Best practices in the design, creation and dissemination of speech corpora at The Language Archive
|
|
|
- Myra Reed
- 5 years ago
- Views:
Transcription


1 LREC Workshop Istanbul Best practices in the design, creation and dissemination of speech corpora at The Language Archive Sebastian Drude, Daan Broeder, Peter Wittenburg, Han Sloetjes The Language Archive Max Planck Institute for Psycholinguistics Nijmegen, The Netherlands
2 BEST PRACTICES AT TLA TOPICS 1. Introduction 2. Corpus Design and Curation 3. Annotation (including Transcription) 4. Metadata & Data Management 5. Data Preservation and Dissemination 6. Legal and Ethical Issues
3 BEST PRACTICES AT TLA TOPICS 1. Introduction 2. Corpus Design and Curation 3. Annotation (including Transcription) 4. Metadata & Data Management 5. Data Preservation and Dissemination 6. Legal and Ethical Issues
4 Introduction The Language Archive: New unit at MPI-PL (NL) Technical aspects (less: content, corpus design) Long-term developments (>15y) TLA Data mostly from two research fields: Language acquisition (CHAT / CHILDES) Focus here: Linguistic fieldwork & Language Documentation (esp. DOBES) TLA: Archive, Lang. Archiving Software ( LAT ) Annotation tool ELAN
5 BEST PRACTICES AT TLA TOPICS 1. Introduction 2. Corpus Design and Curation 3. Annotation (including Transcription) 4. Metadata & Data Management 5. Data Preservation and Dissemination 6. Legal and Ethical Issues
6 Corpus Design and Curation Static vs. growing corpora Static corpora at TLA: Corpus Spoken Dutch (CGN) (COREX) Dutch Bilingualism Database (DBD) Dynamic corpora at TLA ( living archive) : Documentation of Endangered Languages (DOBES) Different teams, goals, methods, standards Challenge: achieve (semantic) interoperability
7 Corpus Design and Curation (DOBES corpora, continued) Multi-purpose by design Often the major/only source of data for a lang. Also for other scientific disciplines: anthropology, ethnomusicology, -botany, -history,... Basis for extensive description (grammar), and for typological studies Details of the analysis may improve over time > evolving annotation
8 BEST PRACTICES AT TLA TOPICS 1. Introduction 2. Corpus Design and Curation 3. Annotation (including Transcription) 4. Metadata & Data Management 5. Data Preservation and Dissemination 6. Legal and Ethical Issues
9 Annotation (Linguistic) primary data are direct representations or results of a speech event, for instance a written text or, in particular, an audio/video recording of a speech event (Linguistic) annotation of data is any systematic symbolic representation of properties of the (speech) event represented in the primary data or of earlier annotation Transcription is (basic) annotation
10 Annotation Technical data format for annotated speech in audio and video recordings: ELAN A.F. (XML) > deeper analysis of sign language > paralinguistic phenomena such as gestures Unlimited number of tiers (for any speaker) Hierarchical relations between tiers DOBES corpora: no agreed format or naming for the types of linguistic levels / annotation layers Challenge for comparisons & interoperability
11 Annotation Basic annotation: A transcription & at least one translation, optionally notes or comments Basic glossing: basic annotation & information on individual units (morphs / words), typically: an individual gloss (meaning or function), perhaps also categorical information (POS tag) Standardized by the Leipzig Glossing Rules Interlinear glosses often with Toolbox program (semi-automatic, lexicon string-matching)

12 ANNEX with ELAN annotation
13 Annotation Abbreviations for abstract functional units vary ISOcat: Data category registry (concepts) hosted at and developed by TLA ELAN tiers and annotations can refer to ISOcat Reference to shared general concepts, or to concepts related with the RELcat registry Advanced glossings include additional other levels, e.g. intonation, syntactic structure, grammatical relations, DOBES GRAID annotation
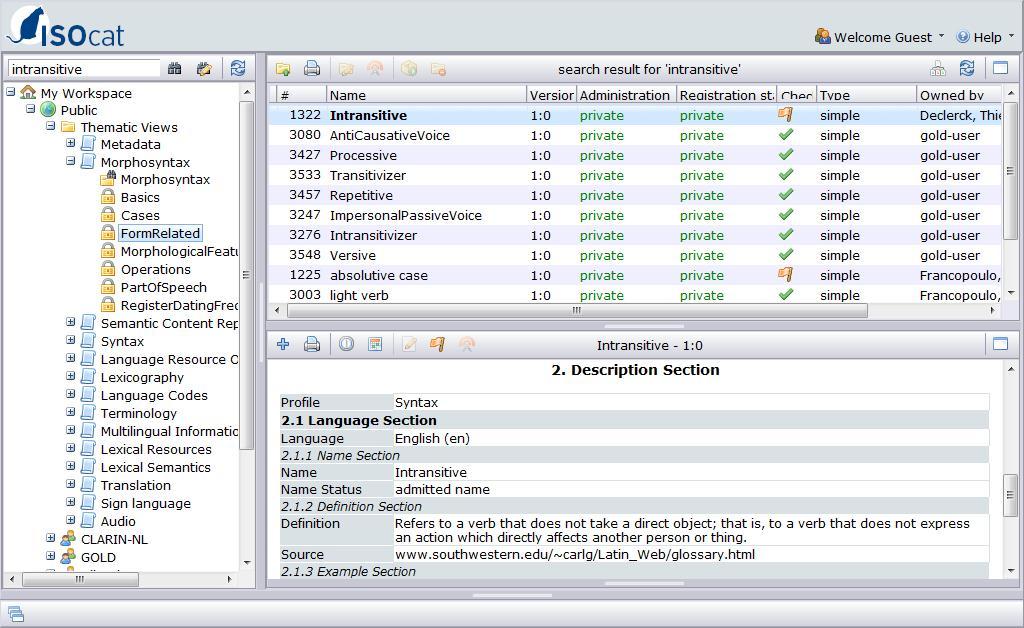
14 ISOcat
15 BEST PRACTICES AT TLA TOPICS 1. Introduction 2. Corpus Design and Curation 3. Annotation (including Transcription) 4. Metadata & Data Management 5. Data Preservation and Dissemination 6. Legal and Ethical Issues
16 Metadata & Data Management Speech data archiving : long-term availability IMDI, an XML-based metadata standard Metadata in separate XML files describe bundles of resources (multimedia & annotation files etc.) Persistent identifiers (handles) point to data f. A virtual hierarchy of sessions > a tree-like structure with sub-corpus IMDI files as nodes resources & metadata stored as separate files IMDI browser (standalone & online / web-based)

17 IMDI-Browser
18 Metadata & Data Management LAMUS, AMS (online tools) upload and integrate sessions and manage the data in online archive TLA involved in European infrastructure project CLARIN (cooperation with DARIAH) Transfer to CLARIN CMDI component metadata ARBIL for creating and editing CMDI metadata Basis for a general virtual research environment for data management in CLARIN and beyond
19 BEST PRACTICES AT TLA TOPICS 1. Introduction 2. Corpus Design and Curation 3. Annotation (including Transcription) 4. Metadata & Data Management 5. Data Preservation and Dissemination 6. Legal and Ethical Issues
20 Data Preservation and Dissemination For DOBES data, currently six copies are created automatically at three locations MPG 50 years bit-stream preservation guarantee Digital data centres: the more often the material is accessed and used, the better Important goal: easy and useful access Tasks for technicians and researchers An important aspect of a fruitful relation between researcher and data centre is trust
21 BEST PRACTICES AT TLA TOPICS 1. Introduction 2. Corpus Design and Curation 3. Annotation (including Transcription) 4. Metadata & Data Management 5. Data Preservation and Dissemination 6. Legal and Ethical Issues
22 Legal and Ethical Issues Human subjects are recorded: intricate issues Privacy of the human subjects Extreme inequality wrt. resources and information Impossibility of anonymizing the speakers International setting of the projects Often access is determined individually Attempts at clear and fair conditions of use Code of conduct: no commercial use and other uses that are disrespectful to the culture Goal: open access as far as possible
23 Legal and Ethical Issues Four levels of access privileges: 1. Directly accessible via the internet 2. Users register and accept the Code of Conduct 3. Users apply to the responsible persons and make their usage intentions explicit 4. Completely closed material, except for the researcher and members of the speech communities Management with AMS exploits the tree structure
24 LREC Workshop Istanbul Best practices in the design, creation and dissemination of speech corpora at The Language Archive Sebastian Drude, Daan Broeder, Peter Wittenburg, Han Sloetjes The Language Archive Max Planck Institute for Psycholinguistics Nijmegen, The Netherlands
Annotation by category - ELAN and ISO DCR
 Annotation by category - ELAN and ISO DCR Han Sloetjes, Peter Wittenburg Max Planck Institute for Psycholinguistics P.O. Box 310, 6500 AH Nijmegen, The Netherlands E-mail: Han.Sloetjes@mpi.nl, Peter.Wittenburg@mpi.nl
Annotation by category - ELAN and ISO DCR Han Sloetjes, Peter Wittenburg Max Planck Institute for Psycholinguistics P.O. Box 310, 6500 AH Nijmegen, The Netherlands E-mail: Han.Sloetjes@mpi.nl, Peter.Wittenburg@mpi.nl
Managing very large Multimedia Archives and their Integration into Federations
 Managing very large Multimedia Archives and their Integration into Federations Daan Broeder, Eric Auer, Marc Kemps-Snijders, Han Sloetjes, Peter Wittenburg, Claus Zinn 1 1 Max-Planck-Institute for Psycholinguistics,
Managing very large Multimedia Archives and their Integration into Federations Daan Broeder, Eric Auer, Marc Kemps-Snijders, Han Sloetjes, Peter Wittenburg, Claus Zinn 1 1 Max-Planck-Institute for Psycholinguistics,
EUDICO, Annotation and Exploitation of Multi Media Corpora over the Internet
 EUDICO, Annotation and Exploitation of Multi Media Corpora over the Internet Hennie Brugman, Albert Russel, Daan Broeder, Peter Wittenburg Max Planck Institute for Psycholinguistics P.O. Box 310, 6500
EUDICO, Annotation and Exploitation of Multi Media Corpora over the Internet Hennie Brugman, Albert Russel, Daan Broeder, Peter Wittenburg Max Planck Institute for Psycholinguistics P.O. Box 310, 6500
Using the data in the archive
 Using the data in the archive Jacquelijn Ringersma The Language Archive Max Planck Institute for Psycholinguistics DGfS-CNRS Summer School on Linguistic Typology A very rich archive A very rich archive
Using the data in the archive Jacquelijn Ringersma The Language Archive Max Planck Institute for Psycholinguistics DGfS-CNRS Summer School on Linguistic Typology A very rich archive A very rich archive
Enhanced ELAN functionality for sign language corpora
 Enhanced ELAN functionality for sign language corpora Onno Crasborn, Han Sloetjes Department of Linguistics, Radboud University Nijmegen PO Box 9103, NL-6500 HD Nijmegen, The Netherlands Max Planck Institute
Enhanced ELAN functionality for sign language corpora Onno Crasborn, Han Sloetjes Department of Linguistics, Radboud University Nijmegen PO Box 9103, NL-6500 HD Nijmegen, The Netherlands Max Planck Institute
(Some) Standards in the Humanities. Sebastian Drude CLARIN ERIC RDA 4 th Plenary, Amsterdam September 2014
 Standards in the Humanities. Sebastian Drude CLARIN ERIC RDA 4 th Plenary, Amsterdam September 2014") (Some) Standards in the Humanities Sebastian Drude CLARIN ERIC RDA 4 th Plenary, Amsterdam September 2014 1. Introduction Overview 2. Written text: the Text Encoding Initiative (TEI) 3. Multimodal: ELAN
(Some) Standards in the Humanities Sebastian Drude CLARIN ERIC RDA 4 th Plenary, Amsterdam September 2014 1. Introduction Overview 2. Written text: the Text Encoding Initiative (TEI) 3. Multimodal: ELAN
An Evolving escience Environment for Research Data in Linguistics
 An Evolving escience Environment for Research Data in Linguistics Claus Zinn, Peter Wittenburg, and Jacquelijn Ringersma Max Planck Institute for Psycholinguistics Wundtlaan 1, 6525 XD Nijmegen, The Netherlands
An Evolving escience Environment for Research Data in Linguistics Claus Zinn, Peter Wittenburg, and Jacquelijn Ringersma Max Planck Institute for Psycholinguistics Wundtlaan 1, 6525 XD Nijmegen, The Netherlands
Improving the exploitation of linguistic annotations in ELAN
 Improving the exploitation of linguistic annotations in ELAN Onno Crasborn, Han Sloetjes Radboud University Nijmegen, Centre for Language Studies; The Language Archive, Max Planck Institute for Psycholinguistics
Improving the exploitation of linguistic annotations in ELAN Onno Crasborn, Han Sloetjes Radboud University Nijmegen, Centre for Language Studies; The Language Archive, Max Planck Institute for Psycholinguistics
How can CLARIN archive and curate my resources?
 How can CLARIN archive and curate my resources? Christoph Draxler draxler@phonetik.uni-muenchen.de Outline! Relevant resources CLARIN infrastructure European Research Infrastructure Consortium National
How can CLARIN archive and curate my resources? Christoph Draxler draxler@phonetik.uni-muenchen.de Outline! Relevant resources CLARIN infrastructure European Research Infrastructure Consortium National
Building metadata components
 Building metadata components Dieter Van Uytvanck Max Planck Institute for Psycholinguistics Dieter.VanUytvanck@mpi.nl Overview Traditional metadata Component metadata Data categories
Building metadata components Dieter Van Uytvanck Max Planck Institute for Psycholinguistics Dieter.VanUytvanck@mpi.nl Overview Traditional metadata Component metadata Data categories
EUDAT. Towards a pan-european Collaborative Data Infrastructure
 EUDAT Towards a pan-european Collaborative Data Infrastructure Damien Lecarpentier CSC-IT Center for Science, Finland CESSDA workshop Tampere, 5 October 2012 EUDAT Towards a pan-european Collaborative
EUDAT Towards a pan-european Collaborative Data Infrastructure Damien Lecarpentier CSC-IT Center for Science, Finland CESSDA workshop Tampere, 5 October 2012 EUDAT Towards a pan-european Collaborative
Key Elements of Global Data Infrastructures
 Key Elements of Global Data Infrastructures Peter Wittenburg CLARIN Research Infrastructure EUDAT Data Infrastructure The Language Archive Max Planck Institute for Psycholinguistics Nijmegen, The Netherlands
Key Elements of Global Data Infrastructures Peter Wittenburg CLARIN Research Infrastructure EUDAT Data Infrastructure The Language Archive Max Planck Institute for Psycholinguistics Nijmegen, The Netherlands
PDF hosted at the Radboud Repository of the Radboud University Nijmegen
 PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/60933
PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/60933
Wittenburg, Peter; Gulrajani, Greg; Broeder, Daan; Uneson, Marcus
 Cross-Disciplinary Integration of Metadata Descriptions Wittenburg, Peter; Gulrajani, Greg; Broeder, Daan; Uneson, Marcus Published in: Proceedings of LREC 2004 2004 Link to publication Citation for published
Cross-Disciplinary Integration of Metadata Descriptions Wittenburg, Peter; Gulrajani, Greg; Broeder, Daan; Uneson, Marcus Published in: Proceedings of LREC 2004 2004 Link to publication Citation for published
Metadata and DCR. <CMD_Component /> Dieter Van Uytvanck. Max Planck Institute for Psycholinguistics
 Metadata and DCR Dieter Van Uytvanck Max Planck Institute for Psycholinguistics Dieter.VanUytvanck@mpi.nl Overview Traditional metadata Component metadata Data categories The big picture
Metadata and DCR Dieter Van Uytvanck Max Planck Institute for Psycholinguistics Dieter.VanUytvanck@mpi.nl Overview Traditional metadata Component metadata Data categories The big picture
PDF hosted at the Radboud Repository of the Radboud University Nijmegen
 PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/119571
PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/119571
The Virtual Language Observatory!
 The Virtual Language Observatory! Dieter Van Uytvanck! CMDI workshop, Nijmegen! 2012-09-13! 1! Overview! VLO?! What is behind it? Relation to CMDI?! How do I get my data in there?! Demo + excercises!!
The Virtual Language Observatory! Dieter Van Uytvanck! CMDI workshop, Nijmegen! 2012-09-13! 1! Overview! VLO?! What is behind it? Relation to CMDI?! How do I get my data in there?! Demo + excercises!!
Arbil 2.4 User Guide. An introduction to editing and managing IMDI metadata
 Arbil 2.4 User Guide An introduction to editing and managing IMDI metadata The latest version can be found at: http://tla.mpi.nl/tools/tla-tools/arbil/ This user guide was last updated on 2012-10-05 The
Arbil 2.4 User Guide An introduction to editing and managing IMDI metadata The latest version can be found at: http://tla.mpi.nl/tools/tla-tools/arbil/ This user guide was last updated on 2012-10-05 The
ELAN Linguistic Annotator
 ELAN Linguistic Annotator Introduction to Speech and Video Annotation with ELAN http://www.lat-mpi.eu/tools/elan Han Sloetjes, Max-Planck-Institute for Psycholinguistics November 2011 Introduction to ELAN
ELAN Linguistic Annotator Introduction to Speech and Video Annotation with ELAN http://www.lat-mpi.eu/tools/elan Han Sloetjes, Max-Planck-Institute for Psycholinguistics November 2011 Introduction to ELAN
Working with CMDI in Arbil Jeroen Geerts - September 2016
 Working with CMDI in Arbil Jeroen Geerts - September 2016 The Language Archive has been migrated to the CMDI metadata standard. CMDI metadata is based on profiles; each containing a certain amount of components.
Working with CMDI in Arbil Jeroen Geerts - September 2016 The Language Archive has been migrated to the CMDI metadata standard. CMDI metadata is based on profiles; each containing a certain amount of components.
Metadata Proposals for Corpora and Lexica
 Metadata Proposals for Corpora and Lexica P. Wittenburg, W. Peters +, D. Broeder Max-Planck-Institute for Psycholinguistics Wundtlaan 1, 6525 XD Nijmegen, The Netherlands peter.wittenburg@mpi.nl + University
Metadata Proposals for Corpora and Lexica P. Wittenburg, W. Peters +, D. Broeder Max-Planck-Institute for Psycholinguistics Wundtlaan 1, 6525 XD Nijmegen, The Netherlands peter.wittenburg@mpi.nl + University
D-SPIN Report R2.2b: The German Resource Landscape and a Portal
 D-SPIN Report R2.2b: The German Resource Landscape and a Portal February 2010 D-SPIN, BMBF-FKZ: 01UG0801A Deliverable: R2.2: The German Language Resource Landscape and a Portal Responsible: Peter Wittenburg
D-SPIN Report R2.2b: The German Resource Landscape and a Portal February 2010 D-SPIN, BMBF-FKZ: 01UG0801A Deliverable: R2.2: The German Language Resource Landscape and a Portal Responsible: Peter Wittenburg
Creating a Language Archive of Insular South East Asia and West New Guinea
 CHAPTER 10 Creating a Language Archive of Insular South East Asia and West New Guinea Marian Klamer, Paul Trilsbeek, Tom Hoogervorst and Chris Haskett Leiden University, Max Planck Institute for Psycholinguistics,
CHAPTER 10 Creating a Language Archive of Insular South East Asia and West New Guinea Marian Klamer, Paul Trilsbeek, Tom Hoogervorst and Chris Haskett Leiden University, Max Planck Institute for Psycholinguistics,
Why Was Arbil Written
 What is Arbil A R B I L i s a n a p p l i c a t i o n f o r o r g a n i s i n g r e s e a r c h d a t a and associated metadata into a format appropriate for A r c h i v i n g. A R B I L i s d e s i g
What is Arbil A R B I L i s a n a p p l i c a t i o n f o r o r g a n i s i n g r e s e a r c h d a t a and associated metadata into a format appropriate for A r c h i v i n g. A R B I L i s d e s i g
Editing and adding content to the deposit page
 Editing and adding content to the deposit page Endangered Languages Archive, 11 April 2017 Overview Each collection in the ELAR catalogue has an introductory page. On this page the user finds general information
Editing and adding content to the deposit page Endangered Languages Archive, 11 April 2017 Overview Each collection in the ELAR catalogue has an introductory page. On this page the user finds general information
OLAC: Accessing the World s Language Resources
 OLAC: Accessing the World s Language Resources Steven Bird CSSE, University of Melbourne LDC, University of Pennsylvania Gary Simons SIL International Graduate Institute of Applied Linguistics What is
OLAC: Accessing the World s Language Resources Steven Bird CSSE, University of Melbourne LDC, University of Pennsylvania Gary Simons SIL International Graduate Institute of Applied Linguistics What is
PIDs for CLARIN. Daan Broeder CLARIN / Max-Planck Institute for Psycholinguistics
 PIDs for CLARIN Daan Broeder CLARIN / Max-Planck Institute for Psycholinguistics CLARIN D Tutorial Sept. 2011 Contents Persistent Identifiers CLARIN requirements & policy PIDs & Granularity PIDs & Versioning
PIDs for CLARIN Daan Broeder CLARIN / Max-Planck Institute for Psycholinguistics CLARIN D Tutorial Sept. 2011 Contents Persistent Identifiers CLARIN requirements & policy PIDs & Granularity PIDs & Versioning
OntoELAN: an Ontology-based Linguistic Multimedia Annotator
 OntoELAN: an Ontology-based Linguistic Multimedia Annotator Artem Chebotko, Yu Deng, Shiyong Lu, Farshad Fotouhi Wayne State University Department of Computer Science 5143 Cass Avenue, Detroit, Michigan
OntoELAN: an Ontology-based Linguistic Multimedia Annotator Artem Chebotko, Yu Deng, Shiyong Lu, Farshad Fotouhi Wayne State University Department of Computer Science 5143 Cass Avenue, Detroit, Michigan
Methods of Language Documentation in the DOBES project
 Methods of Language Documentation in the DOBES project P. Wittenburg, U. Mosel +, A. Dwyer ++ Max-Planck-Institute for Psycholinguistics + University of Kiel ++ University of Kansas Contact: peter.wittenburg@mpi.nl
Methods of Language Documentation in the DOBES project P. Wittenburg, U. Mosel +, A. Dwyer ++ Max-Planck-Institute for Psycholinguistics + University of Kiel ++ University of Kansas Contact: peter.wittenburg@mpi.nl
LEXUS. for creating lexica
 LEXUS for creating lexica LEXUS manual Katarzyna Wojtylak Max Planck Institute for Psycholinguistics, Nijmegen, The Netherlands June 2012 LEXUS for creating lexica LEXUS manual Katarzyna Wojtylak Published
LEXUS for creating lexica LEXUS manual Katarzyna Wojtylak Max Planck Institute for Psycholinguistics, Nijmegen, The Netherlands June 2012 LEXUS for creating lexica LEXUS manual Katarzyna Wojtylak Published
TTNWW. TST tools voor het Nederlands als Webservices in een Workflow. Marc Kemps-Snijders
 TTNWW TST tools voor het Nederlands als Webservices in een Workflow Marc Kemps-Snijders Computational Linguistics in the Netherlands June 25 th, Nijmegen Marc. kemps.snijders@meertens.knaw.nl 1 http://www.clarin.nl
TTNWW TST tools voor het Nederlands als Webservices in een Workflow Marc Kemps-Snijders Computational Linguistics in the Netherlands June 25 th, Nijmegen Marc. kemps.snijders@meertens.knaw.nl 1 http://www.clarin.nl
CLARIN Concept Registry: The New Semantic Registry
 CLARIN Concept Registry: The New Semantic Registry Ineke Schuurman Menzo Windhouwer KU Leuven, Belgium Meertens Institute and Utrecht University, The Netherlands Amsterdam, The Netherlands ineke@ccl.kuleuven.be
CLARIN Concept Registry: The New Semantic Registry Ineke Schuurman Menzo Windhouwer KU Leuven, Belgium Meertens Institute and Utrecht University, The Netherlands Amsterdam, The Netherlands ineke@ccl.kuleuven.be
META-SHARE metadata: Overview of the schema & Interoperability with other schemas
 META-SHARE metadata: Overview of the schema & Interoperability with other schemas Penny Labropoulou & Maria Gavrilidou (ILSP/RC Athena) CMDI Interoperability Workshop Utrecht, Netherlands 4-5 June 2013
META-SHARE metadata: Overview of the schema & Interoperability with other schemas Penny Labropoulou & Maria Gavrilidou (ILSP/RC Athena) CMDI Interoperability Workshop Utrecht, Netherlands 4-5 June 2013
User Guide for ELAN Linguistic Annotator
 User Guide for ELAN Linguistic Annotator version 5.0.0 This user guide was last updated on 2017-05-02 The latest version can be downloaded from: http://tla.mpi.nl/tools/tla-tools/elan/ Author: Maddalena
User Guide for ELAN Linguistic Annotator version 5.0.0 This user guide was last updated on 2017-05-02 The latest version can be downloaded from: http://tla.mpi.nl/tools/tla-tools/elan/ Author: Maddalena
CMDI and granularity
 CMDI and granularity Identifier CLARIND-AP3-007 AP 3 Authors Dieter Van Uytvanck, Twan Goosen, Menzo Windhouwer Responsible Dieter Van Uytvanck Reference(s) Version Date Changes by State 1 2011-01-24 Dieter
CMDI and granularity Identifier CLARIND-AP3-007 AP 3 Authors Dieter Van Uytvanck, Twan Goosen, Menzo Windhouwer Responsible Dieter Van Uytvanck Reference(s) Version Date Changes by State 1 2011-01-24 Dieter
An exchange format for multimodal annotations
 An exchange format for multimodal annotations Thomas Schmidt, Susan Duncan, Oliver Ehmer, Jeffrey Hoyt, Michael Kipp, Dan Loehr, Magnus Magnusson, Travis Rose, Han Sloetjes Background International Society
An exchange format for multimodal annotations Thomas Schmidt, Susan Duncan, Oliver Ehmer, Jeffrey Hoyt, Michael Kipp, Dan Loehr, Magnus Magnusson, Travis Rose, Han Sloetjes Background International Society
EMELD Working Group on Resource Archiving
 EMELD Working Group on Resource Archiving Language Digitization Project, Conference 2003: Digitizing and Annotating Texts and Field Recordings Preamble Sparkling prose that briefly explains why linguists
EMELD Working Group on Resource Archiving Language Digitization Project, Conference 2003: Digitizing and Annotating Texts and Field Recordings Preamble Sparkling prose that briefly explains why linguists
FLAT: A CLARIN-compatible repository solution based on Fedora Commons
 FLAT: A CLARIN-compatible repository solution based on Fedora Commons Paul Trilsbeek The Language Archive Max Planck Institute for Psycholinguistics Nijmegen, The Netherlands Paul.Trilsbeek@mpi.nl Menzo
FLAT: A CLARIN-compatible repository solution based on Fedora Commons Paul Trilsbeek The Language Archive Max Planck Institute for Psycholinguistics Nijmegen, The Netherlands Paul.Trilsbeek@mpi.nl Menzo
Janne Bondi johannessen, Anders Nøklestad, Joel Priestley and Kristin Hagen. WP5: Glossa Integration
 Janne Bondi johannessen, Anders Nøklestad, Joel Priestley and Kristin Hagen WP5: Glossa Integration WP5 Glossa integration The current Glossa corpus interface and analysis tool will be integrated in the
Janne Bondi johannessen, Anders Nøklestad, Joel Priestley and Kristin Hagen WP5: Glossa Integration WP5 Glossa integration The current Glossa corpus interface and analysis tool will be integrated in the
The Ariadne System: A flexible and extensible framework for the modeling and storage of experimental data in the humanities
 The Ariadne System: A flexible and extensible framework for the modeling and storage of experimental data in the humanities Peter Menke, Alexander Mehler Project X1 Multimodal Alignment Corpora CRC 673
The Ariadne System: A flexible and extensible framework for the modeling and storage of experimental data in the humanities Peter Menke, Alexander Mehler Project X1 Multimodal Alignment Corpora CRC 673
CORLI. a linguistic consortium for corpus, language and interaction
 CORLI a linguistic consortium for corpus, language and interaction CORLI and HUMA-NUM CORLI = Corpus, Languages, and Interaction a French consortium of Huma-Num involved in linguistic research and teaching
CORLI a linguistic consortium for corpus, language and interaction CORLI and HUMA-NUM CORLI = Corpus, Languages, and Interaction a French consortium of Huma-Num involved in linguistic research and teaching
ELAN. Multimedia Annotation Tool. Max-Planck-Institute for Psycholinguistics Han Sloetjes
 ELAN Multimedia Annotation Tool Max-Planck-Institute for Psycholinguistics http://www.lat-mpi.eu/tools/elan Han Sloetjes (han.sloetjes@mpi.nl) Augsburg, 30 July 2009 ELAN written in Java programming language
ELAN Multimedia Annotation Tool Max-Planck-Institute for Psycholinguistics http://www.lat-mpi.eu/tools/elan Han Sloetjes (han.sloetjes@mpi.nl) Augsburg, 30 July 2009 ELAN written in Java programming language
CLARIN for Linguists Portal & Searching for Resources. Jan Odijk LOT Summerschool Nijmegen,
 CLARIN for Linguists Portal & Searching for Resources Jan Odijk LOT Summerschool Nijmegen, 2014-06-23 1 Overview CLARIN Portal Find data and tools 2 Overview CLARIN Portal Find data and tools 3 CLARIN
CLARIN for Linguists Portal & Searching for Resources Jan Odijk LOT Summerschool Nijmegen, 2014-06-23 1 Overview CLARIN Portal Find data and tools 2 Overview CLARIN Portal Find data and tools 3 CLARIN
An e-infrastructure for Language Documentation on the Web
 An e-infrastructure for Language Documentation on the Web Gary F. Simons, SIL International William D. Lewis, University of Washington Scott Farrar, University of Arizona D. Terence Langendoen, National
An e-infrastructure for Language Documentation on the Web Gary F. Simons, SIL International William D. Lewis, University of Washington Scott Farrar, University of Arizona D. Terence Langendoen, National
Bringing Europeana and CLARIN together: Dissemination and exploitation of cultural heritage data in a research infrastructure
 Bringing Europeana and CLARIN together: Dissemination and exploitation of cultural heritage data in a research infrastructure Twan Goosen 1 (CLARIN ERIC), Nuno Freire 2, Clemens Neudecker 3, Maria Eskevich
Bringing Europeana and CLARIN together: Dissemination and exploitation of cultural heritage data in a research infrastructure Twan Goosen 1 (CLARIN ERIC), Nuno Freire 2, Clemens Neudecker 3, Maria Eskevich
Implementation of the Data Seal of Approval
 Implementation of the Data Seal of Approval The Data Seal of Approval board hereby confirms that the Trusted Digital repository The Language Bank of Finland complies with the guidelines version 2014-2017
Implementation of the Data Seal of Approval The Data Seal of Approval board hereby confirms that the Trusted Digital repository The Language Bank of Finland complies with the guidelines version 2014-2017
EUDICO Linguistic Annotator (ELAN) from Max Planck Institute for Psycholinguistics
 from Max Planck Institute for Psycholinguistics") Vol. 1, No. 2 (December 2007), pp283-289 http://nflrc.hawaii.edu/ldc/ EUDICO Linguistic Annotator (ELAN) from Max Planck Institute for Psycholinguistics Reviewed by Andrea L. Berez, University of California,
Vol. 1, No. 2 (December 2007), pp283-289 http://nflrc.hawaii.edu/ldc/ EUDICO Linguistic Annotator (ELAN) from Max Planck Institute for Psycholinguistics Reviewed by Andrea L. Berez, University of California,
CLARIN s central infrastructure. Dieter Van Uytvanck CLARIN-PLUS Tools & Services Workshop 2 June 2016 Vienna
 CLARIN s central infrastructure Dieter Van Uytvanck CLARIN-PLUS Tools & Services Workshop 2 June 2016 Vienna CLARIN? Common Language Resources and Technology Infrastructure Research Infrastructure for
CLARIN s central infrastructure Dieter Van Uytvanck CLARIN-PLUS Tools & Services Workshop 2 June 2016 Vienna CLARIN? Common Language Resources and Technology Infrastructure Research Infrastructure for
Formats and standards for metadata, coding and tagging. Paul Meurer
 Formats and standards for metadata, coding and tagging Paul Meurer The FAIR principles FAIR principles for resources (data and metadata): Findable (-> persistent identifier, metadata, registered/indexed)
Formats and standards for metadata, coding and tagging Paul Meurer The FAIR principles FAIR principles for resources (data and metadata): Findable (-> persistent identifier, metadata, registered/indexed)
ELAR: instructions for depositors
 ELAR: instructions for depositors As a requirement of your ELDP grant, you must deposit your data with the Endangered Languages Archive (ELAR) at SOAS on an annual basis at the same time when you hand
ELAR: instructions for depositors As a requirement of your ELDP grant, you must deposit your data with the Endangered Languages Archive (ELAR) at SOAS on an annual basis at the same time when you hand
An Oral History Annotation Tool for INTER- VIEWs
 An Oral History Annotation Tool for INTERVIEWs Eric Sanders, Henk van den Heuvel CLS/CLST, Radboud University Nijmegen, The Netherlands 1 Introduction Interview data can be used in a number of ways, such
An Oral History Annotation Tool for INTERVIEWs Eric Sanders, Henk van den Heuvel CLS/CLST, Radboud University Nijmegen, The Netherlands 1 Introduction Interview data can be used in a number of ways, such
EUDAT Common data infrastructure
 EUDAT Common data infrastructure Giuseppe Fiameni SuperComputing Applications and Innovation CINECA Italy Peter Wittenburg Max Planck Institute for Psycholinguistics Nijmegen, Netherlands some major characteristics
EUDAT Common data infrastructure Giuseppe Fiameni SuperComputing Applications and Innovation CINECA Italy Peter Wittenburg Max Planck Institute for Psycholinguistics Nijmegen, Netherlands some major characteristics
EUDAT. A European Collaborative Data Infrastructure. Daan Broeder The Language Archive MPI for Psycholinguistics CLARIN, DASISH, EUDAT
 EUDAT A European Collaborative Data Infrastructure Daan Broeder The Language Archive MPI for Psycholinguistics CLARIN, DASISH, EUDAT OpenAire Interoperability Workshop Braga, Feb. 8, 2013 EUDAT Key facts
EUDAT A European Collaborative Data Infrastructure Daan Broeder The Language Archive MPI for Psycholinguistics CLARIN, DASISH, EUDAT OpenAire Interoperability Workshop Braga, Feb. 8, 2013 EUDAT Key facts
Segueing from a Data Category Registry to a Data Concept Registry
 Segueing from a Data Category Registry to a Data Concept Registry Sue Ellen Wright, Menzo Windhouwer, Ineke Schuurman, Daan Broeder To cite this version: Sue Ellen Wright, Menzo Windhouwer, Ineke Schuurman,
Segueing from a Data Category Registry to a Data Concept Registry Sue Ellen Wright, Menzo Windhouwer, Ineke Schuurman, Daan Broeder To cite this version: Sue Ellen Wright, Menzo Windhouwer, Ineke Schuurman,
Annotation Science From Theory to Practice and Use Introduction A bit of history
 Annotation Science From Theory to Practice and Use Nancy Ide Department of Computer Science Vassar College Poughkeepsie, New York 12604 USA ide@cs.vassar.edu Introduction Linguistically-annotated corpora
Annotation Science From Theory to Practice and Use Nancy Ide Department of Computer Science Vassar College Poughkeepsie, New York 12604 USA ide@cs.vassar.edu Introduction Linguistically-annotated corpora
Data for linguistics ALEXIS DIMITRIADIS. Contents First Last Prev Next Back Close Quit
 Data for linguistics ALEXIS DIMITRIADIS Text, corpora, and data in the wild 1. Where does language data come from? The usual: Introspection, questionnaires, etc. Corpora, suited to the domain of study:
Data for linguistics ALEXIS DIMITRIADIS Text, corpora, and data in the wild 1. Where does language data come from? The usual: Introspection, questionnaires, etc. Corpora, suited to the domain of study:
clarin:el an infrastructure for documenting, sharing and processing language data
 clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
Metadata Tools Supporting Controlled Vocabulary Services
 Metadata Tools Supporting Controlled Vocabulary Services Daan Broeder, Freddy Offenga, Don Willems Max-Planck Institute for Psycholinguistics daan.broeder@mpi.nl Abstract Within the ISLE Metadata Initiative
Metadata Tools Supporting Controlled Vocabulary Services Daan Broeder, Freddy Offenga, Don Willems Max-Planck Institute for Psycholinguistics daan.broeder@mpi.nl Abstract Within the ISLE Metadata Initiative
D-SPIN. D-SPIN Report 2.1: Formation of Centres
 D-SPIN D-SPIN Report 2.1: Formation of Centres June 2009 D-SPIN, BMBF-FKZ: 01UG0801B Deliverable: R2.1: Formation of Centres Responsible: Peter Wittenburg Editors: Peter Wittenburg 2 Contents 1. Introduction...4
D-SPIN D-SPIN Report 2.1: Formation of Centres June 2009 D-SPIN, BMBF-FKZ: 01UG0801B Deliverable: R2.1: Formation of Centres Responsible: Peter Wittenburg Editors: Peter Wittenburg 2 Contents 1. Introduction...4
Arbil. Arbil 2.4. for editing and managing CMDI metadata. This manual was last updated on
 Arbil Arbil 2.4 for editing and managing CMDI metadata This manual was last updated on The latest version can be found at: http://http://tla.mpi.nl/tools/tla-tools/arbil/ Anastasios Vogiatzis (June 2012)
Arbil Arbil 2.4 for editing and managing CMDI metadata This manual was last updated on The latest version can be found at: http://http://tla.mpi.nl/tools/tla-tools/arbil/ Anastasios Vogiatzis (June 2012)
Arbil. for editing and managing IMDI metadata
 Arbil for editing and managing IMDI metadata Arbil manual Max Planck Institute for Psycholinguistics, Nijmegen, The Netherlands 23 June 2012 Arbil for editing and managing IMDI metadata Arbil manual Table
Arbil for editing and managing IMDI metadata Arbil manual Max Planck Institute for Psycholinguistics, Nijmegen, The Netherlands 23 June 2012 Arbil for editing and managing IMDI metadata Arbil manual Table
Unit 3 Corpus markup
 Unit 3 Corpus markup 3.1 Introduction Data collected using a sampling frame as discussed in unit 2 forms a raw corpus. Yet such data typically needs to be processed before use. For example, spoken data
Unit 3 Corpus markup 3.1 Introduction Data collected using a sampling frame as discussed in unit 2 forms a raw corpus. Yet such data typically needs to be processed before use. For example, spoken data
PDF hosted at the Radboud Repository of the Radboud University Nijmegen
 PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/40896
PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/40896
Gary F. Simons. SIL International
 Gary F. Simons SIL International AARDVARC Symposium, LSA, Portland, OR, 11 Jan 2015 Given the relentless entropy that degrades our field recordings, and innovation that makes the technology we have used
Gary F. Simons SIL International AARDVARC Symposium, LSA, Portland, OR, 11 Jan 2015 Given the relentless entropy that degrades our field recordings, and innovation that makes the technology we have used
Language Resources. Khalid Choukri ELRA/ELDA 55 Rue Brillat-Savarin, F Paris, France Tel Fax.
 Language Resources By the Other Data Center over 15 years fruitful partnership Khalid Choukri ELRA/ELDA 55 Rue Brillat-Savarin, F-75013 Paris, France Tel. +33 1 43 13 33 33 -- Fax. +33 1 43 13 33 30 choukri@elda.org
Language Resources By the Other Data Center over 15 years fruitful partnership Khalid Choukri ELRA/ELDA 55 Rue Brillat-Savarin, F-75013 Paris, France Tel. +33 1 43 13 33 33 -- Fax. +33 1 43 13 33 30 choukri@elda.org
WebAnno: a flexible, web-based annotation tool for CLARIN
 WebAnno: a flexible, web-based annotation tool for CLARIN Richard Eckart de Castilho, Chris Biemann, Iryna Gurevych, Seid Muhie Yimam #WebAnno This work is licensed under a Attribution-NonCommercial-ShareAlike
WebAnno: a flexible, web-based annotation tool for CLARIN Richard Eckart de Castilho, Chris Biemann, Iryna Gurevych, Seid Muhie Yimam #WebAnno This work is licensed under a Attribution-NonCommercial-ShareAlike
Gary F. Simons. SIL International
 Gary F. Simons SIL International CoRSAL Symposium, UNT, Denton, TX, 17 Nov 2017 The digital language archiving enterprise is facing serious bottlenecks in scaling up the submission of new materials and
Gary F. Simons SIL International CoRSAL Symposium, UNT, Denton, TX, 17 Nov 2017 The digital language archiving enterprise is facing serious bottlenecks in scaling up the submission of new materials and
Metadata Infrastructure for Language Resources and Technology
 Metadata Infrastructure for Language Resources and Technology 2009-02-04 - Version 5 Editors: Daan Broeder, Bertrand Gaiffe, Maria Gavrilidou, Erhard Hinrichs, Lothar Lemnitzer, Dieter Van Uytvanck, Andreas
Metadata Infrastructure for Language Resources and Technology 2009-02-04 - Version 5 Editors: Daan Broeder, Bertrand Gaiffe, Maria Gavrilidou, Erhard Hinrichs, Lothar Lemnitzer, Dieter Van Uytvanck, Andreas
META-SHARE : the open exchange platform Overview-Current State-Towards v3.0
 META-SHARE : the open exchange platform Overview-Current State-Towards v3.0 Stelios Piperidis Athena RC, Greece spip@ilsp.gr A Strategy for Multilingual Europe Brussels, Belgium, June 20/21, 2012 Co-funded
META-SHARE : the open exchange platform Overview-Current State-Towards v3.0 Stelios Piperidis Athena RC, Greece spip@ilsp.gr A Strategy for Multilingual Europe Brussels, Belgium, June 20/21, 2012 Co-funded
Implementation of the Data Seal of Approval
 Implementation of the Data Seal of Approval The Data Seal of Approval board hereby confirms that the Trusted Digital repository IDS Repository complies with the guidelines version 2014-2017 set by the.
Implementation of the Data Seal of Approval The Data Seal of Approval board hereby confirms that the Trusted Digital repository IDS Repository complies with the guidelines version 2014-2017 set by the.
On the way to Language Resources sharing: principles, challenges, solutions
 On the way to Language Resources sharing: principles, challenges, solutions Stelios Piperidis ILSP, RC Athena, Greece spip@ilsp.gr Content on the Multilingual Web, 4-5 April, Pisa, 2011 Co-funded by the
On the way to Language Resources sharing: principles, challenges, solutions Stelios Piperidis ILSP, RC Athena, Greece spip@ilsp.gr Content on the Multilingual Web, 4-5 April, Pisa, 2011 Co-funded by the
1. General requirements
 Title CLARIN B Centre Checklist Version 6 Author(s) Peter Wittenburg, Dieter Van Uytvanck, Thomas Zastrow, Pavel Straňák, Daan Broeder, Florian Schiel, Volker Boehlke, Uwe Reichel, Lene Offersgaard Date
Title CLARIN B Centre Checklist Version 6 Author(s) Peter Wittenburg, Dieter Van Uytvanck, Thomas Zastrow, Pavel Straňák, Daan Broeder, Florian Schiel, Volker Boehlke, Uwe Reichel, Lene Offersgaard Date
Documentary and metadocumentary
 Documentary and metadocumentary linguistics Peter K. Austin Endangered Languages Academic Programme SOAS, University of London ICLDC, Hawaii 7 February 2011 www.hrelp.org 1 Documentary linguistics Himmelmann
Documentary and metadocumentary linguistics Peter K. Austin Endangered Languages Academic Programme SOAS, University of London ICLDC, Hawaii 7 February 2011 www.hrelp.org 1 Documentary linguistics Himmelmann
Approaches to digitization and annotation: A survey of language documentation materials in the Alaska Native Language Center Archive
 Approaches to digitization and annotation: A survey of language documentation materials in the Alaska Native Language Center Archive 1. Introduction Gary Holton University of Alaska Fairbanks The design
Approaches to digitization and annotation: A survey of language documentation materials in the Alaska Native Language Center Archive 1. Introduction Gary Holton University of Alaska Fairbanks The design
from Pavel Mihaylov and Dorothee Beermann Reviewed by Sc o t t Fa r r a r, University of Washington
 Vol. 4 (2010), pp. 60-65 http://nflrc.hawaii.edu/ldc/ http://hdl.handle.net/10125/4467 TypeCraft from Pavel Mihaylov and Dorothee Beermann Reviewed by Sc o t t Fa r r a r, University of Washington 1. OVERVIEW.
Vol. 4 (2010), pp. 60-65 http://nflrc.hawaii.edu/ldc/ http://hdl.handle.net/10125/4467 TypeCraft from Pavel Mihaylov and Dorothee Beermann Reviewed by Sc o t t Fa r r a r, University of Washington 1. OVERVIEW.
PubMan usage at the MPI for Psycholinguistics Nijmegen. Karin Kastens escidoc Days 2009 FIZ Karlsruhe, June 16 th, 2009
 PubMan usage at the MPI for Psycholinguistics Nijmegen Karin Kastens escidoc Days 2009 FIZ Karlsruhe, June 16 th, 2009 MPI for Psycholinguistics The Max Planck Institute for Psycholinguistics is an institute
PubMan usage at the MPI for Psycholinguistics Nijmegen Karin Kastens escidoc Days 2009 FIZ Karlsruhe, June 16 th, 2009 MPI for Psycholinguistics The Max Planck Institute for Psycholinguistics is an institute
Growing interests in. Urgent needs of. Develop a fieldworkers toolkit (fwtk) for the research of endangered languages
 for the research of endangered languages") ELPR IV International Conference 2002 Topics Reitaku University College of Foreign Languages Developing Tools for Creating-Maintaining-Analyzing Field Shoju CHIBA Reitaku University, Japan schiba@reitaku-u.ac.jp
ELPR IV International Conference 2002 Topics Reitaku University College of Foreign Languages Developing Tools for Creating-Maintaining-Analyzing Field Shoju CHIBA Reitaku University, Japan schiba@reitaku-u.ac.jp
Centres Network Formation
 Centres Network Formation 2009-02-04 - Version: 9 Editors: Dirk Roorda, Dieter van Uytvanck Peter Wittenburg, Martin Wynne The ultimate objective of CLARIN is to create a European federation of existing
Centres Network Formation 2009-02-04 - Version: 9 Editors: Dirk Roorda, Dieter van Uytvanck Peter Wittenburg, Martin Wynne The ultimate objective of CLARIN is to create a European federation of existing
Linguistic Data Management. Nick Thieberger University of Melbourne March 14th 2013
 Linguistic Data Management Nick Thieberger University of Melbourne March 14th 2013 http://www.rnld.org Linguistics in the Pub 26th March 2013 Things you can do with outputs from language documentation
Linguistic Data Management Nick Thieberger University of Melbourne March 14th 2013 http://www.rnld.org Linguistics in the Pub 26th March 2013 Things you can do with outputs from language documentation
ISLE Metadata Initiative (IMDI) PART 1 B. Metadata Elements for Catalogue Descriptions
 PART 1 B. Metadata Elements for Catalogue Descriptions") ISLE Metadata Initiative (IMDI) PART 1 B Metadata Elements for Catalogue Descriptions Version 3.0.13 August 2009 INDEX 1 INTRODUCTION...3 2 CATALOGUE ELEMENTS OVERVIEW...4 3 METADATA ELEMENT DEFINITIONS...6
ISLE Metadata Initiative (IMDI) PART 1 B Metadata Elements for Catalogue Descriptions Version 3.0.13 August 2009 INDEX 1 INTRODUCTION...3 2 CATALOGUE ELEMENTS OVERVIEW...4 3 METADATA ELEMENT DEFINITIONS...6
Good, Better, and Best Practice
 Good, Better, and Best Practice The Experience of the E-MELD Project Gary Simons, SIL International Helen Aristar Dry, Eastern Michigan U. DGfS 2006, Bielefeld, Germany 1 Good, Better, and Best Practice
Good, Better, and Best Practice The Experience of the E-MELD Project Gary Simons, SIL International Helen Aristar Dry, Eastern Michigan U. DGfS 2006, Bielefeld, Germany 1 Good, Better, and Best Practice
Customizing the IMDI metadata schema for endangered languages
 Customizing the IMDI metadata schema for endangered languages Heidi Johnson Arienne Dwyer The Archive of the Indigenous University of Kansas Languages of Latin America DOBES (Volkswagen Foundation Programme
Customizing the IMDI metadata schema for endangered languages Heidi Johnson Arienne Dwyer The Archive of the Indigenous University of Kansas Languages of Latin America DOBES (Volkswagen Foundation Programme
ISO-standard Metadata Descriptors and Registries
 ISO-standard Metadata Descriptors and Registries Lee Gillam Department of Computing, School of Electronics and Physical Sciences, University of Surrey, Guildford, GU2 7XH, United Kingdom l.gillam@surrey.ac.uk
ISO-standard Metadata Descriptors and Registries Lee Gillam Department of Computing, School of Electronics and Physical Sciences, University of Surrey, Guildford, GU2 7XH, United Kingdom l.gillam@surrey.ac.uk
Persistent and unique Identifiers
 Persistent and unique Identifiers 2009-2-4 Version: 4 Editors: Daan Broeder, Malte Dreyer, Marc Kemps-Snijders, Andreas Witt, Marc Kupietz, Peter Wittenburg www.clarin.eu The ultimate objective of CLARIN
Persistent and unique Identifiers 2009-2-4 Version: 4 Editors: Daan Broeder, Malte Dreyer, Marc Kemps-Snijders, Andreas Witt, Marc Kupietz, Peter Wittenburg www.clarin.eu The ultimate objective of CLARIN
B2FIND: EUDAT Metadata Service. Daan Broeder, et al. EUDAT Metadata Task Force
 B2FIND: EUDAT Metadata Service Daan Broeder, et al. EUDAT Metadata Task Force EUDAT Joint Metadata Domain of Research Data Deliver a service for searching and browsing metadata across communities Appropriate
B2FIND: EUDAT Metadata Service Daan Broeder, et al. EUDAT Metadata Task Force EUDAT Joint Metadata Domain of Research Data Deliver a service for searching and browsing metadata across communities Appropriate
Session Two: OAIS Model & Digital Curation Lifecycle Model
 From the SelectedWorks of Group 4 SundbergVernonDhaliwal Winter January 19, 2016 Session Two: OAIS Model & Digital Curation Lifecycle Model Dr. Eun G Park Available at: https://works.bepress.com/group4-sundbergvernondhaliwal/10/
From the SelectedWorks of Group 4 SundbergVernonDhaliwal Winter January 19, 2016 Session Two: OAIS Model & Digital Curation Lifecycle Model Dr. Eun G Park Available at: https://works.bepress.com/group4-sundbergvernondhaliwal/10/
Data Replication: Automated move and copy of data. PRACE Advanced Training Course on Data Staging and Data Movement Helsinki, September 10 th 2013
 Data Replication: Automated move and copy of data PRACE Advanced Training Course on Data Staging and Data Movement Helsinki, September 10 th 2013 Claudio Cacciari c.cacciari@cineca.it Outline The issue
Data Replication: Automated move and copy of data PRACE Advanced Training Course on Data Staging and Data Movement Helsinki, September 10 th 2013 Claudio Cacciari c.cacciari@cineca.it Outline The issue
E-MELD Electronic Metastructure for Endangered Languages Documentation
 E-MELD Electronic Metastructure for Endangered Languages Documentation 5 year NSF-sponsored project Goal: To aid in the preservation of endangered languages data, and the development of infrastructure
E-MELD Electronic Metastructure for Endangered Languages Documentation 5 year NSF-sponsored project Goal: To aid in the preservation of endangered languages data, and the development of infrastructure
ISLE Metadata Initiative (IMDI) PART 3 A. Vocabulary Taxonomy and Structure
 PART 3 A. Vocabulary Taxonomy and Structure") ISLE Metadata Initiative (IMDI) PART 3 A Vocabulary Taxonomy and Structure Draft Proposal Version 1.1 December, 2001 IMDI 1 Technical Report Max-Planck-Institute for Psycholinguistics NL, Nijmegen 1 For
ISLE Metadata Initiative (IMDI) PART 3 A Vocabulary Taxonomy and Structure Draft Proposal Version 1.1 December, 2001 IMDI 1 Technical Report Max-Planck-Institute for Psycholinguistics NL, Nijmegen 1 For
ARCHIVING AND SHARING LANGUAGE DATA USING XML
 ARCHIVING AND SHARING LANGUAGE DATA USING XML Simon Musgrave Linguistics Program, Monash University The reasons for using XML as the preferred format for archiving text data are powerful and have been
ARCHIVING AND SHARING LANGUAGE DATA USING XML Simon Musgrave Linguistics Program, Monash University The reasons for using XML as the preferred format for archiving text data are powerful and have been
ACDH AUSTRIAN CENTRE FOR DIGITAL HUMANITIES
 ARCHE = A Resource Centre for the HumanitiEs A digital archive for the humanities Implements the OAIS Reference Model for an Open Archival Information System arche.acdh.oeaw.ac.at WHAT IS AN ARCHIVE? Preserves
ARCHE = A Resource Centre for the HumanitiEs A digital archive for the humanities Implements the OAIS Reference Model for an Open Archival Information System arche.acdh.oeaw.ac.at WHAT IS AN ARCHIVE? Preserves
Curation module in action - its preliminary findings on VLO metadata quality
 Curation module in action - its preliminary findings on VLO metadata quality Davor Ostojić, Go Sugimoto, Matej Ďurčo (Austrian Centre for Digital Humanities) CLARIN Annual Conference 2016, Aix-en-Provence,
Curation module in action - its preliminary findings on VLO metadata quality Davor Ostojić, Go Sugimoto, Matej Ďurčo (Austrian Centre for Digital Humanities) CLARIN Annual Conference 2016, Aix-en-Provence,
Common Language Resources and Technology Infrastructure REVISED WEBSITE
 REVISED WEBSITE Responsible: Dan Cristea Contributing Partners: UAIC, FFGZ, DFKI, UIB/Unifob The ultimate objective of CLARIN is to create a European federation of existing digital repositories that include
REVISED WEBSITE Responsible: Dan Cristea Contributing Partners: UAIC, FFGZ, DFKI, UIB/Unifob The ultimate objective of CLARIN is to create a European federation of existing digital repositories that include
Deliverable 3.1 Metadata Integration Report
 Deliverable 3.1 Metadata Integration Report DAM-LR 011841 Distributed Access Management for Language Resources implemented as Specific Support Action Contract Number: 011841 Project Coordinator: Peter
Deliverable 3.1 Metadata Integration Report DAM-LR 011841 Distributed Access Management for Language Resources implemented as Specific Support Action Contract Number: 011841 Project Coordinator: Peter
Preservation. Session 4: Techniques & Audio. Arienne M. Dwyer University of Kansas. Yoshi Ono University of Alberta
 Session 4: Techniques & Audio University of California at Santa Barbara, June 24-27, Arienne M. Dwyer University of Kansas Yoshi Ono University of Alberta 1 Session 4 s focus I. Homework review II. Transcriber
Session 4: Techniques & Audio University of California at Santa Barbara, June 24-27, Arienne M. Dwyer University of Kansas Yoshi Ono University of Alberta 1 Session 4 s focus I. Homework review II. Transcriber
LingSync: Software for language documentation. Joel Dunham, Jessica Coon & Alan Bale
 LingSync: Software for language documentation Joel Dunham, Jessica Coon & Alan Bale Concordia McGill Concordia 4 th International Conference on Language Documentation & Conservation February 28, 2015 LingSync
LingSync: Software for language documentation Joel Dunham, Jessica Coon & Alan Bale Concordia McGill Concordia 4 th International Conference on Language Documentation & Conservation February 28, 2015 LingSync
EUDAT Towards a Collaborative Data Infrastructure
 EUDAT Towards a Collaborative Data Infrastructure Daan Broeder - MPI for Psycholinguistics - EUDAT - CLARIN - DASISH Bielefeld 10 th International Conference Data These days it is so very easy to create
EUDAT Towards a Collaborative Data Infrastructure Daan Broeder - MPI for Psycholinguistics - EUDAT - CLARIN - DASISH Bielefeld 10 th International Conference Data These days it is so very easy to create
Metadata Catalogue Issues. Daan Broeder Max-Planck Institute for Psycholinguistics
 Metadata Catalogue Issues Daan Broeder Max-Planck Institute for Psycholinguistics Introduction Methods of registering resources Metadata Making metadata interoperable Exposing metadata Facilitating resource
Metadata Catalogue Issues Daan Broeder Max-Planck Institute for Psycholinguistics Introduction Methods of registering resources Metadata Making metadata interoperable Exposing metadata Facilitating resource
3 Publishing Technique
 Publishing Tool 32 3 Publishing Technique As discussed in Chapter 2, annotations can be extracted from audio, text, and visual features. The extraction of text features from the audio layer is the approach
Publishing Tool 32 3 Publishing Technique As discussed in Chapter 2, annotations can be extracted from audio, text, and visual features. The extraction of text features from the audio layer is the approach
Corpus methods for sociolinguistics. Emily M. Bender NWAV 31 - October 10, 2002
 Corpus methods for sociolinguistics Emily M. Bender bender@csli.stanford.edu NWAV 31 - October 10, 2002 Overview Introduction Corpora of interest Software for accessing and analyzing corpora (demo) Basic
Corpus methods for sociolinguistics Emily M. Bender bender@csli.stanford.edu NWAV 31 - October 10, 2002 Overview Introduction Corpora of interest Software for accessing and analyzing corpora (demo) Basic