Introduction to MPI part II. Fabio AFFINITO
|
|
|
- Leonard Mills
- 5 years ago
- Views:
Transcription


1 Introduction to MPI part II Fabio AFFINITO
2 Collective communications
3 Communications involving a group of processes. They are called by all the ranks involved in a communicator (or a group) Barrier synchronization Broadcast Gather/scatter Reduction
4 Collective communications will not interfere with point-to-point All processes (in a communicator) call the collective function All collective communications are blocking (in MPI 2.0) No tags are required Receive buffers must match in size (number of bytes) It s a safe communication mode
5 MPI Barrier It stops all processes within a communicator until they are synchronized int MPI_Barrier(MPI_Comm comm);
6 MPI Broadcast Int MPI_Bcast (void *buf, int count, MPI_Datatype datatype, int root, MPI_Comm comm) Note that all processes must specify the same root and same comm.
7 PROGRAM broad_cast INCLUDE mpif.h INTEGER ierr, myid, nproc, root INTEGER status(mpi_status_size) REAL A(2) CALL MPI_INIT(ierr) CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr) CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr) root = 0 IF( myid.eq. 0 ) THEN a(1) = 2.0 a(2) = 4.0 END IF CALL MPI_BCAST(a, 2, MPI_REAL, 0, MPI_COMM_WORLD, ierr) WRITE(6,*) myid, : a(1)=, a(1), a(2)=, a(2) CALL MPI_FINALIZE(ierr)
8 MPI Gather Each process, root included, sends the content of its send buffer to the root process. The root process receives the messages and stores them in the rank order.
9 MPI Scatter The root sends a message. The message is split into n equal segments, the i-th segment is sent to the i-th process in the group and each process receives this message.
10 There are possible combinations of collective functions. For example, MPI Allgather It is a combination of a gather + a broadcast
11 For many collective functions there are extended functionalities. For example it s possible to define the length of arrays to be scattered or gathered with MPI_Scatterv MPI_Gatherv
12 MPI All to all This function makes a redistribution of the content of each process in a way that each process know the buffer of all others. It is a way to implement the matrix data transposition. a1 a2 a3 a4 a1 b1 c1 d1 b1 b2 b3 b4 a2 b2 c2 d2 c1 c2 c3 c4 a3 b3 c3 d3 d1 d2 d3 d4 a4 b4 c4 d4
13 Reduction Reduction operations permits to Collect data from each process Reduce the data to a single value Store the result on the root process (MPI_Reduce) or Store the result on all processes (MPI_Allreduce)
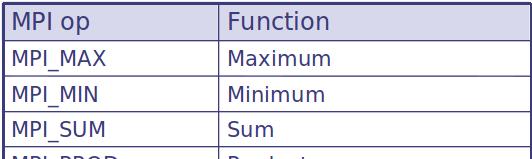
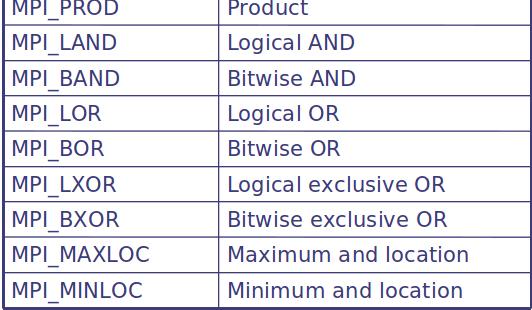
14 Predefined reduction operations
15 PROGRAM scatter INCLUDE mpif.h INTEGER ierr, myid, nproc, nsnd, i REAL A(16), B(2) CALL MPI_INIT(ierr) CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr) CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr) root = 0 IF( myid.eq. root ) THEN DO i = 1, 16 a(i) = REAL(i) END DO END IF nsnd = 2 CALL MPI_SCATTER(a, nsnd, MPI_REAL, b, nsnd, & & MPI_REAL, root, MPI_COMM_WORLD, ierr) WRITE(6,*) myid, : b(1)=, b(1), b(2)=, b(2) CALL MPI_FINALIZE(ierr) END
16 PROGRAM gather INCLUDE mpif.h INTEGER ierr, myid, nproc, nsnd, i REAL A(16), B(2) CALL MPI_INIT(ierr) CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr) CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr) root = 0 b(1) = REAL( myid ) b(2) = REAL( myid ) nsnd = 2 CALL MPI_GATHER(b, nsnd, MPI_REAL, a, nsnd, & MPI_REAL, root, MPI_COMM_WORLD, ierr) IF( myid.eq. root ) THEN DO i = 1, (nsnd*nproc) WRITE(6,*) myid, : a(i)=, a(i) END DO END IF CALL MPI_FINALIZE(ierr) END
17 PROGRAM reduce INCLUDE mpif.h INTEGER ierr, myid, nproc, root REAL A(2), res(2) CALL MPI_INIT(ierr) CALL MPI_COMM_SIZE(MPI_COMM_WORLD, nproc, ierr) CALL MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr) root = 0 a(1) = 2.0 a(2) = 4.0 CALL MPI_REDUCE(a, res, 2, MPI_REAL, MPI_SUM, root, MPI_COMM_WORLD, ierr) IF( myid.eq. 0 ) THEN WRITE(6,*) myid, : res(1)=, res(1), res(2)=, res(2) END IF CALL MPI_FINALIZE(ierr) END
18 MPI communicators and groups 18
19 Many users are familiar with the mostly used communicator: MPI_COMM_WORLD A communicator can be thought as a handle to a group. - a group is a ordered set of processes - each process is associated with a rank - ranks are contiguous and start from zero Groups allow collective operations to be operated on a subset of processes 19
20 Intracommunicators are used for communications within a single group Intercommunicators are used for communications between two disjoint groups 20
21 Group management: - All group operations are local - Groups are not initially associated with communicators - Groups can only be used for message passing within a communicator - We can access groups, construct groups, destroy groups 21
22 Group accessors: - MPI_GROUP_SIZE This routine returns the number of processes in the group - MPI_GROUP_RANK This routine returns the rank of the calling process inside a given group 22
23 Group constructors Group constructors are used to create new groups from existing ones (initially from the group associated with MPI_COMM_WORLD; you can use mpi_comm_group to get this). Group creation is a local operation: no communication is needed After the creation of a group, no communicator has been associated to this group, and hence no communication is possible within the new group 23
24 - MPI_COMM_GROUP(comm,group,ierr) This routine returns the group associated with the communicator comm - MPI_GROUP_UNION(group_a, group_b, newgroup, ierr) This returns the ensemble union of group_a and group_b - MPI_GROUP_INTERSECTION(group_a, group_b, newgroup, ierr) This returns the ensemble intersection of group_a and group_b - MPI_GROUP_DIFFERENCE(group_a, group_b, newgroup, ierr) This returns in newgroup all processes in group_a that rare not in group_b, ordered as in group_a 24
25 - MPI_GROUP_INCL(group, n, ranks, newgroup, ierr) This routine creates a new group that consists of all the n processes with ranks ranks[0]... ranks[n-1] Example: group = {a,b,c,d,e,f,g,h,i,j} n = 5 ranks = {0,3,8,6,2} newgroup = {a,d,i,g,c} 25
26 - MPI_GROUP_EXCL(group,n,ranks,newgroup,ierr) This routine returns a newgroup that consists of all the processes in the group after removing processes with ranks: ranks[0]..ranks[n-1] Example: group = {a,b,c,d,e,f,g,h,i,j} n = 5 ranks = {0,3,8,6,2} newgroup = {b,e,f,h,j} 26
27 Communicator management Communicator access operations are local, not requiring interprocess communication Communicator constructors are collective and may require interprocess communications We will cover in depth only intracommunicators, giving only some notions about intercommunicators. 27
28 Communicator accessors - MPI_COMM_SIZE(comm,size,ierr) Returns the number of processes in the group associated with the comm - MPI_COMM_RANK(comm,rank,ierr) Returns the rank of the calling process within the group associated with the comm - MPI_COMM_COMPARE(comm1,comm2,result,ierr) Returns: - MPI_IDENT if comm1 and comm2 are the same handle - MPI_CONGRUENT if comm1 and comm2 have the same group attribute - MPI_SIMILAR if the groups associated with comm1 and comm2 have the same members but in different rank order - MPI_UNEQUAL otherwise 28
29 Communicator constructors - MPI_COMM_DUP(comm, newcomm,ierr) This returns a communicator newcomm identical to the communicator comm - MPI_COMM_CREATE(comm, group, newcomm,ierr) This collective routine must be called by all the process involved in the group associated with comm. It returns a new communicator that is associated with the group. MPI_COMM_NULL is returned to processes not in the group. Note that group must be a subset of the group associated with comm! 29
30 A practical example: CALL MPI_COMM_RANK (...) CALL MPI_COMM_SIZE (...) CALL MPI_COMM_GROUP (MPI_COMM_WORLD,wgroup,ierr) define something.. CALL MPI_COMM_GROUP_EXCL(wgroup..., newgroup...) CALL MPI_COMM_CREATE(MPI_COMM_WORLD,newgroup,newcomm,ierr) 30
31 - MPI_COMM_SPLIT(comm, color, key, newcomm, ierr) This routine creates as many new groups and communicators as there are distinct values of color. The rankings in the new groups are determined by the value of the key. MPI_UNDEFINED is used as the color for processes to not be included in any of the new groups 31
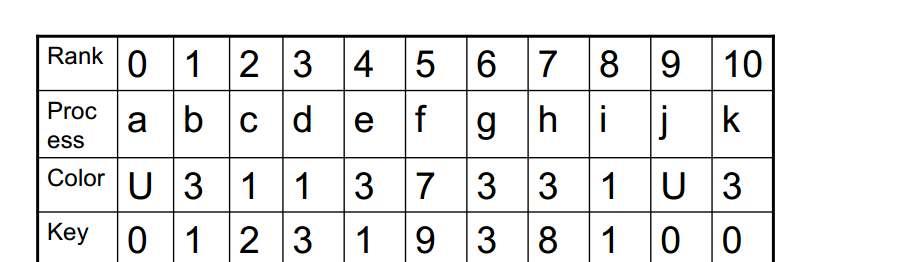
32 32
33 MPI provides functions to manage and to create groups and communicators. MPI_comm_split, for example, creates a communicator... if(myid%2==0){ color=1; }else{ color=2; } MPI_COMM_SPLIT(MPI_COMM_WORLD,color,myid,&subcomm); MPI_COMM_RANK(subcomm,mynewid); printf( rank in MPICOMM_WORLD %d,myid, rank in Subcomm %d,mynewid); I am rank 2 in MPI_COMM_WORLD, but 1 in Comm 1. I am rank 7 in MPI_COMM_WORLD, but 3 in Comm 2. I am rank 0 in MPI_COMM_WORLD, but 0 in Comm 1. I am rank 4 in MPI_COMM_WORLD, but 2 in Comm 1. I am rank 6 in MPI_COMM_WORLD, but 3 in Comm 1. I am rank 3 in MPI_COMM_WORLD, but 1 in Comm 2. I am rank 5 in MPI_COMM_WORLD, but 2 in Comm 2. I am rank 1 in MPI_COMM_WORLD, but 0 in Comm 2.
34 Destructors The communicators and groups from a process viewpoint are just handles. Like all handles, there is a limited number available: you could (in principle) run out! - MPI_GROUP_FREE(group, ierr) - MPI_COMM_FREE(comm,ierr) 34
35 Intercommunicators Intercommunicators are associated with 2 groups of disjoint processes. Intercommunicators are associated with a remote group and a local group The target process (destination for send, source for receive) is its rank in the remote group. A communicator is either intra or inter, never both 35
36 MPI topologies
37 Virtual topologies Virtual topologies MPI supported topologies How to create a cartesian topology Cartesian mapping functions Cartesian partitioning
38 Why a virtual topology can be useful? Convenient process naming Naming scheme to fit the communication pattern Simplifies the writing of the code Can allow MPI to optimize communications
39 How to use a virtual topology? A new topology = a new communicator MPI provides some mapping functions to manage virtual topologies Mapping functions compute processor ranks, based on the topology name scheme

40 Cartesian topology on a 2D torus
41 MPI supports... Cartesian topologies each process is connected to its neighbours in a virtual grid Boundaries can be cyclic Processes can be identified by cartesian coords Graph topologies
42 MPI_Cart_Create MPI_Comm vu; int dim[2], period[2], reorder; dim[0]=4; dim[1]=3; period[0]=true; period[1]=false; reorder=true; MPI_Cart_create(MPI_COMM_WORLD, 2,dim,period,reorder,&vu)
43 Useful functions Grid coords ranks MPI_Cart_rank MPI_Cart_coords ranks Grid coords Moving upwards, downwords, leftside, rightside... MPI_Cart _shift
44 #include<mpi.h> int main(int argc, char *argv[]) { int rank; MPI_Comm vu; int dim[2],period[2],reorder; int coord[2],id; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD,&rank); dim[0]=4; dim[1]=3; period[0]=true; period[1]=false; reorder=true; MPI_Cart_create(MPI_COMM_WORLD,2,dim,period, reorder,&vu); if(rank==5){ MPI_Cart_coords(vu,rank,2,coord); printf("p:%d My coordinates are %d %d\n",rank, coord[0],coord[1]); } if(rank==0){ coord[0]=3; coord[1]=1; MPI_Cart_rank(vu,coord,&id); printf("the processor at position (%d, %d) has rank %d\n",coord[0],coord[1],id); }
45 MPI_Cart_shift It doesn t shift data actually: it returns the correct ranks for a shift that can be used in the subsequent communication call Arguments: Direction: in which direction the shift should be made disp: length of the shift rank_source: where the calling process should receive a message from during the shift rank_dest: where the calling process should send a message to during the shift
46
47 Cartesian partitioning Often we want to do an operation on only a part of an existing cartesian topology Cut a grid up into slices A new communicator (i.e. a new cart. topology) is produced for each slide Each slice can perform its own collective communications
48 int MPI_Cart_sub(MPI_Comm comm, int *remain_dims, MPI_Comm *newcomm)
49 Practical info Yes, ok, but how can I write the right functions?
50
51 From C bindings to Fortran bindings -In Fortran all function are transformed in subroutines and they don t return a type -All functions have an addictional argument (ierror) of type integer -All MPI datatypes in Fortran are defined as integers


52 Now we can seriously start to work...
Introduction to MPI Part II Collective Communications and communicators
 Introduction to MPI Part II Collective Communications and communicators Andrew Emerson, Fabio Affinito {a.emerson,f.affinito}@cineca.it SuperComputing Applications and Innovation Department Collective
Introduction to MPI Part II Collective Communications and communicators Andrew Emerson, Fabio Affinito {a.emerson,f.affinito}@cineca.it SuperComputing Applications and Innovation Department Collective
Fabio AFFINITO.
 Introduction to Message Passing Interface Fabio AFFINITO Collective communications Communications involving a group of processes. They are called by all the ranks involved in a communicator (or a group)
Introduction to Message Passing Interface Fabio AFFINITO Collective communications Communications involving a group of processes. They are called by all the ranks involved in a communicator (or a group)
INTRODUCTION TO MPI COMMUNICATORS AND VIRTUAL TOPOLOGIES
 INTRODUCTION TO MPI COMMUNICATORS AND VIRTUAL TOPOLOGIES Introduction to Parallel Computing with MPI and OpenMP 24 november 2017 a.marani@cineca.it WHAT ARE COMMUNICATORS? Many users are familiar with
INTRODUCTION TO MPI COMMUNICATORS AND VIRTUAL TOPOLOGIES Introduction to Parallel Computing with MPI and OpenMP 24 november 2017 a.marani@cineca.it WHAT ARE COMMUNICATORS? Many users are familiar with
Communicators. MPI Communicators and Topologies. Why Communicators? MPI_Comm_split
 Communicators MPI Communicators and Topologies Based on notes by Science & Technology Support High Performance Computing Ohio Supercomputer Center A communicator is a parameter in all MPI message passing
Communicators MPI Communicators and Topologies Based on notes by Science & Technology Support High Performance Computing Ohio Supercomputer Center A communicator is a parameter in all MPI message passing
Review of MPI Part 2
 Review of MPI Part Russian-German School on High Performance Computer Systems, June, 7 th until July, 6 th 005, Novosibirsk 3. Day, 9 th of June, 005 HLRS, University of Stuttgart Slide Chap. 5 Virtual
Review of MPI Part Russian-German School on High Performance Computer Systems, June, 7 th until July, 6 th 005, Novosibirsk 3. Day, 9 th of June, 005 HLRS, University of Stuttgart Slide Chap. 5 Virtual
INTRODUCTION TO MPI COLLECTIVE COMMUNICATIONS AND COMMUNICATORS. Introduction to Parallel Computing with MPI and OpenMP
 INTRODUCTION TO MPI COLLECTIVE COMMUNICATIONS AND COMMUNICATORS Introduction to Parallel Computing with MPI and OpenMP Part I: Collective communications WHAT ARE COLLECTIVE COMMUNICATIONS? Communications
INTRODUCTION TO MPI COLLECTIVE COMMUNICATIONS AND COMMUNICATORS Introduction to Parallel Computing with MPI and OpenMP Part I: Collective communications WHAT ARE COLLECTIVE COMMUNICATIONS? Communications
Intra and Inter Communicators
 Intra and Inter Communicators Groups A group is a set of processes The group have a size And each process have a rank Creating a group is a local operation Why we need groups To make a clear distinction
Intra and Inter Communicators Groups A group is a set of processes The group have a size And each process have a rank Creating a group is a local operation Why we need groups To make a clear distinction
MPI 8. CSCI 4850/5850 High-Performance Computing Spring 2018
 MPI 8 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
MPI 8 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
INTRODUCTION TO MPI VIRTUAL TOPOLOGIES
 INTRODUCTION TO MPI VIRTUAL TOPOLOGIES Introduction to Parallel Computing with MPI and OpenMP 18-19-20 november 2013 a.marani@cineca.it g.muscianisi@cineca.it l.ferraro@cineca.it VIRTUAL TOPOLOGY Topology:
INTRODUCTION TO MPI VIRTUAL TOPOLOGIES Introduction to Parallel Computing with MPI and OpenMP 18-19-20 november 2013 a.marani@cineca.it g.muscianisi@cineca.it l.ferraro@cineca.it VIRTUAL TOPOLOGY Topology:
IPM Workshop on High Performance Computing (HPC08) IPM School of Physics Workshop on High Perfomance Computing/HPC08
 IPM School of Physics Workshop on High Perfomance Computing/HPC08") IPM School of Physics Workshop on High Perfomance Computing/HPC08 16-21 February 2008 MPI tutorial Luca Heltai Stefano Cozzini Democritos/INFM + SISSA 1 When
IPM School of Physics Workshop on High Perfomance Computing/HPC08 16-21 February 2008 MPI tutorial Luca Heltai Stefano Cozzini Democritos/INFM + SISSA 1 When
A short overview of parallel paradigms. Fabio Affinito, SCAI
 A short overview of parallel paradigms Fabio Affinito, SCAI Why parallel? In principle, if you have more than one computing processing unit you can exploit that to: -Decrease the time to solution - Increase
A short overview of parallel paradigms Fabio Affinito, SCAI Why parallel? In principle, if you have more than one computing processing unit you can exploit that to: -Decrease the time to solution - Increase
Topologies in MPI. Instructor: Dr. M. Taufer
 Topologies in MPI Instructor: Dr. M. Taufer WS2004/2005 Topology We can associate additional information (beyond the group and the context) to a communicator. A linear ranking of processes may not adequately
Topologies in MPI Instructor: Dr. M. Taufer WS2004/2005 Topology We can associate additional information (beyond the group and the context) to a communicator. A linear ranking of processes may not adequately
COSC 4397 Parallel Computation. Introduction to MPI (III) Process Grouping. Terminology (I)
 Process Grouping. Terminology (I)") COSC 4397 Introduction to MPI (III) Process Grouping Spring 2010 Terminology (I) an MPI_Group is the object describing the list of processes forming a logical entity a group has a size MPI_Group_size every
COSC 4397 Introduction to MPI (III) Process Grouping Spring 2010 Terminology (I) an MPI_Group is the object describing the list of processes forming a logical entity a group has a size MPI_Group_size every
High Performance Computing Course Notes Message Passing Programming III
 High Performance Computing Course Notes 2009-2010 2010 Message Passing Programming III Blocking synchronous send the sender doesn t return until it receives the acknowledgement from the receiver that the
High Performance Computing Course Notes 2009-2010 2010 Message Passing Programming III Blocking synchronous send the sender doesn t return until it receives the acknowledgement from the receiver that the
High Performance Computing Course Notes Message Passing Programming III
 High Performance Computing Course Notes 2008-2009 2009 Message Passing Programming III Communication modes Synchronous mode The communication is considered complete when the sender receives the acknowledgement
High Performance Computing Course Notes 2008-2009 2009 Message Passing Programming III Communication modes Synchronous mode The communication is considered complete when the sender receives the acknowledgement
Parallel Computing. MPI Collective communication
 Parallel Computing MPI Collective communication Thorsten Grahs, 18. May 2015 Table of contents Collective Communication Communicator Intercommunicator 18. May 2015 Thorsten Grahs Parallel Computing I SS
Parallel Computing MPI Collective communication Thorsten Grahs, 18. May 2015 Table of contents Collective Communication Communicator Intercommunicator 18. May 2015 Thorsten Grahs Parallel Computing I SS
Department of Informatics V. HPC-Lab. Session 4: MPI, CG M. Bader, A. Breuer. Alex Breuer
 HPC-Lab Session 4: MPI, CG M. Bader, A. Breuer Meetings Date Schedule 10/13/14 Kickoff 10/20/14 Q&A 10/27/14 Presentation 1 11/03/14 H. Bast, Intel 11/10/14 Presentation 2 12/01/14 Presentation 3 12/08/14
HPC-Lab Session 4: MPI, CG M. Bader, A. Breuer Meetings Date Schedule 10/13/14 Kickoff 10/20/14 Q&A 10/27/14 Presentation 1 11/03/14 H. Bast, Intel 11/10/14 Presentation 2 12/01/14 Presentation 3 12/08/14
Reusing this material
 Virtual Topologies Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Virtual Topologies Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Recap of Parallelism & MPI
 Recap of Parallelism & MPI Chris Brady Heather Ratcliffe The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann. Warwick RSE 13/12/2017 Parallel programming Break
Recap of Parallelism & MPI Chris Brady Heather Ratcliffe The Angry Penguin, used under creative commons licence from Swantje Hess and Jannis Pohlmann. Warwick RSE 13/12/2017 Parallel programming Break
High-Performance Computing: MPI (ctd)
") High-Performance Computing: MPI (ctd) Adrian F. Clark: alien@essex.ac.uk 2015 16 Adrian F. Clark: alien@essex.ac.uk High-Performance Computing: MPI (ctd) 2015 16 1 / 22 A reminder Last time, we started
High-Performance Computing: MPI (ctd) Adrian F. Clark: alien@essex.ac.uk 2015 16 Adrian F. Clark: alien@essex.ac.uk High-Performance Computing: MPI (ctd) 2015 16 1 / 22 A reminder Last time, we started
CME 213 SPRING Eric Darve
 CME 213 SPRING 2017 Eric Darve LINEAR ALGEBRA MATRIX-VECTOR PRODUCTS Application example: matrix-vector product We are going to use that example to illustrate additional MPI functionalities. This will
CME 213 SPRING 2017 Eric Darve LINEAR ALGEBRA MATRIX-VECTOR PRODUCTS Application example: matrix-vector product We are going to use that example to illustrate additional MPI functionalities. This will
Topics. Lecture 7. Review. Other MPI collective functions. Collective Communication (cont d) MPI Programming (III)
 MPI Programming (III)") Topics Lecture 7 MPI Programming (III) Collective communication (cont d) Point-to-point communication Basic point-to-point communication Non-blocking point-to-point communication Four modes of blocking
Topics Lecture 7 MPI Programming (III) Collective communication (cont d) Point-to-point communication Basic point-to-point communication Non-blocking point-to-point communication Four modes of blocking
Message Passing Interface
 MPSoC Architectures MPI Alberto Bosio, Associate Professor UM Microelectronic Departement bosio@lirmm.fr Message Passing Interface API for distributed-memory programming parallel code that runs across
MPSoC Architectures MPI Alberto Bosio, Associate Professor UM Microelectronic Departement bosio@lirmm.fr Message Passing Interface API for distributed-memory programming parallel code that runs across
Standard MPI - Message Passing Interface
 c Ewa Szynkiewicz, 2007 1 Standard MPI - Message Passing Interface The message-passing paradigm is one of the oldest and most widely used approaches for programming parallel machines, especially those
c Ewa Szynkiewicz, 2007 1 Standard MPI - Message Passing Interface The message-passing paradigm is one of the oldest and most widely used approaches for programming parallel machines, especially those
Outline. Communication modes MPI Message Passing Interface Standard
 MPI THOAI NAM Outline Communication modes MPI Message Passing Interface Standard TERMs (1) Blocking If return from the procedure indicates the user is allowed to reuse resources specified in the call Non-blocking
MPI THOAI NAM Outline Communication modes MPI Message Passing Interface Standard TERMs (1) Blocking If return from the procedure indicates the user is allowed to reuse resources specified in the call Non-blocking
Copyright The McGraw-Hill Companies, Inc. Permission required for reproduction or display. Chapter 8
 Chapter 8 Matrix-vector Multiplication Chapter Objectives Review matrix-vector multiplicaiton Propose replication of vectors Develop three parallel programs, each based on a different data decomposition
Chapter 8 Matrix-vector Multiplication Chapter Objectives Review matrix-vector multiplicaiton Propose replication of vectors Develop three parallel programs, each based on a different data decomposition
Introduction to Parallel. Programming
 University of Nizhni Novgorod Faculty of Computational Mathematics & Cybernetics Introduction to Parallel Section 4. Part 3. Programming Parallel Programming with MPI Gergel V.P., Professor, D.Sc., Software
University of Nizhni Novgorod Faculty of Computational Mathematics & Cybernetics Introduction to Parallel Section 4. Part 3. Programming Parallel Programming with MPI Gergel V.P., Professor, D.Sc., Software
character :: buffer(100) integer :: position real :: a, b integer :: n position = 0 call MPI_PACK(a, 1, MPI_REAL, buffer, 100, & position, MPI_COMM_WO
 integer :: position real :: a, b integer :: n position = 0 call MPI_PACK(a, 1, MPI_REAL, buffer, 100, & position, MPI_COMM_WO") MPI_PACK and MPI_UNPACK Each communication incurs a latency penalty so it is best to group communications together Requires data to be contiguous in memory with no gaps between variables This is true for
MPI_PACK and MPI_UNPACK Each communication incurs a latency penalty so it is best to group communications together Requires data to be contiguous in memory with no gaps between variables This is true for
Topics. Lecture 6. Point-to-point Communication. Point-to-point Communication. Broadcast. Basic Point-to-point communication. MPI Programming (III)
") Topics Lecture 6 MPI Programming (III) Point-to-point communication Basic point-to-point communication Non-blocking point-to-point communication Four modes of blocking communication Manager-Worker Programming
Topics Lecture 6 MPI Programming (III) Point-to-point communication Basic point-to-point communication Non-blocking point-to-point communication Four modes of blocking communication Manager-Worker Programming
Programming with MPI Collectives
 Programming with MPI Collectives Jan Thorbecke Type to enter text Delft University of Technology Challenge the future Collectives Classes Communication types exercise: BroadcastBarrier Gather Scatter exercise:
Programming with MPI Collectives Jan Thorbecke Type to enter text Delft University of Technology Challenge the future Collectives Classes Communication types exercise: BroadcastBarrier Gather Scatter exercise:
Parallel Programming, MPI Lecture 2
 Parallel Programming, MPI Lecture 2 Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction and Review The Von Neumann Computer Kinds of Parallel
Parallel Programming, MPI Lecture 2 Ehsan Nedaaee Oskoee 1 1 Department of Physics IASBS IPM Grid and HPC workshop IV, 2011 Outline 1 Introduction and Review The Von Neumann Computer Kinds of Parallel
lslogin3$ cd lslogin3$ tar -xvf ~train00/mpibasic_lab.tar cd mpibasic_lab/pi cd mpibasic_lab/decomp1d
 MPI Lab Getting Started Login to ranger.tacc.utexas.edu Untar the lab source code lslogin3$ cd lslogin3$ tar -xvf ~train00/mpibasic_lab.tar Part 1: Getting Started with simple parallel coding hello mpi-world
MPI Lab Getting Started Login to ranger.tacc.utexas.edu Untar the lab source code lslogin3$ cd lslogin3$ tar -xvf ~train00/mpibasic_lab.tar Part 1: Getting Started with simple parallel coding hello mpi-world
CS 6230: High-Performance Computing and Parallelization Introduction to MPI
 CS 6230: High-Performance Computing and Parallelization Introduction to MPI Dr. Mike Kirby School of Computing and Scientific Computing and Imaging Institute University of Utah Salt Lake City, UT, USA
CS 6230: High-Performance Computing and Parallelization Introduction to MPI Dr. Mike Kirby School of Computing and Scientific Computing and Imaging Institute University of Utah Salt Lake City, UT, USA
Parallel Programming. Matrix Decomposition Options (Matrix-Vector Product)
") Parallel Programming Matrix Decomposition Options (Matrix-Vector Product) Matrix Decomposition Sequential algorithm and its complexity Design, analysis, and implementation of three parallel programs using
Parallel Programming Matrix Decomposition Options (Matrix-Vector Product) Matrix Decomposition Sequential algorithm and its complexity Design, analysis, and implementation of three parallel programs using
High Performance Computing Course Notes Message Passing Programming I
 High Performance Computing Course Notes 2008-2009 2009 Message Passing Programming I Message Passing Programming Message Passing is the most widely used parallel programming model Message passing works
High Performance Computing Course Notes 2008-2009 2009 Message Passing Programming I Message Passing Programming Message Passing is the most widely used parallel programming model Message passing works
Parallel Programming in C with MPI and OpenMP
 Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 8 Matrix-vector Multiplication Chapter Objectives Review matrix-vector multiplication Propose replication of vectors Develop three
Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 8 Matrix-vector Multiplication Chapter Objectives Review matrix-vector multiplication Propose replication of vectors Develop three
Intermediate MPI features
 Intermediate MPI features Advanced message passing Collective communication Topologies Group communication Forms of message passing (1) Communication modes: Standard: system decides whether message is
Intermediate MPI features Advanced message passing Collective communication Topologies Group communication Forms of message passing (1) Communication modes: Standard: system decides whether message is
The MPI Message-passing Standard Practical use and implementation (IV) SPD Course 09/03/2016 Massimo Coppola
 SPD Course 09/03/2016 Massimo Coppola") The MPI Message-passing Standard Practical use and implementation (IV) SPD Course 09/03/206 Massimo Coppola COMMUNICATORS AND GROUPS SPD - MPI Standard Use and Implementation (3) 2 Comm.s & Groups motivation
The MPI Message-passing Standard Practical use and implementation (IV) SPD Course 09/03/206 Massimo Coppola COMMUNICATORS AND GROUPS SPD - MPI Standard Use and Implementation (3) 2 Comm.s & Groups motivation
Matrix-vector Multiplication
 Matrix-vector Multiplication Review matrix-vector multiplication Propose replication of vectors Develop three parallel programs, each based on a different data decomposition Outline Sequential algorithm
Matrix-vector Multiplication Review matrix-vector multiplication Propose replication of vectors Develop three parallel programs, each based on a different data decomposition Outline Sequential algorithm
Message Passing with MPI
 Message Passing with MPI PPCES 2016 Hristo Iliev IT Center / JARA-HPC IT Center der RWTH Aachen University Agenda Motivation Part 1 Concepts Point-to-point communication Non-blocking operations Part 2
Message Passing with MPI PPCES 2016 Hristo Iliev IT Center / JARA-HPC IT Center der RWTH Aachen University Agenda Motivation Part 1 Concepts Point-to-point communication Non-blocking operations Part 2
Parallel Programming Using Basic MPI. Presented by Timothy H. Kaiser, Ph.D. San Diego Supercomputer Center
 05 Parallel Programming Using Basic MPI Presented by Timothy H. Kaiser, Ph.D. San Diego Supercomputer Center Talk Overview Background on MPI Documentation Hello world in MPI Basic communications Simple
05 Parallel Programming Using Basic MPI Presented by Timothy H. Kaiser, Ph.D. San Diego Supercomputer Center Talk Overview Background on MPI Documentation Hello world in MPI Basic communications Simple
Parallel Programming using MPI. Supercomputing group CINECA
 Parallel Programming using MPI Supercomputing group CINECA Contents Programming with message passing Introduction to message passing and MPI Basic MPI programs MPI Communicators Send and Receive function
Parallel Programming using MPI Supercomputing group CINECA Contents Programming with message passing Introduction to message passing and MPI Basic MPI programs MPI Communicators Send and Receive function
Distributed Memory Parallel Programming
 COSC Big Data Analytics Parallel Programming using MPI Edgar Gabriel Spring 201 Distributed Memory Parallel Programming Vast majority of clusters are homogeneous Necessitated by the complexity of maintaining
COSC Big Data Analytics Parallel Programming using MPI Edgar Gabriel Spring 201 Distributed Memory Parallel Programming Vast majority of clusters are homogeneous Necessitated by the complexity of maintaining
Practical Scientific Computing: Performanceoptimized
 Practical Scientific Computing: Performanceoptimized Programming Advanced MPI Programming December 13, 2006 Dr. Ralf-Peter Mundani Department of Computer Science Chair V Technische Universität München,
Practical Scientific Computing: Performanceoptimized Programming Advanced MPI Programming December 13, 2006 Dr. Ralf-Peter Mundani Department of Computer Science Chair V Technische Universität München,
Lecture 6: Message Passing Interface
 Lecture 6: Message Passing Interface Introduction The basics of MPI Some simple problems More advanced functions of MPI A few more examples CA463D Lecture Notes (Martin Crane 2013) 50 When is Parallel
Lecture 6: Message Passing Interface Introduction The basics of MPI Some simple problems More advanced functions of MPI A few more examples CA463D Lecture Notes (Martin Crane 2013) 50 When is Parallel
PCAP Assignment I. 1. A. Why is there a large performance gap between many-core GPUs and generalpurpose multicore CPUs. Discuss in detail.
 PCAP Assignment I 1. A. Why is there a large performance gap between many-core GPUs and generalpurpose multicore CPUs. Discuss in detail. The multicore CPUs are designed to maximize the execution speed
PCAP Assignment I 1. A. Why is there a large performance gap between many-core GPUs and generalpurpose multicore CPUs. Discuss in detail. The multicore CPUs are designed to maximize the execution speed
HPC Parallel Programing Multi-node Computation with MPI - I
 HPC Parallel Programing Multi-node Computation with MPI - I Parallelization and Optimization Group TATA Consultancy Services, Sahyadri Park Pune, India TCS all rights reserved April 29, 2013 Copyright
HPC Parallel Programing Multi-node Computation with MPI - I Parallelization and Optimization Group TATA Consultancy Services, Sahyadri Park Pune, India TCS all rights reserved April 29, 2013 Copyright
MPI. (message passing, MIMD)
") MPI (message passing, MIMD) What is MPI? a message-passing library specification extension of C/C++ (and Fortran) message passing for distributed memory parallel programming Features of MPI Point-to-point
MPI (message passing, MIMD) What is MPI? a message-passing library specification extension of C/C++ (and Fortran) message passing for distributed memory parallel programming Features of MPI Point-to-point
MPI MESSAGE PASSING INTERFACE
 MPI MESSAGE PASSING INTERFACE David COLIGNON CÉCI - Consortium des Équipements de Calcul Intensif http://hpc.montefiore.ulg.ac.be Outline Introduction From serial source code to parallel execution MPI
MPI MESSAGE PASSING INTERFACE David COLIGNON CÉCI - Consortium des Équipements de Calcul Intensif http://hpc.montefiore.ulg.ac.be Outline Introduction From serial source code to parallel execution MPI
CS 426. Building and Running a Parallel Application
 CS 426 Building and Running a Parallel Application 1 Task/Channel Model Design Efficient Parallel Programs (or Algorithms) Mainly for distributed memory systems (e.g. Clusters) Break Parallel Computations
CS 426 Building and Running a Parallel Application 1 Task/Channel Model Design Efficient Parallel Programs (or Algorithms) Mainly for distributed memory systems (e.g. Clusters) Break Parallel Computations
Introduzione al Message Passing Interface (MPI) Andrea Clematis IMATI CNR
 Andrea Clematis IMATI CNR") Introduzione al Message Passing Interface (MPI) Andrea Clematis IMATI CNR clematis@ge.imati.cnr.it Ack. & riferimenti An Introduction to MPI Parallel Programming with the Message Passing InterfaceWilliam
Introduzione al Message Passing Interface (MPI) Andrea Clematis IMATI CNR clematis@ge.imati.cnr.it Ack. & riferimenti An Introduction to MPI Parallel Programming with the Message Passing InterfaceWilliam
A few words about MPI (Message Passing Interface) T. Edwald 10 June 2008
 T. Edwald 10 June 2008") A few words about MPI (Message Passing Interface) T. Edwald 10 June 2008 1 Overview Introduction and very short historical review MPI - as simple as it comes Communications Process Topologies (I have no
A few words about MPI (Message Passing Interface) T. Edwald 10 June 2008 1 Overview Introduction and very short historical review MPI - as simple as it comes Communications Process Topologies (I have no
MPI Collective communication
 MPI Collective communication CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) MPI Collective communication Spring 2018 1 / 43 Outline 1 MPI Collective communication
MPI Collective communication CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) MPI Collective communication Spring 2018 1 / 43 Outline 1 MPI Collective communication
Introduction to MPI. Ricardo Fonseca. https://sites.google.com/view/rafonseca2017/
 Introduction to MPI Ricardo Fonseca https://sites.google.com/view/rafonseca2017/ Outline Distributed Memory Programming (MPI) Message Passing Model Initializing and terminating programs Point to point
Introduction to MPI Ricardo Fonseca https://sites.google.com/view/rafonseca2017/ Outline Distributed Memory Programming (MPI) Message Passing Model Initializing and terminating programs Point to point
The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing
 TMA4280 Introduction to Supercomputing") The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Parallelism Decompose the execution into several tasks according to the work to be done: Function/Task
The Message Passing Interface (MPI) TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Parallelism Decompose the execution into several tasks according to the work to be done: Function/Task
Programming SoHPC Course June-July 2015 Vladimir Subotic MPI - Message Passing Interface
 www.bsc.es Programming with Message-Passing Libraries SoHPC Course June-July 2015 Vladimir Subotic 1 Data Transfer Blocking: Function does not return, before message can be accessed again Process is blocked
www.bsc.es Programming with Message-Passing Libraries SoHPC Course June-July 2015 Vladimir Subotic 1 Data Transfer Blocking: Function does not return, before message can be accessed again Process is blocked
Source:
 MPI Message Passing Interface Communicator groups and Process Topologies Source: http://www.netlib.org/utk/papers/mpi-book/mpi-book.html Communicators and Groups Communicators For logical division of processes
MPI Message Passing Interface Communicator groups and Process Topologies Source: http://www.netlib.org/utk/papers/mpi-book/mpi-book.html Communicators and Groups Communicators For logical division of processes
Cornell Theory Center. Discussion: MPI Collective Communication I. Table of Contents. 1. Introduction
 1 of 18 11/1/2006 3:59 PM Cornell Theory Center Discussion: MPI Collective Communication I This is the in-depth discussion layer of a two-part module. For an explanation of the layers and how to navigate
1 of 18 11/1/2006 3:59 PM Cornell Theory Center Discussion: MPI Collective Communication I This is the in-depth discussion layer of a two-part module. For an explanation of the layers and how to navigate
Introduction to Parallel Processing. Lecture #10 May 2002 Guy Tel-Zur
 Introduction to Parallel Processing Lecture #10 May 2002 Guy Tel-Zur Topics Parallel Numerical Algorithms Allen & Wilkinson s book chapter 10 More MPI Commands Home assignment #5 Wilkinson&Allen PDF Direct,
Introduction to Parallel Processing Lecture #10 May 2002 Guy Tel-Zur Topics Parallel Numerical Algorithms Allen & Wilkinson s book chapter 10 More MPI Commands Home assignment #5 Wilkinson&Allen PDF Direct,
MPI Workshop - III. Research Staff Cartesian Topologies in MPI and Passing Structures in MPI Week 3 of 3
 MPI Workshop - III Research Staff Cartesian Topologies in MPI and Passing Structures in MPI Week 3 of 3 Schedule 4Course Map 4Fix environments to run MPI codes 4CartesianTopology! MPI_Cart_create! MPI_
MPI Workshop - III Research Staff Cartesian Topologies in MPI and Passing Structures in MPI Week 3 of 3 Schedule 4Course Map 4Fix environments to run MPI codes 4CartesianTopology! MPI_Cart_create! MPI_
The Message Passing Model
 Introduction to MPI The Message Passing Model Applications that do not share a global address space need a Message Passing Framework. An application passes messages among processes in order to perform
Introduction to MPI The Message Passing Model Applications that do not share a global address space need a Message Passing Framework. An application passes messages among processes in order to perform
Distributed Memory Programming with MPI
 Distributed Memory Programming with MPI Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna moreno.marzolla@unibo.it Algoritmi Avanzati--modulo 2 2 Credits Peter Pacheco,
Distributed Memory Programming with MPI Moreno Marzolla Dip. di Informatica Scienza e Ingegneria (DISI) Università di Bologna moreno.marzolla@unibo.it Algoritmi Avanzati--modulo 2 2 Credits Peter Pacheco,
Introduction to parallel computing concepts and technics
 Introduction to parallel computing concepts and technics Paschalis Korosoglou (support@grid.auth.gr) User and Application Support Unit Scientific Computing Center @ AUTH Overview of Parallel computing
Introduction to parallel computing concepts and technics Paschalis Korosoglou (support@grid.auth.gr) User and Application Support Unit Scientific Computing Center @ AUTH Overview of Parallel computing
More Communication (cont d)
") Data types and the use of communicators can simplify parallel program development and improve code readability Sometimes, however, simply treating the processors as an unstructured collection is less than
Data types and the use of communicators can simplify parallel program development and improve code readability Sometimes, however, simply treating the processors as an unstructured collection is less than
CSE 613: Parallel Programming. Lecture 21 ( The Message Passing Interface )
") CSE 613: Parallel Programming Lecture 21 ( The Message Passing Interface ) Jesmin Jahan Tithi Department of Computer Science SUNY Stony Brook Fall 2013 ( Slides from Rezaul A. Chowdhury ) Principles of
CSE 613: Parallel Programming Lecture 21 ( The Message Passing Interface ) Jesmin Jahan Tithi Department of Computer Science SUNY Stony Brook Fall 2013 ( Slides from Rezaul A. Chowdhury ) Principles of
Outline. Communication modes MPI Message Passing Interface Standard. Khoa Coâng Ngheä Thoâng Tin Ñaïi Hoïc Baùch Khoa Tp.HCM
 THOAI NAM Outline Communication modes MPI Message Passing Interface Standard TERMs (1) Blocking If return from the procedure indicates the user is allowed to reuse resources specified in the call Non-blocking
THOAI NAM Outline Communication modes MPI Message Passing Interface Standard TERMs (1) Blocking If return from the procedure indicates the user is allowed to reuse resources specified in the call Non-blocking
Distributed Memory Systems: Part IV
 Chapter 5 Distributed Memory Systems: Part IV Max Planck Institute Magdeburg Jens Saak, Scientific Computing II 293/342 The Message Passing Interface is a standard for creation of parallel programs using
Chapter 5 Distributed Memory Systems: Part IV Max Planck Institute Magdeburg Jens Saak, Scientific Computing II 293/342 The Message Passing Interface is a standard for creation of parallel programs using
Collective Communication in MPI and Advanced Features
 Collective Communication in MPI and Advanced Features Pacheco s book. Chapter 3 T. Yang, CS240A. Part of slides from the text book, CS267 K. Yelick from UC Berkeley and B. Gropp, ANL Outline Collective
Collective Communication in MPI and Advanced Features Pacheco s book. Chapter 3 T. Yang, CS240A. Part of slides from the text book, CS267 K. Yelick from UC Berkeley and B. Gropp, ANL Outline Collective
Cluster Computing MPI. Industrial Standard Message Passing
 MPI Industrial Standard Message Passing MPI Features Industrial Standard Highly portable Widely available SPMD programming model Synchronous execution MPI Outer scope int MPI_Init( int *argc, char ** argv)
MPI Industrial Standard Message Passing MPI Features Industrial Standard Highly portable Widely available SPMD programming model Synchronous execution MPI Outer scope int MPI_Init( int *argc, char ** argv)
MA471. Lecture 5. Collective MPI Communication
 MA471 Lecture 5 Collective MPI Communication Today: When all the processes want to send, receive or both Excellent website for MPI command syntax available at: http://www-unix.mcs.anl.gov/mpi/www/ 9/10/2003
MA471 Lecture 5 Collective MPI Communication Today: When all the processes want to send, receive or both Excellent website for MPI command syntax available at: http://www-unix.mcs.anl.gov/mpi/www/ 9/10/2003
CS 179: GPU Programming. Lecture 14: Inter-process Communication
 CS 179: GPU Programming Lecture 14: Inter-process Communication The Problem What if we want to use GPUs across a distributed system? GPU cluster, CSIRO Distributed System A collection of computers Each
CS 179: GPU Programming Lecture 14: Inter-process Communication The Problem What if we want to use GPUs across a distributed system? GPU cluster, CSIRO Distributed System A collection of computers Each
Topologies. Ned Nedialkov. McMaster University Canada. SE 4F03 March 2016
 Topologies Ned Nedialkov McMaster University Canada SE 4F03 March 2016 Outline Introduction Cartesian topology Some Cartesian topology functions Some graph topology functions c 2013 16 Ned Nedialkov 2/11
Topologies Ned Nedialkov McMaster University Canada SE 4F03 March 2016 Outline Introduction Cartesian topology Some Cartesian topology functions Some graph topology functions c 2013 16 Ned Nedialkov 2/11
Parallel programming with MPI Part I -Introduction and Point-to-Point
 Parallel programming with MPI Part I -Introduction and Point-to-Point Communications A. Emerson, Supercomputing Applications and Innovation (SCAI), CINECA 1 Contents Introduction to message passing and
Parallel programming with MPI Part I -Introduction and Point-to-Point Communications A. Emerson, Supercomputing Applications and Innovation (SCAI), CINECA 1 Contents Introduction to message passing and
Slides prepared by : Farzana Rahman 1
 Introduction to MPI 1 Background on MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers, and parallel programmers Used to create parallel programs based
Introduction to MPI 1 Background on MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers, and parallel programmers Used to create parallel programs based
Parallel I/O. and split communicators. David Henty, Fiona Ried, Gavin J. Pringle
 Parallel I/O and split communicators David Henty, Fiona Ried, Gavin J. Pringle Dr Gavin J. Pringle Applications Consultant gavin@epcc.ed.ac.uk +44 131 650 6709 4x4 array on 2x2 Process Grid Parallel IO
Parallel I/O and split communicators David Henty, Fiona Ried, Gavin J. Pringle Dr Gavin J. Pringle Applications Consultant gavin@epcc.ed.ac.uk +44 131 650 6709 4x4 array on 2x2 Process Grid Parallel IO
CEE 618 Scientific Parallel Computing (Lecture 5): Message-Passing Interface (MPI) advanced
: Message-Passing Interface (MPI) advanced") 1 / 32 CEE 618 Scientific Parallel Computing (Lecture 5): Message-Passing Interface (MPI) advanced Albert S. Kim Department of Civil and Environmental Engineering University of Hawai i at Manoa 2540 Dole
1 / 32 CEE 618 Scientific Parallel Computing (Lecture 5): Message-Passing Interface (MPI) advanced Albert S. Kim Department of Civil and Environmental Engineering University of Hawai i at Manoa 2540 Dole
Copyright The McGraw-Hill Companies, Inc. Permission required for reproduction or display. Chapter 8
 Chapter 8 Matrix-vector Multiplication Chapter Objectives Review matrix-vector multiplication Propose replication of vectors Develop three parallel programs, each based on a different data decomposition
Chapter 8 Matrix-vector Multiplication Chapter Objectives Review matrix-vector multiplication Propose replication of vectors Develop three parallel programs, each based on a different data decomposition
Programming with MPI. advanced point to point. Type to enter text. Jan Thorbecke. Challenge the future. Delft University of Technology
 Programming with MPI advanced point to point Jan Thorbecke Type to enter text Delft University of Technology Challenge the future Acknowledgments This course is partly based on the MPI courses developed
Programming with MPI advanced point to point Jan Thorbecke Type to enter text Delft University of Technology Challenge the future Acknowledgments This course is partly based on the MPI courses developed
Masterpraktikum - Scientific Computing, High Performance Computing
 Masterpraktikum - Scientific Computing, High Performance Computing Message Passing Interface (MPI) Thomas Auckenthaler Wolfgang Eckhardt Technische Universität München, Germany Outline Hello World P2P
Masterpraktikum - Scientific Computing, High Performance Computing Message Passing Interface (MPI) Thomas Auckenthaler Wolfgang Eckhardt Technische Universität München, Germany Outline Hello World P2P
Message Passing Interface
 Message Passing Interface DPHPC15 TA: Salvatore Di Girolamo DSM (Distributed Shared Memory) Message Passing MPI (Message Passing Interface) A message passing specification implemented
Message Passing Interface DPHPC15 TA: Salvatore Di Girolamo DSM (Distributed Shared Memory) Message Passing MPI (Message Passing Interface) A message passing specification implemented
AMath 483/583 Lecture 21
 AMath 483/583 Lecture 21 Outline: Review MPI, reduce and bcast MPI send and receive Master Worker paradigm References: $UWHPSC/codes/mpi class notes: MPI section class notes: MPI section of bibliography
AMath 483/583 Lecture 21 Outline: Review MPI, reduce and bcast MPI send and receive Master Worker paradigm References: $UWHPSC/codes/mpi class notes: MPI section class notes: MPI section of bibliography
In the simplest sense, parallel computing is the simultaneous use of multiple computing resources to solve a problem.
 1. Introduction to Parallel Processing In the simplest sense, parallel computing is the simultaneous use of multiple computing resources to solve a problem. a) Types of machines and computation. A conventional
1. Introduction to Parallel Processing In the simplest sense, parallel computing is the simultaneous use of multiple computing resources to solve a problem. a) Types of machines and computation. A conventional
Message Passing Interface. most of the slides taken from Hanjun Kim
 Message Passing Interface most of the slides taken from Hanjun Kim Message Passing Pros Scalable, Flexible Cons Someone says it s more difficult than DSM MPI (Message Passing Interface) A standard message
Message Passing Interface most of the slides taken from Hanjun Kim Message Passing Pros Scalable, Flexible Cons Someone says it s more difficult than DSM MPI (Message Passing Interface) A standard message
Parallel programming with MPI Part I -Introduction and Point-to-Point Communications
 Parallel programming with MPI Part I -Introduction and Point-to-Point Communications A. Emerson, A. Marani, Supercomputing Applications and Innovation (SCAI), CINECA 23 February 2016 MPI course 2016 Contents
Parallel programming with MPI Part I -Introduction and Point-to-Point Communications A. Emerson, A. Marani, Supercomputing Applications and Innovation (SCAI), CINECA 23 February 2016 MPI course 2016 Contents
Parallel Programming with MPI: Day 1
 Parallel Programming with MPI: Day 1 Science & Technology Support High Performance Computing Ohio Supercomputer Center 1224 Kinnear Road Columbus, OH 43212-1163 1 Table of Contents Brief History of MPI
Parallel Programming with MPI: Day 1 Science & Technology Support High Performance Computing Ohio Supercomputer Center 1224 Kinnear Road Columbus, OH 43212-1163 1 Table of Contents Brief History of MPI
Parallel Programming Using MPI
 Parallel Programming Using MPI Short Course on HPC 15th February 2019 Aditya Krishna Swamy adityaks@iisc.ac.in SERC, Indian Institute of Science When Parallel Computing Helps? Want to speed up your calculation
Parallel Programming Using MPI Short Course on HPC 15th February 2019 Aditya Krishna Swamy adityaks@iisc.ac.in SERC, Indian Institute of Science When Parallel Computing Helps? Want to speed up your calculation
CSE. Parallel Algorithms on a cluster of PCs. Ian Bush. Daresbury Laboratory (With thanks to Lorna Smith and Mark Bull at EPCC)
") Parallel Algorithms on a cluster of PCs Ian Bush Daresbury Laboratory I.J.Bush@dl.ac.uk (With thanks to Lorna Smith and Mark Bull at EPCC) Overview This lecture will cover General Message passing concepts
Parallel Algorithms on a cluster of PCs Ian Bush Daresbury Laboratory I.J.Bush@dl.ac.uk (With thanks to Lorna Smith and Mark Bull at EPCC) Overview This lecture will cover General Message passing concepts
Introduction to MPI. SuperComputing Applications and Innovation Department 1 / 143
 Introduction to MPI Isabella Baccarelli - i.baccarelli@cineca.it Mariella Ippolito - m.ippolito@cineca.it Cristiano Padrin - c.padrin@cineca.it Vittorio Ruggiero - v.ruggiero@cineca.it SuperComputing Applications
Introduction to MPI Isabella Baccarelli - i.baccarelli@cineca.it Mariella Ippolito - m.ippolito@cineca.it Cristiano Padrin - c.padrin@cineca.it Vittorio Ruggiero - v.ruggiero@cineca.it SuperComputing Applications
CINES MPI. Johanne Charpentier & Gabriel Hautreux
 Training @ CINES MPI Johanne Charpentier & Gabriel Hautreux charpentier@cines.fr hautreux@cines.fr Clusters Architecture OpenMP MPI Hybrid MPI+OpenMP MPI Message Passing Interface 1. Introduction 2. MPI
Training @ CINES MPI Johanne Charpentier & Gabriel Hautreux charpentier@cines.fr hautreux@cines.fr Clusters Architecture OpenMP MPI Hybrid MPI+OpenMP MPI Message Passing Interface 1. Introduction 2. MPI
Introduction to MPI. May 20, Daniel J. Bodony Department of Aerospace Engineering University of Illinois at Urbana-Champaign
 Introduction to MPI May 20, 2013 Daniel J. Bodony Department of Aerospace Engineering University of Illinois at Urbana-Champaign Top500.org PERFORMANCE DEVELOPMENT 1 Eflop/s 162 Pflop/s PROJECTED 100 Pflop/s
Introduction to MPI May 20, 2013 Daniel J. Bodony Department of Aerospace Engineering University of Illinois at Urbana-Champaign Top500.org PERFORMANCE DEVELOPMENT 1 Eflop/s 162 Pflop/s PROJECTED 100 Pflop/s
MPI Tutorial. Shao-Ching Huang. IDRE High Performance Computing Workshop
 MPI Tutorial Shao-Ching Huang IDRE High Performance Computing Workshop 2013-02-13 Distributed Memory Each CPU has its own (local) memory This needs to be fast for parallel scalability (e.g. Infiniband,
MPI Tutorial Shao-Ching Huang IDRE High Performance Computing Workshop 2013-02-13 Distributed Memory Each CPU has its own (local) memory This needs to be fast for parallel scalability (e.g. Infiniband,
Practical Introduction to Message-Passing Interface (MPI)
") 1 Outline of the workshop 2 Practical Introduction to Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Theoretical / practical introduction Parallelizing your
1 Outline of the workshop 2 Practical Introduction to Message-Passing Interface (MPI) Bart Oldeman, Calcul Québec McGill HPC Bart.Oldeman@mcgill.ca Theoretical / practical introduction Parallelizing your
Introduction to MPI. Ekpe Okorafor. School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014
 Introduction to MPI Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Topics Introduction MPI Model and Basic Calls MPI Communication Summary 2 Topics Introduction
Introduction to MPI Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Topics Introduction MPI Model and Basic Calls MPI Communication Summary 2 Topics Introduction
Masterpraktikum - Scientific Computing, High Performance Computing
 Masterpraktikum - Scientific Computing, High Performance Computing Message Passing Interface (MPI) and CG-method Michael Bader Alexander Heinecke Technische Universität München, Germany Outline MPI Hello
Masterpraktikum - Scientific Computing, High Performance Computing Message Passing Interface (MPI) and CG-method Michael Bader Alexander Heinecke Technische Universität München, Germany Outline MPI Hello
MPI and comparison of models Lecture 23, cs262a. Ion Stoica & Ali Ghodsi UC Berkeley April 16, 2018
 MPI and comparison of models Lecture 23, cs262a Ion Stoica & Ali Ghodsi UC Berkeley April 16, 2018 MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers,
MPI and comparison of models Lecture 23, cs262a Ion Stoica & Ali Ghodsi UC Berkeley April 16, 2018 MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers,
Programming Using the Message-Passing Paradigm (Chapter 6) Alexandre David
 Alexandre David") Programming Using the Message-Passing Paradigm (Chapter 6) Alexandre David 1.2.05 1 Topic Overview Principles of Message-Passing Programming MPI: the Message Passing Interface Topologies and Embedding
Programming Using the Message-Passing Paradigm (Chapter 6) Alexandre David 1.2.05 1 Topic Overview Principles of Message-Passing Programming MPI: the Message Passing Interface Topologies and Embedding
Message-Passing Computing
 Chapter 2 Slide 41þþ Message-Passing Computing Slide 42þþ Basics of Message-Passing Programming using userlevel message passing libraries Two primary mechanisms needed: 1. A method of creating separate
Chapter 2 Slide 41þþ Message-Passing Computing Slide 42þþ Basics of Message-Passing Programming using userlevel message passing libraries Two primary mechanisms needed: 1. A method of creating separate
Holland Computing Center Kickstart MPI Intro
 Holland Computing Center Kickstart 2016 MPI Intro Message Passing Interface (MPI) MPI is a specification for message passing library that is standardized by MPI Forum Multiple vendor-specific implementations:
Holland Computing Center Kickstart 2016 MPI Intro Message Passing Interface (MPI) MPI is a specification for message passing library that is standardized by MPI Forum Multiple vendor-specific implementations:
Advanced MPI. Andrew Emerson
 Advanced MPI Andrew Emerson (a.emerson@cineca.it) Agenda 1. One sided Communications (MPI-2) 2. Dynamic processes (MPI-2) 3. Profiling MPI and tracing 4. MPI-I/O 5. MPI-3 11/12/2015 Advanced MPI 2 One
Advanced MPI Andrew Emerson (a.emerson@cineca.it) Agenda 1. One sided Communications (MPI-2) 2. Dynamic processes (MPI-2) 3. Profiling MPI and tracing 4. MPI-I/O 5. MPI-3 11/12/2015 Advanced MPI 2 One
CPS 303 High Performance Computing
 CPS 303 High Performance Computing Wensheng Shen Department of Computational Science SUNY Brockport Chapter 7: Communicators and topologies Communicators: a communicator is a collection of processes that
CPS 303 High Performance Computing Wensheng Shen Department of Computational Science SUNY Brockport Chapter 7: Communicators and topologies Communicators: a communicator is a collection of processes that