A short overview of parallel paradigms. Fabio Affinito, SCAI
|
|
|
- Cora Campbell
- 5 years ago
- Views:
Transcription
1 A short overview of parallel paradigms Fabio Affinito, SCAI
2 Why parallel? In principle, if you have more than one computing processing unit you can exploit that to: -Decrease the time to solution - Increase the size of the problem to be solved The perfect parallelism is achieved when all the processes can run independently to obtain the final result. Parallelism impacts on: -The source structure - the computer architecture
3 Parallel architectures A first division, on the architectural side can be: -Distributed memory systems: each computing unit has its own memory address space - Shared memory systems: computing units (cores/processors) share the same address space. Knowledge of where data is stored is no concern of the programmer. On new MPP this division is not particularly defined. Both the models can live together.
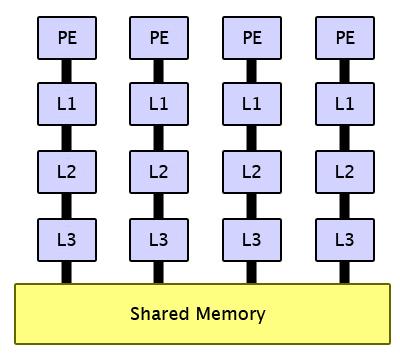



4 Distributed memory Shared memory
5 Programming models Distributed memory systems: -Message-passing approach. A paradigm to send and receive data among processes and synchronize them -Message-passing libraries: -MPI -PVM (out-of-date...) Shared memory systems: -Thread based programming approach -Compiler directives (i.e. OpenMP) -Can be used together with message-passing paradigm
6 Parallel approaches There are several typical cases of problems that are suitable for a parallel approach: -Linear algebra (or FT problems) -Problems where an inversion/multiplication/diagonalization of matrices can be partitioned on different processing units. Communications can be important and it be can be an important limit to the scalability. -Domain (or functional) decomposition -Large size problems can be partitioned on different processors. Typical examples are CFD, geophysical problems, molecular dynamics. Communication is the limit if the domains are correlated by forces, interactions and so on. -Parametric studies (high-througput) -Sensitivity approaches, -Montecarlo calculations, -Ensemble techniques -Communication is close to zero, high scalability.


7
8 Amdahl s law
9 Message Passing Interface -Each process has its own memory -Processes communicate among themselves with messages -The interface (API) for message passing is implemented in a library -Code contains library calls -The code must be deeply modified to implement message-passing algorithms -If well implemented it can lead to high scalability
10 Message Passing Interface -MPI is a message passing standard the 3.0 standard specification has been published very recently it enforces portability of the code to very different architectures it has an interface for Fortran/C/C++ languages (also a Python and Java interfaces are available)
11 Types of communications Communications are the building blocks of MPI They can be distinguished in: - Initialization, finalization and sync calls - Point to point communications - deadlocks - blocking/non-blocking sync) - Collective calls (data movement, reduction operations, - one to many - many to one - many to many
12 A summary of MPI -Point-to-point communications -Collective communications communications -One-sided communications -Communicators structure -User-defined datatypes -Virtual topologies -MPI I/O
13 Hello world! PROGRAM hello IMPLICIT NONE INCLUDE mpif.h INTEGER:: mype, totpes, i, ierr CALL MPI_INIT(ierr) CALL MPI_COMM_RANK( MPI_COMM_WORLD, mype, ierr ) CALL MPI_COMM_SIZE( MPI_COMM_WORLD, totpes, ierr ) PRINT *, mype is, mype, of total, totpes, PEs CALL MPI_FINALIZE(ierr) END PROGRAM hello
14 PROGRAM hello IMPLICIT NONE INCLUDE mpif.h CALL MPI_INIT <- call the MPI library <- let the play start CALL MPI_COMM_RANK( ) <- who am I? CALL MPI_COMM_SIZE( ) <- how many players are there? DO SOME STUFF HERE CALL MPI_FINALIZE(ierr) <- let s go back home END PROGRAM hello
15 Point-to-point It is the basic communication method provided by MPI library. Communication between 2 processes It is conceptually simple: source process A sends a message to destination process B, B receive the message from A. Communication take places within a communicator Source and Destination are identified by their rank in the communicator Des t 2 3 Source 4 Communicat or
16 Blocking mode Most of the MPI point-to-point routines can be used in either blocking or non-blocking mode. Blocking: A blocking send returns after it is safe to modify the application buffer (your send data) for reuse. Safe does not imply that the data was actually received - it may very well be sitting in a system buffer. A blocking send can be synchronous A blocking send can be asynchronous if a system buffer is used to hold the data for eventual delivery to the receive. A blocking receive only "returns" after the data has arrived and is ready for use by the program.
17 Processor 1 Processor 2 Application SEND Application RECV system buffer system buffer Point-to-point flowchart
18 Non blocking Non-blocking: Non-blocking send and receive routines will return almost immediately. They do not wait for any communication events to complete Non-blocking operations simply "request" the MPI library to perform the operation when it is able. The user can not predict when that will happen. It is unsafe to modify the application buffer until you know for a fact the requested non-blocking operation was actually performed by the library. There are "wait" routines used to do this. Non-blocking communications are primarily used to overlap computation with communication.
19 Deadlock Deadlock or a Race condition occurs when 2 (or more) processes are blocked and each is waiting for the other to make progress. 0 init 1 init compute compute Proceed if 1 has taken action B Proceed if 0 has taken action A Action A Action B terminate terminate
20 PROGRAM deadlock INCLUDE mpif.h INTEGER ierr, myid, nproc INTEGER status(mpi_status_size) REAL A(2), B(2) CALL MPI_INIT(ierr) CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr) CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr) IF( myid.eq. 0 ) THEN a(1) = 2.0 a(2) = 4.0 CALL MPI_RECV(b, 2, MPI_REAL, 1, 11, MPI_COMM_WORLD, status, ierr) CALL MPI_SEND(a, 2, MPI_REAL, 1, 10, MPI_COMM_WORLD, ierr) ELSE IF( myid.eq. 1 ) THEN a(1) = 3.0 a(2) = 5.0 CALL MPI_RECV(b, 2, MPI_REAL, 0, 10, MPI_COMM_WORLD, status, ierr) CALL MPI_SEND(a, 2, MPI_REAL, 0, 11, MPI_COMM_WORLD, ierr) END IF WRITE(6,*) myid, : b(1)=, b(1), b(2)=, b(2) CALL MPI_FINALIZE(ierr) END
21 PROGRAM avoid_lock INCLUDE mpif.h INTEGER ierr, myid, nproc INTEGER status(mpi_status_size) REAL A(2), B(2) CALL MPI_INIT(ierr) CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr) CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr) IF( myid.eq. 0 ) THEN a(1) = 2.0 a(2) = 4.0 CALL MPI_RECV(b, 2, MPI_REAL, 1, 11, MPI_COMM_WORLD, status, ierr) CALL MPI_SEND(a, 2, MPI_REAL, 1, 10, MPI_COMM_WORLD, ierr) ELSE IF( myid.eq. 1 ) THEN a(1) = 3.0 a(2) = 5.0 CALL MPI_SEND(a, 2, MPI_REAL, 0, 11, MPI_COMM_WORLD, ierr) CALL MPI_RECV(b, 2, MPI_REAL, 0, 10, MPI_COMM_WORLD, status, ierr) END IF WRITE(6,*) myid, : b(1)=, b(1), b(2)=, b(2) CALL MPI_FINALIZE(ierr) END
22 Collective communications Communications involving a group of processes. They are called by all the ranks involved in a communicator (or a group) Barrier synchronization Broadcast Gather/scatter Reduction Collective communications will not interfere with point-to-point All processes (in a communicator) call the collective function All collective communications are blocking (in MPI 2.0) No tags are required Receive buffers must match in size (number of bytes)
23 An example: Broadcast PROGRAM broad_cast INCLUDE mpif.h INTEGER ierr, myid, nproc, root INTEGER status(mpi_status_size) REAL A(2) CALL MPI_INIT(ierr) CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr) CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr) root = 0 IF( myid.eq. 0 ) THEN a(1) = 2.0 a(2) = 4.0 END IF CALL MPI_BCAST(a, 2, MPI_REAL, 0, MPI_COMM_WORLD, ierr) WRITE(6,*) myid, : a(1)=, a(1), a(2)=, a(2) CALL MPI_FINALIZE(ierr)
24 Most used... MPI_SCATTER MPI_GATHER
25 There are possible combinations of collective functions. For example, MPI Allgather It is a combination of a gather + a broadcast
26 For many collective functions there are extended functionalities. For example it s possible to define the length of arrays to be scattered or gathered with MPI_Scatterv MPI_Gatherv
27 MPI All to all This function makes a redistribution of the content of each process in a way that each process know the buffer of all others. It is a way to implement the matrix data transposition. a1 a2 a3 a4 a1 b1 c1 d1 b1 b2 b3 b4 a2 b2 c2 d2 c1 c2 c3 c4 a3 b3 c3 d3 d1 d2 d3 d4 a4 b4 c4 d4
28 MPI Reduction MPI_REDUCE MPI_SUM 14
29 In addition to the default MPI_COMM_WORLD, MPI offers the possibility to create user-defined communicators to deal with the programmer s needs. Each communicator is defined on a group of MPI processes and it redefines the rank of each process within each communicator. Collective functions take place only inside a defined communicator. User defined communicators can be useful when one needs to manage several levels of parallelism inside the same code.
30 if(myid%2==0){ color=1; }else{ color=2; } MPI_COMM_SPLIT(MPI_COMM_WORLD,color,myid,&subcomm); MPI_COMM_RANK(subcomm,mynewid); printf( rank in MPICOMM_WORLD %d,myid, rank in Subcomm %d,mynewid); I am rank 2 in MPI_COMM_WORLD, but 1 in Comm 1. I am rank 7 in MPI_COMM_WORLD, but 3 in Comm 2. I am rank 0 in MPI_COMM_WORLD, but 0 in Comm 1. I am rank 4 in MPI_COMM_WORLD, but 2 in Comm 1. I am rank 6 in MPI_COMM_WORLD, but 3 in Comm 1. I am rank 3 in MPI_COMM_WORLD, but 1 in Comm 2. I am rank 5 in MPI_COMM_WORLD, but 2 in Comm 2. I am rank 1 in MPI_COMM_WORLD, but 0 in Comm 2.
31 Virtual topologies are particular communicators that reflect a topology in the distribution of the processes. A virtual topology can help the programmer to map a physical problem onto the MPI map of processes. This semplifies the writing of the code and it permit to optimize communications. MPI provides tools to manage virtual topologies with mapping functions.

32 Cartesian topology on a 2D torus

33 -It is an API extension to C/C++ and Fortran languages -Most compilers support version 3.0 -GNU, IBM, Intel, PGI, etc. -Used for writing programs for shared memory architectures

34 OpenMP is based on a fork-join model Master-worker threads OpenMP is implemented through the use of pragmas directives within the source code

35 There s no message passing: all the thread access the same memory address space: communication is implicit. Programmers must take care to define: - local data - shared data between threads.
36 PROGRAM hellomp INTEGER numthreads, thread_id,omp_get_num_threads,omp_get_thread_num!$omp PARALLEL PRIVATE(NUM_THREADS, THREAD_ID) NUM_THREADS=OMP_GET_NUM_THREADS() THREAD_ID=OMP_GET_THREAD_NUM() WRITE(*,*) Hello world from thread num,thread_id!$omp END PARALLEL END #include <iostream.h> #include <omp.h> using namespace std; int main(int argc, char* argv[]){ int thread, num_threads; #pragma omp parallel private(thread_id, num_threads) { #if defined(_openmp) num_threads=omp_get_num_threads(); thread_id=omp_get_thread_num(); #endif printf( Hello world from thread num %d,thread_id); } }
37 API int omp_get_num_threads() int omp_get_thread_num() int omp_get_num_procs() int omp_get_max_threads() double omp_get_wtime() description returns the number of threads in the concurrent team returns the id of the thread inside the parallel region returns the number of processors in the machine returns the max number of threads that will be used in the next parallel region returns the number of seconds since a time in the past And more and more...
38 For each parallel region, the programmer should take care to define the data sharing attributes for each variable, through a number of clauses: Clause default shared private firstprivate lastprivate reduction Description It sets the default sharing attribute when no specified explicitly (caution!) Variable is common among threads Variable inside the parallel construct is a new variable Variable is new, but initialized to its original value Variable s last value is copied outside the construct Variable s value is reduced at the end among all threads
39 INTEGER X X=1!$ OMP PARALLEL SHARED(X) NUM_THREADS(2) X=X+1 PRINT*, X!$ OMP END PARALLEL It will print EITHER 2 or 3 INTEGER X X=1!$ OMP PARALLEL PRIVATE(X) NUM_THREADS(2) X=X+1 PRINT*, X!$ OMP END PARALLEL It will print ANYTHING INTEGER X X=1!$ OMP PARALLEL FIRSTPRIVATE(X) NUM_THREADS(2) X=X+1 PRINT*, X!$ OMP END PARALLEL It will print 2 TWICE
40 OpenMP provides several synchronization mechanisms: -Barrier (synchronizes all threads inside the parallel region) -Master (only the master thread will execute the block) -Critical (only one thread at at time will execute) -Atomic (same as critical but for one memory location) -...
41 INTEGER X X=1!$OMP PARALLEL SHARED(X) NUM_THREADS(2) X=X+1!$OMP BARRIER PRINT*,X!$OMP END PARALLEL 3 3 INTEGER X X=1!$OMP PARALLEL SHARED(X) NUM_THREADS(2)!$OMP MASTER X=X+1!$OMP END MASTER PRINT*,X!$OMP END PARALLEL INTEGER X X=1!$OMP PARALLEL SHARED(X) NUM_THREADS(2)!$OMP ATOMIC X=X+1 PRINT*,X!$OMP END PARALLEL
42 Worksharing constructs: -Threads cooperate in doing some work -Thread identifiers are not used in an explicit manner -Most common use is in loop worksharing -Worksharing constructs may not be nested -DO/for directives are used in order to determine a parallel region
43 Int i,j; #pragma omp parallel #pragma omp for private(j) for(i=0;i<n;i++) { for(j=0;j<n,j++) m[i][j]=f(i,j); } -this loop is parallel on the i variable (private by default) -j must be declared as private explicitly -synchronization is implicitly obtained at the end of the loop
44 You may need that in some region a statement is executed by only one thread, no matter which one. In this case you can use a SINGLE region....!$omp parallel...!$omp single read *,n!$omp end single...!$omp end parallel
45 Using the schedule clause one can determine the distribution of computational work among threads: -static, chunk: the loop is equally divided in pieces of size chunk whic are evenly distributed among threads in a round-robin way -dynamic,chunk: the loop is equally divided among pieces chunk that are distributed for execution dynamically to threads. If no chunk is specified, then chunk=1 -guided: similar to dynamic with the variation that chunk size is reduced as threads grab iterations This is configurable with environment variable OMP_SCHEDULE: -i.e. setenv OMP_SCHEDULE dynamic,4

46
47 The reduction clause can be used when a variable is accumulated at the end of a loop. Using the reduction clause: -a private copy per thread is created and initialized -at the end of the region the compiler safely updates the shared variable!$omp do reduction(+:x) do i=1,n x=x+a(i) End do!$omp end do
48 False sharing -Memory addresses are grouped into cache lines -If one element of the cache line is changed, the whole line is invalidated -If more than one thread is working on the same cache line, this cache line is continously invalidated and there s a lot of traffic between cache and memory. -False sharing is one of the reason of poor scalability in pure OpenMP approaches float data[n], total=0; int ii; #pragma omp parallel num_threads(n) { int n = omp_get_thread_num(); data[n] = 0; while(moretodo(n)) data[n] += calculate_something(n); } for (ii=0; ii<n; ii++) total += data[n];
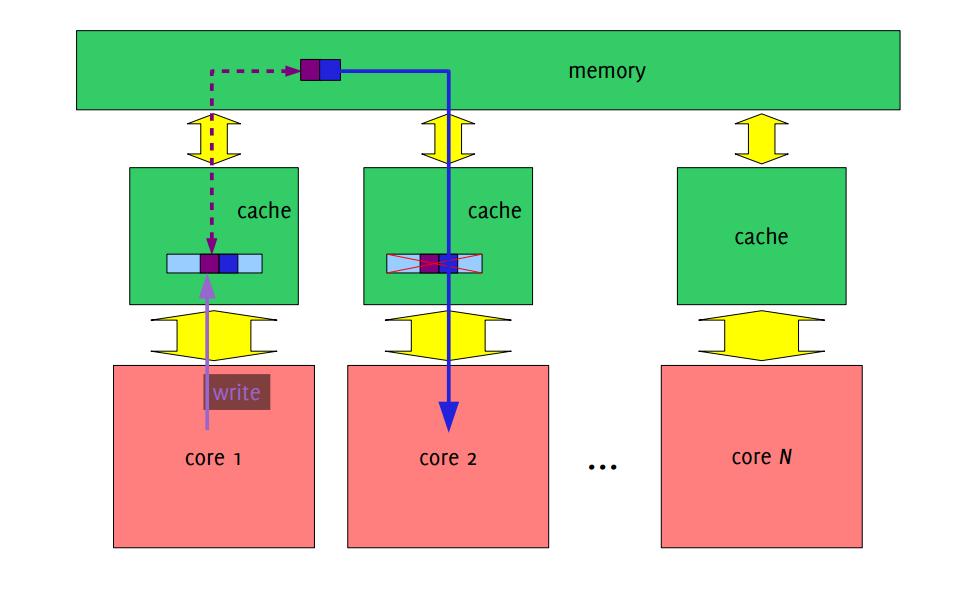
49
50 float data[n], total=0; int ii; #pragma omp parallel num_threads(n) private(data) { int n = omp_get_thread_num(); data[n] = 0; while(moretodo(n)) data[n] += calculate_something(n); } for (ii=0; ii<n; ii++) total += data[n]; use private attribute use padding

51

52 Using together MPI and OpenMP OpenMP MPI
53 Since MPI2, a support is provided for hybrid programming MPI+OpenMP: MPI_INIT_THREAD(required, provided,ierr) There are 4 levels supported: -MPI_THREAD_SINGLE: no threads are allowed -MPI_THREAD_FUNNELED: threads are allowed; Only the master thread can call MPI primitives -MPI_THREAD_SERIAL: threads are allowed. All threads can call MPI primitives. Communications are scheduled in a serial manner. -MPI_THREAD_MULTIPLE: threads are allowed. All threads can call MPI communication primitives in an arbitrary order
54 INCLUDE mpif.h INTEGER :: rnk,sz,n,i,ierr,chunk INTEGER,PARAMETER :: n=100 REAL*8 :: x(n),y(n),buff(n) CALL MPI_INIT(ierr) CALL MPI_COMM_RANK(MPI_COMM_WORLD,rnk,ierr) CALL MPI_COMM_SIZE(MPI_COMM_WORLD,sz,ierr) chunk=n/sz CALL MPI_SCATTER(buff(rnk*chunk),chunk,MPI_DOUBLE,x,chunk,MPI_DOUBLE,0, & MPI_COMM_WORLD,ierr) CALL MPI_SCATTER(buff(rnk*chunk),chunk,MPI_DOUBLE,y,chunk,MPI_DOUBLE,0, & MPI_COMM_WORLD,ierr) & & DO i=1,chunk x(i)=x(i)+y(i) END DO CALL MPI_GATHER(x,chunk,MPI_DOUBLE,buff,chunk,MPI_DOUBLE,0,MPI_COMM_WORLD,ierr) CALL MPI_FINALIZE(ierr) END
55 ... INTEGER :: i INTEGER, PARAMETER :: n=100 REAL*8 :: x(n),y(n),buff(n)!$omp PARALLEL DO PRIVATE(i) SHARED(x,y) DO i=1,n x(i)=x(i)+y(i) END DO
56 INCLUDE mpif.h INTEGER :: rnk,sz,n,i,ierr,info,chunk INTEGER,PARAMETER :: n=100 REAL*8 :: x(n),y(n),buff(n) CALL MPI_INIT_THREAD(MPI_THREAD_FUNNELED,info,ierr) CALL MPI_COMM_RANK(MPI_COMM_WORLD,rnk,ierr) CALL MPI_COMM_SIZE(MPI_COMM_WORLD,sz,ierr) chunk=n/sz CALL MPI_SCATTER(buff(rnk*chunk),chunk,MPI_DOUBLE,x,chunk,MPI_DOUBLE,0, & MPI_COMM_WORLD,ierr) CALL MPI_SCATTER(buff(rnk*chunk),chunk,MPI_DOUBLE,y,chunk,MPI_DOUBLE,0, & MPI_COMM_WORLD,ierr) & &!$OMP PARALLEL DO DO i=1,chunk x(i)=x(i)+y(i) END DO!$OMP END PARALLEL CALL MPI_GATHER(x,chunk,MPI_DOUBLE,buff,chunk,MPI_DOUBLE,0,MPI_COMM_WORLD,ierr) CALL MPI_FINALIZE(ierr) END
57 Task parallelism Definition: A task parallel computation is one in which parallelism is applied by performing distinct computations (i.e. tasks) at the same time. Since the number of tasks is fixed, this parallelism is not scalable OpenMP 3.0 supports tasks parallelism Tasks parallelism introduces a functional dependence between tasks. Is similar to a sort of pipelining of functional units
58 OpenMP task construct #pragma omp task [clauses] { do something } Where clauses is: private, shared, default, if, untied, final, mergeable -Immediately creates a new task but not a new thread -This task is explicit (also threads can be thought as implicit tasks ) -It will be executed by a thread in the current team -It can be deferred until a thread is available to execute -The data environment is built at creation time
Introduction to MPI part II. Fabio AFFINITO
 Introduction to MPI part II Fabio AFFINITO (f.affinito@cineca.it) Collective communications Communications involving a group of processes. They are called by all the ranks involved in a communicator (or
Introduction to MPI part II Fabio AFFINITO (f.affinito@cineca.it) Collective communications Communications involving a group of processes. They are called by all the ranks involved in a communicator (or
Introduction to MPI Part II Collective Communications and communicators
 Introduction to MPI Part II Collective Communications and communicators Andrew Emerson, Fabio Affinito {a.emerson,f.affinito}@cineca.it SuperComputing Applications and Innovation Department Collective
Introduction to MPI Part II Collective Communications and communicators Andrew Emerson, Fabio Affinito {a.emerson,f.affinito}@cineca.it SuperComputing Applications and Innovation Department Collective
HPC Workshop University of Kentucky May 9, 2007 May 10, 2007
 HPC Workshop University of Kentucky May 9, 2007 May 10, 2007 Part 3 Parallel Programming Parallel Programming Concepts Amdahl s Law Parallel Programming Models Tools Compiler (Intel) Math Libraries (Intel)
HPC Workshop University of Kentucky May 9, 2007 May 10, 2007 Part 3 Parallel Programming Parallel Programming Concepts Amdahl s Law Parallel Programming Models Tools Compiler (Intel) Math Libraries (Intel)
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016
 Ion Stoica, UC Berkeley November 19, 2016") MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
Chip Multiprocessors COMP Lecture 9 - OpenMP & MPI
 Chip Multiprocessors COMP35112 Lecture 9 - OpenMP & MPI Graham Riley 14 February 2018 1 Today s Lecture Dividing work to be done in parallel between threads in Java (as you are doing in the labs) is rather
Chip Multiprocessors COMP35112 Lecture 9 - OpenMP & MPI Graham Riley 14 February 2018 1 Today s Lecture Dividing work to be done in parallel between threads in Java (as you are doing in the labs) is rather
Computer Architecture
 Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 2 Part I Programming
Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 2 Part I Programming
Shared Memory programming paradigm: openmp
 IPM School of Physics Workshop on High Performance Computing - HPC08 Shared Memory programming paradigm: openmp Luca Heltai Stefano Cozzini SISSA - Democritos/INFM
IPM School of Physics Workshop on High Performance Computing - HPC08 Shared Memory programming paradigm: openmp Luca Heltai Stefano Cozzini SISSA - Democritos/INFM
Topics. Introduction. Shared Memory Parallelization. Example. Lecture 11. OpenMP Execution Model Fork-Join model 5/15/2012. Introduction OpenMP
 Topics Lecture 11 Introduction OpenMP Some Examples Library functions Environment variables 1 2 Introduction Shared Memory Parallelization OpenMP is: a standard for parallel programming in C, C++, and
Topics Lecture 11 Introduction OpenMP Some Examples Library functions Environment variables 1 2 Introduction Shared Memory Parallelization OpenMP is: a standard for parallel programming in C, C++, and
Introduction to OpenMP
 Introduction to OpenMP Le Yan Scientific computing consultant User services group High Performance Computing @ LSU Goals Acquaint users with the concept of shared memory parallelism Acquaint users with
Introduction to OpenMP Le Yan Scientific computing consultant User services group High Performance Computing @ LSU Goals Acquaint users with the concept of shared memory parallelism Acquaint users with
Introduction to parallel computing concepts and technics
 Introduction to parallel computing concepts and technics Paschalis Korosoglou (support@grid.auth.gr) User and Application Support Unit Scientific Computing Center @ AUTH Overview of Parallel computing
Introduction to parallel computing concepts and technics Paschalis Korosoglou (support@grid.auth.gr) User and Application Support Unit Scientific Computing Center @ AUTH Overview of Parallel computing
OpenMP. António Abreu. Instituto Politécnico de Setúbal. 1 de Março de 2013
 OpenMP António Abreu Instituto Politécnico de Setúbal 1 de Março de 2013 António Abreu (Instituto Politécnico de Setúbal) OpenMP 1 de Março de 2013 1 / 37 openmp what? It s an Application Program Interface
OpenMP António Abreu Instituto Politécnico de Setúbal 1 de Março de 2013 António Abreu (Instituto Politécnico de Setúbal) OpenMP 1 de Março de 2013 1 / 37 openmp what? It s an Application Program Interface
Introduction to OpenMP. OpenMP basics OpenMP directives, clauses, and library routines
 Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Parallel Computing and the MPI environment
 Parallel Computing and the MPI environment Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste http://www.dmi.units.it/~chiarutt/didattica/parallela
Parallel Computing and the MPI environment Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste http://www.dmi.units.it/~chiarutt/didattica/parallela
HPC Practical Course Part 3.1 Open Multi-Processing (OpenMP)
") HPC Practical Course Part 3.1 Open Multi-Processing (OpenMP) V. Akishina, I. Kisel, G. Kozlov, I. Kulakov, M. Pugach, M. Zyzak Goethe University of Frankfurt am Main 2015 Task Parallelism Parallelization
HPC Practical Course Part 3.1 Open Multi-Processing (OpenMP) V. Akishina, I. Kisel, G. Kozlov, I. Kulakov, M. Pugach, M. Zyzak Goethe University of Frankfurt am Main 2015 Task Parallelism Parallelization
OpenMP 2. CSCI 4850/5850 High-Performance Computing Spring 2018
 OpenMP 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
OpenMP 2 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste
 Università di Trieste") Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste http://www.dmi.units.it/~chiarutt/didattica/parallela
Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste http://www.dmi.units.it/~chiarutt/didattica/parallela
Session 4: Parallel Programming with OpenMP
 Session 4: Parallel Programming with OpenMP Xavier Martorell Barcelona Supercomputing Center Agenda Agenda 10:00-11:00 OpenMP fundamentals, parallel regions 11:00-11:30 Worksharing constructs 11:30-12:00
Session 4: Parallel Programming with OpenMP Xavier Martorell Barcelona Supercomputing Center Agenda Agenda 10:00-11:00 OpenMP fundamentals, parallel regions 11:00-11:30 Worksharing constructs 11:30-12:00
Introduction to MPI. May 20, Daniel J. Bodony Department of Aerospace Engineering University of Illinois at Urbana-Champaign
 Introduction to MPI May 20, 2013 Daniel J. Bodony Department of Aerospace Engineering University of Illinois at Urbana-Champaign Top500.org PERFORMANCE DEVELOPMENT 1 Eflop/s 162 Pflop/s PROJECTED 100 Pflop/s
Introduction to MPI May 20, 2013 Daniel J. Bodony Department of Aerospace Engineering University of Illinois at Urbana-Champaign Top500.org PERFORMANCE DEVELOPMENT 1 Eflop/s 162 Pflop/s PROJECTED 100 Pflop/s
Module 10: Open Multi-Processing Lecture 19: What is Parallelization? The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program
 The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
The Lecture Contains: What is Parallelization? Perfectly Load-Balanced Program Amdahl's Law About Data What is Data Race? Overview to OpenMP Components of OpenMP OpenMP Programming Model OpenMP Directives
CS 470 Spring Mike Lam, Professor. OpenMP
 CS 470 Spring 2017 Mike Lam, Professor OpenMP OpenMP Programming language extension Compiler support required "Open Multi-Processing" (open standard; latest version is 4.5) Automatic thread-level parallelism
CS 470 Spring 2017 Mike Lam, Professor OpenMP OpenMP Programming language extension Compiler support required "Open Multi-Processing" (open standard; latest version is 4.5) Automatic thread-level parallelism
Introduction to OpenMP
 Introduction to OpenMP Le Yan HPC Consultant User Services Goals Acquaint users with the concept of shared memory parallelism Acquaint users with the basics of programming with OpenMP Discuss briefly the
Introduction to OpenMP Le Yan HPC Consultant User Services Goals Acquaint users with the concept of shared memory parallelism Acquaint users with the basics of programming with OpenMP Discuss briefly the
CS 470 Spring Mike Lam, Professor. OpenMP
 CS 470 Spring 2018 Mike Lam, Professor OpenMP OpenMP Programming language extension Compiler support required "Open Multi-Processing" (open standard; latest version is 4.5) Automatic thread-level parallelism
CS 470 Spring 2018 Mike Lam, Professor OpenMP OpenMP Programming language extension Compiler support required "Open Multi-Processing" (open standard; latest version is 4.5) Automatic thread-level parallelism
A brief introduction to OpenMP
 A brief introduction to OpenMP Alejandro Duran Barcelona Supercomputing Center Outline 1 Introduction 2 Writing OpenMP programs 3 Data-sharing attributes 4 Synchronization 5 Worksharings 6 Task parallelism
A brief introduction to OpenMP Alejandro Duran Barcelona Supercomputing Center Outline 1 Introduction 2 Writing OpenMP programs 3 Data-sharing attributes 4 Synchronization 5 Worksharings 6 Task parallelism
Introduction to. Slides prepared by : Farzana Rahman 1
 Introduction to OpenMP Slides prepared by : Farzana Rahman 1 Definition of OpenMP Application Program Interface (API) for Shared Memory Parallel Programming Directive based approach with library support
Introduction to OpenMP Slides prepared by : Farzana Rahman 1 Definition of OpenMP Application Program Interface (API) for Shared Memory Parallel Programming Directive based approach with library support
Advanced C Programming Winter Term 2008/09. Guest Lecture by Markus Thiele
 Advanced C Programming Winter Term 2008/09 Guest Lecture by Markus Thiele Lecture 14: Parallel Programming with OpenMP Motivation: Why parallelize? The free lunch is over. Herb
Advanced C Programming Winter Term 2008/09 Guest Lecture by Markus Thiele Lecture 14: Parallel Programming with OpenMP Motivation: Why parallelize? The free lunch is over. Herb
Holland Computing Center Kickstart MPI Intro
 Holland Computing Center Kickstart 2016 MPI Intro Message Passing Interface (MPI) MPI is a specification for message passing library that is standardized by MPI Forum Multiple vendor-specific implementations:
Holland Computing Center Kickstart 2016 MPI Intro Message Passing Interface (MPI) MPI is a specification for message passing library that is standardized by MPI Forum Multiple vendor-specific implementations:
ITCS 4/5145 Parallel Computing Test 1 5:00 pm - 6:15 pm, Wednesday February 17, 2016 Solutions Name:...
 ITCS 4/5145 Parallel Computing Test 1 5:00 pm - 6:15 pm, Wednesday February 17, 016 Solutions Name:... Answer questions in space provided below questions. Use additional paper if necessary but make sure
ITCS 4/5145 Parallel Computing Test 1 5:00 pm - 6:15 pm, Wednesday February 17, 016 Solutions Name:... Answer questions in space provided below questions. Use additional paper if necessary but make sure
OpenMP and MPI. Parallel and Distributed Computing. Department of Computer Science and Engineering (DEI) Instituto Superior Técnico.
 Instituto Superior Técnico.") OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 15, 2010 José Monteiro (DEI / IST) Parallel and Distributed Computing
OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 15, 2010 José Monteiro (DEI / IST) Parallel and Distributed Computing
EE/CSCI 451 Introduction to Parallel and Distributed Computation. Discussion #4 2/3/2017 University of Southern California
 EE/CSCI 451 Introduction to Parallel and Distributed Computation Discussion #4 2/3/2017 University of Southern California 1 USC HPCC Access Compile Submit job OpenMP Today s topic What is OpenMP OpenMP
EE/CSCI 451 Introduction to Parallel and Distributed Computation Discussion #4 2/3/2017 University of Southern California 1 USC HPCC Access Compile Submit job OpenMP Today s topic What is OpenMP OpenMP
DPHPC: Introduction to OpenMP Recitation session
 SALVATORE DI GIROLAMO DPHPC: Introduction to OpenMP Recitation session Based on http://openmp.org/mp-documents/intro_to_openmp_mattson.pdf OpenMP An Introduction What is it? A set of compiler directives
SALVATORE DI GIROLAMO DPHPC: Introduction to OpenMP Recitation session Based on http://openmp.org/mp-documents/intro_to_openmp_mattson.pdf OpenMP An Introduction What is it? A set of compiler directives
The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing
 TMA4280 Introduction to Supercomputing") The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Parallelism Decompose the execution into several tasks according to the work to be done: Function/Task
The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Parallelism Decompose the execution into several tasks according to the work to be done: Function/Task
OpenMP and MPI. Parallel and Distributed Computing. Department of Computer Science and Engineering (DEI) Instituto Superior Técnico.
 Instituto Superior Técnico.") OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 16, 2011 CPD (DEI / IST) Parallel and Distributed Computing 18
OpenMP and MPI Parallel and Distributed Computing Department of Computer Science and Engineering (DEI) Instituto Superior Técnico November 16, 2011 CPD (DEI / IST) Parallel and Distributed Computing 18
ECE 574 Cluster Computing Lecture 10
 ECE 574 Cluster Computing Lecture 10 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 October 2015 Announcements Homework #4 will be posted eventually 1 HW#4 Notes How granular
ECE 574 Cluster Computing Lecture 10 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 1 October 2015 Announcements Homework #4 will be posted eventually 1 HW#4 Notes How granular
Shared memory programming
 CME342- Parallel Methods in Numerical Analysis Shared memory programming May 14, 2014 Lectures 13-14 Motivation Popularity of shared memory systems is increasing: Early on, DSM computers (SGI Origin 3000
CME342- Parallel Methods in Numerical Analysis Shared memory programming May 14, 2014 Lectures 13-14 Motivation Popularity of shared memory systems is increasing: Early on, DSM computers (SGI Origin 3000
OpenMP. A parallel language standard that support both data and functional Parallelism on a shared memory system
 OpenMP A parallel language standard that support both data and functional Parallelism on a shared memory system Use by system programmers more than application programmers Considered a low level primitives
OpenMP A parallel language standard that support both data and functional Parallelism on a shared memory system Use by system programmers more than application programmers Considered a low level primitives
[Potentially] Your first parallel application
![[Potentially] Your first parallel application](/thumbs/71/65941908.jpg "[Potentially] Your first parallel application") [Potentially] Your first parallel application Compute the smallest element in an array as fast as possible small = array[0]; for( i = 0; i < N; i++) if( array[i] < small ) ) small = array[i] 64-bit Intel
[Potentially] Your first parallel application Compute the smallest element in an array as fast as possible small = array[0]; for( i = 0; i < N; i++) if( array[i] < small ) ) small = array[i] 64-bit Intel
Shared Memory Parallelism - OpenMP
 Shared Memory Parallelism - OpenMP Sathish Vadhiyar Credits/Sources: OpenMP C/C++ standard (openmp.org) OpenMP tutorial (http://www.llnl.gov/computing/tutorials/openmp/#introduction) OpenMP sc99 tutorial
Shared Memory Parallelism - OpenMP Sathish Vadhiyar Credits/Sources: OpenMP C/C++ standard (openmp.org) OpenMP tutorial (http://www.llnl.gov/computing/tutorials/openmp/#introduction) OpenMP sc99 tutorial
Parallel Programming with OpenMP. CS240A, T. Yang
 Parallel Programming with OpenMP CS240A, T. Yang 1 A Programmer s View of OpenMP What is OpenMP? Open specification for Multi-Processing Standard API for defining multi-threaded shared-memory programs
Parallel Programming with OpenMP CS240A, T. Yang 1 A Programmer s View of OpenMP What is OpenMP? Open specification for Multi-Processing Standard API for defining multi-threaded shared-memory programs
Hybrid MPI and OpenMP Parallel Programming
 Hybrid MPI and OpenMP Parallel Programming Jemmy Hu SHARCNET HPTC Consultant July 8, 2015 Objectives difference between message passing and shared memory models (MPI, OpenMP) why or why not hybrid? a common
Hybrid MPI and OpenMP Parallel Programming Jemmy Hu SHARCNET HPTC Consultant July 8, 2015 Objectives difference between message passing and shared memory models (MPI, OpenMP) why or why not hybrid? a common
Introduction to OpenMP
 Introduction to OpenMP Le Yan Objectives of Training Acquaint users with the concept of shared memory parallelism Acquaint users with the basics of programming with OpenMP Memory System: Shared Memory
Introduction to OpenMP Le Yan Objectives of Training Acquaint users with the concept of shared memory parallelism Acquaint users with the basics of programming with OpenMP Memory System: Shared Memory
Mango DSP Top manufacturer of multiprocessing video & imaging solutions.
 1 of 11 3/3/2005 10:50 AM Linux Magazine February 2004 C++ Parallel Increase application performance without changing your source code. Mango DSP Top manufacturer of multiprocessing video & imaging solutions.
1 of 11 3/3/2005 10:50 AM Linux Magazine February 2004 C++ Parallel Increase application performance without changing your source code. Mango DSP Top manufacturer of multiprocessing video & imaging solutions.
Lecture 16: Recapitulations. Lecture 16: Recapitulations p. 1
 Lecture 16: Recapitulations Lecture 16: Recapitulations p. 1 Parallel computing and programming in general Parallel computing a form of parallel processing by utilizing multiple computing units concurrently
Lecture 16: Recapitulations Lecture 16: Recapitulations p. 1 Parallel computing and programming in general Parallel computing a form of parallel processing by utilizing multiple computing units concurrently
Parallel Programming using MPI. Supercomputing group CINECA
 Parallel Programming using MPI Supercomputing group CINECA Contents Programming with message passing Introduction to message passing and MPI Basic MPI programs MPI Communicators Send and Receive function
Parallel Programming using MPI Supercomputing group CINECA Contents Programming with message passing Introduction to message passing and MPI Basic MPI programs MPI Communicators Send and Receive function
Shared Memory Programming with OpenMP
 Shared Memory Programming with OpenMP (An UHeM Training) Süha Tuna Informatics Institute, Istanbul Technical University February 12th, 2016 2 Outline - I Shared Memory Systems Threaded Programming Model
Shared Memory Programming with OpenMP (An UHeM Training) Süha Tuna Informatics Institute, Istanbul Technical University February 12th, 2016 2 Outline - I Shared Memory Systems Threaded Programming Model
EPL372 Lab Exercise 5: Introduction to OpenMP
 EPL372 Lab Exercise 5: Introduction to OpenMP References: https://computing.llnl.gov/tutorials/openmp/ http://openmp.org/wp/openmp-specifications/ http://openmp.org/mp-documents/openmp-4.0-c.pdf http://openmp.org/mp-documents/openmp4.0.0.examples.pdf
EPL372 Lab Exercise 5: Introduction to OpenMP References: https://computing.llnl.gov/tutorials/openmp/ http://openmp.org/wp/openmp-specifications/ http://openmp.org/mp-documents/openmp-4.0-c.pdf http://openmp.org/mp-documents/openmp4.0.0.examples.pdf
Barbara Chapman, Gabriele Jost, Ruud van der Pas
 Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
Using OpenMP Portable Shared Memory Parallel Programming Barbara Chapman, Gabriele Jost, Ruud van der Pas The MIT Press Cambridge, Massachusetts London, England c 2008 Massachusetts Institute of Technology
Shared Memory Parallelism using OpenMP
 Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत SE 292: High Performance Computing [3:0][Aug:2014] Shared Memory Parallelism using OpenMP Yogesh Simmhan Adapted from: o
Indian Institute of Science Bangalore, India भ रत य व ज ञ न स स थ न ब गल र, भ रत SE 292: High Performance Computing [3:0][Aug:2014] Shared Memory Parallelism using OpenMP Yogesh Simmhan Adapted from: o
Parallel Programming. Jin-Soo Kim Computer Systems Laboratory Sungkyunkwan University
 Parallel Programming Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Challenges Difficult to write parallel programs Most programmers think sequentially
Parallel Programming Jin-Soo Kim (jinsookim@skku.edu) Computer Systems Laboratory Sungkyunkwan University http://csl.skku.edu Challenges Difficult to write parallel programs Most programmers think sequentially
Introduction to OpenMP.
 Introduction to OpenMP www.openmp.org Motivation Parallelize the following code using threads: for (i=0; i
Introduction to OpenMP www.openmp.org Motivation Parallelize the following code using threads: for (i=0; i
Lecture 4: OpenMP Open Multi-Processing
 CS 4230: Parallel Programming Lecture 4: OpenMP Open Multi-Processing January 23, 2017 01/23/2017 CS4230 1 Outline OpenMP another approach for thread parallel programming Fork-Join execution model OpenMP
CS 4230: Parallel Programming Lecture 4: OpenMP Open Multi-Processing January 23, 2017 01/23/2017 CS4230 1 Outline OpenMP another approach for thread parallel programming Fork-Join execution model OpenMP
OpenMP Algoritmi e Calcolo Parallelo. Daniele Loiacono
 OpenMP Algoritmi e Calcolo Parallelo References Useful references Using OpenMP: Portable Shared Memory Parallel Programming, Barbara Chapman, Gabriele Jost and Ruud van der Pas OpenMP.org http://openmp.org/
OpenMP Algoritmi e Calcolo Parallelo References Useful references Using OpenMP: Portable Shared Memory Parallel Programming, Barbara Chapman, Gabriele Jost and Ruud van der Pas OpenMP.org http://openmp.org/
OpenMP. OpenMP. Portable programming of shared memory systems. It is a quasi-standard. OpenMP-Forum API for Fortran and C/C++
 OpenMP OpenMP Portable programming of shared memory systems. It is a quasi-standard. OpenMP-Forum 1997-2002 API for Fortran and C/C++ directives runtime routines environment variables www.openmp.org 1
OpenMP OpenMP Portable programming of shared memory systems. It is a quasi-standard. OpenMP-Forum 1997-2002 API for Fortran and C/C++ directives runtime routines environment variables www.openmp.org 1
MPI and comparison of models Lecture 23, cs262a. Ion Stoica & Ali Ghodsi UC Berkeley April 16, 2018
 MPI and comparison of models Lecture 23, cs262a Ion Stoica & Ali Ghodsi UC Berkeley April 16, 2018 MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers,
MPI and comparison of models Lecture 23, cs262a Ion Stoica & Ali Ghodsi UC Berkeley April 16, 2018 MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers,
Parallel Programming
 Parallel Programming OpenMP Dr. Hyrum D. Carroll November 22, 2016 Parallel Programming in a Nutshell Load balancing vs Communication This is the eternal problem in parallel computing. The basic approaches
Parallel Programming OpenMP Dr. Hyrum D. Carroll November 22, 2016 Parallel Programming in a Nutshell Load balancing vs Communication This is the eternal problem in parallel computing. The basic approaches
OpenMP Programming. Prof. Thomas Sterling. High Performance Computing: Concepts, Methods & Means
 High Performance Computing: Concepts, Methods & Means OpenMP Programming Prof. Thomas Sterling Department of Computer Science Louisiana State University February 8 th, 2007 Topics Introduction Overview
High Performance Computing: Concepts, Methods & Means OpenMP Programming Prof. Thomas Sterling Department of Computer Science Louisiana State University February 8 th, 2007 Topics Introduction Overview
A Short Introduction to OpenMP. Mark Bull, EPCC, University of Edinburgh
 A Short Introduction to OpenMP Mark Bull, EPCC, University of Edinburgh Overview Shared memory systems Basic Concepts in Threaded Programming Basics of OpenMP Parallel regions Parallel loops 2 Shared memory
A Short Introduction to OpenMP Mark Bull, EPCC, University of Edinburgh Overview Shared memory systems Basic Concepts in Threaded Programming Basics of OpenMP Parallel regions Parallel loops 2 Shared memory
Alfio Lazzaro: Introduction to OpenMP
 First INFN International School on Architectures, tools and methodologies for developing efficient large scale scientific computing applications Ce.U.B. Bertinoro Italy, 12 17 October 2009 Alfio Lazzaro:
First INFN International School on Architectures, tools and methodologies for developing efficient large scale scientific computing applications Ce.U.B. Bertinoro Italy, 12 17 October 2009 Alfio Lazzaro:
CMSC 714 Lecture 4 OpenMP and UPC. Chau-Wen Tseng (from A. Sussman)
") CMSC 714 Lecture 4 OpenMP and UPC Chau-Wen Tseng (from A. Sussman) Programming Model Overview Message passing (MPI, PVM) Separate address spaces Explicit messages to access shared data Send / receive (MPI
CMSC 714 Lecture 4 OpenMP and UPC Chau-Wen Tseng (from A. Sussman) Programming Model Overview Message passing (MPI, PVM) Separate address spaces Explicit messages to access shared data Send / receive (MPI
Parallel Computing: Overview
 Parallel Computing: Overview Jemmy Hu SHARCNET University of Waterloo March 1, 2007 Contents What is Parallel Computing? Why use Parallel Computing? Flynn's Classical Taxonomy Parallel Computer Memory
Parallel Computing: Overview Jemmy Hu SHARCNET University of Waterloo March 1, 2007 Contents What is Parallel Computing? Why use Parallel Computing? Flynn's Classical Taxonomy Parallel Computer Memory
Slides prepared by : Farzana Rahman 1
 Introduction to MPI 1 Background on MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers, and parallel programmers Used to create parallel programs based
Introduction to MPI 1 Background on MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers, and parallel programmers Used to create parallel programs based
Synchronisation in Java - Java Monitor
 Synchronisation in Java - Java Monitor -Every object and class is logically associated with a monitor - the associated monitor protects the variable in the object/class -The monitor of an object/class
Synchronisation in Java - Java Monitor -Every object and class is logically associated with a monitor - the associated monitor protects the variable in the object/class -The monitor of an object/class
Introduction to OpenMP. Martin Čuma Center for High Performance Computing University of Utah
 Introduction to OpenMP Martin Čuma Center for High Performance Computing University of Utah mcuma@chpc.utah.edu Overview Quick introduction. Parallel loops. Parallel loop directives. Parallel sections.
Introduction to OpenMP Martin Čuma Center for High Performance Computing University of Utah mcuma@chpc.utah.edu Overview Quick introduction. Parallel loops. Parallel loop directives. Parallel sections.
OpenMP: Open Multiprocessing
 OpenMP: Open Multiprocessing Erik Schnetter June 7, 2012, IHPC 2012, Iowa City Outline 1. Basic concepts, hardware architectures 2. OpenMP Programming 3. How to parallelise an existing code 4. Advanced
OpenMP: Open Multiprocessing Erik Schnetter June 7, 2012, IHPC 2012, Iowa City Outline 1. Basic concepts, hardware architectures 2. OpenMP Programming 3. How to parallelise an existing code 4. Advanced
Recap of Parallelism & MPI
 Recap of Parallelism & MPI Chris Brady Heather Ratcliffe The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann. Warwick RSE 13/12/2017 Parallel programming Break
Recap of Parallelism & MPI Chris Brady Heather Ratcliffe The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann. Warwick RSE 13/12/2017 Parallel programming Break
Programming with Shared Memory PART II. HPC Fall 2012 Prof. Robert van Engelen
 Programming with Shared Memory PART II HPC Fall 2012 Prof. Robert van Engelen Overview Sequential consistency Parallel programming constructs Dependence analysis OpenMP Autoparallelization Further reading
Programming with Shared Memory PART II HPC Fall 2012 Prof. Robert van Engelen Overview Sequential consistency Parallel programming constructs Dependence analysis OpenMP Autoparallelization Further reading
OpenMPand the PGAS Model. CMSC714 Sept 15, 2015 Guest Lecturer: Ray Chen
 OpenMPand the PGAS Model CMSC714 Sept 15, 2015 Guest Lecturer: Ray Chen LastTime: Message Passing Natural model for distributed-memory systems Remote ( far ) memory must be retrieved before use Programmer
OpenMPand the PGAS Model CMSC714 Sept 15, 2015 Guest Lecturer: Ray Chen LastTime: Message Passing Natural model for distributed-memory systems Remote ( far ) memory must be retrieved before use Programmer
Introduction to OpenMP. Martin Čuma Center for High Performance Computing University of Utah
 Introduction to OpenMP Martin Čuma Center for High Performance Computing University of Utah m.cuma@utah.edu Overview Quick introduction. Parallel loops. Parallel loop directives. Parallel sections. Some
Introduction to OpenMP Martin Čuma Center for High Performance Computing University of Utah m.cuma@utah.edu Overview Quick introduction. Parallel loops. Parallel loop directives. Parallel sections. Some
Programming Shared Memory Systems with OpenMP Part I. Book
 Programming Shared Memory Systems with OpenMP Part I Instructor Dr. Taufer Book Parallel Programming in OpenMP by Rohit Chandra, Leo Dagum, Dave Kohr, Dror Maydan, Jeff McDonald, Ramesh Menon 2 1 Machine
Programming Shared Memory Systems with OpenMP Part I Instructor Dr. Taufer Book Parallel Programming in OpenMP by Rohit Chandra, Leo Dagum, Dave Kohr, Dror Maydan, Jeff McDonald, Ramesh Menon 2 1 Machine
OpenMP Overview. in 30 Minutes. Christian Terboven / Aachen, Germany Stand: Version 2.
 OpenMP Overview in 30 Minutes Christian Terboven 06.12.2010 / Aachen, Germany Stand: 03.12.2010 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda OpenMP: Parallel Regions,
OpenMP Overview in 30 Minutes Christian Terboven 06.12.2010 / Aachen, Germany Stand: 03.12.2010 Version 2.3 Rechen- und Kommunikationszentrum (RZ) Agenda OpenMP: Parallel Regions,
Overview: The OpenMP Programming Model
 Overview: The OpenMP Programming Model motivation and overview the parallel directive: clauses, equivalent pthread code, examples the for directive and scheduling of loop iterations Pi example in OpenMP
Overview: The OpenMP Programming Model motivation and overview the parallel directive: clauses, equivalent pthread code, examples the for directive and scheduling of loop iterations Pi example in OpenMP
OpenMP I. Diego Fabregat-Traver and Prof. Paolo Bientinesi WS16/17. HPAC, RWTH Aachen
 OpenMP I Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS16/17 OpenMP References Using OpenMP: Portable Shared Memory Parallel Programming. The MIT Press,
OpenMP I Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS16/17 OpenMP References Using OpenMP: Portable Shared Memory Parallel Programming. The MIT Press,
Introduction to OpenMP. Martin Čuma Center for High Performance Computing University of Utah
 Introduction to OpenMP Martin Čuma Center for High Performance Computing University of Utah mcuma@chpc.utah.edu Overview Quick introduction. Parallel loops. Parallel loop directives. Parallel sections.
Introduction to OpenMP Martin Čuma Center for High Performance Computing University of Utah mcuma@chpc.utah.edu Overview Quick introduction. Parallel loops. Parallel loop directives. Parallel sections.
AMath 483/583 Lecture 18 May 6, 2011
 AMath 483/583 Lecture 18 May 6, 2011 Today: MPI concepts Communicators, broadcast, reduce Next week: MPI send and receive Iterative methods Read: Class notes and references $CLASSHG/codes/mpi MPI Message
AMath 483/583 Lecture 18 May 6, 2011 Today: MPI concepts Communicators, broadcast, reduce Next week: MPI send and receive Iterative methods Read: Class notes and references $CLASSHG/codes/mpi MPI Message
Programming Shared-memory Platforms with OpenMP. Xu Liu
 Programming Shared-memory Platforms with OpenMP Xu Liu Introduction to OpenMP OpenMP directives concurrency directives parallel regions loops, sections, tasks Topics for Today synchronization directives
Programming Shared-memory Platforms with OpenMP Xu Liu Introduction to OpenMP OpenMP directives concurrency directives parallel regions loops, sections, tasks Topics for Today synchronization directives
Parallel Programming, MPI Lecture 2
 Parallel Programming, MPI Lecture 2 Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction and Review The Von Neumann Computer Kinds of Parallel
Parallel Programming, MPI Lecture 2 Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction and Review The Von Neumann Computer Kinds of Parallel
Introduction to OpenMP
 Introduction to OpenMP Ricardo Fonseca https://sites.google.com/view/rafonseca2017/ Outline Shared Memory Programming OpenMP Fork-Join Model Compiler Directives / Run time library routines Compiling and
Introduction to OpenMP Ricardo Fonseca https://sites.google.com/view/rafonseca2017/ Outline Shared Memory Programming OpenMP Fork-Join Model Compiler Directives / Run time library routines Compiling and
Parallel Programming Using Basic MPI. Presented by Timothy H. Kaiser, Ph.D. San Diego Supercomputer Center
 05 Parallel Programming Using Basic MPI Presented by Timothy H. Kaiser, Ph.D. San Diego Supercomputer Center Talk Overview Background on MPI Documentation Hello world in MPI Basic communications Simple
05 Parallel Programming Using Basic MPI Presented by Timothy H. Kaiser, Ph.D. San Diego Supercomputer Center Talk Overview Background on MPI Documentation Hello world in MPI Basic communications Simple
OpenMP - II. Diego Fabregat-Traver and Prof. Paolo Bientinesi WS15/16. HPAC, RWTH Aachen
 OpenMP - II Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 OpenMP References Using OpenMP: Portable Shared Memory Parallel Programming. The MIT
OpenMP - II Diego Fabregat-Traver and Prof. Paolo Bientinesi HPAC, RWTH Aachen fabregat@aices.rwth-aachen.de WS15/16 OpenMP References Using OpenMP: Portable Shared Memory Parallel Programming. The MIT
Parallel Programming
 Parallel Programming OpenMP Nils Moschüring PhD Student (LMU) Nils Moschüring PhD Student (LMU), OpenMP 1 1 Overview What is parallel software development Why do we need parallel computation? Problems
Parallel Programming OpenMP Nils Moschüring PhD Student (LMU) Nils Moschüring PhD Student (LMU), OpenMP 1 1 Overview What is parallel software development Why do we need parallel computation? Problems
6.189 IAP Lecture 5. Parallel Programming Concepts. Dr. Rodric Rabbah, IBM IAP 2007 MIT
 6.189 IAP 2007 Lecture 5 Parallel Programming Concepts 1 6.189 IAP 2007 MIT Recap Two primary patterns of multicore architecture design Shared memory Ex: Intel Core 2 Duo/Quad One copy of data shared among
6.189 IAP 2007 Lecture 5 Parallel Programming Concepts 1 6.189 IAP 2007 MIT Recap Two primary patterns of multicore architecture design Shared memory Ex: Intel Core 2 Duo/Quad One copy of data shared among
AMath 483/583 Lecture 21
 AMath 483/583 Lecture 21 Outline: Review MPI, reduce and bcast MPI send and receive Master Worker paradigm References: $UWHPSC/codes/mpi class notes: MPI section class notes: MPI section of bibliography
AMath 483/583 Lecture 21 Outline: Review MPI, reduce and bcast MPI send and receive Master Worker paradigm References: $UWHPSC/codes/mpi class notes: MPI section class notes: MPI section of bibliography
DPHPC: Introduction to OpenMP Recitation session
 SALVATORE DI GIROLAMO DPHPC: Introduction to OpenMP Recitation session Based on http://openmp.org/mp-documents/intro_to_openmp_mattson.pdf OpenMP An Introduction What is it? A set
SALVATORE DI GIROLAMO DPHPC: Introduction to OpenMP Recitation session Based on http://openmp.org/mp-documents/intro_to_openmp_mattson.pdf OpenMP An Introduction What is it? A set
Open Multi-Processing: Basic Course
 HPC2N, UmeåUniversity, 901 87, Sweden. May 26, 2015 Table of contents Overview of Paralellism 1 Overview of Paralellism Parallelism Importance Partitioning Data Distributed Memory Working on Abisko 2 Pragmas/Sentinels
HPC2N, UmeåUniversity, 901 87, Sweden. May 26, 2015 Table of contents Overview of Paralellism 1 Overview of Paralellism Parallelism Importance Partitioning Data Distributed Memory Working on Abisko 2 Pragmas/Sentinels
Parallelising Scientific Codes Using OpenMP. Wadud Miah Research Computing Group
 Parallelising Scientific Codes Using OpenMP Wadud Miah Research Computing Group Software Performance Lifecycle Scientific Programming Early scientific codes were mainly sequential and were executed on
Parallelising Scientific Codes Using OpenMP Wadud Miah Research Computing Group Software Performance Lifecycle Scientific Programming Early scientific codes were mainly sequential and were executed on
Practical in Numerical Astronomy, SS 2012 LECTURE 12
 Practical in Numerical Astronomy, SS 2012 LECTURE 12 Parallelization II. Open Multiprocessing (OpenMP) Lecturer Eduard Vorobyov. Email: eduard.vorobiev@univie.ac.at, raum 006.6 1 OpenMP is a shared memory
Practical in Numerical Astronomy, SS 2012 LECTURE 12 Parallelization II. Open Multiprocessing (OpenMP) Lecturer Eduard Vorobyov. Email: eduard.vorobiev@univie.ac.at, raum 006.6 1 OpenMP is a shared memory
MPI MESSAGE PASSING INTERFACE
 MPI MESSAGE PASSING INTERFACE David COLIGNON CÉCI - Consortium des Équipements de Calcul Intensif http://hpc.montefiore.ulg.ac.be Outline Introduction From serial source code to parallel execution MPI
MPI MESSAGE PASSING INTERFACE David COLIGNON CÉCI - Consortium des Équipements de Calcul Intensif http://hpc.montefiore.ulg.ac.be Outline Introduction From serial source code to parallel execution MPI
Introduction to MPI. Ekpe Okorafor. School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014
 Introduction to MPI Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Topics Introduction MPI Model and Basic Calls MPI Communication Summary 2 Topics Introduction
Introduction to MPI Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Topics Introduction MPI Model and Basic Calls MPI Communication Summary 2 Topics Introduction
A few words about MPI (Message Passing Interface) T. Edwald 10 June 2008
 T. Edwald 10 June 2008") A few words about MPI (Message Passing Interface) T. Edwald 10 June 2008 1 Overview Introduction and very short historical review MPI - as simple as it comes Communications Process Topologies (I have no
A few words about MPI (Message Passing Interface) T. Edwald 10 June 2008 1 Overview Introduction and very short historical review MPI - as simple as it comes Communications Process Topologies (I have no
Data Environment: Default storage attributes
 COSC 6374 Parallel Computation Introduction to OpenMP(II) Some slides based on material by Barbara Chapman (UH) and Tim Mattson (Intel) Edgar Gabriel Fall 2014 Data Environment: Default storage attributes
COSC 6374 Parallel Computation Introduction to OpenMP(II) Some slides based on material by Barbara Chapman (UH) and Tim Mattson (Intel) Edgar Gabriel Fall 2014 Data Environment: Default storage attributes
COMP4300/8300: The OpenMP Programming Model. Alistair Rendell. Specifications maintained by OpenMP Architecture Review Board (ARB)
") COMP4300/8300: The OpenMP Programming Model Alistair Rendell See: www.openmp.org Introduction to High Performance Computing for Scientists and Engineers, Hager and Wellein, Chapter 6 & 7 High Performance
COMP4300/8300: The OpenMP Programming Model Alistair Rendell See: www.openmp.org Introduction to High Performance Computing for Scientists and Engineers, Hager and Wellein, Chapter 6 & 7 High Performance
COMP4300/8300: The OpenMP Programming Model. Alistair Rendell
 COMP4300/8300: The OpenMP Programming Model Alistair Rendell See: www.openmp.org Introduction to High Performance Computing for Scientists and Engineers, Hager and Wellein, Chapter 6 & 7 High Performance
COMP4300/8300: The OpenMP Programming Model Alistair Rendell See: www.openmp.org Introduction to High Performance Computing for Scientists and Engineers, Hager and Wellein, Chapter 6 & 7 High Performance
OpenMP programming. Thomas Hauser Director Research Computing Research CU-Boulder
 OpenMP programming Thomas Hauser Director Research Computing thomas.hauser@colorado.edu CU meetup 1 Outline OpenMP Shared-memory model Parallel for loops Declaring private variables Critical sections Reductions
OpenMP programming Thomas Hauser Director Research Computing thomas.hauser@colorado.edu CU meetup 1 Outline OpenMP Shared-memory model Parallel for loops Declaring private variables Critical sections Reductions
IPM Workshop on High Performance Computing (HPC08) IPM School of Physics Workshop on High Perfomance Computing/HPC08
 IPM School of Physics Workshop on High Perfomance Computing/HPC08") IPM School of Physics Workshop on High Perfomance Computing/HPC08 16-21 February 2008 MPI tutorial Luca Heltai Stefano Cozzini Democritos/INFM + SISSA 1 When
IPM School of Physics Workshop on High Perfomance Computing/HPC08 16-21 February 2008 MPI tutorial Luca Heltai Stefano Cozzini Democritos/INFM + SISSA 1 When
Shared memory parallel computing
 Shared memory parallel computing OpenMP Sean Stijven Przemyslaw Klosiewicz Shared-mem. programming API for SMP machines Introduced in 1997 by the OpenMP Architecture Review Board! More high-level than
Shared memory parallel computing OpenMP Sean Stijven Przemyslaw Klosiewicz Shared-mem. programming API for SMP machines Introduced in 1997 by the OpenMP Architecture Review Board! More high-level than
Introduction to OpenMP
 Introduction to OpenMP Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 A little about me! PhD Computer Engineering Texas A&M University Computer Science
Introduction to OpenMP Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 A little about me! PhD Computer Engineering Texas A&M University Computer Science
OpenMP Shared Memory Programming
 OpenMP Shared Memory Programming John Burkardt, Information Technology Department, Virginia Tech.... Mathematics Department, Ajou University, Suwon, Korea, 13 May 2009.... http://people.sc.fsu.edu/ jburkardt/presentations/
OpenMP Shared Memory Programming John Burkardt, Information Technology Department, Virginia Tech.... Mathematics Department, Ajou University, Suwon, Korea, 13 May 2009.... http://people.sc.fsu.edu/ jburkardt/presentations/
Introduction to MPI. Ricardo Fonseca. https://sites.google.com/view/rafonseca2017/
 Introduction to MPI Ricardo Fonseca https://sites.google.com/view/rafonseca2017/ Outline Distributed Memory Programming (MPI) Message Passing Model Initializing and terminating programs Point to point
Introduction to MPI Ricardo Fonseca https://sites.google.com/view/rafonseca2017/ Outline Distributed Memory Programming (MPI) Message Passing Model Initializing and terminating programs Point to point
Shared Memory Programming Paradigm!
 Shared Memory Programming Paradigm! Ivan Girotto igirotto@ictp.it Information & Communication Technology Section (ICTS) International Centre for Theoretical Physics (ICTP) 1 Multi-CPUs & Multi-cores NUMA
Shared Memory Programming Paradigm! Ivan Girotto igirotto@ictp.it Information & Communication Technology Section (ICTS) International Centre for Theoretical Physics (ICTP) 1 Multi-CPUs & Multi-cores NUMA
CS 5220: Shared memory programming. David Bindel
 CS 5220: Shared memory programming David Bindel 2017-09-26 1 Message passing pain Common message passing pattern Logical global structure Local representation per processor Local data may have redundancy
CS 5220: Shared memory programming David Bindel 2017-09-26 1 Message passing pain Common message passing pattern Logical global structure Local representation per processor Local data may have redundancy
CS 426. Building and Running a Parallel Application
 CS 426 Building and Running a Parallel Application 1 Task/Channel Model Design Efficient Parallel Programs (or Algorithms) Mainly for distributed memory systems (e.g. Clusters) Break Parallel Computations
CS 426 Building and Running a Parallel Application 1 Task/Channel Model Design Efficient Parallel Programs (or Algorithms) Mainly for distributed memory systems (e.g. Clusters) Break Parallel Computations