In Between 3D Active Appearance Models and 3D Morphable Models
|
|
|
- Gervais Hawkins
- 5 years ago
- Views:
Transcription
1 In Between 3D Active Appearance Models and 3D Morphable Models Jingu Heo and Marios Savvides Biometrics Lab, CyLab Carnegie Mellon University Pittsburgh, PA Abstract In this paper we propose a novel method of generating 3D Morphable Models (3DMMs) from 2D images. We develop algorithms of 3D face reconstruction from a sparse set of points acquired from 2D images. In order to establish correspondence between images precisely, we Combined Active Shape Models (ASMs) and Active Appearance Models (AAMs)(CASAAMs) in an intelligent way, showing improved performance on pixel-level accuracy and generalization to unseen faces. The CASAAMs are applied to the images of different views of the same person to extract facial shapes across pose. These 2D shapes are combined for reconstructing a sparse 3D model. The point density of the model is increased by the Loop subdivision method, which generates new vertices by a weighted sum of the existing vertices. Then, the depth of the dense 3D model is modified with an average 3D depth-map in order to preserve facial structure more realistically. Finally, all 249 3D models with expression changes are combined to generate a 3DMM for a compact representation. The first session of the Multi-PIE database, consisting of 249 persons with expression and illumination changes, is used for the modeling. Unlike typical 3DMMs, our model can generate 3D human faces more realistically and efficiently (2-3 seconds on P4 machine) under diverse illumination conditions. I.. Introduction Modeling 3D faces is one of the most difficult and challenging tasks because of large variations occurred in human faces. Due to the rapid growth of 3D sensing techniques, the acquisition of 3D face images becomes easier with reasonable quality. These dense 3D geometry of human faces can be used for face recognition [5], showing the potential to overcome the conventional problems of 2D face recognition, such as pose, and illumination. However, without relying on 3D sensors, estimating 3D facial shape from single or multiple images is one of the fundamental problems of computer vision. Research fields include shape-from-shading (SFS), shape-from-stereo, shape-frommotion (SFM), and shape-from-texture. Since the earliest SFS attempted by Horn [17], numerous contributions have been made to recover shape from a gradual variations of shading in images [11] [26]. However, realistic face modeling is still difficult and the quality of the 3D faces, generated from these methods, is often unsatisfactory. In order to generate realistic 3D faces from one or several 2D images, it is often necessary to use prior knowledge of a statistical 3D face model [1] [2]. 3D Morphable Model(3DMMs) [3] have become popular in a variety of research areas including computer graphics, human computer interaction and face recognition. However, these methods are computational expensive and need manual control points. More efficient, fully automatic, realistic, and robust face modeling is desired in numerous applications, such as access control, entertainment, and video conferences, which require less user s cooperation and real-time computation. Although there are several approaches to modeling 3D face efficiently [23] [12], most of the methods require user s manual interaction, camera calibration, and strong prior knowledge of a 3D model, which might have a limited ability to model any face under various conditions. In this paper, we address the problem of generating more realistic, efficient and robust 3D models from 2D images in a fully automated way. No prior knowledge on 3D models is required except an average 3D shape. Given a set of 2D images, taken by multiple cameras or a sequence of images taken by a single camera, our goal is to generate a smooth 3D face. To achieve this, it is important to identify three challenging problems. Our algorithms are designed to solve each sub-problem accordingly. First, automatic facial alignment is the most difficult. Since SFM /09/$ IEEE 20
2 requires precise correspondence points in order to generate model accurately, an automated and accurate landmark point detector (79 points) is designed to solve this problem. Although it is desirable to establish dense correspondence between 2D images, feature detection in a detailed level is a much harder problem. Second, the reconstructed shape has a set of sparse points due to the feature detection problem in 2D images. Dense surface modeling is required in order to generate a smooth human face. The density of point is increased by using the Loop subdivision method, which generates new vertices by a weighted sum of the existing vertices. Finally, generating realistic 3DMMs is a challenging problem. The dense surface needs correction to preserve facial structure. An average shape, acquired from the USF Human-ID database [3], is used to reflect facial structure more realistically. We use a gigantic 2D image database([14]) for finding shapes in 2D images and reconstructing sparse 3D faces. Then, a 3DMM, which reflects more diverse facial variations, is modeled. This paper is organized in the following manner. Section II contains a brief review of related work. In Section III, we propose Combining Active Shape Models (ASMs) and Active Appearance Models (AAMs)(CASAAMs), which improve fitting on unseen faces as well as handling illumination, pose, and expression changes. Section IV explains the SFM method for 3D reconstruction. In Section VI, the generation of the 3DMM is addressed. Finally, we conclude our proposed work. II.. Background Model-based approaches to analyzing shapes and appearances are popular for face modeling. Active Contours (Snakes) [18], Active Shape Models [7], Active Appearance Models [6], and 3D Morphable Models(3DMMs) have been proven to be effective tools for representing shapes or appearances in a compact form. ASMs have been shown to be an effective way for analyzing the shape of objects. This shape analysis process is known as the Point Distribution Model (PDM), which is a method for representing with the mean geometry of a shape and some statistical modes of geometric variation inferred from a training set. By utilizing the shape model, ASMs iteratively deform to fit an example of shapes in new images. ASMs use local appearance models for updating shapes, while AAMs use a global appearance model, although both use the same shape model. An AAM is compromised of a shape model and an shape-free appearance (pixel intensity) model. A compact representation of training images and new images can be achieved through training and model fitting. AAMs interpret new images by minimizing the error between input images and reconstructed images using the model instance. Although ASMs and AAMs are widely used for localizing shapes, the fitting accuracy needs improvement for unseen faces, which are not shown during the training stage. We will detail this problem in Section III. Once facial feature points are established across images for the same person, a 3D face can be generated from SFM. SFM can reconstruct 3D faces defined by camera models. Orthographic, affine, weak perspective, perspective camera models are typically used in practice. For 3D faces, we assume orthographic or weak-perspective models are valid due to their efficiency. The goal of 3D reconstruction is to estimate 3D shape from a set of image point correspondences between images defined by these camera models, by minimizing the geometric error in image coordinate measurements. The Factorization algorithm achieves a Maximum Likelihood (ML) affine reconstruction under isotropic zero-mean Gaussian noise [4]. Bundle adjustment can be used for the refinement of the reconstruction which provides a true ML estimate [16]. The reconstruction based on SFM is often too sparse, since it is difficult to establish dense correspondence between images. Although corners or distinct features [21] can exist in images, typically only a few of points are well localized by current existing methods. Therefore, it is desirable to increase the density of point directly from the sparse 3D faces. Since it is widely used to represent 3D faces by triangle meshes, the density of point can be easily increased by operating on the vertices of each triangle. This scheme is known as Subdivision. Subdivision is a method in computer graphics for the approximation of a smooth surface given a set of sparse triangle meshes. Loop [20] triangle splines generalized the recurrent relations for box splines to irregular meshes. Boor et al. proposed that a smooth surface can be defined using box splines for regular meshes [10]. However, these points, generated by the subdivision methods, often do not preserve facial structure realistically. An average dense shape model, acquired from 3D scanners, is needed to correct these points. In this way, 3D faces can be synthesized by the observed depth information and prototypical facial structure at the same time. These individually generated 3D faces are combined to form a Morphable Model. AAMs and 3DMMs are quite similar in many respects. The representation space of an AAM is 2D whereas that of an 3DMM is 3D. 3D Active Appearance Models (3DAAMs) can achieve similar representations that a 3DMM can. However, 3DAAMS have difficulty in representing appearance changes due to their sparse 3D shape representations. Only 3D shape information is typically used for constraining 2D AAM shape vectors, presented in a combined 2D+3D AAM approach [24]. Since the appearance of a 3DMM is defined per each 3D vertex (point), it allows to understand image formulation of faces under 21
3 various lighting and pose variations. It may be effective to use 2D images for modeling diverse appearance changes and utilize the dense shape information at the same time. We achieve this by mapping 2D frontal images on the 3D face for each person, so that texture values are also defined in 3D. Therefore, our approach lies in between 3DAAMs and 3DMMs, which can model various appearance changes with dense 3D shape changes. III.. CASAAMs From the developments of AAMs and ASMs, we have noticed that it is the major concern of researchers [9] to find relationships among shape, texture and residual error. Although AAMs are computationally more demanding than ASMs, AAMs often tend to fit more accurately than ASMs if test images are similarly taken with a training set. If test images are deviated from training images, AAMs tend to fit poorly. This problem is addressed by several researchers [13] [19]. It is difficult to verify that which algorithms outperform others under various conditions, since the previous evaluations on ASMs and AAMs use a small database under small variations [8]. Unlike conventional methods for focusing on finding relationships for modeling, we emphasize on finding experts for dealing with different image conditions. ASMs and AAMs are compared under the same conditions, especially focusing on the generalization power with a challenging database (MPIE [14]). Only the first session is used for the experiment out of four sessions with totaling 149,400, consisting of 249 persons with 2 expressions and 15 poses under 20 different illumination conditions. View based approaches are used to identify the number of necessary views for both models. For each view, randomly chosen 5 images of the first 100 persons (5,000) are trained, all images of the rest of 149 persons are used for testing. Figure 1 shows the performance comparison of the ASMs and AAMs for testing. The ASMs have better pixel accuracy over the AAMs. Similar results are obtained for profile views. We also evaluated global ASMs vs. view based ASMs and global AAMs vs. view based AAMs by changing the number of training images. Although the global ASM is trained with 5000 images by randomly sampling different images under pose changes, no significance performance degradation is observed. Therefore, the number of the view-specific ASMs can be reduced. Only two ASMs (Frontal, Profile) are enough for handling all views. One profile ASM can handle left or right profile faces if we assume faces are symmetric. However, if the fitting accuracy is a concern, each view based ASM is preferred. On the other hand, the AAMs need more view AAMs. The global AAM cannot handle more views effectively, showing that it has difficulty in modeling appearances associated with non-linearities Fig. 1. The ASMs vs. AAMs (dashed rectangle). The ASMs achieve better performance on fitting over the AAMs. 5 facial features, such as boundary, eyes, mouth, nose, and eyebrows are evaluated separately with the mean and standard deviation respectively. caused by pose changes. In summary, the ASMs achieved a better generalization ability to unseen people, need less view based models and small training size compared to the AAMs. However, the AAMs can assist the ASMs since typical ASMs lack the ability to verify the fitting performance. Figure 2 shows an overview of the proposed approach for combining both ASMs and AAMs. By using the ASMs as an initial shape, a corresponding view-based AAM is activated based on estimated poses. The global ASM is considered an expert on locating shapes for handing view changes with less computational burden. Based on the returned shape, the goal to activate the corresponding view based AAM. Figure 3 shows the performance comparison of the CASAAMS and AAMs, in terms of pixel accuracy for unseen people in the system. Generally, the AAMs are preferred since a precise positioning of the landmark points is important for various applications, such as expression analysis and pose correction. It has been reported that AAMs need good initialization in order to converge into a good solution. If the initial shape is far deviated from the target shape, the solution tends to be stuck in a local minimum. This motivates us to develop a combined approach since the Fig. 2. The proposed work for combining the ASMs and AAMs. The Global ASM is used for better shape initialization for view based ASMs, then the AAMs are applied for final fitting. 22


4 Fig. 3. Performance comparison of the CASAAMs (dashed rectangle) vs ASMs; The ASMs are already proven to be effective enough. However, AAMs can improve the fitting and reduce the variance. shapes, returned by the ASMs, are appropriate for the initialization of the shapes for the AAMs. By removing unnecessary update steps while focusing on the spaces where the optimal solutions reside, the combined approach may improve the AAMs fitting accuracy as well. IV.. Rapid 3D Reconstruction It is well known that the 3D reconstruction problem is much easier and reliable with robust feature detectors in 2D images. An accurate and real-time facial alignment method is introduced to solve this problem in the previous section. In this section, we emphasize on how to utilize 2D observations for 3D reconstruction. A 2D or 3D shape (S) is denoted by a linear combination of the shape base vectors (S i ) through Principal Component Analysis (PCA): S = S m + p i S i (1) i=1 where the coefficients p i are the shape parameters. We use S 2xn for 2D and S 3xn for 3D, where n indicates the number of vertices. In this paper, we use n =79and all points are seen from 3D to 2D projection, thus eliminate the visibility problems [15]. We define the 2D shape matrix S 2xn as the 2D coordinates (x, y) of the n vertices: ( ) x1 x S 2xn = 2...x n. (2) y 1 y 2...y n Similarly, the 3D shape matrix can be represented by the 3D coordinates (x, y, z): x 1 x 2...x n S 3xn = y 1 y 2...y n. (3) z 1 z 2...z n The 3D reconstruction problem from multiple 2D observations is to recover the 3D shape information under noises. The 2D shape is an instance of a projection of 3D with the 2D translation vector t. This can be represented by: s 2d = Ps 3d + t (4) where s 2d = (x, y) T and s 3d = (x, y, z) T indicate each point in 2D and 3D respectively. For multiple(i) camera observations and multiple points (n), the goal of reconstruction is to minimize the overall error arg min s i 2dn (P i s 3dn + t i ) 2. (5) P i,t i,s i 3dn n,i=1 The factorization algorithm achieves the above minimization under Gaussian noise. The following measurement matrix W can be obtained by stacking the 2D observations (S 2xn ): x 1 1 x x 1 n y1 1 y2 1...y 1 n W = (6) x i 1 x i 2...x i n y1 i y2 i...yn i where each point is represented by object centered coordinate systems. The factorization algorithm can estimate S 3xn by decomposing W = P 2ix3 S3xn through Singular Value Decomposition (SVD), since the rank of W is at most 3. In addition, metric upgrade needs to be performed with additional constraints: P 2ix3 = PG, S 3xn = G 1 S (7) Fig. 4. The reconstructed sparse 3D shapes (in points) and their triangle meshes. Rigid and non-rigid 3D shapes are recovered from our approach. 5 images of the same person under pose variations with the same expression are used for each reconstruction. Total 249 3D sparse faces are reconstructed with expressions changes and these models are used for generating 3D shape base vectors for handing a variety of shape changes. where G is a matrix for correcting the shape into an Euclidean structure since the reconstruction is defined up-to any arbitrary affine transformations. There are a few non-rigid structure-from-motion algorithms [25] [22] for tracking purposes. However, given a fixed pose with multiple cameras, the orthogonality or weak-perspective reconstruction is a still efficient and valid camera model. Furthermore, in our cases, it is desirable to reconstruct 3D shapes from rigid and non-rigid separately, then later 23






















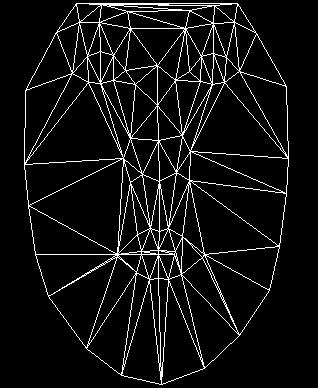

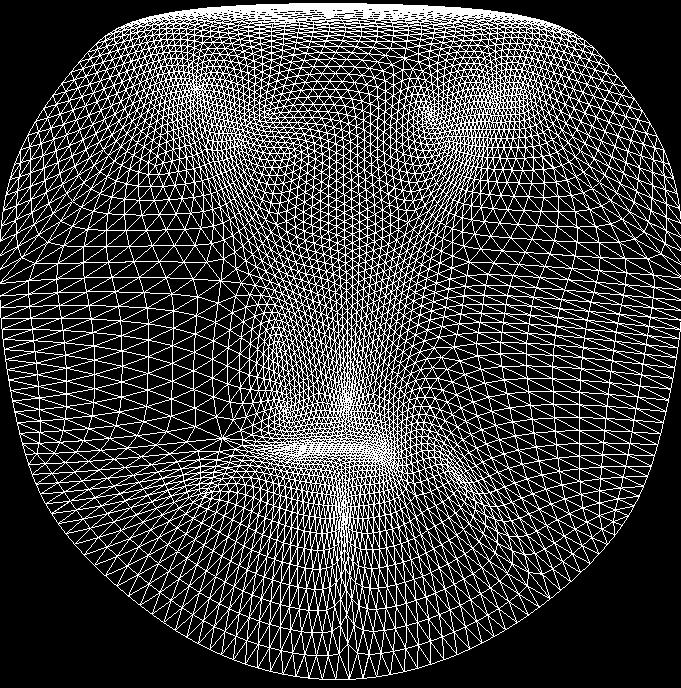

5 Fig. 6. Odd row images are original MPIE images under different poses. Even row images are the corresponding poses generated from our 3D modeling approach. Fig. 5. The reconstructed 3D faces from our proposed approach. these several models are combined to perform non-rigid behaviors. However, the dense surface, after applying subdivision, needs correction to preserve facial structure. An average shape, acquired from the USF Human-ID database [3], is used to reflect facial structure more realistically. Then, the depth of the dense 3D model is modified with an average 3D depth-map in order to preserve facial structure more realistically. Figure 5 shows the reconstructed 3D faces. The second and third column images indicate the rotated images from the images in the same row in the first column respectively. Figure 6 shows the comparison between original MPIE images and synthesized images under different pose changes. V.. In Between 3DAAMs and 3DMMs Fig. 7. The density of points is increased by the Loop subdivision method. At each iteration, new points are generated from the sparse 3D shapes (left) to more denser shapes (right). From the previous section, we focused on 3D reconstruction from a precise set of correspondence. In this section, we describe how to combine all reconstructed 3D shapes in order to represent compactly and allow non-rigid shape changes. Since each shape needs to be aligned to compute the basis, a modified version of 3D procrustes analysis is used to align different shapes under translation, rotation, and scale transformations. This aligning process is the most important step for representing all trained 3D 24
6 Fig. 8. The 3D shape and 3D texture base vectors. The upper-left image for each rectangle box indicates three largest appearance base vectors. The first images, in the second and third rows for each box, are obtained by changing the shape basis. The rotated images of the base images are shown in the second and third columns according to the first image of each box respectively. From a frontal image and a sparse 3D shape, new images under different poses and illumination can be synthesized from these base vectors. Therefore, we can achieve more compact representations of the MPIE database without modeling of non-frontal images. shapes compactly. The translational components can be simply removed by subtracting the mean of a 3D face from all the points so that the mean of all the points lies at the origin. The scale component can be removed by dividing by the norm of all the points. In addition, we use 4 feature points (the eyes (2), the center of the forehead (1), and the upper center of the lip (1)) for performing the rotation alignment. This allows us to align the 3D shapes along the the x, y, and z axis respectively. Once the 3D shapes are aligned, each shape can be represented by a linear combination of the base vectors from the eq. 1. Since the reconstructed 3D shapes are too sparse, dense surface modeling is a necessary step in order to generate a smooth human face. These dense shapes are obtained by increasing the density of points by using the Loop subdivision method. The main idea of the Loop subdivision is to add more control points iteratively. It subdivides each triangle into smaller triangles for the better approximation of the smooth surface based on a set of rules. An illustration of the subdivision method is shown in Figure 7. See [20] for details. In order to model diverse appearance changes, we use frontal images under different illumination conditions per each person. Then each image is being warped onto the 2D mean shape. Then, an appearance image can be represented by the mean and a linear combination of the base vector through PCA: m A( x) =Ā( x)+ λ i A i ( x). (8) i=1 where A( x) is the shape free image, warped onto the mean shape x and Ā( x) is the mean appearance image. λ i are the appearance parameters. Finally, each 2D texture base vector is texture-mapped onto the basis of 3D shapes after applying the subdivision method. This representation is typically used in 3DMMs, while 3DAAMs have difficulty in modeling appearance changes. Figure 8 shows three largest eigenvectors (including the mean appearance) for each 3D shape and 3D texture, where the 2D texture basis are mapped onto the 3D shape basis. By allowing more diverse changes in appearance, the 3DMM, generated from our approach, can be used for understanding of face image formulation. VI.. Conclusion In this paper, we demonstrate 3D human face reconstruction from multiple images. The CASAAMs are designed in order to establish precise correspondence between 2D images automatically. The proposed 3DMM method, generated from 2D images, can model more diverse appearance changes. Therefore, we claim that our approach lies in between 3DAAMs and 3DMMs since we can model various appearance changes with dense 3D shape changes. The computation time for our proposed 3D face method, together with feature detection, takes only 2-3 seconds, while the standard technology (3DMMs) takes 4-5 minutes with manual feature annotation. References [1] J. Atick, P. Griffin, and A. Redlich. Statistical approach to shape from shading: Reconstruction of 3d face surfaces from single 2d images. Computation in Neurological Systems, 7(1), [2] V. Blanz, S. Romdhani, and T. Vetter. Face identification across different poses and illuminations with a 3d morphable model. Proc. Fifth Int l Conf. on Automatic Face and Gesture Recognition, pages , [3] V. Blanz and T. Vetter. Face recognition based on fitting a 3d morphable model. IEEE Trans. on Pattern Analysis and Machine Intelligence, 25(9): , [4] C. T. C and T. Kanade. Shape and motion from image streams under orthography: A factorization method. Int. Journal of Computer Vision, 9(2): ,
7 [5] K. Chang, K. Bowyer, and P. Flynn. A survey of approaches and challenges in 3d and multi-modal 2d+3d face recognition. Computer Vision and Image Understanding, 101(1):1 15, [6] T. Cootes, G. Edwards, and C. Taylor. Active appearance models. roc. of the European Conf. on Computer Vision, 2: , [7] T. Cootes, C. Taylor, D. Cooper, and J. Graham. Active shape models: Their training and application. Computer Vision and Image Understanding, 61(1):38 59, [8] T. F. Cootes, G. Edwards, and C. J. Taylor. Comparing active shape models with active appearance models. British Machine Vision Conf., 1: , [9] T. F. Cootes, G. J. Edwards, and C. J. Taylor. A comparative evaluation of active appearance model algorithms. IEEE Trans. on Pattern Analysis and Machine Intelligence, 2: , [10] C. de Boor, K. Hollig, and S. D. Riemenschneider. Box splines, Springer Verlag. [11] J. D. Durou, M. Falcone, and M. Sagona. survey of numerical methods for shape from shading, Technical Report R, IRIT. [12] D. Fidaleo and G. Medioni. Model-assisted 3d face reconstruction from video. IEEE Intl Workshop on Analysis and Modeling of Faces and Gestures (AMFG), pages , [13] R. Gross, I. Matthews,, and S. Baker. Appearance-based face recognition and light-fields. IEEE Trans. on Pattern Analysis and Machine Intelligence, 26(4): , [14] R. Gross, I. Matthews, J. Cohn, T. Kanade, and S. Baker. Multi-pie. Proc. of Int l Conf. on Automatic Face and Gesture Recognition, [15] L. Gu and T. Kanade. 3d alighment of face in a single image. In Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, [16] R. Hartley and A. Zisserman. Multiple view geometry in computer vision. Cambridge University Press, [17] B. K. P. Horn. Shape from shading: A method for obtaining the shape of a smooth opaque object from one view, PhD thesis, MIT. [18] M. Kass, A. Witkin, and D. Terzopoulos. Snakes: Active contour models. Int l Conf. on Computer Vision, pages , [19] X. Liu. Generic face alignment using boosted appearance model. n Proc. of the IEEE Computer Society Conf. on Computer Vision and Pattern Recognition, [20] C. T. Loop. Smooth subdivision surfaces based on triangles, M.S. Thesis, Department of Mathematics, University of Utah. [21] J. Shi and C. Tomasi. Good features to track. IEEE Conf. Computer Vision and Pattern Recognition, [22] L. Torresani, A. Hertzmann, and C. Bregler. Learning non-rigid 3d shape from 2d motion. In: Proc. Neural Information Processing Systems (NIPS), 16, [23] S. Wang and S. H. Lai. Efficient 3d face reconstruction from a single 2d image by combining statistical and geometrical information. Asian Conference on Computer Vision, pages , [24] J. Xiao, S. Baker, I. Matthews, R. Gross, and T. Kanade. Realtime combined 2d+3d active appearance model. In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition, pages , [25] J. Xiao, J. Chai, and T. Kanade. Closed-form solution to nonrigid shape and motion recovery. In Proc. European Conference on Computer Vision, pages , [26] R. Zhang, P. S. Tsai, J. E. Cryer, and M. Shah. Shape from shading: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 21(8): ,
Rapid 3D Face Modeling using a Frontal Face and a Profile Face for Accurate 2D Pose Synthesis
 Rapid 3D Face Modeling using a Frontal Face and a Profile Face for Accurate 2D Pose Synthesis Jingu Heo and Marios Savvides CyLab Biometrics Center Carnegie Mellon University Pittsburgh, PA 15213 jheo@cmu.edu,
Rapid 3D Face Modeling using a Frontal Face and a Profile Face for Accurate 2D Pose Synthesis Jingu Heo and Marios Savvides CyLab Biometrics Center Carnegie Mellon University Pittsburgh, PA 15213 jheo@cmu.edu,
Nonrigid Surface Modelling. and Fast Recovery. Department of Computer Science and Engineering. Committee: Prof. Leo J. Jia and Prof. K. H.
 Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Face Recognition At-a-Distance Based on Sparse-Stereo Reconstruction
 Face Recognition At-a-Distance Based on Sparse-Stereo Reconstruction Ham Rara, Shireen Elhabian, Asem Ali University of Louisville Louisville, KY {hmrara01,syelha01,amali003}@louisville.edu Mike Miller,
Face Recognition At-a-Distance Based on Sparse-Stereo Reconstruction Ham Rara, Shireen Elhabian, Asem Ali University of Louisville Louisville, KY {hmrara01,syelha01,amali003}@louisville.edu Mike Miller,
On the Dimensionality of Deformable Face Models
 On the Dimensionality of Deformable Face Models CMU-RI-TR-06-12 Iain Matthews, Jing Xiao, and Simon Baker The Robotics Institute Carnegie Mellon University 5000 Forbes Avenue Pittsburgh, PA 15213 Abstract
On the Dimensionality of Deformable Face Models CMU-RI-TR-06-12 Iain Matthews, Jing Xiao, and Simon Baker The Robotics Institute Carnegie Mellon University 5000 Forbes Avenue Pittsburgh, PA 15213 Abstract
Multi-View AAM Fitting and Camera Calibration
 To appear in the IEEE International Conference on Computer Vision Multi-View AAM Fitting and Camera Calibration Seth Koterba, Simon Baker, Iain Matthews, Changbo Hu, Jing Xiao, Jeffrey Cohn, and Takeo
To appear in the IEEE International Conference on Computer Vision Multi-View AAM Fitting and Camera Calibration Seth Koterba, Simon Baker, Iain Matthews, Changbo Hu, Jing Xiao, Jeffrey Cohn, and Takeo
Generic 3D Face Pose Estimation using Facial Shapes
 Generic 3D Face Pose Estimation using Facial Shapes Jingu Heo CyLab Biometrics Center Carnegie Mellon University 5000 Forbes Ave, Pittsburgh, PA 15213 jheo@cmu.edu Marios Savvides CyLab Biometrics Center
Generic 3D Face Pose Estimation using Facial Shapes Jingu Heo CyLab Biometrics Center Carnegie Mellon University 5000 Forbes Ave, Pittsburgh, PA 15213 jheo@cmu.edu Marios Savvides CyLab Biometrics Center
Occluded Facial Expression Tracking
 Occluded Facial Expression Tracking Hugo Mercier 1, Julien Peyras 2, and Patrice Dalle 1 1 Institut de Recherche en Informatique de Toulouse 118, route de Narbonne, F-31062 Toulouse Cedex 9 2 Dipartimento
Occluded Facial Expression Tracking Hugo Mercier 1, Julien Peyras 2, and Patrice Dalle 1 1 Institut de Recherche en Informatique de Toulouse 118, route de Narbonne, F-31062 Toulouse Cedex 9 2 Dipartimento
3D Active Appearance Model for Aligning Faces in 2D Images
 3D Active Appearance Model for Aligning Faces in 2D Images Chun-Wei Chen and Chieh-Chih Wang Abstract Perceiving human faces is one of the most important functions for human robot interaction. The active
3D Active Appearance Model for Aligning Faces in 2D Images Chun-Wei Chen and Chieh-Chih Wang Abstract Perceiving human faces is one of the most important functions for human robot interaction. The active
Fitting a Single Active Appearance Model Simultaneously to Multiple Images
 Fitting a Single Active Appearance Model Simultaneously to Multiple Images Changbo Hu, Jing Xiao, Iain Matthews, Simon Baker, Jeff Cohn, and Takeo Kanade The Robotics Institute, Carnegie Mellon University
Fitting a Single Active Appearance Model Simultaneously to Multiple Images Changbo Hu, Jing Xiao, Iain Matthews, Simon Baker, Jeff Cohn, and Takeo Kanade The Robotics Institute, Carnegie Mellon University
Face Tracking. Synonyms. Definition. Main Body Text. Amit K. Roy-Chowdhury and Yilei Xu. Facial Motion Estimation
 Face Tracking Amit K. Roy-Chowdhury and Yilei Xu Department of Electrical Engineering, University of California, Riverside, CA 92521, USA {amitrc,yxu}@ee.ucr.edu Synonyms Facial Motion Estimation Definition
Face Tracking Amit K. Roy-Chowdhury and Yilei Xu Department of Electrical Engineering, University of California, Riverside, CA 92521, USA {amitrc,yxu}@ee.ucr.edu Synonyms Facial Motion Estimation Definition
Image Coding with Active Appearance Models
 Image Coding with Active Appearance Models Simon Baker, Iain Matthews, and Jeff Schneider CMU-RI-TR-03-13 The Robotics Institute Carnegie Mellon University Abstract Image coding is the task of representing
Image Coding with Active Appearance Models Simon Baker, Iain Matthews, and Jeff Schneider CMU-RI-TR-03-13 The Robotics Institute Carnegie Mellon University Abstract Image coding is the task of representing
2D vs. 3D Deformable Face Models: Representational Power, Construction, and Real-Time Fitting
 2D vs. 3D Deformable Face Models: Representational Power, Construction, and Real-Time Fitting Iain Matthews, Jing Xiao, and Simon Baker The Robotics Institute, Carnegie Mellon University Epsom PAL, Epsom
2D vs. 3D Deformable Face Models: Representational Power, Construction, and Real-Time Fitting Iain Matthews, Jing Xiao, and Simon Baker The Robotics Institute, Carnegie Mellon University Epsom PAL, Epsom
Generic Face Alignment Using an Improved Active Shape Model
 Generic Face Alignment Using an Improved Active Shape Model Liting Wang, Xiaoqing Ding, Chi Fang Electronic Engineering Department, Tsinghua University, Beijing, China {wanglt, dxq, fangchi} @ocrserv.ee.tsinghua.edu.cn
Generic Face Alignment Using an Improved Active Shape Model Liting Wang, Xiaoqing Ding, Chi Fang Electronic Engineering Department, Tsinghua University, Beijing, China {wanglt, dxq, fangchi} @ocrserv.ee.tsinghua.edu.cn
Real-time non-rigid driver head tracking for driver mental state estimation
 Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 2004 Real-time non-rigid driver head tracking for driver mental state estimation Simon Baker Carnegie Mellon
Carnegie Mellon University Research Showcase @ CMU Robotics Institute School of Computer Science 2004 Real-time non-rigid driver head tracking for driver mental state estimation Simon Baker Carnegie Mellon
Active Appearance Models
 Active Appearance Models Edwards, Taylor, and Cootes Presented by Bryan Russell Overview Overview of Appearance Models Combined Appearance Models Active Appearance Model Search Results Constrained Active
Active Appearance Models Edwards, Taylor, and Cootes Presented by Bryan Russell Overview Overview of Appearance Models Combined Appearance Models Active Appearance Model Search Results Constrained Active
Abstract We present a system which automatically generates a 3D face model from a single frontal image of a face. Our system consists of two component
 A Fully Automatic System To Model Faces From a Single Image Zicheng Liu Microsoft Research August 2003 Technical Report MSR-TR-2003-55 Microsoft Research Microsoft Corporation One Microsoft Way Redmond,
A Fully Automatic System To Model Faces From a Single Image Zicheng Liu Microsoft Research August 2003 Technical Report MSR-TR-2003-55 Microsoft Research Microsoft Corporation One Microsoft Way Redmond,
Automatic Construction of Active Appearance Models as an Image Coding Problem
 Automatic Construction of Active Appearance Models as an Image Coding Problem Simon Baker, Iain Matthews, and Jeff Schneider The Robotics Institute Carnegie Mellon University Pittsburgh, PA 1213 Abstract
Automatic Construction of Active Appearance Models as an Image Coding Problem Simon Baker, Iain Matthews, and Jeff Schneider The Robotics Institute Carnegie Mellon University Pittsburgh, PA 1213 Abstract
Face Alignment Under Various Poses and Expressions
 Face Alignment Under Various Poses and Expressions Shengjun Xin and Haizhou Ai Computer Science and Technology Department, Tsinghua University, Beijing 100084, China ahz@mail.tsinghua.edu.cn Abstract.
Face Alignment Under Various Poses and Expressions Shengjun Xin and Haizhou Ai Computer Science and Technology Department, Tsinghua University, Beijing 100084, China ahz@mail.tsinghua.edu.cn Abstract.
An Adaptive Eigenshape Model
 An Adaptive Eigenshape Model Adam Baumberg and David Hogg School of Computer Studies University of Leeds, Leeds LS2 9JT, U.K. amb@scs.leeds.ac.uk Abstract There has been a great deal of recent interest
An Adaptive Eigenshape Model Adam Baumberg and David Hogg School of Computer Studies University of Leeds, Leeds LS2 9JT, U.K. amb@scs.leeds.ac.uk Abstract There has been a great deal of recent interest
DISTANCE MAPS: A ROBUST ILLUMINATION PREPROCESSING FOR ACTIVE APPEARANCE MODELS
 DISTANCE MAPS: A ROBUST ILLUMINATION PREPROCESSING FOR ACTIVE APPEARANCE MODELS Sylvain Le Gallou*, Gaspard Breton*, Christophe Garcia*, Renaud Séguier** * France Telecom R&D - TECH/IRIS 4 rue du clos
DISTANCE MAPS: A ROBUST ILLUMINATION PREPROCESSING FOR ACTIVE APPEARANCE MODELS Sylvain Le Gallou*, Gaspard Breton*, Christophe Garcia*, Renaud Séguier** * France Telecom R&D - TECH/IRIS 4 rue du clos
Passive 3D Photography
 SIGGRAPH 2000 Course on 3D Photography Passive 3D Photography Steve Seitz Carnegie Mellon University University of Washington http://www.cs cs.cmu.edu/~ /~seitz Visual Cues Shading Merle Norman Cosmetics,
SIGGRAPH 2000 Course on 3D Photography Passive 3D Photography Steve Seitz Carnegie Mellon University University of Washington http://www.cs cs.cmu.edu/~ /~seitz Visual Cues Shading Merle Norman Cosmetics,
An Active Illumination and Appearance (AIA) Model for Face Alignment
 Model for Face Alignment") An Active Illumination and Appearance (AIA) Model for Face Alignment Fatih Kahraman, Muhittin Gokmen Istanbul Technical University, Computer Science Dept., Turkey {fkahraman, gokmen}@itu.edu.tr Sune Darkner,
An Active Illumination and Appearance (AIA) Model for Face Alignment Fatih Kahraman, Muhittin Gokmen Istanbul Technical University, Computer Science Dept., Turkey {fkahraman, gokmen}@itu.edu.tr Sune Darkner,
AAM Based Facial Feature Tracking with Kinect
 BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 15, No 3 Sofia 2015 Print ISSN: 1311-9702; Online ISSN: 1314-4081 DOI: 10.1515/cait-2015-0046 AAM Based Facial Feature Tracking
BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 15, No 3 Sofia 2015 Print ISSN: 1311-9702; Online ISSN: 1314-4081 DOI: 10.1515/cait-2015-0046 AAM Based Facial Feature Tracking
REAL-TIME FACE SWAPPING IN VIDEO SEQUENCES: MAGIC MIRROR
 REAL-TIME FACE SWAPPING IN VIDEO SEQUENCES: MAGIC MIRROR Nuri Murat Arar1, Fatma Gu ney1, Nasuh Kaan Bekmezci1, Hua Gao2 and Hazım Kemal Ekenel1,2,3 1 Department of Computer Engineering, Bogazici University,
REAL-TIME FACE SWAPPING IN VIDEO SEQUENCES: MAGIC MIRROR Nuri Murat Arar1, Fatma Gu ney1, Nasuh Kaan Bekmezci1, Hua Gao2 and Hazım Kemal Ekenel1,2,3 1 Department of Computer Engineering, Bogazici University,
Facial Recognition Using Active Shape Models, Local Patches and Support Vector Machines
 Facial Recognition Using Active Shape Models, Local Patches and Support Vector Machines Utsav Prabhu ECE Department Carnegie Mellon University 5000 Forbes Avenue Pittsburgh, PA-15213 uprabhu@andrew.cmu.edu
Facial Recognition Using Active Shape Models, Local Patches and Support Vector Machines Utsav Prabhu ECE Department Carnegie Mellon University 5000 Forbes Avenue Pittsburgh, PA-15213 uprabhu@andrew.cmu.edu
Factorization Method Using Interpolated Feature Tracking via Projective Geometry
 Factorization Method Using Interpolated Feature Tracking via Projective Geometry Hideo Saito, Shigeharu Kamijima Department of Information and Computer Science, Keio University Yokohama-City, 223-8522,
Factorization Method Using Interpolated Feature Tracking via Projective Geometry Hideo Saito, Shigeharu Kamijima Department of Information and Computer Science, Keio University Yokohama-City, 223-8522,
Categorization by Learning and Combining Object Parts
 Categorization by Learning and Combining Object Parts Bernd Heisele yz Thomas Serre y Massimiliano Pontil x Thomas Vetter Λ Tomaso Poggio y y Center for Biological and Computational Learning, M.I.T., Cambridge,
Categorization by Learning and Combining Object Parts Bernd Heisele yz Thomas Serre y Massimiliano Pontil x Thomas Vetter Λ Tomaso Poggio y y Center for Biological and Computational Learning, M.I.T., Cambridge,
Using the Orthographic Projection Model to Approximate the Perspective Projection Model for 3D Facial Reconstruction
 Using the Orthographic Projection Model to Approximate the Perspective Projection Model for 3D Facial Reconstruction Jin-Yi Wu and Jenn-Jier James Lien Department of Computer Science and Information Engineering,
Using the Orthographic Projection Model to Approximate the Perspective Projection Model for 3D Facial Reconstruction Jin-Yi Wu and Jenn-Jier James Lien Department of Computer Science and Information Engineering,
3D Morphable Model Parameter Estimation
 3D Morphable Model Parameter Estimation Nathan Faggian 1, Andrew P. Paplinski 1, and Jamie Sherrah 2 1 Monash University, Australia, Faculty of Information Technology, Clayton 2 Clarity Visual Intelligence,
3D Morphable Model Parameter Estimation Nathan Faggian 1, Andrew P. Paplinski 1, and Jamie Sherrah 2 1 Monash University, Australia, Faculty of Information Technology, Clayton 2 Clarity Visual Intelligence,
Intensity-Depth Face Alignment Using Cascade Shape Regression
 Intensity-Depth Face Alignment Using Cascade Shape Regression Yang Cao 1 and Bao-Liang Lu 1,2 1 Center for Brain-like Computing and Machine Intelligence Department of Computer Science and Engineering Shanghai
Intensity-Depth Face Alignment Using Cascade Shape Regression Yang Cao 1 and Bao-Liang Lu 1,2 1 Center for Brain-like Computing and Machine Intelligence Department of Computer Science and Engineering Shanghai
Model-based 3D Shape Recovery from Single Images of Unknown Pose and Illumination using a Small Number of Feature Points
 Model-based 3D Shape Recovery from Single Images of Unknown Pose and Illumination using a Small Number of Feature Points Ham M. Rara and Aly A. Farag CVIP Laboratory, University of Louisville {hmrara01,
Model-based 3D Shape Recovery from Single Images of Unknown Pose and Illumination using a Small Number of Feature Points Ham M. Rara and Aly A. Farag CVIP Laboratory, University of Louisville {hmrara01,
Parametric Manifold of an Object under Different Viewing Directions
 Parametric Manifold of an Object under Different Viewing Directions Xiaozheng Zhang 1,2, Yongsheng Gao 1,2, and Terry Caelli 3 1 Biosecurity Group, Queensland Research Laboratory, National ICT Australia
Parametric Manifold of an Object under Different Viewing Directions Xiaozheng Zhang 1,2, Yongsheng Gao 1,2, and Terry Caelli 3 1 Biosecurity Group, Queensland Research Laboratory, National ICT Australia
Face View Synthesis Across Large Angles
 Face View Synthesis Across Large Angles Jiang Ni and Henry Schneiderman Robotics Institute, Carnegie Mellon University, Pittsburgh, PA 1513, USA Abstract. Pose variations, especially large out-of-plane
Face View Synthesis Across Large Angles Jiang Ni and Henry Schneiderman Robotics Institute, Carnegie Mellon University, Pittsburgh, PA 1513, USA Abstract. Pose variations, especially large out-of-plane
A Survey of Light Source Detection Methods
 A Survey of Light Source Detection Methods Nathan Funk University of Alberta Mini-Project for CMPUT 603 November 30, 2003 Abstract This paper provides an overview of the most prominent techniques for light
A Survey of Light Source Detection Methods Nathan Funk University of Alberta Mini-Project for CMPUT 603 November 30, 2003 Abstract This paper provides an overview of the most prominent techniques for light
Non-Rigid Shape and Motion Recovery: Degenerate Deformations
 Non-Rigid Shape and Motion Recovery: Degenerate Deformations Jing Xiao Takeo Kanade The Robotics Institute Carnegie Mellon University Pittsburgh, PA 15213 {jxiao, tk}@cscmuedu Abstract This paper studies
Non-Rigid Shape and Motion Recovery: Degenerate Deformations Jing Xiao Takeo Kanade The Robotics Institute Carnegie Mellon University Pittsburgh, PA 15213 {jxiao, tk}@cscmuedu Abstract This paper studies
CS 664 Structure and Motion. Daniel Huttenlocher
 CS 664 Structure and Motion Daniel Huttenlocher Determining 3D Structure Consider set of 3D points X j seen by set of cameras with projection matrices P i Given only image coordinates x ij of each point
CS 664 Structure and Motion Daniel Huttenlocher Determining 3D Structure Consider set of 3D points X j seen by set of cameras with projection matrices P i Given only image coordinates x ij of each point
Robust Model-Free Tracking of Non-Rigid Shape. Abstract
 Robust Model-Free Tracking of Non-Rigid Shape Lorenzo Torresani Stanford University ltorresa@cs.stanford.edu Christoph Bregler New York University chris.bregler@nyu.edu New York University CS TR2003-840
Robust Model-Free Tracking of Non-Rigid Shape Lorenzo Torresani Stanford University ltorresa@cs.stanford.edu Christoph Bregler New York University chris.bregler@nyu.edu New York University CS TR2003-840
Face analysis : identity vs. expressions
 Face analysis : identity vs. expressions Hugo Mercier 1,2 Patrice Dalle 1 1 IRIT - Université Paul Sabatier 118 Route de Narbonne, F-31062 Toulouse Cedex 9, France 2 Websourd 3, passage André Maurois -
Face analysis : identity vs. expressions Hugo Mercier 1,2 Patrice Dalle 1 1 IRIT - Université Paul Sabatier 118 Route de Narbonne, F-31062 Toulouse Cedex 9, France 2 Websourd 3, passage André Maurois -
Human pose estimation using Active Shape Models
 Human pose estimation using Active Shape Models Changhyuk Jang and Keechul Jung Abstract Human pose estimation can be executed using Active Shape Models. The existing techniques for applying to human-body
Human pose estimation using Active Shape Models Changhyuk Jang and Keechul Jung Abstract Human pose estimation can be executed using Active Shape Models. The existing techniques for applying to human-body
Illumination invariant face recognition and impostor rejection using different MINACE filter algorithms
 Illumination invariant face recognition and impostor rejection using different MINACE filter algorithms Rohit Patnaik and David Casasent Dept. of Electrical and Computer Engineering, Carnegie Mellon University,
Illumination invariant face recognition and impostor rejection using different MINACE filter algorithms Rohit Patnaik and David Casasent Dept. of Electrical and Computer Engineering, Carnegie Mellon University,
Perception and Action using Multilinear Forms
 Perception and Action using Multilinear Forms Anders Heyden, Gunnar Sparr, Kalle Åström Dept of Mathematics, Lund University Box 118, S-221 00 Lund, Sweden email: {heyden,gunnar,kalle}@maths.lth.se Abstract
Perception and Action using Multilinear Forms Anders Heyden, Gunnar Sparr, Kalle Åström Dept of Mathematics, Lund University Box 118, S-221 00 Lund, Sweden email: {heyden,gunnar,kalle}@maths.lth.se Abstract
On Modeling Variations for Face Authentication
 On Modeling Variations for Face Authentication Xiaoming Liu Tsuhan Chen B.V.K. Vijaya Kumar Department of Electrical and Computer Engineering, Carnegie Mellon University, Pittsburgh, PA 15213 xiaoming@andrew.cmu.edu
On Modeling Variations for Face Authentication Xiaoming Liu Tsuhan Chen B.V.K. Vijaya Kumar Department of Electrical and Computer Engineering, Carnegie Mellon University, Pittsburgh, PA 15213 xiaoming@andrew.cmu.edu
Lecture 10: Multi view geometry
 Lecture 10: Multi view geometry Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Stereo vision Correspondence problem (Problem Set 2 (Q3)) Active stereo vision systems Structure from
Lecture 10: Multi view geometry Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Stereo vision Correspondence problem (Problem Set 2 (Q3)) Active stereo vision systems Structure from
Face Image Synthesis and Interpretation Using 3D Illumination-Based AAM Models
 Face Image Synthesis and Interpretation Using 3D Illumination-Based AAM Models 40 Salvador E. Ayala-Raggi, Leopoldo Altamirano-Robles and Janeth Cruz-Enriquez Instituto Nacional de Astrofísica Óptica y
Face Image Synthesis and Interpretation Using 3D Illumination-Based AAM Models 40 Salvador E. Ayala-Raggi, Leopoldo Altamirano-Robles and Janeth Cruz-Enriquez Instituto Nacional de Astrofísica Óptica y
NON-RIGID 3D SHAPE RECOVERY USING STEREO FACTORIZATION
 NON-IGID D SHAPE ECOVEY USING STEEO FACTOIZATION Alessio Del Bue ourdes Agapito Department of Computer Science Queen Mary, University of ondon ondon, E1 NS, UK falessio,lourdesg@dcsqmulacuk ABSTACT In
NON-IGID D SHAPE ECOVEY USING STEEO FACTOIZATION Alessio Del Bue ourdes Agapito Department of Computer Science Queen Mary, University of ondon ondon, E1 NS, UK falessio,lourdesg@dcsqmulacuk ABSTACT In
Stereo Vision. MAN-522 Computer Vision
 Stereo Vision MAN-522 Computer Vision What is the goal of stereo vision? The recovery of the 3D structure of a scene using two or more images of the 3D scene, each acquired from a different viewpoint in
Stereo Vision MAN-522 Computer Vision What is the goal of stereo vision? The recovery of the 3D structure of a scene using two or more images of the 3D scene, each acquired from a different viewpoint in
Active Wavelet Networks for Face Alignment
 Active Wavelet Networks for Face Alignment Changbo Hu, Rogerio Feris, Matthew Turk Dept. Computer Science, University of California, Santa Barbara {cbhu,rferis,mturk}@cs.ucsb.edu Abstract The active appearance
Active Wavelet Networks for Face Alignment Changbo Hu, Rogerio Feris, Matthew Turk Dept. Computer Science, University of California, Santa Barbara {cbhu,rferis,mturk}@cs.ucsb.edu Abstract The active appearance
Increasing the Density of Active Appearance Models
 Increasing the Density of Active Appearance Models Krishnan Ramnath ObjectVideo, Inc. Simon Baker Microsoft Research Iain Matthews Weta Digital Ltd. Deva Ramanan UC Irvine Abstract Active Appearance Models
Increasing the Density of Active Appearance Models Krishnan Ramnath ObjectVideo, Inc. Simon Baker Microsoft Research Iain Matthews Weta Digital Ltd. Deva Ramanan UC Irvine Abstract Active Appearance Models
Structure from Motion. Lecture-15
 Structure from Motion Lecture-15 Shape From X Recovery of 3D (shape) from one or two (2D images). Shape From X Stereo Motion Shading Photometric Stereo Texture Contours Silhouettes Defocus Applications
Structure from Motion Lecture-15 Shape From X Recovery of 3D (shape) from one or two (2D images). Shape From X Stereo Motion Shading Photometric Stereo Texture Contours Silhouettes Defocus Applications
Learning based face hallucination techniques: A survey
 Vol. 3 (2014-15) pp. 37-45. : A survey Premitha Premnath K Department of Computer Science & Engineering Vidya Academy of Science & Technology Thrissur - 680501, Kerala, India (email: premithakpnath@gmail.com)
Vol. 3 (2014-15) pp. 37-45. : A survey Premitha Premnath K Department of Computer Science & Engineering Vidya Academy of Science & Technology Thrissur - 680501, Kerala, India (email: premithakpnath@gmail.com)
Structure from motion
 Structure from motion Structure from motion Given a set of corresponding points in two or more images, compute the camera parameters and the 3D point coordinates?? R 1,t 1 R 2,t 2 R 3,t 3 Camera 1 Camera
Structure from motion Structure from motion Given a set of corresponding points in two or more images, compute the camera parameters and the 3D point coordinates?? R 1,t 1 R 2,t 2 R 3,t 3 Camera 1 Camera
22 October, 2012 MVA ENS Cachan. Lecture 5: Introduction to generative models Iasonas Kokkinos
 Machine Learning for Computer Vision 1 22 October, 2012 MVA ENS Cachan Lecture 5: Introduction to generative models Iasonas Kokkinos Iasonas.kokkinos@ecp.fr Center for Visual Computing Ecole Centrale Paris
Machine Learning for Computer Vision 1 22 October, 2012 MVA ENS Cachan Lecture 5: Introduction to generative models Iasonas Kokkinos Iasonas.kokkinos@ecp.fr Center for Visual Computing Ecole Centrale Paris
Enhanced Active Shape Models with Global Texture Constraints for Image Analysis
 Enhanced Active Shape Models with Global Texture Constraints for Image Analysis Shiguang Shan, Wen Gao, Wei Wang, Debin Zhao, Baocai Yin Institute of Computing Technology, Chinese Academy of Sciences,
Enhanced Active Shape Models with Global Texture Constraints for Image Analysis Shiguang Shan, Wen Gao, Wei Wang, Debin Zhao, Baocai Yin Institute of Computing Technology, Chinese Academy of Sciences,
A Factorization Method for Structure from Planar Motion
 A Factorization Method for Structure from Planar Motion Jian Li and Rama Chellappa Center for Automation Research (CfAR) and Department of Electrical and Computer Engineering University of Maryland, College
A Factorization Method for Structure from Planar Motion Jian Li and Rama Chellappa Center for Automation Research (CfAR) and Department of Electrical and Computer Engineering University of Maryland, College
Segmentation and Tracking of Partial Planar Templates
 Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Segmentation and Tracking of Partial Planar Templates Abdelsalam Masoud William Hoff Colorado School of Mines Colorado School of Mines Golden, CO 800 Golden, CO 800 amasoud@mines.edu whoff@mines.edu Abstract
Meticulously Detailed Eye Model and Its Application to Analysis of Facial Image
 Meticulously Detailed Eye Model and Its Application to Analysis of Facial Image Tsuyoshi Moriyama Keio University moriyama@ozawa.ics.keio.ac.jp Jing Xiao Carnegie Mellon University jxiao@cs.cmu.edu Takeo
Meticulously Detailed Eye Model and Its Application to Analysis of Facial Image Tsuyoshi Moriyama Keio University moriyama@ozawa.ics.keio.ac.jp Jing Xiao Carnegie Mellon University jxiao@cs.cmu.edu Takeo
Learning a generic 3D face model from 2D image databases using incremental structure from motion
 Learning a generic 3D face model from 2D image databases using incremental structure from motion Jose Gonzalez-Mora 1,, Fernando De la Torre b, Nicolas Guil 1,, Emilio L. Zapata 1 a Department of Computer
Learning a generic 3D face model from 2D image databases using incremental structure from motion Jose Gonzalez-Mora 1,, Fernando De la Torre b, Nicolas Guil 1,, Emilio L. Zapata 1 a Department of Computer
arxiv: v1 [cs.cv] 28 Sep 2018
![arxiv: v1 [cs.cv] 28 Sep 2018](/thumbs/93/113542646.jpg "arxiv: v1 [cs.cv] 28 Sep 2018") Camera Pose Estimation from Sequence of Calibrated Images arxiv:1809.11066v1 [cs.cv] 28 Sep 2018 Jacek Komorowski 1 and Przemyslaw Rokita 2 1 Maria Curie-Sklodowska University, Institute of Computer Science,
Camera Pose Estimation from Sequence of Calibrated Images arxiv:1809.11066v1 [cs.cv] 28 Sep 2018 Jacek Komorowski 1 and Przemyslaw Rokita 2 1 Maria Curie-Sklodowska University, Institute of Computer Science,
Face Alignment Across Large Poses: A 3D Solution
 Face Alignment Across Large Poses: A 3D Solution Outline Face Alignment Related Works 3D Morphable Model Projected Normalized Coordinate Code Network Structure 3D Image Rotation Performance on Datasets
Face Alignment Across Large Poses: A 3D Solution Outline Face Alignment Related Works 3D Morphable Model Projected Normalized Coordinate Code Network Structure 3D Image Rotation Performance on Datasets
Depth estimation of face images
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 9, Issue 3, Ver. VI (May - Jun. 2014), PP 35-42 Depth estimation of face images 1 Soma.chaitanya,
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 9, Issue 3, Ver. VI (May - Jun. 2014), PP 35-42 Depth estimation of face images 1 Soma.chaitanya,
Vehicle Dimensions Estimation Scheme Using AAM on Stereoscopic Video
 Workshop on Vehicle Retrieval in Surveillance (VRS) in conjunction with 2013 10th IEEE International Conference on Advanced Video and Signal Based Surveillance Vehicle Dimensions Estimation Scheme Using
Workshop on Vehicle Retrieval in Surveillance (VRS) in conjunction with 2013 10th IEEE International Conference on Advanced Video and Signal Based Surveillance Vehicle Dimensions Estimation Scheme Using
Sparse Shape Registration for Occluded Facial Feature Localization
 Shape Registration for Occluded Facial Feature Localization Fei Yang, Junzhou Huang and Dimitris Metaxas Abstract This paper proposes a sparsity driven shape registration method for occluded facial feature
Shape Registration for Occluded Facial Feature Localization Fei Yang, Junzhou Huang and Dimitris Metaxas Abstract This paper proposes a sparsity driven shape registration method for occluded facial feature
A Method of Automated Landmark Generation for Automated 3D PDM Construction
 A Method of Automated Landmark Generation for Automated 3D PDM Construction A. D. Brett and C. J. Taylor Department of Medical Biophysics University of Manchester Manchester M13 9PT, Uk adb@sv1.smb.man.ac.uk
A Method of Automated Landmark Generation for Automated 3D PDM Construction A. D. Brett and C. J. Taylor Department of Medical Biophysics University of Manchester Manchester M13 9PT, Uk adb@sv1.smb.man.ac.uk
Structure from Motion. Introduction to Computer Vision CSE 152 Lecture 10
 Structure from Motion CSE 152 Lecture 10 Announcements Homework 3 is due May 9, 11:59 PM Reading: Chapter 8: Structure from Motion Optional: Multiple View Geometry in Computer Vision, 2nd edition, Hartley
Structure from Motion CSE 152 Lecture 10 Announcements Homework 3 is due May 9, 11:59 PM Reading: Chapter 8: Structure from Motion Optional: Multiple View Geometry in Computer Vision, 2nd edition, Hartley
Factorization with Missing and Noisy Data
 Factorization with Missing and Noisy Data Carme Julià, Angel Sappa, Felipe Lumbreras, Joan Serrat, and Antonio López Computer Vision Center and Computer Science Department, Universitat Autònoma de Barcelona,
Factorization with Missing and Noisy Data Carme Julià, Angel Sappa, Felipe Lumbreras, Joan Serrat, and Antonio López Computer Vision Center and Computer Science Department, Universitat Autònoma de Barcelona,
COMPARATIVE STUDY OF DIFFERENT APPROACHES FOR EFFICIENT RECTIFICATION UNDER GENERAL MOTION
 COMPARATIVE STUDY OF DIFFERENT APPROACHES FOR EFFICIENT RECTIFICATION UNDER GENERAL MOTION Mr.V.SRINIVASA RAO 1 Prof.A.SATYA KALYAN 2 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING PRASAD V POTLURI SIDDHARTHA
COMPARATIVE STUDY OF DIFFERENT APPROACHES FOR EFFICIENT RECTIFICATION UNDER GENERAL MOTION Mr.V.SRINIVASA RAO 1 Prof.A.SATYA KALYAN 2 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING PRASAD V POTLURI SIDDHARTHA
Feature Detection and Tracking with Constrained Local Models
 Feature Detection and Tracking with Constrained Local Models David Cristinacce and Tim Cootes Dept. Imaging Science and Biomedical Engineering University of Manchester, Manchester, M3 9PT, U.K. david.cristinacce@manchester.ac.uk
Feature Detection and Tracking with Constrained Local Models David Cristinacce and Tim Cootes Dept. Imaging Science and Biomedical Engineering University of Manchester, Manchester, M3 9PT, U.K. david.cristinacce@manchester.ac.uk
Structure from motion
 Structure from motion Structure from motion Given a set of corresponding points in two or more images, compute the camera parameters and the 3D point coordinates?? R 1,t 1 R 2,t R 2 3,t 3 Camera 1 Camera
Structure from motion Structure from motion Given a set of corresponding points in two or more images, compute the camera parameters and the 3D point coordinates?? R 1,t 1 R 2,t R 2 3,t 3 Camera 1 Camera
A Framework for Long Distance Face Recognition using Dense- and Sparse-Stereo Reconstruction
 A Framework for Long Distance Face Recognition using Dense- and Sparse-Stereo Reconstruction Ham Rara, Shireen Elhabian, Asem Ali, Travis Gault, Mike Miller, Thomas Starr, and Aly Farag CVIP Laboratory,
A Framework for Long Distance Face Recognition using Dense- and Sparse-Stereo Reconstruction Ham Rara, Shireen Elhabian, Asem Ali, Travis Gault, Mike Miller, Thomas Starr, and Aly Farag CVIP Laboratory,
Probabilistic Facial Feature Extraction Using Joint Distribution of Location and Texture Information
 Probabilistic Facial Feature Extraction Using Joint Distribution of Location and Texture Information Mustafa Berkay Yilmaz, Hakan Erdogan, Mustafa Unel Sabanci University, Faculty of Engineering and Natural
Probabilistic Facial Feature Extraction Using Joint Distribution of Location and Texture Information Mustafa Berkay Yilmaz, Hakan Erdogan, Mustafa Unel Sabanci University, Faculty of Engineering and Natural
Facial Feature Points Tracking Based on AAM with Optical Flow Constrained Initialization
 Journal of Pattern Recognition Research 7 (2012) 72-79 Received Oct 24, 2011. Revised Jan 16, 2012. Accepted Mar 2, 2012. Facial Feature Points Tracking Based on AAM with Optical Flow Constrained Initialization
Journal of Pattern Recognition Research 7 (2012) 72-79 Received Oct 24, 2011. Revised Jan 16, 2012. Accepted Mar 2, 2012. Facial Feature Points Tracking Based on AAM with Optical Flow Constrained Initialization
Depth-Layer-Based Patient Motion Compensation for the Overlay of 3D Volumes onto X-Ray Sequences
 Depth-Layer-Based Patient Motion Compensation for the Overlay of 3D Volumes onto X-Ray Sequences Jian Wang 1,2, Anja Borsdorf 2, Joachim Hornegger 1,3 1 Pattern Recognition Lab, Friedrich-Alexander-Universität
Depth-Layer-Based Patient Motion Compensation for the Overlay of 3D Volumes onto X-Ray Sequences Jian Wang 1,2, Anja Borsdorf 2, Joachim Hornegger 1,3 1 Pattern Recognition Lab, Friedrich-Alexander-Universität
Synthesizing Realistic Facial Expressions from Photographs
 Synthesizing Realistic Facial Expressions from Photographs 1998 F. Pighin, J Hecker, D. Lischinskiy, R. Szeliskiz and D. H. Salesin University of Washington, The Hebrew University Microsoft Research 1
Synthesizing Realistic Facial Expressions from Photographs 1998 F. Pighin, J Hecker, D. Lischinskiy, R. Szeliskiz and D. H. Salesin University of Washington, The Hebrew University Microsoft Research 1
On-line, Incremental Learning of a Robust Active Shape Model
 On-line, Incremental Learning of a Robust Active Shape Model Michael Fussenegger 1, Peter M. Roth 2, Horst Bischof 2, Axel Pinz 1 1 Institute of Electrical Measurement and Measurement Signal Processing
On-line, Incremental Learning of a Robust Active Shape Model Michael Fussenegger 1, Peter M. Roth 2, Horst Bischof 2, Axel Pinz 1 1 Institute of Electrical Measurement and Measurement Signal Processing
Face Re-Lighting from a Single Image under Harsh Lighting Conditions
 Face Re-Lighting from a Single Image under Harsh Lighting Conditions Yang Wang 1, Zicheng Liu 2, Gang Hua 3, Zhen Wen 4, Zhengyou Zhang 2, Dimitris Samaras 5 1 The Robotics Institute, Carnegie Mellon University,
Face Re-Lighting from a Single Image under Harsh Lighting Conditions Yang Wang 1, Zicheng Liu 2, Gang Hua 3, Zhen Wen 4, Zhengyou Zhang 2, Dimitris Samaras 5 1 The Robotics Institute, Carnegie Mellon University,
Structured Light II. Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov
 Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
arxiv: v1 [cs.cv] 2 May 2016
![arxiv: v1 [cs.cv] 2 May 2016](/thumbs/86/93079061.jpg "arxiv: v1 [cs.cv] 2 May 2016") 16-811 Math Fundamentals for Robotics Comparison of Optimization Methods in Optical Flow Estimation Final Report, Fall 2015 arxiv:1605.00572v1 [cs.cv] 2 May 2016 Contents Noranart Vesdapunt Master of Computer
16-811 Math Fundamentals for Robotics Comparison of Optimization Methods in Optical Flow Estimation Final Report, Fall 2015 arxiv:1605.00572v1 [cs.cv] 2 May 2016 Contents Noranart Vesdapunt Master of Computer
Component-based Face Recognition with 3D Morphable Models
 Component-based Face Recognition with 3D Morphable Models Jennifer Huang 1, Bernd Heisele 1,2, and Volker Blanz 3 1 Center for Biological and Computational Learning, M.I.T., Cambridge, MA, USA 2 Honda
Component-based Face Recognition with 3D Morphable Models Jennifer Huang 1, Bernd Heisele 1,2, and Volker Blanz 3 1 Center for Biological and Computational Learning, M.I.T., Cambridge, MA, USA 2 Honda
Pose Normalization for Robust Face Recognition Based on Statistical Affine Transformation
 Pose Normalization for Robust Face Recognition Based on Statistical Affine Transformation Xiujuan Chai 1, 2, Shiguang Shan 2, Wen Gao 1, 2 1 Vilab, Computer College, Harbin Institute of Technology, Harbin,
Pose Normalization for Robust Face Recognition Based on Statistical Affine Transformation Xiujuan Chai 1, 2, Shiguang Shan 2, Wen Gao 1, 2 1 Vilab, Computer College, Harbin Institute of Technology, Harbin,
Head Frontal-View Identification Using Extended LLE
 Head Frontal-View Identification Using Extended LLE Chao Wang Center for Spoken Language Understanding, Oregon Health and Science University Abstract Automatic head frontal-view identification is challenging
Head Frontal-View Identification Using Extended LLE Chao Wang Center for Spoken Language Understanding, Oregon Health and Science University Abstract Automatic head frontal-view identification is challenging
Active Appearance Models
 IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 23, NO. 6, JUNE 2001 681 Active Appearance Models Timothy F. Cootes, Gareth J. Edwards, and Christopher J. Taylor AbstractÐWe describe
IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 23, NO. 6, JUNE 2001 681 Active Appearance Models Timothy F. Cootes, Gareth J. Edwards, and Christopher J. Taylor AbstractÐWe describe
3D Model Acquisition by Tracking 2D Wireframes
 3D Model Acquisition by Tracking 2D Wireframes M. Brown, T. Drummond and R. Cipolla {96mab twd20 cipolla}@eng.cam.ac.uk Department of Engineering University of Cambridge Cambridge CB2 1PZ, UK Abstract
3D Model Acquisition by Tracking 2D Wireframes M. Brown, T. Drummond and R. Cipolla {96mab twd20 cipolla}@eng.cam.ac.uk Department of Engineering University of Cambridge Cambridge CB2 1PZ, UK Abstract
TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA
 TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA Tomoki Hayashi 1, Francois de Sorbier 1 and Hideo Saito 1 1 Graduate School of Science and Technology, Keio University, 3-14-1 Hiyoshi,
TEXTURE OVERLAY ONTO NON-RIGID SURFACE USING COMMODITY DEPTH CAMERA Tomoki Hayashi 1, Francois de Sorbier 1 and Hideo Saito 1 1 Graduate School of Science and Technology, Keio University, 3-14-1 Hiyoshi,
3D Face Modelling Under Unconstrained Pose & Illumination
 David Bryan Ottawa-Carleton Institute for Biomedical Engineering Department of Systems and Computer Engineering Carleton University January 12, 2009 Agenda Problem Overview 3D Morphable Model Fitting Model
David Bryan Ottawa-Carleton Institute for Biomedical Engineering Department of Systems and Computer Engineering Carleton University January 12, 2009 Agenda Problem Overview 3D Morphable Model Fitting Model
BIL Computer Vision Apr 16, 2014
 BIL 719 - Computer Vision Apr 16, 2014 Binocular Stereo (cont d.), Structure from Motion Aykut Erdem Dept. of Computer Engineering Hacettepe University Slide credit: S. Lazebnik Basic stereo matching algorithm
BIL 719 - Computer Vision Apr 16, 2014 Binocular Stereo (cont d.), Structure from Motion Aykut Erdem Dept. of Computer Engineering Hacettepe University Slide credit: S. Lazebnik Basic stereo matching algorithm
Robust AAM Fitting by Fusion of Images and Disparity Data
 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, June 17-22, 2006, Vol. 2, pp.2483-2490 Robust AAM Fitting by Fusion of Images and Disparity Data Joerg Liebelt
IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, June 17-22, 2006, Vol. 2, pp.2483-2490 Robust AAM Fitting by Fusion of Images and Disparity Data Joerg Liebelt
The Template Update Problem
 The Template Update Problem Iain Matthews, Takahiro Ishikawa, and Simon Baker The Robotics Institute Carnegie Mellon University Abstract Template tracking dates back to the 1981 Lucas-Kanade algorithm.
The Template Update Problem Iain Matthews, Takahiro Ishikawa, and Simon Baker The Robotics Institute Carnegie Mellon University Abstract Template tracking dates back to the 1981 Lucas-Kanade algorithm.
Flexible 3D Models from Uncalibrated Cameras
 Flexible 3D Models from Uncalibrated Cameras T.F.Cootes, E.C. Di Mauro, C.J.Taylor, AXanitis Department of Medical Biophysics, University of Manchester Manchester M13 9PT email: bim@svl.smb.man.ac.uk Abstract
Flexible 3D Models from Uncalibrated Cameras T.F.Cootes, E.C. Di Mauro, C.J.Taylor, AXanitis Department of Medical Biophysics, University of Manchester Manchester M13 9PT email: bim@svl.smb.man.ac.uk Abstract
3D Computer Vision. Structured Light II. Prof. Didier Stricker. Kaiserlautern University.
 3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
Facial Expression Recognition Using Non-negative Matrix Factorization
 Facial Expression Recognition Using Non-negative Matrix Factorization Symeon Nikitidis, Anastasios Tefas and Ioannis Pitas Artificial Intelligence & Information Analysis Lab Department of Informatics Aristotle,
Facial Expression Recognition Using Non-negative Matrix Factorization Symeon Nikitidis, Anastasios Tefas and Ioannis Pitas Artificial Intelligence & Information Analysis Lab Department of Informatics Aristotle,
Registration of Expressions Data using a 3D Morphable Model
 Registration of Expressions Data using a 3D Morphable Model Curzio Basso, Pascal Paysan, Thomas Vetter Computer Science Department, University of Basel {curzio.basso,pascal.paysan,thomas.vetter}@unibas.ch
Registration of Expressions Data using a 3D Morphable Model Curzio Basso, Pascal Paysan, Thomas Vetter Computer Science Department, University of Basel {curzio.basso,pascal.paysan,thomas.vetter}@unibas.ch
Selecting Models from Videos for Appearance-Based Face Recognition
 Selecting Models from Videos for Appearance-Based Face Recognition Abdenour Hadid and Matti Pietikäinen Machine Vision Group Infotech Oulu and Department of Electrical and Information Engineering P.O.
Selecting Models from Videos for Appearance-Based Face Recognition Abdenour Hadid and Matti Pietikäinen Machine Vision Group Infotech Oulu and Department of Electrical and Information Engineering P.O.
Facial Feature Detection
 Facial Feature Detection Rainer Stiefelhagen 21.12.2009 Interactive Systems Laboratories, Universität Karlsruhe (TH) Overview Resear rch Group, Universität Karlsruhe (TH H) Introduction Review of already
Facial Feature Detection Rainer Stiefelhagen 21.12.2009 Interactive Systems Laboratories, Universität Karlsruhe (TH) Overview Resear rch Group, Universität Karlsruhe (TH H) Introduction Review of already
DETC D FACE RECOGNITION UNDER ISOMETRIC EXPRESSION DEFORMATIONS
 Proceedings of the ASME 2014 International Design Engineering Technical Conferences & Computers and Information in Engineering Conference IDETC/CIE 2014 August 17-20, 2014, Buffalo, New York, USA DETC2014-34449
Proceedings of the ASME 2014 International Design Engineering Technical Conferences & Computers and Information in Engineering Conference IDETC/CIE 2014 August 17-20, 2014, Buffalo, New York, USA DETC2014-34449
Colorado School of Mines. Computer Vision. Professor William Hoff Dept of Electrical Engineering &Computer Science.
 Professor William Hoff Dept of Electrical Engineering &Computer Science http://inside.mines.edu/~whoff/ 1 Statistical Models for Shape and Appearance Note some material for these slides came from Algorithms
Professor William Hoff Dept of Electrical Engineering &Computer Science http://inside.mines.edu/~whoff/ 1 Statistical Models for Shape and Appearance Note some material for these slides came from Algorithms
Recovering 3D Facial Shape via Coupled 2D/3D Space Learning
 Recovering 3D Facial hape via Coupled 2D/3D pace Learning Annan Li 1,2, higuang han 1, ilin Chen 1, iujuan Chai 3, and Wen Gao 4,1 1 Key Lab of Intelligent Information Processing of CA, Institute of Computing
Recovering 3D Facial hape via Coupled 2D/3D pace Learning Annan Li 1,2, higuang han 1, ilin Chen 1, iujuan Chai 3, and Wen Gao 4,1 1 Key Lab of Intelligent Information Processing of CA, Institute of Computing
CHAPTER 3 DISPARITY AND DEPTH MAP COMPUTATION
 CHAPTER 3 DISPARITY AND DEPTH MAP COMPUTATION In this chapter we will discuss the process of disparity computation. It plays an important role in our caricature system because all 3D coordinates of nodes
CHAPTER 3 DISPARITY AND DEPTH MAP COMPUTATION In this chapter we will discuss the process of disparity computation. It plays an important role in our caricature system because all 3D coordinates of nodes
A Genetic Algorithm for Face Fitting
 A Genetic Algorithm for Face Fitting David Hunter 1, Bernard P. Tiddeman 2 and David I. Perrett 1 1 School of Psychology, University of St Andrews, Fife, Scotland, UK 2 Department of Computing, University
A Genetic Algorithm for Face Fitting David Hunter 1, Bernard P. Tiddeman 2 and David I. Perrett 1 1 School of Psychology, University of St Andrews, Fife, Scotland, UK 2 Department of Computing, University
Single view-based 3D face reconstruction robust to self-occlusion
 Lee et al. EURASIP Journal on Advances in Signal Processing 2012, 2012:176 RESEARCH Open Access Single view-based 3D face reconstruction robust to self-occlusion Youn Joo Lee 1, Sung Joo Lee 2, Kang Ryoung
Lee et al. EURASIP Journal on Advances in Signal Processing 2012, 2012:176 RESEARCH Open Access Single view-based 3D face reconstruction robust to self-occlusion Youn Joo Lee 1, Sung Joo Lee 2, Kang Ryoung
Face Detection and Recognition in an Image Sequence using Eigenedginess
 Face Detection and Recognition in an Image Sequence using Eigenedginess B S Venkatesh, S Palanivel and B Yegnanarayana Department of Computer Science and Engineering. Indian Institute of Technology, Madras
Face Detection and Recognition in an Image Sequence using Eigenedginess B S Venkatesh, S Palanivel and B Yegnanarayana Department of Computer Science and Engineering. Indian Institute of Technology, Madras