Cultural Event Recognition by Subregion Classification with Convolutional Neural Network
|
|
|
- Melinda Dorsey
- 5 years ago
- Views:
Transcription
1 Cultural Event Recognition by Subregion Classification with Convolutional Neural Network Sungheon Park and Nojun Kwak Graduate School of CST, Seoul National University Seoul, Korea Abstract In this paper, a novel cultural event classification algorithm based on convolutional neural networks is proposed. The proposed method firstly extracts regions that contain meaningful information. Then, convolutional neural networks are trained to classify the extracted regions. The final classification of a scene is performed by combining the classification results of each extracted region of the scene probabilistically. Compared to the state-of-the-art methods for classifying Chalearn Looking at People cultural event recognition database, the proposed methods shows competitive results. 1. Introduction Image classification or scene classification is one of the basic tasks in computer vision, and they have drew a lot of attention in recent years. In particular, performance of object detection and classification has been increased significantly in accordance with recent advances on deep learning. While most datasets for object detection or classification such as ImageNet challenge [14] focus on dealing with different kinds of objects, it is also important to classify scenes which contain similar objects common in different scenes. Especially, recognizing and classifying scenes which include people is useful in order to understand cultural characteristics or human behaviors. Chalearn Cultural event classification challenge [1] aims to understand scenes that can be seen at various cultural events throughout the world. The dataset consists of 50 cultural events around the world with about 11,000 images, most of which contain people. Since many images contain similar objects, it is important to find discriminative characteristics of cultural events, for example, garments or makeup of people at the events. It can be expected that these discriminant characteristics will only appear in specific regions of images and that the rest non-specific areas of the images appear com- Input image Find region proposals Region classification Classification of input image Figure 1: Overview of the proposed algorithm. After finding region proposals from an image, each region proposal is classified by CNN. Then, the final classification of an image is calculated by combining the region classification results. monly in multiple events. Following this rationale, we propose a method that classifies an image by gathering subregion classification results. Figure 1 illustrates the classification process of our method. Rather than classifying the whole input image, we detect regions of the image with different sizes and classify those regions individually using convolutional neural networks (CNN). In our experiments, the CNNs are trained successfully without exploiting pre-
2 trained weights. Then, the class probabilities of each region are gathered together to produce the final output for the query image. The proposed framework can be applied not only to the cultural event recognition, but also to any other scene classification problems. Despite the simplicity of our approach, the performance of the proposed algorithm is competitive with those of the top-tier methods in the challenge. 2. Related work Recent advances in deep neural networks boosted the performance of image classification problems. Since the work of Krizhevsky et al. [10], CNN has received wide attention, and many different structures are proposed to improve classification accuracy [7, 17, 18]. Classification using CNN can also be applied to object detection. Unlike classification of an image, object detection needs to locate the object in the input image. To locate an object in an image, classification algorithm should be applied to all the possible subregions of the image. Girshick et al. [6] reduced the search space of the subregions by extracting region proposals from images. The idea of region proposal is adopted in our framework for a different purpose. Cultural event recognition can be regarded as a category of scene classification. SUN database [21] and MIT67 dataset [13] are examples of scene classification datasets which cover various scenes of different categories. There are mainly two approaches for scene classification. The first approach is to exploit Bag-of-Features(BoF) representation [2]. The classification performance can be improved when BoF model is combined with spatial pyramid matching [11] or its variants [22]. The second approach is to classify scenes through CNN. Donahue et al. [4] extracted features from pre-trained CNN and used the features for the scene classification. In [9], spatio-temporal information is learned by extending a CNN in time domain to classify videos. This method is also applied to human action recognition. While human action recognition or pose estimation has drew lots of attention [3, 5, 19], recognizing cultural event from a single image has been rarely studied. In addition, while the previous scene classification datasets contain images of wide area, some of the images in the cultural event classification dataset contain a closeup of people or specific objects. Each cultural event has its own distinctive characteristics, which can be garments, pose of human, eventspecific objects such as beer glasses, or other semantic features. Rather than extracting those information explicitly, we trained CNN with training examples to learn the discriminant features automatically. 3. CNN with region proposals In the images of cultural events, there are regions that distinguish one event from the others. In other words, visual characteristics of a cultural event appear only on the subregions of the image. For instance, images of Oktoberfest contain beer glasses, and images of Sendfest contain lots of sand textures. The motivation of our method is that training and testing with only the discriminant regions will improve the accuracy of the classification. However, it is hard to locate the regions that contain key information of the image. Inspired by [6], we extract region proposals which are candidates of the distinctive regions for cultural event recognition. We will refer to the extracted region proposals as image regions in the paper. The image regions are subimage of the original image whose size and location are defined by a rectangular box. The details of our algorithm is explained in the following subsections Extracting region proposals To extract distinctive and meaningful regions from an image, the extracted regions should be repetitively detected and need to be robust to scale or rotation variations. Though we have no idea of which features are discriminant for cultural event recognition, we expect that the discriminant features are in the object levels. For these reasons, we used [20] to obtain the region proposals which is also used in [6] for object detection tasks. As in [20], possible object locations are extracted via selective search which combines an exhaustive search and segmentation. From the extracted candidate regions, we exclude the ones that is too small (regions whose width or height is less than 10% of the original image) and too tall or fat regions (regions whose width/height ratio is grater than 2 or less than 0.5). After the exclusion step, approximately 200 to 300 image regions are extracted from one image. Data augmentation is another advantage of region proposal extraction. It is able to generate over one million training examples from the thousands of training images, which is sufficient to train our deep CNN Structure of CNN Using the patches extracted in Section 3.1, CNN is trained to classify each patch. The structure of our CNN is illustrated in Figure 2. As shown in the figure, our model consists of 3 convolutional layers, each of which is followed by the corresponding pooling layers (3 pooling layers), and 2 fully connected layers. The filter size of each convolutional layer is 5 5, 3 3, and 3 3 respectively, and the number of filters for each convolutional layer is 96, 128, and 128 respectively. First convolutional layer is applied on the input image with stride of 2, and images in the second and third layers are padded with 1 on both sides before applying convolution. All pooling layers pool over 3 3 regions with stride of 2. Hence, there are overlapping regions
3 Convolution 5 5 Pooling 2 2 Convolution 3 3 Pooling 2 2 Convolution 3 3 Pooling 2 2 Output 129 Input image(rgb) 63 maps 3 maps 3 maps 15 maps 15 maps 7 maps 2048 Fully connected 2048 Fully connected 50 Figure 2: Structures of CNN. Filters at the first convolutional layer is applied with stride of 2, and images at the second and third layers are padded with 1 pixel. Dropout is applied to fully connected layers. for each pooling kernel. There are two fully connected layers, each of which has 2,048 nodes. In the fully connected layers, dropout [17] is applied to improve generalization performance. Rectified Linear Unit(ReLU) is used as the activation function of the network. Finally, softmax classifier is applied on the last layer, where the cross entropy is used as a loss of the model [12]. Caffe framework [8] is used to implement, train, and test our model. Each image region is resized to , and the resized region is randomly cropped to size. In practice, random cropping during the training prevents overfitting and allows robustness on the small translation [10, 15]. The image region is cropped at the center during the testing. The cropped images is fed to the CNN as an input after mean subtraction. Considering number of images in the training set, number of filters for each layer is adjusted to approximately half the size of the model of [10]. Recently, CNN with small filter size showed promising results [16], so we used relatively small filter size in the convolutional layers. The proposed CNN is able to classify the training examples efficiently without pre-training step Training and testing CNN The Chalearn cultural recognition database has 5,875 training, 2,332 validation, and 3,569 test images, respectively. During the validation phase, only the training set is used for training CNN, while both training and validation sets are used to train CNN in the test phase. The number of regions extracted is 1,558,815 for train sets, 624,629 for validation sets, and 951,738 for test sets, respectively. During the training, the cost function is minimized by stochastic gradient descent method with learning rate of 0.01, momentum of 0.9, and weight-decay of The minimization process is performed for 250,000 iterations with mini batch size of 128, which corresponds to around 20 epochs when using only the training set and around 15 epochs when using both the training and validation sets. It took 16 to 17 hours to train the CNN on a single desktop PC with 24GB RAM and GeForce Titan Black GPU. Testing is applied for every extracted region through the trained CNN. Therefore, class probabilities are assigned for each region, and the assigned class probabilities of regions from the same image is gathered together to produce the final prediction of the image. The method how to predict the final probabilities of an image is explained in the next section. 4. Classification of an image 4.1. Rejecting high entropy regions Before gathering the classification results of each region, the image regions whose class probability distribution have high entropy are discarded. The entropy of probability distribution X =[x 1,,x C ] is calculated as H(X) = C P(x i )lnp(x i ), (1) i=1 where C is the number of classes and x i is the probability that the region belongs to class i. Note that the maximum entropy for the cultural event recognition database is about 3.9 since there are 50 classes. The threshold is determined as 2.5 by testing on the validation set, which is fixed for the whole experiments in this paper. The regions that have high entropy values are considered to contain not much discriminant information, and they are not used for classification of the input image Combining the classification probabilities of image regions Several simple schemes are tested for the classification of an image from the class probabilities of each region of the image.
4 Mean of probabilities: As the simplest approach, the class probabilities of an input image can be calculated as the average class probabilities of all the subregions. Hence, the probabilities of each class for the input image x is assigned as N P(class = c r i ) i=1 P(class = c x) =, (2) N where r i is an image region (i = 1, 2,...,N), N is the number of image regions from the input image x, and c is the class for cultural events. Weighted sum of probabilities: This scheme weights the image regions that cover large areas of the input image. The underlying intuition for this scheme is that large regions may contain more information than smaller regions. The area, or the number of pixels, of the image region is used as the weight. Then, the calculated weighted sum is normalized as in the following equation, P(class = c x) = N area(r i )P(class = c r i ) i=1, (3) C N area(r i )P(class = c r i ) c=1 i=1 where area(r i ) denotes the area of the image region r i. Maximum probabilities count: This method counts the label that has maximum probability for each image region. The probability for each class is calculated as N I(argmax P(class = k r i )=c) i=1 k P(class = c x) =, N (4) where I( ) is the indicator function which takes on zero (miss) or one (hit). Hence, this method ignores the probability distribution of each region, and only the label that has maximum probability contributes to the classification. 5. Experimental results In the Chalearn cultural event recognition challenge, performance is measured in terms of mean average precision (map). map is calculated as the average area under the precision-recall curve for each class. The map of our method on validation set using various prediction schemes in Section 4.2 is shown in Table 1. The three methods are abbreviated as mean, weighted sum, and counting respectively. Whether the entropy thresholding (ET) is applied (w/ ET) or not (w/o ET) is also indicated. All methods outperform the baseline method and show similar performance. The simplest approach, mean of the probabilities, shows best result among the three. The performance of mean of probabilities with ET is slightly better than without it, but the difference is marginal. Method map Mean w/ ET Mean w/o ET Weighted sum w/ ET Counting w/ ET Baseline method [1] Table 1: Mean average precision on the validation set Method Top-1 acc. Top-5 acc. Image region w/o ET 43.0% 68.2% Image region w/ ET 50.7% 75.1% Mean w/ ET 69.9% 87.7% Weighted sum w/ ET 69.1% 87.8% Counting w/ ET 69.8% 87.2% Table 2: Classification accuracy on the validation set We also measured the classification accuracy of our methods. Both top-1 accuracy and top-5 accuracy are reported in Table 2. In the table, the first two rows show the average classification accuracy of total 624,629 image regions for the validation set. This accuracy is directly related to the performance of the trained CNN. The image regions with high entropy have little information on the specific cultural event and we can see that the image region classification performance is increased by around 7% by excluding high entropy regions in both top-1 and top-5 accuracies. The lower 3 rows in Table 2 show the image classification performances by combining the class probabilities of each image region as described in Section 4.2. All combining schemes show nearly the same classification accuracy: 69% for the top-1 accuracy and 87% for the top-5 accuracy. Interestingly, image classification accuracy is boosted significantly compared to the image region classification result. Top-1 accuracy is increased by 20% and top-5 accuracy is increased by 12%. Therefore, it can be said that, by classifying multiple subregions from the image and aggregating the results together, the classification accuracy can be boosted. Using the trained CNN, one can find examples of image regions that have high class probability for one class. Figure 3 shows the image regions that have class probability of larger than 0.99 for a specific cultural event. This means that the images in Figure 3 is typical examples of regions that contain distinctive information from the other classes. It can be seen that some images cover wide scenes while others contain closeup of specific objects. Therefore, it can be argued that region extraction in various size influence the performance. Also, by scrutinizing the regions with high probability (or low entropy), the visual characteristics of each cultural event can be easily identified.
5 Team name map MMLAB UPC-STP MIPAL SNU SBU CS MasterBlaster Nyx Table 3: Mean average precision on the test set Lastly, Table 3 shows the mean average precision on the test set, which is the final result of the cultural event recognition challenge. Image regions from both the training and the validation sets are used as training examples. The method used for generating the result of the test set is mean of probabilities with entropy thresholding. The increased performance compared to the result on the validation set can mainly be attributed to the increased number of training image regions. All participants are denoted as their team names, and our method, MIPAL SNU, ranked 3rd among 6 participants. Though our method is inferior to the best method, it has some desirable aspect that it does not require prior knowledge or pre-training. 6. Conclusion In this paper, a cultural event recognition algorithm is proposed based on the extraction of region proposal and convolutional neural networks. The proposed CNN successfully classified training images which are the subregions of images. The classification probabilities of image regions in an image are combined to generate the final image classification result. Our framework is simple, yet powerful enough to achieve the competitive result compared to the other methods of the challenge. Also, due to the generality of the proposed algorithm, it can be applied to any other image classification problems as well as the cultural event recognition. Though simple averaging or counting scheme reasonably improved the classification performance, developing more efficient combining scheme should be considered as a future work. Also, filtering out unnecessary image regions during the training can improve the classification accuracy of the CNN. References [1] X. Baro, J. González, J. Fabian, M. A. Bautista, M. Oliu, I. Guyon, H. J. Escalante, and S. Escalers. Chalearn looking at people 2015 cvpr challenges and results: action spotting and cultural event recognition. In CVPR, ChaLearn Looking at People workshop, , 4 [2] G. Csurka, C. Dance, L. Fan, J. Willamowski, and C. Bray. Visual categorization with bags of keypoints. In Workshop on statistical learning in computer vision, ECCV, volume 1, pages 1 2. Prague, [3] J. Donahue, L. A. Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko, and T. Darrell. Long-term recurrent convolutional networks for visual recognition and description. arxiv preprint arxiv: , [4] J. Donahue, Y. Jia, O. Vinyals, J. Hoffman, N. Zhang, E. Tzeng, and T. Darrell. Decaf: A deep convolutional activation feature for generic visual recognition. arxiv preprint arxiv: , [5] S. Escalera, X. Bar, J. Gonzlez, M. A. Bautista, M. Madadi, M. Reyes, V. Ponce, H. J. Escalante, J. Shotton, and I. Guyon. Chalearn looking at people challenge 2014: Dataset and results. In ECCV Workshops, [6] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages IEEE, [7] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. arxiv preprint arxiv: , [8] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. arxiv preprint arxiv: , [9] A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classification with convolutional neural networks. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages IEEE, [10] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages , , 3 [11] S. Lazebnik, C. Schmid, and J. Ponce. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Computer Vision and Pattern Recognition, 2006 IEEE Computer Society Conference on, volume 2, pages IEEE, [12] K. P. Murphy. Machine learning: a probabilistic perspective. MIT press, [13] A. Quattoni and A. Torralba. Recognizing indoor scenes. In Computer Vision and Pattern Recognition, CVPR IEEE Conference on, pages , June [14] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge, [15] P. Sermanet, D. Eigen, X. Zhang, M. Mathieu, R. Fergus, and Y. LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. arxiv preprint arxiv: , [16] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arxiv preprint arxiv: ,




![[17] N. Srivastava, G.](/docs-images/89/97545584/images/6-4.jpg "Hinton, A. Krizhevsky, I.")



:1929 1958, 2014.")
![2, 3 [18] C. Szegedy, W.](/docs-images/89/97545584/images/6-9.jpg "Liu, Y. Jia, P. Sermanet, S.")



![4842, 2014. 2 [19] A.](/docs-images/89/97545584/images/6-13.jpg "Toshev and C. Szegedy.")








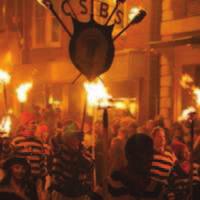


6 Annual Buffalo Basel Fasnacht Chinese New Year Diada de Sant Jordi Lewes Bonfire Figure 3: The examples of image regions that have class probability of larger than 0.99 for each cultural event. [17] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov. Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1): , , 3 [18] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. arxiv preprint arxiv: , [19] A. Toshev and C. Szegedy. Deeppose: Human pose estimation via deep neural networks. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages IEEE, [20] J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition. International journal of computer vision, 104(2): , [21] J. Xiao, K. Ehinger, J. Hays, A. Torralba, and A. Oliva. Sun database: Exploring a large collection of scene categories. International Journal of Computer Vision, pages 1 20, [22] L. Xie, J. Wang, B. Guo, B. Zhang, and Q. Tian. Orientational pyramid matching for recognizing indoor scenes. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages IEEE,
Proceedings of the International MultiConference of Engineers and Computer Scientists 2018 Vol I IMECS 2018, March 14-16, 2018, Hong Kong
 , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
, March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong , March 14-16, 2018, Hong Kong TABLE I CLASSIFICATION ACCURACY OF DIFFERENT PRE-TRAINED MODELS ON THE TEST DATA
Channel Locality Block: A Variant of Squeeze-and-Excitation
 Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
Channel Locality Block: A Variant of Squeeze-and-Excitation 1 st Huayu Li Northern Arizona University Flagstaff, United State Northern Arizona University hl459@nau.edu arxiv:1901.01493v1 [cs.lg] 6 Jan
arxiv: v1 [cs.cv] 5 Oct 2015
![arxiv: v1 [cs.cv] 5 Oct 2015](/thumbs/71/66021937.jpg "arxiv: v1 [cs.cv] 5 Oct 2015") Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
Efficient Object Detection for High Resolution Images Yongxi Lu 1 and Tara Javidi 1 arxiv:1510.01257v1 [cs.cv] 5 Oct 2015 Abstract Efficient generation of high-quality object proposals is an essential
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION
 REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
REGION AVERAGE POOLING FOR CONTEXT-AWARE OBJECT DETECTION Kingsley Kuan 1, Gaurav Manek 1, Jie Lin 1, Yuan Fang 1, Vijay Chandrasekhar 1,2 Institute for Infocomm Research, A*STAR, Singapore 1 Nanyang Technological
Tiny ImageNet Visual Recognition Challenge
 Tiny ImageNet Visual Recognition Challenge Ya Le Department of Statistics Stanford University yle@stanford.edu Xuan Yang Department of Electrical Engineering Stanford University xuany@stanford.edu Abstract
Tiny ImageNet Visual Recognition Challenge Ya Le Department of Statistics Stanford University yle@stanford.edu Xuan Yang Department of Electrical Engineering Stanford University xuany@stanford.edu Abstract
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS. Kuan-Chuan Peng and Tsuhan Chen
 A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
A FRAMEWORK OF EXTRACTING MULTI-SCALE FEATURES USING MULTIPLE CONVOLUTIONAL NEURAL NETWORKS Kuan-Chuan Peng and Tsuhan Chen School of Electrical and Computer Engineering, Cornell University, Ithaca, NY
Deep Neural Networks:
 Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Deep Neural Networks: Part II Convolutional Neural Network (CNN) Yuan-Kai Wang, 2016 Web site of this course: http://pattern-recognition.weebly.com source: CNN for ImageClassification, by S. Lazebnik,
Deep learning for object detection. Slides from Svetlana Lazebnik and many others
 Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Deep learning for object detection Slides from Svetlana Lazebnik and many others Recent developments in object detection 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before deep
Supplementary material for Analyzing Filters Toward Efficient ConvNet
 Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Supplementary material for Analyzing Filters Toward Efficient Net Takumi Kobayashi National Institute of Advanced Industrial Science and Technology, Japan takumi.kobayashi@aist.go.jp A. Orthonormal Steerable
Real-time Object Detection CS 229 Course Project
 Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Real-time Object Detection CS 229 Course Project Zibo Gong 1, Tianchang He 1, and Ziyi Yang 1 1 Department of Electrical Engineering, Stanford University December 17, 2016 Abstract Objection detection
Content-Based Image Recovery
 Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Content-Based Image Recovery Hong-Yu Zhou and Jianxin Wu National Key Laboratory for Novel Software Technology Nanjing University, China zhouhy@lamda.nju.edu.cn wujx2001@nju.edu.cn Abstract. We propose
Robust Scene Classification with Cross-level LLC Coding on CNN Features
 Robust Scene Classification with Cross-level LLC Coding on CNN Features Zequn Jie 1, Shuicheng Yan 2 1 Keio-NUS CUTE Center, National University of Singapore, Singapore 2 Department of Electrical and Computer
Robust Scene Classification with Cross-level LLC Coding on CNN Features Zequn Jie 1, Shuicheng Yan 2 1 Keio-NUS CUTE Center, National University of Singapore, Singapore 2 Department of Electrical and Computer
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition
 Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute of Advanced Industrial Science and Technology (AIST) Tsukuba,
Learning Spatio-Temporal Features with 3D Residual Networks for Action Recognition Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute of Advanced Industrial Science and Technology (AIST) Tsukuba,
In Defense of Fully Connected Layers in Visual Representation Transfer
 In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
In Defense of Fully Connected Layers in Visual Representation Transfer Chen-Lin Zhang, Jian-Hao Luo, Xiu-Shen Wei, Jianxin Wu National Key Laboratory for Novel Software Technology, Nanjing University,
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Convolutional Neural Networks. Computer Vision Jia-Bin Huang, Virginia Tech
 Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Convolutional Neural Networks Computer Vision Jia-Bin Huang, Virginia Tech Today s class Overview Convolutional Neural Network (CNN) Training CNN Understanding and Visualizing CNN Image Categorization:
Multi-Glance Attention Models For Image Classification
 Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
Multi-Glance Attention Models For Image Classification Chinmay Duvedi Stanford University Stanford, CA cduvedi@stanford.edu Pararth Shah Stanford University Stanford, CA pararth@stanford.edu Abstract We
arxiv: v1 [cs.cv] 26 Jun 2017
![arxiv: v1 [cs.cv] 26 Jun 2017](/thumbs/80/82184026.jpg "arxiv: v1 [cs.cv] 26 Jun 2017") Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
Detecting Small Signs from Large Images arxiv:1706.08574v1 [cs.cv] 26 Jun 2017 Zibo Meng, Xiaochuan Fan, Xin Chen, Min Chen and Yan Tong Computer Science and Engineering University of South Carolina, Columbia,
arxiv: v1 [cs.cv] 4 Dec 2014
![arxiv: v1 [cs.cv] 4 Dec 2014](/thumbs/83/87999872.jpg "arxiv: v1 [cs.cv] 4 Dec 2014") Convolutional Neural Networks at Constrained Time Cost Kaiming He Jian Sun Microsoft Research {kahe,jiansun}@microsoft.com arxiv:1412.1710v1 [cs.cv] 4 Dec 2014 Abstract Though recent advanced convolutional
Convolutional Neural Networks at Constrained Time Cost Kaiming He Jian Sun Microsoft Research {kahe,jiansun}@microsoft.com arxiv:1412.1710v1 [cs.cv] 4 Dec 2014 Abstract Though recent advanced convolutional
R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection
 The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18) R-FCN++: Towards Accurate Region-Based Fully Convolutional Networks for Object Detection Zeming Li, 1 Yilun Chen, 2 Gang Yu, 2 Yangdong
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials
 Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials Yuanjun Xiong 1 Kai Zhu 1 Dahua Lin 1 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University
Recognize Complex Events from Static Images by Fusing Deep Channels Supplementary Materials Yuanjun Xiong 1 Kai Zhu 1 Dahua Lin 1 Xiaoou Tang 1,2 1 Department of Information Engineering, The Chinese University
Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset
 Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset Suyash Shetty Manipal Institute of Technology suyash.shashikant@learner.manipal.edu Abstract In
Application of Convolutional Neural Network for Image Classification on Pascal VOC Challenge 2012 dataset Suyash Shetty Manipal Institute of Technology suyash.shashikant@learner.manipal.edu Abstract In
Object Detection Based on Deep Learning
 Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Object Detection Based on Deep Learning Yurii Pashchenko AI Ukraine 2016, Kharkiv, 2016 Image classification (mostly what you ve seen) http://tutorial.caffe.berkeleyvision.org/caffe-cvpr15-detection.pdf
Deep Spatial Pyramid Ensemble for Cultural Event Recognition
 215 IEEE International Conference on Computer Vision Workshops Deep Spatial Pyramid Ensemble for Cultural Event Recognition Xiu-Shen Wei Bin-Bin Gao Jianxin Wu National Key Laboratory for Novel Software
215 IEEE International Conference on Computer Vision Workshops Deep Spatial Pyramid Ensemble for Cultural Event Recognition Xiu-Shen Wei Bin-Bin Gao Jianxin Wu National Key Laboratory for Novel Software
Deep Learning. Visualizing and Understanding Convolutional Networks. Christopher Funk. Pennsylvania State University.
 Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
Visualizing and Understanding Convolutional Networks Christopher Pennsylvania State University February 23, 2015 Some Slide Information taken from Pierre Sermanet (Google) presentation on and Computer
Kaggle Data Science Bowl 2017 Technical Report
 Kaggle Data Science Bowl 2017 Technical Report qfpxfd Team May 11, 2017 1 Team Members Table 1: Team members Name E-Mail University Jia Ding dingjia@pku.edu.cn Peking University, Beijing, China Aoxue Li
Kaggle Data Science Bowl 2017 Technical Report qfpxfd Team May 11, 2017 1 Team Members Table 1: Team members Name E-Mail University Jia Ding dingjia@pku.edu.cn Peking University, Beijing, China Aoxue Li
Video Gesture Recognition with RGB-D-S Data Based on 3D Convolutional Networks
 Video Gesture Recognition with RGB-D-S Data Based on 3D Convolutional Networks August 16, 2016 1 Team details Team name FLiXT Team leader name Yunan Li Team leader address, phone number and email address:
Video Gesture Recognition with RGB-D-S Data Based on 3D Convolutional Networks August 16, 2016 1 Team details Team name FLiXT Team leader name Yunan Li Team leader address, phone number and email address:
KamiNet A Convolutional Neural Network for Tiny ImageNet Challenge
 KamiNet A Convolutional Neural Network for Tiny ImageNet Challenge Shaoming Feng Stanford University superfsm@stanford.edu Liang Shi Stanford University liangs@stanford.edu Abstract In this paper, we address
KamiNet A Convolutional Neural Network for Tiny ImageNet Challenge Shaoming Feng Stanford University superfsm@stanford.edu Liang Shi Stanford University liangs@stanford.edu Abstract In this paper, we address
Part Localization by Exploiting Deep Convolutional Networks
 Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Part Localization by Exploiting Deep Convolutional Networks Marcel Simon, Erik Rodner, and Joachim Denzler Computer Vision Group, Friedrich Schiller University of Jena, Germany www.inf-cv.uni-jena.de Abstract.
Object detection with CNNs
 Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
Object detection with CNNs 80% PASCAL VOC mean0average0precision0(map) 70% 60% 50% 40% 30% 20% 10% Before CNNs After CNNs 0% 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 year Region proposals
3D model classification using convolutional neural network
 3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
3D model classification using convolutional neural network JunYoung Gwak Stanford jgwak@cs.stanford.edu Abstract Our goal is to classify 3D models directly using convolutional neural network. Most of existing
IDENTIFYING PHOTOREALISTIC COMPUTER GRAPHICS USING CONVOLUTIONAL NEURAL NETWORKS
 IDENTIFYING PHOTOREALISTIC COMPUTER GRAPHICS USING CONVOLUTIONAL NEURAL NETWORKS In-Jae Yu, Do-Guk Kim, Jin-Seok Park, Jong-Uk Hou, Sunghee Choi, and Heung-Kyu Lee Korea Advanced Institute of Science and
IDENTIFYING PHOTOREALISTIC COMPUTER GRAPHICS USING CONVOLUTIONAL NEURAL NETWORKS In-Jae Yu, Do-Guk Kim, Jin-Seok Park, Jong-Uk Hou, Sunghee Choi, and Heung-Kyu Lee Korea Advanced Institute of Science and
Deep Learning with Tensorflow AlexNet
 Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
Machine Learning and Computer Vision Group Deep Learning with Tensorflow http://cvml.ist.ac.at/courses/dlwt_w17/ AlexNet Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton, "Imagenet classification
CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015
 CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015 Etienne Gadeski, Hervé Le Borgne, and Adrian Popescu CEA, LIST, Laboratory of Vision and Content Engineering, France
CEA LIST s participation to the Scalable Concept Image Annotation task of ImageCLEF 2015 Etienne Gadeski, Hervé Le Borgne, and Adrian Popescu CEA, LIST, Laboratory of Vision and Content Engineering, France
String distance for automatic image classification
 String distance for automatic image classification Nguyen Hong Thinh*, Le Vu Ha*, Barat Cecile** and Ducottet Christophe** *University of Engineering and Technology, Vietnam National University of HaNoi,
String distance for automatic image classification Nguyen Hong Thinh*, Le Vu Ha*, Barat Cecile** and Ducottet Christophe** *University of Engineering and Technology, Vietnam National University of HaNoi,
Study of Residual Networks for Image Recognition
 Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Study of Residual Networks for Image Recognition Mohammad Sadegh Ebrahimi Stanford University sadegh@stanford.edu Hossein Karkeh Abadi Stanford University hosseink@stanford.edu Abstract Deep neural networks
Elastic Neural Networks for Classification
 Elastic Neural Networks for Classification Yi Zhou 1, Yue Bai 1, Shuvra S. Bhattacharyya 1, 2 and Heikki Huttunen 1 1 Tampere University of Technology, Finland, 2 University of Maryland, USA arxiv:1810.00589v3
Elastic Neural Networks for Classification Yi Zhou 1, Yue Bai 1, Shuvra S. Bhattacharyya 1, 2 and Heikki Huttunen 1 1 Tampere University of Technology, Finland, 2 University of Maryland, USA arxiv:1810.00589v3
HENet: A Highly Efficient Convolutional Neural. Networks Optimized for Accuracy, Speed and Storage
 HENet: A Highly Efficient Convolutional Neural Networks Optimized for Accuracy, Speed and Storage Qiuyu Zhu Shanghai University zhuqiuyu@staff.shu.edu.cn Ruixin Zhang Shanghai University chriszhang96@shu.edu.cn
HENet: A Highly Efficient Convolutional Neural Networks Optimized for Accuracy, Speed and Storage Qiuyu Zhu Shanghai University zhuqiuyu@staff.shu.edu.cn Ruixin Zhang Shanghai University chriszhang96@shu.edu.cn
arxiv: v2 [cs.cv] 23 May 2016
![arxiv: v2 [cs.cv] 23 May 2016](/thumbs/88/115196824.jpg "arxiv: v2 [cs.cv] 23 May 2016") Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition arxiv:1605.06217v2 [cs.cv] 23 May 2016 Xiao Liu Jiang Wang Shilei Wen Errui Ding Yuanqing Lin Baidu Research
Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition arxiv:1605.06217v2 [cs.cv] 23 May 2016 Xiao Liu Jiang Wang Shilei Wen Errui Ding Yuanqing Lin Baidu Research
Comparison of Fine-tuning and Extension Strategies for Deep Convolutional Neural Networks
 Comparison of Fine-tuning and Extension Strategies for Deep Convolutional Neural Networks Nikiforos Pittaras 1, Foteini Markatopoulou 1,2, Vasileios Mezaris 1, and Ioannis Patras 2 1 Information Technologies
Comparison of Fine-tuning and Extension Strategies for Deep Convolutional Neural Networks Nikiforos Pittaras 1, Foteini Markatopoulou 1,2, Vasileios Mezaris 1, and Ioannis Patras 2 1 Information Technologies
arxiv: v1 [cs.cv] 6 Jul 2016
![arxiv: v1 [cs.cv] 6 Jul 2016](/thumbs/80/81416563.jpg "arxiv: v1 [cs.cv] 6 Jul 2016") arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
arxiv:607.079v [cs.cv] 6 Jul 206 Deep CORAL: Correlation Alignment for Deep Domain Adaptation Baochen Sun and Kate Saenko University of Massachusetts Lowell, Boston University Abstract. Deep neural networks
Aggregating Descriptors with Local Gaussian Metrics
 Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Aggregating Descriptors with Local Gaussian Metrics Hideki Nakayama Grad. School of Information Science and Technology The University of Tokyo Tokyo, JAPAN nakayama@ci.i.u-tokyo.ac.jp Abstract Recently,
Convolution Neural Network for Traditional Chinese Calligraphy Recognition
 Convolution Neural Network for Traditional Chinese Calligraphy Recognition Boqi Li Mechanical Engineering Stanford University boqili@stanford.edu Abstract script. Fig. 1 shows examples of the same TCC
Convolution Neural Network for Traditional Chinese Calligraphy Recognition Boqi Li Mechanical Engineering Stanford University boqili@stanford.edu Abstract script. Fig. 1 shows examples of the same TCC
Smart Parking System using Deep Learning. Sheece Gardezi Supervised By: Anoop Cherian Peter Strazdins
 Smart Parking System using Deep Learning Sheece Gardezi Supervised By: Anoop Cherian Peter Strazdins Content Labeling tool Neural Networks Visual Road Map Labeling tool Data set Vgg16 Resnet50 Inception_v3
Smart Parking System using Deep Learning Sheece Gardezi Supervised By: Anoop Cherian Peter Strazdins Content Labeling tool Neural Networks Visual Road Map Labeling tool Data set Vgg16 Resnet50 Inception_v3
arxiv: v1 [cs.cv] 14 Jul 2017
![arxiv: v1 [cs.cv] 14 Jul 2017](/thumbs/74/70463879.jpg "arxiv: v1 [cs.cv] 14 Jul 2017") Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Temporal Modeling Approaches for Large-scale Youtube-8M Video Understanding Fu Li, Chuang Gan, Xiao Liu, Yunlong Bian, Xiang Long, Yandong Li, Zhichao Li, Jie Zhou, Shilei Wen Baidu IDL & Tsinghua University
Faceted Navigation for Browsing Large Video Collection
 Faceted Navigation for Browsing Large Video Collection Zhenxing Zhang, Wei Li, Cathal Gurrin, Alan F. Smeaton Insight Centre for Data Analytics School of Computing, Dublin City University Glasnevin, Co.
Faceted Navigation for Browsing Large Video Collection Zhenxing Zhang, Wei Li, Cathal Gurrin, Alan F. Smeaton Insight Centre for Data Analytics School of Computing, Dublin City University Glasnevin, Co.
Facial Key Points Detection using Deep Convolutional Neural Network - NaimishNet
 1 Facial Key Points Detection using Deep Convolutional Neural Network - NaimishNet Naimish Agarwal, IIIT-Allahabad (irm2013013@iiita.ac.in) Artus Krohn-Grimberghe, University of Paderborn (artus@aisbi.de)
1 Facial Key Points Detection using Deep Convolutional Neural Network - NaimishNet Naimish Agarwal, IIIT-Allahabad (irm2013013@iiita.ac.in) Artus Krohn-Grimberghe, University of Paderborn (artus@aisbi.de)
Industrial Technology Research Institute, Hsinchu, Taiwan, R.O.C ǂ
 Stop Line Detection and Distance Measurement for Road Intersection based on Deep Learning Neural Network Guan-Ting Lin 1, Patrisia Sherryl Santoso *1, Che-Tsung Lin *ǂ, Chia-Chi Tsai and Jiun-In Guo National
Stop Line Detection and Distance Measurement for Road Intersection based on Deep Learning Neural Network Guan-Ting Lin 1, Patrisia Sherryl Santoso *1, Che-Tsung Lin *ǂ, Chia-Chi Tsai and Jiun-In Guo National
Supervised Learning of Classifiers
 Supervised Learning of Classifiers Carlo Tomasi Supervised learning is the problem of computing a function from a feature (or input) space X to an output space Y from a training set T of feature-output
Supervised Learning of Classifiers Carlo Tomasi Supervised learning is the problem of computing a function from a feature (or input) space X to an output space Y from a training set T of feature-output
Groupout: A Way to Regularize Deep Convolutional Neural Network
 Groupout: A Way to Regularize Deep Convolutional Neural Network Eunbyung Park Department of Computer Science University of North Carolina at Chapel Hill eunbyung@cs.unc.edu Abstract Groupout is a new technique
Groupout: A Way to Regularize Deep Convolutional Neural Network Eunbyung Park Department of Computer Science University of North Carolina at Chapel Hill eunbyung@cs.unc.edu Abstract Groupout is a new technique
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Computer Vision Lecture 16 Deep Learning for Object Categorization 14.01.2016 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period
Deconvolutions in Convolutional Neural Networks
 Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Overview Deconvolutions in Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Deconvolutions in CNNs Applications Network visualization
Real Time Monitoring of CCTV Camera Images Using Object Detectors and Scene Classification for Retail and Surveillance Applications
 Real Time Monitoring of CCTV Camera Images Using Object Detectors and Scene Classification for Retail and Surveillance Applications Anand Joshi CS229-Machine Learning, Computer Science, Stanford University,
Real Time Monitoring of CCTV Camera Images Using Object Detectors and Scene Classification for Retail and Surveillance Applications Anand Joshi CS229-Machine Learning, Computer Science, Stanford University,
Neural Networks with Input Specified Thresholds
 Neural Networks with Input Specified Thresholds Fei Liu Stanford University liufei@stanford.edu Junyang Qian Stanford University junyangq@stanford.edu Abstract In this project report, we propose a method
Neural Networks with Input Specified Thresholds Fei Liu Stanford University liufei@stanford.edu Junyang Qian Stanford University junyangq@stanford.edu Abstract In this project report, we propose a method
Visual Inspection of Storm-Water Pipe Systems using Deep Convolutional Neural Networks
 Visual Inspection of Storm-Water Pipe Systems using Deep Convolutional Neural Networks Ruwan Tennakoon, Reza Hoseinnezhad, Huu Tran and Alireza Bab-Hadiashar School of Engineering, RMIT University, Melbourne,
Visual Inspection of Storm-Water Pipe Systems using Deep Convolutional Neural Networks Ruwan Tennakoon, Reza Hoseinnezhad, Huu Tran and Alireza Bab-Hadiashar School of Engineering, RMIT University, Melbourne,
Traffic Multiple Target Detection on YOLOv2
 Traffic Multiple Target Detection on YOLOv2 Junhong Li, Huibin Ge, Ziyang Zhang, Weiqin Wang, Yi Yang Taiyuan University of Technology, Shanxi, 030600, China wangweiqin1609@link.tyut.edu.cn Abstract Background
Traffic Multiple Target Detection on YOLOv2 Junhong Li, Huibin Ge, Ziyang Zhang, Weiqin Wang, Yi Yang Taiyuan University of Technology, Shanxi, 030600, China wangweiqin1609@link.tyut.edu.cn Abstract Background
arxiv: v1 [cs.cv] 26 Jul 2018
![arxiv: v1 [cs.cv] 26 Jul 2018](/thumbs/88/117269915.jpg "arxiv: v1 [cs.cv] 26 Jul 2018") A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
A Better Baseline for AVA Rohit Girdhar João Carreira Carl Doersch Andrew Zisserman DeepMind Carnegie Mellon University University of Oxford arxiv:1807.10066v1 [cs.cv] 26 Jul 2018 Abstract We introduce
Contextual Dropout. Sam Fok. Abstract. 1. Introduction. 2. Background and Related Work
 Contextual Dropout Finding subnets for subtasks Sam Fok samfok@stanford.edu Abstract The feedforward networks widely used in classification are static and have no means for leveraging information about
Contextual Dropout Finding subnets for subtasks Sam Fok samfok@stanford.edu Abstract The feedforward networks widely used in classification are static and have no means for leveraging information about
Structured Prediction using Convolutional Neural Networks
 Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Overview Structured Prediction using Convolutional Neural Networks Bohyung Han bhhan@postech.ac.kr Computer Vision Lab. Convolutional Neural Networks (CNNs) Structured predictions for low level computer
Towards Real-Time Automatic Number Plate. Detection: Dots in the Search Space
 Towards Real-Time Automatic Number Plate Detection: Dots in the Search Space Chi Zhang Department of Computer Science and Technology, Zhejiang University wellyzhangc@zju.edu.cn Abstract Automatic Number
Towards Real-Time Automatic Number Plate Detection: Dots in the Search Space Chi Zhang Department of Computer Science and Technology, Zhejiang University wellyzhangc@zju.edu.cn Abstract Automatic Number
Ryerson University CP8208. Soft Computing and Machine Intelligence. Naive Road-Detection using CNNS. Authors: Sarah Asiri - Domenic Curro
 Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Ryerson University CP8208 Soft Computing and Machine Intelligence Naive Road-Detection using CNNS Authors: Sarah Asiri - Domenic Curro April 24 2016 Contents 1 Abstract 2 2 Introduction 2 3 Motivation
Lecture 5: Object Detection
 Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
Object Detection CSED703R: Deep Learning for Visual Recognition (2017F) Lecture 5: Object Detection Bohyung Han Computer Vision Lab. bhhan@postech.ac.kr 2 Traditional Object Detection Algorithms Region-based
arxiv: v2 [cs.cv] 2 Apr 2018
![arxiv: v2 [cs.cv] 2 Apr 2018](/thumbs/91/106374014.jpg "arxiv: v2 [cs.cv] 2 Apr 2018") Depth of 3D CNNs Depth of 2D CNNs Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet? arxiv:1711.09577v2 [cs.cv] 2 Apr 2018 Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute
Depth of 3D CNNs Depth of 2D CNNs Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet? arxiv:1711.09577v2 [cs.cv] 2 Apr 2018 Kensho Hara, Hirokatsu Kataoka, Yutaka Satoh National Institute
Large-scale gesture recognition based on Multimodal data with C3D and TSN
 Large-scale gesture recognition based on Multimodal data with C3D and TSN July 6, 2017 1 Team details Team name ASU Team leader name Yunan Li Team leader address, phone number and email address: Xidian
Large-scale gesture recognition based on Multimodal data with C3D and TSN July 6, 2017 1 Team details Team name ASU Team leader name Yunan Li Team leader address, phone number and email address: Xidian
CNN BASED REGION PROPOSALS FOR EFFICIENT OBJECT DETECTION. Jawadul H. Bappy and Amit K. Roy-Chowdhury
 CNN BASED REGION PROPOSALS FOR EFFICIENT OBJECT DETECTION Jawadul H. Bappy and Amit K. Roy-Chowdhury Department of Electrical and Computer Engineering, University of California, Riverside, CA 92521 ABSTRACT
CNN BASED REGION PROPOSALS FOR EFFICIENT OBJECT DETECTION Jawadul H. Bappy and Amit K. Roy-Chowdhury Department of Electrical and Computer Engineering, University of California, Riverside, CA 92521 ABSTRACT
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks
 Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
Show, Discriminate, and Tell: A Discriminatory Image Captioning Model with Deep Neural Networks Zelun Luo Department of Computer Science Stanford University zelunluo@stanford.edu Te-Lin Wu Department of
FCHD: A fast and accurate head detector
 JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 FCHD: A fast and accurate head detector Aditya Vora, Johnson Controls Inc. arxiv:1809.08766v2 [cs.cv] 26 Sep 2018 Abstract In this paper, we
JOURNAL OF L A TEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 1 FCHD: A fast and accurate head detector Aditya Vora, Johnson Controls Inc. arxiv:1809.08766v2 [cs.cv] 26 Sep 2018 Abstract In this paper, we
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material
 Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
Volumetric and Multi-View CNNs for Object Classification on 3D Data Supplementary Material Charles R. Qi Hao Su Matthias Nießner Angela Dai Mengyuan Yan Leonidas J. Guibas Stanford University 1. Details
arxiv: v1 [cs.cv] 24 May 2016
![arxiv: v1 [cs.cv] 24 May 2016](/thumbs/80/80473828.jpg "arxiv: v1 [cs.cv] 24 May 2016") Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
Dense CNN Learning with Equivalent Mappings arxiv:1605.07251v1 [cs.cv] 24 May 2016 Jianxin Wu Chen-Wei Xie Jian-Hao Luo National Key Laboratory for Novel Software Technology, Nanjing University 163 Xianlin
CS 1674: Intro to Computer Vision. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh November 16, 2016
 CS 1674: Intro to Computer Vision Neural Networks Prof. Adriana Kovashka University of Pittsburgh November 16, 2016 Announcements Please watch the videos I sent you, if you haven t yet (that s your reading)
CS 1674: Intro to Computer Vision Neural Networks Prof. Adriana Kovashka University of Pittsburgh November 16, 2016 Announcements Please watch the videos I sent you, if you haven t yet (that s your reading)
International Journal of Computer Engineering and Applications, Volume XII, Special Issue, September 18,
 REAL-TIME OBJECT DETECTION WITH CONVOLUTION NEURAL NETWORK USING KERAS Asmita Goswami [1], Lokesh Soni [2 ] Department of Information Technology [1] Jaipur Engineering College and Research Center Jaipur[2]
REAL-TIME OBJECT DETECTION WITH CONVOLUTION NEURAL NETWORK USING KERAS Asmita Goswami [1], Lokesh Soni [2 ] Department of Information Technology [1] Jaipur Engineering College and Research Center Jaipur[2]
arxiv: v1 [cs.cv] 15 Apr 2016
![arxiv: v1 [cs.cv] 15 Apr 2016](/thumbs/89/97852045.jpg "arxiv: v1 [cs.cv] 15 Apr 2016") arxiv:1604.04326v1 [cs.cv] 15 Apr 2016 Improving the Robustness of Deep Neural Networks via Stability Training Stephan Zheng Google, Caltech Yang Song Google Thomas Leung Google Ian Goodfellow Google stzheng@caltech.edu
arxiv:1604.04326v1 [cs.cv] 15 Apr 2016 Improving the Robustness of Deep Neural Networks via Stability Training Stephan Zheng Google, Caltech Yang Song Google Thomas Leung Google Ian Goodfellow Google stzheng@caltech.edu
Deep Learning for Computer Vision II
 IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
IIIT Hyderabad Deep Learning for Computer Vision II C. V. Jawahar Paradigm Shift Feature Extraction (SIFT, HoG, ) Part Models / Encoding Classifier Sparrow Feature Learning Classifier Sparrow L 1 L 2 L
Deep Convolutional Neural Networks for Efficient Pose Estimation in Gesture Videos
 Deep Convolutional Neural Networks for Efficient Pose Estimation in Gesture Videos Tomas Pfister 1, Karen Simonyan 1, James Charles 2 and Andrew Zisserman 1 1 Visual Geometry Group, Department of Engineering
Deep Convolutional Neural Networks for Efficient Pose Estimation in Gesture Videos Tomas Pfister 1, Karen Simonyan 1, James Charles 2 and Andrew Zisserman 1 1 Visual Geometry Group, Department of Engineering
Large-scale Video Classification with Convolutional Neural Networks
 Large-scale Video Classification with Convolutional Neural Networks Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, Li Fei-Fei Note: Slide content mostly from : Bay Area
Large-scale Video Classification with Convolutional Neural Networks Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, Li Fei-Fei Note: Slide content mostly from : Bay Area
Aggregating Frame-level Features for Large-Scale Video Classification
 Aggregating Frame-level Features for Large-Scale Video Classification Shaoxiang Chen 1, Xi Wang 1, Yongyi Tang 2, Xinpeng Chen 3, Zuxuan Wu 1, Yu-Gang Jiang 1 1 Fudan University 2 Sun Yat-Sen University
Aggregating Frame-level Features for Large-Scale Video Classification Shaoxiang Chen 1, Xi Wang 1, Yongyi Tang 2, Xinpeng Chen 3, Zuxuan Wu 1, Yu-Gang Jiang 1 1 Fudan University 2 Sun Yat-Sen University
4D Effect Video Classification with Shot-aware Frame Selection and Deep Neural Networks
 4D Effect Video Classification with Shot-aware Frame Selection and Deep Neural Networks Thomhert S. Siadari 1, Mikyong Han 2, and Hyunjin Yoon 1,2 Korea University of Science and Technology, South Korea
4D Effect Video Classification with Shot-aware Frame Selection and Deep Neural Networks Thomhert S. Siadari 1, Mikyong Han 2, and Hyunjin Yoon 1,2 Korea University of Science and Technology, South Korea
A Torch Library for Action Recognition and Detection Using CNNs and LSTMs
 A Torch Library for Action Recognition and Detection Using CNNs and LSTMs Gary Thung and Helen Jiang Stanford University {gthung, helennn}@stanford.edu Abstract It is very common now to see deep neural
A Torch Library for Action Recognition and Detection Using CNNs and LSTMs Gary Thung and Helen Jiang Stanford University {gthung, helennn}@stanford.edu Abstract It is very common now to see deep neural
DFT-based Transformation Invariant Pooling Layer for Visual Classification
 DFT-based Transformation Invariant Pooling Layer for Visual Classification Jongbin Ryu 1, Ming-Hsuan Yang 2, and Jongwoo Lim 1 1 Hanyang University 2 University of California, Merced Abstract. We propose
DFT-based Transformation Invariant Pooling Layer for Visual Classification Jongbin Ryu 1, Ming-Hsuan Yang 2, and Jongwoo Lim 1 1 Hanyang University 2 University of California, Merced Abstract. We propose
arxiv: v2 [cs.cv] 30 Oct 2018
![arxiv: v2 [cs.cv] 30 Oct 2018](/thumbs/94/118508906.jpg "arxiv: v2 [cs.cv] 30 Oct 2018") Adversarial Noise Layer: Regularize Neural Network By Adding Noise Zhonghui You, Jinmian Ye, Kunming Li, Zenglin Xu, Ping Wang School of Electronics Engineering and Computer Science, Peking University
Adversarial Noise Layer: Regularize Neural Network By Adding Noise Zhonghui You, Jinmian Ye, Kunming Li, Zenglin Xu, Ping Wang School of Electronics Engineering and Computer Science, Peking University
arxiv: v4 [cs.cv] 6 Jul 2016
![arxiv: v4 [cs.cv] 6 Jul 2016](/thumbs/93/112985717.jpg "arxiv: v4 [cs.cv] 6 Jul 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu, C.-C. Jay Kuo (qinhuang@usc.edu) arxiv:1603.09742v4 [cs.cv] 6 Jul 2016 Abstract. Semantic segmentation
arxiv: v1 [cs.cv] 15 Oct 2018
![arxiv: v1 [cs.cv] 15 Oct 2018](/thumbs/89/99052786.jpg "arxiv: v1 [cs.cv] 15 Oct 2018") Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Instance Segmentation and Object Detection with Bounding Shape Masks Ha Young Kim 1,2,*, Ba Rom Kang 2 1 Department of Financial Engineering, Ajou University Worldcupro 206, Yeongtong-gu, Suwon, 16499,
Image Captioning with Object Detection and Localization
 Image Captioning with Object Detection and Localization Zhongliang Yang, Yu-Jin Zhang, Sadaqat ur Rehman, Yongfeng Huang, Department of Electronic Engineering, Tsinghua University, Beijing 100084, China
Image Captioning with Object Detection and Localization Zhongliang Yang, Yu-Jin Zhang, Sadaqat ur Rehman, Yongfeng Huang, Department of Electronic Engineering, Tsinghua University, Beijing 100084, China
3D Densely Convolutional Networks for Volumetric Segmentation. Toan Duc Bui, Jitae Shin, and Taesup Moon
 3D Densely Convolutional Networks for Volumetric Segmentation Toan Duc Bui, Jitae Shin, and Taesup Moon School of Electronic and Electrical Engineering, Sungkyunkwan University, Republic of Korea arxiv:1709.03199v2
3D Densely Convolutional Networks for Volumetric Segmentation Toan Duc Bui, Jitae Shin, and Taesup Moon School of Electronic and Electrical Engineering, Sungkyunkwan University, Republic of Korea arxiv:1709.03199v2
Fast CNN-Based Object Tracking Using Localization Layers and Deep Features Interpolation
 Fast CNN-Based Object Tracking Using Localization Layers and Deep Features Interpolation Al-Hussein A. El-Shafie Faculty of Engineering Cairo University Giza, Egypt elshafie_a@yahoo.com Mohamed Zaki Faculty
Fast CNN-Based Object Tracking Using Localization Layers and Deep Features Interpolation Al-Hussein A. El-Shafie Faculty of Engineering Cairo University Giza, Egypt elshafie_a@yahoo.com Mohamed Zaki Faculty
Finding Tiny Faces Supplementary Materials
 Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
Finding Tiny Faces Supplementary Materials Peiyun Hu, Deva Ramanan Robotics Institute Carnegie Mellon University {peiyunh,deva}@cs.cmu.edu 1. Error analysis Quantitative analysis We plot the distribution
arxiv: v1 [cs.cv] 2 May 2015
![arxiv: v1 [cs.cv] 2 May 2015](/thumbs/75/72350299.jpg "arxiv: v1 [cs.cv] 2 May 2015") Dense Optical Flow Prediction from a Static Image Jacob Walker, Abhinav Gupta, and Martial Hebert Robotics Institute, Carnegie Mellon University {jcwalker, abhinavg, hebert}@cs.cmu.edu arxiv:1505.00295v1
Dense Optical Flow Prediction from a Static Image Jacob Walker, Abhinav Gupta, and Martial Hebert Robotics Institute, Carnegie Mellon University {jcwalker, abhinavg, hebert}@cs.cmu.edu arxiv:1505.00295v1
BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks
 BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks Surat Teerapittayanon Harvard University Email: steerapi@seas.harvard.edu Bradley McDanel Harvard University Email: mcdanel@fas.harvard.edu
BranchyNet: Fast Inference via Early Exiting from Deep Neural Networks Surat Teerapittayanon Harvard University Email: steerapi@seas.harvard.edu Bradley McDanel Harvard University Email: mcdanel@fas.harvard.edu
Deep Learning in Visual Recognition. Thanks Da Zhang for the slides
 Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Deep Learning in Visual Recognition Thanks Da Zhang for the slides Deep Learning is Everywhere 2 Roadmap Introduction Convolutional Neural Network Application Image Classification Object Detection Object
Unified, real-time object detection
 Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
Unified, real-time object detection Final Project Report, Group 02, 8 Nov 2016 Akshat Agarwal (13068), Siddharth Tanwar (13699) CS698N: Recent Advances in Computer Vision, Jul Nov 2016 Instructor: Gaurav
CNNS FROM THE BASICS TO RECENT ADVANCES. Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague
 CNNS FROM THE BASICS TO RECENT ADVANCES Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague ducha.aiki@gmail.com OUTLINE Short review of the CNN design Architecture progress
CNNS FROM THE BASICS TO RECENT ADVANCES Dmytro Mishkin Center for Machine Perception Czech Technical University in Prague ducha.aiki@gmail.com OUTLINE Short review of the CNN design Architecture progress
CS 2750: Machine Learning. Neural Networks. Prof. Adriana Kovashka University of Pittsburgh April 13, 2016
 CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
CS 2750: Machine Learning Neural Networks Prof. Adriana Kovashka University of Pittsburgh April 13, 2016 Plan for today Neural network definition and examples Training neural networks (backprop) Convolutional
arxiv: v1 [cs.cv] 20 Dec 2016
![arxiv: v1 [cs.cv] 20 Dec 2016](/thumbs/73/68905842.jpg "arxiv: v1 [cs.cv] 20 Dec 2016") End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation arxiv:1612.06558v1 [cs.cv] 20 Dec 2016 Heechul Jung heechul@dgist.ac.kr Min-Kook Choi mkchoi@dgist.ac.kr
LARGE-SCALE PERSON RE-IDENTIFICATION AS RETRIEVAL
 LARGE-SCALE PERSON RE-IDENTIFICATION AS RETRIEVAL Hantao Yao 1,2, Shiliang Zhang 3, Dongming Zhang 1, Yongdong Zhang 1,2, Jintao Li 1, Yu Wang 4, Qi Tian 5 1 Key Lab of Intelligent Information Processing
LARGE-SCALE PERSON RE-IDENTIFICATION AS RETRIEVAL Hantao Yao 1,2, Shiliang Zhang 3, Dongming Zhang 1, Yongdong Zhang 1,2, Jintao Li 1, Yu Wang 4, Qi Tian 5 1 Key Lab of Intelligent Information Processing
arxiv: v1 [cs.cv] 4 Jun 2015
![arxiv: v1 [cs.cv] 4 Jun 2015](/thumbs/92/109659580.jpg "arxiv: v1 [cs.cv] 4 Jun 2015") Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks arxiv:1506.01497v1 [cs.cv] 4 Jun 2015 Shaoqing Ren Kaiming He Ross Girshick Jian Sun Microsoft Research {v-shren, kahe, rbg,
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks arxiv:1506.01497v1 [cs.cv] 4 Jun 2015 Shaoqing Ren Kaiming He Ross Girshick Jian Sun Microsoft Research {v-shren, kahe, rbg,
Computer Vision Lecture 16
 Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Announcements Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Seminar registration period starts on Friday We will offer a lab course in the summer semester Deep Robot Learning Topic:
Computer Vision Lecture 16
 Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Computer Vision Lecture 16 Deep Learning Applications 11.01.2017 Bastian Leibe RWTH Aachen http://www.vision.rwth-aachen.de leibe@vision.rwth-aachen.de Announcements Seminar registration period starts
Dense Optical Flow Prediction from a Static Image
 Dense Optical Flow Prediction from a Static Image Jacob Walker, Abhinav Gupta, and Martial Hebert Robotics Institute, Carnegie Mellon University {jcwalker, abhinavg, hebert}@cs.cmu.edu Abstract Given a
Dense Optical Flow Prediction from a Static Image Jacob Walker, Abhinav Gupta, and Martial Hebert Robotics Institute, Carnegie Mellon University {jcwalker, abhinavg, hebert}@cs.cmu.edu Abstract Given a
CSE 559A: Computer Vision
 CSE 559A: Computer Vision Fall 2018: T-R: 11:30-1pm @ Lopata 101 Instructor: Ayan Chakrabarti (ayan@wustl.edu). Course Staff: Zhihao Xia, Charlie Wu, Han Liu http://www.cse.wustl.edu/~ayan/courses/cse559a/
CSE 559A: Computer Vision Fall 2018: T-R: 11:30-1pm @ Lopata 101 Instructor: Ayan Chakrabarti (ayan@wustl.edu). Course Staff: Zhihao Xia, Charlie Wu, Han Liu http://www.cse.wustl.edu/~ayan/courses/cse559a/