Code Migration Methodology for Heterogeneous Systems
|
|
|
- Piers Edwards
- 6 years ago
- Views:
Transcription

1 Code Migration Methodology for Heterogeneous Systems Directives based approach using HMPP - OpenAcc F. Bodin, CAPS CTO
2 Introduction Many-core computing power comes from parallelism o Multiple forms of parallelism cohabiting Multiple devices (e.g. GPUs) with their own address space Multiple threads inside a device Vector/SIMD parallelism inside a thread o Massive parallelism Tens of thousands of threads needed Keeping a unique version of the codes, preferably monolanguage, is a necessity o Reduce maintenance cost o Preserve code assets o Fast moving hardware target context o Write codes that will last many architecture generations Multiple directive based approaches in a converging process o OpenAcc a first step 2
3 Overview of the Talk 1. A few words about many-cores 2. Methodology for legacy codes migration 3. Directive based approach for many-core programming 1. OpenACC 2. HMPP 3



4 Many-Cores Massively parallel devices o Thousands of threads needed CPU and GPUs linked with a PCIx bus Data/stream/vector parallelism to be exploited by GPUs e.g. CUDA / OpenCL 4

5 Where Are We Going? forecast 5


6 Dealing with Legacy Codes THE CRITICAL STEP 6
7 Go / No Go for GPU Target Go Dense execution hotspots Fast kernels Low CPU-GPU data transfers Prepare to many-core parallelism No Go Flat profile Slow GPU kernels (i.e. no speedup to be expected) Binary exact CPU-GPU results (cannot validate execution) Memory space needed 7
")
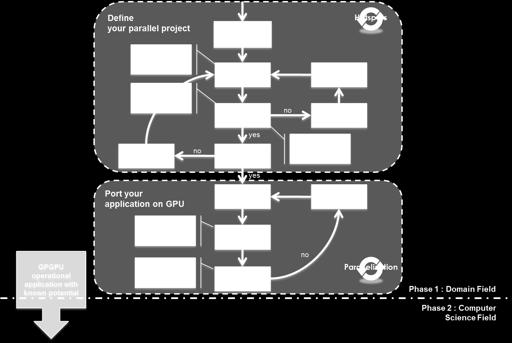
8 Phase 1 (details) 8
")

9 Phase 2 (details) 9

10 An Example Monte Carlo simulation for thermal radiation Resource spent o 1,5 man-month Size o ~1kLoC of C d (DP) GPU C2050 improvement o x6 over 8 Nehalem cores Full hybrid version o x23 with 8 nodes compare to the 8 core machine Main porting operation o adding a few HMPP directives 10
11 Directives Based Approaches Supplement an existing serial languages with directives to express parallelism and data managements o Preserves code basis (e.g. C, Fortran) and serial semantic o Competitive with code hand-written in device dialect (e.g. CUDA) o Incremental approach to many-core programming Many variants o HMPP o PGI Accelerator o OpenAcc o OpenMP Accelerator extension o OpenACC is a new initiative by CAPS, CRAY, PGI and Nvidia o A first common subset 11
12 OpenACC Initiative Express data and computation to be executed on an accelerator o Using marked code regions Main OpenAcc contructs o Parallel and kernel regions o Parallel loops o Data regions o Runtime API Subset of HMPP supported features o OpenAcc constructs interoperable with other HMPP directives o OpenAcc support to be released in HMPP in March 2012 Visit for more information 12



13 OpenAcc Data Management in HMPP Mirroring duplicate a CPU memory block into GPU memory o Mirror identifier is CPU memory block address o Only one mirror per CPU block o Users ensure consistency of copies via directives Master copy. HMPP RT Descriptor Mirror copy. CPU Memory GPU Memory 13

14 OpenAcc Execution Model Host-controlled execution Based on three parallelism levels o Gangs coarse grain o Workers fine grain o Vectors finest grain Gang workers Gang workers Gang workers Gang workers 14
15 Parallel Loops The loop directive can describe what type of parallelism to use to execute the loop and declare loop-private variables and arrays and reduction operations Clauses o gang [(scalar-integer-expression)]! o worker [(scalar-integer-expression)]! o vector [(scalar-integer-expression)] o collapse(n)! o seq! o independent! o private(list)! o reduction(operator:list )! Iteration space distributed over NB gangs #pragma acc loop gang(nb)! for (int i = 0; i < n; ++i){! #pragma acc loop worker(nt)! for (int j = 0; j < m; ++j){! B[i][j] = i * j * A[i][j];! Iteration space distributed over NT workers 15
16 Kernel Regions Parallel loops inside a region are transformed into accelerator kernels (e.g. CUDA kernels) o Each loop nest can have different values for gang and worker numbers Clauses o if(condition)! o async[(scalar-integer-expression)]! o copy(list)copyin(list)! o copyout(list)create(list)! o present(list)! o present_or_copy(list)! o present_or_copyin(list)! o present_or_copyout(list)! o present_or_create(list)! o deviceptr(list)! #pragma acc kernels {! #pragma acc loop independent! for (int i = 0; i < n; ++i){! for (int j = 0; j < n; ++j){! for (int k = 0; k < n; ++k){! B[i][j*k%n] = A[i][j*k%n];! #pragma acc loop gang(nb)! for (int i = 0; i < n; ++i){! #pragma acc loop worker(nt)! for (int j = 0; j < m; ++j){! B[i][j] = i * j * A[i][j];! 16
17 Parallel Regions Start parallel activity on the accelerator device o Gangs of workers are created to execute the accelerator parallel region o Exploit parallel loops o SPMD style code but no barrier #pragma acc parallel num_gangs(bg), num_workers(bw)! o if(condition)! {! o async[(scalar-integer-expression)]! #pragma acc loop gang! o num_gangs(scalar-integer-expression)! for (int i = 0; i < n; ++i){! o num_workers(scalar-integer-expression)! #pragma acc loop worker! o vector_length(scalar-integer-expression)! for (int j = 0; j < n; ++j){! o reduction(operator:list)! B[i][j] = A[i][j];! o copy(list)! o copyin(list)! o copyout(list)! for(int k=0; k < n; k++){! o create(list)! #pragma acc loop gang! o present(list)! for (int i = 0; i < n; ++i){! o present_or_copy(list)! #pragma acc loop worker! o present_or_copyin(list)! for (int j = 0; j < n; ++j){! o present_or_copyout(list)! C[k][i][j] = B[k-1][i+1][j] + ;! o present_or_create(list)! o deviceptr(list)! o private(list)! o firstprivate(list)! Clauses 17
18 Data Management Directives Data regions define scalars, arrays and sub-arrays to be allocated in the device memory for the duration of the region o Explicit management of data transfer using clauses or directives Many clauses o if(condition)! o copy(list)! o copyin(list )! o copyout(list)! o create(list)! o present(list)! o present_or_copy(list)! o present_or_copyin(list)!#pragma acc update host(a)! o present_or_copyout(list)! o present_or_create(list) o deviceptr(list)! #pragma acc data copyin(a[1:n-2][1:m-2]), copyout(b[n][m])! {! #pragma acc kernels! {! #pragma acc loop independant! for (int i = 0; i < N; ++i){! A[i][0] =...;! A[i][M - 1] = 0.0f;! #pragma acc kernels! for (int i = 0; i < n; ++i){! B[i] =...;! 18
19 Runtime API Set of functions for managing device allocation (C version) o int acc_get_num_devices( acc_device_t )! o void acc_set_device_type ( acc_device_t )! o acc_device_t acc_get_device_type ( void )! o void acc_set_device_num( int, acc_device_t )! o int acc_get_device_num( acc_device_t )! o int acc_async_test( int )! o int acc_async_test_all( )! o void acc_async_wait( int )! o void acc_async_wait_all( )! o void acc_init ( acc_device_t )! o void acc_shutdown ( acc_device_t )! o void* acc_malloc ( size_t )! o void acc_free ( void* )! o 19

20 HMPP Heterogeneous Multicore Parallel Programming Codelet and region based directives for many-cores o CUDA, OpenCL code generation, soon Intel MIC, x86 HMPP support of OpenAcc syntax planned for March
21 What is in HMPP that is not in OpenACC Multiple devices management o Data collection / map operation Library integration directives o Needed for a single source many-core code approach Loop transformations directives for kernel tuning o Tuning is very target machine dependent Open performance APIs o Tracing o Auto-tuning (H2 2012) And many more features o Native functions, buffer mode, codelets, 21


22 Collections of Data in HMPP 3.0 d[0] d[1] CPU Memory d[0].data d[1].data struct { float * data ; int size ; } Vec; mirroring GPU 1 Memory GPU 2 Memory GPU 3 Memory 22

; } CPU 0 CPU 1 GPU 0 GPU 1 GPU 2 Main memory")
23 HMPP 3.0 Map Operation on Data Collections #pragma hmpp <mgrp> parallel for(k=0;k<n;k++) { #pragma hmpp <mgrp> f1 callsite myparallelfunc(d[k],n); } CPU 0 CPU 1 GPU 0 GPU 1 GPU 2 Main memory Device memory Device memory Device memory d0 d1 d2 d3 d1 d2 d3 23
24 Dealing with Libraries Library calls can usually only be partially replaced o No one to one mapping between libraries (e.g.blas, FFTW, CuFFT, CULA, LibJacket ) o No access to all code (i.e. avoid side effects) o Don t create dependencies on a specific target library as much as possible o Still want a unique source code Deal with multiple address spaces / multi-gpus o Data location may not be unique (copies) o Usual library calls assume shared memory o Library efficiency depends on updated data location (long term effect) Libraries can be written in many different languages o CUDA, OpenCL, HMPP, etc. There is not one binding choice depending on applications/users o Binding needs to adapt to uses depending on how it interacts with the remainder of the code o Choices depend on development methodology 24
25 Example of Library Uses with HMPP 3.0 Replaces the call to a proxy that handles GPUs C and allows to mix user GPU code with library ones CALL INIT(A,N) CALL ZFFT1D(A,N,0,B)! This call is needed to initialize FFTE CALL DUMP(A,N) CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC C TELL HMPP TO USE THE PROXY FUNCTION FROM THE FFTE PROXY GROUP C CHECK FOR EXECUTION ERROR ON THE GPU!$hmppalt ffte call, name="zfft1d", error="proxy_err" CALL ZFFT1D(A,N,-1,B) CALL DUMP(A,N) C C SAME HERE!$hmppalt ffte call, name="zfft1d", error="proxy_err" CALL ZFFT1D(A,N,1,B) CALL DUMP(A,N) 25
26 Library Interoperability in HMPP 3.0 HMPP Runtime API call libroutine1( )! #pragma hmppalt! call libroutine2( )! call libroutine3( )! proxy2( )! Native GPU Runtime API C/CUDA/ GPU Lib gpulib( )! CPU Lib cpulib1( )! cpulib3( )! 26
27 Code Tuning Directive Directive-based GPU kernel code transformations Uses directives to preserve CPU code #pragma hmpp dgemm codelet, target=cuda, args[c].io=inout void dgemm( int n, double alpha, const double *A, const double *B, double beta, double *C ) { int i; #pragma hmppcg(cuda) grid blocksize "64x1» #pragma hmppcg(cuda) permute j,i #pragma hmppcg(cuda) unroll(8), jam, split, noremainder #pragma hmppcg parallel for( i = 0 ; i < n; i++ ) { int j; #pragma hmppcg(cuda) unroll(4), jam(i), noremainder #pragma hmppcg parallel for( j = 0 ; j < n; j++ ) { int k; double prod = 0.0f; for( k = 0 ; k < n; k++ ) { prod += VA(k,i) * VB(j,k); } VC(j,i) = alpha * prod + beta * VC(j,i); } } } 1D gridification Using 64 threads Loop transformations 27
28 Conclusion Software has to expose massive parallelism o The key to success is the algorithm! o The implementation has just to keep parallelism flexible and easy to exploit Directive-based approaches are currently one of the most promising track for many-cores o Preserve code assets o At node level help separating parallelism exposure from the implementation Performance aware directive programming most promising track for portable performance o Auto-tuning needs to be integrated into programming to define the search space o See the European project Mid-term convergence of directive dialects to be expected o OpenAcc is a first start o Convergence in OpenMP most likely 28
29 Many-core programming Parallelization GPGPU NVIDIA Cuda OpenHMPP Directive-based programming Code Porting Methodology OpenACC Hybrid Many-core Programmin HPC community Petaflops Parallel computing HPC open standard Exaflops Open CL High Performance Computing Code speedup Multi-core programming Massively parallel Hardware accelerators programming GPGPU HMPP Competence Center Parallel programming interface DevDeck Global Solutions for Many-Core Programming
How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO
 F. Bodin, CTO") How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO Foreword How to write code that will survive the many-core revolution? is being setup as a collective
How to write code that will survive the many-core revolution Write once, deploy many(-cores) F. Bodin, CTO Foreword How to write code that will survive the many-core revolution? is being setup as a collective
OpenACC Standard. Credits 19/07/ OpenACC, Directives for Accelerators, Nvidia Slideware
 OpenACC Standard Directives for Accelerators Credits http://www.openacc.org/ o V1.0: November 2011 Specification OpenACC, Directives for Accelerators, Nvidia Slideware CAPS OpenACC Compiler, HMPP Workbench
OpenACC Standard Directives for Accelerators Credits http://www.openacc.org/ o V1.0: November 2011 Specification OpenACC, Directives for Accelerators, Nvidia Slideware CAPS OpenACC Compiler, HMPP Workbench
Programming Heterogeneous Many-cores Using Directives
 Programming Heterogeneous Many-cores Using Directives HMPP - OpenAcc François Bodin, Florent Lebeau, CAPS entreprise Introduction Programming many-core systems faces the following dilemma o The constraint
Programming Heterogeneous Many-cores Using Directives HMPP - OpenAcc François Bodin, Florent Lebeau, CAPS entreprise Introduction Programming many-core systems faces the following dilemma o The constraint
How to Write Code that Will Survive the Many-Core Revolution
 How to Write Code that Will Survive the Many-Core Revolution Write Once, Deploy Many(-Cores) Guillaume BARAT, EMEA Sales Manager CAPS worldwide ecosystem Customers Business Partners Involved in many European
How to Write Code that Will Survive the Many-Core Revolution Write Once, Deploy Many(-Cores) Guillaume BARAT, EMEA Sales Manager CAPS worldwide ecosystem Customers Business Partners Involved in many European
MIGRATION OF LEGACY APPLICATIONS TO HETEROGENEOUS ARCHITECTURES Francois Bodin, CTO, CAPS Entreprise. June 2011
 MIGRATION OF LEGACY APPLICATIONS TO HETEROGENEOUS ARCHITECTURES Francois Bodin, CTO, CAPS Entreprise June 2011 FREE LUNCH IS OVER, CODES HAVE TO MIGRATE! Many existing legacy codes needs to migrate to
MIGRATION OF LEGACY APPLICATIONS TO HETEROGENEOUS ARCHITECTURES Francois Bodin, CTO, CAPS Entreprise June 2011 FREE LUNCH IS OVER, CODES HAVE TO MIGRATE! Many existing legacy codes needs to migrate to
Programming Heterogeneous Many-cores Using Directives
 Programming Heterogeneous Many-cores Using Directives HMPP - OpenAcc François Bodin, Florent Lebeau, CAPS entreprise Introduction Programming many-core systems faces the following dilemma o The constraint
Programming Heterogeneous Many-cores Using Directives HMPP - OpenAcc François Bodin, Florent Lebeau, CAPS entreprise Introduction Programming many-core systems faces the following dilemma o The constraint
Incremental Migration of C and Fortran Applications to GPGPU using HMPP HPC Advisory Council China Conference 2010
 Innovative software for manycore paradigms Incremental Migration of C and Fortran Applications to GPGPU using HMPP HPC Advisory Council China Conference 2010 Introduction Many applications can benefit
Innovative software for manycore paradigms Incremental Migration of C and Fortran Applications to GPGPU using HMPP HPC Advisory Council China Conference 2010 Introduction Many applications can benefit
Heterogeneous Multicore Parallel Programming
 Innovative software for manycore paradigms Heterogeneous Multicore Parallel Programming S. Chauveau & L. Morin & F. Bodin Introduction Numerous legacy applications can benefit from GPU computing Many programming
Innovative software for manycore paradigms Heterogeneous Multicore Parallel Programming S. Chauveau & L. Morin & F. Bodin Introduction Numerous legacy applications can benefit from GPU computing Many programming
Parallelism III. MPI, Vectorization, OpenACC, OpenCL. John Cavazos,Tristan Vanderbruggen, and Will Killian
 Parallelism III MPI, Vectorization, OpenACC, OpenCL John Cavazos,Tristan Vanderbruggen, and Will Killian Dept of Computer & Information Sciences University of Delaware 1 Lecture Overview Introduction MPI
Parallelism III MPI, Vectorization, OpenACC, OpenCL John Cavazos,Tristan Vanderbruggen, and Will Killian Dept of Computer & Information Sciences University of Delaware 1 Lecture Overview Introduction MPI
Pragma-based GPU Programming and HMPP Workbench. Scott Grauer-Gray
 Pragma-based GPU Programming and HMPP Workbench Scott Grauer-Gray Pragma-based GPU programming Write programs for GPU processing without (directly) using CUDA/OpenCL Place pragmas to drive processing on
Pragma-based GPU Programming and HMPP Workbench Scott Grauer-Gray Pragma-based GPU programming Write programs for GPU processing without (directly) using CUDA/OpenCL Place pragmas to drive processing on
Getting Started with Directive-based Acceleration: OpenACC
 Getting Started with Directive-based Acceleration: OpenACC Ahmad Lashgar Member of High-Performance Computing Research Laboratory, School of Computer Science Institute for Research in Fundamental Sciences
Getting Started with Directive-based Acceleration: OpenACC Ahmad Lashgar Member of High-Performance Computing Research Laboratory, School of Computer Science Institute for Research in Fundamental Sciences
OpenACC. Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer
 OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
OpenACC Introduction and Evolutions Sebastien Deldon, GPU Compiler engineer 3 WAYS TO ACCELERATE APPLICATIONS Applications Libraries Compiler Directives Programming Languages Easy to use Most Performance
Greg Scantlen, CEO. GTC 2012 May 15
 Greg Scantlen, CEO GTC 2012 May 15 Contents Stelletto cluster features in portable package CAPS-Enterprise, Francois Bodin, CTO Black Dog Endeavors, Rob Farber, CEO GTC 2012 May 15 Supercomputing 2008
Greg Scantlen, CEO GTC 2012 May 15 Contents Stelletto cluster features in portable package CAPS-Enterprise, Francois Bodin, CTO Black Dog Endeavors, Rob Farber, CEO GTC 2012 May 15 Supercomputing 2008
OPENACC DIRECTIVES FOR ACCELERATORS NVIDIA
 OPENACC DIRECTIVES FOR ACCELERATORS NVIDIA Directives for Accelerators ABOUT OPENACC GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers
OPENACC DIRECTIVES FOR ACCELERATORS NVIDIA Directives for Accelerators ABOUT OPENACC GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers
PGI Accelerator Programming Model for Fortran & C
 PGI Accelerator Programming Model for Fortran & C The Portland Group Published: v1.3 November 2010 Contents 1. Introduction... 5 1.1 Scope... 5 1.2 Glossary... 5 1.3 Execution Model... 7 1.4 Memory Model...
PGI Accelerator Programming Model for Fortran & C The Portland Group Published: v1.3 November 2010 Contents 1. Introduction... 5 1.1 Scope... 5 1.2 Glossary... 5 1.3 Execution Model... 7 1.4 Memory Model...
CAPS Technology. ProHMPT, 2009 March12 th
 CAPS Technology ProHMPT, 2009 March12 th Overview of the Talk 1. HMPP in a nutshell Directives for Hardware Accelerators (HWA) 2. HMPP Code Generation Capabilities Efficient code generation for CUDA 3.
CAPS Technology ProHMPT, 2009 March12 th Overview of the Talk 1. HMPP in a nutshell Directives for Hardware Accelerators (HWA) 2. HMPP Code Generation Capabilities Efficient code generation for CUDA 3.
Mathematical computations with GPUs
 Master Educational Program Information technology in applications Mathematical computations with GPUs Using GPUs for mathematical problems in Fortran, Java and C# Alexey A. Romanenko arom@ccfit.nsu.ru
Master Educational Program Information technology in applications Mathematical computations with GPUs Using GPUs for mathematical problems in Fortran, Java and C# Alexey A. Romanenko arom@ccfit.nsu.ru
Addressing Heterogeneity in Manycore Applications
 Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
Addressing Heterogeneity in Manycore Applications RTM Simulation Use Case stephane.bihan@caps-entreprise.com Oil&Gas HPC Workshop Rice University, Houston, March 2008 www.caps-entreprise.com Introduction
An OpenACC construct is an OpenACC directive and, if applicable, the immediately following statement, loop or structured block.
 API 2.6 R EF ER ENC E G U I D E The OpenACC API 2.6 The OpenACC Application Program Interface describes a collection of compiler directives to specify loops and regions of code in standard C, C++ and Fortran
API 2.6 R EF ER ENC E G U I D E The OpenACC API 2.6 The OpenACC Application Program Interface describes a collection of compiler directives to specify loops and regions of code in standard C, C++ and Fortran
Parallel Hybrid Computing F. Bodin, CAPS Entreprise
 Parallel Hybrid Computing F. Bodin, CAPS Entreprise Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous
Parallel Hybrid Computing F. Bodin, CAPS Entreprise Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous
OpenACC 2.5 and Beyond. Michael Wolfe PGI compiler engineer
 OpenACC 2.5 and Beyond Michael Wolfe PGI compiler engineer michael.wolfe@pgroup.com OpenACC Timeline 2008 PGI Accelerator Model (targeting NVIDIA GPUs) 2011 OpenACC 1.0 (targeting NVIDIA GPUs, AMD GPUs)
OpenACC 2.5 and Beyond Michael Wolfe PGI compiler engineer michael.wolfe@pgroup.com OpenACC Timeline 2008 PGI Accelerator Model (targeting NVIDIA GPUs) 2011 OpenACC 1.0 (targeting NVIDIA GPUs, AMD GPUs)
An Introduc+on to OpenACC Part II
 An Introduc+on to OpenACC Part II Wei Feinstein HPC User Services@LSU LONI Parallel Programming Workshop 2015 Louisiana State University 4 th HPC Parallel Programming Workshop An Introduc+on to OpenACC-
An Introduc+on to OpenACC Part II Wei Feinstein HPC User Services@LSU LONI Parallel Programming Workshop 2015 Louisiana State University 4 th HPC Parallel Programming Workshop An Introduc+on to OpenACC-
OpenACC 2.6 Proposed Features
 OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
OpenACC 2.6 Proposed Features OpenACC.org June, 2017 1 Introduction This document summarizes features and changes being proposed for the next version of the OpenACC Application Programming Interface, tentatively
OpenACC Course. Office Hour #2 Q&A
 OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
OpenACC Course Office Hour #2 Q&A Q1: How many threads does each GPU core have? A: GPU cores execute arithmetic instructions. Each core can execute one single precision floating point instruction per cycle
Programming Heterogeneous Many-cores Using Directives
 Prgramming Hetergeneus Many-cres Using Directives HMPP - OpenAcc Françis Bdin, CAPS entreprise Intrductin Prgramming many-cre systems faces the fllwing dilemma The cnstraint f keeping a unique versin f
Prgramming Hetergeneus Many-cres Using Directives HMPP - OpenAcc Françis Bdin, CAPS entreprise Intrductin Prgramming many-cre systems faces the fllwing dilemma The cnstraint f keeping a unique versin f
Accelerating Financial Applications on the GPU
 Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
Accelerating Financial Applications on the GPU Scott Grauer-Gray Robert Searles William Killian John Cavazos Department of Computer and Information Science University of Delaware Sixth Workshop on General
Hybrid KAUST Many Cores and OpenACC. Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS
 + Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
+ Hybrid Computing @ KAUST Many Cores and OpenACC Alain Clo - KAUST Research Computing Saber Feki KAUST Supercomputing Lab Florent Lebeau - CAPS + Agenda Hybrid Computing n Hybrid Computing n From Multi-Physics
25/01/12. Introduction. Programming Heterogeneous Many-cores Using Directives
 Prgramming Hetergeneus Many-cres sing Directives HMPP - OpenAcc F. Bdin, APS TO Intrductin Many-cre cmputing pwer cmes frm parallelism Multiple frms f parallelism chabiting Multiple devices (e.g. GPs)
Prgramming Hetergeneus Many-cres sing Directives HMPP - OpenAcc F. Bdin, APS TO Intrductin Many-cre cmputing pwer cmes frm parallelism Multiple frms f parallelism chabiting Multiple devices (e.g. GPs)
OPENMP FOR ACCELERATORS
 7th International Workshop on OpenMP Chicago, Illinois, USA James C. Beyer, Eric J. Stotzer, Alistair Hart, and Bronis R. de Supinski OPENMP FOR ACCELERATORS Accelerator programming Why a new model? There
7th International Workshop on OpenMP Chicago, Illinois, USA James C. Beyer, Eric J. Stotzer, Alistair Hart, and Bronis R. de Supinski OPENMP FOR ACCELERATORS Accelerator programming Why a new model? There
OpenACC programming for GPGPUs: Rotor wake simulation
 DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
DLR.de Chart 1 OpenACC programming for GPGPUs: Rotor wake simulation Melven Röhrig-Zöllner, Achim Basermann Simulations- und Softwaretechnik DLR.de Chart 2 Outline Hardware-Architecture (CPU+GPU) GPU computing
INTRODUCTION TO COMPILER DIRECTIVES WITH OPENACC
 INTRODUCTION TO COMPILER DIRECTIVES WITH OPENACC DR. CHRISTOPH ANGERER, NVIDIA *) THANKS TO JEFF LARKIN, NVIDIA, FOR THE SLIDES 3 APPROACHES TO GPU PROGRAMMING Applications Libraries Compiler Directives
INTRODUCTION TO COMPILER DIRECTIVES WITH OPENACC DR. CHRISTOPH ANGERER, NVIDIA *) THANKS TO JEFF LARKIN, NVIDIA, FOR THE SLIDES 3 APPROACHES TO GPU PROGRAMMING Applications Libraries Compiler Directives
OpenACC (Open Accelerators - Introduced in 2012)
") OpenACC (Open Accelerators - Introduced in 2012) Open, portable standard for parallel computing (Cray, CAPS, Nvidia and PGI); introduced in 2012; GNU has an incomplete implementation. Uses directives in
OpenACC (Open Accelerators - Introduced in 2012) Open, portable standard for parallel computing (Cray, CAPS, Nvidia and PGI); introduced in 2012; GNU has an incomplete implementation. Uses directives in
Dealing with Heterogeneous Multicores
 Dealing with Heterogeneous Multicores François Bodin INRIA-UIUC, June 12 th, 2009 Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism
Dealing with Heterogeneous Multicores François Bodin INRIA-UIUC, June 12 th, 2009 Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism
Programming paradigms for GPU devices
 Programming paradigms for GPU devices OpenAcc Introduction Sergio Orlandini s.orlandini@cineca.it 1 OpenACC introduction express parallelism optimize data movements practical examples 2 3 Ways to Accelerate
Programming paradigms for GPU devices OpenAcc Introduction Sergio Orlandini s.orlandini@cineca.it 1 OpenACC introduction express parallelism optimize data movements practical examples 2 3 Ways to Accelerate
Parallel Hybrid Computing Stéphane Bihan, CAPS
 Parallel Hybrid Computing Stéphane Bihan, CAPS Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous hardware
Parallel Hybrid Computing Stéphane Bihan, CAPS Introduction Main stream applications will rely on new multicore / manycore architectures It is about performance not parallelism Various heterogeneous hardware
Introduction to OpenACC
 Introduction to OpenACC Alexander B. Pacheco User Services Consultant LSU HPC & LONI sys-help@loni.org HPC Training Spring 2014 Louisiana State University Baton Rouge March 26, 2014 Introduction to OpenACC
Introduction to OpenACC Alexander B. Pacheco User Services Consultant LSU HPC & LONI sys-help@loni.org HPC Training Spring 2014 Louisiana State University Baton Rouge March 26, 2014 Introduction to OpenACC
HMPP port. G. Colin de Verdière (CEA)
") HMPP port G. Colin de Verdière (CEA) Overview.Uchu prototype HMPP MOD2AS MOD2AM HMPP in a real code 2 The UCHU prototype Bull servers 1 login node 4 nodes 2 Haperton, 8GB 2 NVIDIA Tesla S1070 IB DDR Slurm
HMPP port G. Colin de Verdière (CEA) Overview.Uchu prototype HMPP MOD2AS MOD2AM HMPP in a real code 2 The UCHU prototype Bull servers 1 login node 4 nodes 2 Haperton, 8GB 2 NVIDIA Tesla S1070 IB DDR Slurm
Locality-Aware Automatic Parallelization for GPGPU with OpenHMPP Directives
 Locality-Aware Automatic Parallelization for GPGPU with OpenHMPP Directives José M. Andión, Manuel Arenaz, François Bodin, Gabriel Rodríguez and Juan Touriño 7th International Symposium on High-Level Parallel
Locality-Aware Automatic Parallelization for GPGPU with OpenHMPP Directives José M. Andión, Manuel Arenaz, François Bodin, Gabriel Rodríguez and Juan Touriño 7th International Symposium on High-Level Parallel
OpenACC Fundamentals. Steve Abbott November 13, 2016
 OpenACC Fundamentals Steve Abbott , November 13, 2016 Who Am I? 2005 B.S. Physics Beloit College 2007 M.S. Physics University of Florida 2015 Ph.D. Physics University of New Hampshire
OpenACC Fundamentals Steve Abbott , November 13, 2016 Who Am I? 2005 B.S. Physics Beloit College 2007 M.S. Physics University of Florida 2015 Ph.D. Physics University of New Hampshire
PGI Fortran & C Accelerator Programming Model. The Portland Group
 PGI Fortran & C Accelerator Programming Model The Portland Group Published: v0.72 December 2008 Contents 1. Introduction...3 1.1 Scope...3 1.2 Glossary...3 1.3 Execution Model...4 1.4 Memory Model...5
PGI Fortran & C Accelerator Programming Model The Portland Group Published: v0.72 December 2008 Contents 1. Introduction...3 1.1 Scope...3 1.2 Glossary...3 1.3 Execution Model...4 1.4 Memory Model...5
Introduction to OpenACC. Shaohao Chen Research Computing Services Information Services and Technology Boston University
 Introduction to OpenACC Shaohao Chen Research Computing Services Information Services and Technology Boston University Outline Introduction to GPU and OpenACC Basic syntax and the first OpenACC program:
Introduction to OpenACC Shaohao Chen Research Computing Services Information Services and Technology Boston University Outline Introduction to GPU and OpenACC Basic syntax and the first OpenACC program:
Technology for a better society. hetcomp.com
 Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Technology for a better society hetcomp.com 1 J. Seland, C. Dyken, T. R. Hagen, A. R. Brodtkorb, J. Hjelmervik,E Bjønnes GPU Computing USIT Course Week 16th November 2011 hetcomp.com 2 9:30 10:15 Introduction
Introduction to Compiler Directives with OpenACC
 Introduction to Compiler Directives with OpenACC Agenda Fundamentals of Heterogeneous & GPU Computing What are Compiler Directives? Accelerating Applications with OpenACC - Identifying Available Parallelism
Introduction to Compiler Directives with OpenACC Agenda Fundamentals of Heterogeneous & GPU Computing What are Compiler Directives? Accelerating Applications with OpenACC - Identifying Available Parallelism
OPENACC ONLINE COURSE 2018
 OPENACC ONLINE COURSE 2018 Week 3 Loop Optimizations with OpenACC Jeff Larkin, Senior DevTech Software Engineer, NVIDIA ABOUT THIS COURSE 3 Part Introduction to OpenACC Week 1 Introduction to OpenACC Week
OPENACC ONLINE COURSE 2018 Week 3 Loop Optimizations with OpenACC Jeff Larkin, Senior DevTech Software Engineer, NVIDIA ABOUT THIS COURSE 3 Part Introduction to OpenACC Week 1 Introduction to OpenACC Week
Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators
 Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators CSCE 569 Parallel Computing Department of Computer Science and Engineering Yonghong Yan yanyh@cse.sc.edu
Lecture: Manycore GPU Architectures and Programming, Part 4 -- Introducing OpenMP and HOMP for Accelerators CSCE 569 Parallel Computing Department of Computer Science and Engineering Yonghong Yan yanyh@cse.sc.edu
Programming Models for Multi- Threading. Brian Marshall, Advanced Research Computing
 Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Programming Models for Multi- Threading Brian Marshall, Advanced Research Computing Why Do Parallel Computing? Limits of single CPU computing performance available memory I/O rates Parallel computing allows
Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015
 Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015 Abstract As both an OpenMP and OpenACC insider I will present my opinion of the current status of these two directive sets for programming
Comparing OpenACC 2.5 and OpenMP 4.1 James C Beyer PhD, Sept 29 th 2015 Abstract As both an OpenMP and OpenACC insider I will present my opinion of the current status of these two directive sets for programming
COMP Parallel Computing. Programming Accelerators using Directives
 COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
COMP 633 - Parallel Computing Lecture 15 October 30, 2018 Programming Accelerators using Directives Credits: Introduction to OpenACC and toolkit Jeff Larkin, Nvidia COMP 633 - Prins Directives for Accelerator
Module 10: Open Multi-Processing Lecture 19: What is Parallelization? The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program
 The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
Advanced OpenACC. John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center. Copyright 2018
 Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2018 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015
 Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15: Profiling and Parallelizing with the OpenACC Toolkit
Profiling and Parallelizing with the OpenACC Toolkit OpenACC Course: Lecture 2 October 15, 2015 Oct 1: Introduction to OpenACC Oct 6: Office Hours Oct 15: Profiling and Parallelizing with the OpenACC Toolkit
Designing and Optimizing LQCD code using OpenACC
 Designing and Optimizing LQCD code using OpenACC E Calore, S F Schifano, R Tripiccione Enrico Calore University of Ferrara and INFN-Ferrara, Italy GPU Computing in High Energy Physics Pisa, Sep. 10 th,
Designing and Optimizing LQCD code using OpenACC E Calore, S F Schifano, R Tripiccione Enrico Calore University of Ferrara and INFN-Ferrara, Italy GPU Computing in High Energy Physics Pisa, Sep. 10 th,
Introduction to OpenACC. 16 May 2013
 Introduction to OpenACC 16 May 2013 GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers Oil & Gas CAE CFD Finance Rendering Data Analytics
Introduction to OpenACC 16 May 2013 GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research Universities Supercomputing Centers Oil & Gas CAE CFD Finance Rendering Data Analytics
An Introduction to OpenACC. Zoran Dabic, Rusell Lutrell, Edik Simonian, Ronil Singh, Shrey Tandel
 An Introduction to OpenACC Zoran Dabic, Rusell Lutrell, Edik Simonian, Ronil Singh, Shrey Tandel Chapter 1 Introduction OpenACC is a software accelerator that uses the host and the device. It uses compiler
An Introduction to OpenACC Zoran Dabic, Rusell Lutrell, Edik Simonian, Ronil Singh, Shrey Tandel Chapter 1 Introduction OpenACC is a software accelerator that uses the host and the device. It uses compiler
INTRODUCTION TO OPENACC. Analyzing and Parallelizing with OpenACC, Feb 22, 2017
 INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
INTRODUCTION TO OPENACC Analyzing and Parallelizing with OpenACC, Feb 22, 2017 Objective: Enable you to to accelerate your applications with OpenACC. 2 Today s Objectives Understand what OpenACC is and
Acceleration of a Python-based Tsunami Modelling Application via CUDA and OpenHMPP
 Acceleration of a Python-based Tsunami Modelling Application via CUDA and OpenHMPP Zhe Weng and Peter Strazdins*, Computer Systems Group, Research School of Computer Science, The Australian National University
Acceleration of a Python-based Tsunami Modelling Application via CUDA and OpenHMPP Zhe Weng and Peter Strazdins*, Computer Systems Group, Research School of Computer Science, The Australian National University
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC. Guest Lecturer: Sukhyun Song (original slides by Alan Sussman)
") CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
CMSC 714 Lecture 6 MPI vs. OpenMP and OpenACC Guest Lecturer: Sukhyun Song (original slides by Alan Sussman) Parallel Programming with Message Passing and Directives 2 MPI + OpenMP Some applications can
Overview of research activities Toward portability of performance
 Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Overview of research activities Toward portability of performance Do dynamically what can t be done statically Understand evolution of architectures Enable new programming models Put intelligence into
Advanced OpenACC. John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center. Copyright 2016
 Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2016 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2016 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
S Comparing OpenACC 2.5 and OpenMP 4.5
 April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
April 4-7, 2016 Silicon Valley S6410 - Comparing OpenACC 2.5 and OpenMP 4.5 James Beyer, NVIDIA Jeff Larkin, NVIDIA GTC16 April 7, 2016 History of OpenMP & OpenACC AGENDA Philosophical Differences Technical
OpenStaPLE, an OpenACC Lattice QCD Application
 OpenStaPLE, an OpenACC Lattice QCD Application Enrico Calore Postdoctoral Researcher Università degli Studi di Ferrara INFN Ferrara Italy GTC Europe, October 10 th, 2018 E. Calore (Univ. and INFN Ferrara)
OpenStaPLE, an OpenACC Lattice QCD Application Enrico Calore Postdoctoral Researcher Università degli Studi di Ferrara INFN Ferrara Italy GTC Europe, October 10 th, 2018 E. Calore (Univ. and INFN Ferrara)
Advanced OpenACC. Steve Abbott November 17, 2017
 Advanced OpenACC Steve Abbott , November 17, 2017 AGENDA Expressive Parallelism Pipelining Routines 2 The loop Directive The loop directive gives the compiler additional information
Advanced OpenACC Steve Abbott , November 17, 2017 AGENDA Expressive Parallelism Pipelining Routines 2 The loop Directive The loop directive gives the compiler additional information
Compiling for GPUs. Adarsh Yoga Madhav Ramesh
 Compiling for GPUs Adarsh Yoga Madhav Ramesh Agenda Introduction to GPUs Compute Unified Device Architecture (CUDA) Control Structure Optimization Technique for GPGPU Compiler Framework for Automatic Translation
Compiling for GPUs Adarsh Yoga Madhav Ramesh Agenda Introduction to GPUs Compute Unified Device Architecture (CUDA) Control Structure Optimization Technique for GPGPU Compiler Framework for Automatic Translation
GPU Computing with OpenACC Directives
 GPU Computing with OpenACC Directives Alexey Romanenko Based on Jeff Larkin s PPTs 3 Ways to Accelerate Applications Applications Libraries OpenACC Directives Programming Languages Drop-in Acceleration
GPU Computing with OpenACC Directives Alexey Romanenko Based on Jeff Larkin s PPTs 3 Ways to Accelerate Applications Applications Libraries OpenACC Directives Programming Languages Drop-in Acceleration
OpenACC introduction (part 2)
") OpenACC introduction (part 2) Aleksei Ivakhnenko APC Contents Understanding PGI compiler output Compiler flags and environment variables Compiler limitations in dependencies tracking Organizing data persistence
OpenACC introduction (part 2) Aleksei Ivakhnenko APC Contents Understanding PGI compiler output Compiler flags and environment variables Compiler limitations in dependencies tracking Organizing data persistence
Auto-tuning a High-Level Language Targeted to GPU Codes. By Scott Grauer-Gray, Lifan Xu, Robert Searles, Sudhee Ayalasomayajula, John Cavazos
 Auto-tuning a High-Level Language Targeted to GPU Codes By Scott Grauer-Gray, Lifan Xu, Robert Searles, Sudhee Ayalasomayajula, John Cavazos GPU Computing Utilization of GPU gives speedup on many algorithms
Auto-tuning a High-Level Language Targeted to GPU Codes By Scott Grauer-Gray, Lifan Xu, Robert Searles, Sudhee Ayalasomayajula, John Cavazos GPU Computing Utilization of GPU gives speedup on many algorithms
Shared Memory programming paradigm: openmp
 IPM School of Physics Workshop on High Performance Computing - HPC08 Shared Memory programming paradigm: openmp Luca Heltai Stefano Cozzini SISSA - Democritos/INFM
IPM School of Physics Workshop on High Performance Computing - HPC08 Shared Memory programming paradigm: openmp Luca Heltai Stefano Cozzini SISSA - Democritos/INFM
Advanced OpenACC. John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center. Copyright 2017
 Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
Advanced OpenACC John Urbanic Parallel Computing Scientist Pittsburgh Supercomputing Center Copyright 2017 Outline Loop Directives Data Declaration Directives Data Regions Directives Cache directives Wait
GPU Computing with OpenACC Directives Presented by Bob Crovella For UNC. Authored by Mark Harris NVIDIA Corporation
 GPU Computing with OpenACC Directives Presented by Bob Crovella For UNC Authored by Mark Harris NVIDIA Corporation GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research
GPU Computing with OpenACC Directives Presented by Bob Crovella For UNC Authored by Mark Harris NVIDIA Corporation GPUs Reaching Broader Set of Developers 1,000,000 s 100,000 s Early Adopters Research
OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4
 OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
OpenACC Course Class #1 Q&A Contents OpenACC/CUDA/OpenMP... 1 Languages and Libraries... 3 Multi-GPU support... 4 How OpenACC Works... 4 OpenACC/CUDA/OpenMP Q: Is OpenACC an NVIDIA standard or is it accepted
Parallel Programming. Libraries and Implementations
 Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Parallel Programming Libraries and Implementations Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
An Introduction to OpenAcc
 An Introduction to OpenAcc ECS 158 Final Project Robert Gonzales Matthew Martin Nile Mittow Ryan Rasmuss Spring 2016 1 Introduction: What is OpenAcc? OpenAcc stands for Open Accelerators. Developed by
An Introduction to OpenAcc ECS 158 Final Project Robert Gonzales Matthew Martin Nile Mittow Ryan Rasmuss Spring 2016 1 Introduction: What is OpenAcc? OpenAcc stands for Open Accelerators. Developed by
OmpSs + OpenACC Multi-target Task-Based Programming Model Exploiting OpenACC GPU Kernel
 www.bsc.es OmpSs + OpenACC Multi-target Task-Based Programming Model Exploiting OpenACC GPU Kernel Guray Ozen guray.ozen@bsc.es Exascale in BSC Marenostrum 4 (13.7 Petaflops ) General purpose cluster (3400
www.bsc.es OmpSs + OpenACC Multi-target Task-Based Programming Model Exploiting OpenACC GPU Kernel Guray Ozen guray.ozen@bsc.es Exascale in BSC Marenostrum 4 (13.7 Petaflops ) General purpose cluster (3400
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT
 TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
TOOLS FOR IMPROVING CROSS-PLATFORM SOFTWARE DEVELOPMENT Eric Kelmelis 28 March 2018 OVERVIEW BACKGROUND Evolution of processing hardware CROSS-PLATFORM KERNEL DEVELOPMENT Write once, target multiple hardware
OpenACC Fundamentals. Steve Abbott November 15, 2017
 OpenACC Fundamentals Steve Abbott , November 15, 2017 AGENDA Data Regions Deep Copy 2 while ( err > tol && iter < iter_max ) { err=0.0; JACOBI ITERATION #pragma acc parallel loop reduction(max:err)
OpenACC Fundamentals Steve Abbott , November 15, 2017 AGENDA Data Regions Deep Copy 2 while ( err > tol && iter < iter_max ) { err=0.0; JACOBI ITERATION #pragma acc parallel loop reduction(max:err)
INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC. Jeff Larkin, NVIDIA Developer Technologies
 INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC Jeff Larkin, NVIDIA Developer Technologies AGENDA Accelerated Computing Basics What are Compiler Directives? Accelerating Applications with OpenACC Identifying
INTRODUCTION TO ACCELERATED COMPUTING WITH OPENACC Jeff Larkin, NVIDIA Developer Technologies AGENDA Accelerated Computing Basics What are Compiler Directives? Accelerating Applications with OpenACC Identifying
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17
 Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
Portability of OpenMP Offload Directives Jeff Larkin, OpenMP Booth Talk SC17 11/27/2017 Background Many developers choose OpenMP in hopes of having a single source code that runs effectively anywhere (performance
Introduction to OpenACC
 Introduction to OpenACC Alexander B. Pacheco User Services Consultant LSU HPC & LONI sys-help@loni.org LONI Parallel Programming Workshop Louisiana State University Baton Rouge June 10-12, 2013 HPC@LSU
Introduction to OpenACC Alexander B. Pacheco User Services Consultant LSU HPC & LONI sys-help@loni.org LONI Parallel Programming Workshop Louisiana State University Baton Rouge June 10-12, 2013 HPC@LSU
INTRODUCTION TO OPENACC
 INTRODUCTION TO OPENACC Hossein Pourreza hossein.pourreza@umanitoba.ca March 31, 2016 Acknowledgement: Most of examples and pictures are from PSC (https://www.psc.edu/images/xsedetraining/openacc_may2015/
INTRODUCTION TO OPENACC Hossein Pourreza hossein.pourreza@umanitoba.ca March 31, 2016 Acknowledgement: Most of examples and pictures are from PSC (https://www.psc.edu/images/xsedetraining/openacc_may2015/
Parallel Programming Concepts. What kind of programming model can bridge the gap? Dr. Peter Tröger M.Sc. Frank Feinbube
 Parallel Programming Concepts What kind of programming model can bridge the gap? Dr. Peter Tröger M.Sc. Frank Feinbube 5 Hybrid System GDDR5 Dual Gigabit LAN Dual Gigabit LAN GDDR5 DDR3 Core CPU Core 16x
Parallel Programming Concepts What kind of programming model can bridge the gap? Dr. Peter Tröger M.Sc. Frank Feinbube 5 Hybrid System GDDR5 Dual Gigabit LAN Dual Gigabit LAN GDDR5 DDR3 Core CPU Core 16x
Adrian Tate XK6 / openacc workshop Manno, Mar
 Adrian Tate XK6 / openacc workshop Manno, Mar6-7 2012 1 Overview & Philosophy Two modes of usage Contents Present contents Upcoming releases Optimization of libsci_acc Autotuning Adaptation Asynchronous
Adrian Tate XK6 / openacc workshop Manno, Mar6-7 2012 1 Overview & Philosophy Two modes of usage Contents Present contents Upcoming releases Optimization of libsci_acc Autotuning Adaptation Asynchronous
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU
 NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
NVIDIA Think about Computing as Heterogeneous One Leo Liao, 1/29/2106, NTU GPGPU opens the door for co-design HPC, moreover middleware-support embedded system designs to harness the power of GPUaccelerated
A Uniform Programming Model for Petascale Computing
 A Uniform Programming Model for Petascale Computing Barbara Chapman University of Houston WPSE 2009, Tsukuba March 25, 2009 High Performance Computing and Tools Group http://www.cs.uh.edu/~hpctools Agenda
A Uniform Programming Model for Petascale Computing Barbara Chapman University of Houston WPSE 2009, Tsukuba March 25, 2009 High Performance Computing and Tools Group http://www.cs.uh.edu/~hpctools Agenda
The Design and Implementation of OpenMP 4.5 and OpenACC Backends for the RAJA C++ Performance Portability Layer
 The Design and Implementation of OpenMP 4.5 and OpenACC Backends for the RAJA C++ Performance Portability Layer William Killian Tom Scogland, Adam Kunen John Cavazos Millersville University of Pennsylvania
The Design and Implementation of OpenMP 4.5 and OpenACC Backends for the RAJA C++ Performance Portability Layer William Killian Tom Scogland, Adam Kunen John Cavazos Millersville University of Pennsylvania
GPU Programming. Alan Gray, James Perry EPCC The University of Edinburgh
 GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
GPU Programming EPCC The University of Edinburgh Contents NVIDIA CUDA C Proprietary interface to NVIDIA architecture CUDA Fortran Provided by PGI OpenCL Cross platform API 2 NVIDIA CUDA CUDA allows NVIDIA
Parallel Programming Libraries and implementations
 Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
Parallel Programming Libraries and implementations Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License.
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler
 GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
GPGPU Offloading with OpenMP 4.5 In the IBM XL Compiler Taylor Lloyd Jose Nelson Amaral Ettore Tiotto University of Alberta University of Alberta IBM Canada 1 Why? 2 Supercomputer Power/Performance GPUs
Introduction to Multicore Programming
 Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Automatic Parallelization and OpenMP 3 GPGPU 2 Multithreaded Programming
Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Automatic Parallelization and OpenMP 3 GPGPU 2 Multithreaded Programming
OpenMP 4.0. Mark Bull, EPCC
 OpenMP 4.0 Mark Bull, EPCC OpenMP 4.0 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all devices!
OpenMP 4.0 Mark Bull, EPCC OpenMP 4.0 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all devices!
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems. Ed Hinkel Senior Sales Engineer
 Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
Addressing the Increasing Challenges of Debugging on Accelerated HPC Systems Ed Hinkel Senior Sales Engineer Agenda Overview - Rogue Wave & TotalView GPU Debugging with TotalView Nvdia CUDA Intel Phi 2
arxiv: v1 [hep-lat] 12 Nov 2013
![arxiv: v1 [hep-lat] 12 Nov 2013](/thumbs/87/96002319.jpg "arxiv: v1 [hep-lat] 12 Nov 2013") Lattice Simulations using OpenACC compilers arxiv:13112719v1 [hep-lat] 12 Nov 2013 Indian Association for the Cultivation of Science, Kolkata E-mail: tppm@iacsresin OpenACC compilers allow one to use Graphics
Lattice Simulations using OpenACC compilers arxiv:13112719v1 [hep-lat] 12 Nov 2013 Indian Association for the Cultivation of Science, Kolkata E-mail: tppm@iacsresin OpenACC compilers allow one to use Graphics
An Extension of XcalableMP PGAS Lanaguage for Multi-node GPU Clusters
 An Extension of XcalableMP PGAS Lanaguage for Multi-node Clusters Jinpil Lee, Minh Tuan Tran, Tetsuya Odajima, Taisuke Boku and Mitsuhisa Sato University of Tsukuba 1 Presentation Overview l Introduction
An Extension of XcalableMP PGAS Lanaguage for Multi-node Clusters Jinpil Lee, Minh Tuan Tran, Tetsuya Odajima, Taisuke Boku and Mitsuhisa Sato University of Tsukuba 1 Presentation Overview l Introduction
Parallel Programming: OpenMP
 Parallel Programming: OpenMP Xianyi Zeng xzeng@utep.edu Department of Mathematical Sciences The University of Texas at El Paso. November 10, 2016. An Overview of OpenMP OpenMP: Open Multi-Processing An
Parallel Programming: OpenMP Xianyi Zeng xzeng@utep.edu Department of Mathematical Sciences The University of Texas at El Paso. November 10, 2016. An Overview of OpenMP OpenMP: Open Multi-Processing An
Directive-based Programming for Highly-scalable Nodes
 Directive-based Programming for Highly-scalable Nodes Doug Miles Michael Wolfe PGI Compilers & Tools NVIDIA Cray User Group Meeting May 2016 Talk Outline Increasingly Parallel Nodes Exposing Parallelism
Directive-based Programming for Highly-scalable Nodes Doug Miles Michael Wolfe PGI Compilers & Tools NVIDIA Cray User Group Meeting May 2016 Talk Outline Increasingly Parallel Nodes Exposing Parallelism
Introduction to Multicore Programming
 Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Synchronization 3 Automatic Parallelization and OpenMP 4 GPGPU 5 Q& A 2 Multithreaded
Introduction to Multicore Programming Minsoo Ryu Department of Computer Science and Engineering 2 1 Multithreaded Programming 2 Synchronization 3 Automatic Parallelization and OpenMP 4 GPGPU 5 Q& A 2 Multithreaded
OpenACC and the Cray Compilation Environment James Beyer PhD
 OpenACC and the Cray Compilation Environment James Beyer PhD Agenda A brief introduction to OpenACC Cray Programming Environment (PE) Cray Compilation Environment, CCE An in depth look at CCE 8.2 and OpenACC
OpenACC and the Cray Compilation Environment James Beyer PhD Agenda A brief introduction to OpenACC Cray Programming Environment (PE) Cray Compilation Environment, CCE An in depth look at CCE 8.2 and OpenACC
Parallel Programming. Exploring local computational resources OpenMP Parallel programming for multiprocessors for loops
 Parallel Programming Exploring local computational resources OpenMP Parallel programming for multiprocessors for loops Single computers nowadays Several CPUs (cores) 4 to 8 cores on a single chip Hyper-threading
Parallel Programming Exploring local computational resources OpenMP Parallel programming for multiprocessors for loops Single computers nowadays Several CPUs (cores) 4 to 8 cores on a single chip Hyper-threading
OpenMP 4.0/4.5. Mark Bull, EPCC
 OpenMP 4.0/4.5 Mark Bull, EPCC OpenMP 4.0/4.5 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all
OpenMP 4.0/4.5 Mark Bull, EPCC OpenMP 4.0/4.5 Version 4.0 was released in July 2013 Now available in most production version compilers support for device offloading not in all compilers, and not for all
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools
 Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Productive Performance on the Cray XK System Using OpenACC Compilers and Tools Luiz DeRose Sr. Principal Engineer Programming Environments Director Cray Inc. 1 The New Generation of Supercomputers Hybrid
Compiling a High-level Directive-Based Programming Model for GPGPUs
 Compiling a High-level Directive-Based Programming Model for GPGPUs Xiaonan Tian, Rengan Xu, Yonghong Yan, Zhifeng Yun, Sunita Chandrasekaran, and Barbara Chapman Department of Computer Science, University
Compiling a High-level Directive-Based Programming Model for GPGPUs Xiaonan Tian, Rengan Xu, Yonghong Yan, Zhifeng Yun, Sunita Chandrasekaran, and Barbara Chapman Department of Computer Science, University