Use to exploit extra CPU from busy Tier2 site
|
|
|
- Cora Bishop
- 5 years ago
- Views:
Transcription

1 Use to exploit extra CPU from busy Tier2 site Wenjing Wu 1, David Cameron 2 1. Computer Center, IHEP, China 2. University of Oslo, Norway
2 Outline Running status New features/improvements Use to exploit extra CPU at ATLAS Tier2 Why running on Tier2? How much can be exploited? Impact on Tier2? Can it run on more Tier2 site? Summary 2
3 running status 3
4 Started to run in production from Dec 2013 as has been in steady running ever since Merged into as ATLAS app in Main feature: Use virtualbox to virtualize heterogeneous volunteer hosts to run short and less urgent ATLAS simulation jobs (100 events/job) Recently added new features Support multiple core jobs in virtualbox (2016.6) Support native running (2017.7) Run ATLAS directly on SLC6 hosts Run through Singularity on other Linux hosts 4


5 Long term running status (1) Daily jobs Avg. Per day from the past 400 days: 3300 jobs (finished) 852 CPU days Daily CPU(days) 0.22 Mevents 1 B HS06sec, equal to 1157 CPU days on a core with 10 HS06 5


6 Long term running status (2) Daily Events The gaps are mostly due to lack of tasks for Daily HS06sec Due to long tail tasks, only less urgent tasks are assigned to 6



7 Recent usage (recent 10 days) 1. Added BEIJING Tier2 nodes 2. There are enough tasks for Daily Walltime: 2200 CPU days, Daily CPUtime: 1405 CPU days, Daily events: 0.3 Mevents Avg. CPU efficiency is around 75% (cpu_time/wall_time) 7

 Equivalent to a Grid site of 2700 CPU cores for simulation jobs! (avg. 0.")
8 CPU time does not consider the speed of CPU (HS06) CPU time perevent varies from task to task by a few times even on the same CPU. HS06sec is more comparable, avg. 1.6B HS06sec/day HS06 days/day Equal to 1851 Cores (10 HS06/core, which is the case for most grid site) Equivalent to a Grid site of 2700 CPU cores for simulation jobs! (avg CPU utilization) cpu_util= wall_util * job_eff 8
9 New Features for 9

")

10 with VirtualBox ARC CE ACT PanDA ATLAS app BOINC Server VirtualBox VM: start_atlas Volunteer Host (all platform: Linux, Win, Mac) start_atlas is the wrapper to start the atlas jobs Traditional way to run 10




11 VirtualBox and Native ARC CE ACT PanDA ATLAS app BOINC Server VirtualBox VM: start_atlas Volunteer Host (all platform) Singularity: start_atlas Volunteer Host ( otherlinux) start_atlas Volunteer Host ( SLC 6) Cloud Nodes /PC/Linux servers T2/T3 nodes 11
12 Native For Linux nodes with SLC6, atlas jobs are directly run without containers/virtualbox For other Linux (Cent OS 7, Ubuntu), Singularity is used to run the atlas jobs Some CERN cloud nodes use Cent OS 7 A lot of volunteer hosts use Ubuntu It improves CPU/IO/Network/RAM performance compared to using Virtualization Jobs can be configured to be kept in memory, so they do not lose the previous work during suspending. Requirements on the nodes Have CVMFS installed Have singularity installed and bind mount CVMFS (Cent OS 7/Ubuntu) 12
13 Why running on Tier 2 site 13
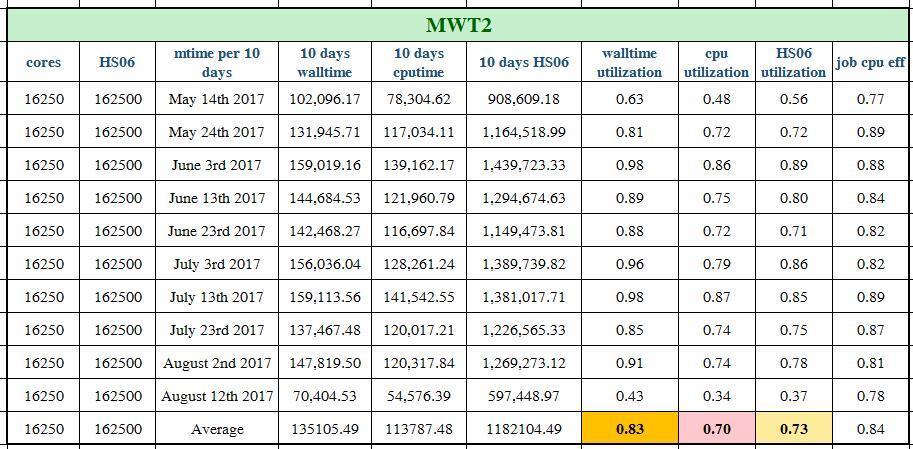
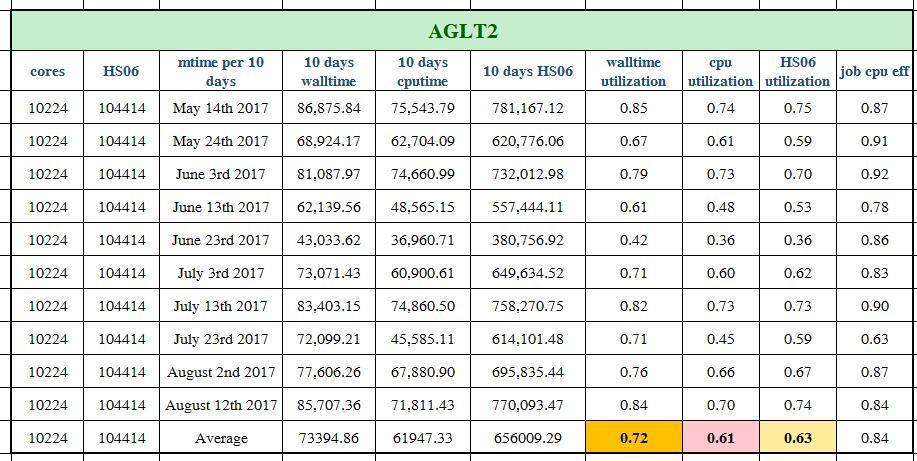
14 Why: Tier2 is not always fully loaded Site downtime Conservative scheduling around downtime (draining jobs/ ramp up jobs slowly) Not enough pilots at site (occasionally) What is the utilization for typical Tier2 site? Choose a few sites with different scale/region Calculate its walltime/(total_cores*24) in the past 100 days, break into every 10 days (to avoid spikes from jobs running over days) Asked the sites for their number of dedicated cores for ATLAS Avg. 85% wall utilization, 70% CPU utilization 14
")

15 Tier 2 site utilization Wall_util=wall_time/(cpu_cores*24) CPU_util=cpu_time/(cpu_cores*24) Based on data from the past 100 days Data source: 15
16 100% wall!= 100% CPU utilization due to job efficiency Job 1: 12 Wall hour Job 1: 12 Wall hour Job 3: 12Wall hour 8 CPU hour Job 2: 12 Wall hour 8 CPU hour Job 2: 12 Wall hour 4 CPU hour Job 2: Wall hour 8 CPU hour 8 CPU hour 4 CPU hour One work node With job 1-2, 100% wall utilization, assume job eff 75%,then 25% CPU is wasted With job 1-4, 200% wall utilization, 100% cpu utilization, job eff 75% and 25% 16
, LRMS do not see it, can still push enough production jobs in.")

17 Put more jobs on work nodes? Not easy to manage with local scheduler Define different job priority? Define more job slots than available cores? Production job job With jobs BOINC is a second scheduler(requesting jobs from ATLAS@home), LRMS do not see it, can still push enough production jobs in. BOINC jobs have the lowest priority in OS (PR=39), production jobs has the highest priority by default (PR=20) On Linux OS, non-preemptive CPU scheduling: High priority process occupies CPU until it voluntarily releases it. BOINC jobs release CPU/memory whenever the production jobs require However, we configure BOINC job to be suspended in memory, so it don t lose the previous work. 17






18 Look into one work node Look for 2 days, it is very full and CPU efficient, BOINC gets only 5% CPU Look for 2 weeks, it is NOT always full, BOINC gets 22% This node runs multi core production jobs (simul and pile), more cpu efficient than other type of jobs 18
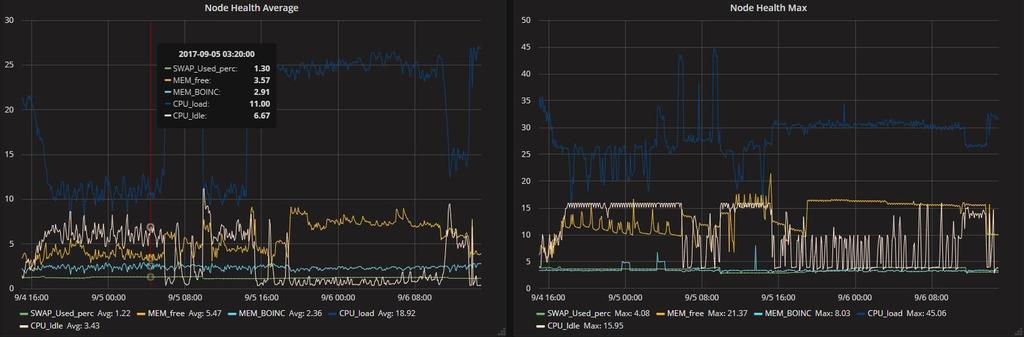
19 Methodology BEIJING ATLAS Tier 2 site has dedicated 420 cores. (ATLAS jobs only), started to run from 25 th August 2017 Generate and visualize the results from ATLAS job stats (ES+Kibana) For each job, cputime, walltime, cpu_eff, cputime_perevent, hs06sec etc. Kibana: Deployed local monitor collects information (Agent+ES+Grafana) #Job : # ATLAS/CMS jobs, # of processes # BOINC running jobs, # BOINC processes, # BOINC queued jobs Node health: system load/ free MEM/ used SWAP/ BOINC_used_MEM/idle CPU/ CPU utilization: Grid CPU usage, BOINC CPU usage 19
20 How much can be exploited? 20
, 420 job slots, PBS managed 84 cores running single")

21 Tier2 Utilization : data from ATLAS Job stats. BEIJING Tier2 site: 420 Cores (No HT), 420 job slots, PBS managed 84 cores running single core (15HS06) 336 cores running multi core (18HS06), 12 core/job Exploited an extra 144 Cores out from 420 Cores in the past 3 week continuous running CPU utilization reaches 90%! (CPU utilization from Grid jobs is 67%) 21

22 Tier 2 utilization: data from local monitor When production wall utilization is over 94%, ATLAS@home exploits 15% CPU time When production is continuously around 86%, ATLAS@home exploits 24% CPU time Work nodes are calm in terms of load, memory usage, swap usage Avg. CPU utilization is 88% 22
23 Data comparison Data source: ATLAS Job stats (ES+Kibana) vs. Local Monitor (Agent+ES+Grafana) Consistent Grid Jobs: Walltime utilization is 86% in both CPU time utilization is 67%(ATLAS) vs. 64% (Local) BOINC Jobs: CPU time utilization is 23% in both Work nodes total CPU time utilization 90% (ATLAS) vs. 88% (Local) 23


24 420 Cores Utilization from ATLAS Job stats. 420 Cores 24



")
25 Utilization from Local monitor Running Processes and Jobs of ATLAS Grid jobs CPU utilization ATLAS Grid jobs: 64.18% BOINC: 23.73% Two scheduled downtime (each 6 hours) during the 3 weeks 25
26 Impact on Tier2? Stability It does not affect the production job failure rate (1-2%) It does not affect the throughput of production jobs with running BOINC, ATLAS grid jobs walltime utilization is around 90% Work nodes have reasonable load/swap usage Efficiency For production jobs, it does not make it less efficient CPU efficient is less than 1% difference or NONE?! For BOINC jobs, it does not make it less efficient CPU time per event is 0.02% difference between dedicated nodes and nodes mixed with production jobs. Manpower to maintain After the right configuration, no manual intervention is needed 26


27 Production jobs 1. Production jobs in a month: (with BOINC jobs) 1-2% failure rate 2. In recent 3 weeks, production jobs uses 90% of the walltime 27


28 Site SAM Tests in a month Site Reliability : 99.29% 28
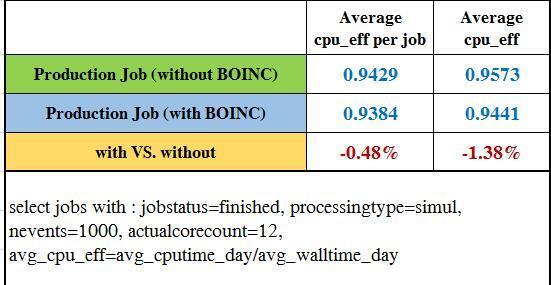
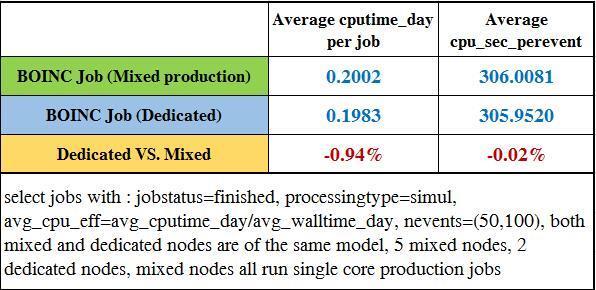
29 Job Efficiency compare 29





30 Production Job Efficiency compare 6 weeks running without BOINC jobs 8 weeks running with BOINC jobs During different period, run different tasks, cpu time per event can be very different, so we only compare cpu_eff 30





31 9 weeks running on nodes mixed with production jobs 9 weeks running on same nodes dedicated for BOINC jobs BOINC Job Efficiency compare Same period (same tasks, cpu time per event is similar), same nodes, so we compare cpu time per event 31
 BOINC")
32 Work nodes health status Avg. sys load is less than 2.5 times of the CPU cores Swap usage is less than 3% (no memory competition) BOINC jobs not use much memory 32
 Monitor: Load, BOINC_used_memory, used_swap, idle_cpu")
33 single core nodes (12 cores) multi core nodes (12 cores) multi core nodes (12 cores) Monitor: Load, BOINC_used_memory, used_swap, idle_cpu 33
34 Can this be tested on other Tier2 site? Scripts available for fast deployment on a cluster Local monitor scripts available ATLAS@home scalability: The current ATLAS@home server can survive 20K jobs/day, bottle neck from submitting to ARC CE (IO) Can run multiple ARC CE with multiple BOINC servers to receive jobs from BOINC_MCORE (PanDA que) The extra exploited CPU time can be counted to sites in ATLAS Job stats. (Kibana visualization) 34
35 Summary has been providing continuous resource since 2013 Equal to a Grid site with 2700 Cores (10 HS06) With recent optimization in scheduling and newly added Tier2 work nodes (serving as stable host group), it can run more important tasks An 23% of extra CPU can be exploited from a full loaded Tier2 site (with 90% Wall utilization), this also increases the CPU utilization to 90% The extra BOINC jobs do not impact the health of work nodes or throughput of production jobs on the Tier2 site, and it does not require extra manpower to maintain once it is setup appropriately. 35
36 Acknowledgements Andrej Filipcic (Jozef Stefan Institute, Slovenia) Nils Hoimyr (CERN IT, BOINC Project) Ilija Vukotic (University of Chicago) Frank Berghaus (University of Victoria) Douglas Gingrich (University of Victoria) Paul Nilsson (BNL) Rod Walker ( LMU-München) 36
37 Thanks!
38 Backup slides

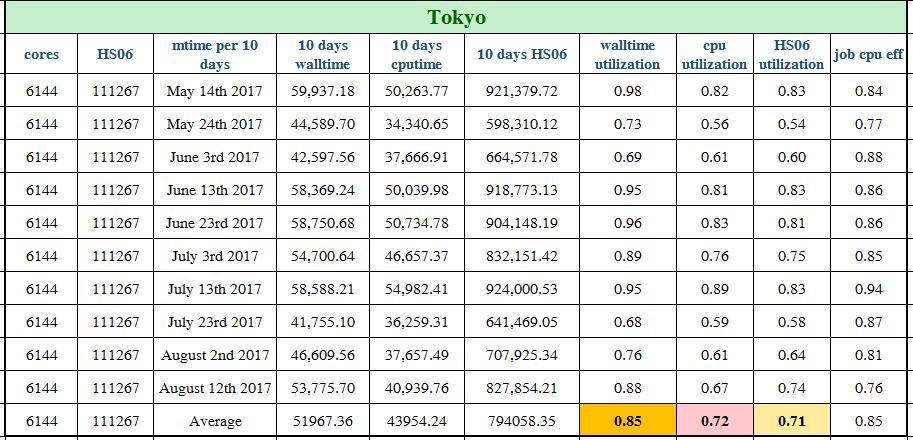
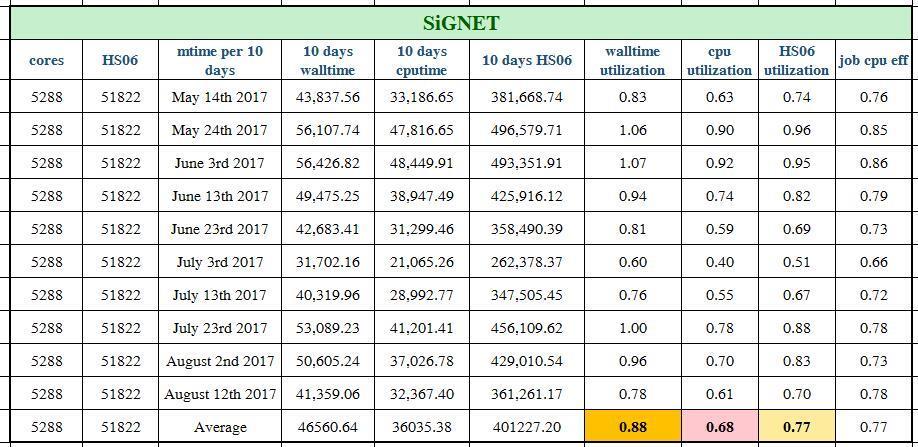

39 Tier 2 Utilization in details CPU/Wall/HS06 time are presented in days and grouped by every 10 days 39
40 Tier 2 Utilization in details 40



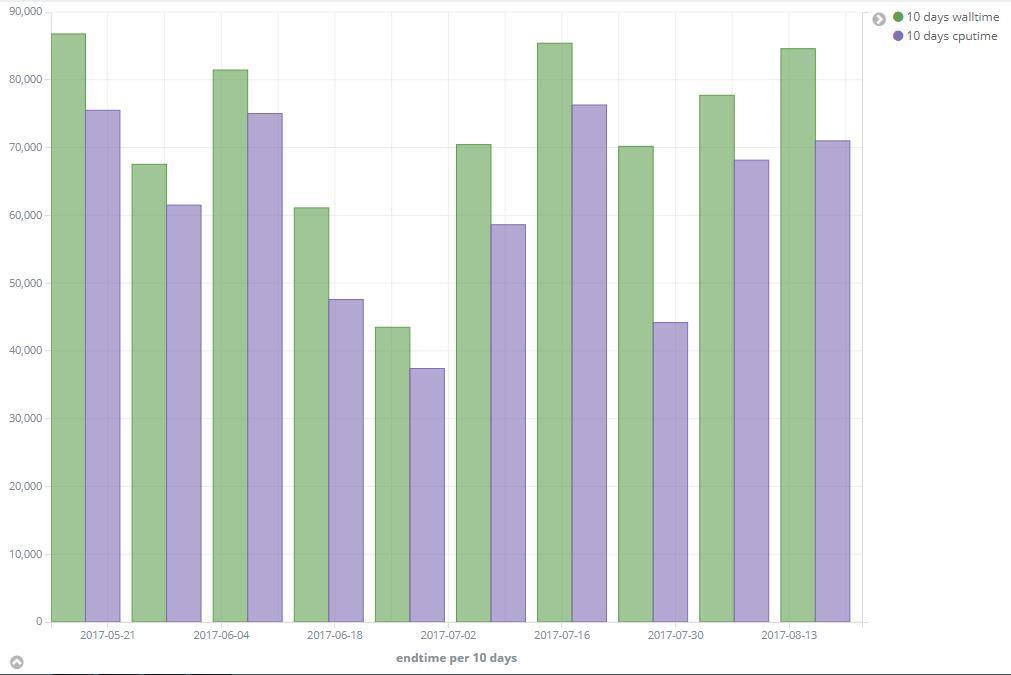
41 BEIJING Tokyo SiGNET Wall time CPU time AGLT2 41
42 How about Tier3? Use 10 ATLS Tier3 nodes for testing 42
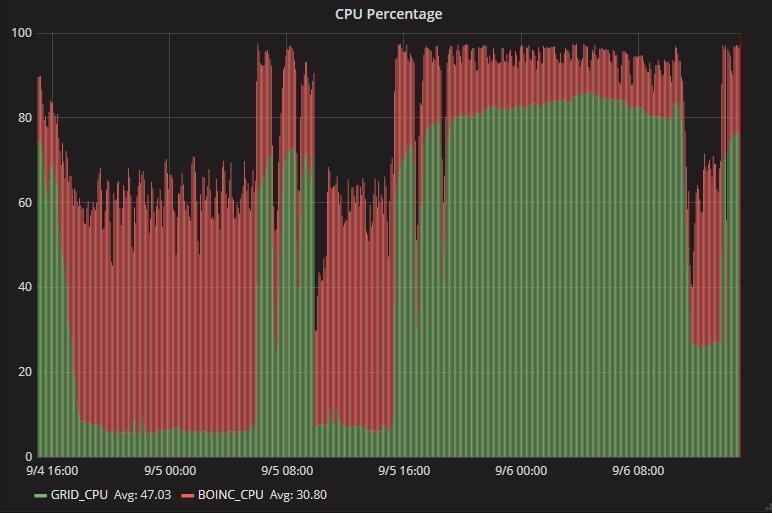
43 43

44 Tier3 node utilization summary 44


45 When production is over 94% in a single day Production wall utilization is over 94% ( avg. 415 jobs running out of 420 jobs slots) ATLAS@home still can exploit 12.62% CPU time 45



46 12 single core nodes 12 multi core nodes 24 multi core nodes Monitor: Load, BOINC_used_memory, used_swap, idle_cpu 46
arxiv: v1 [physics.comp-ph] 29 Nov 2018
![arxiv: v1 [physics.comp-ph] 29 Nov 2018](/thumbs/91/105977977.jpg "arxiv: v1 [physics.comp-ph] 29 Nov 2018") Computing and Software for Big Sciences manuscript No. (will be inserted by the editor) Using ATLAS@Home to exploit extra CPU from busy grid sites Wenjing Wu David Cameron Di Qing arxiv:1811.12578v1 [physics.comp-ph]
Computing and Software for Big Sciences manuscript No. (will be inserted by the editor) Using ATLAS@Home to exploit extra CPU from busy grid sites Wenjing Wu David Cameron Di Qing arxiv:1811.12578v1 [physics.comp-ph]
Explore multi core virtualization on the project
 Explore multi core virtualization on the ATLAS@home project 1 IHEP 19B Yuquan Road, Beijing, 100049 China E-mail:wuwj@ihep.ac.cn David Cameron 2 Department of Physics, University of Oslo P.b. 1048 Blindern,
Explore multi core virtualization on the ATLAS@home project 1 IHEP 19B Yuquan Road, Beijing, 100049 China E-mail:wuwj@ihep.ac.cn David Cameron 2 Department of Physics, University of Oslo P.b. 1048 Blindern,
Volunteer Computing at CERN
 Volunteer Computing at CERN BOINC workshop Sep 2014, Budapest Tomi Asp & Pete Jones, on behalf the LHC@Home team Agenda Overview Status of the LHC@Home projects Additional BOINC projects Service consolidation
Volunteer Computing at CERN BOINC workshop Sep 2014, Budapest Tomi Asp & Pete Jones, on behalf the LHC@Home team Agenda Overview Status of the LHC@Home projects Additional BOINC projects Service consolidation
Andrej Filipčič
 Singularity@SiGNET Andrej Filipčič SiGNET 4.5k cores, 3PB storage, 4.8.17 kernel on WNs and Gentoo host OS 2 ARC-CEs with 700TB cephfs ARC cache and 3 data delivery nodes for input/output file staging
Singularity@SiGNET Andrej Filipčič SiGNET 4.5k cores, 3PB storage, 4.8.17 kernel on WNs and Gentoo host OS 2 ARC-CEs with 700TB cephfs ARC cache and 3 data delivery nodes for input/output file staging
ATLAS Distributed Computing Experience and Performance During the LHC Run-2
 ATLAS Distributed Computing Experience and Performance During the LHC Run-2 A Filipčič 1 for the ATLAS Collaboration 1 Jozef Stefan Institute, Jamova 39, 1000 Ljubljana, Slovenia E-mail: andrej.filipcic@ijs.si
ATLAS Distributed Computing Experience and Performance During the LHC Run-2 A Filipčič 1 for the ATLAS Collaboration 1 Jozef Stefan Institute, Jamova 39, 1000 Ljubljana, Slovenia E-mail: andrej.filipcic@ijs.si
BOSS and LHC computing using CernVM and BOINC
 BOSS and LHC computing using CernVM and BOINC otn-2010-0x openlab Summer Student Report BOSS and LHC computing using CernVM and BOINC Jie Wu (Supervisor: Ben Segal / IT) 1 December 2010 Version 1 Distribution::
BOSS and LHC computing using CernVM and BOINC otn-2010-0x openlab Summer Student Report BOSS and LHC computing using CernVM and BOINC Jie Wu (Supervisor: Ben Segal / IT) 1 December 2010 Version 1 Distribution::
Overview of ATLAS PanDA Workload Management
 Overview of ATLAS PanDA Workload Management T. Maeno 1, K. De 2, T. Wenaus 1, P. Nilsson 2, G. A. Stewart 3, R. Walker 4, A. Stradling 2, J. Caballero 1, M. Potekhin 1, D. Smith 5, for The ATLAS Collaboration
Overview of ATLAS PanDA Workload Management T. Maeno 1, K. De 2, T. Wenaus 1, P. Nilsson 2, G. A. Stewart 3, R. Walker 4, A. Stradling 2, J. Caballero 1, M. Potekhin 1, D. Smith 5, for The ATLAS Collaboration
Monitoring ARC services with GangliARC
 Journal of Physics: Conference Series Monitoring ARC services with GangliARC To cite this article: D Cameron and D Karpenko 2012 J. Phys.: Conf. Ser. 396 032018 View the article online for updates and
Journal of Physics: Conference Series Monitoring ARC services with GangliARC To cite this article: D Cameron and D Karpenko 2012 J. Phys.: Conf. Ser. 396 032018 View the article online for updates and
Operating the Distributed NDGF Tier-1
 Operating the Distributed NDGF Tier-1 Michael Grønager Technical Coordinator, NDGF International Symposium on Grid Computing 08 Taipei, April 10th 2008 Talk Outline What is NDGF? Why a distributed Tier-1?
Operating the Distributed NDGF Tier-1 Michael Grønager Technical Coordinator, NDGF International Symposium on Grid Computing 08 Taipei, April 10th 2008 Talk Outline What is NDGF? Why a distributed Tier-1?
LHCb experience running jobs in virtual machines
 LHCb experience running jobs in virtual machines Andrew McNab, University of Manchester Federico Stagni & Cinzia Luzzi, CERN on behalf of the LHCb collaboration Overview Starting from DIRAC + Grid CernVM
LHCb experience running jobs in virtual machines Andrew McNab, University of Manchester Federico Stagni & Cinzia Luzzi, CERN on behalf of the LHCb collaboration Overview Starting from DIRAC + Grid CernVM
UK Tier-2 site evolution for ATLAS. Alastair Dewhurst
 UK Tier-2 site evolution for ATLAS Alastair Dewhurst Introduction My understanding is that GridPP funding is only part of the story when it comes to paying for a Tier 2 site. Each site is unique. Aim to
UK Tier-2 site evolution for ATLAS Alastair Dewhurst Introduction My understanding is that GridPP funding is only part of the story when it comes to paying for a Tier 2 site. Each site is unique. Aim to
Memory Allocation. Copyright : University of Illinois CS 241 Staff 1
 Memory Allocation Copyright : University of Illinois CS 241 Staff 1 Allocation of Page Frames Scenario Several physical pages allocated to processes A, B, and C. Process B page faults. Which page should
Memory Allocation Copyright : University of Illinois CS 241 Staff 1 Allocation of Page Frames Scenario Several physical pages allocated to processes A, B, and C. Process B page faults. Which page should
What s new in HTCondor? What s coming? HTCondor Week 2018 Madison, WI -- May 22, 2018
 What s new in HTCondor? What s coming? HTCondor Week 2018 Madison, WI -- May 22, 2018 Todd Tannenbaum Center for High Throughput Computing Department of Computer Sciences University of Wisconsin-Madison
What s new in HTCondor? What s coming? HTCondor Week 2018 Madison, WI -- May 22, 2018 Todd Tannenbaum Center for High Throughput Computing Department of Computer Sciences University of Wisconsin-Madison
CMS Grid Computing at TAMU Performance, Monitoring and Current Status of the Brazos Cluster
 CMS Grid Computing at TAMU Performance, Monitoring and Current Status of the Brazos Cluster Vaikunth Thukral Department of Physics and Astronomy Texas A&M University 1 Outline Grid Computing with CMS:
CMS Grid Computing at TAMU Performance, Monitoring and Current Status of the Brazos Cluster Vaikunth Thukral Department of Physics and Astronomy Texas A&M University 1 Outline Grid Computing with CMS:
New data access with HTTP/WebDAV in the ATLAS experiment
 New data access with HTTP/WebDAV in the ATLAS experiment Johannes Elmsheuser on behalf of the ATLAS collaboration Ludwig-Maximilians-Universität München 13 April 2015 21st International Conference on Computing
New data access with HTTP/WebDAV in the ATLAS experiment Johannes Elmsheuser on behalf of the ATLAS collaboration Ludwig-Maximilians-Universität München 13 April 2015 21st International Conference on Computing
XCache plans and studies at LMU Munich
 XCache plans and studies at LMU Munich Nikolai Hartmann, G. Duckeck, C. Mitterer, R. Walker LMU Munich February 22, 2019 1 / 16 LMU ATLAS group Active in ATLAS Computing since the start Operate ATLAS-T2
XCache plans and studies at LMU Munich Nikolai Hartmann, G. Duckeck, C. Mitterer, R. Walker LMU Munich February 22, 2019 1 / 16 LMU ATLAS group Active in ATLAS Computing since the start Operate ATLAS-T2
Towards Ensuring Collective Availability in Volatile Resource Pools via Forecasting
 Towards CloudComputing@home: Ensuring Collective Availability in Volatile Resource Pools via Forecasting Artur Andrzejak Berlin (ZIB) andrzejak[at]zib.de Zuse-Institute Derrick Kondo David P. Anderson
Towards CloudComputing@home: Ensuring Collective Availability in Volatile Resource Pools via Forecasting Artur Andrzejak Berlin (ZIB) andrzejak[at]zib.de Zuse-Institute Derrick Kondo David P. Anderson
UW-ATLAS Experiences with Condor
 UW-ATLAS Experiences with Condor M.Chen, A. Leung, B.Mellado Sau Lan Wu and N.Xu Paradyn / Condor Week, Madison, 05/01/08 Outline Our first success story with Condor - ATLAS production in 2004~2005. CRONUS
UW-ATLAS Experiences with Condor M.Chen, A. Leung, B.Mellado Sau Lan Wu and N.Xu Paradyn / Condor Week, Madison, 05/01/08 Outline Our first success story with Condor - ATLAS production in 2004~2005. CRONUS
SmartSuspend. Achieve 100% Cluster Utilization. Technical Overview
 SmartSuspend Achieve 100% Cluster Utilization Technical Overview 2011 Jaryba, Inc. SmartSuspend TM Technical Overview 1 Table of Contents 1.0 SmartSuspend Overview 3 2.0 How SmartSuspend Works 3 3.0 Job
SmartSuspend Achieve 100% Cluster Utilization Technical Overview 2011 Jaryba, Inc. SmartSuspend TM Technical Overview 1 Table of Contents 1.0 SmartSuspend Overview 3 2.0 How SmartSuspend Works 3 3.0 Job
Evolution of Cloud Computing in ATLAS
 The Evolution of Cloud Computing in ATLAS Ryan Taylor on behalf of the ATLAS collaboration 1 Outline Cloud Usage and IaaS Resource Management Software Services to facilitate cloud use Sim@P1 Performance
The Evolution of Cloud Computing in ATLAS Ryan Taylor on behalf of the ATLAS collaboration 1 Outline Cloud Usage and IaaS Resource Management Software Services to facilitate cloud use Sim@P1 Performance
Application of Virtualization Technologies & CernVM. Benedikt Hegner CERN
 Application of Virtualization Technologies & CernVM Benedikt Hegner CERN Virtualization Use Cases Worker Node Virtualization Software Testing Training Platform Software Deployment }Covered today Server
Application of Virtualization Technologies & CernVM Benedikt Hegner CERN Virtualization Use Cases Worker Node Virtualization Software Testing Training Platform Software Deployment }Covered today Server
Clouds at other sites T2-type computing
 Clouds at other sites T2-type computing Randall Sobie University of Victoria Randall Sobie IPP/Victoria 1 Overview Clouds are used in a variety of ways for Tier-2 type computing MC simulation, production
Clouds at other sites T2-type computing Randall Sobie University of Victoria Randall Sobie IPP/Victoria 1 Overview Clouds are used in a variety of ways for Tier-2 type computing MC simulation, production
ATLAS Tier-3 UniGe
 ATLAS Tier-3 cluster @ UniGe Luis March and Yann Meunier (Université de Genève) CHIPP + CSCS GRID: Face To Face meeting CERN, September 1st 2016 Description of ATLAS Tier-3 cluster at UniGe The ATLAS Tier-3
ATLAS Tier-3 cluster @ UniGe Luis March and Yann Meunier (Université de Genève) CHIPP + CSCS GRID: Face To Face meeting CERN, September 1st 2016 Description of ATLAS Tier-3 cluster at UniGe The ATLAS Tier-3
Monitoring for IT Services and WLCG. Alberto AIMAR CERN-IT for the MONIT Team
 Monitoring for IT Services and WLCG Alberto AIMAR CERN-IT for the MONIT Team 2 Outline Scope and Mandate Architecture and Data Flow Technologies and Usage WLCG Monitoring IT DC and Services Monitoring
Monitoring for IT Services and WLCG Alberto AIMAR CERN-IT for the MONIT Team 2 Outline Scope and Mandate Architecture and Data Flow Technologies and Usage WLCG Monitoring IT DC and Services Monitoring
Singularity tests at CC-IN2P3 for Atlas
 Centre de Calcul de l Institut National de Physique Nucléaire et de Physique des Particules Singularity tests at CC-IN2P3 for Atlas Vamvakopoulos Emmanouil Journées LCG-France, 22-24 Novembre 2017, LPC
Centre de Calcul de l Institut National de Physique Nucléaire et de Physique des Particules Singularity tests at CC-IN2P3 for Atlas Vamvakopoulos Emmanouil Journées LCG-France, 22-24 Novembre 2017, LPC
BACKUP AND RECOVERY OF A HIGHLY VIRTUALIZED ENVIRONMENT
 BACKUP AND RECOVERY OF A HIGHLY VIRTUALIZED ENVIRONMENT Featuring Industry Perspectives from The Enterprise Strategy Group (ESG) 24 January 2013 Jason Buffington (@Jbuff), ESG Senior Analyst, Data Protection
BACKUP AND RECOVERY OF A HIGHLY VIRTUALIZED ENVIRONMENT Featuring Industry Perspectives from The Enterprise Strategy Group (ESG) 24 January 2013 Jason Buffington (@Jbuff), ESG Senior Analyst, Data Protection
ATLAS NorduGrid related activities
 Outline: NorduGrid Introduction ATLAS software preparation and distribution Interface between NorduGrid and Condor NGlogger graphical interface On behalf of: Ugur Erkarslan, Samir Ferrag, Morten Hanshaugen
Outline: NorduGrid Introduction ATLAS software preparation and distribution Interface between NorduGrid and Condor NGlogger graphical interface On behalf of: Ugur Erkarslan, Samir Ferrag, Morten Hanshaugen
Bringing ATLAS production to HPC resources - A use case with the Hydra supercomputer of the Max Planck Society
 Journal of Physics: Conference Series PAPER OPEN ACCESS Bringing ATLAS production to HPC resources - A use case with the Hydra supercomputer of the Max Planck Society To cite this article: J A Kennedy
Journal of Physics: Conference Series PAPER OPEN ACCESS Bringing ATLAS production to HPC resources - A use case with the Hydra supercomputer of the Max Planck Society To cite this article: J A Kennedy
The ATLAS Distributed Analysis System
 The ATLAS Distributed Analysis System F. Legger (LMU) on behalf of the ATLAS collaboration October 17th, 2013 20th International Conference on Computing in High Energy and Nuclear Physics (CHEP), Amsterdam
The ATLAS Distributed Analysis System F. Legger (LMU) on behalf of the ATLAS collaboration October 17th, 2013 20th International Conference on Computing in High Energy and Nuclear Physics (CHEP), Amsterdam
Past. Inputs: Various ATLAS ADC weekly s Next: TIM wkshop in Glasgow, 6-10/06
 Introduction T2s L. Poggioli, LAL Past Machine Learning wkshop 29-31/03 @ CERN HEP Software foundation 2-4/05 @ LAL Will get a report @ next CAF Inputs: Various ATLAS ADC weekly s Next: TIM wkshop in Glasgow,
Introduction T2s L. Poggioli, LAL Past Machine Learning wkshop 29-31/03 @ CERN HEP Software foundation 2-4/05 @ LAL Will get a report @ next CAF Inputs: Various ATLAS ADC weekly s Next: TIM wkshop in Glasgow,
STATUS OF PLANS TO USE CONTAINERS IN THE WORLDWIDE LHC COMPUTING GRID
 The WLCG Motivation and benefits Container engines Experiments status and plans Security considerations Summary and outlook STATUS OF PLANS TO USE CONTAINERS IN THE WORLDWIDE LHC COMPUTING GRID SWISS EXPERIENCE
The WLCG Motivation and benefits Container engines Experiments status and plans Security considerations Summary and outlook STATUS OF PLANS TO USE CONTAINERS IN THE WORLDWIDE LHC COMPUTING GRID SWISS EXPERIENCE
Test-Traffic Project Status and Plans
 Test-Traffic Project Status and Plans Henk Uijterwaal, Fotis Georgatos, Johann Gutauer, Daniel Karrenberg, René Wilhelm RIPE-NCC New Projects Group RIPE-36, Budapest, May 2000 1 Overview Manpower, Email
Test-Traffic Project Status and Plans Henk Uijterwaal, Fotis Georgatos, Johann Gutauer, Daniel Karrenberg, René Wilhelm RIPE-NCC New Projects Group RIPE-36, Budapest, May 2000 1 Overview Manpower, Email
Batch Services at CERN: Status and Future Evolution
 Batch Services at CERN: Status and Future Evolution Helge Meinhard, CERN-IT Platform and Engineering Services Group Leader HTCondor Week 20 May 2015 20-May-2015 CERN batch status and evolution - Helge
Batch Services at CERN: Status and Future Evolution Helge Meinhard, CERN-IT Platform and Engineering Services Group Leader HTCondor Week 20 May 2015 20-May-2015 CERN batch status and evolution - Helge
13th International Workshop on Advanced Computing and Analysis Techniques in Physics Research ACAT 2010 Jaipur, India February
 LHC Cloud Computing with CernVM Ben Segal 1 CERN 1211 Geneva 23, Switzerland E mail: b.segal@cern.ch Predrag Buncic CERN E mail: predrag.buncic@cern.ch 13th International Workshop on Advanced Computing
LHC Cloud Computing with CernVM Ben Segal 1 CERN 1211 Geneva 23, Switzerland E mail: b.segal@cern.ch Predrag Buncic CERN E mail: predrag.buncic@cern.ch 13th International Workshop on Advanced Computing
Singularity tests. ADC TIM at CERN 21 Sep E. Vamvakopoulos
 Centre de Calcul de l Institut National de Physique Nucléaire et de Physique des Particules Singularity tests ADC TIM at CERN 21 Sep 2017 E. Vamvakopoulos Singularity tests We use cloud openstack testbed
Centre de Calcul de l Institut National de Physique Nucléaire et de Physique des Particules Singularity tests ADC TIM at CERN 21 Sep 2017 E. Vamvakopoulos Singularity tests We use cloud openstack testbed
Introduction to Distributed HTC and overlay systems
 Introduction to Distributed HTC and overlay systems Tuesday morning session Igor Sfiligoi University of California San Diego Logistical reminder It is OK to ask questions - During
Introduction to Distributed HTC and overlay systems Tuesday morning session Igor Sfiligoi University of California San Diego Logistical reminder It is OK to ask questions - During
Memory - Paging. Copyright : University of Illinois CS 241 Staff 1
 Memory - Paging Copyright : University of Illinois CS 241 Staff 1 Physical Frame Allocation How do we allocate physical memory across multiple processes? What if Process A needs to evict a page from Process
Memory - Paging Copyright : University of Illinois CS 241 Staff 1 Physical Frame Allocation How do we allocate physical memory across multiple processes? What if Process A needs to evict a page from Process
Conference The Data Challenges of the LHC. Reda Tafirout, TRIUMF
 Conference 2017 The Data Challenges of the LHC Reda Tafirout, TRIUMF Outline LHC Science goals, tools and data Worldwide LHC Computing Grid Collaboration & Scale Key challenges Networking ATLAS experiment
Conference 2017 The Data Challenges of the LHC Reda Tafirout, TRIUMF Outline LHC Science goals, tools and data Worldwide LHC Computing Grid Collaboration & Scale Key challenges Networking ATLAS experiment
Clouds in High Energy Physics
 Clouds in High Energy Physics Randall Sobie University of Victoria Randall Sobie IPP/Victoria 1 Overview Clouds are integral part of our HEP computing infrastructure Primarily Infrastructure-as-a-Service
Clouds in High Energy Physics Randall Sobie University of Victoria Randall Sobie IPP/Victoria 1 Overview Clouds are integral part of our HEP computing infrastructure Primarily Infrastructure-as-a-Service
Extending ATLAS Computing to Commercial Clouds and Supercomputers
 Extending ATLAS Computing to Commercial Clouds and Supercomputers 1 University of Texas at Arlington Physics Dept., 502 Yates St., Room 108 Science Hall, Arlington, Texas 76019, United States E-mail: Paul.Nilsson@cern.ch
Extending ATLAS Computing to Commercial Clouds and Supercomputers 1 University of Texas at Arlington Physics Dept., 502 Yates St., Room 108 Science Hall, Arlington, Texas 76019, United States E-mail: Paul.Nilsson@cern.ch
Azure SQL Database for Gaming Industry Workloads Technical Whitepaper
 Azure SQL Database for Gaming Industry Workloads Technical Whitepaper Author: Pankaj Arora, Senior Software Engineer, Microsoft Contents 1 Introduction... 2 2 Proven Platform... 2 2.1 Azure SQL Database
Azure SQL Database for Gaming Industry Workloads Technical Whitepaper Author: Pankaj Arora, Senior Software Engineer, Microsoft Contents 1 Introduction... 2 2 Proven Platform... 2 2.1 Azure SQL Database
Silicon House. Phone: / / / Enquiry: Visit:
 Silicon House Powering Top Blue Chip Companies and Successful Hot Start Ups around the World Ranked TOP Performer among the registrars by NIXI Serving over 750000 clients in 90+ countries Phone: +91-7667-200-300
Silicon House Powering Top Blue Chip Companies and Successful Hot Start Ups around the World Ranked TOP Performer among the registrars by NIXI Serving over 750000 clients in 90+ countries Phone: +91-7667-200-300
Multiprocessor Scheduling. Multiprocessor Scheduling
 Multiprocessor Scheduling Will consider only shared memory multiprocessor or multi-core CPU Salient features: One or more caches: cache affinity is important Semaphores/locks typically implemented as spin-locks:
Multiprocessor Scheduling Will consider only shared memory multiprocessor or multi-core CPU Salient features: One or more caches: cache affinity is important Semaphores/locks typically implemented as spin-locks:
Constant monitoring of multi-site network connectivity at the Tokyo Tier2 center
 Constant monitoring of multi-site network connectivity at the Tokyo Tier2 center, T. Mashimo, N. Matsui, H. Matsunaga, H. Sakamoto, I. Ueda International Center for Elementary Particle Physics, The University
Constant monitoring of multi-site network connectivity at the Tokyo Tier2 center, T. Mashimo, N. Matsui, H. Matsunaga, H. Sakamoto, I. Ueda International Center for Elementary Particle Physics, The University
Martinos Center Compute Cluster
 Why-N-How: Intro to Launchpad 8 September 2016 Lee Tirrell Laboratory for Computational Neuroimaging Adapted from slides by Jon Kaiser 1. Intro 2. Using launchpad 3. Summary 4. Appendix: Miscellaneous
Why-N-How: Intro to Launchpad 8 September 2016 Lee Tirrell Laboratory for Computational Neuroimaging Adapted from slides by Jon Kaiser 1. Intro 2. Using launchpad 3. Summary 4. Appendix: Miscellaneous
Actifio Test Data Management
 Actifio Test Data Management Oracle MS SQL Faster Time To Market Start Release Time To Market (TTM) Finish Faster App Releases Faster Application Releases Faster TTM Increases Revenue Market Share Competitive
Actifio Test Data Management Oracle MS SQL Faster Time To Market Start Release Time To Market (TTM) Finish Faster App Releases Faster Application Releases Faster TTM Increases Revenue Market Share Competitive
Distributing storage of LHC data - in the nordic countries
 Distributing storage of LHC data - in the nordic countries Gerd Behrmann INTEGRATE ASG Lund, May 11th, 2016 Agenda WLCG: A world wide computing grid for the LHC NDGF: The Nordic Tier 1 dcache: Distributed
Distributing storage of LHC data - in the nordic countries Gerd Behrmann INTEGRATE ASG Lund, May 11th, 2016 Agenda WLCG: A world wide computing grid for the LHC NDGF: The Nordic Tier 1 dcache: Distributed
Scientific data processing at global scale The LHC Computing Grid. fabio hernandez
 Scientific data processing at global scale The LHC Computing Grid Chengdu (China), July 5th 2011 Who I am 2 Computing science background Working in the field of computing for high-energy physics since
Scientific data processing at global scale The LHC Computing Grid Chengdu (China), July 5th 2011 Who I am 2 Computing science background Working in the field of computing for high-energy physics since
ATLAS operations in the GridKa T1/T2 Cloud
 Journal of Physics: Conference Series ATLAS operations in the GridKa T1/T2 Cloud To cite this article: G Duckeck et al 2011 J. Phys.: Conf. Ser. 331 072047 View the article online for updates and enhancements.
Journal of Physics: Conference Series ATLAS operations in the GridKa T1/T2 Cloud To cite this article: G Duckeck et al 2011 J. Phys.: Conf. Ser. 331 072047 View the article online for updates and enhancements.
Scalability / Data / Tasks
 Jožef Stefan Institute Scalability / Data / Tasks Meeting Scalability Requirements with Large Data and Complex Tasks: Adapting Existing Technologies and Best Practices in Slovenia Jan Jona Javoršek Jožef
Jožef Stefan Institute Scalability / Data / Tasks Meeting Scalability Requirements with Large Data and Complex Tasks: Adapting Existing Technologies and Best Practices in Slovenia Jan Jona Javoršek Jožef
Jozef Cernak, Marek Kocan, Eva Cernakova (P. J. Safarik University in Kosice, Kosice, Slovak Republic)
") ARC tools for revision and nightly functional tests Jozef Cernak, Marek Kocan, Eva Cernakova (P. J. Safarik University in Kosice, Kosice, Slovak Republic) Outline Testing strategy in ARC ARC-EMI testing
ARC tools for revision and nightly functional tests Jozef Cernak, Marek Kocan, Eva Cernakova (P. J. Safarik University in Kosice, Kosice, Slovak Republic) Outline Testing strategy in ARC ARC-EMI testing
Evolution of the ATLAS PanDA Workload Management System for Exascale Computational Science
 Evolution of the ATLAS PanDA Workload Management System for Exascale Computational Science T. Maeno, K. De, A. Klimentov, P. Nilsson, D. Oleynik, S. Panitkin, A. Petrosyan, J. Schovancova, A. Vaniachine,
Evolution of the ATLAS PanDA Workload Management System for Exascale Computational Science T. Maeno, K. De, A. Klimentov, P. Nilsson, D. Oleynik, S. Panitkin, A. Petrosyan, J. Schovancova, A. Vaniachine,
Considerations for a grid-based Physics Analysis Facility. Dietrich Liko
 Considerations for a grid-based Physics Analysis Facility Dietrich Liko Introduction Aim of our grid activities is to enable physicists to do their work Latest GANGA developments PANDA Tier-3 Taskforce
Considerations for a grid-based Physics Analysis Facility Dietrich Liko Introduction Aim of our grid activities is to enable physicists to do their work Latest GANGA developments PANDA Tier-3 Taskforce
Workload management at KEK/CRC -- status and plan
 Workload management at KEK/CRC -- status and plan KEK/CRC Hiroyuki Matsunaga Most of the slides are prepared by Koichi Murakami and Go Iwai CPU in KEKCC Work server & Batch server Xeon 5670 (2.93 GHz /
Workload management at KEK/CRC -- status and plan KEK/CRC Hiroyuki Matsunaga Most of the slides are prepared by Koichi Murakami and Go Iwai CPU in KEKCC Work server & Batch server Xeon 5670 (2.93 GHz /
Multiprocessor Scheduling. Multiprocessor Scheduling
 Multiprocessor Scheduling Will consider only shared memory multiprocessor or multi-core CPU Salient features: One or more caches: cache affinity is important Semaphores/locks typically implemented as spin-locks:
Multiprocessor Scheduling Will consider only shared memory multiprocessor or multi-core CPU Salient features: One or more caches: cache affinity is important Semaphores/locks typically implemented as spin-locks:
Multiprocessor Scheduling
 Multiprocessor Scheduling Will consider only shared memory multiprocessor or multi-core CPU Salient features: One or more caches: cache affinity is important Semaphores/locks typically implemented as spin-locks:
Multiprocessor Scheduling Will consider only shared memory multiprocessor or multi-core CPU Salient features: One or more caches: cache affinity is important Semaphores/locks typically implemented as spin-locks:
Evolution of the HEP Content Distribution Network. Dave Dykstra CernVM Workshop 6 June 2016
 Evolution of the HEP Content Distribution Network Dave Dykstra CernVM Workshop 6 June 2016 Current HEP Content Delivery Network The HEP CDN is general purpose squid proxies, at least at all WLCG sites
Evolution of the HEP Content Distribution Network Dave Dykstra CernVM Workshop 6 June 2016 Current HEP Content Delivery Network The HEP CDN is general purpose squid proxies, at least at all WLCG sites
Running HEP Workloads on Distributed Clouds
 Running HEP Workloads on Distributed Clouds R.Seuster, F. Berghaus, K. Casteels, C. Driemel M. Ebert, C. R. Leavett-Brown, M. Paterson, R.Sobie, T. Weiss-Gibson 2017 Fall HEPiX meeting, Tsukuba 16. - 20.
Running HEP Workloads on Distributed Clouds R.Seuster, F. Berghaus, K. Casteels, C. Driemel M. Ebert, C. R. Leavett-Brown, M. Paterson, R.Sobie, T. Weiss-Gibson 2017 Fall HEPiX meeting, Tsukuba 16. - 20.
Transient Compute ARC as Cloud Front-End
 Digital Infrastructures for Research 2016 2016-09-29, 11:30, Cracow 30 min slot AEC ALBERT EINSTEIN CENTER FOR FUNDAMENTAL PHYSICS Transient Compute ARC as Cloud Front-End Sigve Haug, AEC-LHEP University
Digital Infrastructures for Research 2016 2016-09-29, 11:30, Cracow 30 min slot AEC ALBERT EINSTEIN CENTER FOR FUNDAMENTAL PHYSICS Transient Compute ARC as Cloud Front-End Sigve Haug, AEC-LHEP University
Grid Computing at Ljubljana and Nova Gorica
 Grid Computing at Ljubljana and Nova Gorica Marko Bračko 1, Samo Stanič 2 1 J. Stefan Institute, Ljubljana & University of Maribor 2 University of Nova Gorica The outline of the talk: Introduction Resources
Grid Computing at Ljubljana and Nova Gorica Marko Bračko 1, Samo Stanič 2 1 J. Stefan Institute, Ljubljana & University of Maribor 2 University of Nova Gorica The outline of the talk: Introduction Resources
The ATLAS Software Installation System v2 Alessandro De Salvo Mayuko Kataoka, Arturo Sanchez Pineda,Yuri Smirnov CHEP 2015
 The ATLAS Software Installation System v2 Alessandro De Salvo Mayuko Kataoka, Arturo Sanchez Pineda,Yuri Smirnov CHEP 2015 Overview Architecture Performance LJSFi Overview LJSFi is an acronym of Light
The ATLAS Software Installation System v2 Alessandro De Salvo Mayuko Kataoka, Arturo Sanchez Pineda,Yuri Smirnov CHEP 2015 Overview Architecture Performance LJSFi Overview LJSFi is an acronym of Light
Volunteer Computing with BOINC
 Volunteer Computing with BOINC Dr. David P. Anderson University of California, Berkeley SC10 Nov. 14, 2010 Goals Explain volunteer computing Teach how to create a volunteer computing project using BOINC
Volunteer Computing with BOINC Dr. David P. Anderson University of California, Berkeley SC10 Nov. 14, 2010 Goals Explain volunteer computing Teach how to create a volunteer computing project using BOINC
How Container Runtimes matter in Kubernetes?
 How Container Runtimes matter in Kubernetes? Kunal Kushwaha NTT OSS Center About me Works @ NTT Open Source Software Center Contributes to containerd and other related projects. Docker community leader,
How Container Runtimes matter in Kubernetes? Kunal Kushwaha NTT OSS Center About me Works @ NTT Open Source Software Center Contributes to containerd and other related projects. Docker community leader,
The Realities of Virtualization
 The Realities of Virtualization Ted Buiting, Director Infrastructure Optimization Solutions Systems & Technology Unisys David Robinson Lead Architect Real Time Infrastructure Unisys Page 1 So what is Virtual
The Realities of Virtualization Ted Buiting, Director Infrastructure Optimization Solutions Systems & Technology Unisys David Robinson Lead Architect Real Time Infrastructure Unisys Page 1 So what is Virtual
Analytics Platform for ATLAS Computing Services
 Analytics Platform for ATLAS Computing Services Ilija Vukotic for the ATLAS collaboration ICHEP 2016, Chicago, USA Getting the most from distributed resources What we want To understand the system To understand
Analytics Platform for ATLAS Computing Services Ilija Vukotic for the ATLAS collaboration ICHEP 2016, Chicago, USA Getting the most from distributed resources What we want To understand the system To understand
WLCG Lightweight Sites
 WLCG Lightweight Sites Mayank Sharma (IT-DI-LCG) 3/7/18 Document reference 2 WLCG Sites Grid is a diverse environment (Various flavors of CE/Batch/WN/ +various preferred tools by admins for configuration/maintenance)
WLCG Lightweight Sites Mayank Sharma (IT-DI-LCG) 3/7/18 Document reference 2 WLCG Sites Grid is a diverse environment (Various flavors of CE/Batch/WN/ +various preferred tools by admins for configuration/maintenance)
Lecture Topics. Announcements. Today: Advanced Scheduling (Stallings, chapter ) Next: Deadlock (Stallings, chapter
 Next: Deadlock (Stallings, chapter") Lecture Topics Today: Advanced Scheduling (Stallings, chapter 10.1-10.4) Next: Deadlock (Stallings, chapter 6.1-6.6) 1 Announcements Exam #2 returned today Self-Study Exercise #10 Project #8 (due 11/16)
Lecture Topics Today: Advanced Scheduling (Stallings, chapter 10.1-10.4) Next: Deadlock (Stallings, chapter 6.1-6.6) 1 Announcements Exam #2 returned today Self-Study Exercise #10 Project #8 (due 11/16)
On-demand provisioning of HEP compute resources on cloud sites and shared HPC centers
 On-demand provisioning of HEP compute resources on cloud sites and shared HPC centers CHEP 2016 - San Francisco, United States of America Gunther Erli, Frank Fischer, Georg Fleig, Manuel Giffels, Thomas
On-demand provisioning of HEP compute resources on cloud sites and shared HPC centers CHEP 2016 - San Francisco, United States of America Gunther Erli, Frank Fischer, Georg Fleig, Manuel Giffels, Thomas
PROOF-Condor integration for ATLAS
 PROOF-Condor integration for ATLAS G. Ganis,, J. Iwaszkiewicz, F. Rademakers CERN / PH-SFT M. Livny, B. Mellado, Neng Xu,, Sau Lan Wu University Of Wisconsin Condor Week, Madison, 29 Apr 2 May 2008 Outline
PROOF-Condor integration for ATLAS G. Ganis,, J. Iwaszkiewicz, F. Rademakers CERN / PH-SFT M. Livny, B. Mellado, Neng Xu,, Sau Lan Wu University Of Wisconsin Condor Week, Madison, 29 Apr 2 May 2008 Outline
The Elasticity and Plasticity in Semi-Containerized Colocating Cloud Workload: a view from Alibaba Trace
 The Elasticity and Plasticity in Semi-Containerized Colocating Cloud Workload: a view from Alibaba Trace Qixiao Liu* and Zhibin Yu Shenzhen Institute of Advanced Technology Chinese Academy of Science @SoCC
The Elasticity and Plasticity in Semi-Containerized Colocating Cloud Workload: a view from Alibaba Trace Qixiao Liu* and Zhibin Yu Shenzhen Institute of Advanced Technology Chinese Academy of Science @SoCC
Grid Computing Competence Center Large Scale Computing Infrastructures (MINF 4526 HS2011)
") Grid Computing Competence Center Large Scale Computing Infrastructures (MINF 4526 HS2011) Sergio Maffioletti Grid Computing Competence Centre, University of Zurich http://www.gc3.uzh.ch/
Grid Computing Competence Center Large Scale Computing Infrastructures (MINF 4526 HS2011) Sergio Maffioletti Grid Computing Competence Centre, University of Zurich http://www.gc3.uzh.ch/
Practical MySQL Performance Optimization. Peter Zaitsev, CEO, Percona July 02, 2015 Percona Technical Webinars
 Practical MySQL Performance Optimization Peter Zaitsev, CEO, Percona July 02, 2015 Percona Technical Webinars In This Presentation We ll Look at how to approach Performance Optimization Discuss Practical
Practical MySQL Performance Optimization Peter Zaitsev, CEO, Percona July 02, 2015 Percona Technical Webinars In This Presentation We ll Look at how to approach Performance Optimization Discuss Practical
Storage validation at GoDaddy Best practices from the world s #1 web hosting provider
 Storage validation at GoDaddy Best practices from the world s #1 web hosting provider Julia Palmer Storage and Backup Manager Justin Richardson Senior Storage Engineer Agenda and Benefits Agenda Faster,
Storage validation at GoDaddy Best practices from the world s #1 web hosting provider Julia Palmer Storage and Backup Manager Justin Richardson Senior Storage Engineer Agenda and Benefits Agenda Faster,
The vsphere 6.0 Advantages Over Hyper- V
 The Advantages Over Hyper- V The most trusted and complete virtualization platform SDDC Competitive Marketing 2015 Q2 VMware.com/go/PartnerCompete 2015 VMware Inc. All rights reserved. v3b The Most Trusted
The Advantages Over Hyper- V The most trusted and complete virtualization platform SDDC Competitive Marketing 2015 Q2 VMware.com/go/PartnerCompete 2015 VMware Inc. All rights reserved. v3b The Most Trusted
SZDG, ecom4com technology, EDGeS-EDGI in large P. Kacsuk MTA SZTAKI
 SZDG, ecom4com technology, EDGeS-EDGI in large P. Kacsuk MTA SZTAKI The EDGI/EDGeS projects receive(d) Community research funding 1 Outline of the talk SZTAKI Desktop Grid (SZDG) SZDG technology: ecom4com
SZDG, ecom4com technology, EDGeS-EDGI in large P. Kacsuk MTA SZTAKI The EDGI/EDGeS projects receive(d) Community research funding 1 Outline of the talk SZTAKI Desktop Grid (SZDG) SZDG technology: ecom4com
Process Scheduling Part 2
 Operating Systems and Computer Networks Process Scheduling Part 2 pascal.klein@uni-due.de Alexander Maxeiner, M.Sc. Faculty of Engineering Agenda Process Management Time Sharing Synchronization of Processes
Operating Systems and Computer Networks Process Scheduling Part 2 pascal.klein@uni-due.de Alexander Maxeiner, M.Sc. Faculty of Engineering Agenda Process Management Time Sharing Synchronization of Processes
Distributed Systems 27. Process Migration & Allocation
 Distributed Systems 27. Process Migration & Allocation Paul Krzyzanowski pxk@cs.rutgers.edu 12/16/2011 1 Processor allocation Easy with multiprocessor systems Every processor has access to the same memory
Distributed Systems 27. Process Migration & Allocation Paul Krzyzanowski pxk@cs.rutgers.edu 12/16/2011 1 Processor allocation Easy with multiprocessor systems Every processor has access to the same memory
Data storage services at KEK/CRC -- status and plan
 Data storage services at KEK/CRC -- status and plan KEK/CRC Hiroyuki Matsunaga Most of the slides are prepared by Koichi Murakami and Go Iwai KEKCC System Overview KEKCC (Central Computing System) The
Data storage services at KEK/CRC -- status and plan KEK/CRC Hiroyuki Matsunaga Most of the slides are prepared by Koichi Murakami and Go Iwai KEKCC System Overview KEKCC (Central Computing System) The
Batch Systems. Running calculations on HPC resources
 Batch Systems Running calculations on HPC resources Outline What is a batch system? How do I interact with the batch system Job submission scripts Interactive jobs Common batch systems Converting between
Batch Systems Running calculations on HPC resources Outline What is a batch system? How do I interact with the batch system Job submission scripts Interactive jobs Common batch systems Converting between
Guillimin HPC Users Meeting February 11, McGill University / Calcul Québec / Compute Canada Montréal, QC Canada
 Guillimin HPC Users Meeting February 11, 2016 guillimin@calculquebec.ca McGill University / Calcul Québec / Compute Canada Montréal, QC Canada Compute Canada News Scheduler Updates Software Updates Training
Guillimin HPC Users Meeting February 11, 2016 guillimin@calculquebec.ca McGill University / Calcul Québec / Compute Canada Montréal, QC Canada Compute Canada News Scheduler Updates Software Updates Training
Chapter Outline. Chapter 2 Distributed Information Systems Architecture. Layers of an information system. Design strategies.
 Prof. Dr.-Ing. Stefan Deßloch AG Heterogene Informationssysteme Geb. 36, Raum 329 Tel. 0631/205 3275 dessloch@informatik.uni-kl.de Chapter 2 Distributed Information Systems Architecture Chapter Outline
Prof. Dr.-Ing. Stefan Deßloch AG Heterogene Informationssysteme Geb. 36, Raum 329 Tel. 0631/205 3275 dessloch@informatik.uni-kl.de Chapter 2 Distributed Information Systems Architecture Chapter Outline
Identifying Workloads for the Cloud
 Identifying Workloads for the Cloud 1 This brief is based on a webinar in RightScale s I m in the Cloud Now What? series. Browse our entire library for webinars on cloud computing management. Meet our
Identifying Workloads for the Cloud 1 This brief is based on a webinar in RightScale s I m in the Cloud Now What? series. Browse our entire library for webinars on cloud computing management. Meet our
The Cirrus Research Computing Cloud
 The Cirrus Research Computing Cloud Faculty of Science What is Cloud Computing? Cloud computing is a physical cluster which runs virtual machines Unlike a typical cluster there is no one operating system
The Cirrus Research Computing Cloud Faculty of Science What is Cloud Computing? Cloud computing is a physical cluster which runs virtual machines Unlike a typical cluster there is no one operating system
Opportunities for container environments on Cray XC30 with GPU devices
 Opportunities for container environments on Cray XC30 with GPU devices Cray User Group 2016, London Sadaf Alam, Lucas Benedicic, T. Schulthess, Miguel Gila May 12, 2016 Agenda Motivation Container technologies,
Opportunities for container environments on Cray XC30 with GPU devices Cray User Group 2016, London Sadaf Alam, Lucas Benedicic, T. Schulthess, Miguel Gila May 12, 2016 Agenda Motivation Container technologies,
AutoPyFactory: A Scalable Flexible Pilot Factory Implementation
 ATL-SOFT-PROC-2012-045 22 May 2012 Not reviewed, for internal circulation only AutoPyFactory: A Scalable Flexible Pilot Factory Implementation J. Caballero 1, J. Hover 1, P. Love 2, G. A. Stewart 3 on
ATL-SOFT-PROC-2012-045 22 May 2012 Not reviewed, for internal circulation only AutoPyFactory: A Scalable Flexible Pilot Factory Implementation J. Caballero 1, J. Hover 1, P. Love 2, G. A. Stewart 3 on
UF Research Computing: Overview and Running STATA
 UF : Overview and Running STATA www.rc.ufl.edu Mission Improve opportunities for research and scholarship Improve competitiveness in securing external funding Matt Gitzendanner magitz@ufl.edu Provide high-performance
UF : Overview and Running STATA www.rc.ufl.edu Mission Improve opportunities for research and scholarship Improve competitiveness in securing external funding Matt Gitzendanner magitz@ufl.edu Provide high-performance
Scheduling - Overview
 Scheduling - Overview Quick review of textbook scheduling Linux 2.4 scheduler implementation overview Linux 2.4 scheduler code Modified Linux 2.4 scheduler Linux 2.6 scheduler comments Possible Goals of
Scheduling - Overview Quick review of textbook scheduling Linux 2.4 scheduler implementation overview Linux 2.4 scheduler code Modified Linux 2.4 scheduler Linux 2.6 scheduler comments Possible Goals of
Top five Docker performance tips
 Top five Docker performance tips Top five Docker performance tips Table of Contents Introduction... 3 Tip 1: Design design applications as microservices... 5 Tip 2: Deployment deploy Docker components
Top five Docker performance tips Top five Docker performance tips Table of Contents Introduction... 3 Tip 1: Design design applications as microservices... 5 Tip 2: Deployment deploy Docker components
AZURE CONTAINER INSTANCES
 AZURE CONTAINER INSTANCES -Krunal Trivedi ABSTRACT In this article, I am going to explain what are Azure Container Instances, how you can use them for hosting, when you can use them and what are its features.
AZURE CONTAINER INSTANCES -Krunal Trivedi ABSTRACT In this article, I am going to explain what are Azure Container Instances, how you can use them for hosting, when you can use them and what are its features.
Using DC/OS for Continuous Delivery
 Using DC/OS for Continuous Delivery DevPulseCon 2017 Elizabeth K. Joseph, @pleia2 Mesosphere 1 Elizabeth K. Joseph, Developer Advocate, Mesosphere 15+ years working in open source communities 10+ years
Using DC/OS for Continuous Delivery DevPulseCon 2017 Elizabeth K. Joseph, @pleia2 Mesosphere 1 Elizabeth K. Joseph, Developer Advocate, Mesosphere 15+ years working in open source communities 10+ years
The Effectiveness of Deduplication on Virtual Machine Disk Images
 The Effectiveness of Deduplication on Virtual Machine Disk Images Keren Jin & Ethan L. Miller Storage Systems Research Center University of California, Santa Cruz Motivation Virtualization is widely deployed
The Effectiveness of Deduplication on Virtual Machine Disk Images Keren Jin & Ethan L. Miller Storage Systems Research Center University of California, Santa Cruz Motivation Virtualization is widely deployed
The ATLAS EventIndex: Full chain deployment and first operation
 The ATLAS EventIndex: Full chain deployment and first operation Álvaro Fernández Casaní Instituto de Física Corpuscular () Universitat de València CSIC On behalf of the ATLAS Collaboration 1 Outline ATLAS
The ATLAS EventIndex: Full chain deployment and first operation Álvaro Fernández Casaní Instituto de Física Corpuscular () Universitat de València CSIC On behalf of the ATLAS Collaboration 1 Outline ATLAS
Database Services at CERN with Oracle 10g RAC and ASM on Commodity HW
 Database Services at CERN with Oracle 10g RAC and ASM on Commodity HW UKOUG RAC SIG Meeting London, October 24 th, 2006 Luca Canali, CERN IT CH-1211 LCGenève 23 Outline Oracle at CERN Architecture of CERN
Database Services at CERN with Oracle 10g RAC and ASM on Commodity HW UKOUG RAC SIG Meeting London, October 24 th, 2006 Luca Canali, CERN IT CH-1211 LCGenève 23 Outline Oracle at CERN Architecture of CERN
Welcome to the. Migrating SQL Server Databases to Azure
 Welcome to the 1 Migrating SQL Server Databases to Azure Migrating SQL Server Databases to Azure Agenda Overview of SQL Server in Microsoft Azure Getting started with SQL Server in an Azure virtual machine
Welcome to the 1 Migrating SQL Server Databases to Azure Migrating SQL Server Databases to Azure Agenda Overview of SQL Server in Microsoft Azure Getting started with SQL Server in an Azure virtual machine
Big Data Analytics Tools. Applied to ATLAS Event Data
 Big Data Analytics Tools Applied to ATLAS Event Data Ilija Vukotic University of Chicago CHEP 2016, San Francisco Idea Big Data technologies have proven to be very useful for storage, visualization and
Big Data Analytics Tools Applied to ATLAS Event Data Ilija Vukotic University of Chicago CHEP 2016, San Francisco Idea Big Data technologies have proven to be very useful for storage, visualization and
Overview of Distributed Computing. signin.ritlug.com (pray it works!)
") Overview of Distributed Computing signin.ritlug.com (pray it works!) Summary Data crunching (supercomputers) Rendering (render farms, Hollywood, Pixar, etc.) High availability (failover of things like
Overview of Distributed Computing signin.ritlug.com (pray it works!) Summary Data crunching (supercomputers) Rendering (render farms, Hollywood, Pixar, etc.) High availability (failover of things like
Elastic Efficient Execution of Varied Containers. Sharma Podila Nov 7th 2016, QCon San Francisco
 Elastic Efficient Execution of Varied Containers Sharma Podila Nov 7th 2016, QCon San Francisco In other words... How do we efficiently run heterogeneous workloads on an elastic pool of heterogeneous resources,
Elastic Efficient Execution of Varied Containers Sharma Podila Nov 7th 2016, QCon San Francisco In other words... How do we efficiently run heterogeneous workloads on an elastic pool of heterogeneous resources,
Live Migration of Virtualized Edge Networks: Analytical Modeling and Performance Evaluation
 Live Migration of Virtualized Edge Networks: Analytical Modeling and Performance Evaluation Walter Cerroni, Franco Callegati DEI University of Bologna, Italy Outline Motivations Virtualized edge networks
Live Migration of Virtualized Edge Networks: Analytical Modeling and Performance Evaluation Walter Cerroni, Franco Callegati DEI University of Bologna, Italy Outline Motivations Virtualized edge networks
ATLAS Experiment and GCE
 ATLAS Experiment and GCE Google IO Conference San Francisco, CA Sergey Panitkin (BNL) and Andrew Hanushevsky (SLAC), for the ATLAS Collaboration ATLAS Experiment The ATLAS is one of the six particle detectors
ATLAS Experiment and GCE Google IO Conference San Francisco, CA Sergey Panitkin (BNL) and Andrew Hanushevsky (SLAC), for the ATLAS Collaboration ATLAS Experiment The ATLAS is one of the six particle detectors
EGEE and Interoperation
 EGEE and Interoperation Laurence Field CERN-IT-GD ISGC 2008 www.eu-egee.org EGEE and glite are registered trademarks Overview The grid problem definition GLite and EGEE The interoperability problem The
EGEE and Interoperation Laurence Field CERN-IT-GD ISGC 2008 www.eu-egee.org EGEE and glite are registered trademarks Overview The grid problem definition GLite and EGEE The interoperability problem The