Firebird 3.0 statistics and plans
|
|
|
- Shawn Bradley
- 6 years ago
- Views:
Transcription
1 1 Firebird 3.0 statistics and plans Dmitry Kuzmenko, IBSurgeon
2 2 Firebird 2017 Tour: Performance Optimization Firebird Tour 2017 is organized by Firebird Project, IBSurgeon and IBPhoenix, and devoted to Firebird Performance. The Platinum sponsor is Moscow Exchange Tour's locations and dates: October 3, 2017 Prague, Czech Republic October 5, 2017 Bad Sassendorf, Germany November 3, 2017 Moscow, Russia

3 3 Platinum Sponsor Sponsor of «Firebird 2.5 SQL Language Reference» «Firebird 3.0 SQL Language Reference» «Firebird 3.0 Developer Guide» «Firebird 3.0 Operations Guide» Sponsor of Firebird 2017 Tour seminars



4 4 Replication, Recovery and Optimization for Firebird and InterBase since 2002 Platinum Sponsor of Firebird Foundation Based in Moscow, Russia
5 5 Agenda New elements for table statistics Including blob information New elements for index statistics Plan elements Explained plans Optimizer enhancements Firebird 3 and 4
6 6 NEW STATISTICS ELEMENTS
7 7 How to get statistics Gstat r Gstat r t tablename1 t tablename2 Services API HQbird Database Analyst
8 8 Tables JOB (129) Primary pointer page: 228, Index root page: 229 Total formats: 1, used formats: 1 Average record length: 65.58, total records: 31 Average version length: 0.00, total versions: 0, max versions: 0 Average fragment length: 0.00, total fragments: 0, max fragments: 0 Average unpacked length: 96.00, compression ratio: 1.46 Pointer pages: 1, data page slots: 3 Data pages: 3, average fill: 72% Primary pages: 1, secondary pages: 2, swept pages: 1 Empty pages: 0, full pages: 1 Blobs: 39, total length: 4840, blob pages: 0 Level 0: 39, Level 1: 0, Level 2: 0 Fill distribution: 0-19% = % = % = % = % = 1
9 9 Total formats: 1, used formats: 1 Number of table structure changes (except triggers and indices) Limited to 256 After limit exceeded, you need to do backup/restore Used formats how many formats used by primary records. Number of all used formats is unknown (less or equal of Formats)
10 10 Primary, Secondary new storage concept Primary Primary record versions - insert Backversions Secondary Backversions, record fragments - update/delete Small blobs (level 0)
11 11 Swept Processed by garbage collector or sweep Sweep skips swept pages Used for primary pages When no work for garbage collector Cleared when new version is created on the data page
12 12 Average fragment length: 0.00, total fragments: 0, max fragments: 0 Fragments - records that does not fit at a page Big records Big record+versions chain Max fragments the most number of fragments for some record
13 13 Packing Average unpacked length: 96.00, compression ratio: 1.46 Average record length: / = 1.46
14 14 Empty, full Full when there is no space to place new record (version) Empty empty, while not gathered into 8- pages extent. These pages are marked as unused only when all pages in extent are empty.
15 15 Blobs, blob levels Blobs: 463, total length: , blob pages: Level 0: 0, Level 1: 463, Level 2: 0 Level 0 fits to the data page. Record data is sparsed. Page of 4096 bytes can hold blob of 4052 bytes Level 1 pointers to the blob pages. Blobs bigger than page size, and up to ~4mb size can rarefact data same way as 4052 blobs. Because 4052 bytes can fit 1013 links to the blob pages Level 2 pointer to the blob pointer page, that contain pointers to the blob pages
16 16 Level 1 pointers to the blob pages BLOB BLOB Levels Level 0 at data page, as record data BLOB record BLOB page with data BLOB page with data BLOB pointer page Data page BLOB record BLOB data page Level 2 pointers to pointers (BLOB pages with pointers) BLOB Record BLOB pointer page BLOB data page BLOB data page BLOB data page
17 17 What was earlier (ODS < 12) Small blobs (level 0) sparse record data, because they fit at data page Records could be highly sparsed, causing performance loss on scans without accessing blobs To avoid this small blobs needed to be moved to separate table, linked 1:1 to the main table
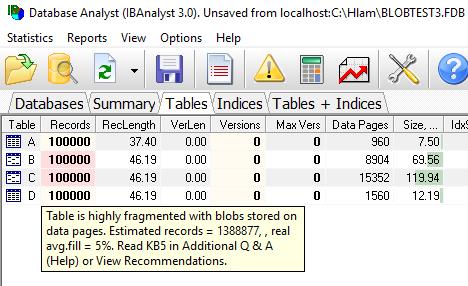
18 18
19 19 Blob level 0 Now blob record, i.e. blob contents, stored at a secondary page, while record is at primary page Eliminates data page sparse Makes scan operations much faster Anything that does not touch blob data
20 20 Blob level 1 Blobs: 463, total length: , blob pages: Level 0: 0, Level 1: 463, Level 2: 0 Here all blobs Bigger than page size (16k) (no Level 0) Less than 64mb (no level 2) Do not interleave record data
21 21 Blob level 2 Blob record points to pages that contain pointers to blob pages For 16k page size blob size must be bigger than 64mb to get Level 2
22 22 Test Page size = 8192 Tables, 100k records, random data A no blobs at all B random blobs from 128 to 1024 bytes size Fits at data page level 0 C fixed blobs 1024 bytes size Fits at data page level 0 D fixed blobs 9000 bytes size Goes to separate blob page level 1 Reading all fields except blob Fetch all, select count
23 23 Reading speed, ms 0,800 0,700 0,600 0,500 0,400 0,300 0,200 0,100 0,000 A B C D FB 2.5 FB 3.0 Performance with B and C may decrease up to 22%
24 24 SELECT * FROM C Fetch All PLAN (C NATURAL) Performance info Prepare time = 16ms Execute time = 875ms Memory buffers = 256 Reads from disk to cache = Writes from cache to disk = 0 Fetches from cache =
25 25 Page reads A B C D FB 2.5 FB 3.0
26 26 Number of pages FB 2.5 FB 3.0 PP SP A B C D
27 27 Results Now blob record is placed at secondary page Blobs and versions may be mixed at secondary pages only Scanning data without blobs is faster and uses less I/O Level 0 in FB 3.0 by performance similar to blobs Level 1 in Firebird 2.5 Scanning - 2x times less fetches Select count - 25% less fetches
28 28 Indices Index MAXSALX (2) Root page: 324, depth: 1, leaf buckets: 1, nodes: 31 Average node length: 14.74, total dup: 5, max dup: 1 Average key length: 13.71, compression ratio: 1.37 Average prefix length: 7.87, average data length: Clustering factor: 1, ratio: 0.03 Fill distribution: 0-19% = % = % = % = % = 0
29 29 Node, key, prefix Average node length: Average key length: 13.71, compression ratio: 1.37 Average prefix length: 7.87, average data length: Node prefix + key + record number Key indexed data (column value) Compression board 0 5 board boarding 5 3 ing boarded 5 2 ed Sequential numbers may be compressed up to 8 times in comparison with GUIDs
30 30 Clustering Factor Data Page 12 Index Key 1 Data Page 25 Index Key 2 Data Page 12 Data Page 28 Index Key 3 Data Page 13 Data Page 44 Index Key 4 Data Page 14 Data Page 57 Index Key 5 Bad Clustering Factor = 5 guid primary key Good Clustering Factor = 3 int/bigint primary key
31 31 Example: Clustering factor: 1066, ratio: 0.01 nodes: Primary pages: 1066 Ratio = Clustering factor / Nodes = 1066/ = 0.01 Ratio * keys in range = future DP reads The best Clustering factor equal to the number of primary data pages
32 32 Example: Clustering factor: 1066, ratio: 0.01 Clustering factor jumps to different primary data pages while walking through index 1066 with 1066 primary pages means the best Another index may have worse clustering factor For example, 2132, i.e. will be 2x primary page reads Cache size will these data pages fit, or not? (will be re-read from disk)
33 33 Clustering factor Clustering factor closer to the primary data pages number good Ratio less is better How clustering factor affects performance? See below
34 34 PLAN ELEMENTS
35 35 Plan elements tablename NATURAL tablename INDEX indexname Tablename ORDER indexname JOIN HASH JOIN SORT SORT MERGE
36 36 PLAN (TABLE NATURAL) select * from employee PLAN (EMPLOYEE NATURAL) The fastest way to read data Record 1 Record 2 Record 3 Record 3 Record 4 Record 5
37 37 PLAN (TABLE INDEX indexname) Search for first key applying to condition Collect all row numbers for keys, that applying to condition Sort array of row numbers Fetch records from sorted array of row numbers select * from employee where emp_no > 5 PLAN (EMPLOYEE INDEX (RDB$PRIMARY7))
38 38 Index -> Table Root Page Pointer Page Keys (Leaf page) Data Pages A C A r55 B r28 r15 r20 r28 A D D C r44 C r68 D r15 E r43 r43 r44 r55 r68 r75
39 39 How to force optimizer to use index We know that all employees have emp_no > 0. Then select * from employee where emp_no > 0 PLAN (EMPLOYEE INDEX (RDB$PRIMARY7)) But, All index pages will be scanned to get row numbers of all keys data pages will be scanned too (to read records) Result bigger page I/O Sometimes this trick allows to change PLAN (and query speed)
40 40 Index bitmap merge select * from employee where emp_no > 5 and last_name > 'b' PLAN (EMPLOYEE INDEX (RDB$PRIMARY7, NAMEX)) employee rdb$primary7 namex emp_no > 5 last_name > b AND, OR
41 41 select * from employee where emp_no > 5 and last_name > 'b' PLAN (EMPLOYEE INDEX (RDB$PRIMARY7, NAMEX)) You will not get that plan in Firebird 3 in employee.fdb Because optimizer eliminates indices on small tables Real plan: PLAN (EMPLOYEE INDEX (RDB$PRIMARY7))
42 42 PLAN (TABLE ORDER INDEX) Table walk by index order select * from employee order by last_name PLAN (EMPLOYEE ORDER NAMEX) Stays on first key (or key by where condition) Read record apply filter, if any Goto next key Read record
43 43 Index -> Table Root Page Pointer Page Keys (Leaf page) Data Pages A C A r55 B r28 r15 r20 r28 A D D C r44 C r68 D r15 E r43 r43 r44 r55 r68 r75
44 44 Clustering Factor Data Page 12 Index Key 1 Data Page 25 Index Key 2 Data Page 12 Data Page 28 Index Key 3 Data Page 13 Data Page 44 Index Key 4 Data Page 14 Data Page 57 Index Key 5 Bad Clustering Factor guid primary key Good Clustering Factor int/bigint primary key
45 45 Summary for table ORDER index Returns first row very quickly Jumping by data pages Causing pages dropping from cache, if cache size can t fit all data pages read Index Clustering factor Order of keys corresponding to records Firebird 3 between pages and rows (less is better) Example
46 46 Index Order Example select count(*) from table (14mln records) Execute time = 42s 500ms Buffers = 2048 Reads = Fetches = select a, count(a) from table group by a PLAN (TABLE ORDER A) Execute time = 45m 55s 469ms Reads = each page was read from disk to cache 31 times Fetches = Can be used to check disk performance pages * page_size / sec = 43mb/sec
47 47 select a from table order by a PLAN (TABLE ORDER A) Execute time = 63ms Buffers = Reads = 48 Fetches = if user will press Ctrl/End, it will take 3 mln reads and 45 minutes to get to the last row
48 48 table ORDER index notes Affects ORDER BY and GROUP BY Difference is only between number of rows returned to the client! Group by may use another access method instead SORT, so do not use GROUP BY for ordering Lot of rows causes huge page I/O Quickly return first rows, takes long time to get to the last row Only one index can be used order of fields, number of fields and order direction must correspond to index
49 49 PLAN SORT select * from employee order by first_name PLAN SORT ((EMPLOYEE NATURAL)) Database Moving rows Memory + temporary file Sorting data Returning data to client
50 50 Sort tuning firebird.conf TempBlockSize = May increase to 2 or 3mln bytes, but not to 16mb TempCacheLimit = SuperServer and SuperClassic. Classic = 8mb. TempDirectories = c:\temp;d:\temp Classic RAM Disk, point TempDirectories to RAM disk first, to hdd next SC, SS tune Temp* parameters
51 51 ORDER vs SORT PLAN (TABLE ORDER A) Execute time = 45m 55s 469ms Buffers = Reads = Fetches = PLAN SORT ((A NATURAL)) Execute time = 2m 5s 485ms Buffers = Reads = Fetches Reads equal to the table size (select count(*)) Takes 2 minutes, then ready to return the whole result without delay Temp file is deleted when last row fetched N of temp files = N of queries with plan sort Need to monitor number of temp files and their size
52 52 Average record length: , total records: Data pages: , average fill: 99% Primary pages: , secondary pages: 0, swept pages: 0 Index BY_CZ (5) Clustering factor: , ratio: 0.15 Index MINS_CLIENT (0) Clustering factor: , ratio: 0.26 Index MINS_DATE (3) Clustering factor: , ratio: 0.54 Index MINS_NUMA (1) Clustering factor: , ratio: 0.58
53 53 EXPLAIN PLAN
54 54 ISQL set planonly; Old and new plan output Old plan example: PLAN SORT (RDB$RELATIONS INDEX (RDB$INDEX_0)) set explain;
55 55 Old and new plan output SELECT * FROM RDB$RELATIONS WHERE RDB$RELATION_NAME > :a ORDER BY RDB$SYSTEM_FLAG PLAN SORT (RDB$RELATIONS INDEX (RDB$INDEX_0)) Select Expression -> Sort (record length: 484, key length: 8) -> Filter -> Table "RDB$RELATIONS" Access By ID -> Bitmap -> Index "RDB$INDEX_0" Range Scan (lower bound: 1/1)
56 56 Old and new plan output SELECT * FROM RDB$RELATIONS WHERE RDB$RELATION_NAME > :a ORDER BY RDB$SYSTEM_FLAG PLAN SORT (RDB$RELATIONS INDEX (RDB$INDEX_0)) Select Expression -> Sort (record length: 484, key length: 8) -> Filter -> Table "RDB$RELATIONS" Access By ID -> Bitmap -> Index "RDB$INDEX_0" Range Scan (lower bound: 1/1)
57 57 Old and new plan output SELECT * FROM RDB$RELATIONS WHERE RDB$RELATION_NAME > :a ORDER BY RDB$SYSTEM_FLAG PLAN SORT (RDB$RELATIONS INDEX (RDB$INDEX_0)) Select Expression -> Sort (record length: 484, key length: 8) -> Filter -> Table "RDB$RELATIONS" Access By ID -> Bitmap -> Index "RDB$INDEX_0" Range Scan (lower bound: 1/1)
58 58 Index Scan Lower bound Upper bound Full scan Unique scan
59 59 Composite indices CREATE INDEX BY_AB ON MYTABLE (A, B) SELECT * FROM MYTABLE WHERE A = 1 AND B > 5 PLAN (MYTABLE INDEX (BY_AB)) A B
60 60 Second column sorted by groups, depending on first column values where A > 1 and B > 5 will not use 2 nd column where A = 1 and B will use first and second column where A = 1 and B = 5 and C
61 61 Index "RDB$INDEX_0" Range Scan (lower bound: 1/1) For composite indices > 1. First how many segments were used Second how many segments index have 1/3 only one segment is used 2/3 first 2 segments are used 3/3 all segments are used 1/3 very ineffective, 2/3 medium effective Consider using single-column indices instead
62 62 Procedure plan Now natural, instead of all plans for all queries
63 63 Cost estimation Cardinality number of records in the table. Computed by scanning pointer pages Selectivity 1/(Keys Total Dup) The less is better. Number of unique key values = keys total_dup
64 64 Cost estimation SELECT * FROM T1 JOIN T2 ON T1.PK = T2.FK WHERE T1.VAL < 100 ORDER BY T1.RANK PLAN SORT ( JOIN ( T1 NATURAL, T2 INDEX (FK) )) Table T1: base cardinality = 1000 Table T2: base cardinality = 5000 Index FK: selectivity = Full Scan cost = 1000 cardinality = 1000 Final Row Set cost = 5000 cardinality = 2500 Sort cost = 5000 cardinality = 2500 Loop Join cost = 4500 cardinality = 2500 Filter cost = 1000 cardinality = 500 Index Scan cost = 7 cardinality = 5
65 65 EXPLAINED PLAN EXAMPLES
66 66 select * from rdb$relations where rdb$relation_name > :a PLAN (RDB$RELATIONS INDEX (RDB$INDEX_0)) Select Expression -> Filter -> Table "RDB$RELATIONS" Access By ID -> Bitmap -> Index "RDB$INDEX_0" Range Scan (lower bound: 1/1)
67 67 select * from a where name > 'b' and a.id > 5 PLAN (A INDEX (ANAME, PK_A)) Select Expression -> Filter -> Table "A" Access By ID -> Bitmap And -> Bitmap -> Index "ANAME" Range Scan (lower bound: 1/1) -> Bitmap -> Index "PK_A" Range Scan (lower bound: 1/1)
68 68 select * from minutes where code = '5' and zone > 5 PLAN (MINUTES INDEX (BY_CZ)) Select Expression -> Filter -> Table "MINUTES" Access By ID -> Bitmap -> Index "BY_CZ" Range Scan (lower bound: 2/2, upper bound: 1/2)
69 69 select * from rdb$relations where rdb$relation_name > :a order by rdb$relation_name PLAN (RDB$RELATIONS ORDER RDB$INDEX_0) Select Expression -> Filter -> Table "RDB$RELATIONS" Access By ID -> Index "RDB$INDEX_0" Range Scan (lower bound: 1/1)! No Bitmap index walk
70 70 select * from rdb$relations where rdb$relation_name > :a order by rdb$relation_name PLAN SORT (RDB$RELATIONS INDEX (RDB$INDEX_0)) Select Expression -> Sort (record length: 582, key length: 100) -> Filter -> Table "RDB$RELATIONS" Access By ID -> Bitmap -> Index "RDB$INDEX_0" Range Scan (lower bound: 1/1)
71 71 select e.last_name, p.proj_id from employee e, employee_project p where e.emp_no = p.emp_no PLAN JOIN (P NATURAL, E INDEX (RDB$PRIMARY7)) Select Expression -> Nested Loop Join (inner) -> Table "EMPLOYEE_PROJECT" as "P" Full Scan -> Filter -> Table "EMPLOYEE" as "E" Access By ID -> Bitmap -> Index "RDB$PRIMARY7" Unique Scan
72 72 select e.last_name, p.proj_id from employee e left join employee_project p on e.emp_no = p.emp_no where p.emp_no is null PLAN JOIN (E NATURAL, P INDEX (RDB$FOREIGN15)) Select Expression -> Filter -> Nested Loop Join (outer) -> Table "EMPLOYEE" as "E" Full Scan -> Filter -> Table "EMPLOYEE_PROJECT" as "P" Access By ID -> Bitmap -> Index "RDB$FOREIGN15" Range Scan (full match)
73 73 select e.* from employee e, employee_project p where e.emp_no+0 = p.emp_no+0 PLAN HASH (E NATURAL, P NATURAL) Select Expression -> Filter -> Hash Join (inner) -> Table "EMPLOYEE" as "E" Full Scan -> Record Buffer (record length: 25) -> Table "EMPLOYEE_PROJECT" as "P" Full Scan
74 74 select * from employee where (emp_no = :param) or (:param is null) where (emp_no = :param) or (:param = 0) Old plan PLAN (EMPLOYEE NATURAL) New plan PLAN (EMPLOYEE NATURAL, EMPLOYEE INDEX (RDB$PRIMARY7))
75 75 Plan change at runtime Select Expression -> Filter -> Condition -> Table "EMPLOYEE" Full Scan -> Table "EMPLOYEE" Access By ID -> Bitmap -> Index "RDB$PRIMARY7" Unique Scan
76 76 select * from employee where last_name = 'b' order by first_name PLAN (EMPLOYEE ORDER NAMEX) Select Expression -> Filter -> Table "EMPLOYEE" Access By ID -> Index "NAMEX" Range Scan (partial match: 1/2)
77 77 select * from employee where emp_no in (1, 2, 3) PLAN (EMPLOYEE INDEX (RDB$PRIMARY7, RDB$PRIMARY7, RDB$PRIMARY7)) Select Expression -> Filter -> Table "EMPLOYEE" Access By ID -> Bitmap Or -> Bitmap Or -> Bitmap -> Index "RDB$PRIMARY7" Unique Scan -> Bitmap -> Index "RDB$PRIMARY7" Unique Scan -> Bitmap -> Index "RDB$PRIMARY7" Unique Scan
78 78 Field in (1,2,3) Uses index 3 times one bitmap, 3 scans Field+0 in (1,2,3) Turns index usage off, completely Field+0 in (1, 2,3) and (field between 1 and 3) Turns index on back, range scan once, to avoid natural scan
79 79 ANOTHER FIREBIRD 3 AND 4 OPTIMIZER FEATURES
80 80 Stream materialization (caching) allows to avoid re-reading the same data from tables (for non-correlated streams) currently used only for hash joins, to be used for subqueries too Hash join join algorithm for non-indexed correlation usually performs better than merge join can be used instead of nested loops to avoid repeating reads of the same rows (in the future)
81 81 FULL JOIN improvements reimplemented as «semi-join union all antijoin» can use available indices now Conditional streams allow to choose between possible plans at runtime currently used only for(field = :PARAM OR :PARAM IS NULL)
82 82 Improved ORDER plan implementation avoid bad plans like «A ORDER I INDEX(I)», use simple «A ORDER I» with a range scan instead allow ORDER plan for «WHERE A = 0 ORDER BY B» if compound index {A, B} exists
83 83 Implicit FIRST ROWS / ALL ROWS hints whether you need to fetch the first rows faster (e.g. interactive grids) or the complete result set choose ORDER or SORT currently used internally for queries with FIRST, EXISTS, ANY prefers ORDER plan, affects join order explicit FIRST/ALL ROWS hints for other query types will appear in v4
84 84 Faster prepare for big tables sampling PP instead of reading them all being field tested Misc improvements improve some cases of ORDER plan usage in complex queries better plans for LEFT JOIN and UNION used together optimize SORT plan for FIRST ROWS strategy
85 85 Planned for v 4 HASH/MERGE for outer joins Execute EXISTS/IN as semi-join LATERAL joins More optimizer statistics and its background update
86 86 Thank you! Contacts:
Firebird Tour 2017: Performance. Vlad Khorsun, Firebird Project
 Firebird Tour 2017: Performance Vlad Khorsun, Firebird Project About Firebird Tour 2017 Firebird Tour 2017 is organized by Firebird Project, IBSurgeon and IBPhoenix, and devoted to Firebird Performance.
Firebird Tour 2017: Performance Vlad Khorsun, Firebird Project About Firebird Tour 2017 Firebird Tour 2017 is organized by Firebird Project, IBSurgeon and IBPhoenix, and devoted to Firebird Performance.
Firebird Tour 2017: Performance. Vlad Khorsun, Firebird Project
 Firebird Tour 2017: Performance Vlad Khorsun, Firebird Project About Firebird Tour 2017 Firebird Tour 2017 is organized by Firebird Project, IBSurgeon and IBPhoenix, and devoted to Firebird Performance.
Firebird Tour 2017: Performance Vlad Khorsun, Firebird Project About Firebird Tour 2017 Firebird Tour 2017 is organized by Firebird Project, IBSurgeon and IBPhoenix, and devoted to Firebird Performance.
Firebird in 2011/2012: Development Review
 Firebird in 2011/2012: Development Review Dmitry Yemanov mailto:dimitr@firebirdsql.org Firebird Project http://www.firebirdsql.org/ Packages Released in 2011 Firebird 2.1.4 March 2011 96 bugs fixed 4 improvements,
Firebird in 2011/2012: Development Review Dmitry Yemanov mailto:dimitr@firebirdsql.org Firebird Project http://www.firebirdsql.org/ Packages Released in 2011 Firebird 2.1.4 March 2011 96 bugs fixed 4 improvements,
Understanding the Optimizer
 Understanding the Optimizer 1 Global topics Introduction At which point does the optimizer his work Optimizer steps Index Questions? 2 Introduction Arno Brinkman BISIT engineering b.v. ABVisie firebird@abvisie.nl
Understanding the Optimizer 1 Global topics Introduction At which point does the optimizer his work Optimizer steps Index Questions? 2 Introduction Arno Brinkman BISIT engineering b.v. ABVisie firebird@abvisie.nl
Advanced Trace API. Vlad Khorsun, Firebird Project. Advanced Trace API. Firebird Tour 2017
 Vlad Khorsun, Firebird Project 1 About is organized by Firebird Project, IBSurgeon and IBPhoenix, and devoted to Firebird Performance. The Platinum sponsor is Moscow Exchange Tour's locations and dates:
Vlad Khorsun, Firebird Project 1 About is organized by Firebird Project, IBSurgeon and IBPhoenix, and devoted to Firebird Performance. The Platinum sponsor is Moscow Exchange Tour's locations and dates:
Diagnosing and fixing Firebird performance problems
 Diagnosing and fixing Firebird performance problems Alex Koviazin ak@ib-aid.com IBSurgeon, www.ib-aid.com Slowness Firebird performance problems can be caused by: 1. Bad transactions management 2. Problems
Diagnosing and fixing Firebird performance problems Alex Koviazin ak@ib-aid.com IBSurgeon, www.ib-aid.com Slowness Firebird performance problems can be caused by: 1. Bad transactions management 2. Problems
How Firebird transactions work
 1 1 How Firebird transactions work Dmitry Kuzmenko www.ibsurgeon.com www.ib-aid.com 2 Thank you! 2 3 3 Tools and consulting Platinum Sponsor of Firebird Foundation Founded in 2002: 12 years of Firebird
1 1 How Firebird transactions work Dmitry Kuzmenko www.ibsurgeon.com www.ib-aid.com 2 Thank you! 2 3 3 Tools and consulting Platinum Sponsor of Firebird Foundation Founded in 2002: 12 years of Firebird
Firebird databases recovery and protection for enterprises and ISVs. Alexey Kovyazin, IBSurgeon
 Firebird databases recovery and protection for enterprises and ISVs Alexey Kovyazin, IBSurgeon www.ib-aid.com About IBSurgeon Tools and consulting Platinum Sponsor of Firebird Foundation Founded in 2002
Firebird databases recovery and protection for enterprises and ISVs Alexey Kovyazin, IBSurgeon www.ib-aid.com About IBSurgeon Tools and consulting Platinum Sponsor of Firebird Foundation Founded in 2002
Firebird performance degradation: tests, myths and truth IBSurgeon, 2014
 Firebird performance degradation: tests, myths and truth Check the original location of this article for updates of this article: http://ib-aid.com/en/articles/firebird-performance-degradation-tests-myths-and-truth/
Firebird performance degradation: tests, myths and truth Check the original location of this article for updates of this article: http://ib-aid.com/en/articles/firebird-performance-degradation-tests-myths-and-truth/
TUNING LINUX, WINDOWS AND FIREBIRD FOR HEAVY WORKLOAD
 TUNING LINUX, WINDOWS AND FIREBIRD FOR HEAVY WORKLOAD Alex Kovyazin, IBSurgeon Firebird Tour 2017: Performance Optimization Prague, Bad Sassendorf, Moscow Firebird 2017 Tour: Performance Optimization Firebird
TUNING LINUX, WINDOWS AND FIREBIRD FOR HEAVY WORKLOAD Alex Kovyazin, IBSurgeon Firebird Tour 2017: Performance Optimization Prague, Bad Sassendorf, Moscow Firebird 2017 Tour: Performance Optimization Firebird
File Structures and Indexing
 File Structures and Indexing CPS352: Database Systems Simon Miner Gordon College Last Revised: 10/11/12 Agenda Check-in Database File Structures Indexing Database Design Tips Check-in Database File Structures
File Structures and Indexing CPS352: Database Systems Simon Miner Gordon College Last Revised: 10/11/12 Agenda Check-in Database File Structures Indexing Database Design Tips Check-in Database File Structures
Firebird performance counters in details
 Firebird performance counters in details Dmitry Yemanov mailto:dimitr@firebirdsql.org Firebird Project http://www.firebirdsql.org/ Thank you FIREBIRD INTERNATIONAL CONFERENCE '2014 2 Analysing bottlenecks
Firebird performance counters in details Dmitry Yemanov mailto:dimitr@firebirdsql.org Firebird Project http://www.firebirdsql.org/ Thank you FIREBIRD INTERNATIONAL CONFERENCE '2014 2 Analysing bottlenecks
Indexing. Jan Chomicki University at Buffalo. Jan Chomicki () Indexing 1 / 25
 Indexing 1 / 25") Indexing Jan Chomicki University at Buffalo Jan Chomicki () Indexing 1 / 25 Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow (nanosec) (10 nanosec) (millisec) (sec) Very small Small
Indexing Jan Chomicki University at Buffalo Jan Chomicki () Indexing 1 / 25 Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow (nanosec) (10 nanosec) (millisec) (sec) Very small Small
Datenbanksysteme II: Caching and File Structures. Ulf Leser
 Datenbanksysteme II: Caching and File Structures Ulf Leser Content of this Lecture Caching Overview Accessing data Cache replacement strategies Prefetching File structure Index Files Ulf Leser: Implementation
Datenbanksysteme II: Caching and File Structures Ulf Leser Content of this Lecture Caching Overview Accessing data Cache replacement strategies Prefetching File structure Index Files Ulf Leser: Implementation
MySQL Indexing. Best Practices. Peter Zaitsev, CEO Percona Inc August 15, 2012
 MySQL Indexing Best Practices Peter Zaitsev, CEO Percona Inc August 15, 2012 You ve Made a Great Choice! Understanding indexing is crucial both for Developers and DBAs Poor index choices are responsible
MySQL Indexing Best Practices Peter Zaitsev, CEO Percona Inc August 15, 2012 You ve Made a Great Choice! Understanding indexing is crucial both for Developers and DBAs Poor index choices are responsible
Storage hierarchy. Textbook: chapters 11, 12, and 13
 Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow Very small Small Bigger Very big (KB) (MB) (GB) (TB) Built-in Expensive Cheap Dirt cheap Disks: data is stored on concentric circular
Storage hierarchy Cache Main memory Disk Tape Very fast Fast Slower Slow Very small Small Bigger Very big (KB) (MB) (GB) (TB) Built-in Expensive Cheap Dirt cheap Disks: data is stored on concentric circular
Kathleen Durant PhD Northeastern University CS Indexes
 Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Kathleen Durant PhD Northeastern University CS 3200 Indexes Outline for the day Index definition Types of indexes B+ trees ISAM Hash index Choosing indexed fields Indexes in InnoDB 2 Indexes A typical
Chapter 12: Indexing and Hashing. Basic Concepts
 Chapter 12: Indexing and Hashing! Basic Concepts! Ordered Indices! B+-Tree Index Files! B-Tree Index Files! Static Hashing! Dynamic Hashing! Comparison of Ordered Indexing and Hashing! Index Definition
Chapter 12: Indexing and Hashing! Basic Concepts! Ordered Indices! B+-Tree Index Files! B-Tree Index Files! Static Hashing! Dynamic Hashing! Comparison of Ordered Indexing and Hashing! Index Definition
Chapter 5: Physical Database Design. Designing Physical Files
 Chapter 5: Physical Database Design Designing Physical Files Technique for physically arranging records of a file on secondary storage File Organizations Sequential (Fig. 5-7a): the most efficient with
Chapter 5: Physical Database Design Designing Physical Files Technique for physically arranging records of a file on secondary storage File Organizations Sequential (Fig. 5-7a): the most efficient with
Outline. Database Management and Tuning. Outline. Join Strategies Running Example. Index Tuning. Johann Gamper. Unit 6 April 12, 2012
 Outline Database Management and Tuning Johann Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Unit 6 April 12, 2012 1 Acknowledgements: The slides are provided by Nikolaus Augsten
Outline Database Management and Tuning Johann Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Unit 6 April 12, 2012 1 Acknowledgements: The slides are provided by Nikolaus Augsten
Chapter 12: Indexing and Hashing
 Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
PS2 out today. Lab 2 out today. Lab 1 due today - how was it?
 6.830 Lecture 7 9/25/2017 PS2 out today. Lab 2 out today. Lab 1 due today - how was it? Project Teams Due Wednesday Those of you who don't have groups -- send us email, or hand in a sheet with just your
6.830 Lecture 7 9/25/2017 PS2 out today. Lab 2 out today. Lab 1 due today - how was it? Project Teams Due Wednesday Those of you who don't have groups -- send us email, or hand in a sheet with just your
Database Management and Tuning
 Database Management and Tuning Index Tuning Johann Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Unit 4 Acknowledgements: The slides are provided by Nikolaus Augsten and have
Database Management and Tuning Index Tuning Johann Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Unit 4 Acknowledgements: The slides are provided by Nikolaus Augsten and have
Outline. Database Management and Tuning. What is an Index? Key of an Index. Index Tuning. Johann Gamper. Unit 4
 Outline Database Management and Tuning Johann Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Unit 4 1 2 Conclusion Acknowledgements: The slides are provided by Nikolaus Augsten
Outline Database Management and Tuning Johann Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Unit 4 1 2 Conclusion Acknowledgements: The slides are provided by Nikolaus Augsten
University of Waterloo Midterm Examination Sample Solution
 1. (4 total marks) University of Waterloo Midterm Examination Sample Solution Winter, 2012 Suppose that a relational database contains the following large relation: Track(ReleaseID, TrackNum, Title, Length,
1. (4 total marks) University of Waterloo Midterm Examination Sample Solution Winter, 2012 Suppose that a relational database contains the following large relation: Track(ReleaseID, TrackNum, Title, Length,
Outline. Database Management and Tuning. Index Data Structures. Outline. Index Tuning. Johann Gamper. Unit 5
 Outline Database Management and Tuning Johann Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Unit 5 1 2 Conclusion Acknowledgements: The slides are provided by Nikolaus Augsten
Outline Database Management and Tuning Johann Gamper Free University of Bozen-Bolzano Faculty of Computer Science IDSE Unit 5 1 2 Conclusion Acknowledgements: The slides are provided by Nikolaus Augsten
Administração e Optimização de Bases de Dados 2012/2013 Index Tuning
 Administração e Optimização de Bases de Dados 2012/2013 Index Tuning Bruno Martins DEI@Técnico e DMIR@INESC-ID Index An index is a data structure that supports efficient access to data Condition on Index
Administração e Optimização de Bases de Dados 2012/2013 Index Tuning Bruno Martins DEI@Técnico e DMIR@INESC-ID Index An index is a data structure that supports efficient access to data Condition on Index
Something to think about. Problems. Purpose. Vocabulary. Query Evaluation Techniques for large DB. Part 1. Fact:
 Query Evaluation Techniques for large DB Part 1 Fact: While data base management systems are standard tools in business data processing they are slowly being introduced to all the other emerging data base
Query Evaluation Techniques for large DB Part 1 Fact: While data base management systems are standard tools in business data processing they are slowly being introduced to all the other emerging data base
COMP 430 Intro. to Database Systems. Indexing
 COMP 430 Intro. to Database Systems Indexing How does DB find records quickly? Various forms of indexing An index is automatically created for primary key. SQL gives us some control, so we should understand
COMP 430 Intro. to Database Systems Indexing How does DB find records quickly? Various forms of indexing An index is automatically created for primary key. SQL gives us some control, so we should understand
Oracle DB-Tuning Essentials
 Infrastructure at your Service. Oracle DB-Tuning Essentials Agenda 1. The DB server and the tuning environment 2. Objective, Tuning versus Troubleshooting, Cost Based Optimizer 3. Object statistics 4.
Infrastructure at your Service. Oracle DB-Tuning Essentials Agenda 1. The DB server and the tuning environment 2. Objective, Tuning versus Troubleshooting, Cost Based Optimizer 3. Object statistics 4.
Mastering the art of indexing
 Mastering the art of indexing Yoshinori Matsunobu Lead of MySQL Professional Services APAC Sun Microsystems Yoshinori.Matsunobu@sun.com 1 Table of contents Speeding up Selects B+TREE index structure Index
Mastering the art of indexing Yoshinori Matsunobu Lead of MySQL Professional Services APAC Sun Microsystems Yoshinori.Matsunobu@sun.com 1 Table of contents Speeding up Selects B+TREE index structure Index
RAID in Practice, Overview of Indexing
 RAID in Practice, Overview of Indexing CS634 Lecture 4, Feb 04 2014 Slides based on Database Management Systems 3 rd ed, Ramakrishnan and Gehrke 1 Disks and Files: RAID in practice For a big enterprise
RAID in Practice, Overview of Indexing CS634 Lecture 4, Feb 04 2014 Slides based on Database Management Systems 3 rd ed, Ramakrishnan and Gehrke 1 Disks and Files: RAID in practice For a big enterprise
Course Modules for MCSA: SQL Server 2016 Database Development Training & Certification Course:
 Course Modules for MCSA: SQL Server 2016 Database Development Training & Certification Course: 20762C Developing SQL 2016 Databases Module 1: An Introduction to Database Development Introduction to the
Course Modules for MCSA: SQL Server 2016 Database Development Training & Certification Course: 20762C Developing SQL 2016 Databases Module 1: An Introduction to Database Development Introduction to the
MySQL Indexing. Best Practices for MySQL 5.6. Peter Zaitsev CEO, Percona MySQL Connect Sep 22, 2013 San Francisco,CA
 MySQL Indexing Best Practices for MySQL 5.6 Peter Zaitsev CEO, Percona MySQL Connect Sep 22, 2013 San Francisco,CA For those who Does not Know Us Percona Helping Businesses to be Successful with MySQL
MySQL Indexing Best Practices for MySQL 5.6 Peter Zaitsev CEO, Percona MySQL Connect Sep 22, 2013 San Francisco,CA For those who Does not Know Us Percona Helping Businesses to be Successful with MySQL
Index Tuning. Index. An index is a data structure that supports efficient access to data. Matching records. Condition on attribute value
 Index Tuning AOBD07/08 Index An index is a data structure that supports efficient access to data Condition on attribute value index Set of Records Matching records (search key) 1 Performance Issues Type
Index Tuning AOBD07/08 Index An index is a data structure that supports efficient access to data Condition on attribute value index Set of Records Matching records (search key) 1 Performance Issues Type
CS 405G: Introduction to Database Systems. Storage
 CS 405G: Introduction to Database Systems Storage It s all about disks! Outline That s why we always draw databases as And why the single most important metric in database processing is the number of disk
CS 405G: Introduction to Database Systems Storage It s all about disks! Outline That s why we always draw databases as And why the single most important metric in database processing is the number of disk
Database Management System
 Database Management System Lecture Join * Some materials adapted from R. Ramakrishnan, J. Gehrke and Shawn Bowers Today s Agenda Join Algorithm Database Management System Join Algorithms Database Management
Database Management System Lecture Join * Some materials adapted from R. Ramakrishnan, J. Gehrke and Shawn Bowers Today s Agenda Join Algorithm Database Management System Join Algorithms Database Management
Chapter 18 Strategies for Query Processing. We focus this discussion w.r.t RDBMS, however, they are applicable to OODBS.
 Chapter 18 Strategies for Query Processing We focus this discussion w.r.t RDBMS, however, they are applicable to OODBS. 1 1. Translating SQL Queries into Relational Algebra and Other Operators - SQL is
Chapter 18 Strategies for Query Processing We focus this discussion w.r.t RDBMS, however, they are applicable to OODBS. 1 1. Translating SQL Queries into Relational Algebra and Other Operators - SQL is
What happens. 376a. Database Design. Execution strategy. Query conversion. Next. Two types of techniques
 376a. Database Design Dept. of Computer Science Vassar College http://www.cs.vassar.edu/~cs376 Class 16 Query optimization What happens Database is given a query Query is scanned - scanner creates a list
376a. Database Design Dept. of Computer Science Vassar College http://www.cs.vassar.edu/~cs376 Class 16 Query optimization What happens Database is given a query Query is scanned - scanner creates a list
Outline. Database Tuning. Join Strategies Running Example. Outline. Index Tuning. Nikolaus Augsten. Unit 6 WS 2014/2015
 Outline Database Tuning Nikolaus Augsten University of Salzburg Department of Computer Science Database Group 1 Examples Unit 6 WS 2014/2015 Adapted from Database Tuning by Dennis Shasha and Philippe Bonnet.
Outline Database Tuning Nikolaus Augsten University of Salzburg Department of Computer Science Database Group 1 Examples Unit 6 WS 2014/2015 Adapted from Database Tuning by Dennis Shasha and Philippe Bonnet.
Eternal Story on Temporary Objects
 Eternal Story on Temporary Objects Dmitri V. Korotkevitch http://aboutsqlserver.com About Me 14+ years of experience working with Microsoft SQL Server Microsoft SQL Server MVP Microsoft Certified Master
Eternal Story on Temporary Objects Dmitri V. Korotkevitch http://aboutsqlserver.com About Me 14+ years of experience working with Microsoft SQL Server Microsoft SQL Server MVP Microsoft Certified Master
Chapter 12: Indexing and Hashing
 Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Chapter 12: Indexing and Hashing Database System Concepts, 5th Ed. See www.db-book.com for conditions on re-use Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree
Query Processing and Query Optimization. Prof Monika Shah
 Query Processing and Query Optimization Query Processing SQL Query Is in Library Cache? System catalog (Dict / Dict cache) Scan and verify relations Parse into parse tree (relational Calculus) View definitions
Query Processing and Query Optimization Query Processing SQL Query Is in Library Cache? System catalog (Dict / Dict cache) Scan and verify relations Parse into parse tree (relational Calculus) View definitions
MASSACHUSETTS INSTITUTE OF TECHNOLOGY Database Systems: Fall 2015 Quiz I
 Department of Electrical Engineering and Computer Science MASSACHUSETTS INSTITUTE OF TECHNOLOGY 6.830 Database Systems: Fall 2015 Quiz I There are 12 questions and 13 pages in this quiz booklet. To receive
Department of Electrical Engineering and Computer Science MASSACHUSETTS INSTITUTE OF TECHNOLOGY 6.830 Database Systems: Fall 2015 Quiz I There are 12 questions and 13 pages in this quiz booklet. To receive
Chapter 11: Storage and File Structure. Silberschatz, Korth and Sudarshan Updated by Bird and Tanin
 Chapter 11: Storage and File Structure Storage Hierarchy 11.2 Storage Hierarchy (Cont.) primary storage: Fastest media but volatile (cache, main memory). secondary storage: next level in hierarchy, non-volatile,
Chapter 11: Storage and File Structure Storage Hierarchy 11.2 Storage Hierarchy (Cont.) primary storage: Fastest media but volatile (cache, main memory). secondary storage: next level in hierarchy, non-volatile,
Query Processing: The Basics. External Sorting
 Query Processing: The Basics Chapter 10 1 External Sorting Sorting is used in implementing many relational operations Problem: Relations are typically large, do not fit in main memory So cannot use traditional
Query Processing: The Basics Chapter 10 1 External Sorting Sorting is used in implementing many relational operations Problem: Relations are typically large, do not fit in main memory So cannot use traditional
Chapter 12: Query Processing
 Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Overview Chapter 12: Query Processing Measures of Query Cost Selection Operation Sorting Join
Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Overview Chapter 12: Query Processing Measures of Query Cost Selection Operation Sorting Join
Relational Database Index Design and the Optimizers
 Relational Database Index Design and the Optimizers DB2, Oracle, SQL Server, et al. Tapio Lahdenmäki Michael Leach (C^WILEY- IX/INTERSCIENCE A JOHN WILEY & SONS, INC., PUBLICATION Contents Preface xv 1
Relational Database Index Design and the Optimizers DB2, Oracle, SQL Server, et al. Tapio Lahdenmäki Michael Leach (C^WILEY- IX/INTERSCIENCE A JOHN WILEY & SONS, INC., PUBLICATION Contents Preface xv 1
Physical Database Design: Outline
 Physical Database Design: Outline File Organization Fixed size records Variable size records Mapping Records to Files Heap Sequentially Hashing Clustered Buffer Management Indexes (Trees and Hashing) Single-level
Physical Database Design: Outline File Organization Fixed size records Variable size records Mapping Records to Files Heap Sequentially Hashing Clustered Buffer Management Indexes (Trees and Hashing) Single-level
Copyright 2016 Ramez Elmasri and Shamkant B. Navathe
 CHAPTER 19 Query Optimization Introduction Query optimization Conducted by a query optimizer in a DBMS Goal: select best available strategy for executing query Based on information available Most RDBMSs
CHAPTER 19 Query Optimization Introduction Query optimization Conducted by a query optimizer in a DBMS Goal: select best available strategy for executing query Based on information available Most RDBMSs
CMPUT 391 Database Management Systems. Query Processing: The Basics. Textbook: Chapter 10. (first edition: Chapter 13) University of Alberta 1
 University of Alberta 1") CMPUT 391 Database Management Systems Query Processing: The Basics Textbook: Chapter 10 (first edition: Chapter 13) Based on slides by Lewis, Bernstein and Kifer University of Alberta 1 External Sorting
CMPUT 391 Database Management Systems Query Processing: The Basics Textbook: Chapter 10 (first edition: Chapter 13) Based on slides by Lewis, Bernstein and Kifer University of Alberta 1 External Sorting
Introduction to Query Processing and Query Optimization Techniques. Copyright 2011 Ramez Elmasri and Shamkant Navathe
 Introduction to Query Processing and Query Optimization Techniques Outline Translating SQL Queries into Relational Algebra Algorithms for External Sorting Algorithms for SELECT and JOIN Operations Algorithms
Introduction to Query Processing and Query Optimization Techniques Outline Translating SQL Queries into Relational Algebra Algorithms for External Sorting Algorithms for SELECT and JOIN Operations Algorithms
External Sorting. Chapter 13. Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1
 External Sorting Chapter 13 Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Why Sort? A classic problem in computer science! Data requested in sorted order e.g., find students in increasing
External Sorting Chapter 13 Database Management Systems 3ed, R. Ramakrishnan and J. Gehrke 1 Why Sort? A classic problem in computer science! Data requested in sorted order e.g., find students in increasing
Chapter 12: Query Processing. Chapter 12: Query Processing
 Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Query Processing Overview Measures of Query Cost Selection Operation Sorting Join
Chapter 12: Query Processing Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 12: Query Processing Overview Measures of Query Cost Selection Operation Sorting Join
Outline. Query Types
 Outline Database Tuning Nikolaus Augsten nikolaus.augsten@sbg.ac.at Department of Computer Sciences University of Salzburg http://dbresearch.uni-salzburg.at 1 Examples SS 2017/18 Version May 14, 2018 Adapted
Outline Database Tuning Nikolaus Augsten nikolaus.augsten@sbg.ac.at Department of Computer Sciences University of Salzburg http://dbresearch.uni-salzburg.at 1 Examples SS 2017/18 Version May 14, 2018 Adapted
Covering indexes. Stéphane Combaudon - SQLI
 Covering indexes Stéphane Combaudon - SQLI Indexing basics Data structure intended to speed up SELECTs Similar to an index in a book Overhead for every write Usually negligeable / speed up for SELECT Possibility
Covering indexes Stéphane Combaudon - SQLI Indexing basics Data structure intended to speed up SELECTs Similar to an index in a book Overhead for every write Usually negligeable / speed up for SELECT Possibility
Query Evaluation Overview, cont.
 Query Evaluation Overview, cont. Lecture 9 Feb. 29, 2016 Slides based on Database Management Systems 3 rd ed, Ramakrishnan and Gehrke Architecture of a DBMS Query Compiler Execution Engine Index/File/Record
Query Evaluation Overview, cont. Lecture 9 Feb. 29, 2016 Slides based on Database Management Systems 3 rd ed, Ramakrishnan and Gehrke Architecture of a DBMS Query Compiler Execution Engine Index/File/Record
Systems Infrastructure for Data Science. Web Science Group Uni Freiburg WS 2014/15
 Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2014/15 Lecture II: Indexing Part I of this course Indexing 3 Database File Organization and Indexing Remember: Database tables
Systems Infrastructure for Data Science Web Science Group Uni Freiburg WS 2014/15 Lecture II: Indexing Part I of this course Indexing 3 Database File Organization and Indexing Remember: Database tables
Review. Support for data retrieval at the physical level:
 Query Processing Review Support for data retrieval at the physical level: Indices: data structures to help with some query evaluation: SELECTION queries (ssn = 123) RANGE queries (100
Query Processing Review Support for data retrieval at the physical level: Indices: data structures to help with some query evaluation: SELECTION queries (ssn = 123) RANGE queries (100
Overview of Storage and Indexing
 Overview of Storage and Indexing UVic C SC 370 Dr. Daniel M. German Department of Computer Science July 2, 2003 Version: 1.1.1 7 1 Overview of Storage and Indexing (1.1.1) CSC 370 dmgerman@uvic.ca Overview
Overview of Storage and Indexing UVic C SC 370 Dr. Daniel M. German Department of Computer Science July 2, 2003 Version: 1.1.1 7 1 Overview of Storage and Indexing (1.1.1) CSC 370 dmgerman@uvic.ca Overview
CSE 530A. B+ Trees. Washington University Fall 2013
 CSE 530A B+ Trees Washington University Fall 2013 B Trees A B tree is an ordered (non-binary) tree where the internal nodes can have a varying number of child nodes (within some range) B Trees When a key
CSE 530A B+ Trees Washington University Fall 2013 B Trees A B tree is an ordered (non-binary) tree where the internal nodes can have a varying number of child nodes (within some range) B Trees When a key
Oracle Database 11g: SQL Tuning Workshop
 Oracle University Contact Us: Local: 0845 777 7 711 Intl: +44 845 777 7 711 Oracle Database 11g: SQL Tuning Workshop Duration: 3 Days What you will learn This Oracle Database 11g: SQL Tuning Workshop Release
Oracle University Contact Us: Local: 0845 777 7 711 Intl: +44 845 777 7 711 Oracle Database 11g: SQL Tuning Workshop Duration: 3 Days What you will learn This Oracle Database 11g: SQL Tuning Workshop Release
Sepand Gojgini. ColumnStore Index Primer
 Sepand Gojgini ColumnStore Index Primer SQLSaturday Sponsors! Titanium & Global Partner Gold Silver Bronze Without the generosity of these sponsors, this event would not be possible! Please, stop by the
Sepand Gojgini ColumnStore Index Primer SQLSaturday Sponsors! Titanium & Global Partner Gold Silver Bronze Without the generosity of these sponsors, this event would not be possible! Please, stop by the
Querying Data with Transact SQL
 Course 20761A: Querying Data with Transact SQL Course details Course Outline Module 1: Introduction to Microsoft SQL Server 2016 This module introduces SQL Server, the versions of SQL Server, including
Course 20761A: Querying Data with Transact SQL Course details Course Outline Module 1: Introduction to Microsoft SQL Server 2016 This module introduces SQL Server, the versions of SQL Server, including
Practical MySQL indexing guidelines
 Practical MySQL indexing guidelines Percona Live October 24th-25th, 2011 London, UK Stéphane Combaudon stephane.combaudon@dailymotion.com Agenda Introduction Bad indexes & performance drops Guidelines
Practical MySQL indexing guidelines Percona Live October 24th-25th, 2011 London, UK Stéphane Combaudon stephane.combaudon@dailymotion.com Agenda Introduction Bad indexes & performance drops Guidelines
Advanced Database Systems
 Lecture IV Query Processing Kyumars Sheykh Esmaili Basic Steps in Query Processing 2 Query Optimization Many equivalent execution plans Choosing the best one Based on Heuristics, Cost Will be discussed
Lecture IV Query Processing Kyumars Sheykh Esmaili Basic Steps in Query Processing 2 Query Optimization Many equivalent execution plans Choosing the best one Based on Heuristics, Cost Will be discussed
Query Optimizer MySQL vs. PostgreSQL
 Percona Live, Frankfurt (DE), 7 November 2018 Christian Antognini @ChrisAntognini antognini.ch/blog BASEL BERN BRUGG DÜSSELDORF FRANKFURT A.M. FREIBURG I.BR. GENEVA HAMBURG COPENHAGEN LAUSANNE MUNICH STUTTGART
Percona Live, Frankfurt (DE), 7 November 2018 Christian Antognini @ChrisAntognini antognini.ch/blog BASEL BERN BRUGG DÜSSELDORF FRANKFURT A.M. FREIBURG I.BR. GENEVA HAMBURG COPENHAGEN LAUSANNE MUNICH STUTTGART
Course Outline. SQL Server Performance & Tuning For Developers. Course Description: Pre-requisites: Course Content: Performance & Tuning.
 SQL Server Performance & Tuning For Developers Course Description: The objective of this course is to provide senior database analysts and developers with a good understanding of SQL Server Architecture
SQL Server Performance & Tuning For Developers Course Description: The objective of this course is to provide senior database analysts and developers with a good understanding of SQL Server Architecture
Query Evaluation Overview, cont.
 Query Evaluation Overview, cont. Lecture 9 Slides based on Database Management Systems 3 rd ed, Ramakrishnan and Gehrke Architecture of a DBMS Query Compiler Execution Engine Index/File/Record Manager
Query Evaluation Overview, cont. Lecture 9 Slides based on Database Management Systems 3 rd ed, Ramakrishnan and Gehrke Architecture of a DBMS Query Compiler Execution Engine Index/File/Record Manager
Indexing Methods. Lecture 9. Storage Requirements of Databases
 Indexing Methods Lecture 9 Storage Requirements of Databases Need data to be stored permanently or persistently for long periods of time Usually too big to fit in main memory Low cost of storage per unit
Indexing Methods Lecture 9 Storage Requirements of Databases Need data to be stored permanently or persistently for long periods of time Usually too big to fit in main memory Low cost of storage per unit
Evaluation of Relational Operations
 Evaluation of Relational Operations Yanlei Diao UMass Amherst March 13 and 15, 2006 Slides Courtesy of R. Ramakrishnan and J. Gehrke 1 Relational Operations We will consider how to implement: Selection
Evaluation of Relational Operations Yanlei Diao UMass Amherst March 13 and 15, 2006 Slides Courtesy of R. Ramakrishnan and J. Gehrke 1 Relational Operations We will consider how to implement: Selection
20 Essential Oracle SQL and PL/SQL Tuning Tips. John Mullins
 20 Essential Oracle SQL and PL/SQL Tuning Tips John Mullins jmullins@themisinc.com www.themisinc.com www.themisinc.com/webinars Presenter John Mullins Themis Inc. (jmullins@themisinc.com) 30+ years of
20 Essential Oracle SQL and PL/SQL Tuning Tips John Mullins jmullins@themisinc.com www.themisinc.com www.themisinc.com/webinars Presenter John Mullins Themis Inc. (jmullins@themisinc.com) 30+ years of
Tips for success. Common mistakes in application development with Firebird and how to avoid them. Pavel Císař IBPhoenix
 Tips for success Common mistakes in application development with Firebird and how to avoid them Pavel Císař IBPhoenix Firebird Conference 2011 Agenda Recipes for disaster Mistakes in database design Wrong
Tips for success Common mistakes in application development with Firebird and how to avoid them Pavel Císař IBPhoenix Firebird Conference 2011 Agenda Recipes for disaster Mistakes in database design Wrong
Chapter 13: Query Processing
 Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Chapter 13: Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 13.1 Basic Steps in Query Processing 1. Parsing
Examples of Physical Query Plan Alternatives. Selected Material from Chapters 12, 14 and 15
 Examples of Physical Query Plan Alternatives Selected Material from Chapters 12, 14 and 15 1 Query Optimization NOTE: SQL provides many ways to express a query. HENCE: System has many options for evaluating
Examples of Physical Query Plan Alternatives Selected Material from Chapters 12, 14 and 15 1 Query Optimization NOTE: SQL provides many ways to express a query. HENCE: System has many options for evaluating
7. Query Processing and Optimization
 7. Query Processing and Optimization Processing a Query 103 Indexing for Performance Simple (individual) index B + -tree index Matching index scan vs nonmatching index scan Unique index one entry and one
7. Query Processing and Optimization Processing a Query 103 Indexing for Performance Simple (individual) index B + -tree index Matching index scan vs nonmatching index scan Unique index one entry and one
Hashing IV and Course Overview
 Date: April 5-6, 2001 CSI 2131 Page: 1 Hashing IV and Course Overview Other Collision Resolution Techniques 1) Double Hashing The first hash function determines the home address If the home address is
Date: April 5-6, 2001 CSI 2131 Page: 1 Hashing IV and Course Overview Other Collision Resolution Techniques 1) Double Hashing The first hash function determines the home address If the home address is
Query Processing. Debapriyo Majumdar Indian Sta4s4cal Ins4tute Kolkata DBMS PGDBA 2016
 Query Processing Debapriyo Majumdar Indian Sta4s4cal Ins4tute Kolkata DBMS PGDBA 2016 Slides re-used with some modification from www.db-book.com Reference: Database System Concepts, 6 th Ed. By Silberschatz,
Query Processing Debapriyo Majumdar Indian Sta4s4cal Ins4tute Kolkata DBMS PGDBA 2016 Slides re-used with some modification from www.db-book.com Reference: Database System Concepts, 6 th Ed. By Silberschatz,
Hash table example. B+ Tree Index by Example Recall binary trees from CSE 143! Clustered vs Unclustered. Example
 Student Introduction to Database Systems CSE 414 Hash table example Index Student_ID on Student.ID Data File Student 10 Tom Hanks 10 20 20 Amy Hanks ID fname lname 10 Tom Hanks 20 Amy Hanks Lecture 26:
Student Introduction to Database Systems CSE 414 Hash table example Index Student_ID on Student.ID Data File Student 10 Tom Hanks 10 20 20 Amy Hanks ID fname lname 10 Tom Hanks 20 Amy Hanks Lecture 26:
State of MariaDB. Igor Babaev Notice: MySQL is a registered trademark of Sun Microsystems, Inc.
 State of MariaDB Igor Babaev igor@askmonty.org New features in MariaDB 5.2 New engines: OQGRAPH, SphinxSE Virtual columns Extended User Statistics Segmented MyISAM key cache Pluggable Authentication Storage-engine-specific
State of MariaDB Igor Babaev igor@askmonty.org New features in MariaDB 5.2 New engines: OQGRAPH, SphinxSE Virtual columns Extended User Statistics Segmented MyISAM key cache Pluggable Authentication Storage-engine-specific
Query Processing with Indexes. Announcements (February 24) Review. CPS 216 Advanced Database Systems
 Review. CPS 216 Advanced Database Systems") Query Processing with Indexes CPS 216 Advanced Database Systems Announcements (February 24) 2 More reading assignment for next week Buffer management (due next Wednesday) Homework #2 due next Thursday
Query Processing with Indexes CPS 216 Advanced Database Systems Announcements (February 24) 2 More reading assignment for next week Buffer management (due next Wednesday) Homework #2 due next Thursday
DATABASE PERFORMANCE AND INDEXES. CS121: Relational Databases Fall 2017 Lecture 11
 DATABASE PERFORMANCE AND INDEXES CS121: Relational Databases Fall 2017 Lecture 11 Database Performance 2 Many situations where query performance needs to be improved e.g. as data size grows, query performance
DATABASE PERFORMANCE AND INDEXES CS121: Relational Databases Fall 2017 Lecture 11 Database Performance 2 Many situations where query performance needs to be improved e.g. as data size grows, query performance
Implementing Relational Operators: Selection, Projection, Join. Database Management Systems, R. Ramakrishnan and J. Gehrke 1
 Implementing Relational Operators: Selection, Projection, Join Database Management Systems, R. Ramakrishnan and J. Gehrke 1 Readings [RG] Sec. 14.1-14.4 Database Management Systems, R. Ramakrishnan and
Implementing Relational Operators: Selection, Projection, Join Database Management Systems, R. Ramakrishnan and J. Gehrke 1 Readings [RG] Sec. 14.1-14.4 Database Management Systems, R. Ramakrishnan and
CS34800 Information Systems
 CS34800 Information Systems Indexing & Hashing Prof. Chris Clifton 31 October 2016 First: Triggers - Limitations Many database functions do not quite work as expected One example: Trigger on a table that
CS34800 Information Systems Indexing & Hashing Prof. Chris Clifton 31 October 2016 First: Triggers - Limitations Many database functions do not quite work as expected One example: Trigger on a table that
Topics to Learn. Important concepts. Tree-based index. Hash-based index
 CS143: Index 1 Topics to Learn Important concepts Dense index vs. sparse index Primary index vs. secondary index (= clustering index vs. non-clustering index) Tree-based vs. hash-based index Tree-based
CS143: Index 1 Topics to Learn Important concepts Dense index vs. sparse index Primary index vs. secondary index (= clustering index vs. non-clustering index) Tree-based vs. hash-based index Tree-based
Advanced Oracle SQL Tuning v3.0 by Tanel Poder
 Advanced Oracle SQL Tuning v3.0 by Tanel Poder /seminar Training overview This training session is entirely about making Oracle SQL execution run faster and more efficiently, understanding the root causes
Advanced Oracle SQL Tuning v3.0 by Tanel Poder /seminar Training overview This training session is entirely about making Oracle SQL execution run faster and more efficiently, understanding the root causes
QUIZ: Is either set of attributes a superkey? A candidate key? Source:
 QUIZ: Is either set of attributes a superkey? A candidate key? Source: http://courses.cs.washington.edu/courses/cse444/06wi/lectures/lecture09.pdf 10.1 QUIZ: MVD What MVDs can you spot in this table? Source:
QUIZ: Is either set of attributes a superkey? A candidate key? Source: http://courses.cs.washington.edu/courses/cse444/06wi/lectures/lecture09.pdf 10.1 QUIZ: MVD What MVDs can you spot in this table? Source:
Selection Queries. to answer a selection query (ssn=10) needs to traverse a full path.
 needs to traverse a full path.") Hashing B+-tree is perfect, but... Selection Queries to answer a selection query (ssn=) needs to traverse a full path. In practice, 3-4 block accesses (depending on the height of the tree, buffering) Any
Hashing B+-tree is perfect, but... Selection Queries to answer a selection query (ssn=) needs to traverse a full path. In practice, 3-4 block accesses (depending on the height of the tree, buffering) Any
Introduction to Database Systems CSE 414. Lecture 26: More Indexes and Operator Costs
 Introduction to Database Systems CSE 414 Lecture 26: More Indexes and Operator Costs CSE 414 - Spring 2018 1 Student ID fname lname Hash table example 10 Tom Hanks Index Student_ID on Student.ID Data File
Introduction to Database Systems CSE 414 Lecture 26: More Indexes and Operator Costs CSE 414 - Spring 2018 1 Student ID fname lname Hash table example 10 Tom Hanks Index Student_ID on Student.ID Data File
Query optimization. Elena Baralis, Silvia Chiusano Politecnico di Torino. DBMS Architecture D B M G. Database Management Systems. Pag.
 Database Management Systems DBMS Architecture SQL INSTRUCTION OPTIMIZER MANAGEMENT OF ACCESS METHODS CONCURRENCY CONTROL BUFFER MANAGER RELIABILITY MANAGEMENT Index Files Data Files System Catalog DATABASE
Database Management Systems DBMS Architecture SQL INSTRUCTION OPTIMIZER MANAGEMENT OF ACCESS METHODS CONCURRENCY CONTROL BUFFER MANAGER RELIABILITY MANAGEMENT Index Files Data Files System Catalog DATABASE
Oracle 9i Application Development and Tuning
 Index 2NF, NOT 3NF or BCNF... 2:17 A Anomalies Present in this Relation... 2:18 Anomalies (Specific) in this Relation... 2:4 Application Design... 1:28 Application Environment... 1:1 Application-Specific
Index 2NF, NOT 3NF or BCNF... 2:17 A Anomalies Present in this Relation... 2:18 Anomalies (Specific) in this Relation... 2:4 Application Design... 1:28 Application Environment... 1:1 Application-Specific
! A relational algebra expression may have many equivalent. ! Cost is generally measured as total elapsed time for
 Chapter 13: Query Processing Basic Steps in Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 1. Parsing and
Chapter 13: Query Processing Basic Steps in Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 1. Parsing and
Chapter 13: Query Processing Basic Steps in Query Processing
 Chapter 13: Query Processing Basic Steps in Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 1. Parsing and
Chapter 13: Query Processing Basic Steps in Query Processing! Overview! Measures of Query Cost! Selection Operation! Sorting! Join Operation! Other Operations! Evaluation of Expressions 1. Parsing and
PostgreSQL Query Optimization. Step by step techniques. Ilya Kosmodemiansky
 PostgreSQL Query Optimization Step by step techniques Ilya Kosmodemiansky (ik@) Agenda 2 1. What is a slow query? 2. How to chose queries to optimize? 3. What is a query plan? 4. Optimization tools 5.
PostgreSQL Query Optimization Step by step techniques Ilya Kosmodemiansky (ik@) Agenda 2 1. What is a slow query? 2. How to chose queries to optimize? 3. What is a query plan? 4. Optimization tools 5.
External Sorting. Chapter 13. Comp 521 Files and Databases Fall
 External Sorting Chapter 13 Comp 521 Files and Databases Fall 2012 1 Why Sort? A classic problem in computer science! Advantages of requesting data in sorted order gathers duplicates allows for efficient
External Sorting Chapter 13 Comp 521 Files and Databases Fall 2012 1 Why Sort? A classic problem in computer science! Advantages of requesting data in sorted order gathers duplicates allows for efficient
Indexing. Week 14, Spring Edited by M. Naci Akkøk, , Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel
 Indexing Week 14, Spring 2005 Edited by M. Naci Akkøk, 5.3.2004, 3.3.2005 Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel Overview Conventional indexes B-trees Hashing schemes
Indexing Week 14, Spring 2005 Edited by M. Naci Akkøk, 5.3.2004, 3.3.2005 Contains slides from 8-9. April 2002 by Hector Garcia-Molina, Vera Goebel Overview Conventional indexes B-trees Hashing schemes
Oracle Database Performance Tuning, Benchmarks & Replication
 Oracle Database Performance Tuning, Benchmarks & Replication Kapil Malhotra kapil.malhotra@software.dell.com Solutions Architect, Information Management Dell Software 2 11/29/2013 Software Database Tuning
Oracle Database Performance Tuning, Benchmarks & Replication Kapil Malhotra kapil.malhotra@software.dell.com Solutions Architect, Information Management Dell Software 2 11/29/2013 Software Database Tuning
(Storage System) Access Methods Buffer Manager
 Access Methods Buffer Manager") 6.830 Lecture 5 9/20/2017 Project partners due next Wednesday. Lab 1 due next Monday start now!!! Recap Anatomy of a database system Major Components: Admission Control Connection Management ---------------------------------------(Query
6.830 Lecture 5 9/20/2017 Project partners due next Wednesday. Lab 1 due next Monday start now!!! Recap Anatomy of a database system Major Components: Admission Control Connection Management ---------------------------------------(Query
6232B: Implementing a Microsoft SQL Server 2008 R2 Database
 6232B: Implementing a Microsoft SQL Server 2008 R2 Database Course Overview This instructor-led course is intended for Microsoft SQL Server database developers who are responsible for implementing a database
6232B: Implementing a Microsoft SQL Server 2008 R2 Database Course Overview This instructor-led course is intended for Microsoft SQL Server database developers who are responsible for implementing a database
Database Applications (15-415)
") Database Applications (15-415) DBMS Internals- Part V Lecture 13, March 10, 2014 Mohammad Hammoud Today Welcome Back from Spring Break! Today Last Session: DBMS Internals- Part IV Tree-based (i.e., B+
Database Applications (15-415) DBMS Internals- Part V Lecture 13, March 10, 2014 Mohammad Hammoud Today Welcome Back from Spring Break! Today Last Session: DBMS Internals- Part IV Tree-based (i.e., B+