Achieving k-anonmity* Privacy Protection Using Generalization and Suppression
|
|
|
- Amy Stafford
- 6 years ago
- Views:
Transcription
1 UT DALLAS Erik Jonsson School of Engineering & Computer Science Achieving k-anonmity* Privacy Protection Using Generalization and Suppression Murat Kantarcioglu Based on Sweeney 2002 paper
2 Releasing Private Data Problem: Publishing private data while, at the same time, protecting individual privacy Challenges: How to quantify privacy protection How to maximize the usefulness of published data How to minimize the risk of disclosure
3 Sanitization Automated de-identification of private data with certain privacy guarantees Opposed to formal determination by statisticians requirement of HIPAA Two major research directions 1. Perturbation (e.g. random noise addition) 2. Anonymization (e.g. k-anonymization)
4 Anonymization HIPAA revisited Limited data set: no unique identifiers Safe enough? Was not for the Governor of Massachusetts # %87 of US citizens can possibly be uniquely identified using ZIP, sex and birth date # # L. Sweeney, k-anonymity: A Model for Protecting Privacy, International Journal on Uncertainty, Fuzziness and Knowledge-Based Systems, 10(5), , 2002.
5 Anonymization Removing unique identifiers is not sufficient Quasi-identifier (QI) Maximal set of attributes that could help identify individuals Assumed to be publicly available (e.g., voter registration lists)
6 Anonymization As a process 1. Remove all unique identifiers 2. Identify QI-attributes, model adversary s background knowledge 3. Enforce some privacy definition (e.g. k-anonymity)
7 k-anonymity Each released record should be indistinguishable from at least (k-1) others on its QI attributes Alternatively: cardinality of any query result on released data should be at least k k-anonymity is (the first) one of many privacy definitions in this line of work l-diversity, t-closeness, m-invariance, delta-presence...
8 Hardness Given some data set R and a QI Q, does R satisfy k- anonymity over Q? Easy to tell in polynomial time, NP! Finding an optimal anonymization is not easy NP-hard: reduction from k-dimensional perfect matching* A polynomial solution implies P = NP Heuristic solutions DataFly, Incognito, Mondrian, TDS, *A. Meyerson and R. Williams. On the complexity of optimal k-anonymity. In PODS 04.
9 Tools Generalization Replacing (recoding) a value with a less specific but semantically consistent one Suppression Not releasing any value at all Advantages 1. Reveals what was done to the data 2. Truthful (no incorrect implications) 3. Trade-off between anonymity and distortion 4. Adjustable to the recipient s needs (only one s)
10 DGH / VGH ZIP attribute Suppression value Ground domain
11 Example QI = {Race, ZIP} k = 2 k-anonymous relation should have at least 2 tuples with the same values on Dom(Race i ) x Dom(ZIP j ) where Race i and ZIP j are chosen from corresponding DGHs
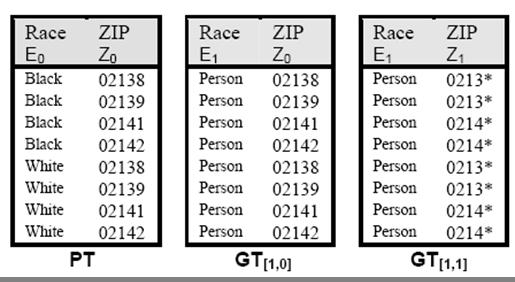
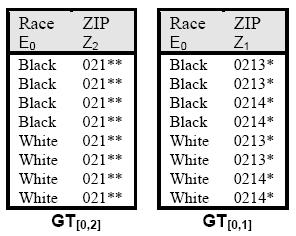
12 Example
13 k-minimal Generalization Given R k, there is always a trivial solution Generalize all attributes to VGH root Not very useful if there exists another k-anonymization with higher granularity (more specific) values k-minimal generalization Satisfies k-anonymity None of its specializations satisfies k-anonymity E.g., [0,2] is not minimal, since [0,1] is k-anonymous E.g., [1,0] is minimal, since [0,0] is not k-anonymous
14 Precision Metric, Prec(.) Multiple k-minimal generalizations may exist E.g., [1,0] and [0,1] from the example Precision metric indicates the generalization with minimal information loss, maximal usefulness Informally, since Prec is not based on entropy Problem: how to define usefulness
15 Precision Metric, Prec(.) Precision: average height of generalized values, normalized by VGH depth per attribute per record N A : number of attributes PT : data set size DGH Ai : depth of the VGH for attribute A i
16 Precision Metric, Prec(.) Notice that precision depends on DGH/VGH Different DGHs result in different precision measurements for the same table Structure of DGHs might determine the generalization of choice DGHs should be semantically meaningful I.e., created by domain experts
17 k-minimal Distortion Most precise release that adheres to k-anonymity Precision measured by Prec(.) Any k-minimal distortion is a k-minimal generalization In the example, only [0,1] is a k-minimal distortion [0,0] is not k-anonymous [1,0] and others are less precise
18 MinGen Algorithm Steps: Generate all generalizations of the private table Discard those that violate k-anonymity Find all generalizations with the highest precision Return one based on some preference criteria Unrealistic Even with attribute level generalization/suppression, there are too many candidates
19 MinGen Algorithm Attribute level global recoding Cell (tuple) level local recoding
20 MinGen Algorithm
21 DataFly Algorithm Steps: Create equivalences over the Cartesian product of QI attributes Heuristically select an attribute to generalize Continue until < k records remain (suppression) Too much distortion due to attribute level generalization and greedy choices k-anonymity is guaranteed
22 DataFly Algorithm
23 μ-argus Algorithm Steps: Generalize until each QI attribute appears k times Check k-anonymity over 2/3-combinations Keeps generalizing according to data holder s choices Suppress any remaining outliers k-anonymity is not guaranteed Faster than DataFly

24 μ-argus Algorithm
25 What s Next? l-diversity: homogenous distribution of sensitive attribute values within anonymized data Japanese Umeko has viral infection Neighbor Bob has cancer
26 UTD Anonymization Library Contains 5 different methods of anonymization Soon to come: Support for 2 other anonymity definitions Integration with Weka Perturbation methods
Data Anonymization - Generalization Algorithms
 Data Anonymization - Generalization Algorithms Li Xiong CS573 Data Privacy and Anonymity Generalization and Suppression Z2 = {410**} Z1 = {4107*. 4109*} Generalization Replace the value with a less specific
Data Anonymization - Generalization Algorithms Li Xiong CS573 Data Privacy and Anonymity Generalization and Suppression Z2 = {410**} Z1 = {4107*. 4109*} Generalization Replace the value with a less specific
K ANONYMITY. Xiaoyong Zhou
 K ANONYMITY LATANYA SWEENEY Xiaoyong Zhou DATA releasing: Privacy vs. Utility Society is experiencing exponential growth in the number and variety of data collections containing person specific specific
K ANONYMITY LATANYA SWEENEY Xiaoyong Zhou DATA releasing: Privacy vs. Utility Society is experiencing exponential growth in the number and variety of data collections containing person specific specific
Slicing Technique For Privacy Preserving Data Publishing
 Slicing Technique For Privacy Preserving Data Publishing D. Mohanapriya #1, Dr. T.Meyyappan M.Sc., MBA. M.Phil., Ph.d., 2 # Department of Computer Science and Engineering, Alagappa University, Karaikudi,
Slicing Technique For Privacy Preserving Data Publishing D. Mohanapriya #1, Dr. T.Meyyappan M.Sc., MBA. M.Phil., Ph.d., 2 # Department of Computer Science and Engineering, Alagappa University, Karaikudi,
Anonymization Algorithms - Microaggregation and Clustering
 Anonymization Algorithms - Microaggregation and Clustering Li Xiong CS573 Data Privacy and Anonymity Anonymization using Microaggregation or Clustering Practical Data-Oriented Microaggregation for Statistical
Anonymization Algorithms - Microaggregation and Clustering Li Xiong CS573 Data Privacy and Anonymity Anonymization using Microaggregation or Clustering Practical Data-Oriented Microaggregation for Statistical
Preserving Privacy during Big Data Publishing using K-Anonymity Model A Survey
 ISSN No. 0976-5697 Volume 8, No. 5, May-June 2017 International Journal of Advanced Research in Computer Science SURVEY REPORT Available Online at www.ijarcs.info Preserving Privacy during Big Data Publishing
ISSN No. 0976-5697 Volume 8, No. 5, May-June 2017 International Journal of Advanced Research in Computer Science SURVEY REPORT Available Online at www.ijarcs.info Preserving Privacy during Big Data Publishing
K-Anonymity and Other Cluster- Based Methods. Ge Ruan Oct. 11,2007
 K-Anonymity and Other Cluster- Based Methods Ge Ruan Oct 11,2007 Data Publishing and Data Privacy Society is experiencing exponential growth in the number and variety of data collections containing person-specific
K-Anonymity and Other Cluster- Based Methods Ge Ruan Oct 11,2007 Data Publishing and Data Privacy Society is experiencing exponential growth in the number and variety of data collections containing person-specific
SIMPLE AND EFFECTIVE METHOD FOR SELECTING QUASI-IDENTIFIER
 31 st July 216. Vol.89. No.2 25-216 JATIT & LLS. All rights reserved. SIMPLE AND EFFECTIVE METHOD FOR SELECTING QUASI-IDENTIFIER 1 AMANI MAHAGOUB OMER, 2 MOHD MURTADHA BIN MOHAMAD 1 Faculty of Computing,
31 st July 216. Vol.89. No.2 25-216 JATIT & LLS. All rights reserved. SIMPLE AND EFFECTIVE METHOD FOR SELECTING QUASI-IDENTIFIER 1 AMANI MAHAGOUB OMER, 2 MOHD MURTADHA BIN MOHAMAD 1 Faculty of Computing,
Survey Result on Privacy Preserving Techniques in Data Publishing
 Survey Result on Privacy Preserving Techniques in Data Publishing S.Deebika PG Student, Computer Science and Engineering, Vivekananda College of Engineering for Women, Namakkal India A.Sathyapriya Assistant
Survey Result on Privacy Preserving Techniques in Data Publishing S.Deebika PG Student, Computer Science and Engineering, Vivekananda College of Engineering for Women, Namakkal India A.Sathyapriya Assistant
Introduction to Data Mining
 Introduction to Data Mining Privacy preserving data mining Li Xiong Slides credits: Chris Clifton Agrawal and Srikant 4/3/2011 1 Privacy Preserving Data Mining Privacy concerns about personal data AOL
Introduction to Data Mining Privacy preserving data mining Li Xiong Slides credits: Chris Clifton Agrawal and Srikant 4/3/2011 1 Privacy Preserving Data Mining Privacy concerns about personal data AOL
Survey of Anonymity Techniques for Privacy Preserving
 2009 International Symposium on Computing, Communication, and Control (ISCCC 2009) Proc.of CSIT vol.1 (2011) (2011) IACSIT Press, Singapore Survey of Anonymity Techniques for Privacy Preserving Luo Yongcheng
2009 International Symposium on Computing, Communication, and Control (ISCCC 2009) Proc.of CSIT vol.1 (2011) (2011) IACSIT Press, Singapore Survey of Anonymity Techniques for Privacy Preserving Luo Yongcheng
Survey of k-anonymity
 NATIONAL INSTITUTE OF TECHNOLOGY ROURKELA Survey of k-anonymity by Ankit Saroha A thesis submitted in partial fulfillment for the degree of Bachelor of Technology under the guidance of Dr. K. S. Babu Department
NATIONAL INSTITUTE OF TECHNOLOGY ROURKELA Survey of k-anonymity by Ankit Saroha A thesis submitted in partial fulfillment for the degree of Bachelor of Technology under the guidance of Dr. K. S. Babu Department
Privacy Preserving Data Publishing: From k-anonymity to Differential Privacy. Xiaokui Xiao Nanyang Technological University
 Privacy Preserving Data Publishing: From k-anonymity to Differential Privacy Xiaokui Xiao Nanyang Technological University Outline Privacy preserving data publishing: What and Why Examples of privacy attacks
Privacy Preserving Data Publishing: From k-anonymity to Differential Privacy Xiaokui Xiao Nanyang Technological University Outline Privacy preserving data publishing: What and Why Examples of privacy attacks
Emerging Measures in Preserving Privacy for Publishing The Data
 Emerging Measures in Preserving Privacy for Publishing The Data K.SIVARAMAN 1 Assistant Professor, Dept. of Computer Science, BIST, Bharath University, Chennai -600073 1 ABSTRACT: The information in the
Emerging Measures in Preserving Privacy for Publishing The Data K.SIVARAMAN 1 Assistant Professor, Dept. of Computer Science, BIST, Bharath University, Chennai -600073 1 ABSTRACT: The information in the
Data Anonymization. Graham Cormode.
 Data Anonymization Graham Cormode graham@research.att.com 1 Why Anonymize? For Data Sharing Give real(istic) data to others to study without compromising privacy of individuals in the data Allows third-parties
Data Anonymization Graham Cormode graham@research.att.com 1 Why Anonymize? For Data Sharing Give real(istic) data to others to study without compromising privacy of individuals in the data Allows third-parties
An efficient hash-based algorithm for minimal k-anonymity
 An efficient hash-based algorithm for minimal k-anonymity Xiaoxun Sun Min Li Hua Wang Ashley Plank Department of Mathematics & Computing University of Southern Queensland Toowoomba, Queensland 4350, Australia
An efficient hash-based algorithm for minimal k-anonymity Xiaoxun Sun Min Li Hua Wang Ashley Plank Department of Mathematics & Computing University of Southern Queensland Toowoomba, Queensland 4350, Australia
A Review of Privacy Preserving Data Publishing Technique
 A Review of Privacy Preserving Data Publishing Technique Abstract:- Amar Paul Singh School of CSE Bahra University Shimla Hills, India Ms. Dhanshri Parihar Asst. Prof (School of CSE) Bahra University Shimla
A Review of Privacy Preserving Data Publishing Technique Abstract:- Amar Paul Singh School of CSE Bahra University Shimla Hills, India Ms. Dhanshri Parihar Asst. Prof (School of CSE) Bahra University Shimla
Privacy Preserving Data Mining. Danushka Bollegala COMP 527
 Privacy Preserving ata Mining anushka Bollegala COMP 527 Privacy Issues ata mining attempts to ind mine) interesting patterns rom large datasets However, some o those patterns might reveal inormation that
Privacy Preserving ata Mining anushka Bollegala COMP 527 Privacy Issues ata mining attempts to ind mine) interesting patterns rom large datasets However, some o those patterns might reveal inormation that
Privacy Preserved Data Publishing Techniques for Tabular Data
 Privacy Preserved Data Publishing Techniques for Tabular Data Keerthy C. College of Engineering Trivandrum Sabitha S. College of Engineering Trivandrum ABSTRACT Almost all countries have imposed strict
Privacy Preserved Data Publishing Techniques for Tabular Data Keerthy C. College of Engineering Trivandrum Sabitha S. College of Engineering Trivandrum ABSTRACT Almost all countries have imposed strict
0x1A Great Papers in Computer Security
 CS 380S 0x1A Great Papers in Computer Security Vitaly Shmatikov http://www.cs.utexas.edu/~shmat/courses/cs380s/ C. Dwork Differential Privacy (ICALP 2006 and many other papers) Basic Setting DB= x 1 x
CS 380S 0x1A Great Papers in Computer Security Vitaly Shmatikov http://www.cs.utexas.edu/~shmat/courses/cs380s/ C. Dwork Differential Privacy (ICALP 2006 and many other papers) Basic Setting DB= x 1 x
Enhanced Slicing Technique for Improving Accuracy in Crowdsourcing Database
 Enhanced Slicing Technique for Improving Accuracy in Crowdsourcing Database T.Malathi 1, S. Nandagopal 2 PG Scholar, Department of Computer Science and Engineering, Nandha College of Technology, Erode,
Enhanced Slicing Technique for Improving Accuracy in Crowdsourcing Database T.Malathi 1, S. Nandagopal 2 PG Scholar, Department of Computer Science and Engineering, Nandha College of Technology, Erode,
Automated Information Retrieval System Using Correlation Based Multi- Document Summarization Method
 Automated Information Retrieval System Using Correlation Based Multi- Document Summarization Method Dr.K.P.Kaliyamurthie HOD, Department of CSE, Bharath University, Tamilnadu, India ABSTRACT: Automated
Automated Information Retrieval System Using Correlation Based Multi- Document Summarization Method Dr.K.P.Kaliyamurthie HOD, Department of CSE, Bharath University, Tamilnadu, India ABSTRACT: Automated
Hiding the Presence of Individuals from Shared Databases: δ-presence
 Consiglio Nazionale delle Ricerche Hiding the Presence of Individuals from Shared Databases: δ-presence M. Ercan Nergiz Maurizio Atzori Chris Clifton Pisa KDD Lab Outline Adversary Models Existential Uncertainty
Consiglio Nazionale delle Ricerche Hiding the Presence of Individuals from Shared Databases: δ-presence M. Ercan Nergiz Maurizio Atzori Chris Clifton Pisa KDD Lab Outline Adversary Models Existential Uncertainty
(α, k)-anonymity: An Enhanced k-anonymity Model for Privacy-Preserving Data Publishing
-anonymity: An Enhanced k-anonymity Model for Privacy-Preserving Data Publishing") (α, k)-anonymity: An Enhanced k-anonymity Model for Privacy-Preserving Data Publishing Raymond Chi-Wing Wong, Jiuyong Li +, Ada Wai-Chee Fu and Ke Wang Department of Computer Science and Engineering +
(α, k)-anonymity: An Enhanced k-anonymity Model for Privacy-Preserving Data Publishing Raymond Chi-Wing Wong, Jiuyong Li +, Ada Wai-Chee Fu and Ke Wang Department of Computer Science and Engineering +
CS573 Data Privacy and Security. Li Xiong
 CS573 Data Privacy and Security Anonymizationmethods Li Xiong Today Clustering based anonymization(cont) Permutation based anonymization Other privacy principles Microaggregation/Clustering Two steps:
CS573 Data Privacy and Security Anonymizationmethods Li Xiong Today Clustering based anonymization(cont) Permutation based anonymization Other privacy principles Microaggregation/Clustering Two steps:
Data Security and Privacy. Topic 18: k-anonymity, l-diversity, and t-closeness
 Data Security and Privacy Topic 18: k-anonymity, l-diversity, and t-closeness 1 Optional Readings for This Lecture t-closeness: Privacy Beyond k-anonymity and l-diversity. Ninghui Li, Tiancheng Li, and
Data Security and Privacy Topic 18: k-anonymity, l-diversity, and t-closeness 1 Optional Readings for This Lecture t-closeness: Privacy Beyond k-anonymity and l-diversity. Ninghui Li, Tiancheng Li, and
NON-CENTRALIZED DISTINCT L-DIVERSITY
 NON-CENTRALIZED DISTINCT L-DIVERSITY Chi Hong Cheong 1, Dan Wu 2, and Man Hon Wong 3 1,3 Department of Computer Science and Engineering, The Chinese University of Hong Kong, Hong Kong {chcheong, mhwong}@cse.cuhk.edu.hk
NON-CENTRALIZED DISTINCT L-DIVERSITY Chi Hong Cheong 1, Dan Wu 2, and Man Hon Wong 3 1,3 Department of Computer Science and Engineering, The Chinese University of Hong Kong, Hong Kong {chcheong, mhwong}@cse.cuhk.edu.hk
Optimal k-anonymity with Flexible Generalization Schemes through Bottom-up Searching
 Optimal k-anonymity with Flexible Generalization Schemes through Bottom-up Searching Tiancheng Li Ninghui Li CERIAS and Department of Computer Science, Purdue University 250 N. University Street, West
Optimal k-anonymity with Flexible Generalization Schemes through Bottom-up Searching Tiancheng Li Ninghui Li CERIAS and Department of Computer Science, Purdue University 250 N. University Street, West
Privacy-Preserving. Introduction to. Data Publishing. Concepts and Techniques. Benjamin C. M. Fung, Ke Wang, Chapman & Hall/CRC. S.
 Chapman & Hall/CRC Data Mining and Knowledge Discovery Series Introduction to Privacy-Preserving Data Publishing Concepts and Techniques Benjamin C M Fung, Ke Wang, Ada Wai-Chee Fu, and Philip S Yu CRC
Chapman & Hall/CRC Data Mining and Knowledge Discovery Series Introduction to Privacy-Preserving Data Publishing Concepts and Techniques Benjamin C M Fung, Ke Wang, Ada Wai-Chee Fu, and Philip S Yu CRC
Anonymized Data: Generation, Models, Usage. Graham Cormode Divesh Srivastava
 Anonymized Data: Generation, Models, Usage Graham Cormode Divesh Srivastava {graham,divesh}@research.att.com Outline Part 1 Introduction to Anonymization and Uncertainty Tabular Data Anonymization Part
Anonymized Data: Generation, Models, Usage Graham Cormode Divesh Srivastava {graham,divesh}@research.att.com Outline Part 1 Introduction to Anonymization and Uncertainty Tabular Data Anonymization Part
Anonymity in Unstructured Data
 Anonymity in Unstructured Data Manolis Terrovitis, Nikos Mamoulis, and Panos Kalnis Department of Computer Science University of Hong Kong Pokfulam Road, Hong Kong rrovitis@cs.hku.hk Department of Computer
Anonymity in Unstructured Data Manolis Terrovitis, Nikos Mamoulis, and Panos Kalnis Department of Computer Science University of Hong Kong Pokfulam Road, Hong Kong rrovitis@cs.hku.hk Department of Computer
MASTER S THESIS. Yohannes Kifle Russom. Computer Science. Study program/ Specialization: Spring semester, Open / Restricted access.
 Faculty of Science and Technology MASTER S THESIS Study program/ Specialization: Computer Science Spring semester, 2013 Open / Restricted access Writer: Yohannes Kifle Russom Faculty supervisor: (Writer
Faculty of Science and Technology MASTER S THESIS Study program/ Specialization: Computer Science Spring semester, 2013 Open / Restricted access Writer: Yohannes Kifle Russom Faculty supervisor: (Writer
A FUZZY BASED APPROACH FOR PRIVACY PRESERVING CLUSTERING
 A FUZZY BASED APPROACH FOR PRIVACY PRESERVING CLUSTERING 1 B.KARTHIKEYAN, 2 G.MANIKANDAN, 3 V.VAITHIYANATHAN 1 Assistant Professor, School of Computing, SASTRA University, TamilNadu, India. 2 Assistant
A FUZZY BASED APPROACH FOR PRIVACY PRESERVING CLUSTERING 1 B.KARTHIKEYAN, 2 G.MANIKANDAN, 3 V.VAITHIYANATHAN 1 Assistant Professor, School of Computing, SASTRA University, TamilNadu, India. 2 Assistant
Evaluating the Classification Accuracy of Data Mining Algorithms for Anonymized Data
 International Journal of Computer Science and Telecommunications [Volume 3, Issue 8, August 2012] 63 ISSN 2047-3338 Evaluating the Classification Accuracy of Data Mining Algorithms for Anonymized Data
International Journal of Computer Science and Telecommunications [Volume 3, Issue 8, August 2012] 63 ISSN 2047-3338 Evaluating the Classification Accuracy of Data Mining Algorithms for Anonymized Data
The K-Anonymization Method Satisfying Personalized Privacy Preservation
 181 A publication of CHEMICAL ENGINEERING TRANSACTIONS VOL. 46, 2015 Guest Editors: Peiyu Ren, Yancang Li, Huiping Song Copyright 2015, AIDIC Servizi S.r.l., ISBN 978-88-95608-37-2; ISSN 2283-9216 The
181 A publication of CHEMICAL ENGINEERING TRANSACTIONS VOL. 46, 2015 Guest Editors: Peiyu Ren, Yancang Li, Huiping Song Copyright 2015, AIDIC Servizi S.r.l., ISBN 978-88-95608-37-2; ISSN 2283-9216 The
A Survey of Privacy Preserving Data Publishing using Generalization and Suppression
 Appl. Math. Inf. Sci. 8, No. 3, 1103-1116 (2014) 1103 Applied Mathematics & Information Sciences An International Journal http://dx.doi.org/10.12785/amis/080321 A Survey of Privacy Preserving Data Publishing
Appl. Math. Inf. Sci. 8, No. 3, 1103-1116 (2014) 1103 Applied Mathematics & Information Sciences An International Journal http://dx.doi.org/10.12785/amis/080321 A Survey of Privacy Preserving Data Publishing
Efficient k-anonymization Using Clustering Techniques
 Efficient k-anonymization Using Clustering Techniques Ji-Won Byun 1,AshishKamra 2, Elisa Bertino 1, and Ninghui Li 1 1 CERIAS and Computer Science, Purdue University {byunj, bertino, ninghui}@cs.purdue.edu
Efficient k-anonymization Using Clustering Techniques Ji-Won Byun 1,AshishKamra 2, Elisa Bertino 1, and Ninghui Li 1 1 CERIAS and Computer Science, Purdue University {byunj, bertino, ninghui}@cs.purdue.edu
Maintaining K-Anonymity against Incremental Updates
 Maintaining K-Anonymity against Incremental Updates Jian Pei Jian Xu Zhibin Wang Wei Wang Ke Wang Simon Fraser University, Canada, {jpei, wang}@cs.sfu.ca Fudan University, China, {xujian, 55, weiwang}@fudan.edu.cn
Maintaining K-Anonymity against Incremental Updates Jian Pei Jian Xu Zhibin Wang Wei Wang Ke Wang Simon Fraser University, Canada, {jpei, wang}@cs.sfu.ca Fudan University, China, {xujian, 55, weiwang}@fudan.edu.cn
K-Anonymity. Definitions. How do you publicly release a database without compromising individual privacy?
 K-Anonymity How do you publicly release a database without compromising individual privacy? The Wrong Approach: REU Summer 2007 Advisors: Ryan Williams and Manuel Blum Just leave out any unique identifiers
K-Anonymity How do you publicly release a database without compromising individual privacy? The Wrong Approach: REU Summer 2007 Advisors: Ryan Williams and Manuel Blum Just leave out any unique identifiers
Comparison and Analysis of Anonymization Techniques for Preserving Privacy in Big Data
 Advances in Computational Sciences and Technology ISSN 0973-6107 Volume 10, Number 2 (2017) pp. 247-253 Research India Publications http://www.ripublication.com Comparison and Analysis of Anonymization
Advances in Computational Sciences and Technology ISSN 0973-6107 Volume 10, Number 2 (2017) pp. 247-253 Research India Publications http://www.ripublication.com Comparison and Analysis of Anonymization
A Theory of Privacy and Utility for Data Sources
 A Theory of Privacy and Utility for Data Sources Lalitha Sankar Princeton University 7/26/2011 Lalitha Sankar (PU) Privacy and Utility 1 Electronic Data Repositories Technological leaps in information
A Theory of Privacy and Utility for Data Sources Lalitha Sankar Princeton University 7/26/2011 Lalitha Sankar (PU) Privacy and Utility 1 Electronic Data Repositories Technological leaps in information
Lightning: Utility-Driven Anonymization of High-Dimensional Data
 161 185 Lightning: Utility-Driven Anonymization of High-Dimensional Data Fabian Prasser, Raffael Bild, Johanna Eicher, Helmut Spengler, Florian Kohlmayer, Klaus A. Kuhn Chair of Biomedical Informatics,
161 185 Lightning: Utility-Driven Anonymization of High-Dimensional Data Fabian Prasser, Raffael Bild, Johanna Eicher, Helmut Spengler, Florian Kohlmayer, Klaus A. Kuhn Chair of Biomedical Informatics,
k-anonymization May Be NP-Hard, but Can it Be Practical?
 k-anonymization May Be NP-Hard, but Can it Be Practical? David Wilson RTI International dwilson@rti.org 1 Introduction This paper discusses the application of k-anonymity to a real-world set of microdata
k-anonymization May Be NP-Hard, but Can it Be Practical? David Wilson RTI International dwilson@rti.org 1 Introduction This paper discusses the application of k-anonymity to a real-world set of microdata
Service-Oriented Architecture for Privacy-Preserving Data Mashup
 Service-Oriented Architecture for Privacy-Preserving Data Mashup Thomas Trojer a Benjamin C. M. Fung b Patrick C. K. Hung c a Quality Engineering, Institute of Computer Science, University of Innsbruck,
Service-Oriented Architecture for Privacy-Preserving Data Mashup Thomas Trojer a Benjamin C. M. Fung b Patrick C. K. Hung c a Quality Engineering, Institute of Computer Science, University of Innsbruck,
Using Multi-objective Optimization to Analyze Data Utility and. Privacy Tradeoffs in Anonymization Techniques
 Using Multi-objective Optimization to Analyze Data Utility and Privacy Tradeoffs in Anonymization Techniques Rinku Dewri, Indrakshi Ray, Indrajit Ray, and Darrell Whitley Department of Computer Science
Using Multi-objective Optimization to Analyze Data Utility and Privacy Tradeoffs in Anonymization Techniques Rinku Dewri, Indrakshi Ray, Indrajit Ray, and Darrell Whitley Department of Computer Science
Utility-Based Anonymization Using Local Recoding
 Utility-Based Anonymization Using Local Recoding Jian Xu 1 Wei Wang 1 Jian Pei Xiaoyuan Wang 1 Baile Shi 1 Ada Wai-Chee Fu 3 1 Fudan University, China, {xujian, weiwang1, xy wang, bshi}@fudan.edu.cn Simon
Utility-Based Anonymization Using Local Recoding Jian Xu 1 Wei Wang 1 Jian Pei Xiaoyuan Wang 1 Baile Shi 1 Ada Wai-Chee Fu 3 1 Fudan University, China, {xujian, weiwang1, xy wang, bshi}@fudan.edu.cn Simon
Microdata Publishing with Algorithmic Privacy Guarantees
 Microdata Publishing with Algorithmic Privacy Guarantees Tiancheng Li and Ninghui Li Department of Computer Science, Purdue University 35 N. University Street West Lafayette, IN 4797-217 {li83,ninghui}@cs.purdue.edu
Microdata Publishing with Algorithmic Privacy Guarantees Tiancheng Li and Ninghui Li Department of Computer Science, Purdue University 35 N. University Street West Lafayette, IN 4797-217 {li83,ninghui}@cs.purdue.edu
Maintaining K-Anonymity against Incremental Updates
 Maintaining K-Anonymity against Incremental Updates Jian Pei 1 Jian Xu 2 Zhibin Wang 2 Wei Wang 2 Ke Wang 1 1 Simon Fraser University, Canada, {jpei, wang}@cs.sfu.ca 2 Fudan University, China, {xujian,
Maintaining K-Anonymity against Incremental Updates Jian Pei 1 Jian Xu 2 Zhibin Wang 2 Wei Wang 2 Ke Wang 1 1 Simon Fraser University, Canada, {jpei, wang}@cs.sfu.ca 2 Fudan University, China, {xujian,
PRACTICAL K-ANONYMITY ON LARGE DATASETS. Benjamin Podgursky. Thesis. Submitted to the Faculty of the. Graduate School of Vanderbilt University
 PRACTICAL K-ANONYMITY ON LARGE DATASETS By Benjamin Podgursky Thesis Submitted to the Faculty of the Graduate School of Vanderbilt University in partial fulfillment of the requirements for the degree of
PRACTICAL K-ANONYMITY ON LARGE DATASETS By Benjamin Podgursky Thesis Submitted to the Faculty of the Graduate School of Vanderbilt University in partial fulfillment of the requirements for the degree of
L-Diversity Algorithm for Incremental Data Release
 Appl. ath. Inf. Sci. 7, No. 5, 2055-2060 (203) 2055 Applied athematics & Information Sciences An International Journal http://dx.doi.org/0.2785/amis/070546 L-Diversity Algorithm for Incremental Data Release
Appl. ath. Inf. Sci. 7, No. 5, 2055-2060 (203) 2055 Applied athematics & Information Sciences An International Journal http://dx.doi.org/0.2785/amis/070546 L-Diversity Algorithm for Incremental Data Release
Introduction To Security and Privacy Einführung in die IT-Sicherheit I
 Introduction To Security and Privacy Einführung in die IT-Sicherheit I Prof. Dr. rer. nat. Doğan Kesdoğan Institut für Wirtschaftsinformatik kesdogan@fb5.uni-siegen.de http://www.uni-siegen.de/fb5/itsec/
Introduction To Security and Privacy Einführung in die IT-Sicherheit I Prof. Dr. rer. nat. Doğan Kesdoğan Institut für Wirtschaftsinformatik kesdogan@fb5.uni-siegen.de http://www.uni-siegen.de/fb5/itsec/
Local and global recoding methods for anonymizing set-valued data
 The VLDB Journal (211) 2:83 16 DOI 1.17/s778-1-192-8 REGULAR PAPER Local and global recoding methods for anonymizing set-valued data Manolis Terrovitis Nikos Mamoulis Panos Kalnis Received: 26 May 29 /
The VLDB Journal (211) 2:83 16 DOI 1.17/s778-1-192-8 REGULAR PAPER Local and global recoding methods for anonymizing set-valued data Manolis Terrovitis Nikos Mamoulis Panos Kalnis Received: 26 May 29 /
Privacy-preserving Anonymization of Set-valued Data
 Privacy-preserving Anonymization of Set-valued Data Manolis Terrovitis Dept. of Computer Science University of Hong Kong rrovitis@cs.hku.hk Panos Kalnis Dept. of Computer Science National University of
Privacy-preserving Anonymization of Set-valued Data Manolis Terrovitis Dept. of Computer Science University of Hong Kong rrovitis@cs.hku.hk Panos Kalnis Dept. of Computer Science National University of
m-privacy for Collaborative Data Publishing
 m-privacy for Collaborative Data Publishing Slawomir Goryczka Emory University Email: sgorycz@emory.edu Li Xiong Emory University Email: lxiong@emory.edu Benjamin C. M. Fung Concordia University Email:
m-privacy for Collaborative Data Publishing Slawomir Goryczka Emory University Email: sgorycz@emory.edu Li Xiong Emory University Email: lxiong@emory.edu Benjamin C. M. Fung Concordia University Email:
SMMCOA: Maintaining Multiple Correlations between Overlapped Attributes Using Slicing Technique
 SMMCOA: Maintaining Multiple Correlations between Overlapped Attributes Using Slicing Technique Sumit Jain 1, Abhishek Raghuvanshi 1, Department of information Technology, MIT, Ujjain Abstract--Knowledge
SMMCOA: Maintaining Multiple Correlations between Overlapped Attributes Using Slicing Technique Sumit Jain 1, Abhishek Raghuvanshi 1, Department of information Technology, MIT, Ujjain Abstract--Knowledge
Towards the Anonymisation of RDF Data
 Towards the Anonymisation of RDF Data Filip Radulovic Ontology Engineering Group ETSI Informáticos Universidad Politécnica de Madrid Madrid, Spain fradulovic@fi.upm.es Raúl García-Castro Ontology Engineering
Towards the Anonymisation of RDF Data Filip Radulovic Ontology Engineering Group ETSI Informáticos Universidad Politécnica de Madrid Madrid, Spain fradulovic@fi.upm.es Raúl García-Castro Ontology Engineering
Parallel Composition Revisited
 Parallel Composition Revisited Chris Clifton 23 October 2017 This is joint work with Keith Merrill and Shawn Merrill This work supported by the U.S. Census Bureau under Cooperative Agreement CB16ADR0160002
Parallel Composition Revisited Chris Clifton 23 October 2017 This is joint work with Keith Merrill and Shawn Merrill This work supported by the U.S. Census Bureau under Cooperative Agreement CB16ADR0160002
Privacy in Statistical Databases
 Privacy in Statistical Databases CSE 598D/STAT 598B Fall 2007 Lecture 2, 9/13/2007 Aleksandra Slavkovic Office hours: MW 3:30-4:30 Office: Thomas 412 Phone: x3-4918 Adam Smith Office hours: Mondays 3-5pm
Privacy in Statistical Databases CSE 598D/STAT 598B Fall 2007 Lecture 2, 9/13/2007 Aleksandra Slavkovic Office hours: MW 3:30-4:30 Office: Thomas 412 Phone: x3-4918 Adam Smith Office hours: Mondays 3-5pm
Comparative Analysis of Anonymization Techniques
 International Journal of Electronic and Electrical Engineering. ISSN 0974-2174 Volume 7, Number 8 (2014), pp. 773-778 International Research Publication House http://www.irphouse.com Comparative Analysis
International Journal of Electronic and Electrical Engineering. ISSN 0974-2174 Volume 7, Number 8 (2014), pp. 773-778 International Research Publication House http://www.irphouse.com Comparative Analysis
The Applicability of the Perturbation Model-based Privacy Preserving Data Mining for Real-world Data
 The Applicability of the Perturbation Model-based Privacy Preserving Data Mining for Real-world Data Li Liu, Murat Kantarcioglu and Bhavani Thuraisingham Computer Science Department University of Texas
The Applicability of the Perturbation Model-based Privacy Preserving Data Mining for Real-world Data Li Liu, Murat Kantarcioglu and Bhavani Thuraisingham Computer Science Department University of Texas
Anonymizing datasets with demographics and diagnosis codes in the presence of utility constraints
 Anonymizing datasets with demographics and diagnosis codes in the presence of utility constraints Giorgos Poulis a, Grigorios Loukides b, Spiros Skiadopoulos a, Aris Gkoulalas-Divanis c a Department of
Anonymizing datasets with demographics and diagnosis codes in the presence of utility constraints Giorgos Poulis a, Grigorios Loukides b, Spiros Skiadopoulos a, Aris Gkoulalas-Divanis c a Department of
An Ad Omnia Approach to Defining and Achiev ing Private Data Analysis
 An Ad Omnia Approach to Defining and Achiev ing Private Data Analysis Mohammad Hammoud CS3525 Dept. of Computer Science University of Pittsburgh Introduction This paper addresses the problem of defining
An Ad Omnia Approach to Defining and Achiev ing Private Data Analysis Mohammad Hammoud CS3525 Dept. of Computer Science University of Pittsburgh Introduction This paper addresses the problem of defining
n-confusion: a generalization of k-anonymity
 n-confusion: a generalization of k-anonymity ABSTRACT Klara Stokes Universitat Rovira i Virgili Dept. of Computer Engineering and Maths UNESCO Chair in Data Privacy Av. Països Catalans 26 43007 Tarragona,
n-confusion: a generalization of k-anonymity ABSTRACT Klara Stokes Universitat Rovira i Virgili Dept. of Computer Engineering and Maths UNESCO Chair in Data Privacy Av. Països Catalans 26 43007 Tarragona,
Utility-Based k-anonymization
 Utility-Based -Anonymization Qingming Tang tqm2004@gmail.com Yinjie Wu yjwu@fzu.edu.cn Shangbin Liao liaoshangbin@ gmail.com Xiaodong Wang wangxd@fzu.edu.cn Abstract--Anonymity is a well-researched mechanism
Utility-Based -Anonymization Qingming Tang tqm2004@gmail.com Yinjie Wu yjwu@fzu.edu.cn Shangbin Liao liaoshangbin@ gmail.com Xiaodong Wang wangxd@fzu.edu.cn Abstract--Anonymity is a well-researched mechanism
On the Tradeoff Between Privacy and Utility in Data Publishing
 On the Tradeoff Between Privacy and Utility in Data Publishing Tiancheng Li and Ninghui Li Department of Computer Science Purdue University {li83, ninghui}@cs.purdue.edu ABSTRACT In data publishing, anonymization
On the Tradeoff Between Privacy and Utility in Data Publishing Tiancheng Li and Ninghui Li Department of Computer Science Purdue University {li83, ninghui}@cs.purdue.edu ABSTRACT In data publishing, anonymization
Privacy Preserving Data Sharing in Data Mining Environment
 Privacy Preserving Data Sharing in Data Mining Environment PH.D DISSERTATION BY SUN, XIAOXUN A DISSERTATION SUBMITTED TO THE UNIVERSITY OF SOUTHERN QUEENSLAND IN FULLFILLMENT OF THE REQUIREMENTS FOR THE
Privacy Preserving Data Sharing in Data Mining Environment PH.D DISSERTATION BY SUN, XIAOXUN A DISSERTATION SUBMITTED TO THE UNIVERSITY OF SOUTHERN QUEENSLAND IN FULLFILLMENT OF THE REQUIREMENTS FOR THE
Pufferfish: A Semantic Approach to Customizable Privacy
 Pufferfish: A Semantic Approach to Customizable Privacy Ashwin Machanavajjhala ashwin AT cs.duke.edu Collaborators: Daniel Kifer (Penn State), Bolin Ding (UIUC, Microsoft Research) idash Privacy Workshop
Pufferfish: A Semantic Approach to Customizable Privacy Ashwin Machanavajjhala ashwin AT cs.duke.edu Collaborators: Daniel Kifer (Penn State), Bolin Ding (UIUC, Microsoft Research) idash Privacy Workshop
Improving Privacy And Data Utility For High- Dimensional Data By Using Anonymization Technique
 Improving Privacy And Data Utility For High- Dimensional Data By Using Anonymization Technique P.Nithya 1, V.Karpagam 2 PG Scholar, Department of Software Engineering, Sri Ramakrishna Engineering College,
Improving Privacy And Data Utility For High- Dimensional Data By Using Anonymization Technique P.Nithya 1, V.Karpagam 2 PG Scholar, Department of Software Engineering, Sri Ramakrishna Engineering College,
Differential Privacy. Cynthia Dwork. Mamadou H. Diallo
 Differential Privacy Cynthia Dwork Mamadou H. Diallo 1 Focus Overview Privacy preservation in statistical databases Goal: to enable the user to learn properties of the population as a whole, while protecting
Differential Privacy Cynthia Dwork Mamadou H. Diallo 1 Focus Overview Privacy preservation in statistical databases Goal: to enable the user to learn properties of the population as a whole, while protecting
Efficient Algorithms for Masking and Finding Quasi-Identifiers
 Efficient Algorithms for Masking and Finding Quasi-Identifiers Rajeev Motwani Ying Xu Abstract A quasi-identifier refers to a subset of attributes that can uniquely identify most tuples in a table. Incautious
Efficient Algorithms for Masking and Finding Quasi-Identifiers Rajeev Motwani Ying Xu Abstract A quasi-identifier refers to a subset of attributes that can uniquely identify most tuples in a table. Incautious
Partition Based Perturbation for Privacy Preserving Distributed Data Mining
 BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 17, No 2 Sofia 2017 Print ISSN: 1311-9702; Online ISSN: 1314-4081 DOI: 10.1515/cait-2017-0015 Partition Based Perturbation
BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 17, No 2 Sofia 2017 Print ISSN: 1311-9702; Online ISSN: 1314-4081 DOI: 10.1515/cait-2017-0015 Partition Based Perturbation
Learning Semantically Robust Rules from Data
 Learning Semantically Robust Rules from Data Yiheng Li Latanya Sweeney February 2004 CMU-CALD-04-100 CMU-ISRI-04-107 Center for Automated Learning and Discovery & Data Privacy Laboratory School of Computer
Learning Semantically Robust Rules from Data Yiheng Li Latanya Sweeney February 2004 CMU-CALD-04-100 CMU-ISRI-04-107 Center for Automated Learning and Discovery & Data Privacy Laboratory School of Computer
A Review on Privacy Preserving Data Mining Approaches
 A Review on Privacy Preserving Data Mining Approaches Anu Thomas Asst.Prof. Computer Science & Engineering Department DJMIT,Mogar,Anand Gujarat Technological University Anu.thomas@djmit.ac.in Jimesh Rana
A Review on Privacy Preserving Data Mining Approaches Anu Thomas Asst.Prof. Computer Science & Engineering Department DJMIT,Mogar,Anand Gujarat Technological University Anu.thomas@djmit.ac.in Jimesh Rana
Incognito: Efficient Full Domain K Anonymity
 Incognito: Efficient Full Domain K Anonymity Kristen LeFevre David J. DeWitt Raghu Ramakrishnan University of Wisconsin Madison 1210 West Dayton St. Madison, WI 53706 Talk Prepared By Parul Halwe(05305002)
Incognito: Efficient Full Domain K Anonymity Kristen LeFevre David J. DeWitt Raghu Ramakrishnan University of Wisconsin Madison 1210 West Dayton St. Madison, WI 53706 Talk Prepared By Parul Halwe(05305002)
HIDE: Privacy Preserving Medical Data Publishing. James Gardner Department of Mathematics and Computer Science Emory University
 HIDE: Privacy Preserving Medical Data Publishing James Gardner Department of Mathematics and Computer Science Emory University jgardn3@emory.edu Motivation De-identification is critical in any health informatics
HIDE: Privacy Preserving Medical Data Publishing James Gardner Department of Mathematics and Computer Science Emory University jgardn3@emory.edu Motivation De-identification is critical in any health informatics
Towards Trajectory Anonymization: A Generalization-Based Approach
 Purdue University Purdue e-pubs Department of Computer Science Technical Reports Department of Computer Science 2008 Towards Trajectory Anonymization: A Generalization-Based Approach Mehmet Ercan Nergiz
Purdue University Purdue e-pubs Department of Computer Science Technical Reports Department of Computer Science 2008 Towards Trajectory Anonymization: A Generalization-Based Approach Mehmet Ercan Nergiz
FREQUENT ITEMSET MINING USING PFP-GROWTH VIA SMART SPLITTING
 FREQUENT ITEMSET MINING USING PFP-GROWTH VIA SMART SPLITTING Neha V. Sonparote, Professor Vijay B. More. Neha V. Sonparote, Dept. of computer Engineering, MET s Institute of Engineering Nashik, Maharashtra,
FREQUENT ITEMSET MINING USING PFP-GROWTH VIA SMART SPLITTING Neha V. Sonparote, Professor Vijay B. More. Neha V. Sonparote, Dept. of computer Engineering, MET s Institute of Engineering Nashik, Maharashtra,
Privacy Preserving Data Publishing for Recommender System
 IT 11 023 Examensarbete 30 hp Maj 2011 Privacy Preserving Data Publishing for Recommender System Xiaoqiang Chen Institutionen för informationsteknologi Department of Information Technology Abstract Privacy
IT 11 023 Examensarbete 30 hp Maj 2011 Privacy Preserving Data Publishing for Recommender System Xiaoqiang Chen Institutionen för informationsteknologi Department of Information Technology Abstract Privacy
Privacy Consensus in Anonymization Systems Via Game Theory
 Privacy Consensus in Anonymization Systems Via Game Theory Rosa Karimi Adl, Mina Askari, Ken Barker, and Reihaneh Safavi-Naini Department of Computer Science, University of Calgary, Canada {rkarimia,maskari,kbarker,rei}@ucalgary.ca
Privacy Consensus in Anonymization Systems Via Game Theory Rosa Karimi Adl, Mina Askari, Ken Barker, and Reihaneh Safavi-Naini Department of Computer Science, University of Calgary, Canada {rkarimia,maskari,kbarker,rei}@ucalgary.ca
Co-clustering for differentially private synthetic data generation
 Co-clustering for differentially private synthetic data generation Tarek Benkhelif, Françoise Fessant, Fabrice Clérot and Guillaume Raschia January 23, 2018 Orange Labs & LS2N Journée thématique EGC &
Co-clustering for differentially private synthetic data generation Tarek Benkhelif, Françoise Fessant, Fabrice Clérot and Guillaume Raschia January 23, 2018 Orange Labs & LS2N Journée thématique EGC &
Clustering Based K-anonymity Algorithm for Privacy Preservation
 International Journal of Network Security, Vol.19, No.6, PP.1062-1071, Nov. 2017 (DOI: 10.6633/IJNS.201711.19(6).23) 1062 Clustering Based K-anonymity Algorithm for Privacy Preservation Sang Ni 1, Mengbo
International Journal of Network Security, Vol.19, No.6, PP.1062-1071, Nov. 2017 (DOI: 10.6633/IJNS.201711.19(6).23) 1062 Clustering Based K-anonymity Algorithm for Privacy Preservation Sang Ni 1, Mengbo
Steps Towards Location Privacy
 Steps Towards Location Privacy Subhasish Mazumdar New Mexico Institute of Mining & Technology Socorro, NM 87801, USA. DataSys 2018 Subhasish.Mazumdar@nmt.edu DataSys 2018 1 / 53 Census A census is vital
Steps Towards Location Privacy Subhasish Mazumdar New Mexico Institute of Mining & Technology Socorro, NM 87801, USA. DataSys 2018 Subhasish.Mazumdar@nmt.edu DataSys 2018 1 / 53 Census A census is vital
On-site Service and Safe Output Checking in Japan
 On-site Service and Safe Output Checking in Japan Ryo Kikuchi, Kazuhiro Minami National Statistics Center / NTT, Tokyo, Japan. kikuchi.ryo@lab.ntt.co.jp, 9h358j30qe@gmail.com National Statistics Center
On-site Service and Safe Output Checking in Japan Ryo Kikuchi, Kazuhiro Minami National Statistics Center / NTT, Tokyo, Japan. kikuchi.ryo@lab.ntt.co.jp, 9h358j30qe@gmail.com National Statistics Center
Approaches to distributed privacy protecting data mining
 Approaches to distributed privacy protecting data mining Bartosz Przydatek CMU Approaches to distributed privacy protecting data mining p.1/11 Introduction Data Mining and Privacy Protection conflicting
Approaches to distributed privacy protecting data mining Bartosz Przydatek CMU Approaches to distributed privacy protecting data mining p.1/11 Introduction Data Mining and Privacy Protection conflicting
Secured Medical Data Publication & Measure the Privacy Closeness Using Earth Mover Distance (EMD)
") Vol.2, Issue.1, Jan-Feb 2012 pp-208-212 ISSN: 2249-6645 Secured Medical Data Publication & Measure the Privacy Closeness Using Earth Mover Distance (EMD) Krishna.V #, Santhana Lakshmi. S * # PG Student,
Vol.2, Issue.1, Jan-Feb 2012 pp-208-212 ISSN: 2249-6645 Secured Medical Data Publication & Measure the Privacy Closeness Using Earth Mover Distance (EMD) Krishna.V #, Santhana Lakshmi. S * # PG Student,
Private Database Synthesis for Outsourced System Evaluation
 Private Database Synthesis for Outsourced System Evaluation Vani Gupta 1, Gerome Miklau 1, and Neoklis Polyzotis 2 1 Dept. of Computer Science, University of Massachusetts, Amherst, MA, USA 2 Dept. of
Private Database Synthesis for Outsourced System Evaluation Vani Gupta 1, Gerome Miklau 1, and Neoklis Polyzotis 2 1 Dept. of Computer Science, University of Massachusetts, Amherst, MA, USA 2 Dept. of
Injector: Mining Background Knowledge for Data Anonymization
 : Mining Background Knowledge for Data Anonymization Tiancheng Li, Ninghui Li Department of Computer Science, Purdue University 35 N. University Street, West Lafayette, IN 4797, USA {li83,ninghui}@cs.purdue.edu
: Mining Background Knowledge for Data Anonymization Tiancheng Li, Ninghui Li Department of Computer Science, Purdue University 35 N. University Street, West Lafayette, IN 4797, USA {li83,ninghui}@cs.purdue.edu
Distributed Bottom up Approach for Data Anonymization using MapReduce framework on Cloud
 Distributed Bottom up Approach for Data Anonymization using MapReduce framework on Cloud R. H. Jadhav 1 P.E.S college of Engineering, Aurangabad, Maharashtra, India 1 rjadhav377@gmail.com ABSTRACT: Many
Distributed Bottom up Approach for Data Anonymization using MapReduce framework on Cloud R. H. Jadhav 1 P.E.S college of Engineering, Aurangabad, Maharashtra, India 1 rjadhav377@gmail.com ABSTRACT: Many
Approximation Algorithms for k-anonymity 1
 Journal of Privacy Technology 20051120001 Approximation Algorithms for k-anonymity 1 Gagan Aggarwal 2 Google Inc., Mountain View, CA Tomas Feder 268 Waverley St., Palo Alto, CA Krishnaram Kenthapadi 3
Journal of Privacy Technology 20051120001 Approximation Algorithms for k-anonymity 1 Gagan Aggarwal 2 Google Inc., Mountain View, CA Tomas Feder 268 Waverley St., Palo Alto, CA Krishnaram Kenthapadi 3
Security Control Methods for Statistical Database
 Security Control Methods for Statistical Database Li Xiong CS573 Data Privacy and Security Statistical Database A statistical database is a database which provides statistics on subsets of records OLAP
Security Control Methods for Statistical Database Li Xiong CS573 Data Privacy and Security Statistical Database A statistical database is a database which provides statistics on subsets of records OLAP
On Syntactic Anonymity and Differential Privacy
 161 183 On Syntactic Anonymity and Differential Privacy Chris Clifton 1, Tamir Tassa 2 1 Department of Computer Science/CERIAS, Purdue University, West Lafayette, IN 47907-2107 USA. 2 The Department of
161 183 On Syntactic Anonymity and Differential Privacy Chris Clifton 1, Tamir Tassa 2 1 Department of Computer Science/CERIAS, Purdue University, West Lafayette, IN 47907-2107 USA. 2 The Department of
Privacy-Preserving Machine Learning
 Privacy-Preserving Machine Learning CS 760: Machine Learning Spring 2018 Mark Craven and David Page www.biostat.wisc.edu/~craven/cs760 1 Goals for the Lecture You should understand the following concepts:
Privacy-Preserving Machine Learning CS 760: Machine Learning Spring 2018 Mark Craven and David Page www.biostat.wisc.edu/~craven/cs760 1 Goals for the Lecture You should understand the following concepts:
An Efficient Clustering Method for k-anonymization
 An Efficient Clustering Method for -Anonymization Jun-Lin Lin Department of Information Management Yuan Ze University Chung-Li, Taiwan jun@saturn.yzu.edu.tw Meng-Cheng Wei Department of Information Management
An Efficient Clustering Method for -Anonymization Jun-Lin Lin Department of Information Management Yuan Ze University Chung-Li, Taiwan jun@saturn.yzu.edu.tw Meng-Cheng Wei Department of Information Management
CERIAS Tech Report Injector: Mining Background Knowledge for Data Anonymization by Tiancheng Li; Ninghui Li Center for Education and Research
 CERIAS Tech Report 28-29 : Mining Background Knowledge for Data Anonymization by Tiancheng Li; Ninghui Li Center for Education and Research Information Assurance and Security Purdue University, West Lafayette,
CERIAS Tech Report 28-29 : Mining Background Knowledge for Data Anonymization by Tiancheng Li; Ninghui Li Center for Education and Research Information Assurance and Security Purdue University, West Lafayette,
Personalized Privacy Preserving Publication of Transactional Datasets Using Concept Learning
 Personalized Privacy Preserving Publication of Transactional Datasets Using Concept Learning S. Ram Prasad Reddy, Kvsvn Raju, and V. Valli Kumari associated with a particular transaction, if the adversary
Personalized Privacy Preserving Publication of Transactional Datasets Using Concept Learning S. Ram Prasad Reddy, Kvsvn Raju, and V. Valli Kumari associated with a particular transaction, if the adversary
Pseudonymization risk analysis in distributed systems
 Neumann et al. Journal of Internet Services and Applications (2019) 10:1 https://doi.org/10.1186/s13174-018-0098-z Journal of Internet Services and Applications RESEARCH Open Access Pseudonymization risk
Neumann et al. Journal of Internet Services and Applications (2019) 10:1 https://doi.org/10.1186/s13174-018-0098-z Journal of Internet Services and Applications RESEARCH Open Access Pseudonymization risk
Privacy Preserving in Knowledge Discovery and Data Publishing
 B.Lakshmana Rao, G.V Konda Reddy and G.Yedukondalu 33 Privacy Preserving in Knowledge Discovery and Data Publishing B.Lakshmana Rao 1, G.V Konda Reddy 2, G.Yedukondalu 3 Abstract Knowledge Discovery is
B.Lakshmana Rao, G.V Konda Reddy and G.Yedukondalu 33 Privacy Preserving in Knowledge Discovery and Data Publishing B.Lakshmana Rao 1, G.V Konda Reddy 2, G.Yedukondalu 3 Abstract Knowledge Discovery is
Introduction to Privacy
 Introduction to Privacy Why We Care? New Information Technologies: A) Digital storage, retrieval, distribution Enormous cost reductions B) Data sharing and processing i.e Data mining C) Ubiquitous Networking,
Introduction to Privacy Why We Care? New Information Technologies: A) Digital storage, retrieval, distribution Enormous cost reductions B) Data sharing and processing i.e Data mining C) Ubiquitous Networking,
Towards Application-Oriented Data Anonymization
 Towards Application-Oriented Data Anonymization Li Xiong Kumudhavalli Rangachari Abstract Data anonymization is of increasing importance for allowing sharing of individual data for a variety of data analysis
Towards Application-Oriented Data Anonymization Li Xiong Kumudhavalli Rangachari Abstract Data anonymization is of increasing importance for allowing sharing of individual data for a variety of data analysis
(δ,l)-diversity: Privacy Preservation for Publication Numerical Sensitive Data
-diversity: Privacy Preservation for Publication Numerical Sensitive Data") (δ,l)-diversity: Privacy Preservation for Publication Numerical Sensitive Data Mohammad-Reza Zare-Mirakabad Department of Computer Engineering Scool of Electrical and Computer Yazd University, Iran mzare@yazduni.ac.ir
(δ,l)-diversity: Privacy Preservation for Publication Numerical Sensitive Data Mohammad-Reza Zare-Mirakabad Department of Computer Engineering Scool of Electrical and Computer Yazd University, Iran mzare@yazduni.ac.ir
3 No-Wait Job Shops with Variable Processing Times
 3 No-Wait Job Shops with Variable Processing Times In this chapter we assume that, on top of the classical no-wait job shop setting, we are given a set of processing times for each operation. We may select
3 No-Wait Job Shops with Variable Processing Times In this chapter we assume that, on top of the classical no-wait job shop setting, we are given a set of processing times for each operation. We may select