A Real-Time Street Actions Detection
|
|
|
- Julius Logan
- 5 years ago
- Views:
Transcription
1 A Real-Time Street Actions Detection Salah Alghyaline Department of Computer Science The World Islamic Sciences and Education University, Amman, Jordan Abstract Human action detection in real time is one of the most important and challenging problems in computer vision. Nowadays, CCTV cameras exist everywhere in our lives. However, the contents of these cameras are monitored and analyzed using human operator. This paper proposes a real time human action detection approach which efficiently detects basic and common actions in the street such as stopping, walking, running, group stopping, group walking, and group running. The proposed approach measures the object movement type based on three techniques: YOLO object detection, Kalman Filter and Homography. Real videos from CCTV camera and BEHAVE dataset are used to test the proposed method. The experimental results show that the proposed method is very effective and accurate to detect basic human actions in the street. The accuracies of the proposed method on the tested videos are 96.9% and 88.4% for the BEHAVE and the created CCTV datasets, respectively. The proposed approach runs in real time with more than 50 fps for BEHAVE dataset and 32 fps for the created CCTV datasets. Keywords Online human action detection; group behavior analysis; CCTV cameras; computer vision I. INTRODUCTION Online human action recognition is a very challenging and unsolved problem in computer vision. The aim of action recognition is to recognize human action in a streaming video or a live camera as soon as possible or even before the action is completed. Human action recognition has many applications such as visual surveillance, video content analysis, and human-computer interaction. Nowadays, we have millions of CCTV cameras everywhere, and human operators are used to monitor the output. However, using humans for monitoring CCTV camera is very expensive and unreliable way to check the CCTV contents. Therefore, it is crucial to develop an automated way for analyzing the content of CCTV cameras. There are many limitations for using the current approaches and datasets in action recognition [1]. In the existing action recognition datasets, each video clip contains a single action type from the beginning to the end of the clip, therefore it is necessary to determine the duration of the action in the video. Whereas in CCTV videos, the action could occur at any time and many action types usually occur in the same scene. Moreover, most of these datasets have a limited number of actions but in the real world there are many actions. Some of these datasets were created especially for testing purposes. In these datasets, video actions are not real and are captured under specific conditions of lighting occlusion and clutter to make them clearer and visible for the testing stage. In the existing action detection methods, most of the existing action recognition approaches [2] [3] work offline and are based on the Bag-of-words (BoW) model [4]. In BoW model, processing one video clip passes through many independent time-consuming stages; it starts by detecting the interest points for each frame, then tracking these interest points in a sequence of frames, after that describing the interest points spatially and temporally using a descriptor such as HOG (Histograms of Oriented Gradients) [5], HOF (Histograms of Optical Flow) [6], SIFT (Scale-invariant feature transform) [7] and SURF (Speeded-up Robust-Features) [8], then clustering the features into a specific number of visual words, this step is usually done using k-means. The visual words are then used to represent each video by a histogram of visual words. Finally, support vector machine (SVM) is used to classify the videos into different kind of actions. In addition to the time consumption problem, the hand-crafted features (such as HOG, HOF, SIFT ) lack the ability to find semantic or meaningful features that can discriminate the action type accurately. Currently Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) have been used in action recognition to achieve superior results [9] [10] [11]. Compared with the traditional hand-crafted based approaches, a deep neural network is employed to automatically discover the semantic features from a large group of videos, however, the majority of the proposed approaches in action recognition are based on CNNs and RNNs and designed for offline detection, and there are few works done in online action detection [12] [13]. To address the above issues, this paper proposes a novel approach to analyze human actions in real time, which makes it applicable for CCTV camera. The proposed action detection method is based on You only Look Once (YOLO) the-state-of the-art in object detection, Kalman filter and Homography. Basically, YOLO is used to detect the required objects and their types inside a single frame, after that the detected objects are tracked along these frames using Kalman filter, then extracting the trajectory of the moving object, finally Homography is used to determine the movement type based on the moved distance during a specific duration of time. In the real world, each surveillance system is interested in a specific kind of actions that serve the business needs, therefore the proposed approach focuses on a specific kind of behaviors. Additionally, a dataset using real live CCTV videos are created to test the performance of the proposed method, unlike many existing methods in action recognition that use short clips or videos that are captured under some circumstances to reduce the noise during the detection process. The contributions of this paper can be summarized as follows: The paper focuses on explaining and finding solutions for the online human action detection problem. 322 P a g e
2 The paper develops action detection system based on three well known approaches in computer vision. YOLO object detection, Kalman filter approach and Homography. Building dataset that includes long and real video streams for online action detection problem. The videos duration is 4 hours and 11 minutes, the dataset videos were captured from live CCTV camera and can be used for training and testing purposes. II. RELATED WORKS A. Action Recognition Action recognition is the ability to detect the action type from a movable object. In general, action recognition is used to analyze human behaviors through surveillance systems, and RGB camera is used to get the input data. Human action recognition attracted many researchers during the last few years for security concerns, however, it is very challenging to develop accurate and real-time applications to recognize human actions automatically from real world scene. Mainly, there are two kinds of features that are used for action recognition: hand-crafted features (like HOG, HOF, and MBH, etc.) and deep learning features (based on convolutional neural networks). B. Group Action Recognition In action recognition the action is performed by a single person, two persons (interaction), or by large number of persons (Crowed), or by two to view number of persons (group action recognition). Cho et al. [14] proposed a method to address the group action recognition problem, the approach proposes to use Group Interaction Zone (GIZ), and the interaction between people is classified into four categories: intimate, personal, social and public, this classification is based on proxemics. Attraction and repulsion concept are used to describe the action type, where the object is moving closer or a way from each other. Yin et al. [15] proposed a framework for small group action recognition, the approach has four stages: mean-shift tracker is used to track the object position during its movement, then clustering the object coordinates into a number of groups, after that building a descriptor based on social network analysis features. Finally, a Gaussian model is used to model different action types. However, most of the proposed approaches in group action recognition are not real time approaches, moreover they do not implement object detection phase and use Ground truth information to know the exact object location (they assume that the object locations are known before the recognition process). III. PROPOSED ONLINE ACTION RECOGNITION METHOD As it is shown in Fig. 1 there are four stages for recognizing the action type in real time according to the proposed method: detecting the object, tracking the object, extracting the movement trajectory and using the Homography to make the recognition decision. Object Detection Object Tracking Trajectry Extracting Movement type Estimating Fig. 1. Main Steps of the Proposed Action Detection System. A. Object Detection There are many proposed algorithms to solve the problem of object detection with high accuracy. Faster R-CNN is an object detection algorithm based on convolution neural network. It can detect the object, give the probability score for the detection, and predict bounding box position at the same time. This algorithm is different from the previous CNN object detection algorithms (Fast R-CNN, Spatial pyramid pooling in deep convolutional networks for visual Recognition), it does not consume additional time for region proposal because it uses shared convolutional network for identifying the object type and the object position at the same time. Faster R-CNN has a good detection accuracy compared with the existing approaches, however the detection speed is about 5 fps which makes it difficult to be used with real time applications. You Only Look Once (YOLO9000) is the-stateof-the-art real time object detection; it is reported that it has slightly better accuracy compared with Faster R-CNN algorithm, and it is much faster (67 fps). Additionally, it can detect objects in a higher speed than real time. One neural network evaluation is used for making prediction for one image which saves a lot of time compared with other R-CNN approaches. In object detection stage a CNN model is trained based on YOLO architecture pictures were captured at different times during the years 2017 and 2018 (summer, winter, morning and evening) from Baltic Live Cam 1, it is a live streaming camera broadcasts live images from Jomas Street in Jurmala one of the famous cities in Latvian. It has been noticed that there are three kinds of objects moving in that street: persons, bikes and strollers, therefore the number of classes was set to 3 during the training stage. We stopped learning the model after iterations and the average loss value was close to 0.6. There was no significant reduction of loss value after iterations. BEHAVE dataset is smaller compared with the created CCTV dataset. A sample frames from BEHAVE dataset are also used to train YOLO model. The input image passes through 19 convolutional neural network layers and 5 max pooling layers, followed by average pooling layer and finally soft max layer. In Fig. 2 (a), the input image with the dimensions is divsided into equal sizes of grid, the final output after applying a sequence of convolutions and pooling layers will be a feature map with the size (similar to the number of grids). The final number of tensors for each image is, where denotes the number of grids and is 5 bounding boxes each box has 8 floating point numbers, the 8 numbers as follows: 3 is the probability for each class (person, bike and stroller) and 5 numbers for the bounding box coordination, width, height of the rectangular box and object confidence score. 1 Baltic Live Cam, [Online]. 323 P a g e

 with Hungarian algorithms [16] is one of the most used methods for object tracking. The following books and papers [17] [18] [19] describe in detail how does KF work.")
, the prediction probability of this predication is also calculated.")
3 (A) (B) (C) Fig. 2. YOLO Object Detection Steps: A) Split the Image Into S S Grid, B) Predict the Bounding Boxes and the Confidence of Each Box C) Make Final Prediction. B. Object Tracking Object tracking is one of the challenging problems in computer vision due to different reasons such as: object detection, occlusions and sudden movement in object location. Kalman filter (KF) with Hungarian algorithms [16] is one of the most used methods for object tracking. The following books and papers [17] [18] [19] describe in detail how does KF work. In KF, the new location of the object can be predicted based on the object movement model and the measured location. At the beginning, KF algorithm predicts the current object location based on the previous position and the motion model (e.g. Motion laws), the prediction probability of this predication is also calculated. In the next step, the measured location of the moving object is obtained (YOLO is used for detecting the object location), the final step is to update the final estimated position by giving a weight for measured and predicted positions, this weight is called Kalman gain. If the gain value is low, then the estimated position tends to be close to predicted value, whereas if the gain value is high, then the estimated position is following the measured value. In many cases, YOLO is not able to detect some of the objects in the frame, therefore KF will not be able to get the measured object position, and in this case the prediction process is used to calculate object location without performing the update state. Different equations of KF will be explained below. ŷ - k = Ay k-1 + Bu k (1) The projection of new state is shown in Eq. (1), where ŷ - k denotes the state of the system at time k. A is the system model that predicts the new location of the object (the model is based on motion laws) and y k-1 is the previous location of the object. B and u k are the control model and control vector, respectively. P - k = AP k-1 A T + Q The projection of error covariance is shown in Eq. (2), where A and A T are the system model as before in Eq. (1) and the transposed of the model vector, respectively. P k-1 is the value of the error at time k-1 and Q is the covariance of the noise error, which describes noise distribution. K = P - kh T (HP - kh T + R) -1 (3) Eq. (3) shows the Kalman Gain equation, P - k is the covariance of the predicted error, H is the model of (2) measurement, and R is the covariance of the measurement noise. ŷ k = ŷ - k + K(z k - H ŷ - k ) (4) Eq. (4) explains updating the estimation which gives the final output of the KF. ŷ k is the output of Kalman filter and it describes the object state at time k, ŷ - k is the previous object state, K denotes the Kalman Gain, z k is the measured value and H ŷ - k is the predicted measurement. P k = (I - KH)P - k (5) Updating the error covariance is shown in Eq. (5), where I is the identity matrix, K represents the Kalman Gain, H is the model of measurement and P - k is previous error covariance. In muli-object tracking it is necessary to apply optimal assignment between the detected objects in the current frame F and the previous frame F-1. First, the distance between the object locations is calculated using Eq. (6), then the Hungarian algorithm is used to make the mapping between the detected objects in frames F and F-1, (6) C. Action Recognition Detecting and tracking the objects are important stages to identify the type of the action. The detection stage identifies the object type, whereas the tracking stage recognizes the movement type based on the trajectory of the moving object. Before making this project, it has been recognized that there are mainly three kinds of moving objects in the selected street (Jomas Street - Jurmala - Latvian): persons, strollers and bikes. Moreover, there are three kinds of movements: Walking, running and stopping actions. The previous objects types and actions can be performed by a single or a group of objects, so we have another three new action types Group walking, group running and group stopping actions. By using object tracker, we can get the object locations during its movement from one point to another in 2D plane. However, the coordinates in the image are measured by pixels, whereas in the real world the distance between different objects are measured by centimeter or meter. Homography H is used to make the projection between 2D image coordinates and 3D real world In Eq. (7), represents a 3D real world point in homogenous coordinate, represents a 2D image coordination, and is the Homography matrix. The Homography is calculated according to this formula, 324 P a g e
 ( ) (7) action speed will be more than 7m in 3 seconds for the most running cases, and stopping distance is usually less than 1 m for the most stopping cases.")
 (8) TABLE I.")


4 where is matrix, and n is the number of used points to find the Homography. ( ) ( ) (7) action speed will be more than 7m in 3 seconds for the most running cases, and stopping distance is usually less than 1 m for the most stopping cases. However another threshold is used to define that a group of people is performing the action within one group, the group area is defined as a circle and the diameter of this circle is set to. is set to 3 meters in all experiments. ( ) (8) TABLE I. DISTANCE RANGE FOR STOPPING, WALKING AND RUNNING ACTIONS ( ) To distinguish between the three actions: Running, Walking and stopping we calculate the movement speed at a specific period of time, which means finding the walked distance during. After that three thresholds are set for each kind of movements separately,. Finally, if, then the movement is classified as walking action. Similarly, the formula can be applied for other actions. In our experiment we set,, to 5 m, 1.5 m and 0 m, respectively as it shown in Table 1, and is set to 3 seconds. The values for these thresholds are set based on experiments and showed a good result to discriminate these action types. The threshold gives us the upper bound distance, for example the walking distance will not exceed (5 m). In the real situation the walked distance will be far from the threshold values for different actions, for example running (9) Distance Stopping Walking Above 5 Possible action type Running IV. DATASET A. The Created Dataset from CCTV Videos Unlike other datasets which are created under certain conditions of lighting, occlusion and clutter (to avoid noise during testing the videos) our dataset videos were captured from live camera, which makes the proposed system more effective and applicable for the real-world applications, the videos used in the experiments were captured during the years 2017 and 2018 in different seasons of the year. Table 2 shows the general characteristics of the used videos for testing the proposed approach. Mainly there are 8 continues videos were taken from Baltic Live Cam. The durations of these videos are ranged from 16 minutes to one hour and 40 minutes. The total time of all these videos is 251 minutes (4 hours and 11 minutes). The tested videos are 1920 pixels wide and 1080 pixels in height, whereas the frame rate is 30 frames per second (FPS) for 6 videos and 20 FPS for 2 videos. Fig. 3 shows sample pictures from the created CCTV dataset. Fig. 3. Sample Pictures from the Created Dataset. TABLE II. CHARACTERISTIC OF THE CREATED DATASET FOR TESTING THE PROPOSED METHOD Duration (minutes) Format Resolution(pixels) Frame rate(frames/second) Video 1 99:00 mp Video 2 9:58 mp Video 3 20:25 mp Video 4 16:29 mp Video 5 30:00 mp Video 6 35:30 mp Video 7 17:39 mp Video 8 22:34 mp P a g e













")



 shows the results of detection")




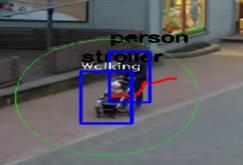


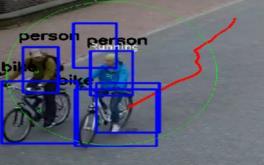
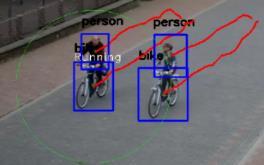



5 B. BEHAVE Dataset To show the efficiency of the proposed method a comparison with other approaches in action recognition is made on the BEHAVE dataset. Unlike other approaches, the proposed approach makes detection on the videos directly without using the Ground truth information that are provided by the BEAHAVE dataset. The dataset is used for group of people activities analysis. BEHAVE provides 10 classes of group activities, mainly: InGroup, WalkTogether, RunTogether, Approach, Meet, Ignore, Split, Fight, Chase, Following. The BEHAVE dataset includes 163 instances of these activities. The dataset is used for group behavior analysis therefor it does not count the individual activates instances (The activities that are done by single person) such as: walking, stopping and running. The frame resolution is , and the video rate is 25 fps. V. EXpERIMENTS The proposed approach is implemented using C language on Intel (R) Core (TM) i5-8600k 3.60GHz with 8 GB RAM and a NVIDIA GeForce GTX 1080 GPU. It is clear from the detection results Fig. 4 that the proposed action detection system is very effective and accurate to identify the 6 targeted action types Fig. 4(A) shows the results of detection stopping action type, a blue rectangle is surrounding the moving object, the action type and the moving object type are written above the box. Stopping action means that the object is not moving a lot and staying at the same place and that can be identified easily by the proposed approach by calculating the total movement during a specific period of time. As it is mentioned before the total object movement during the last seconds is calculated ( is set to 3 seconds) and based on that distance the movement can be classified as stopping, walking and running action types. The red line behind the moving object represents the tracking path of the moving object, the green circle indicates that the action is performed with other objects like person or stroller, the proposed system also can identify the action type if it occurs in a group, according to the proposed system the moving objects are in one group if their locations are within one circle and the diameter of this circle is less than, is set to 5 meters in the experiments. A. Stopping Action B. Walking Action C. Running Action D. Group Stopping Action E. Group Walking Action F Group Running Action Fig. 4. Samples of Detection Results using the Proposed Action Detection System for Each Action Type Separately. 326 P a g e
6 It is not popular to see many running action types yet some of them were detected as shown in Fig. 4(C). Most of the group running actions were done by a group of persons that were riding bicycles as it shown in Fig. 4(F). Table 3 and Table 4 show the precision and the recall results for the proposed approach on the created CCTV dataset. The approach achieved high results especially for walking and group walking actions because in the walking action the object is moving forward with a regular speed and from the beginning to the end of the street which makes the possibility to detect and track the object easier. Another reason is that when the object is moving in a regular way, the object position, size and pose will be changed many times, this also makes the detection process for that object easier. Also, when a group of persons are waking together, the detection of this action will be higher, when there are six persons walking on the street at least four of them will be detected and tracked. It is clear that some videos do not have running actions since walking and group walking actions (families and friends) are the most common behaviors in that street. From Table 5, we can see that the precision for the created CCTV dataset is 92%, whereas the recall is 88.4%. Finally, the proposed approach can run in real time, it can process 32 frames per second; this time includes reading the video and output the detection results to the user on the screen. Table 6 shows the confusion matrix for the proposed action recognition on BEHAVE dataset. Six action types were tested on this dataset: Stopping (S), Walking (W), Running (R), Group Stopping (GS), Group Walking (GW) and finally Group Running (GR). It is clear that the proposed system achieved high accuracy on this dataset for most of the six target actions. However, there is small percentage of confusion between some actions, for example 4.55% of walking actions were recognized as walking in a group, and 7.79% of walking in a group cases recognized as walking actions. This confusion, however, is related to the object detection accuracy, for example the YOLO approach could miss some objects on the scene or could make some false positive detections. For running actions, only four cases were noticed during the whole dataset, the overall accuracy for the proposed system after excluding the running action accuracy is 96.94%. TABLE III. PRECISION FOR THE PROPOSED METHOD Stopping Walking Running StoppingInGroup WalkingInGroup RunningInGroup Video 1 82% 100% 100% 85% 100% 84% Video 2-100% % - Video 3 100% 97% - 75% 100% 100% Video 4 100% 100% - 86% 100% 100% Video 5 91% 100% - 63% 96% 92% Video 6 81% 100% 100% 77% 99% 55% Video 7 63% 100% - 100% 99% 100% Video 8 67% 100% 100% 71% 99% 100% Average 83.4% 99.6% 100% 79.6% 99.1% 90.1% TABLE IV. RECALL FOR THE PROPOSED METHOD Stopping Walking Running StoppingInGroup WalkingInGroup RunningInGroup Video 1 88% 97% 100% 92% 96% 100% Video 2-100% % - Video 3 92% 100% - 100% 96% 82% Video 4 90% 100% - 75% 97% 78% Video 5 83% 94% - 83% 96% 92% Video 6 100% 98% 70% 81% 94% 86% Video 7 83% 97% - 80% 99% 75% Video 8 100% 83% 67% 77% 88% 100% Average 91.3% 96.1% 79% 81.3% 95.1% 87.6% 327 P a g e
7 TABLE V. RECALL AND PRECISION OVERALL ACTIONS AND TESTED VIDEOS USING THE PROPOSED METHOD Precision Recall Average of all actions 92% 88.4% TABLE VI. CONFUSION MATRIX OF THE PROPOSED ACTION RECOGNITION SYSTEM ON BEHAVE DATASET S W R GS GW GR S % 0.00% 0.00% 0.00% 0.00% 0.00% W 0.00% 95.45% 0.00% 0.00% 4.55% 0.00% R 0.00% 0.00% 75.00% 0.00% 0.00% 25.00% GS 2.94% 0.00% 0.00% 97.06% 0.00% 0.00% GW 0.00% 7.79% 0.00% 0.00% 92.21% 0.00% GR 0.00% 0.00% 0.00% 0.00% 0.00% % Comparisons with other human group behavior recognition approaches are made in Table 7 and Table 8. The advantages of the proposed method compared with these approaches are summarized on Table 8. The proposed method can run in more than the real time (from reading the videos frames to making the recognition decision). Another advantage is that there is no need to provide the system with the bounding boxes locations and the class of the object (Ground truth information). The proposed system can detect most of the needed objects and their locations with high accuracy. The proposed method also achieved the highest accuracy for group walking action types with accuracy 92.21%, and the average accuracy for the two compared actions; the Group stopping and Group walking is 94.64%. These accuracies indicate that the system is very efficient to detect the target actions even though it did not use the Ground truth information compared with other approaches and it can run in more than real time. TABLE VII. PERFORMANCE COMPARISON WITH OTHER GROUP BEHAVIOR RECOGNITION APPROACHES The proposed approach [14] [20] [15] SG WG Average [21] TABLE VIII. THE ADVANTAGES OF USING THE PROPOSED METHOD COMPARED WITH OTHER EXISTING GROUP BEHAVIOR RECOGNITION APPROACHES The proposed approach [14] [20] [15] Run in Real time Yes No No No No Use Ground truth information [21] No Yes Yes Yes Yes VI. CONCLUSION This paper proposes a human action detection approach that can be used in the real time with live CCTV camera. The proposed approach is implemented based on three techniques: YOLO object detection which represents the state-of-the-art in object detection, Kalman filter which is one of the most successful techniques for object tracking and Homography to measure the object movement in meter. Another contribution in this paper is that it builds a dataset from a real live CCTV videos, the duration of these videos is more than four hours length, and they were taken under different conditions of lighting, clutter, scaling and occlusion. The experimental results on two datasets show that the proposed approach is very effective and accurate to detect most of the target actions in the tested videos, especially the most common actions in the street like: stopping, walking and running. Moreover, it can detect if the action is performed by a group of people or just by a single person. In future work, I will extend the number of detected action types. REFERENCES [1] R. De Geest, E. Gavves, A. Ghodrati, Z. Li, C. Snoek and T. Tuytelaars, Online action detection, in European Conference on Computer Vision, Springer, 2016, pp [2] S. Alghyaline, J.-W. Hsieh, H.-F. Chiang and R.-Y. Lin, Action classification using data mining and Paris of SURF-based trajectories, in IEEE International Conference on Systems, Man, and Cybernetics (SMC), [3] S. Alghyaline, J.-W. Hsieh and C.-H. Chuang, Video action classification using symmelets and deep learning, in IEEE International Conference on Systems, Man, and Cybernetics (SMC), [4] L. Fei-Fei and P. Perona, A Bayesian Hierarchical Model for Learning Natural Scene Categories, in Proc. IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, [5] N. Dalal and B. Triggs, Histograms of oriented gradients for human detection, in Proc. IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), [6] N. Dalal, B. Triggs and C. Schmid, Human detection using oriented histograms of flow and appearance, in European conference on Computer Vision (ECCV), Graz,Austria, [7] D. G. Lowe, Distinctive image features from scale-invariant keypoints, International journal of computer vision, vol. 60, no. 2, pp , [8] H. Bay, A. Ess, T. Tuytelaars and L. Van Gool, Speeded-Up Robust Features (SURF), Computer Vision and Image Understanding, vol. 110, no. 3, pp , [9] H. Rahmani, A. Mian and M. Shah, Learning a deep model for human action recognition from novel viewpoints, IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 3, pp , [10] R. Hou, C. Chen and M. Shah, Tube convolutional neural network (T- CNN) for action detection in videos, in IEEE International Conference on Computer Vision, [11] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar and L. Fei- Fei, Large-scale video classification with convolutional neural networks, in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, [12] S. Baek, K. I. Kim and T.-K. Kim, Real-time online action detection forests using spatio-temporal contexts, in IEEE Winter Conference on Applications of Computer Vision (WACV), [13] J. Liu, Y. Li, S. Song, J. Xing, C. Lan and W. Zeng, Multi-Modality Multi-Task Recurrent Neural Network for Online Action Detection, IEEE Transactions on Circuits and Systems for Video Technology, P a g e
8 [14] N.-G. Cho, Y.-J. Kim, U. Park, J.-S. Park and S.-W. Lee, Group activity recognition with group interaction zone based on relative distance between human objects, International Journal of Pattern Recognition and Artificial Intelligen, vol. 29, no. 5, p , [15] Y. Yin, G. Yang, J. Xu and H. Man, Small group human activity recognition, in 19th IEEE International Conference on Image Processing (ICIP), [16] H. W. Kuhn, The Hungarian method for the assignment problem, Naval research logistics quarterly, vol. 1, pp. 1-2, [17] S. Bozic, Digital and Kalman filtering: an introduction to discrete-time filtering and optimum linear, New York, NY: Halsted Press, [18] R. G. Brown and P. Y. Hwang, Introduction to random signals and applied Kalman filtering, New York: Wiley, [19] G. Welch and G. Bishop, An introduction to the Kalman filter, in Proc of SIGGRAPH, Course, 8( ), 59., [20] D. Münch, E. Michaelsen and M. Arens, Supporting fuzzy metric temporal logic based situation recognition by mean shift clustering, in Annual Conference on Artificial Intelligence, Berlin, Heidelberg, [21] C. Zhang, X. Yang, W. Lin and J. Zhu, Recognizing human group behaviors with multi-group causalities, in Proceedings of the The 2012 IEEE/WIC/ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technology, Macau, China, P a g e
A Novel Extreme Point Selection Algorithm in SIFT
 A Novel Extreme Point Selection Algorithm in SIFT Ding Zuchun School of Electronic and Communication, South China University of Technolog Guangzhou, China zucding@gmail.com Abstract. This paper proposes
A Novel Extreme Point Selection Algorithm in SIFT Ding Zuchun School of Electronic and Communication, South China University of Technolog Guangzhou, China zucding@gmail.com Abstract. This paper proposes
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Beyond Bags of Features
 : for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
: for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions
 Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions Akitsugu Noguchi and Keiji Yanai Department of Computer Science, The University of Electro-Communications, 1-5-1 Chofugaoka,
Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions Akitsugu Noguchi and Keiji Yanai Department of Computer Science, The University of Electro-Communications, 1-5-1 Chofugaoka,
Traffic Signs Recognition using HP and HOG Descriptors Combined to MLP and SVM Classifiers
 Traffic Signs Recognition using HP and HOG Descriptors Combined to MLP and SVM Classifiers A. Salhi, B. Minaoui, M. Fakir, H. Chakib, H. Grimech Faculty of science and Technology Sultan Moulay Slimane
Traffic Signs Recognition using HP and HOG Descriptors Combined to MLP and SVM Classifiers A. Salhi, B. Minaoui, M. Fakir, H. Chakib, H. Grimech Faculty of science and Technology Sultan Moulay Slimane
Large-scale Video Classification with Convolutional Neural Networks
 Large-scale Video Classification with Convolutional Neural Networks Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, Li Fei-Fei Note: Slide content mostly from : Bay Area
Large-scale Video Classification with Convolutional Neural Networks Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, Li Fei-Fei Note: Slide content mostly from : Bay Area
Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach
 Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach Vandit Gajjar gajjar.vandit.381@ldce.ac.in Ayesha Gurnani gurnani.ayesha.52@ldce.ac.in Yash Khandhediya khandhediya.yash.364@ldce.ac.in
Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach Vandit Gajjar gajjar.vandit.381@ldce.ac.in Ayesha Gurnani gurnani.ayesha.52@ldce.ac.in Yash Khandhediya khandhediya.yash.364@ldce.ac.in
Action Recognition with HOG-OF Features
 Action Recognition with HOG-OF Features Florian Baumann Institut für Informationsverarbeitung, Leibniz Universität Hannover, {last name}@tnt.uni-hannover.de Abstract. In this paper a simple and efficient
Action Recognition with HOG-OF Features Florian Baumann Institut für Informationsverarbeitung, Leibniz Universität Hannover, {last name}@tnt.uni-hannover.de Abstract. In this paper a simple and efficient
Ensemble of Bayesian Filters for Loop Closure Detection
 Ensemble of Bayesian Filters for Loop Closure Detection Mohammad Omar Salameh, Azizi Abdullah, Shahnorbanun Sahran Pattern Recognition Research Group Center for Artificial Intelligence Faculty of Information
Ensemble of Bayesian Filters for Loop Closure Detection Mohammad Omar Salameh, Azizi Abdullah, Shahnorbanun Sahran Pattern Recognition Research Group Center for Artificial Intelligence Faculty of Information
COSC160: Detection and Classification. Jeremy Bolton, PhD Assistant Teaching Professor
 COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
COSC160: Detection and Classification Jeremy Bolton, PhD Assistant Teaching Professor Outline I. Problem I. Strategies II. Features for training III. Using spatial information? IV. Reducing dimensionality
ImageCLEF 2011
 SZTAKI @ ImageCLEF 2011 Bálint Daróczy joint work with András Benczúr, Róbert Pethes Data Mining and Web Search Group Computer and Automation Research Institute Hungarian Academy of Sciences Training/test
SZTAKI @ ImageCLEF 2011 Bálint Daróczy joint work with András Benczúr, Róbert Pethes Data Mining and Web Search Group Computer and Automation Research Institute Hungarian Academy of Sciences Training/test
Storyline Reconstruction for Unordered Images
 Introduction: Storyline Reconstruction for Unordered Images Final Paper Sameedha Bairagi, Arpit Khandelwal, Venkatesh Raizaday Storyline reconstruction is a relatively new topic and has not been researched
Introduction: Storyline Reconstruction for Unordered Images Final Paper Sameedha Bairagi, Arpit Khandelwal, Venkatesh Raizaday Storyline reconstruction is a relatively new topic and has not been researched
Robot localization method based on visual features and their geometric relationship
 , pp.46-50 http://dx.doi.org/10.14257/astl.2015.85.11 Robot localization method based on visual features and their geometric relationship Sangyun Lee 1, Changkyung Eem 2, and Hyunki Hong 3 1 Department
, pp.46-50 http://dx.doi.org/10.14257/astl.2015.85.11 Robot localization method based on visual features and their geometric relationship Sangyun Lee 1, Changkyung Eem 2, and Hyunki Hong 3 1 Department
Detection of Groups of People in Surveillance Videos based on Spatio-Temporal Clues
 Detection of Groups of People in Surveillance Videos based on Spatio-Temporal Clues Rensso V. H. Mora Colque, Guillermo Cámara-Chávez, William Robson Schwartz Computer Science Department, Universidade
Detection of Groups of People in Surveillance Videos based on Spatio-Temporal Clues Rensso V. H. Mora Colque, Guillermo Cámara-Chávez, William Robson Schwartz Computer Science Department, Universidade
Stacked Integral Image
 2010 IEEE International Conference on Robotics and Automation Anchorage Convention District May 3-8, 2010, Anchorage, Alaska, USA Stacked Integral Image Amit Bhatia, Wesley E. Snyder and Griff Bilbro Abstract
2010 IEEE International Conference on Robotics and Automation Anchorage Convention District May 3-8, 2010, Anchorage, Alaska, USA Stacked Integral Image Amit Bhatia, Wesley E. Snyder and Griff Bilbro Abstract
K-Means Based Matching Algorithm for Multi-Resolution Feature Descriptors
 K-Means Based Matching Algorithm for Multi-Resolution Feature Descriptors Shao-Tzu Huang, Chen-Chien Hsu, Wei-Yen Wang International Science Index, Electrical and Computer Engineering waset.org/publication/0007607
K-Means Based Matching Algorithm for Multi-Resolution Feature Descriptors Shao-Tzu Huang, Chen-Chien Hsu, Wei-Yen Wang International Science Index, Electrical and Computer Engineering waset.org/publication/0007607
Mobile Human Detection Systems based on Sliding Windows Approach-A Review
 Mobile Human Detection Systems based on Sliding Windows Approach-A Review Seminar: Mobile Human detection systems Njieutcheu Tassi cedrique Rovile Department of Computer Engineering University of Heidelberg
Mobile Human Detection Systems based on Sliding Windows Approach-A Review Seminar: Mobile Human detection systems Njieutcheu Tassi cedrique Rovile Department of Computer Engineering University of Heidelberg
AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering
 AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering www.csse.uwa.edu.au/~ajmal/ Overview Aim of automatic human action recognition Applications
AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering www.csse.uwa.edu.au/~ajmal/ Overview Aim of automatic human action recognition Applications
Implementation and Comparison of Feature Detection Methods in Image Mosaicing
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p-ISSN: 2278-8735 PP 07-11 www.iosrjournals.org Implementation and Comparison of Feature Detection Methods in Image
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p-ISSN: 2278-8735 PP 07-11 www.iosrjournals.org Implementation and Comparison of Feature Detection Methods in Image
Fast Natural Feature Tracking for Mobile Augmented Reality Applications
 Fast Natural Feature Tracking for Mobile Augmented Reality Applications Jong-Seung Park 1, Byeong-Jo Bae 2, and Ramesh Jain 3 1 Dept. of Computer Science & Eng., University of Incheon, Korea 2 Hyundai
Fast Natural Feature Tracking for Mobile Augmented Reality Applications Jong-Seung Park 1, Byeong-Jo Bae 2, and Ramesh Jain 3 1 Dept. of Computer Science & Eng., University of Incheon, Korea 2 Hyundai
IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION. Maral Mesmakhosroshahi, Joohee Kim
 IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION Maral Mesmakhosroshahi, Joohee Kim Department of Electrical and Computer Engineering Illinois Institute
IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION Maral Mesmakhosroshahi, Joohee Kim Department of Electrical and Computer Engineering Illinois Institute
Object Tracking using HOG and SVM
 Object Tracking using HOG and SVM Siji Joseph #1, Arun Pradeep #2 Electronics and Communication Engineering Axis College of Engineering and Technology, Ambanoly, Thrissur, India Abstract Object detection
Object Tracking using HOG and SVM Siji Joseph #1, Arun Pradeep #2 Electronics and Communication Engineering Axis College of Engineering and Technology, Ambanoly, Thrissur, India Abstract Object detection
Classification of objects from Video Data (Group 30)
") Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
Classification of objects from Video Data (Group 30) Sheallika Singh 12665 Vibhuti Mahajan 12792 Aahitagni Mukherjee 12001 M Arvind 12385 1 Motivation Video surveillance has been employed for a long time
IMAGE RETRIEVAL USING VLAD WITH MULTIPLE FEATURES
 IMAGE RETRIEVAL USING VLAD WITH MULTIPLE FEATURES Pin-Syuan Huang, Jing-Yi Tsai, Yu-Fang Wang, and Chun-Yi Tsai Department of Computer Science and Information Engineering, National Taitung University,
IMAGE RETRIEVAL USING VLAD WITH MULTIPLE FEATURES Pin-Syuan Huang, Jing-Yi Tsai, Yu-Fang Wang, and Chun-Yi Tsai Department of Computer Science and Information Engineering, National Taitung University,
Tensor Decomposition of Dense SIFT Descriptors in Object Recognition
 Tensor Decomposition of Dense SIFT Descriptors in Object Recognition Tan Vo 1 and Dat Tran 1 and Wanli Ma 1 1- Faculty of Education, Science, Technology and Mathematics University of Canberra, Australia
Tensor Decomposition of Dense SIFT Descriptors in Object Recognition Tan Vo 1 and Dat Tran 1 and Wanli Ma 1 1- Faculty of Education, Science, Technology and Mathematics University of Canberra, Australia
SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS
 SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS Cognitive Robotics Original: David G. Lowe, 004 Summary: Coen van Leeuwen, s1460919 Abstract: This article presents a method to extract
SUMMARY: DISTINCTIVE IMAGE FEATURES FROM SCALE- INVARIANT KEYPOINTS Cognitive Robotics Original: David G. Lowe, 004 Summary: Coen van Leeuwen, s1460919 Abstract: This article presents a method to extract
Large-Scale Traffic Sign Recognition based on Local Features and Color Segmentation
 Large-Scale Traffic Sign Recognition based on Local Features and Color Segmentation M. Blauth, E. Kraft, F. Hirschenberger, M. Böhm Fraunhofer Institute for Industrial Mathematics, Fraunhofer-Platz 1,
Large-Scale Traffic Sign Recognition based on Local Features and Color Segmentation M. Blauth, E. Kraft, F. Hirschenberger, M. Böhm Fraunhofer Institute for Industrial Mathematics, Fraunhofer-Platz 1,
The most cited papers in Computer Vision
 COMPUTER VISION, PUBLICATION The most cited papers in Computer Vision In Computer Vision, Paper Talk on February 10, 2012 at 11:10 pm by gooly (Li Yang Ku) Although it s not always the case that a paper
COMPUTER VISION, PUBLICATION The most cited papers in Computer Vision In Computer Vision, Paper Talk on February 10, 2012 at 11:10 pm by gooly (Li Yang Ku) Although it s not always the case that a paper
Tri-modal Human Body Segmentation
 Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
III. VERVIEW OF THE METHODS
 An Analytical Study of SIFT and SURF in Image Registration Vivek Kumar Gupta, Kanchan Cecil Department of Electronics & Telecommunication, Jabalpur engineering college, Jabalpur, India comparing the distance
An Analytical Study of SIFT and SURF in Image Registration Vivek Kumar Gupta, Kanchan Cecil Department of Electronics & Telecommunication, Jabalpur engineering college, Jabalpur, India comparing the distance
arxiv: v1 [cs.cv] 18 Jun 2017
![arxiv: v1 [cs.cv] 18 Jun 2017](/thumbs/75/72105835.jpg "arxiv: v1 [cs.cv] 18 Jun 2017") Using Deep Networks for Drone Detection arxiv:1706.05726v1 [cs.cv] 18 Jun 2017 Cemal Aker, Sinan Kalkan KOVAN Research Lab. Computer Engineering, Middle East Technical University Ankara, Turkey Abstract
Using Deep Networks for Drone Detection arxiv:1706.05726v1 [cs.cv] 18 Jun 2017 Cemal Aker, Sinan Kalkan KOVAN Research Lab. Computer Engineering, Middle East Technical University Ankara, Turkey Abstract
CS231N Section. Video Understanding 6/1/2018
 CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
CS231N Section Video Understanding 6/1/2018 Outline Background / Motivation / History Video Datasets Models Pre-deep learning CNN + RNN 3D convolution Two-stream What we ve seen in class so far... Image
Class 9 Action Recognition
 Class 9 Action Recognition Liangliang Cao, April 4, 2013 EECS 6890 Topics in Information Processing Spring 2013, Columbia University http://rogerioferis.com/visualrecognitionandsearch Visual Recognition
Class 9 Action Recognition Liangliang Cao, April 4, 2013 EECS 6890 Topics in Information Processing Spring 2013, Columbia University http://rogerioferis.com/visualrecognitionandsearch Visual Recognition
Deep Learning For Video Classification. Presented by Natalie Carlebach & Gil Sharon
 Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
Deep Learning For Video Classification Presented by Natalie Carlebach & Gil Sharon Overview Of Presentation Motivation Challenges of video classification Common datasets 4 different methods presented in
An Exploration of Computer Vision Techniques for Bird Species Classification
 An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
An Exploration of Computer Vision Techniques for Bird Species Classification Anne L. Alter, Karen M. Wang December 15, 2017 Abstract Bird classification, a fine-grained categorization task, is a complex
Recognition of Animal Skin Texture Attributes in the Wild. Amey Dharwadker (aap2174) Kai Zhang (kz2213)
 Kai Zhang (kz2213)") Recognition of Animal Skin Texture Attributes in the Wild Amey Dharwadker (aap2174) Kai Zhang (kz2213) Motivation Patterns and textures are have an important role in object description and understanding
Recognition of Animal Skin Texture Attributes in the Wild Amey Dharwadker (aap2174) Kai Zhang (kz2213) Motivation Patterns and textures are have an important role in object description and understanding
Video Processing for Judicial Applications
 Video Processing for Judicial Applications Konstantinos Avgerinakis, Alexia Briassouli, Ioannis Kompatsiaris Informatics and Telematics Institute, Centre for Research and Technology, Hellas Thessaloniki,
Video Processing for Judicial Applications Konstantinos Avgerinakis, Alexia Briassouli, Ioannis Kompatsiaris Informatics and Telematics Institute, Centre for Research and Technology, Hellas Thessaloniki,
Crowd Event Recognition Using HOG Tracker
 Crowd Event Recognition Using HOG Tracker Carolina Gárate Piotr Bilinski Francois Bremond Pulsar Pulsar Pulsar INRIA INRIA INRIA Sophia Antipolis, France Sophia Antipolis, France Sophia Antipolis, France
Crowd Event Recognition Using HOG Tracker Carolina Gárate Piotr Bilinski Francois Bremond Pulsar Pulsar Pulsar INRIA INRIA INRIA Sophia Antipolis, France Sophia Antipolis, France Sophia Antipolis, France
Aggregating Descriptors with Local Gaussian Metrics
 Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Summarization of Egocentric Moving Videos for Generating Walking Route Guidance
 Summarization of Egocentric Moving Videos for Generating Walking Route Guidance Masaya Okamoto and Keiji Yanai Department of Informatics, The University of Electro-Communications 1-5-1 Chofugaoka, Chofu-shi,
Summarization of Egocentric Moving Videos for Generating Walking Route Guidance Masaya Okamoto and Keiji Yanai Department of Informatics, The University of Electro-Communications 1-5-1 Chofugaoka, Chofu-shi,
Pedestrian Detection and Tracking in Images and Videos
 Pedestrian Detection and Tracking in Images and Videos Azar Fazel Stanford University azarf@stanford.edu Viet Vo Stanford University vtvo@stanford.edu Abstract The increase in population density and accessibility
Pedestrian Detection and Tracking in Images and Videos Azar Fazel Stanford University azarf@stanford.edu Viet Vo Stanford University vtvo@stanford.edu Abstract The increase in population density and accessibility
Appearance-Based Place Recognition Using Whole-Image BRISK for Collaborative MultiRobot Localization
 Appearance-Based Place Recognition Using Whole-Image BRISK for Collaborative MultiRobot Localization Jung H. Oh, Gyuho Eoh, and Beom H. Lee Electrical and Computer Engineering, Seoul National University,
Appearance-Based Place Recognition Using Whole-Image BRISK for Collaborative MultiRobot Localization Jung H. Oh, Gyuho Eoh, and Beom H. Lee Electrical and Computer Engineering, Seoul National University,
Automatic visual recognition for metro surveillance
 Automatic visual recognition for metro surveillance F. Cupillard, M. Thonnat, F. Brémond Orion Research Group, INRIA, Sophia Antipolis, France Abstract We propose in this paper an approach for recognizing
Automatic visual recognition for metro surveillance F. Cupillard, M. Thonnat, F. Brémond Orion Research Group, INRIA, Sophia Antipolis, France Abstract We propose in this paper an approach for recognizing
A Novel Image Super-resolution Reconstruction Algorithm based on Modified Sparse Representation
 , pp.162-167 http://dx.doi.org/10.14257/astl.2016.138.33 A Novel Image Super-resolution Reconstruction Algorithm based on Modified Sparse Representation Liqiang Hu, Chaofeng He Shijiazhuang Tiedao University,
, pp.162-167 http://dx.doi.org/10.14257/astl.2016.138.33 A Novel Image Super-resolution Reconstruction Algorithm based on Modified Sparse Representation Liqiang Hu, Chaofeng He Shijiazhuang Tiedao University,
Online Tracking Parameter Adaptation based on Evaluation
 2013 10th IEEE International Conference on Advanced Video and Signal Based Surveillance Online Tracking Parameter Adaptation based on Evaluation Duc Phu Chau Julien Badie François Brémond Monique Thonnat
2013 10th IEEE International Conference on Advanced Video and Signal Based Surveillance Online Tracking Parameter Adaptation based on Evaluation Duc Phu Chau Julien Badie François Brémond Monique Thonnat
LOCAL AND GLOBAL DESCRIPTORS FOR PLACE RECOGNITION IN ROBOTICS
 8th International DAAAM Baltic Conference "INDUSTRIAL ENGINEERING - 19-21 April 2012, Tallinn, Estonia LOCAL AND GLOBAL DESCRIPTORS FOR PLACE RECOGNITION IN ROBOTICS Shvarts, D. & Tamre, M. Abstract: The
8th International DAAAM Baltic Conference "INDUSTRIAL ENGINEERING - 19-21 April 2012, Tallinn, Estonia LOCAL AND GLOBAL DESCRIPTORS FOR PLACE RECOGNITION IN ROBOTICS Shvarts, D. & Tamre, M. Abstract: The
Video annotation based on adaptive annular spatial partition scheme
 Video annotation based on adaptive annular spatial partition scheme Guiguang Ding a), Lu Zhang, and Xiaoxu Li Key Laboratory for Information System Security, Ministry of Education, Tsinghua National Laboratory
Video annotation based on adaptive annular spatial partition scheme Guiguang Ding a), Lu Zhang, and Xiaoxu Li Key Laboratory for Information System Security, Ministry of Education, Tsinghua National Laboratory
Definition, Detection, and Evaluation of Meeting Events in Airport Surveillance Videos
 Definition, Detection, and Evaluation of Meeting Events in Airport Surveillance Videos Sung Chun Lee, Chang Huang, and Ram Nevatia University of Southern California, Los Angeles, CA 90089, USA sungchun@usc.edu,
Definition, Detection, and Evaluation of Meeting Events in Airport Surveillance Videos Sung Chun Lee, Chang Huang, and Ram Nevatia University of Southern California, Los Angeles, CA 90089, USA sungchun@usc.edu,
WP1: Video Data Analysis
 Leading : UNICT Participant: UEDIN Fish4Knowledge Final Review Meeting - November 29, 2013 - Luxembourg Workpackage 1 Objectives Fish Detection: Background/foreground modeling algorithms able to deal with
Leading : UNICT Participant: UEDIN Fish4Knowledge Final Review Meeting - November 29, 2013 - Luxembourg Workpackage 1 Objectives Fish Detection: Background/foreground modeling algorithms able to deal with
Fast Image Matching Using Multi-level Texture Descriptor
 Fast Image Matching Using Multi-level Texture Descriptor Hui-Fuang Ng *, Chih-Yang Lin #, and Tatenda Muindisi * Department of Computer Science, Universiti Tunku Abdul Rahman, Malaysia. E-mail: nghf@utar.edu.my
Fast Image Matching Using Multi-level Texture Descriptor Hui-Fuang Ng *, Chih-Yang Lin #, and Tatenda Muindisi * Department of Computer Science, Universiti Tunku Abdul Rahman, Malaysia. E-mail: nghf@utar.edu.my
Human Motion Detection and Tracking for Video Surveillance
 Human Motion Detection and Tracking for Video Surveillance Prithviraj Banerjee and Somnath Sengupta Department of Electronics and Electrical Communication Engineering Indian Institute of Technology, Kharagpur,
Human Motion Detection and Tracking for Video Surveillance Prithviraj Banerjee and Somnath Sengupta Department of Electronics and Electrical Communication Engineering Indian Institute of Technology, Kharagpur,
Evaluation of Local Space-time Descriptors based on Cuboid Detector in Human Action Recognition
 International Journal of Innovation and Applied Studies ISSN 2028-9324 Vol. 9 No. 4 Dec. 2014, pp. 1708-1717 2014 Innovative Space of Scientific Research Journals http://www.ijias.issr-journals.org/ Evaluation
International Journal of Innovation and Applied Studies ISSN 2028-9324 Vol. 9 No. 4 Dec. 2014, pp. 1708-1717 2014 Innovative Space of Scientific Research Journals http://www.ijias.issr-journals.org/ Evaluation
International Journal of Advanced Research in Computer Science and Software Engineering
 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: Fingerprint Recognition using Robust Local Features Madhuri and
ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: Fingerprint Recognition using Robust Local Features Madhuri and
MULTI ORIENTATION PERFORMANCE OF FEATURE EXTRACTION FOR HUMAN HEAD RECOGNITION
 MULTI ORIENTATION PERFORMANCE OF FEATURE EXTRACTION FOR HUMAN HEAD RECOGNITION Panca Mudjirahardjo, Rahmadwati, Nanang Sulistiyanto and R. Arief Setyawan Department of Electrical Engineering, Faculty of
MULTI ORIENTATION PERFORMANCE OF FEATURE EXTRACTION FOR HUMAN HEAD RECOGNITION Panca Mudjirahardjo, Rahmadwati, Nanang Sulistiyanto and R. Arief Setyawan Department of Electrical Engineering, Faculty of
Feature Detection. Raul Queiroz Feitosa. 3/30/2017 Feature Detection 1
 Feature Detection Raul Queiroz Feitosa 3/30/2017 Feature Detection 1 Objetive This chapter discusses the correspondence problem and presents approaches to solve it. 3/30/2017 Feature Detection 2 Outline
Feature Detection Raul Queiroz Feitosa 3/30/2017 Feature Detection 1 Objetive This chapter discusses the correspondence problem and presents approaches to solve it. 3/30/2017 Feature Detection 2 Outline
International Journal of Modern Engineering and Research Technology
 Volume 4, Issue 3, July 2017 ISSN: 2348-8565 (Online) International Journal of Modern Engineering and Research Technology Website: http://www.ijmert.org Email: editor.ijmert@gmail.com A Novel Approach
Volume 4, Issue 3, July 2017 ISSN: 2348-8565 (Online) International Journal of Modern Engineering and Research Technology Website: http://www.ijmert.org Email: editor.ijmert@gmail.com A Novel Approach
A Unified Method for First and Third Person Action Recognition
 A Unified Method for First and Third Person Action Recognition Ali Javidani Department of Computer Science and Engineering Shahid Beheshti University Tehran, Iran a.javidani@mail.sbu.ac.ir Ahmad Mahmoudi-Aznaveh
A Unified Method for First and Third Person Action Recognition Ali Javidani Department of Computer Science and Engineering Shahid Beheshti University Tehran, Iran a.javidani@mail.sbu.ac.ir Ahmad Mahmoudi-Aznaveh
Collecting outdoor datasets for benchmarking vision based robot localization
 Collecting outdoor datasets for benchmarking vision based robot localization Emanuele Frontoni*, Andrea Ascani, Adriano Mancini, Primo Zingaretti Department of Ingegneria Infromatica, Gestionale e dell
Collecting outdoor datasets for benchmarking vision based robot localization Emanuele Frontoni*, Andrea Ascani, Adriano Mancini, Primo Zingaretti Department of Ingegneria Infromatica, Gestionale e dell
Improvement of SURF Feature Image Registration Algorithm Based on Cluster Analysis
 Sensors & Transducers 2014 by IFSA Publishing, S. L. http://www.sensorsportal.com Improvement of SURF Feature Image Registration Algorithm Based on Cluster Analysis 1 Xulin LONG, 1,* Qiang CHEN, 2 Xiaoya
Sensors & Transducers 2014 by IFSA Publishing, S. L. http://www.sensorsportal.com Improvement of SURF Feature Image Registration Algorithm Based on Cluster Analysis 1 Xulin LONG, 1,* Qiang CHEN, 2 Xiaoya
Face Recognition using SURF Features and SVM Classifier
 International Journal of Electronics Engineering Research. ISSN 0975-6450 Volume 8, Number 1 (016) pp. 1-8 Research India Publications http://www.ripublication.com Face Recognition using SURF Features
International Journal of Electronics Engineering Research. ISSN 0975-6450 Volume 8, Number 1 (016) pp. 1-8 Research India Publications http://www.ripublication.com Face Recognition using SURF Features
Sketchable Histograms of Oriented Gradients for Object Detection
 Sketchable Histograms of Oriented Gradients for Object Detection No Author Given No Institute Given Abstract. In this paper we investigate a new representation approach for visual object recognition. The
Sketchable Histograms of Oriented Gradients for Object Detection No Author Given No Institute Given Abstract. In this paper we investigate a new representation approach for visual object recognition. The
CPPP/UFMS at ImageCLEF 2014: Robot Vision Task
 CPPP/UFMS at ImageCLEF 2014: Robot Vision Task Rodrigo de Carvalho Gomes, Lucas Correia Ribas, Amaury Antônio de Castro Junior, Wesley Nunes Gonçalves Federal University of Mato Grosso do Sul - Ponta Porã
CPPP/UFMS at ImageCLEF 2014: Robot Vision Task Rodrigo de Carvalho Gomes, Lucas Correia Ribas, Amaury Antônio de Castro Junior, Wesley Nunes Gonçalves Federal University of Mato Grosso do Sul - Ponta Porã
2 Related Work. 2.1 Logo Localization
 3rd International Conference on Multimedia Technology(ICMT 2013) Logo Localization and Recognition Based on Spatial Pyramid Matching with Color Proportion Wenya Feng 1, Zhiqian Chen, Yonggan Hou, Long
3rd International Conference on Multimedia Technology(ICMT 2013) Logo Localization and Recognition Based on Spatial Pyramid Matching with Color Proportion Wenya Feng 1, Zhiqian Chen, Yonggan Hou, Long
Video Gesture Recognition with RGB-D-S Data Based on 3D Convolutional Networks
 Video Gesture Recognition with RGB-D-S Data Based on 3D Convolutional Networks August 16, 2016 1 Team details Team name FLiXT Team leader name Yunan Li Team leader address, phone number and email address:
Video Gesture Recognition with RGB-D-S Data Based on 3D Convolutional Networks August 16, 2016 1 Team details Team name FLiXT Team leader name Yunan Li Team leader address, phone number and email address:
FAST HUMAN DETECTION USING TEMPLATE MATCHING FOR GRADIENT IMAGES AND ASC DESCRIPTORS BASED ON SUBTRACTION STEREO
 FAST HUMAN DETECTION USING TEMPLATE MATCHING FOR GRADIENT IMAGES AND ASC DESCRIPTORS BASED ON SUBTRACTION STEREO Makoto Arie, Masatoshi Shibata, Kenji Terabayashi, Alessandro Moro and Kazunori Umeda Course
FAST HUMAN DETECTION USING TEMPLATE MATCHING FOR GRADIENT IMAGES AND ASC DESCRIPTORS BASED ON SUBTRACTION STEREO Makoto Arie, Masatoshi Shibata, Kenji Terabayashi, Alessandro Moro and Kazunori Umeda Course
CS229: Action Recognition in Tennis
 CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
Real-Time* Multiple Object Tracking (MOT) for Autonomous Navigation
 for Autonomous Navigation") Real-Time* Multiple Object Tracking (MOT) for Autonomous Navigation Ankush Agarwal,1 Saurabh Suryavanshi,2 ankushag@stanford.edu saurabhv@stanford.edu Authors contributed equally for this project. 1 Google
Real-Time* Multiple Object Tracking (MOT) for Autonomous Navigation Ankush Agarwal,1 Saurabh Suryavanshi,2 ankushag@stanford.edu saurabhv@stanford.edu Authors contributed equally for this project. 1 Google
A Comparison of SIFT and SURF
 A Comparison of SIFT and SURF P M Panchal 1, S R Panchal 2, S K Shah 3 PG Student, Department of Electronics & Communication Engineering, SVIT, Vasad-388306, India 1 Research Scholar, Department of Electronics
A Comparison of SIFT and SURF P M Panchal 1, S R Panchal 2, S K Shah 3 PG Student, Department of Electronics & Communication Engineering, SVIT, Vasad-388306, India 1 Research Scholar, Department of Electronics
Category-level localization
 Category-level localization Cordelia Schmid Recognition Classification Object present/absent in an image Often presence of a significant amount of background clutter Localization / Detection Localize object
Category-level localization Cordelia Schmid Recognition Classification Object present/absent in an image Often presence of a significant amount of background clutter Localization / Detection Localize object
arxiv: v3 [cs.cv] 3 Oct 2012
![arxiv: v3 [cs.cv] 3 Oct 2012](/thumbs/96/128756091.jpg "arxiv: v3 [cs.cv] 3 Oct 2012") Combined Descriptors in Spatial Pyramid Domain for Image Classification Junlin Hu and Ping Guo arxiv:1210.0386v3 [cs.cv] 3 Oct 2012 Image Processing and Pattern Recognition Laboratory Beijing Normal University,
Combined Descriptors in Spatial Pyramid Domain for Image Classification Junlin Hu and Ping Guo arxiv:1210.0386v3 [cs.cv] 3 Oct 2012 Image Processing and Pattern Recognition Laboratory Beijing Normal University,
An indirect tire identification method based on a two-layered fuzzy scheme
 Journal of Intelligent & Fuzzy Systems 29 (2015) 2795 2800 DOI:10.3233/IFS-151984 IOS Press 2795 An indirect tire identification method based on a two-layered fuzzy scheme Dailin Zhang, Dengming Zhang,
Journal of Intelligent & Fuzzy Systems 29 (2015) 2795 2800 DOI:10.3233/IFS-151984 IOS Press 2795 An indirect tire identification method based on a two-layered fuzzy scheme Dailin Zhang, Dengming Zhang,
Using the Deformable Part Model with Autoencoded Feature Descriptors for Object Detection
 Using the Deformable Part Model with Autoencoded Feature Descriptors for Object Detection Hyunghoon Cho and David Wu December 10, 2010 1 Introduction Given its performance in recent years' PASCAL Visual
Using the Deformable Part Model with Autoencoded Feature Descriptors for Object Detection Hyunghoon Cho and David Wu December 10, 2010 1 Introduction Given its performance in recent years' PASCAL Visual
Person Action Recognition/Detection
 Person Action Recognition/Detection Fabrício Ceschin Visão Computacional Prof. David Menotti Departamento de Informática - Universidade Federal do Paraná 1 In object recognition: is there a chair in the
Person Action Recognition/Detection Fabrício Ceschin Visão Computacional Prof. David Menotti Departamento de Informática - Universidade Federal do Paraná 1 In object recognition: is there a chair in the
A Comparison of SIFT, PCA-SIFT and SURF
 A Comparison of SIFT, PCA-SIFT and SURF Luo Juan Computer Graphics Lab, Chonbuk National University, Jeonju 561-756, South Korea qiuhehappy@hotmail.com Oubong Gwun Computer Graphics Lab, Chonbuk National
A Comparison of SIFT, PCA-SIFT and SURF Luo Juan Computer Graphics Lab, Chonbuk National University, Jeonju 561-756, South Korea qiuhehappy@hotmail.com Oubong Gwun Computer Graphics Lab, Chonbuk National
CS 231A Computer Vision (Winter 2018) Problem Set 3
 Problem Set 3") CS 231A Computer Vision (Winter 2018) Problem Set 3 Due: Feb 28, 2018 (11:59pm) 1 Space Carving (25 points) Dense 3D reconstruction is a difficult problem, as tackling it from the Structure from Motion
CS 231A Computer Vision (Winter 2018) Problem Set 3 Due: Feb 28, 2018 (11:59pm) 1 Space Carving (25 points) Dense 3D reconstruction is a difficult problem, as tackling it from the Structure from Motion
Determinant of homography-matrix-based multiple-object recognition
 Determinant of homography-matrix-based multiple-object recognition 1 Nagachetan Bangalore, Madhu Kiran, Anil Suryaprakash Visio Ingenii Limited F2-F3 Maxet House Liverpool Road Luton, LU1 1RS United Kingdom
Determinant of homography-matrix-based multiple-object recognition 1 Nagachetan Bangalore, Madhu Kiran, Anil Suryaprakash Visio Ingenii Limited F2-F3 Maxet House Liverpool Road Luton, LU1 1RS United Kingdom
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
 5*4%),-
5*4%),- arxiv: v2 [cs.cv] 17 Nov 2014
![arxiv: v2 [cs.cv] 17 Nov 2014](/thumbs/71/65796807.jpg "arxiv: v2 [cs.cv] 17 Nov 2014") WINDOW-BASED DESCRIPTORS FOR ARABIC HANDWRITTEN ALPHABET RECOGNITION: A COMPARATIVE STUDY ON A NOVEL DATASET Marwan Torki, Mohamed E. Hussein, Ahmed Elsallamy, Mahmoud Fayyaz, Shehab Yaser Computer and
WINDOW-BASED DESCRIPTORS FOR ARABIC HANDWRITTEN ALPHABET RECOGNITION: A COMPARATIVE STUDY ON A NOVEL DATASET Marwan Torki, Mohamed E. Hussein, Ahmed Elsallamy, Mahmoud Fayyaz, Shehab Yaser Computer and
Object detection using non-redundant local Binary Patterns
 University of Wollongong Research Online Faculty of Informatics - Papers (Archive) Faculty of Engineering and Information Sciences 2010 Object detection using non-redundant local Binary Patterns Duc Thanh
University of Wollongong Research Online Faculty of Informatics - Papers (Archive) Faculty of Engineering and Information Sciences 2010 Object detection using non-redundant local Binary Patterns Duc Thanh
Target Tracking Based on Mean Shift and KALMAN Filter with Kernel Histogram Filtering
 Target Tracking Based on Mean Shift and KALMAN Filter with Kernel Histogram Filtering Sara Qazvini Abhari (Corresponding author) Faculty of Electrical, Computer and IT Engineering Islamic Azad University
Target Tracking Based on Mean Shift and KALMAN Filter with Kernel Histogram Filtering Sara Qazvini Abhari (Corresponding author) Faculty of Electrical, Computer and IT Engineering Islamic Azad University
Action recognition in videos
 Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Detecting and Identifying Moving Objects in Real-Time
 Chapter 9 Detecting and Identifying Moving Objects in Real-Time For surveillance applications or for human-computer interaction, the automated real-time tracking of moving objects in images from a stationary
Chapter 9 Detecting and Identifying Moving Objects in Real-Time For surveillance applications or for human-computer interaction, the automated real-time tracking of moving objects in images from a stationary
Fast trajectory matching using small binary images
 Title Fast trajectory matching using small binary images Author(s) Zhuo, W; Schnieders, D; Wong, KKY Citation The 3rd International Conference on Multimedia Technology (ICMT 2013), Guangzhou, China, 29
Title Fast trajectory matching using small binary images Author(s) Zhuo, W; Schnieders, D; Wong, KKY Citation The 3rd International Conference on Multimedia Technology (ICMT 2013), Guangzhou, China, 29
EVENT RETRIEVAL USING MOTION BARCODES. Gil Ben-Artzi Michael Werman Shmuel Peleg
 EVENT RETRIEVAL USING MOTION BARCODES Gil Ben-Artzi Michael Werman Shmuel Peleg School of Computer Science and Engineering The Hebrew University of Jerusalem, Israel ABSTRACT We introduce a simple and
EVENT RETRIEVAL USING MOTION BARCODES Gil Ben-Artzi Michael Werman Shmuel Peleg School of Computer Science and Engineering The Hebrew University of Jerusalem, Israel ABSTRACT We introduce a simple and
arxiv: v1 [cs.cv] 1 Jan 2019
![arxiv: v1 [cs.cv] 1 Jan 2019](/thumbs/93/112194933.jpg "arxiv: v1 [cs.cv] 1 Jan 2019") Mapping Areas using Computer Vision Algorithms and Drones Bashar Alhafni Saulo Fernando Guedes Lays Cavalcante Ribeiro Juhyun Park Jeongkyu Lee University of Bridgeport. Bridgeport, CT, 06606. United States
Mapping Areas using Computer Vision Algorithms and Drones Bashar Alhafni Saulo Fernando Guedes Lays Cavalcante Ribeiro Juhyun Park Jeongkyu Lee University of Bridgeport. Bridgeport, CT, 06606. United States
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
AUTOMATIC VISUAL CONCEPT DETECTION IN VIDEOS
 AUTOMATIC VISUAL CONCEPT DETECTION IN VIDEOS Nilam B. Lonkar 1, Dinesh B. Hanchate 2 Student of Computer Engineering, Pune University VPKBIET, Baramati, India Computer Engineering, Pune University VPKBIET,
AUTOMATIC VISUAL CONCEPT DETECTION IN VIDEOS Nilam B. Lonkar 1, Dinesh B. Hanchate 2 Student of Computer Engineering, Pune University VPKBIET, Baramati, India Computer Engineering, Pune University VPKBIET,
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Non-rigid body Object Tracking using Fuzzy Neural System based on Multiple ROIs and Adaptive Motion Frame Method
 Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics San Antonio, TX, USA - October 2009 Non-rigid body Object Tracking using Fuzzy Neural System based on Multiple ROIs
Proceedings of the 2009 IEEE International Conference on Systems, Man, and Cybernetics San Antonio, TX, USA - October 2009 Non-rigid body Object Tracking using Fuzzy Neural System based on Multiple ROIs
Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials
 Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials Yuanjun Xiong 1 Kai Zhu 1 Dahua Lin 1 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University
Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials Yuanjun Xiong 1 Kai Zhu 1 Dahua Lin 1 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University
A System of Image Matching and 3D Reconstruction
 A System of Image Matching and 3D Reconstruction CS231A Project Report 1. Introduction Xianfeng Rui Given thousands of unordered images of photos with a variety of scenes in your gallery, you will find
A System of Image Matching and 3D Reconstruction CS231A Project Report 1. Introduction Xianfeng Rui Given thousands of unordered images of photos with a variety of scenes in your gallery, you will find
Face Recognition Using Vector Quantization Histogram and Support Vector Machine Classifier Rong-sheng LI, Fei-fei LEE *, Yan YAN and Qiu CHEN
 2016 International Conference on Artificial Intelligence: Techniques and Applications (AITA 2016) ISBN: 978-1-60595-389-2 Face Recognition Using Vector Quantization Histogram and Support Vector Machine
2016 International Conference on Artificial Intelligence: Techniques and Applications (AITA 2016) ISBN: 978-1-60595-389-2 Face Recognition Using Vector Quantization Histogram and Support Vector Machine
CS 231A Computer Vision (Winter 2014) Problem Set 3
 Problem Set 3") CS 231A Computer Vision (Winter 2014) Problem Set 3 Due: Feb. 18 th, 2015 (11:59pm) 1 Single Object Recognition Via SIFT (45 points) In his 2004 SIFT paper, David Lowe demonstrates impressive object recognition
CS 231A Computer Vision (Winter 2014) Problem Set 3 Due: Feb. 18 th, 2015 (11:59pm) 1 Single Object Recognition Via SIFT (45 points) In his 2004 SIFT paper, David Lowe demonstrates impressive object recognition
Efficient Acquisition of Human Existence Priors from Motion Trajectories
 Efficient Acquisition of Human Existence Priors from Motion Trajectories Hitoshi Habe Hidehito Nakagawa Masatsugu Kidode Graduate School of Information Science, Nara Institute of Science and Technology
Efficient Acquisition of Human Existence Priors from Motion Trajectories Hitoshi Habe Hidehito Nakagawa Masatsugu Kidode Graduate School of Information Science, Nara Institute of Science and Technology
Real-Time Human Detection using Relational Depth Similarity Features
 Real-Time Human Detection using Relational Depth Similarity Features Sho Ikemura, Hironobu Fujiyoshi Dept. of Computer Science, Chubu University. Matsumoto 1200, Kasugai, Aichi, 487-8501 Japan. si@vision.cs.chubu.ac.jp,
Real-Time Human Detection using Relational Depth Similarity Features Sho Ikemura, Hironobu Fujiyoshi Dept. of Computer Science, Chubu University. Matsumoto 1200, Kasugai, Aichi, 487-8501 Japan. si@vision.cs.chubu.ac.jp,
Segmenting Objects in Weakly Labeled Videos
 Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Segmenting Objects in Weakly Labeled Videos Mrigank Rochan, Shafin Rahman, Neil D.B. Bruce, Yang Wang Department of Computer Science University of Manitoba Winnipeg, Canada {mrochan, shafin12, bruce, ywang}@cs.umanitoba.ca
Indoor Object Recognition of 3D Kinect Dataset with RNNs
 Indoor Object Recognition of 3D Kinect Dataset with RNNs Thiraphat Charoensripongsa, Yue Chen, Brian Cheng 1. Introduction Recent work at Stanford in the area of scene understanding has involved using
Indoor Object Recognition of 3D Kinect Dataset with RNNs Thiraphat Charoensripongsa, Yue Chen, Brian Cheng 1. Introduction Recent work at Stanford in the area of scene understanding has involved using
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Latest development in image feature representation and extraction
 International Journal of Advanced Research and Development ISSN: 2455-4030, Impact Factor: RJIF 5.24 www.advancedjournal.com Volume 2; Issue 1; January 2017; Page No. 05-09 Latest development in image
International Journal of Advanced Research and Development ISSN: 2455-4030, Impact Factor: RJIF 5.24 www.advancedjournal.com Volume 2; Issue 1; January 2017; Page No. 05-09 Latest development in image