TTNWW. TST tools voor het Nederlands als Webservices in een Workflow. Marc Kemps-Snijders
|
|
|
- Frederica Fields
- 6 years ago
- Views:
Transcription
1 TTNWW TST tools voor het Nederlands als Webservices in een Workflow Marc Kemps-Snijders Computational Linguistics in the Netherlands June 25 th, Nijmegen Marc. 1

2 2

3 Views on infrastructures Centers view How do organizations fit in? Data lifecycle view What about the data? Architectural view Tools and services 3
4 Views on infrastructures Centers view How do organizations fit in? Data lifecycle view What about the data? Architectural view Tools and services 4
5 Original CLARIN center idea Scenario where dedicated Scenario services characterized centres of new mainly type by interact accidental in a stable and way and give persistent and easy-to-use services to the temporary community. interactions Researchers must be able to rely on the services offered
 IMS, Universität Stuttgart")
6 CLARIN centers 2014 The following centres have successfully passed the CLARIN centre assessment procedure and now can officially carry the CLARIN B centre label: ASV Leipzig Bayerisches Archiv für Sprachsignale Berlin-Brandenburg Academy of Sciences and Humanities CLARIN Center Vienna Eberhard Karls Universität Tübingen Hamburger Zentrum für Sprachkorpora (HZSK) IMS, Universität Stuttgart Institut für Deutsche Sprache LINDAT-Clarin Meertens Instituut MPI for Psycholinguistics The Clarin center at University of Copenhagen Universität des Saarlandes 6
7 Making data and tools available Note: Static overview of data and tools/services descriptions Note: Information is dynamically harvested from centers 7


8 Making data and tools available Note: Static overview of data and tools/services descriptions Note: Information is dynamically harvested from centers 8
9 Views on infrastructures Centers view How do organizations fit in? Data lifecycle view What about the data? Architectural view Tools and services 9










10 Data management life cycle You are here You are here You are here You are here You are here You are here You are here 10744/mi_a19eb1ae-8e90-4cd6 Naming authority CMDI Component Metadata Infrastructure Suffix DDC data life cycle: 10
11 Views on infrastructures Centers view How do organizations fit in? Data lifecycle view What about the data? Architectural view Tools and services 11


12 Tools and services 12
13 TTNWW A two-year program with the intention to make existing components from previous project (a.o. CGN and STEVIN) available as web services and combine them into workflows for use by HSS researchers with little or no technical background. This enable them to: More easily answer research questoins Provide a basis to formulate new research questions 13
14 What do we provide? Text Make several basic text analysis components available: Corpus cleanup Part of Speech tagging Named Entity Recognition Semantic role labelling Coreference Speech Provide components for speech recognition 14
15 What s the use? For texts more advanced automatic extraction techniques become available. E.g. extraction of persons, locations, events Analysis of large amounts of data becomes possible For speech it becomes possible to (partially) transcribe speech files and make them available for search/browse tools. 15

16 Web service Definition There are many things that might be called "Web services" in the world at large. However, for the purpose of this Working Group and this architecture, and without prejudice toward other definitions, we will use the following definition: A Web service is a software system designed to support interoperable machine-to-machine interaction over a network. It has an interface described in a machine-processable format (specifically WSDL). Other systems interact with the Web service in a manner prescribed by its description using SOAP-messages, typically conveyed using HTTP with an XML serialization in conjunction with other Web-related standards. 16
 as web service solution Services have been largely deployed within HPC")
17 Web services Most technology providers have opted for CLAM (Computational Linguistics Application Mediator) as web service solution Services have been largely deployed within HPC Cloud 17


18 The cloud 18

19 Pos tagging Try it yourself Select your newly created project 19
20 Named Entity Recognition Try it yourself Select your newly created project Copy output from POS tagging into the window 20
21 Workflows Tying services together Workflow is a term used to describe the tasks, procedural steps, organizations or people involved, required input and output information, and tools needed for each step in a business process. Workflows have been commonly used in commercial and scientific processes for decades. 21

22 Workflows Tying services together 1. Create project 2. Upload file 3. Start execution 5. Download file 4. Wait for completion 6. Delete project 22

23 Try it yourself Download Taverna workbench from Use the workflow connecting Frog and Nerd. 23
24 TTNWW application 24



25 Architectuur In SARA HPC cloud gedeployed Currently disabled 25




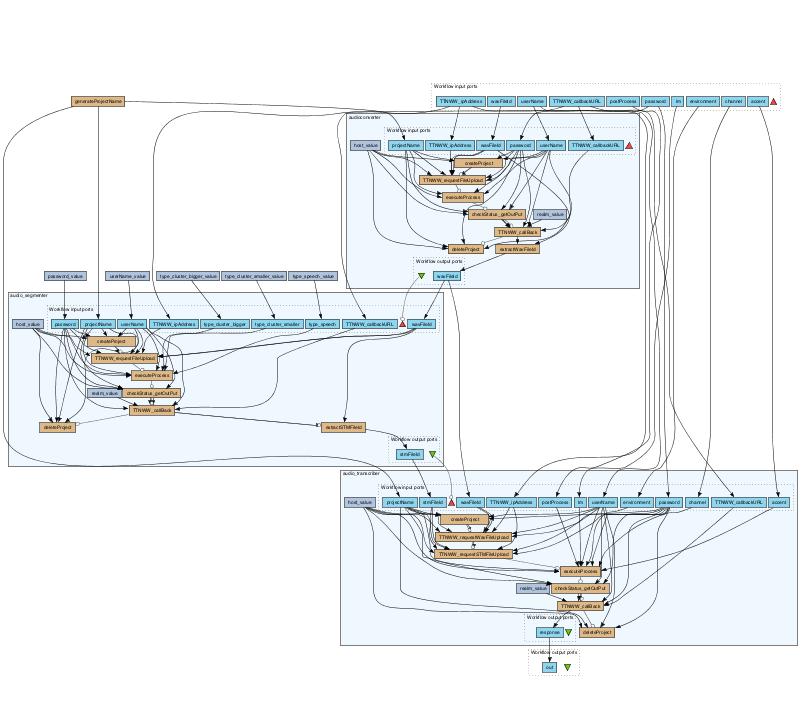

26 TTNWW applicatie Functionaliteiten Data selectie (upload/download) Selectie van processen Aansturing van processen Terugkoppeling resultaten in tijdelijke werkruimte Only generic viewers 26
27 Try it yourself Use TTNWW at 27

28 Wishlist Import from other formats, e.g. Word, PDF Specific viewers for generated file formats Some idiosyncratic features!! Individual service monitoring through Taverna server Extending workflows into search domain Searching across multiple annotated documents Blacklab (Coming soon..?) GrETEL 28
29 Other approaches in the CLARIN domain Weblicht Custom designed workflow system Webbased Panacea Taverna based workflow system Workbench oriented 29


30 Weblicht D-Spin project 30

31 Weblicht D-Spin project 31

32 Weblicht D-Spin project 32

33 Weblicht D-Spin project 33

34 PANACEA project 34

35 35
36 Further reading Martin W. C. Reynaert. Character confusion versus focus word-based correction and OCR variants in corpora Van den Bosch, A., Busser, G.J., Daelemans, W., and Canisius, S. (2007). An efficient memory-based morphosyntactic tagger and parser for Dutch, In F. van Eynde, P. Dirix, I. Schuurman, and V. Vandeghinste (Eds.), Selected Papers of the 17th Computational Linguistics in the Netherlands Meeting, Leuven, Belgium, pp Daelemans, Walter, Sabine Buchholz, and Jorn Veenstra. "Memory-based shallow parsing." arxiv preprint cs/ (1999). Gertjan van Noord. At Last Parsing Is Now Operational. In: Piet Mertens, Cedrick Fairon, Anne Dister, Patrick Watrin (editors): TALN06. Verbum Ex Machina. Actes de la 13e conference sur le traitement automatique des langues naturelles. Page Iris Hendrickx, Gosse Bouma, Walter Daelemans, and Veronique Hoste. "COREA: Coreference Resolution for Extracting Answers for Dutch." Essential Speech and Language Technology for Dutch. Springer Berlin Heidelberg, _7.pdf?auth66= _2af68c8e695d8395e42b6465edc837d1&ext=.pdf Monachesi, Paola, Gerwert Stevens, and Jantine Trapman. "Adding semantic role annotation to a corpus of written Dutch." Proceedings of the Linguistic Annotation Workshop. Association for Computational Linguistics, c.pdf#page=91 Schuurman, Ineke. "Spatiotemporal annotation on top of an existing treebank." Proceedings of the Sixth International Workshop on Treebanks and Linguistic Theories
37 Thank you for your attention. 37
Best practices in the design, creation and dissemination of speech corpora at The Language Archive
 LREC Workshop 18 2012-05-21 Istanbul Best practices in the design, creation and dissemination of speech corpora at The Language Archive Sebastian Drude, Daan Broeder, Peter Wittenburg, Han Sloetjes The
LREC Workshop 18 2012-05-21 Istanbul Best practices in the design, creation and dissemination of speech corpora at The Language Archive Sebastian Drude, Daan Broeder, Peter Wittenburg, Han Sloetjes The
WebLicht: Web-based LRT Services in a Distributed escience Infrastructure
 WebLicht: Web-based LRT Services in a Distributed escience Infrastructure Marie Hinrichs, Thomas Zastrow, Erhard Hinrichs Seminar für Sprachwissenschaft, University of Tübingen Wilhelmstr. 19, 72074 Tübingen
WebLicht: Web-based LRT Services in a Distributed escience Infrastructure Marie Hinrichs, Thomas Zastrow, Erhard Hinrichs Seminar für Sprachwissenschaft, University of Tübingen Wilhelmstr. 19, 72074 Tübingen
Erhard Hinrichs, Thomas Zastrow University of Tübingen
 WebLicht A Service Oriented Architecture for Language Resources and Tools Erhard Hinrichs, Thomas Zastrow University of Tübingen Current Situation Many linguistic resources (corpora, dictionaries, ) and
WebLicht A Service Oriented Architecture for Language Resources and Tools Erhard Hinrichs, Thomas Zastrow University of Tübingen Current Situation Many linguistic resources (corpora, dictionaries, ) and
CLARIN for Linguists Portal & Searching for Resources. Jan Odijk LOT Summerschool Nijmegen,
 CLARIN for Linguists Portal & Searching for Resources Jan Odijk LOT Summerschool Nijmegen, 2014-06-23 1 Overview CLARIN Portal Find data and tools 2 Overview CLARIN Portal Find data and tools 3 CLARIN
CLARIN for Linguists Portal & Searching for Resources Jan Odijk LOT Summerschool Nijmegen, 2014-06-23 1 Overview CLARIN Portal Find data and tools 2 Overview CLARIN Portal Find data and tools 3 CLARIN
FLAT: A CLARIN-compatible repository solution based on Fedora Commons
 FLAT: A CLARIN-compatible repository solution based on Fedora Commons Paul Trilsbeek The Language Archive Max Planck Institute for Psycholinguistics Nijmegen, The Netherlands Paul.Trilsbeek@mpi.nl Menzo
FLAT: A CLARIN-compatible repository solution based on Fedora Commons Paul Trilsbeek The Language Archive Max Planck Institute for Psycholinguistics Nijmegen, The Netherlands Paul.Trilsbeek@mpi.nl Menzo
CLARIN s central infrastructure. Dieter Van Uytvanck CLARIN-PLUS Tools & Services Workshop 2 June 2016 Vienna
 CLARIN s central infrastructure Dieter Van Uytvanck CLARIN-PLUS Tools & Services Workshop 2 June 2016 Vienna CLARIN? Common Language Resources and Technology Infrastructure Research Infrastructure for
CLARIN s central infrastructure Dieter Van Uytvanck CLARIN-PLUS Tools & Services Workshop 2 June 2016 Vienna CLARIN? Common Language Resources and Technology Infrastructure Research Infrastructure for
Metadata and DCR. <CMD_Component /> Dieter Van Uytvanck. Max Planck Institute for Psycholinguistics
 Metadata and DCR Dieter Van Uytvanck Max Planck Institute for Psycholinguistics Dieter.VanUytvanck@mpi.nl Overview Traditional metadata Component metadata Data categories The big picture
Metadata and DCR Dieter Van Uytvanck Max Planck Institute for Psycholinguistics Dieter.VanUytvanck@mpi.nl Overview Traditional metadata Component metadata Data categories The big picture
Building metadata components
 Building metadata components Dieter Van Uytvanck Max Planck Institute for Psycholinguistics Dieter.VanUytvanck@mpi.nl Overview Traditional metadata Component metadata Data categories
Building metadata components Dieter Van Uytvanck Max Planck Institute for Psycholinguistics Dieter.VanUytvanck@mpi.nl Overview Traditional metadata Component metadata Data categories
Common Lab Research Infrastructure for the Arts and Humanities
 Common Lab Research Infrastructure for the Arts and Humanities 1 AnnCor Annotation in AnnCor Annotation of Syntactic Structures Annotation Procedure & Guidelines Preprocessing Annotation Application Annotation
Common Lab Research Infrastructure for the Arts and Humanities 1 AnnCor Annotation in AnnCor Annotation of Syntactic Structures Annotation Procedure & Guidelines Preprocessing Annotation Application Annotation
Parsing partially bracketed input
 Parsing partially bracketed input Martijn Wieling, Mark-Jan Nederhof and Gertjan van Noord Humanities Computing, University of Groningen Abstract A method is proposed to convert a Context Free Grammar
Parsing partially bracketed input Martijn Wieling, Mark-Jan Nederhof and Gertjan van Noord Humanities Computing, University of Groningen Abstract A method is proposed to convert a Context Free Grammar
A first set of integrated web services
 A first set of integrated web services Milestone D2.R7.1 2010-02-12 Version: 2 Editors: Marc Kemps-Snijders www.clarin.eu WG2.7 A first set of integrated web services 2 A first set of integrated web services
A first set of integrated web services Milestone D2.R7.1 2010-02-12 Version: 2 Editors: Marc Kemps-Snijders www.clarin.eu WG2.7 A first set of integrated web services 2 A first set of integrated web services
clarin:el an infrastructure for documenting, sharing and processing language data
 clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
clarin:el an infrastructure for documenting, sharing and processing language data Stelios Piperidis, Penny Labropoulou, Maria Gavrilidou (Athena RC / ILSP) the problem 19/9/2015 ICGL12, FU-Berlin 2 use
WebAnno: a flexible, web-based annotation tool for CLARIN
 WebAnno: a flexible, web-based annotation tool for CLARIN Richard Eckart de Castilho, Chris Biemann, Iryna Gurevych, Seid Muhie Yimam #WebAnno This work is licensed under a Attribution-NonCommercial-ShareAlike
WebAnno: a flexible, web-based annotation tool for CLARIN Richard Eckart de Castilho, Chris Biemann, Iryna Gurevych, Seid Muhie Yimam #WebAnno This work is licensed under a Attribution-NonCommercial-ShareAlike
PDF hosted at the Radboud Repository of the Radboud University Nijmegen
 PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/131547
PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/131547
The Documentalist Support System: a Web-Services based Tool for Semantic Annotation and Browsing
 The Documentalist Support System: a Web-Services based Tool for Semantic Annotation and Browsing Hennie Brugman 1, Véronique Malaisé 2, Luit Gazendam 3, and Guus Schreiber 2 1 MPI for Psycholinguistics,
The Documentalist Support System: a Web-Services based Tool for Semantic Annotation and Browsing Hennie Brugman 1, Véronique Malaisé 2, Luit Gazendam 3, and Guus Schreiber 2 1 MPI for Psycholinguistics,
EUDICO, Annotation and Exploitation of Multi Media Corpora over the Internet
 EUDICO, Annotation and Exploitation of Multi Media Corpora over the Internet Hennie Brugman, Albert Russel, Daan Broeder, Peter Wittenburg Max Planck Institute for Psycholinguistics P.O. Box 310, 6500
EUDICO, Annotation and Exploitation of Multi Media Corpora over the Internet Hennie Brugman, Albert Russel, Daan Broeder, Peter Wittenburg Max Planck Institute for Psycholinguistics P.O. Box 310, 6500
Ortolang Tools : MarsaTag
 Ortolang Tools : MarsaTag Stéphane Rauzy, Philippe Blache, Grégoire de Montcheuil SECOND VARIAMU WORKSHOP LPL, Aix-en-Provence August 20th & 21st, 2014 ORTOLANG received a State aid under the «Investissements
Ortolang Tools : MarsaTag Stéphane Rauzy, Philippe Blache, Grégoire de Montcheuil SECOND VARIAMU WORKSHOP LPL, Aix-en-Provence August 20th & 21st, 2014 ORTOLANG received a State aid under the «Investissements
D-SPIN Report R2.2b: The German Resource Landscape and a Portal
 D-SPIN Report R2.2b: The German Resource Landscape and a Portal February 2010 D-SPIN, BMBF-FKZ: 01UG0801A Deliverable: R2.2: The German Language Resource Landscape and a Portal Responsible: Peter Wittenburg
D-SPIN Report R2.2b: The German Resource Landscape and a Portal February 2010 D-SPIN, BMBF-FKZ: 01UG0801A Deliverable: R2.2: The German Language Resource Landscape and a Portal Responsible: Peter Wittenburg
Data for linguistics ALEXIS DIMITRIADIS. Contents First Last Prev Next Back Close Quit
 Data for linguistics ALEXIS DIMITRIADIS Text, corpora, and data in the wild 1. Where does language data come from? The usual: Introspection, questionnaires, etc. Corpora, suited to the domain of study:
Data for linguistics ALEXIS DIMITRIADIS Text, corpora, and data in the wild 1. Where does language data come from? The usual: Introspection, questionnaires, etc. Corpora, suited to the domain of study:
Implementing a Variety of Linguistic Annotations
 Implementing a Variety of Linguistic Annotations through a Common Web-Service Interface Adam Funk, Ian Roberts, Wim Peters University of Sheffield 18 May 2010 Adam Funk, Ian Roberts, Wim Peters Implementing
Implementing a Variety of Linguistic Annotations through a Common Web-Service Interface Adam Funk, Ian Roberts, Wim Peters University of Sheffield 18 May 2010 Adam Funk, Ian Roberts, Wim Peters Implementing
The Virtual Language Observatory!
 The Virtual Language Observatory! Dieter Van Uytvanck! CMDI workshop, Nijmegen! 2012-09-13! 1! Overview! VLO?! What is behind it? Relation to CMDI?! How do I get my data in there?! Demo + excercises!!
The Virtual Language Observatory! Dieter Van Uytvanck! CMDI workshop, Nijmegen! 2012-09-13! 1! Overview! VLO?! What is behind it? Relation to CMDI?! How do I get my data in there?! Demo + excercises!!
Progress Report STEVIN Projects
 Progress Report STEVIN Projects Project Name Large Scale Syntactic Annotation of Written Dutch Project Number STE05020 Reporting Period October 2009 - March 2010 Participants KU Leuven, University of Groningen
Progress Report STEVIN Projects Project Name Large Scale Syntactic Annotation of Written Dutch Project Number STE05020 Reporting Period October 2009 - March 2010 Participants KU Leuven, University of Groningen
EUDAT. A European Collaborative Data Infrastructure. Daan Broeder The Language Archive MPI for Psycholinguistics CLARIN, DASISH, EUDAT
 EUDAT A European Collaborative Data Infrastructure Daan Broeder The Language Archive MPI for Psycholinguistics CLARIN, DASISH, EUDAT OpenAire Interoperability Workshop Braga, Feb. 8, 2013 EUDAT Key facts
EUDAT A European Collaborative Data Infrastructure Daan Broeder The Language Archive MPI for Psycholinguistics CLARIN, DASISH, EUDAT OpenAire Interoperability Workshop Braga, Feb. 8, 2013 EUDAT Key facts
Beyond SoNaR: towards the facilitation of large corpus building efforts
 Beyond SoNaR: towards the facilitation of large corpus building efforts Martin Reynaert 1, Ineke Schuurman 2, Véronique Hoste 3, Nelleke Oostdijk 4, Maarten van Gompel 4 TiCC, Tilburg University 1 ; CCL,
Beyond SoNaR: towards the facilitation of large corpus building efforts Martin Reynaert 1, Ineke Schuurman 2, Véronique Hoste 3, Nelleke Oostdijk 4, Maarten van Gompel 4 TiCC, Tilburg University 1 ; CCL,
Handling Big Data and Sensitive Data Using EUDAT s Generic Execution Framework and the WebLicht Workflow Engine.
 Handling Big Data and Sensitive Data Using EUDAT s Generic Execution Framework and the WebLicht Workflow Engine. Claus Zinn, Wei Qui, Marie Hinrichs, Emanuel Dima, and Alexandr Chernov University of Tübingen
Handling Big Data and Sensitive Data Using EUDAT s Generic Execution Framework and the WebLicht Workflow Engine. Claus Zinn, Wei Qui, Marie Hinrichs, Emanuel Dima, and Alexandr Chernov University of Tübingen
How can CLARIN archive and curate my resources?
 How can CLARIN archive and curate my resources? Christoph Draxler draxler@phonetik.uni-muenchen.de Outline! Relevant resources CLARIN infrastructure European Research Infrastructure Consortium National
How can CLARIN archive and curate my resources? Christoph Draxler draxler@phonetik.uni-muenchen.de Outline! Relevant resources CLARIN infrastructure European Research Infrastructure Consortium National
1 Overview chart. PIDs: talk with EPIC PIDs: MoU or advice. Assessment wave 3. VLO overhaul CMDI 1.2
 Title Centre Committee work plan 2014 Version 2 Author(s) Dieter Van Uytvanck Date 2014-02- 05 Status To be approved Distribution Centre Committee, NCF, BOD ID CE- 2013-0257 1 Overview chart PIDs: talk
Title Centre Committee work plan 2014 Version 2 Author(s) Dieter Van Uytvanck Date 2014-02- 05 Status To be approved Distribution Centre Committee, NCF, BOD ID CE- 2013-0257 1 Overview chart PIDs: talk
Formats and standards for metadata, coding and tagging. Paul Meurer
 Formats and standards for metadata, coding and tagging Paul Meurer The FAIR principles FAIR principles for resources (data and metadata): Findable (-> persistent identifier, metadata, registered/indexed)
Formats and standards for metadata, coding and tagging Paul Meurer The FAIR principles FAIR principles for resources (data and metadata): Findable (-> persistent identifier, metadata, registered/indexed)
Importing MASC into the ANNIS linguistic database: A case study of mapping GrAF
 Importing MASC into the ANNIS linguistic database: A case study of mapping GrAF Arne Neumann 1 Nancy Ide 2 Manfred Stede 1 1 EB Cognitive Science and SFB 632 University of Potsdam 2 Department of Computer
Importing MASC into the ANNIS linguistic database: A case study of mapping GrAF Arne Neumann 1 Nancy Ide 2 Manfred Stede 1 1 EB Cognitive Science and SFB 632 University of Potsdam 2 Department of Computer
A Corpus Representation Format for Linguistic Web Services: the D-SPIN Text Corpus Format and its Relationship with ISO Standards
 A Corpus Representation Format for Linguistic Web Services: the D-SPIN Text Corpus Format and its Relationship with ISO Standards Ulrich Heid 1, Helmut Schmid 1, Kerstin Eckart 1, Erhard Hinrichs 2 1 Universität
A Corpus Representation Format for Linguistic Web Services: the D-SPIN Text Corpus Format and its Relationship with ISO Standards Ulrich Heid 1, Helmut Schmid 1, Kerstin Eckart 1, Erhard Hinrichs 2 1 Universität
UIMA-based Annotation Type System for a Text Mining Architecture
 UIMA-based Annotation Type System for a Text Mining Architecture Udo Hahn, Ekaterina Buyko, Katrin Tomanek, Scott Piao, Yoshimasa Tsuruoka, John McNaught, Sophia Ananiadou Jena University Language and
UIMA-based Annotation Type System for a Text Mining Architecture Udo Hahn, Ekaterina Buyko, Katrin Tomanek, Scott Piao, Yoshimasa Tsuruoka, John McNaught, Sophia Ananiadou Jena University Language and
Web services and workflow creation
 Web services and workflow creation 2010-07-01 Internal Version: 2 Editors: Marc Kemps-Snijders www.clarin.eu WG2.7 Web services and workflow creation 2 Web services and workflow creation CLARIN-2010-D2R-7b
Web services and workflow creation 2010-07-01 Internal Version: 2 Editors: Marc Kemps-Snijders www.clarin.eu WG2.7 Web services and workflow creation 2 Web services and workflow creation CLARIN-2010-D2R-7b
PDF hosted at the Radboud Repository of the Radboud University Nijmegen
 PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/119571
PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/119571
Managing very large Multimedia Archives and their Integration into Federations
 Managing very large Multimedia Archives and their Integration into Federations Daan Broeder, Eric Auer, Marc Kemps-Snijders, Han Sloetjes, Peter Wittenburg, Claus Zinn 1 1 Max-Planck-Institute for Psycholinguistics,
Managing very large Multimedia Archives and their Integration into Federations Daan Broeder, Eric Auer, Marc Kemps-Snijders, Han Sloetjes, Peter Wittenburg, Claus Zinn 1 1 Max-Planck-Institute for Psycholinguistics,
How do users formulate their queries? A morpho-syntactic analysis
 11th European Conference of Medical and Health Libraries How do users formulate their queries? A morpho-syntactic analysis Nicolas Ariste Fairon Life sciences library, University of Liege, 4000 Liège,
11th European Conference of Medical and Health Libraries How do users formulate their queries? A morpho-syntactic analysis Nicolas Ariste Fairon Life sciences library, University of Liege, 4000 Liège,
CORLI. a linguistic consortium for corpus, language and interaction
 CORLI a linguistic consortium for corpus, language and interaction CORLI and HUMA-NUM CORLI = Corpus, Languages, and Interaction a French consortium of Huma-Num involved in linguistic research and teaching
CORLI a linguistic consortium for corpus, language and interaction CORLI and HUMA-NUM CORLI = Corpus, Languages, and Interaction a French consortium of Huma-Num involved in linguistic research and teaching
Textual Emigration Analysis
 Textual Emigration Analysis Andre Blessing and Jonas Kuhn IMS - Universität Stuttgart, Germany clarin@ims.uni-stuttgart.de Abstract We present a web-based application which is called TEA (Textual Emigration
Textual Emigration Analysis Andre Blessing and Jonas Kuhn IMS - Universität Stuttgart, Germany clarin@ims.uni-stuttgart.de Abstract We present a web-based application which is called TEA (Textual Emigration
CLARIN Concept Registry: The New Semantic Registry
 CLARIN Concept Registry: The New Semantic Registry Ineke Schuurman Menzo Windhouwer KU Leuven, Belgium Meertens Institute and Utrecht University, The Netherlands Amsterdam, The Netherlands ineke@ccl.kuleuven.be
CLARIN Concept Registry: The New Semantic Registry Ineke Schuurman Menzo Windhouwer KU Leuven, Belgium Meertens Institute and Utrecht University, The Netherlands Amsterdam, The Netherlands ineke@ccl.kuleuven.be
D-SPIN Joint Deliverables R5.3: Documentation of the Web Services R5.4: Final Report
 D-SPIN Joint Deliverables R5.3: Documentation of the Web Services R5.4: Final Report March 2011 D-SPIN, BMBF-FKZ: 01UG0801A Deliverables: R5.3: Documentation of the Web Services R5.4: Final Report WP5
D-SPIN Joint Deliverables R5.3: Documentation of the Web Services R5.4: Final Report March 2011 D-SPIN, BMBF-FKZ: 01UG0801A Deliverables: R5.3: Documentation of the Web Services R5.4: Final Report WP5
Sustainability of Text-Technological Resources
 Sustainability of Text-Technological Resources Maik Stührenberg, Michael Beißwenger, Kai-Uwe Kühnberger, Harald Lüngen, Alexander Mehler, Dieter Metzing, Uwe Mönnich Research Group Text-Technological Overview
Sustainability of Text-Technological Resources Maik Stührenberg, Michael Beißwenger, Kai-Uwe Kühnberger, Harald Lüngen, Alexander Mehler, Dieter Metzing, Uwe Mönnich Research Group Text-Technological Overview
Annotation by category - ELAN and ISO DCR
 Annotation by category - ELAN and ISO DCR Han Sloetjes, Peter Wittenburg Max Planck Institute for Psycholinguistics P.O. Box 310, 6500 AH Nijmegen, The Netherlands E-mail: Han.Sloetjes@mpi.nl, Peter.Wittenburg@mpi.nl
Annotation by category - ELAN and ISO DCR Han Sloetjes, Peter Wittenburg Max Planck Institute for Psycholinguistics P.O. Box 310, 6500 AH Nijmegen, The Netherlands E-mail: Han.Sloetjes@mpi.nl, Peter.Wittenburg@mpi.nl
The Functional Extension Parser (FEP) A Document Understanding Platform
 A Document Understanding Platform") The Functional Extension Parser (FEP) A Document Understanding Platform Günter Mühlberger University of Innsbruck Department for German Language and Literature Studies Introduction A book is more than
The Functional Extension Parser (FEP) A Document Understanding Platform Günter Mühlberger University of Innsbruck Department for German Language and Literature Studies Introduction A book is more than
A functional database framework for querying very large multi-layer corpora
 Published in: Hedeland, Hanna/Schmidt, Thomas/Wörner, Kai (eds.): Multilingual Resources and Multilingual Applications. Proceedings of the Conference of the German Society for Computational Linguistics
Published in: Hedeland, Hanna/Schmidt, Thomas/Wörner, Kai (eds.): Multilingual Resources and Multilingual Applications. Proceedings of the Conference of the German Society for Computational Linguistics
The Multilingual Language Library
 The Multilingual Language Library @ LREC 2012 Let s build it together! Nicoletta Calzolari with Riccardo Del Gratta, Francesca Frontini, Francesco Rubino, Irene Russo Istituto di Linguistica Computazionale
The Multilingual Language Library @ LREC 2012 Let s build it together! Nicoletta Calzolari with Riccardo Del Gratta, Francesca Frontini, Francesco Rubino, Irene Russo Istituto di Linguistica Computazionale
Deliverable D Adapted tools for the QTLaunchPad infrastructure
 This document is part of the Coordination and Support Action Preparation and Launch of a Large-scale Action for Quality Translation Technology (QTLaunchPad). This project has received funding from the
This document is part of the Coordination and Support Action Preparation and Launch of a Large-scale Action for Quality Translation Technology (QTLaunchPad). This project has received funding from the
PDF hosted at the Radboud Repository of the Radboud University Nijmegen
 PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/40896
PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is a publisher's version. For additional information about this publication click this link. http://hdl.handle.net/2066/40896
Fast and Effective System for Name Entity Recognition on Big Data
 International Journal of Computer Sciences and Engineering Open Access Research Paper Volume-3, Issue-2 E-ISSN: 2347-2693 Fast and Effective System for Name Entity Recognition on Big Data Jigyasa Nigam
International Journal of Computer Sciences and Engineering Open Access Research Paper Volume-3, Issue-2 E-ISSN: 2347-2693 Fast and Effective System for Name Entity Recognition on Big Data Jigyasa Nigam
Improving the exploitation of linguistic annotations in ELAN
 Improving the exploitation of linguistic annotations in ELAN Onno Crasborn, Han Sloetjes Radboud University Nijmegen, Centre for Language Studies; The Language Archive, Max Planck Institute for Psycholinguistics
Improving the exploitation of linguistic annotations in ELAN Onno Crasborn, Han Sloetjes Radboud University Nijmegen, Centre for Language Studies; The Language Archive, Max Planck Institute for Psycholinguistics
The Prague Bulletin of Mathematical Linguistics NUMBER 91 JANUARY Memory-Based Machine Translation and Language Modeling
 The Prague Bulletin of Mathematical Linguistics NUMBER 91 JANUARY 2009 17 26 Memory-Based Machine Translation and Language Modeling Antal van den Bosch, Peter Berck Abstract We describe a freely available
The Prague Bulletin of Mathematical Linguistics NUMBER 91 JANUARY 2009 17 26 Memory-Based Machine Translation and Language Modeling Antal van den Bosch, Peter Berck Abstract We describe a freely available
XML Support for Annotated Language Resources
 XML Support for Annotated Language Resources Nancy Ide Department of Computer Science Vassar College Poughkeepsie, New York USA ide@cs.vassar.edu Laurent Romary Equipe Langue et Dialogue LORIA/CNRS Vandoeuvre-lès-Nancy,
XML Support for Annotated Language Resources Nancy Ide Department of Computer Science Vassar College Poughkeepsie, New York USA ide@cs.vassar.edu Laurent Romary Equipe Langue et Dialogue LORIA/CNRS Vandoeuvre-lès-Nancy,
Component Metadata Infrastructure Best Practices for CLARIN
 Component Metadata Infrastructure Best Practices for CLARIN CMDI and Metadata Curation Task Forces Thomas Eckart, Twan Goosen, Susanne Haaf, Hanna Hedeland, Oddrun Ohren, Dieter Van Uytvanck and Menzo
Component Metadata Infrastructure Best Practices for CLARIN CMDI and Metadata Curation Task Forces Thomas Eckart, Twan Goosen, Susanne Haaf, Hanna Hedeland, Oddrun Ohren, Dieter Van Uytvanck and Menzo
(Some) Standards in the Humanities. Sebastian Drude CLARIN ERIC RDA 4 th Plenary, Amsterdam September 2014
 Standards in the Humanities. Sebastian Drude CLARIN ERIC RDA 4 th Plenary, Amsterdam September 2014") (Some) Standards in the Humanities Sebastian Drude CLARIN ERIC RDA 4 th Plenary, Amsterdam September 2014 1. Introduction Overview 2. Written text: the Text Encoding Initiative (TEI) 3. Multimodal: ELAN
(Some) Standards in the Humanities Sebastian Drude CLARIN ERIC RDA 4 th Plenary, Amsterdam September 2014 1. Introduction Overview 2. Written text: the Text Encoding Initiative (TEI) 3. Multimodal: ELAN
Enhanced ELAN functionality for sign language corpora
 Enhanced ELAN functionality for sign language corpora Onno Crasborn, Han Sloetjes Department of Linguistics, Radboud University Nijmegen PO Box 9103, NL-6500 HD Nijmegen, The Netherlands Max Planck Institute
Enhanced ELAN functionality for sign language corpora Onno Crasborn, Han Sloetjes Department of Linguistics, Radboud University Nijmegen PO Box 9103, NL-6500 HD Nijmegen, The Netherlands Max Planck Institute
INTERCONNECTING AND MANAGING MULTILINGUAL LEXICAL LINKED DATA. Ernesto William De Luca
 INTERCONNECTING AND MANAGING MULTILINGUAL LEXICAL LINKED DATA Ernesto William De Luca Overview 2 Motivation EuroWordNet RDF/OWL EuroWordNet RDF/OWL LexiRes Tool Conclusions Overview 3 Motivation EuroWordNet
INTERCONNECTING AND MANAGING MULTILINGUAL LEXICAL LINKED DATA Ernesto William De Luca Overview 2 Motivation EuroWordNet RDF/OWL EuroWordNet RDF/OWL LexiRes Tool Conclusions Overview 3 Motivation EuroWordNet
Recent Developments in the Czech National Corpus
 Recent Developments in the Czech National Corpus Michal Křen Charles University in Prague 3 rd Workshop on the Challenges in the Management of Large Corpora Lancaster 20 July 2015 Introduction of the project
Recent Developments in the Czech National Corpus Michal Křen Charles University in Prague 3 rd Workshop on the Challenges in the Management of Large Corpora Lancaster 20 July 2015 Introduction of the project
Building for the Future
 Building for the Future The National Digital Newspaper Program Deborah Thomas US Library of Congress DigCCurr 2007 Chapel Hill, NC April 19, 2007 1 What is NDNP? Provide access to historic newspapers Select
Building for the Future The National Digital Newspaper Program Deborah Thomas US Library of Congress DigCCurr 2007 Chapel Hill, NC April 19, 2007 1 What is NDNP? Provide access to historic newspapers Select
Trusted Digital Archives
 Data Archiving and Networked Services Trusted Digital Archives Peter Doorn Data Archiving and Networked Services 14th General Assembly 29/30 April 2013 Berlin Berlin-Brandenburg Academy of Sciences and
Data Archiving and Networked Services Trusted Digital Archives Peter Doorn Data Archiving and Networked Services 14th General Assembly 29/30 April 2013 Berlin Berlin-Brandenburg Academy of Sciences and
CMDI and granularity
 CMDI and granularity Identifier CLARIND-AP3-007 AP 3 Authors Dieter Van Uytvanck, Twan Goosen, Menzo Windhouwer Responsible Dieter Van Uytvanck Reference(s) Version Date Changes by State 1 2011-01-24 Dieter
CMDI and granularity Identifier CLARIND-AP3-007 AP 3 Authors Dieter Van Uytvanck, Twan Goosen, Menzo Windhouwer Responsible Dieter Van Uytvanck Reference(s) Version Date Changes by State 1 2011-01-24 Dieter
An Oral History Annotation Tool for INTER- VIEWs
 An Oral History Annotation Tool for INTERVIEWs Eric Sanders, Henk van den Heuvel CLS/CLST, Radboud University Nijmegen, The Netherlands 1 Introduction Interview data can be used in a number of ways, such
An Oral History Annotation Tool for INTERVIEWs Eric Sanders, Henk van den Heuvel CLS/CLST, Radboud University Nijmegen, The Netherlands 1 Introduction Interview data can be used in a number of ways, such
CODA CATCHPlus Open Document Annotation. Hennie Brugman OAC II Project Review meeting Chicago July 26-27, 2012
 CODA CATCHPlus Open Document Annotation Hennie Brugman OAC II Project Review meeting Chicago July 26-27, 2012 Annotation context Audiovisual ASR, language, gesture, oral history Text Semantic annotation
CODA CATCHPlus Open Document Annotation Hennie Brugman OAC II Project Review meeting Chicago July 26-27, 2012 Annotation context Audiovisual ASR, language, gesture, oral history Text Semantic annotation
ECP-2008-DILI EuropeanaConnect. D5.7.1 EOD Connector Documentation and Final Prototype. PP (Restricted to other programme participants)
") ECP-2008-DILI-528001 EuropeanaConnect D5.7.1 EOD Connector Documentation and Final Prototype Deliverable number/name D 5.7.1 Dissemination level PP (Restricted to other programme participants) Delivery
ECP-2008-DILI-528001 EuropeanaConnect D5.7.1 EOD Connector Documentation and Final Prototype Deliverable number/name D 5.7.1 Dissemination level PP (Restricted to other programme participants) Delivery
COLDIC, a Lexicographic Platform for LMF Compliant Lexica
 COLDIC, a Lexicographic Platform for LMF Compliant Lexica Núria Bel, Sergio Espeja, Montserrat Marimon, Marta Villegas Institut Universitari de Lingüística Aplicada Universitat Pompeu Fabra Pl. de la Mercè,
COLDIC, a Lexicographic Platform for LMF Compliant Lexica Núria Bel, Sergio Espeja, Montserrat Marimon, Marta Villegas Institut Universitari de Lingüística Aplicada Universitat Pompeu Fabra Pl. de la Mercè,
An Archiving System for Managing Evolution in the Data Web
 An Archiving System for Managing Evolution in the Web Marios Meimaris *, George Papastefanatos and Christos Pateritsas * Institute for the Management of Information Systems, Research Center Athena, Greece
An Archiving System for Managing Evolution in the Web Marios Meimaris *, George Papastefanatos and Christos Pateritsas * Institute for the Management of Information Systems, Research Center Athena, Greece
Cheshire 3 Framework White Paper: Implementing Support for Digital Repositories in a Data Grid Environment
 Cheshire 3 Framework White Paper: Implementing Support for Digital Repositories in a Data Grid Environment Paul Watry Univ. of Liverpool, NaCTeM pwatry@liverpool.ac.uk Ray Larson Univ. of California, Berkeley
Cheshire 3 Framework White Paper: Implementing Support for Digital Repositories in a Data Grid Environment Paul Watry Univ. of Liverpool, NaCTeM pwatry@liverpool.ac.uk Ray Larson Univ. of California, Berkeley
The German Reference Corpus: New developments building on almost 50 years of experience
 Publsihed in: Arranz, Victoria/Eerten, Laura van (eds.): Language Resources: From Storyboard to Sustainability and LR Lifecycle Management, Workshop held at the seventh conference on International Language
Publsihed in: Arranz, Victoria/Eerten, Laura van (eds.): Language Resources: From Storyboard to Sustainability and LR Lifecycle Management, Workshop held at the seventh conference on International Language
PubMan Workshop. This work is licensed under a Creative Commons Attribution 3.0 Germany License
 PubMan Workshop Agenda (1) PubMan Facts (2) PubMan Re-Use Possibilities (3) PubMan Concepts Organizational Units Publication Workflows Validation Rules Contexts/Collections (4) PubMan Metadata Genre-specific
PubMan Workshop Agenda (1) PubMan Facts (2) PubMan Re-Use Possibilities (3) PubMan Concepts Organizational Units Publication Workflows Validation Rules Contexts/Collections (4) PubMan Metadata Genre-specific
Final Project Discussion. Adam Meyers Montclair State University
 Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
Final Project Discussion Adam Meyers Montclair State University Summary Project Timeline Project Format Details/Examples for Different Project Types Linguistic Resource Projects: Annotation, Lexicons,...
ANC2Go: A Web Application for Customized Corpus Creation
 ANC2Go: A Web Application for Customized Corpus Creation Nancy Ide, Keith Suderman, Brian Simms Department of Computer Science, Vassar College Poughkeepsie, New York 12604 USA {ide, suderman, brsimms}@cs.vassar.edu
ANC2Go: A Web Application for Customized Corpus Creation Nancy Ide, Keith Suderman, Brian Simms Department of Computer Science, Vassar College Poughkeepsie, New York 12604 USA {ide, suderman, brsimms}@cs.vassar.edu
Data Replication: Automated move and copy of data. PRACE Advanced Training Course on Data Staging and Data Movement Helsinki, September 10 th 2013
 Data Replication: Automated move and copy of data PRACE Advanced Training Course on Data Staging and Data Movement Helsinki, September 10 th 2013 Claudio Cacciari c.cacciari@cineca.it Outline The issue
Data Replication: Automated move and copy of data PRACE Advanced Training Course on Data Staging and Data Movement Helsinki, September 10 th 2013 Claudio Cacciari c.cacciari@cineca.it Outline The issue
On the way to Language Resources sharing: principles, challenges, solutions
 On the way to Language Resources sharing: principles, challenges, solutions Stelios Piperidis ILSP, RC Athena, Greece spip@ilsp.gr Content on the Multilingual Web, 4-5 April, Pisa, 2011 Co-funded by the
On the way to Language Resources sharing: principles, challenges, solutions Stelios Piperidis ILSP, RC Athena, Greece spip@ilsp.gr Content on the Multilingual Web, 4-5 April, Pisa, 2011 Co-funded by the
1. General requirements
 Title CLARIN B Centre Checklist Version 6 Author(s) Peter Wittenburg, Dieter Van Uytvanck, Thomas Zastrow, Pavel Straňák, Daan Broeder, Florian Schiel, Volker Boehlke, Uwe Reichel, Lene Offersgaard Date
Title CLARIN B Centre Checklist Version 6 Author(s) Peter Wittenburg, Dieter Van Uytvanck, Thomas Zastrow, Pavel Straňák, Daan Broeder, Florian Schiel, Volker Boehlke, Uwe Reichel, Lene Offersgaard Date
Modeling Linguistic Research Data for a Repository for Historical Corpora. Carolin Odebrecht Humboldt-Universität zu Berlin LAUDATIO-repository.
 Modeling Linguistic Research Data for a Repository for Historical Corpora Carolin Odebrecht Humboldt-Universität zu Berlin LAUDATIO-repository.org Motivation to enable the search for, the access of and
Modeling Linguistic Research Data for a Repository for Historical Corpora Carolin Odebrecht Humboldt-Universität zu Berlin LAUDATIO-repository.org Motivation to enable the search for, the access of and
Re-designing Online Terminology Resources for German Grammar
 Re-designing Online Terminology Resources for German Grammar Project Report Karolina Suchowolec, Christian Lang, and Roman Schneider Institut für Deutsche Sprache (IDS), Mannheim, Germany {suchowolec,
Re-designing Online Terminology Resources for German Grammar Project Report Karolina Suchowolec, Christian Lang, and Roman Schneider Institut für Deutsche Sprache (IDS), Mannheim, Germany {suchowolec,
AT&T: The Tag&Parse Approach to Semantic Parsing of Robot Spatial Commands
 AT&T: The Tag&Parse Approach to Semantic Parsing of Robot Spatial Commands Svetlana Stoyanchev, Hyuckchul Jung, John Chen, Srinivas Bangalore AT&T Labs Research 1 AT&T Way Bedminster NJ 07921 {sveta,hjung,jchen,srini}@research.att.com
AT&T: The Tag&Parse Approach to Semantic Parsing of Robot Spatial Commands Svetlana Stoyanchev, Hyuckchul Jung, John Chen, Srinivas Bangalore AT&T Labs Research 1 AT&T Way Bedminster NJ 07921 {sveta,hjung,jchen,srini}@research.att.com
Incremental Integer Linear Programming for Non-projective Dependency Parsing
 Incremental Integer Linear Programming for Non-projective Dependency Parsing Sebastian Riedel and James Clarke School of Informatics, University of Edinburgh 2 Bucclecuch Place, Edinburgh EH8 9LW, UK s.r.riedel@sms.ed.ac.uk,
Incremental Integer Linear Programming for Non-projective Dependency Parsing Sebastian Riedel and James Clarke School of Informatics, University of Edinburgh 2 Bucclecuch Place, Edinburgh EH8 9LW, UK s.r.riedel@sms.ed.ac.uk,
A cocktail approach to the VideoCLEF 09 linking task
 A cocktail approach to the VideoCLEF 09 linking task Stephan Raaijmakers Corné Versloot Joost de Wit TNO Information and Communication Technology Delft, The Netherlands {stephan.raaijmakers,corne.versloot,
A cocktail approach to the VideoCLEF 09 linking task Stephan Raaijmakers Corné Versloot Joost de Wit TNO Information and Communication Technology Delft, The Netherlands {stephan.raaijmakers,corne.versloot,
Initial authorization and authentication scheme plan exists
 Initial authorization and authentication scheme plan exists CLARIN-2010-1 EC FP7 project no. 212230 Milestone: M7S-2.1 Responsible: UHEL Contributing Partners: UHEL Contributing Members: CSC all rights
Initial authorization and authentication scheme plan exists CLARIN-2010-1 EC FP7 project no. 212230 Milestone: M7S-2.1 Responsible: UHEL Contributing Partners: UHEL Contributing Members: CSC all rights
CEN MetaLex. Facilitating Interchange in E- Government. Alexander Boer
 CEN MetaLex Facilitating Interchange in E- Government Alexander Boer aboer@uva.nl MetaLex Initiative taken by us in 2002 Workshop on an open XML interchange format for legal and legislative resources www.metalex.eu
CEN MetaLex Facilitating Interchange in E- Government Alexander Boer aboer@uva.nl MetaLex Initiative taken by us in 2002 Workshop on an open XML interchange format for legal and legislative resources www.metalex.eu
META-SHARE metadata: Overview of the schema & Interoperability with other schemas
 META-SHARE metadata: Overview of the schema & Interoperability with other schemas Penny Labropoulou & Maria Gavrilidou (ILSP/RC Athena) CMDI Interoperability Workshop Utrecht, Netherlands 4-5 June 2013
META-SHARE metadata: Overview of the schema & Interoperability with other schemas Penny Labropoulou & Maria Gavrilidou (ILSP/RC Athena) CMDI Interoperability Workshop Utrecht, Netherlands 4-5 June 2013
Implementation of the Data Seal of Approval
 Implementation of the Data Seal of Approval The Data Seal of Approval board hereby confirms that the Trusted Digital repository IDS Repository complies with the guidelines version 2014-2017 set by the.
Implementation of the Data Seal of Approval The Data Seal of Approval board hereby confirms that the Trusted Digital repository IDS Repository complies with the guidelines version 2014-2017 set by the.
Automatic Annotation and Manual Evaluation of the Diachronic German Corpus TüBa-D/DC
 Automatic Annotation and Manual Evaluation of the Diachronic German Corpus TüBa-D/DC Erhard Hinrichs, Thomas Zastrow University of Tübingen Wilhelmstr. 19, 72074 Tübingen, Germany [erhard.hinrichs, thomas.zastrow]@uni-tuebingen.de
Automatic Annotation and Manual Evaluation of the Diachronic German Corpus TüBa-D/DC Erhard Hinrichs, Thomas Zastrow University of Tübingen Wilhelmstr. 19, 72074 Tübingen, Germany [erhard.hinrichs, thomas.zastrow]@uni-tuebingen.de
Discriminative Training with Perceptron Algorithm for POS Tagging Task
 Discriminative Training with Perceptron Algorithm for POS Tagging Task Mahsa Yarmohammadi Center for Spoken Language Understanding Oregon Health & Science University Portland, Oregon yarmoham@ohsu.edu
Discriminative Training with Perceptron Algorithm for POS Tagging Task Mahsa Yarmohammadi Center for Spoken Language Understanding Oregon Health & Science University Portland, Oregon yarmoham@ohsu.edu
International Journal of Computer Science Trends and Technology (IJCST) Volume 3 Issue 4, Jul-Aug 2015
 Volume 3 Issue 4, Jul-Aug 2015") RESEARCH ARTICLE OPEN ACCESS Multi-Lingual Ontology Server (MOS) For Discovering Web Services Abdelrahman Abbas Ibrahim [1], Dr. Nael Salman [2] Department of Software Engineering [1] Sudan University
RESEARCH ARTICLE OPEN ACCESS Multi-Lingual Ontology Server (MOS) For Discovering Web Services Abdelrahman Abbas Ibrahim [1], Dr. Nael Salman [2] Department of Software Engineering [1] Sudan University
Corpus Linguistics: corpus annotation
 Corpus Linguistics: corpus annotation Karën Fort karen.fort@inist.fr November 30, 2010 Introduction Methodology Annotation Issues Annotation Formats From Formats to Schemes Sources Most of this course
Corpus Linguistics: corpus annotation Karën Fort karen.fort@inist.fr November 30, 2010 Introduction Methodology Annotation Issues Annotation Formats From Formats to Schemes Sources Most of this course
Namescape: Named Entity Recognition from a Literary Perspective
 CHAPTER 30 Namescape: Named Entity Recognition from a Literary Perspective Jesse de Does a, Katrien Depuydt a, Karina van Dalen-Oskam b,c and Maarten Marx c a Dutch Language Institute, Leiden, jesse.dedoes@ivdnt.org,
CHAPTER 30 Namescape: Named Entity Recognition from a Literary Perspective Jesse de Does a, Katrien Depuydt a, Karina van Dalen-Oskam b,c and Maarten Marx c a Dutch Language Institute, Leiden, jesse.dedoes@ivdnt.org,
1 Web references are marked by bracketed number order and can be found at the end of this squib.
 Squibs The Language Resource Switchboard Claus Zinn University of Tübingen Department of Computational Linguistics claus.zinn@uni-tuebingen.de The CLARIN research infrastructure gives users access to an
Squibs The Language Resource Switchboard Claus Zinn University of Tübingen Department of Computational Linguistics claus.zinn@uni-tuebingen.de The CLARIN research infrastructure gives users access to an
TEXT MINING: THE NEXT DATA FRONTIER
 TEXT MINING: THE NEXT DATA FRONTIER An Infrastructural Approach Dr. Petr Knoth CORE (core.ac.uk) Knowledge Media institute, The Open University United Kingdom 2 OpenMinTeD Establish an open and sustainable
TEXT MINING: THE NEXT DATA FRONTIER An Infrastructural Approach Dr. Petr Knoth CORE (core.ac.uk) Knowledge Media institute, The Open University United Kingdom 2 OpenMinTeD Establish an open and sustainable
Integration of Language Resources into Web service infrastructure
 Integration of Language Resources into Web service infrastructure 2011-03-14 Version: 0.9 Editors: Maciej Ogrodniczuk, Adam Przepiórkowski The ultimate objective of CLARIN is to create a European federation
Integration of Language Resources into Web service infrastructure 2011-03-14 Version: 0.9 Editors: Maciej Ogrodniczuk, Adam Przepiórkowski The ultimate objective of CLARIN is to create a European federation
Research partnerships, user participation, extended outreach some of ETH Library s steps beyond digitization
 IFLA Satellite Meeting 2017: Digital Humanities, Berlin, 15 17 August 2017 Research partnerships, user participation, extended outreach some of ETH Library s steps beyond digitization From «boutique» to
IFLA Satellite Meeting 2017: Digital Humanities, Berlin, 15 17 August 2017 Research partnerships, user participation, extended outreach some of ETH Library s steps beyond digitization From «boutique» to
Implementation of the Data Seal of Approval
 Implementation of the Data Seal of Approval The Data Seal of Approval board hereby confirms that the Trusted Digital repository LINDAT-Clarin - Centre for Language Research Infrastructure in the Czech
Implementation of the Data Seal of Approval The Data Seal of Approval board hereby confirms that the Trusted Digital repository LINDAT-Clarin - Centre for Language Research Infrastructure in the Czech
SEMANTIC WEB POWERED PORTAL INFRASTRUCTURE
 SEMANTIC WEB POWERED PORTAL INFRASTRUCTURE YING DING 1 Digital Enterprise Research Institute Leopold-Franzens Universität Innsbruck Austria DIETER FENSEL Digital Enterprise Research Institute National
SEMANTIC WEB POWERED PORTAL INFRASTRUCTURE YING DING 1 Digital Enterprise Research Institute Leopold-Franzens Universität Innsbruck Austria DIETER FENSEL Digital Enterprise Research Institute National
Profiling Medical Journal Articles Using a Gene Ontology Semantic Tagger. Mahmoud El-Haj Paul Rayson Scott Piao Jo Knight
 Profiling Medical Journal Articles Using a Gene Ontology Semantic Tagger Mahmoud El-Haj Paul Rayson Scott Piao Jo Knight Origin and Outcomes Currently funded through a Wellcome Trust Seed award Collaboration
Profiling Medical Journal Articles Using a Gene Ontology Semantic Tagger Mahmoud El-Haj Paul Rayson Scott Piao Jo Knight Origin and Outcomes Currently funded through a Wellcome Trust Seed award Collaboration
Introduction to Web Services & SOA
 References: Web Services, A Technical Introduction, Deitel & Deitel Building Scalable and High Performance Java Web Applications, Barish Web Service Definition The term "Web Services" can be confusing.
References: Web Services, A Technical Introduction, Deitel & Deitel Building Scalable and High Performance Java Web Applications, Barish Web Service Definition The term "Web Services" can be confusing.
Text Corpus Format (Version 0.4) Helmut Schmid SfS Tübingen / IMS StuDgart
 Helmut Schmid SfS Tübingen / IMS StuDgart") Text Corpus Format (Version 0.4) Helmut Schmid SfS Tübingen / IMS StuDgart Why Do We Need a TCF? We want to chain together many different NLP tools (tokenizers, POS taggers, lemmarzers, parsers etc.) Why
Text Corpus Format (Version 0.4) Helmut Schmid SfS Tübingen / IMS StuDgart Why Do We Need a TCF? We want to chain together many different NLP tools (tokenizers, POS taggers, lemmarzers, parsers etc.) Why
Number game Experience of a European research infrastructure (CLARIN) for the analysis of web traffic
 for the analysis of web traffic") Number game Experience of a European research infrastructure (CLARIN) for the analysis of web traffic Go Sugimoto (Austrian Center for Digital Humanities) CLARIN Annual Conference 2016, Aix-en-Provence,
Number game Experience of a European research infrastructure (CLARIN) for the analysis of web traffic Go Sugimoto (Austrian Center for Digital Humanities) CLARIN Annual Conference 2016, Aix-en-Provence,
Conversion and Annotation Web Services for Spoken Language Data in CLARIN
 Conversion and Annotation Web Services for Spoken Language Data in CLARIN Thomas Schmidt Institute for the German Language (IDS) Mannheim thomas.schmidt@ ids-mannheim.de Hanna Hedeland Hamburg Centre for
Conversion and Annotation Web Services for Spoken Language Data in CLARIN Thomas Schmidt Institute for the German Language (IDS) Mannheim thomas.schmidt@ ids-mannheim.de Hanna Hedeland Hamburg Centre for
A prototype infrastructure for DSpin
 A prototype infrastructure for DSpin - DSpin/Clarin, LLS, prototype, toolwrappers, roadmap - Volker Boehlke University of Leipzig Institut für Informatik Some facts about me - iba Consulting Gesellschaft
A prototype infrastructure for DSpin - DSpin/Clarin, LLS, prototype, toolwrappers, roadmap - Volker Boehlke University of Leipzig Institut für Informatik Some facts about me - iba Consulting Gesellschaft
Towards a roadmap for standardization in language technology
 Towards a roadmap for standardization in language technology Laurent Romary & Nancy Ide Loria-INRIA Vassar College Overview General background on standardization Available standards On-going activities
Towards a roadmap for standardization in language technology Laurent Romary & Nancy Ide Loria-INRIA Vassar College Overview General background on standardization Available standards On-going activities
Annotating Spatio-Temporal Information in Documents
 Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
Annotating Spatio-Temporal Information in Documents Jannik Strötgen University of Heidelberg Institute of Computer Science Database Systems Research Group http://dbs.ifi.uni-heidelberg.de stroetgen@uni-hd.de
EUDAT- Towards a Global Collaborative Data Infrastructure
 EUDAT- Towards a Global Collaborative Data Infrastructure FOT-Net Data Stakeholder Meeting Brussels, 8 March 2016 Yann Le Franc, PhD e-science Data Factory, France CEO and founder EUDAT receives funding
EUDAT- Towards a Global Collaborative Data Infrastructure FOT-Net Data Stakeholder Meeting Brussels, 8 March 2016 Yann Le Franc, PhD e-science Data Factory, France CEO and founder EUDAT receives funding