Learning View-invariant Sparse Representations for Cross-view Action Recognition
|
|
|
- Kelley Wright
- 6 years ago
- Views:
Transcription



1 2013 IEEE International Conference on Computer Vision Learning View-invariant Sparse Representations for Cross-view Action Recognition Jingjing Zheng, Zhuolin Jiang University of Maryland, College Park, MD, USA Noah s Ark Lab, Huawei Technologies zjngjng@umiacs.umd.edu, zhuolin.jiang@huawei.com Abstract We present an approach to jointly learn a set of viewspecific dictionaries and a common dictionary for crossview action recognition. The set of view-specific dictionaries is learned for specific views while the common dictionary is shared across different views. Our approach represents videos in each view using both the corresponding view-specific dictionary and the common dictionary. More importantly, it encourages the set of videos taken from different views of the same action to have similar sparse representations. In this way, we can align view-specific features in the sparse feature spaces spanned by the viewspecific dictionary set and transfer the view-shared features in the sparse feature space spanned by the common dictionary. Meanwhile, the incoherence between the common dictionary and the view-specific dictionary set enables us to exploit the discrimination information encoded in viewspecific features and view-shared features separately. In addition, the learned common dictionary not only has the capability to represent actions from unseen views, but also makes our approach effective in a semi-supervised setting where no correspondence videos exist and only a few labels exist in the target view. Extensive experiments using the multi-view IXMAS dataset demonstrate that our approach outperforms many recent approaches for cross-view action recognition. 1. Introduction Action recognition has many potential applications in multimedia retrieval, video surveillance and human computer interaction. In order to accurately recognize human actions, most existing approaches focus on developing different discriminative features, such as spatio-temporal interest point (STIP) based features [32, 2, 13, 19], shape [16, 3, 21] and optical flow based features [5, 17, 16]. These features are effective for recognizing actions taken from similar viewpoints, but perform poorly when viewpoints vary significantly. Extensive experiments in [20, 33] have This research was supported by a MURI from the US Office of Naval Research under the Grant N Source View Target View y 1 y 2 Transfer view-shared features D D x 1 x 2 Align D view-specific s features Figure 1. Joint learning of a view-specific dictionary pair and a common dictionary. We not only learn a common dictionary D to model view-shared features of corresponding videos in both views, but also learn two view-specific dictionaries D s and D t that are incoherent to D to align the view-specific features. The sparse representations (x1 and x2, z1 and z2) share the same sparsity patterns (selecting the same items). shown that failing to handle feature variations caused by viewpoints may yield inferior results. This is because the same action looks quite different from different viewpoints as shown in Figure 1. Thus action models learned from one view become less discriminative for recognizing actions in a much different view. A very fruitful line of work for cross-view action recognition based on transfer learning is to construct the mappings or connections between different views, by using videos taken from different views of the same action [6, 7, 20, 8]. [6] exploited the frame-to-frame correspondence in pairs of videos taken from two views of the same action by transferring the split-based features of video frames in the source view to the corresponding video frames in the target view. [20] proposed to exploit the correspondence between the view-dependent codebooks constructed by k-means clustering on videos in each view. However, the frame-to-frame correspondence [6] is computationally expensive, and the codebook-to-codebook correspondence [20] is not accurate enough to guarantee that a pair of videos observed in the source and target views will have similar feature representations. In order to overcome these drawbacks, we propose a dictionary learning framework to exploit the video-to-video correspondence by encouraging pairs of videos taken in two D t z 1 z /13 $ IEEE DOI /ICCV
2 views to have similar sparse representations. Figure 1 illustrates our dictionary learning framework. Our approach not only learns a common dictionary shared by different views to model the view-shared features, but also learns a dictionary pair corresponding to the source and target views to model and align view-specific features in the two views. Both the common dictionary and the corresponding view-specific dictionary are used to represent videos in each view. Instead of transferring the split-features as in [6], we transfer the indices of the non-zero elements (i.e., the indices of selected dictionary items) in sparse codes of videos from the source view to sparse codes of the corresponding videos from the target view. In other words, we not only use the same subset of dictionary items from the common dictionary to represent view-shared features in correspondence videos from different views, but also use the same subset of dictionary items from different view-specific dictionaries to represent view-specific features. In this way, videos across different views of the same action tend to have similar sparse representations. Note that our approach enforces the common dictionary to be incoherent with viewspecific dictionaries, so that the discrimination information encoded in view-specific features and view-shared features are exploited separately and makes view-specific dictionaries more compact. Actions are categorized into two types: shared actions observed in both views and orphan actions that are only observed in the source view. Note that only pairs of videos taken from two views of the shared actions are used for dictionary learning. In addition, we consider two scenarios for the shared actions: (1) shared actions in both views are unlabeled. (2) shared actions in both views are labeled. These two scenarios are referred to as unsupervised and supervised settings, respectively, in subsequent discussions Contributions The main contributions of this paper are: We propose to simultaneously learn a set of viewspecific dictionaries to exploit the video-level correspondence across views and a common dictionary to model the common patterns shared by different views. The incoherence between the common dictionary and the view-specific dictionaries enables our approach to drive the shared pattern to the common dictionary and focus on exploiting the discriminative correspondence information encoded by the view-specific dictionaries. With the separation of the common dictionary, our approach not only learns more compact view-specific dictionaries, but also bridges the gap of the sparse representations of correspondence videos taken from different views of the same action using a more flexible method. Our framework is a general approach and can be applied to cross-view and multi-view action recognition under both unsupervised and supervised settings. 2. Related Work Recently, several transfer learning techniques have been proposed for cross-view action recognition [6, 20, 8, 33]. Specifically, [6] proposed to generate the same split-based features for correspondence video frames from both the source and target views. It is computationally expensive because it requires the construction of feature-to-feature correspondence at the frame-level and learning an additional mapping from original features to the split-based features. [20] used a bipartite graph to model the relationship between two view-dependent codebooks. Even though this approach exploits the codebook-to-codebook correspondence between two views, it can not guarantee that videos taken at different views of shared actions will have similar features. [8] used canonical correlation analysis to derive a correlation subspace as a joint representation from different bag-of-words models at different views and incorporate a corresponding correlation regularizer into the formulation of support vector machine. [33] proposed a dictionary learning framework for cross-view action recognition with the assumption that sparse representations of videos from different views of the same action should be strictly equal. However, this assumption is too strong to flexibly model the relationship between different views. Many view-invariant approaches that use 2D image data acquired by multiple cameras have also been proposed. [25, 22, 23] proposed view-invariant representations based on view-invariant canonical body poses and trajectories in 2D invariance space. [11, 10] captured the structure of temporal similarities and dissimilarities within an action sequence using a Self-Similarity Matrix. [27] proposed a view-invariant matching method based on epipolar geometry between actor silhouettes without tracking and explicit point correspondences. [15] learned two view-specific transformations for the source and target views, and then generated a sequence of linear transformations of action descriptors as the virtual views to connect two views. [14] proposed the Hankel matrix of a short tracklet which is a view-invariant feature to recognize actions across different viewpoints. Another fruitful line of work for cross-view action recognition concentrates on using the 3D image data. The method introduced in [28] employed three dimensional occupancy grids built from multi-view points to model actions. [31] developed a 4D view-invariant action feature extraction to encode the shape and motion information of actors observed from multiple views. Both of these approaches lead to computationally intense algorithms because they need to find the best match between a 3D model and a 2D observation over a large model parameter space. [29] developed a robust
3 and view-invariant hierarchical classification method based on 3D HOG to represent a test sequence. 3. Learning View-invariant Sparse Representations via Dictionary Learning 3.1. Unsupervised Learning In the unsupervised setting, our goal is to find viewinvariant feature representations by making use of correspondence between videos of the shared actions taken from different views. Let Y v = [y1, v..., yn v ] Rd N denote d-dimensional feature representations of N videos of the shared actions taken in the v-th view. Y i = [yi 1,..., yv i ] are V action videos of the shared action y i taken from V views, which are referred to as correspondence videos. On one hand, we would like to learn a common dictionary D R d J with a size of J shared by different views to represent videos from all views. On the other hand, for each view, we learn D v R d J v to model the view-specific features. The objective function for the unsupervised setting is: N { { yi v Dx v i yi v Dx v i D v zi v 2 2} i=1 + λ X i 2,1 + λ Z i 2,1 } + η D T D v 2 F where X i = [x 1 i,..., xv i ],Z i = [zi 1,..., zv i ] are the joint sparse representations for y i across V views. This objective function consists of five terms: (1) 1. The first two terms are the reconstruction errors of videos from different views using D only or using both D and D v. The minimization of the first reconstruction error enables D to encode view-shared features as much as possible while the minimization of the second reconstruction error enables D v to encode and align view-specific features that can not be modeled by D. 2. The third and fourth terms are the sparse representations via L 2,1 -norm regularization using D and D v respectively. The L 2,1 -norm minimization for X and Z can make the entries in each row of the two matrices to be all zeros or non-zeros at the same time. This means that we not only encourage to use the same subset of dictionary items in D to represent the correspondence videos from different views, but also encourage to use dictionary items from D v with the same index of selected dictionary items to further reduce the reconstruction error of videos in each view. Therefore the testing videos taken from different views of the same action will be encouraged to have similar sparse representations when using the learned D and D v. 3. The last term regularizes the common dictionary to be incoherent to the view-specific dictionaries. The incoherence between D and D v enables our approach to separately exploit the discriminative information encoded in the view-specific features and view-shared features Supervised Learning Given the action categories of correspondence videos, we can learn a discriminative common dictionary and discriminative views-specific dictionaries by leveraging the category information. We partition the dictionary items in each dictionary into disjoint subsets and associate each subset with one specific class label. For videos from action class k, we aim to represent them using the same subset of dictionary items associated with class k. For videos from different classes, we represent them using disjoint subsets of dictionary items. This is supported by the intuition that action videos from the same class tend to have the similar features and each action video can be well represented by other videos from the same class [30]. We incorporate the discriminative sparse code error term introduced in [9] to achieve this goal. Assume there are K shared action classes, and D = [D 1,..., D K ], D v = [D1, v..., DK v ] where D k R d J k, K k=1 J k = J, and Dk v Rd J v k K, k=1 J k v = J v, the objective function for the supervised setting is: N { { yi v Dx v i yi v Dx v i D v zi v 2 2 i=1 + q i Ax v i qi v Bzi v 2 2} + λ X i 2,1 + λ Z i 2,1 } + η D T D v 2 F where q i = [q i1,..., q ik ] T R J 1 and qi v = [qi v 1,..., qi v K ] T R J v 1 called discriminative sparse coefficients associated with D and D v respectively. When a video yi v is from class k at the v-th view, then q i k and qi v k are ones and other entries in q i and qi v are zeros. A RJ J and B R J v J v are called transformation matrices which transform x v i and zv i to approximate q i and qi v respectively. The discriminative sparse-code error terms q i Ax v i 2 2 and qi v Bzv i 2 2 encourage the dictionary items with class k to be selected to reconstruct those videos from class k. Note that the L 2,1 -norm regularization only regularize the relationship between the sparse codes of correspondence videos, but can not regularize the relationship between the sparse codes of videos from the same action class in each view. The integration of discriminative sparse code error term in the objective function can address this issue. In other words, our approach not only encourages the videos taken from different views of the same action to have similar sparse representations, but also encourages videos from the same class in each view to have similar sparse representations. (2)
4 3.3. Optimization Here we only describe the optimization of the objective function in (2) while the optimization of (1) utilizes the similar procedure except that A and B components are excluded. This optimization problem is divided into three subproblems: (1) computing sparse codes with fixed D v,d and A, B; (2) updating D v,d with fixed sparse codes and A, B; (3) updating A, B with fixed D v,dand sparse codes Computing Sparse Codes Given fixed D v,dand A, B, we solve the sparse coding problem of the correspondence videos set by set and (2) is reduced to: { yi v Dx v i yi v Dx v i D v zi v q i Ax v i q v i Bz v i 2 2} + λ X i 2,1 + λ Z i 2,1 }. (3) We rewrite (3) as follows: where ỹ v i = [ x v i z v i ỹi v D v z i v λ Z i 2,1 (4) y v i y v i q i q v i, Dv = D O 1 D D v A O 2 O 3 B, zv i = ], Z i = [ z 1 i,..., zv i ] and O 1 R d J v,o 2 R J J v,o 3 R J v J are matrices of all zeros. The minimization of (4) is known as a multi-task group lasso problem [18] where each view is treated as a task. We use the software SLEP in [18] for computing sparse codes Updating Dictionaries Given fixed sparse codes and A, B, (2) is reduced to: N i=1 + η { yi v Dx v i yi v Dx v i D v zi v 2 2} D T D v 2 F V We rewrite (5): { Y v DX v 2 F + Y v DX v D v Z v 2 F } + η V DT D v 2 F where Y v = [y1, v..., yn v ],Xv = [x v 1,..., x v N ],Zv = [z1, v..., zn v ]. Motivated by [12], we first fix D v and then update D = [d 1,..., d J ] atom by atom, i.e. updating d j while fixing other column atoms in D. Specifically, let Ŷ v = Y v m j d mx v (m) where xv (m) corresponds to the m-th row of X v, we solve the following problem for updating d j in (5) D: arg min dj f(d j )= V { Ŷ v d j x v (j) 2 F + Ŷ v D v Z v d j x v (j) 2 F +η dt j Dv 2 F. Let the first-order derivative of f(d j ) with respect to d j equal to zero, i.e. f(d j) d j = 0, then we can update d j as: d j = 1 2 ( x v (j) 2 2I + η 2 Dv D vt ) 1 (2Ŷ v D v Z v )x vt (j). NowwefixD and update D v atom by atom. Each item d v j in D v is updated as : (6) d v j = 1 2 ( zv (j) 2 2I + η 2 DDT ) 1 Ȳ v z vt (j). (7) where Ȳ v = Y v DX v m j dv mz v (m) Updating A, B Given sparse codes and all the dictionaries, we employ the multivariate ridge regression model [24] to update A, B with the quadratic loss and l 2 norm regularization: min A min B N i=1 N i=1 q i Ax v i λ 1 A 2 2 qi v Bzi v λ 2 B 2 2 which yields the following solutions: A = Q X vt ( X v X vt + λ 1 I) 1, Q =[q 1,..., q N ],X =[x 1,..., x N ], B = Q v Z vt ( Z v Z vt + λ 2 I) 1, Q v =[q v 1,..., q v N ],Z v =[z v 1,..., z v N ]. Algorithm 1 summarizes our approach. The algorithm converged after a few iterations in our experiments. 4. Experiments We evaluated our approach for both cross-view and multi-view action recognition on the IXMAS multi-view dataset [28]. This dataset contains 11 actions performed three times by ten actors taken from four side views and one top view. Figure 3 shows some example frames. We follow the experiment setting in [20] for extracting the local STIP feature [4]. We first detect up to 200 interest points from each action video and then extract a 100-dimensional gradient-based descriptors around these interest points via PCA. Then these interest points-based descriptors are clustered into 1000 visual words by k-mean clustering and (8)
![Algorithm 1 Learning View-invariant Sparse Representations for Cross-view Action Recognition 1: Input: Y v =[Y v 1,..., Y v K ],Q,Qv,v =1,.](/docs-images/72/67390328/images/5-0.jpg ".., V, λ, η 2: Initialize D and D v 3: for k =1 K do 4: Initialize class-specific dictionary D k in D by solving D k = arg min Dk,α k [Y 1 k.")
![..y V k ] D kα k 2 F + λ α k 1 5: Initialize class-specific dictionary D v k in Dv by solving D v k = arg min D v,β v Y v k k k Dv k βv k 2 F + λ β k 1 6: end for 7: repeat 8: Compute sparse codes x](/docs-images/72/67390328/images/5-1.jpg "v i,zv i of a set of correspondence videos yv i by solving the multi-task group LASSO problem in (4) using the SLEP [18] 9: Update each atom d j in D and d v j in Dv using (6) and (7) respectively")
![10: Update transformation matrices A, B using (8) 11: until convergence or certain rounds 12: Output: D =[D 1,..., D K ],D v =[D v 1,.](/docs-images/72/67390328/images/5-2.jpg ".., Dv K ] each action video is represented by a 1000-dimensional histogram.")
![For the global feature, we extract shape-flow descriptors introduced in [26] and learn a codebook of size 500 by k-means clustering on these shape-flow descriptors.](/docs-images/72/67390328/images/5-4.jpg "Similarly, this codebook is used to encode shape-flow descriptors and each action video is represented by a 500- dimensional histogram.")
5 Algorithm 1 Learning View-invariant Sparse Representations for Cross-view Action Recognition 1: Input: Y v =[Y v 1,..., Y v K ],Q,Qv,v =1,..., V, λ, η 2: Initialize D and D v 3: for k =1 K do 4: Initialize class-specific dictionary D k in D by solving D k = arg min Dk,α k [Y 1 k...y V k ] D kα k 2 F + λ α k 1 5: Initialize class-specific dictionary D v k in Dv by solving D v k = arg min D v,β v Y v k k k Dv k βv k 2 F + λ β k 1 6: end for 7: repeat 8: Compute sparse codes x v i,zv i of a set of correspondence videos yv i by solving the multi-task group LASSO problem in (4) using the SLEP [18] 9: Update each atom d j in D and d v j in Dv using (6) and (7) respectively 10: Update transformation matrices A, B using (8) 11: until convergence or certain rounds 12: Output: D =[D 1,..., D K ],D v =[D v 1,..., Dv K ] each action video is represented by a 1000-dimensional histogram. For the global feature, we extract shape-flow descriptors introduced in [26] and learn a codebook of size 500 by k-means clustering on these shape-flow descriptors. Similarly, this codebook is used to encode shape-flow descriptors and each action video is represented by a 500- dimensional histogram. Then the local and global feature descriptors are concatenated to form a 1500-dimensional descriptor to represent an action video. For fair comparison to [6, 20, 15], we use three evaluation modes: (1) unsupervised correspondence mode; (2) supervised correspondence mode ; (3) partially labeled mode. For the first two correspondence mode, we use the leaveone-action-class-out strategy for choosing the orphan action which means that each time we only consider one action class for testing in the target view. And all videos of the orphan action are excluded when learning the quantized visual words and constructing dictionaries. The only difference between the first and the second mode is whether the category labels of the correspondence videos are available or not. For the third mode, we follow [15] to consider a semi-supervised setting where a small portion of videos from the target view is labeled and no matched correspondence videos exist. From this we want to show that our framework can be applied to the domain adaptation problem. Two comparing methods for the third mode are two types of SVMs used in [1]. The first one is AUGSVM, which creates a feature-augmented version of each individual feature as the new feature. The second one is MIXSVM which trains two SVM s on the source and target views and learns an optimal linear combination of them. Note that the test actions from the source and target views are not seen during dictionary learning whereas the test action can be seen in the source view for classifier training in the first two evaluation modes. On the contrary, the test action from different views can be seen during both dictionary learning and classifier training in the third mode. For all modes, we report the classification accuracy by av- Wave Walk Getup Camera0 Camera1 Camera2 Camera3 Camera4 Figure 3. Exemplar frames from the IXMAS multi-view dataset. Each row shows one action viewed across different angles. eraging the results over different combinations of selecting orphan actions Benefits of the Separation of the Common and View-specific Dictionaries In this section, we demonstrate the benefits of the separation of the common and view-specific dictionaries. For visualization purpose, two action classes check-watch and waving taken by Camera0 and Camera2 from the IX- MAS dataset was selected to construct a simple cross-view dataset. We extract the shape descriptor [16] for each video frame and learn a common dictionary and two-view specific dictionaries using our approach. We then reconstruct a pair of frames taken from Camera0 and Camer2 views of the action waving using two methods. The first one is to use the common dictionary only to reconstruct the frame pair. The other one is use both the common dictionary and the viewspecific dictionary for reconstruction. Figure 2(b) shows the original shape feature and the reconstructed shape features of two frames of action waving from two seen views and one unseen view using the mentioned two methods. First, comparing dictionary items in D and {D s,d t }, we see that some items in D mainly encode the body and body outline which are just shared by frames of the same action from two view while items in {D s,d t } mainly encode different arm poses that reflects the class information in the two views. It demonstrates that the common dictionary has the ability to exploit view-shared features from different views. Second, it can be observed that better reconstruction is achieved by using both the common dictionary D and view-specific dictionaries. This is because the common dictionary may not reconstruct the more detailed view-specific features well such as arm poses. The separation of the common dictionary enables the view-specific dictionaries to focus on exploiting and aligning view-specific features from different views. Third, from the last row in Figure 2(b), we find that a good reconstruction of an action frame taken from the unseen view can be achieved by using the common dictionary only. It demonstrates that the common dictionary learned from two seen views has the capability to represent videos of the same action from an unseen view. Moreover, two








")





 and")
 Figures from 2 5")









































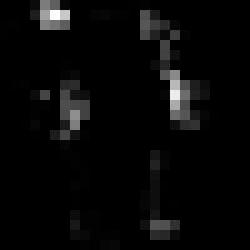



6 (a) Visualization of all dictionary items from the common and view-specific dictionaries. Original recon recon Original recon recon Original recon recon (b) Reconstruction of shape features of action waving from two seen views and one unseen view. Figure 2. Illustration of the benefits of the common dictionary. (a) Visualization of all dictionary atoms in D (green color), D s (red color) and D t (purple color). (b) Figures from 2 5 columns show the reconstruction result using D only. Figures from 6 11 columns show the reconstruction result using {D, D s }, {D, D t } and {D, D s,d t } respectively. Only at most top-3 dictionary items are shown. % C0 C1 C2 C3 C4 C0 (77.6, 79.9, 81.8, 99.1) (69.4, 76.8, 88.1, 90.9) (70.3, 76.8, 87.5, 88.7) (44.8, 74.8, 81.4, 95.5) C1 (77.3, 81.2, 87.5, 97.8) (73.9, 75.8, 82.0, 91.2) (67.3, 78.0, 92.3, 78.4) (43.9, 70.4, 74.2, 88.4) C2 (66.1, 79.6, 85.3, 99.4) (70.6, 76.6, 82.6, 97.6) (63.6, 79.8, 82.6, 91.2) (53.6, 72.8, 76.5, 100.0) C3 (69.4, 73.0, 82.1, 87.6) (70.0, 74.4, 81.5, 98.2) (63.0, 66.9, 80.2, 99.4) (44.2, 66.9, 70.0, 95.4) C4 (39.1, 82.0, 78.8, 87.3) (38.8, 68.3, 73.8, 87.8) (51.8, 74.0, 77.7, 92.1) (34.2, 71.1, 78.7, 90.0) Ave. (63.0, 79.0, 83.4, 93.0) (64.3, 74.7, 79.9, 95.6) (64.5, 75.2, 82.0, 93.4) (58.9, 76.4, 85.3, 87.1) (46.6, 71.2, 75.5, 95.1) Table 1. Cross-view action recognition accuracies of different approaches on the IXMAS dataset using unsupervised correspondence mode. Each row corresponds to a source (training) view and each column a target (test) view. The four accuracy numbers in the bracket are the average recognition accuracies of [11], [20], [15] and our unsupervised approach respectively. % C0 C1 C2 C3 C4 C0 (79, 98.5) (79, 99.7) (68, 99.7) (76, 99.7) C1 (72, 100.0) (74, 97.0) (70, 89.7) (66, 100.0) C2 (71, 99.1) (82, 99.3) (76, 100.0) (72, 99.7) C3 (75, 90.0) (75, 99.7) (73, 98.2) (76, 96.4) C4 (80, 99.7) (73, 95.7) (73, 100.0) (79, 98.5) Ave. (74, 97.2) (77, 98.3) (76, 98.7) (73, 97.0) (72, 98.9) Table 2. Cross-view action recognition accuracies of different approaches on the IXMAS dataset using supervised correspondence mode. Each row corresponds to a source (training) view and each column a target (test) view. The accuracy numbers in the bracket are the average recognition accuracies of [7] and our supervised approach respectively
7 % C0 C1 C2 C3 C4 C0 (42.8, 36.8, 63.6, 64.9) (45.2, 46.8, 60.0, 64.1) (47.2, 42.7, 61.2, 67.1) (30.5, 36.7, 52.6, 65.5) C1 (44.1, 39.4, 61.0, 63.6) (43.5, 51.8, 62.1, 60.2) (47.1, 45.8, 65.1, 66.7) (43.6, 40.2, 54.2, 66.8) C2 (53.7, 49.1, 63.2, 65.4) (50.5, 49.4, 62.4, 63.2) (53.5, 45.0, 71.7, 67.1) (39.1, 46.9, 58.2, 65.9) C3 (46.3, 39.3, 64.2, 65.4) (42.5, 42.5, 71.0, 61.9) (48.8, 51.2, 64.3, 65.4) (37.5, 38.9, 56.6, 61.6) C4 (37.0, 40.3, 50.0, 65.8) (35.0, 42.5, 59.7, 62.7) (44.4, 40.4, 60.7, 64.5) (37.2, 40.7, 61.1, 61.9) Ave. (45.3, 42.6, 59.6, 65.0) (42.7, 42.8, 64.2, 63.2) (45.4, 47.5, 61.9, 63.5) (46.2, 43.5, 64.8, 65.7) (37.6, 40.7, 55.4, 65.0) Table 3. Cross-view action recognition accuracies of different approaches on the IXMAS dataset using partially labeling mode. Each row corresponds to a source (training) view and each column a target (test) view. The accuracy numbers in the bracket are the average recognition accuracies of AUGSVM, MIXSVM from [1], [15], and our approach respectively. methods have nearly the same reconstruction performance for frames of the same action from the unseen view. This is because {D s,d t } are learned by exploiting features that are specific for the two seen views. In addition, the separation of the common dictionary and view-specific dictionaries can enable us to learn more compact view-specific dictionaries Cross-view Action Recognition We evaluate our approach using three different modes. We first learn a common dictionary D and two view-specific dictionaries {D s,d t } corresponding to the source and target views respectively. Both D and D s are used to represent the training videos in the source view. Similarly, for a test video y in the target view, we encode it over ˆD =[D D t ], i.e. β = arg min β y ˆDβ λ 0 β 1 where λ 0 is a parameter to balance the reconstruction error and sparsity. For the first two modes, a k-nn classifier is used to classify the test video in the sparse feature space. For the third mode, we use SRC method [30] to predict the label of y, i.e. k = arg min k y ˆD k β k λ 0 β k 1 where ˆD k =[D k Dk t ] and β k is the associated sparse codes. As shown in Tables 1 and 2, our approach yields a much better performance for all 20 combinations for the first two modes. Moreover, the proposed approach achieves more than 90% recognition accuracy for most combinations. The higher recognition accuracy obtained by our supervised setting over our unsupervised setting demonstrates that the dictionaries learned using labeled information across views are more discriminative. For the partially labeled mode, our approach outperforms other approaches for most of source-target combinations in Table 3. It is interesting to note that for the case where Camera4 is the source or target view, the recognition accuracies of comparing approaches are a little lower than other combinations of piecewise views. This is because the Camera4 was set above the actors and different actions look very similarly from the top view. However, our approach still achieves a very high recognition accuracy for these combinations, which further demonstrates the effectiveness of our approach. % C0 C1 C2 C3 C4 Avg Ours (mode1) Ours (mode2) [33] (mode1) [33] (mode2) [20] [11] [19] N/A 73.8 [29] Table 4. Multi-view action recognition results using the unsupervised and supervised correspondence modes. Each column corresponds to one target view. % C0 C1 C2 C3 C4 Ours (mode3) [15] AUGSVM MIXSVM Table 5. Multi-view action recognition results using the partially labeled mode. Each column corresponds to one target view Multi-view Action Recognition We select one camera as a target view and use all other four cameras as source views to explore the benefits of combining multiple source views. Here we use the same classification scheme used for cross-view action recognition. Both D and the set of correspondence dictionaries D v are learned by aligning the sparse representations of shared action videos across all views. Since videos from all views are aligned into a common view-invariant sparse feature space, we do not need to differentiate the training videos from each source view in this common view-invariant sparse feature space. Table 4 shows the average accuracy of the proposed approach for the first two evaluation modes. Note that the comparing approaches are evaluated using the unsupervised correspondence mode. Both our unsupervised and supervised approaches outperform other comparing approaches and achieve nearly perfect performance for all target views. Furthermore, [20, 33] and our unsupervised approach only use training videos from four source views to train a classifier while other approaches used all the training videos from all five views to train the classifier. Table 5 shows the av
8 erage accuracy of different approaches using the partially labeled evaluation mode. The proposed approach outperforms [15] on four out of five target views. Overall, we accomplish a comparable accuracy with [15] under the partially labeled mode. 5. Conclusion We presented a novel dictionary learning framework to learn view-invariant sparse representations for cross-view action recognition. We propose to simultaneously learn a common dictionary to model view-shared features and a set of view-specific dictionaries to align view-specific features from different views. Both the common dictionary and the corresponding view-specific dictionary are used to represent videos from each view. We transfer the indices of nonzeros in the sparse codes of videos from the source view to the sparse codes of the corresponding videos from the target view. In this way, the mapping between the source and target views is encoded in the common dictionary and viewspecific dictionaries. Meanwhile, the associated sparse representations are view-invariant because non-zero positions in the sparse codes of correspondence videos share the same set of indices. Our approach can be applied to cross-view and multi-view action recognition under unsupervised, supervised and domain adaptation settings. References [1] L. T. Alessandro Bergamo. Exploiting weakly-labeled web images to improve object classification: a domain adaptation approach. In NIPS, , 7 [2] M. Blank, L. Gorelick, E. Shechtman, M. Irani, and R. Basri. Actions as space-time shapes. In ICCV, [3] G. K. M. Cheung, S. Baker, and T. Kanade. Shape-fromsilhouette of articulated objects and its use for human body kinematics estimation and motion capture. In CVPR, [4] P. Dollár, V. Rabaud, G. Cottrell, and S. Belongie. Behavior recognition via sparse spatio-temporal features. In VS-PETS. 4 [5] A. A. Efros, A. C. Berg, G. Mori, and J. Malik. Recognizing action at a distance. In ICCV, [6] A. Farhadi and M. K. Tabrizi. Learning to recognize activities from the wrong view point. In ECCV, , 2, 5 [7] A. Farhadi, M. K. Tabrizi, I. Endres, and D. A. Forsyth. A latent model of discriminative aspect. In ICCV, , 6 [8] C.-H. Huang, Y.-R. Yeh, and Y.-C. F. Wang. Recognizing actions across cameras by exploring the correlated subspace. In ECCV Workshops, , 2 [9] Z. Jiang, Z. Lin, and L. S. Davis. Learning a discriminative dictionary for sparse coding via label consistent k-svd. In CVPR, [10] I. N. Junejo, E. Dexter, I. Laptev, and P. Pérez. View-independent action recognition from temporal selfsimilarities. IEEE Trans. Pattern Anal. Mach. Intell. 2 [11] I. N. Junejo, E. Dexter, I. Laptev, and P. Pérez. Cross-view action recognition from temporal self-similarities. In ECCV, , 6, 7 [12] S. Kong and D. Wang. A dictionary learning approach for classification: Separating the particularity and the commonality. In ECCV, [13] I. Laptev and T. Lindeberg. Space-time interest points. In ICCV, [14] B. Li, O. I. Camps, and M. Sznaier. Cross-view activity recognition using hankelets. In CVPR, [15] R. Li and T. Zickler. Discriminative virtual views for crossview action recognition. In CVPR, , 5, 6, 7, 8 [16] Z. Lin, Z. Jiang, and L. S. Davis. Recognizing actions by shape-motion prototype trees. In ICCV, , 5 [17] J. Little and J. E. Boyd. Recognizing people by their gait: The shape of motion. Videre, [18] J. Liu, S. Ji, and J. Ye. SLEP: Sparse Learning with Efficient Projections. Arizona State University, , 5 [19] J. Liu and M. Shah. Learning human actions via information maximization. In CVPR, , 7 [20] J. Liu, M. Shah, B. Kuipers, and S. Savarese. Cross-view action recognition via view knowledge transfer. In CVPR, , 2, 4, 5, 6, 7 [21] F. Lv and R. Nevatia. Single view human action recognition using key pose matching and viterbi path searching. In CVPR, [22] V. Parameswaran and R. Chellappa. Human actionrecognition using mutual invariants. CVIU, [23] V. Parameswaran and R. Chellappa. View invariance for human action recognition. IJCV, [24] D.-S. Pham and S. Venkatesh. Joint learning and dictionary construction for pattern recognition. In CVPR, [25] C. Rao, A. Yilmaz, and M. Shah. View-invariant representation and recognition of actions. IJCV, [26] D. Tran and A. Sorokin. Human activity recognition with metric learning. In ECCV, [27] A. ul Haq, I. Gondal, and M. Murshed. On dynamic scene geometry for view-invariant action matching. In CVPR, [28] D. Weinland, E. Boyer, and R. Ronfard. Action recognition from arbitrary views using 3d exemplars. In ICCV, , 4 [29] D. Weinland, M. Özuysal, and P. Fua. Making action recognition robust to occlusions and viewpoint changes. In ECCV, , 7 [30] J. Wright, A. Y. Yang, A. Ganesh, S. S. Sastry, and Y. Ma. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell., , 7 [31] P. Yan, S. M. Khan, and M. Shah. Learning 4d action feature models for arbitrary view action recognition. In CVPR, [32] A. Yilmaz and M. Shah. Actions sketch: A novel action representation. In CVPR, [33] J. Zheng, Z. Jiang, J. Phillips, and R. Chellappa. Crossview action recognition via a transferable dictionary pair. In BMVC, , 2,
Cross-View Action Recognition via a Transferable Dictionary Pair
 ZHENG et al:: CROSS-VIEW ACTION RECOGNITION 1 Cross-View Action Recognition via a Transferable Dictionary Pair Jingjing Zheng 1 zjngjng@umiacs.umd.edu Zhuolin Jiang 2 zhuolin@umiacs.umd.edu P. Jonathon
ZHENG et al:: CROSS-VIEW ACTION RECOGNITION 1 Cross-View Action Recognition via a Transferable Dictionary Pair Jingjing Zheng 1 zjngjng@umiacs.umd.edu Zhuolin Jiang 2 zhuolin@umiacs.umd.edu P. Jonathon
Arbitrary View Action Recognition via Transfer Dictionary Learning on Synthetic Training Data
 Arbitrary View Action Recognition via Transfer Dictionary Learning on Synthetic Training Data Jingtian Zhang, Student Member, IEEE, Lining Zhang, Member, IEEE, Hubert P. H. Shum, Member, IEEE, Ling Shao,
Arbitrary View Action Recognition via Transfer Dictionary Learning on Synthetic Training Data Jingtian Zhang, Student Member, IEEE, Lining Zhang, Member, IEEE, Hubert P. H. Shum, Member, IEEE, Ling Shao,
Lecture 18: Human Motion Recognition
 Lecture 18: Human Motion Recognition Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Introduction Motion classification using template matching Motion classification i using spatio
Lecture 18: Human Motion Recognition Professor Fei Fei Li Stanford Vision Lab 1 What we will learn today? Introduction Motion classification using template matching Motion classification i using spatio
Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions
 Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions Akitsugu Noguchi and Keiji Yanai Department of Computer Science, The University of Electro-Communications, 1-5-1 Chofugaoka,
Extracting Spatio-temporal Local Features Considering Consecutiveness of Motions Akitsugu Noguchi and Keiji Yanai Department of Computer Science, The University of Electro-Communications, 1-5-1 Chofugaoka,
Learning 4D Action Feature Models for Arbitrary View Action Recognition
 Learning 4D Action Feature Models for Arbitrary View Action Recognition Pingkun Yan, Saad M. Khan, Mubarak Shah Computer Vision Lab, University of Central Florida, Orlando, FL http://www.eecs.ucf.edu/
Learning 4D Action Feature Models for Arbitrary View Action Recognition Pingkun Yan, Saad M. Khan, Mubarak Shah Computer Vision Lab, University of Central Florida, Orlando, FL http://www.eecs.ucf.edu/
Evaluation of Local Space-time Descriptors based on Cuboid Detector in Human Action Recognition
 International Journal of Innovation and Applied Studies ISSN 2028-9324 Vol. 9 No. 4 Dec. 2014, pp. 1708-1717 2014 Innovative Space of Scientific Research Journals http://www.ijias.issr-journals.org/ Evaluation
International Journal of Innovation and Applied Studies ISSN 2028-9324 Vol. 9 No. 4 Dec. 2014, pp. 1708-1717 2014 Innovative Space of Scientific Research Journals http://www.ijias.issr-journals.org/ Evaluation
REJECTION-BASED CLASSIFICATION FOR ACTION RECOGNITION USING A SPATIO-TEMPORAL DICTIONARY. Stefen Chan Wai Tim, Michele Rombaut, Denis Pellerin
 REJECTION-BASED CLASSIFICATION FOR ACTION RECOGNITION USING A SPATIO-TEMPORAL DICTIONARY Stefen Chan Wai Tim, Michele Rombaut, Denis Pellerin Univ. Grenoble Alpes, GIPSA-Lab, F-38000 Grenoble, France ABSTRACT
REJECTION-BASED CLASSIFICATION FOR ACTION RECOGNITION USING A SPATIO-TEMPORAL DICTIONARY Stefen Chan Wai Tim, Michele Rombaut, Denis Pellerin Univ. Grenoble Alpes, GIPSA-Lab, F-38000 Grenoble, France ABSTRACT
Action Recognition in Video by Sparse Representation on Covariance Manifolds of Silhouette Tunnels
 Action Recognition in Video by Sparse Representation on Covariance Manifolds of Silhouette Tunnels Kai Guo, Prakash Ishwar, and Janusz Konrad Department of Electrical & Computer Engineering Motivation
Action Recognition in Video by Sparse Representation on Covariance Manifolds of Silhouette Tunnels Kai Guo, Prakash Ishwar, and Janusz Konrad Department of Electrical & Computer Engineering Motivation
Cross-View Action Recognition from Temporal Self-Similarities
 Appears at ECCV 8 Cross-View Action Recognition from Temporal Self-Similarities Imran N. Junejo, Emilie Dexter, Ivan Laptev and Patrick Pérez INRIA Rennes - Bretagne Atlantique Rennes Cedex - FRANCE Abstract.
Appears at ECCV 8 Cross-View Action Recognition from Temporal Self-Similarities Imran N. Junejo, Emilie Dexter, Ivan Laptev and Patrick Pérez INRIA Rennes - Bretagne Atlantique Rennes Cedex - FRANCE Abstract.
Distributed and Lightweight Multi-Camera Human Activity Classification
 Distributed and Lightweight Multi-Camera Human Activity Classification Gaurav Srivastava, Hidekazu Iwaki, Johnny Park and Avinash C. Kak School of Electrical and Computer Engineering Purdue University,
Distributed and Lightweight Multi-Camera Human Activity Classification Gaurav Srivastava, Hidekazu Iwaki, Johnny Park and Avinash C. Kak School of Electrical and Computer Engineering Purdue University,
Incremental Action Recognition Using Feature-Tree
 Incremental Action Recognition Using Feature-Tree Kishore K Reddy Computer Vision Lab University of Central Florida kreddy@cs.ucf.edu Jingen Liu Computer Vision Lab University of Central Florida liujg@cs.ucf.edu
Incremental Action Recognition Using Feature-Tree Kishore K Reddy Computer Vision Lab University of Central Florida kreddy@cs.ucf.edu Jingen Liu Computer Vision Lab University of Central Florida liujg@cs.ucf.edu
Robust Face Recognition via Sparse Representation Authors: John Wright, Allen Y. Yang, Arvind Ganesh, S. Shankar Sastry, and Yi Ma
 Robust Face Recognition via Sparse Representation Authors: John Wright, Allen Y. Yang, Arvind Ganesh, S. Shankar Sastry, and Yi Ma Presented by Hu Han Jan. 30 2014 For CSE 902 by Prof. Anil K. Jain: Selected
Robust Face Recognition via Sparse Representation Authors: John Wright, Allen Y. Yang, Arvind Ganesh, S. Shankar Sastry, and Yi Ma Presented by Hu Han Jan. 30 2014 For CSE 902 by Prof. Anil K. Jain: Selected
CS229: Action Recognition in Tennis
 CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
CS229: Action Recognition in Tennis Aman Sikka Stanford University Stanford, CA 94305 Rajbir Kataria Stanford University Stanford, CA 94305 asikka@stanford.edu rkataria@stanford.edu 1. Motivation As active
Space-Time Shapelets for Action Recognition
 Space-Time Shapelets for Action Recognition Dhruv Batra 1 Tsuhan Chen 1 Rahul Sukthankar 2,1 batradhruv@cmu.edu tsuhan@cmu.edu rahuls@cs.cmu.edu 1 Carnegie Mellon University 2 Intel Research Pittsburgh
Space-Time Shapelets for Action Recognition Dhruv Batra 1 Tsuhan Chen 1 Rahul Sukthankar 2,1 batradhruv@cmu.edu tsuhan@cmu.edu rahuls@cs.cmu.edu 1 Carnegie Mellon University 2 Intel Research Pittsburgh
EVENT DETECTION AND HUMAN BEHAVIOR RECOGNITION. Ing. Lorenzo Seidenari
 EVENT DETECTION AND HUMAN BEHAVIOR RECOGNITION Ing. Lorenzo Seidenari e-mail: seidenari@dsi.unifi.it What is an Event? Dictionary.com definition: something that occurs in a certain place during a particular
EVENT DETECTION AND HUMAN BEHAVIOR RECOGNITION Ing. Lorenzo Seidenari e-mail: seidenari@dsi.unifi.it What is an Event? Dictionary.com definition: something that occurs in a certain place during a particular
Bag of Optical Flow Volumes for Image Sequence Recognition 1
 RIEMENSCHNEIDER, DONOSER, BISCHOF: BAG OF OPTICAL FLOW VOLUMES 1 Bag of Optical Flow Volumes for Image Sequence Recognition 1 Hayko Riemenschneider http://www.icg.tugraz.at/members/hayko Michael Donoser
RIEMENSCHNEIDER, DONOSER, BISCHOF: BAG OF OPTICAL FLOW VOLUMES 1 Bag of Optical Flow Volumes for Image Sequence Recognition 1 Hayko Riemenschneider http://www.icg.tugraz.at/members/hayko Michael Donoser
Temporal Feature Weighting for Prototype-Based Action Recognition
 Temporal Feature Weighting for Prototype-Based Action Recognition Thomas Mauthner, Peter M. Roth, and Horst Bischof Institute for Computer Graphics and Vision Graz University of Technology {mauthner,pmroth,bischof}@icg.tugraz.at
Temporal Feature Weighting for Prototype-Based Action Recognition Thomas Mauthner, Peter M. Roth, and Horst Bischof Institute for Computer Graphics and Vision Graz University of Technology {mauthner,pmroth,bischof}@icg.tugraz.at
Aggregating Descriptors with Local Gaussian Metrics
 Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
on learned visual embedding patrick pérez Allegro Workshop Inria Rhônes-Alpes 22 July 2015
 on learned visual embedding patrick pérez Allegro Workshop Inria Rhônes-Alpes 22 July 2015 Vector visual representation Fixed-size image representation High-dim (100 100,000) Generic, unsupervised: BoW,
on learned visual embedding patrick pérez Allegro Workshop Inria Rhônes-Alpes 22 July 2015 Vector visual representation Fixed-size image representation High-dim (100 100,000) Generic, unsupervised: BoW,
IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION. Maral Mesmakhosroshahi, Joohee Kim
 IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION Maral Mesmakhosroshahi, Joohee Kim Department of Electrical and Computer Engineering Illinois Institute
IMPROVING SPATIO-TEMPORAL FEATURE EXTRACTION TECHNIQUES AND THEIR APPLICATIONS IN ACTION CLASSIFICATION Maral Mesmakhosroshahi, Joohee Kim Department of Electrical and Computer Engineering Illinois Institute
Bilevel Sparse Coding
 Adobe Research 345 Park Ave, San Jose, CA Mar 15, 2013 Outline 1 2 The learning model The learning algorithm 3 4 Sparse Modeling Many types of sensory data, e.g., images and audio, are in high-dimensional
Adobe Research 345 Park Ave, San Jose, CA Mar 15, 2013 Outline 1 2 The learning model The learning algorithm 3 4 Sparse Modeling Many types of sensory data, e.g., images and audio, are in high-dimensional
Multi-View Pedestrian Recognition using Shared Dictionary Learning with Group Sparsity
 Multi-View Pedestrian Recognition using Shared Dictionary Learning with Group Sparsity Shuai Zheng, Bo Xie 2, Kaiqi Huang, and Dacheng Tao 3. National Laboratory of Pattern Recognition Institute of Automation,
Multi-View Pedestrian Recognition using Shared Dictionary Learning with Group Sparsity Shuai Zheng, Bo Xie 2, Kaiqi Huang, and Dacheng Tao 3. National Laboratory of Pattern Recognition Institute of Automation,
STOP: Space-Time Occupancy Patterns for 3D Action Recognition from Depth Map Sequences
 STOP: Space-Time Occupancy Patterns for 3D Action Recognition from Depth Map Sequences Antonio W. Vieira 1,2,EricksonR.Nascimento 1, Gabriel L. Oliveira 1, Zicheng Liu 3,andMarioF.M.Campos 1, 1 DCC - Universidade
STOP: Space-Time Occupancy Patterns for 3D Action Recognition from Depth Map Sequences Antonio W. Vieira 1,2,EricksonR.Nascimento 1, Gabriel L. Oliveira 1, Zicheng Liu 3,andMarioF.M.Campos 1, 1 DCC - Universidade
EigenJoints-based Action Recognition Using Naïve-Bayes-Nearest-Neighbor
 EigenJoints-based Action Recognition Using Naïve-Bayes-Nearest-Neighbor Xiaodong Yang and YingLi Tian Department of Electrical Engineering The City College of New York, CUNY {xyang02, ytian}@ccny.cuny.edu
EigenJoints-based Action Recognition Using Naïve-Bayes-Nearest-Neighbor Xiaodong Yang and YingLi Tian Department of Electrical Engineering The City College of New York, CUNY {xyang02, ytian}@ccny.cuny.edu
Human Activity Recognition Using a Dynamic Texture Based Method
 Human Activity Recognition Using a Dynamic Texture Based Method Vili Kellokumpu, Guoying Zhao and Matti Pietikäinen Machine Vision Group University of Oulu, P.O. Box 4500, Finland {kello,gyzhao,mkp}@ee.oulu.fi
Human Activity Recognition Using a Dynamic Texture Based Method Vili Kellokumpu, Guoying Zhao and Matti Pietikäinen Machine Vision Group University of Oulu, P.O. Box 4500, Finland {kello,gyzhao,mkp}@ee.oulu.fi
Action recognition in videos
 Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Action recognition in videos Cordelia Schmid INRIA Grenoble Joint work with V. Ferrari, A. Gaidon, Z. Harchaoui, A. Klaeser, A. Prest, H. Wang Action recognition - goal Short actions, i.e. drinking, sit
Human Upper Body Pose Estimation in Static Images
 1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
Local Features and Bag of Words Models
 10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
10/14/11 Local Features and Bag of Words Models Computer Vision CS 143, Brown James Hays Slides from Svetlana Lazebnik, Derek Hoiem, Antonio Torralba, David Lowe, Fei Fei Li and others Computer Engineering
Nonrigid Surface Modelling. and Fast Recovery. Department of Computer Science and Engineering. Committee: Prof. Leo J. Jia and Prof. K. H.
 Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Nonrigid Surface Modelling and Fast Recovery Zhu Jianke Supervisor: Prof. Michael R. Lyu Committee: Prof. Leo J. Jia and Prof. K. H. Wong Department of Computer Science and Engineering May 11, 2007 1 2
Submodular Attribute Selection for Action Recognition in Video
 Submodular Attribute Selection for Action Recognition in Video Jinging Zheng UMIACS, University of Maryland College Park, MD, USA zjngjng@umiacs.umd.edu Rama Chellappa UMIACS, University of Maryland College
Submodular Attribute Selection for Action Recognition in Video Jinging Zheng UMIACS, University of Maryland College Park, MD, USA zjngjng@umiacs.umd.edu Rama Chellappa UMIACS, University of Maryland College
Gesture Recognition Under Small Sample Size
 Gesture Recognition Under Small Sample Size Tae-Kyun Kim 1 and Roberto Cipolla 2 1 Sidney Sussex College, University of Cambridge, Cambridge, CB2 3HU, UK 2 Department of Engineering, University of Cambridge,
Gesture Recognition Under Small Sample Size Tae-Kyun Kim 1 and Roberto Cipolla 2 1 Sidney Sussex College, University of Cambridge, Cambridge, CB2 3HU, UK 2 Department of Engineering, University of Cambridge,
Dynamic Shape Tracking via Region Matching
 Dynamic Shape Tracking via Region Matching Ganesh Sundaramoorthi Asst. Professor of EE and AMCS KAUST (Joint work with Yanchao Yang) The Problem: Shape Tracking Given: exact object segmentation in frame1
Dynamic Shape Tracking via Region Matching Ganesh Sundaramoorthi Asst. Professor of EE and AMCS KAUST (Joint work with Yanchao Yang) The Problem: Shape Tracking Given: exact object segmentation in frame1
Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction
 Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction Atul Kanaujia, CBIM, Rutgers Cristian Sminchisescu, TTI-C Dimitris Metaxas,CBIM, Rutgers 3D Human Pose Inference Difficulties Towards
Semi-Supervised Hierarchical Models for 3D Human Pose Reconstruction Atul Kanaujia, CBIM, Rutgers Cristian Sminchisescu, TTI-C Dimitris Metaxas,CBIM, Rutgers 3D Human Pose Inference Difficulties Towards
Spatial Latent Dirichlet Allocation
 Spatial Latent Dirichlet Allocation Xiaogang Wang and Eric Grimson Computer Science and Computer Science and Artificial Intelligence Lab Massachusetts Tnstitute of Technology, Cambridge, MA, 02139, USA
Spatial Latent Dirichlet Allocation Xiaogang Wang and Eric Grimson Computer Science and Computer Science and Artificial Intelligence Lab Massachusetts Tnstitute of Technology, Cambridge, MA, 02139, USA
Leveraging Textural Features for Recognizing Actions in Low Quality Videos
 Leveraging Textural Features for Recognizing Actions in Low Quality Videos Saimunur Rahman, John See, Chiung Ching Ho Centre of Visual Computing, Faculty of Computing and Informatics Multimedia University,
Leveraging Textural Features for Recognizing Actions in Low Quality Videos Saimunur Rahman, John See, Chiung Ching Ho Centre of Visual Computing, Faculty of Computing and Informatics Multimedia University,
Dimensionality Reduction using Relative Attributes
 Dimensionality Reduction using Relative Attributes Mohammadreza Babaee 1, Stefanos Tsoukalas 1, Maryam Babaee Gerhard Rigoll 1, and Mihai Datcu 1 Institute for Human-Machine Communication, Technische Universität
Dimensionality Reduction using Relative Attributes Mohammadreza Babaee 1, Stefanos Tsoukalas 1, Maryam Babaee Gerhard Rigoll 1, and Mihai Datcu 1 Institute for Human-Machine Communication, Technische Universität
Learning Human Motion Models from Unsegmented Videos
 In IEEE International Conference on Pattern Recognition (CVPR), pages 1-7, Alaska, June 2008. Learning Human Motion Models from Unsegmented Videos Roman Filipovych Eraldo Ribeiro Computer Vision and Bio-Inspired
In IEEE International Conference on Pattern Recognition (CVPR), pages 1-7, Alaska, June 2008. Learning Human Motion Models from Unsegmented Videos Roman Filipovych Eraldo Ribeiro Computer Vision and Bio-Inspired
Middle-Level Representation for Human Activities Recognition: the Role of Spatio-temporal Relationships
 Middle-Level Representation for Human Activities Recognition: the Role of Spatio-temporal Relationships Fei Yuan 1, Véronique Prinet 1, and Junsong Yuan 2 1 LIAMA & NLPR, CASIA, Chinese Academy of Sciences,
Middle-Level Representation for Human Activities Recognition: the Role of Spatio-temporal Relationships Fei Yuan 1, Véronique Prinet 1, and Junsong Yuan 2 1 LIAMA & NLPR, CASIA, Chinese Academy of Sciences,
Action Recognition By Learnt Class-Specific Overcomplete Dictionaries
 Action Recognition By Learnt Class-Specific Overcomplete Dictionaries Tanaya Guha Electrical and Computer Engineering University of British Columbia Vancouver, Canada Email: tanaya@ece.ubc.ca Rabab K.
Action Recognition By Learnt Class-Specific Overcomplete Dictionaries Tanaya Guha Electrical and Computer Engineering University of British Columbia Vancouver, Canada Email: tanaya@ece.ubc.ca Rabab K.
Detecting Burnscar from Hyperspectral Imagery via Sparse Representation with Low-Rank Interference
 Detecting Burnscar from Hyperspectral Imagery via Sparse Representation with Low-Rank Interference Minh Dao 1, Xiang Xiang 1, Bulent Ayhan 2, Chiman Kwan 2, Trac D. Tran 1 Johns Hopkins Univeristy, 3400
Detecting Burnscar from Hyperspectral Imagery via Sparse Representation with Low-Rank Interference Minh Dao 1, Xiang Xiang 1, Bulent Ayhan 2, Chiman Kwan 2, Trac D. Tran 1 Johns Hopkins Univeristy, 3400
Geodesic Flow Kernel for Unsupervised Domain Adaptation
 Geodesic Flow Kernel for Unsupervised Domain Adaptation Boqing Gong University of Southern California Joint work with Yuan Shi, Fei Sha, and Kristen Grauman 1 Motivation TRAIN TEST Mismatch between different
Geodesic Flow Kernel for Unsupervised Domain Adaptation Boqing Gong University of Southern California Joint work with Yuan Shi, Fei Sha, and Kristen Grauman 1 Motivation TRAIN TEST Mismatch between different
IMAGE RETRIEVAL USING VLAD WITH MULTIPLE FEATURES
 IMAGE RETRIEVAL USING VLAD WITH MULTIPLE FEATURES Pin-Syuan Huang, Jing-Yi Tsai, Yu-Fang Wang, and Chun-Yi Tsai Department of Computer Science and Information Engineering, National Taitung University,
IMAGE RETRIEVAL USING VLAD WITH MULTIPLE FEATURES Pin-Syuan Huang, Jing-Yi Tsai, Yu-Fang Wang, and Chun-Yi Tsai Department of Computer Science and Information Engineering, National Taitung University,
LEARNING A SPARSE DICTIONARY OF VIDEO STRUCTURE FOR ACTIVITY MODELING. Nandita M. Nayak, Amit K. Roy-Chowdhury. University of California, Riverside
 LEARNING A SPARSE DICTIONARY OF VIDEO STRUCTURE FOR ACTIVITY MODELING Nandita M. Nayak, Amit K. Roy-Chowdhury University of California, Riverside ABSTRACT We present an approach which incorporates spatiotemporal
LEARNING A SPARSE DICTIONARY OF VIDEO STRUCTURE FOR ACTIVITY MODELING Nandita M. Nayak, Amit K. Roy-Chowdhury University of California, Riverside ABSTRACT We present an approach which incorporates spatiotemporal
Fast Motion Consistency through Matrix Quantization
 Fast Motion Consistency through Matrix Quantization Pyry Matikainen 1 ; Rahul Sukthankar,1 ; Martial Hebert 1 ; Yan Ke 1 The Robotics Institute, Carnegie Mellon University Intel Research Pittsburgh Microsoft
Fast Motion Consistency through Matrix Quantization Pyry Matikainen 1 ; Rahul Sukthankar,1 ; Martial Hebert 1 ; Yan Ke 1 The Robotics Institute, Carnegie Mellon University Intel Research Pittsburgh Microsoft
Facial Expression Recognition Using Non-negative Matrix Factorization
 Facial Expression Recognition Using Non-negative Matrix Factorization Symeon Nikitidis, Anastasios Tefas and Ioannis Pitas Artificial Intelligence & Information Analysis Lab Department of Informatics Aristotle,
Facial Expression Recognition Using Non-negative Matrix Factorization Symeon Nikitidis, Anastasios Tefas and Ioannis Pitas Artificial Intelligence & Information Analysis Lab Department of Informatics Aristotle,
Class 5: Attributes and Semantic Features
 Class 5: Attributes and Semantic Features Rogerio Feris, Feb 21, 2013 EECS 6890 Topics in Information Processing Spring 2013, Columbia University http://rogerioferis.com/visualrecognitionandsearch Project
Class 5: Attributes and Semantic Features Rogerio Feris, Feb 21, 2013 EECS 6890 Topics in Information Processing Spring 2013, Columbia University http://rogerioferis.com/visualrecognitionandsearch Project
Adaptive Action Detection
 Adaptive Action Detection Illinois Vision Workshop Dec. 1, 2009 Liangliang Cao Dept. ECE, UIUC Zicheng Liu Microsoft Research Thomas Huang Dept. ECE, UIUC Motivation Action recognition is important in
Adaptive Action Detection Illinois Vision Workshop Dec. 1, 2009 Liangliang Cao Dept. ECE, UIUC Zicheng Liu Microsoft Research Thomas Huang Dept. ECE, UIUC Motivation Action recognition is important in
Multiple-Choice Questionnaire Group C
 Family name: Vision and Machine-Learning Given name: 1/28/2011 Multiple-Choice naire Group C No documents authorized. There can be several right answers to a question. Marking-scheme: 2 points if all right
Family name: Vision and Machine-Learning Given name: 1/28/2011 Multiple-Choice naire Group C No documents authorized. There can be several right answers to a question. Marking-scheme: 2 points if all right
Robust and Secure Iris Recognition
 Robust and Secure Iris Recognition Vishal M. Patel University of Maryland, UMIACS pvishalm@umiacs.umd.edu IJCB 2011 Tutorial Sparse Representation and Low-Rank Representation for Biometrics Outline Iris
Robust and Secure Iris Recognition Vishal M. Patel University of Maryland, UMIACS pvishalm@umiacs.umd.edu IJCB 2011 Tutorial Sparse Representation and Low-Rank Representation for Biometrics Outline Iris
Face Recognition via Sparse Representation
 Face Recognition via Sparse Representation John Wright, Allen Y. Yang, Arvind, S. Shankar Sastry and Yi Ma IEEE Trans. PAMI, March 2008 Research About Face Face Detection Face Alignment Face Recognition
Face Recognition via Sparse Representation John Wright, Allen Y. Yang, Arvind, S. Shankar Sastry and Yi Ma IEEE Trans. PAMI, March 2008 Research About Face Face Detection Face Alignment Face Recognition
A Hierarchical Model of Shape and Appearance for Human Action Classification
 A Hierarchical Model of Shape and Appearance for Human Action Classification Juan Carlos Niebles Universidad del Norte, Colombia University of Illinois at Urbana-Champaign, USA jnieble2@uiuc.edu Li Fei-Fei
A Hierarchical Model of Shape and Appearance for Human Action Classification Juan Carlos Niebles Universidad del Norte, Colombia University of Illinois at Urbana-Champaign, USA jnieble2@uiuc.edu Li Fei-Fei
Partial Least Squares Regression on Grassmannian Manifold for Emotion Recognition
 Emotion Recognition In The Wild Challenge and Workshop (EmotiW 2013) Partial Least Squares Regression on Grassmannian Manifold for Emotion Recognition Mengyi Liu, Ruiping Wang, Zhiwu Huang, Shiguang Shan,
Emotion Recognition In The Wild Challenge and Workshop (EmotiW 2013) Partial Least Squares Regression on Grassmannian Manifold for Emotion Recognition Mengyi Liu, Ruiping Wang, Zhiwu Huang, Shiguang Shan,
Computation Strategies for Volume Local Binary Patterns applied to Action Recognition
 Computation Strategies for Volume Local Binary Patterns applied to Action Recognition F. Baumann, A. Ehlers, B. Rosenhahn Institut für Informationsverarbeitung (TNT) Leibniz Universität Hannover, Germany
Computation Strategies for Volume Local Binary Patterns applied to Action Recognition F. Baumann, A. Ehlers, B. Rosenhahn Institut für Informationsverarbeitung (TNT) Leibniz Universität Hannover, Germany
Representing Pairwise Spatial and Temporal Relations for Action Recognition
 Representing Pairwise Spatial and Temporal Relations for Action Recognition Pyry Matikainen 1, Martial Hebert 1, and Rahul Sukthankar 2,1 1 The Robotics Institute, Carnegie Mellon University 2 Intel Labs
Representing Pairwise Spatial and Temporal Relations for Action Recognition Pyry Matikainen 1, Martial Hebert 1, and Rahul Sukthankar 2,1 1 The Robotics Institute, Carnegie Mellon University 2 Intel Labs
Human Activity Recognition with Metric Learning
 Human Activity Recognition with Metric Learning Du Tran and Alexander Sorokin University of Illinois at Urbana-Champaign Urbana, IL, 61801, USA {dutran2,sorokin2}@uiuc.edu Abstract. This paper proposes
Human Activity Recognition with Metric Learning Du Tran and Alexander Sorokin University of Illinois at Urbana-Champaign Urbana, IL, 61801, USA {dutran2,sorokin2}@uiuc.edu Abstract. This paper proposes
Recognizing Actions by Shape-Motion Prototype Trees
 Recognizing Actions by Shape-Motion Prototype Trees Zhe Lin, Zhuolin Jiang, Larry S. Davis Institute for Advanced Computer Studies, University of Maryland, College Park, MD 20742 {zhelin,zhuolin,lsd}@umiacs.umd.edu
Recognizing Actions by Shape-Motion Prototype Trees Zhe Lin, Zhuolin Jiang, Larry S. Davis Institute for Advanced Computer Studies, University of Maryland, College Park, MD 20742 {zhelin,zhuolin,lsd}@umiacs.umd.edu
IMA Preprint Series # 2281
 DICTIONARY LEARNING AND SPARSE CODING FOR UNSUPERVISED CLUSTERING By Pablo Sprechmann and Guillermo Sapiro IMA Preprint Series # 2281 ( September 2009 ) INSTITUTE FOR MATHEMATICS AND ITS APPLICATIONS UNIVERSITY
DICTIONARY LEARNING AND SPARSE CODING FOR UNSUPERVISED CLUSTERING By Pablo Sprechmann and Guillermo Sapiro IMA Preprint Series # 2281 ( September 2009 ) INSTITUTE FOR MATHEMATICS AND ITS APPLICATIONS UNIVERSITY
Sparse coding for image classification
 Sparse coding for image classification Columbia University Electrical Engineering: Kun Rong(kr2496@columbia.edu) Yongzhou Xiang(yx2211@columbia.edu) Yin Cui(yc2776@columbia.edu) Outline Background Introduction
Sparse coding for image classification Columbia University Electrical Engineering: Kun Rong(kr2496@columbia.edu) Yongzhou Xiang(yx2211@columbia.edu) Yin Cui(yc2776@columbia.edu) Outline Background Introduction
Discriminative human action recognition using pairwise CSP classifiers
 Discriminative human action recognition using pairwise CSP classifiers Ronald Poppe and Mannes Poel University of Twente, Dept. of Computer Science, Human Media Interaction Group P.O. Box 217, 7500 AE
Discriminative human action recognition using pairwise CSP classifiers Ronald Poppe and Mannes Poel University of Twente, Dept. of Computer Science, Human Media Interaction Group P.O. Box 217, 7500 AE
Multiple-View Object Recognition in Band-Limited Distributed Camera Networks
 in Band-Limited Distributed Camera Networks Allen Y. Yang, Subhransu Maji, Mario Christoudas, Kirak Hong, Posu Yan Trevor Darrell, Jitendra Malik, and Shankar Sastry Fusion, 2009 Classical Object Recognition
in Band-Limited Distributed Camera Networks Allen Y. Yang, Subhransu Maji, Mario Christoudas, Kirak Hong, Posu Yan Trevor Darrell, Jitendra Malik, and Shankar Sastry Fusion, 2009 Classical Object Recognition
Beyond Bags of Features
 : for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
: for Recognizing Natural Scene Categories Matching and Modeling Seminar Instructed by Prof. Haim J. Wolfson School of Computer Science Tel Aviv University December 9 th, 2015
Learning based face hallucination techniques: A survey
 Vol. 3 (2014-15) pp. 37-45. : A survey Premitha Premnath K Department of Computer Science & Engineering Vidya Academy of Science & Technology Thrissur - 680501, Kerala, India (email: premithakpnath@gmail.com)
Vol. 3 (2014-15) pp. 37-45. : A survey Premitha Premnath K Department of Computer Science & Engineering Vidya Academy of Science & Technology Thrissur - 680501, Kerala, India (email: premithakpnath@gmail.com)
Evaluation of local descriptors for action recognition in videos
 Evaluation of local descriptors for action recognition in videos Piotr Bilinski and Francois Bremond INRIA Sophia Antipolis - PULSAR group 2004 route des Lucioles - BP 93 06902 Sophia Antipolis Cedex,
Evaluation of local descriptors for action recognition in videos Piotr Bilinski and Francois Bremond INRIA Sophia Antipolis - PULSAR group 2004 route des Lucioles - BP 93 06902 Sophia Antipolis Cedex,
Real-time multi-view human action recognition using a wireless camera network
 Real-time multi-view human action recognition using a wireless camera network S. Ramagiri, R. Kavi,. Kulathumani Dept. of Computer Science and Electrical Engineering West irginia University Email: {sramagir,
Real-time multi-view human action recognition using a wireless camera network S. Ramagiri, R. Kavi,. Kulathumani Dept. of Computer Science and Electrical Engineering West irginia University Email: {sramagir,
Vision and Image Processing Lab., CRV Tutorial day- May 30, 2010 Ottawa, Canada
 Spatio-Temporal Salient Features Amir H. Shabani Vision and Image Processing Lab., University of Waterloo, ON CRV Tutorial day- May 30, 2010 Ottawa, Canada 1 Applications Automated surveillance for scene
Spatio-Temporal Salient Features Amir H. Shabani Vision and Image Processing Lab., University of Waterloo, ON CRV Tutorial day- May 30, 2010 Ottawa, Canada 1 Applications Automated surveillance for scene
Temporal Poselets for Collective Activity Detection and Recognition
 Temporal Poselets for Collective Activity Detection and Recognition Moin Nabi Alessio Del Bue Vittorio Murino Pattern Analysis and Computer Vision (PAVIS) Istituto Italiano di Tecnologia (IIT) Via Morego
Temporal Poselets for Collective Activity Detection and Recognition Moin Nabi Alessio Del Bue Vittorio Murino Pattern Analysis and Computer Vision (PAVIS) Istituto Italiano di Tecnologia (IIT) Via Morego
Action Recognition from a Small Number of Frames
 Computer Vision Winter Workshop 2009, Adrian Ion and Walter G. Kropatsch (eds.) Eibiswald, Austria, February 4 6 Publisher: PRIP, Vienna University of Technology, Austria Action Recognition from a Small
Computer Vision Winter Workshop 2009, Adrian Ion and Walter G. Kropatsch (eds.) Eibiswald, Austria, February 4 6 Publisher: PRIP, Vienna University of Technology, Austria Action Recognition from a Small
Learning Human Actions via Information Maximization
 Learning Human Actions via Information Maximization Jingen Liu Computer Vision Lab University of Central Florida liujg@cs.ucf.edu Mubarak Shah Computer Vision Lab University of Central Florida shah@cs.ucf.edu
Learning Human Actions via Information Maximization Jingen Liu Computer Vision Lab University of Central Florida liujg@cs.ucf.edu Mubarak Shah Computer Vision Lab University of Central Florida shah@cs.ucf.edu
Action Recognition by Learning Mid-level Motion Features
 Action Recognition by Learning Mid-level Motion Features Alireza Fathi and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada {alirezaf,mori}@cs.sfu.ca Abstract This paper
Action Recognition by Learning Mid-level Motion Features Alireza Fathi and Greg Mori School of Computing Science Simon Fraser University Burnaby, BC, Canada {alirezaf,mori}@cs.sfu.ca Abstract This paper
View Invariant Movement Recognition by using Adaptive Neural Fuzzy Inference System
 View Invariant Movement Recognition by using Adaptive Neural Fuzzy Inference System V. Anitha #1, K.S.Ravichandran *2, B. Santhi #3 School of Computing, SASTRA University, Thanjavur-613402, India 1 anithavijay28@gmail.com
View Invariant Movement Recognition by using Adaptive Neural Fuzzy Inference System V. Anitha #1, K.S.Ravichandran *2, B. Santhi #3 School of Computing, SASTRA University, Thanjavur-613402, India 1 anithavijay28@gmail.com
Spatial-Temporal correlatons for unsupervised action classification
 Spatial-Temporal correlatons for unsupervised action classification Silvio Savarese 1, Andrey DelPozo 2, Juan Carlos Niebles 3,4, Li Fei-Fei 3 1 Beckman Institute, University of Illinois at Urbana Champaign,
Spatial-Temporal correlatons for unsupervised action classification Silvio Savarese 1, Andrey DelPozo 2, Juan Carlos Niebles 3,4, Li Fei-Fei 3 1 Beckman Institute, University of Illinois at Urbana Champaign,
Human Activity Recognition Based on R Transform and Fourier Mellin Transform
 Human Activity Recognition Based on R Transform and Fourier Mellin Transform Pengfei Zhu, Weiming Hu, Li Li, and Qingdi Wei Institute of Automation, Chinese Academy of Sciences, Beijing, China {pfzhu,wmhu,lli,qdwei}@nlpr.ia.ac.cn
Human Activity Recognition Based on R Transform and Fourier Mellin Transform Pengfei Zhu, Weiming Hu, Li Li, and Qingdi Wei Institute of Automation, Chinese Academy of Sciences, Beijing, China {pfzhu,wmhu,lli,qdwei}@nlpr.ia.ac.cn
An Approach for Reduction of Rain Streaks from a Single Image
 An Approach for Reduction of Rain Streaks from a Single Image Vijayakumar Majjagi 1, Netravati U M 2 1 4 th Semester, M. Tech, Digital Electronics, Department of Electronics and Communication G M Institute
An Approach for Reduction of Rain Streaks from a Single Image Vijayakumar Majjagi 1, Netravati U M 2 1 4 th Semester, M. Tech, Digital Electronics, Department of Electronics and Communication G M Institute
Multiresponse Sparse Regression with Application to Multidimensional Scaling
 Multiresponse Sparse Regression with Application to Multidimensional Scaling Timo Similä and Jarkko Tikka Helsinki University of Technology, Laboratory of Computer and Information Science P.O. Box 54,
Multiresponse Sparse Regression with Application to Multidimensional Scaling Timo Similä and Jarkko Tikka Helsinki University of Technology, Laboratory of Computer and Information Science P.O. Box 54,
IMPROVED FACE RECOGNITION USING ICP TECHNIQUES INCAMERA SURVEILLANCE SYSTEMS. Kirthiga, M.E-Communication system, PREC, Thanjavur
 IMPROVED FACE RECOGNITION USING ICP TECHNIQUES INCAMERA SURVEILLANCE SYSTEMS Kirthiga, M.E-Communication system, PREC, Thanjavur R.Kannan,Assistant professor,prec Abstract: Face Recognition is important
IMPROVED FACE RECOGNITION USING ICP TECHNIQUES INCAMERA SURVEILLANCE SYSTEMS Kirthiga, M.E-Communication system, PREC, Thanjavur R.Kannan,Assistant professor,prec Abstract: Face Recognition is important
An evaluation of local action descriptors for human action classification in the presence of occlusion
 An evaluation of local action descriptors for human action classification in the presence of occlusion Iveel Jargalsaikhan, Cem Direkoglu, Suzanne Little, and Noel E. O Connor INSIGHT Centre for Data Analytics,
An evaluation of local action descriptors for human action classification in the presence of occlusion Iveel Jargalsaikhan, Cem Direkoglu, Suzanne Little, and Noel E. O Connor INSIGHT Centre for Data Analytics,
Discriminative classifiers for image recognition
 Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Discriminative classifiers for image recognition May 26 th, 2015 Yong Jae Lee UC Davis Outline Last time: window-based generic object detection basic pipeline face detection with boosting as case study
Chapter 2 Action Representation
 Chapter 2 Action Representation Abstract In this chapter, various action recognition issues are covered in a concise manner. Various approaches are presented here. In Chap. 1, nomenclatures, various aspects
Chapter 2 Action Representation Abstract In this chapter, various action recognition issues are covered in a concise manner. Various approaches are presented here. In Chap. 1, nomenclatures, various aspects
Experiments of Image Retrieval Using Weak Attributes
 Columbia University Computer Science Department Technical Report # CUCS 005-12 (2012) Experiments of Image Retrieval Using Weak Attributes Felix X. Yu, Rongrong Ji, Ming-Hen Tsai, Guangnan Ye, Shih-Fu
Columbia University Computer Science Department Technical Report # CUCS 005-12 (2012) Experiments of Image Retrieval Using Weak Attributes Felix X. Yu, Rongrong Ji, Ming-Hen Tsai, Guangnan Ye, Shih-Fu
ActivityRepresentationUsing3DShapeModels
 ActivityRepresentationUsing3DShapeModels AmitK.Roy-Chowdhury RamaChellappa UmutAkdemir University of California University of Maryland University of Maryland Riverside, CA 9252 College Park, MD 274 College
ActivityRepresentationUsing3DShapeModels AmitK.Roy-Chowdhury RamaChellappa UmutAkdemir University of California University of Maryland University of Maryland Riverside, CA 9252 College Park, MD 274 College
Shape Descriptor using Polar Plot for Shape Recognition.
 Shape Descriptor using Polar Plot for Shape Recognition. Brijesh Pillai ECE Graduate Student, Clemson University bpillai@clemson.edu Abstract : This paper presents my work on computing shape models that
Shape Descriptor using Polar Plot for Shape Recognition. Brijesh Pillai ECE Graduate Student, Clemson University bpillai@clemson.edu Abstract : This paper presents my work on computing shape models that
Tri-modal Human Body Segmentation
 Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Part based models for recognition. Kristen Grauman
 Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
Part based models for recognition Kristen Grauman UT Austin Limitations of window-based models Not all objects are box-shaped Assuming specific 2d view of object Local components themselves do not necessarily
FAST HUMAN DETECTION USING TEMPLATE MATCHING FOR GRADIENT IMAGES AND ASC DESCRIPTORS BASED ON SUBTRACTION STEREO
 FAST HUMAN DETECTION USING TEMPLATE MATCHING FOR GRADIENT IMAGES AND ASC DESCRIPTORS BASED ON SUBTRACTION STEREO Makoto Arie, Masatoshi Shibata, Kenji Terabayashi, Alessandro Moro and Kazunori Umeda Course
FAST HUMAN DETECTION USING TEMPLATE MATCHING FOR GRADIENT IMAGES AND ASC DESCRIPTORS BASED ON SUBTRACTION STEREO Makoto Arie, Masatoshi Shibata, Kenji Terabayashi, Alessandro Moro and Kazunori Umeda Course
Spatio-temporal Shape and Flow Correlation for Action Recognition
 Spatio-temporal Shape and Flow Correlation for Action Recognition Yan Ke 1, Rahul Sukthankar 2,1, Martial Hebert 1 1 School of Computer Science, Carnegie Mellon; 2 Intel Research Pittsburgh {yke,rahuls,hebert}@cs.cmu.edu
Spatio-temporal Shape and Flow Correlation for Action Recognition Yan Ke 1, Rahul Sukthankar 2,1, Martial Hebert 1 1 School of Computer Science, Carnegie Mellon; 2 Intel Research Pittsburgh {yke,rahuls,hebert}@cs.cmu.edu
Activities as Time Series of Human Postures
 Activities as Time Series of Human Postures William Brendel and Sinisa Todorovic Oregon State University, Kelley Engineering Center, Corvallis, OR 97331, USA brendelw@onid.orst.edu,sinisa@eecs.oregonstate.edu
Activities as Time Series of Human Postures William Brendel and Sinisa Todorovic Oregon State University, Kelley Engineering Center, Corvallis, OR 97331, USA brendelw@onid.orst.edu,sinisa@eecs.oregonstate.edu
Face2Face Comparing faces with applications Patrick Pérez. Inria, Rennes 2 Oct. 2014
 Face2Face Comparing faces with applications Patrick Pérez Inria, Rennes 2 Oct. 2014 Outline Metric learning for face comparison Expandable parts model and occlusions Face sets comparison Identity-based
Face2Face Comparing faces with applications Patrick Pérez Inria, Rennes 2 Oct. 2014 Outline Metric learning for face comparison Expandable parts model and occlusions Face sets comparison Identity-based
Action Recognition & Categories via Spatial-Temporal Features
 Action Recognition & Categories via Spatial-Temporal Features 华俊豪, 11331007 huajh7@gmail.com 2014/4/9 Talk at Image & Video Analysis taught by Huimin Yu. Outline Introduction Frameworks Feature extraction
Action Recognition & Categories via Spatial-Temporal Features 华俊豪, 11331007 huajh7@gmail.com 2014/4/9 Talk at Image & Video Analysis taught by Huimin Yu. Outline Introduction Frameworks Feature extraction
QMUL-ACTIVA: Person Runs detection for the TRECVID Surveillance Event Detection task
 QMUL-ACTIVA: Person Runs detection for the TRECVID Surveillance Event Detection task Fahad Daniyal and Andrea Cavallaro Queen Mary University of London Mile End Road, London E1 4NS (United Kingdom) {fahad.daniyal,andrea.cavallaro}@eecs.qmul.ac.uk
QMUL-ACTIVA: Person Runs detection for the TRECVID Surveillance Event Detection task Fahad Daniyal and Andrea Cavallaro Queen Mary University of London Mile End Road, London E1 4NS (United Kingdom) {fahad.daniyal,andrea.cavallaro}@eecs.qmul.ac.uk
Previously. Part-based and local feature models for generic object recognition. Bag-of-words model 4/20/2011
 Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
Previously Part-based and local feature models for generic object recognition Wed, April 20 UT-Austin Discriminative classifiers Boosting Nearest neighbors Support vector machines Useful for object recognition
AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering
 AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering www.csse.uwa.edu.au/~ajmal/ Overview Aim of automatic human action recognition Applications
AUTOMATIC 3D HUMAN ACTION RECOGNITION Ajmal Mian Associate Professor Computer Science & Software Engineering www.csse.uwa.edu.au/~ajmal/ Overview Aim of automatic human action recognition Applications
Human Daily Action Analysis with Multi-View and Color-Depth Data
 Human Daily Action Analysis with Multi-View and Color-Depth Data Zhongwei Cheng 1, Lei Qin 2, Yituo Ye 1, Qingming Huang 1,2, and Qi Tian 3 1 Graduate University of Chinese Academy of Sciences, Beijing
Human Daily Action Analysis with Multi-View and Color-Depth Data Zhongwei Cheng 1, Lei Qin 2, Yituo Ye 1, Qingming Huang 1,2, and Qi Tian 3 1 Graduate University of Chinese Academy of Sciences, Beijing
Part-based and local feature models for generic object recognition
 Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
Part-based and local feature models for generic object recognition May 28 th, 2015 Yong Jae Lee UC Davis Announcements PS2 grades up on SmartSite PS2 stats: Mean: 80.15 Standard Dev: 22.77 Vote on piazza
AN ENHANCED ATTRIBUTE RERANKING DESIGN FOR WEB IMAGE SEARCH
 AN ENHANCED ATTRIBUTE RERANKING DESIGN FOR WEB IMAGE SEARCH Sai Tejaswi Dasari #1 and G K Kishore Babu *2 # Student,Cse, CIET, Lam,Guntur, India * Assistant Professort,Cse, CIET, Lam,Guntur, India Abstract-
AN ENHANCED ATTRIBUTE RERANKING DESIGN FOR WEB IMAGE SEARCH Sai Tejaswi Dasari #1 and G K Kishore Babu *2 # Student,Cse, CIET, Lam,Guntur, India * Assistant Professort,Cse, CIET, Lam,Guntur, India Abstract-
Dynamic Human Shape Description and Characterization
 Dynamic Human Shape Description and Characterization Z. Cheng*, S. Mosher, Jeanne Smith H. Cheng, and K. Robinette Infoscitex Corporation, Dayton, Ohio, USA 711 th Human Performance Wing, Air Force Research
Dynamic Human Shape Description and Characterization Z. Cheng*, S. Mosher, Jeanne Smith H. Cheng, and K. Robinette Infoscitex Corporation, Dayton, Ohio, USA 711 th Human Performance Wing, Air Force Research
Human detection using local shape and nonredundant
 University of Wollongong Research Online Faculty of Informatics - Papers (Archive) Faculty of Engineering and Information Sciences 2010 Human detection using local shape and nonredundant binary patterns
University of Wollongong Research Online Faculty of Informatics - Papers (Archive) Faculty of Engineering and Information Sciences 2010 Human detection using local shape and nonredundant binary patterns
Pose Locality Constrained Representation for 3D Human Pose Reconstruction
 Pose Locality Constrained Representation for 3D Human Pose Reconstruction Xiaochuan Fan, Kang Zheng, Youjie Zhou, Song Wang Department of Computer Science & Engineering, University of South Carolina {fan23,zheng37,zhou42}@email.sc.edu,
Pose Locality Constrained Representation for 3D Human Pose Reconstruction Xiaochuan Fan, Kang Zheng, Youjie Zhou, Song Wang Department of Computer Science & Engineering, University of South Carolina {fan23,zheng37,zhou42}@email.sc.edu,
METRIC PLANE RECTIFICATION USING SYMMETRIC VANISHING POINTS
 METRIC PLANE RECTIFICATION USING SYMMETRIC VANISHING POINTS M. Lefler, H. Hel-Or Dept. of CS, University of Haifa, Israel Y. Hel-Or School of CS, IDC, Herzliya, Israel ABSTRACT Video analysis often requires
METRIC PLANE RECTIFICATION USING SYMMETRIC VANISHING POINTS M. Lefler, H. Hel-Or Dept. of CS, University of Haifa, Israel Y. Hel-Or School of CS, IDC, Herzliya, Israel ABSTRACT Video analysis often requires
An Efficient Part-Based Approach to Action Recognition from RGB-D Video with BoW-Pyramid Representation
 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) November 3-7, 2013. Tokyo, Japan An Efficient Part-Based Approach to Action Recognition from RGB-D Video with BoW-Pyramid
2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) November 3-7, 2013. Tokyo, Japan An Efficient Part-Based Approach to Action Recognition from RGB-D Video with BoW-Pyramid
Improving Recognition through Object Sub-categorization
 Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,
Improving Recognition through Object Sub-categorization Al Mansur and Yoshinori Kuno Graduate School of Science and Engineering, Saitama University, 255 Shimo-Okubo, Sakura-ku, Saitama-shi, Saitama 338-8570,