Hybrid Analysis and its Application to Thread Level Parallelization. Lawrence Rauchwerger
|
|
|
- Stella Little
- 5 years ago
- Views:
Transcription

1 Hybrid Analysis and its Application to Thread Level Parallelization Lawrence Rauchwerger
2 Thread (Loop) Level Parallelization Thread level Parallelization Extracting parallel threads from a sequential program Manual Very expensive for sequential legacy code: MPI - OpenMP Automatic So far not very successful due to: weak static analysis Decisions depend on dynamic values (input dependent) 2
3 What is a parallel loop? Parallelizable loop DO DO i = 1, 1, a[i] = a[i] + b[i] ENDDO Sequential loop DO DO i = 1, 1, a[i+1] = a[i] + b[i] ENDDO i=1 RW i=1 R W i=2 RW i=2 R W i=3 RW i=3 R W i=4 RW i=4 R W flow, i i+1 3
4 Static Data Dependence Analysis: Linear Reference Patterns No cross iteration dependences DO DO j = 1, 1, a(j) a(j) = a(j+40) ENDDO ENDDO No integer solutions: 1 j w 10 1 j r 10 j w j r j w = j r +40 Geometric view: Polytope model Some convex body contains no integral points Simplified solutions: GCD Test, Banerjee Test etc Potentially overly conservative General solution: Presburger formula decidability Omega Test: Precise, potentially slow Restricted to linear addressing and control: mostly small kernels 4
5 Static Data Dependence Analysis: Nonlinear Reference Patterns DO DO j = 1, 1, IF IF (x(j)>0) THEN THEN a(f(j)) = ENDIF ENDIF ENDDO ENDDO No known solution in general Common cases: Indirect access (subscripted subscripts) Control dependence on data values Recurrence without closed form Linear Approximation Maslov 94; Creusillet, Irigoin 96 Range Test (Blume, Eigenmann 94) Monotonicity (Wu, Cohen, Padua 01) Symbolic Unknowns Uninterpreted Function Symbols (Pugh, Wonnacott 95) Fuzzy Array Dataflow (Barthou, Collard, Feautrier 95) User assistance Uninterpreted Function Symbols (Pugh, Wonnacott 95) SUIF Explorer (Liao 00) Most nonlinear cases not solvable statically: need run time analysis 5
6 Alternative: Run-time Analysis READ *, N DO j=1,n a(j)=a(j+40) ENDDO Linear, very simple, but not decidable statically! Solution: LRPD Run-time Test (Rauchwerger and Padua 95) Instrument all relevant memory references N = 5 WRITE READ Analyze the resulting trace at run time Independent N = 45 WRITE READ Dependent Accurate, but overhead proportional to the dynamic memory reference count Minimum necessary information for parallelization: N 40 6
7 Compile-time vs. Run-time Compile Time Run-time, reference by reference PROs No run-time overhead PROs Always finds answers CONs: too conservative when Input/computed values Indirection Control Weak symbolic analysis Complex recurrences Impractical symbolic analysis Combinatorial explosion CONs Run-time overhead proportional to dynamic memory reference count Unnecessary work: Ignores partial compile-time results 7
8 Why Did We Fail? Static Analysis cannot be sufficient (weak and/or input sensitive) Dynamic Analysis (misunderstood as only speculation) is not a substitute for Static Analysis (too costly) No program level representation suitable for representing statically unanalyzable code 8
9 Hybrid Analysis of memory Reference Patterns (Rus ICS 02, 07) Compile-time Analysis Hybrid Analysis Run-time Analysis DYNAMIC STATIC Symbolic analysis Symbolic analysis Extract Extract conditions Evaluate conditions Full Full reference-byreference analysis Framework: Hybrid memory reference analysis Application: Automatic parallelization 9
10 Hybrid Analysis DO DO j=1,n j=1,n a(j)=a(j+40) ENDDO ENDDO. 4.a) If we can prove 10 N 30, generate parallel.loop 4.b) If N is unknown, Extract run-time test. N 40 Parallel Loop DO PARALLEL j=1,n a(j)=a(j+40) ENDDO No run-time tests performed if not necessary! Compile Time Run Time Parallel Loop Sequential Loop Run-time Test IF (N 40) THEN DO PARALLEL j=1,n a(j)=a(j+40) ENDDO ELSE DO j=1,n a(j)=a(j+40) ENDDO ENDIF 10
11 Hybrid Analysis Compile-time Phase DO DO j=1,n j=1,n a(j)=a(j+40) ENDDO ENDDO Under what conditions can the loop be executed in parallel? x j+40 j=1,n j j=1,n READ x WRITE 1. Collect and classify memory references. 41:40+N READ 1:N WRITE 2. Aggregate them symbolically 41:40+N READ Empty? 1:N WRITE 3. Formulate independence test. 4.a) If we can prove 10 N 30, Declare loop parallel. 4.b) If N is unknown, Extract run-time test. N 40 11
12 Aggregation of Linear References Across an Iteration Space WF pattern for A: 1:100 DO DO j=1,100 A(j) A(j) = ENDDO ENDDO LMAD = Linear Memory Access Descriptor (Hoeflinger 98) Multidimensional, strided intervals 12
13 Gate Operator Postpone Analysis Failure The truth value of (x=0) is not known # IF IF (x=0) (x=0) THEN THEN DO DO j=1,100 A(j) A(j) = ENDDO ENDDO ENDIF ENDIF 1:100 x=0 13
14 Recurrence Operator Postpone Static Analysis Failure due to Nonlinear Reference Pattern Recurrence with no closed form on x # x j=1,3 DO DO j=1,3 j=1,3 x = f(x) f(x) IF IF (x=0) (x=0) THEN THEN DO DO j=1,100 A(j) A(j) = ENDDO ENDDO ENDIF ENDIF ENDDO ENDDO 1:100 x=0 14
15 Uniform Set of References (USR) Closed under composition at program level T= { LMAD,,,, (, ), #,, Θ, Gate, Recurrence, Call Site} N = { USR } { USR LMAD (USR ) S = USR USR USR X P = USR USR USR USR USR USR USR Gate # USR USR Recurrence USR USR Call Site Θ USR } # 1:100 x=0 j=1,3 LMAD = Start + [Stride 1 :Span 1, Stride 2 :Span 2,...] 15
16 READ READ *, *, N DO DO j=1,n j=1,n a(j)=a(j+40) ENDDO ENDDO Are there any cross-iteration dependences? x x j+40 j=1,n j j=1,n READ WRITE 1. Collect references. 41:40+N READ Empty? 41:40+N READ N 40 1:N WRITE 1:N WRITE 2. Aggregate them symbolically & Classify Reference Type 3. Formulate independence test Extract lowest-cost runtime test.
17 Data Dependences Given: Loop expression: j = 1,N Per-iteration aggregated descriptors RO j, WF j, RW j Solve equation RO WF = Empty? x x RO j At compile-time: j=1,n WF j RO WF evaluates to independent RO WF evaluates to a set that is not empty dependent All other cases: run-time dependence test j=1,n Similar equations for privatization and reduction recognition 17
18 READ READ *, *, N DO DO j=1,n j=1,n a(j)=a(j+40) ENDDO ENDDO Are there any cross-iteration dependences? x x j+40 j=1,n j j=1,n READ WRITE 1. Collect references. 41:40+N READ Empty? 41:40+N READ N 40 1:N WRITE 1:N WRITE 2. Aggregate them symbolically & Classify Reference Type 3. Formulate independence test Extract lowest-cost runtime test.
19 Algorithm: Recursive Descent # Empty? 41:40+n 1:n 1. Distribute Intersection Empty? # 1:n DO j = 1, n A(j) = A(j+40) IF (x>0) THEN A(j) = A(j) + A(j+20) ENDIF ENDDO 41:40+n Empty? 1:n 21:20+n x>0 21:20+n x>0 2 (n 20 or x 0) and n 40 4 n 20 x 0 n 40 3 Empty? x 0 n 40 21:20+n 1:n 19
20 Novel Static/Dynamic Interface: Predicate DAG Represents any dynamic condition for loop parallelization T= { Logical Expression,,,,, Θ, Recurrence, Call Site, Library Routine} N = { PDAG } S = PDAG P = { PDAG Logical Expression PDAG PDAG PDAG PDAG PDAG PDAG PDAG PDAG Recurrence PDAG PDAG Recurrence PDAG PDAG Θ Call Site PDAG Library Routine } n 100 x 0 n 200 Expressive: arbitrary dependence questions Inexpensive: evaluates quickly at run-time 20
21 PDAG Extraction Input: USR equation D = Output: PDAG P Such that: P D = Optimistic: Sufficient predicate: Pessimistic: Necessary predicate: P D = D = P, or P D 21
22 Fallback DO j=1,100 A(ind 1 (j)) = A(ind 2 (j)) ENDDO Not all equations can be reversed Empty? x x ind 1 (j) j=1,100 ind 2 (j) j=1,100 Fallback Solutions Trace based. Speculation Possibly Aggregated 22
23 Hybrid Analysis: Run Time O(1) Scalar Comparison Fail O(n/k) Comparisons Fail Reference Based Pass Pass Pass Fail Independent Dependent 23
24 Evaluation Methodology Automatic parallelization using Hybrid Analysis in Polaris Analyses/Transformations: Dependence analysis, privatization, reduction, pushback Candidate loop selection: Profiling No scheduling or memory locality optimization Simple dynamic mechanism to rule out very small loops Polaris Fortran 77 Fortran 77 + HA OpenMP Intel ifort version 9.0 Executable Code Experiment Setup SPEC , PERFECT, Other SPEC -Dual Core CoreDuo Intel, Lenovo X60s Dual Core AMD, quad socket Sun 24

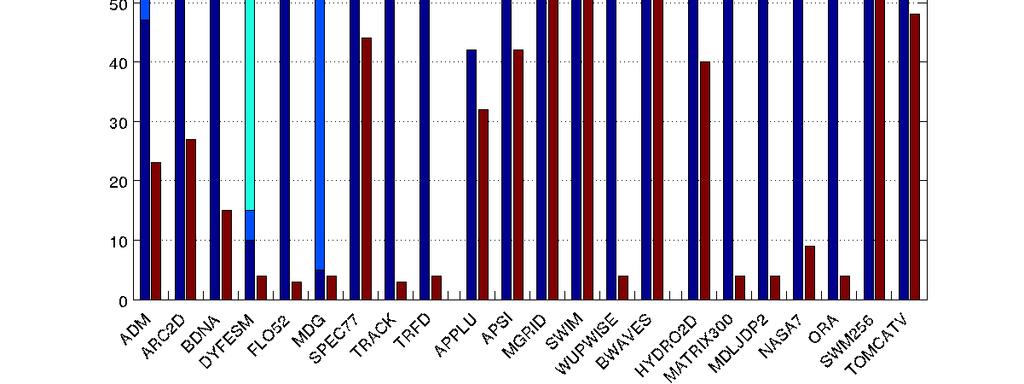
25 Polaris-HA vs. Ifort Coverage: PERFECT/SPEC89/92 25


26 Polaris-HA vs. Ifort Coverage: PERFECT Benchmarks 26


27 Polaris-HA vs. Ifort Coverage: SPEC 89/92 27


28 Polaris-HA vs. Ifort Coverage: SPEC2000/06 28

29 Speedups SPEC2000/06: AMD dual core/quad socket 29

30 Speedups Perfect/Spec89/92: Intel Core Duo 30

31 Speedups PERFECT: Intel CoreDuo 31

32 Speedups SPEC 89/92: Intel Core Duo 32
33 Conclusions: HA + Autopar Hybrid memory reference analysis is a general framework for optimization Representation is crucial -- USR Closed-form representation that tolerates analysis failure PDAG: Input sensitivity of optimization decisions Continuum of compile-time to run-time solutions Efficient automatic parallelization Good Speedups on FP benchmark applications 33
Sensitivity Analysis for Automatic Parallelization on Multi-Cores
 Sensitivity Analysis for Automatic Parallelization on Multi-Cores Silvius Rus Texas A&M University Dept. of Computer Science Parasol Laboratory 3112 TAMUS College Station, TX 77843 silvius.rus@gmail.com
Sensitivity Analysis for Automatic Parallelization on Multi-Cores Silvius Rus Texas A&M University Dept. of Computer Science Parasol Laboratory 3112 TAMUS College Station, TX 77843 silvius.rus@gmail.com
Implementation of Sensitivity Analysis for Automatic Parallelization
 Implementation of Sensitivity Analysis for Automatic Parallelization Silvius Rus, Maikel Pennings, and Lawrence Rauchwerger Parasol Lab, Department of Computer Science, Texas A&M University rus@google.com,
Implementation of Sensitivity Analysis for Automatic Parallelization Silvius Rus, Maikel Pennings, and Lawrence Rauchwerger Parasol Lab, Department of Computer Science, Texas A&M University rus@google.com,
The Value Evolution Graph and its Use in Memory Reference Analysis
 The Value Evolution Graph and its Use in Memory Reference Analysis Silvius Rus Texas A&M University silviusr@cs.tamu.edu Dongmin Zhang Texas A&M University dzhang@cs.tamu.edu Lawrence Rauchwerger Texas
The Value Evolution Graph and its Use in Memory Reference Analysis Silvius Rus Texas A&M University silviusr@cs.tamu.edu Dongmin Zhang Texas A&M University dzhang@cs.tamu.edu Lawrence Rauchwerger Texas
Scalable Conditional Induction Variables (CIV) Analysis
 Analysis") Scalable Conditional Induction Variables (CIV) Analysis Cosmin E. Oancea Department of Computer Science University of Copenhagen cosmin.oancea@diku.dk Lawrence Rauchwerger Department of Computer Science
Scalable Conditional Induction Variables (CIV) Analysis Cosmin E. Oancea Department of Computer Science University of Copenhagen cosmin.oancea@diku.dk Lawrence Rauchwerger Department of Computer Science
INTERPROCEDURAL PARALLELIZATION USING MEMORY CLASSIFICATION ANALYSIS BY JAY PHILIP HOEFLINGER B.S., University of Illinois, 1974 M.S., University of I
 cflcopyright by Jay Philip Hoeflinger 2000 INTERPROCEDURAL PARALLELIZATION USING MEMORY CLASSIFICATION ANALYSIS BY JAY PHILIP HOEFLINGER B.S., University of Illinois, 1974 M.S., University of Illinois,
cflcopyright by Jay Philip Hoeflinger 2000 INTERPROCEDURAL PARALLELIZATION USING MEMORY CLASSIFICATION ANALYSIS BY JAY PHILIP HOEFLINGER B.S., University of Illinois, 1974 M.S., University of Illinois,
Region Array SSA. Guobin He Texas A&M University. Silvius Rus Texas A&M University. Christophe Alias ENS Lyon
 Region Array SSA Silvius Rus Texas A&M University Guobin He Texas A&M University Christophe Alias ENS Lyon Lawrence Rauchwerger Texas A&M University ABSTRACT Static Single Assignment (SSA) has become the
Region Array SSA Silvius Rus Texas A&M University Guobin He Texas A&M University Christophe Alias ENS Lyon Lawrence Rauchwerger Texas A&M University ABSTRACT Static Single Assignment (SSA) has become the
Speculative Parallelization Technology s only constant is CHANGE. Devarshi Ghoshal Sreesudhan
 Speculative Parallelization Technology s only constant is CHANGE Devarshi Ghoshal Sreesudhan Agenda Moore s law What is speculation? What is parallelization? Amdahl s law Communication between parallely
Speculative Parallelization Technology s only constant is CHANGE Devarshi Ghoshal Sreesudhan Agenda Moore s law What is speculation? What is parallelization? Amdahl s law Communication between parallely
Is OpenMP for Grids?
 Is OpenMP for Grids? Rudolf Eigenmann, Jay Hoeflinger, Robert H. Kuhn Ayon Basumallik, Seung-Jai Min, Jiajing Zhu, David Padua, Purdue University KAI Software/Intel Americas, Inc. University of Illinois
Is OpenMP for Grids? Rudolf Eigenmann, Jay Hoeflinger, Robert H. Kuhn Ayon Basumallik, Seung-Jai Min, Jiajing Zhu, David Padua, Purdue University KAI Software/Intel Americas, Inc. University of Illinois
Techniques for Reducing the Overhead of Run-time Parallelization
 Techniques for Reducing the Overhead of Run-time Parallelization Hao Yu and Lawrence Rauchwerger Dept. of Computer Science Texas A&M University College Station, TX 77843-3112 hy8494,rwerger @cs.tamu.edu
Techniques for Reducing the Overhead of Run-time Parallelization Hao Yu and Lawrence Rauchwerger Dept. of Computer Science Texas A&M University College Station, TX 77843-3112 hy8494,rwerger @cs.tamu.edu
Symbolic Evaluation of Sums for Parallelising Compilers
 Symbolic Evaluation of Sums for Parallelising Compilers Rizos Sakellariou Department of Computer Science University of Manchester Oxford Road Manchester M13 9PL United Kingdom e-mail: rizos@csmanacuk Keywords:
Symbolic Evaluation of Sums for Parallelising Compilers Rizos Sakellariou Department of Computer Science University of Manchester Oxford Road Manchester M13 9PL United Kingdom e-mail: rizos@csmanacuk Keywords:
Introduction to OpenMP. OpenMP basics OpenMP directives, clauses, and library routines
 Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Divide-and-Conquer. Divide-and conquer is a general algorithm design paradigm:
 Presentation for use with the textbook Data Structures and Algorithms in Java, 6 th edition, by M. T. Goodrich, R. Tamassia, and M. H. Goldwasser, Wiley, 2014 Merge Sort 7 2 9 4 2 4 7 9 7 2 2 7 9 4 4 9
Presentation for use with the textbook Data Structures and Algorithms in Java, 6 th edition, by M. T. Goodrich, R. Tamassia, and M. H. Goldwasser, Wiley, 2014 Merge Sort 7 2 9 4 2 4 7 9 7 2 2 7 9 4 4 9
FADA : Fuzzy Array Dataflow Analysis
 FADA : Fuzzy Array Dataflow Analysis M. Belaoucha, D. Barthou, S. Touati 27/06/2008 Abstract This document explains the basis of fuzzy data dependence analysis (FADA) and its applications on code fragment
FADA : Fuzzy Array Dataflow Analysis M. Belaoucha, D. Barthou, S. Touati 27/06/2008 Abstract This document explains the basis of fuzzy data dependence analysis (FADA) and its applications on code fragment
Yukinori Sato (JAIST, JST CREST) Yasushi Inoguchi (JAIST) Tadao Nakamura (Keio University)
 Yasushi Inoguchi (JAIST) Tadao Nakamura (Keio University)") Whole Program Data Dependence Profiling to Unveil Parallel Regions in the Dynamic Execution Yukinori Sato (JAIST, JST CREST) Yasushi Inoguchi (JAIST) Tadao Nakamura (Keio University) 2012 IEEE International
Whole Program Data Dependence Profiling to Unveil Parallel Regions in the Dynamic Execution Yukinori Sato (JAIST, JST CREST) Yasushi Inoguchi (JAIST) Tadao Nakamura (Keio University) 2012 IEEE International
Chapter 3:- Divide and Conquer. Compiled By:- Sanjay Patel Assistant Professor, SVBIT.
 Chapter 3:- Divide and Conquer Compiled By:- Assistant Professor, SVBIT. Outline Introduction Multiplying large Integers Problem Problem Solving using divide and conquer algorithm - Binary Search Sorting
Chapter 3:- Divide and Conquer Compiled By:- Assistant Professor, SVBIT. Outline Introduction Multiplying large Integers Problem Problem Solving using divide and conquer algorithm - Binary Search Sorting
On the Automatic Parallelization of the Perfect Benchmarks
 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 9, NO. 1, JANUARY 1998 5 On the Automatic Parallelization of the Perfect Benchmarks Rudolf Eigenmann, Member, IEEE, Jay Hoeflinger, and David
IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 9, NO. 1, JANUARY 1998 5 On the Automatic Parallelization of the Perfect Benchmarks Rudolf Eigenmann, Member, IEEE, Jay Hoeflinger, and David
PROGRAM EFFICIENCY & COMPLEXITY ANALYSIS
 Lecture 03-04 PROGRAM EFFICIENCY & COMPLEXITY ANALYSIS By: Dr. Zahoor Jan 1 ALGORITHM DEFINITION A finite set of statements that guarantees an optimal solution in finite interval of time 2 GOOD ALGORITHMS?
Lecture 03-04 PROGRAM EFFICIENCY & COMPLEXITY ANALYSIS By: Dr. Zahoor Jan 1 ALGORITHM DEFINITION A finite set of statements that guarantees an optimal solution in finite interval of time 2 GOOD ALGORITHMS?
Run-Time Parallelization: It s Time Has Come
 Run-Time Parallelization: It s Time Has Come Lawrence Rauchwerger Department of Computer Science Texas A&M University College Station, TX 77843 Corresponding Author: Lawrence Rauchwerger telephone: (409)
Run-Time Parallelization: It s Time Has Come Lawrence Rauchwerger Department of Computer Science Texas A&M University College Station, TX 77843 Corresponding Author: Lawrence Rauchwerger telephone: (409)
UMIACS-TR November, Univ. of Maryland, College Park, MD Abstract
 UMIACS-TR-94-123 November, 1994 CS-TR-3372 Nonlinear Array Dependence Analysis William Pugh pugh@cs.umd.edu Institute for Advanced Computer Studies Dept. of Computer Science David Wonnacott davew@cs.umd.edu
UMIACS-TR-94-123 November, 1994 CS-TR-3372 Nonlinear Array Dependence Analysis William Pugh pugh@cs.umd.edu Institute for Advanced Computer Studies Dept. of Computer Science David Wonnacott davew@cs.umd.edu
OpenMP: Open Multiprocessing
 OpenMP: Open Multiprocessing Erik Schnetter May 20-22, 2013, IHPC 2013, Iowa City 2,500 BC: Military Invents Parallelism Outline 1. Basic concepts, hardware architectures 2. OpenMP Programming 3. How to
OpenMP: Open Multiprocessing Erik Schnetter May 20-22, 2013, IHPC 2013, Iowa City 2,500 BC: Military Invents Parallelism Outline 1. Basic concepts, hardware architectures 2. OpenMP Programming 3. How to
The LRPD Test: Speculative Run Time Parallelization of Loops with Privatization and Reduction Parallelization
 The LRPD Test: Speculative Run Time Parallelization of Loops with Privatization and Reduction Parallelization Lawrence Rauchwerger and David Padua University of Illinois at Urbana-Champaign Abstract Current
The LRPD Test: Speculative Run Time Parallelization of Loops with Privatization and Reduction Parallelization Lawrence Rauchwerger and David Padua University of Illinois at Urbana-Champaign Abstract Current
A Source-to-Source OpenMP Compiler
 A Source-to-Source OpenMP Compiler Mario Soukup and Tarek S. Abdelrahman The Edward S. Rogers Sr. Department of Electrical and Computer Engineering University of Toronto Toronto, Ontario, Canada M5S 3G4
A Source-to-Source OpenMP Compiler Mario Soukup and Tarek S. Abdelrahman The Edward S. Rogers Sr. Department of Electrical and Computer Engineering University of Toronto Toronto, Ontario, Canada M5S 3G4
Module 17: Loops Lecture 34: Symbolic Analysis. The Lecture Contains: Symbolic Analysis. Example: Triangular Lower Limits. Multiple Loop Limits
 The Lecture Contains: Symbolic Analysis Example: Triangular Lower Limits Multiple Loop Limits Exit in The Middle of a Loop Dependence System Solvers Single Equation Simple Test GCD Test Extreme Value Test
The Lecture Contains: Symbolic Analysis Example: Triangular Lower Limits Multiple Loop Limits Exit in The Middle of a Loop Dependence System Solvers Single Equation Simple Test GCD Test Extreme Value Test
The Polyhedral Model (Transformations)
") The Polyhedral Model (Transformations) Announcements HW4 is due Wednesday February 22 th Project proposal is due NEXT Friday, extension so that example with tool is possible (see resources website for
The Polyhedral Model (Transformations) Announcements HW4 is due Wednesday February 22 th Project proposal is due NEXT Friday, extension so that example with tool is possible (see resources website for
Data Dependences and Parallelization
 Data Dependences and Parallelization 1 Agenda Introduction Single Loop Nested Loops Data Dependence Analysis 2 Motivation DOALL loops: loops whose iterations can execute in parallel for i = 11, 20 a[i]
Data Dependences and Parallelization 1 Agenda Introduction Single Loop Nested Loops Data Dependence Analysis 2 Motivation DOALL loops: loops whose iterations can execute in parallel for i = 11, 20 a[i]
i=1 i=2 i=3 i=4 i=5 x(4) x(6) x(8)
 x(6) x(8)") Vectorization Using Reversible Data Dependences Peiyi Tang and Nianshu Gao Technical Report ANU-TR-CS-94-08 October 21, 1994 Vectorization Using Reversible Data Dependences Peiyi Tang Department of Computer
Vectorization Using Reversible Data Dependences Peiyi Tang and Nianshu Gao Technical Report ANU-TR-CS-94-08 October 21, 1994 Vectorization Using Reversible Data Dependences Peiyi Tang Department of Computer
Lecture 9 Basic Parallelization
 Lecture 9 Basic Parallelization I. Introduction II. Data Dependence Analysis III. Loop Nests + Locality IV. Interprocedural Parallelization Chapter 11.1-11.1.4 CS243: Parallelization 1 Machine Learning
Lecture 9 Basic Parallelization I. Introduction II. Data Dependence Analysis III. Loop Nests + Locality IV. Interprocedural Parallelization Chapter 11.1-11.1.4 CS243: Parallelization 1 Machine Learning
Lecture 9 Basic Parallelization
 Lecture 9 Basic Parallelization I. Introduction II. Data Dependence Analysis III. Loop Nests + Locality IV. Interprocedural Parallelization Chapter 11.1-11.1.4 CS243: Parallelization 1 Machine Learning
Lecture 9 Basic Parallelization I. Introduction II. Data Dependence Analysis III. Loop Nests + Locality IV. Interprocedural Parallelization Chapter 11.1-11.1.4 CS243: Parallelization 1 Machine Learning
Speculative Synchronization
 Speculative Synchronization José F. Martínez Department of Computer Science University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu/martinez Problem 1: Conservative Parallelization No parallelization
Speculative Synchronization José F. Martínez Department of Computer Science University of Illinois at Urbana-Champaign http://iacoma.cs.uiuc.edu/martinez Problem 1: Conservative Parallelization No parallelization
Autotuning. John Cavazos. University of Delaware UNIVERSITY OF DELAWARE COMPUTER & INFORMATION SCIENCES DEPARTMENT
 Autotuning John Cavazos University of Delaware What is Autotuning? Searching for the best code parameters, code transformations, system configuration settings, etc. Search can be Quasi-intelligent: genetic
Autotuning John Cavazos University of Delaware What is Autotuning? Searching for the best code parameters, code transformations, system configuration settings, etc. Search can be Quasi-intelligent: genetic
Parallelizing While Loops for Multiprocessor Systems
 CSRD Technical Report 1349 Parallelizing While Loops for Multiprocessor Systems Lawrence Rauchwerger and David Padua Center for Supercomputing Research and Development University of Illinois at Urbana-Champaign
CSRD Technical Report 1349 Parallelizing While Loops for Multiprocessor Systems Lawrence Rauchwerger and David Padua Center for Supercomputing Research and Development University of Illinois at Urbana-Champaign
Polyèdres et compilation
 Polyèdres et compilation François Irigoin & Mehdi Amini & Corinne Ancourt & Fabien Coelho & Béatrice Creusillet & Ronan Keryell MINES ParisTech - Centre de Recherche en Informatique 12 May 2011 François
Polyèdres et compilation François Irigoin & Mehdi Amini & Corinne Ancourt & Fabien Coelho & Béatrice Creusillet & Ronan Keryell MINES ParisTech - Centre de Recherche en Informatique 12 May 2011 François
6.189 IAP Lecture 11. Parallelizing Compilers. Prof. Saman Amarasinghe, MIT IAP 2007 MIT
 6.189 IAP 2007 Lecture 11 Parallelizing Compilers 1 6.189 IAP 2007 MIT Outline Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities Generation of Parallel
6.189 IAP 2007 Lecture 11 Parallelizing Compilers 1 6.189 IAP 2007 MIT Outline Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities Generation of Parallel
Lecture 27. Pros and Cons of Pointers. Basics Design Options Pointer Analysis Algorithms Pointer Analysis Using BDDs Probabilistic Pointer Analysis
 Pros and Cons of Pointers Lecture 27 Pointer Analysis Basics Design Options Pointer Analysis Algorithms Pointer Analysis Using BDDs Probabilistic Pointer Analysis Many procedural languages have pointers
Pros and Cons of Pointers Lecture 27 Pointer Analysis Basics Design Options Pointer Analysis Algorithms Pointer Analysis Using BDDs Probabilistic Pointer Analysis Many procedural languages have pointers
Lecture 20 Pointer Analysis
 Lecture 20 Pointer Analysis Basics Design Options Pointer Analysis Algorithms Pointer Analysis Using BDDs Probabilistic Pointer Analysis (Slide content courtesy of Greg Steffan, U. of Toronto) 15-745:
Lecture 20 Pointer Analysis Basics Design Options Pointer Analysis Algorithms Pointer Analysis Using BDDs Probabilistic Pointer Analysis (Slide content courtesy of Greg Steffan, U. of Toronto) 15-745:
The LRPD Test: Speculative Run-Time Parallelization of Loops with Privatization and Reduction Parallelization
 160 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 10, NO. 2, FEBRUARY 1999 The LRPD Test: Speculative Run-Time Parallelization of Loops with Privatization and Reduction Parallelization Lawrence
160 IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL. 10, NO. 2, FEBRUARY 1999 The LRPD Test: Speculative Run-Time Parallelization of Loops with Privatization and Reduction Parallelization Lawrence
OpenMP: Open Multiprocessing
 OpenMP: Open Multiprocessing Erik Schnetter June 7, 2012, IHPC 2012, Iowa City Outline 1. Basic concepts, hardware architectures 2. OpenMP Programming 3. How to parallelise an existing code 4. Advanced
OpenMP: Open Multiprocessing Erik Schnetter June 7, 2012, IHPC 2012, Iowa City Outline 1. Basic concepts, hardware architectures 2. OpenMP Programming 3. How to parallelise an existing code 4. Advanced
CSC D70: Compiler Optimization Prefetching
 CSC D70: Compiler Optimization Prefetching Prof. Gennady Pekhimenko University of Toronto Winter 2018 The content of this lecture is adapted from the lectures of Todd Mowry and Phillip Gibbons DRAM Improvement
CSC D70: Compiler Optimization Prefetching Prof. Gennady Pekhimenko University of Toronto Winter 2018 The content of this lecture is adapted from the lectures of Todd Mowry and Phillip Gibbons DRAM Improvement
Allows program to be incrementally parallelized
 Basic OpenMP What is OpenMP An open standard for shared memory programming in C/C+ + and Fortran supported by Intel, Gnu, Microsoft, Apple, IBM, HP and others Compiler directives and library support OpenMP
Basic OpenMP What is OpenMP An open standard for shared memory programming in C/C+ + and Fortran supported by Intel, Gnu, Microsoft, Apple, IBM, HP and others Compiler directives and library support OpenMP
Dynamically Adaptive Parallel Programs
 Dynamically Adaptive Parallel Programs Michael Voss and Rudolf Eigenmann Purdue University, School of Electrical and Computer Engineering Abstract. Dynamic program optimization is the only recourse for
Dynamically Adaptive Parallel Programs Michael Voss and Rudolf Eigenmann Purdue University, School of Electrical and Computer Engineering Abstract. Dynamic program optimization is the only recourse for
SHARCNET Workshop on Parallel Computing. Hugh Merz Laurentian University May 2008
 SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
SHARCNET Workshop on Parallel Computing Hugh Merz Laurentian University May 2008 What is Parallel Computing? A computational method that utilizes multiple processing elements to solve a problem in tandem
Program Analysis. Program Analysis
 Program Analysis Class #4 Program Analysis Dynamic Analysis 1 Static VS Dynamic Analysis Static analysis operates on a model of the SW (without executing it) If successful, produces definitive information
Program Analysis Class #4 Program Analysis Dynamic Analysis 1 Static VS Dynamic Analysis Static analysis operates on a model of the SW (without executing it) If successful, produces definitive information
Parallel Computing. Hwansoo Han (SKKU)
") Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Parallel Computing Hwansoo Han (SKKU) Unicore Limitations Performance scaling stopped due to Power consumption Wire delay DRAM latency Limitation in ILP 10000 SPEC CINT2000 2 cores/chip Xeon 3.0GHz Core2duo
Overpartioning with the Rice dhpf Compiler
 Overpartioning with the Rice dhpf Compiler Strategies for Achieving High Performance in High Performance Fortran Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/hug00overpartioning.pdf
Overpartioning with the Rice dhpf Compiler Strategies for Achieving High Performance in High Performance Fortran Ken Kennedy Rice University http://www.cs.rice.edu/~ken/presentations/hug00overpartioning.pdf
Bill Blume Rudolf Eigenmann Keith Faigin John Grout. Jay Hoeinger David Padua Paul Petersen Bill Pottenger
 Polaris: The Next Generation in Parallelizing Compilers Bill Blume Rudolf Eigenmann Keith Faigin John Grout Jay Hoeinger David Padua Paul Petersen Bill Pottenger Lawrence Rauchwerger Peng Tu Stephen Weatherford
Polaris: The Next Generation in Parallelizing Compilers Bill Blume Rudolf Eigenmann Keith Faigin John Grout Jay Hoeinger David Padua Paul Petersen Bill Pottenger Lawrence Rauchwerger Peng Tu Stephen Weatherford
Lecture 16 Pointer Analysis
 Pros and Cons of Pointers Lecture 16 Pointer Analysis Basics Design Options Pointer Analysis Algorithms Pointer Analysis Using BDDs Probabilistic Pointer Analysis Many procedural languages have pointers
Pros and Cons of Pointers Lecture 16 Pointer Analysis Basics Design Options Pointer Analysis Algorithms Pointer Analysis Using BDDs Probabilistic Pointer Analysis Many procedural languages have pointers
Interprocedural Symbolic Range Propagation for Optimizing Compilers
 Interprocedural Symbolic Range Propagation for Optimizing Compilers Hansang Bae and Rudolf Eigenmann School of Electrical and Computer Engineering Purdue University, West Lafayette, IN 47907 {baeh,eigenman}@purdue.edu
Interprocedural Symbolic Range Propagation for Optimizing Compilers Hansang Bae and Rudolf Eigenmann School of Electrical and Computer Engineering Purdue University, West Lafayette, IN 47907 {baeh,eigenman}@purdue.edu
Combined Compile-time and Runtime-driven, Pro-active Data Movement in Software DSM Systems
 Combined Compile-time and Runtime-driven, Pro-active Data Movement in Software DSM Systems Seung-Jai Min and Rudolf Eigenmann School of Electrical and Computer Engineering Purdue University Abstract Scientific
Combined Compile-time and Runtime-driven, Pro-active Data Movement in Software DSM Systems Seung-Jai Min and Rudolf Eigenmann School of Electrical and Computer Engineering Purdue University Abstract Scientific
Array Optimizations in OCaml
 Array Optimizations in OCaml Michael Clarkson Cornell University clarkson@cs.cornell.edu Vaibhav Vaish Cornell University vaibhav@cs.cornell.edu May 7, 2001 Abstract OCaml is a modern programming language
Array Optimizations in OCaml Michael Clarkson Cornell University clarkson@cs.cornell.edu Vaibhav Vaish Cornell University vaibhav@cs.cornell.edu May 7, 2001 Abstract OCaml is a modern programming language
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok
 Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
Scheduling FFT Computation on SMP and Multicore Systems Ayaz Ali, Lennart Johnsson & Jaspal Subhlok Texas Learning and Computation Center Department of Computer Science University of Houston Outline Motivation
17/05/2018. Outline. Outline. Divide and Conquer. Control Abstraction for Divide &Conquer. Outline. Module 2: Divide and Conquer
 Module 2: Divide and Conquer Divide and Conquer Control Abstraction for Divide &Conquer 1 Recurrence equation for Divide and Conquer: If the size of problem p is n and the sizes of the k sub problems are
Module 2: Divide and Conquer Divide and Conquer Control Abstraction for Divide &Conquer 1 Recurrence equation for Divide and Conquer: If the size of problem p is n and the sizes of the k sub problems are
CS691/SC791: Parallel & Distributed Computing
 CS691/SC791: Parallel & Distributed Computing Introduction to OpenMP 1 Contents Introduction OpenMP Programming Model and Examples OpenMP programming examples Task parallelism. Explicit thread synchronization.
CS691/SC791: Parallel & Distributed Computing Introduction to OpenMP 1 Contents Introduction OpenMP Programming Model and Examples OpenMP programming examples Task parallelism. Explicit thread synchronization.
Lecture 14 Pointer Analysis
 Lecture 14 Pointer Analysis Basics Design Options Pointer Analysis Algorithms Pointer Analysis Using BDDs Probabilistic Pointer Analysis [ALSU 12.4, 12.6-12.7] Phillip B. Gibbons 15-745: Pointer Analysis
Lecture 14 Pointer Analysis Basics Design Options Pointer Analysis Algorithms Pointer Analysis Using BDDs Probabilistic Pointer Analysis [ALSU 12.4, 12.6-12.7] Phillip B. Gibbons 15-745: Pointer Analysis
Chapter 1: Interprocedural Parallelization Analysis: A Case Study. Abstract
 Chapter 1: Interprocedural Parallelization Analysis: A Case Study Mary W. Hall Brian R. Murphy Saman P. Amarasinghe Abstract We present an overview of our interprocedural analysis system, which applies
Chapter 1: Interprocedural Parallelization Analysis: A Case Study Mary W. Hall Brian R. Murphy Saman P. Amarasinghe Abstract We present an overview of our interprocedural analysis system, which applies
Polyhedral Optimizations of Explicitly Parallel Programs
 Habanero Extreme Scale Software Research Group Department of Computer Science Rice University The 24th International Conference on Parallel Architectures and Compilation Techniques (PACT) October 19, 2015
Habanero Extreme Scale Software Research Group Department of Computer Science Rice University The 24th International Conference on Parallel Architectures and Compilation Techniques (PACT) October 19, 2015
Turbostream: A CFD solver for manycore
 Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Turbostream: A CFD solver for manycore processors Tobias Brandvik Whittle Laboratory University of Cambridge Aim To produce an order of magnitude reduction in the run-time of CFD solvers for the same hardware
Compiler Optimizations. Chapter 8, Section 8.5 Chapter 9, Section 9.1.7
 Compiler Optimizations Chapter 8, Section 8.5 Chapter 9, Section 9.1.7 2 Local vs. Global Optimizations Local: inside a single basic block Simple forms of common subexpression elimination, dead code elimination,
Compiler Optimizations Chapter 8, Section 8.5 Chapter 9, Section 9.1.7 2 Local vs. Global Optimizations Local: inside a single basic block Simple forms of common subexpression elimination, dead code elimination,
Parallelizing While Loops for Multiprocessor Systems y
 Submitted to IEEE Transactions on Parallel and Distributed Systems. (CSRD Technical Report 1349.) Parallelizing While Loops for Multiprocessor Systems y Lawrence Rauchwerger and David Padua Center for
Submitted to IEEE Transactions on Parallel and Distributed Systems. (CSRD Technical Report 1349.) Parallelizing While Loops for Multiprocessor Systems y Lawrence Rauchwerger and David Padua Center for
Field Analysis. Last time Exploit encapsulation to improve memory system performance
 Field Analysis Last time Exploit encapsulation to improve memory system performance This time Exploit encapsulation to simplify analysis Two uses of field analysis Escape analysis Object inlining April
Field Analysis Last time Exploit encapsulation to improve memory system performance This time Exploit encapsulation to simplify analysis Two uses of field analysis Escape analysis Object inlining April
Pipeline Parallelism and the OpenMP Doacross Construct. COMP515 - guest lecture October 27th, 2015 Jun Shirako
 Pipeline Parallelism and the OpenMP Doacross Construct COMP515 - guest lecture October 27th, 2015 Jun Shirako Doall Parallelization (Recap) No loop-carried dependence among iterations of doall loop Parallel
Pipeline Parallelism and the OpenMP Doacross Construct COMP515 - guest lecture October 27th, 2015 Jun Shirako Doall Parallelization (Recap) No loop-carried dependence among iterations of doall loop Parallel
A Parallelizing Compiler for Multicore Systems
 A Parallelizing Compiler for Multicore Systems José M. Andión, Manuel Arenaz, Gabriel Rodríguez and Juan Touriño 17th International Workshop on Software and Compilers for Embedded Systems (SCOPES 2014)
A Parallelizing Compiler for Multicore Systems José M. Andión, Manuel Arenaz, Gabriel Rodríguez and Juan Touriño 17th International Workshop on Software and Compilers for Embedded Systems (SCOPES 2014)
Towards a Holistic Approach to Auto-Parallelization
 Towards a Holistic Approach to Auto-Parallelization Integrating Profile-Driven Parallelism Detection and Machine-Learning Based Mapping Georgios Tournavitis, Zheng Wang, Björn Franke and Michael F.P. O
Towards a Holistic Approach to Auto-Parallelization Integrating Profile-Driven Parallelism Detection and Machine-Learning Based Mapping Georgios Tournavitis, Zheng Wang, Björn Franke and Michael F.P. O
Fast Fuzzy Clustering of Infrared Images. 2. brfcm
 Fast Fuzzy Clustering of Infrared Images Steven Eschrich, Jingwei Ke, Lawrence O. Hall and Dmitry B. Goldgof Department of Computer Science and Engineering, ENB 118 University of South Florida 4202 E.
Fast Fuzzy Clustering of Infrared Images Steven Eschrich, Jingwei Ke, Lawrence O. Hall and Dmitry B. Goldgof Department of Computer Science and Engineering, ENB 118 University of South Florida 4202 E.
Speculative Parallelisation
 Speculative Parallelisation Michael O Boyle March, 2012 1 Course Structure 5 lectures on high level restructuring for parallelism Dependence Analysis Program Transformations Automatic vectorisation Automatic
Speculative Parallelisation Michael O Boyle March, 2012 1 Course Structure 5 lectures on high level restructuring for parallelism Dependence Analysis Program Transformations Automatic vectorisation Automatic
William Blume, Rudolf Eigenmann, Keith Faigin, John Grout, Jay Hoeinger, David Padua, Paul
 Polaris: Improving the Eectiveness of Parallelizing Compilers William Blume, Rudolf Eigenmann, Keith Faigin, John Grout, Jay Hoeinger, David Padua, Paul Petersen, William Pottenger, Lawrence Rauchwerger,
Polaris: Improving the Eectiveness of Parallelizing Compilers William Blume, Rudolf Eigenmann, Keith Faigin, John Grout, Jay Hoeinger, David Padua, Paul Petersen, William Pottenger, Lawrence Rauchwerger,
Designing for Performance. Patrick Happ Raul Feitosa
 Designing for Performance Patrick Happ Raul Feitosa Objective In this section we examine the most common approach to assessing processor and computer system performance W. Stallings Designing for Performance
Designing for Performance Patrick Happ Raul Feitosa Objective In this section we examine the most common approach to assessing processor and computer system performance W. Stallings Designing for Performance
Little Motivation Outline Introduction OpenMP Architecture Working with OpenMP Future of OpenMP End. OpenMP. Amasis Brauch German University in Cairo
 OpenMP Amasis Brauch German University in Cairo May 4, 2010 Simple Algorithm 1 void i n c r e m e n t e r ( short a r r a y ) 2 { 3 long i ; 4 5 for ( i = 0 ; i < 1000000; i ++) 6 { 7 a r r a y [ i ]++;
OpenMP Amasis Brauch German University in Cairo May 4, 2010 Simple Algorithm 1 void i n c r e m e n t e r ( short a r r a y ) 2 { 3 long i ; 4 5 for ( i = 0 ; i < 1000000; i ++) 6 { 7 a r r a y [ i ]++;
Static and dynamic analysis: synergy and duality
 Static and dynamic analysis: synergy and duality Michael Ernst MIT Computer Science & Artificial Intelligence Lab http://pag.csail.mit.edu/~mernst/ PASTE June 7, 2004 Michael Ernst, page 1 Goals Theme:
Static and dynamic analysis: synergy and duality Michael Ernst MIT Computer Science & Artificial Intelligence Lab http://pag.csail.mit.edu/~mernst/ PASTE June 7, 2004 Michael Ernst, page 1 Goals Theme:
A Data Dependence Graph in Polaris. July 17, Center for Supercomputing Research and Development. Abstract
 A Data Dependence Graph in Polaris Yunheung Paek Paul Petersen July 17, 1996 Center for Supercomputing Research and Development University of Illinois at Urbana-Champaign Urbana, Illinois 61801 Abstract
A Data Dependence Graph in Polaris Yunheung Paek Paul Petersen July 17, 1996 Center for Supercomputing Research and Development University of Illinois at Urbana-Champaign Urbana, Illinois 61801 Abstract
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 5)
") Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 5) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3, 3.9, and Appendix C) Hardware
Chapter 3 Instruction-Level Parallelism and its Exploitation (Part 5) ILP vs. Parallel Computers Dynamic Scheduling (Section 3.4, 3.5) Dynamic Branch Prediction (Section 3.3, 3.9, and Appendix C) Hardware
Principles of Program Analysis. Lecture 1 Harry Xu Spring 2013
 Principles of Program Analysis Lecture 1 Harry Xu Spring 2013 An Imperfect World Software has bugs The northeast blackout of 2003, affected 10 million people in Ontario and 45 million in eight U.S. states
Principles of Program Analysis Lecture 1 Harry Xu Spring 2013 An Imperfect World Software has bugs The northeast blackout of 2003, affected 10 million people in Ontario and 45 million in eight U.S. states
Automatic Translation of Fortran Programs to Vector Form. Randy Allen and Ken Kennedy
 Automatic Translation of Fortran Programs to Vector Form Randy Allen and Ken Kennedy The problem New (as of 1987) vector machines such as the Cray-1 have proven successful Most Fortran code is written
Automatic Translation of Fortran Programs to Vector Form Randy Allen and Ken Kennedy The problem New (as of 1987) vector machines such as the Cray-1 have proven successful Most Fortran code is written
Efficiently Building the Gated Single Assignment Form in Codes with Pointers in Modern Optimizing Compilers
 Efficiently Building the Gated Single Assignment Form in Codes with Pointers in Modern Optimizing Compilers Manuel Arenaz, Pedro Amoedo, and Juan Touriño Computer Architecture Group Department of Electronics
Efficiently Building the Gated Single Assignment Form in Codes with Pointers in Modern Optimizing Compilers Manuel Arenaz, Pedro Amoedo, and Juan Touriño Computer Architecture Group Department of Electronics
Compiling for GPUs. Adarsh Yoga Madhav Ramesh
 Compiling for GPUs Adarsh Yoga Madhav Ramesh Agenda Introduction to GPUs Compute Unified Device Architecture (CUDA) Control Structure Optimization Technique for GPGPU Compiler Framework for Automatic Translation
Compiling for GPUs Adarsh Yoga Madhav Ramesh Agenda Introduction to GPUs Compute Unified Device Architecture (CUDA) Control Structure Optimization Technique for GPGPU Compiler Framework for Automatic Translation
Integrating Profile-Driven Parallelism Detection and Machine-Learning-Based Mapping
 Integrating Profile-Driven Parallelism Detection and Machine-Learning-Based Mapping ZHENG WANG, Lancaster University, United Kingdom GEORGIOS TOURNAVITIS, Intel Barcelona Research Center, Spain BJÖRN FRANKE
Integrating Profile-Driven Parallelism Detection and Machine-Learning-Based Mapping ZHENG WANG, Lancaster University, United Kingdom GEORGIOS TOURNAVITIS, Intel Barcelona Research Center, Spain BJÖRN FRANKE
AUTOMATICALLY TUNING PARALLEL AND PARALLELIZED PROGRAMS
 AUTOMATICALLY TUNING PARALLEL AND PARALLELIZED PROGRAMS Chirag Dave and Rudolf Eigenmann Purdue University cdave,eigenman@purdue.edu Abstract. In today s multicore era, parallelization of serial code is
AUTOMATICALLY TUNING PARALLEL AND PARALLELIZED PROGRAMS Chirag Dave and Rudolf Eigenmann Purdue University cdave,eigenman@purdue.edu Abstract. In today s multicore era, parallelization of serial code is
Introductory OpenMP June 2008
 5: http://people.sc.fsu.edu/ jburkardt/presentations/ fdi 2008 lecture5.pdf... John Information Technology Department Virginia Tech... FDI Summer Track V: Parallel Programming 10-12 June 2008 Introduction
5: http://people.sc.fsu.edu/ jburkardt/presentations/ fdi 2008 lecture5.pdf... John Information Technology Department Virginia Tech... FDI Summer Track V: Parallel Programming 10-12 June 2008 Introduction
Outline. Why Parallelism Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities
 Parallelization Outline Why Parallelism Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities Moore s Law From Hennessy and Patterson, Computer Architecture:
Parallelization Outline Why Parallelism Parallel Execution Parallelizing Compilers Dependence Analysis Increasing Parallelization Opportunities Moore s Law From Hennessy and Patterson, Computer Architecture:
Compiler techniques for leveraging ILP
 Compiler techniques for leveraging ILP Purshottam and Sajith October 12, 2011 Purshottam and Sajith (IU) Compiler techniques for leveraging ILP October 12, 2011 1 / 56 Parallelism in your pocket LINPACK
Compiler techniques for leveraging ILP Purshottam and Sajith October 12, 2011 Purshottam and Sajith (IU) Compiler techniques for leveraging ILP October 12, 2011 1 / 56 Parallelism in your pocket LINPACK
Page # Let the Compiler Do it Pros and Cons Pros. Exploiting ILP through Software Approaches. Cons. Perhaps a mixture of the two?
 Exploiting ILP through Software Approaches Venkatesh Akella EEC 270 Winter 2005 Based on Slides from Prof. Al. Davis @ cs.utah.edu Let the Compiler Do it Pros and Cons Pros No window size limitation, the
Exploiting ILP through Software Approaches Venkatesh Akella EEC 270 Winter 2005 Based on Slides from Prof. Al. Davis @ cs.utah.edu Let the Compiler Do it Pros and Cons Pros No window size limitation, the
Parallelization System. Abstract. We present an overview of our interprocedural analysis system,
 Overview of an Interprocedural Automatic Parallelization System Mary W. Hall Brian R. Murphy y Saman P. Amarasinghe y Shih-Wei Liao y Monica S. Lam y Abstract We present an overview of our interprocedural
Overview of an Interprocedural Automatic Parallelization System Mary W. Hall Brian R. Murphy y Saman P. Amarasinghe y Shih-Wei Liao y Monica S. Lam y Abstract We present an overview of our interprocedural
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #7 2/5/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
EE/CSCI 451: Parallel and Distributed Computation Lecture #7 2/5/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
First Experiences with Intel Cluster OpenMP
 First Experiences with Intel Christian Terboven, Dieter an Mey, Dirk Schmidl, Marcus Wagner surname@rz.rwth aachen.de Center for Computing and Communication RWTH Aachen University, Germany IWOMP 2008 May
First Experiences with Intel Christian Terboven, Dieter an Mey, Dirk Schmidl, Marcus Wagner surname@rz.rwth aachen.de Center for Computing and Communication RWTH Aachen University, Germany IWOMP 2008 May
ECE 695 Numerical Simulations Lecture 3: Practical Assessment of Code Performance. Prof. Peter Bermel January 13, 2017
 ECE 695 Numerical Simulations Lecture 3: Practical Assessment of Code Performance Prof. Peter Bermel January 13, 2017 Outline Time Scaling Examples General performance strategies Computer architectures
ECE 695 Numerical Simulations Lecture 3: Practical Assessment of Code Performance Prof. Peter Bermel January 13, 2017 Outline Time Scaling Examples General performance strategies Computer architectures
Compiler Optimizations. Chapter 8, Section 8.5 Chapter 9, Section 9.1.7
 Compiler Optimizations Chapter 8, Section 8.5 Chapter 9, Section 9.1.7 2 Local vs. Global Optimizations Local: inside a single basic block Simple forms of common subexpression elimination, dead code elimination,
Compiler Optimizations Chapter 8, Section 8.5 Chapter 9, Section 9.1.7 2 Local vs. Global Optimizations Local: inside a single basic block Simple forms of common subexpression elimination, dead code elimination,
A Compiler-Directed Cache Coherence Scheme Using Data Prefetching
 A Compiler-Directed Cache Coherence Scheme Using Data Prefetching Hock-Beng Lim Center for Supercomputing R & D University of Illinois Urbana, IL 61801 hblim@csrd.uiuc.edu Pen-Chung Yew Dept. of Computer
A Compiler-Directed Cache Coherence Scheme Using Data Prefetching Hock-Beng Lim Center for Supercomputing R & D University of Illinois Urbana, IL 61801 hblim@csrd.uiuc.edu Pen-Chung Yew Dept. of Computer
Redundant Computation Elimination Optimizations. Redundancy Elimination. Value Numbering CS2210
 Redundant Computation Elimination Optimizations CS2210 Lecture 20 Redundancy Elimination Several categories: Value Numbering local & global Common subexpression elimination (CSE) local & global Loop-invariant
Redundant Computation Elimination Optimizations CS2210 Lecture 20 Redundancy Elimination Several categories: Value Numbering local & global Common subexpression elimination (CSE) local & global Loop-invariant
Point-to-Point Synchronisation on Shared Memory Architectures
 Point-to-Point Synchronisation on Shared Memory Architectures J. Mark Bull and Carwyn Ball EPCC, The King s Buildings, The University of Edinburgh, Mayfield Road, Edinburgh EH9 3JZ, Scotland, U.K. email:
Point-to-Point Synchronisation on Shared Memory Architectures J. Mark Bull and Carwyn Ball EPCC, The King s Buildings, The University of Edinburgh, Mayfield Road, Edinburgh EH9 3JZ, Scotland, U.K. email:
Dependence Analysis. Hwansoo Han
 Dependence Analysis Hwansoo Han Dependence analysis Dependence Control dependence Data dependence Dependence graph Usage The way to represent dependences Dependence types, latencies Instruction scheduling
Dependence Analysis Hwansoo Han Dependence analysis Dependence Control dependence Data dependence Dependence graph Usage The way to represent dependences Dependence types, latencies Instruction scheduling
Unit #8: Shared-Memory Parallelism and Concurrency
 Unit #8: Shared-Memory Parallelism and Concurrency CPSC 221: Algorithms and Data Structures Will Evans and Jan Manuch 2016W1 Unit Outline History and Motivation Parallelism versus Concurrency Counting
Unit #8: Shared-Memory Parallelism and Concurrency CPSC 221: Algorithms and Data Structures Will Evans and Jan Manuch 2016W1 Unit Outline History and Motivation Parallelism versus Concurrency Counting
Parallelization. Saman Amarasinghe. Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology
 Spring 2 Parallelization Saman Amarasinghe Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Outline Why Parallelism Parallel Execution Parallelizing Compilers
Spring 2 Parallelization Saman Amarasinghe Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Outline Why Parallelism Parallel Execution Parallelizing Compilers
Parallel Computing Using OpenMP/MPI. Presented by - Jyotsna 29/01/2008
 Parallel Computing Using OpenMP/MPI Presented by - Jyotsna 29/01/2008 Serial Computing Serially solving a problem Parallel Computing Parallelly solving a problem Parallel Computer Memory Architecture Shared
Parallel Computing Using OpenMP/MPI Presented by - Jyotsna 29/01/2008 Serial Computing Serially solving a problem Parallel Computing Parallelly solving a problem Parallel Computer Memory Architecture Shared
Compiler Design. Fall Data-Flow Analysis. Sample Exercises and Solutions. Prof. Pedro C. Diniz
 Compiler Design Fall 2015 Data-Flow Analysis Sample Exercises and Solutions Prof. Pedro C. Diniz USC / Information Sciences Institute 4676 Admiralty Way, Suite 1001 Marina del Rey, California 90292 pedro@isi.edu
Compiler Design Fall 2015 Data-Flow Analysis Sample Exercises and Solutions Prof. Pedro C. Diniz USC / Information Sciences Institute 4676 Admiralty Way, Suite 1001 Marina del Rey, California 90292 pedro@isi.edu
OpenMP Programming. Prof. Thomas Sterling. High Performance Computing: Concepts, Methods & Means
 High Performance Computing: Concepts, Methods & Means OpenMP Programming Prof. Thomas Sterling Department of Computer Science Louisiana State University February 8 th, 2007 Topics Introduction Overview
High Performance Computing: Concepts, Methods & Means OpenMP Programming Prof. Thomas Sterling Department of Computer Science Louisiana State University February 8 th, 2007 Topics Introduction Overview
A Unified Framework for Nonlinear Dependence Testing and Symbolic Analysis
 A Unified Framework for Nonlinear Dependence Testing and Symbolic Analysis Robert A. van Engelen Department of Computer Science Florida State University Tallahassee, FL 32306-4530 engelen@cs.fsu.edu J.
A Unified Framework for Nonlinear Dependence Testing and Symbolic Analysis Robert A. van Engelen Department of Computer Science Florida State University Tallahassee, FL 32306-4530 engelen@cs.fsu.edu J.
Parallel Programming. Exploring local computational resources OpenMP Parallel programming for multiprocessors for loops
 Parallel Programming Exploring local computational resources OpenMP Parallel programming for multiprocessors for loops Single computers nowadays Several CPUs (cores) 4 to 8 cores on a single chip Hyper-threading
Parallel Programming Exploring local computational resources OpenMP Parallel programming for multiprocessors for loops Single computers nowadays Several CPUs (cores) 4 to 8 cores on a single chip Hyper-threading
UvA-SARA High Performance Computing Course June Clemens Grelck, University of Amsterdam. Parallel Programming with Compiler Directives: OpenMP
 Parallel Programming with Compiler Directives OpenMP Clemens Grelck University of Amsterdam UvA-SARA High Performance Computing Course June 2013 OpenMP at a Glance Loop Parallelization Scheduling Parallel
Parallel Programming with Compiler Directives OpenMP Clemens Grelck University of Amsterdam UvA-SARA High Performance Computing Course June 2013 OpenMP at a Glance Loop Parallelization Scheduling Parallel
41st Cray User Group Conference Minneapolis, Minnesota
 41st Cray User Group Conference Minneapolis, Minnesota (MSP) Technical Lead, MSP Compiler The Copyright SGI Multi-Stream 1999, SGI Processor We know Multi-level parallelism experts for 25 years Multiple,
41st Cray User Group Conference Minneapolis, Minnesota (MSP) Technical Lead, MSP Compiler The Copyright SGI Multi-Stream 1999, SGI Processor We know Multi-level parallelism experts for 25 years Multiple,
Outline. Register Allocation. Issues. Storing values between defs and uses. Issues. Issues P3 / 2006
 P3 / 2006 Register Allocation What is register allocation Spilling More Variations and Optimizations Kostis Sagonas 2 Spring 2006 Storing values between defs and uses Program computes with values value
P3 / 2006 Register Allocation What is register allocation Spilling More Variations and Optimizations Kostis Sagonas 2 Spring 2006 Storing values between defs and uses Program computes with values value
Introduction to tuning on many core platforms. Gilles Gouaillardet RIST
 Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need
Introduction to tuning on many core platforms Gilles Gouaillardet RIST gilles@rist.or.jp Agenda Why do we need many core platforms? Single-thread optimization Parallelization Conclusions Why do we need