GYROPHONE RECOGNIZING SPEECH FROM GYROSCOPE SIGNALS. Yan Michalevsky (1), Gabi Nakibly (2) and Dan Boneh (1)
|
|
|
- Gyles Lambert
- 5 years ago
- Views:
Transcription

 and Dan Boneh (1) (1)")

1 GYROPHONE RECOGNIZING SPEECH FROM GYROSCOPE SIGNALS Yan Michalevsky (1), Gabi Nakibly (2) and Dan Boneh (1) (1) Stanford University (2) National Research and Simulation Center, Rafael Ltd. 0

2
3 MICROPHONE ACCESS REQUIRES PERMISSIONS

4 GYROSCOPE ACCESS DOES NOT REQUIRE PERMISSIONS

")
5 MEMS GYROSCOPES Major vendors: STM Microelectronics (Samsung Galaxy) InvenSense (Google Nexus)
6 GYROSCOPES ARE SUSCEPTIBLE TO SOUND 70 HZ TONE POWER SPECTRAL DENSITY 50 HZ TONE POWER SPECTRAL DENSITY
7 GYROSCOPES ARE (LOUSY, BUT STILL) MICROPHONES Hardware sampling frequency: InvenSense: up to 8000 Hz STM Microelectronics: 800 Hz Software sampling frequency: Android: 200 Hz ios: 100 Hz
8 GYROSCOPES ARE (LOUSY, BUT STILL) MICROPHONES Very low SNR (Signal-to-Noise Ratio) Acoustic sensitivity threshold: ~70 db Comparable to a loud conversation. Sensitive to sound angle of arrival Directional microphone (due to 3 axes)
9 BROWSERS ALLOW GYROSCOPE ACCESS TOO
10 BROWSERS ALLOW GYROSCOPE ACCESS TOO
11 BROWSERS ALLOW GYROSCOPE ACCESS TOO


12 BROWSERS ALLOW GYROSCOPE ACCESS TOO
13 PROBLEM: HOW DO WE LOOK INTO HIGHER FREQUENCIES? SPEECH RANGE Adult male Hz Adult female Hz
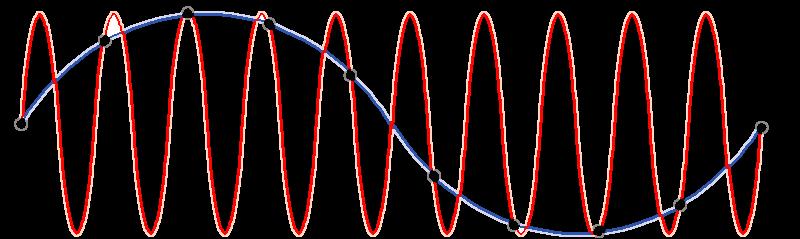
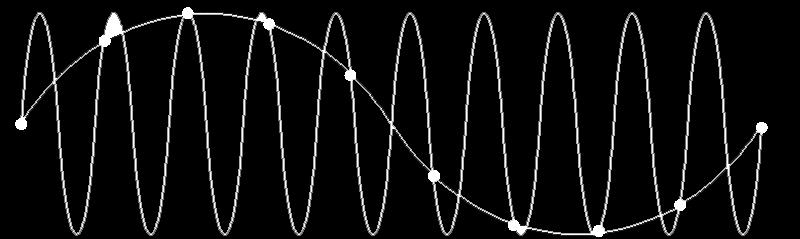
14 ALIASING

15 WE CAN SENSE HIGH FREQUENCY SIGNALS DUE TO ALIASING THE RESULT OF RECORDING TONES BETWEEN 120 AND 160 HZ ON A NEXUS 7 DEVICE

16 EXPERIMENTAL SETUP Room. Simple speakers. Smartphone. Subset of TIDigits speech recognition corpus 10 speakers 11 samples 2 pronunciations = 220 total samples

17 SPEECH ANALYSIS USING A SINGLE GYROSCOPE Gender identification Speaker identification Isolated word recognition

18 Speech recognition engine developed at CMU Tested for isolated word recognition 14% success rate (random guess is 9%)
19 PREPROCESSING All samples are converted to audio files in WAV format Upsampled to 8 KHz Silence removal (based on voiced/unvoiced segment classification)
20 FEATURES MFCC - Mel-Frequency Cepstral Coefficients Statistical features are used (mean and variance) delta-mfcc Spectral centroid RMS energy STFT - Short-Time Fourier Transform
21 CLASSIFIERS SVM (and Multi-class SVM) GMM (Gaussian Mixture Model) DTW (Dynamic Time Warping)


22 DYNAMIC TIME WARPING EUCLIDEAN DISTANCE DTW DISTANCE

23 GENDER IDENTIFICATION Binary SVM with spectral features DTW with STFT features Window size: 512 samples - corresponds to 64 ms under 8 KHz sampling rate
24 WE CAN SUCCESSFULLY IDENTIFY GENDER NEXUS 4 84% (DTW) GALAXY S III 82% (SVM) Random guess probability is 50%


25 SPEAKER IDENTIFICATION Multi-class SVM and GMM with spectral features DTW with STFT features (same as before)
26 A GOOD CHANCE TO IDENTIFY THE SPEAKER Nexus 4 Mixed Female/Male 50% (DTW) Female speakers 45% (DTW) Male speakers 65% (DTW) Random guess probability is 20% for one gender and 10% for a mixed set
 Confusion matrix corresponds to the mixed set results using DTW Random guess probability is 9%")
27 ISOLATED WORDS RECOGNITION SPEAKER INDEPENDENT Nexus 4 Mixed Female/Male 17% (DTW) Female speakers 26% (DTW) Male speakers 23% (DTW) Confusion matrix corresponds to the mixed set results using DTW Random guess probability is 9%

28 ISOLATED WORDS RECOGNITION SPEAKER DEPENDENT Confusion matrix corresponds to the DTW results Random guess probability is 9%

29 HOW CAN WE LEVERAGE EAVESDROPPING SIMULTANEOUSLY ON TWO DEVICES?
30 SIMILAR TO TIME-INTERLEAVED ADC's
31 SIMILAR TO TIME-INTERLEAVED ADC's DC component removal
32 SIMILAR TO TIME-INTERLEAVED ADC's Normalization / use a reference signal

33 SIMILAR TO TIME-INTERLEAVED ADC's Background or foreground calibration

34 NON-UNIFORM RECONSTRUCTION REQUIRES KNOWING PRECISE TIME-SKEWS Filterbank interpolation based on Eldar and Oppenheim's paper

35 PRACTICAL COMPROMISE Interleaving samples from multiple devices
36 EVALUATION (Tested for the case of speaker dependent word recognition) Single device Two devices Exhibits improvement over using a single device Using even more devices might yield even better results Not a proper non-uniform reconstruction

37 FURTHER ATTACKS
38 SOURCE SEPARATION Use the 3 axes of the gyro Learn the number of sound sources around Use angle of arrival information for source separation
39 AMBIENT SOUND RECOGNITION IS THE USER IN A ROOM/OUTDOORS/ON A STREET?

40 DEFENSES
41 SOFTWARE DEFENSES Low-pass filter the raw samples 0-20 Hz range should be enough for browser based applications (according to WebKit) Access to high sampling rate should require a special permission
42 HARDWARE DEFENSES Hardware filtering of sensor signals (Not subject to configuration) Acoustic masking (won't help against vibration of the surface)
43 CONCLUSION Giving applications direct access to hardware is dangerous. Especially given the high sampling rate.
44 THANK YOU VERY MUCH QUESTIONS? CRYPTO.STANFORD.EDU/GYROPHONE

45 IT IS POSSIBLE TO SAMPLE THROUGH JAVASCRIPT
46 FAQ Did you experiment with an anechoic chamber? Yes, and did not find it beneficial at this stage.
47 FAQ Perhaps the gyro actually measures the vibrations of the surface? Maybe, but tests suggest it's not only that. In any case it is still dangerous.
48 FAQ Is it possible to use measurements from multiple devices in other ways? Yes. For example as in MIMO: EGC (Equal Gain Combining).
Neetha Das Prof. Andy Khong
 Neetha Das Prof. Andy Khong Contents Introduction and aim Current system at IMI Proposed new classification model Support Vector Machines Initial audio data collection and processing Features and their
Neetha Das Prof. Andy Khong Contents Introduction and aim Current system at IMI Proposed new classification model Support Vector Machines Initial audio data collection and processing Features and their
Real Time Speaker Recognition System using MFCC and Vector Quantization Technique
 Real Time Speaker Recognition System using MFCC and Vector Quantization Technique Roma Bharti Mtech, Manav rachna international university Faridabad ABSTRACT This paper represents a very strong mathematical
Real Time Speaker Recognition System using MFCC and Vector Quantization Technique Roma Bharti Mtech, Manav rachna international university Faridabad ABSTRACT This paper represents a very strong mathematical
Voice Command Based Computer Application Control Using MFCC
 Voice Command Based Computer Application Control Using MFCC Abinayaa B., Arun D., Darshini B., Nataraj C Department of Embedded Systems Technologies, Sri Ramakrishna College of Engineering, Coimbatore,
Voice Command Based Computer Application Control Using MFCC Abinayaa B., Arun D., Darshini B., Nataraj C Department of Embedded Systems Technologies, Sri Ramakrishna College of Engineering, Coimbatore,
Dia: AutoDirective Audio Capturing Through a Synchronized Smartphone Array
 Dia: AutoDirective Audio Capturing Through a Synchronized Smartphone Array Sanjib Sur Teng Wei and Xinyu Zhang University of Wisconsin - Madison 1 Multimedia applications in smartphones Growing mobile
Dia: AutoDirective Audio Capturing Through a Synchronized Smartphone Array Sanjib Sur Teng Wei and Xinyu Zhang University of Wisconsin - Madison 1 Multimedia applications in smartphones Growing mobile
Dietrich Paulus Joachim Hornegger. Pattern Recognition of Images and Speech in C++
 Dietrich Paulus Joachim Hornegger Pattern Recognition of Images and Speech in C++ To Dorothea, Belinda, and Dominik In the text we use the following names which are protected, trademarks owned by a company
Dietrich Paulus Joachim Hornegger Pattern Recognition of Images and Speech in C++ To Dorothea, Belinda, and Dominik In the text we use the following names which are protected, trademarks owned by a company
Speaker Diarization System Based on GMM and BIC
 Speaer Diarization System Based on GMM and BIC Tantan Liu 1, Xiaoxing Liu 1, Yonghong Yan 1 1 ThinIT Speech Lab, Institute of Acoustics, Chinese Academy of Sciences Beijing 100080 {tliu, xliu,yyan}@hccl.ioa.ac.cn
Speaer Diarization System Based on GMM and BIC Tantan Liu 1, Xiaoxing Liu 1, Yonghong Yan 1 1 ThinIT Speech Lab, Institute of Acoustics, Chinese Academy of Sciences Beijing 100080 {tliu, xliu,yyan}@hccl.ioa.ac.cn
Implementing a Speech Recognition System on a GPU using CUDA. Presented by Omid Talakoub Astrid Yi
 Implementing a Speech Recognition System on a GPU using CUDA Presented by Omid Talakoub Astrid Yi Outline Background Motivation Speech recognition algorithm Implementation steps GPU implementation strategies
Implementing a Speech Recognition System on a GPU using CUDA Presented by Omid Talakoub Astrid Yi Outline Background Motivation Speech recognition algorithm Implementation steps GPU implementation strategies
Accelerometer Gesture Recognition
 Accelerometer Gesture Recognition Michael Xie xie@cs.stanford.edu David Pan napdivad@stanford.edu December 12, 2014 Abstract Our goal is to make gesture-based input for smartphones and smartwatches accurate
Accelerometer Gesture Recognition Michael Xie xie@cs.stanford.edu David Pan napdivad@stanford.edu December 12, 2014 Abstract Our goal is to make gesture-based input for smartphones and smartwatches accurate
Detection of Acoustic Events in Meeting-Room Environment
 11/Dec/2008 Detection of Acoustic Events in Meeting-Room Environment Presented by Andriy Temko Department of Electrical and Electronic Engineering Page 2 of 34 Content Introduction State of the Art Acoustic
11/Dec/2008 Detection of Acoustic Events in Meeting-Room Environment Presented by Andriy Temko Department of Electrical and Electronic Engineering Page 2 of 34 Content Introduction State of the Art Acoustic
Input speech signal. Selected /Rejected. Pre-processing Feature extraction Matching algorithm. Database. Figure 1: Process flow in ASR
 Volume 5, Issue 1, January 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Feature Extraction
Volume 5, Issue 1, January 2015 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Feature Extraction
Dynamic Time Warping
 Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Dynamic Time Warping Dr Philip Jackson Acoustic features Distance measures Pattern matching Distortion penalties DTW
Centre for Vision Speech & Signal Processing University of Surrey, Guildford GU2 7XH. Dynamic Time Warping Dr Philip Jackson Acoustic features Distance measures Pattern matching Distortion penalties DTW
The Automatic Musicologist
 The Automatic Musicologist Douglas Turnbull Department of Computer Science and Engineering University of California, San Diego UCSD AI Seminar April 12, 2004 Based on the paper: Fast Recognition of Musical
The Automatic Musicologist Douglas Turnbull Department of Computer Science and Engineering University of California, San Diego UCSD AI Seminar April 12, 2004 Based on the paper: Fast Recognition of Musical
Activity recognition and energy expenditure estimation
 Activity recognition and energy expenditure estimation A practical approach with Python WebValley 2015 Bojan Milosevic Scope Goal: Use wearable sensors to estimate energy expenditure during everyday activities
Activity recognition and energy expenditure estimation A practical approach with Python WebValley 2015 Bojan Milosevic Scope Goal: Use wearable sensors to estimate energy expenditure during everyday activities
Multifactor Fusion for Audio-Visual Speaker Recognition
 Proceedings of the 7th WSEAS International Conference on Signal, Speech and Image Processing, Beijing, China, September 15-17, 2007 70 Multifactor Fusion for Audio-Visual Speaker Recognition GIRIJA CHETTY
Proceedings of the 7th WSEAS International Conference on Signal, Speech and Image Processing, Beijing, China, September 15-17, 2007 70 Multifactor Fusion for Audio-Visual Speaker Recognition GIRIJA CHETTY
Comparative Evaluation of Feature Normalization Techniques for Speaker Verification
 Comparative Evaluation of Feature Normalization Techniques for Speaker Verification Md Jahangir Alam 1,2, Pierre Ouellet 1, Patrick Kenny 1, Douglas O Shaughnessy 2, 1 CRIM, Montreal, Canada {Janagir.Alam,
Comparative Evaluation of Feature Normalization Techniques for Speaker Verification Md Jahangir Alam 1,2, Pierre Ouellet 1, Patrick Kenny 1, Douglas O Shaughnessy 2, 1 CRIM, Montreal, Canada {Janagir.Alam,
Flexible Stand-Alone Keyword Recognition Application Using Dynamic Time Warping
 Flexible Stand-Alone Keyword Recognition Application Using Dynamic Time Warping Miquel Ferrarons 1,2, Xavier Anguera 1 and Jordi Luque 1 1 Telefonica Research, Edificio Telefonica-Diagonal 00, 08019, Barcelona,
Flexible Stand-Alone Keyword Recognition Application Using Dynamic Time Warping Miquel Ferrarons 1,2, Xavier Anguera 1 and Jordi Luque 1 1 Telefonica Research, Edificio Telefonica-Diagonal 00, 08019, Barcelona,
Embedded Audio & Robotic Ear
 Embedded Audio & Robotic Ear Marc HERVIEU IoT Marketing Manager Marc.Hervieu@st.com Voice Communication: key driver of innovation since 1800 s 2 IoT Evolution of Voice Automation: the IoT Voice Assistant
Embedded Audio & Robotic Ear Marc HERVIEU IoT Marketing Manager Marc.Hervieu@st.com Voice Communication: key driver of innovation since 1800 s 2 IoT Evolution of Voice Automation: the IoT Voice Assistant
Separating Speech From Noise Challenge
 Separating Speech From Noise Challenge We have used the data from the PASCAL CHiME challenge with the goal of training a Support Vector Machine (SVM) to estimate a noise mask that labels time-frames/frequency-bins
Separating Speech From Noise Challenge We have used the data from the PASCAL CHiME challenge with the goal of training a Support Vector Machine (SVM) to estimate a noise mask that labels time-frames/frequency-bins
Implementation of Speech Based Stress Level Monitoring System
 4 th International Conference on Computing, Communication and Sensor Network, CCSN2015 Implementation of Speech Based Stress Level Monitoring System V.Naveen Kumar 1,Dr.Y.Padma sai 2, K.Sonali Swaroop
4 th International Conference on Computing, Communication and Sensor Network, CCSN2015 Implementation of Speech Based Stress Level Monitoring System V.Naveen Kumar 1,Dr.Y.Padma sai 2, K.Sonali Swaroop
A text-independent speaker verification model: A comparative analysis
 A text-independent speaker verification model: A comparative analysis Rishi Charan, Manisha.A, Karthik.R, Raesh Kumar M, Senior IEEE Member School of Electronic Engineering VIT University Tamil Nadu, India
A text-independent speaker verification model: A comparative analysis Rishi Charan, Manisha.A, Karthik.R, Raesh Kumar M, Senior IEEE Member School of Electronic Engineering VIT University Tamil Nadu, India
SCREAM AND GUNSHOT DETECTION IN NOISY ENVIRONMENTS
 SCREAM AND GUNSHOT DETECTION IN NOISY ENVIRONMENTS L. Gerosa, G. Valenzise, M. Tagliasacchi, F. Antonacci, A. Sarti Dipartimento di Elettronica e Informazione, Politecnico di Milano Piazza Leonardo da
SCREAM AND GUNSHOT DETECTION IN NOISY ENVIRONMENTS L. Gerosa, G. Valenzise, M. Tagliasacchi, F. Antonacci, A. Sarti Dipartimento di Elettronica e Informazione, Politecnico di Milano Piazza Leonardo da
i436 ons Studio is no mic plugged into false? Answer 1 : This is the false roll-off MicW TN 1402
 Technical Note 1402 i436 - Frequent Asked Questio ons Question 1 : Studio Six Digital acclaimed that Wee have thoroughly tested MicW, and our conclusion n is thatt it does not improve on the performance
Technical Note 1402 i436 - Frequent Asked Questio ons Question 1 : Studio Six Digital acclaimed that Wee have thoroughly tested MicW, and our conclusion n is thatt it does not improve on the performance
2014, IJARCSSE All Rights Reserved Page 461
 Volume 4, Issue 1, January 2014 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Real Time Speech
Volume 4, Issue 1, January 2014 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Real Time Speech
FUSION MODEL BASED ON CONVOLUTIONAL NEURAL NETWORKS WITH TWO FEATURES FOR ACOUSTIC SCENE CLASSIFICATION
 Please contact the conference organizers at dcasechallenge@gmail.com if you require an accessible file, as the files provided by ConfTool Pro to reviewers are filtered to remove author information, and
Please contact the conference organizers at dcasechallenge@gmail.com if you require an accessible file, as the files provided by ConfTool Pro to reviewers are filtered to remove author information, and
Audio-coding standards
 Audio-coding standards The goal is to provide CD-quality audio over telecommunications networks. Almost all CD audio coders are based on the so-called psychoacoustic model of the human auditory system.
Audio-coding standards The goal is to provide CD-quality audio over telecommunications networks. Almost all CD audio coders are based on the so-called psychoacoustic model of the human auditory system.
Pitch Prediction from Mel-frequency Cepstral Coefficients Using Sparse Spectrum Recovery
 Pitch Prediction from Mel-frequency Cepstral Coefficients Using Sparse Spectrum Recovery Achuth Rao MV, Prasanta Kumar Ghosh SPIRE LAB Electrical Engineering, Indian Institute of Science (IISc), Bangalore,
Pitch Prediction from Mel-frequency Cepstral Coefficients Using Sparse Spectrum Recovery Achuth Rao MV, Prasanta Kumar Ghosh SPIRE LAB Electrical Engineering, Indian Institute of Science (IISc), Bangalore,
THE PERFORMANCE of automatic speech recognition
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 6, NOVEMBER 2006 2109 Subband Likelihood-Maximizing Beamforming for Speech Recognition in Reverberant Environments Michael L. Seltzer,
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 6, NOVEMBER 2006 2109 Subband Likelihood-Maximizing Beamforming for Speech Recognition in Reverberant Environments Michael L. Seltzer,
IMPROVED SPEAKER RECOGNITION USING DCT COEFFICIENTS AS FEATURES. Mitchell McLaren, Yun Lei
 IMPROVED SPEAKER RECOGNITION USING DCT COEFFICIENTS AS FEATURES Mitchell McLaren, Yun Lei Speech Technology and Research Laboratory, SRI International, California, USA {mitch,yunlei}@speech.sri.com ABSTRACT
IMPROVED SPEAKER RECOGNITION USING DCT COEFFICIENTS AS FEATURES Mitchell McLaren, Yun Lei Speech Technology and Research Laboratory, SRI International, California, USA {mitch,yunlei}@speech.sri.com ABSTRACT
Environment Recognition for Digital Audio Forensics Using MPEG-7 and Mel Cepstral Features
 The International Arab Journal of Information Technology, Vol. 10, No. 1, January 2013 43 Environment Recognition for Digital Audio Forensics Using MPEG-7 and Mel Cepstral Features Ghulam Muhammad 1, 2
The International Arab Journal of Information Technology, Vol. 10, No. 1, January 2013 43 Environment Recognition for Digital Audio Forensics Using MPEG-7 and Mel Cepstral Features Ghulam Muhammad 1, 2
Audio-coding standards
 Audio-coding standards The goal is to provide CD-quality audio over telecommunications networks. Almost all CD audio coders are based on the so-called psychoacoustic model of the human auditory system.
Audio-coding standards The goal is to provide CD-quality audio over telecommunications networks. Almost all CD audio coders are based on the so-called psychoacoustic model of the human auditory system.
A Novel Template Matching Approach To Speaker-Independent Arabic Spoken Digit Recognition
 Special Session: Intelligent Knowledge Management A Novel Template Matching Approach To Speaker-Independent Arabic Spoken Digit Recognition Jiping Sun 1, Jeremy Sun 1, Kacem Abida 2, and Fakhri Karray
Special Session: Intelligent Knowledge Management A Novel Template Matching Approach To Speaker-Independent Arabic Spoken Digit Recognition Jiping Sun 1, Jeremy Sun 1, Kacem Abida 2, and Fakhri Karray
ON THE WINDOW-DISJOINT-ORTHOGONALITY OF SPEECH SOURCES IN REVERBERANT HUMANOID SCENARIOS
 ON THE WINDOW-DISJOINT-ORTHOGONALITY OF SPEECH SOURCES IN REVERBERANT HUMANOID SCENARIOS Sylvia Schulz and Thorsten Herfet Telecommunications Lab, Saarland University, Germany {schulz,herfet}@nt.uni-saarland.de
ON THE WINDOW-DISJOINT-ORTHOGONALITY OF SPEECH SOURCES IN REVERBERANT HUMANOID SCENARIOS Sylvia Schulz and Thorsten Herfet Telecommunications Lab, Saarland University, Germany {schulz,herfet}@nt.uni-saarland.de
Frequency Response (min max)
") TDK InvenSense was the first company to deliver Motion Interface solutions with fully integrated sensors and robust MotionFusion firmware algorithms. Their MotionTracking devices enable our customers to
TDK InvenSense was the first company to deliver Motion Interface solutions with fully integrated sensors and robust MotionFusion firmware algorithms. Their MotionTracking devices enable our customers to
Replacing ECMs with Premium MEMS Microphones
 Replacing ECMs with Premium MEMS Microphones About this document Scope and purpose This document provides reasons to replace electret condenser microphones (ECM) with premium MEMS microphones. Intended
Replacing ECMs with Premium MEMS Microphones About this document Scope and purpose This document provides reasons to replace electret condenser microphones (ECM) with premium MEMS microphones. Intended
Improving Mobile Phone Based Query Recognition with a Microphone Array
 Improving Mobile Phone Based Query Recognition with a Microphone Array Shrikant Venkataramani, Rajbabu Velmurugan and Preeti Rao Department of Electrical Engineering Indian Institute of Technology Bombay
Improving Mobile Phone Based Query Recognition with a Microphone Array Shrikant Venkataramani, Rajbabu Velmurugan and Preeti Rao Department of Electrical Engineering Indian Institute of Technology Bombay
Dimensionality reduction for acoustic vehicle classification with spectral clustering
 Dimensionality reduction for acoustic vehicle classification with spectral clustering Justin Sunu Institute of Mathematical Sciences Claremont Graduate University Claremont, CA 91711 justinsunu@gmail.com
Dimensionality reduction for acoustic vehicle classification with spectral clustering Justin Sunu Institute of Mathematical Sciences Claremont Graduate University Claremont, CA 91711 justinsunu@gmail.com
SpeakUp click. Contents. Applications. SpeakUp Firwmware. Algorithm. SpeakUp and SpeakUp 2 click. From MikroElektonika Documentation
 Page 1 of 8 SpeakUp click From MikroElektonika Documentation SpeakUp click and Speakup 2 click are speaker dependent speech recognition click boards with standalone capabilities. They work by matching
Page 1 of 8 SpeakUp click From MikroElektonika Documentation SpeakUp click and Speakup 2 click are speaker dependent speech recognition click boards with standalone capabilities. They work by matching
2-2-2, Hikaridai, Seika-cho, Soraku-gun, Kyoto , Japan 2 Graduate School of Information Science, Nara Institute of Science and Technology
 ISCA Archive STREAM WEIGHT OPTIMIZATION OF SPEECH AND LIP IMAGE SEQUENCE FOR AUDIO-VISUAL SPEECH RECOGNITION Satoshi Nakamura 1 Hidetoshi Ito 2 Kiyohiro Shikano 2 1 ATR Spoken Language Translation Research
ISCA Archive STREAM WEIGHT OPTIMIZATION OF SPEECH AND LIP IMAGE SEQUENCE FOR AUDIO-VISUAL SPEECH RECOGNITION Satoshi Nakamura 1 Hidetoshi Ito 2 Kiyohiro Shikano 2 1 ATR Spoken Language Translation Research
Speaker Verification with Adaptive Spectral Subband Centroids
 Speaker Verification with Adaptive Spectral Subband Centroids Tomi Kinnunen 1, Bingjun Zhang 2, Jia Zhu 2, and Ye Wang 2 1 Speech and Dialogue Processing Lab Institution for Infocomm Research (I 2 R) 21
Speaker Verification with Adaptive Spectral Subband Centroids Tomi Kinnunen 1, Bingjun Zhang 2, Jia Zhu 2, and Ye Wang 2 1 Speech and Dialogue Processing Lab Institution for Infocomm Research (I 2 R) 21
ENVIRONMENT RECOGNITION FOR DIGITAL AUDIO FORENSICS USING MPEG 7 AND MEL CEPSTRAL FEATURES
 Journal of ELECTRICAL ENGINEERING, VOL. 62, NO. 4, 2011, 199 205 ENVIRONMENT RECOGNITION FOR DIGITAL AUDIO FORENSICS USING MPEG 7 AND MEL CEPSTRAL FEATURES Ghulam MUHAMMAD Khalid ALGHATHBAR Environment
Journal of ELECTRICAL ENGINEERING, VOL. 62, NO. 4, 2011, 199 205 ENVIRONMENT RECOGNITION FOR DIGITAL AUDIO FORENSICS USING MPEG 7 AND MEL CEPSTRAL FEATURES Ghulam MUHAMMAD Khalid ALGHATHBAR Environment
An Environmental Audio Based Context Recognition System Using Smartphones
 University of Twente Master Thesis An Environmental Audio Based Context Recognition System Using Smartphones Author: Gebremedhin T. Abreha Supervisor: Dr. Nirvana Meratnia Committee: Prof. Paul Havinga
University of Twente Master Thesis An Environmental Audio Based Context Recognition System Using Smartphones Author: Gebremedhin T. Abreha Supervisor: Dr. Nirvana Meratnia Committee: Prof. Paul Havinga
Introducing Audio Signal Processing & Audio Coding. Dr Michael Mason Senior Manager, CE Technology Dolby Australia Pty Ltd
 Introducing Audio Signal Processing & Audio Coding Dr Michael Mason Senior Manager, CE Technology Dolby Australia Pty Ltd Overview Audio Signal Processing Applications @ Dolby Audio Signal Processing Basics
Introducing Audio Signal Processing & Audio Coding Dr Michael Mason Senior Manager, CE Technology Dolby Australia Pty Ltd Overview Audio Signal Processing Applications @ Dolby Audio Signal Processing Basics
Bo#leneck Features from SNR- Adap9ve Denoising Deep Classifier for Speaker Iden9fica9on
 Bo#leneck Features from SNR- Adap9ve Denoising Deep Classifier for Speaker Iden9fica9on TAN Zhili & MAK Man-Wai APSIPA 2015 Department of Electronic and Informa2on Engineering The Hong Kong Polytechnic
Bo#leneck Features from SNR- Adap9ve Denoising Deep Classifier for Speaker Iden9fica9on TAN Zhili & MAK Man-Wai APSIPA 2015 Department of Electronic and Informa2on Engineering The Hong Kong Polytechnic
Introducing Audio Signal Processing & Audio Coding. Dr Michael Mason Snr Staff Eng., Team Lead (Applied Research) Dolby Australia Pty Ltd
 Dolby Australia Pty Ltd") Introducing Audio Signal Processing & Audio Coding Dr Michael Mason Snr Staff Eng., Team Lead (Applied Research) Dolby Australia Pty Ltd Introducing Audio Signal Processing & Audio Coding 2013 Dolby Laboratories,
Introducing Audio Signal Processing & Audio Coding Dr Michael Mason Snr Staff Eng., Team Lead (Applied Research) Dolby Australia Pty Ltd Introducing Audio Signal Processing & Audio Coding 2013 Dolby Laboratories,
Mpeg 1 layer 3 (mp3) general overview
 general overview") Mpeg 1 layer 3 (mp3) general overview 1 Digital Audio! CD Audio:! 16 bit encoding! 2 Channels (Stereo)! 44.1 khz sampling rate 2 * 44.1 khz * 16 bits = 1.41 Mb/s + Overhead (synchronization, error correction,
Mpeg 1 layer 3 (mp3) general overview 1 Digital Audio! CD Audio:! 16 bit encoding! 2 Channels (Stereo)! 44.1 khz sampling rate 2 * 44.1 khz * 16 bits = 1.41 Mb/s + Overhead (synchronization, error correction,
Secure E- Commerce Transaction using Noisy Password with Voiceprint and OTP
 Secure E- Commerce Transaction using Noisy Password with Voiceprint and OTP Komal K. Kumbhare Department of Computer Engineering B. D. C. O. E. Sevagram, India komalkumbhare27@gmail.com Prof. K. V. Warkar
Secure E- Commerce Transaction using Noisy Password with Voiceprint and OTP Komal K. Kumbhare Department of Computer Engineering B. D. C. O. E. Sevagram, India komalkumbhare27@gmail.com Prof. K. V. Warkar
Aditi Upadhyay Research Scholar, Department of Electronics & Communication Engineering Jaipur National University, Jaipur, Rajasthan, India
 Analysis of Different Classifier Using Feature Extraction in Speaker Identification and Verification under Adverse Acoustic Condition for Different Scenario Shrikant Upadhyay Assistant Professor, Department
Analysis of Different Classifier Using Feature Extraction in Speaker Identification and Verification under Adverse Acoustic Condition for Different Scenario Shrikant Upadhyay Assistant Professor, Department
MACHINE LEARNING: CLUSTERING, AND CLASSIFICATION. Steve Tjoa June 25, 2014
 MACHINE LEARNING: CLUSTERING, AND CLASSIFICATION Steve Tjoa kiemyang@gmail.com June 25, 2014 Review from Day 2 Supervised vs. Unsupervised Unsupervised - clustering Supervised binary classifiers (2 classes)
MACHINE LEARNING: CLUSTERING, AND CLASSIFICATION Steve Tjoa kiemyang@gmail.com June 25, 2014 Review from Day 2 Supervised vs. Unsupervised Unsupervised - clustering Supervised binary classifiers (2 classes)
MP3 Speech and Speaker Recognition with Nearest Neighbor. ECE417 Multimedia Signal Processing Fall 2017
 MP3 Speech and Speaker Recognition with Nearest Neighbor ECE417 Multimedia Signal Processing Fall 2017 Goals Given a dataset of N audio files: Features Raw Features, Cepstral (Hz), Cepstral (Mel) Classifier
MP3 Speech and Speaker Recognition with Nearest Neighbor ECE417 Multimedia Signal Processing Fall 2017 Goals Given a dataset of N audio files: Features Raw Features, Cepstral (Hz), Cepstral (Mel) Classifier
DETECTING INDOOR SOUND EVENTS
 DETECTING INDOOR SOUND EVENTS Toma TELEMBICI, Lacrimioara GRAMA Signal Processing Group, Basis of Electronics Department, Faculty of Electronics, Telecommunications and Information Technology, Technical
DETECTING INDOOR SOUND EVENTS Toma TELEMBICI, Lacrimioara GRAMA Signal Processing Group, Basis of Electronics Department, Faculty of Electronics, Telecommunications and Information Technology, Technical
Speech Recognition on DSP: Algorithm Optimization and Performance Analysis
 Speech Recognition on DSP: Algorithm Optimization and Performance Analysis YUAN Meng A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Philosophy in Electronic Engineering
Speech Recognition on DSP: Algorithm Optimization and Performance Analysis YUAN Meng A Thesis Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Philosophy in Electronic Engineering
Multimedia Database Systems. Retrieval by Content
 Multimedia Database Systems Retrieval by Content MIR Motivation Large volumes of data world-wide are not only based on text: Satellite images (oil spill), deep space images (NASA) Medical images (X-rays,
Multimedia Database Systems Retrieval by Content MIR Motivation Large volumes of data world-wide are not only based on text: Satellite images (oil spill), deep space images (NASA) Medical images (X-rays,
RECOGNITION OF EMOTION FROM MARATHI SPEECH USING MFCC AND DWT ALGORITHMS
 RECOGNITION OF EMOTION FROM MARATHI SPEECH USING MFCC AND DWT ALGORITHMS Dipti D. Joshi, M.B. Zalte (EXTC Department, K.J. Somaiya College of Engineering, University of Mumbai, India) Diptijoshi3@gmail.com
RECOGNITION OF EMOTION FROM MARATHI SPEECH USING MFCC AND DWT ALGORITHMS Dipti D. Joshi, M.B. Zalte (EXTC Department, K.J. Somaiya College of Engineering, University of Mumbai, India) Diptijoshi3@gmail.com
Introduction to Massive Data Interpretation
 Introduction to Massive Data Interpretation JERKER HAMMARBERG JAKOB FREDSLUND THE ALEXANDRA INSTITUTE 2013 2/12 Introduction Cases C1. Bird Vocalization Recognition C2. Body Movement Classification C3.
Introduction to Massive Data Interpretation JERKER HAMMARBERG JAKOB FREDSLUND THE ALEXANDRA INSTITUTE 2013 2/12 Introduction Cases C1. Bird Vocalization Recognition C2. Body Movement Classification C3.
Lecture 16 Perceptual Audio Coding
 EECS 225D Audio Signal Processing in Humans and Machines Lecture 16 Perceptual Audio Coding 2012-3-14 Professor Nelson Morgan today s lecture by John Lazzaro www.icsi.berkeley.edu/eecs225d/spr12/ Hero
EECS 225D Audio Signal Processing in Humans and Machines Lecture 16 Perceptual Audio Coding 2012-3-14 Professor Nelson Morgan today s lecture by John Lazzaro www.icsi.berkeley.edu/eecs225d/spr12/ Hero
[N569] Wavelet speech enhancement based on voiced/unvoiced decision
![[N569] Wavelet speech enhancement based on voiced/unvoiced decision](/thumbs/90/102431372.jpg "[N569] Wavelet speech enhancement based on voiced/unvoiced decision") The 32nd International Congress and Exposition on Noise Control Engineering Jeju International Convention Center, Seogwipo, Korea, August 25-28, 2003 [N569] Wavelet speech enhancement based on voiced/unvoiced
The 32nd International Congress and Exposition on Noise Control Engineering Jeju International Convention Center, Seogwipo, Korea, August 25-28, 2003 [N569] Wavelet speech enhancement based on voiced/unvoiced
IVM 4. Audio Presets Details SST 4. AKG Acoustics 2008
 IVM 4 Audio Presets Details SST 4 AKG Acoustics 2008 2 COMPRESSOR All COMPRESSOR Presets have one GOAL: Create a precise and well-balanced monitoring level by maintaining all sound nuances and a natural
IVM 4 Audio Presets Details SST 4 AKG Acoustics 2008 2 COMPRESSOR All COMPRESSOR Presets have one GOAL: Create a precise and well-balanced monitoring level by maintaining all sound nuances and a natural
Sound Lab by Gold Line. Noise Level Analysis
 Sound Lab by Gold Line Noise Level Analysis About NLA The NLA module of Sound Lab is used to analyze noise over a specified period of time. NLA can be set to run for as short as one minute or as long as
Sound Lab by Gold Line Noise Level Analysis About NLA The NLA module of Sound Lab is used to analyze noise over a specified period of time. NLA can be set to run for as short as one minute or as long as
Authentication of Fingerprint Recognition Using Natural Language Processing
 Authentication of Fingerprint Recognition Using Natural Language Shrikala B. Digavadekar 1, Prof. Ravindra T. Patil 2 1 Tatyasaheb Kore Institute of Engineering & Technology, Warananagar, India 2 Tatyasaheb
Authentication of Fingerprint Recognition Using Natural Language Shrikala B. Digavadekar 1, Prof. Ravindra T. Patil 2 1 Tatyasaheb Kore Institute of Engineering & Technology, Warananagar, India 2 Tatyasaheb
Measurement of 3D Room Impulse Responses with a Spherical Microphone Array
 Measurement of 3D Room Impulse Responses with a Spherical Microphone Array Jean-Jacques Embrechts Department of Electrical Engineering and Computer Science/Acoustic lab, University of Liège, Sart-Tilman
Measurement of 3D Room Impulse Responses with a Spherical Microphone Array Jean-Jacques Embrechts Department of Electrical Engineering and Computer Science/Acoustic lab, University of Liège, Sart-Tilman
SPEECH FEATURE EXTRACTION USING WEIGHTED HIGHER-ORDER LOCAL AUTO-CORRELATION
 Far East Journal of Electronics and Communications Volume 3, Number 2, 2009, Pages 125-140 Published Online: September 14, 2009 This paper is available online at http://www.pphmj.com 2009 Pushpa Publishing
Far East Journal of Electronics and Communications Volume 3, Number 2, 2009, Pages 125-140 Published Online: September 14, 2009 This paper is available online at http://www.pphmj.com 2009 Pushpa Publishing
ACOUSTIC BASED SKETCH RECOGNITION. A Thesis WENZHE LI
 ACOUSTIC BASED SKETCH RECOGNITION A Thesis by WENZHE LI Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE
ACOUSTIC BASED SKETCH RECOGNITION A Thesis by WENZHE LI Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE
Testing Approaches for Characterization and Selection of MEMS Inertial Sensors 2016, 2016, ACUTRONIC 1
 Testing Approaches for Characterization and Selection of MEMS Inertial Sensors by Dino Smajlovic and Roman Tkachev 2016, 2016, ACUTRONIC 1 Table of Contents Summary & Introduction 3 Sensor Parameter Definitions
Testing Approaches for Characterization and Selection of MEMS Inertial Sensors by Dino Smajlovic and Roman Tkachev 2016, 2016, ACUTRONIC 1 Table of Contents Summary & Introduction 3 Sensor Parameter Definitions
VSEW_mk2-8g. Data Sheet. Dec Bruno Paillard
 VSEW_mk2-8g Data Sheet Dec 4 2017 Bruno Paillard 1 PRODUCT DESCRIPTION 2 2 APPLICATIONS 2 3 SPECIFICATIONS 3 3.1 Frequency Response 5 3.1.1 Upper Frequency Limit 5 3.1.2 Low-Frequency Limit 6 3.2 Noise
VSEW_mk2-8g Data Sheet Dec 4 2017 Bruno Paillard 1 PRODUCT DESCRIPTION 2 2 APPLICATIONS 2 3 SPECIFICATIONS 3 3.1 Frequency Response 5 3.1.1 Upper Frequency Limit 5 3.1.2 Low-Frequency Limit 6 3.2 Noise
MATLAB Apps for Teaching Digital Speech Processing
 MATLAB Apps for Teaching Digital Speech Processing Lawrence Rabiner, Rutgers University Ronald Schafer, Stanford University GUI LITE 2.5 editor written by Maria d Souza and Dan Litvin MATLAB coding support
MATLAB Apps for Teaching Digital Speech Processing Lawrence Rabiner, Rutgers University Ronald Schafer, Stanford University GUI LITE 2.5 editor written by Maria d Souza and Dan Litvin MATLAB coding support
Dr Andrew Abel University of Stirling, Scotland
 Dr Andrew Abel University of Stirling, Scotland University of Stirling - Scotland Cognitive Signal Image and Control Processing Research (COSIPRA) Cognitive Computation neurobiology, cognitive psychology
Dr Andrew Abel University of Stirling, Scotland University of Stirling - Scotland Cognitive Signal Image and Control Processing Research (COSIPRA) Cognitive Computation neurobiology, cognitive psychology
Auto-Digitizer for Fast Graph-to-Data Conversion
 Auto-Digitizer for Fast Graph-to-Data Conversion EE 368 Final Project Report, Winter 2018 Deepti Sanjay Mahajan dmahaj@stanford.edu Sarah Pao Radzihovsky sradzi13@stanford.edu Ching-Hua (Fiona) Wang chwang9@stanford.edu
Auto-Digitizer for Fast Graph-to-Data Conversion EE 368 Final Project Report, Winter 2018 Deepti Sanjay Mahajan dmahaj@stanford.edu Sarah Pao Radzihovsky sradzi13@stanford.edu Ching-Hua (Fiona) Wang chwang9@stanford.edu
Programming-By-Example Gesture Recognition Kevin Gabayan, Steven Lansel December 15, 2006
 Programming-By-Example Gesture Recognition Kevin Gabayan, Steven Lansel December 15, 6 Abstract Machine learning and hardware improvements to a programming-by-example rapid prototyping system are proposed.
Programming-By-Example Gesture Recognition Kevin Gabayan, Steven Lansel December 15, 6 Abstract Machine learning and hardware improvements to a programming-by-example rapid prototyping system are proposed.
The 5.8mm diameter ROM-2235L-HD-R is designed for extreme fidelity in a compact housing with true 20 Hz to 20 khz performance.
 Data Sheet ROM-2235L-HD-R PUI Audio s all-new HD Series microphones use premium-grade FETs and diaphragms for high sensitivity and superior signal-to-noise ratio. Each microphone features GSM buzz-blocking
Data Sheet ROM-2235L-HD-R PUI Audio s all-new HD Series microphones use premium-grade FETs and diaphragms for high sensitivity and superior signal-to-noise ratio. Each microphone features GSM buzz-blocking
Further Studies of a FFT-Based Auditory Spectrum with Application in Audio Classification
 ICSP Proceedings Further Studies of a FFT-Based Auditory with Application in Audio Classification Wei Chu and Benoît Champagne Department of Electrical and Computer Engineering McGill University, Montréal,
ICSP Proceedings Further Studies of a FFT-Based Auditory with Application in Audio Classification Wei Chu and Benoît Champagne Department of Electrical and Computer Engineering McGill University, Montréal,
Acoustic to Articulatory Mapping using Memory Based Regression and Trajectory Smoothing
 Acoustic to Articulatory Mapping using Memory Based Regression and Trajectory Smoothing Samer Al Moubayed Center for Speech Technology, Department of Speech, Music, and Hearing, KTH, Sweden. sameram@kth.se
Acoustic to Articulatory Mapping using Memory Based Regression and Trajectory Smoothing Samer Al Moubayed Center for Speech Technology, Department of Speech, Music, and Hearing, KTH, Sweden. sameram@kth.se
Multimedia Systems Speech I Mahdi Amiri February 2011 Sharif University of Technology
 Course Presentation Multimedia Systems Speech I Mahdi Amiri February 2011 Sharif University of Technology Sound Sound is a sequence of waves of pressure which propagates through compressible media such
Course Presentation Multimedia Systems Speech I Mahdi Amiri February 2011 Sharif University of Technology Sound Sound is a sequence of waves of pressure which propagates through compressible media such
Separation Of Speech From Noise Challenge
 Separation Of Speech From Noise Challenge NagaChaitanya Vellanki vellanki@stanford.edu December 14, 2012 1 Introduction The goal of this project is to implement the methods submitted for the PASCAL CHiME
Separation Of Speech From Noise Challenge NagaChaitanya Vellanki vellanki@stanford.edu December 14, 2012 1 Introduction The goal of this project is to implement the methods submitted for the PASCAL CHiME
Human Activity Recognition via Cellphone Sensor Data
 Human Activity Recognition via Cellphone Sensor Data Wei Ji, Heguang Liu, Jonathan Fisher Abstract The purpose of this project is to identify human activities while using cell phones via mobile sensor
Human Activity Recognition via Cellphone Sensor Data Wei Ji, Heguang Liu, Jonathan Fisher Abstract The purpose of this project is to identify human activities while using cell phones via mobile sensor
Environment Independent Speech Recognition System using MFCC (Mel-frequency cepstral coefficient)
") Environment Independent Speech Recognition System using MFCC (Mel-frequency cepstral coefficient) Kamalpreet kaur #1, Jatinder Kaur *2 #1, *2 Department of Electronics and Communication Engineering, CGCTC,
Environment Independent Speech Recognition System using MFCC (Mel-frequency cepstral coefficient) Kamalpreet kaur #1, Jatinder Kaur *2 #1, *2 Department of Electronics and Communication Engineering, CGCTC,
SOUND EVENT DETECTION AND CONTEXT RECOGNITION 1 INTRODUCTION. Toni Heittola 1, Annamaria Mesaros 1, Tuomas Virtanen 1, Antti Eronen 2
 Toni Heittola 1, Annamaria Mesaros 1, Tuomas Virtanen 1, Antti Eronen 2 1 Department of Signal Processing, Tampere University of Technology Korkeakoulunkatu 1, 33720, Tampere, Finland toni.heittola@tut.fi,
Toni Heittola 1, Annamaria Mesaros 1, Tuomas Virtanen 1, Antti Eronen 2 1 Department of Signal Processing, Tampere University of Technology Korkeakoulunkatu 1, 33720, Tampere, Finland toni.heittola@tut.fi,
A Gaussian Mixture Model Spectral Representation for Speech Recognition
 A Gaussian Mixture Model Spectral Representation for Speech Recognition Matthew Nicholas Stuttle Hughes Hall and Cambridge University Engineering Department PSfrag replacements July 2003 Dissertation submitted
A Gaussian Mixture Model Spectral Representation for Speech Recognition Matthew Nicholas Stuttle Hughes Hall and Cambridge University Engineering Department PSfrag replacements July 2003 Dissertation submitted
VentriLock: Exploring voice-based authentication systems
 VentriLock: Exploring voice-based authentication systems Chaouki KASMI & José LOPES ESTEVES ANSSI, FRANCE Hack In Paris 06/2017 2 WHO WE ARE Chaouki Kasmi and José Lopes Esteves ANSSI-FNISA / Wireless
VentriLock: Exploring voice-based authentication systems Chaouki KASMI & José LOPES ESTEVES ANSSI, FRANCE Hack In Paris 06/2017 2 WHO WE ARE Chaouki Kasmi and José Lopes Esteves ANSSI-FNISA / Wireless
Complex Identification Decision Based on Several Independent Speaker Recognition Methods. Ilya Oparin Speech Technology Center
 Complex Identification Decision Based on Several Independent Speaker Recognition Methods Ilya Oparin Speech Technology Center Corporate Overview Global provider of voice biometric solutions Company name:
Complex Identification Decision Based on Several Independent Speaker Recognition Methods Ilya Oparin Speech Technology Center Corporate Overview Global provider of voice biometric solutions Company name:
Detection of goal event in soccer videos
 Detection of goal event in soccer videos Hyoung-Gook Kim, Steffen Roeber, Amjad Samour, Thomas Sikora Department of Communication Systems, Technical University of Berlin, Einsteinufer 17, D-10587 Berlin,
Detection of goal event in soccer videos Hyoung-Gook Kim, Steffen Roeber, Amjad Samour, Thomas Sikora Department of Communication Systems, Technical University of Berlin, Einsteinufer 17, D-10587 Berlin,
SAS: A speaker verification spoofing database containing diverse attacks
 SAS: A speaker verification spoofing database containing diverse attacks Zhizheng Wu 1, Ali Khodabakhsh 2, Cenk Demiroglu 2, Junichi Yamagishi 1,3, Daisuke Saito 4, Tomoki Toda 5, Simon King 1 1 University
SAS: A speaker verification spoofing database containing diverse attacks Zhizheng Wu 1, Ali Khodabakhsh 2, Cenk Demiroglu 2, Junichi Yamagishi 1,3, Daisuke Saito 4, Tomoki Toda 5, Simon King 1 1 University
Audio-visual interaction in sparse representation features for noise robust audio-visual speech recognition
 ISCA Archive http://www.isca-speech.org/archive Auditory-Visual Speech Processing (AVSP) 2013 Annecy, France August 29 - September 1, 2013 Audio-visual interaction in sparse representation features for
ISCA Archive http://www.isca-speech.org/archive Auditory-Visual Speech Processing (AVSP) 2013 Annecy, France August 29 - September 1, 2013 Audio-visual interaction in sparse representation features for
Archetypal Analysis Based Sparse Convex Sequence Kernel for Bird Activity Detection
 Archetypal Analysis Based Sparse Convex Sequence Kernel for Bird Activity Detection V. Abrol, P. Sharma, A. Thakur, P. Rajan, A. D. Dileep, Anil K. Sao School of Computing and Electrical Engineering, Indian
Archetypal Analysis Based Sparse Convex Sequence Kernel for Bird Activity Detection V. Abrol, P. Sharma, A. Thakur, P. Rajan, A. D. Dileep, Anil K. Sao School of Computing and Electrical Engineering, Indian
NON-UNIFORM SPEAKER NORMALIZATION USING FREQUENCY-DEPENDENT SCALING FUNCTION
 NON-UNIFORM SPEAKER NORMALIZATION USING FREQUENCY-DEPENDENT SCALING FUNCTION S. V. Bharath Kumar Imaging Technologies Lab General Electric - Global Research JFWTC, Bangalore - 560086, INDIA bharath.sv@geind.ge.com
NON-UNIFORM SPEAKER NORMALIZATION USING FREQUENCY-DEPENDENT SCALING FUNCTION S. V. Bharath Kumar Imaging Technologies Lab General Electric - Global Research JFWTC, Bangalore - 560086, INDIA bharath.sv@geind.ge.com
Analyzing Vocal Patterns to Determine Emotion Maisy Wieman, Andy Sun
 Analyzing Vocal Patterns to Determine Emotion Maisy Wieman, Andy Sun 1. Introduction The human voice is very versatile and carries a multitude of emotions. Emotion in speech carries extra insight about
Analyzing Vocal Patterns to Determine Emotion Maisy Wieman, Andy Sun 1. Introduction The human voice is very versatile and carries a multitude of emotions. Emotion in speech carries extra insight about
BINAURAL SOUND LOCALIZATION FOR UNTRAINED DIRECTIONS BASED ON A GAUSSIAN MIXTURE MODEL
 BINAURAL SOUND LOCALIZATION FOR UNTRAINED DIRECTIONS BASED ON A GAUSSIAN MIXTURE MODEL Takanori Nishino and Kazuya Takeda Center for Information Media Studies, Nagoya University Furo-cho, Chikusa-ku, Nagoya,
BINAURAL SOUND LOCALIZATION FOR UNTRAINED DIRECTIONS BASED ON A GAUSSIAN MIXTURE MODEL Takanori Nishino and Kazuya Takeda Center for Information Media Studies, Nagoya University Furo-cho, Chikusa-ku, Nagoya,
Speech-Coding Techniques. Chapter 3
 Speech-Coding Techniques Chapter 3 Introduction Efficient speech-coding techniques Advantages for VoIP Digital streams of ones and zeros The lower the bandwidth, the lower the quality RTP payload types
Speech-Coding Techniques Chapter 3 Introduction Efficient speech-coding techniques Advantages for VoIP Digital streams of ones and zeros The lower the bandwidth, the lower the quality RTP payload types
Multi-Modal Audio, Video, and Physiological Sensor Learning for Continuous Emotion Prediction
 Multi-Modal Audio, Video, and Physiological Sensor Learning for Continuous Emotion Prediction Youngjune Gwon 1, Kevin Brady 1, Pooya Khorrami 2, Elizabeth Godoy 1, William Campbell 1, Charlie Dagli 1,
Multi-Modal Audio, Video, and Physiological Sensor Learning for Continuous Emotion Prediction Youngjune Gwon 1, Kevin Brady 1, Pooya Khorrami 2, Elizabeth Godoy 1, William Campbell 1, Charlie Dagli 1,
Sound Source Separation Algorithm Using Phase Difference and Angle Distribution Modeling Near the Target
 Sound Source Separation Algorithm Using Phase Difference and Angle Distribution Modeling Near the Target Chanwoo Kim 1, Kean K. Chin 2 Google, Mountain View CA 94043 USA {chanwcom,kkchin}@google.com Abstract
Sound Source Separation Algorithm Using Phase Difference and Angle Distribution Modeling Near the Target Chanwoo Kim 1, Kean K. Chin 2 Google, Mountain View CA 94043 USA {chanwcom,kkchin}@google.com Abstract
Variable-Component Deep Neural Network for Robust Speech Recognition
 Variable-Component Deep Neural Network for Robust Speech Recognition Rui Zhao 1, Jinyu Li 2, and Yifan Gong 2 1 Microsoft Search Technology Center Asia, Beijing, China 2 Microsoft Corporation, One Microsoft
Variable-Component Deep Neural Network for Robust Speech Recognition Rui Zhao 1, Jinyu Li 2, and Yifan Gong 2 1 Microsoft Search Technology Center Asia, Beijing, China 2 Microsoft Corporation, One Microsoft
Least Squares Signal Declipping for Robust Speech Recognition
 Least Squares Signal Declipping for Robust Speech Recognition Mark J. Harvilla and Richard M. Stern Department of Electrical and Computer Engineering Carnegie Mellon University, Pittsburgh, PA 15213 USA
Least Squares Signal Declipping for Robust Speech Recognition Mark J. Harvilla and Richard M. Stern Department of Electrical and Computer Engineering Carnegie Mellon University, Pittsburgh, PA 15213 USA
Chapter 3. Speech segmentation. 3.1 Preprocessing
 , as done in this dissertation, refers to the process of determining the boundaries between phonemes in the speech signal. No higher-level lexical information is used to accomplish this. This chapter presents
, as done in this dissertation, refers to the process of determining the boundaries between phonemes in the speech signal. No higher-level lexical information is used to accomplish this. This chapter presents
AUTOMATIC speech recognition (ASR) systems suffer
 systems suffer") 1 A High-Dimensional Subband Speech Representation and SVM Framework for Robust Speech Recognition Jibran Yousafzai, Member, IEEE Zoran Cvetković, Senior Member, IEEE Peter Sollich Matthew Ager Abstract
1 A High-Dimensional Subband Speech Representation and SVM Framework for Robust Speech Recognition Jibran Yousafzai, Member, IEEE Zoran Cvetković, Senior Member, IEEE Peter Sollich Matthew Ager Abstract
CHROMA AND MFCC BASED PATTERN RECOGNITION IN AUDIO FILES UTILIZING HIDDEN MARKOV MODELS AND DYNAMIC PROGRAMMING. Alexander Wankhammer Peter Sciri
 1 CHROMA AND MFCC BASED PATTERN RECOGNITION IN AUDIO FILES UTILIZING HIDDEN MARKOV MODELS AND DYNAMIC PROGRAMMING Alexander Wankhammer Peter Sciri introduction./the idea > overview What is musical structure?
1 CHROMA AND MFCC BASED PATTERN RECOGNITION IN AUDIO FILES UTILIZING HIDDEN MARKOV MODELS AND DYNAMIC PROGRAMMING Alexander Wankhammer Peter Sciri introduction./the idea > overview What is musical structure?
SPEECH is the natural and easiest way to communicate
 Evaluation of eatures Extraction Algorithms for a Real-Time Isolated Word Recognition System Tomyslav Sledevič, Artūras Serackis, Gintautas Tamulevičius, Dalius Navakauskas Abstract Paper presents an comparative
Evaluation of eatures Extraction Algorithms for a Real-Time Isolated Word Recognition System Tomyslav Sledevič, Artūras Serackis, Gintautas Tamulevičius, Dalius Navakauskas Abstract Paper presents an comparative
Voiced-Unvoiced-Silence Classification via Hierarchical Dual Geometry Analysis
 Voiced-Unvoiced-Silence Classification via Hierarchical Dual Geometry Analysis Maya Harel, David Dov, Israel Cohen, Ronen Talmon and Ron Meir Andrew and Erna Viterbi Faculty of Electrical Engineering Technion
Voiced-Unvoiced-Silence Classification via Hierarchical Dual Geometry Analysis Maya Harel, David Dov, Israel Cohen, Ronen Talmon and Ron Meir Andrew and Erna Viterbi Faculty of Electrical Engineering Technion
Applications of Keyword-Constraining in Speaker Recognition. Howard Lei. July 2, Introduction 3
 Applications of Keyword-Constraining in Speaker Recognition Howard Lei hlei@icsi.berkeley.edu July 2, 2007 Contents 1 Introduction 3 2 The keyword HMM system 4 2.1 Background keyword HMM training............................
Applications of Keyword-Constraining in Speaker Recognition Howard Lei hlei@icsi.berkeley.edu July 2, 2007 Contents 1 Introduction 3 2 The keyword HMM system 4 2.1 Background keyword HMM training............................
Xing Fan, Carlos Busso and John H.L. Hansen
 Xing Fan, Carlos Busso and John H.L. Hansen Center for Robust Speech Systems (CRSS) Erik Jonsson School of Engineering & Computer Science Department of Electrical Engineering University of Texas at Dallas
Xing Fan, Carlos Busso and John H.L. Hansen Center for Robust Speech Systems (CRSS) Erik Jonsson School of Engineering & Computer Science Department of Electrical Engineering University of Texas at Dallas
Vulnerability of Voice Verification System with STC anti-spoofing detector to different methods of spoofing attacks
 Vulnerability of Voice Verification System with STC anti-spoofing detector to different methods of spoofing attacks Vadim Shchemelinin 1,2, Alexandr Kozlov 2, Galina Lavrentyeva 2, Sergey Novoselov 1,2
Vulnerability of Voice Verification System with STC anti-spoofing detector to different methods of spoofing attacks Vadim Shchemelinin 1,2, Alexandr Kozlov 2, Galina Lavrentyeva 2, Sergey Novoselov 1,2
Chapter 14 MPEG Audio Compression
 Chapter 14 MPEG Audio Compression 14.1 Psychoacoustics 14.2 MPEG Audio 14.3 Other Commercial Audio Codecs 14.4 The Future: MPEG-7 and MPEG-21 14.5 Further Exploration 1 Li & Drew c Prentice Hall 2003 14.1
Chapter 14 MPEG Audio Compression 14.1 Psychoacoustics 14.2 MPEG Audio 14.3 Other Commercial Audio Codecs 14.4 The Future: MPEG-7 and MPEG-21 14.5 Further Exploration 1 Li & Drew c Prentice Hall 2003 14.1