Recent Developments in the Czech National Corpus
|
|
|
- Roy Palmer
- 5 years ago
- Views:
Transcription
1 Recent Developments in the Czech National Corpus Michal Křen Charles University in Prague 3 rd Workshop on the Challenges in the Management of Large Corpora Lancaster 20 July 2015
2 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
3 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
4 Czech National Corpus long-term project (since 1994) continuous mapping of Czech language compilation, maintenance and providing public access to various language corpora research infrastructure (since 2012) service-oriented operation more than 4,500 registered active users almost 1,900 queries a day
5 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
6 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
7 corpus size contents time span SYN mil. representative most of the texts from SYN mil. representative most of the texts from SYN mil. representative most of the texts from SYN2006PUB 300 mil. newspaper SYN2009PUB 700 mil. newspaper SYN2013PUB 935 mil. newspaper SYN (version 3) mil. union Currently available SYN-series corpora. traditional corpora with detailed bibliographical information lemmatized & morphologically tagged
8 corpus size contents time span SYN mil. representative most of the texts from SYN mil. representative most of the texts from SYN mil. representative most of the texts from SYN2006PUB 300 mil. newspaper SYN2009PUB 700 mil. newspaper SYN2013PUB 935 mil. newspaper SYN (version 3) mil. union Currently available SYN-series corpora. traditional corpora with detailed bibliographical information lemmatized & morphologically tagged outlook: new representative corpus SYN2015 fresh data in SYN ( added)
9 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
10 corpus size coverage time span ORAL mil. Bohemia recordings from ORAL mil. Bohemia recordings from ORAL mil. Czech Republic recordings from Currently available ORAL-series corpora. only unscripted, informal dialogical speech ORAL2013 designed as a representation of contemporary spontaneous spoken Czech manual one-layer transcription
11 corpus size coverage time span ORAL mil. Bohemia recordings from ORAL mil. Bohemia recordings from ORAL mil. Czech Republic recordings from Currently available ORAL-series corpora. only unscripted, informal dialogical speech ORAL2013 designed as a representation of contemporary spontaneous spoken Czech manual one-layer transcription outlook: lemmatization & tagging two-layer ORTOFON series
12 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
13 InterCorp large parallel corpus texts aligned on sentence level with their translations between Czech and a number of other languages consists of two major parts: core: manually revised alignment, mostly fiction collections: automatic alignment, various domains
14 InterCorp large parallel corpus texts aligned on sentence level with their translations between Czech and a number of other languages consists of two major parts: core: manually revised alignment, mostly fiction collections: automatic alignment, various domains Version 8 (June 2015) 38 foreign languages, out of which 20 lemmatized and/or tagged foreign-language texts: size of the core: 194 mil., total size of the InterCorp: 1,423 mil. words collections included: journalistic texts: Project Syndicate, Presseurop Acquis Communautaire, EuroParl, Open Subtitles
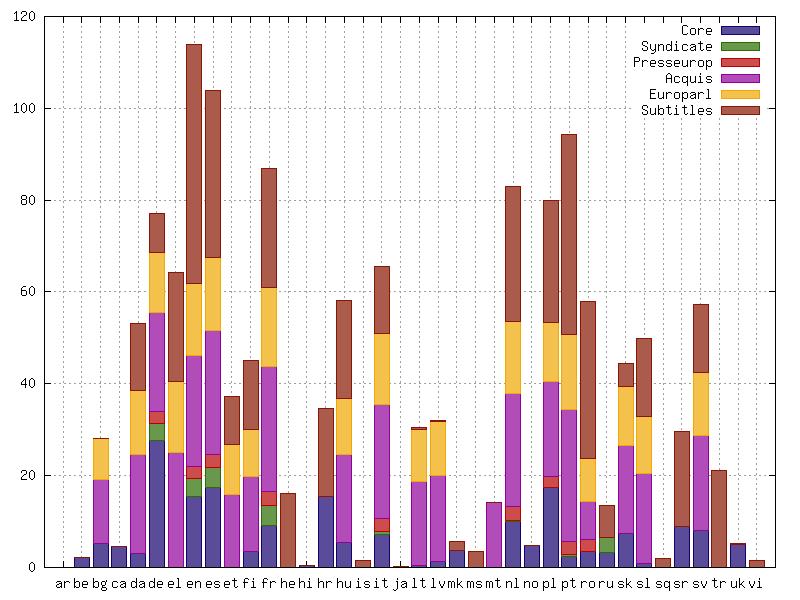
15
16 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
17 DIAKORP diachronic corpus of historical Czech (from 14 th century onwards, with current focus on the 19 th century) current size 2 mil. words, major update soon
18 DIAKORP diachronic corpus of historical Czech (from 14 th century onwards, with current focus on the 19 th century) current size 2 mil. words, major update soon DIALEKT dialectal corpus target size 200,000 words (end of 2016)
19 DIAKORP diachronic corpus of historical Czech (from 14 th century onwards, with current focus on the 19 th century) current size 2 mil. words, major update soon DIALEKT dialectal corpus target size 200,000 words (end of 2016) DEAF corpus of Czech texts written by the deaf target size 200,000 words (end of 2016)
20 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
21 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
22 Project management tools software environments for internal work flow management web-based wrappers that combine both CNC and third-party tools
23 SynKorp database interconnected with data processing toolchain data collection and processing of the written language corpora customizable text conversion and clean-up bibliographic annotation and text classification
24 Mluvka database and integrated project management system coordination of spoken and dialectal data collection large networks of external collaborators three-level project coordination hierarchy manual two-layer annotation (orthographic and phonetic) formal compliance checks and expert revisions balancing of the collected material payment calculation
25 InterCorp database database and integrated project management system coordination of data collection for InterCorp large networks of external collaborators three-level project coordination hierarchy work flow management of the individual texts manual verification and revision of the alignment (using InterText, a project-independent editor of aligned parallel texts) payment calculation
26 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
27 Tools for linguistic annotation morphological and syntactic level typical model: Czech-specific tools built upon language-independent third-party ones
28 Morphological level morphological analysis continuous CNC feedback to the dictionary provided by LINDAT/CLARIN disambiguation third-party stochastic tagger rule-based components developed by the CNC
29 Morphological level morphological analysis continuous CNC feedback to the dictionary provided by LINDAT/CLARIN disambiguation third-party stochastic tagger rule-based components developed by the CNC Syntactic level dependency parsing third-party stochastic parser rule-based corrections and other enhancement methods
30 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
31
32 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
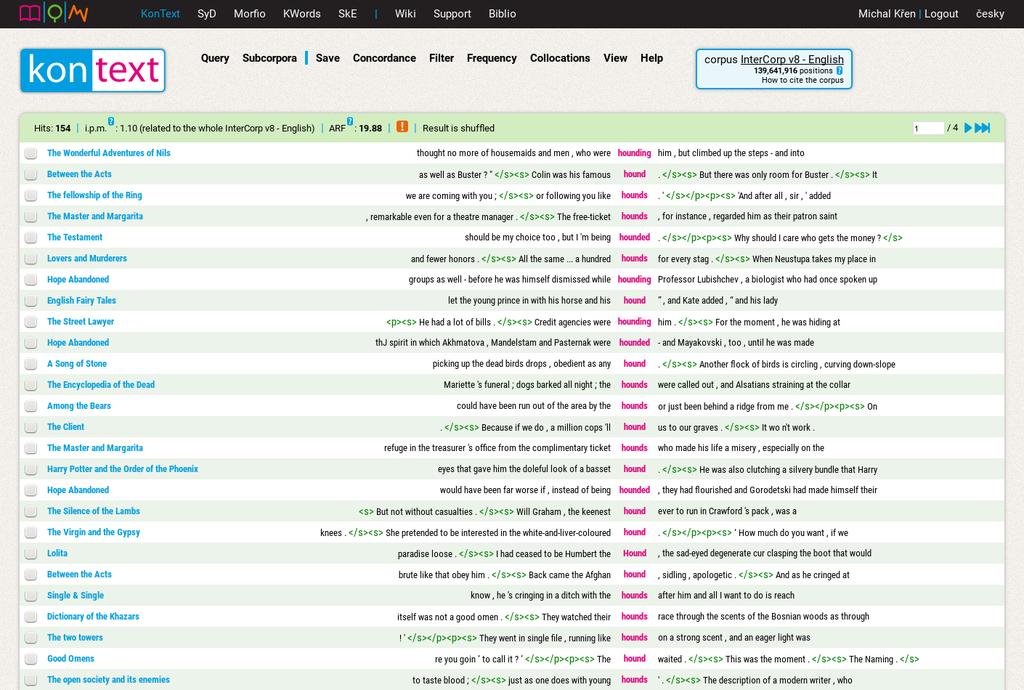
33 KonText web-based general-purpose corpus concordancer CNC fork of the NoSketch Engine single interface to all corpus types (including parallel and spoken corpora) built-in basic statistical functions, subcorpus manager, filtering etc. requires user registration to switch from restricted functionality
34
35 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
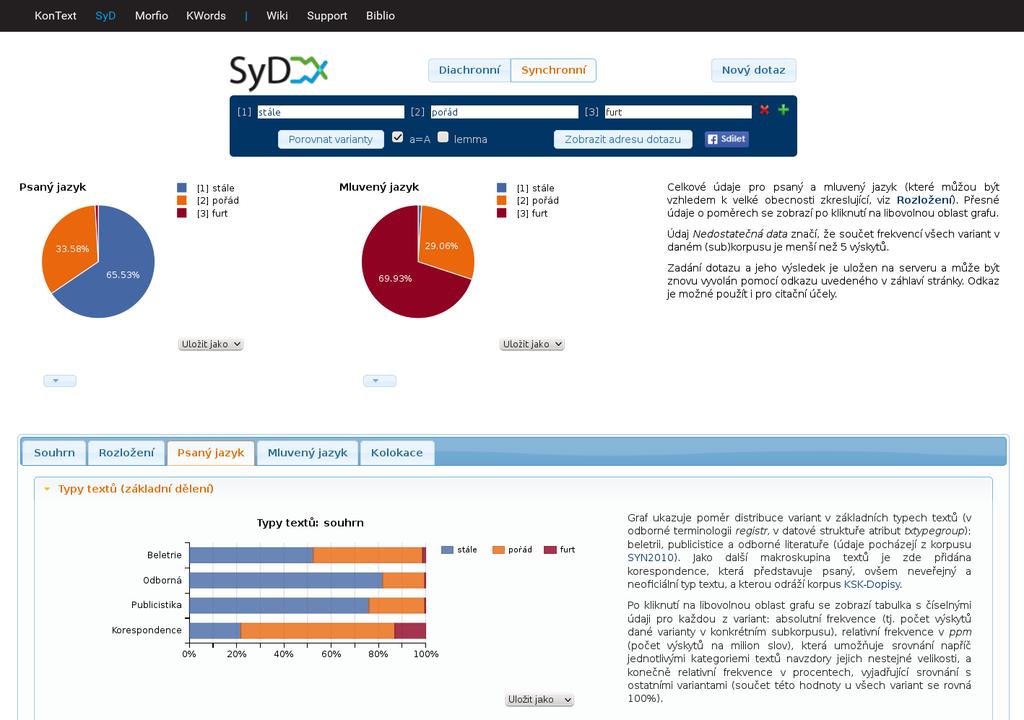
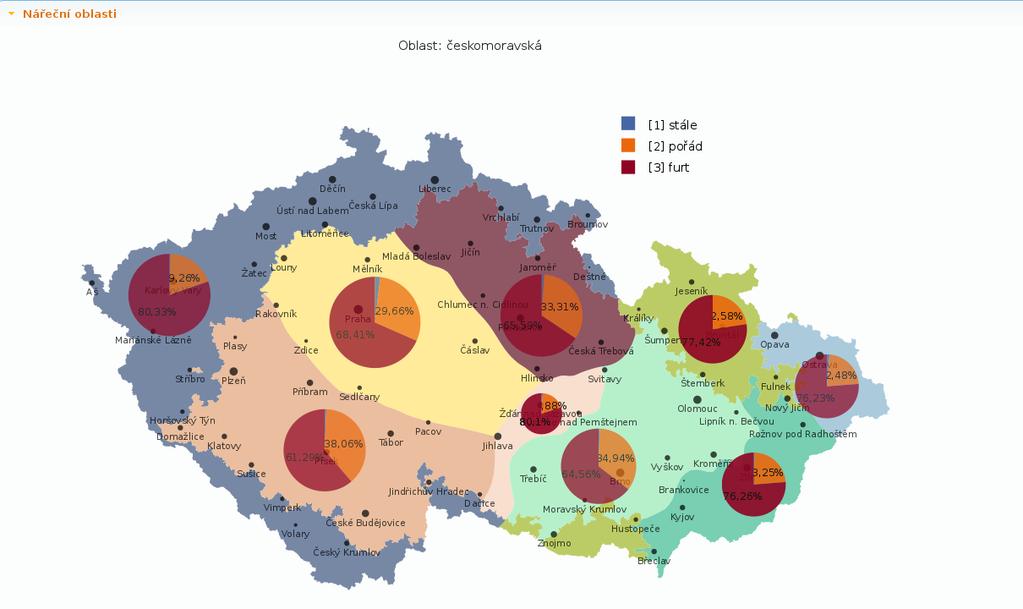
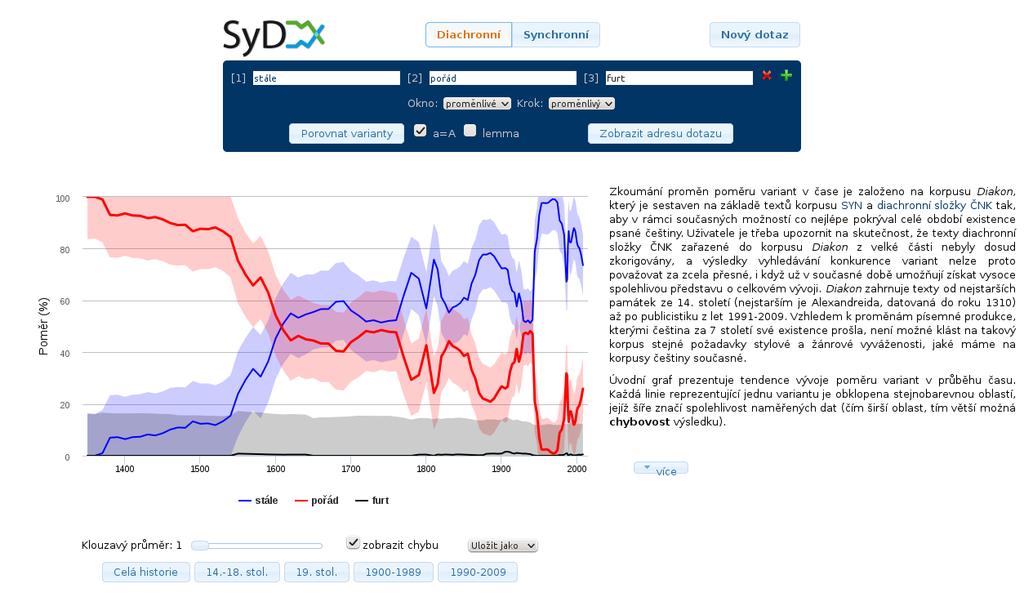
36 SyD corpus-based analysis of language variants synchronic and diachronic component synchronic comparison of frequency distribution of variants across different domains of contemporary written and spoken texts diachronic development over time available without registration
37
38
39
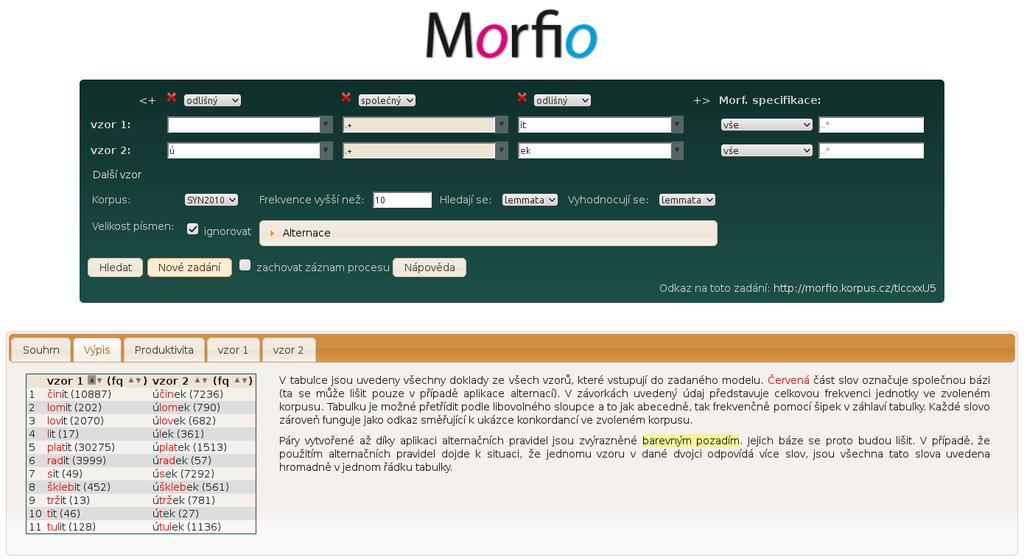
40 Morfio word formation and derivational morphology identifies selected derivational patterns specified by affixes and word roots analysis of their morphological productivity available without registration
41
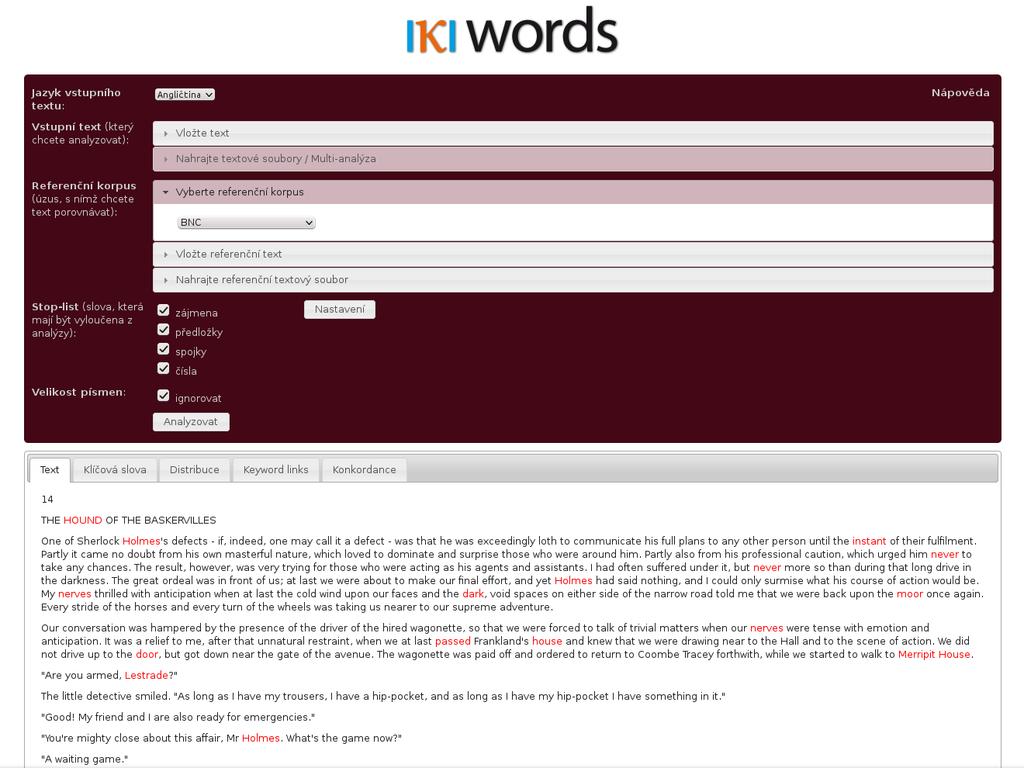
42 KWords corpus-based keyword and discourse analysis possibility to upload texts to be analyzed and/or the reference text visualization of distance-based keyword relations available without registration
43
44 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
45 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
46 CNC Wiki description of corpora available reference manual of KonText including a tutorial in 7 lessons introduction to corpus linguistics available without registration
47 User Forum advisory centre with Q&A bug reporting requests for new features available only to registered users
48 Biblio repository of CNC-based research outputs references and/or uploaded full papers available without registration motivation: bibliography of Czech corpus linguistics promoting Open Access promoting individual papers helping the CNC project
49 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
50 Corpus hosting service offered to other research groups consisting in: final technical processing of their corpus data (possibly extensive) consistency checks publication, maintenance, public access and related services mutual advantage, credit always given examples: CzeSL series of Czech learner corpora (by Karel Šebesta et al.) DOTKO and HOTKO (Lower and Upper Sorbian, respectively; by Sorbian Institute, Bautzen, Germany) Aranea series of large comparable web corpora (currently 14 languages; by Vladimír Benko)
51 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
52 Data packages providing corpus-derived data with less restrictive licensing offered to users who need direct access to the corpus data (NLP) availability: LINDAT/CLARIN repository ( standard packages ) on demand, in accordance with individual requirements licensing depends on the nature of the data and it ranges between: CC-BY (e.g. word lists or n-grams for small n) restrictive proprietary license that permits neither commercial use nor redistribution (e.g. full texts shuffled at sentence level)
53 Introduction of the project Corpus compilation Written corpora Spoken corpora Parallel corpus Specialized corpora Data processing and annotation Project management tools Tools for linguistic annotation User application development KonText SyD, Morfio & KWords Services Wiki, Support & Biblio Corpus hosting Data packages Future plans
54 User applications continuous maintenance, adding new functionality KonText enhancements: module leading the users to appropriate statistical evaluation and interpretation of the results multidimensional frequency distribution with attractive visualisation (e.g. diachronic development) advanced collocational component subcorpus blending module
55 User applications continuous maintenance, adding new functionality KonText enhancements: module leading the users to appropriate statistical evaluation and interpretation of the results multidimensional frequency distribution with attractive visualisation (e.g. diachronic development) advanced collocational component subcorpus blending module Data collection semi-formal spoken Czech semi-official internet language (blogs, discussion forums etc.) monitor corpus of written Czech (1850 present)
56 Thank you for your attention!
57 Selected references Čermák, F. Rosen, A. (2012). The case of InterCorp, a multilingual parallel corpus. International Journal of Corpus Linguistics, 13 (3), Hnátková, M. Křen, M. Procházka, P. Skoumalová, H. (2014). The SYN-series corpora of written Czech. In: Proceedings of LREC 2014, Reykjavík: ELRA. Jelínek, T. (2014). Improvements to Dependency Parsing Using Automatic Simplification of Data. In: Proceedings of LREC 2014, Reykjavík: ELRA. Kopřivová, M. Goláňová, H. Klimešová, P. Lukeš, D. (2014). Mapping Diatopic and Diachronic Variation in Spoken Czech: the Ortofon and Dialekt Corpora. In: Proceedings of LREC 2014, Reykjavík: ELRA. Kučera, K. Stluka, M. (2014). Corpus of 19th-century Czech Texts: Problems and Solutions. In: Proceedings of LREC 2014, Reykjavík: ELRA. Petkevič, P. (2006). Reliable Morphological Disambiguation of Czech: Rule-Based Approach is Necessary. In: Insight into Slovak and Czech Corpus Linguistics, Bratislava: Veda. Rosen, A. Vavřín, M. (2012). Building a multilingual parallel corpus for human users. In: Proceedings of LREC 2012, İstanbul: ELRA. Válková, L. Waclawičová, M. Křen, M. (2012). Balanced data repository of spontaneous spoken Czech. In: Proceedings of LREC 2012, İstanbul: ELRA. Vondřička, P. (2014). Aligning Parallel Texts with InterText. In: Proceedings of LREC 2014, Reykjavík: ELRA.
Data for linguistics ALEXIS DIMITRIADIS. Contents First Last Prev Next Back Close Quit
 Data for linguistics ALEXIS DIMITRIADIS Text, corpora, and data in the wild 1. Where does language data come from? The usual: Introspection, questionnaires, etc. Corpora, suited to the domain of study:
Data for linguistics ALEXIS DIMITRIADIS Text, corpora, and data in the wild 1. Where does language data come from? The usual: Introspection, questionnaires, etc. Corpora, suited to the domain of study:
Aligning parallel texts with InterText
 Aligning parallel texts with InterText Pavel Vondřička Institute of the Czech National Corpus, Charles University in Prague Faculty of Arts, nám. J. Palacha 2, CZ-11638 Praha 1, Czech Republic Pavel.Vondricka@ff.cuni.cz
Aligning parallel texts with InterText Pavel Vondřička Institute of the Czech National Corpus, Charles University in Prague Faculty of Arts, nám. J. Palacha 2, CZ-11638 Praha 1, Czech Republic Pavel.Vondricka@ff.cuni.cz
LING203: Corpus. March 9, 2009
 LING203: Corpus March 9, 2009 Corpus A collection of machine readable texts SJSU LLD have many corpora http://linguistics.sjsu.edu/bin/view/public/chltcorpora Each corpus has a link to a description page
LING203: Corpus March 9, 2009 Corpus A collection of machine readable texts SJSU LLD have many corpora http://linguistics.sjsu.edu/bin/view/public/chltcorpora Each corpus has a link to a description page
Contents. List of Figures. List of Tables. Acknowledgements
 Contents List of Figures List of Tables Acknowledgements xiii xv xvii 1 Introduction 1 1.1 Linguistic Data Analysis 3 1.1.1 What's data? 3 1.1.2 Forms of data 3 1.1.3 Collecting and analysing data 7 1.2
Contents List of Figures List of Tables Acknowledgements xiii xv xvii 1 Introduction 1 1.1 Linguistic Data Analysis 3 1.1.1 What's data? 3 1.1.2 Forms of data 3 1.1.3 Collecting and analysing data 7 1.2
Corpus Linguistics: corpus annotation
 Corpus Linguistics: corpus annotation Karën Fort karen.fort@inist.fr November 30, 2010 Introduction Methodology Annotation Issues Annotation Formats From Formats to Schemes Sources Most of this course
Corpus Linguistics: corpus annotation Karën Fort karen.fort@inist.fr November 30, 2010 Introduction Methodology Annotation Issues Annotation Formats From Formats to Schemes Sources Most of this course
TectoMT: Modular NLP Framework
 : Modular NLP Framework Martin Popel, Zdeněk Žabokrtský ÚFAL, Charles University in Prague IceTAL, 7th International Conference on Natural Language Processing August 17, 2010, Reykjavik Outline Motivation
: Modular NLP Framework Martin Popel, Zdeněk Žabokrtský ÚFAL, Charles University in Prague IceTAL, 7th International Conference on Natural Language Processing August 17, 2010, Reykjavik Outline Motivation
clarin:el an infrastructure for documenting, sharing and processing language data
 clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
Influence of Word Normalization on Text Classification
 Influence of Word Normalization on Text Classification Michal Toman a, Roman Tesar a and Karel Jezek a a University of West Bohemia, Faculty of Applied Sciences, Plzen, Czech Republic In this paper we
Influence of Word Normalization on Text Classification Michal Toman a, Roman Tesar a and Karel Jezek a a University of West Bohemia, Faculty of Applied Sciences, Plzen, Czech Republic In this paper we
How can CLARIN archive and curate my resources?
 How can CLARIN archive and curate my resources? Christoph Draxler draxler@phonetik.uni-muenchen.de Outline! Relevant resources CLARIN infrastructure European Research Infrastructure Consortium National
How can CLARIN archive and curate my resources? Christoph Draxler draxler@phonetik.uni-muenchen.de Outline! Relevant resources CLARIN infrastructure European Research Infrastructure Consortium National
Automatic Lemmatizer Construction with Focus on OOV Words Lemmatization
 Automatic Lemmatizer Construction with Focus on OOV Words Lemmatization Jakub Kanis, Luděk Müller University of West Bohemia, Department of Cybernetics, Univerzitní 8, 306 14 Plzeň, Czech Republic {jkanis,muller}@kky.zcu.cz
Automatic Lemmatizer Construction with Focus on OOV Words Lemmatization Jakub Kanis, Luděk Müller University of West Bohemia, Department of Cybernetics, Univerzitní 8, 306 14 Plzeň, Czech Republic {jkanis,muller}@kky.zcu.cz
ANC2Go: A Web Application for Customized Corpus Creation
 ANC2Go: A Web Application for Customized Corpus Creation Nancy Ide, Keith Suderman, Brian Simms Department of Computer Science, Vassar College Poughkeepsie, New York 12604 USA {ide, suderman, brsimms}@cs.vassar.edu
ANC2Go: A Web Application for Customized Corpus Creation Nancy Ide, Keith Suderman, Brian Simms Department of Computer Science, Vassar College Poughkeepsie, New York 12604 USA {ide, suderman, brsimms}@cs.vassar.edu
META-SHARE : the open exchange platform Overview-Current State-Towards v3.0
 META-SHARE : the open exchange platform Overview-Current State-Towards v3.0 Stelios Piperidis Athena RC, Greece spip@ilsp.gr A Strategy for Multilingual Europe Brussels, Belgium, June 20/21, 2012 Co-funded
META-SHARE : the open exchange platform Overview-Current State-Towards v3.0 Stelios Piperidis Athena RC, Greece spip@ilsp.gr A Strategy for Multilingual Europe Brussels, Belgium, June 20/21, 2012 Co-funded
LIDER Survey. Overview. Number of participants: 24. Participant profile (organisation type, industry sector) Relevant use-cases
 Relevant use-cases") LIDER Survey Overview Participant profile (organisation type, industry sector) Relevant use-cases Discovering and extracting information Understanding opinion Content and data (Data Management) Monitoring
LIDER Survey Overview Participant profile (organisation type, industry sector) Relevant use-cases Discovering and extracting information Understanding opinion Content and data (Data Management) Monitoring
Corpus methods for sociolinguistics. Emily M. Bender NWAV 31 - October 10, 2002
 Corpus methods for sociolinguistics Emily M. Bender bender@csli.stanford.edu NWAV 31 - October 10, 2002 Overview Introduction Corpora of interest Software for accessing and analyzing corpora (demo) Basic
Corpus methods for sociolinguistics Emily M. Bender bender@csli.stanford.edu NWAV 31 - October 10, 2002 Overview Introduction Corpora of interest Software for accessing and analyzing corpora (demo) Basic
Ortolang Tools : MarsaTag
 Ortolang Tools : MarsaTag Stéphane Rauzy, Philippe Blache, Grégoire de Montcheuil SECOND VARIAMU WORKSHOP LPL, Aix-en-Provence August 20th & 21st, 2014 ORTOLANG received a State aid under the «Investissements
Ortolang Tools : MarsaTag Stéphane Rauzy, Philippe Blache, Grégoire de Montcheuil SECOND VARIAMU WORKSHOP LPL, Aix-en-Provence August 20th & 21st, 2014 ORTOLANG received a State aid under the «Investissements
Knowledge Engineering with Semantic Web Technologies
 This file is licensed under the Creative Commons Attribution-NonCommercial 3.0 (CC BY-NC 3.0) Knowledge Engineering with Semantic Web Technologies Lecture 5: Ontological Engineering 5.3 Ontology Learning
This file is licensed under the Creative Commons Attribution-NonCommercial 3.0 (CC BY-NC 3.0) Knowledge Engineering with Semantic Web Technologies Lecture 5: Ontological Engineering 5.3 Ontology Learning
Army Research Laboratory
 Army Research Laboratory Arabic Natural Language Processing System Code Library by Stephen C. Tratz ARL-TN-0609 June 2014 Approved for public release; distribution is unlimited. NOTICES Disclaimers The
Army Research Laboratory Arabic Natural Language Processing System Code Library by Stephen C. Tratz ARL-TN-0609 June 2014 Approved for public release; distribution is unlimited. NOTICES Disclaimers The
Semantics Isn t Easy Thoughts on the Way Forward
 Semantics Isn t Easy Thoughts on the Way Forward NANCY IDE, VASSAR COLLEGE REBECCA PASSONNEAU, COLUMBIA UNIVERSITY COLLIN BAKER, ICSI/UC BERKELEY CHRISTIANE FELLBAUM, PRINCETON UNIVERSITY New York University
Semantics Isn t Easy Thoughts on the Way Forward NANCY IDE, VASSAR COLLEGE REBECCA PASSONNEAU, COLUMBIA UNIVERSITY COLLIN BAKER, ICSI/UC BERKELEY CHRISTIANE FELLBAUM, PRINCETON UNIVERSITY New York University
Natural Language Processing. SoSe Question Answering
 Natural Language Processing SoSe 2017 Question Answering Dr. Mariana Neves July 5th, 2017 Motivation Find small segments of text which answer users questions (http://start.csail.mit.edu/) 2 3 Motivation
Natural Language Processing SoSe 2017 Question Answering Dr. Mariana Neves July 5th, 2017 Motivation Find small segments of text which answer users questions (http://start.csail.mit.edu/) 2 3 Motivation
Processing XML Text with Python and ElementTree a Practical Experience
 Processing XML Text with Python and ElementTree a Practical Experience Radovan Garabík L udovít Štúr Institute of Linguistics Slovak Academy of Sciences Bratislava, Slovakia Abstract In this paper, we
Processing XML Text with Python and ElementTree a Practical Experience Radovan Garabík L udovít Štúr Institute of Linguistics Slovak Academy of Sciences Bratislava, Slovakia Abstract In this paper, we
Janne Bondi johannessen, Anders Nøklestad, Joel Priestley and Kristin Hagen. WP5: Glossa Integration
 Janne Bondi johannessen, Anders Nøklestad, Joel Priestley and Kristin Hagen WP5: Glossa Integration WP5 Glossa integration The current Glossa corpus interface and analysis tool will be integrated in the
Janne Bondi johannessen, Anders Nøklestad, Joel Priestley and Kristin Hagen WP5: Glossa Integration WP5 Glossa integration The current Glossa corpus interface and analysis tool will be integrated in the
Shrey Patel B.E. Computer Engineering, Gujarat Technological University, Ahmedabad, Gujarat, India
 International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
International Journal of Scientific Research in Computer Science, Engineering and Information Technology 2018 IJSRCSEIT Volume 3 Issue 3 ISSN : 2456-3307 Some Issues in Application of NLP to Intelligent
Machine Translation Research in META-NET
 Machine Translation Research in META-NET Jan Hajič Institute of Formal and Applied Linguistics Charles University in Prague, CZ hajic@ufal.mff.cuni.cz Solutions for Multilingual Europe Budapest, Hungary,
Machine Translation Research in META-NET Jan Hajič Institute of Formal and Applied Linguistics Charles University in Prague, CZ hajic@ufal.mff.cuni.cz Solutions for Multilingual Europe Budapest, Hungary,
A platform for collaborative semantic annotation
 A platform for collaborative semantic annotation Valerio Basile and Johan Bos and Kilian Evang and Noortje Venhuizen {v.basile,johan.bos,k.evang,n.j.venhuizen}@rug.nl Center for Language and Cognition
A platform for collaborative semantic annotation Valerio Basile and Johan Bos and Kilian Evang and Noortje Venhuizen {v.basile,johan.bos,k.evang,n.j.venhuizen}@rug.nl Center for Language and Cognition
Apache UIMA and Mayo ctakes
 Apache and Mayo and how it is used in the clinical domain March 16, 2012 Apache and Mayo Outline 1 Apache and Mayo Outline 1 2 Introducing Pipeline Modules Apache and Mayo What is? (You - eee - muh) Unstructured
Apache and Mayo and how it is used in the clinical domain March 16, 2012 Apache and Mayo Outline 1 Apache and Mayo Outline 1 2 Introducing Pipeline Modules Apache and Mayo What is? (You - eee - muh) Unstructured
NLPL - The Nordic Language Processing Laboratory.
 NLPL - The Nordic Language Processing Laboratory http://nlpl.eu/ What is NLPL? Vision virtual laboratory for large-scale NLP research share high-performance computing and data resources across language
NLPL - The Nordic Language Processing Laboratory http://nlpl.eu/ What is NLPL? Vision virtual laboratory for large-scale NLP research share high-performance computing and data resources across language
Utilizing Semantic Equivalence Classes of Japanese Functional Expressions in Machine Translation
 Utilizing Semantic Equivalence Classes of Japanese Functional Expressions in Machine Translation Akiko Sakamoto Takehito Utsuro University of Tsukuba Tsukuba, Ibaraki, 305-8573, JAPAN Suguru Matsuyoshi
Utilizing Semantic Equivalence Classes of Japanese Functional Expressions in Machine Translation Akiko Sakamoto Takehito Utsuro University of Tsukuba Tsukuba, Ibaraki, 305-8573, JAPAN Suguru Matsuyoshi
Introducing XAIRA. Lou Burnard Tony Dodd. An XML aware tool for corpus indexing and searching. Research Technology Services, OUCS
 Introducing XAIRA An XML aware tool for corpus indexing and searching Lou Burnard Tony Dodd Research Technology Services, OUCS What is XAIRA? XML Aware Indexing and Retrieval Architecture Developed from
Introducing XAIRA An XML aware tool for corpus indexing and searching Lou Burnard Tony Dodd Research Technology Services, OUCS What is XAIRA? XML Aware Indexing and Retrieval Architecture Developed from
CORLI. a linguistic consortium for corpus, language and interaction
 CORLI a linguistic consortium for corpus, language and interaction CORLI and HUMA-NUM CORLI = Corpus, Languages, and Interaction a French consortium of Huma-Num involved in linguistic research and teaching
CORLI a linguistic consortium for corpus, language and interaction CORLI and HUMA-NUM CORLI = Corpus, Languages, and Interaction a French consortium of Huma-Num involved in linguistic research and teaching
Enabling Semantic Search in Large Open Source Communities
 Enabling Semantic Search in Large Open Source Communities Gregor Leban, Lorand Dali, Inna Novalija Jožef Stefan Institute, Jamova cesta 39, 1000 Ljubljana {gregor.leban, lorand.dali, inna.koval}@ijs.si
Enabling Semantic Search in Large Open Source Communities Gregor Leban, Lorand Dali, Inna Novalija Jožef Stefan Institute, Jamova cesta 39, 1000 Ljubljana {gregor.leban, lorand.dali, inna.koval}@ijs.si
Mini Demonstration of Japanese Corpora
 Mini Demonstration of Japanese Corpora Toshinobu OGISO Department of Corpus Studies, NINJAL togiso@ninjal.ac.jp Center for Corpus Development, NINJAL Corpus: a collection of written or spoken material
Mini Demonstration of Japanese Corpora Toshinobu OGISO Department of Corpus Studies, NINJAL togiso@ninjal.ac.jp Center for Corpus Development, NINJAL Corpus: a collection of written or spoken material
NLP in practice, an example: Semantic Role Labeling
 NLP in practice, an example: Semantic Role Labeling Anders Björkelund Lund University, Dept. of Computer Science anders.bjorkelund@cs.lth.se October 15, 2010 Anders Björkelund NLP in practice, an example:
NLP in practice, an example: Semantic Role Labeling Anders Björkelund Lund University, Dept. of Computer Science anders.bjorkelund@cs.lth.se October 15, 2010 Anders Björkelund NLP in practice, an example:
Parmenides. Semi-automatic. Ontology. construction and maintenance. Ontology. Document convertor/basic processing. Linguistic. Background knowledge
 Discover hidden information from your texts! Information overload is a well known issue in the knowledge industry. At the same time most of this information becomes available in natural language which
Discover hidden information from your texts! Information overload is a well known issue in the knowledge industry. At the same time most of this information becomes available in natural language which
Treex: Modular NLP Framework
 : Modular NLP Framework Martin Popel ÚFAL (Institute of Formal and Applied Linguistics) Charles University in Prague September 2015, Prague, MT Marathon Outline Motivation, vs. architecture internals Future
: Modular NLP Framework Martin Popel ÚFAL (Institute of Formal and Applied Linguistics) Charles University in Prague September 2015, Prague, MT Marathon Outline Motivation, vs. architecture internals Future
Best practices in the design, creation and dissemination of speech corpora at The Language Archive
 LREC Workshop 18 2012-05-21 Istanbul Best practices in the design, creation and dissemination of speech corpora at The Language Archive Sebastian Drude, Daan Broeder, Peter Wittenburg, Han Sloetjes The
LREC Workshop 18 2012-05-21 Istanbul Best practices in the design, creation and dissemination of speech corpora at The Language Archive Sebastian Drude, Daan Broeder, Peter Wittenburg, Han Sloetjes The
Building and Annotating Corpora of Collaborative Authoring in Wikipedia
 Building and Annotating Corpora of Collaborative Authoring in Wikipedia Johannes Daxenberger, Oliver Ferschke and Iryna Gurevych Workshop: Building Corpora of Computer-Mediated Communication: Issues, Challenges,
Building and Annotating Corpora of Collaborative Authoring in Wikipedia Johannes Daxenberger, Oliver Ferschke and Iryna Gurevych Workshop: Building Corpora of Computer-Mediated Communication: Issues, Challenges,
TIPSTER Text Phase II Architecture Requirements
 1.0 INTRODUCTION TIPSTER Text Phase II Architecture Requirements 1.1 Requirements Traceability Version 2.0p 3 June 1996 Architecture Commitee tipster @ tipster.org The requirements herein are derived from
1.0 INTRODUCTION TIPSTER Text Phase II Architecture Requirements 1.1 Requirements Traceability Version 2.0p 3 June 1996 Architecture Commitee tipster @ tipster.org The requirements herein are derived from
Spock - a Spoken Corpus Client
 Spock - a Spoken Corpus Client Maarten Janssen, Tiago Freitas IULA/ILTEC, ILTEC Plaça de la Mercé 10-12 Barcelona, Rua Conde de Redondo 74-5 Lisboa maarten@iltec.pt, taf@iltec.pt Abstract Spock is an open
Spock - a Spoken Corpus Client Maarten Janssen, Tiago Freitas IULA/ILTEC, ILTEC Plaça de la Mercé 10-12 Barcelona, Rua Conde de Redondo 74-5 Lisboa maarten@iltec.pt, taf@iltec.pt Abstract Spock is an open
The Turkish National Corpus (TNC): Comparing the Architectures of v1 and v2
: Comparing the Architectures of v1 and v2") The Turkish National Corpus (): Comparing the Architectures and Yeşim Aksan Selma Ayşe Özel Mersin University Mersin, Turkey yesimaksan@gmail.com Çukurova University Adana, Turkey saozel@gmail.com Hakan
The Turkish National Corpus (): Comparing the Architectures and Yeşim Aksan Selma Ayşe Özel Mersin University Mersin, Turkey yesimaksan@gmail.com Çukurova University Adana, Turkey saozel@gmail.com Hakan
The American National Corpus First Release
 The American National Corpus First Release Nancy Ide and Keith Suderman Department of Computer Science, Vassar College, Poughkeepsie, NY 12604-0520 USA ide@cs.vassar.edu, suderman@cs.vassar.edu Abstract
The American National Corpus First Release Nancy Ide and Keith Suderman Department of Computer Science, Vassar College, Poughkeepsie, NY 12604-0520 USA ide@cs.vassar.edu, suderman@cs.vassar.edu Abstract
Profiling Medical Journal Articles Using a Gene Ontology Semantic Tagger. Mahmoud El-Haj Paul Rayson Scott Piao Jo Knight
 Profiling Medical Journal Articles Using a Gene Ontology Semantic Tagger Mahmoud El-Haj Paul Rayson Scott Piao Jo Knight Origin and Outcomes Currently funded through a Wellcome Trust Seed award Collaboration
Profiling Medical Journal Articles Using a Gene Ontology Semantic Tagger Mahmoud El-Haj Paul Rayson Scott Piao Jo Knight Origin and Outcomes Currently funded through a Wellcome Trust Seed award Collaboration
Parallel Concordancing and Translation. Michael Barlow
 [Translating and the Computer 26, November 2004 [London: Aslib, 2004] Parallel Concordancing and Translation Michael Barlow Dept. of Applied Language Studies and Linguistics University of Auckland Auckland,
[Translating and the Computer 26, November 2004 [London: Aslib, 2004] Parallel Concordancing and Translation Michael Barlow Dept. of Applied Language Studies and Linguistics University of Auckland Auckland,
Better translations with user collaboration - Integrated MT at Microsoft
 Better s with user collaboration - Integrated MT at Microsoft Chris Wendt Microsoft Research One Microsoft Way Redmond, WA 98052 christw@microsoft.com Abstract This paper outlines the methodologies Microsoft
Better s with user collaboration - Integrated MT at Microsoft Chris Wendt Microsoft Research One Microsoft Way Redmond, WA 98052 christw@microsoft.com Abstract This paper outlines the methodologies Microsoft
An UIMA based Tool Suite for Semantic Text Processing
 An UIMA based Tool Suite for Semantic Text Processing Katrin Tomanek, Ekaterina Buyko, Udo Hahn Jena University Language & Information Engineering Lab StemNet Knowledge Management for Immunology in life
An UIMA based Tool Suite for Semantic Text Processing Katrin Tomanek, Ekaterina Buyko, Udo Hahn Jena University Language & Information Engineering Lab StemNet Knowledge Management for Immunology in life
The Dictionary Parsing Project: Steps Toward a Lexicographer s Workstation
 The Dictionary Parsing Project: Steps Toward a Lexicographer s Workstation Ken Litkowski ken@clres.com http://www.clres.com http://www.clres.com/dppdemo/index.html Dictionary Parsing Project Purpose: to
The Dictionary Parsing Project: Steps Toward a Lexicographer s Workstation Ken Litkowski ken@clres.com http://www.clres.com http://www.clres.com/dppdemo/index.html Dictionary Parsing Project Purpose: to
Corpus collection and analysis for the linguistic layman: The Gromoteur
 Corpus collection and analysis for the linguistic layman: The Gromoteur Kim Gerdes LPP, Université Sorbonne Nouvelle & CNRS Abstract This paper presents a tool for corpus collection, handling, and statistical
Corpus collection and analysis for the linguistic layman: The Gromoteur Kim Gerdes LPP, Université Sorbonne Nouvelle & CNRS Abstract This paper presents a tool for corpus collection, handling, and statistical
EUDICO, Annotation and Exploitation of Multi Media Corpora over the Internet
 EUDICO, Annotation and Exploitation of Multi Media Corpora over the Internet Hennie Brugman, Albert Russel, Daan Broeder, Peter Wittenburg Max Planck Institute for Psycholinguistics P.O. Box 310, 6500
EUDICO, Annotation and Exploitation of Multi Media Corpora over the Internet Hennie Brugman, Albert Russel, Daan Broeder, Peter Wittenburg Max Planck Institute for Psycholinguistics P.O. Box 310, 6500
@Note2 tutorial. Hugo Costa Ruben Rodrigues Miguel Rocha
 @Note2 tutorial Hugo Costa (hcosta@silicolife.com) Ruben Rodrigues (pg25227@alunos.uminho.pt) Miguel Rocha (mrocha@di.uminho.pt) 23-01-2018 The document presents a typical workflow using @Note2 platform
@Note2 tutorial Hugo Costa (hcosta@silicolife.com) Ruben Rodrigues (pg25227@alunos.uminho.pt) Miguel Rocha (mrocha@di.uminho.pt) 23-01-2018 The document presents a typical workflow using @Note2 platform
Annotating Spatio-Temporal Information in Documents
 Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
The Multilingual Language Library
 The Multilingual Language Library @ LREC 2012 Let s build it together! Nicoletta Calzolari with Riccardo Del Gratta, Francesca Frontini, Francesco Rubino, Irene Russo Istituto di Linguistica Computazionale
The Multilingual Language Library @ LREC 2012 Let s build it together! Nicoletta Calzolari with Riccardo Del Gratta, Francesca Frontini, Francesco Rubino, Irene Russo Istituto di Linguistica Computazionale
Procedure (Steps) for Applying Online at Student Support Portal
 for Applying Online at Student Support Portal") Procedure (Steps) for Applying Online at Student Support Portal Step-1: Visit University Website (www.ptu.ac.in) Click on Student Support Centre (support.ptu.ac.in) Step-2: If you are new User Click on
Procedure (Steps) for Applying Online at Student Support Portal Step-1: Visit University Website (www.ptu.ac.in) Click on Student Support Centre (support.ptu.ac.in) Step-2: If you are new User Click on
Towards Corpus Annotation Standards The MATE Workbench 1
 Towards Corpus Annotation Standards The MATE Workbench 1 Laila Dybkjær, Niels Ole Bernsen Natural Interactive Systems Laboratory Science Park 10, 5230 Odense M, Denmark E-post: laila@nis.sdu.dk, nob@nis.sdu.dk
Towards Corpus Annotation Standards The MATE Workbench 1 Laila Dybkjær, Niels Ole Bernsen Natural Interactive Systems Laboratory Science Park 10, 5230 Odense M, Denmark E-post: laila@nis.sdu.dk, nob@nis.sdu.dk
Kielipankki and Korp
 Kielipankki and Korp Mietta Lennes and Jyrki Niemi, FIN-CLARIN / University of Helsinki Korp & Språkbanken workshop 17.10.2018 This document is licensed under Creative Commons Attribution 4.0. www.kielipankki.fi
Kielipankki and Korp Mietta Lennes and Jyrki Niemi, FIN-CLARIN / University of Helsinki Korp & Språkbanken workshop 17.10.2018 This document is licensed under Creative Commons Attribution 4.0. www.kielipankki.fi
TwNC: a Multifaceted Dutch News Corpus
 TwNC: a Multifaceted Dutch News Corpus Roeland Ordelman, Franciska de Jong, Arjan van Hessen, Hendri Hondorp. University of Twente (UT) Department of Electrical Engineering, Mathematics and Computer Science
TwNC: a Multifaceted Dutch News Corpus Roeland Ordelman, Franciska de Jong, Arjan van Hessen, Hendri Hondorp. University of Twente (UT) Department of Electrical Engineering, Mathematics and Computer Science
An Integrated Digital Tool for Accessing Language Resources
 An Integrated Digital Tool for Accessing Language Resources Anil Kumar Singh, Bharat Ram Ambati Langauge Technologies Research Centre, International Institute of Information Technology Hyderabad, India
An Integrated Digital Tool for Accessing Language Resources Anil Kumar Singh, Bharat Ram Ambati Langauge Technologies Research Centre, International Institute of Information Technology Hyderabad, India
CompuScholar, Inc. Alignment to Utah's Web Development I Standards
 Course Title: KidCoder: Web Design Course ISBN: 978-0-9887070-3-0 Course Year: 2015 CompuScholar, Inc. Alignment to Utah's Web Development I Standards Note: Citation(s) listed may represent a subset of
Course Title: KidCoder: Web Design Course ISBN: 978-0-9887070-3-0 Course Year: 2015 CompuScholar, Inc. Alignment to Utah's Web Development I Standards Note: Citation(s) listed may represent a subset of
A Test Environment for Natural Language Understanding Systems
 A Test Environment for Natural Language Understanding Systems Li Li, Deborah A. Dahl, Lewis M. Norton, Marcia C. Linebarger, Dongdong Chen Unisys Corporation 2476 Swedesford Road Malvern, PA 19355, U.S.A.
A Test Environment for Natural Language Understanding Systems Li Li, Deborah A. Dahl, Lewis M. Norton, Marcia C. Linebarger, Dongdong Chen Unisys Corporation 2476 Swedesford Road Malvern, PA 19355, U.S.A.
Improving the exploitation of linguistic annotations in ELAN
 Improving the exploitation of linguistic annotations in ELAN Onno Crasborn, Han Sloetjes Radboud University Nijmegen, Centre for Language Studies; The Language Archive, Max Planck Institute for Psycholinguistics
Improving the exploitation of linguistic annotations in ELAN Onno Crasborn, Han Sloetjes Radboud University Nijmegen, Centre for Language Studies; The Language Archive, Max Planck Institute for Psycholinguistics
Extending the Facets concept by applying NLP tools to catalog records of scientific literature
 Extending the Facets concept by applying NLP tools to catalog records of scientific literature *E. Picchi, *M. Sassi, **S. Biagioni, **S. Giannini *Institute of Computational Linguistics **Institute of
Extending the Facets concept by applying NLP tools to catalog records of scientific literature *E. Picchi, *M. Sassi, **S. Biagioni, **S. Giannini *Institute of Computational Linguistics **Institute of
UIMA-based Annotation Type System for a Text Mining Architecture
 UIMA-based Annotation Type System for a Text Mining Architecture Udo Hahn, Ekaterina Buyko, Katrin Tomanek, Scott Piao, Yoshimasa Tsuruoka, John McNaught, Sophia Ananiadou Jena University Language and
UIMA-based Annotation Type System for a Text Mining Architecture Udo Hahn, Ekaterina Buyko, Katrin Tomanek, Scott Piao, Yoshimasa Tsuruoka, John McNaught, Sophia Ananiadou Jena University Language and
Language Resources. Khalid Choukri ELRA/ELDA 55 Rue Brillat-Savarin, F Paris, France Tel Fax.
 Language Resources By the Other Data Center over 15 years fruitful partnership Khalid Choukri ELRA/ELDA 55 Rue Brillat-Savarin, F-75013 Paris, France Tel. +33 1 43 13 33 33 -- Fax. +33 1 43 13 33 30 choukri@elda.org
Language Resources By the Other Data Center over 15 years fruitful partnership Khalid Choukri ELRA/ELDA 55 Rue Brillat-Savarin, F-75013 Paris, France Tel. +33 1 43 13 33 33 -- Fax. +33 1 43 13 33 30 choukri@elda.org
Using the Ellogon Natural Language Engineering Infrastructure
 Using the Ellogon Natural Language Engineering Infrastructure Georgios Petasis, Vangelis Karkaletsis, Georgios Paliouras, and Constantine D. Spyropoulos Software and Knowledge Engineering Laboratory, Institute
Using the Ellogon Natural Language Engineering Infrastructure Georgios Petasis, Vangelis Karkaletsis, Georgios Paliouras, and Constantine D. Spyropoulos Software and Knowledge Engineering Laboratory, Institute
Constructing a Japanese Basic Named Entity Corpus of Various Genres
 Constructing a Japanese Basic Named Entity Corpus of Various Genres Tomoya Iwakura 1, Ryuichi Tachibana 2, and Kanako Komiya 3 1 Fujitsu Laboratories Ltd. 2 Commerce Link Inc. 3 Ibaraki University Abstract
Constructing a Japanese Basic Named Entity Corpus of Various Genres Tomoya Iwakura 1, Ryuichi Tachibana 2, and Kanako Komiya 3 1 Fujitsu Laboratories Ltd. 2 Commerce Link Inc. 3 Ibaraki University Abstract
INTERCONNECTING AND MANAGING MULTILINGUAL LEXICAL LINKED DATA. Ernesto William De Luca
 INTERCONNECTING AND MANAGING MULTILINGUAL LEXICAL LINKED DATA Ernesto William De Luca Overview 2 Motivation EuroWordNet RDF/OWL EuroWordNet RDF/OWL LexiRes Tool Conclusions Overview 3 Motivation EuroWordNet
INTERCONNECTING AND MANAGING MULTILINGUAL LEXICAL LINKED DATA Ernesto William De Luca Overview 2 Motivation EuroWordNet RDF/OWL EuroWordNet RDF/OWL LexiRes Tool Conclusions Overview 3 Motivation EuroWordNet
Lider Roadmapping Workshop
 Deutsche Nationalbibliothek Software-supported Bibliographic Recording and Linked Data Lider Roadmapping Workshop Mark Zöpfgen Leipzig, 02.09.2014 1 Overview - DNB German National Library - Activities
Deutsche Nationalbibliothek Software-supported Bibliographic Recording and Linked Data Lider Roadmapping Workshop Mark Zöpfgen Leipzig, 02.09.2014 1 Overview - DNB German National Library - Activities
META-SHARE metadata: Overview of the schema & Interoperability with other schemas
 META-SHARE metadata: Overview of the schema & Interoperability with other schemas Penny Labropoulou & Maria Gavrilidou (ILSP/RC Athena) CMDI Interoperability Workshop Utrecht, Netherlands 4-5 June 2013
META-SHARE metadata: Overview of the schema & Interoperability with other schemas Penny Labropoulou & Maria Gavrilidou (ILSP/RC Athena) CMDI Interoperability Workshop Utrecht, Netherlands 4-5 June 2013
PDF hosted at the Radboud Repository of the Radboud University Nijmegen
 PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/40896
PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/40896
Final Project Discussion. Adam Meyers Montclair State University
 Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Deliverable D1.4 Report Describing Integration Strategies and Experiments
 DEEPTHOUGHT Hybrid Deep and Shallow Methods for Knowledge-Intensive Information Extraction Deliverable D1.4 Report Describing Integration Strategies and Experiments The Consortium October 2004 Report Describing
DEEPTHOUGHT Hybrid Deep and Shallow Methods for Knowledge-Intensive Information Extraction Deliverable D1.4 Report Describing Integration Strategies and Experiments The Consortium October 2004 Report Describing
Knowledge Retrieval. Franz J. Kurfess. Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A.
 Knowledge Retrieval Franz J. Kurfess Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A. 1 Acknowledgements This lecture series has been sponsored by the European
Knowledge Retrieval Franz J. Kurfess Computer Science Department California Polytechnic State University San Luis Obispo, CA, U.S.A. 1 Acknowledgements This lecture series has been sponsored by the European
Constraints for corpora development and validation 1
 Constraints for corpora development and validation 1 Kiril Simov, Alexander Simov, Milen Kouylekov BulTreeBank project http://www.bultreebank.org Linguistic Modelling Laboratory - CLPPI, Bulgarian Academy
Constraints for corpora development and validation 1 Kiril Simov, Alexander Simov, Milen Kouylekov BulTreeBank project http://www.bultreebank.org Linguistic Modelling Laboratory - CLPPI, Bulgarian Academy
Background and Context for CLASP. Nancy Ide, Vassar College
 Background and Context for CLASP Nancy Ide, Vassar College The Situation Standards efforts have been on-going for over 20 years Interest and activity mainly in Europe in 90 s and early 2000 s Text Encoding
Background and Context for CLASP Nancy Ide, Vassar College The Situation Standards efforts have been on-going for over 20 years Interest and activity mainly in Europe in 90 s and early 2000 s Text Encoding
Cf. Gasch (2008), chapter 1.2 Generic and project-specific XML Schema design", p. 23 f. 5
, chapter 1.2 Generic and project-specific XML Schema design, p. 23 f. 5") DGD 2.0: A Web-based Navigation Platform for the Visualization, Presentation and Retrieval of German Speech Corpora 1. Introduction 1.1 The Collection of German Speech Corpora at the IDS The "Institut
DGD 2.0: A Web-based Navigation Platform for the Visualization, Presentation and Retrieval of German Speech Corpora 1. Introduction 1.1 The Collection of German Speech Corpora at the IDS The "Institut
Annotation Tool Development for Large-Scale Corpus Creation Projects at the Linguistic Data Consortium
 Annotation Tool Development for Large-Scale Corpus Creation Projects at the Linguistic Data Consortium Kazuaki Maeda, Haejoong Lee, Shawn Medero, Julie Medero, Robert Parker, Stephanie Strassel Linguistic
Annotation Tool Development for Large-Scale Corpus Creation Projects at the Linguistic Data Consortium Kazuaki Maeda, Haejoong Lee, Shawn Medero, Julie Medero, Robert Parker, Stephanie Strassel Linguistic
A Flexible Distributed Architecture for Natural Language Analyzers
 A Flexible Distributed Architecture for Natural Language Analyzers Xavier Carreras & Lluís Padró TALP Research Center Departament de Llenguatges i Sistemes Informàtics Universitat Politècnica de Catalunya
A Flexible Distributed Architecture for Natural Language Analyzers Xavier Carreras & Lluís Padró TALP Research Center Departament de Llenguatges i Sistemes Informàtics Universitat Politècnica de Catalunya
Tools for Annotating and Searching Corpora Practical Session 1: Annotating
 Tools for Annotating and Searching Corpora Practical Session 1: Annotating Stefanie Dipper Institute of Linguistics Ruhr-University Bochum Corpus Linguistics Fest (CLiF) June 6-10, 2016 Indiana University,
Tools for Annotating and Searching Corpora Practical Session 1: Annotating Stefanie Dipper Institute of Linguistics Ruhr-University Bochum Corpus Linguistics Fest (CLiF) June 6-10, 2016 Indiana University,
Utilising ANNIS for search and analysis of historical data
 Utilising ANNIS for search and analysis of historical data Stephan Druskat Thomas Krause Carolin Odebrecht Institut für deutsche Sprache und Linguistik Humboldt-Universität zu Berlin Reuse or New Development:
Utilising ANNIS for search and analysis of historical data Stephan Druskat Thomas Krause Carolin Odebrecht Institut für deutsche Sprache und Linguistik Humboldt-Universität zu Berlin Reuse or New Development:
CACAO PROJECT AT THE 2009 TASK
 CACAO PROJECT AT THE TEL@CLEF 2009 TASK Alessio Bosca, Luca Dini Celi s.r.l. - 10131 Torino - C. Moncalieri, 21 alessio.bosca, dini@celi.it Abstract This paper presents the participation of the CACAO prototype
CACAO PROJECT AT THE TEL@CLEF 2009 TASK Alessio Bosca, Luca Dini Celi s.r.l. - 10131 Torino - C. Moncalieri, 21 alessio.bosca, dini@celi.it Abstract This paper presents the participation of the CACAO prototype
Introduction to Text Mining. Aris Xanthos - University of Lausanne
 Introduction to Text Mining Aris Xanthos - University of Lausanne Preliminary notes Presentation designed for a novice audience Text mining = text analysis = text analytics: using computational and quantitative
Introduction to Text Mining Aris Xanthos - University of Lausanne Preliminary notes Presentation designed for a novice audience Text mining = text analysis = text analytics: using computational and quantitative
Manning Chapter: Text Retrieval (Selections) Text Retrieval Tasks. Vorhees & Harman (Bulkpack) Evaluation The Vector Space Model Advanced Techniques
 Text Retrieval Tasks. Vorhees & Harman (Bulkpack) Evaluation The Vector Space Model Advanced Techniques") Text Retrieval Readings Introduction Manning Chapter: Text Retrieval (Selections) Text Retrieval Tasks Vorhees & Harman (Bulkpack) Evaluation The Vector Space Model Advanced Techniues 1 2 Text Retrieval:
Text Retrieval Readings Introduction Manning Chapter: Text Retrieval (Selections) Text Retrieval Tasks Vorhees & Harman (Bulkpack) Evaluation The Vector Space Model Advanced Techniues 1 2 Text Retrieval:
MIRACLE at ImageCLEFmed 2008: Evaluating Strategies for Automatic Topic Expansion
 MIRACLE at ImageCLEFmed 2008: Evaluating Strategies for Automatic Topic Expansion Sara Lana-Serrano 1,3, Julio Villena-Román 2,3, José C. González-Cristóbal 1,3 1 Universidad Politécnica de Madrid 2 Universidad
MIRACLE at ImageCLEFmed 2008: Evaluating Strategies for Automatic Topic Expansion Sara Lana-Serrano 1,3, Julio Villena-Román 2,3, José C. González-Cristóbal 1,3 1 Universidad Politécnica de Madrid 2 Universidad
RLAT Rapid Language Adaptation Toolkit
 RLAT Rapid Language Adaptation Toolkit Tim Schlippe May 15, 2012 RLAT Rapid Language Adaptation Toolkit - 2 RLAT Rapid Language Adaptation Toolkit RLAT Rapid Language Adaptation Toolkit - 3 Outline Introduction
RLAT Rapid Language Adaptation Toolkit Tim Schlippe May 15, 2012 RLAT Rapid Language Adaptation Toolkit - 2 RLAT Rapid Language Adaptation Toolkit RLAT Rapid Language Adaptation Toolkit - 3 Outline Introduction
Implementing a Variety of Linguistic Annotations
 Implementing a Variety of Linguistic Annotations through a Common Web-Service Interface Adam Funk, Ian Roberts, Wim Peters University of Sheffield 18 May 2010 Adam Funk, Ian Roberts, Wim Peters Implementing
Implementing a Variety of Linguistic Annotations through a Common Web-Service Interface Adam Funk, Ian Roberts, Wim Peters University of Sheffield 18 May 2010 Adam Funk, Ian Roberts, Wim Peters Implementing
Modeling Linguistic Research Data for a Repository for Historical Corpora. Carolin Odebrecht Humboldt-Universität zu Berlin LAUDATIO-repository.
 Modeling Linguistic Research Data for a Repository for Historical Corpora Carolin Odebrecht Humboldt-Universität zu Berlin LAUDATIO-repository.org Motivation to enable the search for, the access of and
Modeling Linguistic Research Data for a Repository for Historical Corpora Carolin Odebrecht Humboldt-Universität zu Berlin LAUDATIO-repository.org Motivation to enable the search for, the access of and
Wikipedia and the Web of Confusable Entities: Experience from Entity Linking Query Creation for TAC 2009 Knowledge Base Population
 Wikipedia and the Web of Confusable Entities: Experience from Entity Linking Query Creation for TAC 2009 Knowledge Base Population Heather Simpson 1, Stephanie Strassel 1, Robert Parker 1, Paul McNamee
Wikipedia and the Web of Confusable Entities: Experience from Entity Linking Query Creation for TAC 2009 Knowledge Base Population Heather Simpson 1, Stephanie Strassel 1, Robert Parker 1, Paul McNamee
WASA: A Web Application for Sequence Annotation
 WASA: A Web Application for Sequence Annotation Fahad AlGhamdi, and Mona Diab Department of Computer Science The George Washington University Washington, DC {fghamdi, mtdiab}@gwu.edu Abstract Data annotation
WASA: A Web Application for Sequence Annotation Fahad AlGhamdi, and Mona Diab Department of Computer Science The George Washington University Washington, DC {fghamdi, mtdiab}@gwu.edu Abstract Data annotation
Syntax Analysis. Chapter 4
 Syntax Analysis Chapter 4 Check (Important) http://www.engineersgarage.com/contributio n/difference-between-compiler-andinterpreter Introduction covers the major parsing methods that are typically used
Syntax Analysis Chapter 4 Check (Important) http://www.engineersgarage.com/contributio n/difference-between-compiler-andinterpreter Introduction covers the major parsing methods that are typically used
Text Mining. Representation of Text Documents
 Data Mining is typically concerned with the detection of patterns in numeric data, but very often important (e.g., critical to business) information is stored in the form of text. Unlike numeric data,
Data Mining is typically concerned with the detection of patterns in numeric data, but very often important (e.g., critical to business) information is stored in the form of text. Unlike numeric data,
Making Sense Out of the Web
 Making Sense Out of the Web Rada Mihalcea University of North Texas Department of Computer Science rada@cs.unt.edu Abstract. In the past few years, we have witnessed a tremendous growth of the World Wide
Making Sense Out of the Web Rada Mihalcea University of North Texas Department of Computer Science rada@cs.unt.edu Abstract. In the past few years, we have witnessed a tremendous growth of the World Wide
Linked Data and cultural heritage data: an overview of the approaches from Europeana and The European Library
 Linked Data and cultural heritage data: an overview of the approaches from Europeana and The European Library Nuno Freire Chief data officer The European Library Pacific Neighbourhood Consortium 2014 Annual
Linked Data and cultural heritage data: an overview of the approaches from Europeana and The European Library Nuno Freire Chief data officer The European Library Pacific Neighbourhood Consortium 2014 Annual
An Architecture for Editing Complex Digital Documents
 An Architecture for Editing Complex Digital Documents Tomaž Erjavec Dept. of Knowledge Technologies Jožef Stefan Institute Jamova cesta 39, Ljubljana, Slovenia tomaz.erjavec@ijs.si Summary In several on-going
An Architecture for Editing Complex Digital Documents Tomaž Erjavec Dept. of Knowledge Technologies Jožef Stefan Institute Jamova cesta 39, Ljubljana, Slovenia tomaz.erjavec@ijs.si Summary In several on-going
Automatic Extraction of Time Expressions and Representation of Temporal Constraints
 Automatic Extraction of Time Expressions and Representation of Temporal Constraints N-GSLT: Natural Language Processing Term Paper Margus Treumuth Institute of Computer Science University of Tartu, Tartu,
Automatic Extraction of Time Expressions and Representation of Temporal Constraints N-GSLT: Natural Language Processing Term Paper Margus Treumuth Institute of Computer Science University of Tartu, Tartu,
Text mining tools for semantically enriching the scientific literature
 Text mining tools for semantically enriching the scientific literature Sophia Ananiadou Director National Centre for Text Mining School of Computer Science University of Manchester Need for enriching the
Text mining tools for semantically enriching the scientific literature Sophia Ananiadou Director National Centre for Text Mining School of Computer Science University of Manchester Need for enriching the
How to.. What is the point of it?
 Program's name: Linguistic Toolbox 3.0 α-version Short name: LIT Authors: ViatcheslavYatsko, Mikhail Starikov Platform: Windows System requirements: 1 GB free disk space, 512 RAM,.Net Farmework Supported
Program's name: Linguistic Toolbox 3.0 α-version Short name: LIT Authors: ViatcheslavYatsko, Mikhail Starikov Platform: Windows System requirements: 1 GB free disk space, 512 RAM,.Net Farmework Supported
A Short Introduction to CATMA
 A Short Introduction to CATMA Outline: I. Getting Started II. Analyzing Texts - Search Queries in CATMA III. Annotating Texts (collaboratively) with CATMA IV. Further Search Queries: Analyze Your Annotations
A Short Introduction to CATMA Outline: I. Getting Started II. Analyzing Texts - Search Queries in CATMA III. Annotating Texts (collaboratively) with CATMA IV. Further Search Queries: Analyze Your Annotations
Sustainability of Text-Technological Resources
 Sustainability of Text-Technological Resources Maik Stührenberg, Michael Beißwenger, Kai-Uwe Kühnberger, Harald Lüngen, Alexander Mehler, Dieter Metzing, Uwe Mönnich Research Group Text-Technological Overview
Sustainability of Text-Technological Resources Maik Stührenberg, Michael Beißwenger, Kai-Uwe Kühnberger, Harald Lüngen, Alexander Mehler, Dieter Metzing, Uwe Mönnich Research Group Text-Technological Overview
AUTOMATIC DIALOG ACT CORPUS CREATION FROM WEB PAGES
 AUTOMATIC DIALOG ACT CORPUS CREATION FROM WEB PAGES Pavel Král Department of Computer Science and Engineering, University of West Bohemia, Plzeň, Czech Republic pkral@kiv.zcu.cz Christophe Cerisara LORIA
AUTOMATIC DIALOG ACT CORPUS CREATION FROM WEB PAGES Pavel Král Department of Computer Science and Engineering, University of West Bohemia, Plzeň, Czech Republic pkral@kiv.zcu.cz Christophe Cerisara LORIA
Benedikt Perak, * Filip Rodik,
 Building a corpus of the Croatian parliamentary debates using UDPipe open source NLP tools and Neo4j graph database for creation of social ontology model, text classification and extraction of semantic
Building a corpus of the Croatian parliamentary debates using UDPipe open source NLP tools and Neo4j graph database for creation of social ontology model, text classification and extraction of semantic
Natural Language Processing Pipelines to Annotate BioC Collections with an Application to the NCBI Disease Corpus
 Natural Language Processing Pipelines to Annotate BioC Collections with an Application to the NCBI Disease Corpus Donald C. Comeau *, Haibin Liu, Rezarta Islamaj Doğan and W. John Wilbur National Center
Natural Language Processing Pipelines to Annotate BioC Collections with an Application to the NCBI Disease Corpus Donald C. Comeau *, Haibin Liu, Rezarta Islamaj Doğan and W. John Wilbur National Center
Corpus Linguistics. Seminar Resources for Computational Linguists SS Magdalena Wolska & Michaela Regneri
 Seminar Resources for Computational Linguists SS 2007 Magdalena Wolska & Michaela Regneri Armchair Linguists vs. Corpus Linguists Competence Performance 2 Motivation (for ) 3 Outline Corpora Annotation
Seminar Resources for Computational Linguists SS 2007 Magdalena Wolska & Michaela Regneri Armchair Linguists vs. Corpus Linguists Competence Performance 2 Motivation (for ) 3 Outline Corpora Annotation