Multiprocessors and Thread-Level Parallelism. Department of Electrical & Electronics Engineering, Amrita School of Engineering
|
|
|
- Vincent Hawkins
- 6 years ago
- Views:
Transcription
1 Multiprocessors and Thread-Level Parallelism
2 Multithreading Increasing performance by ILP has the great advantage that it is reasonable transparent to the programmer, ILP can be quite limited or hard to exploit in some applications When the processor is stalled waiting on a cache miss, the utilization of functional units drops Other forms of parallelism multithreading Multithreading allows multiple threads to share the functional units of a single processor in an overlapping fashion. General method to exploit thread-level parallelism (TLP) is with a multiprocessor that has multiple independent threads operating at once and in parallel. Multithreading shares processor core among a set of threads duplicating registers and program counter.
3 Multithreading For sharing, the processor must duplicate the independent state of each thread In addition the hardware must support the ability to change to a different thread relatively quickly Three main hardware approaches to multithreading Fine-grained multithreading Coarse-grained multithreading Simultaneous multithreading
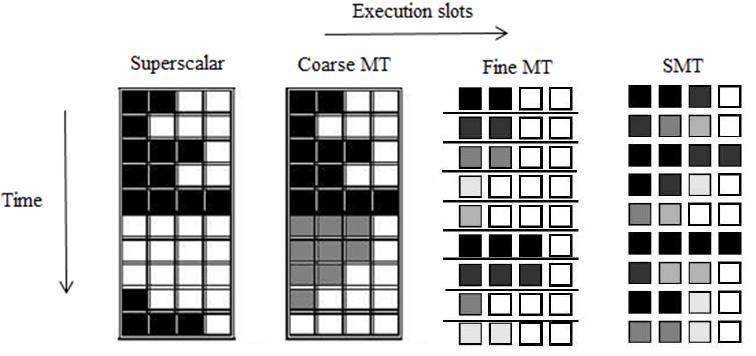
4 Fine-grained multithreading It switches between threads on each instruction, causing the execution of multiple threads to be interleaved. Round-robin fashion skipping any thread that are stalled at that time CPU must be able to switch threads on every clock cycle It can hide the throughput losses that arise from both short and long stalls, since instructions from other threads can be executed when one thread stalls It slows down the execution of the individual threads, since a thread that is ready to execute without stalls will be delayed by instructions from other threads
5 Coarse-grained multithreading Switches threads only on costly stalls, such as level two or three cache misses Relieves the need to have thread switching likely to slow the processor down, since the instructions form other threads will only be issued when a thread encounters a costly stall It is limited in its ability to overcome throughput losses, especially from shorter stalls There is a pipeline start up cost, because a CPU with CGM issues instruction form a single thread, when a stall occurs, the pipeline must be emptied. Next thread must fill the pipeline before instructions will be able to complete. More useful in reducing penalty of high cost stalls where pipeline fill is negligible compared to stall time
6 Simultaneous multithreading Simultaneous multithreading (SMT) is a variation on multithreading that uses the resources of a multiple issue, dynamically-scheduled processor to exploit TLP at the same time it exploits ILP. Modern multiple- issue processors often have more functional unit parallelism available than a single thread. With register renaming and dynamic scheduling, multiple instructions from independent threads can be issued without regard to the dependences among them; the resolution of the dependences can be handled by the dynamic scheduling capability.
7 Superscalar Processor Superscalar with no multithreading Superscalar with coarse-grained multithreading Superscalar with fine-grained multithreading Superscalar with Simultaneous multithreading
8
9 Multiprocessing Other than ILP, the only scalable and general purpose way to increase performance faster is through multiprocessing Increased importance of miultiprocessing Growing interest in high-end servers as cloud computing and software-as-a-service become more important Growth in data-intensive applications driven by the availability of massive amounts of data on the internet. Multiprocessors exploit thread level parallelism through two different software models Tightly coupled set of threads collaborating on a single task parallel processing Execution of multiple, relatively independent processes from one or more users request level parallelism such as database responding to queries multiprogramming

10 Multiprocessor Architecture multiple processors increase performance Flynn s proposed a simple model of categorizing all computers looked at the parallelism in the instruction and data streams and placed all the computers into one of the 4 categories: (Flynn s Taxonomy)
11 SISD uniprocessor SIMD The same instruction is executed by multiple processors using different data streams Exploit data level parallelism by applying the same operations to multiple items of data in parallel Each processor has its own data memory, but there is a single instruction memory and control processor, which fetches and dispatches the instruction The multimedia extension, vector architecture are the largest class of SIMD architectures. 11
12 MISD No commercial multiprocessor of this type has been built to date MIMD Each processor fetches its own instruction and operated on its own data They exploit TLP, bz. multiple threads operate in parallel In general, TLP is more flexible than DLP They offers flexibility. With the correct hardware and software, they can function as single user multiprocessors focusing on high performance for one application, as multi programmed multiprocessors running many tasks simultaneously, or as some combination of these functions. 12
13 With MIMD, each processor is executing its own instruction stream or process. A process is a segment of code that may be run independently The state of the process contains all the information necessary to execute that program on a processor It is also useful to be able to have multiple processors executing a single program and sharing the code and most of their address space When multiple process share code and data in this way, they are often called threads. To take advantage of an MIMD multiprocessors with n processors, we must have at least n threads or processes to execute. 13
14 The important qualitative distinction of TLP from ILP is that TLP is identified at a high level by the software system and that the threads consist of hundreds to millions of instructions that may be executed in parallel. Threads can also be used to exploit DLP, but with higher overhead The grain size (the amount of computation assigned to a thread) must be sufficiently large to exploit the parallelism efficiently. 14
15 MIMD MIMD multiprocessors fall into two classes, depending on the number of processors involved, which in turn dictates a memory organization and interconnect strategy Centralized shared memory architecture Small number of cores Share single memory with uniform memory latency Symmetric relationship to all processors uniform access time often called as Symmetric multiprocessors (SMPs) Distributed shared memory architecture Physically distributed memory Non-uniform memory access/latency (NUMA) Processors connected via direct (switched) and non-direct (multi-hop) interconnection networks

16 MIMD Centralized shared memory Distributed shared memory
17 Distributed shared memory Most of the access are to the local memory in the node Reduces latency for access to the memory Scales memory bandwidth
18 Models for communication and memory architecture A large multi processor must use multiple memories that are physically distributed with the processors There are two alternative architectural approaches that differ in the method used for communicating data among processors: Distributed shared-memory (DSM) architecture Communication occurs through a shared address space, as it does in a symmetric shared-memory architecture The physically separate memories can be addressed as one logically shared address space Memory reference can be made by any processor to any memory location Shared-memory refers to the shared address space The same physical address on two processors refers to the same location in memory Shared memory does not mean that there is a single centralized memory In contrast to symmetric shared memory multiprocessors which is also know as UMAs, the DSM multiprocessors are also known as NUMAs, since the access time depends on the location of a data word in memory
19 Centralized Shared-Memory Architectures Use of large, multilevel caches substantially reduce the memory bandwidth demands of a processor If memory bandwidth is reduced, multiple processors may be able to share the same memory Because of the small size of the processor and the significant reduction in bus bandwidth achieved by large caches, symmetric processors were extremely cost effective, provided that a sufficient amount of memory bandwidth existed. Symmetric shared-memory machines usually support the caching of both shared and private data
20 Private data are used by a single processor Shared data are used by multiple processors, essentially providing communication among the processors through reads and writes of the shared data When a private item is cached, its location is migrated to the cache, reducing the average access time as well as the memory bandwidth required (uniprocessor) When shared data are cached, the shared value may be replicated in multiple caches In addition to reduction in access latency and required memory band width, replication also provides a reduction in contention that may exist for shared data items that are being read by multiple processors simultaneously Caching of shared data introduces a new problem: cache coherence




21 Multiprocessor Cache Coherence Caching shared data introduces a new problem because the view of memory held by two different processors is through their individual caches, which with out any additional precautions, could end up seeing two different values cache coherence problem
22 Memory system is coherent if any read of a data item returns the most recently written value of that data item. Two different aspects of memory system Coherence, defines what values can be returned by a read Consistency, determines when a written value will be returned by a read
23 A memory system is coherent if: A read by a processor P to a location X that follows a write by P to X, with no writes of X by another processor occurring between the write and the read by P, always returns the value written by P. preserves program order A read by a processor to location X that follows a write by another processor to X return the written value if the read and write are sufficiently separated in time and no other writes to X occur between the two accesses. coherence Write to the same location are serialized, that is two writes to the same location by any two processors are seen in the same order by all processors. If the value 1 and 2 are written to a location, processors can never read the value of the location as 2 and then later read it as 1. serialization
24 Question of when a written value will be seen is also important The issue of exactly when a written value must be seen by a reader is defined by a memory consistency model Coherence and consistency are complementary Coherence defines the behavior of reads and writes to the same memory location, while consistency defines the behavior of reads and writes with respect to accesses to other memory locations Make following assumptions: A write does not complete until all processors have seen the effect of that write The processor does not change the order of any write w.r.t. any other memory access These assumptions means that if a processor write location A followed by B, any processor that sees the new value of B must also see the new value of A These restrictions allow the processor to reorder the reads, but forces the processor to finish a write in program order
25 Basic Schemes for Enforcing Coherence A program running on multi processors will have copies of the same data in several caches. In a coherent multi processor, the caches provide both migration and replication of shared data items. Coherent caches provides migration - data item can be moved to a local cache and used there in a transparent fashion, reducing both the latency and the BW demand on the shared data Coherent caches also provide replication for shared data that are being simultaneously read, since the caches make a copy of the data item in the local cache, reducing both latency and contention for a read shared data item. Supporting this migration and replication is critical to performance in accessing shared data Small scale multi processors adopt a hardware solution by introducing a protocol to maintain coherent caches
26 Basic Schemes for Enforcing Coherence The protocol to maintain coherence for multiple processors are called cache coherence protocols. Key to implementing a cache coherence protocol is tracking the state of any sharing of data block. There are two classes of protocols: Directory based - the sharing status of a block of physical memory is kept in just one location, called the directory Snooping - every cache that has a copy of the data from a block of physical memory also has a copy of the sharing status of the block, but no centralized status is kept. These caches are all accessible via some broadcast medium and all cache controllers monitor or snoop on the medium to determine whether or not they have a copy of a block that is requested on a bus Snooping Protocols Write invalidate protocol Write update or write broadcast protocol




27 Snooping Protocols Write invalidate Protocol to ensure that a processor has exclusive access to a data item before it writes that item because it invalidates other copies on a write. Exclusive access ensures that no other readable or writable copies of an item exist when the write occurs. All other cache copies of the item are invalidated.
28 Snooping Protocols Consider a write followed by a read by another processor: since the write requires exclusive access, any copy held by the reading processor must be invalidated. When the read occurs, it misses in the cache and is forced to fetch the new copy of the data For a write, prevent any other processor from being able to write simultaneously If two processors try to write the same data simultaneously, one of them will win, causing the other processor s copy to be invalidated. For the other processor to complete its write, it must obtain a new copy of the data, which must now contain the updated value. Therefore this protocol enforces write serialization
29 Snooping Protocols Write update or write broadcast protocol - update all the cached copies of a data item when that item is written. A write update protocol must broadcast all writes to shared cache lines, it consumes considerably more bandwidth. For this reason, all recent multiprocessors have opted to implement a write invalidate protocol.
30 Basic Implementation Techniques The key to implementing an invalidate protocol is the use of the bus, or another broadcast medium, to perform invalidates. To perform an invalidate, the processor acquires bus access and broadcasts the address to be invalidated on the bus The processors check whether the address on the bus is in their cache. If so, the corresponding data in the cache are invalidated When a write to a block that is shared occurs, the writing processor must acquire bus access to broadcast its invalidation If two processors attempt to write shared blocks at the same time, their attempts to broadcast an invalidate operation will be serialized when they arbitrate for the bus
31 The first processor to obtain bus access will cause any other copies of the block it is writing to be invalidated If the processors were attempting to write to the same block, the serialization enforced by the bus also serializes their writes All coherence schemes require some sort of serializing access to the communication medium or another shared structure In addition to invalidating outstanding copies of a cache block that is being written into, it is required to locate a data item when a cache miss occurs In a write-through cache, it is easy to find the recent value of the data item, since all written data are always sent to the memory, from which most recent value of data can be fetched. In a design with adequate memory bandwidth to support the write traffic, using write-through simplifies the implementation of cache coherence
32 For a write-back cache, finding the most recent value is harder, since the most recent value can be in a cache rather than in memory Write-back cache can use the same snooping scheme both for cache miss and for writes Each processor snoops every address placed on the bus If a processor finds that it has a dirty copy of the requested cache, it provides that cache block in response to the read request and causes the memory access to be aborted. The additional complexity comes from having to retrieve the cache block from the processor s cache, which often take longer time than retrieving form shared memory if the processor are in separate chips. Since write-back caches generate lower requirements for memory bandwidth, they support larger number of faster processors and used in most multiprocessors.
33 For a write-back cache, finding the most recent value is harder, since the most recent value can be in a cache rather than in memory Write-back cache can use the same snooping scheme both for cache miss and for writes Each processor snoops every address placed on the bus If a processor finds that it has a dirty copy of the requested cache, it provides that cache block in response to the read request and causes the memory access to be aborted. The additional complexity comes from having to retrieve the cache block from the processor s cache, which often take longer time than retrieving form shared memory if the processor are in separate chips. Since write-back caches generate lower requirements for memory bandwidth, they support larger number of faster processors and used in most multiprocessors.
Computer Systems Architecture
 Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 23 Mahadevan Gomathisankaran April 27, 2010 04/27/2010 Lecture 23 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture
 Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Computer Systems Architecture Lecture 24 Mahadevan Gomathisankaran April 29, 2010 04/29/2010 Lecture 24 CSCE 4610/5610 1 Reminder ABET Feedback: http://www.cse.unt.edu/exitsurvey.cgi?csce+4610+001 Student
Multiple Issue and Static Scheduling. Multiple Issue. MSc Informatics Eng. Beyond Instruction-Level Parallelism
 Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Computing Systems & Performance Beyond Instruction-Level Parallelism MSc Informatics Eng. 2012/13 A.J.Proença From ILP to Multithreading and Shared Cache (most slides are borrowed) When exploiting ILP,
Handout 3 Multiprocessor and thread level parallelism
 Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
Handout 3 Multiprocessor and thread level parallelism Outline Review MP Motivation SISD v SIMD (SIMT) v MIMD Centralized vs Distributed Memory MESI and Directory Cache Coherency Synchronization and Relaxed
MULTIPROCESSORS AND THREAD LEVEL PARALLELISM
 UNIT III MULTIPROCESSORS AND THREAD LEVEL PARALLELISM 1. Symmetric Shared Memory Architectures: The Symmetric Shared Memory Architecture consists of several processors with a single physical memory shared
UNIT III MULTIPROCESSORS AND THREAD LEVEL PARALLELISM 1. Symmetric Shared Memory Architectures: The Symmetric Shared Memory Architecture consists of several processors with a single physical memory shared
Chap. 4 Multiprocessors and Thread-Level Parallelism
 Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Chap. 4 Multiprocessors and Thread-Level Parallelism Uniprocessor performance Performance (vs. VAX-11/780) 10000 1000 100 10 From Hennessy and Patterson, Computer Architecture: A Quantitative Approach,
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Multiprocessors & Thread Level Parallelism
 Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Multiprocessors & Thread Level Parallelism COE 403 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Introduction
Parallel Processing SIMD, Vector and GPU s cont.
 Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Parallel Processing SIMD, Vector and GPU s cont. EECS4201 Fall 2016 York University 1 Multithreading First, we start with multithreading Multithreading is used in GPU s 2 1 Thread Level Parallelism ILP
Computer and Information Sciences College / Computer Science Department CS 207 D. Computer Architecture. Lecture 9: Multiprocessors
 Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Computer and Information Sciences College / Computer Science Department CS 207 D Computer Architecture Lecture 9: Multiprocessors Challenges of Parallel Processing First challenge is % of program inherently
Multiprocessor Cache Coherence. Chapter 5. Memory System is Coherent If... From ILP to TLP. Enforcing Cache Coherence. Multiprocessor Types
 Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
Chapter 5 Multiprocessor Cache Coherence Thread-Level Parallelism 1: read 2: read 3: write??? 1 4 From ILP to TLP Memory System is Coherent If... ILP became inefficient in terms of Power consumption Silicon
MULTIPROCESSORS AND THREAD-LEVEL. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM. B649 Parallel Architectures and Programming
 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM B649 Parallel Architectures and Programming Motivation behind Multiprocessors Limitations of ILP (as already discussed) Growing interest in servers and server-performance
10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems
 1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
1 License: http://creativecommons.org/licenses/by-nc-nd/3.0/ 10 Parallel Organizations: Multiprocessor / Multicore / Multicomputer Systems To enhance system performance and, in some cases, to increase
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM (PART 1)
") 1 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM (PART 1) Chapter 5 Appendix F Appendix I OUTLINE Introduction (5.1) Multiprocessor Architecture Challenges in Parallel Processing Centralized Shared Memory
1 MULTIPROCESSORS AND THREAD-LEVEL PARALLELISM (PART 1) Chapter 5 Appendix F Appendix I OUTLINE Introduction (5.1) Multiprocessor Architecture Challenges in Parallel Processing Centralized Shared Memory
Shared Symmetric Memory Systems
 Shared Symmetric Memory Systems Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
Shared Symmetric Memory Systems Computer Architecture J. Daniel García Sánchez (coordinator) David Expósito Singh Francisco Javier García Blas ARCOS Group Computer Science and Engineering Department University
THREAD LEVEL PARALLELISM
 THREAD LEVEL PARALLELISM Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 4 is due on Dec. 11 th This lecture
THREAD LEVEL PARALLELISM Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 4 is due on Dec. 11 th This lecture
Computer parallelism Flynn s categories
 04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
04 Multi-processors 04.01-04.02 Taxonomy and communication Parallelism Taxonomy Communication alessandro bogliolo isti information science and technology institute 1/9 Computer parallelism Flynn s categories
Parallel Processing. Computer Architecture. Computer Architecture. Outline. Multiple Processor Organization
 Computer Architecture Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Parallel Processing http://www.yildiz.edu.tr/~naydin 1 2 Outline Multiple Processor
Computer Architecture Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Parallel Processing http://www.yildiz.edu.tr/~naydin 1 2 Outline Multiple Processor
Chapter-4 Multiprocessors and Thread-Level Parallelism
 Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
Chapter-4 Multiprocessors and Thread-Level Parallelism We have seen the renewed interest in developing multiprocessors in early 2000: - The slowdown in uniprocessor performance due to the diminishing returns
 Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Exploring different level of parallelism Instruction-level parallelism (ILP): how many of the operations/instructions in a computer program can be performed simultaneously 1. e = a + b 2. f = c + d 3.
Multiprocessors. Flynn Taxonomy. Classifying Multiprocessors. why would you want a multiprocessor? more is better? Cache Cache Cache.
 Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
Multiprocessors why would you want a multiprocessor? Multiprocessors and Multithreading more is better? Cache Cache Cache Classifying Multiprocessors Flynn Taxonomy Flynn Taxonomy Interconnection Network
EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor
 EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration I/O MultiProcessor Summary 2 Virtual memory benifits Using physical memory efficiently
EITF20: Computer Architecture Part 5.2.1: IO and MultiProcessor Liang Liu liang.liu@eit.lth.se 1 Outline Reiteration I/O MultiProcessor Summary 2 Virtual memory benifits Using physical memory efficiently
Multiprocessors 1. Outline
 Multiprocessors 1 Outline Multiprocessing Coherence Write Consistency Snooping Building Blocks Snooping protocols and examples Coherence traffic and performance on MP Directory-based protocols and examples
Multiprocessors 1 Outline Multiprocessing Coherence Write Consistency Snooping Building Blocks Snooping protocols and examples Coherence traffic and performance on MP Directory-based protocols and examples
Multi-Processor / Parallel Processing
 Parallel Processing: Multi-Processor / Parallel Processing Originally, the computer has been viewed as a sequential machine. Most computer programming languages require the programmer to specify algorithms
Parallel Processing: Multi-Processor / Parallel Processing Originally, the computer has been viewed as a sequential machine. Most computer programming languages require the programmer to specify algorithms
TDT Coarse-Grained Multithreading. Review on ILP. Multi-threaded execution. Contents. Fine-Grained Multithreading
 Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
Review on ILP TDT 4260 Chap 5 TLP & Hierarchy What is ILP? Let the compiler find the ILP Advantages? Disadvantages? Let the HW find the ILP Advantages? Disadvantages? Contents Multi-threading Chap 3.5
WHY PARALLEL PROCESSING? (CE-401)
") PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
PARALLEL PROCESSING (CE-401) COURSE INFORMATION 2 + 1 credits (60 marks theory, 40 marks lab) Labs introduced for second time in PP history of SSUET Theory marks breakup: Midterm Exam: 15 marks Assignment:
Page 1. Instruction-Level Parallelism (ILP) CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism
 CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism") CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism Michela Taufer Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
CISC 662 Graduate Computer Architecture Lectures 16 and 17 - Multiprocessors and Thread-Level Parallelism Michela Taufer Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer Architecture,
Lecture 30: Multiprocessors Flynn Categories, Large vs. Small Scale, Cache Coherency Professor Randy H. Katz Computer Science 252 Spring 1996
 Lecture 30: Multiprocessors Flynn Categories, Large vs. Small Scale, Cache Coherency Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Flynn Categories SISD (Single Instruction Single
Lecture 30: Multiprocessors Flynn Categories, Large vs. Small Scale, Cache Coherency Professor Randy H. Katz Computer Science 252 Spring 1996 RHK.S96 1 Flynn Categories SISD (Single Instruction Single
COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence
 1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
1 COEN-4730 Computer Architecture Lecture 08 Thread Level Parallelism and Coherence Cristinel Ababei Dept. of Electrical and Computer Engineering Marquette University Credits: Slides adapted from presentations
Chapter 8. Multiprocessors. In-Cheol Park Dept. of EE, KAIST
 Chapter 8. Multiprocessors In-Cheol Park Dept. of EE, KAIST Can the rapid rate of uniprocessor performance growth be sustained indefinitely? If the pace does slow down, multiprocessor architectures will
Chapter 8. Multiprocessors In-Cheol Park Dept. of EE, KAIST Can the rapid rate of uniprocessor performance growth be sustained indefinitely? If the pace does slow down, multiprocessor architectures will
COSC4201 Multiprocessors
 COSC4201 Multiprocessors Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Multiprocessing We are dedicating all of our future product development to multicore
COSC4201 Multiprocessors Prof. Mokhtar Aboelaze Parts of these slides are taken from Notes by Prof. David Patterson (UCB) Multiprocessing We are dedicating all of our future product development to multicore
CS 590: High Performance Computing. Parallel Computer Architectures. Lab 1 Starts Today. Already posted on Canvas (under Assignment) Let s look at it
 Let s look at it") Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Lab 1 Starts Today Already posted on Canvas (under Assignment) Let s look at it CS 590: High Performance Computing Parallel Computer Architectures Fengguang Song Department of Computer Science IUPUI 1
Multiprocessing and Scalability. A.R. Hurson Computer Science and Engineering The Pennsylvania State University
 A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
A.R. Hurson Computer Science and Engineering The Pennsylvania State University 1 Large-scale multiprocessor systems have long held the promise of substantially higher performance than traditional uniprocessor
COSC 6385 Computer Architecture - Thread Level Parallelism (I)
") COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
COSC 6385 Computer Architecture - Thread Level Parallelism (I) Edgar Gabriel Spring 2014 Long-term trend on the number of transistor per integrated circuit Number of transistors double every ~18 month
Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Non-uniform memory access machine or (NUMA) is a system where the memory access time to any region of memory is not the same for all processors.
 is a system where the memory access time to any region of memory is not the same for all processors.") CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
CS 320 Ch. 17 Parallel Processing Multiple Processor Organization The author makes the statement: "Processors execute programs by executing machine instructions in a sequence one at a time." He also says
Computer Architecture. A Quantitative Approach, Fifth Edition. Chapter 5. Multiprocessors and Thread-Level Parallelism
 Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Computer Architecture A Quantitative Approach, Fifth Edition Chapter 5 Multiprocessors and Thread-Level Parallelism 1 Introduction Thread-Level parallelism Have multiple program counters Uses MIMD model
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano
 Prof. Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Introduction to Multiprocessors (Part I) Prof. Cristina Silvano Politecnico di Milano Outline Key issues to design multiprocessors Interconnection network Centralized shared-memory architectures Distributed
Multiprocessors and Locking
 Types of Multiprocessors (MPs) Uniform memory-access (UMA) MP Access to all memory occurs at the same speed for all processors. Multiprocessors and Locking COMP9242 2008/S2 Week 12 Part 1 Non-uniform memory-access
Types of Multiprocessors (MPs) Uniform memory-access (UMA) MP Access to all memory occurs at the same speed for all processors. Multiprocessors and Locking COMP9242 2008/S2 Week 12 Part 1 Non-uniform memory-access
Course II Parallel Computer Architecture. Week 2-3 by Dr. Putu Harry Gunawan
 Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Course II Parallel Computer Architecture Week 2-3 by Dr. Putu Harry Gunawan www.phg-simulation-laboratory.com Review Review Review Review Review Review Review Review Review Review Review Review Processor
Module 18: "TLP on Chip: HT/SMT and CMP" Lecture 39: "Simultaneous Multithreading and Chip-multiprocessing" TLP on Chip: HT/SMT and CMP SMT
 TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
TLP on Chip: HT/SMT and CMP SMT Multi-threading Problems of SMT CMP Why CMP? Moore s law Power consumption? Clustered arch. ABCs of CMP Shared cache design Hierarchical MP file:///e /parallel_com_arch/lecture39/39_1.htm[6/13/2012
UNIT I (Two Marks Questions & Answers)
") UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
UNIT I (Two Marks Questions & Answers) Discuss the different ways how instruction set architecture can be classified? Stack Architecture,Accumulator Architecture, Register-Memory Architecture,Register-
Parallel Processors. The dream of computer architects since 1950s: replicate processors to add performance vs. design a faster processor
 Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Multiprocessing Parallel Computers Definition: A parallel computer is a collection of processing elements that cooperate and communicate to solve large problems fast. Almasi and Gottlieb, Highly Parallel
Lecture-13 (ROB and Multi-threading) CS422-Spring
 CS422-Spring") Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
Lecture-13 (ROB and Multi-threading) CS422-Spring 2018 Biswa@CSE-IITK Cycle 62 (Scoreboard) vs 57 in Tomasulo Instruction status: Read Exec Write Exec Write Instruction j k Issue Oper Comp Result Issue
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 11
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 11
Flynn s Classification
 Flynn s Classification SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data) No machine is built yet for this type SIMD (Single Instruction Multiple Data) Examples:
Flynn s Classification SISD (Single Instruction Single Data) Uniprocessors MISD (Multiple Instruction Single Data) No machine is built yet for this type SIMD (Single Instruction Multiple Data) Examples:
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING UNIT-1
 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III/VI Section : CSE-1 & CSE-2 Subject Code : CS2354 Subject Name : Advanced Computer Architecture Degree & Branch : B.E C.S.E. UNIT-1 1.
Parallel Computers. CPE 631 Session 20: Multiprocessors. Flynn s Tahonomy (1972) Why Multiprocessors?
 Why Multiprocessors?") Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Parallel Computers CPE 63 Session 20: Multiprocessors Department of Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection of processing
Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano
 Cristina Silvano Politecnico di Milano") Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano Outline The problem of cache coherence Snooping protocols Directory-based protocols Prof. Cristina Silvano, Politecnico
Introduction to Multiprocessors (Part II) Cristina Silvano Politecnico di Milano Outline The problem of cache coherence Snooping protocols Directory-based protocols Prof. Cristina Silvano, Politecnico
SMD149 - Operating Systems - Multiprocessing
 SMD149 - Operating Systems - Multiprocessing Roland Parviainen December 1, 2005 1 / 55 Overview Introduction Multiprocessor systems Multiprocessor, operating system and memory organizations 2 / 55 Introduction
SMD149 - Operating Systems - Multiprocessing Roland Parviainen December 1, 2005 1 / 55 Overview Introduction Multiprocessor systems Multiprocessor, operating system and memory organizations 2 / 55 Introduction
Overview. SMD149 - Operating Systems - Multiprocessing. Multiprocessing architecture. Introduction SISD. Flynn s taxonomy
 Overview SMD149 - Operating Systems - Multiprocessing Roland Parviainen Multiprocessor systems Multiprocessor, operating system and memory organizations December 1, 2005 1/55 2/55 Multiprocessor system
Overview SMD149 - Operating Systems - Multiprocessing Roland Parviainen Multiprocessor systems Multiprocessor, operating system and memory organizations December 1, 2005 1/55 2/55 Multiprocessor system
Online Course Evaluation. What we will do in the last week?
 Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Online Course Evaluation Please fill in the online form The link will expire on April 30 (next Monday) So far 10 students have filled in the online form Thank you if you completed it. 1 What we will do
Chapter Seven. Idea: create powerful computers by connecting many smaller ones
 Chapter Seven Multiprocessors Idea: create powerful computers by connecting many smaller ones good news: works for timesharing (better than supercomputer) vector processing may be coming back bad news:
Chapter Seven Multiprocessors Idea: create powerful computers by connecting many smaller ones good news: works for timesharing (better than supercomputer) vector processing may be coming back bad news:
Lecture 26: Parallel Processing. Spring 2018 Jason Tang
 Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
Lecture 26: Parallel Processing Spring 2018 Jason Tang 1 Topics Static multiple issue pipelines Dynamic multiple issue pipelines Hardware multithreading 2 Taxonomy of Parallel Architectures Flynn categories:
Hardware-Based Speculation
 Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
Hardware-Based Speculation Execute instructions along predicted execution paths but only commit the results if prediction was correct Instruction commit: allowing an instruction to update the register
COSC4201. Multiprocessors and Thread Level Parallelism. Prof. Mokhtar Aboelaze York University
 COSC4201 Multiprocessors and Thread Level Parallelism Prof. Mokhtar Aboelaze York University COSC 4201 1 Introduction Why multiprocessor The turning away from the conventional organization came in the
COSC4201 Multiprocessors and Thread Level Parallelism Prof. Mokhtar Aboelaze York University COSC 4201 1 Introduction Why multiprocessor The turning away from the conventional organization came in the
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading)
") CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
CMSC 411 Computer Systems Architecture Lecture 13 Instruction Level Parallelism 6 (Limits to ILP & Threading) Limits to ILP Conflicting studies of amount of ILP Benchmarks» vectorized Fortran FP vs. integer
Multithreading: Exploiting Thread-Level Parallelism within a Processor
 Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Multithreading: Exploiting Thread-Level Parallelism within a Processor Instruction-Level Parallelism (ILP): What we ve seen so far Wrap-up on multiple issue machines Beyond ILP Multithreading Advanced
Computer Science 146. Computer Architecture
 Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Computer Architecture Spring 24 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture 2: More Multiprocessors Computation Taxonomy SISD SIMD MISD MIMD ILP Vectors, MM-ISAs Shared Memory
Lecture 24: Virtual Memory, Multiprocessors
 Lecture 24: Virtual Memory, Multiprocessors Today s topics: Virtual memory Multiprocessors, cache coherence 1 Virtual Memory Processes deal with virtual memory they have the illusion that a very large
Lecture 24: Virtual Memory, Multiprocessors Today s topics: Virtual memory Multiprocessors, cache coherence 1 Virtual Memory Processes deal with virtual memory they have the illusion that a very large
CISC 662 Graduate Computer Architecture Lectures 15 and 16 - Multiprocessors and Thread-Level Parallelism
 CISC 662 Graduate Computer Architecture Lectures 15 and 16 - Multiprocessors and Thread-Level Parallelism Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from
CISC 662 Graduate Computer Architecture Lectures 15 and 16 - Multiprocessors and Thread-Level Parallelism Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from
ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols CA SMP and cache coherence
 Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
Computer Architecture ESE 545 Computer Architecture Symmetric Multiprocessors and Snoopy Cache Coherence Protocols 1 Shared Memory Multiprocessor Memory Bus P 1 Snoopy Cache Physical Memory P 2 Snoopy
Outline EEL 5764 Graduate Computer Architecture. Chapter 3 Limits to ILP and Simultaneous Multithreading. Overcoming Limits - What do we need??
 Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
Outline EEL 7 Graduate Computer Architecture Chapter 3 Limits to ILP and Simultaneous Multithreading! Limits to ILP! Thread Level Parallelism! Multithreading! Simultaneous Multithreading Ann Gordon-Ross
COSC 6385 Computer Architecture - Multi Processor Systems
 COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
COSC 6385 Computer Architecture - Multi Processor Systems Fall 2006 Classification of Parallel Architectures Flynn s Taxonomy SISD: Single instruction single data Classical von Neumann architecture SIMD:
3/13/2008 Csci 211 Lecture %/year. Manufacturer/Year. Processors/chip Threads/Processor. Threads/chip 3/13/2008 Csci 211 Lecture 8 4
 Outline CSCI Computer System Architecture Lec 8 Multiprocessor Introduction Xiuzhen Cheng Department of Computer Sciences The George Washington University MP Motivation SISD v. SIMD v. MIMD Centralized
Outline CSCI Computer System Architecture Lec 8 Multiprocessor Introduction Xiuzhen Cheng Department of Computer Sciences The George Washington University MP Motivation SISD v. SIMD v. MIMD Centralized
Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol
 Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu
Lecture 23: Thread Level Parallelism -- Introduction, SMP and Snooping Cache Coherence Protocol CSE 564 Computer Architecture Summer 2017 Department of Computer Science and Engineering Yonghong Yan yan@oakland.edu
18-447: Computer Architecture Lecture 30B: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013
 18-447: Computer Architecture Lecture 30B: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013 Readings: Multiprocessing Required Amdahl, Validity of the single processor
18-447: Computer Architecture Lecture 30B: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2013, 4/22/2013 Readings: Multiprocessing Required Amdahl, Validity of the single processor
Computing architectures Part 2 TMA4280 Introduction to Supercomputing
 Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Computing architectures Part 2 TMA4280 Introduction to Supercomputing NTNU, IMF January 16. 2017 1 Supercomputing What is the motivation for Supercomputing? Solve complex problems fast and accurately:
Introduction to parallel computers and parallel programming. Introduction to parallel computersand parallel programming p. 1
 Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Introduction to parallel computers and parallel programming Introduction to parallel computersand parallel programming p. 1 Content A quick overview of morden parallel hardware Parallelism within a chip
Advanced Topics in Computer Architecture
 Advanced Topics in Computer Architecture Lecture 5 Multiprocessors and Thread-Level Parallelism Marenglen Biba Department of Computer Science University of New York Tirana Outline Introduction Symmetric
Advanced Topics in Computer Architecture Lecture 5 Multiprocessors and Thread-Level Parallelism Marenglen Biba Department of Computer Science University of New York Tirana Outline Introduction Symmetric
! Readings! ! Room-level, on-chip! vs.!
 1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
1! 2! Suggested Readings!! Readings!! H&P: Chapter 7 especially 7.1-7.8!! (Over next 2 weeks)!! Introduction to Parallel Computing!! https://computing.llnl.gov/tutorials/parallel_comp/!! POSIX Threads
Parallel Architectures
 Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
Parallel Architectures Part 1: The rise of parallel machines Intel Core i7 4 CPU cores 2 hardware thread per core (8 cores ) Lab Cluster Intel Xeon 4/10/16/18 CPU cores 2 hardware thread per core (8/20/32/36
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP
 CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 13 - Limits of ILP Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture Notes from John Hennessy and David Patterson s: Computer
CSCI 4717 Computer Architecture
 CSCI 4717/5717 Computer Architecture Topic: Symmetric Multiprocessors & Clusters Reading: Stallings, Sections 18.1 through 18.4 Classifications of Parallel Processing M. Flynn classified types of parallel
CSCI 4717/5717 Computer Architecture Topic: Symmetric Multiprocessors & Clusters Reading: Stallings, Sections 18.1 through 18.4 Classifications of Parallel Processing M. Flynn classified types of parallel
Aleksandar Milenkovich 1
 Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
Parallel Computers Lecture 8: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Definition: A parallel computer is a collection
Computer Architecture Lecture 27: Multiprocessors. Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015
 18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
18-447 Computer Architecture Lecture 27: Multiprocessors Prof. Onur Mutlu Carnegie Mellon University Spring 2015, 4/6/2015 Assignments Lab 7 out Due April 17 HW 6 Due Friday (April 10) Midterm II April
Serial. Parallel. CIT 668: System Architecture 2/14/2011. Topics. Serial and Parallel Computation. Parallel Computing
 CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
CIT 668: System Architecture Parallel Computing Topics 1. What is Parallel Computing? 2. Why use Parallel Computing? 3. Types of Parallelism 4. Amdahl s Law 5. Flynn s Taxonomy of Parallel Computers 6.
Thread- Level Parallelism. ECE 154B Dmitri Strukov
 Thread- Level Parallelism ECE 154B Dmitri Strukov Introduc?on Thread- Level parallelism Have mul?ple program counters and resources Uses MIMD model Targeted for?ghtly- coupled shared- memory mul?processors
Thread- Level Parallelism ECE 154B Dmitri Strukov Introduc?on Thread- Level parallelism Have mul?ple program counters and resources Uses MIMD model Targeted for?ghtly- coupled shared- memory mul?processors
Computer Organization. Chapter 16
 William Stallings Computer Organization and Architecture t Chapter 16 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data
William Stallings Computer Organization and Architecture t Chapter 16 Parallel Processing Multiple Processor Organization Single instruction, single data stream - SISD Single instruction, multiple data
Module 5 Introduction to Parallel Processing Systems
 Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Module 5 Introduction to Parallel Processing Systems 1. What is the difference between pipelining and parallelism? In general, parallelism is simply multiple operations being done at the same time.this
Lecture Topics. Announcements. Today: Advanced Scheduling (Stallings, chapter ) Next: Deadlock (Stallings, chapter
 Next: Deadlock (Stallings, chapter") Lecture Topics Today: Advanced Scheduling (Stallings, chapter 10.1-10.4) Next: Deadlock (Stallings, chapter 6.1-6.6) 1 Announcements Exam #2 returned today Self-Study Exercise #10 Project #8 (due 11/16)
Lecture Topics Today: Advanced Scheduling (Stallings, chapter 10.1-10.4) Next: Deadlock (Stallings, chapter 6.1-6.6) 1 Announcements Exam #2 returned today Self-Study Exercise #10 Project #8 (due 11/16)
Introduction II. Overview
 Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Introduction II Overview Today we will introduce multicore hardware (we will introduce many-core hardware prior to learning OpenCL) We will also consider the relationship between computer hardware and
Lecture 25: Board Notes: Threads and GPUs
 Lecture 25: Board Notes: Threads and GPUs Announcements: - Reminder: HW 7 due today - Reminder: Submit project idea via (plain text) email by 11/24 Recap: - Slide 4: Lecture 23: Introduction to Parallel
Lecture 25: Board Notes: Threads and GPUs Announcements: - Reminder: HW 7 due today - Reminder: Submit project idea via (plain text) email by 11/24 Recap: - Slide 4: Lecture 23: Introduction to Parallel
CS425 Computer Systems Architecture
 CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
CS425 Computer Systems Architecture Fall 2017 Thread Level Parallelism (TLP) CS425 - Vassilis Papaefstathiou 1 Multiple Issue CPI = CPI IDEAL + Stalls STRUC + Stalls RAW + Stalls WAR + Stalls WAW + Stalls
06-Dec-17. Credits:4. Notes by Pritee Parwekar,ANITS 06-Dec-17 1
 Credits:4 1 Understand the Distributed Systems and the challenges involved in Design of the Distributed Systems. Understand how communication is created and synchronized in Distributed systems Design and
Credits:4 1 Understand the Distributed Systems and the challenges involved in Design of the Distributed Systems. Understand how communication is created and synchronized in Distributed systems Design and
Comp. Org II, Spring
 Lecture 11 Parallel Processor Architectures Flynn s taxonomy from 1972 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing (Sta09 Fig 17.1) 2 Parallel
Lecture 11 Parallel Processor Architectures Flynn s taxonomy from 1972 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing (Sta09 Fig 17.1) 2 Parallel
Parallel Computing: Parallel Architectures Jin, Hai
 Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Parallel Computing: Parallel Architectures Jin, Hai School of Computer Science and Technology Huazhong University of Science and Technology Peripherals Computer Central Processing Unit Main Memory Computer
Computer Architecture Spring 2016
 Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Computer Architecture Spring 2016 Lecture 19: Multiprocessing Shuai Wang Department of Computer Science and Technology Nanjing University [Slides adapted from CSE 502 Stony Brook University] Getting More
Multiprocessor Cache Coherency. What is Cache Coherence?
 Multiprocessor Cache Coherency CS448 1 What is Cache Coherence? Two processors can have two different values for the same memory location 2 1 Terminology Coherence Defines what values can be returned by
Multiprocessor Cache Coherency CS448 1 What is Cache Coherence? Two processors can have two different values for the same memory location 2 1 Terminology Coherence Defines what values can be returned by
Parallel Processing & Multicore computers
 Lecture 11 Parallel Processing & Multicore computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1)
Lecture 11 Parallel Processing & Multicore computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1)
Issues in Multiprocessors
 Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores message passing explicit sends & receives Which execution model control parallel
Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores message passing explicit sends & receives Which execution model control parallel
Aleksandar Milenkovic, Electrical and Computer Engineering University of Alabama in Huntsville
 Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
Lecture 18: Multiprocessors Aleksandar Milenkovic, milenka@ece.uah.edu Electrical and Computer Engineering University of Alabama in Huntsville Parallel Computers Definition: A parallel computer is a collection
1. Memory technology & Hierarchy
 1. Memory technology & Hierarchy Back to caching... Advances in Computer Architecture Andy D. Pimentel Caches in a multi-processor context Dealing with concurrent updates Multiprocessor architecture In
1. Memory technology & Hierarchy Back to caching... Advances in Computer Architecture Andy D. Pimentel Caches in a multi-processor context Dealing with concurrent updates Multiprocessor architecture In
Lecture 18: Coherence Protocols. Topics: coherence protocols for symmetric and distributed shared-memory multiprocessors (Sections
 Lecture 18: Coherence Protocols Topics: coherence protocols for symmetric and distributed shared-memory multiprocessors (Sections 4.2-4.4) 1 SMP/UMA/Centralized Memory Multiprocessor Main Memory I/O System
Lecture 18: Coherence Protocols Topics: coherence protocols for symmetric and distributed shared-memory multiprocessors (Sections 4.2-4.4) 1 SMP/UMA/Centralized Memory Multiprocessor Main Memory I/O System
Comp. Org II, Spring
 Lecture 11 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1) Computer
Lecture 11 Parallel Processing & computers 8th edition: Ch 17 & 18 Earlier editions contain only Parallel Processing Parallel Processor Architectures Flynn s taxonomy from 1972 (Sta09 Fig 17.1) Computer
Lecture 9: MIMD Architecture
 Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Lecture 9: MIMD Architecture Introduction and classification Symmetric multiprocessors NUMA architecture Cluster machines Zebo Peng, IDA, LiTH 1 Introduction MIMD: a set of general purpose processors is
Issues in Multiprocessors
 Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores SPARCCenter, SGI Challenge, Cray T3D, Convex Exemplar, KSR-1&2, today s CMPs message
Issues in Multiprocessors Which programming model for interprocessor communication shared memory regular loads & stores SPARCCenter, SGI Challenge, Cray T3D, Convex Exemplar, KSR-1&2, today s CMPs message
Lecture 7: Parallel Processing
 Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction
Lecture 7: Parallel Processing Introduction and motivation Architecture classification Performance evaluation Interconnection network Zebo Peng, IDA, LiTH 1 Performance Improvement Reduction of instruction