More on Experimental Designs
|
|
|
- Claud Thompson
- 5 years ago
- Views:
Transcription
1 Chapter 9 More on Experimental Designs The one and two way Anova designs, completely randomized block design and split plot designs are the building blocks for more complicated designs. Some split plot designs can be written as a linear model, Y = x T β + e, but the errors are dependent with a complicated correlation structure. 9.1 Split Plot Designs Definition 9.1. Split plot designs have two units. The large units are called whole plots and contain blocks of small units called subplots. The whole plots get assigned to Factor A while the subplots get assigned to factor B (randomly if the units are experimental but not randomly if the units are observational). A and B are crossed so the AB interaction can be studied. The split plot design depends on how whole plots are assigned to A. Three common methods are described below, and methods a) and b) are described in more detail in the following subsections. The randomization and split plot Anova table depend on the design used for assigning the whole plots to factor A. a) The whole plots are assigned to A completely at random, as in a one way Anova. b) The whole plots are assigned to A and to a blocking variable as in a completely randomized block design (if the whole plots are experimental, but a complete block design is used if the whole plots are observational). c) The whole plots are assigned to A, torowblocksandtocolumnblocks as in a Latin Square. 311
2 The key feature of a split plot design is that there are two units of different sizes: one size for each of the 2 factors of interest. The larger units are assigned to A. The large units contain blocks of small units assigned to factor B. Also factors A and B are crossed Whole Plots Randomly Assigned to A Shown below is the split plot Anova table when the whole plots are assigned to factor A as in a one way Anova design. The whole plot error is error(w) and can be obtained as an A*replication interaction. The subplot error is error(s). F A = MSA/MSEW, F B = MSB/MSES and F AB = MSAB/MSES. R computes the three test statistics and pvalues correctly, but for SAS F A and the pvalue p A need to be computed using MSA, MSEW, df A and df ew obtained from the Anova table. Sometimes error(w) is also denoted as residuals. There are ma whole plots, and each whole plot contains b subplots. Thus there are mab subplots. Source df SS MS F p-value A a 1 SSA MSA F A p A error(w) or A*repl a(m 1) SSEW MSEW B b 1 SSB MSB F B p B AB (a 1)(b 1) SSAB MSAB F AB p AB residuals or error(s) a(m 1)(b 1) SSES MSES The tests of interest for this split plot design are nearly identical to those of a two way Anova model. Y ijk has i =1,..., a, j =1,..., b and k =1,..., m. Keep A and B in the model if there is an AB interaction. a) The 4 step test for AB interaction is i) Ho there is no interaction H A there is an interaction ii) F AB is obtained from output. iv) If pvalue <δreject Ho and conclude that there is an interaction between A and B, otherwise fail to reject Ho and conclude that there is no interaction between A and B. b) The 4 step test for A main effects is i) Ho µ 100 = = µ a00 H A not Ho ii) F A is obtained from output. 312
3 iv) If pvalue <δreject Ho and conclude that the mean response depends on the level of A, otherwise fail to reject Ho and conclude that the mean response does not depend on the level of A. c) The 4 step test for B main effects is i) Ho µ 010 = = µ 0b0 H A not Ho ii) F B is obtained from output. iv) If pvalue <δreject Ho and conclude that the mean response depends on the level of B, otherwise fail to reject Ho and conclude that the mean response does not depend on the level of B. Source df SS MS F p-value variety MSEW treatment variety*treatment error(s) Example 9.1. This split plot data is from Chambers and Hastie (1993, p. 158). There are 8 varieties of guayule (rubber plant) and 4 treatments were applied to seeds. The response was the rate of germination. The whole plots were greenhouse flats and the subplots were 4 subplots of the flats. Each flat received seeds of one variety (A). Each subplot contained 100 seeds and was treated with one of the treatments (B). There were m = 3 replications so each variety was planted in 3 flats for a total of 24 flats and 4(24) = 96 observations. Factorial crossing: Variety and treatments (A and B) are crossed since all combinations of variety and treatment occur. Hence the AB interaction can be measured. Blocking: The whole plots are the 24 greenhouse flats. Each flat is a block of 4 subplots. Each of the 4 subplots gets one of the 4 treatments. Randomization: The 24 flats are assigned to the 8 varieties completely at random. Use the sample(24) command to generate a random permutation. The first 3 numbers of the permutation get variety one, the next 3 get variety 2,..., the last 3 get variety 8. The use the sample(4) command 24 times, once for each flat. If 2, 4, 1, 3 was the permutation for the ith flat, then the 1st subplot gets treatment 3, the 2nd gets treatment 1, the 3rd gets 313
4 treatment 4, and the 4th subplot gets treatment 2. a) Perform the test corresponding to A. b) Perform the test corresponding to B. c) Perform the test corresponding to AB. Solution: a) Ho µ 100 = = µ 800 Ha not Ho F A =1.232 pval = Fail to reject Ho, the mean rate of germination does not depend on variety. (This test would make more sense if there was no variety * treatment interaction.) b) Ho µ 010 = = µ 040 Ha not Ho F B = pval = 0.00 Reject Ho, the mean rate of germination depends on treatment. c) Ho no interaction Ha there is an interaction F AB =5.15 pval = 0.00 Reject Ho, there is a variety * treatment interaction Whole Plots Assigned to A as in a CRBD Shown below is the split plot Anova table when the whole plots are assigned to factor A and a blocking variable as in a completely randomized block design. The whole plot error is error(w) and can be obtained as an block*a interaction. The subplot error is error(s). F A = MSA/MSEW, F B = MSB/MSES and F AB = MSAB/MSES. Factor A has a levels and factor B has b levels. There are r blocks of a whole plots. Each whole plot contains b subplots, and each block contains a whole plots and thus ab subplots. Hence there are ra whole plots and rab subplots. SAS computes the last two test statistics and pvalues correctly, and the last line of SAS output gives F A and the pvalue p A. The initial line of output for A is not correct. The output for blocks is probably not correct. 314
5 Source df SS MS F p-value blocks r 1 A a 1 SSA MSA F A p A error(w) or block*a (r 1)(a 1) SSEW MSEW B b 1 SSB MSB F B p B AB (a 1)(b 1) SSAB MSAB F AB p AB error(s) a(r 1)(b 1) SSES MSES The tests of interest for this split plot design are nearly identical to those of a two way Anova model. Y ijk has i =1,..., a, j =1,..., b and k =1,..., r. Keep A and B in the model if there is an AB interaction. a) The 4 step test for AB interaction is i) Ho there is no interaction H A there is an interaction ii) F AB is obtained from output. iv) If pvalue <δreject Ho and conclude that there is an interaction between A and B, otherwise fail to reject Ho and conclude that there is no interaction between A and B. b) The 4 step test for A main effects is i) Ho µ 100 = = µ a00 H A not Ho ii) F A is obtained from output. iv) If pvalue <δreject Ho and conclude that the mean response depends on the level of A, otherwise fail to reject Ho and conclude that the mean response does not depend on the level of A. c) The 4 step test for B main effects is i) Ho µ 010 = = µ 0b0 H A not Ho ii) F B is obtained from output. iv) If pvalue <δreject Ho and conclude that the mean response depends on the level of B, otherwise fail to reject Ho and conclude that the mean response does not depend on the level of B. 315
6 Source df SS MS F p-value Block Variety Block*Variety Date Variety*Date error(s) Example 9.2. The Anova table above is for the Snedecor and Cochran (1967, p ) split plot data where the whole plots are assigned to factor A and to blocks in a completely randomized block design. Factor A = variety of alfalfa (ladak, cossack, ranger). Each field had two cuttings, with the second cutting on July 7, Factor B = date of third cutting (none, Sept. 1, Sept. 20, Oct. 7) in The response variable was yield (tons per acre) in The 6 blocks were fields of land divided into 3 plots of land, one for each variety. Each of these 3 plots was divided into 4 subplots for date of third cutting. So each block had 3 whole plots and 12 subplots. a) Perform the test corresponding to A. b) Perform the test corresponding to B. c) Perform the test corresponding to AB. Solution: a) Ho µ 100 = = µ 300 Ha not Ho F A =0.65 pval = Fail to reject Ho, the mean yield does not depend on variety. b) Ho µ 010 = = µ 040 Ha not Ho F B =23.39 pval = 0.0 Reject Ho, the mean yield depends on cutting date. c) Ho no interaction Ha there is an interaction F AB =1.25 pval = Fail to reject Ho, there is no interaction between variety and cutting date. Warning: Although the split plot model can be written as a linear model, the errors are not iid and have a complicated correlation structure. It is also 316
7 difficult to get fitted values and residuals from the software, so the model can t be easily checked with response and residual plots. These facts make the split plot model very hard to use for most researchers. 9.2 Review of the DOE Models The three basic principles of DOE (design of experiments) are i) use randomization to assign treatments to units. ii) Use factorial crossing to compare the effects (main effects, pairwise interactions,..., J-fold interaction) of J 2 factors. If A 1,..., A J are the factors with l i levels for i = 1,..., J; then there are l 1 l 2 l J treatments where each treatment uses exactly one level from each factor. iii) Blocking is used to divide units into blocks of similar units where similar means the units are likely to have similar values of the response when given the same treatment. Within each block randomly assign units to treatments. Next the 10 designs of Chapter 5 to Section 9.1 are summarized. If the randomization can not be done as described, then much stronger assumptions on the data are needed for inference to be approximately correct. There are three common ways of assigning units. For inference i) requires the least assumptions and iii) the most. i) Experimental units are randomly assigned. ii) Observational units are a random sample of units from a population of units. Each combination of levels determines a population. So a two way Anova design has ab populations. iii) Units (such as time slots) can be assigned systematically due to constraints (eg physical, cost or time constraints). I) One way Anova: Factor A has p levels. a) For a fixed effects one way Anova model, the levels are fixed. b) For a random effects one way Anova model, the levels are a random sample from a population of levels. Randomization: Let n = p i=1 m i and do the sample(n) command. Assign the first m 1 units to treatment (level) 1, the next m 2 units to treatment 2,..., the last m p units to treatment p. II) Two way Anova: Factor A has a levels and factor B has b levels. The two factors are crossed, forming ab cells. 317
8 Randomization: Let n = mab and do the sample(n) command. Randomly assign m units to each of the ab cells. Assign the first m units to the (A, B) =(1, 1) cell, the next m units to the (1,2) cell,..., the last m units to the (a, b) cell. III) k way Anova: There are k factors A 1,..., A k with a 1,..., a k levels, respectively. The k factors are crossed, forming k i=1 a i cells. Randomization: Let n = m k i=1 a i and do the sample(n) command. Randomly assign m units to each cell. Each cell is a combination of levels, so the (1, 1,..., 1, 1) cell gets the 1st m units. IV) Completely randomized block design: Factor A has k levels (treatments), and there are b blocks (a blocking variable has b levels) of k units. Randomization: Let n = kb and do the sample(k) command b times. Within each block of k units, randomly assign 1 unit to each treatment. V) Latin squares: Factor A has a levels (treatments), the row blocking variable has a blocks of a units and the column blocking variable has a blocks of a units. There are a 2 units since the row and column blocking variables are crossed. The treatment factor, row blocking variable and column blocking variable are also crossed. A Latin square is such that each of the a treatments occurs once in each row and once in each column. Randomization: Pick an a a Latin square. Use the sample(a) command to assign row levels to numbers 1 to a. Usethesample(a) command to assign column levels to numbers 1 to a. Use the sample(a) command to assign treatment levels to the first a capital letters. If possible, use the sample(a 2 ) command to assign units, 1 unit to each cell of the Latin square. VI) 2 k factorial design: There are k factors, each with 2 levels. Randomization: Let n = m2 k and do the sample(n) command. Randomly assign m units to each cell. Each cell corresponds to a run which is determined by a string of k + s and s corresponding to the k main effects. VII) 2 k f R fractional factorial design: There are k factors, each with 2 levels. Randomization: Let n =2 k f and do the sample(n) command. Randomly assign 1 unit to each run which is determined by a string of k + s and s corresponding to the k main effects. VIII)PlackettBurmanPB(n) design: There are k factors, each with 2 levels. Randomization: Let n =4J for some J. Do the sample(n) command. 318
9 Randomly assign 1 unit to each run which is a string of n 1 + s and s. (Each run corresponds to a row in the design matrix, so we are ignoring the column of 1 s corresponding to I in the design matrix.) IX) Split plot design where the whole plots are assigned to A as in a one way Anova design: The whole plot factor A has a levels and each whole plot is a block of b subplots used to study factor B which has b levels. Split plot designs have two types of units: the whole plots are the larger units and the subplots are the smaller units. Randomization: a) Suppose there are n = ma whole plots. Randomly assign m whole plots to each level of A with the sample(n) command. Assign the first m units (whole plots) to treatment (level) 1, the next m units to treatment 2,..., the last m units to treatment a. b) Do the sample(b) command ma times, once for each whole plot. Within each whole plot, randomly assign 1 subplot (unit) to each of the b levels of B. X) Split plot design where the whole plots are assigned to A and a blocking variable as in a completely randomized block design: The whole plot factor A has a levels and each whole plot is a block of b subplots used to study factor B which has b levels. Split plot designs have two types of units: the whole plots are the larger units and the subplots are the smaller units. There are also r blocks of a whole plots. Each whole plot has b subplots. Thus there are ra whole plots and rab subplots. Randomization: a) Do the sample(a) command r times, once for each block. For each block of a whole plots, randomly assign 1 whole plot to each of the a levels of A. b) Do the sample(b) command ra times, once for each whole plot. Within each whole plot, randomly assign 1 subplot to each of the b levels of B. Try to become familiar with the designs and their randomization so that you can recognize a design given a story problem. Example 9.3. Cobb (1998, p ) describes an experiment on weight gain for baby pigs. The response Y was the average daily weight gain in pounds for each piglet (over a period of time). Factor A consisted of 0 mg of an antibiotic or 40 mg of an antibiotic while factor B consisted of 0 mg of vitamin B12 or 5 mg of B12. Hence there were 4 diets (A, B) = (0,0), (40,0), (0,5) or (40,5). If there were 12 piglets and 3 were randomly assigned to each diet, what type of experimental design was used? 319
10 Solution: A and B are crossed with each combination of (A, B) levels formingadiet.sothetwowayanova(or2 2 factorial) design was used. Example 9.4. In 2008, a PhD student was designing software to analyze a complex image. 100 portions of the image need to be analyzed correctly, and the response variable is the proportion of errors. Sixteen test images are available and thought to be representative. The goal is to achieve an average error rate of less than 0.3 if many images were examined. The student has identified 3 factors to reduce the error rate. Each factor has 2 levels. Thus there are 8 versions of the software that analyze images. The student selects a single test image and runs a 2 3 design with 8 time slots as units. Factor A is active but factors B and C are inert. When A was at the (+) level the error rate was about Briefly explain why this experiment does not give much information about how the software will behave on many images. Solution: More images are needed, 1 image is not enough. (A better design is a completely randomized block design that uses each of the 16 images as a block and factor A = software version with 8 levels. The units for the block are 8 time slots so each of the 8 versions of the software is tested on each test image.) 9.3 Summary 1) The analysis of the response, not that of the residuals, is of primary importance. The response plot can be used to analyze the response in the background of the fitted model. For linear models such as experimental designs, the estimated mean function is the identity line and should be added as a visual aid. 2) Assume that the residual degrees of freedom are large enough for testing. Then the response and residual plots contain much information. Linearity and constant variance may be reasonable if the plotted points scatter about the identity line in a (roughly) evenly populated band. Then the residuals should scatter about the r = 0 line in an evenly populated band. It is easier to check linearity with the response plot and constant variance with the residual plot. Curvature is often easier to see in a residual plot, but the response plot can be used to check whether the curvature is monotone or not. The response plot is more effective for determining whether the signal 320
11 to noise ratio is strong or weak, and for detecting outliers, influential cases or a critical mix. 3) The three basic principles of DOE (design of experiments) are i) use randomization to assign units to treatments. ii) Use factorial crossing to compare the effects (main effects, pairwise interactions,..., J-fold interaction) for J 2 factors. If A 1,..., A J are the factors with l i levels for i =1,..., J; then there are l 1 l 2 l J treatments where each treatment uses exactly one level from each factor. iii) Blocking is used to divide units into blocks of similar units where similar means the units are likely to have similar values of the response when given the same treatment. Within each block randomly assign units to treatments. 4) Split plot designs have two units. The large units are called whole plots and contain blocks of small units called subplots. The whole plots get assigned to Factor A while the subplots get assigned to factor B (randomly if the units are experimental but not randomly if the units are observational). A and B are crossed so the AB interaction can be studied. 5) The split plot design depends on how whole plots are assigned to A. Three common methods are a) the whole plots are assigned to A completely at random, as in a one way Anova, b) the whole plots are assigned to A and to a blocking variable as in a completely randomized block design (if the whole plots are experimental, a complete block design is used if the whole plots are observational), c) the whole plots are assigned to A, to row blocks and to column blocks as in a Latin Square. 6) The split plot Anova table when whole plots are assigned to levels of A as in a one way Anova is shown on the following page. The whole plot error is error(w) and can be obtained as an A*replication interaction. The subplot error is error(s). F A = MSA/MSEW, F B = MSB/MSES and F AB = MSAB/MSES. R computes the three test statistics and pvalues correctly, but for SAS F A and the pvalue p A need to be computed using MSA, MSEW, df A and df ew obtained from the Anova table. 321
12 Source df SS MS F p-value A a 1 SSA MSA F A p A error(w) or A*repl a(m 1) SSEW MSEW B b 1 SSB MSB F B p B AB (a 1)(b 1) SSAB MSAB F AB p AB residuals or error(s) a(m 1)(b 1) SSES MSES 7) The tests of interest corresponding to 6) are nearly identical to those of a two way Anova model. Y ijk has i =1,..., a, j =1,..., b and k =1,..., m. Keep A and B in the model if there is an AB interaction. a) The 4 step test for AB interaction is i) Ho there is no interaction H A there is an interaction ii) F AB is obtained from output. iv) If pvalue <δreject Ho and conclude that there is an interaction between A and B, otherwise fail to reject Ho and conclude that there is no interaction between A and B. b) The 4 step test for A main effects is i) Ho µ 100 = = µ a00 H A not Ho ii) F A is obtained from output. iv) If pvalue <δreject Ho and conclude that the mean response depends on the level of A, otherwise fail to reject Ho and conclude that the mean response does not depend on the level of A. c) The 4 step test for B main effects is i) Ho µ 010 = = µ 0b0 H A not Ho ii) F B is obtained from output. iv) If pvalue <δreject Ho and conclude that the mean response depends on the level of B, otherwise fail to reject Ho and conclude that the mean response does not depend on the level of B. 8) The split plot Anova table when whole plots are assigned to levels of A as in a completely randomized block design is shown on the following page. The whole plot error is error(w) and can be obtained as an block*a interaction. The subplot error is error(s). F A = MSA/MSEW, F B = MSB/MSES and F AB = MSAB/MSES. SAS computes the last two test statistics and pvalues correctly, and the last line of SAS output 322
13 gives F A and the pvalue p A. The initial line of output for A is not correct. The output for blocks is probably not correct. Source df SS MS F p-value blocks r 1 A a 1 SSA MSA F A p A error(w) or block*a (r 1)(a 1) SSEW MSEW B b 1 SSB MSB F B p B AB (a 1)(b 1) SSAB MSAB F AB p AB error(s) a(r 1)(b 1) SSES MSES 9) The tests of interest corresponding to 8) are nearly identical to those of a two way Anova model and point 7). Y ijk has i =1,..., a, j =1,..., b and k =1,..., r. Keep A and B in the model if there is an AB interaction. a) The 4 step test for AB interaction is i) Ho there is no interaction H A there is an interaction ii) F AB is obtained from output. iv) If pvalue <δreject Ho and conclude that there is an interaction between A and B, otherwise fail to reject Ho and conclude that there is no interaction between A and B. b) The 4 step test for A main effects is i) Ho µ 100 = = µ a00 H A not Ho ii) F A is obtained from output. iv) If pvalue <δreject Ho and conclude that the mean response depends on the level of A, otherwise fail to reject Ho and conclude that the mean response does not depend on the level of A. c) The 4 step test for B main effects is i) Ho µ 010 = = µ 0b0 H A not Ho ii) F B is obtained from output. iv) If pvalue <δreject Ho and conclude that the mean response depends on the level of B, otherwise fail to reject Ho and conclude that the mean response does not depend on the level of B. 323
14 9.4 Complements See Robinson, Brenneman and Myers (2009) for a comparison of completely randomized designs, completely randomized block designs and split plot designs. Some history of experimental designs is given by Box (1980, 1984). Also see David (1995, ) and Hahn (1982). The importance of DOE is discussed in Gelman (2005), and a review is given by Steinberg and Hunter (1984). For experiments done as class projects, see Hunter (1977). 9.5 Problems Problems with an asterisk * are especially important. Source df SS MS F p-value Block Method Block*Method Temp Method*Temp error(s) The Anova table above is for the Montgomery (1984, p ) split plot data where the whole plots are assigned to factor A and to blocks in a completely randomized block design. The response variable is tensile strength of paper. Factor A is (preparation) method with 3 levels (1, 2, 3). Factor B is temperature with 4 levels (200, 225, 250, 275). The pilot plant can make 12 runs a day and the experiment is repeated each day, with days as blocks. A batch of pulp is made by one of the 3 preparation methods. Then the batch of pulp is divided into 4 samples, and each sample is cooked at one of the four temperatures. a) Perform the test corresponding to A. b) Perform the test corresponding to B. c) Perform the test corresponding to AB. 324
15 Source df SS MS F p-value Block Nitrogen Block*Nitrogen Thatch Nitrogen*Thatch error(s) The Anova table above is for the Kuehl (1994, p ) split plot data where the whole plots are assigned to factor A and to blocks in a completely randomized block design. The response variable is the average chlorophyll content (mg/gm of turf grass clippings). Factor A is nitrogen fertilizer with 4 levels (1, 2, 3, 4). Factor B is length of time that thatch was allowed to accumulate with 3 levels (2, 5, or 8 years). There were 2 blocks of 4 whole plots to which the levels of Factor A were assigned. The 2 blocks formed a golf green which was seeded with turf grass. The 8 whole plots were plots of golf green. Each whole plot had 3 subplots to which the levels of Factor B were randomly assigned. a) Perform the test corresponding to A. b) Perform the test corresponding to B. c) Perform the test corresponding to AB. Source df SS MS F p-value Block Variety Block*Variety Date Variety*Date error(s) The Anova table above is for the Snedecor and Cochran (1967, p ) split plot data where the whole plots are assigned to factor A and to blocks in a completely randomized block design. Factor A = variety of alfalfa (ladak, cossack, ranger). Each field had two cuttings, with the second cutting on July 7, Factor B = date of third cutting (none, Sept. 1, Sept. 20, Oct. 7) in The response variable was yield (tons per acre) in The 6 blocks were fields of land divided into 3 plots of land, one for 325
16 each variety. Each of these 3 plots was divided into 4 subplots for date of third cutting. So each block had 3 whole plots and 12 subplots. a) Perform the test corresponding to A. b) Perform the test corresponding to B. c) Perform the test corresponding to AB Following Montgomery (1984, p ), suppose the response variable is tensile strength of paper. One factor is (preparation) method with 3 levels (1, 2, 3). Another factor is temperature with 4 levels (200, 225, 250, 275). a) Suppose the pilot plant can make 12 runs a day and the experiment is repeated each day, with days as blocks. A batch of pulp is made by one of the 3 preparation methods. Then the batch of pulp is divided into 4 samples, and each sample is cooked at one of the four temperatures. Which factor, method or temperature is assigned to subplots? b) Suppose the pilot plant could make 36 runs in one day. Suppose that 9 batches of pulp are made, that each batch of pulp is divided into 4 samples, and each sample is cooked at one of the four temperatures. How should the 9 batches be allocated to the three preparation methods and how should the 4 samples be allocated to the four temperatures? c) Suppose the pilot plant can make 36 runs in one day and that the units are 36 batches of material to be made into pulp. Each of the 12 method temperature combinations is to be replicated 3 times. What type of experimental design should be used? (Hint: not a split plot.) 9.5. a) Download ( into R, and type the following commands. Then copy and paste the output into Notepad and print the output. attach(guay) out <- aov(plants~variety*treatment + Error(flats),guay) summary(out) detach(guay) This split plot data is from Chambers and Hastie (1993, p. 158). There are 8 varieties of guayule (rubber plant) and 4 treatments were applied to seeds. The response was the rate of germination. The whole plots were greenhouse flats and the subplots were subplots of the flats. Each flat received 326
17 seeds of one variety (A). Each subplot contained 100 seeds and was treated with one of the treatments (B). There were m = 3 replications so each variety was planted in 3 flats for a total of 24 flats and 4(24) = 96 observations. b) Use the output to test whether the response depends on variety Download ( into R, and type the following commands. Then copy and paste the output into Notepad and print the output. attach(steel) out <- aov(resistance~heat*coating + Error(wplots),steel) summary(out) detach(steel) This split plot steel data is from Box, Hunter and Hunter (2005, p. 336). The whole plots are time slots to use a furnace, which can hold 4 steel bars at one time. Factor A = heat has 3 levels (360, 370, 380 o F). Factor B = coating has 4 levels (4 types of coating: c1, c2, c3 and c4). The response was corrosion resistance. a) Perform the test corresponding to A. b) Perform the test corresponding to B. c) Perform the test corresponding to AB This is the same data as in Problem 9.6, using SAS. Copy and paste the SAS program from ( into SAS, run the program, then print the output. Only include the second page of output. To get the correct F statistic for heat, you need to divide MS heat by MS wplots a) Copy and paste the SAS program from ( into SAS, run the program, then print the output. Only include the second page of output. This data is from the SAS Institute (1985, p ). The B and AB Anova table entries are correct, but the correct entry for A is the last line of output where Block*A is used as the error. b) Perform the test corresponding to A. c) Perform the test corresponding to B. d) Perform the test corresponding to AB. 327
18 9.9. Suppose the response variable is tensile strength of paper. One factor is preparation method with 3 levels (1, 2, 3). Another factor is temperature with 4 levels (200, 225, 250, 275). Suppose the pilot plant can make 36 runs in one day and that the units are 36 batches of material to be made into pulp. Each of the 12 method temperature combinations is to be replicated 3 times. What type of experimental design should be used? 328
Section 4 General Factorial Tutorials
 Section 4 General Factorial Tutorials General Factorial Part One: Categorical Introduction Design-Ease software version 6 offers a General Factorial option on the Factorial tab. If you completed the One
Section 4 General Factorial Tutorials General Factorial Part One: Categorical Introduction Design-Ease software version 6 offers a General Factorial option on the Factorial tab. If you completed the One
Split-Plot General Multilevel-Categoric Factorial Tutorial
 DX10-04-1-SplitPlotGen Rev. 1/27/2016 Split-Plot General Multilevel-Categoric Factorial Tutorial Introduction In some experiment designs you must restrict the randomization. Otherwise it wouldn t be practical
DX10-04-1-SplitPlotGen Rev. 1/27/2016 Split-Plot General Multilevel-Categoric Factorial Tutorial Introduction In some experiment designs you must restrict the randomization. Otherwise it wouldn t be practical
NCSS Statistical Software. Design Generator
 Chapter 268 Introduction This program generates factorial, repeated measures, and split-plots designs with up to ten factors. The design is placed in the current database. Crossed Factors Two factors are
Chapter 268 Introduction This program generates factorial, repeated measures, and split-plots designs with up to ten factors. The design is placed in the current database. Crossed Factors Two factors are
Comparison of Means: The Analysis of Variance: ANOVA
 Comparison of Means: The Analysis of Variance: ANOVA The Analysis of Variance (ANOVA) is one of the most widely used basic statistical techniques in experimental design and data analysis. In contrast to
Comparison of Means: The Analysis of Variance: ANOVA The Analysis of Variance (ANOVA) is one of the most widely used basic statistical techniques in experimental design and data analysis. In contrast to
Multi-Factored Experiments
 Design and Analysis of Multi-Factored Experiments Advanced Designs -Hard to Change Factors- Split-Plot Design and Analysis L. M. Lye DOE Course 1 Hard-to-Change Factors Assume that a factor can be varied,
Design and Analysis of Multi-Factored Experiments Advanced Designs -Hard to Change Factors- Split-Plot Design and Analysis L. M. Lye DOE Course 1 Hard-to-Change Factors Assume that a factor can be varied,
Analysis of Two-Level Designs
 Chapter 213 Analysis of Two-Level Designs Introduction Several analysis programs are provided for the analysis of designed experiments. The GLM-ANOVA and the Multiple Regression programs are often used.
Chapter 213 Analysis of Two-Level Designs Introduction Several analysis programs are provided for the analysis of designed experiments. The GLM-ANOVA and the Multiple Regression programs are often used.
SAS/STAT 13.1 User s Guide. The NESTED Procedure
 SAS/STAT 13.1 User s Guide The NESTED Procedure This document is an individual chapter from SAS/STAT 13.1 User s Guide. The correct bibliographic citation for the complete manual is as follows: SAS Institute
SAS/STAT 13.1 User s Guide The NESTED Procedure This document is an individual chapter from SAS/STAT 13.1 User s Guide. The correct bibliographic citation for the complete manual is as follows: SAS Institute
Recall the expression for the minimum significant difference (w) used in the Tukey fixed-range method for means separation:
 used in the Tukey fixed-range method for means separation:") Topic 11. Unbalanced Designs [ST&D section 9.6, page 219; chapter 18] 11.1 Definition of missing data Accidents often result in loss of data. Crops are destroyed in some plots, plants and animals die,
Topic 11. Unbalanced Designs [ST&D section 9.6, page 219; chapter 18] 11.1 Definition of missing data Accidents often result in loss of data. Crops are destroyed in some plots, plants and animals die,
General Factorial Models
 In Chapter 8 in Oehlert STAT:5201 Week 9 - Lecture 2 1 / 34 It is possible to have many factors in a factorial experiment. In DDD we saw an example of a 3-factor study with ball size, height, and surface
In Chapter 8 in Oehlert STAT:5201 Week 9 - Lecture 2 1 / 34 It is possible to have many factors in a factorial experiment. In DDD we saw an example of a 3-factor study with ball size, height, and surface
Fly wing length data Sokal and Rohlf Box 10.1 Ch13.xls. on chalk board
 Model Based Statistics in Biology. Part IV. The General Linear Model. Multiple Explanatory Variables. Chapter 13.6 Nested Factors (Hierarchical ANOVA ReCap. Part I (Chapters 1,2,3,4), Part II (Ch 5, 6,
Model Based Statistics in Biology. Part IV. The General Linear Model. Multiple Explanatory Variables. Chapter 13.6 Nested Factors (Hierarchical ANOVA ReCap. Part I (Chapters 1,2,3,4), Part II (Ch 5, 6,
RSM Split-Plot Designs & Diagnostics Solve Real-World Problems
 RSM Split-Plot Designs & Diagnostics Solve Real-World Problems Shari Kraber Pat Whitcomb Martin Bezener Stat-Ease, Inc. Stat-Ease, Inc. Stat-Ease, Inc. 221 E. Hennepin Ave. 221 E. Hennepin Ave. 221 E.
RSM Split-Plot Designs & Diagnostics Solve Real-World Problems Shari Kraber Pat Whitcomb Martin Bezener Stat-Ease, Inc. Stat-Ease, Inc. Stat-Ease, Inc. 221 E. Hennepin Ave. 221 E. Hennepin Ave. 221 E.
The NESTED Procedure (Chapter)
") SAS/STAT 9.3 User s Guide The NESTED Procedure (Chapter) SAS Documentation This document is an individual chapter from SAS/STAT 9.3 User s Guide. The correct bibliographic citation for the complete manual
SAS/STAT 9.3 User s Guide The NESTED Procedure (Chapter) SAS Documentation This document is an individual chapter from SAS/STAT 9.3 User s Guide. The correct bibliographic citation for the complete manual
General Factorial Models
 In Chapter 8 in Oehlert STAT:5201 Week 9 - Lecture 1 1 / 31 It is possible to have many factors in a factorial experiment. We saw some three-way factorials earlier in the DDD book (HW 1 with 3 factors:
In Chapter 8 in Oehlert STAT:5201 Week 9 - Lecture 1 1 / 31 It is possible to have many factors in a factorial experiment. We saw some three-way factorials earlier in the DDD book (HW 1 with 3 factors:
R-Square Coeff Var Root MSE y Mean
 STAT:50 Applied Statistics II Exam - Practice 00 possible points. Consider a -factor study where each of the factors has 3 levels. The factors are Diet (,,3) and Drug (A,B,C) and there are n = 3 observations
STAT:50 Applied Statistics II Exam - Practice 00 possible points. Consider a -factor study where each of the factors has 3 levels. The factors are Diet (,,3) and Drug (A,B,C) and there are n = 3 observations
SAS data statements and data: /*Factor A: angle Factor B: geometry Factor C: speed*/
 STAT:5201 Applied Statistic II (Factorial with 3 factors as 2 3 design) Three-way ANOVA (Factorial with three factors) with replication Factor A: angle (low=0/high=1) Factor B: geometry (shape A=0/shape
STAT:5201 Applied Statistic II (Factorial with 3 factors as 2 3 design) Three-way ANOVA (Factorial with three factors) with replication Factor A: angle (low=0/high=1) Factor B: geometry (shape A=0/shape
CHAPTER 3 AN OVERVIEW OF DESIGN OF EXPERIMENTS AND RESPONSE SURFACE METHODOLOGY
 23 CHAPTER 3 AN OVERVIEW OF DESIGN OF EXPERIMENTS AND RESPONSE SURFACE METHODOLOGY 3.1 DESIGN OF EXPERIMENTS Design of experiments is a systematic approach for investigation of a system or process. A series
23 CHAPTER 3 AN OVERVIEW OF DESIGN OF EXPERIMENTS AND RESPONSE SURFACE METHODOLOGY 3.1 DESIGN OF EXPERIMENTS Design of experiments is a systematic approach for investigation of a system or process. A series
EXAMINATIONS OF THE ROYAL STATISTICAL SOCIETY
 EXAMINATIONS OF THE ROYAL STATISTICAL SOCIETY GRADUATE DIPLOMA, 2015 MODULE 4 : Modelling experimental data Time allowed: Three hours Candidates should answer FIVE questions. All questions carry equal
EXAMINATIONS OF THE ROYAL STATISTICAL SOCIETY GRADUATE DIPLOMA, 2015 MODULE 4 : Modelling experimental data Time allowed: Three hours Candidates should answer FIVE questions. All questions carry equal
For our example, we will look at the following factors and factor levels.
 In order to review the calculations that are used to generate the Analysis of Variance, we will use the statapult example. By adjusting various settings on the statapult, you are able to throw the ball
In order to review the calculations that are used to generate the Analysis of Variance, we will use the statapult example. By adjusting various settings on the statapult, you are able to throw the ball
Analysis of variance - ANOVA
 Analysis of variance - ANOVA Based on a book by Julian J. Faraway University of Iceland (UI) Estimation 1 / 50 Anova In ANOVAs all predictors are categorical/qualitative. The original thinking was to try
Analysis of variance - ANOVA Based on a book by Julian J. Faraway University of Iceland (UI) Estimation 1 / 50 Anova In ANOVAs all predictors are categorical/qualitative. The original thinking was to try
Design and Analysis of Experiments Prof. Jhareswar Maiti Department of Industrial and Systems Engineering Indian Institute of Technology, Kharagpur
 Design and Analysis of Experiments Prof. Jhareswar Maiti Department of Industrial and Systems Engineering Indian Institute of Technology, Kharagpur Lecture 59 Fractional Factorial Design using MINITAB
Design and Analysis of Experiments Prof. Jhareswar Maiti Department of Industrial and Systems Engineering Indian Institute of Technology, Kharagpur Lecture 59 Fractional Factorial Design using MINITAB
Lab #9: ANOVA and TUKEY tests
 Lab #9: ANOVA and TUKEY tests Objectives: 1. Column manipulation in SAS 2. Analysis of variance 3. Tukey test 4. Least Significant Difference test 5. Analysis of variance with PROC GLM 6. Levene test for
Lab #9: ANOVA and TUKEY tests Objectives: 1. Column manipulation in SAS 2. Analysis of variance 3. Tukey test 4. Least Significant Difference test 5. Analysis of variance with PROC GLM 6. Levene test for
Sta$s$cs & Experimental Design with R. Barbara Kitchenham Keele University
 Sta$s$cs & Experimental Design with R Barbara Kitchenham Keele University 1 Analysis of Variance Mul$ple groups with Normally distributed data 2 Experimental Design LIST Factors you may be able to control
Sta$s$cs & Experimental Design with R Barbara Kitchenham Keele University 1 Analysis of Variance Mul$ple groups with Normally distributed data 2 Experimental Design LIST Factors you may be able to control
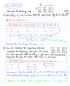 # For the data in problem 5.28 in book # a) Produce the ANOVA Table for the full model (By hand). # b) Make a qqplot of the residuals, and the residuals plots (vs. predicted, # versus factor1, versus factor2,
# For the data in problem 5.28 in book # a) Produce the ANOVA Table for the full model (By hand). # b) Make a qqplot of the residuals, and the residuals plots (vs. predicted, # versus factor1, versus factor2,
D-Optimal Designs. Chapter 888. Introduction. D-Optimal Design Overview
 Chapter 888 Introduction This procedure generates D-optimal designs for multi-factor experiments with both quantitative and qualitative factors. The factors can have a mixed number of levels. For example,
Chapter 888 Introduction This procedure generates D-optimal designs for multi-factor experiments with both quantitative and qualitative factors. The factors can have a mixed number of levels. For example,
One way ANOVA when the data are not normally distributed (The Kruskal-Wallis test).
.") One way ANOVA when the data are not normally distributed (The Kruskal-Wallis test). Suppose you have a one way design, and want to do an ANOVA, but discover that your data are seriously not normal? Just
One way ANOVA when the data are not normally distributed (The Kruskal-Wallis test). Suppose you have a one way design, and want to do an ANOVA, but discover that your data are seriously not normal? Just
One Factor Experiments
 One Factor Experiments 20-1 Overview Computation of Effects Estimating Experimental Errors Allocation of Variation ANOVA Table and F-Test Visual Diagnostic Tests Confidence Intervals For Effects Unequal
One Factor Experiments 20-1 Overview Computation of Effects Estimating Experimental Errors Allocation of Variation ANOVA Table and F-Test Visual Diagnostic Tests Confidence Intervals For Effects Unequal
Data Analysis and Solver Plugins for KSpread USER S MANUAL. Tomasz Maliszewski
 Data Analysis and Solver Plugins for KSpread USER S MANUAL Tomasz Maliszewski tmaliszewski@wp.pl Table of Content CHAPTER 1: INTRODUCTION... 3 1.1. ABOUT DATA ANALYSIS PLUGIN... 3 1.3. ABOUT SOLVER PLUGIN...
Data Analysis and Solver Plugins for KSpread USER S MANUAL Tomasz Maliszewski tmaliszewski@wp.pl Table of Content CHAPTER 1: INTRODUCTION... 3 1.1. ABOUT DATA ANALYSIS PLUGIN... 3 1.3. ABOUT SOLVER PLUGIN...
Unit 5: Estimating with Confidence
 Unit 5: Estimating with Confidence Section 8.3 The Practice of Statistics, 4 th edition For AP* STARNES, YATES, MOORE Unit 5 Estimating with Confidence 8.1 8.2 8.3 Confidence Intervals: The Basics Estimating
Unit 5: Estimating with Confidence Section 8.3 The Practice of Statistics, 4 th edition For AP* STARNES, YATES, MOORE Unit 5 Estimating with Confidence 8.1 8.2 8.3 Confidence Intervals: The Basics Estimating
nag anova factorial (g04cac)
") g04 Analysis of Variance g04cac 1. Purpose nag anova factorial (g04cac) nag anova factorial (g04cac) computes an analysis of variance table and treatment means for a complete factorial design. 2. Specification
g04 Analysis of Variance g04cac 1. Purpose nag anova factorial (g04cac) nag anova factorial (g04cac) computes an analysis of variance table and treatment means for a complete factorial design. 2. Specification
Modeling Effects and Additive Two-Factor Models (i.e. without interaction)
") Modeling Effects and Additive Two-Factor Models (i.e. without interaction) STAT:5201 Week 4: Lecture 3 1 / 16 Modeling & Effects To model the data......to break-down into its component parts....to define
Modeling Effects and Additive Two-Factor Models (i.e. without interaction) STAT:5201 Week 4: Lecture 3 1 / 16 Modeling & Effects To model the data......to break-down into its component parts....to define
DESIGN OF EXPERIMENTS and ROBUST DESIGN
 DESIGN OF EXPERIMENTS and ROBUST DESIGN Problems in design and production environments often require experiments to find a solution. Design of experiments are a collection of statistical methods that,
DESIGN OF EXPERIMENTS and ROBUST DESIGN Problems in design and production environments often require experiments to find a solution. Design of experiments are a collection of statistical methods that,
Chapter 15 Mixed Models. Chapter Table of Contents. Introduction Split Plot Experiment Clustered Data References...
 Chapter 15 Mixed Models Chapter Table of Contents Introduction...309 Split Plot Experiment...311 Clustered Data...320 References...326 308 Chapter 15. Mixed Models Chapter 15 Mixed Models Introduction
Chapter 15 Mixed Models Chapter Table of Contents Introduction...309 Split Plot Experiment...311 Clustered Data...320 References...326 308 Chapter 15. Mixed Models Chapter 15 Mixed Models Introduction
STAT 5200 Handout #25. R-Square & Design Matrix in Mixed Models
 STAT 5200 Handout #25 R-Square & Design Matrix in Mixed Models I. R-Square in Mixed Models (with Example from Handout #20): For mixed models, the concept of R 2 is a little complicated (and neither PROC
STAT 5200 Handout #25 R-Square & Design Matrix in Mixed Models I. R-Square in Mixed Models (with Example from Handout #20): For mixed models, the concept of R 2 is a little complicated (and neither PROC
EFFECT OF CUTTING SPEED, FEED RATE AND DEPTH OF CUT ON SURFACE ROUGHNESS OF MILD STEEL IN TURNING OPERATION
 EFFECT OF CUTTING SPEED, FEED RATE AND DEPTH OF CUT ON SURFACE ROUGHNESS OF MILD STEEL IN TURNING OPERATION Mr. M. G. Rathi1, Ms. Sharda R. Nayse2 1 mgrathi_kumar@yahoo.co.in, 2 nsharda@rediffmail.com
EFFECT OF CUTTING SPEED, FEED RATE AND DEPTH OF CUT ON SURFACE ROUGHNESS OF MILD STEEL IN TURNING OPERATION Mr. M. G. Rathi1, Ms. Sharda R. Nayse2 1 mgrathi_kumar@yahoo.co.in, 2 nsharda@rediffmail.com
Stat 5303 (Oehlert): Split Plots 1
: Split Plots 1") Stat 50 (Oehlert): Split Plots Cmd> print(y,format:"f7.",labels:f) y: More emulsion data. Eight samples of unprocessed gum from acacia senegal trees are obtained. Four samples come from one batch of gum,
Stat 50 (Oehlert): Split Plots Cmd> print(y,format:"f7.",labels:f) y: More emulsion data. Eight samples of unprocessed gum from acacia senegal trees are obtained. Four samples come from one batch of gum,
BIOMETRICS INFORMATION
 BIOMETRICS INFORMATION (You re 95% likely to need this information) PAMPHLET NO. # 57 DATE: September 5, 1997 SUBJECT: Interpreting Main Effects when a Two-way Interaction is Present Interpreting the analysis
BIOMETRICS INFORMATION (You re 95% likely to need this information) PAMPHLET NO. # 57 DATE: September 5, 1997 SUBJECT: Interpreting Main Effects when a Two-way Interaction is Present Interpreting the analysis
Data Management - 50%
 Exam 1: SAS Big Data Preparation, Statistics, and Visual Exploration Data Management - 50% Navigate within the Data Management Studio Interface Register a new QKB Create and connect to a repository Define
Exam 1: SAS Big Data Preparation, Statistics, and Visual Exploration Data Management - 50% Navigate within the Data Management Studio Interface Register a new QKB Create and connect to a repository Define
Math 214 Introductory Statistics Summer Class Notes Sections 3.2, : 1-21 odd 3.3: 7-13, Measures of Central Tendency
 Math 14 Introductory Statistics Summer 008 6-9-08 Class Notes Sections 3, 33 3: 1-1 odd 33: 7-13, 35-39 Measures of Central Tendency odd Notation: Let N be the size of the population, n the size of the
Math 14 Introductory Statistics Summer 008 6-9-08 Class Notes Sections 3, 33 3: 1-1 odd 33: 7-13, 35-39 Measures of Central Tendency odd Notation: Let N be the size of the population, n the size of the
Two-Stage Least Squares
 Chapter 316 Two-Stage Least Squares Introduction This procedure calculates the two-stage least squares (2SLS) estimate. This method is used fit models that include instrumental variables. 2SLS includes
Chapter 316 Two-Stage Least Squares Introduction This procedure calculates the two-stage least squares (2SLS) estimate. This method is used fit models that include instrumental variables. 2SLS includes
Variations on Split Plot and Split Block Experiment Designs
 Variations on Split Plot and Split Block Experiment Designs WALTER T. FEDERER Cornell University Departments of Biological Statistics and Computational Biology and Statistical Sciences Ithaca, NY FREEDOM
Variations on Split Plot and Split Block Experiment Designs WALTER T. FEDERER Cornell University Departments of Biological Statistics and Computational Biology and Statistical Sciences Ithaca, NY FREEDOM
Lab 5 - Risk Analysis, Robustness, and Power
 Type equation here.biology 458 Biometry Lab 5 - Risk Analysis, Robustness, and Power I. Risk Analysis The process of statistical hypothesis testing involves estimating the probability of making errors
Type equation here.biology 458 Biometry Lab 5 - Risk Analysis, Robustness, and Power I. Risk Analysis The process of statistical hypothesis testing involves estimating the probability of making errors
Regression Analysis and Linear Regression Models
 Regression Analysis and Linear Regression Models University of Trento - FBK 2 March, 2015 (UNITN-FBK) Regression Analysis and Linear Regression Models 2 March, 2015 1 / 33 Relationship between numerical
Regression Analysis and Linear Regression Models University of Trento - FBK 2 March, 2015 (UNITN-FBK) Regression Analysis and Linear Regression Models 2 March, 2015 1 / 33 Relationship between numerical
Introductory Applied Statistics: A Variable Approach TI Manual
 Introductory Applied Statistics: A Variable Approach TI Manual John Gabrosek and Paul Stephenson Department of Statistics Grand Valley State University Allendale, MI USA Version 1.1 August 2014 2 Copyright
Introductory Applied Statistics: A Variable Approach TI Manual John Gabrosek and Paul Stephenson Department of Statistics Grand Valley State University Allendale, MI USA Version 1.1 August 2014 2 Copyright
Anova exercise class Sylvain 15th of December 2014
 Anova exercise class Sylvain 15th of December 2014 Organization Question hour: Th. 15.01.2015 from 2 to 3pm in HG G26.3 Exam date (no guarantee): Sat. 31.01.2015 from 9 to 11am (Höngg) Exam review: We.
Anova exercise class Sylvain 15th of December 2014 Organization Question hour: Th. 15.01.2015 from 2 to 3pm in HG G26.3 Exam date (no guarantee): Sat. 31.01.2015 from 9 to 11am (Höngg) Exam review: We.
SAS PROC GLM and PROC MIXED. for Recovering Inter-Effect Information
 SAS PROC GLM and PROC MIXED for Recovering Inter-Effect Information Walter T. Federer Biometrics Unit Cornell University Warren Hall Ithaca, NY -0 biometrics@comell.edu Russell D. Wolfinger SAS Institute
SAS PROC GLM and PROC MIXED for Recovering Inter-Effect Information Walter T. Federer Biometrics Unit Cornell University Warren Hall Ithaca, NY -0 biometrics@comell.edu Russell D. Wolfinger SAS Institute
Source df SS MS F A a-1 [A] [T] SS A. / MS S/A S/A (a)(n-1) [AS] [A] SS S/A. / MS BxS/A A x B (a-1)(b-1) [AB] [A] [B] + [T] SS AxB
![Source df SS MS F A a-1 [A] [T] SS A. / MS S/A S/A (a)(n-1) [AS] [A] SS S/A. / MS BxS/A A x B (a-1)(b-1) [AB] [A] [B] + [T] SS AxB](/thumbs/96/128510119.jpg "Source df SS MS F A a-1 [A] [T] SS A. / MS S/A S/A (a)(n-1) [AS] [A] SS S/A. / MS BxS/A A x B (a-1)(b-1) [AB] [A] [B] + [T] SS AxB") Keppel, G. Design and Analysis: Chapter 17: The Mixed Two-Factor Within-Subjects Design: The Overall Analysis and the Analysis of Main Effects and Simple Effects Keppel describes an Ax(BxS) design, which
Keppel, G. Design and Analysis: Chapter 17: The Mixed Two-Factor Within-Subjects Design: The Overall Analysis and the Analysis of Main Effects and Simple Effects Keppel describes an Ax(BxS) design, which
Statistical Analysis of Metabolomics Data. Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte
 Statistical Analysis of Metabolomics Data Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte Outline Introduction Data pre-treatment 1. Normalization 2. Centering,
Statistical Analysis of Metabolomics Data Xiuxia Du Department of Bioinformatics & Genomics University of North Carolina at Charlotte Outline Introduction Data pre-treatment 1. Normalization 2. Centering,
STAT 2607 REVIEW PROBLEMS Word problems must be answered in words of the problem.
 STAT 2607 REVIEW PROBLEMS 1 REMINDER: On the final exam 1. Word problems must be answered in words of the problem. 2. "Test" means that you must carry out a formal hypothesis testing procedure with H0,
STAT 2607 REVIEW PROBLEMS 1 REMINDER: On the final exam 1. Word problems must be answered in words of the problem. 2. "Test" means that you must carry out a formal hypothesis testing procedure with H0,
Lecture Notes #4: Randomized Block, Latin Square, and Factorials4-1
 Lecture Notes #4: Randomized Block, Latin Square, and Factorials4-1 Richard Gonzalez Psych 613 Version 2.5 (Oct 2016) LECTURE NOTES #4: Randomized Block, Latin Square, and Factorial Designs Reading Assignment
Lecture Notes #4: Randomized Block, Latin Square, and Factorials4-1 Richard Gonzalez Psych 613 Version 2.5 (Oct 2016) LECTURE NOTES #4: Randomized Block, Latin Square, and Factorial Designs Reading Assignment
Statistics Lab #7 ANOVA Part 2 & ANCOVA
 Statistics Lab #7 ANOVA Part 2 & ANCOVA PSYCH 710 7 Initialize R Initialize R by entering the following commands at the prompt. You must type the commands exactly as shown. options(contrasts=c("contr.sum","contr.poly")
Statistics Lab #7 ANOVA Part 2 & ANCOVA PSYCH 710 7 Initialize R Initialize R by entering the following commands at the prompt. You must type the commands exactly as shown. options(contrasts=c("contr.sum","contr.poly")
STATISTICAL MODELLING. Appendix B Randomized layouts and sample size computations in R
 App B 1 STATISTICAL MODELLING Appendix B Randomized layouts and sample size computations in R B.1. Completely randomized design... B-2 B.2. Randomized complete block design... B-3 B.3. Generalized randomized
App B 1 STATISTICAL MODELLING Appendix B Randomized layouts and sample size computations in R B.1. Completely randomized design... B-2 B.2. Randomized complete block design... B-3 B.3. Generalized randomized
CHAPTER 2 DESIGN DEFINITION
 CHAPTER 2 DESIGN DEFINITION Wizard Option The Wizard is a powerful tool available in DOE Wisdom to help with the set-up and analysis of your Screening or Modeling experiment. The Wizard walks you through
CHAPTER 2 DESIGN DEFINITION Wizard Option The Wizard is a powerful tool available in DOE Wisdom to help with the set-up and analysis of your Screening or Modeling experiment. The Wizard walks you through
ST512. Fall Quarter, Exam 1. Directions: Answer questions as directed. Please show work. For true/false questions, circle either true or false.
 ST512 Fall Quarter, 2005 Exam 1 Name: Directions: Answer questions as directed. Please show work. For true/false questions, circle either true or false. 1. (42 points) A random sample of n = 30 NBA basketball
ST512 Fall Quarter, 2005 Exam 1 Name: Directions: Answer questions as directed. Please show work. For true/false questions, circle either true or false. 1. (42 points) A random sample of n = 30 NBA basketball
CREATING THE ANALYSIS
 Chapter 14 Multiple Regression Chapter Table of Contents CREATING THE ANALYSIS...214 ModelInformation...217 SummaryofFit...217 AnalysisofVariance...217 TypeIIITests...218 ParameterEstimates...218 Residuals-by-PredictedPlot...219
Chapter 14 Multiple Regression Chapter Table of Contents CREATING THE ANALYSIS...214 ModelInformation...217 SummaryofFit...217 AnalysisofVariance...217 TypeIIITests...218 ParameterEstimates...218 Residuals-by-PredictedPlot...219
General Multilevel-Categoric Factorial Tutorial
 DX10-02-3-Gen2Factor.docx Rev. 1/27/2016 General Multilevel-Categoric Factorial Tutorial Part 1 Categoric Treatment Introduction A Case Study on Battery Life Design-Expert software version 10 offers a
DX10-02-3-Gen2Factor.docx Rev. 1/27/2016 General Multilevel-Categoric Factorial Tutorial Part 1 Categoric Treatment Introduction A Case Study on Battery Life Design-Expert software version 10 offers a
Computer Experiments. Designs
 Computer Experiments Designs Differences between physical and computer Recall experiments 1. The code is deterministic. There is no random error (measurement error). As a result, no replication is needed.
Computer Experiments Designs Differences between physical and computer Recall experiments 1. The code is deterministic. There is no random error (measurement error). As a result, no replication is needed.
Factorial ANOVA with SAS
 Factorial ANOVA with SAS /* potato305.sas */ options linesize=79 noovp formdlim='_' ; title 'Rotten potatoes'; title2 ''; proc format; value tfmt 1 = 'Cool' 2 = 'Warm'; data spud; infile 'potato2.data'
Factorial ANOVA with SAS /* potato305.sas */ options linesize=79 noovp formdlim='_' ; title 'Rotten potatoes'; title2 ''; proc format; value tfmt 1 = 'Cool' 2 = 'Warm'; data spud; infile 'potato2.data'
Learner Expectations UNIT 1: GRAPICAL AND NUMERIC REPRESENTATIONS OF DATA. Sept. Fathom Lab: Distributions and Best Methods of Display
 CURRICULUM MAP TEMPLATE Priority Standards = Approximately 70% Supporting Standards = Approximately 20% Additional Standards = Approximately 10% HONORS PROBABILITY AND STATISTICS Essential Questions &
CURRICULUM MAP TEMPLATE Priority Standards = Approximately 70% Supporting Standards = Approximately 20% Additional Standards = Approximately 10% HONORS PROBABILITY AND STATISTICS Essential Questions &
2014 Stat-Ease, Inc. All Rights Reserved.
 What s New in Design-Expert version 9 Factorial split plots (Two-Level, Multilevel, Optimal) Definitive Screening and Single Factor designs Journal Feature Design layout Graph Columns Design Evaluation
What s New in Design-Expert version 9 Factorial split plots (Two-Level, Multilevel, Optimal) Definitive Screening and Single Factor designs Journal Feature Design layout Graph Columns Design Evaluation
Resources for statistical assistance. Quantitative covariates and regression analysis. Methods for predicting continuous outcomes.
 Resources for statistical assistance Quantitative covariates and regression analysis Carolyn Taylor Applied Statistics and Data Science Group (ASDa) Department of Statistics, UBC January 24, 2017 Department
Resources for statistical assistance Quantitative covariates and regression analysis Carolyn Taylor Applied Statistics and Data Science Group (ASDa) Department of Statistics, UBC January 24, 2017 Department
Two-Level Designs. Chapter 881. Introduction. Experimental Design. Experimental Design Definitions. Alias. Blocking
 Chapter 881 Introduction This program generates a 2 k factorial design for up to seven factors. It allows the design to be blocked and replicated. The design rows may be output in standard or random order.
Chapter 881 Introduction This program generates a 2 k factorial design for up to seven factors. It allows the design to be blocked and replicated. The design rows may be output in standard or random order.
CCSSM Curriculum Analysis Project Tool 1 Interpreting Functions in Grades 9-12
 Tool 1: Standards for Mathematical ent: Interpreting Functions CCSSM Curriculum Analysis Project Tool 1 Interpreting Functions in Grades 9-12 Name of Reviewer School/District Date Name of Curriculum Materials:
Tool 1: Standards for Mathematical ent: Interpreting Functions CCSSM Curriculum Analysis Project Tool 1 Interpreting Functions in Grades 9-12 Name of Reviewer School/District Date Name of Curriculum Materials:
Stat 5303 (Oehlert): Unreplicated 2-Series Factorials 1
: Unreplicated 2-Series Factorials 1") Stat 5303 (Oehlert): Unreplicated 2-Series Factorials 1 Cmd> a
Stat 5303 (Oehlert): Unreplicated 2-Series Factorials 1 Cmd> a
Causes of spatial variation
 Field Trials Plant breeding trials Laid out in a grid (rows and columns) From few entries (3-5) to many entries (100s) Plots close together are more similar than those far away. Causes of spatial variation
Field Trials Plant breeding trials Laid out in a grid (rows and columns) From few entries (3-5) to many entries (100s) Plots close together are more similar than those far away. Causes of spatial variation
Recall the crossover design set up as a Latin rectangle: Sequence=Subject A B C A B C 3 C A B B C A
 D. More on Crossover Designs: # periods = # trts Recall the crossover design set up as a Latin rectangle: Period Sequence=Subject 1 2 3 4 5 6 1 A B C A B C 2 B C A C A B 3 C A B B C A With one subject
D. More on Crossover Designs: # periods = # trts Recall the crossover design set up as a Latin rectangle: Period Sequence=Subject 1 2 3 4 5 6 1 A B C A B C 2 B C A C A B 3 C A B B C A With one subject
THIS IS NOT REPRESNTATIVE OF CURRENT CLASS MATERIAL. STOR 455 Midterm 1 September 28, 2010
 THIS IS NOT REPRESNTATIVE OF CURRENT CLASS MATERIAL STOR 455 Midterm September 8, INSTRUCTIONS: BOTH THE EXAM AND THE BUBBLE SHEET WILL BE COLLECTED. YOU MUST PRINT YOUR NAME AND SIGN THE HONOR PLEDGE
THIS IS NOT REPRESNTATIVE OF CURRENT CLASS MATERIAL STOR 455 Midterm September 8, INSTRUCTIONS: BOTH THE EXAM AND THE BUBBLE SHEET WILL BE COLLECTED. YOU MUST PRINT YOUR NAME AND SIGN THE HONOR PLEDGE
Chapter 14 Introduction to the FACTEX Procedure
 Chapter 14 Introduction to the FACTEX Procedure Chapter Table of Contents OVERVIEW...429 Features...429 Learning about the FACTEX Procedure...430 GETTING STARTED...431 ExampleofaTwo-LevelFullFactorialDesign...431
Chapter 14 Introduction to the FACTEX Procedure Chapter Table of Contents OVERVIEW...429 Features...429 Learning about the FACTEX Procedure...430 GETTING STARTED...431 ExampleofaTwo-LevelFullFactorialDesign...431
Example 5.25: (page 228) Screenshots from JMP. These examples assume post-hoc analysis using a Protected LSD or Protected Welch strategy.
 Screenshots from JMP. These examples assume post-hoc analysis using a Protected LSD or Protected Welch strategy.") JMP Output from Chapter 5 Factorial Analysis through JMP Example 5.25: (page 228) Screenshots from JMP. These examples assume post-hoc analysis using a Protected LSD or Protected Welch strategy. Fitting
JMP Output from Chapter 5 Factorial Analysis through JMP Example 5.25: (page 228) Screenshots from JMP. These examples assume post-hoc analysis using a Protected LSD or Protected Welch strategy. Fitting
Application of Taguchi Method in the Optimization of Cutting Parameters for Surface Roughness in Turning on EN-362 Steel
 IJIRST International Journal for Innovative Research in Science & Technology Volume 2 Issue 02 July 2015 ISSN (online): 2349-6010 Application of Taguchi Method in the Optimization of Cutting Parameters
IJIRST International Journal for Innovative Research in Science & Technology Volume 2 Issue 02 July 2015 ISSN (online): 2349-6010 Application of Taguchi Method in the Optimization of Cutting Parameters
MULTIPLE COMPARISONS PROCEDURES FOR SOME SPLIT PLOT AND SPLIT BLOCK DESIGNS
 MULTIPLE COMPARISONS PROCEDURES FOR SOME SPLIT PLOT AND SPLIT BLOCK DESIGNS Halter T. Federer Biometrics Unit Cornell University Ithaca, New York Charles E. McCulloch Biometrics Unit Cornell University
MULTIPLE COMPARISONS PROCEDURES FOR SOME SPLIT PLOT AND SPLIT BLOCK DESIGNS Halter T. Federer Biometrics Unit Cornell University Ithaca, New York Charles E. McCulloch Biometrics Unit Cornell University
Tuning Genetic Programming Parameters with Factorial Designs
 Tuning Genetic Programming Parameters with Factorial Designs Elisa Boari de Lima, Gisele L. Pappa, Jussara Marques de Almeida, Marcos A. Gonçalves and Wagner Meira Júnior Abstract Parameter setting of
Tuning Genetic Programming Parameters with Factorial Designs Elisa Boari de Lima, Gisele L. Pappa, Jussara Marques de Almeida, Marcos A. Gonçalves and Wagner Meira Júnior Abstract Parameter setting of
Table of Contents (As covered from textbook)
") Table of Contents (As covered from textbook) Ch 1 Data and Decisions Ch 2 Displaying and Describing Categorical Data Ch 3 Displaying and Describing Quantitative Data Ch 4 Correlation and Linear Regression
Table of Contents (As covered from textbook) Ch 1 Data and Decisions Ch 2 Displaying and Describing Categorical Data Ch 3 Displaying and Describing Quantitative Data Ch 4 Correlation and Linear Regression
Statistical Bioinformatics (Biomedical Big Data) Notes 2: Installing and Using R
 Notes 2: Installing and Using R") Statistical Bioinformatics (Biomedical Big Data) Notes 2: Installing and Using R In this course we will be using R (for Windows) for most of our work. These notes are to help students install R and then
Statistical Bioinformatics (Biomedical Big Data) Notes 2: Installing and Using R In this course we will be using R (for Windows) for most of our work. These notes are to help students install R and then
STATS PAD USER MANUAL
 STATS PAD USER MANUAL For Version 2.0 Manual Version 2.0 1 Table of Contents Basic Navigation! 3 Settings! 7 Entering Data! 7 Sharing Data! 8 Managing Files! 10 Running Tests! 11 Interpreting Output! 11
STATS PAD USER MANUAL For Version 2.0 Manual Version 2.0 1 Table of Contents Basic Navigation! 3 Settings! 7 Entering Data! 7 Sharing Data! 8 Managing Files! 10 Running Tests! 11 Interpreting Output! 11
STAT 311 (3 CREDITS) VARIANCE AND REGRESSION ANALYSIS ELECTIVE: ALL STUDENTS. CONTENT Introduction to Computer application of variance and regression
 VARIANCE AND REGRESSION ANALYSIS ELECTIVE: ALL STUDENTS. CONTENT Introduction to Computer application of variance and regression") STAT 311 (3 CREDITS) VARIANCE AND REGRESSION ANALYSIS ELECTIVE: ALL STUDENTS. CONTENT Introduction to Computer application of variance and regression analysis. Analysis of Variance: one way classification,
STAT 311 (3 CREDITS) VARIANCE AND REGRESSION ANALYSIS ELECTIVE: ALL STUDENTS. CONTENT Introduction to Computer application of variance and regression analysis. Analysis of Variance: one way classification,
TAGUCHI TECHNIQUES FOR 2 k FRACTIONAL FACTORIAL EXPERIMENTS
 Hacettepe Journal of Mathematics and Statistics Volume 4 (200), 8 9 TAGUCHI TECHNIQUES FOR 2 k FRACTIONAL FACTORIAL EXPERIMENTS Nazan Danacıoğlu and F.Zehra Muluk Received 0: 0: 200 : Accepted 14: 06:
Hacettepe Journal of Mathematics and Statistics Volume 4 (200), 8 9 TAGUCHI TECHNIQUES FOR 2 k FRACTIONAL FACTORIAL EXPERIMENTS Nazan Danacıoğlu and F.Zehra Muluk Received 0: 0: 200 : Accepted 14: 06:
5.5 Regression Estimation
 5.5 Regression Estimation Assume a SRS of n pairs (x, y ),..., (x n, y n ) is selected from a population of N pairs of (x, y) data. The goal of regression estimation is to take advantage of a linear relationship
5.5 Regression Estimation Assume a SRS of n pairs (x, y ),..., (x n, y n ) is selected from a population of N pairs of (x, y) data. The goal of regression estimation is to take advantage of a linear relationship
nag anova random (g04bbc)
") g04 Analysis of Variance g04bbc 1. Purpose nag anova random (g04bbc) nag anova random (g04bbc) computes the analysis of variance and treatment means and standard errors for a randomized block or completely
g04 Analysis of Variance g04bbc 1. Purpose nag anova random (g04bbc) nag anova random (g04bbc) computes the analysis of variance and treatment means and standard errors for a randomized block or completely
The Power and Sample Size Application
 Chapter 72 The Power and Sample Size Application Contents Overview: PSS Application.................................. 6148 SAS Power and Sample Size............................... 6148 Getting Started:
Chapter 72 The Power and Sample Size Application Contents Overview: PSS Application.................................. 6148 SAS Power and Sample Size............................... 6148 Getting Started:
Introductory Guide to SAS:
 Introductory Guide to SAS: For UVM Statistics Students By Richard Single Contents 1 Introduction and Preliminaries 2 2 Reading in Data: The DATA Step 2 2.1 The DATA Statement............................................
Introductory Guide to SAS: For UVM Statistics Students By Richard Single Contents 1 Introduction and Preliminaries 2 2 Reading in Data: The DATA Step 2 2.1 The DATA Statement............................................
An introduction to SPSS
 An introduction to SPSS To open the SPSS software using U of Iowa Virtual Desktop... Go to https://virtualdesktop.uiowa.edu and choose SPSS 24. Contents NOTE: Save data files in a drive that is accessible
An introduction to SPSS To open the SPSS software using U of Iowa Virtual Desktop... Go to https://virtualdesktop.uiowa.edu and choose SPSS 24. Contents NOTE: Save data files in a drive that is accessible
The Solution to the Factorial Analysis of Variance
 The Solution to the Factorial Analysis of Variance As shown in the Excel file, Howell -2, the ANOVA analysis (in the ToolPac) yielded the following table: Anova: Two-Factor With Replication SUMMARYCounting
The Solution to the Factorial Analysis of Variance As shown in the Excel file, Howell -2, the ANOVA analysis (in the ToolPac) yielded the following table: Anova: Two-Factor With Replication SUMMARYCounting
Frequencies, Unequal Variance Weights, and Sampling Weights: Similarities and Differences in SAS
 ABSTRACT Paper 1938-2018 Frequencies, Unequal Variance Weights, and Sampling Weights: Similarities and Differences in SAS Robert M. Lucas, Robert M. Lucas Consulting, Fort Collins, CO, USA There is confusion
ABSTRACT Paper 1938-2018 Frequencies, Unequal Variance Weights, and Sampling Weights: Similarities and Differences in SAS Robert M. Lucas, Robert M. Lucas Consulting, Fort Collins, CO, USA There is confusion
MR-2010I %MktEx Macro %MktEx Macro
 MR-2010I %MktEx Macro 1017 %MktEx Macro The %MktEx autocall macro creates efficient factorial designs. The %MktEx macro is designed to be very simple to use and to run in seconds for trivial problems,
MR-2010I %MktEx Macro 1017 %MktEx Macro The %MktEx autocall macro creates efficient factorial designs. The %MktEx macro is designed to be very simple to use and to run in seconds for trivial problems,
Introduction to Stata: An In-class Tutorial
 Introduction to Stata: An I. The Basics - Stata is a command-driven statistical software program. In other words, you type in a command, and Stata executes it. You can use the drop-down menus to avoid
Introduction to Stata: An I. The Basics - Stata is a command-driven statistical software program. In other words, you type in a command, and Stata executes it. You can use the drop-down menus to avoid
Tips on JMP ing into Mixture Experimentation
 Tips on JMP ing into Mixture Experimentation Daniell. Obermiller, The Dow Chemical Company, Midland, MI Abstract Mixture experimentation has unique challenges due to the fact that the proportion of the
Tips on JMP ing into Mixture Experimentation Daniell. Obermiller, The Dow Chemical Company, Midland, MI Abstract Mixture experimentation has unique challenges due to the fact that the proportion of the
Factorial ANOVA. Skipping... Page 1 of 18
 Factorial ANOVA The potato data: Batches of potatoes randomly assigned to to be stored at either cool or warm temperature, infected with one of three bacterial types. Then wait a set period. The dependent
Factorial ANOVA The potato data: Batches of potatoes randomly assigned to to be stored at either cool or warm temperature, infected with one of three bacterial types. Then wait a set period. The dependent
Data can be in the form of numbers, words, measurements, observations or even just descriptions of things.
 + What is Data? Data is a collection of facts. Data can be in the form of numbers, words, measurements, observations or even just descriptions of things. In most cases, data needs to be interpreted and
+ What is Data? Data is a collection of facts. Data can be in the form of numbers, words, measurements, observations or even just descriptions of things. In most cases, data needs to be interpreted and
SAS (Statistical Analysis Software/System)
") SAS (Statistical Analysis Software/System) SAS Adv. Analytics or Predictive Modelling:- Class Room: Training Fee & Duration : 30K & 3 Months Online Training Fee & Duration : 33K & 3 Months Learning SAS:
SAS (Statistical Analysis Software/System) SAS Adv. Analytics or Predictive Modelling:- Class Room: Training Fee & Duration : 30K & 3 Months Online Training Fee & Duration : 33K & 3 Months Learning SAS:
Topic:- DU_J18_MA_STATS_Topic01
 DU MA MSc Statistics Topic:- DU_J18_MA_STATS_Topic01 1) In analysis of variance problem involving 3 treatments with 10 observations each, SSE= 399.6. Then the MSE is equal to: [Question ID = 2313] 1. 14.8
DU MA MSc Statistics Topic:- DU_J18_MA_STATS_Topic01 1) In analysis of variance problem involving 3 treatments with 10 observations each, SSE= 399.6. Then the MSE is equal to: [Question ID = 2313] 1. 14.8
Modeling Plant Succession with Markov Matrices
 Modeling Plant Succession with Markov Matrices 1 Modeling Plant Succession with Markov Matrices Concluding Paper Undergraduate Biology and Math Training Program New Jersey Institute of Technology Catherine
Modeling Plant Succession with Markov Matrices 1 Modeling Plant Succession with Markov Matrices Concluding Paper Undergraduate Biology and Math Training Program New Jersey Institute of Technology Catherine
Screening Design Selection
 Screening Design Selection Summary... 1 Data Input... 2 Analysis Summary... 5 Power Curve... 7 Calculations... 7 Summary The STATGRAPHICS experimental design section can create a wide variety of designs
Screening Design Selection Summary... 1 Data Input... 2 Analysis Summary... 5 Power Curve... 7 Calculations... 7 Summary The STATGRAPHICS experimental design section can create a wide variety of designs
Getting Started with Minitab 17
 2014, 2016 by Minitab Inc. All rights reserved. Minitab, Quality. Analysis. Results. and the Minitab logo are all registered trademarks of Minitab, Inc., in the United States and other countries. See minitab.com/legal/trademarks
2014, 2016 by Minitab Inc. All rights reserved. Minitab, Quality. Analysis. Results. and the Minitab logo are all registered trademarks of Minitab, Inc., in the United States and other countries. See minitab.com/legal/trademarks
STAT 5200 Handout #24: Power Calculation in Mixed Models
 STAT 5200 Handout #24: Power Calculation in Mixed Models Statistical power is the probability of finding an effect (i.e., calling a model term significant), given that the effect is real. ( Effect here
STAT 5200 Handout #24: Power Calculation in Mixed Models Statistical power is the probability of finding an effect (i.e., calling a model term significant), given that the effect is real. ( Effect here
OPTIMISATION OF PIN FIN HEAT SINK USING TAGUCHI METHOD
 CHAPTER - 5 OPTIMISATION OF PIN FIN HEAT SINK USING TAGUCHI METHOD The ever-increasing demand to lower the production costs due to increased competition has prompted engineers to look for rigorous methods
CHAPTER - 5 OPTIMISATION OF PIN FIN HEAT SINK USING TAGUCHI METHOD The ever-increasing demand to lower the production costs due to increased competition has prompted engineers to look for rigorous methods
Contrasts. 1 An experiment with two factors. Chapter 5
 Chapter 5 Contrasts 5 Contrasts 1 1 An experiment with two factors................. 1 2 The data set........................... 2 3 Interpretation of coefficients for one factor........... 5 3.1 Without
Chapter 5 Contrasts 5 Contrasts 1 1 An experiment with two factors................. 1 2 The data set........................... 2 3 Interpretation of coefficients for one factor........... 5 3.1 Without
Biostatistics and Design of Experiments Prof. Mukesh Doble Department of Biotechnology Indian Institute of Technology, Madras
 Biostatistics and Design of Experiments Prof. Mukesh Doble Department of Biotechnology Indian Institute of Technology, Madras Lecture - 37 Other Designs/Second Order Designs Welcome to the course on Biostatistics
Biostatistics and Design of Experiments Prof. Mukesh Doble Department of Biotechnology Indian Institute of Technology, Madras Lecture - 37 Other Designs/Second Order Designs Welcome to the course on Biostatistics
8. MINITAB COMMANDS WEEK-BY-WEEK
 8. MINITAB COMMANDS WEEK-BY-WEEK In this section of the Study Guide, we give brief information about the Minitab commands that are needed to apply the statistical methods in each week s study. They are
8. MINITAB COMMANDS WEEK-BY-WEEK In this section of the Study Guide, we give brief information about the Minitab commands that are needed to apply the statistical methods in each week s study. They are
Getting Started with Minitab 18
 2017 by Minitab Inc. All rights reserved. Minitab, Quality. Analysis. Results. and the Minitab logo are registered trademarks of Minitab, Inc., in the United States and other countries. Additional trademarks
2017 by Minitab Inc. All rights reserved. Minitab, Quality. Analysis. Results. and the Minitab logo are registered trademarks of Minitab, Inc., in the United States and other countries. Additional trademarks
Minitab 17 commands Prepared by Jeffrey S. Simonoff
 Minitab 17 commands Prepared by Jeffrey S. Simonoff Data entry and manipulation To enter data by hand, click on the Worksheet window, and enter the values in as you would in any spreadsheet. To then save
Minitab 17 commands Prepared by Jeffrey S. Simonoff Data entry and manipulation To enter data by hand, click on the Worksheet window, and enter the values in as you would in any spreadsheet. To then save