Lecture 17: Transactional Memories I
|
|
|
- Arron Shaw
- 5 years ago
- Views:
Transcription
1 Lecture 17: Transactional Memories I Papers: A Scalable Non-Blocking Approach to Transactional Memory, HPCA 07, Stanford The Common Case Transactional Behavior of Multi-threaded Programs, HPCA 06, Stanford Characterization of TCC on Chip Multiprocessors, PACT 05, Stanford 1
2 TM Overview Recall the basic TM implementation: Every transaction maintains read-set and write-set Writes are not propagated until commit time At commit, acquire permission to commit from a central arbiter (no parallel commit for now) Send write-set to other nodes if the write-set intersects with the node s read-set, the node s transaction is aborted and re-started 2
3 Implementation Issues Design details: On attempting a write (the Tx is not yet ready to commit), must obtain the most recently committed version of the block in read-only state (the block is not yet part of the read-set, though) At the time of commit, either write-thru to memory (there is no M state in the coherence protocol), or move from S to M state (write-back policy) (a dirty line can t handle speculative writes, though) For parallel commits: is an ordering implied between these transactions? is a write-set/read-set conflict allowed? is a read-set/write-set conflict allowed? is a write-set/write-set conflict allowed? 3
4 Parallel Commits I Ordering is implied: a programmer believes that a transaction executes in isolation Write-set/Read-set conflict should cause an abort: hence, the second transaction must: confirm there is no conflict before propagating writes or propagate writes in a manner that does not affect correctness (can t employ write-thru or write-update, can t respond to others read requests / or must keep track of dependences) Read-set/Write-set conflict need not cause an abort: the ordering should indicate that the first transaction need not abort Write-set/Write-set conflict need not cause an abort: a mechanism is required to ensure that everyone sees writes in the same correct order * Reading your own write is truly not a problem, but since info is maintained at block granularity, the block is included in the read-set 4
5 Parallel Commits II Conflicting writes must be merged correctly (note that the writes may be to different words in the same line) If we re not checking early for Write-set/Read-set conflicts, the first transaction must inform the next transaction after it is done (received all acks) Consistency model: two parallel transactions are sending their write-sets to other nodes over unordered networks: Just as we saw for SC, a reader must not proceed unless everyone has seen the write (the entire transaction need not have committed) Writes to a location must be serialized 5
6 The Stanford Approach Transactions are ordered (by contacting a central agent) A transaction first engages in validation and proceeds with commit only if it is guaranteed to not have any conflicts Write-set/Read-set conflicts are not allowed (T i checks its read-set directories and proceeds only after those directories have seen previous writes) Read-set/Write-set conflicts are allowed (Ti will ignore write notices from transactions >i) Write-set/Write-set conflicts are allowed To maintain write serialization, T i confirms that a directory is done with all transactions <i 6
7 Algorithm Probe your write-set to see if it is your turn to write (helps serialize writes) Let others know that you don t plan to write (thereby allowing parallel commits to unrelated directories) Mark your write-set (helps hide latency) Probe your read-set to see if previous writes have completed Validation is now complete send the actual commit message to the write set 7
8 Example TID Vendor Rd X Wr X P1 P2 Rd Y Wr Z NS: 1 NS: 1 D: X Z D: Y 8
9 Example TID Vendor TID=2 Rd X Wr X P1 TID=1 P2 Rd Y Wr Z NS: 1 NS: 1 D: X Z D: Y 9
10 Example Rd X Wr X P1 TID=1 TID Vendor TID=2 P2 Rd Y Wr Z Probe to write-set to see if it can proceed No writes here. I m done with you. NS: 1 NS: 3 D: X Z D: Y P2 sends the same set of probes/notifications 10
11 Example Can go ahead with my wr Rd X Wr X P1 TID=1 TID Vendor TID=2 P2 Must wait my turn Rd Y Wr Z Mark X NS: 1 NS: 3 D: X Z D: Y Mark messages are hiding the latency for the subsequent commit 11
12 Example Rd X Wr X P1 TID=1 TID Vendor TID=2 P2 Keep probing and waiting Rd Y Wr Z Probe read set and make sure they re done NS: 1 NS: 3 D: X Z D: Y 12
13 Example Rd X Wr X P1 TID=1 TID Vendor TID=2 P2 Keep probing and waiting Rd Y Wr Z Commit NS: 2 Invalidate sharers; NS: 3 D: X Z May cause aborts D: Y 13
14 Example Rd X Wr X P1 TID=1 TID Vendor TID=2 P2 Rd Y Wr Z NS: 2 NS: 3 D: X Z D: Y P2: Probe finally successful. Can mark Z. Will then check read-set. Then proceed with commit 14
15 Algorithm Probe your write-set to see if it is your turn to write (helps serialize writes) Let others know that you don t plan to write (thereby allowing parallel commits to unrelated directories) Mark your write-set (helps hide latency) Probe your read-set to see if previous writes have completed Validation is now complete send the actual commit message to the write set 15
16 Issues The protocol requires many messages: enables latency hiding for the commit process, though There may be high directory locality for a NUMA machine, but possibly not for a single large-scale CMP with a directory-based cache coherence protocol To support a write-back cache policy, a new non-speculative cache is introduced (so that a transaction does not speculatively over-write a dirty line) 16
17 Evaluation 17


18 Results Applications with small transactions suffer more from commit latency 18


19 Results 19


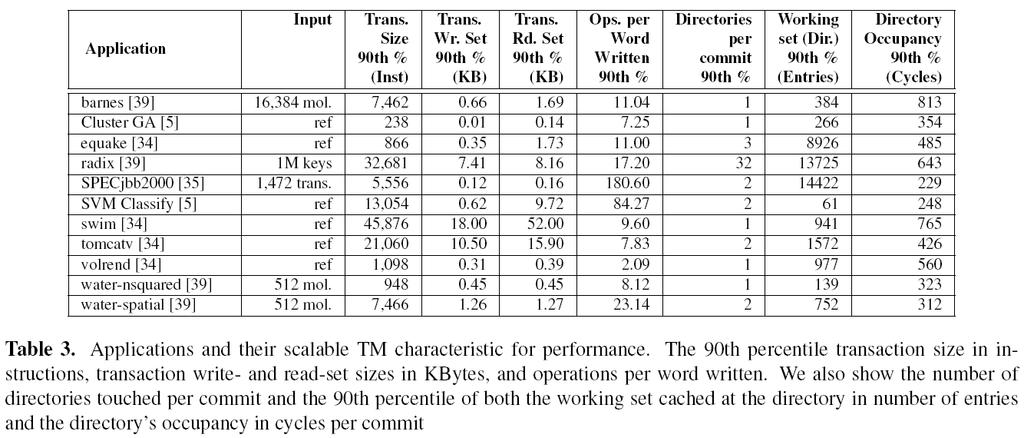
20 Transaction Characteristics An evaluation of 35 multi-threaded programs Transaction length Sizes of read and write sets 20

21 Transaction Characteristics 21
22 Title Bullet 22
Lecture 10: TM Implementations. Topics: wrap-up of eager implementation (LogTM), scalable lazy implementation
, scalable lazy implementation") Lecture 10: TM Implementations Topics: wrap-up of eager implementation (LogTM), scalable lazy implementation 1 Eager Overview Topics: Logs Log optimization Conflict examples Handling deadlocks Sticky scenarios
Lecture 10: TM Implementations Topics: wrap-up of eager implementation (LogTM), scalable lazy implementation 1 Eager Overview Topics: Logs Log optimization Conflict examples Handling deadlocks Sticky scenarios
Lecture 8: Transactional Memory TCC. Topics: lazy implementation (TCC)
") Lecture 8: Transactional Memory TCC Topics: lazy implementation (TCC) 1 Other Issues Nesting: when one transaction calls another flat nesting: collapse all nested transactions into one large transaction
Lecture 8: Transactional Memory TCC Topics: lazy implementation (TCC) 1 Other Issues Nesting: when one transaction calls another flat nesting: collapse all nested transactions into one large transaction
Lecture 4: Directory Protocols and TM. Topics: corner cases in directory protocols, lazy TM
 Lecture 4: Directory Protocols and TM Topics: corner cases in directory protocols, lazy TM 1 Handling Reads When the home receives a read request, it looks up memory (speculative read) and directory in
Lecture 4: Directory Protocols and TM Topics: corner cases in directory protocols, lazy TM 1 Handling Reads When the home receives a read request, it looks up memory (speculative read) and directory in
Lecture 6: Lazy Transactional Memory. Topics: TM semantics and implementation details of lazy TM
 Lecture 6: Lazy Transactional Memory Topics: TM semantics and implementation details of lazy TM 1 Transactions Access to shared variables is encapsulated within transactions the system gives the illusion
Lecture 6: Lazy Transactional Memory Topics: TM semantics and implementation details of lazy TM 1 Transactions Access to shared variables is encapsulated within transactions the system gives the illusion
Lecture: Consistency Models, TM. Topics: consistency models, TM intro (Section 5.6)
") Lecture: Consistency Models, TM Topics: consistency models, TM intro (Section 5.6) 1 Coherence Vs. Consistency Recall that coherence guarantees (i) that a write will eventually be seen by other processors,
Lecture: Consistency Models, TM Topics: consistency models, TM intro (Section 5.6) 1 Coherence Vs. Consistency Recall that coherence guarantees (i) that a write will eventually be seen by other processors,
Lecture 21: Transactional Memory. Topics: Hardware TM basics, different implementations
 Lecture 21: Transactional Memory Topics: Hardware TM basics, different implementations 1 Transactions New paradigm to simplify programming instead of lock-unlock, use transaction begin-end locks are blocking,
Lecture 21: Transactional Memory Topics: Hardware TM basics, different implementations 1 Transactions New paradigm to simplify programming instead of lock-unlock, use transaction begin-end locks are blocking,
Lecture: Transactional Memory. Topics: TM implementations
 Lecture: Transactional Memory Topics: TM implementations 1 Summary of TM Benefits As easy to program as coarse-grain locks Performance similar to fine-grain locks Avoids deadlock 2 Design Space Data Versioning
Lecture: Transactional Memory Topics: TM implementations 1 Summary of TM Benefits As easy to program as coarse-grain locks Performance similar to fine-grain locks Avoids deadlock 2 Design Space Data Versioning
Lecture 18: Coherence Protocols. Topics: coherence protocols for symmetric and distributed shared-memory multiprocessors (Sections
 Lecture 18: Coherence Protocols Topics: coherence protocols for symmetric and distributed shared-memory multiprocessors (Sections 4.2-4.4) 1 SMP/UMA/Centralized Memory Multiprocessor Main Memory I/O System
Lecture 18: Coherence Protocols Topics: coherence protocols for symmetric and distributed shared-memory multiprocessors (Sections 4.2-4.4) 1 SMP/UMA/Centralized Memory Multiprocessor Main Memory I/O System
Lecture: Consistency Models, TM
 Lecture: Consistency Models, TM Topics: consistency models, TM intro (Section 5.6) No class on Monday (please watch TM videos) Wednesday: TM wrap-up, interconnection networks 1 Coherence Vs. Consistency
Lecture: Consistency Models, TM Topics: consistency models, TM intro (Section 5.6) No class on Monday (please watch TM videos) Wednesday: TM wrap-up, interconnection networks 1 Coherence Vs. Consistency
Lecture: Transactional Memory, Networks. Topics: TM implementations, on-chip networks
 Lecture: Transactional Memory, Networks Topics: TM implementations, on-chip networks 1 Summary of TM Benefits As easy to program as coarse-grain locks Performance similar to fine-grain locks Avoids deadlock
Lecture: Transactional Memory, Networks Topics: TM implementations, on-chip networks 1 Summary of TM Benefits As easy to program as coarse-grain locks Performance similar to fine-grain locks Avoids deadlock
Lecture 25: Multiprocessors. Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization
 Lecture 25: Multiprocessors Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 Snooping-Based Protocols Three states for a block: invalid,
Lecture 25: Multiprocessors Today s topics: Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 Snooping-Based Protocols Three states for a block: invalid,
Lecture 12: TM, Consistency Models. Topics: TM pathologies, sequential consistency, hw and hw/sw optimizations
 Lecture 12: TM, Consistency Models Topics: TM pathologies, sequential consistency, hw and hw/sw optimizations 1 Paper on TM Pathologies (ISCA 08) LL: lazy versioning, lazy conflict detection, committing
Lecture 12: TM, Consistency Models Topics: TM pathologies, sequential consistency, hw and hw/sw optimizations 1 Paper on TM Pathologies (ISCA 08) LL: lazy versioning, lazy conflict detection, committing
Lecture 7: Implementing Cache Coherence. Topics: implementation details
 Lecture 7: Implementing Cache Coherence Topics: implementation details 1 Implementing Coherence Protocols Correctness and performance are not the only metrics Deadlock: a cycle of resource dependencies,
Lecture 7: Implementing Cache Coherence Topics: implementation details 1 Implementing Coherence Protocols Correctness and performance are not the only metrics Deadlock: a cycle of resource dependencies,
Commit Algorithms for Scalable Hardware Transactional Memory. Abstract
 Commit Algorithms for Scalable Hardware Transactional Memory Seth H. Pugsley, Rajeev Balasubramonian UUCS-07-016 School of Computing University of Utah Salt Lake City, UT 84112 USA August 9, 2007 Abstract
Commit Algorithms for Scalable Hardware Transactional Memory Seth H. Pugsley, Rajeev Balasubramonian UUCS-07-016 School of Computing University of Utah Salt Lake City, UT 84112 USA August 9, 2007 Abstract
Lecture 25: Multiprocessors
 Lecture 25: Multiprocessors Today s topics: Virtual memory wrap-up Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 TLB and Cache Is the cache indexed
Lecture 25: Multiprocessors Today s topics: Virtual memory wrap-up Snooping-based cache coherence protocol Directory-based cache coherence protocol Synchronization 1 TLB and Cache Is the cache indexed
Lecture 21: Transactional Memory. Topics: consistency model recap, introduction to transactional memory
 Lecture 21: Transactional Memory Topics: consistency model recap, introduction to transactional memory 1 Example Programs Initially, A = B = 0 P1 P2 A = 1 B = 1 if (B == 0) if (A == 0) critical section
Lecture 21: Transactional Memory Topics: consistency model recap, introduction to transactional memory 1 Example Programs Initially, A = B = 0 P1 P2 A = 1 B = 1 if (B == 0) if (A == 0) critical section
Lecture 8: Directory-Based Cache Coherence. Topics: scalable multiprocessor organizations, directory protocol design issues
 Lecture 8: Directory-Based Cache Coherence Topics: scalable multiprocessor organizations, directory protocol design issues 1 Scalable Multiprocessors P1 P2 Pn C1 C2 Cn 1 CA1 2 CA2 n CAn Scalable interconnection
Lecture 8: Directory-Based Cache Coherence Topics: scalable multiprocessor organizations, directory protocol design issues 1 Scalable Multiprocessors P1 P2 Pn C1 C2 Cn 1 CA1 2 CA2 n CAn Scalable interconnection
Lecture 18: Coherence and Synchronization. Topics: directory-based coherence protocols, synchronization primitives (Sections
 Lecture 18: Coherence and Synchronization Topics: directory-based coherence protocols, synchronization primitives (Sections 5.1-5.5) 1 Cache Coherence Protocols Directory-based: A single location (directory)
Lecture 18: Coherence and Synchronization Topics: directory-based coherence protocols, synchronization primitives (Sections 5.1-5.5) 1 Cache Coherence Protocols Directory-based: A single location (directory)
Lecture 24: Virtual Memory, Multiprocessors
 Lecture 24: Virtual Memory, Multiprocessors Today s topics: Virtual memory Multiprocessors, cache coherence 1 Virtual Memory Processes deal with virtual memory they have the illusion that a very large
Lecture 24: Virtual Memory, Multiprocessors Today s topics: Virtual memory Multiprocessors, cache coherence 1 Virtual Memory Processes deal with virtual memory they have the illusion that a very large
Module 9: Addendum to Module 6: Shared Memory Multiprocessors Lecture 17: Multiprocessor Organizations and Cache Coherence. The Lecture Contains:
 The Lecture Contains: Shared Memory Multiprocessors Shared Cache Private Cache/Dancehall Distributed Shared Memory Shared vs. Private in CMPs Cache Coherence Cache Coherence: Example What Went Wrong? Implementations
The Lecture Contains: Shared Memory Multiprocessors Shared Cache Private Cache/Dancehall Distributed Shared Memory Shared vs. Private in CMPs Cache Coherence Cache Coherence: Example What Went Wrong? Implementations
Lecture 8: Snooping and Directory Protocols. Topics: split-transaction implementation details, directory implementations (memory- and cache-based)
") Lecture 8: Snooping and Directory Protocols Topics: split-transaction implementation details, directory implementations (memory- and cache-based) 1 Split Transaction Bus So far, we have assumed that a
Lecture 8: Snooping and Directory Protocols Topics: split-transaction implementation details, directory implementations (memory- and cache-based) 1 Split Transaction Bus So far, we have assumed that a
Lecture 5: Directory Protocols. Topics: directory-based cache coherence implementations
 Lecture 5: Directory Protocols Topics: directory-based cache coherence implementations 1 Flat Memory-Based Directories Block size = 128 B Memory in each node = 1 GB Cache in each node = 1 MB For 64 nodes
Lecture 5: Directory Protocols Topics: directory-based cache coherence implementations 1 Flat Memory-Based Directories Block size = 128 B Memory in each node = 1 GB Cache in each node = 1 MB For 64 nodes
Lecture 13: Consistency Models. Topics: sequential consistency, requirements to implement sequential consistency, relaxed consistency models
 Lecture 13: Consistency Models Topics: sequential consistency, requirements to implement sequential consistency, relaxed consistency models 1 Coherence Vs. Consistency Recall that coherence guarantees
Lecture 13: Consistency Models Topics: sequential consistency, requirements to implement sequential consistency, relaxed consistency models 1 Coherence Vs. Consistency Recall that coherence guarantees
Lecture 12: Hardware/Software Trade-Offs. Topics: COMA, Software Virtual Memory
 Lecture 12: Hardware/Software Trade-Offs Topics: COMA, Software Virtual Memory 1 Capacity Limitations P P P P B1 C C B1 C C Mem Coherence Monitor Mem Coherence Monitor B2 In a Sequent NUMA-Q design above,
Lecture 12: Hardware/Software Trade-Offs Topics: COMA, Software Virtual Memory 1 Capacity Limitations P P P P B1 C C B1 C C Mem Coherence Monitor Mem Coherence Monitor B2 In a Sequent NUMA-Q design above,
Lecture 6: TM Eager Implementations. Topics: Eager conflict detection (LogTM), TM pathologies
, TM pathologies") Lecture 6: TM Eager Implementations Topics: Eager conflict detection (LogTM), TM pathologies 1 Design Space Data Versioning Eager: based on an undo log Lazy: based on a write buffer Typically, versioning
Lecture 6: TM Eager Implementations Topics: Eager conflict detection (LogTM), TM pathologies 1 Design Space Data Versioning Eager: based on an undo log Lazy: based on a write buffer Typically, versioning
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Shared-Memory Multi-Processors Shared-Memory Multiprocessors Multiple threads use shared memory (address space) SysV Shared Memory or Threads in software Communication implicit
CSE 502: Computer Architecture Shared-Memory Multi-Processors Shared-Memory Multiprocessors Multiple threads use shared memory (address space) SysV Shared Memory or Threads in software Communication implicit
Lecture 3: Directory Protocol Implementations. Topics: coherence vs. msg-passing, corner cases in directory protocols
 Lecture 3: Directory Protocol Implementations Topics: coherence vs. msg-passing, corner cases in directory protocols 1 Future Scalable Designs Intel s Single Cloud Computer (SCC): an example prototype
Lecture 3: Directory Protocol Implementations Topics: coherence vs. msg-passing, corner cases in directory protocols 1 Future Scalable Designs Intel s Single Cloud Computer (SCC): an example prototype
Lecture 8: Eager Transactional Memory. Topics: implementation details of eager TM, various TM pathologies
 Lecture 8: Eager Transactional Memory Topics: implementation details of eager TM, various TM pathologies 1 Eager Overview Topics: Logs Log optimization Conflict examples Handling deadlocks Sticky scenarios
Lecture 8: Eager Transactional Memory Topics: implementation details of eager TM, various TM pathologies 1 Eager Overview Topics: Logs Log optimization Conflict examples Handling deadlocks Sticky scenarios
Module 9: "Introduction to Shared Memory Multiprocessors" Lecture 16: "Multiprocessor Organizations and Cache Coherence" Shared Memory Multiprocessors
 Shared Memory Multiprocessors Shared memory multiprocessors Shared cache Private cache/dancehall Distributed shared memory Shared vs. private in CMPs Cache coherence Cache coherence: Example What went
Shared Memory Multiprocessors Shared memory multiprocessors Shared cache Private cache/dancehall Distributed shared memory Shared vs. private in CMPs Cache coherence Cache coherence: Example What went
EazyHTM: Eager-Lazy Hardware Transactional Memory
 EazyHTM: Eager-Lazy Hardware Transactional Memory Saša Tomić, Cristian Perfumo, Chinmay Kulkarni, Adrià Armejach, Adrián Cristal, Osman Unsal, Tim Harris, Mateo Valero Barcelona Supercomputing Center,
EazyHTM: Eager-Lazy Hardware Transactional Memory Saša Tomić, Cristian Perfumo, Chinmay Kulkarni, Adrià Armejach, Adrián Cristal, Osman Unsal, Tim Harris, Mateo Valero Barcelona Supercomputing Center,
Incoherent each cache copy behaves as an individual copy, instead of as the same memory location.
 Cache Coherence This lesson discusses the problems and solutions for coherence. Different coherence protocols are discussed, including: MSI, MOSI, MOESI, and Directory. Each has advantages and disadvantages
Cache Coherence This lesson discusses the problems and solutions for coherence. Different coherence protocols are discussed, including: MSI, MOSI, MOESI, and Directory. Each has advantages and disadvantages
Scalable and Reliable Communication for Hardware Transactional Memory
 Scalable and Reliable Communication for Hardware Transactional Memory Seth H. Pugsley School of Computing, University of Utah, USA pugsley@cs.utah.edu Naveen Muralimanohar School of Computing, University
Scalable and Reliable Communication for Hardware Transactional Memory Seth H. Pugsley School of Computing, University of Utah, USA pugsley@cs.utah.edu Naveen Muralimanohar School of Computing, University
BulkCommit: Scalable and Fast Commit of Atomic Blocks in a Lazy Multiprocessor Environment
 BulkCommit: Scalable and Fast Commit of Atomic Blocks in a Lazy Multiprocessor Environment, Benjamin Sahelices Josep Torrellas, Depei Qian University of Illinois University of Illinois http://iacoma.cs.uiuc.edu/
BulkCommit: Scalable and Fast Commit of Atomic Blocks in a Lazy Multiprocessor Environment, Benjamin Sahelices Josep Torrellas, Depei Qian University of Illinois University of Illinois http://iacoma.cs.uiuc.edu/
Cache Coherence. (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri
 Mainak Chaudhuri") Cache Coherence (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri mainakc@cse.iitk.ac.in 1 Setting Agenda Software: shared address space Hardware: shared memory multiprocessors Cache
Cache Coherence (Architectural Supports for Efficient Shared Memory) Mainak Chaudhuri mainakc@cse.iitk.ac.in 1 Setting Agenda Software: shared address space Hardware: shared memory multiprocessors Cache
Cache Coherence. Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T.
 Coherence Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T. L25-1 Coherence Avoids Stale Data Multicores have multiple private caches for performance Need to provide the illusion
Coherence Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T. L25-1 Coherence Avoids Stale Data Multicores have multiple private caches for performance Need to provide the illusion
Foundations of Computer Systems
 18-600 Foundations of Computer Systems Lecture 21: Multicore Cache Coherence John P. Shen & Zhiyi Yu November 14, 2016 Prevalence of multicore processors: 2006: 75% for desktops, 85% for servers 2007:
18-600 Foundations of Computer Systems Lecture 21: Multicore Cache Coherence John P. Shen & Zhiyi Yu November 14, 2016 Prevalence of multicore processors: 2006: 75% for desktops, 85% for servers 2007:
Module 5: Performance Issues in Shared Memory and Introduction to Coherence Lecture 10: Introduction to Coherence. The Lecture Contains:
 The Lecture Contains: Four Organizations Hierarchical Design Cache Coherence Example What Went Wrong? Definitions Ordering Memory op Bus-based SMP s file:///d /...audhary,%20dr.%20sanjeev%20k%20aggrwal%20&%20dr.%20rajat%20moona/multi-core_architecture/lecture10/10_1.htm[6/14/2012
The Lecture Contains: Four Organizations Hierarchical Design Cache Coherence Example What Went Wrong? Definitions Ordering Memory op Bus-based SMP s file:///d /...audhary,%20dr.%20sanjeev%20k%20aggrwal%20&%20dr.%20rajat%20moona/multi-core_architecture/lecture10/10_1.htm[6/14/2012
Potential violations of Serializability: Example 1
 CSCE 6610:Advanced Computer Architecture Review New Amdahl s law A possible idea for a term project Explore my idea about changing frequency based on serial fraction to maintain fixed energy or keep same
CSCE 6610:Advanced Computer Architecture Review New Amdahl s law A possible idea for a term project Explore my idea about changing frequency based on serial fraction to maintain fixed energy or keep same
COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence
 1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
Goldibear and the 3 Locks. Programming With Locks Is Tricky. More Lock Madness. And To Make It Worse. Transactional Memory: The Big Idea
 Programming With Locks s Tricky Multicore processors are the way of the foreseeable future thread-level parallelism anointed as parallelism model of choice Just one problem Writing lock-based multi-threaded
Programming With Locks s Tricky Multicore processors are the way of the foreseeable future thread-level parallelism anointed as parallelism model of choice Just one problem Writing lock-based multi-threaded
Transactional Memory. Prof. Hsien-Hsin S. Lee School of Electrical and Computer Engineering Georgia Tech
 Transactional Memory Prof. Hsien-Hsin S. Lee School of Electrical and Computer Engineering Georgia Tech (Adapted from Stanford TCC group and MIT SuperTech Group) Motivation Uniprocessor Systems Frequency
Transactional Memory Prof. Hsien-Hsin S. Lee School of Electrical and Computer Engineering Georgia Tech (Adapted from Stanford TCC group and MIT SuperTech Group) Motivation Uniprocessor Systems Frequency
PARALLEL MEMORY ARCHITECTURE
 PARALLEL MEMORY ARCHITECTURE Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 6 is due tonight n The last
PARALLEL MEMORY ARCHITECTURE Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 6 is due tonight n The last
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Lecture 7: Transactional Memory Intro. Topics: introduction to transactional memory, lazy implementation
 Lecture 7: Transactional Memory Intro Topics: introduction to transactional memory, lazy implementation 1 Transactions New paradigm to simplify programming instead of lock-unlock, use transaction begin-end
Lecture 7: Transactional Memory Intro Topics: introduction to transactional memory, lazy implementation 1 Transactions New paradigm to simplify programming instead of lock-unlock, use transaction begin-end
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Transactional Memory
 Transactional Memory Architectural Support for Practical Parallel Programming The TCC Research Group Computer Systems Lab Stanford University http://tcc.stanford.edu TCC Overview - January 2007 The Era
Transactional Memory Architectural Support for Practical Parallel Programming The TCC Research Group Computer Systems Lab Stanford University http://tcc.stanford.edu TCC Overview - January 2007 The Era
A Scalable, Non-blocking Approach to Transactional Memory
 A Scalable, Non-blocking Approach to Transactional Memory Hassan Chafi Jared Casper Brian D. Carlstrom Austen McDonald Chi Cao Minh Woongki Baek Christos Kozyrakis Kunle Olukotun Computer Systems Laboratory
A Scalable, Non-blocking Approach to Transactional Memory Hassan Chafi Jared Casper Brian D. Carlstrom Austen McDonald Chi Cao Minh Woongki Baek Christos Kozyrakis Kunle Olukotun Computer Systems Laboratory
Scalable Cache Coherence
 Scalable Cache Coherence [ 8.1] All of the cache-coherent systems we have talked about until now have had a bus. Not only does the bus guarantee serialization of transactions; it also serves as convenient
Scalable Cache Coherence [ 8.1] All of the cache-coherent systems we have talked about until now have had a bus. Not only does the bus guarantee serialization of transactions; it also serves as convenient
Memory Hierarchy in a Multiprocessor
 EEC 581 Computer Architecture Multiprocessor and Coherence Department of Electrical Engineering and Computer Science Cleveland State University Hierarchy in a Multiprocessor Shared cache Fully-connected
EEC 581 Computer Architecture Multiprocessor and Coherence Department of Electrical Engineering and Computer Science Cleveland State University Hierarchy in a Multiprocessor Shared cache Fully-connected
Multiprocessor Cache Coherency. What is Cache Coherence?
 Multiprocessor Cache Coherency CS448 1 What is Cache Coherence? Two processors can have two different values for the same memory location 2 1 Terminology Coherence Defines what values can be returned by
Multiprocessor Cache Coherency CS448 1 What is Cache Coherence? Two processors can have two different values for the same memory location 2 1 Terminology Coherence Defines what values can be returned by
Lecture 26: Multiprocessors. Today s topics: Directory-based coherence Synchronization Consistency Shared memory vs message-passing
 Lecture 26: Multiprocessors Today s topics: Directory-based coherence Synchronization Consistency Shared memory vs message-passing 1 Cache Coherence Protocols Directory-based: A single location (directory)
Lecture 26: Multiprocessors Today s topics: Directory-based coherence Synchronization Consistency Shared memory vs message-passing 1 Cache Coherence Protocols Directory-based: A single location (directory)
BulkCommit: Scalable and Fast Commit of Atomic Blocks in a Lazy Multiprocessor Environment
 BulkCommit: Scalable and Fast Commit of Atomic Blocks in a Lazy Multiprocessor Environment Xuehai Qian, Josep Torrellas University of Illinois, USA {xqian2, torrella}@illinois.edu http://iacoma.cs.uiuc.edu
BulkCommit: Scalable and Fast Commit of Atomic Blocks in a Lazy Multiprocessor Environment Xuehai Qian, Josep Torrellas University of Illinois, USA {xqian2, torrella}@illinois.edu http://iacoma.cs.uiuc.edu
Lecture 1: Introduction
 Lecture 1: Introduction ourse organization: 4 lectures on cache coherence and consistency 2 lectures on transactional memory 2 lectures on interconnection networks 4 lectures on caches 4 lectures on memory
Lecture 1: Introduction ourse organization: 4 lectures on cache coherence and consistency 2 lectures on transactional memory 2 lectures on interconnection networks 4 lectures on caches 4 lectures on memory
Lecture: Coherence, Synchronization. Topics: directory-based coherence, synchronization primitives (Sections )
") Lecture: Coherence, Synchronization Topics: directory-based coherence, synchronization primitives (Sections 5.1-5.5) 1 Cache Coherence Protocols Directory-based: A single location (directory) keeps track
Lecture: Coherence, Synchronization Topics: directory-based coherence, synchronization primitives (Sections 5.1-5.5) 1 Cache Coherence Protocols Directory-based: A single location (directory) keeps track
Overview: Memory Consistency
 Overview: Memory Consistency the ordering of memory operations basic definitions; sequential consistency comparison with cache coherency relaxing memory consistency write buffers the total store ordering
Overview: Memory Consistency the ordering of memory operations basic definitions; sequential consistency comparison with cache coherency relaxing memory consistency write buffers the total store ordering
Cache Coherence. Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T.
 Coherence Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T. L5- Coherence Avoids Stale Data Multicores have multiple private caches for performance Need to provide the illusion
Coherence Silvina Hanono Wachman Computer Science & Artificial Intelligence Lab M.I.T. L5- Coherence Avoids Stale Data Multicores have multiple private caches for performance Need to provide the illusion
Lecture 3: Snooping Protocols. Topics: snooping-based cache coherence implementations
 Lecture 3: Snooping Protocols Topics: snooping-based cache coherence implementations 1 Design Issues, Optimizations When does memory get updated? demotion from modified to shared? move from modified in
Lecture 3: Snooping Protocols Topics: snooping-based cache coherence implementations 1 Design Issues, Optimizations When does memory get updated? demotion from modified to shared? move from modified in
Lecture 16: Checkpointed Processors. Department of Electrical Engineering Stanford University
 Lecture 16: Checkpointed Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 18-1 Announcements Reading for today: class notes Your main focus:
Lecture 16: Checkpointed Processors Department of Electrical Engineering Stanford University http://eeclass.stanford.edu/ee382a Lecture 18-1 Announcements Reading for today: class notes Your main focus:
Lecture 7: PCM Wrap-Up, Cache coherence. Topics: handling PCM errors and writes, cache coherence intro
 Lecture 7: M Wrap-Up, ache coherence Topics: handling M errors and writes, cache coherence intro 1 Optimizations for Writes (Energy, Lifetime) Read a line before writing and only write the modified bits
Lecture 7: M Wrap-Up, ache coherence Topics: handling M errors and writes, cache coherence intro 1 Optimizations for Writes (Energy, Lifetime) Read a line before writing and only write the modified bits
Multiprocessor Cache Coherence. Chapter 5. Memory System is Coherent If... From ILP to TLP. Enforcing Cache Coherence. Multiprocessor Types
 Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
 Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Multiprocessors and Thread-Level Parallelism Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to
Lecture: Coherence Protocols. Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols
 Lecture: Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Future Memory Trends pin count is not increasing High memory bandwidth requires
Lecture: Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Future Memory Trends pin count is not increasing High memory bandwidth requires
CMSC 411 Computer Systems Architecture Lecture 21 Multiprocessors 3
 MS 411 omputer Systems rchitecture Lecture 21 Multiprocessors 3 Outline Review oherence Write onsistency dministrivia Snooping Building Blocks Snooping protocols and examples oherence traffic and performance
MS 411 omputer Systems rchitecture Lecture 21 Multiprocessors 3 Outline Review oherence Write onsistency dministrivia Snooping Building Blocks Snooping protocols and examples oherence traffic and performance
Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano
 Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano Outline The problem of cache coherence Snooping protocols Directory-based protocols Prof. Cristina Silvano, Politecnico
Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano Outline The problem of cache coherence Snooping protocols Directory-based protocols Prof. Cristina Silvano, Politecnico
Handout 3 Multiprocessor and thread level parallelism
 Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
The Problems with OOO
 Multiprocessors 1 The Problems with OOO Limited per-thread ILP Bigger windows don t buy you that much Complexity Building and verifying large OOO machines is hard (but doable) Area efficiency (per-xtr
Multiprocessors 1 The Problems with OOO Limited per-thread ILP Bigger windows don t buy you that much Complexity Building and verifying large OOO machines is hard (but doable) Area efficiency (per-xtr
Lecture 7: PCM, Cache coherence. Topics: handling PCM errors and writes, cache coherence intro
 Lecture 7: M, ache coherence Topics: handling M errors and writes, cache coherence intro 1 hase hange Memory Emerging NVM technology that can replace Flash and DRAM Much higher density; much better scalability;
Lecture 7: M, ache coherence Topics: handling M errors and writes, cache coherence intro 1 hase hange Memory Emerging NVM technology that can replace Flash and DRAM Much higher density; much better scalability;
Lecture 1: Parallel Architecture Intro
 Lecture 1: Parallel Architecture Intro Course organization: ~13 lectures based on textbook ~10 lectures on recent papers ~5 lectures on parallel algorithms and multi-thread programming New topics: interconnection
Lecture 1: Parallel Architecture Intro Course organization: ~13 lectures based on textbook ~10 lectures on recent papers ~5 lectures on parallel algorithms and multi-thread programming New topics: interconnection
EECS 570 Final Exam - SOLUTIONS Winter 2015
 EECS 570 Final Exam - SOLUTIONS Winter 2015 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points 1 / 21 2 / 32
EECS 570 Final Exam - SOLUTIONS Winter 2015 Name: unique name: Sign the honor code: I have neither given nor received aid on this exam nor observed anyone else doing so. Scores: # Points 1 / 21 2 / 32
Log-Based Transactional Memory
 Log-Based Transactional Memory Kevin E. Moore University of Wisconsin-Madison Motivation Chip-multiprocessors/Multi-core/Many-core are here Intel has 1 projects in the works that contain four or more computing
Log-Based Transactional Memory Kevin E. Moore University of Wisconsin-Madison Motivation Chip-multiprocessors/Multi-core/Many-core are here Intel has 1 projects in the works that contain four or more computing
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Scalable Multiprocessors
 Scalable Multiprocessors [ 11.1] scalable system is one in which resources can be added to the system without reaching a hard limit. Of course, there may still be economic limits. s the size of the system
Scalable Multiprocessors [ 11.1] scalable system is one in which resources can be added to the system without reaching a hard limit. Of course, there may still be economic limits. s the size of the system
Shared Symmetric Memory Systems
 Shared Symmetric Memory Systems Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Shared Symmetric Memory Systems Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Lecture 13: Cache Hierarchies. Today: cache access basics and innovations (Sections )
") Lecture 13: Cache Hierarchies Today: cache access basics and innovations (Sections 5.1-5.2) 1 The Cache Hierarchy Core L1 L2 L3 Off-chip memory 2 Accessing the Cache Byte address 101000 Offset 8-byte words
Lecture 13: Cache Hierarchies Today: cache access basics and innovations (Sections 5.1-5.2) 1 The Cache Hierarchy Core L1 L2 L3 Off-chip memory 2 Accessing the Cache Byte address 101000 Offset 8-byte words
Portland State University ECE 588/688. Transactional Memory
 Portland State University ECE 588/688 Transactional Memory Copyright by Alaa Alameldeen 2018 Issues with Lock Synchronization Priority Inversion A lower-priority thread is preempted while holding a lock
Portland State University ECE 588/688 Transactional Memory Copyright by Alaa Alameldeen 2018 Issues with Lock Synchronization Priority Inversion A lower-priority thread is preempted while holding a lock
Midterm Exam 02/09/2009
 Portland State University Department of Electrical and Computer Engineering ECE 588/688 Advanced Computer Architecture II Winter 2009 Midterm Exam 02/09/2009 Answer All Questions PSU ID#: Please Turn Over
Portland State University Department of Electrical and Computer Engineering ECE 588/688 Advanced Computer Architecture II Winter 2009 Midterm Exam 02/09/2009 Answer All Questions PSU ID#: Please Turn Over
Lecture: Coherence and Synchronization. Topics: synchronization primitives, consistency models intro (Sections )
") Lecture: Coherence and Synchronization Topics: synchronization primitives, consistency models intro (Sections 5.4-5.5) 1 Performance Improvements What determines performance on a multiprocessor: What fraction
Lecture: Coherence and Synchronization Topics: synchronization primitives, consistency models intro (Sections 5.4-5.5) 1 Performance Improvements What determines performance on a multiprocessor: What fraction
Interconnect Routing
 Interconnect Routing store-and-forward routing switch buffers entire message before passing it on latency = [(message length / bandwidth) + fixed overhead] * # hops wormhole routing pipeline message through
Interconnect Routing store-and-forward routing switch buffers entire message before passing it on latency = [(message length / bandwidth) + fixed overhead] * # hops wormhole routing pipeline message through
SIGNET: NETWORK-ON-CHIP FILTERING FOR COARSE VECTOR DIRECTORIES. Natalie Enright Jerger University of Toronto
 SIGNET: NETWORK-ON-CHIP FILTERING FOR COARSE VECTOR DIRECTORIES University of Toronto Interaction of Coherence and Network 2 Cache coherence protocol drives network-on-chip traffic Scalable coherence protocols
SIGNET: NETWORK-ON-CHIP FILTERING FOR COARSE VECTOR DIRECTORIES University of Toronto Interaction of Coherence and Network 2 Cache coherence protocol drives network-on-chip traffic Scalable coherence protocols
CMSC Computer Architecture Lecture 15: Memory Consistency and Synchronization. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 15: Memory Consistency and Synchronization Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 5 (multi-core) " Basic requirements: out later today
CMSC 22200 Computer Architecture Lecture 15: Memory Consistency and Synchronization Prof. Yanjing Li University of Chicago Administrative Stuff! Lab 5 (multi-core) " Basic requirements: out later today
Computer Architecture
 Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 83 Part III Multi-Core
Jens Teubner Computer Architecture Summer 2016 1 Computer Architecture Jens Teubner, TU Dortmund jens.teubner@cs.tu-dortmund.de Summer 2016 Jens Teubner Computer Architecture Summer 2016 83 Part III Multi-Core
Lecture 17. NUMA Architecture and Programming
 Lecture 17 NUMA Architecture and Programming Announcements Extended office hours today until 6pm Weds after class? Partitioning and communication in Particle method project 2012 Scott B. Baden /CSE 260/
Lecture 17 NUMA Architecture and Programming Announcements Extended office hours today until 6pm Weds after class? Partitioning and communication in Particle method project 2012 Scott B. Baden /CSE 260/
Thread-level Parallelism for the Masses. Kunle Olukotun Computer Systems Lab Stanford University 2007
 Thread-level Parallelism for the Masses Kunle Olukotun Computer Systems Lab Stanford University 2007 The World has Changed Process Technology Stops Improving! Moore s law but! Transistors don t get faster
Thread-level Parallelism for the Masses Kunle Olukotun Computer Systems Lab Stanford University 2007 The World has Changed Process Technology Stops Improving! Moore s law but! Transistors don t get faster
Three Tier Proximity Aware Cache Hierarchy for Multi-core Processors
 Three Tier Proximity Aware Cache Hierarchy for Multi-core Processors Akshay Chander, Aravind Narayanan, Madhan R and A.P. Shanti Department of Computer Science & Engineering, College of Engineering Guindy,
Three Tier Proximity Aware Cache Hierarchy for Multi-core Processors Akshay Chander, Aravind Narayanan, Madhan R and A.P. Shanti Department of Computer Science & Engineering, College of Engineering Guindy,
CSC/ECE 506: Architecture of Parallel Computers Sample Final Examination with Answers
 CSC/ECE 506: Architecture of Parallel Computers Sample Final Examination with Answers This was a 180-minute open-book test. You were to answer five of the six questions. Each question was worth 20 points.
CSC/ECE 506: Architecture of Parallel Computers Sample Final Examination with Answers This was a 180-minute open-book test. You were to answer five of the six questions. Each question was worth 20 points.
A Memory System Design Framework: Creating Smart Memories
 A Memory System Design Framework: Creating Smart Memories Amin Firoozshahian, Alex Solomatnikov Hicamp Systems Inc. Ofer Shacham, Zain Asgar, http://www.c2s2.org Stephen Richardson, Christos Kozyrakis,
A Memory System Design Framework: Creating Smart Memories Amin Firoozshahian, Alex Solomatnikov Hicamp Systems Inc. Ofer Shacham, Zain Asgar, http://www.c2s2.org Stephen Richardson, Christos Kozyrakis,
Review on ichat: Inter Cache Hardware Assistant Data Transfer for Heterogeneous Chip Multiprocessors. By: Anvesh Polepalli Raj Muchhala
 Review on ichat: Inter Cache Hardware Assistant Data Transfer for Heterogeneous Chip Multiprocessors By: Anvesh Polepalli Raj Muchhala Introduction Integrating CPU and GPU into a single chip for performance
Review on ichat: Inter Cache Hardware Assistant Data Transfer for Heterogeneous Chip Multiprocessors By: Anvesh Polepalli Raj Muchhala Introduction Integrating CPU and GPU into a single chip for performance
FlexTM. Flexible Decoupled Transactional Memory Support. Arrvindh Shriraman Sandhya Dwarkadas Michael L. Scott Department of Computer Science
 FlexTM Flexible Decoupled Transactional Memory Support Arrvindh Shriraman Sandhya Dwarkadas Michael L. Scott Department of Computer Science 1 Transactions: Our Goal Lazy Txs (i.e., optimistic conflict
FlexTM Flexible Decoupled Transactional Memory Support Arrvindh Shriraman Sandhya Dwarkadas Michael L. Scott Department of Computer Science 1 Transactions: Our Goal Lazy Txs (i.e., optimistic conflict
COMP Parallel Computing. CC-NUMA (1) CC-NUMA implementation
 CC-NUMA implementation") COP 633 - Parallel Computing Lecture 10 September 27, 2018 CC-NUA (1) CC-NUA implementation Reading for next time emory consistency models tutorial (sections 1-6, pp 1-17) COP 633 - Prins CC-NUA (1) Topics
COP 633 - Parallel Computing Lecture 10 September 27, 2018 CC-NUA (1) CC-NUA implementation Reading for next time emory consistency models tutorial (sections 1-6, pp 1-17) COP 633 - Prins CC-NUA (1) Topics
Scalable Cache Coherent Systems
 NUM SS Scalable ache oherent Systems Scalable distributed shared memory machines ssumptions: rocessor-ache-memory nodes connected by scalable network. Distributed shared physical address space. ommunication
NUM SS Scalable ache oherent Systems Scalable distributed shared memory machines ssumptions: rocessor-ache-memory nodes connected by scalable network. Distributed shared physical address space. ommunication
Lecture 11: Large Cache Design
 Lecture 11: Large Cache Design Topics: large cache basics and An Adaptive, Non-Uniform Cache Structure for Wire-Dominated On-Chip Caches, Kim et al., ASPLOS 02 Distance Associativity for High-Performance
Lecture 11: Large Cache Design Topics: large cache basics and An Adaptive, Non-Uniform Cache Structure for Wire-Dominated On-Chip Caches, Kim et al., ASPLOS 02 Distance Associativity for High-Performance
Suggested Readings! What makes a memory system coherent?! Lecture 27" Cache Coherency! ! Readings! ! Program order!! Sequential writes!! Causality!
 1! 2! Suggested Readings! Readings!! H&P: Chapter 5.8! Could also look at material on CD referenced on p. 538 of your text! Lecture 27" Cache Coherency! 3! Processor components! Multicore processors and
1! 2! Suggested Readings! Readings!! H&P: Chapter 5.8! Could also look at material on CD referenced on p. 538 of your text! Lecture 27" Cache Coherency! 3! Processor components! Multicore processors and
Lecture: Memory Technology Innovations
 Lecture: Memory Technology Innovations Topics: memory schedulers, refresh, state-of-the-art and upcoming changes: buffer chips, 3D stacking, non-volatile cells, photonics Multiprocessor intro 1 Row Buffers
Lecture: Memory Technology Innovations Topics: memory schedulers, refresh, state-of-the-art and upcoming changes: buffer chips, 3D stacking, non-volatile cells, photonics Multiprocessor intro 1 Row Buffers
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Today s Outline: Shared Memory Review. Shared Memory & Concurrency. Concurrency v. Parallelism. Thread-Level Parallelism. CS758: Multicore Programming
 CS758: Multicore Programming Today s Outline: Shared Memory Review Shared Memory & Concurrency Introduction to Shared Memory Thread-Level Parallelism Shared Memory Prof. David A. Wood University of Wisconsin-Madison
CS758: Multicore Programming Today s Outline: Shared Memory Review Shared Memory & Concurrency Introduction to Shared Memory Thread-Level Parallelism Shared Memory Prof. David A. Wood University of Wisconsin-Madison
TSO-CC: Consistency-directed Coherence for TSO. Vijay Nagarajan
 TSO-CC: Consistency-directed Coherence for TSO Vijay Nagarajan 1 People Marco Elver (Edinburgh) Bharghava Rajaram (Edinburgh) Changhui Lin (Samsung) Rajiv Gupta (UCR) Susmit Sarkar (St Andrews) 2 Multicores
TSO-CC: Consistency-directed Coherence for TSO Vijay Nagarajan 1 People Marco Elver (Edinburgh) Bharghava Rajaram (Edinburgh) Changhui Lin (Samsung) Rajiv Gupta (UCR) Susmit Sarkar (St Andrews) 2 Multicores
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Lecture 11: Snooping Cache Coherence: Part II. CMU : Parallel Computer Architecture and Programming (Spring 2012)
") Lecture 11: Snooping Cache Coherence: Part II CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Announcements Assignment 2 due tonight 11:59 PM - Recall 3-late day policy Assignment
Lecture 11: Snooping Cache Coherence: Part II CMU 15-418: Parallel Computer Architecture and Programming (Spring 2012) Announcements Assignment 2 due tonight 11:59 PM - Recall 3-late day policy Assignment
Lecture: Memory, Coherence Protocols. Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols
 Lecture: Memory, Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Modern Memory System...... PROC.. 4 DDR3 channels 64-bit data channels
Lecture: Memory, Coherence Protocols Topics: wrap-up of memory systems, multi-thread programming models, snooping-based protocols 1 Modern Memory System...... PROC.. 4 DDR3 channels 64-bit data channels
5 Chip Multiprocessors (II) Chip Multiprocessors (ACS MPhil) Robert Mullins
 Chip Multiprocessors (ACS MPhil) Robert Mullins") 5 Chip Multiprocessors (II) Chip Multiprocessors (ACS MPhil) Robert Mullins Overview Synchronization hardware primitives Cache Coherency Issues Coherence misses, false sharing Cache coherence and interconnects
5 Chip Multiprocessors (II) Chip Multiprocessors (ACS MPhil) Robert Mullins Overview Synchronization hardware primitives Cache Coherency Issues Coherence misses, false sharing Cache coherence and interconnects