Parallel programming in Matlab environment on CRESCO cluster, interactive and batch mode
|
|
|
- Jeffry Booker
- 6 years ago
- Views:
Transcription
 b ENEA-FIM, Enea-Sede, Lungotevere Thaon di Revel n.")
 Introduction Matlab (MATrix LABoratory) provides an environment for numeric elaboration and an interpreted programming language widely")








.")











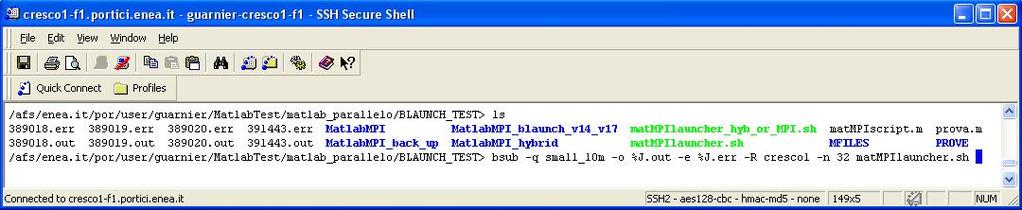
1 Parallel programming in Matlab environment on CRESCO cluster, interactive and batch mode Authors: G. Guarnieri a, S. Migliori b, S. Podda c a ENEA-FIM, Portici Research Center, Via Vecchio Macello - Loc. Granatello Portici (Naples) b ENEA-FIM, Enea-Sede, Lungotevere Thaon di Revel n. 76, Roma, c ENEA-FIM, Frascati Research Center, Via E. Fermi 45, Frascati (Roma) Introduction Matlab (MATrix LABoratory) provides an environment for numeric elaboration and an interpreted programming language widely used in science and technology. The package is equipped with specialized libraries (toolboxes) which can solve problems in several fields. For some years the implementation of parallel programming in Matlab environment has been under study. Mathworks, the producer of Matlab, distributes toolboxes with this target, but there are also third party projects with the same aim. Among them is the MatlabMPI library developed by Lincoln Laboratories of the Massachusetts Institute of Technology. ENEA GRID, by the introduction of CRESCO machines, has achieved a very high computational power. So, the possibility of parallel programming in Matlab on this structure becomes a meaningful aim. We have chosen to modify and install the MatlabMPI library for Linux machines of ENEA GRID and particularly for CRESCO cluster. This functions library, written in pure Matlab language, implements a subset of the functions defined in the MPI standard and allows to run, at the same time, several Matlab processes both on multicore machines and computer clusters. Data exchange among the processes does not happen by real message sending and receiving, but via file system access operations. Some code changes were required to install MatlabMPI on ENEA GRID and to adapt the use of the library to CRESCO submission mode. To enable the launching of Matlab jobs on remote machines in interactive such as in batch mode we have resorted to the ENEA GRID submission tool. The use of this library along with the multithreading programming mode on multicore nodes, enabled in latest versions of Matlab, also permit to enforce a hybrid programming mode on CRESCO cluster. The user can exploit the parallelism assured by multithreading on multicore nodes and implement the communication among the nodes with MatlabMPI. MatlabMPI. ("Parallel Programming with MatlabMPI", Jeremy Kepner, Proceedings of the High Performance Embedded Computing (HPEC 2001) workshop, Sep 2001, MIT Lincoln Laboratory, Lexington, MA). MatlabMPI library contains the following items: MPI_Run MPI_Init MPI_Comm_size MPI_Comm_rank MPI_Send MPI_Recv MPI_Finalize MPI_Abort MPI_Bcast MPI_Probe MPI_cc MatMPI_Comm_dir MatMPI_Save_messages MatMPI_Delete_all MatMPI_Comm_settings MatMPI_Buffer_file MatMPI_Lock_file MatMPI_Commands MatMPI_Comm_init MatlabMPI: Message exchange. The send operation consists of storing the data to send in a file in a common directory that all processes can access. The name of this file contains the information about the message to exchange, the sending process and the receiving one. The receive operation, instead, consists of detecting the file from which to load the message by means of the information contained in its name, of waiting for the end of send operation and finally of loading the data with a reading operation. Fig.2. How to launch in interactive mode a session with MatlabMPI on ENEA GRID machines. MatlabMPI on CRESCO cluster. CRESCO HPC system consists of more than 2700 cores, divided into three main sections. This cluster has been integrated in ENEA GRID. The main software components are the LSF scheduler, the openafs distributed file system and the integrated Kerberos 5 authentication. There are eight front-end nodes by which users can access the system and submit their jobs on computational nodes. In order to adapt MatlabMPI library to submit jobs on CRESCO cluster in batch mode it was necessary to further modify the code. We have created some scripts to interface the library with the scheduler environment. Sender Process Receiver Process Send operations Receive operations MPI_Send MPI_Recv Data File Variable Save operation Common file system Load operation Variable Fig.3. How to launch in batch mode a session with MatlabMPI on CRESCO cluster from a front-end command line. We submit with bsub command the script matmpilauncher.sh on the default queue small_10m. Fig.1. Graphic description of a message exchange between two parallel Matlab processes using MatlabMPI functions MPI_Send and MPI_Recv. matmpilaucher.sh LSF Scheduled Resources Since the library consists of pure Matlab code, it s possibile to use it involving heterogeneous sets of platforms as long as they support Matlab environment. On a shared memory system a single licence is enough to use all available cores, whereas on distributed memory systems the user needs a licence for every engaged node. However it is possibile to compile Matlab scripts with the mcc command, in this way only one Matlab licence is enough on distributed memory systems too. MatlabMPI on ENEA GRID. ENEA GRID is based on AFS distributed fyle system, which allows users to access their home directory from every point of the grid. This supports the use of MatlabMPI because the parallel Matlab processes can simply share a common working directory. The library is presently installed on ENEA GRID and it s available for all Linux machines and for the following Matlab releases: 1) (R14) 2) R2007a 3) R2008a We have modified in some points the original code to adapt the use of MatlabMPI to our computational grid. Primarily, to enable the launching of Matlab jobs on remote machines, allowing them to access the AFS file system without losing reading and writing permissions, or to be more precise to ensure token preservation for the user, we have resorted to the ENEA-GRID submission tool. Moreover, in ENEA there are a limited number of Matlab licences and therefore at run time the number of available ones may be insufficient to launch all required Matlab processes, this could cause an error in the elaboration that MatlabMPI cannot detect. We have introduced a shell script that checks the number of available Matlab licences; if this number is insufficient the program exits with an appropriate error message. This script is called by MPI_Run before the stage of processes spawning. MPI_Run function was also modified in order to detect the version of Matlab that is in use and to check the number of available licences for the appropriate version. In this way the user can avoid the risk of creating pending processes with subsequent deadlock errors. References MATLAB matmpiscript.m MatlabMPI + blaunch.sh Fig.4. The script matmpilauncher.sh reads some LSF environmental variables in which are contained the scheduled resources for the request expressed in the command line of Fig.3 and launch Matlab with the M-File matmpiscript.m. The latter passes the scheduled resources as argument to MatlabMPI functions. In batch mode the launch of the parallel Matlab jobs happens by means of blaunch command. Hybrid programming mode on CRESCO cluster - MatlabMPI+. MatlabMPI Fig.5. As the CRESCO architecture is distributed with multicore nodes the best parallel programming style is the hybrid one. This technique combines together multithreading on shared memory machines and message passing for comunication among nodes. The latest Matlab versions enable multithreading on a single multicore node thus the MatlabMPI library fully exploits the CRESCO capabilities.
2
3 Fig.3 Benefits of multicluster queue.
4 ENEA-FIM, C.R. Portici
5 References sp12_graf3d/
300x Matlab. Dr. Jeremy Kepner. MIT Lincoln Laboratory. September 25, 2002 HPEC Workshop Lexington, MA
 300x Matlab Dr. Jeremy Kepner September 25, 2002 HPEC Workshop Lexington, MA This work is sponsored by the High Performance Computing Modernization Office under Air Force Contract F19628-00-C-0002. Opinions,
300x Matlab Dr. Jeremy Kepner September 25, 2002 HPEC Workshop Lexington, MA This work is sponsored by the High Performance Computing Modernization Office under Air Force Contract F19628-00-C-0002. Opinions,
Introduction to Parallel Programming (Session 2: MPI + Matlab/Octave/R)
") Introduction to Parallel Programming (Session 2: MPI + Matlab/Octave/R) Xingfu Wu Department of Computer Science & Engineering Texas A&M University IAMCS, Feb 24, 2012 Survey n Who is mainly programming
Introduction to Parallel Programming (Session 2: MPI + Matlab/Octave/R) Xingfu Wu Department of Computer Science & Engineering Texas A&M University IAMCS, Feb 24, 2012 Survey n Who is mainly programming
Matlab MPI. Shuxia Zhang Supercomputing Institute Tel: (direct) (help)
 (help)") Matlab MPI Shuxia Zhang Supercomputing Institute e-mail: szhang@msi.umn.edu help@msi.umn.edu Tel: 612-624-8858 (direct) 612-626-0802(help) Outline: Introduction MatlabMPI functions/syntax Matlab functions
Matlab MPI Shuxia Zhang Supercomputing Institute e-mail: szhang@msi.umn.edu help@msi.umn.edu Tel: 612-624-8858 (direct) 612-626-0802(help) Outline: Introduction MatlabMPI functions/syntax Matlab functions
Numerical and Statistical tools for images analysis. based on the database from Frascati Tokamak Upgrade. Main System Skills
 Numerical and Statistical tools for images analysis based on the database from Frascati Tokamak Upgrade M. Chinnici a, S. Cuomo b, S. Migliori c a ENEA- FIM-INFOPPQ, Casaccia Research Center, Via Anguillarese
Numerical and Statistical tools for images analysis based on the database from Frascati Tokamak Upgrade M. Chinnici a, S. Cuomo b, S. Migliori c a ENEA- FIM-INFOPPQ, Casaccia Research Center, Via Anguillarese
Parallel Matlab: The Next Generation
 : The Next Generation Dr. Jeremy Kepner / Ms. Nadya Travinin / This work is sponsored by the Department of Defense under Air Force Contract F19628-00-C-0002. Opinions, interpretations, conclusions, and
: The Next Generation Dr. Jeremy Kepner / Ms. Nadya Travinin / This work is sponsored by the Department of Defense under Air Force Contract F19628-00-C-0002. Opinions, interpretations, conclusions, and
ENEA, the Italian agency for the energy,
 FINAL WORKSHOP OF GRID PROJECTS, PON RICERCA 2000-2006, AVVISO 1575 1 CRESCO HPC System Integrated into ENEA-GRID Environment G. Bracco 1, S. Podda 1, S. Migliori 1, P. D Angelo 1, A. Quintiliani 1, D.
FINAL WORKSHOP OF GRID PROJECTS, PON RICERCA 2000-2006, AVVISO 1575 1 CRESCO HPC System Integrated into ENEA-GRID Environment G. Bracco 1, S. Podda 1, S. Migliori 1, P. D Angelo 1, A. Quintiliani 1, D.
Supercomputing in Plain English Exercise #6: MPI Point to Point
 Supercomputing in Plain English Exercise #6: MPI Point to Point In this exercise, we ll use the same conventions and commands as in Exercises #1, #2, #3, #4 and #5. You should refer back to the Exercise
Supercomputing in Plain English Exercise #6: MPI Point to Point In this exercise, we ll use the same conventions and commands as in Exercises #1, #2, #3, #4 and #5. You should refer back to the Exercise
Tutorial on MPI: part I
 Workshop on High Performance Computing (HPC08) School of Physics, IPM February 16-21, 2008 Tutorial on MPI: part I Stefano Cozzini CNR/INFM Democritos and SISSA/eLab Agenda first part WRAP UP of the yesterday's
Workshop on High Performance Computing (HPC08) School of Physics, IPM February 16-21, 2008 Tutorial on MPI: part I Stefano Cozzini CNR/INFM Democritos and SISSA/eLab Agenda first part WRAP UP of the yesterday's
Parallel Matlab: The Next Generation
 : The Next Generation Jeremy Kepner (kepner@ll.mit.edu) and Nadya Travinin (nt@ll.mit.edu), Lexington, MA 02420 Abstract The true costs of high performance computing are currently dominated by software.
: The Next Generation Jeremy Kepner (kepner@ll.mit.edu) and Nadya Travinin (nt@ll.mit.edu), Lexington, MA 02420 Abstract The true costs of high performance computing are currently dominated by software.
Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine
 Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike
Batch Systems & Parallel Application Launchers Running your jobs on an HPC machine Partners Funding Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike
Introduction to the Message Passing Interface (MPI)
") Introduction to the Message Passing Interface (MPI) CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction to the Message Passing Interface (MPI) Spring 2018
Introduction to the Message Passing Interface (MPI) CPS343 Parallel and High Performance Computing Spring 2018 CPS343 (Parallel and HPC) Introduction to the Message Passing Interface (MPI) Spring 2018
Batch Systems. Running your jobs on an HPC machine
 Batch Systems Running your jobs on an HPC machine Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
Batch Systems Running your jobs on an HPC machine Reusing this material This work is licensed under a Creative Commons Attribution- NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/deed.en_us
COSC 6374 Parallel Computation. Message Passing Interface (MPI ) I Introduction. Distributed memory machines
 I Introduction. Distributed memory machines") Network card Network card 1 COSC 6374 Parallel Computation Message Passing Interface (MPI ) I Introduction Edgar Gabriel Fall 015 Distributed memory machines Each compute node represents an independent
Network card Network card 1 COSC 6374 Parallel Computation Message Passing Interface (MPI ) I Introduction Edgar Gabriel Fall 015 Distributed memory machines Each compute node represents an independent
Part One: The Files. C MPI Slurm Tutorial - Hello World. Introduction. Hello World! hello.tar. The files, summary. Output Files, summary
 C MPI Slurm Tutorial - Hello World Introduction The example shown here demonstrates the use of the Slurm Scheduler for the purpose of running a C/MPI program. Knowledge of C is assumed. Having read the
C MPI Slurm Tutorial - Hello World Introduction The example shown here demonstrates the use of the Slurm Scheduler for the purpose of running a C/MPI program. Knowledge of C is assumed. Having read the
MPI 1. CSCI 4850/5850 High-Performance Computing Spring 2018
 MPI 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
MPI 1 CSCI 4850/5850 High-Performance Computing Spring 2018 Tae-Hyuk (Ted) Ahn Department of Computer Science Program of Bioinformatics and Computational Biology Saint Louis University Learning Objectives
To connect to the cluster, simply use a SSH or SFTP client to connect to:
 RIT Computer Engineering Cluster The RIT Computer Engineering cluster contains 12 computers for parallel programming using MPI. One computer, phoenix.ce.rit.edu, serves as the master controller or head
RIT Computer Engineering Cluster The RIT Computer Engineering cluster contains 12 computers for parallel programming using MPI. One computer, phoenix.ce.rit.edu, serves as the master controller or head
To connect to the cluster, simply use a SSH or SFTP client to connect to:
 RIT Computer Engineering Cluster The RIT Computer Engineering cluster contains 12 computers for parallel programming using MPI. One computer, cluster-head.ce.rit.edu, serves as the master controller or
RIT Computer Engineering Cluster The RIT Computer Engineering cluster contains 12 computers for parallel programming using MPI. One computer, cluster-head.ce.rit.edu, serves as the master controller or
The Accelerator Toolbox (AT) is a heavily matured collection of tools and scripts
 is a heavily matured collection of tools and scripts") 1. Abstract The Accelerator Toolbox (AT) is a heavily matured collection of tools and scripts specifically oriented toward solving problems dealing with computational accelerator physics. It is integrated
1. Abstract The Accelerator Toolbox (AT) is a heavily matured collection of tools and scripts specifically oriented toward solving problems dealing with computational accelerator physics. It is integrated
Distributed Simulation in CUBINlab
 Distributed Simulation in CUBINlab John Papandriopoulos http://www.cubinlab.ee.mu.oz.au/ ARC Special Research Centre for Ultra-Broadband Information Networks Outline Clustering overview The CUBINlab cluster
Distributed Simulation in CUBINlab John Papandriopoulos http://www.cubinlab.ee.mu.oz.au/ ARC Special Research Centre for Ultra-Broadband Information Networks Outline Clustering overview The CUBINlab cluster
Calcul intensif et Stockage de Masse. CÉCI/CISM HPC training sessions Use of Matlab on the clusters
 Calcul intensif et Stockage de Masse CÉCI/ HPC training sessions Use of Matlab on the clusters Typical usage... Interactive Batch Type in and get an answer Submit job and fetch results Sequential Parallel
Calcul intensif et Stockage de Masse CÉCI/ HPC training sessions Use of Matlab on the clusters Typical usage... Interactive Batch Type in and get an answer Submit job and fetch results Sequential Parallel
CSE. Parallel Algorithms on a cluster of PCs. Ian Bush. Daresbury Laboratory (With thanks to Lorna Smith and Mark Bull at EPCC)
") Parallel Algorithms on a cluster of PCs Ian Bush Daresbury Laboratory I.J.Bush@dl.ac.uk (With thanks to Lorna Smith and Mark Bull at EPCC) Overview This lecture will cover General Message passing concepts
Parallel Algorithms on a cluster of PCs Ian Bush Daresbury Laboratory I.J.Bush@dl.ac.uk (With thanks to Lorna Smith and Mark Bull at EPCC) Overview This lecture will cover General Message passing concepts
Calcul intensif et Stockage de Masse. CÉCI/CISM HPC training sessions
 Calcul intensif et Stockage de Masse CÉCI/ HPC training sessions Calcul intensif et Stockage de Masse Parallel Matlab on the cluster /CÉCI Training session www.uclouvain.be/cism www.ceci-hpc.be November
Calcul intensif et Stockage de Masse CÉCI/ HPC training sessions Calcul intensif et Stockage de Masse Parallel Matlab on the cluster /CÉCI Training session www.uclouvain.be/cism www.ceci-hpc.be November
CSinParallel Workshop. OnRamp: An Interactive Learning Portal for Parallel Computing Environments
 CSinParallel Workshop : An Interactive Learning for Parallel Computing Environments Samantha Foley ssfoley@cs.uwlax.edu http://cs.uwlax.edu/~ssfoley Josh Hursey jjhursey@cs.uwlax.edu http://cs.uwlax.edu/~jjhursey/
CSinParallel Workshop : An Interactive Learning for Parallel Computing Environments Samantha Foley ssfoley@cs.uwlax.edu http://cs.uwlax.edu/~ssfoley Josh Hursey jjhursey@cs.uwlax.edu http://cs.uwlax.edu/~jjhursey/
arxiv:astro-ph/ v1 6 May 2003
 MatlabMPI arxiv:astro-ph/0305090v1 6 May 2003 Jeremy Kepner (kepner@ll.mit.edu) MIT Lincoln Laboratory, Lexington, MA 02420 Stan Ahalt (sca@ee.eng.ohio-state.edu) Department of Electrical Engineering The
MatlabMPI arxiv:astro-ph/0305090v1 6 May 2003 Jeremy Kepner (kepner@ll.mit.edu) MIT Lincoln Laboratory, Lexington, MA 02420 Stan Ahalt (sca@ee.eng.ohio-state.edu) Department of Electrical Engineering The
Details and description of Application
 CUDA based implementation of parallelized Pollard's Rho algorithm for ECDLP M. Chinnici a, S. Cuomo b, M. Laporta c, B. Pennacchio d, A. Pizzirani e, S. Migliori f a,d ENEA- FIM-INFOPPQ, Casaccia Research
CUDA based implementation of parallelized Pollard's Rho algorithm for ECDLP M. Chinnici a, S. Cuomo b, M. Laporta c, B. Pennacchio d, A. Pizzirani e, S. Migliori f a,d ENEA- FIM-INFOPPQ, Casaccia Research
Implementing GRID interoperability
 AFS & Kerberos Best Practices Workshop University of Michigan, Ann Arbor June 12-16 2006 Implementing GRID interoperability G. Bracco, P. D'Angelo, L. Giammarino*, S.Migliori, A. Quintiliani, C. Scio**,
AFS & Kerberos Best Practices Workshop University of Michigan, Ann Arbor June 12-16 2006 Implementing GRID interoperability G. Bracco, P. D'Angelo, L. Giammarino*, S.Migliori, A. Quintiliani, C. Scio**,
Practical Introduction to Message-Passing Interface (MPI)
") 1 Practical Introduction to Message-Passing Interface (MPI) October 1st, 2015 By: Pier-Luc St-Onge Partners and Sponsors 2 Setup for the workshop 1. Get a user ID and password paper (provided in class):
1 Practical Introduction to Message-Passing Interface (MPI) October 1st, 2015 By: Pier-Luc St-Onge Partners and Sponsors 2 Setup for the workshop 1. Get a user ID and password paper (provided in class):
Getting started with the CEES Grid
 Getting started with the CEES Grid October, 2013 CEES HPC Manager: Dennis Michael, dennis@stanford.edu, 723-2014, Mitchell Building room 415. Please see our web site at http://cees.stanford.edu. Account
Getting started with the CEES Grid October, 2013 CEES HPC Manager: Dennis Michael, dennis@stanford.edu, 723-2014, Mitchell Building room 415. Please see our web site at http://cees.stanford.edu. Account
LLGrid: On-Demand Grid Computing with gridmatlab and pmatlab
 LLGrid: On-Demand Grid Computing with gridmatlab and pmatlab Albert Reuther 29 September 2004 This work is sponsored by the Department of the Air Force under Air Force contract F19628-00-C-0002. Opinions,
LLGrid: On-Demand Grid Computing with gridmatlab and pmatlab Albert Reuther 29 September 2004 This work is sponsored by the Department of the Air Force under Air Force contract F19628-00-C-0002. Opinions,
STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2. (Mouse over to the left to see thumbnails of all of the slides)
") STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2 (Mouse over to the left to see thumbnails of all of the slides) ALLINEA DDT Allinea DDT is a powerful, easy-to-use graphical debugger capable of debugging a
STARTING THE DDT DEBUGGER ON MIO, AUN, & MC2 (Mouse over to the left to see thumbnails of all of the slides) ALLINEA DDT Allinea DDT is a powerful, easy-to-use graphical debugger capable of debugging a
Batch Systems. Running calculations on HPC resources
 Batch Systems Running calculations on HPC resources Outline What is a batch system? How do I interact with the batch system Job submission scripts Interactive jobs Common batch systems Converting between
Batch Systems Running calculations on HPC resources Outline What is a batch system? How do I interact with the batch system Job submission scripts Interactive jobs Common batch systems Converting between
Introduction to High-Performance Computing (HPC)
") Introduction to High-Performance Computing (HPC) Computer components CPU : Central Processing Unit CPU cores : individual processing units within a Storage : Disk drives HDD : Hard Disk Drive SSD : Solid
Introduction to High-Performance Computing (HPC) Computer components CPU : Central Processing Unit CPU cores : individual processing units within a Storage : Disk drives HDD : Hard Disk Drive SSD : Solid
Outline. Communication modes MPI Message Passing Interface Standard. Khoa Coâng Ngheä Thoâng Tin Ñaïi Hoïc Baùch Khoa Tp.HCM
 THOAI NAM Outline Communication modes MPI Message Passing Interface Standard TERMs (1) Blocking If return from the procedure indicates the user is allowed to reuse resources specified in the call Non-blocking
THOAI NAM Outline Communication modes MPI Message Passing Interface Standard TERMs (1) Blocking If return from the procedure indicates the user is allowed to reuse resources specified in the call Non-blocking
Distributed Memory Parallel Programming
 COSC Big Data Analytics Parallel Programming using MPI Edgar Gabriel Spring 201 Distributed Memory Parallel Programming Vast majority of clusters are homogeneous Necessitated by the complexity of maintaining
COSC Big Data Analytics Parallel Programming using MPI Edgar Gabriel Spring 201 Distributed Memory Parallel Programming Vast majority of clusters are homogeneous Necessitated by the complexity of maintaining
Holland Computing Center Kickstart MPI Intro
 Holland Computing Center Kickstart 2016 MPI Intro Message Passing Interface (MPI) MPI is a specification for message passing library that is standardized by MPI Forum Multiple vendor-specific implementations:
Holland Computing Center Kickstart 2016 MPI Intro Message Passing Interface (MPI) MPI is a specification for message passing library that is standardized by MPI Forum Multiple vendor-specific implementations:
MPI Runtime Error Detection with MUST
 MPI Runtime Error Detection with MUST At the 27th VI-HPS Tuning Workshop Joachim Protze IT Center RWTH Aachen University April 2018 How many issues can you spot in this tiny example? #include #include
MPI Runtime Error Detection with MUST At the 27th VI-HPS Tuning Workshop Joachim Protze IT Center RWTH Aachen University April 2018 How many issues can you spot in this tiny example? #include #include
PPCES 2016: MPI Lab March 2016 Hristo Iliev, Portions thanks to: Christian Iwainsky, Sandra Wienke
 PPCES 2016: MPI Lab 16 17 March 2016 Hristo Iliev, iliev@itc.rwth-aachen.de Portions thanks to: Christian Iwainsky, Sandra Wienke Synopsis The purpose of this hands-on lab is to make you familiar with
PPCES 2016: MPI Lab 16 17 March 2016 Hristo Iliev, iliev@itc.rwth-aachen.de Portions thanks to: Christian Iwainsky, Sandra Wienke Synopsis The purpose of this hands-on lab is to make you familiar with
Docker task in HPC Pack
 Docker task in HPC Pack We introduced docker task in HPC Pack 2016 Update1. To use this feature, set the environment variable CCP_DOCKER_IMAGE of a task so that it could be run in a docker container on
Docker task in HPC Pack We introduced docker task in HPC Pack 2016 Update1. To use this feature, set the environment variable CCP_DOCKER_IMAGE of a task so that it could be run in a docker container on
Installing and running COMSOL 4.3a on a Linux cluster COMSOL. All rights reserved.
 Installing and running COMSOL 4.3a on a Linux cluster 2012 COMSOL. All rights reserved. Introduction This quick guide explains how to install and operate COMSOL Multiphysics 4.3a on a Linux cluster. It
Installing and running COMSOL 4.3a on a Linux cluster 2012 COMSOL. All rights reserved. Introduction This quick guide explains how to install and operate COMSOL Multiphysics 4.3a on a Linux cluster. It
ACEnet for CS6702 Ross Dickson, Computational Research Consultant 29 Sep 2009
 ACEnet for CS6702 Ross Dickson, Computational Research Consultant 29 Sep 2009 What is ACEnet? Shared resource......for research computing... physics, chemistry, oceanography, biology, math, engineering,
ACEnet for CS6702 Ross Dickson, Computational Research Consultant 29 Sep 2009 What is ACEnet? Shared resource......for research computing... physics, chemistry, oceanography, biology, math, engineering,
Programming Scalable Systems with MPI. Clemens Grelck, University of Amsterdam
 Clemens Grelck University of Amsterdam UvA / SurfSARA High Performance Computing and Big Data Course June 2014 Parallel Programming with Compiler Directives: OpenMP Message Passing Gentle Introduction
Clemens Grelck University of Amsterdam UvA / SurfSARA High Performance Computing and Big Data Course June 2014 Parallel Programming with Compiler Directives: OpenMP Message Passing Gentle Introduction
Getting Started with Serial and Parallel MATLAB on bwgrid
 Getting Started with Serial and Parallel MATLAB on bwgrid CONFIGURATION Download either bwgrid.remote.r2014b.zip (Windows) or bwgrid.remote.r2014b.tar (Linux/Mac) For Windows users, unzip the download
Getting Started with Serial and Parallel MATLAB on bwgrid CONFIGURATION Download either bwgrid.remote.r2014b.zip (Windows) or bwgrid.remote.r2014b.tar (Linux/Mac) For Windows users, unzip the download
An Introduction to MPI
 An Introduction to MPI Parallel Programming with the Message Passing Interface William Gropp Ewing Lusk Argonne National Laboratory 1 Outline Background The message-passing model Origins of MPI and current
An Introduction to MPI Parallel Programming with the Message Passing Interface William Gropp Ewing Lusk Argonne National Laboratory 1 Outline Background The message-passing model Origins of MPI and current
LLgrid: Enabling On-Demand Grid Computing With gridmatlab and pmatlab
 LLgrid: Enabling On-Demand Grid Computing With gridmatlab and pmatlab Albert Reuther, Tim Currie, Jeremy Kepner, Hahn G. Kim, Andrew McCabe, Michael P. Moore, and Nadya Travinin, Lexington, MA 02420 Phone:
LLgrid: Enabling On-Demand Grid Computing With gridmatlab and pmatlab Albert Reuther, Tim Currie, Jeremy Kepner, Hahn G. Kim, Andrew McCabe, Michael P. Moore, and Nadya Travinin, Lexington, MA 02420 Phone:
Introduction to MPI. Ekpe Okorafor. School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014
 Introduction to MPI Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Topics Introduction MPI Model and Basic Calls MPI Communication Summary 2 Topics Introduction
Introduction to MPI Ekpe Okorafor School of Parallel Programming & Parallel Architecture for HPC ICTP October, 2014 Topics Introduction MPI Model and Basic Calls MPI Communication Summary 2 Topics Introduction
MPI Correctness Checking with MUST
 Center for Information Services and High Performance Computing (ZIH) MPI Correctness Checking with MUST Parallel Programming Course, Dresden, 8.- 12. February 2016 Mathias Korepkat (mathias.korepkat@tu-dresden.de
Center for Information Services and High Performance Computing (ZIH) MPI Correctness Checking with MUST Parallel Programming Course, Dresden, 8.- 12. February 2016 Mathias Korepkat (mathias.korepkat@tu-dresden.de
Multi-thread and Mpi usage in GRID Roberto Alfieri - Parma University & INFN, Gr.Coll. di Parma
 SuperB Computing R&D Workshop Multi-thread and Mpi usage in GRID Roberto Alfieri - Parma University & INFN, Gr.Coll. di Parma Ferrara, Thursday, March 11, 2010 1 Outline MPI and multi-thread support in
SuperB Computing R&D Workshop Multi-thread and Mpi usage in GRID Roberto Alfieri - Parma University & INFN, Gr.Coll. di Parma Ferrara, Thursday, March 11, 2010 1 Outline MPI and multi-thread support in
Számítogépes modellezés labor (MSc)
") Számítogépes modellezés labor (MSc) Running Simulations on Supercomputers Gábor Rácz Physics of Complex Systems Department Eötvös Loránd University, Budapest September 19, 2018, Budapest, Hungary Outline
Számítogépes modellezés labor (MSc) Running Simulations on Supercomputers Gábor Rácz Physics of Complex Systems Department Eötvös Loránd University, Budapest September 19, 2018, Budapest, Hungary Outline
Survey of Parallel Computing with MATLAB
 EUROPEAN ACADEMIC RESEARCH Vol. II, Issue 5/ August 2014 ISSN 2286-4822 www.euacademic.org Impact Factor: 3.1 (UIF) DRJI Value: 5.9 (B+) Survey of Parallel Computing with MATLAB ZAID ABDI ALKAREEM ALYASSERI
EUROPEAN ACADEMIC RESEARCH Vol. II, Issue 5/ August 2014 ISSN 2286-4822 www.euacademic.org Impact Factor: 3.1 (UIF) DRJI Value: 5.9 (B+) Survey of Parallel Computing with MATLAB ZAID ABDI ALKAREEM ALYASSERI
NUSGRID a computational grid at NUS
 NUSGRID a computational grid at NUS Grace Foo (SVU/Academic Computing, Computer Centre) SVU is leading an initiative to set up a campus wide computational grid prototype at NUS. The initiative arose out
NUSGRID a computational grid at NUS Grace Foo (SVU/Academic Computing, Computer Centre) SVU is leading an initiative to set up a campus wide computational grid prototype at NUS. The initiative arose out
CS 426. Building and Running a Parallel Application
 CS 426 Building and Running a Parallel Application 1 Task/Channel Model Design Efficient Parallel Programs (or Algorithms) Mainly for distributed memory systems (e.g. Clusters) Break Parallel Computations
CS 426 Building and Running a Parallel Application 1 Task/Channel Model Design Efficient Parallel Programs (or Algorithms) Mainly for distributed memory systems (e.g. Clusters) Break Parallel Computations
pmatlab: Parallel Matlab Toolbox
 pmatlab: Parallel Matlab Toolbox Ed Hall edhall@virginia.edu Research Computing Support Center Wilson Hall, Room 244 University of Virginia Phone: 243-8800 Email: Res-Consult@Virginia.EDU URL: www.itc.virginia.edu/researchers/services.html
pmatlab: Parallel Matlab Toolbox Ed Hall edhall@virginia.edu Research Computing Support Center Wilson Hall, Room 244 University of Virginia Phone: 243-8800 Email: Res-Consult@Virginia.EDU URL: www.itc.virginia.edu/researchers/services.html
The Message Passing Interface (MPI): Parallelism on Multiple (Possibly Heterogeneous) CPUs
: Parallelism on Multiple (Possibly Heterogeneous) CPUs") 1 The Message Passing Interface (MPI): Parallelism on Multiple (Possibly Heterogeneous) s http://mpi-forum.org https://www.open-mpi.org/ Mike Bailey mjb@cs.oregonstate.edu Oregon State University mpi.pptx
1 The Message Passing Interface (MPI): Parallelism on Multiple (Possibly Heterogeneous) s http://mpi-forum.org https://www.open-mpi.org/ Mike Bailey mjb@cs.oregonstate.edu Oregon State University mpi.pptx
Parallel Processing. Majid AlMeshari John W. Conklin. Science Advisory Committee Meeting September 3, 2010 Stanford University
 Parallel Processing Majid AlMeshari John W. Conklin 1 Outline Challenge Requirements Resources Approach Status Tools for Processing 2 Challenge A computationally intensive algorithm is applied on a huge
Parallel Processing Majid AlMeshari John W. Conklin 1 Outline Challenge Requirements Resources Approach Status Tools for Processing 2 Challenge A computationally intensive algorithm is applied on a huge
Practical Course Scientific Computing and Visualization
 July 5, 2006 Page 1 of 21 1. Parallelization Architecture our target architecture: MIMD distributed address space machines program1 data1 program2 data2 program program3 data data3.. program(data) program1(data1)
July 5, 2006 Page 1 of 21 1. Parallelization Architecture our target architecture: MIMD distributed address space machines program1 data1 program2 data2 program program3 data data3.. program(data) program1(data1)
Introduction to parallel computing concepts and technics
 Introduction to parallel computing concepts and technics Paschalis Korosoglou (support@grid.auth.gr) User and Application Support Unit Scientific Computing Center @ AUTH Overview of Parallel computing
Introduction to parallel computing concepts and technics Paschalis Korosoglou (support@grid.auth.gr) User and Application Support Unit Scientific Computing Center @ AUTH Overview of Parallel computing
Improved Infrastructure Accessibility and Control with LSF for LS-DYNA
 4 th European LS-DYNA Users Conference LS-DYNA Environment I Improved Infrastructure Accessibility and Control with LSF for LS-DYNA Author: Bernhard Schott Christof Westhues Platform Computing GmbH, Ratingen,
4 th European LS-DYNA Users Conference LS-DYNA Environment I Improved Infrastructure Accessibility and Control with LSF for LS-DYNA Author: Bernhard Schott Christof Westhues Platform Computing GmbH, Ratingen,
SAS Grid Manager and Kerberos Authentication
 SAS Grid Manager and Kerberos Authentication Learn the considerations for implementing Kerberos authentication so you can submit workload to SAS Grid Manager. SAS Grid Manager and Kerberos Authentication
SAS Grid Manager and Kerberos Authentication Learn the considerations for implementing Kerberos authentication so you can submit workload to SAS Grid Manager. SAS Grid Manager and Kerberos Authentication
ECE 574 Cluster Computing Lecture 13
 ECE 574 Cluster Computing Lecture 13 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 15 October 2015 Announcements Homework #3 and #4 Grades out soon Homework #5 will be posted
ECE 574 Cluster Computing Lecture 13 Vince Weaver http://www.eece.maine.edu/~vweaver vincent.weaver@maine.edu 15 October 2015 Announcements Homework #3 and #4 Grades out soon Homework #5 will be posted
Beginner's Guide for UK IBM systems
 Beginner's Guide for UK IBM systems This document is intended to provide some basic guidelines for those who already had certain programming knowledge with high level computer languages (e.g. Fortran,
Beginner's Guide for UK IBM systems This document is intended to provide some basic guidelines for those who already had certain programming knowledge with high level computer languages (e.g. Fortran,
Parallel Computing and the MPI environment
 Parallel Computing and the MPI environment Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste http://www.dmi.units.it/~chiarutt/didattica/parallela
Parallel Computing and the MPI environment Claudio Chiaruttini Dipartimento di Matematica e Informatica Centro Interdipartimentale per le Scienze Computazionali (CISC) Università di Trieste http://www.dmi.units.it/~chiarutt/didattica/parallela
COMP528: Multi-core and Multi-Processor Computing
 COMP528: Multi-core and Multi-Processor Computing Dr Michael K Bane, G14, Computer Science, University of Liverpool m.k.bane@liverpool.ac.uk https://cgi.csc.liv.ac.uk/~mkbane/comp528 2X So far Why and
COMP528: Multi-core and Multi-Processor Computing Dr Michael K Bane, G14, Computer Science, University of Liverpool m.k.bane@liverpool.ac.uk https://cgi.csc.liv.ac.uk/~mkbane/comp528 2X So far Why and
MPI MESSAGE PASSING INTERFACE
 MPI MESSAGE PASSING INTERFACE David COLIGNON, ULiège CÉCI - Consortium des Équipements de Calcul Intensif http://www.ceci-hpc.be Outline Introduction From serial source code to parallel execution MPI functions
MPI MESSAGE PASSING INTERFACE David COLIGNON, ULiège CÉCI - Consortium des Équipements de Calcul Intensif http://www.ceci-hpc.be Outline Introduction From serial source code to parallel execution MPI functions
Examples of Big Data analytics in ENEA: data sources and information extraction strategies
 Examples of Big Data analytics in ENEA: data sources and information extraction strategies Ing. Giovanni Ponti, PhD ENEA DTE-ICT-HPC giovanni.ponti@enea.it DISRUPTIVE DATA 2017 5 Maggio, 2017, Via Santa
Examples of Big Data analytics in ENEA: data sources and information extraction strategies Ing. Giovanni Ponti, PhD ENEA DTE-ICT-HPC giovanni.ponti@enea.it DISRUPTIVE DATA 2017 5 Maggio, 2017, Via Santa
The Message Passing Interface (MPI): Parallelism on Multiple (Possibly Heterogeneous) CPUs
: Parallelism on Multiple (Possibly Heterogeneous) CPUs") 1 The Message Passing Interface (MPI): Parallelism on Multiple (Possibly Heterogeneous) CPUs http://mpi-forum.org https://www.open-mpi.org/ Mike Bailey mjb@cs.oregonstate.edu Oregon State University mpi.pptx
1 The Message Passing Interface (MPI): Parallelism on Multiple (Possibly Heterogeneous) CPUs http://mpi-forum.org https://www.open-mpi.org/ Mike Bailey mjb@cs.oregonstate.edu Oregon State University mpi.pptx
Parallel Processing Experience on Low cost Pentium Machines
 Parallel Processing Experience on Low cost Pentium Machines By Syed Misbahuddin Computer Engineering Department Sir Syed University of Engineering and Technology, Karachi doctorsyedmisbah@yahoo.com Presentation
Parallel Processing Experience on Low cost Pentium Machines By Syed Misbahuddin Computer Engineering Department Sir Syed University of Engineering and Technology, Karachi doctorsyedmisbah@yahoo.com Presentation
Fixed Bugs for IBM Platform LSF Version
 Fixed Bugs for IBM LSF Version 9.1.1.1 Release Date: July 2013 The following bugs have been fixed in LSF Version 9.1.1.1 since March 2013 until June 24, 2013: 173446 Date 2013-01-11 The full pending reason
Fixed Bugs for IBM LSF Version 9.1.1.1 Release Date: July 2013 The following bugs have been fixed in LSF Version 9.1.1.1 since March 2013 until June 24, 2013: 173446 Date 2013-01-11 The full pending reason
High Performance Computing Cluster Advanced course
 High Performance Computing Cluster Advanced course Jeremie Vandenplas, Gwen Dawes 9 November 2017 Outline Introduction to the Agrogenomics HPC Submitting and monitoring jobs on the HPC Parallel jobs on
High Performance Computing Cluster Advanced course Jeremie Vandenplas, Gwen Dawes 9 November 2017 Outline Introduction to the Agrogenomics HPC Submitting and monitoring jobs on the HPC Parallel jobs on
Presented By: Gregory M. Kurtzer HPC Systems Architect Lawrence Berkeley National Laboratory CONTAINERS IN HPC WITH SINGULARITY
 Presented By: Gregory M. Kurtzer HPC Systems Architect Lawrence Berkeley National Laboratory gmkurtzer@lbl.gov CONTAINERS IN HPC WITH SINGULARITY A QUICK REVIEW OF THE LANDSCAPE Many types of virtualization
Presented By: Gregory M. Kurtzer HPC Systems Architect Lawrence Berkeley National Laboratory gmkurtzer@lbl.gov CONTAINERS IN HPC WITH SINGULARITY A QUICK REVIEW OF THE LANDSCAPE Many types of virtualization
Interactive, On-Demand Parallel Computing with pmatlab and gridmatlab
 Interactive, On-Demand Parallel Computing with pmatlab and gridmatlab Albert Reuther, Nadya Bliss, Robert Bond, Jeremy Kepner, and Hahn Kim June 15, 26 This work is sponsored by the Defense Advanced Research
Interactive, On-Demand Parallel Computing with pmatlab and gridmatlab Albert Reuther, Nadya Bliss, Robert Bond, Jeremy Kepner, and Hahn Kim June 15, 26 This work is sponsored by the Defense Advanced Research
Introduction to MPI. SHARCNET MPI Lecture Series: Part I of II. Paul Preney, OCT, M.Sc., B.Ed., B.Sc.
 Introduction to MPI SHARCNET MPI Lecture Series: Part I of II Paul Preney, OCT, M.Sc., B.Ed., B.Sc. preney@sharcnet.ca School of Computer Science University of Windsor Windsor, Ontario, Canada Copyright
Introduction to MPI SHARCNET MPI Lecture Series: Part I of II Paul Preney, OCT, M.Sc., B.Ed., B.Sc. preney@sharcnet.ca School of Computer Science University of Windsor Windsor, Ontario, Canada Copyright
Using LSF with Condor Checkpointing
 Overview Using LSF with Condor Checkpointing This chapter discusses how obtain, install, and configure the files needed to use Condor checkpointing with LSF. Contents Introduction on page 3 Obtaining Files
Overview Using LSF with Condor Checkpointing This chapter discusses how obtain, install, and configure the files needed to use Condor checkpointing with LSF. Contents Introduction on page 3 Obtaining Files
Distributed Memory Programming with Message-Passing
 Distributed Memory Programming with Message-Passing Pacheco s book Chapter 3 T. Yang, CS240A Part of slides from the text book and B. Gropp Outline An overview of MPI programming Six MPI functions and
Distributed Memory Programming with Message-Passing Pacheco s book Chapter 3 T. Yang, CS240A Part of slides from the text book and B. Gropp Outline An overview of MPI programming Six MPI functions and
Fast Access to Remote Objects 2.0 A renewed gateway to ENEAGRID distributed computing resources
 Fast Access to Remote Objects 2.0 A renewed gateway to ENEAGRID distributed computing resources Angelo Mariano, Giulio D Amato, Fiorenzo Ambrosino, Giuseppe Aprea, Antonio Colavincenzo, Marco Fina, Agostino
Fast Access to Remote Objects 2.0 A renewed gateway to ENEAGRID distributed computing resources Angelo Mariano, Giulio D Amato, Fiorenzo Ambrosino, Giuseppe Aprea, Antonio Colavincenzo, Marco Fina, Agostino
No Time to Read This Book?
 Chapter 1 No Time to Read This Book? We know what it feels like to be under pressure. Try out a few quick and proven optimization stunts described below. They may provide a good enough performance gain
Chapter 1 No Time to Read This Book? We know what it feels like to be under pressure. Try out a few quick and proven optimization stunts described below. They may provide a good enough performance gain
LOAD BALANCING DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS Hermann Härtig
 LOAD BALANCING DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS 2016 Hermann Härtig LECTURE OBJECTIVES starting points independent Unix processes and block synchronous execution which component (point in
LOAD BALANCING DISTRIBUTED OPERATING SYSTEMS, SCALABILITY, SS 2016 Hermann Härtig LECTURE OBJECTIVES starting points independent Unix processes and block synchronous execution which component (point in
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016
 Ion Stoica, UC Berkeley November 19, 2016") MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
MPI and OpenMP (Lecture 25, cs262a) Ion Stoica, UC Berkeley November 19, 2016 Message passing vs. Shared memory Client Client Client Client send(msg) recv(msg) send(msg) recv(msg) MSG MSG MSG IPC Shared
A Message Passing Standard for MPP and Workstations
 A Message Passing Standard for MPP and Workstations Communications of the ACM, July 1996 J.J. Dongarra, S.W. Otto, M. Snir, and D.W. Walker Message Passing Interface (MPI) Message passing library Can be
A Message Passing Standard for MPP and Workstations Communications of the ACM, July 1996 J.J. Dongarra, S.W. Otto, M. Snir, and D.W. Walker Message Passing Interface (MPI) Message passing library Can be
Introduction to HPC Using zcluster at GACRC
 Introduction to HPC Using zcluster at GACRC On-class PBIO/BINF8350 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What
Introduction to HPC Using zcluster at GACRC On-class PBIO/BINF8350 Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What
Rapid prototyping of radar algorithms [Applications Corner]
![Rapid prototyping of radar algorithms [Applications Corner]](/thumbs/81/83836667.jpg "Rapid prototyping of radar algorithms [Applications Corner]") Rapid prototyping of radar algorithms [Applications Corner] The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation As Published
Rapid prototyping of radar algorithms [Applications Corner] The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation As Published
L17: Introduction to Irregular Algorithms and MPI, cont.! November 8, 2011!
 L17: Introduction to Irregular Algorithms and MPI, cont.! November 8, 2011! Administrative Class cancelled, Tuesday, November 15 Guest Lecture, Thursday, November 17, Ganesh Gopalakrishnan CUDA Project
L17: Introduction to Irregular Algorithms and MPI, cont.! November 8, 2011! Administrative Class cancelled, Tuesday, November 15 Guest Lecture, Thursday, November 17, Ganesh Gopalakrishnan CUDA Project
Job Management System Extension To Support SLAAC-1V Reconfigurable Hardware
 Job Management System Extension To Support SLAAC-1V Reconfigurable Hardware Mohamed Taher 1, Kris Gaj 2, Tarek El-Ghazawi 1, and Nikitas Alexandridis 1 1 The George Washington University 2 George Mason
Job Management System Extension To Support SLAAC-1V Reconfigurable Hardware Mohamed Taher 1, Kris Gaj 2, Tarek El-Ghazawi 1, and Nikitas Alexandridis 1 1 The George Washington University 2 George Mason
Allinea DDT Debugger. Dan Mazur, McGill HPC March 5,
 Allinea DDT Debugger Dan Mazur, McGill HPC daniel.mazur@mcgill.ca guillimin@calculquebec.ca March 5, 2015 1 Outline Introduction and motivation Guillimin login and DDT configuration Compiling for a debugger
Allinea DDT Debugger Dan Mazur, McGill HPC daniel.mazur@mcgill.ca guillimin@calculquebec.ca March 5, 2015 1 Outline Introduction and motivation Guillimin login and DDT configuration Compiling for a debugger
Parallelizing AT with MatlabMPI. Evan Y. Li
 SLAC-TN-11-009 Parallelizing AT with MatlabMPI Evan Y. Li Office of Science, Science Undergraduate Laboratory Internship (SULI) Brown University SLAC National Accelerator Laboratory Menlo Park, CA August
SLAC-TN-11-009 Parallelizing AT with MatlabMPI Evan Y. Li Office of Science, Science Undergraduate Laboratory Internship (SULI) Brown University SLAC National Accelerator Laboratory Menlo Park, CA August
Best practices. Using Affinity Scheduling in IBM Platform LSF. IBM Platform LSF
 IBM Platform LSF Best practices Using Affinity Scheduling in IBM Platform LSF Rong Song Shen Software Developer: LSF Systems & Technology Group Sam Sanjabi Senior Software Developer Systems & Technology
IBM Platform LSF Best practices Using Affinity Scheduling in IBM Platform LSF Rong Song Shen Software Developer: LSF Systems & Technology Group Sam Sanjabi Senior Software Developer Systems & Technology
DDT: A visual, parallel debugger on Ra
 DDT: A visual, parallel debugger on Ra David M. Larue dlarue@mines.edu High Performance & Research Computing Campus Computing, Communications, and Information Technologies Colorado School of Mines March,
DDT: A visual, parallel debugger on Ra David M. Larue dlarue@mines.edu High Performance & Research Computing Campus Computing, Communications, and Information Technologies Colorado School of Mines March,
Introduction to Parallel Programming with MPI
 Introduction to Parallel Programming with MPI PICASso Tutorial October 25-26, 2006 Stéphane Ethier (ethier@pppl.gov) Computational Plasma Physics Group Princeton Plasma Physics Lab Why Parallel Computing?
Introduction to Parallel Programming with MPI PICASso Tutorial October 25-26, 2006 Stéphane Ethier (ethier@pppl.gov) Computational Plasma Physics Group Princeton Plasma Physics Lab Why Parallel Computing?
Testing of PVODE, a Parallel ODE Solver
 Testing of PVODE, a Parallel ODE Solver Michael R. Wittman Lawrence Livermore National Laboratory Center for Applied Scientific Computing UCRL-ID-125562 August 1996 DISCLAIMER This document was prepared
Testing of PVODE, a Parallel ODE Solver Michael R. Wittman Lawrence Livermore National Laboratory Center for Applied Scientific Computing UCRL-ID-125562 August 1996 DISCLAIMER This document was prepared
A Login Shell interface for INFN-GRID
 A Login Shell interface for INFN-GRID S.Pardi2,3, E. Calloni1,2, R. De Rosa1,2, F. Garufi1,2, L. Milano1,2, G. Russo1,2 1Università degli Studi di Napoli Federico II, Dipartimento di Scienze Fisiche, Complesso
A Login Shell interface for INFN-GRID S.Pardi2,3, E. Calloni1,2, R. De Rosa1,2, F. Garufi1,2, L. Milano1,2, G. Russo1,2 1Università degli Studi di Napoli Federico II, Dipartimento di Scienze Fisiche, Complesso
Grid Engine Users Guide. 5.5 Edition
 Grid Engine Users Guide 5.5 Edition Grid Engine Users Guide : 5.5 Edition Published May 08 2012 Copyright 2012 University of California and Scalable Systems This document is subject to the Rocks License
Grid Engine Users Guide 5.5 Edition Grid Engine Users Guide : 5.5 Edition Published May 08 2012 Copyright 2012 University of California and Scalable Systems This document is subject to the Rocks License
Developing a Thin and High Performance Implementation of Message Passing Interface 1
 Developing a Thin and High Performance Implementation of Message Passing Interface 1 Theewara Vorakosit and Putchong Uthayopas Parallel Research Group Computer and Network System Research Laboratory Department
Developing a Thin and High Performance Implementation of Message Passing Interface 1 Theewara Vorakosit and Putchong Uthayopas Parallel Research Group Computer and Network System Research Laboratory Department
CISC 879 Software Support for Multicore Architectures Spring Student Presentation 6: April 8. Presenter: Pujan Kafle, Deephan Mohan
 CISC 879 Software Support for Multicore Architectures Spring 2008 Student Presentation 6: April 8 Presenter: Pujan Kafle, Deephan Mohan Scribe: Kanik Sem The following two papers were presented: A Synchronous
CISC 879 Software Support for Multicore Architectures Spring 2008 Student Presentation 6: April 8 Presenter: Pujan Kafle, Deephan Mohan Scribe: Kanik Sem The following two papers were presented: A Synchronous
Parallel MATLAB at VT
 Parallel MATLAB at VT Gene Cliff (AOE/ICAM - ecliff@vt.edu ) James McClure (ARC/ICAM - mcclurej@vt.edu) Justin Krometis (ARC/ICAM - jkrometis@vt.edu) 11:00am - 11:50am, Thursday, 25 September 2014... NLI...
Parallel MATLAB at VT Gene Cliff (AOE/ICAM - ecliff@vt.edu ) James McClure (ARC/ICAM - mcclurej@vt.edu) Justin Krometis (ARC/ICAM - jkrometis@vt.edu) 11:00am - 11:50am, Thursday, 25 September 2014... NLI...
Platform LSF Security. Platform LSF Version 7.0 Update 5 Release date: March 2009 Last modified: March 16, 2009
 Platform LSF Security Platform LSF Version 7.0 Update 5 Release date: March 2009 Last modified: March 16, 2009 Copyright 1994-2009 Platform Computing Inc. Although the information in this document has
Platform LSF Security Platform LSF Version 7.0 Update 5 Release date: March 2009 Last modified: March 16, 2009 Copyright 1994-2009 Platform Computing Inc. Although the information in this document has
30 Nov Dec Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy
 Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy Why serial is not enough Computing architectures Parallel paradigms Message Passing Interface How
Advanced School in High Performance and GRID Computing Concepts and Applications, ICTP, Trieste, Italy Why serial is not enough Computing architectures Parallel paradigms Message Passing Interface How
Introduction to HPC Using zcluster at GACRC
 Introduction to HPC Using zcluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is HPC Concept? What is
Introduction to HPC Using zcluster at GACRC Georgia Advanced Computing Resource Center University of Georgia Zhuofei Hou, HPC Trainer zhuofei@uga.edu Outline What is GACRC? What is HPC Concept? What is
Parallel Programming in C with MPI and OpenMP
 Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 4 Message-Passing Programming Learning Objectives n Understanding how MPI programs execute n Familiarity with fundamental MPI functions
Parallel Programming in C with MPI and OpenMP Michael J. Quinn Chapter 4 Message-Passing Programming Learning Objectives n Understanding how MPI programs execute n Familiarity with fundamental MPI functions
MPI Runtime Error Detection with MUST and Marmot For the 8th VI-HPS Tuning Workshop
 MPI Runtime Error Detection with MUST and Marmot For the 8th VI-HPS Tuning Workshop Tobias Hilbrich and Joachim Protze ZIH, Technische Universität Dresden September 2011 Content MPI Usage Errors Error
MPI Runtime Error Detection with MUST and Marmot For the 8th VI-HPS Tuning Workshop Tobias Hilbrich and Joachim Protze ZIH, Technische Universität Dresden September 2011 Content MPI Usage Errors Error
Introduction to OpenMP. OpenMP basics OpenMP directives, clauses, and library routines
 Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
Introduction to OpenMP Introduction OpenMP basics OpenMP directives, clauses, and library routines What is OpenMP? What does OpenMP stands for? What does OpenMP stands for? Open specifications for Multi
The MPI Message-passing Standard Lab Time Hands-on. SPD Course 11/03/2014 Massimo Coppola
 The MPI Message-passing Standard Lab Time Hands-on SPD Course 11/03/2014 Massimo Coppola What was expected so far Prepare for the lab sessions Install a version of MPI which works on your O.S. OpenMPI
The MPI Message-passing Standard Lab Time Hands-on SPD Course 11/03/2014 Massimo Coppola What was expected so far Prepare for the lab sessions Install a version of MPI which works on your O.S. OpenMPI