CS 229 Midterm Review
|
|
|
- Stephany Webster
- 5 years ago
- Views:
Transcription
1 CS 229 Midterm Review Course Staff Fall /2/2018
2 Outline Today: SVMs Kernels Tree Ensembles EM Algorithm / Mixture Models [ Focus on building intuition, less so on solving specific problems. Ask questions! ]
3 SVMs
4 Optimal margin classifier Two classes separable by linear decision boundary. But first what is a hyperplane? In d-dimensional space, a (d 1)-dimensional affine subspace Examples: line in 2D, plane in 3D Hyperplane in d-dimensional space: [Separates space into two half-spaces.]
5 Hyperplanes
6 Optimal margin classifier Idea: Use a separating hyperplane for binary classification. Key assumption: Classes can be separated by a linear decision boundary.

7 Optimal margin classifier To classify new data points: Assign class by location of new data point with respect to hyperplane:
8 Optimal margin classifier Problem Many possible separating hyperplanes!
9 Optimal margin classifier Which linear decision boundary? Separating hyperplane farthest from the training data. Optimal margin
10 Optimal margin classifier Which linear decision boundary? Separating hyperplane farthest from the training data Margin: smallest distance between any training observation and the hyperplane Support vectors: the training observations equidistant from the hyperplane
11 Regularization and the non-separable case Disadvantage Can be sensitive to individual observations. May overfit training data.
12 Regularization and the non-separable case So far we ve assumed that classes can be separated by a linear decision boundary. What if there s no separating hyperplane?
13 Regularization and the non-separable case What if there s no separating hyperplane? Support Vector Classifier: Allows training samples on the wrong side of the margin or hyperplane.
14 Regularization and the non-separable case Penalty parameter C Budget for violations, allows at most C misclassifications on training set. Support vectors Observations on margin or violating margin.
15 Quizz
16 Non-linear decision boundary Disadvantage What if we have a non-linear decision boundary?
17 Expanding feature space Some data sets are not linearly separable... But they become linearly separable when transformed into a higher dimensional space
18 Expanding feature space Variables: X1, X2 Variables: X1, X2, X1X2
19 Non-linear decision boundary Suppose our original data has d features: Expand feature space to include quadratic terms: Decision boundary will be non-linear in original feature space (ellipse), but linear in the expanded feature space.
20 Non-linear decision boundary
21 Non-linear decision boundary
22 Non-linear decision boundary Large number of features becomes computationally challenging. We need an efficient way to work with large number of features.
23 Kernels
24 Kernels Kernel: Generalization of inner product. Kernels (implicitly) map data into higher-dimensional space Why use kernels instead of explicitly constructing larger feature space? Computational advantage when n << d [see the following slide]
25 Kernels Consider two equivalent ways to represent a linear classifier. Left: Right: If,, much more space efficient to use kernelized representation.
26 Tree Ensembles
27 Tree Ensembles Decision Tree: recursively partition space to make predictions. Prediction: simply predict the average of labels in leaf.
28 Tree Ensembles Recursive partitioning: split on thresholds of features. How to choose? Take average loss in children produced by split. Classification: cross-entropy loss Regression: mean squared-error loss
29 Tree Ensembles Decision tree tuning: Minimum leaf size Maximum depth Maximum number of nodes Minimum decrease in loss Pruning with validation set Advantage: easy to interpret! Disadvantage: easy to overfit.
 features per split. Each decision tree has high bias, but averaging them together yields low variance.")
30 Tree Ensembles Random forests: Take the average prediction of many decision trees, 1. Each constructed on a bagged dataset of the original. 2. Only use a subset (typically p) features per split. Each decision tree has high bias, but averaging them together yields low variance. Bagging: resample of the same size as the original dataset, with replacement.
31 EM Algorithm / Mixtures
32 Mixture Models Gaussian Mixture Model We have data points, which we suppose come from Here, We hypothesize Gaussians.

33 Mixture Models GMMs can be extremely effective at modeling distributions! [Richardson and Weiss 2018: On GANs and GMMs]
34 EM Algorithm Problem: how do we estimate parameters when there are latent variables? Idea: maximize marginal likelihood. But this is difficult to compute! Example: Mixture of Gaussians.
35 EM Algorithm Algorithm 1. Begin with an initial guess for 2. Alternate between: a. [E-step] Hallucinate missing values by computing, for all possible values, b. [M-step] Use hallucinated dataset to maximize lower bound on log-likelihood
![EM Algorithm [E-step] Hallucinate missing values by computing, for all possible values, In the GMM example: for](/docs-images/94/120600440/images/36-1.jpg "this data point, compute: Now repeat for all data points. Creates augmented dataset, weighted by probabilities.")
36 EM Algorithm [E-step] Hallucinate missing values by computing, for all possible values, In the GMM example: for this data point, compute: Now repeat for all data points. Creates augmented dataset, weighted by probabilities.
37 EM Algorithm [M-step] Use hallucinated dataset to maximize lower bound on log-likelihood We simply now fit using the augmented dataset with weights.
38 EM Algorithm Theory It turns out that we re maximizing a lower bound on the true log-likelihood. Here we use Jensen s inequality.
39 EM Algorithm Intuition
40 EM Algorithm Sanity Check EM is guaranteed to converge to a local optimum. Why? Runtime per iteration?
41 EM Algorithm Sanity Check EM is guaranteed to converge to a local optimum. Why? Our estimated only ever increases. Runtime per iteration? In general, need to hallucinate one new data point per possible value of. For GMMS, need to hallucinate data points thanks to independence.
42 K Means and More GMMs
43 K Means - Motivation
44 K Means - Algorithm(*)
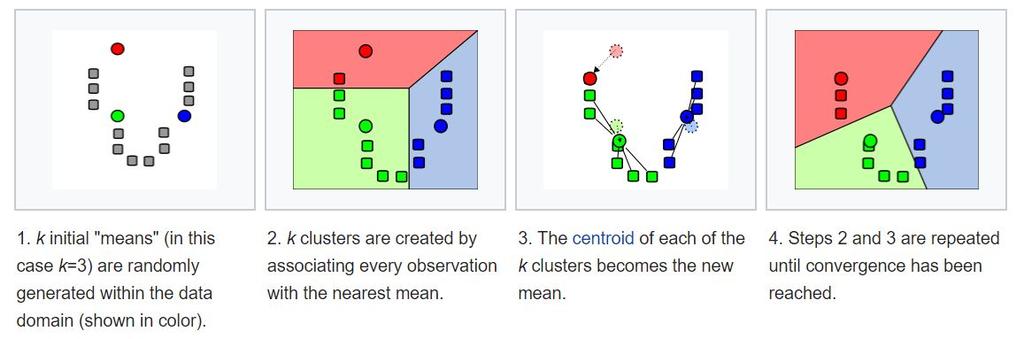
45 K Means
46 K Means
47 K Means

48 Real-World Example: Mixture of Gaussians Note: data is unlabeled
49 How do we fit a GMM - the EM
50 Observations Only the distribution of X matters. You can change things like ordering of the components without affecting the distribution and hence not affecting the algorithm. Mixing two distributions from a parametric family might give us a third distribution from the same family. A mixture of 2 Bernoullis is another Bernoulli. Probabilistic clustering - Putting similar data points together into clusters, where clusters are represented by the component distributions.
51 Sample Question How do constraints on the covariance matrix change the gaussian that is being fit?
52 Tied
53 Diag

54 Spherical (K-Means!)
Clustering Lecture 5: Mixture Model
 Clustering Lecture 5: Mixture Model Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced topics
Clustering Lecture 5: Mixture Model Jing Gao SUNY Buffalo 1 Outline Basics Motivation, definition, evaluation Methods Partitional Hierarchical Density-based Mixture model Spectral methods Advanced topics
Unsupervised Learning: Clustering
 Unsupervised Learning: Clustering Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein & Luke Zettlemoyer Machine Learning Supervised Learning Unsupervised Learning
Unsupervised Learning: Clustering Vibhav Gogate The University of Texas at Dallas Slides adapted from Carlos Guestrin, Dan Klein & Luke Zettlemoyer Machine Learning Supervised Learning Unsupervised Learning
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
Robot Learning. There are generally three types of robot learning: Learning from data. Learning by demonstration. Reinforcement learning
 Robot Learning 1 General Pipeline 1. Data acquisition (e.g., from 3D sensors) 2. Feature extraction and representation construction 3. Robot learning: e.g., classification (recognition) or clustering (knowledge
Robot Learning 1 General Pipeline 1. Data acquisition (e.g., from 3D sensors) 2. Feature extraction and representation construction 3. Robot learning: e.g., classification (recognition) or clustering (knowledge
Module 4. Non-linear machine learning econometrics: Support Vector Machine
 Module 4. Non-linear machine learning econometrics: Support Vector Machine THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction When the assumption of linearity
Module 4. Non-linear machine learning econometrics: Support Vector Machine THE CONTRACTOR IS ACTING UNDER A FRAMEWORK CONTRACT CONCLUDED WITH THE COMMISSION Introduction When the assumption of linearity
All lecture slides will be available at CSC2515_Winter15.html
 CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 9: Support Vector Machines All lecture slides will be available at http://www.cs.toronto.edu/~urtasun/courses/csc2515/ CSC2515_Winter15.html Many
CSC2515 Fall 2015 Introduc3on to Machine Learning Lecture 9: Support Vector Machines All lecture slides will be available at http://www.cs.toronto.edu/~urtasun/courses/csc2515/ CSC2515_Winter15.html Many
CS229 Lecture notes. Raphael John Lamarre Townshend
 CS229 Lecture notes Raphael John Lamarre Townshend Decision Trees We now turn our attention to decision trees, a simple yet flexible class of algorithms. We will first consider the non-linear, region-based
CS229 Lecture notes Raphael John Lamarre Townshend Decision Trees We now turn our attention to decision trees, a simple yet flexible class of algorithms. We will first consider the non-linear, region-based
STA 4273H: Statistical Machine Learning
 STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 12 Combining
STA 4273H: Statistical Machine Learning Russ Salakhutdinov Department of Statistics! rsalakhu@utstat.toronto.edu! http://www.utstat.utoronto.ca/~rsalakhu/ Sidney Smith Hall, Room 6002 Lecture 12 Combining
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
CSE 573: Artificial Intelligence Autumn 2010
 CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
CSE 573: Artificial Intelligence Autumn 2010 Lecture 16: Machine Learning Topics 12/7/2010 Luke Zettlemoyer Most slides over the course adapted from Dan Klein. 1 Announcements Syllabus revised Machine
Lecture 9: Support Vector Machines
 Lecture 9: Support Vector Machines William Webber (william@williamwebber.com) COMP90042, 2014, Semester 1, Lecture 8 What we ll learn in this lecture Support Vector Machines (SVMs) a highly robust and
Lecture 9: Support Vector Machines William Webber (william@williamwebber.com) COMP90042, 2014, Semester 1, Lecture 8 What we ll learn in this lecture Support Vector Machines (SVMs) a highly robust and
Generative and discriminative classification techniques
 Generative and discriminative classification techniques Machine Learning and Category Representation 013-014 Jakob Verbeek, December 13+0, 013 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.13.14
Generative and discriminative classification techniques Machine Learning and Category Representation 013-014 Jakob Verbeek, December 13+0, 013 Course website: http://lear.inrialpes.fr/~verbeek/mlcr.13.14
Support Vector Machines
 Support Vector Machines . Importance of SVM SVM is a discriminative method that brings together:. computational learning theory. previously known methods in linear discriminant functions 3. optimization
Support Vector Machines . Importance of SVM SVM is a discriminative method that brings together:. computational learning theory. previously known methods in linear discriminant functions 3. optimization
Expectation Maximization (EM) and Gaussian Mixture Models
 and Gaussian Mixture Models") Expectation Maximization (EM) and Gaussian Mixture Models Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 2 3 4 5 6 7 8 Unsupervised Learning Motivation
Expectation Maximization (EM) and Gaussian Mixture Models Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 2 3 4 5 6 7 8 Unsupervised Learning Motivation
Introduction to Machine Learning CMU-10701
 Introduction to Machine Learning CMU-10701 Clustering and EM Barnabás Póczos & Aarti Singh Contents Clustering K-means Mixture of Gaussians Expectation Maximization Variational Methods 2 Clustering 3 K-
Introduction to Machine Learning CMU-10701 Clustering and EM Barnabás Póczos & Aarti Singh Contents Clustering K-means Mixture of Gaussians Expectation Maximization Variational Methods 2 Clustering 3 K-
Lecture 7: Support Vector Machine
 Lecture 7: Support Vector Machine Hien Van Nguyen University of Houston 9/28/2017 Separating hyperplane Red and green dots can be separated by a separating hyperplane Two classes are separable, i.e., each
Lecture 7: Support Vector Machine Hien Van Nguyen University of Houston 9/28/2017 Separating hyperplane Red and green dots can be separated by a separating hyperplane Two classes are separable, i.e., each
Lecture 7: Decision Trees
 Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Overview Citation. ML Introduction. Overview Schedule. ML Intro Dataset. Introduction to Semi-Supervised Learning Review 10/4/2010
 INFORMATICS SEMINAR SEPT. 27 & OCT. 4, 2010 Introduction to Semi-Supervised Learning Review 2 Overview Citation X. Zhu and A.B. Goldberg, Introduction to Semi- Supervised Learning, Morgan & Claypool Publishers,
INFORMATICS SEMINAR SEPT. 27 & OCT. 4, 2010 Introduction to Semi-Supervised Learning Review 2 Overview Citation X. Zhu and A.B. Goldberg, Introduction to Semi- Supervised Learning, Morgan & Claypool Publishers,
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines
 Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2007 c 2007,
Non-Bayesian Classifiers Part II: Linear Discriminants and Support Vector Machines Selim Aksoy Department of Computer Engineering Bilkent University saksoy@cs.bilkent.edu.tr CS 551, Spring 2007 c 2007,
CPSC 340: Machine Learning and Data Mining. More Linear Classifiers Fall 2017
 CPSC 340: Machine Learning and Data Mining More Linear Classifiers Fall 2017 Admin Assignment 3: Due Friday of next week. Midterm: Can view your exam during instructor office hours next week, or after
CPSC 340: Machine Learning and Data Mining More Linear Classifiers Fall 2017 Admin Assignment 3: Due Friday of next week. Midterm: Can view your exam during instructor office hours next week, or after
Machine Learning. Topic 5: Linear Discriminants. Bryan Pardo, EECS 349 Machine Learning, 2013
 Machine Learning Topic 5: Linear Discriminants Bryan Pardo, EECS 349 Machine Learning, 2013 Thanks to Mark Cartwright for his extensive contributions to these slides Thanks to Alpaydin, Bishop, and Duda/Hart/Stork
Machine Learning Topic 5: Linear Discriminants Bryan Pardo, EECS 349 Machine Learning, 2013 Thanks to Mark Cartwright for his extensive contributions to these slides Thanks to Alpaydin, Bishop, and Duda/Hart/Stork
The Curse of Dimensionality
 The Curse of Dimensionality ACAS 2002 p1/66 Curse of Dimensionality The basic idea of the curse of dimensionality is that high dimensional data is difficult to work with for several reasons: Adding more
The Curse of Dimensionality ACAS 2002 p1/66 Curse of Dimensionality The basic idea of the curse of dimensionality is that high dimensional data is difficult to work with for several reasons: Adding more
Supervised vs unsupervised clustering
 Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Classification Supervised vs unsupervised clustering Cluster analysis: Classes are not known a- priori. Classification: Classes are defined a-priori Sometimes called supervised clustering Extract useful
Classification: Feature Vectors
 Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Classification: Feature Vectors Hello, Do you want free printr cartriges? Why pay more when you can get them ABSOLUTELY FREE! Just # free YOUR_NAME MISSPELLED FROM_FRIEND... : : : : 2 0 2 0 PIXEL 7,12
Support Vector Machines
 Support Vector Machines Chapter 9 Chapter 9 1 / 50 1 91 Maximal margin classifier 2 92 Support vector classifiers 3 93 Support vector machines 4 94 SVMs with more than two classes 5 95 Relationshiop to
Support Vector Machines Chapter 9 Chapter 9 1 / 50 1 91 Maximal margin classifier 2 92 Support vector classifiers 3 93 Support vector machines 4 94 SVMs with more than two classes 5 95 Relationshiop to
Network Traffic Measurements and Analysis
 DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
DEIB - Politecnico di Milano Fall, 2017 Sources Hastie, Tibshirani, Friedman: The Elements of Statistical Learning James, Witten, Hastie, Tibshirani: An Introduction to Statistical Learning Andrew Ng:
Practice EXAM: SPRING 2012 CS 6375 INSTRUCTOR: VIBHAV GOGATE
 Practice EXAM: SPRING 0 CS 6375 INSTRUCTOR: VIBHAV GOGATE The exam is closed book. You are allowed four pages of double sided cheat sheets. Answer the questions in the spaces provided on the question sheets.
Practice EXAM: SPRING 0 CS 6375 INSTRUCTOR: VIBHAV GOGATE The exam is closed book. You are allowed four pages of double sided cheat sheets. Answer the questions in the spaces provided on the question sheets.
Linear methods for supervised learning
 Linear methods for supervised learning LDA Logistic regression Naïve Bayes PLA Maximum margin hyperplanes Soft-margin hyperplanes Least squares resgression Ridge regression Nonlinear feature maps Sometimes
Linear methods for supervised learning LDA Logistic regression Naïve Bayes PLA Maximum margin hyperplanes Soft-margin hyperplanes Least squares resgression Ridge regression Nonlinear feature maps Sometimes
Applied Statistics for Neuroscientists Part IIa: Machine Learning
 Applied Statistics for Neuroscientists Part IIa: Machine Learning Dr. Seyed-Ahmad Ahmadi 04.04.2017 16.11.2017 Outline Machine Learning Difference between statistics and machine learning Modeling the problem
Applied Statistics for Neuroscientists Part IIa: Machine Learning Dr. Seyed-Ahmad Ahmadi 04.04.2017 16.11.2017 Outline Machine Learning Difference between statistics and machine learning Modeling the problem
Kernel Methods & Support Vector Machines
 & Support Vector Machines & Support Vector Machines Arvind Visvanathan CSCE 970 Pattern Recognition 1 & Support Vector Machines Question? Draw a single line to separate two classes? 2 & Support Vector
& Support Vector Machines & Support Vector Machines Arvind Visvanathan CSCE 970 Pattern Recognition 1 & Support Vector Machines Question? Draw a single line to separate two classes? 2 & Support Vector
LOGISTIC REGRESSION FOR MULTIPLE CLASSES
 Peter Orbanz Applied Data Mining Not examinable. 111 LOGISTIC REGRESSION FOR MULTIPLE CLASSES Bernoulli and multinomial distributions The mulitnomial distribution of N draws from K categories with parameter
Peter Orbanz Applied Data Mining Not examinable. 111 LOGISTIC REGRESSION FOR MULTIPLE CLASSES Bernoulli and multinomial distributions The mulitnomial distribution of N draws from K categories with parameter
Pattern Recognition. Kjell Elenius. Speech, Music and Hearing KTH. March 29, 2007 Speech recognition
 Pattern Recognition Kjell Elenius Speech, Music and Hearing KTH March 29, 2007 Speech recognition 2007 1 Ch 4. Pattern Recognition 1(3) Bayes Decision Theory Minimum-Error-Rate Decision Rules Discriminant
Pattern Recognition Kjell Elenius Speech, Music and Hearing KTH March 29, 2007 Speech recognition 2007 1 Ch 4. Pattern Recognition 1(3) Bayes Decision Theory Minimum-Error-Rate Decision Rules Discriminant
CS6375: Machine Learning Gautam Kunapuli. Mid-Term Review
 Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Gautam Kunapuli Machine Learning Data is identically and independently distributed Goal is to learn a function that maps to Data is generated using an unknown function Learn a hypothesis that minimizes
Random projection for non-gaussian mixture models
 Random projection for non-gaussian mixture models Győző Gidófalvi Department of Computer Science and Engineering University of California, San Diego La Jolla, CA 92037 gyozo@cs.ucsd.edu Abstract Recently,
Random projection for non-gaussian mixture models Győző Gidófalvi Department of Computer Science and Engineering University of California, San Diego La Jolla, CA 92037 gyozo@cs.ucsd.edu Abstract Recently,
Topics in Machine Learning
 Topics in Machine Learning Gilad Lerman School of Mathematics University of Minnesota Text/slides stolen from G. James, D. Witten, T. Hastie, R. Tibshirani and A. Ng Machine Learning - Motivation Arthur
Topics in Machine Learning Gilad Lerman School of Mathematics University of Minnesota Text/slides stolen from G. James, D. Witten, T. Hastie, R. Tibshirani and A. Ng Machine Learning - Motivation Arthur
Kernels and Clustering
 Kernels and Clustering Robert Platt Northeastern University All slides in this file are adapted from CS188 UC Berkeley Case-Based Learning Non-Separable Data Case-Based Reasoning Classification from similarity
Kernels and Clustering Robert Platt Northeastern University All slides in this file are adapted from CS188 UC Berkeley Case-Based Learning Non-Separable Data Case-Based Reasoning Classification from similarity
Announcements. CS 188: Artificial Intelligence Spring Classification: Feature Vectors. Classification: Weights. Learning: Binary Perceptron
 CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/20/2010 Announcements W7 due Thursday [that s your last written for the semester!] Project 5 out Thursday Contest running
CS 188: Artificial Intelligence Spring 2010 Lecture 24: Perceptrons and More! 4/20/2010 Announcements W7 due Thursday [that s your last written for the semester!] Project 5 out Thursday Contest running
Supervised vs. Unsupervised Learning. Supervised vs. Unsupervised Learning. Supervised vs. Unsupervised Learning. Supervised vs. Unsupervised Learning
 Overview T7 - SVM and s Christian Vögeli cvoegeli@inf.ethz.ch Supervised/ s Support Vector Machines Kernels Based on slides by P. Orbanz & J. Keuchel Task: Apply some machine learning method to data from
Overview T7 - SVM and s Christian Vögeli cvoegeli@inf.ethz.ch Supervised/ s Support Vector Machines Kernels Based on slides by P. Orbanz & J. Keuchel Task: Apply some machine learning method to data from
More on Classification: Support Vector Machine
 More on Classification: Support Vector Machine The Support Vector Machine (SVM) is a classification method approach developed in the computer science field in the 1990s. It has shown good performance in
More on Classification: Support Vector Machine The Support Vector Machine (SVM) is a classification method approach developed in the computer science field in the 1990s. It has shown good performance in
Kernels + K-Means Introduction to Machine Learning. Matt Gormley Lecture 29 April 25, 2018
 10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Kernels + K-Means Matt Gormley Lecture 29 April 25, 2018 1 Reminders Homework 8:
10-601 Introduction to Machine Learning Machine Learning Department School of Computer Science Carnegie Mellon University Kernels + K-Means Matt Gormley Lecture 29 April 25, 2018 1 Reminders Homework 8:
Decision trees. Decision trees are useful to a large degree because of their simplicity and interpretability
 Decision trees A decision tree is a method for classification/regression that aims to ask a few relatively simple questions about an input and then predicts the associated output Decision trees are useful
Decision trees A decision tree is a method for classification/regression that aims to ask a few relatively simple questions about an input and then predicts the associated output Decision trees are useful
Support Vector Machines
 Support Vector Machines SVM Discussion Overview. Importance of SVMs. Overview of Mathematical Techniques Employed 3. Margin Geometry 4. SVM Training Methodology 5. Overlapping Distributions 6. Dealing
Support Vector Machines SVM Discussion Overview. Importance of SVMs. Overview of Mathematical Techniques Employed 3. Margin Geometry 4. SVM Training Methodology 5. Overlapping Distributions 6. Dealing
Clustering. CS294 Practical Machine Learning Junming Yin 10/09/06
 Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Clustering CS294 Practical Machine Learning Junming Yin 10/09/06 Outline Introduction Unsupervised learning What is clustering? Application Dissimilarity (similarity) of objects Clustering algorithm K-means,
Introduction to Automated Text Analysis. bit.ly/poir599
 Introduction to Automated Text Analysis Pablo Barberá School of International Relations University of Southern California pablobarbera.com Lecture materials: bit.ly/poir599 Today 1. Solutions for last
Introduction to Automated Text Analysis Pablo Barberá School of International Relations University of Southern California pablobarbera.com Lecture materials: bit.ly/poir599 Today 1. Solutions for last
Contents. Preface to the Second Edition
 Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Preface to the Second Edition v 1 Introduction 1 1.1 What Is Data Mining?....................... 4 1.2 Motivating Challenges....................... 5 1.3 The Origins of Data Mining....................
Support Vector Machines.
 Support Vector Machines srihari@buffalo.edu SVM Discussion Overview. Importance of SVMs. Overview of Mathematical Techniques Employed 3. Margin Geometry 4. SVM Training Methodology 5. Overlapping Distributions
Support Vector Machines srihari@buffalo.edu SVM Discussion Overview. Importance of SVMs. Overview of Mathematical Techniques Employed 3. Margin Geometry 4. SVM Training Methodology 5. Overlapping Distributions
Classification. Vladimir Curic. Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University
 Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Classification Vladimir Curic Centre for Image Analysis Swedish University of Agricultural Sciences Uppsala University Outline An overview on classification Basics of classification How to choose appropriate
Density estimation. In density estimation problems, we are given a random from an unknown density. Our objective is to estimate
 Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
Density estimation In density estimation problems, we are given a random sample from an unknown density Our objective is to estimate? Applications Classification If we estimate the density for each class,
Classification/Regression Trees and Random Forests
 Classification/Regression Trees and Random Forests Fabio G. Cozman - fgcozman@usp.br November 6, 2018 Classification tree Consider binary class variable Y and features X 1,..., X n. Decide Ŷ after a series
Classification/Regression Trees and Random Forests Fabio G. Cozman - fgcozman@usp.br November 6, 2018 Classification tree Consider binary class variable Y and features X 1,..., X n. Decide Ŷ after a series
CS 343: Artificial Intelligence
 CS 343: Artificial Intelligence Kernels and Clustering Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 343: Artificial Intelligence Kernels and Clustering Prof. Scott Niekum The University of Texas at Austin [These slides based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
Unsupervised Learning
 Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Unsupervised Learning Learning without Class Labels (or correct outputs) Density Estimation Learn P(X) given training data for X Clustering Partition data into clusters Dimensionality Reduction Discover
Algorithms: Decision Trees
 Algorithms: Decision Trees A small dataset: Miles Per Gallon Suppose we want to predict MPG From the UCI repository A Decision Stump Recursion Step Records in which cylinders = 4 Records in which cylinders
Algorithms: Decision Trees A small dataset: Miles Per Gallon Suppose we want to predict MPG From the UCI repository A Decision Stump Recursion Step Records in which cylinders = 4 Records in which cylinders
Introduction to Support Vector Machines
 Introduction to Support Vector Machines CS 536: Machine Learning Littman (Wu, TA) Administration Slides borrowed from Martin Law (from the web). 1 Outline History of support vector machines (SVM) Two classes,
Introduction to Support Vector Machines CS 536: Machine Learning Littman (Wu, TA) Administration Slides borrowed from Martin Law (from the web). 1 Outline History of support vector machines (SVM) Two classes,
COMS 4771 Support Vector Machines. Nakul Verma
 COMS 4771 Support Vector Machines Nakul Verma Last time Decision boundaries for classification Linear decision boundary (linear classification) The Perceptron algorithm Mistake bound for the perceptron
COMS 4771 Support Vector Machines Nakul Verma Last time Decision boundaries for classification Linear decision boundary (linear classification) The Perceptron algorithm Mistake bound for the perceptron
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Data Mining Practical Machine Learning Tools and Techniques. Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank
 Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank Implementation: Real machine learning schemes Decision trees Classification
Data Mining Practical Machine Learning Tools and Techniques Slides for Chapter 6 of Data Mining by I. H. Witten and E. Frank Implementation: Real machine learning schemes Decision trees Classification
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
Big Data Methods. Chapter 5: Machine learning. Big Data Methods, Chapter 5, Slide 1
 Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Support Vector Machines. James McInerney Adapted from slides by Nakul Verma
 Support Vector Machines James McInerney Adapted from slides by Nakul Verma Last time Decision boundaries for classification Linear decision boundary (linear classification) The Perceptron algorithm Mistake
Support Vector Machines James McInerney Adapted from slides by Nakul Verma Last time Decision boundaries for classification Linear decision boundary (linear classification) The Perceptron algorithm Mistake
Computer Vision Group Prof. Daniel Cremers. 8. Boosting and Bagging
 Prof. Daniel Cremers 8. Boosting and Bagging Repetition: Regression We start with a set of basis functions (x) =( 0 (x), 1(x),..., M 1(x)) x 2 í d The goal is to fit a model into the data y(x, w) =w T
Prof. Daniel Cremers 8. Boosting and Bagging Repetition: Regression We start with a set of basis functions (x) =( 0 (x), 1(x),..., M 1(x)) x 2 í d The goal is to fit a model into the data y(x, w) =w T
1 Case study of SVM (Rob)
") DRAFT a final version will be posted shortly COS 424: Interacting with Data Lecturer: Rob Schapire and David Blei Lecture # 8 Scribe: Indraneel Mukherjee March 1, 2007 In the previous lecture we saw how
DRAFT a final version will be posted shortly COS 424: Interacting with Data Lecturer: Rob Schapire and David Blei Lecture # 8 Scribe: Indraneel Mukherjee March 1, 2007 In the previous lecture we saw how
Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models
 Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models DB Tsai Steven Hillion Outline Introduction Linear / Nonlinear Classification Feature Engineering - Polynomial Expansion Big-data
Large-Scale Lasso and Elastic-Net Regularized Generalized Linear Models DB Tsai Steven Hillion Outline Introduction Linear / Nonlinear Classification Feature Engineering - Polynomial Expansion Big-data
The exam is closed book, closed notes except your one-page (two-sided) cheat sheet.
 cheat sheet.") CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
CS 189 Spring 2015 Introduction to Machine Learning Final You have 2 hours 50 minutes for the exam. The exam is closed book, closed notes except your one-page (two-sided) cheat sheet. No calculators or
Introduction to Machine Learning
 Introduction to Machine Learning Maximum Margin Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Introduction to Machine Learning Maximum Margin Methods Varun Chandola Computer Science & Engineering State University of New York at Buffalo Buffalo, NY, USA chandola@buffalo.edu Chandola@UB CSE 474/574
Data Mining: Concepts and Techniques. Chapter 9 Classification: Support Vector Machines. Support Vector Machines (SVMs)
") Data Mining: Concepts and Techniques Chapter 9 Classification: Support Vector Machines 1 Support Vector Machines (SVMs) SVMs are a set of related supervised learning methods used for classification Based
Data Mining: Concepts and Techniques Chapter 9 Classification: Support Vector Machines 1 Support Vector Machines (SVMs) SVMs are a set of related supervised learning methods used for classification Based
Business Club. Decision Trees
 Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Business Club Decision Trees Business Club Analytics Team December 2017 Index 1. Motivation- A Case Study 2. The Trees a. What is a decision tree b. Representation 3. Regression v/s Classification 4. Building
Lecture 11: E-M and MeanShift. CAP 5415 Fall 2007
 Lecture 11: E-M and MeanShift CAP 5415 Fall 2007 Review on Segmentation by Clustering Each Pixel Data Vector Example (From Comanciu and Meer) Review of k-means Let's find three clusters in this data These
Lecture 11: E-M and MeanShift CAP 5415 Fall 2007 Review on Segmentation by Clustering Each Pixel Data Vector Example (From Comanciu and Meer) Review of k-means Let's find three clusters in this data These
An introduction to random forests
 An introduction to random forests Eric Debreuve / Team Morpheme Institutions: University Nice Sophia Antipolis / CNRS / Inria Labs: I3S / Inria CRI SA-M / ibv Outline Machine learning Decision tree Random
An introduction to random forests Eric Debreuve / Team Morpheme Institutions: University Nice Sophia Antipolis / CNRS / Inria Labs: I3S / Inria CRI SA-M / ibv Outline Machine learning Decision tree Random
Supervised Learning for Image Segmentation
 Supervised Learning for Image Segmentation Raphael Meier 06.10.2016 Raphael Meier MIA 2016 06.10.2016 1 / 52 References A. Ng, Machine Learning lecture, Stanford University. A. Criminisi, J. Shotton, E.
Supervised Learning for Image Segmentation Raphael Meier 06.10.2016 Raphael Meier MIA 2016 06.10.2016 1 / 52 References A. Ng, Machine Learning lecture, Stanford University. A. Criminisi, J. Shotton, E.
Support Vector Machines.
 Support Vector Machines srihari@buffalo.edu SVM Discussion Overview 1. Overview of SVMs 2. Margin Geometry 3. SVM Optimization 4. Overlapping Distributions 5. Relationship to Logistic Regression 6. Dealing
Support Vector Machines srihari@buffalo.edu SVM Discussion Overview 1. Overview of SVMs 2. Margin Geometry 3. SVM Optimization 4. Overlapping Distributions 5. Relationship to Logistic Regression 6. Dealing
Probabilistic Graphical Models
 School of Computer Science Probabilistic Graphical Models Theory of Variational Inference: Inner and Outer Approximation Eric Xing Lecture 14, February 29, 2016 Reading: W & J Book Chapters Eric Xing @
School of Computer Science Probabilistic Graphical Models Theory of Variational Inference: Inner and Outer Approximation Eric Xing Lecture 14, February 29, 2016 Reading: W & J Book Chapters Eric Xing @
Applying Supervised Learning
 Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
Applying Supervised Learning When to Consider Supervised Learning A supervised learning algorithm takes a known set of input data (the training set) and known responses to the data (output), and trains
CPSC 340: Machine Learning and Data Mining. Probabilistic Classification Fall 2017
 CPSC 340: Machine Learning and Data Mining Probabilistic Classification Fall 2017 Admin Assignment 0 is due tonight: you should be almost done. 1 late day to hand it in Monday, 2 late days for Wednesday.
CPSC 340: Machine Learning and Data Mining Probabilistic Classification Fall 2017 Admin Assignment 0 is due tonight: you should be almost done. 1 late day to hand it in Monday, 2 late days for Wednesday.
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning
 COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
COMP 551 Applied Machine Learning Lecture 13: Unsupervised learning Associate Instructor: Herke van Hoof (herke.vanhoof@mail.mcgill.ca) Slides mostly by: (jpineau@cs.mcgill.ca) Class web page: www.cs.mcgill.ca/~jpineau/comp551
Fall 09, Homework 5
 5-38 Fall 09, Homework 5 Due: Wednesday, November 8th, beginning of the class You can work in a group of up to two people. This group does not need to be the same group as for the other homeworks. You
5-38 Fall 09, Homework 5 Due: Wednesday, November 8th, beginning of the class You can work in a group of up to two people. This group does not need to be the same group as for the other homeworks. You
Feature Extractors. CS 188: Artificial Intelligence Fall Some (Vague) Biology. The Binary Perceptron. Binary Decision Rule.
 Biology. The Binary Perceptron. Binary Decision Rule.") CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
CS 188: Artificial Intelligence Fall 2008 Lecture 24: Perceptrons II 11/24/2008 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit
Bagging for One-Class Learning
 Bagging for One-Class Learning David Kamm December 13, 2008 1 Introduction Consider the following outlier detection problem: suppose you are given an unlabeled data set and make the assumptions that one
Bagging for One-Class Learning David Kamm December 13, 2008 1 Introduction Consider the following outlier detection problem: suppose you are given an unlabeled data set and make the assumptions that one
CS570: Introduction to Data Mining
 CS570: Introduction to Data Mining Classification Advanced Reading: Chapter 8 & 9 Han, Chapters 4 & 5 Tan Anca Doloc-Mihu, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei. Data Mining.
CS570: Introduction to Data Mining Classification Advanced Reading: Chapter 8 & 9 Han, Chapters 4 & 5 Tan Anca Doloc-Mihu, Ph.D. Slides courtesy of Li Xiong, Ph.D., 2011 Han, Kamber & Pei. Data Mining.
Midterm Examination CS540-2: Introduction to Artificial Intelligence
 Midterm Examination CS540-2: Introduction to Artificial Intelligence March 15, 2018 LAST NAME: FIRST NAME: Problem Score Max Score 1 12 2 13 3 9 4 11 5 8 6 13 7 9 8 16 9 9 Total 100 Question 1. [12] Search
Midterm Examination CS540-2: Introduction to Artificial Intelligence March 15, 2018 LAST NAME: FIRST NAME: Problem Score Max Score 1 12 2 13 3 9 4 11 5 8 6 13 7 9 8 16 9 9 Total 100 Question 1. [12] Search
MIT Samberg Center Cambridge, MA, USA. May 30 th June 2 nd, by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA
 Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Exploratory Machine Learning studies for disruption prediction on DIII-D by C. Rea, R.S. Granetz MIT Plasma Science and Fusion Center, Cambridge, MA, USA Presented at the 2 nd IAEA Technical Meeting on
Machine Learning. Chao Lan
 Machine Learning Chao Lan Machine Learning Prediction Models Regression Model - linear regression (least square, ridge regression, Lasso) Classification Model - naive Bayes, logistic regression, Gaussian
Machine Learning Chao Lan Machine Learning Prediction Models Regression Model - linear regression (least square, ridge regression, Lasso) Classification Model - naive Bayes, logistic regression, Gaussian
Feature Extractors. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. The Perceptron Update Rule.
 CS 188: Artificial Intelligence Fall 2007 Lecture 26: Kernels 11/29/2007 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit your
CS 188: Artificial Intelligence Fall 2007 Lecture 26: Kernels 11/29/2007 Dan Klein UC Berkeley Feature Extractors A feature extractor maps inputs to feature vectors Dear Sir. First, I must solicit your
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning. Decision Trees. Manfred Huber
 Machine Learning Decision Trees Manfred Huber 2015 1 Decision Trees Classifiers covered so far have been Non-parametric (KNN) Probabilistic with independence (Naïve Bayes) Linear in features (Logistic
Machine Learning Decision Trees Manfred Huber 2015 1 Decision Trees Classifiers covered so far have been Non-parametric (KNN) Probabilistic with independence (Naïve Bayes) Linear in features (Logistic
Performance Evaluation of Various Classification Algorithms
 Performance Evaluation of Various Classification Algorithms Shafali Deora Amritsar College of Engineering & Technology, Punjab Technical University -----------------------------------------------------------***----------------------------------------------------------
Performance Evaluation of Various Classification Algorithms Shafali Deora Amritsar College of Engineering & Technology, Punjab Technical University -----------------------------------------------------------***----------------------------------------------------------
Machine Learning. Unsupervised Learning. Manfred Huber
 Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
Machine Learning Unsupervised Learning Manfred Huber 2015 1 Unsupervised Learning In supervised learning the training data provides desired target output for learning In unsupervised learning the training
An Introduction to Machine Learning
 TRIPODS Summer Boorcamp: Topology and Machine Learning August 6, 2018 General Set-up Introduction Set-up and Goal Suppose we have X 1,X 2,...,X n data samples. Can we predict properites about any given
TRIPODS Summer Boorcamp: Topology and Machine Learning August 6, 2018 General Set-up Introduction Set-up and Goal Suppose we have X 1,X 2,...,X n data samples. Can we predict properites about any given
Preface to the Second Edition. Preface to the First Edition. 1 Introduction 1
 Preface to the Second Edition Preface to the First Edition vii xi 1 Introduction 1 2 Overview of Supervised Learning 9 2.1 Introduction... 9 2.2 Variable Types and Terminology... 9 2.3 Two Simple Approaches
Preface to the Second Edition Preface to the First Edition vii xi 1 Introduction 1 2 Overview of Supervised Learning 9 2.1 Introduction... 9 2.2 Variable Types and Terminology... 9 2.3 Two Simple Approaches
CS Machine Learning
 CS 60050 Machine Learning Decision Tree Classifier Slides taken from course materials of Tan, Steinbach, Kumar 10 10 Illustrating Classification Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K
CS 60050 Machine Learning Decision Tree Classifier Slides taken from course materials of Tan, Steinbach, Kumar 10 10 Illustrating Classification Task Tid Attrib1 Attrib2 Attrib3 Class 1 Yes Large 125K
Case-Based Reasoning. CS 188: Artificial Intelligence Fall Nearest-Neighbor Classification. Parametric / Non-parametric.
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008
 CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
CS 188: Artificial Intelligence Fall 2008 Lecture 25: Kernels and Clustering 12/2/2008 Dan Klein UC Berkeley 1 1 Case-Based Reasoning Similarity for classification Case-based reasoning Predict an instance
6.034 Quiz 2, Spring 2005
 6.034 Quiz 2, Spring 2005 Open Book, Open Notes Name: Problem 1 (13 pts) 2 (8 pts) 3 (7 pts) 4 (9 pts) 5 (8 pts) 6 (16 pts) 7 (15 pts) 8 (12 pts) 9 (12 pts) Total (100 pts) Score 1 1 Decision Trees (13
6.034 Quiz 2, Spring 2005 Open Book, Open Notes Name: Problem 1 (13 pts) 2 (8 pts) 3 (7 pts) 4 (9 pts) 5 (8 pts) 6 (16 pts) 7 (15 pts) 8 (12 pts) 9 (12 pts) Total (100 pts) Score 1 1 Decision Trees (13
Classification. Instructor: Wei Ding
 Classification Decision Tree Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Preliminaries Each data record is characterized by a tuple (x, y), where x is the attribute
Classification Decision Tree Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/2004 1 Preliminaries Each data record is characterized by a tuple (x, y), where x is the attribute
CSE 40171: Artificial Intelligence. Learning from Data: Unsupervised Learning
 CSE 40171: Artificial Intelligence Learning from Data: Unsupervised Learning 32 Homework #6 has been released. It is due at 11:59PM on 11/7. 33 CSE Seminar: 11/1 Amy Reibman Purdue University 3:30pm DBART
CSE 40171: Artificial Intelligence Learning from Data: Unsupervised Learning 32 Homework #6 has been released. It is due at 11:59PM on 11/7. 33 CSE Seminar: 11/1 Amy Reibman Purdue University 3:30pm DBART
Classification: Linear Discriminant Functions
 Classification: Linear Discriminant Functions CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Discriminant functions Linear Discriminant functions
Classification: Linear Discriminant Functions CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Discriminant functions Linear Discriminant functions
K-Means Clustering. Sargur Srihari
 K-Means Clustering Sargur srihari@cedar.buffalo.edu 1 Topics in Mixture Models and EM Mixture models K-means Clustering Mixtures of Gaussians Maximum Likelihood EM for Gaussian mistures EM Algorithm Gaussian
K-Means Clustering Sargur srihari@cedar.buffalo.edu 1 Topics in Mixture Models and EM Mixture models K-means Clustering Mixtures of Gaussians Maximum Likelihood EM for Gaussian mistures EM Algorithm Gaussian
Multivariate Data Analysis and Machine Learning in High Energy Physics (V)
") Multivariate Data Analysis and Machine Learning in High Energy Physics (V) Helge Voss (MPI K, Heidelberg) Graduierten-Kolleg, Freiburg, 11.5-15.5, 2009 Outline last lecture Rule Fitting Support Vector
Multivariate Data Analysis and Machine Learning in High Energy Physics (V) Helge Voss (MPI K, Heidelberg) Graduierten-Kolleg, Freiburg, 11.5-15.5, 2009 Outline last lecture Rule Fitting Support Vector
Classifiers and Detection. D.A. Forsyth
 Classifiers and Detection D.A. Forsyth Classifiers Take a measurement x, predict a bit (yes/no; 1/-1; 1/0; etc) Detection with a classifier Search all windows at relevant scales Prepare features Classify
Classifiers and Detection D.A. Forsyth Classifiers Take a measurement x, predict a bit (yes/no; 1/-1; 1/0; etc) Detection with a classifier Search all windows at relevant scales Prepare features Classify
Neural Networks. CE-725: Statistical Pattern Recognition Sharif University of Technology Spring Soleymani
 Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
Neural Networks CE-725: Statistical Pattern Recognition Sharif University of Technology Spring 2013 Soleymani Outline Biological and artificial neural networks Feed-forward neural networks Single layer
9.1. K-means Clustering
 424 9. MIXTURE MODELS AND EM Section 9.2 Section 9.3 Section 9.4 view of mixture distributions in which the discrete latent variables can be interpreted as defining assignments of data points to specific
424 9. MIXTURE MODELS AND EM Section 9.2 Section 9.3 Section 9.4 view of mixture distributions in which the discrete latent variables can be interpreted as defining assignments of data points to specific