrios Kyranas 2 1 Fujitsu Technology Solutions
Fermi Cluster for Real-Time Hyperspectral Scene Generation
 Fermi Cluster for Real-Time Hyperspectral Scene Generation Gary McMillian, Ph.D. Crossfield Technology LLC 9390 Research Blvd, Suite I200 Austin, TX 78759-7366 (512)795-0220 x151 gary.mcmillian@crossfieldtech.com
Fermi Cluster for Real-Time Hyperspectral Scene Generation Gary McMillian, Ph.D. Crossfield Technology LLC 9390 Research Blvd, Suite I200 Austin, TX 78759-7366 (512)795-0220 x151 gary.mcmillian@crossfieldtech.com
ANSYS Fluent 14 Performance Benchmark and Profiling. October 2012
 ANSYS Fluent 14 Performance Benchmark and Profiling October 2012 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information
ANSYS Fluent 14 Performance Benchmark and Profiling October 2012 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information
Intel Xeon E v4, Windows Server 2016 Standard, 16GB Memory, 1TB SAS Hard Drive and a 3 Year Warranty
 pe_r430_11598_b Datasheet Check its price: Click Here Overview delivers peak 2-socket performance for HPC, web tech and infrastructure scale-out. R430 provides Intel Xeon processor E5-2600 v4 product family
pe_r430_11598_b Datasheet Check its price: Click Here Overview delivers peak 2-socket performance for HPC, web tech and infrastructure scale-out. R430 provides Intel Xeon processor E5-2600 v4 product family
Dell PowerEdge R720xd with PERC H710P: A Balanced Configuration for Microsoft Exchange 2010 Solutions
 Dell PowerEdge R720xd with PERC H710P: A Balanced Configuration for Microsoft Exchange 2010 Solutions A comparative analysis with PowerEdge R510 and PERC H700 Global Solutions Engineering Dell Product
Dell PowerEdge R720xd with PERC H710P: A Balanced Configuration for Microsoft Exchange 2010 Solutions A comparative analysis with PowerEdge R510 and PERC H700 Global Solutions Engineering Dell Product
Introduction: Modern computer architecture. The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes
 Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
Introduction: Modern computer architecture The stored program computer and its inherent bottlenecks Multi- and manycore chips and nodes Motivation: Multi-Cores where and why Introduction: Moore s law Intel
HA-PACS/TCA: Tightly Coupled Accelerators for Low-Latency Communication between GPUs
 HA-PACS/TCA: Tightly Coupled Accelerators for Low-Latency Communication between GPUs Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba,
HA-PACS/TCA: Tightly Coupled Accelerators for Low-Latency Communication between GPUs Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba,
Longhorn Project TACC s XD Visualization Resource
 Longhorn Project TACC s XD Visualization Resource DOE Computer Graphics Forum April 14, 2010 Longhorn Visualization and Data Analysis In November 2008, NSF accepted proposals for the Extreme Digital Resources
Longhorn Project TACC s XD Visualization Resource DOE Computer Graphics Forum April 14, 2010 Longhorn Visualization and Data Analysis In November 2008, NSF accepted proposals for the Extreme Digital Resources
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA
 HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
HETEROGENEOUS HPC, ARCHITECTURAL OPTIMIZATION, AND NVLINK STEVE OBERLIN CTO, TESLA ACCELERATED COMPUTING NVIDIA STATE OF THE ART 2012 18,688 Tesla K20X GPUs 27 PetaFLOPS FLAGSHIP SCIENTIFIC APPLICATIONS
OCTOPUS Performance Benchmark and Profiling. June 2015
 OCTOPUS Performance Benchmark and Profiling June 2015 2 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the
OCTOPUS Performance Benchmark and Profiling June 2015 2 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the
IBM Power AC922 Server
 IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
IBM Power AC922 Server The Best Server for Enterprise AI Highlights More accuracy - GPUs access system RAM for larger models Faster insights - significant deep learning speedups Rapid deployment - integrated
irods at TACC: Secure Infrastructure for Open Science Chris Jordan
 irods at TACC: Secure Infrastructure for Open Science Chris Jordan What is TACC? Texas Advanced Computing Center Cyberinfrastructure Resources for Open Science University of Texas System 9 Academic, 6
irods at TACC: Secure Infrastructure for Open Science Chris Jordan What is TACC? Texas Advanced Computing Center Cyberinfrastructure Resources for Open Science University of Texas System 9 Academic, 6
Dell Solution for High Density GPU Infrastructure
 Dell Solution for High Density GPU Infrastructure 李信乾 (Clayton Li) 產品技術顧問 HPC@DELL Key partnerships & programs Customer inputs & new ideas Collaboration Innovation Core & new technologies Critical adoption
Dell Solution for High Density GPU Infrastructure 李信乾 (Clayton Li) 產品技術顧問 HPC@DELL Key partnerships & programs Customer inputs & new ideas Collaboration Innovation Core & new technologies Critical adoption
Inspur AI Computing Platform
 Inspur Server Inspur AI Computing Platform 3 Server NF5280M4 (2CPU + 3 ) 4 Server NF5280M5 (2 CPU + 4 ) Node (2U 4 Only) 8 Server NF5288M5 (2 CPU + 8 ) 16 Server SR BOX (16 P40 Only) Server target market
Inspur Server Inspur AI Computing Platform 3 Server NF5280M4 (2CPU + 3 ) 4 Server NF5280M5 (2 CPU + 4 ) Node (2U 4 Only) 8 Server NF5288M5 (2 CPU + 8 ) 16 Server SR BOX (16 P40 Only) Server target market
Intel Workstation Technology
 Intel Workstation Technology Turning Imagination Into Reality November, 2008 1 Step up your Game Real Workstations Unleash your Potential 2 Yesterday s Super Computer Today s Workstation = = #1 Super Computer
Intel Workstation Technology Turning Imagination Into Reality November, 2008 1 Step up your Game Real Workstations Unleash your Potential 2 Yesterday s Super Computer Today s Workstation = = #1 Super Computer
Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance
 Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for Simulia
Dell EMC Ready Bundle for HPC Digital Manufacturing Dassault Systѐmes Simulia Abaqus Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for Simulia
Datura The new HPC-Plant at Albert Einstein Institute
 Datura The new HPC-Plant at Albert Einstein Institute Nico Budewitz Max Planck Institue for Gravitational Physics, Germany Cluster Day, 2011 Outline 1 History HPC-Plants at AEI -2009 Peyote, Lagavulin,
Datura The new HPC-Plant at Albert Einstein Institute Nico Budewitz Max Planck Institue for Gravitational Physics, Germany Cluster Day, 2011 Outline 1 History HPC-Plants at AEI -2009 Peyote, Lagavulin,
Microsoft Exchange Server 2010 workload optimization on the new IBM PureFlex System
 Microsoft Exchange Server 2010 workload optimization on the new IBM PureFlex System Best practices Roland Mueller IBM Systems and Technology Group ISV Enablement April 2012 Copyright IBM Corporation, 2012
Microsoft Exchange Server 2010 workload optimization on the new IBM PureFlex System Best practices Roland Mueller IBM Systems and Technology Group ISV Enablement April 2012 Copyright IBM Corporation, 2012
Remote & Collaborative Visualization. Texas Advanced Computing Center
 Remote & Collaborative Visualization Texas Advanced Computing Center TACC Remote Visualization Systems Longhorn NSF XD Dell Visualization Cluster 256 nodes, each 8 cores, 48 GB (or 144 GB) memory, 2 NVIDIA
Remote & Collaborative Visualization Texas Advanced Computing Center TACC Remote Visualization Systems Longhorn NSF XD Dell Visualization Cluster 256 nodes, each 8 cores, 48 GB (or 144 GB) memory, 2 NVIDIA
MILC Performance Benchmark and Profiling. April 2013
 MILC Performance Benchmark and Profiling April 2013 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
MILC Performance Benchmark and Profiling April 2013 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
Large Scale Remote Interactive Visualization
 Large Scale Remote Interactive Visualization Kelly Gaither Director of Visualization Senior Research Scientist Texas Advanced Computing Center The University of Texas at Austin March 1, 2012 Visualization
Large Scale Remote Interactive Visualization Kelly Gaither Director of Visualization Senior Research Scientist Texas Advanced Computing Center The University of Texas at Austin March 1, 2012 Visualization
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER. Adrian
 INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
INTRODUCTION TO THE ARCHER KNIGHTS LANDING CLUSTER Adrian Jackson adrianj@epcc.ed.ac.uk @adrianjhpc Processors The power used by a CPU core is proportional to Clock Frequency x Voltage 2 In the past, computers
Power Technology For a Smarter Future
 2011 IBM Power Systems Technical University October 10-14 Fontainebleau Miami Beach Miami, FL IBM Power Technology For a Smarter Future Jeffrey Stuecheli Power Processor Development Copyright IBM Corporation
2011 IBM Power Systems Technical University October 10-14 Fontainebleau Miami Beach Miami, FL IBM Power Technology For a Smarter Future Jeffrey Stuecheli Power Processor Development Copyright IBM Corporation
IBM Power Advanced Compute (AC) AC922 Server
 AC922 Server") IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
IBM Power Advanced Compute (AC) AC922 Server The Best Server for Enterprise AI Highlights IBM Power Systems Accelerated Compute (AC922) server is an acceleration superhighway to enterprise- class AI. A
IBM CORAL HPC System Solution
 IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
IBM CORAL HPC System Solution HPC and HPDA towards Cognitive, AI and Deep Learning Deep Learning AI / Deep Learning Strategy for Power Power AI Platform High Performance Data Analytics Big Data Strategy
ABySS Performance Benchmark and Profiling. May 2010
 ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
NCAR Workload Analysis on Yellowstone. March 2015 V5.0
 NCAR Workload Analysis on Yellowstone March 2015 V5.0 Purpose and Scope of the Analysis Understanding the NCAR application workload is a critical part of making efficient use of Yellowstone and in scoping
NCAR Workload Analysis on Yellowstone March 2015 V5.0 Purpose and Scope of the Analysis Understanding the NCAR application workload is a critical part of making efficient use of Yellowstone and in scoping
Tiny GPU Cluster for Big Spatial Data: A Preliminary Performance Evaluation
 Tiny GPU Cluster for Big Spatial Data: A Preliminary Performance Evaluation Jianting Zhang 1,2 Simin You 2, Le Gruenwald 3 1 Depart of Computer Science, CUNY City College (CCNY) 2 Department of Computer
Tiny GPU Cluster for Big Spatial Data: A Preliminary Performance Evaluation Jianting Zhang 1,2 Simin You 2, Le Gruenwald 3 1 Depart of Computer Science, CUNY City College (CCNY) 2 Department of Computer
Tightly Coupled Accelerators Architecture
 Tightly Coupled Accelerators Architecture Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba, Japan 1 What is Tightly Coupled Accelerators
Tightly Coupled Accelerators Architecture Yuetsu Kodama Division of High Performance Computing Systems Center for Computational Sciences University of Tsukuba, Japan 1 What is Tightly Coupled Accelerators
MAHA. - Supercomputing System for Bioinformatics
 MAHA - Supercomputing System for Bioinformatics - 2013.01.29 Outline 1. MAHA HW 2. MAHA SW 3. MAHA Storage System 2 ETRI HPC R&D Area - Overview Research area Computing HW MAHA System HW - Rpeak : 0.3
MAHA - Supercomputing System for Bioinformatics - 2013.01.29 Outline 1. MAHA HW 2. MAHA SW 3. MAHA Storage System 2 ETRI HPC R&D Area - Overview Research area Computing HW MAHA System HW - Rpeak : 0.3
Parallel Visualization At TACC. Greg Abram
 Parallel Visualization At TACC Greg Abram Visualization Problems * With thanks to Sean Ahern for the metaphor Huge problems: Data cannot be moved off system where it is computed Large Visualization problems:
Parallel Visualization At TACC Greg Abram Visualization Problems * With thanks to Sean Ahern for the metaphor Huge problems: Data cannot be moved off system where it is computed Large Visualization problems:
Data Sheet Fujitsu PRIMERGY BX920 S2 Dual Socket Server Blade
 Data Sheet Fujitsu PRIMERGY BX920 S2 Dual Socket Server Blade Universal dual socket server blade with high computing and I/O performance in a small form factor The PRIMERGY BX Blade Servers are the ideal
Data Sheet Fujitsu PRIMERGY BX920 S2 Dual Socket Server Blade Universal dual socket server blade with high computing and I/O performance in a small form factor The PRIMERGY BX Blade Servers are the ideal
Altair OptiStruct 13.0 Performance Benchmark and Profiling. May 2015
 Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
Altair OptiStruct 13.0 Performance Benchmark and Profiling May 2015 Note The following research was performed under the HPC Advisory Council activities Participating vendors: Intel, Dell, Mellanox Compute
LCE: Lustre at CEA. Stéphane Thiell CEA/DAM
 LCE: Lustre at CEA Stéphane Thiell CEA/DAM (stephane.thiell@cea.fr) 1 Lustre at CEA: Outline Lustre at CEA updates (2009) Open Computing Center (CCRT) updates CARRIOCAS (Lustre over WAN) project 2009-2010
LCE: Lustre at CEA Stéphane Thiell CEA/DAM (stephane.thiell@cea.fr) 1 Lustre at CEA: Outline Lustre at CEA updates (2009) Open Computing Center (CCRT) updates CARRIOCAS (Lustre over WAN) project 2009-2010
CPMD Performance Benchmark and Profiling. February 2014
 CPMD Performance Benchmark and Profiling February 2014 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
CPMD Performance Benchmark and Profiling February 2014 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
SUN CUSTOMER READY HPC CLUSTER: REFERENCE CONFIGURATIONS WITH SUN FIRE X4100, X4200, AND X4600 SERVERS Jeff Lu, Systems Group Sun BluePrints OnLine
 SUN CUSTOMER READY HPC CLUSTER: REFERENCE CONFIGURATIONS WITH SUN FIRE X4100, X4200, AND X4600 SERVERS Jeff Lu, Systems Group Sun BluePrints OnLine April 2007 Part No 820-1270-11 Revision 1.1, 4/18/07
SUN CUSTOMER READY HPC CLUSTER: REFERENCE CONFIGURATIONS WITH SUN FIRE X4100, X4200, AND X4600 SERVERS Jeff Lu, Systems Group Sun BluePrints OnLine April 2007 Part No 820-1270-11 Revision 1.1, 4/18/07
Vector Engine Processor of SX-Aurora TSUBASA
 Vector Engine Processor of SX-Aurora TSUBASA Shintaro Momose, Ph.D., NEC Deutschland GmbH 9 th October, 2018 WSSP 1 NEC Corporation 2018 Contents 1) Introduction 2) VE Processor Architecture 3) Performance
Vector Engine Processor of SX-Aurora TSUBASA Shintaro Momose, Ph.D., NEC Deutschland GmbH 9 th October, 2018 WSSP 1 NEC Corporation 2018 Contents 1) Introduction 2) VE Processor Architecture 3) Performance
DATARMOR: Comment s'y préparer? Tina Odaka
 DATARMOR: Comment s'y préparer? Tina Odaka 30.09.2016 PLAN DATARMOR: Detailed explanation on hard ware What can you do today to be ready for DATARMOR DATARMOR : convention de nommage ClusterHPC REF SCRATCH
DATARMOR: Comment s'y préparer? Tina Odaka 30.09.2016 PLAN DATARMOR: Detailed explanation on hard ware What can you do today to be ready for DATARMOR DATARMOR : convention de nommage ClusterHPC REF SCRATCH
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science
 Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
Gateways to Discovery: Cyberinfrastructure for the Long Tail of Science ECSS Symposium, 12/16/14 M. L. Norman, R. L. Moore, D. Baxter, G. Fox (Indiana U), A Majumdar, P Papadopoulos, W Pfeiffer, R. S.
High Performance Computing and Data Resources at SDSC
 High Performance Computing and Data Resources at SDSC "! Mahidhar Tatineni (mahidhar@sdsc.edu)! SDSC Summer Institute! August 05, 2013! HPC Resources at SDSC Hardware Overview HPC Systems : Gordon, Trestles
High Performance Computing and Data Resources at SDSC "! Mahidhar Tatineni (mahidhar@sdsc.edu)! SDSC Summer Institute! August 05, 2013! HPC Resources at SDSC Hardware Overview HPC Systems : Gordon, Trestles
Scaling to Petaflop. Ola Torudbakken Distinguished Engineer. Sun Microsystems, Inc
 Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
Scaling to Petaflop Ola Torudbakken Distinguished Engineer Sun Microsystems, Inc HPC Market growth is strong CAGR increased from 9.2% (2006) to 15.5% (2007) Market in 2007 doubled from 2003 (Source: IDC
Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid Architectures
 Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
Procedia Computer Science Volume 51, 2015, Pages 2774 2778 ICCS 2015 International Conference On Computational Science Big Data Analytics Performance for Large Out-Of- Core Matrix Solvers on Advanced Hybrid
LS-DYNA Performance Benchmark and Profiling. October 2017
 LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
LS-DYNA Performance Benchmark and Profiling October 2017 2 Note The following research was performed under the HPC Advisory Council activities Participating vendors: LSTC, Huawei, Mellanox Compute resource
Dell EMC Ready Bundle for HPC Digital Manufacturing ANSYS Performance
 Dell EMC Ready Bundle for HPC Digital Manufacturing ANSYS Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for ANSYS Mechanical, ANSYS Fluent, and
Dell EMC Ready Bundle for HPC Digital Manufacturing ANSYS Performance This Dell EMC technical white paper discusses performance benchmarking results and analysis for ANSYS Mechanical, ANSYS Fluent, and
Agenda. Sun s x Sun s x86 Strategy. 2. Sun s x86 Product Portfolio. 3. Virtualization < 1 >
 Agenda Sun s x86 1. Sun s x86 Strategy 2. Sun s x86 Product Portfolio 3. Virtualization < 1 > 1. SUN s x86 Strategy Customer Challenges Power and cooling constraints are very real issues Energy costs are
Agenda Sun s x86 1. Sun s x86 Strategy 2. Sun s x86 Product Portfolio 3. Virtualization < 1 > 1. SUN s x86 Strategy Customer Challenges Power and cooling constraints are very real issues Energy costs are