Machine Learning. Cross Validation
|
|
|
- Shannon Moody
- 5 years ago
- Views:
Transcription

1 Machine Learning Cross Validation
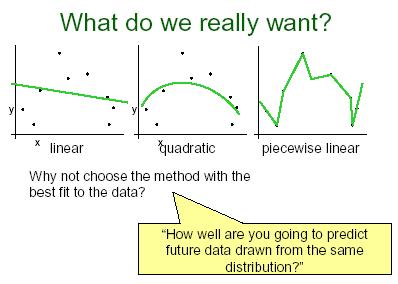
2 Cross Validation Cross validation is a model evaluation method that is better than residuals. The problem with residual evaluations is that they do not give an indication of how well the learner will do when it is asked to make new predictions for data it has not already seen. One way to overcome this problem is to.. not use the entire data set when training a learner. Some of the data is removed before training begins. Then when training is done, the data that was removed can be used to test the performance of the learned model on ``new'' data. This is the basic idea for a whole class of model evaluation methods called cross validation. 2
3 3
4 4
5 5
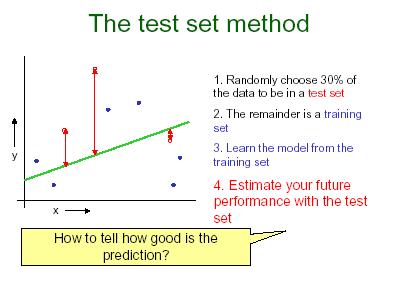
6 The holdout method The holdout method is the simplest kind of cross validation. The data set is separated into two sets, called the training set and the testing set. The function approximator fits a function using the training set only. Then the function approximator is asked to predict the output values for the data in the testing set (it has never seen these output values before). 6
7 Chapter 7 7
8 8
9 9
10 10
11 11
12 12

13 13

14 14
15 The holdout method The errors it makes are accumulated as before to give the mean absolute test set error, which is used to evaluate the model. The advantage of this method is that it is usually preferable to the residual method and takes no longer to compute. However, its evaluation can have a high variance. The evaluation may depend heavily on which data points end up in the training set and which end up in the test set, the evaluation may be significantly different depending on how the division is made. 15
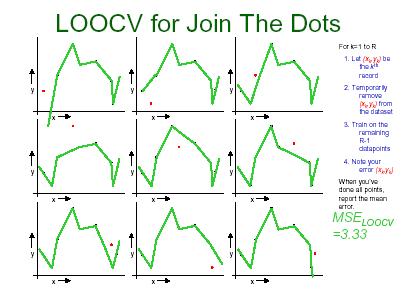
16 Leave-one-out cross validation Leave-one-out cross validation (LOOCV) is K-fold cross validation taken to its logical extreme, with K equal to N, the number of data points in the set. That means that N separate times, the function approximator is trained on all the data except for one point and a prediction is made for that point. As before the average error is computed and used to evaluate the model. 16
17 17
18 18
19 19
20 20
21 21
22 22
23 23
24 24

25 Leave-one-out cross validation The evaluation given by leave-one-out cross validation error (LOO-CVE) is good, but at first pass it seems very expensive to compute. Fortunately, locally weighted learners can make LOO predictions just as easily as they make regular predictions. That means computing the LOO-CVE takes no more time than computing the residual error and it is a much better way to evaluate models. 25

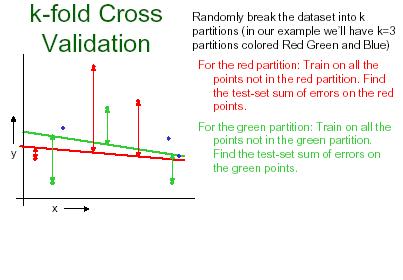
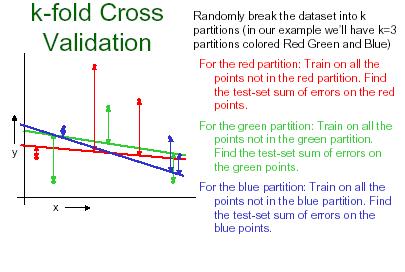
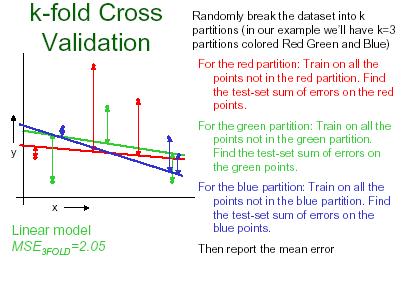
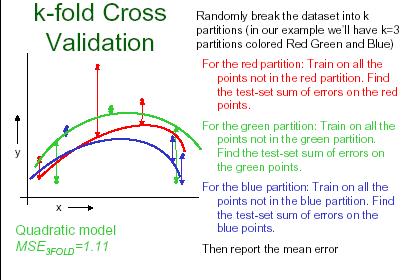
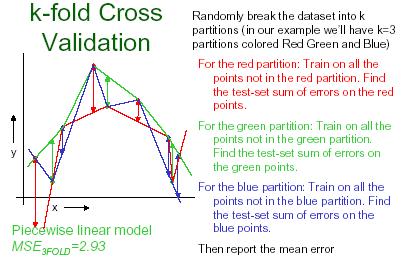
26 K-fold cross validation K-fold cross validation is one way to improve over the holdout method. The data set is divided into k subsets, and the holdout method is repeated k times. Each time, one of the k subsets is used as the test set and the other k-1 subsets are put together to form a training set. Then the average error across all k trials is computed. The advantage of this method is that it matters less how the data gets divided. Every data point gets to be in a test set exactly once, and gets to be in a training set k-1 times. 26
27 27
28 28
29 29
30 30
31 31
32 32
33 33
34 K-fold cross validation The variance of the resulting estimate is reduced as k is increased. The disadvantage of this method is that the training algorithm has to be rerun from scratch k times, which means it takes k times as much computation to make an evaluation. A variant of this method... is to... randomly divide the data into a test and training set k different times. The advantage of doing this is that you can independently choose how large each test set is and how many trials you average over. 34
35 Which kind of Cross Validation? Test-set Leave-oneout 10-fold 3-fold R-fold Downside Variance: unreiable estimate of future perfomance Expensive. Has some weird behavior Wastes 10% of the data. 10 times more expensive tan test set Wastier tan 10-fold. Expensivier tan test set Identical to Leave-one-out Upside Cheap Doesn t waste data Only wastes 10%. Only 10 times more expensive instead of R times Slightly better tan test-set 35
36 36
37 For classification problems, one typically uses stratified k-fold cross-validation, in which the folds are selected so that each fold contains roughly the same proportions of class labels. In repeated cross-validation, the cross-validation procedure is repeated n times, yielding n random partitions of the original sample. The n results are again averaged (or otherwise combined) to produce a single estimation. 37
38 Now, one of most commonly asked question is, How to choose right value of k? Always remember, lower value of K is more biased and hence undesirable. On the other hand, higher value of K is less biased, but can suffer from large variability. It is good to know that, smaller value of k always takes us towards validation set approach, where as higher value of k leads to LOOCV approach. Hence, it is often suggested to use k=10. 38
39 How to measure the model s bias-variance? After k-fold cross validation, we ll get k different model estimation errors (e1, e2..ek). In ideal scenario, these error values should add to zero. To return the model s bias, we take the average of all the errors. Lower the average value, better the model. Similarly for calculating model variance, we take standard deviation of all errors. Lower value of standard deviation suggests our model does not vary a lot with different subset of training data. We should focus on achieving a balance between bias and variance. This can be done by reducing the variance and controlling bias to an extent. It ll result in better predictive model. This trade-off usually leads to building less complex predictive models. 39
Assignment No: 2. Assessment as per Schedule. Specifications Readability Assignments
 Specifications Readability Assignments Assessment as per Schedule Oral Total 6 4 4 2 4 20 Date of Performance:... Expected Date of Completion:... Actual Date of Completion:... ----------------------------------------------------------------------------------------------------------------
Specifications Readability Assignments Assessment as per Schedule Oral Total 6 4 4 2 4 20 Date of Performance:... Expected Date of Completion:... Actual Date of Completion:... ----------------------------------------------------------------------------------------------------------------
LECTURE 6: CROSS VALIDATION
 LECTURE 6: CROSS VALIDATION CSCI 4352 Machine Learning Dongchul Kim, Ph.D. Department of Computer Science A Regression Problem Given a data set, how can we evaluate our (linear) model? Cross Validation
LECTURE 6: CROSS VALIDATION CSCI 4352 Machine Learning Dongchul Kim, Ph.D. Department of Computer Science A Regression Problem Given a data set, how can we evaluate our (linear) model? Cross Validation
A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection (Kohavi, 1995)
") A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection (Kohavi, 1995) Department of Information, Operations and Management Sciences Stern School of Business, NYU padamopo@stern.nyu.edu
A Study of Cross-Validation and Bootstrap for Accuracy Estimation and Model Selection (Kohavi, 1995) Department of Information, Operations and Management Sciences Stern School of Business, NYU padamopo@stern.nyu.edu
How do we obtain reliable estimates of performance measures?
 How do we obtain reliable estimates of performance measures? 1 Estimating Model Performance How do we estimate performance measures? Error on training data? Also called resubstitution error. Not a good
How do we obtain reliable estimates of performance measures? 1 Estimating Model Performance How do we estimate performance measures? Error on training data? Also called resubstitution error. Not a good
Cross- Valida+on & ROC curve. Anna Helena Reali Costa PCS 5024
 Cross- Valida+on & ROC curve Anna Helena Reali Costa PCS 5024 Resampling Methods Involve repeatedly drawing samples from a training set and refibng a model on each sample. Used in model assessment (evalua+ng
Cross- Valida+on & ROC curve Anna Helena Reali Costa PCS 5024 Resampling Methods Involve repeatedly drawing samples from a training set and refibng a model on each sample. Used in model assessment (evalua+ng
RESAMPLING METHODS. Chapter 05
 1 RESAMPLING METHODS Chapter 05 2 Outline Cross Validation The Validation Set Approach Leave-One-Out Cross Validation K-fold Cross Validation Bias-Variance Trade-off for k-fold Cross Validation Cross Validation
1 RESAMPLING METHODS Chapter 05 2 Outline Cross Validation The Validation Set Approach Leave-One-Out Cross Validation K-fold Cross Validation Bias-Variance Trade-off for k-fold Cross Validation Cross Validation
Cross-validation. Cross-validation is a resampling method.
 Cross-validation Cross-validation is a resampling method. It refits a model of interest to samples formed from the training set, in order to obtain additional information about the fitted model. For example,
Cross-validation Cross-validation is a resampling method. It refits a model of interest to samples formed from the training set, in order to obtain additional information about the fitted model. For example,
ECLT 5810 Evaluation of Classification Quality
 ECLT 5810 Evaluation of Classification Quality Reference: Data Mining Practical Machine Learning Tools and Techniques, by I. Witten, E. Frank, and M. Hall, Morgan Kaufmann Testing and Error Error rate:
ECLT 5810 Evaluation of Classification Quality Reference: Data Mining Practical Machine Learning Tools and Techniques, by I. Witten, E. Frank, and M. Hall, Morgan Kaufmann Testing and Error Error rate:
Performance Estimation and Regularization. Kasthuri Kannan, PhD. Machine Learning, Spring 2018
 Performance Estimation and Regularization Kasthuri Kannan, PhD. Machine Learning, Spring 2018 Bias- Variance Tradeoff Fundamental to machine learning approaches Bias- Variance Tradeoff Error due to Bias:
Performance Estimation and Regularization Kasthuri Kannan, PhD. Machine Learning, Spring 2018 Bias- Variance Tradeoff Fundamental to machine learning approaches Bias- Variance Tradeoff Error due to Bias:
Bias-Variance Decomposition Error Estimators
 Bias-Variance Decomposition Error Estimators Cross-Validation Bias-Variance tradeoff Intuition Model too simple does not fit the data well a biased solution. Model too comple small changes to the data,
Bias-Variance Decomposition Error Estimators Cross-Validation Bias-Variance tradeoff Intuition Model too simple does not fit the data well a biased solution. Model too comple small changes to the data,
Bias-Variance Decomposition Error Estimators Cross-Validation
 Bias-Variance Decomposition Error Estimators Cross-Validation Bias-Variance tradeoff Intuition Model too simple does not fit the data well a biased solution. Model too comple small changes to the data,
Bias-Variance Decomposition Error Estimators Cross-Validation Bias-Variance tradeoff Intuition Model too simple does not fit the data well a biased solution. Model too comple small changes to the data,
Multicollinearity and Validation CIVL 7012/8012
 Multicollinearity and Validation CIVL 7012/8012 2 In Today s Class Recap Multicollinearity Model Validation MULTICOLLINEARITY 1. Perfect Multicollinearity 2. Consequences of Perfect Multicollinearity 3.
Multicollinearity and Validation CIVL 7012/8012 2 In Today s Class Recap Multicollinearity Model Validation MULTICOLLINEARITY 1. Perfect Multicollinearity 2. Consequences of Perfect Multicollinearity 3.
Cross-validation for detecting and preventing overfitting
 Cross-validation for detecting and preventing overfitting Andrew W. Moore/Anna Goldenberg School of Computer Science Carnegie Mellon Universit Copright 2001, Andrew W. Moore Apr 1st, 2004 Want to learn
Cross-validation for detecting and preventing overfitting Andrew W. Moore/Anna Goldenberg School of Computer Science Carnegie Mellon Universit Copright 2001, Andrew W. Moore Apr 1st, 2004 Want to learn
Machine Learning and Bioinformatics 機器學習與生物資訊學
 Molecular Biomedical Informatics 分子生醫資訊實驗室 機器學習與生物資訊學 Machine Learning & Bioinformatics 1 Evaluation The key to success 2 Three datasets of which the answers must be known 3 Note on parameter tuning It
Molecular Biomedical Informatics 分子生醫資訊實驗室 機器學習與生物資訊學 Machine Learning & Bioinformatics 1 Evaluation The key to success 2 Three datasets of which the answers must be known 3 Note on parameter tuning It
Lecture 7. CS4442/9542b: Artificial Intelligence II Prof. Olga Veksler. Outline. Machine Learning: Cross Validation. Performance evaluation methods
 CS4442/9542b: Artificial Intelligence II Prof. Olga Veksler Lecture 7 Machine Learning: Cross Validation Outline Performance evaluation methods test/train sets cross-validation k-fold Leave-one-out 1 A
CS4442/9542b: Artificial Intelligence II Prof. Olga Veksler Lecture 7 Machine Learning: Cross Validation Outline Performance evaluation methods test/train sets cross-validation k-fold Leave-one-out 1 A
Statistical Consulting Topics Using cross-validation for model selection. Cross-validation is a technique that can be used for model evaluation.
 Statistical Consulting Topics Using cross-validation for model selection Cross-validation is a technique that can be used for model evaluation. We often fit a model to a full data set and then perform
Statistical Consulting Topics Using cross-validation for model selection Cross-validation is a technique that can be used for model evaluation. We often fit a model to a full data set and then perform
CS4491/CS 7265 BIG DATA ANALYTICS
 CS4491/CS 7265 BIG DATA ANALYTICS EVALUATION * Some contents are adapted from Dr. Hung Huang and Dr. Chengkai Li at UT Arlington Dr. Mingon Kang Computer Science, Kennesaw State University Evaluation for
CS4491/CS 7265 BIG DATA ANALYTICS EVALUATION * Some contents are adapted from Dr. Hung Huang and Dr. Chengkai Li at UT Arlington Dr. Mingon Kang Computer Science, Kennesaw State University Evaluation for
Classification Part 4
 Classification Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Model Evaluation Metrics for Performance Evaluation How to evaluate
Classification Part 4 Dr. Sanjay Ranka Professor Computer and Information Science and Engineering University of Florida, Gainesville Model Evaluation Metrics for Performance Evaluation How to evaluate
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART V Credibility: Evaluating what s been learned 10/25/2000 2 Evaluation: the key to success How
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART V Credibility: Evaluating what s been learned 10/25/2000 2 Evaluation: the key to success How
Cross-validation for detecting and preventing overfitting
 Cross-validation for detecting and preventing overfitting Note to other teachers and users of these slides. Andrew would be delighted if ou found this source material useful in giving our own lectures.
Cross-validation for detecting and preventing overfitting Note to other teachers and users of these slides. Andrew would be delighted if ou found this source material useful in giving our own lectures.
Cross-validation for detecting and preventing overfitting
 Cross-validation for detecting and preventing overfitting Note to other teachers and users of these slides. Andrew would be delighted if ou found this source material useful in giving our own lectures.
Cross-validation for detecting and preventing overfitting Note to other teachers and users of these slides. Andrew would be delighted if ou found this source material useful in giving our own lectures.
Nonparametric Methods Recap
 Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
Nonparametric Methods Recap Aarti Singh Machine Learning 10-701/15-781 Oct 4, 2010 Nonparametric Methods Kernel Density estimate (also Histogram) Weighted frequency Classification - K-NN Classifier Majority
COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18. Lecture 6: k-nn Cross-validation Regularization
 SS18. Lecture 6: k-nn Cross-validation Regularization") COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 6: k-nn Cross-validation Regularization LEARNING METHODS Lazy vs eager learning Eager learning generalizes training data before
COMPUTATIONAL INTELLIGENCE SEW (INTRODUCTION TO MACHINE LEARNING) SS18 Lecture 6: k-nn Cross-validation Regularization LEARNING METHODS Lazy vs eager learning Eager learning generalizes training data before
Evaluating Classifiers
 Evaluating Classifiers Charles Elkan elkan@cs.ucsd.edu January 18, 2011 In a real-world application of supervised learning, we have a training set of examples with labels, and a test set of examples with
Evaluating Classifiers Charles Elkan elkan@cs.ucsd.edu January 18, 2011 In a real-world application of supervised learning, we have a training set of examples with labels, and a test set of examples with
Model Complexity and Generalization
 HT2015: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Generalization Learning Curves Underfit Generalization
HT2015: SC4 Statistical Data Mining and Machine Learning Dino Sejdinovic Department of Statistics Oxford http://www.stats.ox.ac.uk/~sejdinov/sdmml.html Generalization Learning Curves Underfit Generalization
CS435 Introduction to Big Data Spring 2018 Colorado State University. 3/21/2018 Week 10-B Sangmi Lee Pallickara. FAQs. Collaborative filtering
 W10.B.0.0 CS435 Introduction to Big Data W10.B.1 FAQs Term project 5:00PM March 29, 2018 PA2 Recitation: Friday PART 1. LARGE SCALE DATA AALYTICS 4. RECOMMEDATIO SYSTEMS 5. EVALUATIO AD VALIDATIO TECHIQUES
W10.B.0.0 CS435 Introduction to Big Data W10.B.1 FAQs Term project 5:00PM March 29, 2018 PA2 Recitation: Friday PART 1. LARGE SCALE DATA AALYTICS 4. RECOMMEDATIO SYSTEMS 5. EVALUATIO AD VALIDATIO TECHIQUES
2017 ITRON EFG Meeting. Abdul Razack. Specialist, Load Forecasting NV Energy
 2017 ITRON EFG Meeting Abdul Razack Specialist, Load Forecasting NV Energy Topics 1. Concepts 2. Model (Variable) Selection Methods 3. Cross- Validation 4. Cross-Validation: Time Series 5. Example 1 6.
2017 ITRON EFG Meeting Abdul Razack Specialist, Load Forecasting NV Energy Topics 1. Concepts 2. Model (Variable) Selection Methods 3. Cross- Validation 4. Cross-Validation: Time Series 5. Example 1 6.
Regularization and model selection
 CS229 Lecture notes Andrew Ng Part VI Regularization and model selection Suppose we are trying select among several different models for a learning problem. For instance, we might be using a polynomial
CS229 Lecture notes Andrew Ng Part VI Regularization and model selection Suppose we are trying select among several different models for a learning problem. For instance, we might be using a polynomial
Simple Model Selection Cross Validation Regularization Neural Networks
 Neural Nets: Many possible refs e.g., Mitchell Chapter 4 Simple Model Selection Cross Validation Regularization Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February
Neural Nets: Many possible refs e.g., Mitchell Chapter 4 Simple Model Selection Cross Validation Regularization Neural Networks Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February
CPSC 340: Machine Learning and Data Mining
 CPSC 340: Machine Learning and Data Mining Fundamentals of learning (continued) and the k-nearest neighbours classifier Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart.
CPSC 340: Machine Learning and Data Mining Fundamentals of learning (continued) and the k-nearest neighbours classifier Original version of these slides by Mark Schmidt, with modifications by Mike Gelbart.
Data Mining: Classifier Evaluation. CSCI-B490 Seminar in Computer Science (Data Mining)
") Data Mining: Classifier Evaluation CSCI-B490 Seminar in Computer Science (Data Mining) Predictor Evaluation 1. Question: how good is our algorithm? how will we estimate its performance? 2. Question: what
Data Mining: Classifier Evaluation CSCI-B490 Seminar in Computer Science (Data Mining) Predictor Evaluation 1. Question: how good is our algorithm? how will we estimate its performance? 2. Question: what
Model validation T , , Heli Hiisilä
 Model validation T-61.6040, 03.10.2006, Heli Hiisilä Testing Neural Models: How to Use Re-Sampling Techniques? A. Lendasse & Fast bootstrap methodology for model selection, A. Lendasse, G. Simon, V. Wertz,
Model validation T-61.6040, 03.10.2006, Heli Hiisilä Testing Neural Models: How to Use Re-Sampling Techniques? A. Lendasse & Fast bootstrap methodology for model selection, A. Lendasse, G. Simon, V. Wertz,
CSE 446 Bias-Variance & Naïve Bayes
 CSE 446 Bias-Variance & Naïve Bayes Administrative Homework 1 due next week on Friday Good to finish early Homework 2 is out on Monday Check the course calendar Start early (midterm is right before Homework
CSE 446 Bias-Variance & Naïve Bayes Administrative Homework 1 due next week on Friday Good to finish early Homework 2 is out on Monday Check the course calendar Start early (midterm is right before Homework
The Basics of Decision Trees
 Tree-based Methods Here we describe tree-based methods for regression and classification. These involve stratifying or segmenting the predictor space into a number of simple regions. Since the set of splitting
Tree-based Methods Here we describe tree-based methods for regression and classification. These involve stratifying or segmenting the predictor space into a number of simple regions. Since the set of splitting
I211: Information infrastructure II
 Data Mining: Classifier Evaluation I211: Information infrastructure II 3-nearest neighbor labeled data find class labels for the 4 data points 1 0 0 6 0 0 0 5 17 1.7 1 1 4 1 7.1 1 1 1 0.4 1 2 1 3.0 0 0.1
Data Mining: Classifier Evaluation I211: Information infrastructure II 3-nearest neighbor labeled data find class labels for the 4 data points 1 0 0 6 0 0 0 5 17 1.7 1 1 4 1 7.1 1 1 1 0.4 1 2 1 3.0 0 0.1
Boosting Simple Model Selection Cross Validation Regularization
 Boosting: (Linked from class website) Schapire 01 Boosting Simple Model Selection Cross Validation Regularization Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 8 th,
Boosting: (Linked from class website) Schapire 01 Boosting Simple Model Selection Cross Validation Regularization Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University February 8 th,
Algorithms: Decision Trees
 Algorithms: Decision Trees A small dataset: Miles Per Gallon Suppose we want to predict MPG From the UCI repository A Decision Stump Recursion Step Records in which cylinders = 4 Records in which cylinders
Algorithms: Decision Trees A small dataset: Miles Per Gallon Suppose we want to predict MPG From the UCI repository A Decision Stump Recursion Step Records in which cylinders = 4 Records in which cylinders
Data Mining Lecture 8: Decision Trees
 Data Mining Lecture 8: Decision Trees Jo Houghton ECS Southampton March 8, 2019 1 / 30 Decision Trees - Introduction A decision tree is like a flow chart. E. g. I need to buy a new car Can I afford it?
Data Mining Lecture 8: Decision Trees Jo Houghton ECS Southampton March 8, 2019 1 / 30 Decision Trees - Introduction A decision tree is like a flow chart. E. g. I need to buy a new car Can I afford it?
10601 Machine Learning. Model and feature selection
 10601 Machine Learning Model and feature selection Model selection issues We have seen some of this before Selecting features (or basis functions) Logistic regression SVMs Selecting parameter value Prior
10601 Machine Learning Model and feature selection Model selection issues We have seen some of this before Selecting features (or basis functions) Logistic regression SVMs Selecting parameter value Prior
Model Assessment and Selection. Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer
 Model Assessment and Selection Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 Model Training data Testing data Model Testing error rate Training error
Model Assessment and Selection Reference: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, J. Friedman, Springer 1 Model Training data Testing data Model Testing error rate Training error
CS249: ADVANCED DATA MINING
 CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
CS249: ADVANCED DATA MINING Classification Evaluation and Practical Issues Instructor: Yizhou Sun yzsun@cs.ucla.edu April 24, 2017 Homework 2 out Announcements Due May 3 rd (11:59pm) Course project proposal
IOM 530: Intro. to Statistical Learning 1 RESAMPLING METHODS. Chapter 05
 IOM 530: Intro. to Statistical Learning 1 RESAMPLING METHODS Chapter 05 IOM 530: Intro. to Statistical Learning 2 Outline Cross Validation The Validation Set Approach Leave-One-Out Cross Validation K-fold
IOM 530: Intro. to Statistical Learning 1 RESAMPLING METHODS Chapter 05 IOM 530: Intro. to Statistical Learning 2 Outline Cross Validation The Validation Set Approach Leave-One-Out Cross Validation K-fold
Evaluating Machine-Learning Methods. Goals for the lecture
 Evaluating Machine-Learning Methods Mark Craven and David Page Computer Sciences 760 Spring 2018 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from
Evaluating Machine-Learning Methods Mark Craven and David Page Computer Sciences 760 Spring 2018 www.biostat.wisc.edu/~craven/cs760/ Some of the slides in these lectures have been adapted/borrowed from
Overfitting. Machine Learning CSE546 Carlos Guestrin University of Washington. October 2, Bias-Variance Tradeoff
 Overfitting Machine Learning CSE546 Carlos Guestrin University of Washington October 2, 2013 1 Bias-Variance Tradeoff Choice of hypothesis class introduces learning bias More complex class less bias More
Overfitting Machine Learning CSE546 Carlos Guestrin University of Washington October 2, 2013 1 Bias-Variance Tradeoff Choice of hypothesis class introduces learning bias More complex class less bias More
Principles of Machine Learning
 Principles of Machine Learning Lab 3 Improving Machine Learning Models Overview In this lab you will explore techniques for improving and evaluating the performance of machine learning models. You will
Principles of Machine Learning Lab 3 Improving Machine Learning Models Overview In this lab you will explore techniques for improving and evaluating the performance of machine learning models. You will
CPSC 340: Machine Learning and Data Mining. Probabilistic Classification Fall 2017
 CPSC 340: Machine Learning and Data Mining Probabilistic Classification Fall 2017 Admin Assignment 0 is due tonight: you should be almost done. 1 late day to hand it in Monday, 2 late days for Wednesday.
CPSC 340: Machine Learning and Data Mining Probabilistic Classification Fall 2017 Admin Assignment 0 is due tonight: you should be almost done. 1 late day to hand it in Monday, 2 late days for Wednesday.
Sample 1. Dataset Distribution F Sample 2. Real world Distribution F. Sample k
 can not be emphasized enough that no claim whatsoever is It made in this paper that all algorithms are equivalent in being in the real world. In particular, no claim is being made practice, one should
can not be emphasized enough that no claim whatsoever is It made in this paper that all algorithms are equivalent in being in the real world. In particular, no claim is being made practice, one should
Boosting Simple Model Selection Cross Validation Regularization. October 3 rd, 2007 Carlos Guestrin [Schapire, 1989]
![Boosting Simple Model Selection Cross Validation Regularization. October 3 rd, 2007 Carlos Guestrin [Schapire, 1989]](/thumbs/85/91370094.jpg "Boosting Simple Model Selection Cross Validation Regularization. October 3 rd, 2007 Carlos Guestrin [Schapire, 1989]") Boosting Simple Model Selection Cross Validation Regularization Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 3 rd, 2007 1 Boosting [Schapire, 1989] Idea: given a weak
Boosting Simple Model Selection Cross Validation Regularization Machine Learning 10701/15781 Carlos Guestrin Carnegie Mellon University October 3 rd, 2007 1 Boosting [Schapire, 1989] Idea: given a weak
Naïve Bayes Classification. Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others
 Naïve Bayes Classification Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others Things We d Like to Do Spam Classification Given an email, predict
Naïve Bayes Classification Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others Things We d Like to Do Spam Classification Given an email, predict
Lecture 3: Linear Classification
 Lecture 3: Linear Classification Roger Grosse 1 Introduction Last week, we saw an example of a learning task called regression. There, the goal was to predict a scalar-valued target from a set of features.
Lecture 3: Linear Classification Roger Grosse 1 Introduction Last week, we saw an example of a learning task called regression. There, the goal was to predict a scalar-valued target from a set of features.
Tree-based methods for classification and regression
 Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
Tree-based methods for classification and regression Ryan Tibshirani Data Mining: 36-462/36-662 April 11 2013 Optional reading: ISL 8.1, ESL 9.2 1 Tree-based methods Tree-based based methods for predicting
Lecture 7. Memory Management
 Lecture 7 Memory Management 1 Lecture Contents 1. Memory Management Requirements 2. Memory Partitioning 3. Paging 4. Segmentation 2 Memory Memory is an array of words or bytes, each with its own address.
Lecture 7 Memory Management 1 Lecture Contents 1. Memory Management Requirements 2. Memory Partitioning 3. Paging 4. Segmentation 2 Memory Memory is an array of words or bytes, each with its own address.
Leveling Up as a Data Scientist. ds/2014/10/level-up-ds.jpg
 Model Optimization Leveling Up as a Data Scientist http://shorelinechurch.org/wp-content/uploa ds/2014/10/level-up-ds.jpg Bias and Variance Error = (expected loss of accuracy) 2 + flexibility of model
Model Optimization Leveling Up as a Data Scientist http://shorelinechurch.org/wp-content/uploa ds/2014/10/level-up-ds.jpg Bias and Variance Error = (expected loss of accuracy) 2 + flexibility of model
Naïve Bayes Classification. Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others
 Naïve Bayes Classification Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others Things We d Like to Do Spam Classification Given an email, predict
Naïve Bayes Classification Material borrowed from Jonathan Huang and I. H. Witten s and E. Frank s Data Mining and Jeremy Wyatt and others Things We d Like to Do Spam Classification Given an email, predict
Evaluating Machine Learning Methods: Part 1
 Evaluating Machine Learning Methods: Part 1 CS 760@UW-Madison Goals for the lecture you should understand the following concepts bias of an estimator learning curves stratified sampling cross validation
Evaluating Machine Learning Methods: Part 1 CS 760@UW-Madison Goals for the lecture you should understand the following concepts bias of an estimator learning curves stratified sampling cross validation
More on Neural Networks. Read Chapter 5 in the text by Bishop, except omit Sections 5.3.3, 5.3.4, 5.4, 5.5.4, 5.5.5, 5.5.6, 5.5.7, and 5.
 More on Neural Networks Read Chapter 5 in the text by Bishop, except omit Sections 5.3.3, 5.3.4, 5.4, 5.5.4, 5.5.5, 5.5.6, 5.5.7, and 5.6 Recall the MLP Training Example From Last Lecture log likelihood
More on Neural Networks Read Chapter 5 in the text by Bishop, except omit Sections 5.3.3, 5.3.4, 5.4, 5.5.4, 5.5.5, 5.5.6, 5.5.7, and 5.6 Recall the MLP Training Example From Last Lecture log likelihood
Metrics for Performance Evaluation How to evaluate the performance of a model? Methods for Performance Evaluation How to obtain reliable estimates?
 Model Evaluation Metrics for Performance Evaluation How to evaluate the performance of a model? Methods for Performance Evaluation How to obtain reliable estimates? Methods for Model Comparison How to
Model Evaluation Metrics for Performance Evaluation How to evaluate the performance of a model? Methods for Performance Evaluation How to obtain reliable estimates? Methods for Model Comparison How to
Classification. Instructor: Wei Ding
 Classification Part II Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1 Practical Issues of Classification Underfitting and Overfitting Missing Values Costs of Classification
Classification Part II Instructor: Wei Ding Tan,Steinbach, Kumar Introduction to Data Mining 4/18/004 1 Practical Issues of Classification Underfitting and Overfitting Missing Values Costs of Classification
Random Forests and Boosting
 Random Forests and Boosting Tree-based methods are simple and useful for interpretation. However they typically are not competitive with the best supervised learning approaches in terms of prediction accuracy.
Random Forests and Boosting Tree-based methods are simple and useful for interpretation. However they typically are not competitive with the best supervised learning approaches in terms of prediction accuracy.
Model selection and validation 1: Cross-validation
 Model selection and validation 1: Cross-validation Ryan Tibshirani Data Mining: 36-462/36-662 March 26 2013 Optional reading: ISL 2.2, 5.1, ESL 7.4, 7.10 1 Reminder: modern regression techniques Over the
Model selection and validation 1: Cross-validation Ryan Tibshirani Data Mining: 36-462/36-662 March 26 2013 Optional reading: ISL 2.2, 5.1, ESL 7.4, 7.10 1 Reminder: modern regression techniques Over the
CSC411/2515 Tutorial: K-NN and Decision Tree
 CSC411/2515 Tutorial: K-NN and Decision Tree Mengye Ren csc{411,2515}ta@cs.toronto.edu September 25, 2016 Cross-validation K-nearest-neighbours Decision Trees Review: Motivation for Validation Framework:
CSC411/2515 Tutorial: K-NN and Decision Tree Mengye Ren csc{411,2515}ta@cs.toronto.edu September 25, 2016 Cross-validation K-nearest-neighbours Decision Trees Review: Motivation for Validation Framework:
Cross-validation and the Bootstrap
 Cross-validation and the Bootstrap In the section we discuss two resampling methods: cross-validation and the bootstrap. These methods refit a model of interest to samples formed from the training set,
Cross-validation and the Bootstrap In the section we discuss two resampling methods: cross-validation and the bootstrap. These methods refit a model of interest to samples formed from the training set,
3 Virtual attribute subsetting
 3 Virtual attribute subsetting Portions of this chapter were previously presented at the 19 th Australian Joint Conference on Artificial Intelligence (Horton et al., 2006). Virtual attribute subsetting
3 Virtual attribute subsetting Portions of this chapter were previously presented at the 19 th Australian Joint Conference on Artificial Intelligence (Horton et al., 2006). Virtual attribute subsetting
Operating Systems 2230
 Operating Systems 2230 Computer Science & Software Engineering Lecture 6: Memory Management Allocating Primary Memory to Processes The important task of allocating memory to processes, and efficiently
Operating Systems 2230 Computer Science & Software Engineering Lecture 6: Memory Management Allocating Primary Memory to Processes The important task of allocating memory to processes, and efficiently
CSE446: Linear Regression. Spring 2017
 CSE446: Linear Regression Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Prediction of continuous variables Billionaire says: Wait, that s not what I meant! You say: Chill
CSE446: Linear Regression Spring 2017 Ali Farhadi Slides adapted from Carlos Guestrin and Luke Zettlemoyer Prediction of continuous variables Billionaire says: Wait, that s not what I meant! You say: Chill
Machine Learning: An Applied Econometric Approach Online Appendix
 Machine Learning: An Applied Econometric Approach Online Appendix Sendhil Mullainathan mullain@fas.harvard.edu Jann Spiess jspiess@fas.harvard.edu April 2017 A How We Predict In this section, we detail
Machine Learning: An Applied Econometric Approach Online Appendix Sendhil Mullainathan mullain@fas.harvard.edu Jann Spiess jspiess@fas.harvard.edu April 2017 A How We Predict In this section, we detail
Machine Learning Techniques for Data Mining
 Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Machine Learning Techniques for Data Mining Eibe Frank University of Waikato New Zealand 10/25/2000 1 PART VII Moving on: Engineering the input and output 10/25/2000 2 Applying a learner is not all Already
Combine the PA Algorithm with a Proximal Classifier
 Combine the Passive and Aggressive Algorithm with a Proximal Classifier Yuh-Jye Lee Joint work with Y.-C. Tseng Dept. of Computer Science & Information Engineering TaiwanTech. Dept. of Statistics@NCKU
Combine the Passive and Aggressive Algorithm with a Proximal Classifier Yuh-Jye Lee Joint work with Y.-C. Tseng Dept. of Computer Science & Information Engineering TaiwanTech. Dept. of Statistics@NCKU
CS178: Machine Learning and Data Mining. Complexity & Nearest Neighbor Methods
 + CS78: Machine Learning and Data Mining Complexity & Nearest Neighbor Methods Prof. Erik Sudderth Some materials courtesy Alex Ihler & Sameer Singh Machine Learning Complexity and Overfitting Nearest
+ CS78: Machine Learning and Data Mining Complexity & Nearest Neighbor Methods Prof. Erik Sudderth Some materials courtesy Alex Ihler & Sameer Singh Machine Learning Complexity and Overfitting Nearest
Slides for Data Mining by I. H. Witten and E. Frank
 Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
Slides for Data Mining by I. H. Witten and E. Frank 7 Engineering the input and output Attribute selection Scheme-independent, scheme-specific Attribute discretization Unsupervised, supervised, error-
1.1 The Real Number System
 1.1 The Real Number System Contents: Number Lines Absolute Value Definition of a Number Real Numbers Natural Numbers Whole Numbers Integers Rational Numbers Decimals as Fractions Repeating Decimals Rewriting
1.1 The Real Number System Contents: Number Lines Absolute Value Definition of a Number Real Numbers Natural Numbers Whole Numbers Integers Rational Numbers Decimals as Fractions Repeating Decimals Rewriting
PARAMETER OPTIMIZATION FOR AUTOMATED SIGNAL ANALYSIS FOR CONDITION MONITORING OF AIRCRAFT SYSTEMS. Mike Gerdes 1, Dieter Scholz 1
 AST 2011 Workshop on Aviation System Technology PARAMETER OPTIMIZATION FOR AUTOMATED SIGNAL ANALYSIS FOR CONDITION MONITORING OF AIRCRAFT SYSTEMS Mike Gerdes 1, Dieter Scholz 1 1 Aero - Aircraft Design
AST 2011 Workshop on Aviation System Technology PARAMETER OPTIMIZATION FOR AUTOMATED SIGNAL ANALYSIS FOR CONDITION MONITORING OF AIRCRAFT SYSTEMS Mike Gerdes 1, Dieter Scholz 1 1 Aero - Aircraft Design
Building Classifiers using Bayesian Networks
 Building Classifiers using Bayesian Networks Nir Friedman and Moises Goldszmidt 1997 Presented by Brian Collins and Lukas Seitlinger Paper Summary The Naive Bayes classifier has reasonable performance
Building Classifiers using Bayesian Networks Nir Friedman and Moises Goldszmidt 1997 Presented by Brian Collins and Lukas Seitlinger Paper Summary The Naive Bayes classifier has reasonable performance
What is Learning? CS 343: Artificial Intelligence Machine Learning. Raymond J. Mooney. Problem Solving / Planning / Control.
 What is Learning? CS 343: Artificial Intelligence Machine Learning Herbert Simon: Learning is any process by which a system improves performance from experience. What is the task? Classification Problem
What is Learning? CS 343: Artificial Intelligence Machine Learning Herbert Simon: Learning is any process by which a system improves performance from experience. What is the task? Classification Problem
School of Computer and Information Science
 School of Computer and Information Science CIS Research Placement Report Multiple threads in floating-point sort operations Name: Quang Do Date: 8/6/2012 Supervisor: Grant Wigley Abstract Despite the vast
School of Computer and Information Science CIS Research Placement Report Multiple threads in floating-point sort operations Name: Quang Do Date: 8/6/2012 Supervisor: Grant Wigley Abstract Despite the vast
Tutorial on Machine Learning Tools
 Tutorial on Machine Learning Tools Yanbing Xue Milos Hauskrecht Why do we need these tools? Widely deployed classical models No need to code from scratch Easy-to-use GUI Outline Matlab Apps Weka 3 UI TensorFlow
Tutorial on Machine Learning Tools Yanbing Xue Milos Hauskrecht Why do we need these tools? Widely deployed classical models No need to code from scratch Easy-to-use GUI Outline Matlab Apps Weka 3 UI TensorFlow
Tutorial Case studies
 1 Topic Wrapper for feature subset selection Continuation. This tutorial is the continuation of the preceding one about the wrapper feature selection in the supervised learning context (http://data-mining-tutorials.blogspot.com/2010/03/wrapper-forfeature-selection.html).
1 Topic Wrapper for feature subset selection Continuation. This tutorial is the continuation of the preceding one about the wrapper feature selection in the supervised learning context (http://data-mining-tutorials.blogspot.com/2010/03/wrapper-forfeature-selection.html).
LECTURE 12: LINEAR MODEL SELECTION PT. 3. October 23, 2017 SDS 293: Machine Learning
 LECTURE 12: LINEAR MODEL SELECTION PT. 3 October 23, 2017 SDS 293: Machine Learning Announcements 1/2 Presentation of the CS Major & Minors TODAY @ lunch Ford 240 FREE FOOD! Announcements 2/2 CS Internship
LECTURE 12: LINEAR MODEL SELECTION PT. 3 October 23, 2017 SDS 293: Machine Learning Announcements 1/2 Presentation of the CS Major & Minors TODAY @ lunch Ford 240 FREE FOOD! Announcements 2/2 CS Internship
CS 584 Data Mining. Classification 3
 CS 584 Data Mining Classification 3 Today Model evaluation & related concepts Additional classifiers Naïve Bayes classifier Support Vector Machine Ensemble methods 2 Model Evaluation Metrics for Performance
CS 584 Data Mining Classification 3 Today Model evaluation & related concepts Additional classifiers Naïve Bayes classifier Support Vector Machine Ensemble methods 2 Model Evaluation Metrics for Performance
OVERVIEW & RECAP COLE OTT MILESTONE WRITEUP GENERALIZABLE IMAGE ANALOGIES FOCUS
 COLE OTT MILESTONE WRITEUP GENERALIZABLE IMAGE ANALOGIES OVERVIEW & RECAP FOCUS The goal of my project is to use existing image analogies research in order to learn filters between images. SIMPLIFYING
COLE OTT MILESTONE WRITEUP GENERALIZABLE IMAGE ANALOGIES OVERVIEW & RECAP FOCUS The goal of my project is to use existing image analogies research in order to learn filters between images. SIMPLIFYING
Natural Language Processing CS 6320 Lecture 6 Neural Language Models. Instructor: Sanda Harabagiu
 Natural Language Processing CS 6320 Lecture 6 Neural Language Models Instructor: Sanda Harabagiu In this lecture We shall cover: Deep Neural Models for Natural Language Processing Introduce Feed Forward
Natural Language Processing CS 6320 Lecture 6 Neural Language Models Instructor: Sanda Harabagiu In this lecture We shall cover: Deep Neural Models for Natural Language Processing Introduce Feed Forward
Using Genetic Algorithms to Solve the Box Stacking Problem
 Using Genetic Algorithms to Solve the Box Stacking Problem Jenniffer Estrada, Kris Lee, Ryan Edgar October 7th, 2010 Abstract The box stacking or strip stacking problem is exceedingly difficult to solve
Using Genetic Algorithms to Solve the Box Stacking Problem Jenniffer Estrada, Kris Lee, Ryan Edgar October 7th, 2010 Abstract The box stacking or strip stacking problem is exceedingly difficult to solve
Hyperparameter optimization. CS6787 Lecture 6 Fall 2017
 Hyperparameter optimization CS6787 Lecture 6 Fall 2017 Review We ve covered many methods Stochastic gradient descent Step size/learning rate, how long to run Mini-batching Batch size Momentum Momentum
Hyperparameter optimization CS6787 Lecture 6 Fall 2017 Review We ve covered many methods Stochastic gradient descent Step size/learning rate, how long to run Mini-batching Batch size Momentum Momentum
RAID SEMINAR REPORT /09/2004 Asha.P.M NO: 612 S7 ECE
 RAID SEMINAR REPORT 2004 Submitted on: Submitted by: 24/09/2004 Asha.P.M NO: 612 S7 ECE CONTENTS 1. Introduction 1 2. The array and RAID controller concept 2 2.1. Mirroring 3 2.2. Parity 5 2.3. Error correcting
RAID SEMINAR REPORT 2004 Submitted on: Submitted by: 24/09/2004 Asha.P.M NO: 612 S7 ECE CONTENTS 1. Introduction 1 2. The array and RAID controller concept 2 2.1. Mirroring 3 2.2. Parity 5 2.3. Error correcting
CITS4009 Introduction to Data Science
 School of Computer Science and Software Engineering CITS4009 Introduction to Data Science SEMESTER 2, 2017: CHAPTER 4 MANAGING DATA 1 Chapter Objectives Fixing data quality problems Organizing your data
School of Computer Science and Software Engineering CITS4009 Introduction to Data Science SEMESTER 2, 2017: CHAPTER 4 MANAGING DATA 1 Chapter Objectives Fixing data quality problems Organizing your data
The Problem of Overfitting with Maximum Likelihood
 The Problem of Overfitting with Maximum Likelihood In the previous example, continuing training to find the absolute maximum of the likelihood produced overfitted results. The effect is much bigger if
The Problem of Overfitting with Maximum Likelihood In the previous example, continuing training to find the absolute maximum of the likelihood produced overfitted results. The effect is much bigger if
7. Decision or classification trees
 7. Decision or classification trees Next we are going to consider a rather different approach from those presented so far to machine learning that use one of the most common and important data structure,
7. Decision or classification trees Next we are going to consider a rather different approach from those presented so far to machine learning that use one of the most common and important data structure,
Statistics: Normal Distribution, Sampling, Function Fitting & Regression Analysis (Grade 12) *
 *") OpenStax-CNX module: m39305 1 Statistics: Normal Distribution, Sampling, Function Fitting & Regression Analysis (Grade 12) * Free High School Science Texts Project This work is produced by OpenStax-CNX
OpenStax-CNX module: m39305 1 Statistics: Normal Distribution, Sampling, Function Fitting & Regression Analysis (Grade 12) * Free High School Science Texts Project This work is produced by OpenStax-CNX
Four equations are necessary to evaluate these coefficients. Eqn
 1.2 Splines 11 A spline function is a piecewise defined function with certain smoothness conditions [Cheney]. A wide variety of functions is potentially possible; polynomial functions are almost exclusively
1.2 Splines 11 A spline function is a piecewise defined function with certain smoothness conditions [Cheney]. A wide variety of functions is potentially possible; polynomial functions are almost exclusively
Random Search Report An objective look at random search performance for 4 problem sets
 Random Search Report An objective look at random search performance for 4 problem sets Dudon Wai Georgia Institute of Technology CS 7641: Machine Learning Atlanta, GA dwai3@gatech.edu Abstract: This report
Random Search Report An objective look at random search performance for 4 problem sets Dudon Wai Georgia Institute of Technology CS 7641: Machine Learning Atlanta, GA dwai3@gatech.edu Abstract: This report
Identifying Important Communications
 Identifying Important Communications Aaron Jaffey ajaffey@stanford.edu Akifumi Kobashi akobashi@stanford.edu Abstract As we move towards a society increasingly dependent on electronic communication, our
Identifying Important Communications Aaron Jaffey ajaffey@stanford.edu Akifumi Kobashi akobashi@stanford.edu Abstract As we move towards a society increasingly dependent on electronic communication, our
A Study for Branch Predictors to Alleviate the Aliasing Problem
 A Study for Branch Predictors to Alleviate the Aliasing Problem Tieling Xie, Robert Evans, and Yul Chu Electrical and Computer Engineering Department Mississippi State University chu@ece.msstate.edu Abstract
A Study for Branch Predictors to Alleviate the Aliasing Problem Tieling Xie, Robert Evans, and Yul Chu Electrical and Computer Engineering Department Mississippi State University chu@ece.msstate.edu Abstract
Cross-validation and the Bootstrap
 Cross-validation and the Bootstrap In the section we discuss two resampling methods: cross-validation and the bootstrap. 1/44 Cross-validation and the Bootstrap In the section we discuss two resampling
Cross-validation and the Bootstrap In the section we discuss two resampling methods: cross-validation and the bootstrap. 1/44 Cross-validation and the Bootstrap In the section we discuss two resampling
Lecture 25: Review I
 Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
Lecture 25: Review I Reading: Up to chapter 5 in ISLR. STATS 202: Data mining and analysis Jonathan Taylor 1 / 18 Unsupervised learning In unsupervised learning, all the variables are on equal standing,
10 Classification: Evaluation
 CSE4334/5334 Data Mining 10 Classification: Evaluation Chengkai Li Department of Computer Science and Engineering University of Texas at Arlington Fall 2018 (Slides courtesy of Pang-Ning Tan, Michael Steinbach
CSE4334/5334 Data Mining 10 Classification: Evaluation Chengkai Li Department of Computer Science and Engineering University of Texas at Arlington Fall 2018 (Slides courtesy of Pang-Ning Tan, Michael Steinbach
Big Data Methods. Chapter 5: Machine learning. Big Data Methods, Chapter 5, Slide 1
 Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Big Data Methods Chapter 5: Machine learning Big Data Methods, Chapter 5, Slide 1 5.1 Introduction to machine learning What is machine learning? Concerned with the study and development of algorithms that
Lecture 13: Model selection and regularization
 Lecture 13: Model selection and regularization Reading: Sections 6.1-6.2.1 STATS 202: Data mining and analysis October 23, 2017 1 / 17 What do we know so far In linear regression, adding predictors always
Lecture 13: Model selection and regularization Reading: Sections 6.1-6.2.1 STATS 202: Data mining and analysis October 23, 2017 1 / 17 What do we know so far In linear regression, adding predictors always
CS 31: Intro to Systems Caching. Kevin Webb Swarthmore College March 24, 2015
 CS 3: Intro to Systems Caching Kevin Webb Swarthmore College March 24, 205 Reading Quiz Abstraction Goal Reality: There is no one type of memory to rule them all! Abstraction: hide the complex/undesirable
CS 3: Intro to Systems Caching Kevin Webb Swarthmore College March 24, 205 Reading Quiz Abstraction Goal Reality: There is no one type of memory to rule them all! Abstraction: hide the complex/undesirable
Random Forest A. Fornaser
 Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Random Forest A. Fornaser alberto.fornaser@unitn.it Sources Lecture 15: decision trees, information theory and random forests, Dr. Richard E. Turner Trees and Random Forests, Adele Cutler, Utah State University
Ranking Clustered Data with Pairwise Comparisons
 Ranking Clustered Data with Pairwise Comparisons Alisa Maas ajmaas@cs.wisc.edu 1. INTRODUCTION 1.1 Background Machine learning often relies heavily on being able to rank the relative fitness of instances
Ranking Clustered Data with Pairwise Comparisons Alisa Maas ajmaas@cs.wisc.edu 1. INTRODUCTION 1.1 Background Machine learning often relies heavily on being able to rank the relative fitness of instances