Transformer Looping Functions for Pivoting the data :
|
|
|
- Joshua French
- 6 years ago
- Views:
Transcription


1 Transformer Looping Functions for Pivoting the data : Convert a single row into multiple rows using Transformer Looping Function? (Pivoting of data using parallel transformer in Datastage 8.5,8.7 and 9.1) Refer This link for more details : Looping Concept in Datastage Now you can argue that this is possible using a pivot stage. But for the sake of this article lets try doing this using a Transformer! Below is a screenshot of our input data We are going to read the above data from a sequential file and transform it to look like this

2 So lets get to the job design Step 1: Read the input data. Step 2: Logic for Looping in Transformer Properties In the adjacent image you can see a new box called Loop Condition. This where we are going to control the loop variables. Below is the screenshot when we expand the Loop Condition box



3 The Loop While constraint is used to implement a functionality similar to WHILE statement in programming. So, similar to a while statement need to have a condition to identify how many times the loop is supposed to be executed. To achieve system variable was introduced. In our example we need to loop the data 3 times to get the column data onto subsequent rows. So lets <=3 Now create a new Loop variable with the name LoopName The derivation for this loop variable should be Then DSLink2.Name1 Else Then DSLink2.Name2


4 Else DSLink2.Name3 Below is a screenshot illustrating the same Now all we have to do is map this Loop variable Loop Name to our output column Name


5 Lets map the output to a sequential file stage and see if the output is a desired. After running the job, we did a view data on the output stage and here is the data as desired. Making some tweaks to the above design we can implement things like 1. Adding new rows to existing rows 2. Splitting data in a single column to multiple rows and many more such stuff.. Posted by Devendra Kumar Yadav at 4:37 AM No comments:
6 Partitioning considerations For Best Performance Of datastage Jobs This Blog give you a complete details, how we can improve the performance of datastage Parallel jobs using appropriate partitioning methods. Refer These links as well : 1. Datastage Partitioning Methods and Use 2. Datastage Jobs Performance Improvement Tips1 3. Datastage Performance Tuning Tips 1.0 Partitioning considerations: Choose a partition method which makes sure that the number of rows per partition is close to equal. This will minimize the processing work load and there by improves the overall run time. Any stage that process a group of related records must be partitioned using a keyed partition technique. (Egs in the case of Aggregator stage, Remove duplicate, Change capture, Change apply, Join, Merge stages etc, as well as for transformers that process group of related records) Minimize repartitioning as it decreases the performance unless the partition distribution is highly skewed. Repartitioning results in overhead of network transport as well as even distribution of data among partitions is also gets disturbed. Specify hash partitioning for stages that require processing of group of related records. Partitioning keys should include only those key columns that are necessary for proper grouping If the grouping is on a single integer key column, go for Modulus partition on the same key column If the data is highly skewed and the key column values and distribution will not change significantly over time, use the Range partitioning technique Use Round robin partition to distribute data evenly across all partitions. (If grouping is not needed).this is very much suggested when the input data is in sequential mode or it is very much skewed Same partitioning requires minimum resources and can be used for optimization of job and to eliminate repartitioning of the already partitioned data

7 When the input data set is sorted in parallel, we need to use Sort merge collector, which will produce a single sorted stream of rows. When the input data set is sorted in parallel and range partitioned, the ordered collector method is more preferred for collection For round robin partitioned input data set use round robin collector to reconstruct rows in input order, as the long as the data set has not been re partitioned or reduced. Minimize the use of sorts in a job. Figure: Partitioning tab in a Datastage stage properties
8 Posted by Devendra Kumar Yadav at 12:22 AM No comments: Datastage Jobs Best Practices and Performance Tuning This Blog give you a complete details, how we can improve the performance of datastage Parallel jobs. Best practices we have to follow, while creating the datastage jobs. This Blog will help you on following topics. 1. Performance Tuning Guidelines 1.1 General Job Design 1.2 Transformer Stage 1.3 Data grouping Stages 1.4 ODBC Stages Refer This link as well : Parallel Job Performance Tuning Tips1 1.0 Performance Tuning Guidelines 1.1 General Job Design Jobs need to be developed using the modular development approach. Large jobs can be broken down in to smaller modules, which help in improving the performance. In scenarios where same data (huge number of records) is to be shared among more than one jobs in the same project, use dataset stage approach instead of re-reading the same data again. Eliminate unused columns
9 Eliminate unused references If the input file has huge number of records and the business logic allows splitting up of the data, then run the job in parallel to have a significant improvement in the performance 1.2 Transformer stage Use parallel transformer stage instead of filter/switch stages ( filter/switch stages will take more resources for execution. For egs: in the case of filter stage the were clause will get executed during run time, thus creating the requirement for more resources, there by decaying the job performance)

10 Figure: Example of using a Transformer stage instead of using a filter stage. The filter condition is given in the constraint section of the transformer stage properties. Use BuildOp stage only when the required logic cannot be implemented using the parallel transformer stage. Avoid calling routines in derivations in the transformer stage. Implement the logic in derivation. This will avoid the over head of procedure call

11 Implement the logic using stage variables and call these stage variables in the derivations. During processing the execution starts with stage variables then constraints and then to individual columns. If ever there is a prerequisite formulae which can be used by both constraints and also individual columns then we can define it in stage variables so that it can be processed once and can be used by multiple records. If ever we require the formulae to be modified for each and every row then it is advisable to place in code in record level than stage variable level Figure: Example for using stage variables in and using it in the derivations.

12 1.3 Data grouping stages When dealing with stages like Aggregator, Filter etc, always try to use sorted data for better performance Figure: Sorting the input data on the grouping keys in an aggregator stage The example shown in the figure is the properties window for an aggregator stage that finds out the sum of a quantity column by grouping on the columns shown above. In such scenarios, we will do sorting of the input data on the same columns so that the records with same/similar values for these grouping columns will come together there by increasing the performance. Also note that if we are using more than one node, then the input dataset should be properly partitioned so that the similar records will be available in the same node.

13 1.4 ODBC Stages If possible sort the data in ODBC stage itself; this will reduce the over head of DS sorting the data. Don t use the sort stage when we have ORDER BY clause in ODBC sql Select only the required records or Remove the unwanted rows as early, so that the job need not deal with unnecessary records causing performance degrade Using a constraint to filter a record is much slower as compared to having a SELECT.WHERE in ODBC stage. User the power of database where ever possible and reduce the over head for DS.
14 Figure: Using the User-defined SQL option in ODBC stages to reduce the overhead of datastage by specifying the WHERE and ORDER BY clause in the SQL used to get data. Avoid using like operator in user defined queries in ODBC stages. But one thing to be noted here is that, if our custom sql requires a must scenario like it is doing a filter on some string pattern, we will be forced to use the like pattern to get the requirement done. Avoid using Stored Proceedures until and unless the functionality cannot be implemented in Data Stage jobs. Posted by Devendra Kumar Yadav at 12:07 AM No comments: TUESDAY, OCTOBER 22, 2013 Know about Conductor Node, Section Leaders and Players Process in Datastage Details about Conductor Node, Section Leaders and Players Process in Datastage Refer This Link as well For More Details : Job Run Time Architecture Jobs developed with DataStage Enterprise Edition (EE) are independent of the actual hardware and degree of parallelism used to run the job. The parallel Configuration File provides a mapping at runtime between the job and the actual runtime infrastructure and resources by defining logical processing nodes. To facilitate scalability across the boundaries of a single server, and to maintain platform independence, the parallel framework uses a multi-process architecture. The runtime architecture of the parallel framework uses a process-based architecture that enables scalability beyond server boundaries while avoiding platformdependent threading calls. The actual runtime deployment for a given job design is composed of a hierarchical relationship of operating system processes, running on one or more physical servers Section Leaders (one per logical processing node): used to create and manage player processes which perform the actual job execution. The Section Leaders also manage communication between the individual player processes and the master Conductor Node.
15 Players: one or more logical groups of processes used to execute the data flow logic. All players are created as groups on the same server as their managing Section Leader process. Conductor Node (one per job): the main process used to startup jobs, determine resource assignments, and create Section Leader processes on one or more processing nodes. Acts as a single coordinator for status and error messages, manages orderly shutdown when processing completes or in the event of a fatal error. The conductor node is run from the primary server It is a main process to 1. Start up jobs 2. Resource assignments 3. Responsible to create Section leader (used to create & manage player player process which perform actual job execution). 4. Single coordinator for status and error messages. 5. manages orderly shutdown when processing completes in the event of fatal error. When the job is initiated the primary process (called the conductor ) reads the job design, which is a generated Orchestrate shell (osh) script. The conductor also reads the parallel execution configuration file specified by the current setting of the APT_CONFIG_FILE environment variable. Once the execution nodes are known (from the configuration file) the conductor causes a coordinating process called a section leader to be started on each; by forking a child process if the node is on the same machine as the conductor or by remote shell execution if the node is on a different machine from the conductor (things are a little more dynamic in a grid configuration, but essentially this is what happens). Communication between the conductor, section leaders and player processes in a parallel job is effected via TCP. Senario's To Calculate the Processes : Sample APT CONFIG FILE : See in bold to mention conductor node. {node "node1" { fastname "DevServer1"pools "conductor" resource disk "/datastage/ascential/datastage/datasets/node1" {pools "conductor"} resource scratchdisk "/datastage/ascential/datastage/scratch/node1" {pools ""} } node "node2" {
16 fastname "DevServer1" pools "" resource disk "/datastage/ascential/datastage/datasets/node2" {pools ""} resource scratchdisk "/datastage/ascential/datastage/scratch/node2" {pools ""} } } Please find the below different answers : For every job that starts there will be one (1) conductor process (started on the conductor node), There will be one (1) section leader for each node in the configuration file and There will be one (1) player process (may or may not be true) for each stage in your job for each node. So if you have a job that uses a two (2) node configuration file and has 3 stages then your job will have 1 Conductor Node 2 Section leaders (2 Nodes * 1 Section leader per node) 6 Player processes (3 stages * 2 Nodes)Your dump score may show that your job will run 9 processes on 2 nodes. This kind of information is very helpful when determining the impact that a particular job or process will have on the underlying operating system and system resources. Posted by Devendra Kumar Yadav at 11:53 PM No comments: Situations to choose Parallel or Server Datastage Jobs Situations to choose Parallel or Server Datastage Jobs 1. The choice of server or parallel depends upon time to implement, functionality and cost. 2. When we have lots of functionality to implement for lower volume and hardware is less and ease of implementation we can go for Server jobs. 3. Parallel jobs are costly due to high scale of hardware, difficult to implement, extreme processing capabilities for absurd volumes with vast array of operators for high-performance manipulation. 4. When the data volume is less it is better to go for Server job as parallel jobs can have a longer start up time. 5. When data volume is high, it is better to choose parallel job than server job. Parallel job will be a lot faster than server job even if it runs on single node.
17 The obvious incentive for going parallel is data volume. Parallel jobs can remove bottlenecks and run across multiple nodes in a cluster for almost unlimited scalability. At this point parallel jobs become the faster and easier option. A parallel sort stage is lot faster than server stage. A Transformer stage in parallel job with the same transformations in server job is faster. Even on one node with a compiled transformer stage, the parallel version was three times faster. On 1 node configuration that does not have a lot of parallel processing also we can still get big performance improvements from an Enterprise Edition job. The improvements will be multiplied 10 or more than that if we work on 2CPU machines and two nodes in most stages. 6. Parallel jobs take advantage of both pipeline parallelism and partitioning parallelism. 7. We can improve the performance of server job by enabling inter process row buffering. This helps stages to exchange data as soon as it is available in the link. IPC stage also helps passive stage to read data from another as soon as data is available. In other words, stages do not have to wait for the entire set of records to be read first and then transferred to the next stage. Link partitioner and link collector stages can be used to achieve a certain degree of partitioning parallelism. 8. Look up with sequential file is possible in parallel jobs and not possible in server jobs. 9. Datastage EE jobs are compiled into OSH (Orchestrate Shell script language). OSH executes operators - instances of executable C++ classes, pre-built components representing stages used in Datastage jobs. Server Jobs are compiled into Basic which is an interpreted pseudo-code. This is why parallel jobs run faster, even if processed on one CPU. 10. The major difference between Infosphere Datastage Enterprise and Server edition is that Enterprise Edition (EE) introduces Parallel jobs. Parallel jobs support a completely new set of stages, which implement the scalable and parallel data processing mechanisms. In most cases parallel jobs and stages look similiar to the Datastage Server objects, however their capababilities are way different. In rough outline: Parallel jobs are executable datastage programs, managed and controlled by Datastage Server runtime environment Parallel jobs have a built-in mechanism for Pipelining, Partitioning and Parallelism. In most cases no manual intervention is needed to implement optimally those techniques. Parallel jobs are a lot faster in such ETL tasks like sorting, filtering, aggregating Refer This Link to Know More about parallel Jobs Stages: Parallel Jobs Stages Posted by Devendra Kumar Yadav at 11:02 PM No comments:
18 Surrogate Key Generator Implementation Surrogate Key Generator Implementation in Datastage 8.1, 8.5 & 9.1 The Surrogate Key Generator stage is a processing stage that generates surrogate key columns and maintains the key source. A surrogate key is a unique primary key that is not derived from the data that it represents, therefore changes to the data will not change the primary key. In a star schema database, surrogate keys are used to join a fact table to a dimension table. Surrogate key generator stage uses: 1. Create or delete the key source before other jobs run 2. Update a state file with a range of key values 3. Generate surrogate key columns and pass them to the next stage in the job 4. View the contents of the state file Generated keys are 64 bit integers and the key source can be stat file or database sequence. Surrogate keys are used to join a dimension table to a fact table in a star schema database. When the SCD stage performs a dimension lookup : A) If a matching record is found, it retrieves the value of the existing surrogate key. B) If a match is not found, the stage obtains a new surrogate key value by using the derivation of the Surrogate Key column on the Dim Update tab. If you want the SCD stage to generate new surrogate keys by using a key source that you created with a Surrogate Key Generator stage as described in Surrogate Key Generator. If you want to use your own method to handle surrogate keys, you should derive the Surrogate Key column from a source column. You can replace the dimension information in the source data stream with the

19 surrogate key value by mapping the Surrogate Key column to the output link. Creating the key Source : Drag the surrogate key stage from palette to parallel job canvas with no input and output links. Double click on the surrogate key stage and click on properties tab.
20 Properties: Key Source Action = create Source Type : FlatFile or Database sequence(in this case we are using FlatFile) When you run the job it will create an empty file. If you want to the check the content change the View Stat File = YES and check the job log for details. skey_genstage,0: State file /tmp/skeycutomerdim.stat is empty. if you try to create the same file again job will abort with the following error. skey_genstage,0: Unable to create state file /tmp/skeycutomerdim.stat: File exists. Deleting the key source:

21 Updating the stat File: To update the stat file add surrogate key stage to the job with single input link from other stage. We use this process to update the stat file if it is corrupted or deleted Open the surrogate key stage editor and go to the properties tab.
22

23 If the stat file exists we can update otherwise we can create and update it. We are using SkeyValue parameter to update the stat file using transformer stage.
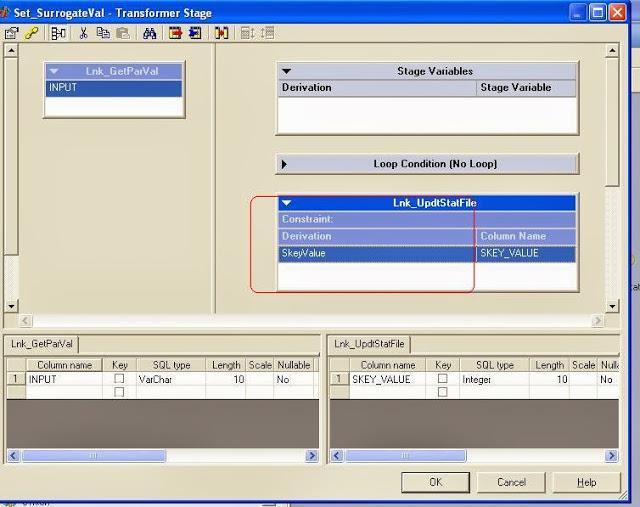
24

25 Generating Surrogate Keys: Now we have created stat file and will generate keys using the stat key file. Click on the surrogate keys stage and go to properties add add type a name for the surrogate key column in the Generated Output Column Name property.

26 Go to ouput and define the mapping like below.

27 Rowgen we are using 10 rows and hence when we run the job we see 10 skey values in the output.i have updated the stat file with 100 and below is the output.

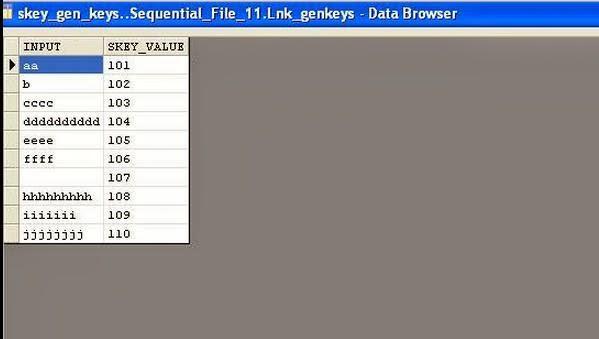
28

29 If you want to generate the key value from begining you can use following property in the surrogate key stage. A. If the key source is a flat file, specify how keys are generated: 1. To generate keys in sequence from the highest value that was last used, set the Generate Key from Last Highest Value property to Yes. Any gaps in the key range are ignored. 2. To specify a value to initialize the key source, add the File Initial Value property to the Options group, and specify the start value for key generation. 3. To control the block size for key ranges, add the File Block Size property to the Options group, set this property to User specified, and specify a value for the block size. B. If there is no input link, add the Number of Records property to the Options group, and specify how many records to generate.
Operator Combination and Control
 Operator Combination and Control Introduction Orchestrate Shell (OSH), a scripting language used to create a parallel job application, is integrated with the DataStage Suite as Parallel Extender (now called
Operator Combination and Control Introduction Orchestrate Shell (OSH), a scripting language used to create a parallel job application, is integrated with the DataStage Suite as Parallel Extender (now called
Topic 1, Volume A QUESTION NO: 1 In your ETL application design you have found several areas of common processing requirements in the mapping specific
 Vendor: IBM Exam Code: C2090-303 Exam Name: IBM InfoSphere DataStage v9.1 Version: Demo Topic 1, Volume A QUESTION NO: 1 In your ETL application design you have found several areas of common processing
Vendor: IBM Exam Code: C2090-303 Exam Name: IBM InfoSphere DataStage v9.1 Version: Demo Topic 1, Volume A QUESTION NO: 1 In your ETL application design you have found several areas of common processing
A Examcollection.Premium.Exam.47q
 A2090-303.Examcollection.Premium.Exam.47q Number: A2090-303 Passing Score: 800 Time Limit: 120 min File Version: 32.7 http://www.gratisexam.com/ Exam Code: A2090-303 Exam Name: Assessment: IBM InfoSphere
A2090-303.Examcollection.Premium.Exam.47q Number: A2090-303 Passing Score: 800 Time Limit: 120 min File Version: 32.7 http://www.gratisexam.com/ Exam Code: A2090-303 Exam Name: Assessment: IBM InfoSphere
C Exam Code: C Exam Name: IBM InfoSphere DataStage v9.1
 C2090-303 Number: C2090-303 Passing Score: 800 Time Limit: 120 min File Version: 36.8 Exam Code: C2090-303 Exam Name: IBM InfoSphere DataStage v9.1 Actualtests QUESTION 1 In your ETL application design
C2090-303 Number: C2090-303 Passing Score: 800 Time Limit: 120 min File Version: 36.8 Exam Code: C2090-303 Exam Name: IBM InfoSphere DataStage v9.1 Actualtests QUESTION 1 In your ETL application design
Call: Datastage 8.5 Course Content:35-40hours Course Outline
 Datastage 8.5 Course Content:35-40hours Course Outline Unit -1 : Data Warehouse Fundamentals An introduction to Data Warehousing purpose of Data Warehouse Data Warehouse Architecture Operational Data Store
Datastage 8.5 Course Content:35-40hours Course Outline Unit -1 : Data Warehouse Fundamentals An introduction to Data Warehousing purpose of Data Warehouse Data Warehouse Architecture Operational Data Store
Passit4sure.P questions
 Passit4sure.P2090-045.55 questions Number: P2090-045 Passing Score: 800 Time Limit: 120 min File Version: 5.2 http://www.gratisexam.com/ P2090-045 IBM InfoSphere Information Server for Data Integration
Passit4sure.P2090-045.55 questions Number: P2090-045 Passing Score: 800 Time Limit: 120 min File Version: 5.2 http://www.gratisexam.com/ P2090-045 IBM InfoSphere Information Server for Data Integration
IBM WEB Sphere Datastage and Quality Stage Version 8.5. Step-3 Process of ETL (Extraction,
 IBM WEB Sphere Datastage and Quality Stage Version 8.5 Step-1 Data Warehouse Fundamentals An Introduction of Data warehousing purpose of Data warehouse Data ware Architecture OLTP Vs Data warehouse Applications
IBM WEB Sphere Datastage and Quality Stage Version 8.5 Step-1 Data Warehouse Fundamentals An Introduction of Data warehousing purpose of Data warehouse Data ware Architecture OLTP Vs Data warehouse Applications
Optimizing Performance for Partitioned Mappings
 Optimizing Performance for Partitioned Mappings 1993-2015 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise)
Optimizing Performance for Partitioned Mappings 1993-2015 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise)
Perform scalable data exchange using InfoSphere DataStage DB2 Connector
 Perform scalable data exchange using InfoSphere DataStage Angelia Song (azsong@us.ibm.com) Technical Consultant IBM 13 August 2015 Brian Caufield (bcaufiel@us.ibm.com) Software Architect IBM Fan Ding (fding@us.ibm.com)
Perform scalable data exchange using InfoSphere DataStage Angelia Song (azsong@us.ibm.com) Technical Consultant IBM 13 August 2015 Brian Caufield (bcaufiel@us.ibm.com) Software Architect IBM Fan Ding (fding@us.ibm.com)
ETL Transformations Performance Optimization
 ETL Transformations Performance Optimization Sunil Kumar, PMP 1, Dr. M.P. Thapliyal 2 and Dr. Harish Chaudhary 3 1 Research Scholar at Department Of Computer Science and Engineering, Bhagwant University,
ETL Transformations Performance Optimization Sunil Kumar, PMP 1, Dr. M.P. Thapliyal 2 and Dr. Harish Chaudhary 3 1 Research Scholar at Department Of Computer Science and Engineering, Bhagwant University,
Course Contents: 1 Datastage Online Training
 IQ Online training facility offers Data stage online training by trainers who have expert knowledge in the Data stage and proven record of training hundreds of students. Our Data stage training is regarded
IQ Online training facility offers Data stage online training by trainers who have expert knowledge in the Data stage and proven record of training hundreds of students. Our Data stage training is regarded
IBM A IBM InfoSphere DataStage v9.1 Assessment. Download Full Version :
 IBM A2090-303 IBM InfoSphere DataStage v9.1 Assessment Download Full Version : https://killexams.com/pass4sure/exam-detail/a2090-303 QUESTION 100 You have finished changes to many jobs and shared containers.
IBM A2090-303 IBM InfoSphere DataStage v9.1 Assessment Download Full Version : https://killexams.com/pass4sure/exam-detail/a2090-303 QUESTION 100 You have finished changes to many jobs and shared containers.
Informatica Power Center 10.1 Developer Training
 Informatica Power Center 10.1 Developer Training Course Overview An introduction to Informatica Power Center 10.x which is comprised of a server and client workbench tools that Developers use to create,
Informatica Power Center 10.1 Developer Training Course Overview An introduction to Informatica Power Center 10.x which is comprised of a server and client workbench tools that Developers use to create,
Lookup Transformation in IBM DataStage Lab#12
 Lookup Transformation in IBM DataStage 8.5 - Lab#12 Description: BISP is committed to provide BEST learning material to the beginners and advance learners. In the same series, we have prepared a complete
Lookup Transformation in IBM DataStage 8.5 - Lab#12 Description: BISP is committed to provide BEST learning material to the beginners and advance learners. In the same series, we have prepared a complete
Data Set Buffering. Introduction
 Data Set Buffering Introduction In IBM InfoSphere DataStage job data flow, the data is moved between stages (or operators) through a data link, in the form of virtual data sets. An upstream operator will
Data Set Buffering Introduction In IBM InfoSphere DataStage job data flow, the data is moved between stages (or operators) through a data link, in the form of virtual data sets. An upstream operator will
PASS4TEST. IT Certification Guaranteed, The Easy Way! We offer free update service for one year
 PASS4TEST \ http://www.pass4test.com We offer free update service for one year Exam : C2090-303 Title : IBM InfoSphere DataStage v9.1 Vendors : IBM Version : DEMO Get Latest & Valid C2090-303 Exam's Question
PASS4TEST \ http://www.pass4test.com We offer free update service for one year Exam : C2090-303 Title : IBM InfoSphere DataStage v9.1 Vendors : IBM Version : DEMO Get Latest & Valid C2090-303 Exam's Question
Designing your BI Architecture
 IBM Software Group Designing your BI Architecture Data Movement and Transformation David Cope EDW Architect Asia Pacific 2007 IBM Corporation DataStage and DWE SQW Complex Files SQL Scripts ERP ETL Engine
IBM Software Group Designing your BI Architecture Data Movement and Transformation David Cope EDW Architect Asia Pacific 2007 IBM Corporation DataStage and DWE SQW Complex Files SQL Scripts ERP ETL Engine
Jyotheswar Kuricheti
 Jyotheswar Kuricheti 1 Agenda: 1. Performance Tuning Overview 2. Identify Bottlenecks 3. Optimizing at different levels : Target Source Mapping Session System 2 3 Performance Tuning Overview: 4 What is
Jyotheswar Kuricheti 1 Agenda: 1. Performance Tuning Overview 2. Identify Bottlenecks 3. Optimizing at different levels : Target Source Mapping Session System 2 3 Performance Tuning Overview: 4 What is
! Parallel machines are becoming quite common and affordable. ! Databases are growing increasingly large
 Chapter 20: Parallel Databases Introduction! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems!
Chapter 20: Parallel Databases Introduction! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems!
Chapter 20: Parallel Databases
 Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Chapter 20: Parallel Databases. Introduction
 Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Chapter 20: Parallel Databases! Introduction! I/O Parallelism! Interquery Parallelism! Intraquery Parallelism! Intraoperation Parallelism! Interoperation Parallelism! Design of Parallel Systems 20.1 Introduction!
Chapter 17: Parallel Databases
 Chapter 17: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery Parallelism Intraoperation Parallelism Interoperation Parallelism Design of Parallel Systems Database Systems
Chapter 17: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery Parallelism Intraoperation Parallelism Interoperation Parallelism Design of Parallel Systems Database Systems
Chapter 18: Parallel Databases
 Chapter 18: Parallel Databases Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery
Chapter 18: Parallel Databases Database System Concepts, 6 th Ed. See www.db-book.com for conditions on re-use Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery
Chapter 18: Parallel Databases. Chapter 18: Parallel Databases. Parallelism in Databases. Introduction
 Chapter 18: Parallel Databases Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery Parallelism Intraoperation Parallelism Interoperation Parallelism Design of
Chapter 18: Parallel Databases Chapter 18: Parallel Databases Introduction I/O Parallelism Interquery Parallelism Intraquery Parallelism Intraoperation Parallelism Interoperation Parallelism Design of
IBM IBM WebSphere IIS DataStage Enterprise Edition v7.5. Download Full Version :
 IBM 000-415 IBM WebSphere IIS DataStage Enterprise Edition v7.5 Download Full Version : https://killexams.com/pass4sure/exam-detail/000-415 B. the orchadmin tool C. the DataStage Administrator D. the Data
IBM 000-415 IBM WebSphere IIS DataStage Enterprise Edition v7.5 Download Full Version : https://killexams.com/pass4sure/exam-detail/000-415 B. the orchadmin tool C. the DataStage Administrator D. the Data
Data Warehouse Tuning. Without SQL Modification
 Data Warehouse Tuning Without SQL Modification Agenda About Me Tuning Objectives Data Access Profile Data Access Analysis Performance Baseline Potential Model Changes Model Change Testing Testing Results
Data Warehouse Tuning Without SQL Modification Agenda About Me Tuning Objectives Data Access Profile Data Access Analysis Performance Baseline Potential Model Changes Model Change Testing Testing Results
Database Architectures
 Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 4/15/15 Agenda Check-in Parallelism and Distributed Databases Technology Research Project Introduction to NoSQL
Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 4/15/15 Agenda Check-in Parallelism and Distributed Databases Technology Research Project Introduction to NoSQL
PowerCenter 7 Architecture and Performance Tuning
 PowerCenter 7 Architecture and Performance Tuning Erwin Dral Sales Consultant 1 Agenda PowerCenter Architecture Performance tuning step-by-step Eliminating Common bottlenecks 2 PowerCenter Architecture:
PowerCenter 7 Architecture and Performance Tuning Erwin Dral Sales Consultant 1 Agenda PowerCenter Architecture Performance tuning step-by-step Eliminating Common bottlenecks 2 PowerCenter Architecture:
1. Attempt any two of the following: 10 a. State and justify the characteristics of a Data Warehouse with suitable examples.
 Instructions to the Examiners: 1. May the Examiners not look for exact words from the text book in the Answers. 2. May any valid example be accepted - example may or may not be from the text book 1. Attempt
Instructions to the Examiners: 1. May the Examiners not look for exact words from the text book in the Answers. 2. May any valid example be accepted - example may or may not be from the text book 1. Attempt
Actual4Test. Actual4test - actual test exam dumps-pass for IT exams
 Actual4Test http://www.actual4test.com Actual4test - actual test exam dumps-pass for IT exams Exam : C2090-418 Title : IBM Websphere Datastage V.8.0 Vendors : IBM Version : DEMO Get Latest & Valid C2090-418
Actual4Test http://www.actual4test.com Actual4test - actual test exam dumps-pass for IT exams Exam : C2090-418 Title : IBM Websphere Datastage V.8.0 Vendors : IBM Version : DEMO Get Latest & Valid C2090-418
data parallelism Chris Olston Yahoo! Research
 data parallelism Chris Olston Yahoo! Research set-oriented computation data management operations tend to be set-oriented, e.g.: apply f() to each member of a set compute intersection of two sets easy
data parallelism Chris Olston Yahoo! Research set-oriented computation data management operations tend to be set-oriented, e.g.: apply f() to each member of a set compute intersection of two sets easy
Huge market -- essentially all high performance databases work this way
 11/5/2017 Lecture 16 -- Parallel & Distributed Databases Parallel/distributed databases: goal provide exactly the same API (SQL) and abstractions (relational tables), but partition data across a bunch
11/5/2017 Lecture 16 -- Parallel & Distributed Databases Parallel/distributed databases: goal provide exactly the same API (SQL) and abstractions (relational tables), but partition data across a bunch
Performance Tuning for the BI Professional. Jonathan Stewart
 Performance Tuning for the BI Professional Jonathan Stewart Jonathan Stewart Business Intelligence Consultant SQLLocks, LLC. @sqllocks jonathan.stewart@sqllocks.net Agenda Shared Solutions SSIS SSRS
Performance Tuning for the BI Professional Jonathan Stewart Jonathan Stewart Business Intelligence Consultant SQLLocks, LLC. @sqllocks jonathan.stewart@sqllocks.net Agenda Shared Solutions SSIS SSRS
White Paper. What Is DataStage?
 White Paper What Is? White Paper: What Is? Sometimes is sold to and installed in an organization and its IT support staff are expected to maintain it and to solve users' problems. In some cases IT support
White Paper What Is? White Paper: What Is? Sometimes is sold to and installed in an organization and its IT support staff are expected to maintain it and to solve users' problems. In some cases IT support
Data Stage ETL Implementation Best Practices
 Data Stage ETL Implementation Best Practices Copyright (C) SIMCA IJIS Dr. B. L. Desai Bhimappa.desai@capgemini.com ABSTRACT: This paper is the out come of the expertise gained from live implementation
Data Stage ETL Implementation Best Practices Copyright (C) SIMCA IJIS Dr. B. L. Desai Bhimappa.desai@capgemini.com ABSTRACT: This paper is the out come of the expertise gained from live implementation
Performance Optimization for Informatica Data Services ( Hotfix 3)
") Performance Optimization for Informatica Data Services (9.5.0-9.6.1 Hotfix 3) 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic,
Performance Optimization for Informatica Data Services (9.5.0-9.6.1 Hotfix 3) 1993-2015 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic,
Advanced Database Systems
 Lecture IV Query Processing Kyumars Sheykh Esmaili Basic Steps in Query Processing 2 Query Optimization Many equivalent execution plans Choosing the best one Based on Heuristics, Cost Will be discussed
Lecture IV Query Processing Kyumars Sheykh Esmaili Basic Steps in Query Processing 2 Query Optimization Many equivalent execution plans Choosing the best one Based on Heuristics, Cost Will be discussed
Working with Pentaho Interactive Reporting and Metadata
 Working with Pentaho Interactive Reporting and Metadata Change log (if you want to use it): Date Version Author Changes Contents Overview... 1 Before You Begin... 1 Other Prerequisites... Error! Bookmark
Working with Pentaho Interactive Reporting and Metadata Change log (if you want to use it): Date Version Author Changes Contents Overview... 1 Before You Begin... 1 Other Prerequisites... Error! Bookmark
COPYRIGHTED MATERIAL. Contents. Introduction. Chapter 1: Welcome to SQL Server Integration Services 1. Chapter 2: The SSIS Tools 21
 Introduction xxix Chapter 1: Welcome to SQL Server Integration Services 1 SQL Server SSIS Historical Overview 2 What s New in SSIS 2 Getting Started 3 Import and Export Wizard 3 The Business Intelligence
Introduction xxix Chapter 1: Welcome to SQL Server Integration Services 1 SQL Server SSIS Historical Overview 2 What s New in SSIS 2 Getting Started 3 Import and Export Wizard 3 The Business Intelligence
Integration Services. Creating an ETL Solution with SSIS. Module Overview. Introduction to ETL with SSIS Implementing Data Flow
 Pipeline Integration Services Creating an ETL Solution with SSIS Module Overview Introduction to ETL with SSIS Implementing Data Flow Lesson 1: Introduction to ETL with SSIS What Is SSIS? SSIS Projects
Pipeline Integration Services Creating an ETL Solution with SSIS Module Overview Introduction to ETL with SSIS Implementing Data Flow Lesson 1: Introduction to ETL with SSIS What Is SSIS? SSIS Projects
Informatica Developer Tips for Troubleshooting Common Issues PowerCenter 8 Standard Edition. Eugene Gonzalez Support Enablement Manager, Informatica
 Informatica Developer Tips for Troubleshooting Common Issues PowerCenter 8 Standard Edition Eugene Gonzalez Support Enablement Manager, Informatica 1 Agenda Troubleshooting PowerCenter issues require a
Informatica Developer Tips for Troubleshooting Common Issues PowerCenter 8 Standard Edition Eugene Gonzalez Support Enablement Manager, Informatica 1 Agenda Troubleshooting PowerCenter issues require a
Announcement. Reading Material. Overview of Query Evaluation. Overview of Query Evaluation. Overview of Query Evaluation 9/26/17
 Announcement CompSci 516 Database Systems Lecture 10 Query Evaluation and Join Algorithms Project proposal pdf due on sakai by 5 pm, tomorrow, Thursday 09/27 One per group by any member Instructor: Sudeepa
Announcement CompSci 516 Database Systems Lecture 10 Query Evaluation and Join Algorithms Project proposal pdf due on sakai by 5 pm, tomorrow, Thursday 09/27 One per group by any member Instructor: Sudeepa
Advanced Databases. Lecture 15- Parallel Databases (continued) Masood Niazi Torshiz Islamic Azad University- Mashhad Branch
 Masood Niazi Torshiz Islamic Azad University- Mashhad Branch") Advanced Databases Lecture 15- Parallel Databases (continued) Masood Niazi Torshiz Islamic Azad University- Mashhad Branch www.mniazi.ir Parallel Join The join operation requires pairs of tuples to be
Advanced Databases Lecture 15- Parallel Databases (continued) Masood Niazi Torshiz Islamic Azad University- Mashhad Branch www.mniazi.ir Parallel Join The join operation requires pairs of tuples to be
Data Modeling and Databases Ch 10: Query Processing - Algorithms. Gustavo Alonso Systems Group Department of Computer Science ETH Zürich
 Data Modeling and Databases Ch 10: Query Processing - Algorithms Gustavo Alonso Systems Group Department of Computer Science ETH Zürich Transactions (Locking, Logging) Metadata Mgmt (Schema, Stats) Application
Data Modeling and Databases Ch 10: Query Processing - Algorithms Gustavo Alonso Systems Group Department of Computer Science ETH Zürich Transactions (Locking, Logging) Metadata Mgmt (Schema, Stats) Application
Performance Tuning in Informatica Developer
 Performance Tuning in Informatica Developer 2010 Informatica Abstract The Data Integration Service uses optimization methods to improve the performance of a mapping. You can choose an optimizer level to
Performance Tuning in Informatica Developer 2010 Informatica Abstract The Data Integration Service uses optimization methods to improve the performance of a mapping. You can choose an optimizer level to
Home Datastage Related Datastage Training Big Data Unix Database Interview Related Certifications Discussion Forum Feedback Share This Blog..!!
 0 More Next Blog» Create Blog Sign In Home Datastage Related Datastage Training Big Data Unix Database Interview Related Certifications Discussion Forum Feedback Like 0 Many thanks for visiting my Blog..!!Please
0 More Next Blog» Create Blog Sign In Home Datastage Related Datastage Training Big Data Unix Database Interview Related Certifications Discussion Forum Feedback Like 0 Many thanks for visiting my Blog..!!Please
Data Modeling and Databases Ch 9: Query Processing - Algorithms. Gustavo Alonso Systems Group Department of Computer Science ETH Zürich
 Data Modeling and Databases Ch 9: Query Processing - Algorithms Gustavo Alonso Systems Group Department of Computer Science ETH Zürich Transactions (Locking, Logging) Metadata Mgmt (Schema, Stats) Application
Data Modeling and Databases Ch 9: Query Processing - Algorithms Gustavo Alonso Systems Group Department of Computer Science ETH Zürich Transactions (Locking, Logging) Metadata Mgmt (Schema, Stats) Application
Chapter 18: Parallel Databases
 Chapter 18: Parallel Databases Introduction Parallel machines are becoming quite common and affordable Prices of microprocessors, memory and disks have dropped sharply Recent desktop computers feature
Chapter 18: Parallel Databases Introduction Parallel machines are becoming quite common and affordable Prices of microprocessors, memory and disks have dropped sharply Recent desktop computers feature
Hyperion Interactive Reporting Reports & Dashboards Essentials
 Oracle University Contact Us: +27 (0)11 319-4111 Hyperion Interactive Reporting 11.1.1 Reports & Dashboards Essentials Duration: 5 Days What you will learn The first part of this course focuses on two
Oracle University Contact Us: +27 (0)11 319-4111 Hyperion Interactive Reporting 11.1.1 Reports & Dashboards Essentials Duration: 5 Days What you will learn The first part of this course focuses on two
Database Architectures
 Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 11/15/12 Agenda Check-in Centralized and Client-Server Models Parallelism Distributed Databases Homework 6 Check-in
Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 11/15/12 Agenda Check-in Centralized and Client-Server Models Parallelism Distributed Databases Homework 6 Check-in
Optimizing Testing Performance With Data Validation Option
 Optimizing Testing Performance With Data Validation Option 1993-2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording
Optimizing Testing Performance With Data Validation Option 1993-2016 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording
Design Studio Data Flow performance optimization
 Design Studio Data Flow performance optimization Overview Plan sources Plan sinks Plan sorts Example New Features Summary Exercises Introduction Plan sources Plan sinks Plan sorts Example New Features
Design Studio Data Flow performance optimization Overview Plan sources Plan sinks Plan sorts Example New Features Summary Exercises Introduction Plan sources Plan sinks Plan sorts Example New Features
Best ETL Design Practices. Helpful coding insights in SAS DI studio. Techniques and implementation using the Key transformations in SAS DI studio.
 SESUG Paper SD-185-2017 Guide to ETL Best Practices in SAS Data Integration Studio Sai S Potluri, Synectics for Management Decisions; Ananth Numburi, Synectics for Management Decisions; ABSTRACT This Paper
SESUG Paper SD-185-2017 Guide to ETL Best Practices in SAS Data Integration Studio Sai S Potluri, Synectics for Management Decisions; Ananth Numburi, Synectics for Management Decisions; ABSTRACT This Paper
Evaluation of Relational Operations: Other Techniques
 Evaluation of Relational Operations: Other Techniques [R&G] Chapter 14, Part B CS4320 1 Using an Index for Selections Cost depends on #qualifying tuples, and clustering. Cost of finding qualifying data
Evaluation of Relational Operations: Other Techniques [R&G] Chapter 14, Part B CS4320 1 Using an Index for Selections Cost depends on #qualifying tuples, and clustering. Cost of finding qualifying data
Infosphere DataStage Hive Connector to read data from Hive data sources
 Infosphere DataStage Hive Connector to read data from Hive Alekhya Telekicherla (alekhya102@in.ibm.com) Software Developer IBM 22 March 2017 Pallavi Koganti (palkogan@in.ibm.com) Software Developer IBM
Infosphere DataStage Hive Connector to read data from Hive Alekhya Telekicherla (alekhya102@in.ibm.com) Software Developer IBM 22 March 2017 Pallavi Koganti (palkogan@in.ibm.com) Software Developer IBM
White Paper. Major Performance Tuning Considerations for Weblogic Server
 White Paper Major Performance Tuning Considerations for Weblogic Server Table of Contents Introduction and Background Information... 2 Understanding the Performance Objectives... 3 Measuring your Performance
White Paper Major Performance Tuning Considerations for Weblogic Server Table of Contents Introduction and Background Information... 2 Understanding the Performance Objectives... 3 Measuring your Performance
Chapter 12: Indexing and Hashing
 Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 12: Indexing and Hashing Basic Concepts Ordered Indices B+-Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Netezza The Analytics Appliance
 Software 2011 Netezza The Analytics Appliance Michael Eden Information Management Brand Executive Central & Eastern Europe Vilnius 18 October 2011 Information Management 2011IBM Corporation Thought for
Software 2011 Netezza The Analytics Appliance Michael Eden Information Management Brand Executive Central & Eastern Europe Vilnius 18 October 2011 Information Management 2011IBM Corporation Thought for
Evaluation of Relational Operations: Other Techniques
 Evaluation of Relational Operations: Other Techniques Chapter 14, Part B Database Management Systems 3ed, R. Ramakrishnan and Johannes Gehrke 1 Using an Index for Selections Cost depends on #qualifying
Evaluation of Relational Operations: Other Techniques Chapter 14, Part B Database Management Systems 3ed, R. Ramakrishnan and Johannes Gehrke 1 Using an Index for Selections Cost depends on #qualifying
1 Dulcian, Inc., 2001 All rights reserved. Oracle9i Data Warehouse Review. Agenda
 Agenda Oracle9i Warehouse Review Dulcian, Inc. Oracle9i Server OLAP Server Analytical SQL Mining ETL Infrastructure 9i Warehouse Builder Oracle 9i Server Overview E-Business Intelligence Platform 9i Server:
Agenda Oracle9i Warehouse Review Dulcian, Inc. Oracle9i Server OLAP Server Analytical SQL Mining ETL Infrastructure 9i Warehouse Builder Oracle 9i Server Overview E-Business Intelligence Platform 9i Server:
PARALLEL & DISTRIBUTED DATABASES CS561-SPRING 2012 WPI, MOHAMED ELTABAKH
 PARALLEL & DISTRIBUTED DATABASES CS561-SPRING 2012 WPI, MOHAMED ELTABAKH 1 INTRODUCTION In centralized database: Data is located in one place (one server) All DBMS functionalities are done by that server
PARALLEL & DISTRIBUTED DATABASES CS561-SPRING 2012 WPI, MOHAMED ELTABAKH 1 INTRODUCTION In centralized database: Data is located in one place (one server) All DBMS functionalities are done by that server
Tuning the Hive Engine for Big Data Management
 Tuning the Hive Engine for Big Data Management Copyright Informatica LLC 2017. Informatica, the Informatica logo, Big Data Management, PowerCenter, and PowerExchange are trademarks or registered trademarks
Tuning the Hive Engine for Big Data Management Copyright Informatica LLC 2017. Informatica, the Informatica logo, Big Data Management, PowerCenter, and PowerExchange are trademarks or registered trademarks
Database Applications (15-415)
") Database Applications (15-415) DBMS Internals- Part VI Lecture 17, March 24, 2015 Mohammad Hammoud Today Last Two Sessions: DBMS Internals- Part V External Sorting How to Start a Company in Five (maybe
Database Applications (15-415) DBMS Internals- Part VI Lecture 17, March 24, 2015 Mohammad Hammoud Today Last Two Sessions: DBMS Internals- Part V External Sorting How to Start a Company in Five (maybe
Lecture 23 Database System Architectures
 CMSC 461, Database Management Systems Spring 2018 Lecture 23 Database System Architectures These slides are based on Database System Concepts 6 th edition book (whereas some quotes and figures are used
CMSC 461, Database Management Systems Spring 2018 Lecture 23 Database System Architectures These slides are based on Database System Concepts 6 th edition book (whereas some quotes and figures are used
Performance Tuning. Chapter 25
 Chapter 25 Performance Tuning This chapter covers the following topics: Overview, 618 Identifying the Performance Bottleneck, 619 Optimizing the Target Database, 624 Optimizing the Source Database, 627
Chapter 25 Performance Tuning This chapter covers the following topics: Overview, 618 Identifying the Performance Bottleneck, 619 Optimizing the Target Database, 624 Optimizing the Source Database, 627
Chapter 20: Database System Architectures
 Chapter 20: Database System Architectures Chapter 20: Database System Architectures Centralized and Client-Server Systems Server System Architectures Parallel Systems Distributed Systems Network Types
Chapter 20: Database System Architectures Chapter 20: Database System Architectures Centralized and Client-Server Systems Server System Architectures Parallel Systems Distributed Systems Network Types
Chapter 18: Database System Architectures.! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems!
 Chapter 18: Database System Architectures! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types 18.1 Centralized Systems! Run on a single computer system and
Chapter 18: Database System Architectures! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types 18.1 Centralized Systems! Run on a single computer system and
Informatica Data Explorer Performance Tuning
 Informatica Data Explorer Performance Tuning 2011 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise)
Informatica Data Explorer Performance Tuning 2011 Informatica Corporation. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying, recording or otherwise)
PASS4TEST. IT Certification Guaranteed, The Easy Way! We offer free update service for one year
 PASS4TEST IT Certification Guaranteed, The Easy Way! \ http://www.pass4test.com We offer free update service for one year Exam : 000-415 Title : IBM WebSphere IIS DataStage Enterprise Edition v7.5 Vendors
PASS4TEST IT Certification Guaranteed, The Easy Way! \ http://www.pass4test.com We offer free update service for one year Exam : 000-415 Title : IBM WebSphere IIS DataStage Enterprise Edition v7.5 Vendors
INFORMATICA PERFORMANCE
 CLEARPEAKS BI LAB INFORMATICA PERFORMANCE OPTIMIZATION TECHNIQUES July, 2016 Author: Syed TABLE OF CONTENTS INFORMATICA PERFORMANCE OPTIMIZATION TECHNIQUES 3 STEP 1: IDENTIFYING BOTTLENECKS 3 STEP 2: RESOLVING
CLEARPEAKS BI LAB INFORMATICA PERFORMANCE OPTIMIZATION TECHNIQUES July, 2016 Author: Syed TABLE OF CONTENTS INFORMATICA PERFORMANCE OPTIMIZATION TECHNIQUES 3 STEP 1: IDENTIFYING BOTTLENECKS 3 STEP 2: RESOLVING
Pentaho 3.2 Data Integration
 Pentaho 3.2 Data Integration Beginner's Guide Explore, transform, validate, and integrate your data with ease Marfa Carina Roldan "- PUBLISHING - 1 BIRMINGHAM - MUMBAI Preface Chapter 1: Getting started
Pentaho 3.2 Data Integration Beginner's Guide Explore, transform, validate, and integrate your data with ease Marfa Carina Roldan "- PUBLISHING - 1 BIRMINGHAM - MUMBAI Preface Chapter 1: Getting started
Solutions for Netezza Performance Issues
 Solutions for Netezza Performance Issues Vamsi Krishna Parvathaneni Tata Consultancy Services Netezza Architect Netherlands vamsi.parvathaneni@tcs.com Lata Walekar Tata Consultancy Services IBM SW ATU
Solutions for Netezza Performance Issues Vamsi Krishna Parvathaneni Tata Consultancy Services Netezza Architect Netherlands vamsi.parvathaneni@tcs.com Lata Walekar Tata Consultancy Services IBM SW ATU
Evaluation of Relational Operations: Other Techniques
 Evaluation of Relational Operations: Other Techniques Chapter 12, Part B Database Management Systems 3ed, R. Ramakrishnan and Johannes Gehrke 1 Using an Index for Selections v Cost depends on #qualifying
Evaluation of Relational Operations: Other Techniques Chapter 12, Part B Database Management Systems 3ed, R. Ramakrishnan and Johannes Gehrke 1 Using an Index for Selections v Cost depends on #qualifying
CSE 190D Spring 2017 Final Exam
 CSE 190D Spring 2017 Final Exam Full Name : Student ID : Major : INSTRUCTIONS 1. You have up to 2 hours and 59 minutes to complete this exam. 2. You can have up to one letter/a4-sized sheet of notes, formulae,
CSE 190D Spring 2017 Final Exam Full Name : Student ID : Major : INSTRUCTIONS 1. You have up to 2 hours and 59 minutes to complete this exam. 2. You can have up to one letter/a4-sized sheet of notes, formulae,
Chapter 12: Indexing and Hashing. Basic Concepts
 Chapter 12: Indexing and Hashing! Basic Concepts! Ordered Indices! B+-Tree Index Files! B-Tree Index Files! Static Hashing! Dynamic Hashing! Comparison of Ordered Indexing and Hashing! Index Definition
Chapter 12: Indexing and Hashing! Basic Concepts! Ordered Indices! B+-Tree Index Files! B-Tree Index Files! Static Hashing! Dynamic Hashing! Comparison of Ordered Indexing and Hashing! Index Definition
Manual Trigger Sql Server 2008 Inserted Table Examples Insert
 Manual Trigger Sql Server 2008 Inserted Table Examples Insert This tutorial is applicable for all versions of SQL Server i.e. 2005, 2008, 2012, Whenever a row is inserted in the Customers Table, the following
Manual Trigger Sql Server 2008 Inserted Table Examples Insert This tutorial is applicable for all versions of SQL Server i.e. 2005, 2008, 2012, Whenever a row is inserted in the Customers Table, the following
Regard as 32 runs of length 1. Split into two scratch files of 4 blocks each, writing alternate blocks to each file.
 Consider the problem of sorting the following file using two way external merge sort. Assume it consists of 8 blocks of 4 records each, and that main memory is only large enough to sort 1 block at a time.
Consider the problem of sorting the following file using two way external merge sort. Assume it consists of 8 blocks of 4 records each, and that main memory is only large enough to sort 1 block at a time.
CSE 544: Principles of Database Systems
 CSE 544: Principles of Database Systems Anatomy of a DBMS, Parallel Databases 1 Announcements Lecture on Thursday, May 2nd: Moved to 9am-10:30am, CSE 403 Paper reviews: Anatomy paper was due yesterday;
CSE 544: Principles of Database Systems Anatomy of a DBMS, Parallel Databases 1 Announcements Lecture on Thursday, May 2nd: Moved to 9am-10:30am, CSE 403 Paper reviews: Anatomy paper was due yesterday;
Simply Accounting Intelligence Tips and Tricks Booklet Vol. 1
 Simply Accounting Intelligence Tips and Tricks Booklet Vol. 1 1 Contents Accessing the SAI reports... 3 Copying, Pasting and Renaming Reports... 4 Creating and linking a report... 6 Auto e-mailing reports...
Simply Accounting Intelligence Tips and Tricks Booklet Vol. 1 1 Contents Accessing the SAI reports... 3 Copying, Pasting and Renaming Reports... 4 Creating and linking a report... 6 Auto e-mailing reports...
Testkings.C QA
 Testkings.C2090-421.194.QA Number: C2090-421 Passing Score: 800 Time Limit: 120 min File Version: 3.3 C2090-421 InfoSphere DataStage v8.5 This VCE provide you the way to your desires to attain success.
Testkings.C2090-421.194.QA Number: C2090-421 Passing Score: 800 Time Limit: 120 min File Version: 3.3 C2090-421 InfoSphere DataStage v8.5 This VCE provide you the way to your desires to attain success.
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
IBM KM423G - IBM INFOSPHERE DATASTAGE V ADVANCED DATA PROCESSING
 IBM KM423G - IBM INFOSPHERE DATASTAGE V11.5 - ADVANCED DATA PROCESSING Dauer: 2 Tage Durchführungsart: Präsenztraining Zielgruppe: Experienced DataStage developers seeking training in more advanced DataStage
IBM KM423G - IBM INFOSPHERE DATASTAGE V11.5 - ADVANCED DATA PROCESSING Dauer: 2 Tage Durchführungsart: Präsenztraining Zielgruppe: Experienced DataStage developers seeking training in more advanced DataStage
Building a Scalable Architecture for Web Apps - Part I (Lessons Directi)
") Intelligent People. Uncommon Ideas. Building a Scalable Architecture for Web Apps - Part I (Lessons Learned @ Directi) By Bhavin Turakhia CEO, Directi (http://www.directi.com http://wiki.directi.com http://careers.directi.com)
Intelligent People. Uncommon Ideas. Building a Scalable Architecture for Web Apps - Part I (Lessons Learned @ Directi) By Bhavin Turakhia CEO, Directi (http://www.directi.com http://wiki.directi.com http://careers.directi.com)
Hash-Based Indexing 1
 Hash-Based Indexing 1 Tree Indexing Summary Static and dynamic data structures ISAM and B+ trees Speed up both range and equality searches B+ trees very widely used in practice ISAM trees can be useful
Hash-Based Indexing 1 Tree Indexing Summary Static and dynamic data structures ISAM and B+ trees Speed up both range and equality searches B+ trees very widely used in practice ISAM trees can be useful
EMC GREENPLUM MANAGEMENT ENABLED BY AGINITY WORKBENCH
 White Paper EMC GREENPLUM MANAGEMENT ENABLED BY AGINITY WORKBENCH A Detailed Review EMC SOLUTIONS GROUP Abstract This white paper discusses the features, benefits, and use of Aginity Workbench for EMC
White Paper EMC GREENPLUM MANAGEMENT ENABLED BY AGINITY WORKBENCH A Detailed Review EMC SOLUTIONS GROUP Abstract This white paper discusses the features, benefits, and use of Aginity Workbench for EMC
Selection Queries. to answer a selection query (ssn=10) needs to traverse a full path.
 needs to traverse a full path.") Hashing B+-tree is perfect, but... Selection Queries to answer a selection query (ssn=) needs to traverse a full path. In practice, 3-4 block accesses (depending on the height of the tree, buffering) Any
Hashing B+-tree is perfect, but... Selection Queries to answer a selection query (ssn=) needs to traverse a full path. In practice, 3-4 block accesses (depending on the height of the tree, buffering) Any
EE/CSCI 451: Parallel and Distributed Computation
 EE/CSCI 451: Parallel and Distributed Computation Lecture #7 2/5/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
EE/CSCI 451: Parallel and Distributed Computation Lecture #7 2/5/2017 Xuehai Qian Xuehai.qian@usc.edu http://alchem.usc.edu/portal/xuehaiq.html University of Southern California 1 Outline From last class
CSE 190D Spring 2017 Final Exam Answers
 CSE 190D Spring 2017 Final Exam Answers Q 1. [20pts] For the following questions, clearly circle True or False. 1. The hash join algorithm always has fewer page I/Os compared to the block nested loop join
CSE 190D Spring 2017 Final Exam Answers Q 1. [20pts] For the following questions, clearly circle True or False. 1. The hash join algorithm always has fewer page I/Os compared to the block nested loop join
Product Overview. Technical Summary, Samples, and Specifications
 Product Overview Technical Summary, Samples, and Specifications Introduction IRI FACT (Fast Extract) is a high-performance unload utility for very large database (VLDB) systems. It s primarily for data
Product Overview Technical Summary, Samples, and Specifications Introduction IRI FACT (Fast Extract) is a high-performance unload utility for very large database (VLDB) systems. It s primarily for data
Database Applications (15-415)
") Database Applications (15-415) DBMS Internals- Part VI Lecture 14, March 12, 2014 Mohammad Hammoud Today Last Session: DBMS Internals- Part V Hash-based indexes (Cont d) and External Sorting Today s Session:
Database Applications (15-415) DBMS Internals- Part VI Lecture 14, March 12, 2014 Mohammad Hammoud Today Last Session: DBMS Internals- Part V Hash-based indexes (Cont d) and External Sorting Today s Session:
"Charting the Course... MOC C: Developing SQL Databases. Course Summary
 Course Summary Description This five-day instructor-led course provides students with the knowledge and skills to develop a Microsoft SQL database. The course focuses on teaching individuals how to use
Course Summary Description This five-day instructor-led course provides students with the knowledge and skills to develop a Microsoft SQL database. The course focuses on teaching individuals how to use
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a)
") Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Blended Learning Outline: Developer Training for Apache Spark and Hadoop (180404a) Cloudera s Developer Training for Apache Spark and Hadoop delivers the key concepts and expertise need to develop high-performance
Chapter 11: Indexing and Hashing
 Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
Chapter 11: Indexing and Hashing Basic Concepts Ordered Indices B + -Tree Index Files B-Tree Index Files Static Hashing Dynamic Hashing Comparison of Ordered Indexing and Hashing Index Definition in SQL
8 Introduction to Distributed Computing
 CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 8, 4/26/2017. Scribed by A. Santucci. 8 Introduction
CME 323: Distributed Algorithms and Optimization, Spring 2017 http://stanford.edu/~rezab/dao. Instructor: Reza Zadeh, Matroid and Stanford. Lecture 8, 4/26/2017. Scribed by A. Santucci. 8 Introduction
Midterm 1: CS186, Spring I. Storage: Disk, Files, Buffers [11 points] SOLUTION. cs186-
![Midterm 1: CS186, Spring I. Storage: Disk, Files, Buffers [11 points] SOLUTION. cs186-](/thumbs/75/72967709.jpg "Midterm 1: CS186, Spring I. Storage: Disk, Files, Buffers [11 points] SOLUTION. cs186-") Midterm 1: CS186, Spring 2016 Name: Class Login: SOLUTION cs186- You should receive 1 double-sided answer sheet and an 10-page exam. Mark your name and login on both sides of the answer sheet, and in the
Midterm 1: CS186, Spring 2016 Name: Class Login: SOLUTION cs186- You should receive 1 double-sided answer sheet and an 10-page exam. Mark your name and login on both sides of the answer sheet, and in the
Hash-Based Indexing 165
 Hash-Based Indexing 165 h 1 h 0 h 1 h 0 Next = 0 000 00 64 32 8 16 000 00 64 32 8 16 A 001 01 9 25 41 73 001 01 9 25 41 73 B 010 10 10 18 34 66 010 10 10 18 34 66 C Next = 3 011 11 11 19 D 011 11 11 19
Hash-Based Indexing 165 h 1 h 0 h 1 h 0 Next = 0 000 00 64 32 8 16 000 00 64 32 8 16 A 001 01 9 25 41 73 001 01 9 25 41 73 B 010 10 10 18 34 66 010 10 10 18 34 66 C Next = 3 011 11 11 19 D 011 11 11 19
File Structures and Indexing
 File Structures and Indexing CPS352: Database Systems Simon Miner Gordon College Last Revised: 10/11/12 Agenda Check-in Database File Structures Indexing Database Design Tips Check-in Database File Structures
File Structures and Indexing CPS352: Database Systems Simon Miner Gordon College Last Revised: 10/11/12 Agenda Check-in Database File Structures Indexing Database Design Tips Check-in Database File Structures
Increasing Performance for PowerCenter Sessions that Use Partitions
 Increasing Performance for PowerCenter Sessions that Use Partitions 1993-2015 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying,
Increasing Performance for PowerCenter Sessions that Use Partitions 1993-2015 Informatica LLC. No part of this document may be reproduced or transmitted in any form, by any means (electronic, photocopying,
Call: SAS BI Course Content:35-40hours
 SAS BI Course Content:35-40hours Course Outline SAS Data Integration Studio 4.2 Introduction * to SAS DIS Studio Features of SAS DIS Studio Tasks performed by SAS DIS Studio Navigation to SAS DIS Studio
SAS BI Course Content:35-40hours Course Outline SAS Data Integration Studio 4.2 Introduction * to SAS DIS Studio Features of SAS DIS Studio Tasks performed by SAS DIS Studio Navigation to SAS DIS Studio
Lambda Architecture for Batch and Stream Processing. October 2018
 Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.