Analyzing Mel Frequency Cepstral Coefficient for Recognition of Isolated English Word using DTW Matching
|
|
|
- Claud Stokes
- 6 years ago
- Views:
Transcription
1 Abstract- Analyzing Mel Frequency Cepstral Coefficient for Recognition of Isolated English Word using DTW Matching Mr. Nitin Goyal, Dr. R.K.Purwar PG student, USICT NewDelhi, Associate Professor, USICT NewDelhi In this paper we proposed Mel-frequency cepstrum coefficients feature extraction and Dynamic Time Warping matching algorithm for speech recognition. Feature vector (Mel-frequency cepstrum coefficients) obtained from speech frame by using Fast Fourier Transform and Discrete Cosine Transform. DTW matching algorithm was applied on feature vector thus obtained by varying number of MFCC coefficients. Clustered database was prepared for template matching. The effectiveness of varying vector size over matching was considered. appropriate matching system command is invoked. This paper focuses on an effective method for recognition of English words and generating particular system command to open particular application. The rest of the paper is organized as follows: the Methodology is discussed in section 2, which is followed by feature extraction and feature matching. result and conclusion has been explained subsequently II. METHODOLOGY Keywords Feature Extraction, Mel Frequency Cepstral Coefficients(MFCC),Dynamic Time Warping(DTW), Discrete Cosine Transform(DCT) I. Introduction Speech is the fundamental mode of communication for human beings. Computer s usage has become inevitable in modern era. Exchange of information between human and computer became a natural complication thus speech recognition system comes into light. The recognition system converts words spoken by humans into a form in which a computer can understand and can respond accordingly [1]. There are mainly two phase of a speech recognition system. One is training phase and another testing phase [2]. It is impossible to recognize all the English words by a system. For methods like DTW, HMM training is necessary [1][2]. The speech recognition system starts with converting human voice (continuous signal) into digital signal [3]. Then feature is extracted from digitalize speech using MFCC technique[4][5]. Further voice feature coefficients are compared with template patterns in the database using Dynamic Time Warping (DTW) in order to find the exact spoken word. After In order to perform the isolated English word recognition two algorithms are utilized in this paper. Feature extraction is done by using MFCC [6]. Feature matching concept can be implemented by using DTW. Feature extraction stage is the most important among all stages because it is responsible for extracting relevant information from the speech frames as feature vectors [7][8]. For matching stage, DTW algorithm is used which is based on Dynamic Programming [9][10]. This algorithm is used for measuring similarity between two non linear time series III. FEATURE EXTRACTION The first stage in the speech recognition process is feature extraction. MFCCs are said to be the coefficients that together represent the short-term power spectrum of the sound which is based on a linear cosine transform of a log power spectrum on a nonlinear Mel Scale of frequency [6]. MFCC is used to extract feature vector from the sound wave. MFCC algorithm is based on human hearing perceptions and having Mel Scale based filter. The process of feature extraction is explained in the given block diagram Page 436
2 Acquisition setup Discrete Fourier Transform Fig.1. Speech signal s front end analysis Fig.2. Speech signal s feature extraction MFCC algorithm can be completed in the following steps [5]: A. Acquisition setup To achieve a audio file, the recording is done by microphone in the normal soundproof room. The sampling frequency for all recordings was 8000 Hz at the normal room temperature and normal humidity. The speakers were sitting in front of microphone at a distance of cm. In this way we achieved digitalization of Continuous Speech Signal. B. Pre-emphasis In the spectrum of speech sound we will notice less energy in the highest frequencies with strictly decreasing slope. Objective of the pre-emphasis filter is to counter-balance and flatten the spectrum. x_pre-emphasis = filter([1,-.095],1,x(n)) (1) The speech signal x(n) is sent to a high-pass filter: y(n) = x(n) a * x(n-1) (2) where y(n) is the output signal and ranges between 0.95 to 0.97 C. Frame Blocking Preemphasis Mel Filter Bank Frame Blocking and Windowing Discrete Cosine Transform Speech signal is segmented into frames of 20~30 msec. Suppose we have taken frame duration 20 msec and sampling frequency 16 khz. Then the number of sample in a frame is 320. Now speech signal in short time interval is available for processing.each frame is supposed to have stationary behavior and smooth transition from frame to frame is the goal of frame blocking. Here sampled speech signal is blocked into frames of K samples where the adjacent frames is separated by P (P<K) [7]. D. Windowing In order to reduce the discontinuities of the speech signal at the edges of each frame, a tapered window is applied to each one. The most common used window is Hamming window [9]. Each frame has to be multiplied with a hamming window in order to keep the continuity of the first and the last points in the frame (i.e. to reduce Gibbs effect). Signal in a frame is denoted by x(n), n = 0, N-1, then the signal after Hamming windowing is x(n)*w(n), where w(n) is the Hamming window defined by: w(n) = (1 a) a cos, 0 n M 1 (3) Different values of a corresponds to different curves for the Hamming E. Discrete Fourier Transform (DFT) The time domain sample is converted into frequency domain by using FFT. FFT is efficient algorithm of DFT. We usually perform FFT to obtain the magnitude frequency response for each frame Y(w)=FFT [h(t)*x(t)] = H(w) * X(w) (4) In the above equation X (w), H (w) and Y (w) are the Fourier Transform of X (t), H (t) and Y (t) respectively. It converts each frame of K samples from the time domain into the frequency domain F. Mel Filter Bank Mel filter bank consists of triangular filters. Here filters are equally spaced along the Mel frequency, which is related to the common linear frequency f by the following equation: F (Mel) = [ 2595 * log10 [1 + f /700] (5) Mel-frequency is proportional to the logarithm of the linear frequency, reflecting similar effects in the human's subjective aural perception [5]. G. Discrete Cosine Transform In this last stage the Mel frequency Cepstral Coefficients are obtained.we apply DCT on the energy Ek obtained from the triangular bandpass Page 437
![filters to have L mel-scale cepstral coefficients. The formula for DCT is given by C m = cos [ (. ) ]*E k m=1,2,.](/docs-images/72/67917292/images/3-0.jpg ".., L (6) where N is the number of triangular bandpass filters, L is the number of mel-scale cepstral coefficients.")
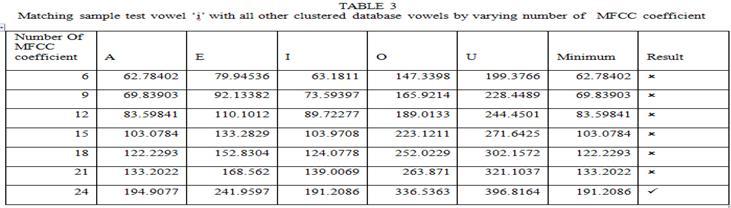
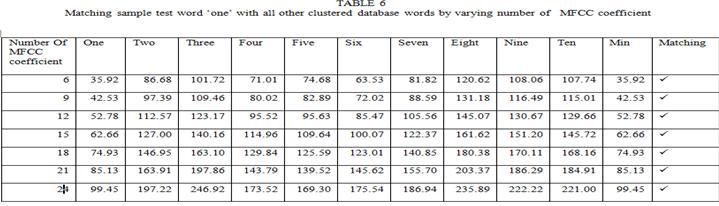
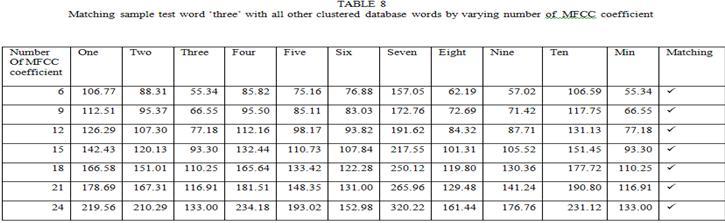
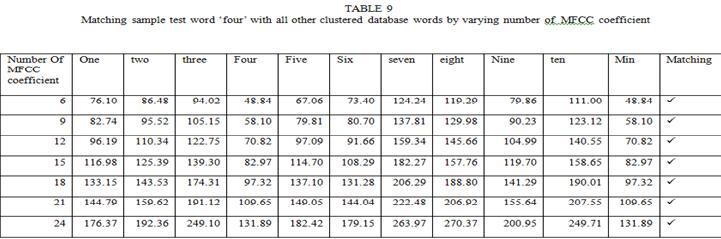
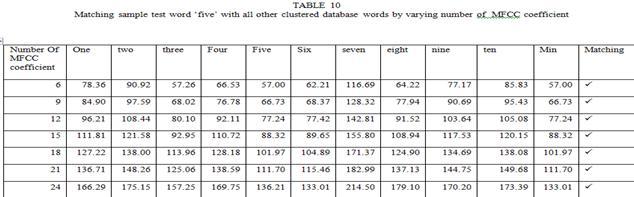
3 filters to have L mel-scale cepstral coefficients. The formula for DCT is given by C m = cos [ (. ) ]*E k m=1,2,..., L (6) where N is the number of triangular bandpass filters, L is the number of mel-scale cepstral coefficients. We have performed FFT, DCT transforms the frequency domain into a time-like domain called quefrency domain. The obtained features are referred to as the mel-scale cepstral coefficients or MFCC. IV. FEATURE MATCHING Dynamic Time Warping (DTW) is used to perform the feature matching technique. Dynamic Programming (DP) is guaranteed to find the lowest path distance through the matrix, while minimizing the amount of computation. DTW is a speech recognition technique based on template matching and non-parametric method. DTW algorithm has been widely used in speech recognition of a particular person. The DTW algorithm was first introduced to recognize spoken words in 1978 by Sakoe and Chiba. It compares test word with reference word template. The basic idea of which is in the training phase, the feature vector sequence of speech corresponding to each word in the vocabulary table was extracted as the template, and then was stored to the characteristics template library [9]. Then, in the recognition phase, to compare the feature vector sequences of the speech to be recognized with each template of template library by dynamic time warping algorithm [10]. V. RESULT AND CONCLUSION We have taken two sets of data. Dataset 1 is ONE through TEN digits in English. The other is the vowels of English Language a to u. Each word and vowel were uttered 6 times by a speaker and recorded with sampling frequency 8khz. Out of 6 utterance of each word, 5 is used for clustering and 1 is used for testing. One representative comes out of 5 after clustering kept in database. This technique is economical in terms of reducing processing time by reducing training sample 5 to 1. Test sample of two datasets are taken as input and features are extracted as MFCC coefficient.these coefficient is represented as a feature vector. These feature vectors are matched with clustered reference template that has already stored. This matching is DTW based where minimum distance between two time series (may be non linear in time) measure is chosen as matched one. Number of MFCC coefficients consideration might effects matching. By default 12 coefficient were taken into consideration. We had taken 6 to 24 coefficients in interval of 3. TABLE 1-5 shows dataset 1 matching and TABLE 6-15 shows dataset 2 matching Page 438


4 Page 439


5 Page 440


6 Page 441



7 The tables` result conclude that dataset 1 has 60% matching without varying number of MFCC coefficients because at default number (i.e. 12) a and I do not match. But by varying number of MFCC coefficient to 24 we achieved 100% matching. In turns number of MFCC coefficients increase processing overhead. Dataset2 has 90% matching ( nine does not match). The table s result concludes that there is no effect of varying number of MFCC coefficients which is only processing overhead. As the matching succeeds, appropriate system commands can be invoked by some predicate mean. Hence this paper presented isolated English word recognition for small application like robot for handicapped person, small embedded systems etc. REFERENCES [1] Lawrence Rabiner,Biing-Hwang Juang and B.Yegnanarayana. Fundamentals of Speech Recognition, Dorling Kindersley (India) Pvt. Ltd Pp [2] Santosh K. Gaikward, Bharti W. Gawali and Pravin Yannawar rs. A Review on Speech Recognition Technique, International Journal of Computer Page 442
8 Applications ( ) Volume 10-No. 3 November 2010, pp 16-24; [3] Cormen et al. Introduction to Algorithms, Edition 3, 31 Jul, 2009[7] Shanthi Therese S.,Chelpa Lingam, Review of Feature Extraction Techniques in Automatic Speech Recognition, International Journal of Scientific Engineering and Technology (ISSN : )Volume No.2, Issue No.6, pp : [4] Chadawan Ittichaichareon, Siwat Suksri and Thaweesak Yingthawornsuk, Speech recognition using MFCC, International Conference on Computer Graphics, Simulation and Modeling (ICGSM'2012) July 28-29, 2012 [5] Md. Afzal; Sheeraz Memon; Gregory, Mark; A novel approach for MFCC feature extraction, 4th international conference on signal processing and communication systems, pages. 1-5, Gold Coast Australia, [6] J. Chen, K. K. Paliwal, M. Mizumachi and S. Nakamura, "Robust mfccs derived from differentiated power spectrum " Eurospeech 2001, Scandinavia, [7] IEEE International Multitopic Conference, INMIC 2007, 2007 pp. Wang Chen, Miao Zhenjiang and Meng Xiao, "Comparison of different implementations of mfcc," J. Computer Science & Technology, 2001, pp. 16(16): [8] Han Chunguang, Li Hua, Approach to Improve Robust Performance of Mel frequency Coefficient Cepstral, Computer Engineering and Design, [9] Sakoe H. and Chiba, H.S. Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. Speech Signal Process, 1978, 26,(1), pp [10] Gregory N, Stainhaour and George Carayannis, New Parallel Impementations for DTW Algorithms, IEEE Transactions on Acoustics, Speech, and Signal Processing. Vol. 38, No. 4, 1990, pp [11] Dalmiya C.P, Dharun V.S and Rajesh K,P, An Efficient Method for Tamil Speech, Proceeding of IEEE conference on ICT,2013 [12] Thomas H. Cormen, Charkes E. Leiserson and Ronald L. Rivest, Approximation Algorthm. Introduction to Algorithms Prentic Hall of India Private Limited 2001, ISBN pp [13] Waibel Alexander, Krishanan N and Reddy Dabbala Rajagopal, Minimizing computational cost for dynamic programming algorithms(1981), Carnegie Mellon University, Computer Science Department, Paper [14] Anany Levitin, Introduction to The Design & Analysis of Algorithm, Villanova University. Pearson Education (Singapur)Pvt. Ltd Pp Page 443
Voice Command Based Computer Application Control Using MFCC
 Voice Command Based Computer Application Control Using MFCC Abinayaa B., Arun D., Darshini B., Nataraj C Department of Embedded Systems Technologies, Sri Ramakrishna College of Engineering, Coimbatore,
Voice Command Based Computer Application Control Using MFCC Abinayaa B., Arun D., Darshini B., Nataraj C Department of Embedded Systems Technologies, Sri Ramakrishna College of Engineering, Coimbatore,
Authentication of Fingerprint Recognition Using Natural Language Processing
 Authentication of Fingerprint Recognition Using Natural Language Shrikala B. Digavadekar 1, Prof. Ravindra T. Patil 2 1 Tatyasaheb Kore Institute of Engineering & Technology, Warananagar, India 2 Tatyasaheb
Authentication of Fingerprint Recognition Using Natural Language Shrikala B. Digavadekar 1, Prof. Ravindra T. Patil 2 1 Tatyasaheb Kore Institute of Engineering & Technology, Warananagar, India 2 Tatyasaheb
Speech Based Voice Recognition System for Natural Language Processing
 Speech Based Voice Recognition System for Natural Language Processing Dr. Kavitha. R 1, Nachammai. N 2, Ranjani. R 2, Shifali. J 2, 1 Assitant Professor-II,CSE, 2 BE..- IV year students School of Computing,
Speech Based Voice Recognition System for Natural Language Processing Dr. Kavitha. R 1, Nachammai. N 2, Ranjani. R 2, Shifali. J 2, 1 Assitant Professor-II,CSE, 2 BE..- IV year students School of Computing,
IJETST- Vol. 03 Issue 05 Pages May ISSN
 International Journal of Emerging Trends in Science and Technology Implementation of MFCC Extraction Architecture and DTW Technique in Speech Recognition System R.M.Sneha 1, K.L.Hemalatha 2 1 PG Student,
International Journal of Emerging Trends in Science and Technology Implementation of MFCC Extraction Architecture and DTW Technique in Speech Recognition System R.M.Sneha 1, K.L.Hemalatha 2 1 PG Student,
Intelligent Hands Free Speech based SMS System on Android
 Intelligent Hands Free Speech based SMS System on Android Gulbakshee Dharmale 1, Dr. Vilas Thakare 3, Dr. Dipti D. Patil 2 1,3 Computer Science Dept., SGB Amravati University, Amravati, INDIA. 2 Computer
Intelligent Hands Free Speech based SMS System on Android Gulbakshee Dharmale 1, Dr. Vilas Thakare 3, Dr. Dipti D. Patil 2 1,3 Computer Science Dept., SGB Amravati University, Amravati, INDIA. 2 Computer
Design of Feature Extraction Circuit for Speech Recognition Applications
 Design of Feature Extraction Circuit for Speech Recognition Applications SaambhaviVB, SSSPRao and PRajalakshmi Indian Institute of Technology Hyderabad Email: ee10m09@iithacin Email: sssprao@cmcltdcom
Design of Feature Extraction Circuit for Speech Recognition Applications SaambhaviVB, SSSPRao and PRajalakshmi Indian Institute of Technology Hyderabad Email: ee10m09@iithacin Email: sssprao@cmcltdcom
Implementing a Speech Recognition System on a GPU using CUDA. Presented by Omid Talakoub Astrid Yi
 Implementing a Speech Recognition System on a GPU using CUDA Presented by Omid Talakoub Astrid Yi Outline Background Motivation Speech recognition algorithm Implementation steps GPU implementation strategies
Implementing a Speech Recognition System on a GPU using CUDA Presented by Omid Talakoub Astrid Yi Outline Background Motivation Speech recognition algorithm Implementation steps GPU implementation strategies
Implementation of Speech Based Stress Level Monitoring System
 4 th International Conference on Computing, Communication and Sensor Network, CCSN2015 Implementation of Speech Based Stress Level Monitoring System V.Naveen Kumar 1,Dr.Y.Padma sai 2, K.Sonali Swaroop
4 th International Conference on Computing, Communication and Sensor Network, CCSN2015 Implementation of Speech Based Stress Level Monitoring System V.Naveen Kumar 1,Dr.Y.Padma sai 2, K.Sonali Swaroop
ACEEE Int. J. on Electrical and Power Engineering, Vol. 02, No. 02, August 2011
 DOI: 01.IJEPE.02.02.69 ACEEE Int. J. on Electrical and Power Engineering, Vol. 02, No. 02, August 2011 Dynamic Spectrum Derived Mfcc and Hfcc Parameters and Human Robot Speech Interaction Krishna Kumar
DOI: 01.IJEPE.02.02.69 ACEEE Int. J. on Electrical and Power Engineering, Vol. 02, No. 02, August 2011 Dynamic Spectrum Derived Mfcc and Hfcc Parameters and Human Robot Speech Interaction Krishna Kumar
RECOGNITION OF EMOTION FROM MARATHI SPEECH USING MFCC AND DWT ALGORITHMS
 RECOGNITION OF EMOTION FROM MARATHI SPEECH USING MFCC AND DWT ALGORITHMS Dipti D. Joshi, M.B. Zalte (EXTC Department, K.J. Somaiya College of Engineering, University of Mumbai, India) Diptijoshi3@gmail.com
RECOGNITION OF EMOTION FROM MARATHI SPEECH USING MFCC AND DWT ALGORITHMS Dipti D. Joshi, M.B. Zalte (EXTC Department, K.J. Somaiya College of Engineering, University of Mumbai, India) Diptijoshi3@gmail.com
2014, IJARCSSE All Rights Reserved Page 461
 Volume 4, Issue 1, January 2014 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Real Time Speech
Volume 4, Issue 1, January 2014 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Real Time Speech
Software/Hardware Co-Design of HMM Based Isolated Digit Recognition System
 154 JOURNAL OF COMPUTERS, VOL. 4, NO. 2, FEBRUARY 2009 Software/Hardware Co-Design of HMM Based Isolated Digit Recognition System V. Amudha, B.Venkataramani, R. Vinoth kumar and S. Ravishankar Department
154 JOURNAL OF COMPUTERS, VOL. 4, NO. 2, FEBRUARY 2009 Software/Hardware Co-Design of HMM Based Isolated Digit Recognition System V. Amudha, B.Venkataramani, R. Vinoth kumar and S. Ravishankar Department
Voice & Speech Based Security System Using MATLAB
 Silvy Achankunju, Chiranjeevi Mondikathi 1 Voice & Speech Based Security System Using MATLAB 1. Silvy Achankunju 2. Chiranjeevi Mondikathi M Tech II year Assistant Professor-EC Dept. silvy.jan28@gmail.com
Silvy Achankunju, Chiranjeevi Mondikathi 1 Voice & Speech Based Security System Using MATLAB 1. Silvy Achankunju 2. Chiranjeevi Mondikathi M Tech II year Assistant Professor-EC Dept. silvy.jan28@gmail.com
ON THE PERFORMANCE OF SEGMENT AVERAGING OF DISCRETE COSINE TRANSFORM COEFFICIENTS ON MUSICAL INSTRUMENTS TONE RECOGNITION
 O THE PERFORMACE OF SEGMET AVERAGIG OF DISCRETE COSIE TRASFORM COEFFICIETS O MUSICAL ISTRUMETS TOE RECOGITIO Linggo Sumarno Electrical Engineering Study Program, Sanata Dharma University, Yogyakarta, Indonesia
O THE PERFORMACE OF SEGMET AVERAGIG OF DISCRETE COSIE TRASFORM COEFFICIETS O MUSICAL ISTRUMETS TOE RECOGITIO Linggo Sumarno Electrical Engineering Study Program, Sanata Dharma University, Yogyakarta, Indonesia
Real Time Speaker Recognition System using MFCC and Vector Quantization Technique
 Real Time Speaker Recognition System using MFCC and Vector Quantization Technique Roma Bharti Mtech, Manav rachna international university Faridabad ABSTRACT This paper represents a very strong mathematical
Real Time Speaker Recognition System using MFCC and Vector Quantization Technique Roma Bharti Mtech, Manav rachna international university Faridabad ABSTRACT This paper represents a very strong mathematical
Image Transformation Techniques Dr. Rajeev Srivastava Dept. of Computer Engineering, ITBHU, Varanasi
 Image Transformation Techniques Dr. Rajeev Srivastava Dept. of Computer Engineering, ITBHU, Varanasi 1. Introduction The choice of a particular transform in a given application depends on the amount of
Image Transformation Techniques Dr. Rajeev Srivastava Dept. of Computer Engineering, ITBHU, Varanasi 1. Introduction The choice of a particular transform in a given application depends on the amount of
Speech Recognition on DSP: Algorithm Optimization and Performance Analysis
 Speech Recognition on DSP: Algorithm Optimization and Performance Analysis YUAN Meng A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Philosophy in Electronic Engineering
Speech Recognition on DSP: Algorithm Optimization and Performance Analysis YUAN Meng A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Philosophy in Electronic Engineering
: A MATLAB TOOL FOR SPEECH PROCESSING, ANALYSIS AND RECOGNITION: SAR-LAB
 2006-472: A MATLAB TOOL FOR SPEECH PROCESSING, ANALYSIS AND RECOGNITION: SAR-LAB Veton Kepuska, Florida Tech Kepuska has joined FIT in 2003 after past 12 years of R&D experience in high-tech industry in
2006-472: A MATLAB TOOL FOR SPEECH PROCESSING, ANALYSIS AND RECOGNITION: SAR-LAB Veton Kepuska, Florida Tech Kepuska has joined FIT in 2003 after past 12 years of R&D experience in high-tech industry in
Environment Independent Speech Recognition System using MFCC (Mel-frequency cepstral coefficient)
") Environment Independent Speech Recognition System using MFCC (Mel-frequency cepstral coefficient) Kamalpreet kaur #1, Jatinder Kaur *2 #1, *2 Department of Electronics and Communication Engineering, CGCTC,
Environment Independent Speech Recognition System using MFCC (Mel-frequency cepstral coefficient) Kamalpreet kaur #1, Jatinder Kaur *2 #1, *2 Department of Electronics and Communication Engineering, CGCTC,
Aditi Upadhyay Research Scholar, Department of Electronics & Communication Engineering Jaipur National University, Jaipur, Rajasthan, India
 Analysis of Different Classifier Using Feature Extraction in Speaker Identification and Verification under Adverse Acoustic Condition for Different Scenario Shrikant Upadhyay Assistant Professor, Department
Analysis of Different Classifier Using Feature Extraction in Speaker Identification and Verification under Adverse Acoustic Condition for Different Scenario Shrikant Upadhyay Assistant Professor, Department
Text-Independent Speaker Identification
 December 8, 1999 Text-Independent Speaker Identification Til T. Phan and Thomas Soong 1.0 Introduction 1.1 Motivation The problem of speaker identification is an area with many different applications.
December 8, 1999 Text-Independent Speaker Identification Til T. Phan and Thomas Soong 1.0 Introduction 1.1 Motivation The problem of speaker identification is an area with many different applications.
Chapter 3. Speech segmentation. 3.1 Preprocessing
 , as done in this dissertation, refers to the process of determining the boundaries between phonemes in the speech signal. No higher-level lexical information is used to accomplish this. This chapter presents
, as done in this dissertation, refers to the process of determining the boundaries between phonemes in the speech signal. No higher-level lexical information is used to accomplish this. This chapter presents
Human Computer Interaction Using Speech Recognition Technology
 International Bulletin of Mathematical Research Volume 2, Issue 1, March 2015 Pages 231-235, ISSN: 2394-7802 Human Computer Interaction Using Recognition Technology Madhu Joshi 1 and Saurabh Ranjan Srivastava
International Bulletin of Mathematical Research Volume 2, Issue 1, March 2015 Pages 231-235, ISSN: 2394-7802 Human Computer Interaction Using Recognition Technology Madhu Joshi 1 and Saurabh Ranjan Srivastava
STUDY OF SPEAKER RECOGNITION SYSTEMS
 STUDY OF SPEAKER RECOGNITION SYSTEMS A THESIS SUBMITTED IN PARTIAL FULFILMENT OF THE REQUIREMENTS FOR BACHELOR IN TECHNOLOGY IN ELECTRONICS & COMMUNICATION BY ASHISH KUMAR PANDA (107EC016) AMIT KUMAR SAHOO
STUDY OF SPEAKER RECOGNITION SYSTEMS A THESIS SUBMITTED IN PARTIAL FULFILMENT OF THE REQUIREMENTS FOR BACHELOR IN TECHNOLOGY IN ELECTRONICS & COMMUNICATION BY ASHISH KUMAR PANDA (107EC016) AMIT KUMAR SAHOO
Speech User Interface for Information Retrieval
 Speech User Interface for Information Retrieval Urmila Shrawankar Dept. of Information Technology Govt. Polytechnic Institute, Nagpur Sadar, Nagpur 440001 (INDIA) urmilas@rediffmail.com Cell : +919422803996
Speech User Interface for Information Retrieval Urmila Shrawankar Dept. of Information Technology Govt. Polytechnic Institute, Nagpur Sadar, Nagpur 440001 (INDIA) urmilas@rediffmail.com Cell : +919422803996
Efficient Speech Recognition System for Isolated Digits
 Efficient Speech Recognition System for Isolated Digits Santosh V. Chapaneri *1, Dr. Deepak J. Jayaswal 2 1 Assistant Professor, 2 Professor Department of Electronics and Telecommunication Engineering
Efficient Speech Recognition System for Isolated Digits Santosh V. Chapaneri *1, Dr. Deepak J. Jayaswal 2 1 Assistant Professor, 2 Professor Department of Electronics and Telecommunication Engineering
A Novel Template Matching Approach To Speaker-Independent Arabic Spoken Digit Recognition
 Special Session: Intelligent Knowledge Management A Novel Template Matching Approach To Speaker-Independent Arabic Spoken Digit Recognition Jiping Sun 1, Jeremy Sun 1, Kacem Abida 2, and Fakhri Karray
Special Session: Intelligent Knowledge Management A Novel Template Matching Approach To Speaker-Independent Arabic Spoken Digit Recognition Jiping Sun 1, Jeremy Sun 1, Kacem Abida 2, and Fakhri Karray
MP3 Speech and Speaker Recognition with Nearest Neighbor. ECE417 Multimedia Signal Processing Fall 2017
 MP3 Speech and Speaker Recognition with Nearest Neighbor ECE417 Multimedia Signal Processing Fall 2017 Goals Given a dataset of N audio files: Features Raw Features, Cepstral (Hz), Cepstral (Mel) Classifier
MP3 Speech and Speaker Recognition with Nearest Neighbor ECE417 Multimedia Signal Processing Fall 2017 Goals Given a dataset of N audio files: Features Raw Features, Cepstral (Hz), Cepstral (Mel) Classifier
Device Activation based on Voice Recognition using Mel Frequency Cepstral Coefficients (MFCC s) Algorithm
 Algorithm") Device Activation based on Voice Recognition using Mel Frequency Cepstral Coefficients (MFCC s) Algorithm Hassan Mohammed Obaid Al Marzuqi 1, Shaik Mazhar Hussain 2, Dr Anilloy Frank 3 1,2,3Middle East
Device Activation based on Voice Recognition using Mel Frequency Cepstral Coefficients (MFCC s) Algorithm Hassan Mohammed Obaid Al Marzuqi 1, Shaik Mazhar Hussain 2, Dr Anilloy Frank 3 1,2,3Middle East
SPEECH WATERMARKING USING DISCRETE WAVELET TRANSFORM, DISCRETE COSINE TRANSFORM AND SINGULAR VALUE DECOMPOSITION
 SPEECH WATERMARKING USING DISCRETE WAVELET TRANSFORM, DISCRETE COSINE TRANSFORM AND SINGULAR VALUE DECOMPOSITION D. AMBIKA *, Research Scholar, Department of Computer Science, Avinashilingam Institute
SPEECH WATERMARKING USING DISCRETE WAVELET TRANSFORM, DISCRETE COSINE TRANSFORM AND SINGULAR VALUE DECOMPOSITION D. AMBIKA *, Research Scholar, Department of Computer Science, Avinashilingam Institute
Secure E- Commerce Transaction using Noisy Password with Voiceprint and OTP
 Secure E- Commerce Transaction using Noisy Password with Voiceprint and OTP Komal K. Kumbhare Department of Computer Engineering B. D. C. O. E. Sevagram, India komalkumbhare27@gmail.com Prof. K. V. Warkar
Secure E- Commerce Transaction using Noisy Password with Voiceprint and OTP Komal K. Kumbhare Department of Computer Engineering B. D. C. O. E. Sevagram, India komalkumbhare27@gmail.com Prof. K. V. Warkar
A text-independent speaker verification model: A comparative analysis
 A text-independent speaker verification model: A comparative analysis Rishi Charan, Manisha.A, Karthik.R, Raesh Kumar M, Senior IEEE Member School of Electronic Engineering VIT University Tamil Nadu, India
A text-independent speaker verification model: A comparative analysis Rishi Charan, Manisha.A, Karthik.R, Raesh Kumar M, Senior IEEE Member School of Electronic Engineering VIT University Tamil Nadu, India
NON-UNIFORM SPEAKER NORMALIZATION USING FREQUENCY-DEPENDENT SCALING FUNCTION
 NON-UNIFORM SPEAKER NORMALIZATION USING FREQUENCY-DEPENDENT SCALING FUNCTION S. V. Bharath Kumar Imaging Technologies Lab General Electric - Global Research JFWTC, Bangalore - 560086, INDIA bharath.sv@geind.ge.com
NON-UNIFORM SPEAKER NORMALIZATION USING FREQUENCY-DEPENDENT SCALING FUNCTION S. V. Bharath Kumar Imaging Technologies Lab General Electric - Global Research JFWTC, Bangalore - 560086, INDIA bharath.sv@geind.ge.com
Processing and Recognition of Voice
 International Archive of Applied Sciences and Technology Int. Arch. App. Sci. Technol; Vol 4 [4]Decemebr 2013: 31-40 2013 Society of Education, India [ISO9001: 2008 Certified Organization] www.soeagra.com/iaast.html
International Archive of Applied Sciences and Technology Int. Arch. App. Sci. Technol; Vol 4 [4]Decemebr 2013: 31-40 2013 Society of Education, India [ISO9001: 2008 Certified Organization] www.soeagra.com/iaast.html
DETECTING INDOOR SOUND EVENTS
 DETECTING INDOOR SOUND EVENTS Toma TELEMBICI, Lacrimioara GRAMA Signal Processing Group, Basis of Electronics Department, Faculty of Electronics, Telecommunications and Information Technology, Technical
DETECTING INDOOR SOUND EVENTS Toma TELEMBICI, Lacrimioara GRAMA Signal Processing Group, Basis of Electronics Department, Faculty of Electronics, Telecommunications and Information Technology, Technical
The Un-normalized Graph p-laplacian based Semi-supervised Learning Method and Speech Recognition Problem
 Int. J. Advance Soft Compu. Appl, Vol. 9, No. 1, March 2017 ISSN 2074-8523 The Un-normalized Graph p-laplacian based Semi-supervised Learning Method and Speech Recognition Problem Loc Tran 1 and Linh Tran
Int. J. Advance Soft Compu. Appl, Vol. 9, No. 1, March 2017 ISSN 2074-8523 The Un-normalized Graph p-laplacian based Semi-supervised Learning Method and Speech Recognition Problem Loc Tran 1 and Linh Tran
Neetha Das Prof. Andy Khong
 Neetha Das Prof. Andy Khong Contents Introduction and aim Current system at IMI Proposed new classification model Support Vector Machines Initial audio data collection and processing Features and their
Neetha Das Prof. Andy Khong Contents Introduction and aim Current system at IMI Proposed new classification model Support Vector Machines Initial audio data collection and processing Features and their
Detection of goal event in soccer videos
 Detection of goal event in soccer videos Hyoung-Gook Kim, Steffen Roeber, Amjad Samour, Thomas Sikora Department of Communication Systems, Technical University of Berlin, Einsteinufer 17, D-10587 Berlin,
Detection of goal event in soccer videos Hyoung-Gook Kim, Steffen Roeber, Amjad Samour, Thomas Sikora Department of Communication Systems, Technical University of Berlin, Einsteinufer 17, D-10587 Berlin,
Copyright Detection System for Videos Using TIRI-DCT Algorithm
 Research Journal of Applied Sciences, Engineering and Technology 4(24): 5391-5396, 2012 ISSN: 2040-7467 Maxwell Scientific Organization, 2012 Submitted: March 18, 2012 Accepted: June 15, 2012 Published:
Research Journal of Applied Sciences, Engineering and Technology 4(24): 5391-5396, 2012 ISSN: 2040-7467 Maxwell Scientific Organization, 2012 Submitted: March 18, 2012 Accepted: June 15, 2012 Published:
EE482: Digital Signal Processing Applications
 Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 13 Audio Signal Processing 14/04/01 http://www.ee.unlv.edu/~b1morris/ee482/
Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 13 Audio Signal Processing 14/04/01 http://www.ee.unlv.edu/~b1morris/ee482/
Robust DTW-based Recognition Algorithm for Hand-held Consumer Devices
 C. Kim and K.-d. Seo: Robust DTW-based Recognition for Hand-held Consumer Devices Robust DTW-based Recognition for Hand-held Consumer Devices 699 Chanwoo Kim and Kwang-deok Seo, Member, IEEE Abstract This
C. Kim and K.-d. Seo: Robust DTW-based Recognition for Hand-held Consumer Devices Robust DTW-based Recognition for Hand-held Consumer Devices 699 Chanwoo Kim and Kwang-deok Seo, Member, IEEE Abstract This
Footprint Recognition using Modified Sequential Haar Energy Transform (MSHET)
") 47 Footprint Recognition using Modified Sequential Haar Energy Transform (MSHET) V. D. Ambeth Kumar 1 M. Ramakrishnan 2 1 Research scholar in sathyabamauniversity, Chennai, Tamil Nadu- 600 119, India.
47 Footprint Recognition using Modified Sequential Haar Energy Transform (MSHET) V. D. Ambeth Kumar 1 M. Ramakrishnan 2 1 Research scholar in sathyabamauniversity, Chennai, Tamil Nadu- 600 119, India.
2-2-2, Hikaridai, Seika-cho, Soraku-gun, Kyoto , Japan 2 Graduate School of Information Science, Nara Institute of Science and Technology
 ISCA Archive STREAM WEIGHT OPTIMIZATION OF SPEECH AND LIP IMAGE SEQUENCE FOR AUDIO-VISUAL SPEECH RECOGNITION Satoshi Nakamura 1 Hidetoshi Ito 2 Kiyohiro Shikano 2 1 ATR Spoken Language Translation Research
ISCA Archive STREAM WEIGHT OPTIMIZATION OF SPEECH AND LIP IMAGE SEQUENCE FOR AUDIO-VISUAL SPEECH RECOGNITION Satoshi Nakamura 1 Hidetoshi Ito 2 Kiyohiro Shikano 2 1 ATR Spoken Language Translation Research
Input speech signal. Selected /Rejected. Pre-processing Feature extraction Matching algorithm. Database. Figure 1: Process flow in ASR
 Volume 5, Issue 1, January 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Feature Extraction
Volume 5, Issue 1, January 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Feature Extraction
Acoustic to Articulatory Mapping using Memory Based Regression and Trajectory Smoothing
 Acoustic to Articulatory Mapping using Memory Based Regression and Trajectory Smoothing Samer Al Moubayed Center for Speech Technology, Department of Speech, Music, and Hearing, KTH, Sweden. sameram@kth.se
Acoustic to Articulatory Mapping using Memory Based Regression and Trajectory Smoothing Samer Al Moubayed Center for Speech Technology, Department of Speech, Music, and Hearing, KTH, Sweden. sameram@kth.se
IMAGE FUSION PARAMETER ESTIMATION AND COMPARISON BETWEEN SVD AND DWT TECHNIQUE
 IMAGE FUSION PARAMETER ESTIMATION AND COMPARISON BETWEEN SVD AND DWT TECHNIQUE Gagandeep Kour, Sharad P. Singh M. Tech Student, Department of EEE, Arni University, Kathgarh, Himachal Pardesh, India-7640
IMAGE FUSION PARAMETER ESTIMATION AND COMPARISON BETWEEN SVD AND DWT TECHNIQUE Gagandeep Kour, Sharad P. Singh M. Tech Student, Department of EEE, Arni University, Kathgarh, Himachal Pardesh, India-7640
Robust speech recognition using features based on zero crossings with peak amplitudes
 Robust speech recognition using features based on zero crossings with peak amplitudes Author Gajic, Bojana, Paliwal, Kuldip Published 200 Conference Title Proceedings of the 200 IEEE International Conference
Robust speech recognition using features based on zero crossings with peak amplitudes Author Gajic, Bojana, Paliwal, Kuldip Published 200 Conference Title Proceedings of the 200 IEEE International Conference
Speech Recognizing Robotic Arm for Writing Process
 Speech Recognizing Robotic Arm for Writing Process 1 Dhanshri R. Pange, 2 Dr. Anil R. Karwankar 1 M. E. Electronics Student, 2 Professor, Department of Electronics and Telecommunication Govt. Engineering
Speech Recognizing Robotic Arm for Writing Process 1 Dhanshri R. Pange, 2 Dr. Anil R. Karwankar 1 M. E. Electronics Student, 2 Professor, Department of Electronics and Telecommunication Govt. Engineering
Emotion recognition using Speech Signal: A Review
 Emotion recognition using Speech Signal: A Review Dhruvi desai ME student, Communication System Engineering (E&C), Sarvajanik College of Engineering & Technology Surat, Gujarat, India. ---------------------------------------------------------------------***---------------------------------------------------------------------
Emotion recognition using Speech Signal: A Review Dhruvi desai ME student, Communication System Engineering (E&C), Sarvajanik College of Engineering & Technology Surat, Gujarat, India. ---------------------------------------------------------------------***---------------------------------------------------------------------
A New Approach to Compressed Image Steganography Using Wavelet Transform
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 5, Ver. III (Sep. Oct. 2015), PP 53-59 www.iosrjournals.org A New Approach to Compressed Image Steganography
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 5, Ver. III (Sep. Oct. 2015), PP 53-59 www.iosrjournals.org A New Approach to Compressed Image Steganography
Introducing Audio Signal Processing & Audio Coding. Dr Michael Mason Snr Staff Eng., Team Lead (Applied Research) Dolby Australia Pty Ltd
 Dolby Australia Pty Ltd") Introducing Audio Signal Processing & Audio Coding Dr Michael Mason Snr Staff Eng., Team Lead (Applied Research) Dolby Australia Pty Ltd Introducing Audio Signal Processing & Audio Coding 2013 Dolby Laboratories,
Introducing Audio Signal Processing & Audio Coding Dr Michael Mason Snr Staff Eng., Team Lead (Applied Research) Dolby Australia Pty Ltd Introducing Audio Signal Processing & Audio Coding 2013 Dolby Laboratories,
GYROPHONE RECOGNIZING SPEECH FROM GYROSCOPE SIGNALS. Yan Michalevsky (1), Gabi Nakibly (2) and Dan Boneh (1)
, Gabi Nakibly (2) and Dan Boneh (1)") GYROPHONE RECOGNIZING SPEECH FROM GYROSCOPE SIGNALS Yan Michalevsky (1), Gabi Nakibly (2) and Dan Boneh (1) (1) Stanford University (2) National Research and Simulation Center, Rafael Ltd. 0 MICROPHONE
GYROPHONE RECOGNIZING SPEECH FROM GYROSCOPE SIGNALS Yan Michalevsky (1), Gabi Nakibly (2) and Dan Boneh (1) (1) Stanford University (2) National Research and Simulation Center, Rafael Ltd. 0 MICROPHONE
SOUND EVENT DETECTION AND CONTEXT RECOGNITION 1 INTRODUCTION. Toni Heittola 1, Annamaria Mesaros 1, Tuomas Virtanen 1, Antti Eronen 2
 Toni Heittola 1, Annamaria Mesaros 1, Tuomas Virtanen 1, Antti Eronen 2 1 Department of Signal Processing, Tampere University of Technology Korkeakoulunkatu 1, 33720, Tampere, Finland toni.heittola@tut.fi,
Toni Heittola 1, Annamaria Mesaros 1, Tuomas Virtanen 1, Antti Eronen 2 1 Department of Signal Processing, Tampere University of Technology Korkeakoulunkatu 1, 33720, Tampere, Finland toni.heittola@tut.fi,
A Modified SVD-DCT Method for Enhancement of Low Contrast Satellite Images
 A Modified SVD-DCT Method for Enhancement of Low Contrast Satellite Images G.Praveena 1, M.Venkatasrinu 2, 1 M.tech student, Department of Electronics and Communication Engineering, Madanapalle Institute
A Modified SVD-DCT Method for Enhancement of Low Contrast Satellite Images G.Praveena 1, M.Venkatasrinu 2, 1 M.tech student, Department of Electronics and Communication Engineering, Madanapalle Institute
Institutionen för systemteknik Department of Electrical Engineering
 Institutionen för systemteknik Department of Electrical Engineering Examensarbete Text-Dependent Speaker Verification Implemented in Matlab Using MFCC and DTW Master thesis performed in Information Coding
Institutionen för systemteknik Department of Electrical Engineering Examensarbete Text-Dependent Speaker Verification Implemented in Matlab Using MFCC and DTW Master thesis performed in Information Coding
Module 9 : Numerical Relaying II : DSP Perspective
 Module 9 : Numerical Relaying II : DSP Perspective Lecture 36 : Fast Fourier Transform Objectives In this lecture, We will introduce Fast Fourier Transform (FFT). We will show equivalence between FFT and
Module 9 : Numerical Relaying II : DSP Perspective Lecture 36 : Fast Fourier Transform Objectives In this lecture, We will introduce Fast Fourier Transform (FFT). We will show equivalence between FFT and
Digital Signal Processing. Soma Biswas
 Digital Signal Processing Soma Biswas 2017 Partial credit for slides: Dr. Manojit Pramanik Outline What is FFT? Types of FFT covered in this lecture Decimation in Time (DIT) Decimation in Frequency (DIF)
Digital Signal Processing Soma Biswas 2017 Partial credit for slides: Dr. Manojit Pramanik Outline What is FFT? Types of FFT covered in this lecture Decimation in Time (DIT) Decimation in Frequency (DIF)
Fatima Michael College of Engineering & Technology
 DEPARTMENT OF ECE V SEMESTER ECE QUESTION BANK EC6502 PRINCIPLES OF DIGITAL SIGNAL PROCESSING UNIT I DISCRETE FOURIER TRANSFORM PART A 1. Obtain the circular convolution of the following sequences x(n)
DEPARTMENT OF ECE V SEMESTER ECE QUESTION BANK EC6502 PRINCIPLES OF DIGITAL SIGNAL PROCESSING UNIT I DISCRETE FOURIER TRANSFORM PART A 1. Obtain the circular convolution of the following sequences x(n)
Speaker Recognition for Mobile User Authentication
 Author manuscript, published in "8ème Conférence sur la Sécurité des Architectures Réseaux et Systèmes d'information (SAR SSI), France (2013)" Speaker Recognition for Mobile User Authentication K. Brunet
Author manuscript, published in "8ème Conférence sur la Sécurité des Architectures Réseaux et Systèmes d'information (SAR SSI), France (2013)" Speaker Recognition for Mobile User Authentication K. Brunet
Pitch Prediction from Mel-frequency Cepstral Coefficients Using Sparse Spectrum Recovery
 Pitch Prediction from Mel-frequency Cepstral Coefficients Using Sparse Spectrum Recovery Achuth Rao MV, Prasanta Kumar Ghosh SPIRE LAB Electrical Engineering, Indian Institute of Science (IISc), Bangalore,
Pitch Prediction from Mel-frequency Cepstral Coefficients Using Sparse Spectrum Recovery Achuth Rao MV, Prasanta Kumar Ghosh SPIRE LAB Electrical Engineering, Indian Institute of Science (IISc), Bangalore,
DWT-SVD based Multiple Watermarking Techniques
 International Journal of Engineering Science Invention (IJESI) ISSN (Online): 2319 6734, ISSN (Print): 2319 6726 www.ijesi.org PP. 01-05 DWT-SVD based Multiple Watermarking Techniques C. Ananth 1, Dr.M.Karthikeyan
International Journal of Engineering Science Invention (IJESI) ISSN (Online): 2319 6734, ISSN (Print): 2319 6726 www.ijesi.org PP. 01-05 DWT-SVD based Multiple Watermarking Techniques C. Ananth 1, Dr.M.Karthikeyan
MODIFIED IMDCT-DECODER BASED MP3 MULTICHANNEL AUDIO DECODING SYSTEM Shanmuga Raju.S 1, Karthik.R 2, Sai Pradeep.K.P 3, Varadharajan.
 MODIFIED IMDCT-DECODER BASED MP3 MULTICHANNEL AUDIO DECODING SYSTEM Shanmuga Raju.S 1, Karthik.R 2, Sai Pradeep.K.P 3, Varadharajan.E 4 Assistant Professor, Dept. of ECE, Dr.NGP Institute of Technology,
MODIFIED IMDCT-DECODER BASED MP3 MULTICHANNEL AUDIO DECODING SYSTEM Shanmuga Raju.S 1, Karthik.R 2, Sai Pradeep.K.P 3, Varadharajan.E 4 Assistant Professor, Dept. of ECE, Dr.NGP Institute of Technology,
Optimization of HMM by the Tabu Search Algorithm
 JOURNAL OF INFORMATION SCIENCE AND ENGINEERING 20, 949-957 (2004) Optimization of HMM by the Tabu Search Algorithm TSONG-YI CHEN, XIAO-DAN MEI *, JENG-SHYANG PAN AND SHENG-HE SUN * Department of Electronic
JOURNAL OF INFORMATION SCIENCE AND ENGINEERING 20, 949-957 (2004) Optimization of HMM by the Tabu Search Algorithm TSONG-YI CHEN, XIAO-DAN MEI *, JENG-SHYANG PAN AND SHENG-HE SUN * Department of Electronic
Spatial, Transform and Fractional Domain Digital Image Watermarking Techniques
 Spatial, Transform and Fractional Domain Digital Image Watermarking Techniques Dr.Harpal Singh Professor, Chandigarh Engineering College, Landran, Mohali, Punjab, Pin code 140307, India Puneet Mehta Faculty,
Spatial, Transform and Fractional Domain Digital Image Watermarking Techniques Dr.Harpal Singh Professor, Chandigarh Engineering College, Landran, Mohali, Punjab, Pin code 140307, India Puneet Mehta Faculty,
Introducing Audio Signal Processing & Audio Coding. Dr Michael Mason Senior Manager, CE Technology Dolby Australia Pty Ltd
 Introducing Audio Signal Processing & Audio Coding Dr Michael Mason Senior Manager, CE Technology Dolby Australia Pty Ltd Overview Audio Signal Processing Applications @ Dolby Audio Signal Processing Basics
Introducing Audio Signal Processing & Audio Coding Dr Michael Mason Senior Manager, CE Technology Dolby Australia Pty Ltd Overview Audio Signal Processing Applications @ Dolby Audio Signal Processing Basics
Comparative Analysis of 2-Level and 4-Level DWT for Watermarking and Tampering Detection
 International Journal of Latest Engineering and Management Research (IJLEMR) ISSN: 2455-4847 Volume 1 Issue 4 ǁ May 2016 ǁ PP.01-07 Comparative Analysis of 2-Level and 4-Level for Watermarking and Tampering
International Journal of Latest Engineering and Management Research (IJLEMR) ISSN: 2455-4847 Volume 1 Issue 4 ǁ May 2016 ǁ PP.01-07 Comparative Analysis of 2-Level and 4-Level for Watermarking and Tampering
Content-based retrieval of music using mel frequency cepstral coefficient (MFCC)
") Content-based retrieval of music using mel frequency cepstral coefficient (MFCC) Abstract Xin Luo*, Xuezheng Liu, Ran Tao, Youqun Shi School of Computer Science and Technology, Donghua University, Songjiang
Content-based retrieval of music using mel frequency cepstral coefficient (MFCC) Abstract Xin Luo*, Xuezheng Liu, Ran Tao, Youqun Shi School of Computer Science and Technology, Donghua University, Songjiang
Flexible Stand-Alone Keyword Recognition Application Using Dynamic Time Warping
 Flexible Stand-Alone Keyword Recognition Application Using Dynamic Time Warping Miquel Ferrarons 1,2, Xavier Anguera 1 and Jordi Luque 1 1 Telefonica Research, Edificio Telefonica-Diagonal 00, 08019, Barcelona,
Flexible Stand-Alone Keyword Recognition Application Using Dynamic Time Warping Miquel Ferrarons 1,2, Xavier Anguera 1 and Jordi Luque 1 1 Telefonica Research, Edificio Telefonica-Diagonal 00, 08019, Barcelona,
Forensic Image Recognition using a Novel Image Fingerprinting and Hashing Technique
 Forensic Image Recognition using a Novel Image Fingerprinting and Hashing Technique R D Neal, R J Shaw and A S Atkins Faculty of Computing, Engineering and Technology, Staffordshire University, Stafford
Forensic Image Recognition using a Novel Image Fingerprinting and Hashing Technique R D Neal, R J Shaw and A S Atkins Faculty of Computing, Engineering and Technology, Staffordshire University, Stafford
WHO WANTS TO BE A MILLIONAIRE?
 IDIAP COMMUNICATION REPORT WHO WANTS TO BE A MILLIONAIRE? Huseyn Gasimov a Aleksei Triastcyn Hervé Bourlard Idiap-Com-03-2012 JULY 2012 a EPFL Centre du Parc, Rue Marconi 19, PO Box 592, CH - 1920 Martigny
IDIAP COMMUNICATION REPORT WHO WANTS TO BE A MILLIONAIRE? Huseyn Gasimov a Aleksei Triastcyn Hervé Bourlard Idiap-Com-03-2012 JULY 2012 a EPFL Centre du Parc, Rue Marconi 19, PO Box 592, CH - 1920 Martigny
SPEAKER RECOGNITION. 1. Speech Signal
 SPEAKER RECOGNITION Speaker Recognition is the problem of identifying a speaker from a recording of their speech. It is an important topic in Speech Signal Processing and has a variety of applications,
SPEAKER RECOGNITION Speaker Recognition is the problem of identifying a speaker from a recording of their speech. It is an important topic in Speech Signal Processing and has a variety of applications,
Adaptive Filtering using Steepest Descent and LMS Algorithm
 IJSTE - International Journal of Science Technology & Engineering Volume 2 Issue 4 October 2015 ISSN (online): 2349-784X Adaptive Filtering using Steepest Descent and LMS Algorithm Akash Sawant Mukesh
IJSTE - International Journal of Science Technology & Engineering Volume 2 Issue 4 October 2015 ISSN (online): 2349-784X Adaptive Filtering using Steepest Descent and LMS Algorithm Akash Sawant Mukesh
Further Studies of a FFT-Based Auditory Spectrum with Application in Audio Classification
 ICSP Proceedings Further Studies of a FFT-Based Auditory with Application in Audio Classification Wei Chu and Benoît Champagne Department of Electrical and Computer Engineering McGill University, Montréal,
ICSP Proceedings Further Studies of a FFT-Based Auditory with Application in Audio Classification Wei Chu and Benoît Champagne Department of Electrical and Computer Engineering McGill University, Montréal,
Speech Recognition Based on Efficient DTW Algorithm and Its DSP Implementation
 Available online at www.sciencedirect.com Procedia Engineering 29 (2012) 832 836 2012 International Workshop on Information and Electronics Engineering (IWIEE) Speech Recognition Based on Efficient DTW
Available online at www.sciencedirect.com Procedia Engineering 29 (2012) 832 836 2012 International Workshop on Information and Electronics Engineering (IWIEE) Speech Recognition Based on Efficient DTW
SPEECH FEATURE EXTRACTION USING WEIGHTED HIGHER-ORDER LOCAL AUTO-CORRELATION
 Far East Journal of Electronics and Communications Volume 3, Number 2, 2009, Pages 125-140 Published Online: September 14, 2009 This paper is available online at http://www.pphmj.com 2009 Pushpa Publishing
Far East Journal of Electronics and Communications Volume 3, Number 2, 2009, Pages 125-140 Published Online: September 14, 2009 This paper is available online at http://www.pphmj.com 2009 Pushpa Publishing
Speech Recognition: Increasing Efficiency of Support Vector Machines
 Speech Recognition: Increasing Efficiency of Support Vector Machines Aamir Khan COMSATS Insititute of Information Technology, WahCantt. Pujnab, Pakistan Muhammad Farhan University of Science and Technology
Speech Recognition: Increasing Efficiency of Support Vector Machines Aamir Khan COMSATS Insititute of Information Technology, WahCantt. Pujnab, Pakistan Muhammad Farhan University of Science and Technology
Cryptographic Key Regeneration from Speech
 , July 3-5, 2013, London, U.K. Cryptographic Key Regeneration from Speech K. Inthavisas and N. Sungprasert Abstract We propose a mapping algorithm using multi-thresholds that are determined by incorporation
, July 3-5, 2013, London, U.K. Cryptographic Key Regeneration from Speech K. Inthavisas and N. Sungprasert Abstract We propose a mapping algorithm using multi-thresholds that are determined by incorporation
HIERARCHICAL LARGE-MARGIN GAUSSIAN MIXTURE MODELS FOR PHONETIC CLASSIFICATION. Hung-An Chang and James R. Glass
 HIERARCHICAL LARGE-MARGIN GAUSSIAN MIXTURE MODELS FOR PHONETIC CLASSIFICATION Hung-An Chang and James R. Glass MIT Computer Science and Artificial Intelligence Laboratory Cambridge, Massachusetts, 02139,
HIERARCHICAL LARGE-MARGIN GAUSSIAN MIXTURE MODELS FOR PHONETIC CLASSIFICATION Hung-An Chang and James R. Glass MIT Computer Science and Artificial Intelligence Laboratory Cambridge, Massachusetts, 02139,
Spoken Document Retrieval (SDR) for Broadcast News in Indian Languages
 for Broadcast News in Indian Languages") Spoken Document Retrieval (SDR) for Broadcast News in Indian Languages Chirag Shah Dept. of CSE IIT Madras Chennai - 600036 Tamilnadu, India. chirag@speech.iitm.ernet.in A. Nayeemulla Khan Dept. of CSE
Spoken Document Retrieval (SDR) for Broadcast News in Indian Languages Chirag Shah Dept. of CSE IIT Madras Chennai - 600036 Tamilnadu, India. chirag@speech.iitm.ernet.in A. Nayeemulla Khan Dept. of CSE
Optimization of Observation Membership Function By Particle Swarm Method for Enhancing Performances of Speaker Identification
 Proceedings of the 6th WSEAS International Conference on SIGNAL PROCESSING, Dallas, Texas, USA, March 22-24, 2007 52 Optimization of Observation Membership Function By Particle Swarm Method for Enhancing
Proceedings of the 6th WSEAS International Conference on SIGNAL PROCESSING, Dallas, Texas, USA, March 22-24, 2007 52 Optimization of Observation Membership Function By Particle Swarm Method for Enhancing
Feature-level Fusion for Effective Palmprint Authentication
 Feature-level Fusion for Effective Palmprint Authentication Adams Wai-Kin Kong 1, 2 and David Zhang 1 1 Biometric Research Center, Department of Computing The Hong Kong Polytechnic University, Kowloon,
Feature-level Fusion for Effective Palmprint Authentication Adams Wai-Kin Kong 1, 2 and David Zhang 1 1 Biometric Research Center, Department of Computing The Hong Kong Polytechnic University, Kowloon,
NAVAL POSTGRADUATE SCHOOL THESIS
 NAVAL POSTGRADUATE SCHOOL MONTEREY, CALIFORNIA THESIS REAL-TIME SPEECH RECOGNITION SYSTEM FOR ROBOTIC CONTROL APPLICATIONS USING AN EAR- MICROPHONE by Dimitrios S. Koliousis June 2007 Thesis Advisor: Co-Advisors:
NAVAL POSTGRADUATE SCHOOL MONTEREY, CALIFORNIA THESIS REAL-TIME SPEECH RECOGNITION SYSTEM FOR ROBOTIC CONTROL APPLICATIONS USING AN EAR- MICROPHONE by Dimitrios S. Koliousis June 2007 Thesis Advisor: Co-Advisors:
Volume 2, Issue 9, September 2014 ISSN
 Fingerprint Verification of the Digital Images by Using the Discrete Cosine Transformation, Run length Encoding, Fourier transformation and Correlation. Palvee Sharma 1, Dr. Rajeev Mahajan 2 1M.Tech Student
Fingerprint Verification of the Digital Images by Using the Discrete Cosine Transformation, Run length Encoding, Fourier transformation and Correlation. Palvee Sharma 1, Dr. Rajeev Mahajan 2 1M.Tech Student
Principles of Audio Coding
 Principles of Audio Coding Topics today Introduction VOCODERS Psychoacoustics Equal-Loudness Curve Frequency Masking Temporal Masking (CSIT 410) 2 Introduction Speech compression algorithm focuses on exploiting
Principles of Audio Coding Topics today Introduction VOCODERS Psychoacoustics Equal-Loudness Curve Frequency Masking Temporal Masking (CSIT 410) 2 Introduction Speech compression algorithm focuses on exploiting
Smart Home Implementation Using Data Mining
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume - 3 Issue -9 September, 2014 Page No. 8276-8280 Smart Home Implementation Using Data Mining Gayatri D. Kulkarni
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume - 3 Issue -9 September, 2014 Page No. 8276-8280 Smart Home Implementation Using Data Mining Gayatri D. Kulkarni
Filterbanks and transforms
 Filterbanks and transforms Sources: Zölzer, Digital audio signal processing, Wiley & Sons. Saramäki, Multirate signal processing, TUT course. Filterbanks! Introduction! Critical sampling, half-band filter!
Filterbanks and transforms Sources: Zölzer, Digital audio signal processing, Wiley & Sons. Saramäki, Multirate signal processing, TUT course. Filterbanks! Introduction! Critical sampling, half-band filter!
Dynamic Time Warping
 Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Dynamic Time Warping Dr Philip Jackson Acoustic features Distance measures Pattern matching Distortion penalties DTW
Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Dynamic Time Warping Dr Philip Jackson Acoustic features Distance measures Pattern matching Distortion penalties DTW
Speaker Verification in JAVA
 Speaker Verification in JAVA A thesis submitted in partial fulfillment of the requirements for the degree of Master of Computer and Information Engineering School of Microelectronic Engineering Griffith
Speaker Verification in JAVA A thesis submitted in partial fulfillment of the requirements for the degree of Master of Computer and Information Engineering School of Microelectronic Engineering Griffith
Production of Video Images by Computer Controlled Cameras and Its Application to TV Conference System
 Proc. of IEEE Conference on Computer Vision and Pattern Recognition, vol.2, II-131 II-137, Dec. 2001. Production of Video Images by Computer Controlled Cameras and Its Application to TV Conference System
Proc. of IEEE Conference on Computer Vision and Pattern Recognition, vol.2, II-131 II-137, Dec. 2001. Production of Video Images by Computer Controlled Cameras and Its Application to TV Conference System
Human Gait Recognition Using Bezier Curves
 Human Gait Recognition Using Bezier Curves Pratibha Mishra Samrat Ashok Technology Institute Vidisha, (M.P.) India Shweta Ezra Dhar Polytechnic College Dhar, (M.P.) India Abstract-- Gait recognition refers
Human Gait Recognition Using Bezier Curves Pratibha Mishra Samrat Ashok Technology Institute Vidisha, (M.P.) India Shweta Ezra Dhar Polytechnic College Dhar, (M.P.) India Abstract-- Gait recognition refers
Appendix 4. Audio coding algorithms
 Appendix 4. Audio coding algorithms 1 Introduction The main application of audio compression systems is to obtain compact digital representations of high-quality (CD-quality) wideband audio signals. Typically
Appendix 4. Audio coding algorithms 1 Introduction The main application of audio compression systems is to obtain compact digital representations of high-quality (CD-quality) wideband audio signals. Typically
OCR For Handwritten Marathi Script
 International Journal of Scientific & Engineering Research Volume 3, Issue 8, August-2012 1 OCR For Handwritten Marathi Script Mrs.Vinaya. S. Tapkir 1, Mrs.Sushma.D.Shelke 2 1 Maharashtra Academy Of Engineering,
International Journal of Scientific & Engineering Research Volume 3, Issue 8, August-2012 1 OCR For Handwritten Marathi Script Mrs.Vinaya. S. Tapkir 1, Mrs.Sushma.D.Shelke 2 1 Maharashtra Academy Of Engineering,
Audio-Visual Speech Activity Detection
 Institut für Technische Informatik und Kommunikationsnetze Semester Thesis at the Department of Information Technology and Electrical Engineering Audio-Visual Speech Activity Detection Salome Mannale Advisors:
Institut für Technische Informatik und Kommunikationsnetze Semester Thesis at the Department of Information Technology and Electrical Engineering Audio-Visual Speech Activity Detection Salome Mannale Advisors:
THE PERFORMANCE of automatic speech recognition
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 6, NOVEMBER 2006 2109 Subband Likelihood-Maximizing Beamforming for Speech Recognition in Reverberant Environments Michael L. Seltzer,
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 6, NOVEMBER 2006 2109 Subband Likelihood-Maximizing Beamforming for Speech Recognition in Reverberant Environments Michael L. Seltzer,
Audio-coding standards
 Audio-coding standards The goal is to provide CD-quality audio over telecommunications networks. Almost all CD audio coders are based on the so-called psychoacoustic model of the human auditory system.
Audio-coding standards The goal is to provide CD-quality audio over telecommunications networks. Almost all CD audio coders are based on the so-called psychoacoustic model of the human auditory system.
An Integrated Skew Detection And Correction Using Fast Fourier Transform And DCT
 An Integrated Skew Detection And Correction Using Fast Fourier Transform And DCT Mandip Kaur, Simpel Jindal Abstract: Skew detection and correction is very important task before pre-processing of an image
An Integrated Skew Detection And Correction Using Fast Fourier Transform And DCT Mandip Kaur, Simpel Jindal Abstract: Skew detection and correction is very important task before pre-processing of an image
Multi-Modal Human Verification Using Face and Speech
 22 Multi-Modal Human Verification Using Face and Speech Changhan Park 1 and Joonki Paik 2 1 Advanced Technology R&D Center, Samsung Thales Co., Ltd., 2 Graduate School of Advanced Imaging Science, Multimedia,
22 Multi-Modal Human Verification Using Face and Speech Changhan Park 1 and Joonki Paik 2 1 Advanced Technology R&D Center, Samsung Thales Co., Ltd., 2 Graduate School of Advanced Imaging Science, Multimedia,
Perceptual coding. A psychoacoustic model is used to identify those signals that are influenced by both these effects.
 Perceptual coding Both LPC and CELP are used primarily for telephony applications and hence the compression of a speech signal. Perceptual encoders, however, have been designed for the compression of general
Perceptual coding Both LPC and CELP are used primarily for telephony applications and hence the compression of a speech signal. Perceptual encoders, however, have been designed for the compression of general
Module 9 AUDIO CODING. Version 2 ECE IIT, Kharagpur
 Module 9 AUDIO CODING Lesson 29 Transform and Filter banks Instructional Objectives At the end of this lesson, the students should be able to: 1. Define the three layers of MPEG-1 audio coding. 2. Define
Module 9 AUDIO CODING Lesson 29 Transform and Filter banks Instructional Objectives At the end of this lesson, the students should be able to: 1. Define the three layers of MPEG-1 audio coding. 2. Define
Simultaneous Design of Feature Extractor and Pattern Classifer Using the Minimum Classification Error Training Algorithm
 Griffith Research Online https://research-repository.griffith.edu.au Simultaneous Design of Feature Extractor and Pattern Classifer Using the Minimum Classification Error Training Algorithm Author Paliwal,
Griffith Research Online https://research-repository.griffith.edu.au Simultaneous Design of Feature Extractor and Pattern Classifer Using the Minimum Classification Error Training Algorithm Author Paliwal,