Introduction to Data Mining
|
|
|
- Theresa Lyons
- 5 years ago
- Views:
Transcription
1 Introduction to Data Mining Privacy preserving data mining Li Xiong Slides credits: Chris Clifton Agrawal and Srikant 4/3/2011 1
2 Privacy Preserving Data Mining Privacy concerns about personal data AOL query log release Netflix challenge Data scraping
3 A race to the bottom: privacy ranking of Internet service companies A study done by Privacy International into the privacy practices of key Internet based companies Amazon, AOL, Apple, BBC, ebay, Facebook, Friendster, Google, LinkedIn, LiveJournal, Microsoft, MySpace, Skype, Wikipedia, LiveSpace, Yahoo!, YouTube
4 A Race to the Bottom: Methodologies Corporate administrative details Data collection and processing Data retention Openness and transparency Customer and user control Privacy enhancing innovations and privacy invasive innovations



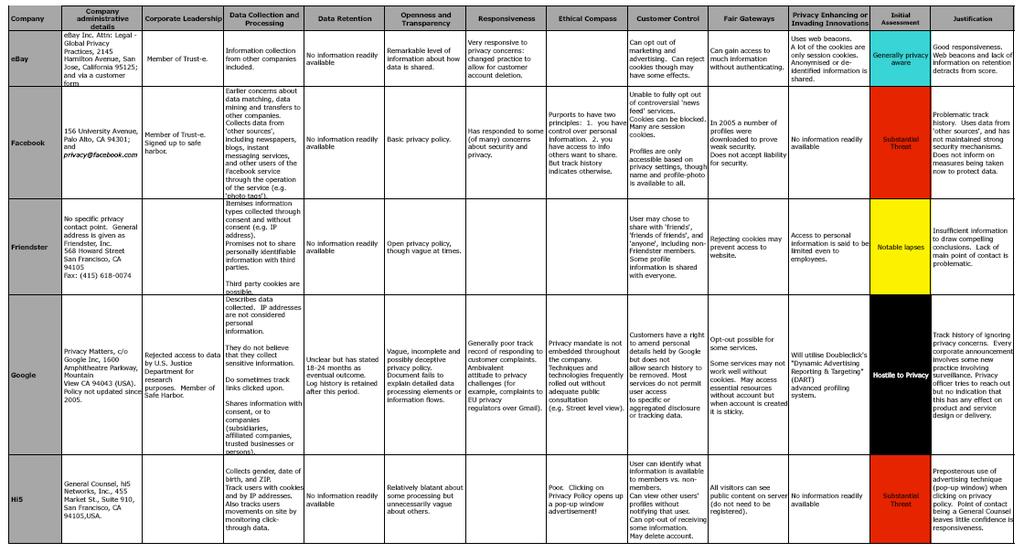
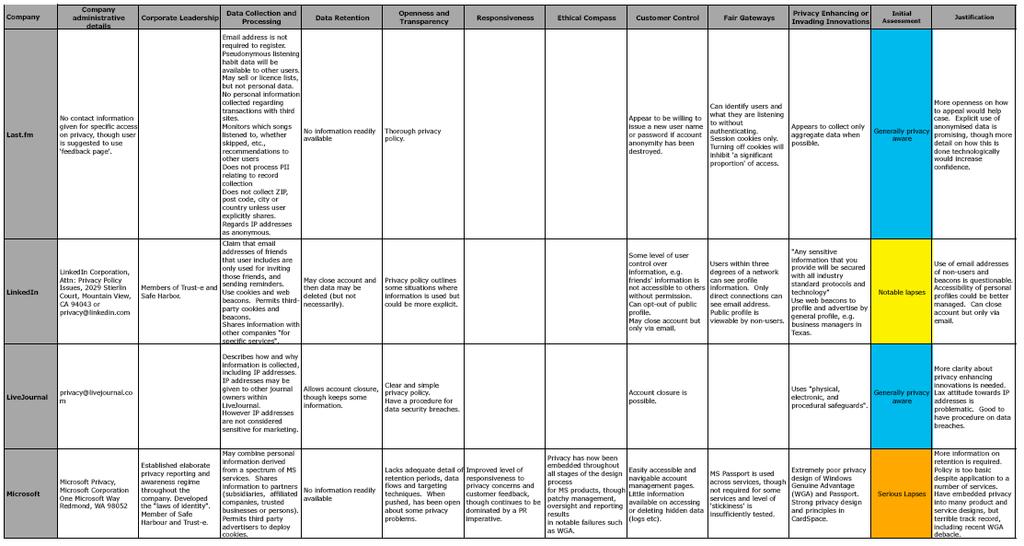
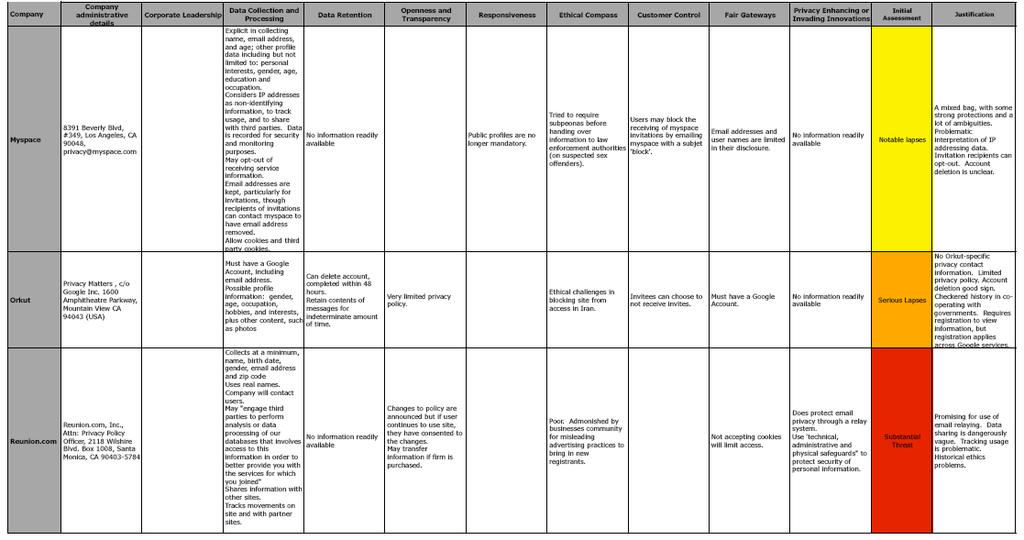
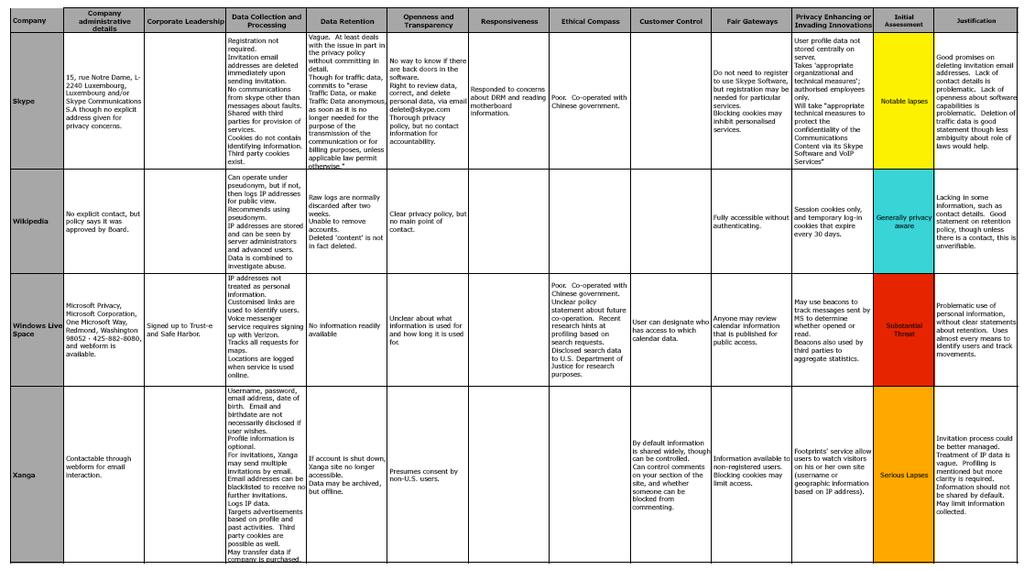
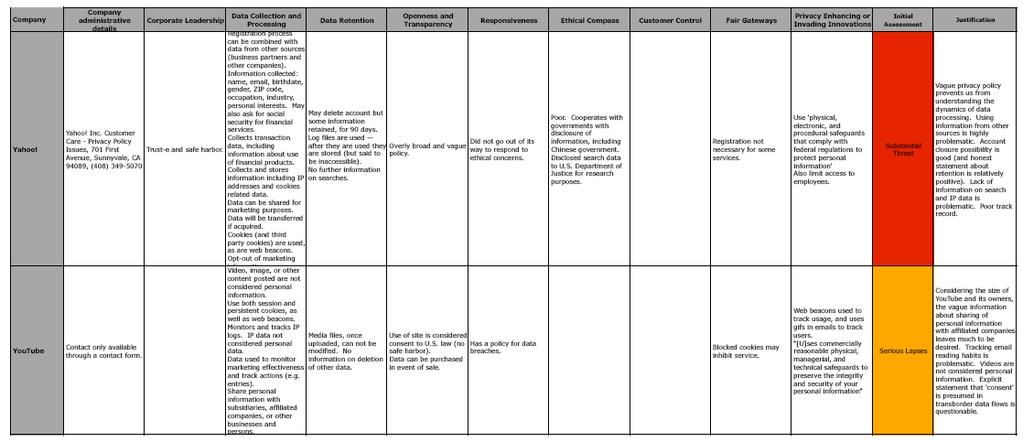

5 A race to the bottom: interim results revealed
6 Why Google Retains a large quantity of information about users, often for an unstated or indefinite length of time, without clear limitation on subsequent use or disclosure Maintains records of all search strings with associated IP and time stamps for at least months Additional personal information from user profiles in Orkut Use advanced profiling system for ads


7 Remember, they are always watching
8 Some advice from privacy Use cash when you can. campaigners Do not give your phone number, social-security number or address, unless you absolutely have to. Do not fill in questionnaires or respond to telemarketers. Demand that credit and data-marketing firms produce all information they have on you, correct errors and remove you from marketing lists. Check your medical records often. Block caller ID on your phone, and keep your number unlisted. Never leave your mobile phone on, your movements can be traced. Do not user store credit or discount cards If you must use the Internet, encrypt your , reject all cookies and never give your real name when registering at websites Better still, use somebody else s computer
9 Privacy-Preserving Data Mining Data obfuscation (non-interactive model) Original Data Anonymization Sanitized Data Miner Output perturbation (interactive model) Original Data Access Interface Perturbed Results Miner
10 Classes of Solutions Methods Input obfuscation Perturbation Generalization Output perturbation Metrics Differential privacy Privacy vs. Utility
11 Data randomization Data Perturbation Randomization (additive noise) Geometric perturbation and projection (multiplicative noise) Randomized response technique (categorical data)
12 Randomization Based Decision Tree Learning (Agrawal and Srikant 00) Basic idea: Perturb Data with Value Distortion User provides x i +r instead of x i r is a random value Uniform, uniform distribution between [-α, α] Gaussian, normal distribution with µ = 0, σ Hypothesis Miner doesn t see the real data or can t reconstruct real values Miner can reconstruct enough information to identify patterns
13 Classification using Randomization Data Alice s age 30 70K K Add random number to Age 30 becomes 65 (30+35) Randomizer Randomizer 65 20K K......? Classification Algorithm Model
14 Output: A Decision Tree for buys_computer age? <=30 overcast >40 student? yes credit rating? no yes excellent fair no yes yes February 12, 2008 Data Mining: Concepts and Techniques 14
15 Attribute Selection Measure: Gini index (CART) If a data set D contains examples from n classes, gini index, gini(d) is defined as gini ( D) = 1 n p 2 j j = 1 where p j is the relative frequency of class j in D If a data set D is split on A into two subsets D 1 and D 2, the gini index gini(d) is defined as Reduction in Impurity: D ( ) 1 D ( ) 2 gini A D = gini D1 + gini ( D 2) D D gini( A) = gini( D) gini ( D) The attribute provides the smallest gini split (D) (or the largest reduction in impurity) is chosen to split the node A February 12, 2008 Data Mining: Concepts and Techniques 15
16 Randomization Approach Overview Alice s age 30 70K K Add random number to Age 30 becomes 65 (30+35) Randomizer Randomizer 65 20K K Reconstruct Distribution of Age Reconstruct Distribution of Salary... Classification Algorithm Model
17 Original Distribution Reconstruction x 1, x 2,, x n are the n original data values Drawn from n iid random variables with distribution X Using value distortion, The given values are w 1 = x 1 + y 1, w 2 = x 2 + y 2,, w n = x n + y n y i s are from n iid random variables with distribution Y Reconstruction Problem: Given F Y and w i s, estimate F X
18 Original Distribution Reconstruction: Method Bayes theorem for continuous distribution The estimated density function (minimum mean square error estimator): n 1 f Y ( w i a) f X ( a) f X ( a ) = n i= 1 f w z f zdz Iterative estimation The initial estimate for f X at j=0: uniform distribution Iterative estimation f j X ( a) = n n i= 1 Y ( ) ( ) f Y f Y i Stopping Criterion: difference between successive iterations is small X j ( wi a) fx ( a) j ( w z) f ( z) i X dz
19 Reconstruction of Distribution 1200 People Number of Original Randomized Reconstructed Age
20 Original Distribution Reconstruction
21 Original Distribution Construction for Decision Tree When are the distributions reconstructed? Global Reconstruct for each attribute once at the beginning Build the decision tree using the reconstructed data ByClass First split the training data Reconstruct for each class separately Build the decision tree using the reconstructed data Local First split the training data Reconstruct for each class separately Reconstruct at each node while building the tree
22 Accuracy vs. Randomization Level Fn 3 Accuracy Randomization Level Original Randomized ByClass
23 More Results Global performs worse than ByClass and Local ByClass and Local have accuracy within 5% to 15% (absolute error) of the Original accuracy Overall, all are much better than the Randomized accuracy
24 Privacy metrics Privacy metrics of random additive data perturbation 4/3/2011 Data Mining: Principles and Algorithms 24
25 Unfortunately Random additive data perturbation are subject to data reconstruction attacks Original data can be estimated using spectral filtering techniques H. Kargupta, S. Datta. On the privacy preserving properties of random data perturbation techniques, in ICDM /3/2011 Data Mining: Principles and Algorithms 25
26 Estimating distribution and data values 4/3/2011 Data Mining: Principles and Algorithms 26
27 Follow-up Work Multiplicative randomization Geometric randomization Also subjective to data reconstruction attacks! Known input-output Known samples 4/3/2011 Data Mining: Principles and Algorithms 27
28 Data randomization Data Perturbation Randomization (additive noise) Geometric perturbation and projection (multiplicative noise) Randomized response technique (categorical data)
29 Data Collection Model Data cannot be shared directly because of privacy concern
 = θ Head Yes P( Head) = θ ( θ 0.5) θ 0.")
30 Background: Randomized Response The true answer is Yes Do you smoke? Biased coin: P( Yes) = θ Head Yes P( Head) = θ ( θ 0.5) θ 0.5 Tail No P'(Yes) =P(Yes) θ +P(No) (1 θ) P'(No) =P(Yes) (1 θ) +P(No) θ
31 Decision Tree Mining using Randomized Response Multiple attributes encoded in bits Biased coin: P( Yes) = θ Head True answer E: 110 P ( Head ) = θ θ 0.5 ( θ 0.5) Tail False answer!e: 001 Column distribution can be estimated for learning a decision tree Using Randomized Response Techniques for Privacy-Preserving Data Mining, Du, 2003
32 Generalization for Multi-Valued Categorical Data q1 q2 q3 q4 S i S i+1 S i+2 True Value: S i S i+3 P'(s1) P'(s2) P'(s3) P'(s4) = q1 q4 q3 q2 P(s1) q2 q1 M q4 q3 P(s2) q3 q2 q1 q4 P(s3) q4 q3 q2 q1 P(s4)
33 A Generalization RR Matrices [Warner 65], [R.Agrawal 05], [S. Agrawal 05] RR Matrix can be arbitrary a 11 a 12 a 13 a 14 a M = 21 a 22 a 23 a 24 a 31 a 32 a 33 a 34 a 41 a 42 a 43 a 44 Can we find optimal RR matrices? OptRR:Optimizing Randomized Response Schemes for Privacy-Preserving Data Mining, Huang, 2008
34 What is an optimal matrix? Which of the following is better? M 1 = M 2 = Privacy: M 2 is better Utility: M 1 is better So, what is an optimal matrix?
35 Optimal RR Matrix An RR matrix M is optimal if no other RR matrix s privacy and utility are both better than M (i, e, no other matrix dominates M). Privacy Quantification Utility Quantification Privacy and utility metrics Privacy: how accurately one can estimate individual info. Utility: how accurately we can estimate aggregate info.
36 Optimization algorithm Evolutionary Multi-Objective Optimization (EMOO) The algorithm Start with a set of initial RR matrices Repeat the following steps in each iteration Mating: selecting two RR matrices in the pool Crossover: exchanging several columns between the two RR matrices Mutation: change some values in a RR matrix Meet the privacy bound: filtering the resultant matrices Evaluate the fitness value for the new RR matrices. Note : the fitness values is defined in terms of privacy and utility metrics
37 Output of Optimization The optimal set is often plotted in the objective space as Pareto front. Worse M 6 M 5 M 8 M 7 M 4 Utility M 1 M 2 M 3 Privacy Better
38 Classes of Solutions Methods Input obfuscation Perturbation Generalization Output perturbation Differential privacy Metrics Privacy vs. Utility
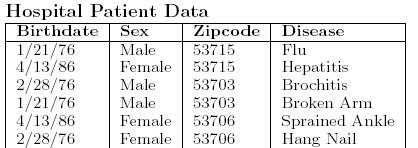
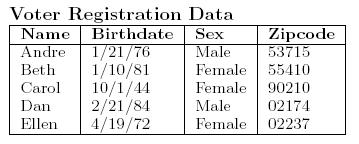
39 Data Re-identification Disease Birthdate Sex Zip Name
40 k-anonymity & l-diversity 40
41 Privacy preserving data mining Generalization principles k-anonymity, l-diversity, Methods Optimal Greedy Top-down vs. bottom-up 41
42 Mondrian: Greedy Partitioning Algorithm Problem Need an algorithm to find multi-dimensional partitions Optimal k-anonymous strict multi-dimensional partitioning is NP-hard Solution Use a greedy algorithm Based on k-d trees Complexity O(nlogn)
43 Example k = 2; Quasi Identifiers: Age, Zipcode What should be the splitting criteria? Patient Data Multi-Dimensional
44 Unfortunately Generalization based principles and methods are subjective to attacks Background knowledge sensitive Attack dependent 4/3/2011 Data Mining: Principles and Algorithms 44
45 Classes of Solutions Methods Input obfuscation Perturbation Generalization Output perturbation Metrics Differential privacy Privacy vs. Utility
46 Differential Privacy Differential privacy requires the outcome to be formally indistinguishable when run with and without any particular record in the data set D1 Bob in D2 Bob out Differentially Private Interface Q Q(D1) + Y1 User Q(D2) + Y2 A(D1) A(D2)
47 Differential Privacy Differential privacy Laplace mechanism Q(D) + Y where Y is drawn from Query sensitivity D1 Bob in D2 Bob out Differentially Private Interface Q(D1) + Y1 Q Q(D2) + Y2 User A(D1) A(D2)
48 Coming up Data mining algorithms using differential privacy Decision tree learning (Data Mining with Differential Privacy, SIGKDD 10) Frequent itemsets mining (discovering frequent patterns in sensitive data, SIGKDD 10) 4/3/2011 Data Mining: Principles and Algorithms 48
49 Midterm Exam Adjusted mean: 85.3 Adjusted max: 101 Your favorite topics: Clustering, frequent itemsets mining, decision tree Your favorite assignments: Apriori Your least favorite: SOM, Weka analysis 4/3/2011 Data Mining: Principles and Algorithms 49
The Applicability of the Perturbation Model-based Privacy Preserving Data Mining for Real-world Data
 The Applicability of the Perturbation Model-based Privacy Preserving Data Mining for Real-world Data Li Liu, Murat Kantarcioglu and Bhavani Thuraisingham Computer Science Department University of Texas
The Applicability of the Perturbation Model-based Privacy Preserving Data Mining for Real-world Data Li Liu, Murat Kantarcioglu and Bhavani Thuraisingham Computer Science Department University of Texas
CS573 Data Privacy and Security. Li Xiong
 CS573 Data Privacy and Security Anonymizationmethods Li Xiong Today Clustering based anonymization(cont) Permutation based anonymization Other privacy principles Microaggregation/Clustering Two steps:
CS573 Data Privacy and Security Anonymizationmethods Li Xiong Today Clustering based anonymization(cont) Permutation based anonymization Other privacy principles Microaggregation/Clustering Two steps:
Extra readings beyond the lecture slides are important:
 1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
1 Notes To preview next lecture: Check the lecture notes, if slides are not available: http://web.cse.ohio-state.edu/~sun.397/courses/au2017/cse5243-new.html Check UIUC course on the same topic. All their
Privacy-Preserving. Introduction to. Data Publishing. Concepts and Techniques. Benjamin C. M. Fung, Ke Wang, Chapman & Hall/CRC. S.
 Chapman & Hall/CRC Data Mining and Knowledge Discovery Series Introduction to Privacy-Preserving Data Publishing Concepts and Techniques Benjamin C M Fung, Ke Wang, Ada Wai-Chee Fu, and Philip S Yu CRC
Chapman & Hall/CRC Data Mining and Knowledge Discovery Series Introduction to Privacy-Preserving Data Publishing Concepts and Techniques Benjamin C M Fung, Ke Wang, Ada Wai-Chee Fu, and Philip S Yu CRC
Achieving k-anonmity* Privacy Protection Using Generalization and Suppression
 UT DALLAS Erik Jonsson School of Engineering & Computer Science Achieving k-anonmity* Privacy Protection Using Generalization and Suppression Murat Kantarcioglu Based on Sweeney 2002 paper Releasing Private
UT DALLAS Erik Jonsson School of Engineering & Computer Science Achieving k-anonmity* Privacy Protection Using Generalization and Suppression Murat Kantarcioglu Based on Sweeney 2002 paper Releasing Private
Co-clustering for differentially private synthetic data generation
 Co-clustering for differentially private synthetic data generation Tarek Benkhelif, Françoise Fessant, Fabrice Clérot and Guillaume Raschia January 23, 2018 Orange Labs & LS2N Journée thématique EGC &
Co-clustering for differentially private synthetic data generation Tarek Benkhelif, Françoise Fessant, Fabrice Clérot and Guillaume Raschia January 23, 2018 Orange Labs & LS2N Journée thématique EGC &
CS573 Data Privacy and Security. Differential Privacy. Li Xiong
 CS573 Data Privacy and Security Differential Privacy Li Xiong Outline Differential Privacy Definition Basic techniques Composition theorems Statistical Data Privacy Non-interactive vs interactive Privacy
CS573 Data Privacy and Security Differential Privacy Li Xiong Outline Differential Privacy Definition Basic techniques Composition theorems Statistical Data Privacy Non-interactive vs interactive Privacy
0x1A Great Papers in Computer Security
 CS 380S 0x1A Great Papers in Computer Security Vitaly Shmatikov http://www.cs.utexas.edu/~shmat/courses/cs380s/ C. Dwork Differential Privacy (ICALP 2006 and many other papers) Basic Setting DB= x 1 x
CS 380S 0x1A Great Papers in Computer Security Vitaly Shmatikov http://www.cs.utexas.edu/~shmat/courses/cs380s/ C. Dwork Differential Privacy (ICALP 2006 and many other papers) Basic Setting DB= x 1 x
Privacy Preserving Data Mining. Danushka Bollegala COMP 527
 Privacy Preserving ata Mining anushka Bollegala COMP 527 Privacy Issues ata mining attempts to ind mine) interesting patterns rom large datasets However, some o those patterns might reveal inormation that
Privacy Preserving ata Mining anushka Bollegala COMP 527 Privacy Issues ata mining attempts to ind mine) interesting patterns rom large datasets However, some o those patterns might reveal inormation that
COMP 465: Data Mining Classification Basics
 Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
Supervised vs. Unsupervised Learning COMP 465: Data Mining Classification Basics Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and Techniques, 3 rd ed. Supervised
A Review on Privacy Preserving Data Mining Approaches
 A Review on Privacy Preserving Data Mining Approaches Anu Thomas Asst.Prof. Computer Science & Engineering Department DJMIT,Mogar,Anand Gujarat Technological University Anu.thomas@djmit.ac.in Jimesh Rana
A Review on Privacy Preserving Data Mining Approaches Anu Thomas Asst.Prof. Computer Science & Engineering Department DJMIT,Mogar,Anand Gujarat Technological University Anu.thomas@djmit.ac.in Jimesh Rana
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering
 Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Clustering Hierarchical Clustering, Density based clustering Grid based clustering Team 2 Prof. Anita Wasilewska CSE 634 Data Mining All Sources Used for the Presentation Olson CF. Parallel algorithms
Data Anonymization - Generalization Algorithms
 Data Anonymization - Generalization Algorithms Li Xiong CS573 Data Privacy and Anonymity Generalization and Suppression Z2 = {410**} Z1 = {4107*. 4109*} Generalization Replace the value with a less specific
Data Anonymization - Generalization Algorithms Li Xiong CS573 Data Privacy and Anonymity Generalization and Suppression Z2 = {410**} Z1 = {4107*. 4109*} Generalization Replace the value with a less specific
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3
 Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3 January 25, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
Data Mining: Concepts and Techniques Classification and Prediction Chapter 6.1-3 January 25, 2007 CSE-4412: Data Mining 1 Chapter 6 Classification and Prediction 1. What is classification? What is prediction?
Data Anonymization. Graham Cormode.
 Data Anonymization Graham Cormode graham@research.att.com 1 Why Anonymize? For Data Sharing Give real(istic) data to others to study without compromising privacy of individuals in the data Allows third-parties
Data Anonymization Graham Cormode graham@research.att.com 1 Why Anonymize? For Data Sharing Give real(istic) data to others to study without compromising privacy of individuals in the data Allows third-parties
Security Control Methods for Statistical Database
 Security Control Methods for Statistical Database Li Xiong CS573 Data Privacy and Security Statistical Database A statistical database is a database which provides statistics on subsets of records OLAP
Security Control Methods for Statistical Database Li Xiong CS573 Data Privacy and Security Statistical Database A statistical database is a database which provides statistics on subsets of records OLAP
A FUZZY BASED APPROACH FOR PRIVACY PRESERVING CLUSTERING
 A FUZZY BASED APPROACH FOR PRIVACY PRESERVING CLUSTERING 1 B.KARTHIKEYAN, 2 G.MANIKANDAN, 3 V.VAITHIYANATHAN 1 Assistant Professor, School of Computing, SASTRA University, TamilNadu, India. 2 Assistant
A FUZZY BASED APPROACH FOR PRIVACY PRESERVING CLUSTERING 1 B.KARTHIKEYAN, 2 G.MANIKANDAN, 3 V.VAITHIYANATHAN 1 Assistant Professor, School of Computing, SASTRA University, TamilNadu, India. 2 Assistant
Accumulative Privacy Preserving Data Mining Using Gaussian Noise Data Perturbation at Multi Level Trust
 Accumulative Privacy Preserving Data Mining Using Gaussian Noise Data Perturbation at Multi Level Trust G.Mareeswari 1, V.Anusuya 2 ME, Department of CSE, PSR Engineering College, Sivakasi, Tamilnadu,
Accumulative Privacy Preserving Data Mining Using Gaussian Noise Data Perturbation at Multi Level Trust G.Mareeswari 1, V.Anusuya 2 ME, Department of CSE, PSR Engineering College, Sivakasi, Tamilnadu,
Differential Privacy. Seminar: Robust Data Mining Techniques. Thomas Edlich. July 16, 2017
 Differential Privacy Seminar: Robust Techniques Thomas Edlich Technische Universität München Department of Informatics kdd.in.tum.de July 16, 2017 Outline 1. Introduction 2. Definition and Features of
Differential Privacy Seminar: Robust Techniques Thomas Edlich Technische Universität München Department of Informatics kdd.in.tum.de July 16, 2017 Outline 1. Introduction 2. Definition and Features of
Data Mining in Bioinformatics Day 1: Classification
 Data Mining in Bioinformatics Day 1: Classification Karsten Borgwardt February 18 to March 1, 2013 Machine Learning & Computational Biology Research Group Max Planck Institute Tübingen and Eberhard Karls
Data Mining in Bioinformatics Day 1: Classification Karsten Borgwardt February 18 to March 1, 2013 Machine Learning & Computational Biology Research Group Max Planck Institute Tübingen and Eberhard Karls
Data Mining. 3.2 Decision Tree Classifier. Fall Instructor: Dr. Masoud Yaghini. Chapter 5: Decision Tree Classifier
 Data Mining 3.2 Decision Tree Classifier Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction Basic Algorithm for Decision Tree Induction Attribute Selection Measures Information Gain Gain Ratio
Data Mining 3.2 Decision Tree Classifier Fall 2008 Instructor: Dr. Masoud Yaghini Outline Introduction Basic Algorithm for Decision Tree Induction Attribute Selection Measures Information Gain Gain Ratio
Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Partition Based Perturbation for Privacy Preserving Distributed Data Mining
 BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 17, No 2 Sofia 2017 Print ISSN: 1311-9702; Online ISSN: 1314-4081 DOI: 10.1515/cait-2017-0015 Partition Based Perturbation
BULGARIAN ACADEMY OF SCIENCES CYBERNETICS AND INFORMATION TECHNOLOGIES Volume 17, No 2 Sofia 2017 Print ISSN: 1311-9702; Online ISSN: 1314-4081 DOI: 10.1515/cait-2017-0015 Partition Based Perturbation
ADDITIVE GAUSSIAN NOISE BASED DATA PERTURBATION IN MULTI-LEVEL TRUST PRIVACY PRESERVING DATA MINING
 ADDITIVE GAUSSIAN NOISE BASED DATA PERTURBATION IN MULTI-LEVEL TRUST PRIVACY PRESERVING DATA MINING R.Kalaivani #1,S.Chidambaram #2 # Department of Information Techology, National Engineering College,
ADDITIVE GAUSSIAN NOISE BASED DATA PERTURBATION IN MULTI-LEVEL TRUST PRIVACY PRESERVING DATA MINING R.Kalaivani #1,S.Chidambaram #2 # Department of Information Techology, National Engineering College,
An Approach for Privacy Preserving in Association Rule Mining Using Data Restriction
 International Journal of Engineering Science Invention Volume 2 Issue 1 January. 2013 An Approach for Privacy Preserving in Association Rule Mining Using Data Restriction Janakiramaiah Bonam 1, Dr.RamaMohan
International Journal of Engineering Science Invention Volume 2 Issue 1 January. 2013 An Approach for Privacy Preserving in Association Rule Mining Using Data Restriction Janakiramaiah Bonam 1, Dr.RamaMohan
Classification with Decision Tree Induction
 Classification with Decision Tree Induction This algorithm makes Classification Decision for a test sample with the help of tree like structure (Similar to Binary Tree OR k-ary tree) Nodes in the tree
Classification with Decision Tree Induction This algorithm makes Classification Decision for a test sample with the help of tree like structure (Similar to Binary Tree OR k-ary tree) Nodes in the tree
Privacy in Statistical Databases
 Privacy in Statistical Databases CSE 598D/STAT 598B Fall 2007 Lecture 2, 9/13/2007 Aleksandra Slavkovic Office hours: MW 3:30-4:30 Office: Thomas 412 Phone: x3-4918 Adam Smith Office hours: Mondays 3-5pm
Privacy in Statistical Databases CSE 598D/STAT 598B Fall 2007 Lecture 2, 9/13/2007 Aleksandra Slavkovic Office hours: MW 3:30-4:30 Office: Thomas 412 Phone: x3-4918 Adam Smith Office hours: Mondays 3-5pm
Privacy Preserving Data Publishing: From k-anonymity to Differential Privacy. Xiaokui Xiao Nanyang Technological University
 Privacy Preserving Data Publishing: From k-anonymity to Differential Privacy Xiaokui Xiao Nanyang Technological University Outline Privacy preserving data publishing: What and Why Examples of privacy attacks
Privacy Preserving Data Publishing: From k-anonymity to Differential Privacy Xiaokui Xiao Nanyang Technological University Outline Privacy preserving data publishing: What and Why Examples of privacy attacks
CS 2750 Machine Learning. Lecture 19. Clustering. CS 2750 Machine Learning. Clustering. Groups together similar instances in the data sample
 Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Lecture 9 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem: distribute data into k different groups
Part I. Hierarchical clustering. Hierarchical Clustering. Hierarchical clustering. Produces a set of nested clusters organized as a
 Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
Week 9 Based in part on slides from textbook, slides of Susan Holmes Part I December 2, 2012 Hierarchical Clustering 1 / 1 Produces a set of nested clusters organized as a Hierarchical hierarchical clustering
On Privacy-Preservation of Text and Sparse Binary Data with Sketches
 On Privacy-Preservation of Text and Sparse Binary Data with Sketches Charu C. Aggarwal Philip S. Yu Abstract In recent years, privacy preserving data mining has become very important because of the proliferation
On Privacy-Preservation of Text and Sparse Binary Data with Sketches Charu C. Aggarwal Philip S. Yu Abstract In recent years, privacy preserving data mining has become very important because of the proliferation
Research Paper SECURED UTILITY ENHANCEMENT IN MINING USING GENETIC ALGORITHM
 Research Paper SECURED UTILITY ENHANCEMENT IN MINING USING GENETIC ALGORITHM 1 Dr.G.Kirubhakar and 2 Dr.C.Venkatesh Address for Correspondence 1 Department of Computer Science and Engineering, Surya Engineering
Research Paper SECURED UTILITY ENHANCEMENT IN MINING USING GENETIC ALGORITHM 1 Dr.G.Kirubhakar and 2 Dr.C.Venkatesh Address for Correspondence 1 Department of Computer Science and Engineering, Surya Engineering
Incognito: Efficient Full Domain K Anonymity
 Incognito: Efficient Full Domain K Anonymity Kristen LeFevre David J. DeWitt Raghu Ramakrishnan University of Wisconsin Madison 1210 West Dayton St. Madison, WI 53706 Talk Prepared By Parul Halwe(05305002)
Incognito: Efficient Full Domain K Anonymity Kristen LeFevre David J. DeWitt Raghu Ramakrishnan University of Wisconsin Madison 1210 West Dayton St. Madison, WI 53706 Talk Prepared By Parul Halwe(05305002)
Pufferfish: A Semantic Approach to Customizable Privacy
 Pufferfish: A Semantic Approach to Customizable Privacy Ashwin Machanavajjhala ashwin AT cs.duke.edu Collaborators: Daniel Kifer (Penn State), Bolin Ding (UIUC, Microsoft Research) idash Privacy Workshop
Pufferfish: A Semantic Approach to Customizable Privacy Ashwin Machanavajjhala ashwin AT cs.duke.edu Collaborators: Daniel Kifer (Penn State), Bolin Ding (UIUC, Microsoft Research) idash Privacy Workshop
The applicability of the perturbation based privacy preserving data mining for real-world data
 Available online at www.sciencedirect.com Data & Knowledge Engineering 65 (2008) 5 21 www.elsevier.com/locate/datak The applicability of the perturbation based privacy preserving data mining for real-world
Available online at www.sciencedirect.com Data & Knowledge Engineering 65 (2008) 5 21 www.elsevier.com/locate/datak The applicability of the perturbation based privacy preserving data mining for real-world
FREQUENT ITEMSET MINING USING PFP-GROWTH VIA SMART SPLITTING
 FREQUENT ITEMSET MINING USING PFP-GROWTH VIA SMART SPLITTING Neha V. Sonparote, Professor Vijay B. More. Neha V. Sonparote, Dept. of computer Engineering, MET s Institute of Engineering Nashik, Maharashtra,
FREQUENT ITEMSET MINING USING PFP-GROWTH VIA SMART SPLITTING Neha V. Sonparote, Professor Vijay B. More. Neha V. Sonparote, Dept. of computer Engineering, MET s Institute of Engineering Nashik, Maharashtra,
Lecture 7: Decision Trees
 Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Lecture 7: Decision Trees Instructor: Outline 1 Geometric Perspective of Classification 2 Decision Trees Geometric Perspective of Classification Perspective of Classification Algorithmic Geometric Probabilistic...
Privacy Preserving in Knowledge Discovery and Data Publishing
 B.Lakshmana Rao, G.V Konda Reddy and G.Yedukondalu 33 Privacy Preserving in Knowledge Discovery and Data Publishing B.Lakshmana Rao 1, G.V Konda Reddy 2, G.Yedukondalu 3 Abstract Knowledge Discovery is
B.Lakshmana Rao, G.V Konda Reddy and G.Yedukondalu 33 Privacy Preserving in Knowledge Discovery and Data Publishing B.Lakshmana Rao 1, G.V Konda Reddy 2, G.Yedukondalu 3 Abstract Knowledge Discovery is
10-701/15-781, Fall 2006, Final
 -7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
-7/-78, Fall 6, Final Dec, :pm-8:pm There are 9 questions in this exam ( pages including this cover sheet). If you need more room to work out your answer to a question, use the back of the page and clearly
What is Learning? CS 343: Artificial Intelligence Machine Learning. Raymond J. Mooney. Problem Solving / Planning / Control.
 What is Learning? CS 343: Artificial Intelligence Machine Learning Herbert Simon: Learning is any process by which a system improves performance from experience. What is the task? Classification Problem
What is Learning? CS 343: Artificial Intelligence Machine Learning Herbert Simon: Learning is any process by which a system improves performance from experience. What is the task? Classification Problem
Clustering. Supervised vs. Unsupervised Learning
 Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Clustering Supervised vs. Unsupervised Learning So far we have assumed that the training samples used to design the classifier were labeled by their class membership (supervised learning) We assume now
Review on Techniques of Collaborative Tagging
 Review on Techniques of Collaborative Tagging Ms. Benazeer S. Inamdar 1, Mrs. Gyankamal J. Chhajed 2 1 Student, M. E. Computer Engineering, VPCOE Baramati, Savitribai Phule Pune University, India benazeer.inamdar@gmail.com
Review on Techniques of Collaborative Tagging Ms. Benazeer S. Inamdar 1, Mrs. Gyankamal J. Chhajed 2 1 Student, M. E. Computer Engineering, VPCOE Baramati, Savitribai Phule Pune University, India benazeer.inamdar@gmail.com
Coverage Approximation Algorithms
 DATA MINING LECTURE 12 Coverage Approximation Algorithms Example Promotion campaign on a social network We have a social network as a graph. People are more likely to buy a product if they have a friend
DATA MINING LECTURE 12 Coverage Approximation Algorithms Example Promotion campaign on a social network We have a social network as a graph. People are more likely to buy a product if they have a friend
Distributed Bottom up Approach for Data Anonymization using MapReduce framework on Cloud
 Distributed Bottom up Approach for Data Anonymization using MapReduce framework on Cloud R. H. Jadhav 1 P.E.S college of Engineering, Aurangabad, Maharashtra, India 1 rjadhav377@gmail.com ABSTRACT: Many
Distributed Bottom up Approach for Data Anonymization using MapReduce framework on Cloud R. H. Jadhav 1 P.E.S college of Engineering, Aurangabad, Maharashtra, India 1 rjadhav377@gmail.com ABSTRACT: Many
Randomized Response Technique in Data Mining
 Randomized Response Technique in Data Mining Monika Soni Arya College of Engineering and IT, Jaipur(Raj.) 12.monika@gmail.com Vishal Shrivastva Arya College of Engineering and IT, Jaipur(Raj.) vishal500371@yahoo.co.in
Randomized Response Technique in Data Mining Monika Soni Arya College of Engineering and IT, Jaipur(Raj.) 12.monika@gmail.com Vishal Shrivastva Arya College of Engineering and IT, Jaipur(Raj.) vishal500371@yahoo.co.in
K ANONYMITY. Xiaoyong Zhou
 K ANONYMITY LATANYA SWEENEY Xiaoyong Zhou DATA releasing: Privacy vs. Utility Society is experiencing exponential growth in the number and variety of data collections containing person specific specific
K ANONYMITY LATANYA SWEENEY Xiaoyong Zhou DATA releasing: Privacy vs. Utility Society is experiencing exponential growth in the number and variety of data collections containing person specific specific
Privacy Preserving Decision Tree Mining from Perturbed Data
 Privacy Preserving Decision Tree Mining from Perturbed Data Li Liu Global Information Security ebay Inc. liiliu@ebay.com Murat Kantarcioglu and Bhavani Thuraisingham Computer Science Department University
Privacy Preserving Decision Tree Mining from Perturbed Data Li Liu Global Information Security ebay Inc. liiliu@ebay.com Murat Kantarcioglu and Bhavani Thuraisingham Computer Science Department University
Exam Advanced Data Mining Date: Time:
 Exam Advanced Data Mining Date: 11-11-2010 Time: 13.30-16.30 General Remarks 1. You are allowed to consult 1 A4 sheet with notes written on both sides. 2. Always show how you arrived at the result of your
Exam Advanced Data Mining Date: 11-11-2010 Time: 13.30-16.30 General Remarks 1. You are allowed to consult 1 A4 sheet with notes written on both sides. 2. Always show how you arrived at the result of your
The exam is closed book, closed notes except your one-page cheat sheet.
 CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
CS 189 Fall 2015 Introduction to Machine Learning Final Please do not turn over the page before you are instructed to do so. You have 2 hours and 50 minutes. Please write your initials on the top-right
Data Security and Privacy. Topic 18: k-anonymity, l-diversity, and t-closeness
 Data Security and Privacy Topic 18: k-anonymity, l-diversity, and t-closeness 1 Optional Readings for This Lecture t-closeness: Privacy Beyond k-anonymity and l-diversity. Ninghui Li, Tiancheng Li, and
Data Security and Privacy Topic 18: k-anonymity, l-diversity, and t-closeness 1 Optional Readings for This Lecture t-closeness: Privacy Beyond k-anonymity and l-diversity. Ninghui Li, Tiancheng Li, and
Service-Oriented Architecture for Privacy-Preserving Data Mashup
 Service-Oriented Architecture for Privacy-Preserving Data Mashup Thomas Trojer a Benjamin C. M. Fung b Patrick C. K. Hung c a Quality Engineering, Institute of Computer Science, University of Innsbruck,
Service-Oriented Architecture for Privacy-Preserving Data Mashup Thomas Trojer a Benjamin C. M. Fung b Patrick C. K. Hung c a Quality Engineering, Institute of Computer Science, University of Innsbruck,
Microdata Publishing with Algorithmic Privacy Guarantees
 Microdata Publishing with Algorithmic Privacy Guarantees Tiancheng Li and Ninghui Li Department of Computer Science, Purdue University 35 N. University Street West Lafayette, IN 4797-217 {li83,ninghui}@cs.purdue.edu
Microdata Publishing with Algorithmic Privacy Guarantees Tiancheng Li and Ninghui Li Department of Computer Science, Purdue University 35 N. University Street West Lafayette, IN 4797-217 {li83,ninghui}@cs.purdue.edu
Privacy Preserving Data Mining: An approach to safely share and use sensible medical data
 Privacy Preserving Data Mining: An approach to safely share and use sensible medical data Gerhard Kranner, Viscovery Biomax Symposium, June 24 th, 2016, Munich www.viscovery.net Privacy protection vs knowledge
Privacy Preserving Data Mining: An approach to safely share and use sensible medical data Gerhard Kranner, Viscovery Biomax Symposium, June 24 th, 2016, Munich www.viscovery.net Privacy protection vs knowledge
SOCIAL MEDIA MINING. Data Mining Essentials
 SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
SOCIAL MEDIA MINING Data Mining Essentials Dear instructors/users of these slides: Please feel free to include these slides in your own material, or modify them as you see fit. If you decide to incorporate
Data Mining. Jeff M. Phillips. January 7, 2019 CS 5140 / CS 6140
 Data Mining CS 5140 / CS 6140 Jeff M. Phillips January 7, 2019 What is Data Mining? What is Data Mining? Finding structure in data? Machine learning on large data? Unsupervised learning? Large scale computational
Data Mining CS 5140 / CS 6140 Jeff M. Phillips January 7, 2019 What is Data Mining? What is Data Mining? Finding structure in data? Machine learning on large data? Unsupervised learning? Large scale computational
IJSER. Privacy and Data Mining
 Privacy and Data Mining 2177 Shilpa M.S Dept. of Computer Science Mohandas College of Engineering and Technology Anad,Trivandrum shilpams333@gmail.com Shalini.L Dept. of Computer Science Mohandas College
Privacy and Data Mining 2177 Shilpa M.S Dept. of Computer Science Mohandas College of Engineering and Technology Anad,Trivandrum shilpams333@gmail.com Shalini.L Dept. of Computer Science Mohandas College
Approaches to distributed privacy protecting data mining
 Approaches to distributed privacy protecting data mining Bartosz Przydatek CMU Approaches to distributed privacy protecting data mining p.1/11 Introduction Data Mining and Privacy Protection conflicting
Approaches to distributed privacy protecting data mining Bartosz Przydatek CMU Approaches to distributed privacy protecting data mining p.1/11 Introduction Data Mining and Privacy Protection conflicting
Anonymization Algorithms - Microaggregation and Clustering
 Anonymization Algorithms - Microaggregation and Clustering Li Xiong CS573 Data Privacy and Anonymity Anonymization using Microaggregation or Clustering Practical Data-Oriented Microaggregation for Statistical
Anonymization Algorithms - Microaggregation and Clustering Li Xiong CS573 Data Privacy and Anonymity Anonymization using Microaggregation or Clustering Practical Data-Oriented Microaggregation for Statistical
Secure Frequent Itemset Hiding Techniques in Data Mining
 Secure Frequent Itemset Hiding Techniques in Data Mining Arpit Agrawal 1 Asst. Professor Department of Computer Engineering Institute of Engineering & Technology Devi Ahilya University M.P., India Jitendra
Secure Frequent Itemset Hiding Techniques in Data Mining Arpit Agrawal 1 Asst. Professor Department of Computer Engineering Institute of Engineering & Technology Devi Ahilya University M.P., India Jitendra
A generic and distributed privacy preserving classification method with a worst-case privacy guarantee
 Distrib Parallel Databases (2014) 32:5 35 DOI 10.1007/s10619-013-7126-6 A generic and distributed privacy preserving classification method with a worst-case privacy guarantee Madhushri Banerjee Zhiyuan
Distrib Parallel Databases (2014) 32:5 35 DOI 10.1007/s10619-013-7126-6 A generic and distributed privacy preserving classification method with a worst-case privacy guarantee Madhushri Banerjee Zhiyuan
PRACTICAL K-ANONYMITY ON LARGE DATASETS. Benjamin Podgursky. Thesis. Submitted to the Faculty of the. Graduate School of Vanderbilt University
 PRACTICAL K-ANONYMITY ON LARGE DATASETS By Benjamin Podgursky Thesis Submitted to the Faculty of the Graduate School of Vanderbilt University in partial fulfillment of the requirements for the degree of
PRACTICAL K-ANONYMITY ON LARGE DATASETS By Benjamin Podgursky Thesis Submitted to the Faculty of the Graduate School of Vanderbilt University in partial fulfillment of the requirements for the degree of
CSE 565 Computer Security Fall 2018
 CSE 565 Computer Security Fall 2018 Lecture 12: Database Security Department of Computer Science and Engineering University at Buffalo 1 Review of Access Control Types We previously studied four types
CSE 565 Computer Security Fall 2018 Lecture 12: Database Security Department of Computer Science and Engineering University at Buffalo 1 Review of Access Control Types We previously studied four types
Differentially Private Multi- Dimensional Time Series Release for Traffic Monitoring
 DBSec 13 Differentially Private Multi- Dimensional Time Series Release for Traffic Monitoring Liyue Fan, Li Xiong, Vaidy Sunderam Department of Math & Computer Science Emory University 9/4/2013 DBSec'13:
DBSec 13 Differentially Private Multi- Dimensional Time Series Release for Traffic Monitoring Liyue Fan, Li Xiong, Vaidy Sunderam Department of Math & Computer Science Emory University 9/4/2013 DBSec'13:
Best First and Greedy Search Based CFS and Naïve Bayes Algorithms for Hepatitis Diagnosis
 Best First and Greedy Search Based CFS and Naïve Bayes Algorithms for Hepatitis Diagnosis CHAPTER 3 BEST FIRST AND GREEDY SEARCH BASED CFS AND NAÏVE BAYES ALGORITHMS FOR HEPATITIS DIAGNOSIS 3.1 Introduction
Best First and Greedy Search Based CFS and Naïve Bayes Algorithms for Hepatitis Diagnosis CHAPTER 3 BEST FIRST AND GREEDY SEARCH BASED CFS AND NAÏVE BAYES ALGORITHMS FOR HEPATITIS DIAGNOSIS 3.1 Introduction
Overview of Clustering
 based on Loïc Cerfs slides (UFMG) April 2017 UCBL LIRIS DM2L Example of applicative problem Student profiles Given the marks received by students for different courses, how to group the students so that
based on Loïc Cerfs slides (UFMG) April 2017 UCBL LIRIS DM2L Example of applicative problem Student profiles Given the marks received by students for different courses, how to group the students so that
Classification and Regression Trees
 Classification and Regression Trees Matthew S. Shotwell, Ph.D. Department of Biostatistics Vanderbilt University School of Medicine Nashville, TN, USA March 16, 2018 Introduction trees partition feature
Classification and Regression Trees Matthew S. Shotwell, Ph.D. Department of Biostatistics Vanderbilt University School of Medicine Nashville, TN, USA March 16, 2018 Introduction trees partition feature
Statistics 202: Data Mining. c Jonathan Taylor. Outliers Based in part on slides from textbook, slides of Susan Holmes.
 Outliers Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Concepts What is an outlier? The set of data points that are considerably different than the remainder of the
Outliers Based in part on slides from textbook, slides of Susan Holmes December 2, 2012 1 / 1 Concepts What is an outlier? The set of data points that are considerably different than the remainder of the
Indrajit Roy, Srinath T.V. Setty, Ann Kilzer, Vitaly Shmatikov, Emmett Witchel The University of Texas at Austin
 Airavat: Security and Privacy for MapReduce Indrajit Roy, Srinath T.V. Setty, Ann Kilzer, Vitaly Shmatikov, Emmett Witchel The University of Texas at Austin Computing in the year 201X 2 Data Illusion of
Airavat: Security and Privacy for MapReduce Indrajit Roy, Srinath T.V. Setty, Ann Kilzer, Vitaly Shmatikov, Emmett Witchel The University of Texas at Austin Computing in the year 201X 2 Data Illusion of
Survey Result on Privacy Preserving Techniques in Data Publishing
 Survey Result on Privacy Preserving Techniques in Data Publishing S.Deebika PG Student, Computer Science and Engineering, Vivekananda College of Engineering for Women, Namakkal India A.Sathyapriya Assistant
Survey Result on Privacy Preserving Techniques in Data Publishing S.Deebika PG Student, Computer Science and Engineering, Vivekananda College of Engineering for Women, Namakkal India A.Sathyapriya Assistant
Example of DT Apply Model Example Learn Model Hunt s Alg. Measures of Node Impurity DT Examples and Characteristics. Classification.
 lassification-decision Trees, Slide 1/56 Classification Decision Trees Huiping Cao lassification-decision Trees, Slide 2/56 Examples of a Decision Tree Tid Refund Marital Status Taxable Income Cheat 1
lassification-decision Trees, Slide 1/56 Classification Decision Trees Huiping Cao lassification-decision Trees, Slide 2/56 Examples of a Decision Tree Tid Refund Marital Status Taxable Income Cheat 1
Preserving Privacy during Big Data Publishing using K-Anonymity Model A Survey
 ISSN No. 0976-5697 Volume 8, No. 5, May-June 2017 International Journal of Advanced Research in Computer Science SURVEY REPORT Available Online at www.ijarcs.info Preserving Privacy during Big Data Publishing
ISSN No. 0976-5697 Volume 8, No. 5, May-June 2017 International Journal of Advanced Research in Computer Science SURVEY REPORT Available Online at www.ijarcs.info Preserving Privacy during Big Data Publishing
Classification: Decision Trees
 Classification: Decision Trees IST557 Data Mining: Techniques and Applications Jessie Li, Penn State University 1 Decision Tree Example Will a pa)ent have high-risk based on the ini)al 24-hour observa)on?
Classification: Decision Trees IST557 Data Mining: Techniques and Applications Jessie Li, Penn State University 1 Decision Tree Example Will a pa)ent have high-risk based on the ini)al 24-hour observa)on?
Basic Data Mining Technique
 Basic Data Mining Technique What is classification? What is prediction? Supervised and Unsupervised Learning Decision trees Association rule K-nearest neighbor classifier Case-based reasoning Genetic algorithm
Basic Data Mining Technique What is classification? What is prediction? Supervised and Unsupervised Learning Decision trees Association rule K-nearest neighbor classifier Case-based reasoning Genetic algorithm
Improving Privacy And Data Utility For High- Dimensional Data By Using Anonymization Technique
 Improving Privacy And Data Utility For High- Dimensional Data By Using Anonymization Technique P.Nithya 1, V.Karpagam 2 PG Scholar, Department of Software Engineering, Sri Ramakrishna Engineering College,
Improving Privacy And Data Utility For High- Dimensional Data By Using Anonymization Technique P.Nithya 1, V.Karpagam 2 PG Scholar, Department of Software Engineering, Sri Ramakrishna Engineering College,
Data mining: concepts and algorithms
 Data mining: concepts and algorithms Practice Data mining Objective Exploit data mining algorithms to analyze a real dataset using the RapidMiner machine learning tool. The practice session is organized
Data mining: concepts and algorithms Practice Data mining Objective Exploit data mining algorithms to analyze a real dataset using the RapidMiner machine learning tool. The practice session is organized
2. (a) Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.
 Briefly discuss the forms of Data preprocessing with neat diagram. (b) Explain about concept hierarchy generation for categorical data.") Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
Code No: M0502/R05 Set No. 1 1. (a) Explain data mining as a step in the process of knowledge discovery. (b) Differentiate operational database systems and data warehousing. [8+8] 2. (a) Briefly discuss
K-Anonymity and Other Cluster- Based Methods. Ge Ruan Oct. 11,2007
 K-Anonymity and Other Cluster- Based Methods Ge Ruan Oct 11,2007 Data Publishing and Data Privacy Society is experiencing exponential growth in the number and variety of data collections containing person-specific
K-Anonymity and Other Cluster- Based Methods Ge Ruan Oct 11,2007 Data Publishing and Data Privacy Society is experiencing exponential growth in the number and variety of data collections containing person-specific
Preserving Data Mining through Data Perturbation
 Preserving Data Mining through Data Perturbation Mr. Swapnil Kadam, Prof. Navnath Pokale Abstract Data perturbation, a widely employed and accepted Privacy Preserving Data Mining (PPDM) approach, tacitly
Preserving Data Mining through Data Perturbation Mr. Swapnil Kadam, Prof. Navnath Pokale Abstract Data perturbation, a widely employed and accepted Privacy Preserving Data Mining (PPDM) approach, tacitly
CSE4334/5334 DATA MINING
 CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
CSE4334/5334 DATA MINING Lecture 4: Classification (1) CSE4334/5334 Data Mining, Fall 2014 Department of Computer Science and Engineering, University of Texas at Arlington Chengkai Li (Slides courtesy
Laplacian Eigenmaps and Bayesian Clustering Based Layout Pattern Sampling and Its Applications to Hotspot Detection and OPC
 Laplacian Eigenmaps and Bayesian Clustering Based Layout Pattern Sampling and Its Applications to Hotspot Detection and OPC Tetsuaki Matsunawa 1, Bei Yu 2 and David Z. Pan 3 1 Toshiba Corporation 2 The
Laplacian Eigenmaps and Bayesian Clustering Based Layout Pattern Sampling and Its Applications to Hotspot Detection and OPC Tetsuaki Matsunawa 1, Bei Yu 2 and David Z. Pan 3 1 Toshiba Corporation 2 The
Data Mining Concepts & Techniques
 Data Mining Concepts & Techniques Lecture No. 03 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data Mining Concepts & Techniques Lecture No. 03 Data Processing, Data Mining Naeem Ahmed Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
A Review of Privacy Preserving Data Publishing Technique
 A Review of Privacy Preserving Data Publishing Technique Abstract:- Amar Paul Singh School of CSE Bahra University Shimla Hills, India Ms. Dhanshri Parihar Asst. Prof (School of CSE) Bahra University Shimla
A Review of Privacy Preserving Data Publishing Technique Abstract:- Amar Paul Singh School of CSE Bahra University Shimla Hills, India Ms. Dhanshri Parihar Asst. Prof (School of CSE) Bahra University Shimla
Behavioral Data Mining. Lecture 9 Modeling People
 Behavioral Data Mining Lecture 9 Modeling People Outline Power Laws Big-5 Personality Factors Social Network Structure Power Laws Y-axis = frequency of word, X-axis = rank in decreasing order Power Laws
Behavioral Data Mining Lecture 9 Modeling People Outline Power Laws Big-5 Personality Factors Social Network Structure Power Laws Y-axis = frequency of word, X-axis = rank in decreasing order Power Laws
Secure Multiparty Computation Introduction to Privacy Preserving Distributed Data Mining
 CS573 Data Privacy and Security Secure Multiparty Computation Introduction to Privacy Preserving Distributed Data Mining Li Xiong Slides credit: Chris Clifton, Purdue University; Murat Kantarcioglu, UT
CS573 Data Privacy and Security Secure Multiparty Computation Introduction to Privacy Preserving Distributed Data Mining Li Xiong Slides credit: Chris Clifton, Purdue University; Murat Kantarcioglu, UT
Research Trends in Privacy Preserving in Association Rule Mining (PPARM) On Horizontally Partitioned Database
 On Horizontally Partitioned Database") 204 IJEDR Volume 2, Issue ISSN: 232-9939 Research Trends in Privacy Preserving in Association Rule Mining (PPARM) On Horizontally Partitioned Database Rachit Adhvaryu, 2 Nikunj Domadiya PG Student, 2 Professor
204 IJEDR Volume 2, Issue ISSN: 232-9939 Research Trends in Privacy Preserving in Association Rule Mining (PPARM) On Horizontally Partitioned Database Rachit Adhvaryu, 2 Nikunj Domadiya PG Student, 2 Professor
CS 1675 Introduction to Machine Learning Lecture 18. Clustering. Clustering. Groups together similar instances in the data sample
 CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
CS 1675 Introduction to Machine Learning Lecture 18 Clustering Milos Hauskrecht milos@cs.pitt.edu 539 Sennott Square Clustering Groups together similar instances in the data sample Basic clustering problem:
Clustering: Classic Methods and Modern Views
 Clustering: Classic Methods and Modern Views Marina Meilă University of Washington mmp@stat.washington.edu June 22, 2015 Lorentz Center Workshop on Clusters, Games and Axioms Outline Paradigms for clustering
Clustering: Classic Methods and Modern Views Marina Meilă University of Washington mmp@stat.washington.edu June 22, 2015 Lorentz Center Workshop on Clusters, Games and Axioms Outline Paradigms for clustering
Statistics 202: Statistical Aspects of Data Mining
 Statistics 202: Statistical Aspects of Data Mining Professor Rajan Patel Lecture 11 = Chapter 8 Agenda: 1)Reminder about final exam 2)Finish Chapter 5 3)Chapter 8 1 Class Project The class project is due
Statistics 202: Statistical Aspects of Data Mining Professor Rajan Patel Lecture 11 = Chapter 8 Agenda: 1)Reminder about final exam 2)Finish Chapter 5 3)Chapter 8 1 Class Project The class project is due
Final Exam DATA MINING I - 1DL360
 Uppsala University Department of Information Technology Kjell Orsborn Final Exam 2012-10-17 DATA MINING I - 1DL360 Date... Wednesday, October 17, 2012 Time... 08:00-13:00 Teacher on duty... Kjell Orsborn,
Uppsala University Department of Information Technology Kjell Orsborn Final Exam 2012-10-17 DATA MINING I - 1DL360 Date... Wednesday, October 17, 2012 Time... 08:00-13:00 Teacher on duty... Kjell Orsborn,
Privacy Preserving Machine Learning: A Theoretically Sound App
 Privacy Preserving Machine Learning: A Theoretically Sound Approach Outline 1 2 3 4 5 6 Privacy Leakage Events AOL search data leak: New York Times journalist was able to identify users from the anonymous
Privacy Preserving Machine Learning: A Theoretically Sound Approach Outline 1 2 3 4 5 6 Privacy Leakage Events AOL search data leak: New York Times journalist was able to identify users from the anonymous
Emerging Measures in Preserving Privacy for Publishing The Data
 Emerging Measures in Preserving Privacy for Publishing The Data K.SIVARAMAN 1 Assistant Professor, Dept. of Computer Science, BIST, Bharath University, Chennai -600073 1 ABSTRACT: The information in the
Emerging Measures in Preserving Privacy for Publishing The Data K.SIVARAMAN 1 Assistant Professor, Dept. of Computer Science, BIST, Bharath University, Chennai -600073 1 ABSTRACT: The information in the
7. Decision or classification trees
 7. Decision or classification trees Next we are going to consider a rather different approach from those presented so far to machine learning that use one of the most common and important data structure,
7. Decision or classification trees Next we are going to consider a rather different approach from those presented so far to machine learning that use one of the most common and important data structure,
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Classification (Basic Concepts) Huan Sun, CSE@The Ohio State University 09/12/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han Classification: Basic Concepts
CSE 5243 INTRO. TO DATA MINING Classification (Basic Concepts) Huan Sun, CSE@The Ohio State University 09/12/2017 Slides adapted from UIUC CS412, Fall 2017, by Prof. Jiawei Han Classification: Basic Concepts
CLASSIFICATION OF C4.5 AND CART ALGORITHMS USING DECISION TREE METHOD
 CLASSIFICATION OF C4.5 AND CART ALGORITHMS USING DECISION TREE METHOD Khin Lay Myint 1, Aye Aye Cho 2, Aye Mon Win 3 1 Lecturer, Faculty of Information Science, University of Computer Studies, Hinthada,
CLASSIFICATION OF C4.5 AND CART ALGORITHMS USING DECISION TREE METHOD Khin Lay Myint 1, Aye Aye Cho 2, Aye Mon Win 3 1 Lecturer, Faculty of Information Science, University of Computer Studies, Hinthada,
Chapter 14 Global Search Algorithms
 Chapter 14 Global Search Algorithms An Introduction to Optimization Spring, 2015 Wei-Ta Chu 1 Introduction We discuss various search methods that attempts to search throughout the entire feasible set.
Chapter 14 Global Search Algorithms An Introduction to Optimization Spring, 2015 Wei-Ta Chu 1 Introduction We discuss various search methods that attempts to search throughout the entire feasible set.
Topics in Machine Learning-EE 5359 Model Assessment and Selection
 Topics in Machine Learning-EE 5359 Model Assessment and Selection Ioannis D. Schizas Electrical Engineering Department University of Texas at Arlington 1 Training and Generalization Training stage: Utilizing
Topics in Machine Learning-EE 5359 Model Assessment and Selection Ioannis D. Schizas Electrical Engineering Department University of Texas at Arlington 1 Training and Generalization Training stage: Utilizing
On the Tradeoff Between Privacy and Utility in Data Publishing
 On the Tradeoff Between Privacy and Utility in Data Publishing Tiancheng Li and Ninghui Li Department of Computer Science Purdue University {li83, ninghui}@cs.purdue.edu ABSTRACT In data publishing, anonymization
On the Tradeoff Between Privacy and Utility in Data Publishing Tiancheng Li and Ninghui Li Department of Computer Science Purdue University {li83, ninghui}@cs.purdue.edu ABSTRACT In data publishing, anonymization
SCHEME OF COURSE WORK. Data Warehousing and Data mining
 SCHEME OF COURSE WORK Course Details: Course Title Course Code Program: Specialization: Semester Prerequisites Department of Information Technology Data Warehousing and Data mining : 15CT1132 : B.TECH
SCHEME OF COURSE WORK Course Details: Course Title Course Code Program: Specialization: Semester Prerequisites Department of Information Technology Data Warehousing and Data mining : 15CT1132 : B.TECH
Accountability in Privacy-Preserving Data Mining
 PORTIA Privacy, Obligations, and Rights in Technologies of Information Assessment Accountability in Privacy-Preserving Data Mining Rebecca Wright Computer Science Department Stevens Institute of Technology
PORTIA Privacy, Obligations, and Rights in Technologies of Information Assessment Accountability in Privacy-Preserving Data Mining Rebecca Wright Computer Science Department Stevens Institute of Technology
Nominal Data. May not have a numerical representation Distance measures might not make sense. PR and ANN
 NonMetric Data Nominal Data So far we consider patterns to be represented by feature vectors of real or integer values Easy to come up with a distance (similarity) measure by using a variety of mathematical
NonMetric Data Nominal Data So far we consider patterns to be represented by feature vectors of real or integer values Easy to come up with a distance (similarity) measure by using a variety of mathematical