Search Engines. Gertjan van Noord. September 17, 2018
|
|
|
- Felicia Green
- 5 years ago
- Views:
Transcription
1 Search Engines Gertjan van Noord September 17, 2018
2 About the course Information about the course is available from:
3 Last week Normalization (case, diacritics, stemming, decompounding,... ) Posting List intersection with Skip Pointers Phrase Queries Posting List with positions
4 Promised: decompounding is harder than you think omroepers paperassen rotspartij zonnestroom plantenteelt uitslover kredietverstrekkers
5 Promised: decompounding is harder than you think omroepers paperassen rotspartij zonnestroom plantenteelt uitslover kredietverstrekkers om roe pers paper assen rot spar tij zon nest room plan tent eelt uit s lover krediet verstrek kers
6 Book Exercises
7 This week: Tolerant Retrieval Wildcard queries Spell correction Alternative indexes Finding the most similar terms
8 Wildcard queries: * mon*: find documents with words that starts with mon. *mon: find documents with words that end with mon. Harder. mo*n: find documents with words that start with mo and end with n. harder. Even m*o*n: Yet harder.
9 Wildcard queries Step 1: find all terms that fall within the wildcard definition Step 2: find all documents containing any of these terms
10 Wildcard queries Step 1: find all terms that fall within the wildcard definition B-trees Permuterm index K-gram index Step 2: find all documents containing any of these terms
11 Dictionary structures Hash. Very efficient lookup and construction, but a hash cannot be used to find terms that are close to the key. Python dictionaries are implemented by hashes. Binary tree, B-tree, Tries. Data-structures in which data is kept sorted (and balanced). Fairly efficient search, but more costly to construct. Words with same suffix are close together in the result, and therefore these structures can potentially be used for tolerant retrieval.
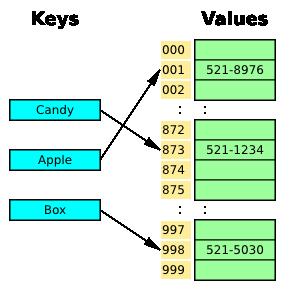
12 Hash
13 Binary tree
14 B-tree Extension of binary tree in which the tree remains balanced
15 Trie
16 Wildcard queries: * mon*: Easy with B-tree, easy with trie. *mon: Maintain additional B-tree or trie for all words in reverse mo*n: Intersect mo* and *n. Use reverse tree for *n. m*o*n:??
17 Wildcard queries: * mon*: Easy with B-tree, easy with trie. *mon: Maintain additional B-tree or trie for all words in reverse mo*n: Intersect mo* and *n. Use reverse tree for *n. m*o*n:?? Use permuterm index or K-gram index
18 K-gram index K-gram: group of K consecutive items. Here: characters. For example, if K=3, the K-gram index has keys of three consecutive characters. The key points to all terms which contain that sequence of three characters. Index for dictionary lookup, not for document retrieval. In a k-gram index, a key points to all relevant search terms.
19 Split words in K-grams, K=3 kitchen \/ $kitchen$ \/ $ki kit itc tch che hen en$
20 K-gram index, K=3 In a k-gram index, a key points to all relevant terms. $ki en$ che ink itt kit ==> {kinkiten kitchen kitten} ==> {kinkiten kitchen kitten kzen} ==> {bitch kitchen witch} ==> {kinkiten kinky} ==> {bitter kitten} ==> {kinkiten kitchen kitten}
21 K-gram index, K=3 In a k-gram index, a key points to all relevant terms. $ki en$ che ink itt kit ==> {kinkiten kitchen kitten} ==> {kinkiten kitchen kitten kzen} ==> {bitch kitchen witch} ==> {kinkiten kinky} ==> {bitter kitten} ==> {kinkiten kitchen kitten} The terms are sorted (why?)
22 K-gram index for wildcard queries Initial Query: kit*en Mapped to: $kit*en$ Search in K-gram index: $ki AND kit AND en$
23 K-gram index for wildcard queries Initial Query: kit*en Mapped to: $kit*en$ Search in K-gram index: $ki AND kit AND en$ Result: kinkiten kitchen kitten Postprocessing required: kinkiten
24 K-gram index for wildcard queries Initial Query: kit*en Mapped to: $kit*en$ Search in K-gram index: $ki AND kit AND en$ Result: kinkiten kitchen kitten Postprocessing required: kinkiten The remaining terms are used in OR query: kitchen OR kitten
25 Query processing What to do for this query: se*ate AND fil*er Expand se*ate to OR-query, e.g., selfhate OR seagate Expand fil*er to OR-query, e.g., filter OR filler Combine into ((selfhate OR seagate) AND (filter OR filler))
26 Spell Correction for Query Terms If a query term is not present in the term index (or if it is very rare)... Find similar terms Calculate similarity to the query term Use most similar one(s) Use most frequent one(s)
27 Spell Correction for Query Terms Find similar terms: K-gram index Calculate similarity to the query term: Jaccard, Levenshtein Use most similar one(s) Use most frequent one(s)
28 Spell Correction for Query Terms Find similar terms: K-gram index For instance: a term t 1 is similar to t 2 if one of the 3-grams of t 1 and t 2 are identical. For unknown term t 1, collect all of the terms in the 3-gram index of all 3-grams. Lots of candidates, only use good ones?
29 Spell Correction for Query Terms Query: brook $bro broek, brok, brommen, brons roo roomijs,vuurrood,brood,rook ook wierookstaafjes,stookolie,brood,rook ok$ werknemersblok,varkenshok,rook
30 Spell Correction for Query Terms Query: brook $bro broek, brok, brommen, brons roo roomijs,vuurrood,brood,rook ook wierookstaafjes,stookolie,brood,rook ok$ werknemersblok,varkenshok,rook From all those, only select the ones that are close to the original term
31 Spell Correction for Query Terms Calculate similarity to the query term Jaccard Jaccard coefficient: A B A B A: trigrams in term t 1 B: trigrams in term t 2
32 Jacard A B A B A: brook: $br,bro,roo,ook,ok$ B: rook: $ro,roo,ook,ok$
33 Jacard A B A B A: brook: $br,bro,roo,ook,ok$ B: rook: $ro,roo,ook,ok$ A B: roo,ook,ok$ A B: $br,bro,roo,ook,ok$,$ro
34 Jacard A B A B A: brook: $br,bro,roo,ook,ok$ B: rook: $ro,roo,ook,ok$ A B: roo,ook,ok$ A B: $br,bro,roo,ook,ok$,$ro Jaccard: 3/6 = 0.5
35 More precise Minimum Edit Distance Levenshtein Distance
36 Levenshtein Distance Distance between A and B: Minimum number of insertions, deletions or substitutions to map A to B
37 Levenshtein Distance Distance between A and B: Minimum number of insertions, deletions or substitutions to map A to B A: brook B: rook
38 Levenshtein Distance Distance between A and B: Minimum number of insertions, deletions or substitutions to map A to B A: brook B: rook Distance: 1
39 Levenshtein distance bakker brak otter boter bloed bode ondersteboven binnenstebuiten
40 Efficient Algorithm try out all possibilities? No. First compute Levenshtein distance for all prefixes Dynamic programming Suppose we need to compute distance for: ondersteboven,binnenstebuiten and we are given the following: dist(onderstebove,binnenstebuite) = 7 dist(onderstebove,binnenstebuiten) = 8 dist(ondersteboven,binnenstebuite) = 8
41 Efficient Algorithm x and y are strings a and b are symbols Suppose we need to compute distance for dist(xa,yb) and we have dist(x,y) dist(xa,y) dist(x,yb)
42 Efficient Algorithm? dist(xa,yb) and we have dist(x,y) dist(xa,y) dist(x,yb)
43 Efficient Algorithm cost(a,b): 0 if a==b; 1 otherwise There are three ways to construct xa,yb: dist(x,y) + cost(a,b) (substitution) dist(xa,y) + 1 (insdel) dist(x,yb) + 1 (insdel)
44 Efficient Algorithm cost(a,b): 0 if a==b; 1 otherwise There are three ways to construct xa,yb: dist(x,y) + cost(a,b) (substitution) dist(xa,y) + 1 (insdel) dist(x,yb) + 1 (insdel) Take the minimum
45 # b l o e d # b o d e Efficient Algorithm: matrix
46 # b l o e d # b 1 o d e Efficient Algorithm: matrix
47 # b l o e d # b o d e Efficient Algorithm: matrix
48 Efficient algorithm: matrix Each cell in the matrix represents the distance between the corresponding prefixes The final result, therefore, can be found in... Other cost functions can be possible too E.g., substitutions for characters that are pronounced similarly could be given lower cost Sometimes, other basic edit operations can be considered (e.g. transposition)
Tolerant Retrieval. Searching the Dictionary Tolerant Retrieval. Information Retrieval & Extraction Misbhauddin 1
 Tolerant Retrieval Searching the Dictionary Tolerant Retrieval Information Retrieval & Extraction Misbhauddin 1 Query Retrieval Dictionary data structures Tolerant retrieval Wild-card queries Soundex Spelling
Tolerant Retrieval Searching the Dictionary Tolerant Retrieval Information Retrieval & Extraction Misbhauddin 1 Query Retrieval Dictionary data structures Tolerant retrieval Wild-card queries Soundex Spelling
3-1. Dictionaries and Tolerant Retrieval. Most slides were adapted from Stanford CS 276 course and University of Munich IR course.
 3-1. Dictionaries and Tolerant Retrieval Most slides were adapted from Stanford CS 276 course and University of Munich IR course. 1 Dictionary data structures for inverted indexes Sec. 3.1 The dictionary
3-1. Dictionaries and Tolerant Retrieval Most slides were adapted from Stanford CS 276 course and University of Munich IR course. 1 Dictionary data structures for inverted indexes Sec. 3.1 The dictionary
Recap of the previous lecture. This lecture. A naïve dictionary. Introduction to Information Retrieval. Dictionary data structures Tolerant retrieval
 Ch. 2 Recap of the previous lecture Introduction to Information Retrieval Lecture 3: Dictionaries and tolerant retrieval The type/token distinction Terms are normalized types put in the dictionary Tokenization
Ch. 2 Recap of the previous lecture Introduction to Information Retrieval Lecture 3: Dictionaries and tolerant retrieval The type/token distinction Terms are normalized types put in the dictionary Tokenization
Overview. Lecture 3: Index Representation and Tolerant Retrieval. Type/token distinction. IR System components
 Overview Lecture 3: Index Representation and Tolerant Retrieval Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group 1 Recap 2
Overview Lecture 3: Index Representation and Tolerant Retrieval Information Retrieval Computer Science Tripos Part II Ronan Cummins 1 Natural Language and Information Processing (NLIP) Group 1 Recap 2
Text Technologies for Data Science INFR Indexing (2) Instructor: Walid Magdy
 Instructor: Walid Magdy") Text Technologies for Data Science INFR11145 Indexing (2) Instructor: Walid Magdy 03-Oct-2018 Lecture Objectives Learn more about indexing: Structured documents Extent index Index compression Data structure
Text Technologies for Data Science INFR11145 Indexing (2) Instructor: Walid Magdy 03-Oct-2018 Lecture Objectives Learn more about indexing: Structured documents Extent index Index compression Data structure
Text Technologies for Data Science INFR Indexing (2) Instructor: Walid Magdy
 Instructor: Walid Magdy") Text Technologies for Data Science INFR11145 Indexing (2) Instructor: Walid Magdy 10-Oct-2017 Lecture Objectives Learn more about indexing: Structured documents Extent index Index compression Data structure
Text Technologies for Data Science INFR11145 Indexing (2) Instructor: Walid Magdy 10-Oct-2017 Lecture Objectives Learn more about indexing: Structured documents Extent index Index compression Data structure
Dictionaries and Tolerant retrieval
 Dictionaries and Tolerant retrieval Slides adapted from Stanford CS297:Introduction to Information Retrieval A skipped lecture The type/token distinction Terms are normalized types put in the dictionary
Dictionaries and Tolerant retrieval Slides adapted from Stanford CS297:Introduction to Information Retrieval A skipped lecture The type/token distinction Terms are normalized types put in the dictionary
Information Retrieval
 Information Retrieval Dictionaries & Tolerant Retrieval Gintarė Grigonytė gintare@ling.su.se Department of Linguistics and Philology Uppsala University Slides based on previous IR course given by Jörg
Information Retrieval Dictionaries & Tolerant Retrieval Gintarė Grigonytė gintare@ling.su.se Department of Linguistics and Philology Uppsala University Slides based on previous IR course given by Jörg
Recap of last time CS276A Information Retrieval
 Recap of last time CS276A Information Retrieval Index compression Space estimation Lecture 4 This lecture Tolerant retrieval Wild-card queries Spelling correction Soundex Wild-card queries Wild-card queries:
Recap of last time CS276A Information Retrieval Index compression Space estimation Lecture 4 This lecture Tolerant retrieval Wild-card queries Spelling correction Soundex Wild-card queries Wild-card queries:
Dictionaries and tolerant retrieval. Slides by Manning, Raghavan, Schutze
 Dictionaries and tolerant retrieval 1 Ch. 2 Recap of the previous lecture The type/token distinction Terms are normalized types put in the dictionary Tokenization problems: Hyphens, apostrophes, compounds,
Dictionaries and tolerant retrieval 1 Ch. 2 Recap of the previous lecture The type/token distinction Terms are normalized types put in the dictionary Tokenization problems: Hyphens, apostrophes, compounds,
Information Retrieval
 Introduction to Information Retrieval Lecture 3: Dictionaries and tolerant retrieval 1 Outline Dictionaries Wildcard queries skip Edit distance skip Spelling correction skip Soundex 2 Inverted index Our
Introduction to Information Retrieval Lecture 3: Dictionaries and tolerant retrieval 1 Outline Dictionaries Wildcard queries skip Edit distance skip Spelling correction skip Soundex 2 Inverted index Our
Introduction to Information Retrieval (Manning, Raghavan, Schutze)
") Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 3 Dictionaries and Tolerant retrieval Chapter 4 Index construction Chapter 5 Index compression Content Dictionary data structures
Introduction to Information Retrieval (Manning, Raghavan, Schutze) Chapter 3 Dictionaries and Tolerant retrieval Chapter 4 Index construction Chapter 5 Index compression Content Dictionary data structures
Indexing and Searching
 Indexing and Searching Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References: 1. Modern Information Retrieval, chapter 8 2. Information Retrieval:
Indexing and Searching Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References: 1. Modern Information Retrieval, chapter 8 2. Information Retrieval:
Data-analysis and Retrieval Boolean retrieval, posting lists and dictionaries
 Data-analysis and Retrieval Boolean retrieval, posting lists and dictionaries Hans Philippi (based on the slides from the Stanford course on IR) April 25, 2018 Boolean retrieval, posting lists & dictionaries
Data-analysis and Retrieval Boolean retrieval, posting lists and dictionaries Hans Philippi (based on the slides from the Stanford course on IR) April 25, 2018 Boolean retrieval, posting lists & dictionaries
Indexing and Searching
 Indexing and Searching Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References: 1. Modern Information Retrieval, chapter 9 2. Information Retrieval:
Indexing and Searching Berlin Chen Department of Computer Science & Information Engineering National Taiwan Normal University References: 1. Modern Information Retrieval, chapter 9 2. Information Retrieval:
Information Retrieval
 Information Retrieval Suan Lee - Information Retrieval - 03 Dictionaries and Tolerant Retrieval 1 03 Dictionaries and Tolerant Retrieval - Information Retrieval - 03 Dictionaries and Tolerant Retrieval
Information Retrieval Suan Lee - Information Retrieval - 03 Dictionaries and Tolerant Retrieval 1 03 Dictionaries and Tolerant Retrieval - Information Retrieval - 03 Dictionaries and Tolerant Retrieval
Dictionaries and tolerant retrieval CE-324 : Modern Information Retrieval Sharif University of Technology
 Dictionaries and tolerant retrieval CE-324 : Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Nayak & Raghavan (CS- 276, Stanford)
Dictionaries and tolerant retrieval CE-324 : Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2014 Most slides have been adapted from: Profs. Nayak & Raghavan (CS- 276, Stanford)
CSCI 104 Tries. Mark Redekopp David Kempe
 1 CSCI 104 Tries Mark Redekopp David Kempe TRIES 2 3 Review of Set/Map Again Recall the operations a set or map performs Insert(key) Remove(key) find(key) : bool/iterator/pointer Get(key) : value [Map
1 CSCI 104 Tries Mark Redekopp David Kempe TRIES 2 3 Review of Set/Map Again Recall the operations a set or map performs Insert(key) Remove(key) find(key) : bool/iterator/pointer Get(key) : value [Map
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Data Structures and Methods. Johan Bollen Old Dominion University Department of Computer Science
 Data Structures and Methods Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen January 20, 2004 Page 1 Lecture Objectives 1. To this point:
Data Structures and Methods Johan Bollen Old Dominion University Department of Computer Science jbollen@cs.odu.edu http://www.cs.odu.edu/ jbollen January 20, 2004 Page 1 Lecture Objectives 1. To this point:
Lecture Notes on Tries
 Lecture Notes on Tries 15-122: Principles of Imperative Computation Thomas Cortina, Frank Pfenning, Rob Simmons, Penny Anderson Lecture 21 November 10, 2014 1 Introduction In the data structures implementing
Lecture Notes on Tries 15-122: Principles of Imperative Computation Thomas Cortina, Frank Pfenning, Rob Simmons, Penny Anderson Lecture 21 November 10, 2014 1 Introduction In the data structures implementing
Overview of Storage and Indexing
 Overview of Storage and Indexing Chapter 8 Instructor: Vladimir Zadorozhny vladimir@sis.pitt.edu Information Science Program School of Information Sciences, University of Pittsburgh 1 Data on External
Overview of Storage and Indexing Chapter 8 Instructor: Vladimir Zadorozhny vladimir@sis.pitt.edu Information Science Program School of Information Sciences, University of Pittsburgh 1 Data on External
Lecture 3: Phrasal queries and wildcards
 Lecture 3: Phrasal queries and wildcards Trevor Cohn (tcohn@unimelb.edu.au) COMP90042, 2015, Semester 1 What we ll learn today Building on the boolean index and query mechanism to support multi-word queries
Lecture 3: Phrasal queries and wildcards Trevor Cohn (tcohn@unimelb.edu.au) COMP90042, 2015, Semester 1 What we ll learn today Building on the boolean index and query mechanism to support multi-word queries
Indexing and Searching
 Indexing and Searching Introduction How to retrieval information? A simple alternative is to search the whole text sequentially Another option is to build data structures over the text (called indices)
Indexing and Searching Introduction How to retrieval information? A simple alternative is to search the whole text sequentially Another option is to build data structures over the text (called indices)
Inverted Indexes. Indexing and Searching, Modern Information Retrieval, Addison Wesley, 2010 p. 5
 Inverted Indexes Indexing and Searching, Modern Information Retrieval, Addison Wesley, 2010 p. 5 Basic Concepts Inverted index: a word-oriented mechanism for indexing a text collection to speed up the
Inverted Indexes Indexing and Searching, Modern Information Retrieval, Addison Wesley, 2010 p. 5 Basic Concepts Inverted index: a word-oriented mechanism for indexing a text collection to speed up the
Indexing. UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze
 Indexing UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze All slides Addison Wesley, 2008 Table of Content Inverted index with positional information
Indexing UCSB 290N. Mainly based on slides from the text books of Croft/Metzler/Strohman and Manning/Raghavan/Schutze All slides Addison Wesley, 2008 Table of Content Inverted index with positional information
OUTLINE. Documents Terms. General + Non-English English. Skip pointers. Phrase queries
 WECHAT GROUP 1 OUTLINE Documents Terms General + Non-English English Skip pointers Phrase queries 2 Phrase queries We want to answer a query such as [stanford university] as a phrase. Thus The inventor
WECHAT GROUP 1 OUTLINE Documents Terms General + Non-English English Skip pointers Phrase queries 2 Phrase queries We want to answer a query such as [stanford university] as a phrase. Thus The inventor
Suffix-based text indices, construction algorithms, and applications.
 Suffix-based text indices, construction algorithms, and applications. F. Franek Computing and Software McMaster University Hamilton, Ontario 2nd CanaDAM Conference Centre de recherches mathématiques in
Suffix-based text indices, construction algorithms, and applications. F. Franek Computing and Software McMaster University Hamilton, Ontario 2nd CanaDAM Conference Centre de recherches mathématiques in
Methods for High Degrees of Similarity. Index-Based Methods Exploiting Prefixes and Suffixes Exploiting Length
 Methods for High Degrees of Similarity Index-Based Methods Exploiting Prefixes and Suffixes Exploiting Length 1 Overview LSH-based methods are excellent for similarity thresholds that are not too high.
Methods for High Degrees of Similarity Index-Based Methods Exploiting Prefixes and Suffixes Exploiting Length 1 Overview LSH-based methods are excellent for similarity thresholds that are not too high.
Birkbeck (University of London)
") Birkbeck (University of London) MSc Examination for Internal Students Department of Computer Science and Information Systems Information Retrieval and Organisation (COIY64H7) Credit Value: 5 Date of Examination:
Birkbeck (University of London) MSc Examination for Internal Students Department of Computer Science and Information Systems Information Retrieval and Organisation (COIY64H7) Credit Value: 5 Date of Examination:
Predecessor. Predecessor Problem van Emde Boas Tries. Philip Bille
 Predecessor Predecessor Problem van Emde Boas Tries Philip Bille Predecessor Predecessor Problem van Emde Boas Tries Predecessors Predecessor problem. Maintain a set S U = {,..., u-} supporting predecessor(x):
Predecessor Predecessor Problem van Emde Boas Tries Philip Bille Predecessor Predecessor Problem van Emde Boas Tries Predecessors Predecessor problem. Maintain a set S U = {,..., u-} supporting predecessor(x):
Boolean Queries. Keywords combined with Boolean operators:
 Query Languages 1 Boolean Queries Keywords combined with Boolean operators: OR: (e 1 OR e 2 ) AND: (e 1 AND e 2 ) BUT: (e 1 BUT e 2 ) Satisfy e 1 but not e 2 Negation only allowed using BUT to allow efficient
Query Languages 1 Boolean Queries Keywords combined with Boolean operators: OR: (e 1 OR e 2 ) AND: (e 1 AND e 2 ) BUT: (e 1 BUT e 2 ) Satisfy e 1 but not e 2 Negation only allowed using BUT to allow efficient
Chapter 12: Indexing and Hashing. Basic Concepts
 Chapter 12: Indexing and Hashing! Basic Concepts! Ordered Indices! B+-Tree Index Files! B-Tree Index Files! Static Hashing! Dynamic Hashing! Comparison of Ordered Indexing and Hashing! Index Definition
Chapter 12: Indexing and Hashing! Basic Concepts! Ordered Indices! B+-Tree Index Files! B-Tree Index Files! Static Hashing! Dynamic Hashing! Comparison of Ordered Indexing and Hashing! Index Definition
Index extensions. Manning, Raghavan and Schütze, Chapter 2. Daniël de Kok
 Index extensions Manning, Raghavan and Schütze, Chapter 2 Daniël de Kok Today We will discuss some extensions to the inverted index to accommodate boolean processing: Skip pointers: improve performance
Index extensions Manning, Raghavan and Schütze, Chapter 2 Daniël de Kok Today We will discuss some extensions to the inverted index to accommodate boolean processing: Skip pointers: improve performance
Chapter 12: Indexing and Hashing
 Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
4.1 COMPUTATIONAL THINKING AND PROBLEM-SOLVING
 4.1 COMPUTATIONAL THINKING AND PROBLEM-SOLVING 4.1.2 ALGORITHMS ALGORITHM An Algorithm is a procedure or formula for solving a problem. It is a step-by-step set of operations to be performed. It is almost
4.1 COMPUTATIONAL THINKING AND PROBLEM-SOLVING 4.1.2 ALGORITHMS ALGORITHM An Algorithm is a procedure or formula for solving a problem. It is a step-by-step set of operations to be performed. It is almost
Dictionaries and tolerant retrieval CE-324 : Modern Information Retrieval Sharif University of Technology
 Dictionaries and tolerant retrieval CE-324 : Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Nayak & Raghavan (CS- 276, Stanford)
Dictionaries and tolerant retrieval CE-324 : Modern Information Retrieval Sharif University of Technology M. Soleymani Fall 2016 Most slides have been adapted from: Profs. Nayak & Raghavan (CS- 276, Stanford)
Lecture Notes on Tries
 Lecture Notes on Tries 15-122: Principles of Imperative Computation Thomas Cortina Notes by Frank Pfenning Lecture 24 April 19, 2011 1 Introduction In the data structures implementing associative arrays
Lecture Notes on Tries 15-122: Principles of Imperative Computation Thomas Cortina Notes by Frank Pfenning Lecture 24 April 19, 2011 1 Introduction In the data structures implementing associative arrays
Predecessor. Predecessor. Predecessors. Predecessors. Predecessor Problem van Emde Boas Tries. Predecessor Problem van Emde Boas Tries.
 Philip Bille s problem. Maintain a set S U = {,..., u-} supporting predecessor(x): return the largest element in S that is x. sucessor(x): return the smallest element in S that is x. insert(x): set S =
Philip Bille s problem. Maintain a set S U = {,..., u-} supporting predecessor(x): return the largest element in S that is x. sucessor(x): return the smallest element in S that is x. insert(x): set S =
CPSC 340: Machine Learning and Data Mining. Finding Similar Items Fall 2017
 CPSC 340: Machine Learning and Data Mining Finding Similar Items Fall 2017 Assignment 1 is due tonight. Admin 1 late day to hand in Monday, 2 late days for Wednesday. Assignment 2 will be up soon. Start
CPSC 340: Machine Learning and Data Mining Finding Similar Items Fall 2017 Assignment 1 is due tonight. Admin 1 late day to hand in Monday, 2 late days for Wednesday. Assignment 2 will be up soon. Start
Boolean Retrieval. Manning, Raghavan and Schütze, Chapter 1. Daniël de Kok
 Boolean Retrieval Manning, Raghavan and Schütze, Chapter 1 Daniël de Kok Boolean query model Pose a query as a boolean query: Terms Operations: AND, OR, NOT Example: Brutus AND Caesar AND NOT Calpuria
Boolean Retrieval Manning, Raghavan and Schütze, Chapter 1 Daniël de Kok Boolean query model Pose a query as a boolean query: Terms Operations: AND, OR, NOT Example: Brutus AND Caesar AND NOT Calpuria
Indexing. Week 14, Spring Edited by M. Naci Akkøk, , Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel
 Indexing Week 14, Spring 2005 Edited by M. Naci Akkøk, 5.3.2004, 3.3.2005 Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel Overview Conventional indexes B-trees Hashing schemes
Indexing Week 14, Spring 2005 Edited by M. Naci Akkøk, 5.3.2004, 3.3.2005 Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel Overview Conventional indexes B-trees Hashing schemes
Information Retrieval
 Information Retrieval Suan Lee - Information Retrieval - 04 Index Construction 1 04 Index Construction - Information Retrieval - 04 Index Construction 2 Plan Last lecture: Dictionary data structures Tolerant
Information Retrieval Suan Lee - Information Retrieval - 04 Index Construction 1 04 Index Construction - Information Retrieval - 04 Index Construction 2 Plan Last lecture: Dictionary data structures Tolerant
Introduction to Parallel Computing Errata
 Introduction to Parallel Computing Errata John C. Kirk 27 November, 2004 Overview Book: Introduction to Parallel Computing, Second Edition, first printing (hardback) ISBN: 0-201-64865-2 Official book website:
Introduction to Parallel Computing Errata John C. Kirk 27 November, 2004 Overview Book: Introduction to Parallel Computing, Second Edition, first printing (hardback) ISBN: 0-201-64865-2 Official book website:
1 Probability Review. CS 124 Section #8 Hashing, Skip Lists 3/20/17. Expectation (weighted average): the expectation of a random quantity X is:
: the expectation of a random quantity X is:") CS 124 Section #8 Hashing, Skip Lists 3/20/17 1 Probability Review Expectation (weighted average): the expectation of a random quantity X is: x= x P (X = x) For each value x that X can take on, we look
CS 124 Section #8 Hashing, Skip Lists 3/20/17 1 Probability Review Expectation (weighted average): the expectation of a random quantity X is: x= x P (X = x) For each value x that X can take on, we look
Information Retrieval
 Introduction to Information Retrieval CS3245 Information Retrieval Lecture 4: Dictionaries and Tolerant Retrieval4 Last Time: Terms and Postings Details Ch. 2 Skip pointers Encoding a tree-like structure
Introduction to Information Retrieval CS3245 Information Retrieval Lecture 4: Dictionaries and Tolerant Retrieval4 Last Time: Terms and Postings Details Ch. 2 Skip pointers Encoding a tree-like structure
Methods for High Degrees of Similarity. Index-Based Methods Exploiting Prefixes and Suffixes Exploiting Length
 Methods for High Degrees of Similarity Index-Based Methods Exploiting Prefixes and Suffixes Exploiting Length 1 Overview LSH-based methods are excellent for similarity thresholds that are not too high.
Methods for High Degrees of Similarity Index-Based Methods Exploiting Prefixes and Suffixes Exploiting Length 1 Overview LSH-based methods are excellent for similarity thresholds that are not too high.
More B-trees, Hash Tables, etc. CS157B Chris Pollett Feb 21, 2005.
 More B-trees, Hash Tables, etc. CS157B Chris Pollett Feb 21, 2005. Outline B-tree Domain of Application B-tree Operations Hash Tables on Disk Hash Table Operations Extensible Hash Tables Multidimensional
More B-trees, Hash Tables, etc. CS157B Chris Pollett Feb 21, 2005. Outline B-tree Domain of Application B-tree Operations Hash Tables on Disk Hash Table Operations Extensible Hash Tables Multidimensional
Announcements. Reading Material. Recap. Today 9/17/17. Storage (contd. from Lecture 6)
") CompSci 16 Intensive Computing Systems Lecture 7 Storage and Index Instructor: Sudeepa Roy Announcements HW1 deadline this week: Due on 09/21 (Thurs), 11: pm, no late days Project proposal deadline: Preliminary
CompSci 16 Intensive Computing Systems Lecture 7 Storage and Index Instructor: Sudeepa Roy Announcements HW1 deadline this week: Due on 09/21 (Thurs), 11: pm, no late days Project proposal deadline: Preliminary
Finding Similar Sets. Applications Shingling Minhashing Locality-Sensitive Hashing
 Finding Similar Sets Applications Shingling Minhashing Locality-Sensitive Hashing Goals Many Web-mining problems can be expressed as finding similar sets:. Pages with similar words, e.g., for classification
Finding Similar Sets Applications Shingling Minhashing Locality-Sensitive Hashing Goals Many Web-mining problems can be expressed as finding similar sets:. Pages with similar words, e.g., for classification
Non-word Error Detection and Correction
 Non-word rror Detection and Correction Prof. Bidyut B. Chaudhuri J. C. Bose Fellow & Head CVPR Unit, Indian Statistical Statistics Kolkata 700 108 email: bbcisical@gmail.com 1 2 Word Mis-typing or Unknown
Non-word rror Detection and Correction Prof. Bidyut B. Chaudhuri J. C. Bose Fellow & Head CVPR Unit, Indian Statistical Statistics Kolkata 700 108 email: bbcisical@gmail.com 1 2 Word Mis-typing or Unknown
Physical Level of Databases: B+-Trees
 Physical Level of Databases: B+-Trees Adnan YAZICI Computer Engineering Department METU (Fall 2005) 1 B + -Tree Index Files l Disadvantage of indexed-sequential files: performance degrades as file grows,
Physical Level of Databases: B+-Trees Adnan YAZICI Computer Engineering Department METU (Fall 2005) 1 B + -Tree Index Files l Disadvantage of indexed-sequential files: performance degrades as file grows,
 Ordered Indices To gain fast random access to records in a file, we can use an index structure. Each index structure is associated with a particular search key. Just like index of a book, library catalog,
Ordered Indices To gain fast random access to records in a file, we can use an index structure. Each index structure is associated with a particular search key. Just like index of a book, library catalog,
Information Retrieval 6. Index compression
 Ghislain Fourny Information Retrieval 6. Index compression Picture copyright: donest /123RF Stock Photo What we have seen so far 2 Boolean retrieval lawyer AND Penang AND NOT silver query Input Set of
Ghislain Fourny Information Retrieval 6. Index compression Picture copyright: donest /123RF Stock Photo What we have seen so far 2 Boolean retrieval lawyer AND Penang AND NOT silver query Input Set of
Text Analytics. Index-Structures for Information Retrieval. Ulf Leser
 Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
x-fast and y-fast Tries
 x-fast and y-fast Tries Problem Problem Set Set 7 due due in in the the box box up up front. front. That's That's the the last last problem problem set set of of the the quarter! quarter! Outline for Today
x-fast and y-fast Tries Problem Problem Set Set 7 due due in in the the box box up up front. front. That's That's the the last last problem problem set set of of the the quarter! quarter! Outline for Today
Indexing. Lecture Objectives. Text Technologies for Data Science INFR Learn about and implement Boolean search Inverted index Positional index
 Text Technologies for Data Science INFR11145 Indexing Instructor: Walid Magdy 03-Oct-2017 Lecture Objectives Learn about and implement Boolean search Inverted index Positional index 2 1 Indexing Process
Text Technologies for Data Science INFR11145 Indexing Instructor: Walid Magdy 03-Oct-2017 Lecture Objectives Learn about and implement Boolean search Inverted index Positional index 2 1 Indexing Process
11/5/13 Comp 555 Fall
 11/5/13 Comp 555 Fall 2013 1 Example of repeats: ATGGTCTAGGTCCTAGTGGTC Motivation to find them: Phenotypes arise from copy-number variations Genomic rearrangements are often associated with repeats Trace
11/5/13 Comp 555 Fall 2013 1 Example of repeats: ATGGTCTAGGTCCTAGTGGTC Motivation to find them: Phenotypes arise from copy-number variations Genomic rearrangements are often associated with repeats Trace
Solutions to Problem Set 1
 CSCI-GA.3520-001 Honors Analysis of Algorithms Solutions to Problem Set 1 Problem 1 An O(n) algorithm that finds the kth integer in an array a = (a 1,..., a n ) of n distinct integers. Basic Idea Using
CSCI-GA.3520-001 Honors Analysis of Algorithms Solutions to Problem Set 1 Problem 1 An O(n) algorithm that finds the kth integer in an array a = (a 1,..., a n ) of n distinct integers. Basic Idea Using
String Matching. Pedro Ribeiro 2016/2017 DCC/FCUP. Pedro Ribeiro (DCC/FCUP) String Matching 2016/ / 42
 String Matching 2016/ / 42") String Matching Pedro Ribeiro DCC/FCUP 2016/2017 Pedro Ribeiro (DCC/FCUP) String Matching 2016/2017 1 / 42 On this lecture The String Matching Problem Naive Algorithm Deterministic Finite Automata Knuth-Morris-Pratt
String Matching Pedro Ribeiro DCC/FCUP 2016/2017 Pedro Ribeiro (DCC/FCUP) String Matching 2016/2017 1 / 42 On this lecture The String Matching Problem Naive Algorithm Deterministic Finite Automata Knuth-Morris-Pratt
ECE 122. Engineering Problem Solving Using Java
 ECE 122 Engineering Problem Solving Using Java Lecture 27 Linear and Binary Search Overview Problem: How can I efficiently locate data within a data structure Searching for data is a fundamental function
ECE 122 Engineering Problem Solving Using Java Lecture 27 Linear and Binary Search Overview Problem: How can I efficiently locate data within a data structure Searching for data is a fundamental function
SUMMARY OF DATABASE STORAGE AND QUERYING
 SUMMARY OF DATABASE STORAGE AND QUERYING 1. Why Is It Important? Usually users of a database do not have to care the issues on this level. Actually, they should focus more on the logical model of a database
SUMMARY OF DATABASE STORAGE AND QUERYING 1. Why Is It Important? Usually users of a database do not have to care the issues on this level. Actually, they should focus more on the logical model of a database
x-fast and y-fast Tries
 x-fast and y-fast Tries Outline for Today Bitwise Tries A simple ordered dictionary for integers. x-fast Tries Tries + Hashing y-fast Tries Tries + Hashing + Subdivision + Balanced Trees + Amortization
x-fast and y-fast Tries Outline for Today Bitwise Tries A simple ordered dictionary for integers. x-fast Tries Tries + Hashing y-fast Tries Tries + Hashing + Subdivision + Balanced Trees + Amortization
CSCI3381-Cryptography
 CSCI3381-Cryptography Project 1: Automated Cryptanalysis of Monoalphabetic Substitution Cipher September 3, 2014 There s not much in the way of modern cryptography in this project (it probably has more
CSCI3381-Cryptography Project 1: Automated Cryptanalysis of Monoalphabetic Substitution Cipher September 3, 2014 There s not much in the way of modern cryptography in this project (it probably has more
Dictionaries. Priority Queues
 Red-Black-Trees.1 Dictionaries Sets and Multisets; Opers: (Ins., Del., Mem.) Sequential sorted or unsorted lists. Linked sorted or unsorted lists. Tries and Hash Tables. Binary Search Trees. Priority Queues
Red-Black-Trees.1 Dictionaries Sets and Multisets; Opers: (Ins., Del., Mem.) Sequential sorted or unsorted lists. Linked sorted or unsorted lists. Tries and Hash Tables. Binary Search Trees. Priority Queues
58093 String Processing Algorithms. Lectures, Autumn 2013, period II
 58093 String Processing Algorithms Lectures, Autumn 2013, period II Juha Kärkkäinen 1 Contents 0. Introduction 1. Sets of strings Search trees, string sorting, binary search 2. Exact string matching Finding
58093 String Processing Algorithms Lectures, Autumn 2013, period II Juha Kärkkäinen 1 Contents 0. Introduction 1. Sets of strings Search trees, string sorting, binary search 2. Exact string matching Finding
Indexing: Part IV. Announcements (February 17) Keyword search. CPS 216 Advanced Database Systems
 Keyword search. CPS 216 Advanced Database Systems") Indexing: Part IV CPS 216 Advanced Database Systems Announcements (February 17) 2 Homework #2 due in two weeks Reading assignments for this and next week The query processing survey by Graefe Due next
Indexing: Part IV CPS 216 Advanced Database Systems Announcements (February 17) 2 Homework #2 due in two weeks Reading assignments for this and next week The query processing survey by Graefe Due next
Trees in java.util. A set is an object that stores unique elements In Java, two implementations are available:
 Trees in java.util A set is an object that stores unique elements In Java, two implementations are available: The class HashSet implements the set with a hash table and a hash function The class TreeSet,
Trees in java.util A set is an object that stores unique elements In Java, two implementations are available: The class HashSet implements the set with a hash table and a hash function The class TreeSet,
Introduction. hashing performs basic operations, such as insertion, better than other ADTs we ve seen so far
 Chapter 5 Hashing 2 Introduction hashing performs basic operations, such as insertion, deletion, and finds in average time better than other ADTs we ve seen so far 3 Hashing a hash table is merely an hashing
Chapter 5 Hashing 2 Introduction hashing performs basic operations, such as insertion, deletion, and finds in average time better than other ADTs we ve seen so far 3 Hashing a hash table is merely an hashing
ΕΠΛ660. Ανάκτηση µε το µοντέλο διανυσµατικού χώρου
 Ανάκτηση µε το µοντέλο διανυσµατικού χώρου Σηµερινό ερώτηµα Typically we want to retrieve the top K docs (in the cosine ranking for the query) not totally order all docs in the corpus can we pick off docs
Ανάκτηση µε το µοντέλο διανυσµατικού χώρου Σηµερινό ερώτηµα Typically we want to retrieve the top K docs (in the cosine ranking for the query) not totally order all docs in the corpus can we pick off docs
A Modern spell(1) Abhinav Upadhyay EuroBSDCon 2017, Paris
 Abhinav Upadhyay EuroBSDCon 2017, Paris") A Modern spell(1) Abhinav Upadhyay EuroBSDCon 2017, Paris Outline Shortcomings in the old spell(1) Feature Requirements of a modern spell(1) Implementation Details of new spell(1)
A Modern spell(1) Abhinav Upadhyay EuroBSDCon 2017, Paris Outline Shortcomings in the old spell(1) Feature Requirements of a modern spell(1) Implementation Details of new spell(1)
Introduction p. 1 Pseudocode p. 2 Algorithm Header p. 2 Purpose, Conditions, and Return p. 3 Statement Numbers p. 4 Variables p. 4 Algorithm Analysis
 Introduction p. 1 Pseudocode p. 2 Algorithm Header p. 2 Purpose, Conditions, and Return p. 3 Statement Numbers p. 4 Variables p. 4 Algorithm Analysis p. 5 Statement Constructs p. 5 Pseudocode Example p.
Introduction p. 1 Pseudocode p. 2 Algorithm Header p. 2 Purpose, Conditions, and Return p. 3 Statement Numbers p. 4 Variables p. 4 Algorithm Analysis p. 5 Statement Constructs p. 5 Pseudocode Example p.
Information Retrieval CS-E credits
 Information Retrieval CS-E4420 5 credits Tokenization, further indexing issues Antti Ukkonen antti.ukkonen@aalto.fi Slides are based on materials by Tuukka Ruotsalo, Hinrich Schütze and Christina Lioma
Information Retrieval CS-E4420 5 credits Tokenization, further indexing issues Antti Ukkonen antti.ukkonen@aalto.fi Slides are based on materials by Tuukka Ruotsalo, Hinrich Schütze and Christina Lioma
Information Retrieval
 Introduction to Information Retrieval Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden mo
Introduction to Information Retrieval Lecture 4: Index Construction 1 Plan Last lecture: Dictionary data structures Tolerant retrieval Wildcards Spell correction Soundex a-hu hy-m n-z $m mace madden mo
R16 SET - 1 '' ''' '' ''' Code No: R
 1. a) Define Latency time and Transmission time? (2M) b) Define Hash table and Hash function? (2M) c) Explain the Binary Heap Structure Property? (3M) d) List the properties of Red-Black trees? (3M) e)
1. a) Define Latency time and Transmission time? (2M) b) Define Hash table and Hash function? (2M) c) Explain the Binary Heap Structure Property? (3M) d) List the properties of Red-Black trees? (3M) e)
Predecessor Data Structures. Philip Bille
 Predecessor Data Structures Philip Bille Outline Predecessor problem First tradeoffs Simple tries x-fast tries y-fast tries Predecessor Problem Predecessor Problem The predecessor problem: Maintain a set
Predecessor Data Structures Philip Bille Outline Predecessor problem First tradeoffs Simple tries x-fast tries y-fast tries Predecessor Problem Predecessor Problem The predecessor problem: Maintain a set
11/5/09 Comp 590/Comp Fall
 11/5/09 Comp 590/Comp 790-90 Fall 2009 1 Example of repeats: ATGGTCTAGGTCCTAGTGGTC Motivation to find them: Genomic rearrangements are often associated with repeats Trace evolutionary secrets Many tumors
11/5/09 Comp 590/Comp 790-90 Fall 2009 1 Example of repeats: ATGGTCTAGGTCCTAGTGGTC Motivation to find them: Genomic rearrangements are often associated with repeats Trace evolutionary secrets Many tumors
Efficiency. Efficiency: Indexing. Indexing. Efficiency Techniques. Inverted Index. Inverted Index (COSC 488)
") Efficiency Efficiency: Indexing (COSC 488) Nazli Goharian nazli@cs.georgetown.edu Difficult to analyze sequential IR algorithms: data and query dependency (query selectivity). O(q(cf max )) -- high estimate-
Efficiency Efficiency: Indexing (COSC 488) Nazli Goharian nazli@cs.georgetown.edu Difficult to analyze sequential IR algorithms: data and query dependency (query selectivity). O(q(cf max )) -- high estimate-
CLOSET+:Searching for the Best Strategies for Mining Frequent Closed Itemsets
 CLOSET+:Searching for the Best Strategies for Mining Frequent Closed Itemsets Jianyong Wang, Jiawei Han, Jian Pei Presentation by: Nasimeh Asgarian Department of Computing Science University of Alberta
CLOSET+:Searching for the Best Strategies for Mining Frequent Closed Itemsets Jianyong Wang, Jiawei Han, Jian Pei Presentation by: Nasimeh Asgarian Department of Computing Science University of Alberta
Chapter 17 Indexing Structures for Files and Physical Database Design
 Chapter 17 Indexing Structures for Files and Physical Database Design We assume that a file already exists with some primary organization unordered, ordered or hash. The index provides alternate ways to
Chapter 17 Indexing Structures for Files and Physical Database Design We assume that a file already exists with some primary organization unordered, ordered or hash. The index provides alternate ways to
Lecture Notes on Tries
 Lecture Notes on Tries 15-122: Principles of Imperative Computation Thomas Cortina, Frank Pfenning, Rob Simmons, Penny Anderson Lecture 22 June 20, 2014 1 Introduction In the data structures implementing
Lecture Notes on Tries 15-122: Principles of Imperative Computation Thomas Cortina, Frank Pfenning, Rob Simmons, Penny Anderson Lecture 22 June 20, 2014 1 Introduction In the data structures implementing
IN4325 Indexing and query processing. Claudia Hauff (WIS, TU Delft)
") IN4325 Indexing and query processing Claudia Hauff (WIS, TU Delft) The big picture Information need Topic the user wants to know more about The essence of IR Query Translation of need into an input for
IN4325 Indexing and query processing Claudia Hauff (WIS, TU Delft) The big picture Information need Topic the user wants to know more about The essence of IR Query Translation of need into an input for
Chapter 5 Hashing. Introduction. Hashing. Hashing Functions. hashing performs basic operations, such as insertion,
 Introduction Chapter 5 Hashing hashing performs basic operations, such as insertion, deletion, and finds in average time 2 Hashing a hash table is merely an of some fixed size hashing converts into locations
Introduction Chapter 5 Hashing hashing performs basic operations, such as insertion, deletion, and finds in average time 2 Hashing a hash table is merely an of some fixed size hashing converts into locations
CISC-235* Test #3 March 19, 2018
 CISC-235* Test #3 March 19, 2018 Student Number (Required) Name (Optional) This is a closed book test. You may not refer to any resources. This is a 50 minute test. Please write your answers in ink. Pencil
CISC-235* Test #3 March 19, 2018 Student Number (Required) Name (Optional) This is a closed book test. You may not refer to any resources. This is a 50 minute test. Please write your answers in ink. Pencil
CS347. Lecture 2 April 9, Prabhakar Raghavan
 CS347 Lecture 2 April 9, 2001 Prabhakar Raghavan Today s topics Inverted index storage Compressing dictionaries into memory Processing Boolean queries Optimizing term processing Skip list encoding Wild-card
CS347 Lecture 2 April 9, 2001 Prabhakar Raghavan Today s topics Inverted index storage Compressing dictionaries into memory Processing Boolean queries Optimizing term processing Skip list encoding Wild-card
Data Structures and Algorithms 2018
 Question 1 (12 marks) Data Structures and Algorithms 2018 Assignment 4 25% of Continuous Assessment Mark Deadline : 5pm Monday 12 th March, via Canvas Sort the array [5, 3, 4, 6, 8, 4, 1, 9, 7, 1, 2] using
Question 1 (12 marks) Data Structures and Algorithms 2018 Assignment 4 25% of Continuous Assessment Mark Deadline : 5pm Monday 12 th March, via Canvas Sort the array [5, 3, 4, 6, 8, 4, 1, 9, 7, 1, 2] using
Today s topics CS347. Inverted index storage. Inverted index storage. Processing Boolean queries. Lecture 2 April 9, 2001 Prabhakar Raghavan
 Today s topics CS347 Lecture 2 April 9, 2001 Prabhakar Raghavan Inverted index storage Compressing dictionaries into memory Processing Boolean queries Optimizing term processing Skip list encoding Wild-card
Today s topics CS347 Lecture 2 April 9, 2001 Prabhakar Raghavan Inverted index storage Compressing dictionaries into memory Processing Boolean queries Optimizing term processing Skip list encoding Wild-card
MITOCW watch?v=ninwepprkdq
 MITOCW watch?v=ninwepprkdq The following content is provided under a Creative Commons license. Your support will help MIT OpenCourseWare continue to offer high quality educational resources for free. To
MITOCW watch?v=ninwepprkdq The following content is provided under a Creative Commons license. Your support will help MIT OpenCourseWare continue to offer high quality educational resources for free. To
Text Analytics. Index-Structures for Information Retrieval. Ulf Leser
 Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Text Analytics Index-Structures for Information Retrieval Ulf Leser Content of this Lecture Inverted files Storage structures Phrase and proximity search Building and updating the index Using a RDBMS Ulf
Suffix Trees and Arrays
 Suffix Trees and Arrays Yufei Tao KAIST May 1, 2013 We will discuss the following substring matching problem: Problem (Substring Matching) Let σ be a single string of n characters. Given a query string
Suffix Trees and Arrays Yufei Tao KAIST May 1, 2013 We will discuss the following substring matching problem: Problem (Substring Matching) Let σ be a single string of n characters. Given a query string
CS61B Fall 2015 Guerrilla Section 3 Worksheet. 8 November 2015
 Fall 2015 8 November 2015 Directions: In groups of 4-5, work on the following exercises. Do not proceed to the next exercise until everyone in your group has the answer and understands why the answer is
Fall 2015 8 November 2015 Directions: In groups of 4-5, work on the following exercises. Do not proceed to the next exercise until everyone in your group has the answer and understands why the answer is
MARKING KEY The University of British Columbia MARKING KEY Computer Science 260 Midterm #2 Examination 12:30 noon, Thursday, March 15, 2012
 MARKING KEY The University of British Columbia MARKING KEY Computer Science 260 Midterm #2 Examination 12:30 noon, Thursday, March 15, 2012 Instructor: K. S. Booth Time: 70 minutes (one hour ten minutes)
MARKING KEY The University of British Columbia MARKING KEY Computer Science 260 Midterm #2 Examination 12:30 noon, Thursday, March 15, 2012 Instructor: K. S. Booth Time: 70 minutes (one hour ten minutes)
Outline for Today. How can we speed up operations that work on integer data? A simple data structure for ordered dictionaries.
 van Emde Boas Trees Outline for Today Data Structures on Integers How can we speed up operations that work on integer data? Tiered Bitvectors A simple data structure for ordered dictionaries. van Emde
van Emde Boas Trees Outline for Today Data Structures on Integers How can we speed up operations that work on integer data? Tiered Bitvectors A simple data structure for ordered dictionaries. van Emde
Table of Contents. Chapter 1: Introduction to Data Structures... 1
 Table of Contents Chapter 1: Introduction to Data Structures... 1 1.1 Data Types in C++... 2 Integer Types... 2 Character Types... 3 Floating-point Types... 3 Variables Names... 4 1.2 Arrays... 4 Extraction
Table of Contents Chapter 1: Introduction to Data Structures... 1 1.1 Data Types in C++... 2 Integer Types... 2 Character Types... 3 Floating-point Types... 3 Variables Names... 4 1.2 Arrays... 4 Extraction
Index-assisted approximate matching
 Index-assisted approximate matching Ben Langmead Department of Computer Science You are free to use these slides. If you do, please sign the guestbook (www.langmead-lab.org/teaching-materials), or email
Index-assisted approximate matching Ben Langmead Department of Computer Science You are free to use these slides. If you do, please sign the guestbook (www.langmead-lab.org/teaching-materials), or email
CMSC424: Database Design. Instructor: Amol Deshpande
 CMSC424: Database Design Instructor: Amol Deshpande amol@cs.umd.edu Databases Data Models Conceptual representa1on of the data Data Retrieval How to ask ques1ons of the database How to answer those ques1ons
CMSC424: Database Design Instructor: Amol Deshpande amol@cs.umd.edu Databases Data Models Conceptual representa1on of the data Data Retrieval How to ask ques1ons of the database How to answer those ques1ons
Information Retrieval
 Information Retrieval Data Processing and Storage Ilya Markov i.markov@uva.nl University of Amsterdam Ilya Markov i.markov@uva.nl Information Retrieval 1 Course overview Offline Data Acquisition Data Processing
Information Retrieval Data Processing and Storage Ilya Markov i.markov@uva.nl University of Amsterdam Ilya Markov i.markov@uva.nl Information Retrieval 1 Course overview Offline Data Acquisition Data Processing
Outline for Today. How can we speed up operations that work on integer data? A simple data structure for ordered dictionaries.
 van Emde Boas Trees Outline for Today Data Structures on Integers How can we speed up operations that work on integer data? Tiered Bitvectors A simple data structure for ordered dictionaries. van Emde
van Emde Boas Trees Outline for Today Data Structures on Integers How can we speed up operations that work on integer data? Tiered Bitvectors A simple data structure for ordered dictionaries. van Emde
Information Retrieval
 Information Retrieval WS 2016 / 2017 Lecture 5, Tuesday November 22 nd, 2016 (Fuzzy Search, Edit Distance, q-gram Index) Prof. Dr. Hannah Bast Chair of Algorithms and Data Structures Department of Computer
Information Retrieval WS 2016 / 2017 Lecture 5, Tuesday November 22 nd, 2016 (Fuzzy Search, Edit Distance, q-gram Index) Prof. Dr. Hannah Bast Chair of Algorithms and Data Structures Department of Computer
Kathleen Durant PhD Northeastern University CS Indexes
 Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical