Towards scalable RDMA locking on a NIC
|
|
|
- Shauna Barber
- 6 years ago
- Views:
Transcription

1 TORSTEN HOEFLER spcl.inf.ethz.ch Towards scalable RDMA locking on a NIC with support of Patrick Schmid, Maciej Besta, Salvatore di SPCL presented at HP Labs, Palo Alto, CA, USA


2 NEED FOR EFFICIENT LARGE-SCALE SYNCHRONIZATION spcl.inf.ethz.ch



3 LOCKS An example structure Proc p Proc q Inuitive semantics Various performance penalties
4 LOCKS: CHALLENGES P1 P2 P3 P4
5 LOCKS: CHALLENGES We need intra- and inter-node topologyawareness We need to cover arbitrary topologies P P P P P P P P P P P P

6 LOCKS: CHALLENGES We need to distinguish Writer between Reader readers Reader and writers Reader Reader Reader Reader Writer Reader Reader We need flexible performance for both types of processes [1] V. Venkataramani et al. Tao: How facebook serves the social graph. SIGMOD 12.

7 What will we use in the design? spcl.inf.ethz.ch
8 WHAT WE WILL USE MCS Locks Proc Proc Proc Proc Cannot enter Cannot enter Cannot enter Can enter Next proc Next proc... Next proc Next proc Pointer to the queue tail
9 WHAT WE WILL USE Reader-Writer Locks W R R R... R
10 How to manage the design complexity? How to ensure tunable performance? What mechanism to use for efficient implementation?

11 REMOTE MEMORY ACCESS (RMA) PROGRAMMING Process p Process q Memory A A put A Memory B get B flush B Cray BlueWaters











12 REMOTE MEMORY ACCESS PROGRAMMING Implemented in hardware in NICs in the majority of HPC networks support RDMA
13 How to manage the design complexity? How to ensure tunable performance? What mechanism to use for efficient implementation?
 Modular design W1 W3 W5 W8 MCS queues form a distributed tree (DT) 2 2 3 2 R4")
14 How to manage the design complexity? Each element has its own distributed MCS queue (DQ) of writers R1 R2... R9 W3 W8 Readers and writers synchronize with a distributed counter (DC) Modular design W1 W3 W5 W8 MCS queues form a distributed tree (DT) R4 R2 R1 R5 R3 R8 R6 R7 R9 W1 W2 W3 W4 W5 W6 W7 W8
15 R1 R2... How to ensure tunable performance? R9 W3 W8 Each DQ: fairness vs throughput of writers DC: a parameter for the latency of readers vs writers A tradeoff parameter for every structure W1 W3 W5 W8 DT: a parameter for the throughput of readers vs writers R4 R2 R1 R5 R3 R8 R6 R7 R9 W1 W2 W3 W4 W5 W6 W7 W8
16 DISTRIBUTED MCS QUEUES (DQS) Throughput vs Fairness Larger T L,i : more throughput at level i. Smaller T L,i : more fairness at level i. T L,3 W3 W8 Each DQ: The maximum number of lock passings within a DQ at level i, before it is passed to another DQ at i. T L,i T L,2 T L,2 W1 W3 W5 W8 T L,1 T L,1 T L,1 T L,1 W1 W2 W3 W4 W5 W6 W7 W8
17 DISTRIBUTED TREE OF QUEUES (DT) Throughput of readers vs writers R1 R2... R9 T L,3 W3 W8 DT: The maximum number of consecutive lock passings within readers ( ). T R T L,2 T L,2 W1 W3 W5 W8 T L,1 T L,1 T L,1 T L,1 W1 W2 W3 W4 W5 W6 W7 W8
18 DISTRIBUTED COUNTER (DC) Latency of readers vs writers DC: every kth compute node hosts a partial counter, all of which constitute the DC. k = T DC A writer holds the lock Readers that arrived at the CS b x y T DC = 1 T DC = 2 Readers that left the CS R R4 R R2 R3 R8 R6 R7 R
19 Locality vs fairness (for writers) spcl.inf.ethz.ch THE SPACE OF DESIGNS T L,i Design B Design A Higher throughput of writers vs readers T R T DC
20 LOCK ACQUIRE BY READERS A lightweight acquire protocol for readers: only one atomic fetch-and-add (FAA) operation FAA R FAA R4 A writer holds the lock Readers that arrived at the CS b x y Readers that left the CS FAA R2 FAA R3
21 LOCK ACQUIRE BY WRITERS R1 R2... R9 W9 W3 W8 Acquire the main MCS lock Acquire the main lock Acquire MCS Acquire MCS W9 W1 W3 W5 W W9 W1 W2 W3 W4 W5 W6 W7 W8

22 EVALUATION CSCS Piz Daint (Cray XC30) 5272 compute nodes 8 cores per node 169TB memory
23 EVALUATION CONSIDERED BENCHMARKS Throughput benchmarks: The latency benchmark Empty-critical-section Single-operation Wait-after-release Workload-critical-section DHT Distributed hashtable evaluation
24 EVALUATION DISTRIBUTED COUNTER ANALYSIS Throughput, 2% writers Single-operation benchmark
25 EVALUATION READER THRESHOLD ANALYSIS Throughput, 0.2% writers, Empty-critical-section benchmark
26 EVALUATION COMPARISON TO THE STATE-OF-THE-ART [1] R. Gerstenberger et al. Enabling Highly-scalable Remote Memory Access Programming with MPI-3 One Sided. ACM/IEEE Supercomputing 2013.
27 EVALUATION COMPARISON TO THE STATE-OF-THE-ART Throughput, single-operation benchmark [1] R. Gerstenberger et al. Enabling Highly-scalable Remote Memory Access Programming with MPI-3 One Sided. ACM/IEEE Supercomputing 2013.
28 EVALUATION DISTRIBUTED HASHTABLE 20% writers 10% writers [1] R. Gerstenberger et al. Enabling Highly-scalable Remote Memory Access Programming with MPI-3 One Sided. ACM/IEEE Supercomputing 2013.
29 EVALUATION DISTRIBUTED HASHTABLE 2% of writers 0% of writers [1] R. Gerstenberger et al. Enabling Highly-scalable Remote Memory Access Programming with MPI-3 One Sided. ACM/IEEE Supercomputing 2013.
30 OTHER ANALYSES spcl.inf.ethz.ch





31 But why stop at RDMA -- A brief history How to program We need an QsNet? abstraction! Lossy Networks Ethernet Lossless Networks RDMA How to offload in libfabric? How to offload in Portals 4? Device Programming Offload 1980 s 2000 s 2020 s 35
")


; L2: send b to")

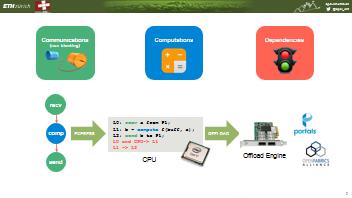
32 Communications (non-blocking) Computations Dependencies recv comp EXPRESS L0: recv a from P1; L1: b = compute f(buff, a); L2: send b to P1; L0 and CPU-> L1 L1 -> L2 OFFLOAD send CPU Offload Engine 36
g P0{ L0: recv m1 from P1; L1: send m2 to P1; } P1{ L0: recv m1")
![from P1; L1: send m2 to P1; L0 -> L1 } [1] A. Alexandrov et al.](/docs-images/72/67995629/images/33-3.jpg "\"LogGP: incorporating long messages into the LogP model one step closer")

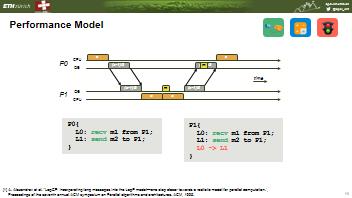
33 Performance Model P0 CPU OE o (s-1)g (s-1)g m o time P1 OE CP U (s-1)g o m o (s-1)g P0{ L0: recv m1 from P1; L1: send m2 to P1; } P1{ L0: recv m1 from P1; L1: send m2 to P1; L0 -> L1 } [1] A. Alexandrov et al. "LogGP: incorporating long messages into the LogP model one step closer towards a realistic model for parallel computation., Proceedings of the seventh annual ACM symposium on Parallel algorithms and architectures. ACM,
34 Fully Offloaded Collectives Collective communication: A communication that involves a group of processes Non-blocking collective: Once initiated the operation may progress independently of any computation or other communication at participating processes P0 P1 P2 P3 P4 P5 P6 P7 38


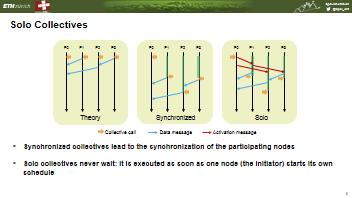
35 Fully Offloaded Collectives Collective communication: A communication that involves a group of processes Non-blocking collective: Once initiated the operation may progress independently of any computation or other communication at participating processes P0 S Fully Offloading: P1 P2 P3 1. No synchronization is required in order to start the collective operation 2. Once a collective operation is started, no further CPU intervention R is required in order to progress or complete it. P4 P5 P6 C C R P7 39
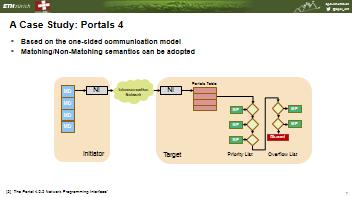
36 A Case Study: Portals 4 Based on the one-sided communication model Matching/Non-Matching semantics can be adopted M D M D M D M D NI Interconnection Network NI Portals Table ME ME ME ME ME Discard Initiator Target Priority List Overflow List [2] The Portal Network Programming Interface 40

37 A Case Study: Portals 4 Communication primitives Put/Get operations are natively supported by Portals 4 One-sided + matching semantic Atomic operations Operands are the data specified by the MD at the initiator and by the ME at the target Available operators: min, max, sum, prod, swap, and, or, Counters Associated with MDs or MEs x Count specific ct events (e.g., operation ct completion) y Triggered operations Put/Get/Atomic associated with a counter x x y y Executed when the associated counter reaches the specified threshold ct z ct 41
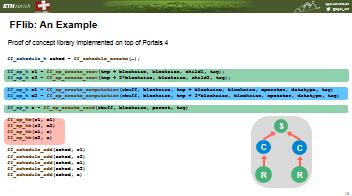
38 FFlib: An Example Proof of concept library implemented on top of Portals 4 ff_schedule_h sched = ff_schedule_create( ); ff_op_h r1 = ff_op_create_recv(tmp + blocksize, blocksize, child1, tag); ff_op_h r2 = ff_op_create_recv(tmp + 2*blocksize, blocksize, child2, tag); ff_op_h c1 = ff_op_create_computation(rbuff, blocksize, tmp + blocksize, blocksize, operator, datatype, tag) ff_op_h c2 = ff_op_create_computation(rbuff, blocksize, tmp + 2*blocksize, blocksize, operator, datatype, tag) ff_op_h s = ff_op_create_send(rbuff, blocksize, parent, tag) ff_op_hb(r1, c1) ff_op_hb(r2, c2) ff_op_hb(c1, s) ff_op_hb(c2, s) ff_schedule_add(sched, r1) ff_schedule_add(sched, r2) ff_schedule_add(sched, c1) ff_schedule_add(sched, c2) ff_schedule_add(sched, s) C R S C R 42
39 Experimental Results Target machine: Curie 5,040 nodes 2 eight-core Intel Sandy Bridge processors Full fat-tree Infiniband QDR OMPI/P4: Open MPI Portals 4 RL FFLIB: proof of concept library More about FFLIB at : 43
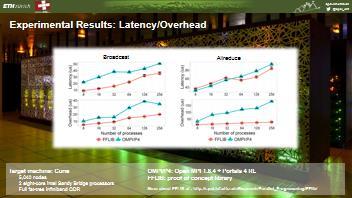
40 Experimental Results: Latency/Overhead Broadcast Allreduce Target machine: Curie 5,040 nodes 2 eight-core Intel Sandy Bridge processors Full fat-tree Infiniband QDR OMPI/P4: Open MPI Portals 4 RL FFLIB: proof of concept library More about FFLIB at : 44
41 Experimental Results: Latency/Overhead Scatter Allgather Target machine: Curie 5,040 nodes 2 eight-core Intel Sandy Bridge processors Full fat-tree Infiniband QDR OMPI/P4: Open MPI Portals 4 RL FFLIB: proof of concept library More about FFLIB at : 45


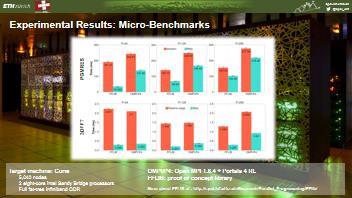
42 PGMRES 3DFFT spcl.inf.ethz.ch Experimental Results: Micro-Benchmarks P=64 P=128 P=256 Target machine: Curie 5,040 nodes 2 eight-core Intel Sandy Bridge processors Full fat-tree Infiniband QDR OMPI/P4: Open MPI Portals 4 RL FFLIB: proof of concept library More about FFLIB at : 46
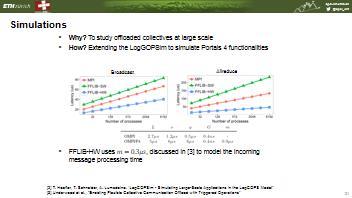
43 Simulations Why? To study offloaded collectives at large scale How? Extending the LogGOPSim to simulate Portals 4 functionalities Broadcast Allreduce L o g G m P4-SW 5μs 6μs 6μs 0.4ns 0.9ns P4-HW 2.7μs 1.2μs 0.5μs 0.4ns 0.3ns [4] [3] T. Hoefler, T. Schneider, A. Lumsdaine. LogGOPSim - Simulating Large-Scale Applications in the LogGOPS Model, In Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing (HPDC '10). ACM, [4] Underwood et al., "Enabling Flexible Collective Communication Offload with Triggered Operations, IEEE 19th Annual Symposium on High Performance Interconnects (HOTI 11). IEEE, 2011.


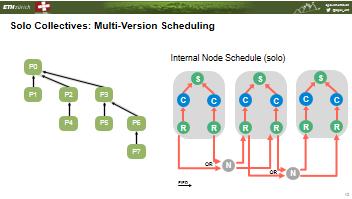
44 Abstract Machine Model Offloading Collectives Solo Collectives Mapping to Portals 4 FFlib Result s


45 CONCLUSIONS Modular distributed RMA lock, correctness with SPIN Parameter-based design, feasible with various RMA libs/languages Thank you for your attention Improves latency and throughput over state-of-the-art Enables high-performance distributed hashtabled
High-Performance Distributed RMA Locks
 High-Performance Distributed RMA Locks PATRICK SCHMID, MACIEJ BESTA, TORSTEN HOEFLER NEED FOR EFFICIENT LARGE-SCALE SYNCHRONIZATION spcl.inf.ethz.ch LOCKS An example structure Proc p Proc q Inuitive semantics
High-Performance Distributed RMA Locks PATRICK SCHMID, MACIEJ BESTA, TORSTEN HOEFLER NEED FOR EFFICIENT LARGE-SCALE SYNCHRONIZATION spcl.inf.ethz.ch LOCKS An example structure Proc p Proc q Inuitive semantics
High-Performance Distributed RMA Locks
 High-Performance Distributed RMA Locks PATRICK SCHMID, MACIEJ BESTA, TORSTEN HOEFLER Presented at ARM Research, Austin, Texas, USA, Feb. 2017 NEED FOR EFFICIENT LARGE-SCALE SYNCHRONIZATION spcl.inf.ethz.ch
High-Performance Distributed RMA Locks PATRICK SCHMID, MACIEJ BESTA, TORSTEN HOEFLER Presented at ARM Research, Austin, Texas, USA, Feb. 2017 NEED FOR EFFICIENT LARGE-SCALE SYNCHRONIZATION spcl.inf.ethz.ch
Exploiting Offload Enabled Network Interfaces
 spcl.inf.ethz.ch S. DI GIROLAMO, P. JOLIVET, K. D. UNDERWOOD, T. HOEFLER Exploiting Offload Enabled Network Interfaces How to We program need an abstraction! QsNet? Lossy Networks Ethernet Lossless Networks
spcl.inf.ethz.ch S. DI GIROLAMO, P. JOLIVET, K. D. UNDERWOOD, T. HOEFLER Exploiting Offload Enabled Network Interfaces How to We program need an abstraction! QsNet? Lossy Networks Ethernet Lossless Networks
High-Performance Distributed RMA Locks
 TORSTEN HOEFLER High-Performance Distributed RMA Locks with support of Patrick Schmid, Maciej Besta @ SPCL presented at Wuxi, China, Sept. 2016 ETH, CS, Systems Group, SPCL ETH Zurich top university in
TORSTEN HOEFLER High-Performance Distributed RMA Locks with support of Patrick Schmid, Maciej Besta @ SPCL presented at Wuxi, China, Sept. 2016 ETH, CS, Systems Group, SPCL ETH Zurich top university in
spin: High-performance streaming Processing in the Network
 T. HOEFLER, S. DI GIROLAMO, K. TARANOV, R. E. GRANT, R. BRIGHTWELL spin: High-performance streaming Processing in the Network spcl.inf.ethz.ch The Development of High-Performance Networking Interfaces
T. HOEFLER, S. DI GIROLAMO, K. TARANOV, R. E. GRANT, R. BRIGHTWELL spin: High-performance streaming Processing in the Network spcl.inf.ethz.ch The Development of High-Performance Networking Interfaces
Enabling Highly-Scalable Remote Memory Access Programming with MPI-3 One Sided
 Enabling Highly-Scalable Remote Memory Access Programming with MPI-3 One Sided ROBERT GERSTENBERGER, MACIEJ BESTA, TORSTEN HOEFLER MPI-3.0 RMA MPI-3.0 supports RMA ( MPI One Sided ) Designed to react to
Enabling Highly-Scalable Remote Memory Access Programming with MPI-3 One Sided ROBERT GERSTENBERGER, MACIEJ BESTA, TORSTEN HOEFLER MPI-3.0 RMA MPI-3.0 supports RMA ( MPI One Sided ) Designed to react to
Enabling Highly-Scalable Remote Memory Access Programming with MPI-3 One Sided
 Enabling Highly-Scalable Remote Memory Access Programming with MPI-3 One Sided ROBERT GERSTENBERGER, MACIEJ BESTA, TORSTEN HOEFLER MPI-3.0 REMOTE MEMORY ACCESS MPI-3.0 supports RMA ( MPI One Sided ) Designed
Enabling Highly-Scalable Remote Memory Access Programming with MPI-3 One Sided ROBERT GERSTENBERGER, MACIEJ BESTA, TORSTEN HOEFLER MPI-3.0 REMOTE MEMORY ACCESS MPI-3.0 supports RMA ( MPI One Sided ) Designed
Efficient and Truly Passive MPI-3 RMA Synchronization Using InfiniBand Atomics
 1 Efficient and Truly Passive MPI-3 RMA Synchronization Using InfiniBand Atomics Mingzhe Li Sreeram Potluri Khaled Hamidouche Jithin Jose Dhabaleswar K. Panda Network-Based Computing Laboratory Department
1 Efficient and Truly Passive MPI-3 RMA Synchronization Using InfiniBand Atomics Mingzhe Li Sreeram Potluri Khaled Hamidouche Jithin Jose Dhabaleswar K. Panda Network-Based Computing Laboratory Department
In-Network Computing. Paving the Road to Exascale. 5th Annual MVAPICH User Group (MUG) Meeting, August 2017
 Meeting, August 2017") In-Network Computing Paving the Road to Exascale 5th Annual MVAPICH User Group (MUG) Meeting, August 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric
In-Network Computing Paving the Road to Exascale 5th Annual MVAPICH User Group (MUG) Meeting, August 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric
Accelerating Irregular Computations with Hardware Transactional Memory and Active Messages
 MACIEJ BESTA, TORSTEN HOEFLER spcl.inf.ethz.ch Accelerating Irregular Computations with Hardware Transactional Memory and Active Messages LARGE-SCALE IRREGULAR GRAPH PROCESSING Becoming more important
MACIEJ BESTA, TORSTEN HOEFLER spcl.inf.ethz.ch Accelerating Irregular Computations with Hardware Transactional Memory and Active Messages LARGE-SCALE IRREGULAR GRAPH PROCESSING Becoming more important
Challenges and Opportunities for HPC Interconnects and MPI
 Challenges and Opportunities for HPC Interconnects and MPI Ron Brightwell, R&D Manager Scalable System Software Department Sandia National Laboratories is a multi-mission laboratory managed and operated
Challenges and Opportunities for HPC Interconnects and MPI Ron Brightwell, R&D Manager Scalable System Software Department Sandia National Laboratories is a multi-mission laboratory managed and operated
In-Network Computing. Sebastian Kalcher, Senior System Engineer HPC. May 2017
 In-Network Computing Sebastian Kalcher, Senior System Engineer HPC May 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait
In-Network Computing Sebastian Kalcher, Senior System Engineer HPC May 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait
High-Performance and Scalable Non-Blocking All-to-All with Collective Offload on InfiniBand Clusters: A study with Parallel 3DFFT
 High-Performance and Scalable Non-Blocking All-to-All with Collective Offload on InfiniBand Clusters: A study with Parallel 3DFFT Krishna Kandalla (1), Hari Subramoni (1), Karen Tomko (2), Dmitry Pekurovsky
High-Performance and Scalable Non-Blocking All-to-All with Collective Offload on InfiniBand Clusters: A study with Parallel 3DFFT Krishna Kandalla (1), Hari Subramoni (1), Karen Tomko (2), Dmitry Pekurovsky
Operational Robustness of Accelerator Aware MPI
 Operational Robustness of Accelerator Aware MPI Sadaf Alam Swiss National Supercomputing Centre (CSSC) Switzerland 2nd Annual MVAPICH User Group (MUG) Meeting, 2014 Computing Systems @ CSCS http://www.cscs.ch/computers
Operational Robustness of Accelerator Aware MPI Sadaf Alam Swiss National Supercomputing Centre (CSSC) Switzerland 2nd Annual MVAPICH User Group (MUG) Meeting, 2014 Computing Systems @ CSCS http://www.cscs.ch/computers
Adaptive Lock. Madhav Iyengar < >, Nathaniel Jeffries < >
 Adaptive Lock Madhav Iyengar < miyengar@andrew.cmu.edu >, Nathaniel Jeffries < njeffrie@andrew.cmu.edu > ABSTRACT Busy wait synchronization, the spinlock, is the primitive at the core of all other synchronization
Adaptive Lock Madhav Iyengar < miyengar@andrew.cmu.edu >, Nathaniel Jeffries < njeffrie@andrew.cmu.edu > ABSTRACT Busy wait synchronization, the spinlock, is the primitive at the core of all other synchronization
Slim Fly: A Cost Effective Low-Diameter Network Topology
 TORSTEN HOEFLER, MACIEJ BESTA Slim Fly: A Cost Effective Low-Diameter Network Topology Images belong to their creator! NETWORKS, LIMITS, AND DESIGN SPACE Networks cost 25-30% of a large supercomputer Hard
TORSTEN HOEFLER, MACIEJ BESTA Slim Fly: A Cost Effective Low-Diameter Network Topology Images belong to their creator! NETWORKS, LIMITS, AND DESIGN SPACE Networks cost 25-30% of a large supercomputer Hard
High-Performance Key-Value Store on OpenSHMEM
 High-Performance Key-Value Store on OpenSHMEM Huansong Fu*, Manjunath Gorentla Venkata, Ahana Roy Choudhury*, Neena Imam, Weikuan Yu* *Florida State University Oak Ridge National Laboratory Outline Background
High-Performance Key-Value Store on OpenSHMEM Huansong Fu*, Manjunath Gorentla Venkata, Ahana Roy Choudhury*, Neena Imam, Weikuan Yu* *Florida State University Oak Ridge National Laboratory Outline Background
Designing Next-Generation Data- Centers with Advanced Communication Protocols and Systems Services. Presented by: Jitong Chen
 Designing Next-Generation Data- Centers with Advanced Communication Protocols and Systems Services Presented by: Jitong Chen Outline Architecture of Web-based Data Center Three-Stage framework to benefit
Designing Next-Generation Data- Centers with Advanced Communication Protocols and Systems Services Presented by: Jitong Chen Outline Architecture of Web-based Data Center Three-Stage framework to benefit
Chelsio 10G Ethernet Open MPI OFED iwarp with Arista Switch
 PERFORMANCE BENCHMARKS Chelsio 10G Ethernet Open MPI OFED iwarp with Arista Switch Chelsio Communications www.chelsio.com sales@chelsio.com +1-408-962-3600 Executive Summary Ethernet provides a reliable
PERFORMANCE BENCHMARKS Chelsio 10G Ethernet Open MPI OFED iwarp with Arista Switch Chelsio Communications www.chelsio.com sales@chelsio.com +1-408-962-3600 Executive Summary Ethernet provides a reliable
High Performance Distributed Lock Management Services using Network-based Remote Atomic Operations
 High Performance Distributed Lock Management Services using Network-based Remote Atomic Operations S. Narravula, A. Mamidala, A. Vishnu, K. Vaidyanathan, and D. K. Panda Presented by Lei Chai Network Based
High Performance Distributed Lock Management Services using Network-based Remote Atomic Operations S. Narravula, A. Mamidala, A. Vishnu, K. Vaidyanathan, and D. K. Panda Presented by Lei Chai Network Based
Advanced Computer Networks. Flow Control
 Advanced Computer Networks 263 3501 00 Flow Control Patrick Stuedi Spring Semester 2017 1 Oriana Riva, Department of Computer Science ETH Zürich Last week TCP in Datacenters Avoid incast problem - Reduce
Advanced Computer Networks 263 3501 00 Flow Control Patrick Stuedi Spring Semester 2017 1 Oriana Riva, Department of Computer Science ETH Zürich Last week TCP in Datacenters Avoid incast problem - Reduce
TORSTEN HOEFLER
 TORSTEN HOEFLER Performance Modeling for Future Computing Technologies Presentation at Tsinghua University, Beijing, China Part of the 60 th anniversary celebration of the Computer Science Department (#9)
TORSTEN HOEFLER Performance Modeling for Future Computing Technologies Presentation at Tsinghua University, Beijing, China Part of the 60 th anniversary celebration of the Computer Science Department (#9)
The Exascale Architecture
 The Exascale Architecture Richard Graham HPC Advisory Council China 2013 Overview Programming-model challenges for Exascale Challenges for scaling MPI to Exascale InfiniBand enhancements Dynamically Connected
The Exascale Architecture Richard Graham HPC Advisory Council China 2013 Overview Programming-model challenges for Exascale Challenges for scaling MPI to Exascale InfiniBand enhancements Dynamically Connected
Interconnect Your Future
 Interconnect Your Future Paving the Road to Exascale August 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait for the Data
Interconnect Your Future Paving the Road to Exascale August 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect CPU-Centric (Onload) Data-Centric (Offload) Must Wait for the Data
Design of Parallel and High-Performance Computing Fall 2017 Lecture: distributed memory
 Design of Parallel and High-Performance Computing Fall 2017 Lecture: distributed memory Motivational video: https://www.youtube.com/watch?v=pucx50fdsic Instructor: Torsten Hoefler & Markus Püschel TA:
Design of Parallel and High-Performance Computing Fall 2017 Lecture: distributed memory Motivational video: https://www.youtube.com/watch?v=pucx50fdsic Instructor: Torsten Hoefler & Markus Püschel TA:
Hardware Acceleration of Barrier Communication for Large Scale Parallel Computer
 013 8th International Conference on Communications and Networking in China (CHINACOM) Hardware Acceleration of Barrier Communication for Large Scale Parallel Computer Pang Zhengbin, Wang Shaogang, Wu Dan,
013 8th International Conference on Communications and Networking in China (CHINACOM) Hardware Acceleration of Barrier Communication for Large Scale Parallel Computer Pang Zhengbin, Wang Shaogang, Wu Dan,
Hybrid MPI - A Case Study on the Xeon Phi Platform
 Hybrid MPI - A Case Study on the Xeon Phi Platform Udayanga Wickramasinghe Center for Research on Extreme Scale Technologies (CREST) Indiana University Greg Bronevetsky Lawrence Livermore National Laboratory
Hybrid MPI - A Case Study on the Xeon Phi Platform Udayanga Wickramasinghe Center for Research on Extreme Scale Technologies (CREST) Indiana University Greg Bronevetsky Lawrence Livermore National Laboratory
Sayantan Sur, Intel. SEA Symposium on Overlapping Computation and Communication. April 4 th, 2018
 Sayantan Sur, Intel SEA Symposium on Overlapping Computation and Communication April 4 th, 2018 Legal Disclaimer & Benchmark results were obtained prior to implementation of recent software patches and
Sayantan Sur, Intel SEA Symposium on Overlapping Computation and Communication April 4 th, 2018 Legal Disclaimer & Benchmark results were obtained prior to implementation of recent software patches and
Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures
 Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures M. Bayatpour, S. Chakraborty, H. Subramoni, X. Lu, and D. K. Panda Department of Computer Science and Engineering
Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures M. Bayatpour, S. Chakraborty, H. Subramoni, X. Lu, and D. K. Panda Department of Computer Science and Engineering
Interconnect Your Future
 Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
Interconnect Your Future Smart Interconnect for Next Generation HPC Platforms Gilad Shainer, August 2016, 4th Annual MVAPICH User Group (MUG) Meeting Mellanox Connects the World s Fastest Supercomputer
2008 International ANSYS Conference
 2008 International ANSYS Conference Maximizing Productivity With InfiniBand-Based Clusters Gilad Shainer Director of Technical Marketing Mellanox Technologies 2008 ANSYS, Inc. All rights reserved. 1 ANSYS,
2008 International ANSYS Conference Maximizing Productivity With InfiniBand-Based Clusters Gilad Shainer Director of Technical Marketing Mellanox Technologies 2008 ANSYS, Inc. All rights reserved. 1 ANSYS,
Message Passing Improvements to Shared Address Space Thread Synchronization Techniques DAN STAFFORD, ROBERT RELYEA
 Message Passing Improvements to Shared Address Space Thread Synchronization Techniques DAN STAFFORD, ROBERT RELYEA Agenda Background Motivation Remote Memory Request Shared Address Synchronization Remote
Message Passing Improvements to Shared Address Space Thread Synchronization Techniques DAN STAFFORD, ROBERT RELYEA Agenda Background Motivation Remote Memory Request Shared Address Synchronization Remote
1/5/2012. Overview of Interconnects. Presentation Outline. Myrinet and Quadrics. Interconnects. Switch-Based Interconnects
 Overview of Interconnects Myrinet and Quadrics Leading Modern Interconnects Presentation Outline General Concepts of Interconnects Myrinet Latest Products Quadrics Latest Release Our Research Interconnects
Overview of Interconnects Myrinet and Quadrics Leading Modern Interconnects Presentation Outline General Concepts of Interconnects Myrinet Latest Products Quadrics Latest Release Our Research Interconnects
Initial Performance Evaluation of the Cray SeaStar Interconnect
 Initial Performance Evaluation of the Cray SeaStar Interconnect Ron Brightwell Kevin Pedretti Keith Underwood Sandia National Laboratories Scalable Computing Systems Department 13 th IEEE Symposium on
Initial Performance Evaluation of the Cray SeaStar Interconnect Ron Brightwell Kevin Pedretti Keith Underwood Sandia National Laboratories Scalable Computing Systems Department 13 th IEEE Symposium on
A Distributed Hash Table for Shared Memory
 A Distributed Hash Table for Shared Memory Wytse Oortwijn Formal Methods and Tools, University of Twente August 31, 2015 Wytse Oortwijn (Formal Methods and Tools, AUniversity Distributed of Twente) Hash
A Distributed Hash Table for Shared Memory Wytse Oortwijn Formal Methods and Tools, University of Twente August 31, 2015 Wytse Oortwijn (Formal Methods and Tools, AUniversity Distributed of Twente) Hash
Cray XC Scalability and the Aries Network Tony Ford
 Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Cray XC Scalability and the Aries Network Tony Ford June 29, 2017 Exascale Scalability Which scalability metrics are important for Exascale? Performance (obviously!) What are the contributing factors?
Interconnect Your Future
 Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
Interconnect Your Future Gilad Shainer 2nd Annual MVAPICH User Group (MUG) Meeting, August 2014 Complete High-Performance Scalable Interconnect Infrastructure Comprehensive End-to-End Software Accelerators
SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience
 SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience Jithin Jose, Mingzhe Li, Xiaoyi Lu, Krishna Kandalla, Mark Arnold and Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory
SR-IOV Support for Virtualization on InfiniBand Clusters: Early Experience Jithin Jose, Mingzhe Li, Xiaoyi Lu, Krishna Kandalla, Mark Arnold and Dhabaleswar K. (DK) Panda Network-Based Computing Laboratory
USING OPEN FABRIC INTERFACE IN INTEL MPI LIBRARY
 14th ANNUAL WORKSHOP 2018 USING OPEN FABRIC INTERFACE IN INTEL MPI LIBRARY Michael Chuvelev, Software Architect Intel April 11, 2018 INTEL MPI LIBRARY Optimized MPI application performance Application-specific
14th ANNUAL WORKSHOP 2018 USING OPEN FABRIC INTERFACE IN INTEL MPI LIBRARY Michael Chuvelev, Software Architect Intel April 11, 2018 INTEL MPI LIBRARY Optimized MPI application performance Application-specific
Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures Mohammadreza Bayatpour, Hari Subramoni, D. K.
 Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures Mohammadreza Bayatpour, Hari Subramoni, D. K. Panda Department of Computer Science and Engineering The Ohio
Accelerating MPI Message Matching and Reduction Collectives For Multi-/Many-core Architectures Mohammadreza Bayatpour, Hari Subramoni, D. K. Panda Department of Computer Science and Engineering The Ohio
Multiprocessors II: CC-NUMA DSM. CC-NUMA for Large Systems
 Multiprocessors II: CC-NUMA DSM DSM cache coherence the hardware stuff Today s topics: what happens when we lose snooping new issues: global vs. local cache line state enter the directory issues of increasing
Multiprocessors II: CC-NUMA DSM DSM cache coherence the hardware stuff Today s topics: what happens when we lose snooping new issues: global vs. local cache line state enter the directory issues of increasing
Advanced Computer Networks. End Host Optimization
 Oriana Riva, Department of Computer Science ETH Zürich 263 3501 00 End Host Optimization Patrick Stuedi Spring Semester 2017 1 Today End-host optimizations: NUMA-aware networking Kernel-bypass Remote Direct
Oriana Riva, Department of Computer Science ETH Zürich 263 3501 00 End Host Optimization Patrick Stuedi Spring Semester 2017 1 Today End-host optimizations: NUMA-aware networking Kernel-bypass Remote Direct
ABySS Performance Benchmark and Profiling. May 2010
 ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
ABySS Performance Benchmark and Profiling May 2010 Note The following research was performed under the HPC Advisory Council activities Participating vendors: AMD, Dell, Mellanox Compute resource - HPC
Interconnect Your Future
 #OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
#OpenPOWERSummit Interconnect Your Future Scot Schultz, Director HPC / Technical Computing Mellanox Technologies OpenPOWER Summit, San Jose CA March 2015 One-Generation Lead over the Competition Mellanox
Performance Analysis and Evaluation of Mellanox ConnectX InfiniBand Architecture with Multi-Core Platforms
 Performance Analysis and Evaluation of Mellanox ConnectX InfiniBand Architecture with Multi-Core Platforms Sayantan Sur, Matt Koop, Lei Chai Dhabaleswar K. Panda Network Based Computing Lab, The Ohio State
Performance Analysis and Evaluation of Mellanox ConnectX InfiniBand Architecture with Multi-Core Platforms Sayantan Sur, Matt Koop, Lei Chai Dhabaleswar K. Panda Network Based Computing Lab, The Ohio State
Design of MPI Passive Target Synchronization for a Non-Cache- Coherent Many-Core Processor
 Design of MPI Passive Target Synchronization for a Non-Cache- Coherent Many-Core Processor 27th PARS Workshop, Hagen, Germany, May 5 2017 Steffen Christgau, Bettina Schnor Operating Systems and Distributed
Design of MPI Passive Target Synchronization for a Non-Cache- Coherent Many-Core Processor 27th PARS Workshop, Hagen, Germany, May 5 2017 Steffen Christgau, Bettina Schnor Operating Systems and Distributed
Non-Blocking Collectives for MPI
 Non-Blocking Collectives for MPI overlap at the highest level Torsten Höfler Open Systems Lab Indiana University Bloomington, IN, USA Institut für Wissenschaftliches Rechnen Technische Universität Dresden
Non-Blocking Collectives for MPI overlap at the highest level Torsten Höfler Open Systems Lab Indiana University Bloomington, IN, USA Institut für Wissenschaftliches Rechnen Technische Universität Dresden
Communication Models for Resource Constrained Hierarchical Ethernet Networks
 Communication Models for Resource Constrained Hierarchical Ethernet Networks Speaker: Konstantinos Katrinis # Jun Zhu +, Alexey Lastovetsky *, Shoukat Ali #, Rolf Riesen # + Technical University of Eindhoven,
Communication Models for Resource Constrained Hierarchical Ethernet Networks Speaker: Konstantinos Katrinis # Jun Zhu +, Alexey Lastovetsky *, Shoukat Ali #, Rolf Riesen # + Technical University of Eindhoven,
Technical Computing Suite supporting the hybrid system
 Technical Computing Suite supporting the hybrid system Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster Hybrid System Configuration Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster 6D mesh/torus Interconnect
Technical Computing Suite supporting the hybrid system Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster Hybrid System Configuration Supercomputer PRIMEHPC FX10 PRIMERGY x86 cluster 6D mesh/torus Interconnect
Characterizing the Influence of System Noise on Large-Scale Applications by Simulation Torsten Hoefler, Timo Schneider, Andrew Lumsdaine
 Characterizing the Influence of System Noise on Large-Scale Applications by Simulation Torsten Hoefler, Timo Schneider, Andrew Lumsdaine System Noise Introduction and History CPUs are time-shared Deamons,
Characterizing the Influence of System Noise on Large-Scale Applications by Simulation Torsten Hoefler, Timo Schneider, Andrew Lumsdaine System Noise Introduction and History CPUs are time-shared Deamons,
High Performance Packet Processing with FlexNIC
 High Performance Packet Processing with FlexNIC Antoine Kaufmann, Naveen Kr. Sharma Thomas Anderson, Arvind Krishnamurthy University of Washington Simon Peter The University of Texas at Austin Ethernet
High Performance Packet Processing with FlexNIC Antoine Kaufmann, Naveen Kr. Sharma Thomas Anderson, Arvind Krishnamurthy University of Washington Simon Peter The University of Texas at Austin Ethernet
The Road to ExaScale. Advances in High-Performance Interconnect Infrastructure. September 2011
 The Road to ExaScale Advances in High-Performance Interconnect Infrastructure September 2011 diego@mellanox.com ExaScale Computing Ambitious Challenges Foster Progress Demand Research Institutes, Universities
The Road to ExaScale Advances in High-Performance Interconnect Infrastructure September 2011 diego@mellanox.com ExaScale Computing Ambitious Challenges Foster Progress Demand Research Institutes, Universities
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries
 Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Oncilla - a Managed GAS Runtime for Accelerating Data Warehousing Queries Jeffrey Young, Alex Merritt, Se Hoon Shon Advisor: Sudhakar Yalamanchili 4/16/13 Sponsors: Intel, NVIDIA, NSF 2 The Problem Big
Uni-Address Threads: Scalable Thread Management for RDMA-based Work Stealing
 Uni-Address Threads: Scalable Thread Management for RDMA-based Work Stealing Shigeki Akiyama, Kenjiro Taura The University of Tokyo June 17, 2015 HPDC 15 Lightweight Threads Lightweight threads enable
Uni-Address Threads: Scalable Thread Management for RDMA-based Work Stealing Shigeki Akiyama, Kenjiro Taura The University of Tokyo June 17, 2015 HPDC 15 Lightweight Threads Lightweight threads enable
GPU-centric communication for improved efficiency
 GPU-centric communication for improved efficiency Benjamin Klenk *, Lena Oden, Holger Fröning * * Heidelberg University, Germany Fraunhofer Institute for Industrial Mathematics, Germany GPCDP Workshop
GPU-centric communication for improved efficiency Benjamin Klenk *, Lena Oden, Holger Fröning * * Heidelberg University, Germany Fraunhofer Institute for Industrial Mathematics, Germany GPCDP Workshop
Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters
 Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters Matthew Koop 1 Miao Luo D. K. Panda matthew.koop@nasa.gov {luom, panda}@cse.ohio-state.edu 1 NASA Center for Computational
Reducing Network Contention with Mixed Workloads on Modern Multicore Clusters Matthew Koop 1 Miao Luo D. K. Panda matthew.koop@nasa.gov {luom, panda}@cse.ohio-state.edu 1 NASA Center for Computational
Designing High Performance DSM Systems using InfiniBand Features
 Designing High Performance DSM Systems using InfiniBand Features Ranjit Noronha and Dhabaleswar K. Panda The Ohio State University NBC Outline Introduction Motivation Design and Implementation Results
Designing High Performance DSM Systems using InfiniBand Features Ranjit Noronha and Dhabaleswar K. Panda The Ohio State University NBC Outline Introduction Motivation Design and Implementation Results
Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems.
 Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
Cluster Networks Introduction Communication has significant impact on application performance. Interconnection networks therefore have a vital role in cluster systems. As usual, the driver is performance
CSC2/458 Parallel and Distributed Systems Scalable Synchronization
 CSC2/458 Parallel and Distributed Systems Scalable Synchronization Sreepathi Pai February 20, 2018 URCS Outline Scalable Locking Barriers Outline Scalable Locking Barriers An alternative lock ticket lock
CSC2/458 Parallel and Distributed Systems Scalable Synchronization Sreepathi Pai February 20, 2018 URCS Outline Scalable Locking Barriers Outline Scalable Locking Barriers An alternative lock ticket lock
FaSST: Fast, Scalable, and Simple Distributed Transactions with Two-Sided (RDMA) Datagram RPCs
 Datagram RPCs") FaSST: Fast, Scalable, and Simple Distributed Transactions with Two-Sided (RDMA) Datagram RPCs Anuj Kalia (CMU), Michael Kaminsky (Intel Labs), David Andersen (CMU) RDMA RDMA is a network feature that
FaSST: Fast, Scalable, and Simple Distributed Transactions with Two-Sided (RDMA) Datagram RPCs Anuj Kalia (CMU), Michael Kaminsky (Intel Labs), David Andersen (CMU) RDMA RDMA is a network feature that
Open Fabrics Interfaces Architecture Introduction. Sean Hefty Intel Corporation
 Open Fabrics Interfaces Architecture Introduction Sean Hefty Intel Corporation Current State of Affairs OFED software Widely adopted low-level RDMA API Ships with upstream Linux but OFED SW was not designed
Open Fabrics Interfaces Architecture Introduction Sean Hefty Intel Corporation Current State of Affairs OFED software Widely adopted low-level RDMA API Ships with upstream Linux but OFED SW was not designed
CP2K Performance Benchmark and Profiling. April 2011
 CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council HPC works working group activities Participating vendors: HP, Intel, Mellanox
CP2K Performance Benchmark and Profiling April 2011 Note The following research was performed under the HPC Advisory Council HPC works working group activities Participating vendors: HP, Intel, Mellanox
Portable SHMEMCache: A High-Performance Key-Value Store on OpenSHMEM and MPI
 Portable SHMEMCache: A High-Performance Key-Value Store on OpenSHMEM and MPI Huansong Fu*, Manjunath Gorentla Venkata, Neena Imam, Weikuan Yu* *Florida State University Oak Ridge National Laboratory Outline
Portable SHMEMCache: A High-Performance Key-Value Store on OpenSHMEM and MPI Huansong Fu*, Manjunath Gorentla Venkata, Neena Imam, Weikuan Yu* *Florida State University Oak Ridge National Laboratory Outline
In-Network Computing. Paving the Road to Exascale. June 2017
 In-Network Computing Paving the Road to Exascale June 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect -Centric (Onload) Data-Centric (Offload) Must Wait for the Data Creates
In-Network Computing Paving the Road to Exascale June 2017 Exponential Data Growth The Need for Intelligent and Faster Interconnect -Centric (Onload) Data-Centric (Offload) Must Wait for the Data Creates
Myths and reality of communication/computation overlap in MPI applications
 Myths and reality of communication/computation overlap in MPI applications Alessandro Fanfarillo National Center for Atmospheric Research Boulder, Colorado, USA elfanfa@ucar.edu Oct 12th, 2017 (elfanfa@ucar.edu)
Myths and reality of communication/computation overlap in MPI applications Alessandro Fanfarillo National Center for Atmospheric Research Boulder, Colorado, USA elfanfa@ucar.edu Oct 12th, 2017 (elfanfa@ucar.edu)
RDMA over Commodity Ethernet at Scale
 RDMA over Commodity Ethernet at Scale Chuanxiong Guo, Haitao Wu, Zhong Deng, Gaurav Soni, Jianxi Ye, Jitendra Padhye, Marina Lipshteyn ACM SIGCOMM 2016 August 24 2016 Outline RDMA/RoCEv2 background DSCP-based
RDMA over Commodity Ethernet at Scale Chuanxiong Guo, Haitao Wu, Zhong Deng, Gaurav Soni, Jianxi Ye, Jitendra Padhye, Marina Lipshteyn ACM SIGCOMM 2016 August 24 2016 Outline RDMA/RoCEv2 background DSCP-based
Impact of Cache Coherence Protocols on the Processing of Network Traffic
 Impact of Cache Coherence Protocols on the Processing of Network Traffic Amit Kumar and Ram Huggahalli Communication Technology Lab Corporate Technology Group Intel Corporation 12/3/2007 Outline Background
Impact of Cache Coherence Protocols on the Processing of Network Traffic Amit Kumar and Ram Huggahalli Communication Technology Lab Corporate Technology Group Intel Corporation 12/3/2007 Outline Background
Advanced Computer Networks. Flow Control
 Advanced Computer Networks 263 3501 00 Flow Control Patrick Stuedi, Qin Yin, Timothy Roscoe Spring Semester 2015 Oriana Riva, Department of Computer Science ETH Zürich 1 Today Flow Control Store-and-forward,
Advanced Computer Networks 263 3501 00 Flow Control Patrick Stuedi, Qin Yin, Timothy Roscoe Spring Semester 2015 Oriana Riva, Department of Computer Science ETH Zürich 1 Today Flow Control Store-and-forward,
BlueGene/L. Computer Science, University of Warwick. Source: IBM
 BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
BlueGene/L Source: IBM 1 BlueGene/L networking BlueGene system employs various network types. Central is the torus interconnection network: 3D torus with wrap-around. Each node connects to six neighbours
Harp-DAAL for High Performance Big Data Computing
 Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
Harp-DAAL for High Performance Big Data Computing Large-scale data analytics is revolutionizing many business and scientific domains. Easy-touse scalable parallel techniques are necessary to process big
Designing Power-Aware Collective Communication Algorithms for InfiniBand Clusters
 Designing Power-Aware Collective Communication Algorithms for InfiniBand Clusters Krishna Kandalla, Emilio P. Mancini, Sayantan Sur, and Dhabaleswar. K. Panda Department of Computer Science & Engineering,
Designing Power-Aware Collective Communication Algorithms for InfiniBand Clusters Krishna Kandalla, Emilio P. Mancini, Sayantan Sur, and Dhabaleswar. K. Panda Department of Computer Science & Engineering,
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
FOEDUS: OLTP Engine for a Thousand Cores and NVRAM
 FOEDUS: OLTP Engine for a Thousand Cores and NVRAM Hideaki Kimura HP Labs, Palo Alto, CA Slides By : Hideaki Kimura Presented By : Aman Preet Singh Next-Generation Server Hardware? HP The Machine UC Berkeley
FOEDUS: OLTP Engine for a Thousand Cores and NVRAM Hideaki Kimura HP Labs, Palo Alto, CA Slides By : Hideaki Kimura Presented By : Aman Preet Singh Next-Generation Server Hardware? HP The Machine UC Berkeley
GLocks: Efficient Support for Highly- Contended Locks in Many-Core CMPs
 GLocks: Efficient Support for Highly- Contended Locks in Many-Core CMPs Authors: Jos e L. Abell an, Juan Fern andez and Manuel E. Acacio Presenter: Guoliang Liu Outline Introduction Motivation Background
GLocks: Efficient Support for Highly- Contended Locks in Many-Core CMPs Authors: Jos e L. Abell an, Juan Fern andez and Manuel E. Acacio Presenter: Guoliang Liu Outline Introduction Motivation Background
MULTI-CONNECTION AND MULTI-CORE AWARE ALL-GATHER ON INFINIBAND CLUSTERS
 MULTI-CONNECTION AND MULTI-CORE AWARE ALL-GATHER ON INFINIBAND CLUSTERS Ying Qian Mohammad J. Rashti Ahmad Afsahi Department of Electrical and Computer Engineering, Queen s University Kingston, ON, CANADA
MULTI-CONNECTION AND MULTI-CORE AWARE ALL-GATHER ON INFINIBAND CLUSTERS Ying Qian Mohammad J. Rashti Ahmad Afsahi Department of Electrical and Computer Engineering, Queen s University Kingston, ON, CANADA
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA
 Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
Performance Optimizations via Connect-IB and Dynamically Connected Transport Service for Maximum Performance on LS-DYNA Pak Lui, Gilad Shainer, Brian Klaff Mellanox Technologies Abstract From concept to
The Role of InfiniBand Technologies in High Performance Computing. 1 Managed by UT-Battelle for the Department of Energy
 The Role of InfiniBand Technologies in High Performance Computing 1 Managed by UT-Battelle Contributors Gil Bloch Noam Bloch Hillel Chapman Manjunath Gorentla- Venkata Richard Graham Michael Kagan Vasily
The Role of InfiniBand Technologies in High Performance Computing 1 Managed by UT-Battelle Contributors Gil Bloch Noam Bloch Hillel Chapman Manjunath Gorentla- Venkata Richard Graham Michael Kagan Vasily
Building the Most Efficient Machine Learning System
 Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
Building the Most Efficient Machine Learning System Mellanox The Artificial Intelligence Interconnect Company June 2017 Mellanox Overview Company Headquarters Yokneam, Israel Sunnyvale, California Worldwide
1. Define algorithm complexity 2. What is called out of order in detail? 3. Define Hardware prefetching. 4. Define software prefetching. 5. Define wor
 CS6801-MULTICORE ARCHECTURES AND PROGRAMMING UN I 1. Difference between Symmetric Memory Architecture and Distributed Memory Architecture. 2. What is Vector Instruction? 3. What are the factor to increasing
CS6801-MULTICORE ARCHECTURES AND PROGRAMMING UN I 1. Difference between Symmetric Memory Architecture and Distributed Memory Architecture. 2. What is Vector Instruction? 3. What are the factor to increasing
Advanced Software for the Supercomputer PRIMEHPC FX10. Copyright 2011 FUJITSU LIMITED
 Advanced Software for the Supercomputer PRIMEHPC FX10 System Configuration of PRIMEHPC FX10 nodes Login Compilation Job submission 6D mesh/torus Interconnect Local file system (Temporary area occupied
Advanced Software for the Supercomputer PRIMEHPC FX10 System Configuration of PRIMEHPC FX10 nodes Login Compilation Job submission 6D mesh/torus Interconnect Local file system (Temporary area occupied
MILC Performance Benchmark and Profiling. April 2013
 MILC Performance Benchmark and Profiling April 2013 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
MILC Performance Benchmark and Profiling April 2013 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information on the supporting
ANSYS Fluent 14 Performance Benchmark and Profiling. October 2012
 ANSYS Fluent 14 Performance Benchmark and Profiling October 2012 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information
ANSYS Fluent 14 Performance Benchmark and Profiling October 2012 Note The following research was performed under the HPC Advisory Council activities Special thanks for: HP, Mellanox For more information
Data Processing on Emerging Hardware
 Data Processing on Emerging Hardware Gustavo Alonso Systems Group Department of Computer Science ETH Zurich, Switzerland 3 rd International Summer School on Big Data, Munich, Germany, 2017 www.systems.ethz.ch
Data Processing on Emerging Hardware Gustavo Alonso Systems Group Department of Computer Science ETH Zurich, Switzerland 3 rd International Summer School on Big Data, Munich, Germany, 2017 www.systems.ethz.ch
Parallel Patterns for Window-based Stateful Operators on Data Streams: an Algorithmic Skeleton Approach
 Parallel Patterns for Window-based Stateful Operators on Data Streams: an Algorithmic Skeleton Approach Tiziano De Matteis, Gabriele Mencagli University of Pisa Italy INTRODUCTION The recent years have
Parallel Patterns for Window-based Stateful Operators on Data Streams: an Algorithmic Skeleton Approach Tiziano De Matteis, Gabriele Mencagli University of Pisa Italy INTRODUCTION The recent years have
Sayantan Sur, Intel. ExaComm Workshop held in conjunction with ISC 2018
 Sayantan Sur, Intel ExaComm Workshop held in conjunction with ISC 2018 Legal Disclaimer & Optimization Notice Software and workloads used in performance tests may have been optimized for performance only
Sayantan Sur, Intel ExaComm Workshop held in conjunction with ISC 2018 Legal Disclaimer & Optimization Notice Software and workloads used in performance tests may have been optimized for performance only
Lecture 9: Multiprocessor OSs & Synchronization. CSC 469H1F Fall 2006 Angela Demke Brown
 Lecture 9: Multiprocessor OSs & Synchronization CSC 469H1F Fall 2006 Angela Demke Brown The Problem Coordinated management of shared resources Resources may be accessed by multiple threads Need to control
Lecture 9: Multiprocessor OSs & Synchronization CSC 469H1F Fall 2006 Angela Demke Brown The Problem Coordinated management of shared resources Resources may be accessed by multiple threads Need to control
Protocols for Fully Offloaded Collective Operations on Accelerated Network Adapters
 Protocols for Fully Offloaded Collective Operations on Accelerated Network Adapters Timo Schneider, Torsten Hoefler ETH Zurich Dept. of Computer Science Universitätstr. 6 8092 Zurich, Switzerland Email:
Protocols for Fully Offloaded Collective Operations on Accelerated Network Adapters Timo Schneider, Torsten Hoefler ETH Zurich Dept. of Computer Science Universitätstr. 6 8092 Zurich, Switzerland Email:
BzTree: A High-Performance Latch-free Range Index for Non-Volatile Memory
 BzTree: A High-Performance Latch-free Range Index for Non-Volatile Memory JOY ARULRAJ JUSTIN LEVANDOSKI UMAR FAROOQ MINHAS PER-AKE LARSON Microsoft Research NON-VOLATILE MEMORY [NVM] PERFORMANCE DRAM VOLATILE
BzTree: A High-Performance Latch-free Range Index for Non-Volatile Memory JOY ARULRAJ JUSTIN LEVANDOSKI UMAR FAROOQ MINHAS PER-AKE LARSON Microsoft Research NON-VOLATILE MEMORY [NVM] PERFORMANCE DRAM VOLATILE
Enabling highly-scalable remote memory access programming with MPI-3 One Sided 1
 Scientific Programming 22 (2014) 75 91 75 DOI 10.3233/SPR-140383 IOS Press Enabling highly-scalable remote memory access programming with MPI-3 One Sided 1 Robert Gerstenberger, Maciej Besta and Torsten
Scientific Programming 22 (2014) 75 91 75 DOI 10.3233/SPR-140383 IOS Press Enabling highly-scalable remote memory access programming with MPI-3 One Sided 1 Robert Gerstenberger, Maciej Besta and Torsten
The Tofu Interconnect D
 The Tofu Interconnect D 11 September 2018 Yuichiro Ajima, Takahiro Kawashima, Takayuki Okamoto, Naoyuki Shida, Kouichi Hirai, Toshiyuki Shimizu, Shinya Hiramoto, Yoshiro Ikeda, Takahide Yoshikawa, Kenji
The Tofu Interconnect D 11 September 2018 Yuichiro Ajima, Takahiro Kawashima, Takayuki Okamoto, Naoyuki Shida, Kouichi Hirai, Toshiyuki Shimizu, Shinya Hiramoto, Yoshiro Ikeda, Takahide Yoshikawa, Kenji
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구
 MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
MELLANOX EDR UPDATE & GPUDIRECT MELLANOX SR. SE 정연구 Leading Supplier of End-to-End Interconnect Solutions Analyze Enabling the Use of Data Store ICs Comprehensive End-to-End InfiniBand and Ethernet Portfolio
Using Lamport s Logical Clocks
 Fast Classification of MPI Applications Using Lamport s Logical Clocks Zhou Tong, Scott Pakin, Michael Lang, Xin Yuan Florida State University Los Alamos National Laboratory 1 Motivation Conventional trace-based
Fast Classification of MPI Applications Using Lamport s Logical Clocks Zhou Tong, Scott Pakin, Michael Lang, Xin Yuan Florida State University Los Alamos National Laboratory 1 Motivation Conventional trace-based
The Impact of Inter-node Latency versus Intra-node Latency on HPC Applications The 23 rd IASTED International Conference on PDCS 2011
 The Impact of Inter-node Latency versus Intra-node Latency on HPC Applications The 23 rd IASTED International Conference on PDCS 2011 HPC Scale Working Group, Dec 2011 Gilad Shainer, Pak Lui, Tong Liu,
The Impact of Inter-node Latency versus Intra-node Latency on HPC Applications The 23 rd IASTED International Conference on PDCS 2011 HPC Scale Working Group, Dec 2011 Gilad Shainer, Pak Lui, Tong Liu,
Design Alternatives for Implementing Fence Synchronization in MPI-2 One-Sided Communication for InfiniBand Clusters
 Design Alternatives for Implementing Fence Synchronization in MPI-2 One-Sided Communication for InfiniBand Clusters G.Santhanaraman, T. Gangadharappa, S.Narravula, A.Mamidala and D.K.Panda Presented by:
Design Alternatives for Implementing Fence Synchronization in MPI-2 One-Sided Communication for InfiniBand Clusters G.Santhanaraman, T. Gangadharappa, S.Narravula, A.Mamidala and D.K.Panda Presented by:
Can Memory-Less Network Adapters Benefit Next-Generation InfiniBand Systems?
 Can Memory-Less Network Adapters Benefit Next-Generation InfiniBand Systems? Sayantan Sur, Abhinav Vishnu, Hyun-Wook Jin, Wei Huang and D. K. Panda {surs, vishnu, jinhy, huanwei, panda}@cse.ohio-state.edu
Can Memory-Less Network Adapters Benefit Next-Generation InfiniBand Systems? Sayantan Sur, Abhinav Vishnu, Hyun-Wook Jin, Wei Huang and D. K. Panda {surs, vishnu, jinhy, huanwei, panda}@cse.ohio-state.edu
Optimizing non-blocking Collective Operations for InfiniBand
 Optimizing non-blocking Collective Operations for InfiniBand Open Systems Lab Indiana University Bloomington, USA IPDPS 08 - CAC 08 Workshop Miami, FL, USA April, 14th 2008 Introduction Non-blocking collective
Optimizing non-blocking Collective Operations for InfiniBand Open Systems Lab Indiana University Bloomington, USA IPDPS 08 - CAC 08 Workshop Miami, FL, USA April, 14th 2008 Introduction Non-blocking collective
Synchronization. Jinkyu Jeong Computer Systems Laboratory Sungkyunkwan University
 Synchronization Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Types of Synchronization Mutual Exclusion Locks Event Synchronization Global or group-based
Synchronization Jinkyu Jeong (jinkyu@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Types of Synchronization Mutual Exclusion Locks Event Synchronization Global or group-based
A PCIe Congestion-Aware Performance Model for Densely Populated Accelerator Servers
 A PCIe Congestion-Aware Performance Model for Densely Populated Accelerator Servers Maxime Martinasso, Grzegorz Kwasniewski, Sadaf R. Alam, Thomas C. Schulthess, Torsten Hoefler Swiss National Supercomputing
A PCIe Congestion-Aware Performance Model for Densely Populated Accelerator Servers Maxime Martinasso, Grzegorz Kwasniewski, Sadaf R. Alam, Thomas C. Schulthess, Torsten Hoefler Swiss National Supercomputing
Using RDMA for Lock Management
 Using RDMA for Lock Management Yeounoh Chung Erfan Zamanian {yeounoh, erfanz}@cs.brown.edu Supervised by: John Meehan Stan Zdonik {john, sbz}@cs.brown.edu Abstract arxiv:1507.03274v2 [cs.dc] 20 Jul 2015
Using RDMA for Lock Management Yeounoh Chung Erfan Zamanian {yeounoh, erfanz}@cs.brown.edu Supervised by: John Meehan Stan Zdonik {john, sbz}@cs.brown.edu Abstract arxiv:1507.03274v2 [cs.dc] 20 Jul 2015
Scalable, multithreaded, shared memory machine Designed for single word random global access patterns Very good at large graph problems
 Cray XMT Scalable, multithreaded, shared memory machine Designed for single word random global access patterns Very good at large graph problems Next Generation Cray XMT Goals Memory System Improvements
Cray XMT Scalable, multithreaded, shared memory machine Designed for single word random global access patterns Very good at large graph problems Next Generation Cray XMT Goals Memory System Improvements