Automatic Tuning of Sparse Matrix Kernels
|
|
|
- Austin Parrish
- 6 years ago
- Views:
Transcription
1 Automatic Tuning of Sparse Matrix Kernels Kathy Yelick U.C. Berkeley and Lawrence Berkeley National Laboratory Richard Vuduc, Lawrence Livermore National Laboratory James Demmel, U.C. Berkeley Berkeley Benchmarking and OPtimization (BeBOP) Group bebop.cs.berkeley.edu
2 Motivation for Tuning Sparse Matrices Sparse matrix kernels can dominate solver time Sparse matrix-vector multiply (SpMV) SpMV: runs at < 10% of peak Improving SpMV s performance is hard Performance depends on machine, kernel, matrix Matrix known only at run-time Best data structure + implementation can be surprising Tuning becoming more difficult over time Approach: Empirical modeling and search Off-line benchmarking + run-time models Up to 4x speedups and 31% of peak for SpMV Other kernels: 1.8x triangular solve, 4x A T A x, 2x A 2 x
3 OSKI: Optimized Sparse Kernel Interface Sparse kernels tuned for user s matrix & machine Hides complexity of run-time tuning Low-level BLAS-style functionality Includes fast locality-aware kernels: A T A x, A k x Initial target: cache-based superscalar uniprocessors Target users: advanced users & solver library writers Current focus on uniprocessor tuning Shared/distributed memory versions in progress Open-source (BSD) C library 1.0 available: bebop.cs.berkeley.edu/oski Being integrated into PETSc


4 Compressed Sparse Row (CSR) Storage x Representation of A y A Matrix-vector multiply kernel: y(i) y(i) + A(i,j) x(j) for each row i for k=ptr[i] to ptr[i+1] do y[i] = y[i] + val[k]*x[ind[k]]
5 Example: The Difficulty of Tuning n = nnz = 1.5 M kernel: SpMV Source: NASA structural analysis problem

6 Example: The Difficulty of Tuning n = nnz = 1.5 M kernel: SpMV Source: NASA structural analysis problem 8x8 dense substructure
7 What We Expect Assume Cost(SpMV) = time to read matrix 1 double-word = 2 integers r, c in {1, 2, 4, 8} CSR: 1 int / non-zero BCSR(r x c): 1 int / (r*c non-zeros) As r*c increases, speedup should Increase smoothly Approach 1.5 Speedup = T T BCSR CSR ( r, c) rc r, c= 1.5
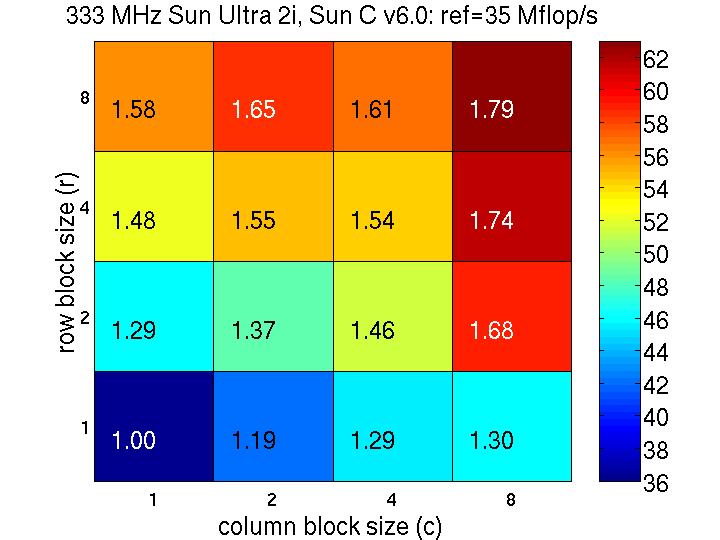
8 What We Get (The Need for Search) Mflop/s Best: 4x2 Reference Mflop/s



9 SpMV Performance raefsky3



10 SpMV Performance raefsky3
11 Still More Surprises More complicated non-zero structure in general

12 Still More Surprises More complicated non-zero structure in general Example: 3x3 blocking Logical grid of 3x3 cells
13 Extra Work Can Improve Efficiency! More complicated non-zero structure in general Example: 3x3 blocking Logical grid of 3x3 cells Fill-in explicit zeros Unroll 3x3 block multiplies Fill ratio = 1.5 On Pentium III: 1.5x speedup!
14 How OSKI Tunes (Overview) Library Install-Time (offline) Application Run-Time 1. Build for Target Arch. 2. Benchmark Matrix Workload from program monitoring History Generated code variants Benchmark data 1. Evaluate Models Heuristic models 2. Select Data Struct. & Code To user: Matrix handle for kernel calls Extensibility: Advanced users may write & dynamically add Code variants and Heuristic models to system.
15 Example of a Tuning Heuristic Example: Selecting the r x c block size Off-line benchmark: characterize the machine Precompute Mflops(r,c) using dense matrix for each r x c Once per machine/architecture Run-time search : characterize the matrix Sample A to estimate Fill(r,c) for each r x c Run-time heuristic model Choose r, c to maximize Mflops(r,c) / Fill(r,c) Run-time costs Up to ~40 SpMVs (empirical worst case) Dominated by conversion May be amortized if pattern fixed
16 DGEMV Accuracy of the Tuning Heuristics (1/4) NOTE: Fair flops used (ops on explicit zeros not counted as work )
17 DGEMV Accuracy of the Tuning Heuristics (2/4) NOTE: Fair flops used (ops on explicit zeros not counted as work )
18 Calling OSKI: Interface Design Support legacy applications Gradual migration of apps to use OSKI Must call tune routine explicitly Exposes cost of tuning and data structure reorganization May provide tuning hints Structural: Hints about matrix Workload: Hints about frequency of calls, to limit tuning time May save/restore tuning results To apply on future runs with similar matrix Stored in human-readable format
19 Exploiting Problem-Specific Structure Optimizations for SpMV Register blocking (up to 4x over CSR) Variable block splitting (2.1x over CSR, 1.8x over RB) Diagonals (2x over CSR) Reordering to create dense structure + splitting (2x over CSR) Symmetry (2.8x over CSR, 2.6x over RB) Cache blocking (2.2x over CSR) Multiple vectors (7x over CSR) And combinations Sparse triangular solve Hybrid sparse/dense data structure (1.8x over CSR) Higher-level kernels AA T x, A T A x (4x over CSR, 1.8x over RB) A 2 x (2x over CSR, 1.5x over RB)

20 Example: Variable Block Structure 2.1x over CSR 1.8x over RB

21 Example: Row-Segmented Diagonals 2x over CSR

22 Mixed Diagonal and Block Structure
23 Example: Sparse Triangular Factor Raefsky4 (structural problem) + SuperLU + colmmd N=19779, nnz=12.6 M Dense trailing triangle: dim=2268, 20% of total nz Can be as high as 90+%! 1.8x over CSR
24 Example applications T3P Accelerator Design Ko Register blocking, Symmetric Storage, Multiple vector 1.68x faster on Itanium 2 for one vector 4.4x faster for 8 vectors Omega3P Accelerator Design Ko Register blocking, Symmetric storage, Reordering 2.1x faster on Power4 Semiconductor Industry: 1.9x speedup over SPOOLES in CG at design firm Recent integration of OSKI into PETSc
25 Status and Future Work OSKI Release 1.0 and docs available bebop.cs.berkeley.edu/oski Performance bounds modeling (ongoing) Future OSKI work Release of PETSc version with OSKI Better low-level tuning, including vectors Automatically tuned parallel sparse kernels Development of a new HPC Challenge Benchmark Evaluate platforms based on tuned (blocked) SpMV performance Tuning higher level algorithms using A k x Models indicate large speedups possible
OSKI: A Library of Automatically Tuned Sparse Matrix Kernels
 OSKI: A Library of Automatically Tuned Sparse Matrix Kernels Richard Vuduc (LLNL), James Demmel, Katherine Yelick Berkeley Benchmarking and OPtimization (BeBOP) Project bebop.cs.berkeley.edu EECS Department,
OSKI: A Library of Automatically Tuned Sparse Matrix Kernels Richard Vuduc (LLNL), James Demmel, Katherine Yelick Berkeley Benchmarking and OPtimization (BeBOP) Project bebop.cs.berkeley.edu EECS Department,
OSKI: Autotuned sparse matrix kernels
 : Autotuned sparse matrix kernels Richard Vuduc LLNL / Georgia Tech [Work in this talk: Berkeley] James Demmel, Kathy Yelick, UCB [BeBOP group] CScADS Autotuning Workshop What does the sparse case add
: Autotuned sparse matrix kernels Richard Vuduc LLNL / Georgia Tech [Work in this talk: Berkeley] James Demmel, Kathy Yelick, UCB [BeBOP group] CScADS Autotuning Workshop What does the sparse case add
Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply
 Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply University of California, Berkeley Berkeley Benchmarking and Optimization Group (BeBOP) http://bebop.cs.berkeley.edu
Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply University of California, Berkeley Berkeley Benchmarking and Optimization Group (BeBOP) http://bebop.cs.berkeley.edu
Adaptable benchmarks for register blocked sparse matrix-vector multiplication
 Adaptable benchmarks for register blocked sparse matrix-vector multiplication Berkeley Benchmarking and Optimization group (BeBOP) Hormozd Gahvari and Mark Hoemmen Based on research of: Eun-Jin Im Rich
Adaptable benchmarks for register blocked sparse matrix-vector multiplication Berkeley Benchmarking and Optimization group (BeBOP) Hormozd Gahvari and Mark Hoemmen Based on research of: Eun-Jin Im Rich
Fast sparse matrix-vector multiplication by exploiting variable block structure
 Fast sparse matrix-vector multiplication by exploiting variable block structure Richard W. Vuduc 1 and Hyun-Jin Moon 2 1 Lawrence Livermore National Laboratory (richie@llnl.gov) 2 University of California,
Fast sparse matrix-vector multiplication by exploiting variable block structure Richard W. Vuduc 1 and Hyun-Jin Moon 2 1 Lawrence Livermore National Laboratory (richie@llnl.gov) 2 University of California,
Lecture 15: More Iterative Ideas
 Lecture 15: More Iterative Ideas David Bindel 15 Mar 2010 Logistics HW 2 due! Some notes on HW 2. Where we are / where we re going More iterative ideas. Intro to HW 3. More HW 2 notes See solution code!
Lecture 15: More Iterative Ideas David Bindel 15 Mar 2010 Logistics HW 2 due! Some notes on HW 2. Where we are / where we re going More iterative ideas. Intro to HW 3. More HW 2 notes See solution code!
Performance Optimizations and Bounds for Sparse Symmetric Matrix - Multiple Vector Multiply
 Performance Optimizations and Bounds for Sparse Symmetric Matrix - Multiple Vector Multiply Benjamin C. Lee Richard W. Vuduc James W. Demmel Katherine A. Yelick Michael de Lorimier Lijue Zhong Report No.
Performance Optimizations and Bounds for Sparse Symmetric Matrix - Multiple Vector Multiply Benjamin C. Lee Richard W. Vuduc James W. Demmel Katherine A. Yelick Michael de Lorimier Lijue Zhong Report No.
poski: Parallel Optimized Sparse Kernel Interface Library User s Guide for Version 1.0.0
 poski: Parallel Optimized Sparse Kernel Interface Library User s Guide for Version 1.0.0 Jong-Ho Byun James W. Demmel Richard Lin Katherine A. Yelick Berkeley Benchmarking and Optimization (BeBOP) Group
poski: Parallel Optimized Sparse Kernel Interface Library User s Guide for Version 1.0.0 Jong-Ho Byun James W. Demmel Richard Lin Katherine A. Yelick Berkeley Benchmarking and Optimization (BeBOP) Group
How to Write Fast Numerical Code
 How to Write Fast Numerical Code Lecture: Memory bound computation, sparse linear algebra, OSKI Instructor: Markus Püschel TA: Alen Stojanov, Georg Ofenbeck, Gagandeep Singh ATLAS Mflop/s Compile Execute
How to Write Fast Numerical Code Lecture: Memory bound computation, sparse linear algebra, OSKI Instructor: Markus Püschel TA: Alen Stojanov, Georg Ofenbeck, Gagandeep Singh ATLAS Mflop/s Compile Execute
How to Write Fast Numerical Code Spring 2012 Lecture 13. Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato
 How to Write Fast Numerical Code Spring 2012 Lecture 13 Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato ATLAS Mflop/s Compile Execute Measure Detect Hardware Parameters L1Size NR MulAdd
How to Write Fast Numerical Code Spring 2012 Lecture 13 Instructor: Markus Püschel TAs: Georg Ofenbeck & Daniele Spampinato ATLAS Mflop/s Compile Execute Measure Detect Hardware Parameters L1Size NR MulAdd
Optimizing Sparse Data Structures for Matrix-Vector Multiply
 Summary Optimizing Sparse Data Structures for Matrix-Vector Multiply William Gropp (UIUC) and Dahai Guo (NCSA) Algorithms and Data Structures need to take memory prefetch hardware into account This talk
Summary Optimizing Sparse Data Structures for Matrix-Vector Multiply William Gropp (UIUC) and Dahai Guo (NCSA) Algorithms and Data Structures need to take memory prefetch hardware into account This talk
Memory Hierarchy Optimizations and Performance Bounds for Sparse A T Ax
 Memory Hierarchy Optimizations and Performance Bounds for Sparse A T Ax Richard Vuduc, Attila Gyulassy, James W. Demmel, and Katherine A. Yelick Computer Science Division, University of California, Berkeley
Memory Hierarchy Optimizations and Performance Bounds for Sparse A T Ax Richard Vuduc, Attila Gyulassy, James W. Demmel, and Katherine A. Yelick Computer Science Division, University of California, Berkeley
Behavioral Data Mining. Lecture 12 Machine Biology
 Behavioral Data Mining Lecture 12 Machine Biology Outline CPU geography Mass storage Buses and Networks Main memory Design Principles Intel i7 close-up From Computer Architecture a Quantitative Approach
Behavioral Data Mining Lecture 12 Machine Biology Outline CPU geography Mass storage Buses and Networks Main memory Design Principles Intel i7 close-up From Computer Architecture a Quantitative Approach
Outline CS267 Lecture 15. Automatic Performance Tuning and Sparse-Matrix-Vector-Multiplication (SpMV) Motivation for Automatic Performance Tuning
 Motivation for Automatic Performance Tuning") Outline CS267 Lecture 15 Automatic Performance Tuning and Sparse-Matri-Vector-Multiplication (SpMV) James Demmel www.cs.berkeley.edu/~demmel/cs267_spr16 Motivation for Automatic Performance Tuning Results
Outline CS267 Lecture 15 Automatic Performance Tuning and Sparse-Matri-Vector-Multiplication (SpMV) James Demmel www.cs.berkeley.edu/~demmel/cs267_spr16 Motivation for Automatic Performance Tuning Results
Self Adapting Linear Algebra Algorithms and Software
 1 Self Adapting Linear Algebra Algorithms and Software Jim Demmel[1], Jack Dongarra[2], Victor Eijkhout[2], Erika Fuentes[2], Antoine Petitet[3], Rich Vuduc[1], R. Clint Whaley[4], Katherine Yelick[1]
1 Self Adapting Linear Algebra Algorithms and Software Jim Demmel[1], Jack Dongarra[2], Victor Eijkhout[2], Erika Fuentes[2], Antoine Petitet[3], Rich Vuduc[1], R. Clint Whaley[4], Katherine Yelick[1]
Self Adapting Linear Algebra Algorithms and Software
 Self Adapting Linear Algebra Algorithms and Software Jim Demmel, Jack Dongarra, Victor Eijkhout, Erika Fuentes, Antoine Petitet, Rich Vuduc, R. Clint Whaley, Katherine Yelick October 17, 2004 Abstract
Self Adapting Linear Algebra Algorithms and Software Jim Demmel, Jack Dongarra, Victor Eijkhout, Erika Fuentes, Antoine Petitet, Rich Vuduc, R. Clint Whaley, Katherine Yelick October 17, 2004 Abstract
Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply
 Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply Benjamin C. Lee, Richard W. Vuduc, James W. Demmel, Katherine A. Yelick University of California, Berkeley
Performance Models for Evaluation and Automatic Tuning of Symmetric Sparse Matrix-Vector Multiply Benjamin C. Lee, Richard W. Vuduc, James W. Demmel, Katherine A. Yelick University of California, Berkeley
The Optimized Sparse Kernel Interface (OSKI) Library User s Guide for Version 1.0.1h
 Library User s Guide for Version 1.0.1h") The Optimized Sparse Kernel Interface (OSKI) Library User s Guide for Version 1.0.1h Richard Vuduc James W. Demmel Katherine A. Yelick Berkeley Benchmarking and OPtimization (BeBOP) Group University of
The Optimized Sparse Kernel Interface (OSKI) Library User s Guide for Version 1.0.1h Richard Vuduc James W. Demmel Katherine A. Yelick Berkeley Benchmarking and OPtimization (BeBOP) Group University of
Self-Adapting Linear Algebra Algorithms and Software
 Self-Adapting Linear Algebra Algorithms and Software JAMES DEMMEL, FELLOW, IEEE, JACK DONGARRA, FELLOW, IEEE, VICTOR EIJKHOUT, ERIKA FUENTES, ANTOINE PETITET, RICHARD VUDUC, R. CLINT WHALEY, AND KATHERINE
Self-Adapting Linear Algebra Algorithms and Software JAMES DEMMEL, FELLOW, IEEE, JACK DONGARRA, FELLOW, IEEE, VICTOR EIJKHOUT, ERIKA FUENTES, ANTOINE PETITET, RICHARD VUDUC, R. CLINT WHALEY, AND KATHERINE
Master Informatics Eng.
 Advanced Architectures Master Informatics Eng. 207/8 A.J.Proença The Roofline Performance Model (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 207/8 AJProença, Advanced Architectures,
Advanced Architectures Master Informatics Eng. 207/8 A.J.Proença The Roofline Performance Model (most slides are borrowed) AJProença, Advanced Architectures, MiEI, UMinho, 207/8 AJProença, Advanced Architectures,
Communication-avoidance!
 Communication-avoidance! and! Automatic performance tuning! Nick Knight! UC-Berkeley Parlab (Bebop group)! 1 Students and Collaborators (Bebop) PIs! James Demmel! Kathy Yelick! Students! Marghoob Mohiyuddin!
Communication-avoidance! and! Automatic performance tuning! Nick Knight! UC-Berkeley Parlab (Bebop group)! 1 Students and Collaborators (Bebop) PIs! James Demmel! Kathy Yelick! Students! Marghoob Mohiyuddin!
Lecture 17: More Fun With Sparse Matrices
 Lecture 17: More Fun With Sparse Matrices David Bindel 26 Oct 2011 Logistics Thanks for info on final project ideas. HW 2 due Monday! Life lessons from HW 2? Where an error occurs may not be where you
Lecture 17: More Fun With Sparse Matrices David Bindel 26 Oct 2011 Logistics Thanks for info on final project ideas. HW 2 due Monday! Life lessons from HW 2? Where an error occurs may not be where you
Automatic Performance Tuning and Analysis of Sparse Triangular Solve p.1/31
 Automatic Performance Tuning and Analysis of Sparse Triangular Solve Richard Vuduc, Shoaib Kamil, Jen Hsu, Rajesh Nishtala James W. Demmel, Katherine A. Yelick June 22, 2002 Berkeley Benchmarking and OPtimization
Automatic Performance Tuning and Analysis of Sparse Triangular Solve Richard Vuduc, Shoaib Kamil, Jen Hsu, Rajesh Nishtala James W. Demmel, Katherine A. Yelick June 22, 2002 Berkeley Benchmarking and OPtimization
Lecture 13: March 25
 CISC 879 Software Support for Multicore Architectures Spring 2007 Lecture 13: March 25 Lecturer: John Cavazos Scribe: Ying Yu 13.1. Bryan Youse-Optimization of Sparse Matrix-Vector Multiplication on Emerging
CISC 879 Software Support for Multicore Architectures Spring 2007 Lecture 13: March 25 Lecturer: John Cavazos Scribe: Ying Yu 13.1. Bryan Youse-Optimization of Sparse Matrix-Vector Multiplication on Emerging
Research Project. Approval for the Report and Comprehensive Examination: Committee: Professor Katherine Yelick Research Advisor.
 poski: An Extensible Autotuning Framework to Perform Optimized SpMVs on Multicore Architectures by Ankit Jain ankit@berkeley.edu Computer Science Division, University of California, Berkeley Research Project
poski: An Extensible Autotuning Framework to Perform Optimized SpMVs on Multicore Architectures by Ankit Jain ankit@berkeley.edu Computer Science Division, University of California, Berkeley Research Project
Intel Math Kernel Library (Intel MKL) BLAS. Victor Kostin Intel MKL Dense Solvers team manager
 BLAS. Victor Kostin Intel MKL Dense Solvers team manager") Intel Math Kernel Library (Intel MKL) BLAS Victor Kostin Intel MKL Dense Solvers team manager Intel MKL BLAS/Sparse BLAS Original ( dense ) BLAS available from www.netlib.org Additionally Intel MKL provides
Intel Math Kernel Library (Intel MKL) BLAS Victor Kostin Intel MKL Dense Solvers team manager Intel MKL BLAS/Sparse BLAS Original ( dense ) BLAS available from www.netlib.org Additionally Intel MKL provides
Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA. NVIDIA Corporation
 Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA NVIDIA Corporation Outline! Overview of CG benchmark! Overview of CUDA Libraries! CUSPARSE! CUBLAS! Porting Sequence! Algorithm Analysis! Data/Code
Porting the NAS-NPB Conjugate Gradient Benchmark to CUDA NVIDIA Corporation Outline! Overview of CG benchmark! Overview of CUDA Libraries! CUSPARSE! CUBLAS! Porting Sequence! Algorithm Analysis! Data/Code
Achieving Efficient Strong Scaling with PETSc Using Hybrid MPI/OpenMP Optimisation
 Achieving Efficient Strong Scaling with PETSc Using Hybrid MPI/OpenMP Optimisation Michael Lange 1 Gerard Gorman 1 Michele Weiland 2 Lawrence Mitchell 2 Xiaohu Guo 3 James Southern 4 1 AMCG, Imperial College
Achieving Efficient Strong Scaling with PETSc Using Hybrid MPI/OpenMP Optimisation Michael Lange 1 Gerard Gorman 1 Michele Weiland 2 Lawrence Mitchell 2 Xiaohu Guo 3 James Southern 4 1 AMCG, Imperial College
When Cache Blocking of Sparse Matrix Vector Multiply Works and Why
 When Cache Blocking of Sparse Matrix Vector Multiply Works and Why Rajesh Nishtala 1, Richard W. Vuduc 1, James W. Demmel 1, and Katherine A. Yelick 1 University of California at Berkeley, Computer Science
When Cache Blocking of Sparse Matrix Vector Multiply Works and Why Rajesh Nishtala 1, Richard W. Vuduc 1, James W. Demmel 1, and Katherine A. Yelick 1 University of California at Berkeley, Computer Science
SPARSITY: Optimization Framework for Sparse Matrix Kernels
 SPARSITY: Optimization Framework for Sparse Matrix Kernels Eun-Jin Im School of Computer Science, Kookmin University, Seoul, Korea Katherine Yelick Richard Vuduc Computer Science Division, University of
SPARSITY: Optimization Framework for Sparse Matrix Kernels Eun-Jin Im School of Computer Science, Kookmin University, Seoul, Korea Katherine Yelick Richard Vuduc Computer Science Division, University of
BLAS. Christoph Ortner Stef Salvini
 BLAS Christoph Ortner Stef Salvini The BLASics Basic Linear Algebra Subroutines Building blocks for more complex computations Very widely used Level means number of operations Level 1: vector-vector operations
BLAS Christoph Ortner Stef Salvini The BLASics Basic Linear Algebra Subroutines Building blocks for more complex computations Very widely used Level means number of operations Level 1: vector-vector operations
Generating Optimized Sparse Matrix Vector Product over Finite Fields
 Generating Optimized Sparse Matrix Vector Product over Finite Fields Pascal Giorgi 1 and Bastien Vialla 1 LIRMM, CNRS, Université Montpellier 2, pascal.giorgi@lirmm.fr, bastien.vialla@lirmm.fr Abstract.
Generating Optimized Sparse Matrix Vector Product over Finite Fields Pascal Giorgi 1 and Bastien Vialla 1 LIRMM, CNRS, Université Montpellier 2, pascal.giorgi@lirmm.fr, bastien.vialla@lirmm.fr Abstract.
Automatic Performance Tuning and Analysis of Sparse Triangular Solve
 Automatic Performance Tuning and Analysis of Sparse Triangular Solve Richard Vuduc Shoaib Kamil Jen Hsu Rajesh Nishtala James W. Demmel Katherine A. Yelick Computer Science Division, U.C. Berkeley Berkeley,
Automatic Performance Tuning and Analysis of Sparse Triangular Solve Richard Vuduc Shoaib Kamil Jen Hsu Rajesh Nishtala James W. Demmel Katherine A. Yelick Computer Science Division, U.C. Berkeley Berkeley,
Matrix Multiplication
 Matrix Multiplication CPS343 Parallel and High Performance Computing Spring 2013 CPS343 (Parallel and HPC) Matrix Multiplication Spring 2013 1 / 32 Outline 1 Matrix operations Importance Dense and sparse
Matrix Multiplication CPS343 Parallel and High Performance Computing Spring 2013 CPS343 (Parallel and HPC) Matrix Multiplication Spring 2013 1 / 32 Outline 1 Matrix operations Importance Dense and sparse
Optimizing the operations with sparse matrices on Intel architecture
 Optimizing the operations with sparse matrices on Intel architecture Gladkikh V. S. victor.s.gladkikh@intel.com Intel Xeon, Intel Itanium are trademarks of Intel Corporation in the U.S. and other countries.
Optimizing the operations with sparse matrices on Intel architecture Gladkikh V. S. victor.s.gladkikh@intel.com Intel Xeon, Intel Itanium are trademarks of Intel Corporation in the U.S. and other countries.
Bandwidth Avoiding Stencil Computations
 Bandwidth Avoiding Stencil Computations By Kaushik Datta, Sam Williams, Kathy Yelick, and Jim Demmel, and others Berkeley Benchmarking and Optimization Group UC Berkeley March 13, 2008 http://bebop.cs.berkeley.edu
Bandwidth Avoiding Stencil Computations By Kaushik Datta, Sam Williams, Kathy Yelick, and Jim Demmel, and others Berkeley Benchmarking and Optimization Group UC Berkeley March 13, 2008 http://bebop.cs.berkeley.edu
OSKI: A library of automatically tuned sparse matrix kernels
 OSKI: A library of automatically tuned sparse matrix kernels Richard Vuduc 1, James W Demmel 2, and Katherine A Yelick 3 1 Center for Applied Scientific Computing, Lawrence Livermore National Laboratory,
OSKI: A library of automatically tuned sparse matrix kernels Richard Vuduc 1, James W Demmel 2, and Katherine A Yelick 3 1 Center for Applied Scientific Computing, Lawrence Livermore National Laboratory,
CSE 599 I Accelerated Computing - Programming GPUS. Parallel Pattern: Sparse Matrices
 CSE 599 I Accelerated Computing - Programming GPUS Parallel Pattern: Sparse Matrices Objective Learn about various sparse matrix representations Consider how input data affects run-time performance of
CSE 599 I Accelerated Computing - Programming GPUS Parallel Pattern: Sparse Matrices Objective Learn about various sparse matrix representations Consider how input data affects run-time performance of
A cache-oblivious sparse matrix vector multiplication scheme based on the Hilbert curve
 A cache-oblivious sparse matrix vector multiplication scheme based on the Hilbert curve A. N. Yzelman and Rob H. Bisseling Abstract The sparse matrix vector (SpMV) multiplication is an important kernel
A cache-oblivious sparse matrix vector multiplication scheme based on the Hilbert curve A. N. Yzelman and Rob H. Bisseling Abstract The sparse matrix vector (SpMV) multiplication is an important kernel
PARLab Parallel Boot Camp PARLab Parallel Boot Camp. Computational Patterns and Autotuning
 PARLab Parallel Boot Camp PARLab Parallel Boot Camp Computational Patterns and Autotuning Jim Demmel EECS and Mathematics University of California, Berkeley Outline Productive parallel computing depends
PARLab Parallel Boot Camp PARLab Parallel Boot Camp Computational Patterns and Autotuning Jim Demmel EECS and Mathematics University of California, Berkeley Outline Productive parallel computing depends
Evaluation of sparse LU factorization and triangular solution on multicore architectures. X. Sherry Li
 Evaluation of sparse LU factorization and triangular solution on multicore architectures X. Sherry Li Lawrence Berkeley National Laboratory ParLab, April 29, 28 Acknowledgement: John Shalf, LBNL Rich Vuduc,
Evaluation of sparse LU factorization and triangular solution on multicore architectures X. Sherry Li Lawrence Berkeley National Laboratory ParLab, April 29, 28 Acknowledgement: John Shalf, LBNL Rich Vuduc,
AMS526: Numerical Analysis I (Numerical Linear Algebra)
") AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 5: Sparse Linear Systems and Factorization Methods Xiangmin Jiao Stony Brook University Xiangmin Jiao Numerical Analysis I 1 / 18 Sparse
AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 5: Sparse Linear Systems and Factorization Methods Xiangmin Jiao Stony Brook University Xiangmin Jiao Numerical Analysis I 1 / 18 Sparse
Exploiting GPU Caches in Sparse Matrix Vector Multiplication. Yusuke Nagasaka Tokyo Institute of Technology
 Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Exploiting GPU Caches in Sparse Matrix Vector Multiplication Yusuke Nagasaka Tokyo Institute of Technology Sparse Matrix Generated by FEM, being as the graph data Often require solving sparse linear equation
Dynamic Selection of Auto-tuned Kernels to the Numerical Libraries in the DOE ACTS Collection
 Numerical Libraries in the DOE ACTS Collection The DOE ACTS Collection SIAM Parallel Processing for Scientific Computing, Savannah, Georgia Feb 15, 2012 Tony Drummond Computational Research Division Lawrence
Numerical Libraries in the DOE ACTS Collection The DOE ACTS Collection SIAM Parallel Processing for Scientific Computing, Savannah, Georgia Feb 15, 2012 Tony Drummond Computational Research Division Lawrence
Outline. Parallel Algorithms for Linear Algebra. Number of Processors and Problem Size. Speedup and Efficiency
 1 2 Parallel Algorithms for Linear Algebra Richard P. Brent Computer Sciences Laboratory Australian National University Outline Basic concepts Parallel architectures Practical design issues Programming
1 2 Parallel Algorithms for Linear Algebra Richard P. Brent Computer Sciences Laboratory Australian National University Outline Basic concepts Parallel architectures Practical design issues Programming
Scientific Computing. Some slides from James Lambers, Stanford
 Scientific Computing Some slides from James Lambers, Stanford Dense Linear Algebra Scaling and sums Transpose Rank-one updates Rotations Matrix vector products Matrix Matrix products BLAS Designing Numerical
Scientific Computing Some slides from James Lambers, Stanford Dense Linear Algebra Scaling and sums Transpose Rank-one updates Rotations Matrix vector products Matrix Matrix products BLAS Designing Numerical
MAGMA. Matrix Algebra on GPU and Multicore Architectures
 MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
MAGMA Matrix Algebra on GPU and Multicore Architectures Innovative Computing Laboratory Electrical Engineering and Computer Science University of Tennessee Piotr Luszczek (presenter) web.eecs.utk.edu/~luszczek/conf/
Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development
 Development") Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development M. Serdar Celebi
Available online at www.prace-ri.eu Partnership for Advanced Computing in Europe Performance Analysis of BLAS Libraries in SuperLU_DIST for SuperLU_MCDT (Multi Core Distributed) Development M. Serdar Celebi
Matrix Multiplication
 Matrix Multiplication CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Matrix Multiplication Spring 2018 1 / 32 Outline 1 Matrix operations Importance Dense and sparse
Matrix Multiplication CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Matrix Multiplication Spring 2018 1 / 32 Outline 1 Matrix operations Importance Dense and sparse
Administrative Issues. L11: Sparse Linear Algebra on GPUs. Triangular Solve (STRSM) A Few Details 2/25/11. Next assignment, triangular solve
 A Few Details 2/25/11. Next assignment, triangular solve") Administrative Issues L11: Sparse Linear Algebra on GPUs Next assignment, triangular solve Due 5PM, Tuesday, March 15 handin cs6963 lab 3 Project proposals Due 5PM, Wednesday, March 7 (hard
Administrative Issues L11: Sparse Linear Algebra on GPUs Next assignment, triangular solve Due 5PM, Tuesday, March 15 handin cs6963 lab 3 Project proposals Due 5PM, Wednesday, March 7 (hard
Towards Realistic Performance Bounds for Implicit CFD Codes
 Towards Realistic Performance Bounds for Implicit CFD Codes W. D. Gropp, a D. K. Kaushik, b D. E. Keyes, c and B. F. Smith d a Mathematics and Computer Science Division, Argonne National Laboratory, Argonne,
Towards Realistic Performance Bounds for Implicit CFD Codes W. D. Gropp, a D. K. Kaushik, b D. E. Keyes, c and B. F. Smith d a Mathematics and Computer Science Division, Argonne National Laboratory, Argonne,
Roofline Model (Will be using this in HW2)
") Parallel Architecture Announcements HW0 is due Friday night, thank you for those who have already submitted HW1 is due Wednesday night Today Computing operational intensity Dwarves and Motifs Stencil computation
Parallel Architecture Announcements HW0 is due Friday night, thank you for those who have already submitted HW1 is due Wednesday night Today Computing operational intensity Dwarves and Motifs Stencil computation
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM
 Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Efficient Multi-GPU CUDA Linear Solvers for OpenFOAM Alexander Monakov, amonakov@ispras.ru Institute for System Programming of Russian Academy of Sciences March 20, 2013 1 / 17 Problem Statement In OpenFOAM,
Understanding the performances of sparse compression formats using data parallel programming model
 2017 International Conference on High Performance Computing & Simulation Understanding the performances of sparse compression formats using data parallel programming model Ichrak MEHREZ, Olfa HAMDI-LARBI,
2017 International Conference on High Performance Computing & Simulation Understanding the performances of sparse compression formats using data parallel programming model Ichrak MEHREZ, Olfa HAMDI-LARBI,
Algorithms and Architecture. William D. Gropp Mathematics and Computer Science
 Algorithms and Architecture William D. Gropp Mathematics and Computer Science www.mcs.anl.gov/~gropp Algorithms What is an algorithm? A set of instructions to perform a task How do we evaluate an algorithm?
Algorithms and Architecture William D. Gropp Mathematics and Computer Science www.mcs.anl.gov/~gropp Algorithms What is an algorithm? A set of instructions to perform a task How do we evaluate an algorithm?
Optimizations & Bounds for Sparse Symmetric Matrix-Vector Multiply
 Optimizations & Bounds for Sparse Symmetric Matrix-Vector Multiply Berkeley Benchmarking and Optimization Group (BeBOP) http://bebop.cs.berkeley.edu Benjamin C. Lee, Richard W. Vuduc, James W. Demmel,
Optimizations & Bounds for Sparse Symmetric Matrix-Vector Multiply Berkeley Benchmarking and Optimization Group (BeBOP) http://bebop.cs.berkeley.edu Benjamin C. Lee, Richard W. Vuduc, James W. Demmel,
ACCELERATING MATRIX PROCESSING WITH GPUs. Nicholas Malaya, Shuai Che, Joseph Greathouse, Rene van Oostrum, and Michael Schulte AMD Research
 ACCELERATING MATRIX PROCESSING WITH GPUs Nicholas Malaya, Shuai Che, Joseph Greathouse, Rene van Oostrum, and Michael Schulte AMD Research ACCELERATING MATRIX PROCESSING WITH GPUS MOTIVATION Matrix operations
ACCELERATING MATRIX PROCESSING WITH GPUs Nicholas Malaya, Shuai Che, Joseph Greathouse, Rene van Oostrum, and Michael Schulte AMD Research ACCELERATING MATRIX PROCESSING WITH GPUS MOTIVATION Matrix operations
AMS526: Numerical Analysis I (Numerical Linear Algebra)
") AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 20: Sparse Linear Systems; Direct Methods vs. Iterative Methods Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 26
AMS526: Numerical Analysis I (Numerical Linear Algebra) Lecture 20: Sparse Linear Systems; Direct Methods vs. Iterative Methods Xiangmin Jiao SUNY Stony Brook Xiangmin Jiao Numerical Analysis I 1 / 26
BUILDING HIGH PERFORMANCE INPUT-ADAPTIVE GPU APPLICATIONS WITH NITRO
 BUILDING HIGH PERFORMANCE INPUT-ADAPTIVE GPU APPLICATIONS WITH NITRO Saurav Muralidharan University of Utah nitro-tuner.github.io Disclaimers This research was funded in part by the U.S. Government. The
BUILDING HIGH PERFORMANCE INPUT-ADAPTIVE GPU APPLICATIONS WITH NITRO Saurav Muralidharan University of Utah nitro-tuner.github.io Disclaimers This research was funded in part by the U.S. Government. The
Optimizing Cache Performance in Matrix Multiplication. UCSB CS240A, 2017 Modified from Demmel/Yelick s slides
 Optimizing Cache Performance in Matrix Multiplication UCSB CS240A, 2017 Modified from Demmel/Yelick s slides 1 Case Study with Matrix Multiplication An important kernel in many problems Optimization ideas
Optimizing Cache Performance in Matrix Multiplication UCSB CS240A, 2017 Modified from Demmel/Yelick s slides 1 Case Study with Matrix Multiplication An important kernel in many problems Optimization ideas
How HPC Hardware and Software are Evolving Towards Exascale
 How HPC Hardware and Software are Evolving Towards Exascale Kathy Yelick Associate Laboratory Director and NERSC Director Lawrence Berkeley National Laboratory EECS Professor, UC Berkeley NERSC Overview
How HPC Hardware and Software are Evolving Towards Exascale Kathy Yelick Associate Laboratory Director and NERSC Director Lawrence Berkeley National Laboratory EECS Professor, UC Berkeley NERSC Overview
Performance Strategies for Parallel Mathematical Libraries Based on Historical Knowledgebase
 Performance Strategies for Parallel Mathematical Libraries Based on Historical Knowledgebase CScADS workshop 29 Eduardo Cesar, Anna Morajko, Ihab Salawdeh Universitat Autònoma de Barcelona Objective Mathematical
Performance Strategies for Parallel Mathematical Libraries Based on Historical Knowledgebase CScADS workshop 29 Eduardo Cesar, Anna Morajko, Ihab Salawdeh Universitat Autònoma de Barcelona Objective Mathematical
Communication-Avoiding Parallel Sparse-Dense Matrix-Matrix Multiplication
 ommunication-voiding Parallel Sparse-Dense Matrix-Matrix Multiplication Penporn Koanantakool 1,2, riful zad 2, ydin Buluç 2,Dmitriy Morozov 2, Sang-Yun Oh 2,3, Leonid Oliker 2, Katherine Yelick 1,2 1 omputer
ommunication-voiding Parallel Sparse-Dense Matrix-Matrix Multiplication Penporn Koanantakool 1,2, riful zad 2, ydin Buluç 2,Dmitriy Morozov 2, Sang-Yun Oh 2,3, Leonid Oliker 2, Katherine Yelick 1,2 1 omputer
Statistical Models for Automatic Performance Tuning
 Statistical Models for Automatic Performance Tuning Richard Vuduc, James Demmel (U.C. Berkeley, EECS) {richie,demmel}@cs.berkeley.edu Jeff Bilmes (Univ. of Washington, EE) bilmes@ee.washington.edu May
Statistical Models for Automatic Performance Tuning Richard Vuduc, James Demmel (U.C. Berkeley, EECS) {richie,demmel}@cs.berkeley.edu Jeff Bilmes (Univ. of Washington, EE) bilmes@ee.washington.edu May
Alleviating memory-bandwidth limitations for scalability and energy efficiency
 .. Alleviating memory-bandwidth limitations for scalability and energy efficiency Lessons learned from the optimization of SpMxV Georgios Goumas goumas@cslab.ece.ntua.gr Computing Systems Laboratory National
.. Alleviating memory-bandwidth limitations for scalability and energy efficiency Lessons learned from the optimization of SpMxV Georgios Goumas goumas@cslab.ece.ntua.gr Computing Systems Laboratory National
Mixed Precision Methods
 Mixed Precision Methods Mixed precision, use the lowest precision required to achieve a given accuracy outcome " Improves runtime, reduce power consumption, lower data movement " Reformulate to find correction
Mixed Precision Methods Mixed precision, use the lowest precision required to achieve a given accuracy outcome " Improves runtime, reduce power consumption, lower data movement " Reformulate to find correction
The Roofline Model: EECS. A pedagogical tool for program analysis and optimization
 P A R A L L E L C O M P U T I N G L A B O R A T O R Y The Roofline Model: A pedagogical tool for program analysis and optimization Samuel Williams,, David Patterson, Leonid Oliker,, John Shalf, Katherine
P A R A L L E L C O M P U T I N G L A B O R A T O R Y The Roofline Model: A pedagogical tool for program analysis and optimization Samuel Williams,, David Patterson, Leonid Oliker,, John Shalf, Katherine
Future of High Performance Linear Algebra Libraries. Jim Demmel CScADS 31 July Collaborators
 Future of High Performance Linear Algebra Libraries Jim Demmel CScADS 31 July 2007 Dense: Collaborators Jack Dongarra, Julien Langou, Julie Langou, Laura Grigori, Jessica Schoen, Yozo Hida, Jason Riedy,
Future of High Performance Linear Algebra Libraries Jim Demmel CScADS 31 July 2007 Dense: Collaborators Jack Dongarra, Julien Langou, Julie Langou, Laura Grigori, Jessica Schoen, Yozo Hida, Jason Riedy,
DAG-Scheduled Linear Algebra Using Template-Based Building Blocks
 DAG-Scheduled Linear Algebra Using Template-Based Building Blocks Jonathan Hogg STFC Rutherford Appleton Laboratory 1 / 20 19 March 2015 GPU Technology Conference San Jose, California * Thanks also to
DAG-Scheduled Linear Algebra Using Template-Based Building Blocks Jonathan Hogg STFC Rutherford Appleton Laboratory 1 / 20 19 March 2015 GPU Technology Conference San Jose, California * Thanks also to
CS Software Engineering for Scientific Computing Lecture 10:Dense Linear Algebra
 CS 294-73 Software Engineering for Scientific Computing Lecture 10:Dense Linear Algebra Slides from James Demmel and Kathy Yelick 1 Outline What is Dense Linear Algebra? Where does the time go in an algorithm?
CS 294-73 Software Engineering for Scientific Computing Lecture 10:Dense Linear Algebra Slides from James Demmel and Kathy Yelick 1 Outline What is Dense Linear Algebra? Where does the time go in an algorithm?
GPU Acceleration of the Longwave Rapid Radiative Transfer Model in WRF using CUDA Fortran. G. Ruetsch, M. Fatica, E. Phillips, N.
 GPU Acceleration of the Longwave Rapid Radiative Transfer Model in WRF using CUDA Fortran G. Ruetsch, M. Fatica, E. Phillips, N. Juffa Outline WRF and RRTM Previous Work CUDA Fortran Features RRTM in CUDA
GPU Acceleration of the Longwave Rapid Radiative Transfer Model in WRF using CUDA Fortran G. Ruetsch, M. Fatica, E. Phillips, N. Juffa Outline WRF and RRTM Previous Work CUDA Fortran Features RRTM in CUDA
Nested-Dissection Orderings for Sparse LU with Partial Pivoting
 Nested-Dissection Orderings for Sparse LU with Partial Pivoting Igor Brainman 1 and Sivan Toledo 1 School of Mathematical Sciences, Tel-Aviv University Tel-Aviv 69978, ISRAEL Email: sivan@math.tau.ac.il
Nested-Dissection Orderings for Sparse LU with Partial Pivoting Igor Brainman 1 and Sivan Toledo 1 School of Mathematical Sciences, Tel-Aviv University Tel-Aviv 69978, ISRAEL Email: sivan@math.tau.ac.il
(Sparse) Linear Solvers
 Linear Solvers") (Sparse) Linear Solvers Ax = B Why? Many geometry processing applications boil down to: solve one or more linear systems Parameterization Editing Reconstruction Fairing Morphing 2 Don t you just invert
(Sparse) Linear Solvers Ax = B Why? Many geometry processing applications boil down to: solve one or more linear systems Parameterization Editing Reconstruction Fairing Morphing 2 Don t you just invert
Implicit and Explicit Optimizations for Stencil Computations
 Implicit and Explicit Optimizations for Stencil Computations By Shoaib Kamil 1,2, Kaushik Datta 1, Samuel Williams 1,2, Leonid Oliker 2, John Shalf 2 and Katherine A. Yelick 1,2 1 BeBOP Project, U.C. Berkeley
Implicit and Explicit Optimizations for Stencil Computations By Shoaib Kamil 1,2, Kaushik Datta 1, Samuel Williams 1,2, Leonid Oliker 2, John Shalf 2 and Katherine A. Yelick 1,2 1 BeBOP Project, U.C. Berkeley
Server Side Applications (i.e., public/private Clouds and HPC)
") Server Side Applications (i.e., public/private Clouds and HPC) Kathy Yelick UC Berkeley Lawrence Berkeley National Laboratory Proposed DOE Exascale Science Problems Accelerators Carbon Capture Cosmology
Server Side Applications (i.e., public/private Clouds and HPC) Kathy Yelick UC Berkeley Lawrence Berkeley National Laboratory Proposed DOE Exascale Science Problems Accelerators Carbon Capture Cosmology
Generating and Automatically Tuning OpenCL Code for Sparse Linear Algebra
 Generating and Automatically Tuning OpenCL Code for Sparse Linear Algebra Dominik Grewe Anton Lokhmotov Media Processing Division ARM School of Informatics University of Edinburgh December 13, 2010 Introduction
Generating and Automatically Tuning OpenCL Code for Sparse Linear Algebra Dominik Grewe Anton Lokhmotov Media Processing Division ARM School of Informatics University of Edinburgh December 13, 2010 Introduction
Optimizing the Performance of Sparse Matrix-Vector Multiplication by Eun-Jin Im Bachelor of Science, Seoul National University, Seoul, 1991 Master of
 Optimizing the Performance of Sparse Matrix-Vector Multiplication Eun-Jin Im Report No. UCB/CSD-00-1104 June 2000 Computer Science Division (EECS) University of California Berkeley, California 94720 Optimizing
Optimizing the Performance of Sparse Matrix-Vector Multiplication Eun-Jin Im Report No. UCB/CSD-00-1104 June 2000 Computer Science Division (EECS) University of California Berkeley, California 94720 Optimizing
COSC6365. Introduction to HPC. Lecture 21. Lennart Johnsson Department of Computer Science
 Introduction to HPC Lecture 21 Department of Computer Science Most slides from UC Berkeley CS 267 Spring 2011, Lecture 12, Dense Linear Algebra (part 2), Parallel Gaussian Elimination. Jim Demmel Dense
Introduction to HPC Lecture 21 Department of Computer Science Most slides from UC Berkeley CS 267 Spring 2011, Lecture 12, Dense Linear Algebra (part 2), Parallel Gaussian Elimination. Jim Demmel Dense
Scan Primitives for GPU Computing
 Scan Primitives for GPU Computing Shubho Sengupta, Mark Harris *, Yao Zhang, John Owens University of California Davis, *NVIDIA Corporation Motivation Raw compute power and bandwidth of GPUs increasing
Scan Primitives for GPU Computing Shubho Sengupta, Mark Harris *, Yao Zhang, John Owens University of California Davis, *NVIDIA Corporation Motivation Raw compute power and bandwidth of GPUs increasing
Automatically Generating and Tuning GPU Code for Sparse Matrix-Vector Multiplication from a High-Level Representation
 Automatically Generating and Tuning GPU Code for Sparse Matrix-Vector Multiplication from a High-Level Representation Dominik Grewe Institute for Computing Systems Architecture School of Informatics University
Automatically Generating and Tuning GPU Code for Sparse Matrix-Vector Multiplication from a High-Level Representation Dominik Grewe Institute for Computing Systems Architecture School of Informatics University
Contents. F10: Parallel Sparse Matrix Computations. Parallel algorithms for sparse systems Ax = b. Discretized domain a metal sheet
 Contents 2 F10: Parallel Sparse Matrix Computations Figures mainly from Kumar et. al. Introduction to Parallel Computing, 1st ed Chap. 11 Bo Kågström et al (RG, EE, MR) 2011-05-10 Sparse matrices and storage
Contents 2 F10: Parallel Sparse Matrix Computations Figures mainly from Kumar et. al. Introduction to Parallel Computing, 1st ed Chap. 11 Bo Kågström et al (RG, EE, MR) 2011-05-10 Sparse matrices and storage
Accelerating GPU kernels for dense linear algebra
 Accelerating GPU kernels for dense linear algebra Rajib Nath, Stanimire Tomov, and Jack Dongarra Department of Electrical Engineering and Computer Science, University of Tennessee, Knoxville {rnath1, tomov,
Accelerating GPU kernels for dense linear algebra Rajib Nath, Stanimire Tomov, and Jack Dongarra Department of Electrical Engineering and Computer Science, University of Tennessee, Knoxville {rnath1, tomov,
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS. Kyle Spagnoli. Research EM Photonics 3/20/2013
 GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
GTC 2013: DEVELOPMENTS IN GPU-ACCELERATED SPARSE LINEAR ALGEBRA ALGORITHMS Kyle Spagnoli Research Engineer @ EM Photonics 3/20/2013 INTRODUCTION» Sparse systems» Iterative solvers» High level benchmarks»
How to perform HPL on CPU&GPU clusters. Dr.sc. Draško Tomić
 How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
How to perform HPL on CPU&GPU clusters Dr.sc. Draško Tomić email: drasko.tomic@hp.com Forecasting is not so easy, HPL benchmarking could be even more difficult Agenda TOP500 GPU trends Some basics about
Techniques for Optimizing FEM/MoM Codes
 Techniques for Optimizing FEM/MoM Codes Y. Ji, T. H. Hubing, and H. Wang Electromagnetic Compatibility Laboratory Department of Electrical & Computer Engineering University of Missouri-Rolla Rolla, MO
Techniques for Optimizing FEM/MoM Codes Y. Ji, T. H. Hubing, and H. Wang Electromagnetic Compatibility Laboratory Department of Electrical & Computer Engineering University of Missouri-Rolla Rolla, MO
Intel MKL Sparse Solvers. Software Solutions Group - Developer Products Division
 Intel MKL Sparse Solvers - Agenda Overview Direct Solvers Introduction PARDISO: main features PARDISO: advanced functionality DSS Performance data Iterative Solvers Performance Data Reference Copyright
Intel MKL Sparse Solvers - Agenda Overview Direct Solvers Introduction PARDISO: main features PARDISO: advanced functionality DSS Performance data Iterative Solvers Performance Data Reference Copyright
Optimizations & Bounds for Sparse Symmetric Matrix-Vector Multiply
 Optimizations & Bounds for Sparse Symmetric Matrix-Vector Multiply Berkeley Benchmarking and Optimization Group (BeBOP) http://bebop.cs.berkeley.edu Benjamin C. Lee, Richard W. Vuduc, James W. Demmel,
Optimizations & Bounds for Sparse Symmetric Matrix-Vector Multiply Berkeley Benchmarking and Optimization Group (BeBOP) http://bebop.cs.berkeley.edu Benjamin C. Lee, Richard W. Vuduc, James W. Demmel,
On the limits of (and opportunities for?) GPU acceleration
 GPU acceleration") On the limits of (and opportunities for?) GPU acceleration Aparna Chandramowlishwaran, Jee Choi, Kenneth Czechowski, Murat (Efe) Guney, Logan Moon, Aashay Shringarpure, Richard (Rich) Vuduc HotPar 10,
On the limits of (and opportunities for?) GPU acceleration Aparna Chandramowlishwaran, Jee Choi, Kenneth Czechowski, Murat (Efe) Guney, Logan Moon, Aashay Shringarpure, Richard (Rich) Vuduc HotPar 10,
Lawrence Berkeley National Laboratory Recent Work
 Lawrence Berkeley National Laboratory Recent Work Title The roofline model: A pedagogical tool for program analysis and optimization Permalink https://escholarship.org/uc/item/3qf33m0 ISBN 9767379 Authors
Lawrence Berkeley National Laboratory Recent Work Title The roofline model: A pedagogical tool for program analysis and optimization Permalink https://escholarship.org/uc/item/3qf33m0 ISBN 9767379 Authors
Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication. Steve Rennich Nvidia Developer Technology - Compute
 Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication Steve Rennich Nvidia Developer Technology - Compute Block Sparse Matrix Vector Multiplication Sparse Matrix-Vector Multiplication
Leveraging Matrix Block Structure In Sparse Matrix-Vector Multiplication Steve Rennich Nvidia Developer Technology - Compute Block Sparse Matrix Vector Multiplication Sparse Matrix-Vector Multiplication
BLAS and LAPACK + Data Formats for Sparse Matrices. Part of the lecture Wissenschaftliches Rechnen. Hilmar Wobker
 BLAS and LAPACK + Data Formats for Sparse Matrices Part of the lecture Wissenschaftliches Rechnen Hilmar Wobker Institute of Applied Mathematics and Numerics, TU Dortmund email: hilmar.wobker@math.tu-dortmund.de
BLAS and LAPACK + Data Formats for Sparse Matrices Part of the lecture Wissenschaftliches Rechnen Hilmar Wobker Institute of Applied Mathematics and Numerics, TU Dortmund email: hilmar.wobker@math.tu-dortmund.de
Intel Math Kernel Library (Intel MKL) Sparse Solvers. Alexander Kalinkin Intel MKL developer, Victor Kostin Intel MKL Dense Solvers team manager
 Sparse Solvers. Alexander Kalinkin Intel MKL developer, Victor Kostin Intel MKL Dense Solvers team manager") Intel Math Kernel Library (Intel MKL) Sparse Solvers Alexander Kalinkin Intel MKL developer, Victor Kostin Intel MKL Dense Solvers team manager Copyright 3, Intel Corporation. All rights reserved. Sparse
Intel Math Kernel Library (Intel MKL) Sparse Solvers Alexander Kalinkin Intel MKL developer, Victor Kostin Intel MKL Dense Solvers team manager Copyright 3, Intel Corporation. All rights reserved. Sparse
PARDISO Version Reference Sheet Fortran
 PARDISO Version 5.0.0 1 Reference Sheet Fortran CALL PARDISO(PT, MAXFCT, MNUM, MTYPE, PHASE, N, A, IA, JA, 1 PERM, NRHS, IPARM, MSGLVL, B, X, ERROR, DPARM) 1 Please note that this version differs significantly
PARDISO Version 5.0.0 1 Reference Sheet Fortran CALL PARDISO(PT, MAXFCT, MNUM, MTYPE, PHASE, N, A, IA, JA, 1 PERM, NRHS, IPARM, MSGLVL, B, X, ERROR, DPARM) 1 Please note that this version differs significantly
Solving Dense Linear Systems on Graphics Processors
 Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Solving Dense Linear Systems on Graphics Processors Sergio Barrachina Maribel Castillo Francisco Igual Rafael Mayo Enrique S. Quintana-Ortí High Performance Computing & Architectures Group Universidad
Combinatorial problems in a Parallel Hybrid Linear Solver
 Combinatorial problems in a Parallel Hybrid Linear Solver Ichitaro Yamazaki and Xiaoye Li Lawrence Berkeley National Laboratory François-Henry Rouet and Bora Uçar ENSEEIHT-IRIT and LIP, ENS-Lyon SIAM workshop
Combinatorial problems in a Parallel Hybrid Linear Solver Ichitaro Yamazaki and Xiaoye Li Lawrence Berkeley National Laboratory François-Henry Rouet and Bora Uçar ENSEEIHT-IRIT and LIP, ENS-Lyon SIAM workshop
Optimizing Sparse Matrix Computations for Register Reuse in SPARSITY
 Optimizing Sparse Matrix Computations for Register Reuse in SPARSITY Eun-Jin Im 1 and Katherine Yelick 2 1 School of Computer Science, Kookmin University, Seoul, Korea ejim@cs.kookmin.ac.kr, 2 Computer
Optimizing Sparse Matrix Computations for Register Reuse in SPARSITY Eun-Jin Im 1 and Katherine Yelick 2 1 School of Computer Science, Kookmin University, Seoul, Korea ejim@cs.kookmin.ac.kr, 2 Computer
Uniprocessor Optimizations. Idealized Uniprocessor Model
 Uniprocessor Optimizations Arvind Krishnamurthy Fall 2004 Idealized Uniprocessor Model Processor names bytes, words, etc. in its address space These represent integers, floats, pointers, arrays, etc. Exist
Uniprocessor Optimizations Arvind Krishnamurthy Fall 2004 Idealized Uniprocessor Model Processor names bytes, words, etc. in its address space These represent integers, floats, pointers, arrays, etc. Exist
Solving Sparse Linear Systems. Forward and backward substitution for solving lower or upper triangular systems
 AMSC 6 /CMSC 76 Advanced Linear Numerical Analysis Fall 7 Direct Solution of Sparse Linear Systems and Eigenproblems Dianne P. O Leary c 7 Solving Sparse Linear Systems Assumed background: Gauss elimination
AMSC 6 /CMSC 76 Advanced Linear Numerical Analysis Fall 7 Direct Solution of Sparse Linear Systems and Eigenproblems Dianne P. O Leary c 7 Solving Sparse Linear Systems Assumed background: Gauss elimination
Introduction to Parallel Programming & Cluster Computing
 Introduction to Parallel Programming & Cluster Computing Scientific Libraries & I/O Libraries Joshua Alexander, U Oklahoma Ivan Babic, Earlham College Michial Green, Contra Costa College Mobeen Ludin,
Introduction to Parallel Programming & Cluster Computing Scientific Libraries & I/O Libraries Joshua Alexander, U Oklahoma Ivan Babic, Earlham College Michial Green, Contra Costa College Mobeen Ludin,
Formal Loop Merging for Signal Transforms
 Formal Loop Merging for Signal Transforms Franz Franchetti Yevgen S. Voronenko Markus Püschel Department of Electrical & Computer Engineering Carnegie Mellon University This work was supported by NSF through
Formal Loop Merging for Signal Transforms Franz Franchetti Yevgen S. Voronenko Markus Püschel Department of Electrical & Computer Engineering Carnegie Mellon University This work was supported by NSF through