Frequent Pattern Mining S L I D E S B Y : S H R E E J A S W A L
|
|
|
- Janice Merritt
- 6 years ago
- Views:
Transcription
1 Frequent Pattern Mining S L I D E S B Y : S H R E E J A S W A L
2 Topics to be covered Market Basket Analysis, Frequent Itemsets, Closed Itemsets, and Association Rules; Frequent Pattern Mining, Efficient and Scalable Frequent Itemset Mining Methods, The Apriori Algorithm for finding Frequent Itemsets Using Candidate Generation, Generating Association Rules from Frequent Itemsets, Improving the Efficiency of Apriori, A pattern growth approach for mining Frequent Itemsets; Mining Frequent itemsets using vertical data formats; Mining closed and maximal patterns; Introduction to Mining Multilevel Association Rules and Multidimensional Association Rules; From Association Mining to Correlation Analysis, Pattern Evaluation Measures; Introduction to Constraint-Based Association Mining. 2
3 Which Chapter from which Text Book? Chapter 6: Mining Frequent Patterns, Associations and Correlations: Basic Concepts and Methods from Han, Kamber, "Data Mining Concepts and Techniques", Morgan Kaufmann 3nd Edition Chapter 7: Advanced Pattern Mining from Han, Kamber, "Data Mining Concepts and Techniques", Morgan Kaufmann 3nd Edition 3
4 What Is Frequent Pattern Analysis? Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set First proposed by Agrawal, Imielinski, and Swami [AIS93] in the context of frequent itemsets and association rule mining Motivation: Finding inherent regularities in data What products were often purchased together? Beer and diapers?! What are the subsequent purchases after buying a PC? What kinds of DNA are sensitive to this new drug? Can we automatically classify web documents? Applications Basket data analysis, cross-marketing, catalog design, sale campaign analysis, Web log (click stream) analysis, and DNA sequence analysis. 4
5 Why Is Freq. Pattern Mining Important? Discloses an intrinsic and important property of data sets Forms the foundation for many essential data mining tasks Association, correlation, and causality analysis Sequential, structural (e.g., sub-graph) patterns Pattern analysis in spatiotemporal, multimedia, timeseries, and stream data Classification: associative classification Cluster analysis: frequent pattern-based clustering Data warehousing: iceberg cube and cube-gradient Semantic data compression: fascicles Broad applications 5
6 Association Rule Mining Given a set of transactions, find rules that will predict the occurrence of an item based on the occurrences of other items in the transaction 7 Market-Basket transactions TID Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke Example of Association Rules {Diaper} {Beer}, {Milk, Bread} {Eggs,Coke}, {Beer, Bread} {Milk}, Implication means co-occurrence, not causality!
7 Definition: Frequent Itemset Itemset A collection of one or more items Example: {Milk, Bread, Diaper} k-itemset An itemset that contains k items Support count ( ) Frequency of occurrence of an itemset E.g. ({Milk, Bread,Diaper}) = 2 Support Fraction of transactions that contain an itemset E.g. s({milk, Bread, Diaper}) = 2/5 Frequent Itemset An itemset whose support is greater than or equal to a minsup threshold TID Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke
8 Association Rule Definition: Association Rule An implication expression of the form X Y, where X and Y are itemsets Example: {Milk, Diaper} {Beer} Rule Evaluation Metrics Support (s) Fraction of transactions that contain both X and Y i.e P(X U Y) Confidence (c) Measures how often items in Y appear in transactions that contain X i.e. P(X Y) 9 TID Example: Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke { Milk, Diaper} Beer (Milk, Diaper, Beer) s T (Milk,Diaper, Beer) c (Milk, Diaper)
9 Association Rule Mining Task Given a set of transactions T, the goal of association rule mining is to find all rules having support minsup threshold 10 confidence minconf threshold Brute-force approach: List all possible association rules Compute the support and confidence for each rule Prune rules that fail the minsup and minconf thresholds Computationally prohibitive!
10 Mining Association Rules 11 TID Items 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke Observations: Example of Rules: {Milk,Diaper} {Beer} (s=0.4, c=0.67) {Milk,Beer} {Diaper} (s=0.4, c=1.0) {Diaper,Beer} {Milk} (s=0.4, c=0.67) {Beer} {Milk,Diaper} (s=0.4, c=0.67) {Diaper} {Milk,Beer} (s=0.4, c=0.5) {Milk} {Diaper,Beer} (s=0.4, c=0.5) All the above rules are binary partitions of the same itemset: {Milk, Diaper, Beer} Rules originating from the same itemset have identical support but can have different confidence Thus, we may decouple the support and confidence requirements
11 Two-step approach: Mining Association Rules 1. Frequent Itemset Generation Generate all itemsets whose support minsup 2. Rule Generation Generate high confidence rules from each frequent itemset, where each rule is a binary partitioning of a frequent itemset Frequent itemset generation is still computationally expensive 12
12 Frequent Itemset Generation null 13 A B C D E AB AC AD AE BC BD BE CD CE DE ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE ABCD ABCE ABDE ACDE BCDE ABCDE Given d items, there are 2 d possible candidate itemsets
13 Closed Patterns and Max-Patterns A long pattern contains a combinatorial number of subpatterns, e.g., {a 1,, a 100 } contains ( 1001 ) + ( 1002 ) + + ( ) = = 1.27*10 30 sub-patterns! 14 Solution: Mine closed patterns and max-patterns instead An itemset X is closed if X is frequent and there exists no super-pattern Y כ X, with the same support as X (proposed by Pasquier, et ICDT 99) An itemset X is a max-pattern if X is frequent and there exists no frequent super-pattern Y כ X (proposed by SIGMOD 98) Closed pattern is a lossless compression of freq. patterns Reducing the # of patterns and rules
14 Closed Patterns and Max-Patterns Exercise. DB = {<a 1,, a 100 >, < a 1,, a 50 >} Min_sup = 1. What is the set of closed itemset? <a 1,, a 100 >: 1 < a 1,, a 50 >: 2 What is the set of max-pattern? <a 1,, a 100 >: 1 15
15 Scalable Methods for Mining Frequent Patterns The downward closure property of frequent patterns Any subset of a frequent itemset must be frequent If {beer, diaper, nuts} is frequent, so is {beer, diaper} i.e., every transaction having {beer, diaper, nuts} also contains {beer, diaper} Scalable mining methods: Three major approaches Apriori (Agrawal & Srikant@VLDB 94) Freq. pattern growth (FPgrowth Han, Pei & 00) Vertical data format approach (Charm Zaki & 02) 16
16 Apriori: A Candidate Generation-and-Test Approach Apriori pruning principle: If there is any itemset which is 17 infrequent, its superset should not be generated/tested! (Agrawal & 94, Mannila, et KDD 94) That is, If an itemset is frequent, then all of its subsets must also be frequent Apriori principle holds due to the following property of the support measure: X, Y : ( X Y) s( X) s( Y) Support of an itemset never exceeds the support of its subsets This is known as the anti-monotone property of support
17 Apriori: A Candidate Generation-and-Test Approach Method: Initially, scan DB once to get frequent 1-itemset Generate length (k+1) candidate itemsets from length k frequent itemsets Test the candidates against DB Terminate when no frequent or candidate set can be generated 18
18 Illustrating Apriori Principle Item Count Bread 4 Coke 2 Milk 4 Beer 3 Diaper 4 Eggs 1 Minimum Support = 3 Items (1-itemsets) 19 Itemset Count {Bread,Milk} 3 {Bread,Beer} 2 {Bread,Diaper} 3 {Milk,Beer} 2 {Milk,Diaper} 3 {Beer,Diaper} 3 Pairs (2-itemsets) (No need to generate candidates involving Coke or Eggs) Triplets (3-itemsets) If every subset is considered, 6 C C C 3 = 41 With support-based pruning, = 13 Itemset Count {Bread,Milk,Diaper} 3
19 Illustrating Apriori Principle null A B C D E AB AC AD AE BC BD BE CD CE DE Found to be Infrequent ABC ABD ABE ACD ACE ADE BCD BCE BDE CDE ABCD ABCE ABDE ACDE BCDE Pruned supersets ABCDE 20
20 The Apriori Algorithm An Example Sup Itemset sup Database TDB min = 2 {A} 2 L Tid Items C 1 1 {B} 3 10 A, C, D 20 B, C, E 30 A, B, C, E 40 B, E 1 st scan C 2 C 2 {A, B} 1 L 2 Itemset sup 2 nd scan {A, C} 2 {B, C} 2 {B, E} 3 {C, E} 2 Itemset 21 {C} 3 {D} 1 {E} 3 sup {A, C} 2 {A, E} 1 {B, C} 2 {B, E} 3 {C, E} 2 Itemset sup {A} 2 {B} 3 {C} 3 {E} 3 Itemset {A, B} {A, C} {A, E} {B, C} {B, E} {C, E} C Itemset 3 3 rd scan L 3 {B, C, E} Itemset sup {B, C, E} 2
21 The Apriori Algorithm Pseudo-code: C k : Candidate itemset of size k L k : frequent itemset of size k L 1 = {frequent items}; for (k = 1; L k!= ; k++) do begin C k+1 = candidates generated from L k ; for each transaction t in database do L k+1 22 increment the count of all candidates in C k+1 that are contained in t = candidates in C k+1 with min_support end return L 1 = k L k ;
22 Important Details of Apriori How to generate candidates? Step 1: self-joining L k Step 2: pruning How to count supports of candidates? Example of Candidate-generation L 3 ={abc, abd, acd, ace, bcd} Self-joining: L 3 *L 3 abcd from abc and abd acde from acd and ace Pruning: 23 acde is removed because ade is not in L 3 C 4 ={abcd}
23 What s Next? 24 Having found all of the frequent items. This completes our Apriori Algorithm. What s Next? These frequent itemsets will be used to generate strong association rules( where strong association rules satisfy both minimum support & minimum confidence).
24 Generating Association Rules from Frequent Itemsets Procedure: 25 For each frequent itemset l, generate all nonempty subsets of l. For every nonempty subset s of l, output the rule s ->(l-s) if support_count(l)/support_count(s) >= min_conf where min_conf is minimum confidence threshold. Lets take l = {I1,I2,I5}. Its all nonempty subsets are {I1,I2}, {I1,I5}, {I2,I5}, {I1}, {I2}, {I5}.

25 26

26 27
27 Methods to Improve Apriori s Efficiency Hash-based technique can be used to reduce the size of the candidate k-itemsets, Ck, for k>1. For example when scanning each transaction in the database to generate the frequent 1-itemsetes, L1, from the candidate 1-itemsets in C1, we can generate all of the 2- itemsets for each transaction, hash them into a different buckets of a hash table structure and increase the corresponding bucket counts: a. H(x,y)=((order of x)*10+(order of y)) mod 7 e.g. H(I1,I4)=((1*10)+4))mod7=0 b. A 2-itemset whose corresponding bucket count in the hash table is below the threshold cannot be frequent and thus should be removed from the candidate set.
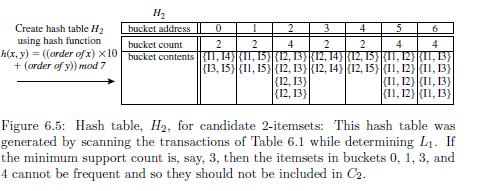
28 30
29 Methods to Improve Apriori s Efficiency contd Transaction reduction a transaction that does not contain any frequent k itemsets cannot contain any frequent k+1 itemsets. Therefore, such a transaction can be marked or removed from further consideration because subsequent scans of the database for j-itemsets, where j>k, will not require it.
30 Methods to Improve Apriori s Efficiency contd Partitioning (partitioning the data to find candidate itemsets): A partitioning technique can be used that requires just two database scans to mine the frequent itemsets. It consists of two phases. In phase I, the algorithm subdivides the transactions of D into n nonoverlapping partitions. If the minimum support threshold for transactions in D is min_sup, then the minimum support count for a partition is min_sup * the number of transactions in that partition. For each partition, all frequent itemsets within the partition are found. These are referred to as local frequent itemsets. A local frequent itemset may or may not be frequent with respect to the entire database, D. Any itemset that is potentially frequent with respect to D must occur as a frequent itemset in at least one of the partitions. Therefore all local frequent itemsets are candidate itemsets with respect to D. The collection of frequent itemsets from all partitions forms the global candidate itemsets with respect to D. In phase II, a second scan of D is conducted in which the actual support of each candidate is assessed in order to determine the global frequent itemsets
31 33
32 Methods to Improve Apriori s Efficiency contd Sampling (mining on a subset of a given data): The basic idea of the sampling approach is to pick a random sample S of the given data D, and then search for frequent itemsets in S instead of D. In this way, we trade off some degree of accuracy against efficiency. The sample size of S is such that the search for frequent itemsets in S can be done in main memory, and so only one scan of the transactions in S in required overall. Because we are searching for frequent itemsets in S rather than in D, it is possible that we will miss some of the global frequent itemsets. To lessen this possibility, we use a lower support threshold than minimum support to find the frequent itemsets local to S.
33 Methods to Improve Apriori s Efficiency contd Dynamic itemset counting (adding candidate itemsets at different points during a scan): A dynamic itemset counting technique was proposed in which the database is partitioned into blocks marked by start points. In this variation new candidate itemsets can be added at any start point, which determines new candidate itemsets only immediately before each complete database scan. The resulting algorithm requires fewer database scan than Apriori.
34 Mining Frequent Patterns Without Candidate Generation 36 Compress a large database into a compact, Frequent- Pattern tree (FP-tree)structure highly condensed, but complete for frequent pattern mining avoid costly database scans Develop an efficient, FP-tree-based frequent pattern mining method A divide-and-conquer methodology: decompose mining tasks into smaller ones Avoid candidate generation: sub-database test only!
35 FP-Growth Method: Construction of FP-Tree First, create the root of the tree, labeled with null. Scan the database D a second time. (First time we scanned it to create 1-itemset and then L). The items in each transaction are processed in L order (i.e. descending order). A branch is created for each transaction with items having their support count separated by colon. Whenever the same node is encountered in another transaction, we just increment the support count of the common node or Prefix. To facilitate tree traversal, an item header table is built so that each item points to its occurrences in the tree via a chain of node-links. Now, The problem of mining frequent patterns in database is transformed to that of mining the FP-Tree. 37
36 FP-Growth Method: Construction of FP-Tree 38
37 Mining the FP-Tree by Creating Conditional (sub) pattern bases Steps: 1.Start from each frequent length-1 pattern(as an initial suffix pattern). 2.Construct its conditional pattern base which consists of the set of prefix paths in the FP-Tree co-occurring with suffix pattern. 3.Then, Construct its conditional FP-Tree& perform mining on such a tree. 4.The pattern grow this achieved by concatenation of the suffix pattern with the frequent patterns generated from a conditional FP-Tree. 5.The union of all frequent patterns (generated by step 4) gives the required frequent itemset. 39


38 FP-Tree Example Continued 40
39 FP-Tree Example Continued 41 Out of these, Only I1 & I2 is selected in the conditional FP- Tree because I3 is not satisfying the minimum support count. For I1, support count in conditional pattern base = = 2 For I2, support count in conditional pattern base = = 2 For I3, support count in conditional pattern base = 1 Thus support count for I3 is less than required min_sup which is2 here. Now, We have conditional FP-Tree with us. All frequent pattern corresponding to suffix I5 are generated by considering all possible combinations of I5 and conditional FP-Tree. The same procedure is applied to suffixes I4, I3 and I1. Note:I2 is not taken into consideration for suffix because it doesn t have any prefix at all.
40 Why Frequent Pattern Growth Fast? Performance study shows 43 FP-growth is an order of magnitude faster than Apriori, and is also faster than tree-projection Reasoning No candidate generation, no candidate test Use compact data structure Eliminate repeated database scan Basic operation is counting and FP-tree building
41 Example 1 44 Transaction T1 T2 T3 T4 T5 Items a, c, d, f, g, i, m, p a, b, c, f, l, m, o b, f, h, j, o b, c, k, n, p a, c, e, f, l, m, n, p Min support = 60%
42 Step 1 45 Find support of every item. Item Support Item Support a 3 i 1 b 3 j 1 c 4 k 1 d 1 l 2 e 1 m 3 f 4 n 2 g 1 o 2 h 1 p 3
43 Step 2 Choose items that are above min support and arrange them in descending order. 46 item support f 4 c 4 a 3 b 3 m 3 p 3
44 Step 3 47 Rewrite transactions with only those items that have more than min support, in descending order Transactio n Items Frequent items T1 a, c, d, f, g, i, m, p f, c, a, m, p T2 a, b, c, f, l, m, o f, c, a, b, m T3 b, f, h, j, o f, b T4 b, c, k, n, p c, b, p T5 a, c, e, f, l, m, n, p f, c, a, m, p
45 Step 4 48 Introduce a Root Node Root = NULL Give the first transaction to the root. Transaction T1: f, c, a, m, p NULL Root f : 1 c : 1 a : 1 m : 1 p : 1
46 Transaction T2: f, c, a, b, m 49 Root f : 2 c : 2 a : 2 m : 1 b : 1 p : 1 m : 1
47 Transaction T3 : f, b 50 Root f : 3 c : 2 b : 1 a : 2 m : 1 b : 1 p : 1 m : 1
48 Transaction T4: c, b, p 51 Root f : 3 c : 1 c : 2 b : 1 a : 2 b : 1 m : 1 b : 1 p : 1 p : 1 m : 1
49 Transaction T5: f, c, a, m, p 52 Root f : 4 c : 1 c : 3 b : 1 a : 3 b : 1 m : 2 b : 1 p : 1 p : 2 m : 1
50 Mining the FP Tree 53 Frequent items Condition pattern Conditional tree p fcam:2, cb: 1 c:3 {c,p:3} Frequent Patterns m fca: 2, fcab: 1 f:3, c:3, a:3 {f,m:3},{c,m:3},{a,m:3},{a,c,f,m:3} b fca:1, f:1, c:1 Empty {b:3} a fc:3 f:3, c:3 {f,a:3},{c,a:3},{f,c,a:3} c f:3 f:3 {f,c:3} f Empty Empty {f:4}
51 Example 2 54 Transaction Id t1 t2 t3 t4 t5 Items Purchased b, e a, b, c, e b, c, e a, c, d a Given: min support = 40%
52 Step 1/ 2: Step: 3 55 Items Support a 3 b 3 c 3 d 1 e 3 Transactions t1 t2 t3 t4 t5 Items in desc order b, e b, e, c, a b, e, c a, c a
53 Step: 4 Root 56 b : 3 a : 2 e: 3 c:1 c:2 a : 1 Step: 5 Mining the FP Tree Item Conditional pattern conditional tree a bec: 1 empty b empty empty c be: 2, a: 1 b:2, e:2 e b:3 b:3
54 Mining frequent itemsets using vertical data format 57 The Apriori and the FP-growth methods mine frequent patterns from a set of transactions in TIDitemset format, where TID is a transaction id and itemset is the set of items bought in transaction TID. This data format is known as horizontal data format. Alternatively data can also be presented in item- TID_set format, where item is an item name and TID_set is the set of transaction identifiers containing the item. This format is known as vertical data format.
55 Procedure 58 First we transform the horizontally formatted data to the vertical format by scanning the data set once. The support count of an itemset is simply the length of the TID_set of the itemset. Starting with k=1 the frequent k-itemsets can be used to construct the candidate (k+1)-itemsets. This process repeats with k incremented by 1 each time until no frequent itemsets or no candidate itemsets can be found.
56 Example 59
57 60
58 61
59 62
60 Advantages Advantages of this algorithm: Better than Apriori in the generation of candidate (k+1)-itemset from frequent k itemsets There is no need to scan the database to find the support (k+1) itemsets (for k>=1). This is because the TID_set of each k-itemset carries the complete information required for counting such support. The disadvantage of this algorithm consist in the TID_set being to long, taking substantial memory space as well as computation time for intersecting the long sets. 63
61 Multilevel AR It is difficult to find interesting patterns at a too primitive level high support = too few rules low support = too many rules, most uninteresting Approach: reason at suitable level of abstraction 64 A common form of background knowledge is that an attribute may be generalized or specialized according to a hierarchy of concepts Dimensions and levels can be efficiently encoded in transactions Multilevel Association Rules: rules which combine associations with hierarchy of concepts
62 Hierarchy of concepts 65 Department FoodStuff Sector Frozen Refrigerated Fresh Bakery Etc... Family Vegetable Fruit Dairy Etc... Product Banana Apple Orange Etc...
![Multilevel AR 66 Fresh [support = 20%] Dairy [support = 6%] Fruit [support = 1%] Vegetable](/docs-images/80/81281160/images/63-0.jpg "[support = 7%] Fresh Bakery [20%, 60%] Dairy Bread [6%, 50%] Fruit Bread [1%, 50%] is not")
63 Multilevel AR 66 Fresh [support = 20%] Dairy [support = 6%] Fruit [support = 1%] Vegetable [support = 7%] Fresh Bakery [20%, 60%] Dairy Bread [6%, 50%] Fruit Bread [1%, 50%] is not valid
64 Support and Confidence of Multilevel Association Rules Generalizing/specializing values of attributes affects support and confidence 67 from specialized to general: support of rules increases (new rules may become valid) from general to specialized: support of rules decreases (rules may become not valid, their support falls under the threshold)
65 Mining Multilevel AR 68 Hierarchical attributes: age, salary Association Rule: (age, young) (salary, 40k) age salary young middle-aged old low medium high k 40k 50k 60k 70k 80k 100k Candidate Association Rules: (age, 18 ) (salary, 40k), (age, young) (salary, low), (age, 18 ) (salary, low)
66 Mining Multilevel AR Calculate frequent itemsets at each concept level, until no more frequent itemsets can be found For each level use Apriori A top_down, progressive deepening approach: First find high-level strong rules: fresh bakery [20%, 60%]. Then find their lower-level weaker rules: fruit bread [6%, 50%]. Variations at mining multiple-level association rules. Level-crossed association rules: fruit wheat bread 69
67 Mining Multiple-Level Association Rules 70 Items often form hierarchies Flexible support settings Items at the lower level are expected to have lower support Exploration of shared multi-level mining (Agrawal & 95, Han & 95) uniform support Level 1 min_sup = 5% Milk [support = 10%] reduced support Level 1 min_sup = 5% Level 2 min_sup = 5% 2% Milk [support = 6%] Skim Milk [support = 4%] Level 2 min_sup = 3%
68 Multi-level Association: Uniform Support vs. Reduced Support Uniform Support: the same minimum support for all levels 71 One minimum support threshold. No need to examine itemsets containing any item whose ancestors do not have minimum support. If support threshold too high miss low level associations. too low generate too many high level associations. Reduced Support: reduced minimum support at lower levels - different strategies possible.
69 Multi-level Association: Redundancy Filtering 72 Some rules may be redundant due to ancestor relationships between items. Example milk wheat bread [support = 8%, confidence = 70%] 2% milk wheat bread [support = 2%, confidence = 72%] We say the first rule is an ancestor of the second rule. A rule is redundant if its support is close to the expected value, based on the rule s ancestor.
70 Mining Multi-Dimensional Association Single-dimensional rules: 73 buys(x, milk ) buys(x, bread ) Multi-dimensional rules: 2 dimensions or predicates Inter-dimension assoc. rules (no repeated predicates) age(x, ) occupation(x, student ) buys(x, coke ) hybrid-dimension assoc. rules (repeated predicates) age(x, ) buys(x, popcorn ) buys(x, coke ) Categorical(nominal) Attributes: finite number of possible values, no ordering among values data cube approach Quantitative Attributes: numeric, implicit ordering among values discretization, clustering, and gradient approaches
71 Interestingness Measure: Correlations (Lift) play basketball eat cereal [40%, 66.7%] is misleading The overall % of students eating cereal is 75% > 66.7%. play basketball not eat cereal [20%, 33.3%] is more accurate, although with lower support and confidence Measure of dependent/correlated events: lift If value less than 1 then negatively correlated and if value greater than 1 then positively correlated If value equal to 1 then they are independent lift P( A B) P( A) P( B) Basketball Not basketball Sum (row) Cereal Not cereal Sum(col.) / / 5000 lift( B, C) 0.89 lift( B, C) / 5000*3750 / / 5000*1250 / 5000 Jaswal Slides by Shree 74
72 Constraint-based (Query-Directed) Mining Finding all the patterns in a database autonomously? unrealistic! The patterns could be too many but not focused! Data mining should be an interactive process 77 User directs what to be mined using a data mining query language (or a graphical user interface) Constraint-based mining User flexibility: provides constraints on what to be mined System optimization: explores such constraints for efficient mining constraint-based mining
73 Constraints in Data Mining 78 Knowledge type constraint: classification, association, etc. Data constraint using SQL-like queries find product pairs sold together in stores in Mumbai in Dec. 16 Dimension/level constraint in relevance to region, price, brand, customer category Rule (or pattern) constraint small sales (price < $10) triggers big sales (sum > $200) Interestingness constraint strong rules: min_support 3%, min_confidence 60%
74 Constrained Mining vs. Constraint-Based Search Constrained mining vs. constraint-based search/reasoning Both are aimed at reducing search space Finding all patterns satisfying constraints vs. finding some (or one) answer in constraint-based search in AI Constraint-pushing vs. heuristic search 79 It is an interesting research problem on how to integrate them Constrained mining vs. query processing in DBMS Database query processing requires to find all Constrained pattern mining shares a similar philosophy as pushing selections deeply in query processing
Data Mining: Concepts and Techniques. Chapter 5. SS Chung. April 5, 2013 Data Mining: Concepts and Techniques 1
 Data Mining: Concepts and Techniques Chapter 5 SS Chung April 5, 2013 Data Mining: Concepts and Techniques 1 Chapter 5: Mining Frequent Patterns, Association and Correlations Basic concepts and a road
Data Mining: Concepts and Techniques Chapter 5 SS Chung April 5, 2013 Data Mining: Concepts and Techniques 1 Chapter 5: Mining Frequent Patterns, Association and Correlations Basic concepts and a road
Association rules. Marco Saerens (UCL), with Christine Decaestecker (ULB)
, with Christine Decaestecker (ULB)") Association rules Marco Saerens (UCL), with Christine Decaestecker (ULB) 1 Slides references Many slides and figures have been adapted from the slides associated to the following books: Alpaydin (2004),
Association rules Marco Saerens (UCL), with Christine Decaestecker (ULB) 1 Slides references Many slides and figures have been adapted from the slides associated to the following books: Alpaydin (2004),
Chapter 4: Mining Frequent Patterns, Associations and Correlations
 Chapter 4: Mining Frequent Patterns, Associations and Correlations 4.1 Basic Concepts 4.2 Frequent Itemset Mining Methods 4.3 Which Patterns Are Interesting? Pattern Evaluation Methods 4.4 Summary Frequent
Chapter 4: Mining Frequent Patterns, Associations and Correlations 4.1 Basic Concepts 4.2 Frequent Itemset Mining Methods 4.3 Which Patterns Are Interesting? Pattern Evaluation Methods 4.4 Summary Frequent
Chapter 6: Basic Concepts: Association Rules. Basic Concepts: Frequent Patterns. (absolute) support, or, support. (relative) support, s, is the
 support, or, support. (relative) support, s, is the") Chapter 6: What Is Frequent ent Pattern Analysis? Frequent pattern: a pattern (a set of items, subsequences, substructures, etc) that occurs frequently in a data set frequent itemsets and association rule
Chapter 6: What Is Frequent ent Pattern Analysis? Frequent pattern: a pattern (a set of items, subsequences, substructures, etc) that occurs frequently in a data set frequent itemsets and association rule
Apriori Algorithm. 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke
 Apriori Algorithm For a given set of transactions, the main aim of Association Rule Mining is to find rules that will predict the occurrence of an item based on the occurrences of the other items in the
Apriori Algorithm For a given set of transactions, the main aim of Association Rule Mining is to find rules that will predict the occurrence of an item based on the occurrences of the other items in the
Association Rules. A. Bellaachia Page: 1
 Association Rules 1. Objectives... 2 2. Definitions... 2 3. Type of Association Rules... 7 4. Frequent Itemset generation... 9 5. Apriori Algorithm: Mining Single-Dimension Boolean AR 13 5.1. Join Step:...
Association Rules 1. Objectives... 2 2. Definitions... 2 3. Type of Association Rules... 7 4. Frequent Itemset generation... 9 5. Apriori Algorithm: Mining Single-Dimension Boolean AR 13 5.1. Join Step:...
Association Rule Mining. Entscheidungsunterstützungssysteme
 Association Rule Mining Entscheidungsunterstützungssysteme Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set
Association Rule Mining Entscheidungsunterstützungssysteme Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R,
 Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R, statistics foundations 5 Introduction to D3, visual analytics
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R, statistics foundations 5 Introduction to D3, visual analytics
Basic Concepts: Association Rules. What Is Frequent Pattern Analysis? COMP 465: Data Mining Mining Frequent Patterns, Associations and Correlations
 What Is Frequent Pattern Analysis? COMP 465: Data Mining Mining Frequent Patterns, Associations and Correlations Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and
What Is Frequent Pattern Analysis? COMP 465: Data Mining Mining Frequent Patterns, Associations and Correlations Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and
ANU MLSS 2010: Data Mining. Part 2: Association rule mining
 ANU MLSS 2010: Data Mining Part 2: Association rule mining Lecture outline What is association mining? Market basket analysis and association rule examples Basic concepts and formalism Basic rule measurements
ANU MLSS 2010: Data Mining Part 2: Association rule mining Lecture outline What is association mining? Market basket analysis and association rule examples Basic concepts and formalism Basic rule measurements
Frequent Pattern Mining. Based on: Introduction to Data Mining by Tan, Steinbach, Kumar
 Frequent Pattern Mining Based on: Introduction to Data Mining by Tan, Steinbach, Kumar Item sets A New Type of Data Some notation: All possible items: Database: T is a bag of transactions Transaction transaction
Frequent Pattern Mining Based on: Introduction to Data Mining by Tan, Steinbach, Kumar Item sets A New Type of Data Some notation: All possible items: Database: T is a bag of transactions Transaction transaction
Mining Association Rules in Large Databases
 Mining Association Rules in Large Databases Association rules Given a set of transactions D, find rules that will predict the occurrence of an item (or a set of items) based on the occurrences of other
Mining Association Rules in Large Databases Association rules Given a set of transactions D, find rules that will predict the occurrence of an item (or a set of items) based on the occurrences of other
CS570 Introduction to Data Mining
 CS570 Introduction to Data Mining Frequent Pattern Mining and Association Analysis Cengiz Gunay Partial slide credits: Li Xiong, Jiawei Han and Micheline Kamber George Kollios 1 Mining Frequent Patterns,
CS570 Introduction to Data Mining Frequent Pattern Mining and Association Analysis Cengiz Gunay Partial slide credits: Li Xiong, Jiawei Han and Micheline Kamber George Kollios 1 Mining Frequent Patterns,
BCB 713 Module Spring 2011
 Association Rule Mining COMP 790-90 Seminar BCB 713 Module Spring 2011 The UNIVERSITY of NORTH CAROLINA at CHAPEL HILL Outline What is association rule mining? Methods for association rule mining Extensions
Association Rule Mining COMP 790-90 Seminar BCB 713 Module Spring 2011 The UNIVERSITY of NORTH CAROLINA at CHAPEL HILL Outline What is association rule mining? Methods for association rule mining Extensions
Fundamental Data Mining Algorithms
 2018 EE448, Big Data Mining, Lecture 3 Fundamental Data Mining Algorithms Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html REVIEW What is Data
2018 EE448, Big Data Mining, Lecture 3 Fundamental Data Mining Algorithms Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html REVIEW What is Data
Association Rules. Berlin Chen References:
 Association Rules Berlin Chen 2005 References: 1. Data Mining: Concepts, Models, Methods and Algorithms, Chapter 8 2. Data Mining: Concepts and Techniques, Chapter 6 Association Rules: Basic Concepts A
Association Rules Berlin Chen 2005 References: 1. Data Mining: Concepts, Models, Methods and Algorithms, Chapter 8 2. Data Mining: Concepts and Techniques, Chapter 6 Association Rules: Basic Concepts A
Chapter 4: Association analysis:
 Chapter 4: Association analysis: 4.1 Introduction: Many business enterprises accumulate large quantities of data from their day-to-day operations, huge amounts of customer purchase data are collected daily
Chapter 4: Association analysis: 4.1 Introduction: Many business enterprises accumulate large quantities of data from their day-to-day operations, huge amounts of customer purchase data are collected daily
Frequent Pattern Mining
 Frequent Pattern Mining How Many Words Is a Picture Worth? E. Aiden and J-B Michel: Uncharted. Reverhead Books, 2013 Jian Pei: CMPT 741/459 Frequent Pattern Mining (1) 2 Burnt or Burned? E. Aiden and J-B
Frequent Pattern Mining How Many Words Is a Picture Worth? E. Aiden and J-B Michel: Uncharted. Reverhead Books, 2013 Jian Pei: CMPT 741/459 Frequent Pattern Mining (1) 2 Burnt or Burned? E. Aiden and J-B
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 6
 Chapter 6") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2017 Han, Kamber & Pei. All
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2017 Han, Kamber & Pei. All
Data Mining Part 3. Associations Rules
 Data Mining Part 3. Associations Rules 3.2 Efficient Frequent Itemset Mining Methods Fall 2009 Instructor: Dr. Masoud Yaghini Outline Apriori Algorithm Generating Association Rules from Frequent Itemsets
Data Mining Part 3. Associations Rules 3.2 Efficient Frequent Itemset Mining Methods Fall 2009 Instructor: Dr. Masoud Yaghini Outline Apriori Algorithm Generating Association Rules from Frequent Itemsets
Nesnelerin İnternetinde Veri Analizi
 Bölüm 4. Frequent Patterns in Data Streams w3.gazi.edu.tr/~suatozdemir What Is Pattern Discovery? What are patterns? Patterns: A set of items, subsequences, or substructures that occur frequently together
Bölüm 4. Frequent Patterns in Data Streams w3.gazi.edu.tr/~suatozdemir What Is Pattern Discovery? What are patterns? Patterns: A set of items, subsequences, or substructures that occur frequently together
Effectiveness of Freq Pat Mining
 Effectiveness of Freq Pat Mining Too many patterns! A pattern a 1 a 2 a n contains 2 n -1 subpatterns Understanding many patterns is difficult or even impossible for human users Non-focused mining A manager
Effectiveness of Freq Pat Mining Too many patterns! A pattern a 1 a 2 a n contains 2 n -1 subpatterns Understanding many patterns is difficult or even impossible for human users Non-focused mining A manager
Mining Frequent Patterns without Candidate Generation
 Mining Frequent Patterns without Candidate Generation Outline of the Presentation Outline Frequent Pattern Mining: Problem statement and an example Review of Apriori like Approaches FP Growth: Overview
Mining Frequent Patterns without Candidate Generation Outline of the Presentation Outline Frequent Pattern Mining: Problem statement and an example Review of Apriori like Approaches FP Growth: Overview
Interestingness Measurements
 Interestingness Measurements Objective measures Two popular measurements: support and confidence Subjective measures [Silberschatz & Tuzhilin, KDD95] A rule (pattern) is interesting if it is unexpected
Interestingness Measurements Objective measures Two popular measurements: support and confidence Subjective measures [Silberschatz & Tuzhilin, KDD95] A rule (pattern) is interesting if it is unexpected
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University 10/19/2017 Slides adapted from Prof. Jiawei Han @UIUC, Prof.
CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University 10/19/2017 Slides adapted from Prof. Jiawei Han @UIUC, Prof.
Interestingness Measurements
 Interestingness Measurements Objective measures Two popular measurements: support and confidence Subjective measures [Silberschatz & Tuzhilin, KDD95] A rule (pattern) is interesting if it is unexpected
Interestingness Measurements Objective measures Two popular measurements: support and confidence Subjective measures [Silberschatz & Tuzhilin, KDD95] A rule (pattern) is interesting if it is unexpected
1. Interpret single-dimensional Boolean association rules from transactional databases
 1 STARTSTUDING.COM 1. Interpret single-dimensional Boolean association rules from transactional databases Association rule mining: Finding frequent patterns, associations, correlations, or causal structures
1 STARTSTUDING.COM 1. Interpret single-dimensional Boolean association rules from transactional databases Association rule mining: Finding frequent patterns, associations, correlations, or causal structures
Chapter 7: Frequent Itemsets and Association Rules
 Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2013/14 VII.1&2 1 Motivational Example Assume you run an on-line
Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2013/14 VII.1&2 1 Motivational Example Assume you run an on-line
Product presentations can be more intelligently planned
 Association Rules Lecture /DMBI/IKI8303T/MTI/UI Yudho Giri Sucahyo, Ph.D, CISA (yudho@cs.ui.ac.id) Faculty of Computer Science, Objectives Introduction What is Association Mining? Mining Association Rules
Association Rules Lecture /DMBI/IKI8303T/MTI/UI Yudho Giri Sucahyo, Ph.D, CISA (yudho@cs.ui.ac.id) Faculty of Computer Science, Objectives Introduction What is Association Mining? Mining Association Rules
Data Mining for Knowledge Management. Association Rules
 1 Data Mining for Knowledge Management Association Rules Themis Palpanas University of Trento http://disi.unitn.eu/~themis 1 Thanks for slides to: Jiawei Han George Kollios Zhenyu Lu Osmar R. Zaïane Mohammad
1 Data Mining for Knowledge Management Association Rules Themis Palpanas University of Trento http://disi.unitn.eu/~themis 1 Thanks for slides to: Jiawei Han George Kollios Zhenyu Lu Osmar R. Zaïane Mohammad
Association Rule Mining
 Association Rule Mining Generating assoc. rules from frequent itemsets Assume that we have discovered the frequent itemsets and their support How do we generate association rules? Frequent itemsets: {1}
Association Rule Mining Generating assoc. rules from frequent itemsets Assume that we have discovered the frequent itemsets and their support How do we generate association rules? Frequent itemsets: {1}
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
Association Analysis. CSE 352 Lecture Notes. Professor Anita Wasilewska
 Association Analysis CSE 352 Lecture Notes Professor Anita Wasilewska Association Rules Mining An Introduction This is an intuitive (more or less ) introduction It contains explanation of the main ideas:
Association Analysis CSE 352 Lecture Notes Professor Anita Wasilewska Association Rules Mining An Introduction This is an intuitive (more or less ) introduction It contains explanation of the main ideas:
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 6
 Chapter 6") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2016 Han, Kamber & Pei. All
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2016 Han, Kamber & Pei. All
Market baskets Frequent itemsets FP growth. Data mining. Frequent itemset Association&decision rule mining. University of Szeged.
 Frequent itemset Association&decision rule mining University of Szeged What frequent itemsets could be used for? Features/observations frequently co-occurring in some database can gain us useful insights
Frequent itemset Association&decision rule mining University of Szeged What frequent itemsets could be used for? Features/observations frequently co-occurring in some database can gain us useful insights
Mining Association Rules in Large Databases
 Mining Association Rules in Large Databases Vladimir Estivill-Castro School of Computing and Information Technology With contributions fromj. Han 1 Association Rule Mining A typical example is market basket
Mining Association Rules in Large Databases Vladimir Estivill-Castro School of Computing and Information Technology With contributions fromj. Han 1 Association Rule Mining A typical example is market basket
Scalable Frequent Itemset Mining Methods
 Scalable Frequent Itemset Mining Methods The Downward Closure Property of Frequent Patterns The Apriori Algorithm Extensions or Improvements of Apriori Mining Frequent Patterns by Exploring Vertical Data
Scalable Frequent Itemset Mining Methods The Downward Closure Property of Frequent Patterns The Apriori Algorithm Extensions or Improvements of Apriori Mining Frequent Patterns by Exploring Vertical Data
Chapter 6: Association Rules
 Chapter 6: Association Rules Association rule mining Proposed by Agrawal et al in 1993. It is an important data mining model. Transaction data (no time-dependent) Assume all data are categorical. No good
Chapter 6: Association Rules Association rule mining Proposed by Agrawal et al in 1993. It is an important data mining model. Transaction data (no time-dependent) Assume all data are categorical. No good
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 6
 Chapter 6") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2011 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2011 Han, Kamber & Pei. All rights
Association Rules Apriori Algorithm
 Association Rules Apriori Algorithm Market basket analysis n Market basket analysis might tell a retailer that customers often purchase shampoo and conditioner n Putting both items on promotion at the
Association Rules Apriori Algorithm Market basket analysis n Market basket analysis might tell a retailer that customers often purchase shampoo and conditioner n Putting both items on promotion at the
Chapter 4 Data Mining A Short Introduction
 Chapter 4 Data Mining A Short Introduction Data Mining - 1 1 Today's Question 1. Data Mining Overview 2. Association Rule Mining 3. Clustering 4. Classification Data Mining - 2 2 1. Data Mining Overview
Chapter 4 Data Mining A Short Introduction Data Mining - 1 1 Today's Question 1. Data Mining Overview 2. Association Rule Mining 3. Clustering 4. Classification Data Mining - 2 2 1. Data Mining Overview
Association Rule Mining (ARM) Komate AMPHAWAN
 Komate AMPHAWAN") Association Rule Mining (ARM) Komate AMPHAWAN 1 J-O-K-E???? 2 What can be inferred? I purchase diapers I purchase a new car I purchase OTC cough (ไอ) medicine I purchase a prescription medication (ใบส
Association Rule Mining (ARM) Komate AMPHAWAN 1 J-O-K-E???? 2 What can be inferred? I purchase diapers I purchase a new car I purchase OTC cough (ไอ) medicine I purchase a prescription medication (ใบส
2 CONTENTS
 Contents 5 Mining Frequent Patterns, Associations, and Correlations 3 5.1 Basic Concepts and a Road Map..................................... 3 5.1.1 Market Basket Analysis: A Motivating Example........................
Contents 5 Mining Frequent Patterns, Associations, and Correlations 3 5.1 Basic Concepts and a Road Map..................................... 3 5.1.1 Market Basket Analysis: A Motivating Example........................
Frequent Pattern Mining
 Frequent Pattern Mining...3 Frequent Pattern Mining Frequent Patterns The Apriori Algorithm The FP-growth Algorithm Sequential Pattern Mining Summary 44 / 193 Netflix Prize Frequent Pattern Mining Frequent
Frequent Pattern Mining...3 Frequent Pattern Mining Frequent Patterns The Apriori Algorithm The FP-growth Algorithm Sequential Pattern Mining Summary 44 / 193 Netflix Prize Frequent Pattern Mining Frequent
D Data Mining: Concepts and and Tech Techniques
 Data Mining: Concepts and Techniques (3 rd ed.) Chapter 5 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2009 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 5 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2009 Han, Kamber & Pei. All rights
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING Set Data: Frequent Pattern Mining Instructor: Yizhou Sun yzsun@cs.ucla.edu November 22, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification
CS145: INTRODUCTION TO DATA MINING Set Data: Frequent Pattern Mining Instructor: Yizhou Sun yzsun@cs.ucla.edu November 22, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Set Data: Frequent Pattern Mining Instructor: Yizhou Sun yzsun@ccs.neu.edu November 1, 2015 Midterm Reminder Next Monday (Nov. 9), 2-hour (6-8pm) in class Closed-book exam,
CS6220: DATA MINING TECHNIQUES Set Data: Frequent Pattern Mining Instructor: Yizhou Sun yzsun@ccs.neu.edu November 1, 2015 Midterm Reminder Next Monday (Nov. 9), 2-hour (6-8pm) in class Closed-book exam,
What Is Data Mining? CMPT 354: Database I -- Data Mining 2
 Data Mining What Is Data Mining? Mining data mining knowledge Data mining is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data CMPT
Data Mining What Is Data Mining? Mining data mining knowledge Data mining is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data CMPT
Roadmap. PCY Algorithm
 1 Roadmap Frequent Patterns A-Priori Algorithm Improvements to A-Priori Park-Chen-Yu Algorithm Multistage Algorithm Approximate Algorithms Compacting Results Data Mining for Knowledge Management 50 PCY
1 Roadmap Frequent Patterns A-Priori Algorithm Improvements to A-Priori Park-Chen-Yu Algorithm Multistage Algorithm Approximate Algorithms Compacting Results Data Mining for Knowledge Management 50 PCY
Association Rules. Juliana Freire. Modified from Jeff Ullman, Jure Lescovek, Bing Liu, Jiawei Han
 Association Rules Juliana Freire Modified from Jeff Ullman, Jure Lescovek, Bing Liu, Jiawei Han Association Rules: Some History Bar code technology allowed retailers to collect massive volumes of sales
Association Rules Juliana Freire Modified from Jeff Ullman, Jure Lescovek, Bing Liu, Jiawei Han Association Rules: Some History Bar code technology allowed retailers to collect massive volumes of sales
DATA MINING II - 1DL460
 DATA MINING II - 1DL460 Spring 2013 " An second class in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt13 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
DATA MINING II - 1DL460 Spring 2013 " An second class in data mining http://www.it.uu.se/edu/course/homepage/infoutv2/vt13 Kjell Orsborn Uppsala Database Laboratory Department of Information Technology,
Which Null-Invariant Measure Is Better? Which Null-Invariant Measure Is Better?
 Which Null-Invariant Measure Is Better? D 1 is m,c positively correlated, many null transactions D 2 is m,c positively correlated, little null transactions D 3 is m,c negatively correlated, many null transactions
Which Null-Invariant Measure Is Better? D 1 is m,c positively correlated, many null transactions D 2 is m,c positively correlated, little null transactions D 3 is m,c negatively correlated, many null transactions
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 7
 Chapter 7") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 7 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2017 Han and Kamber & Pei.
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 7 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2017 Han and Kamber & Pei.
Data Structures. Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali Association Rules: Basic Concepts and Application
 Data Structures Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali 2009-2010 Association Rules: Basic Concepts and Application 1. Association rules: Given a set of transactions, find
Data Structures Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali 2009-2010 Association Rules: Basic Concepts and Application 1. Association rules: Given a set of transactions, find
Pattern Mining. Knowledge Discovery and Data Mining 1. Roman Kern KTI, TU Graz. Roman Kern (KTI, TU Graz) Pattern Mining / 42
 Pattern Mining / 42") Pattern Mining Knowledge Discovery and Data Mining 1 Roman Kern KTI, TU Graz 2016-01-14 Roman Kern (KTI, TU Graz) Pattern Mining 2016-01-14 1 / 42 Outline 1 Introduction 2 Apriori Algorithm 3 FP-Growth
Pattern Mining Knowledge Discovery and Data Mining 1 Roman Kern KTI, TU Graz 2016-01-14 Roman Kern (KTI, TU Graz) Pattern Mining 2016-01-14 1 / 42 Outline 1 Introduction 2 Apriori Algorithm 3 FP-Growth
Information Management course
 Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 18: 01/12/2015 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 18: 01/12/2015 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Decision Support Systems
 Decision Support Systems 2011/2012 Week 6. Lecture 11 HELLO DATA MINING! THE PLAN: MINING FREQUENT PATTERNS (Classes 11-13) Homework 5 CLUSTER ANALYSIS (Classes 14-16) Homework 6 SUPERVISED LEARNING (Classes
Decision Support Systems 2011/2012 Week 6. Lecture 11 HELLO DATA MINING! THE PLAN: MINING FREQUENT PATTERNS (Classes 11-13) Homework 5 CLUSTER ANALYSIS (Classes 14-16) Homework 6 SUPERVISED LEARNING (Classes
Roadmap DB Sys. Design & Impl. Association rules - outline. Citations. Association rules - idea. Association rules - idea.
 15-721 DB Sys. Design & Impl. Association Rules Christos Faloutsos www.cs.cmu.edu/~christos Roadmap 1) Roots: System R and Ingres... 7) Data Analysis - data mining datacubes and OLAP classifiers association
15-721 DB Sys. Design & Impl. Association Rules Christos Faloutsos www.cs.cmu.edu/~christos Roadmap 1) Roots: System R and Ingres... 7) Data Analysis - data mining datacubes and OLAP classifiers association
Association Pattern Mining. Lijun Zhang
 Association Pattern Mining Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction The Frequent Pattern Mining Model Association Rule Generation Framework Frequent Itemset Mining Algorithms
Association Pattern Mining Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction The Frequent Pattern Mining Model Association Rule Generation Framework Frequent Itemset Mining Algorithms
Knowledge Discovery in Databases
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 3: Frequent Itemsets
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 3: Frequent Itemsets
Unsupervised learning: Data Mining. Associa6on rules and frequent itemsets mining
 Unsupervised learning: Data Mining Associa6on rules and frequent itemsets mining Data Mining concepts Is the computa6onal process of discovering pa
Unsupervised learning: Data Mining Associa6on rules and frequent itemsets mining Data Mining concepts Is the computa6onal process of discovering pa
Frequent Item Sets & Association Rules
 Frequent Item Sets & Association Rules V. CHRISTOPHIDES vassilis.christophides@inria.fr https://who.rocq.inria.fr/vassilis.christophides/big/ Ecole CentraleSupélec 1 Some History Bar code technology allowed
Frequent Item Sets & Association Rules V. CHRISTOPHIDES vassilis.christophides@inria.fr https://who.rocq.inria.fr/vassilis.christophides/big/ Ecole CentraleSupélec 1 Some History Bar code technology allowed
FP-Growth algorithm in Data Compression frequent patterns
 FP-Growth algorithm in Data Compression frequent patterns Mr. Nagesh V Lecturer, Dept. of CSE Atria Institute of Technology,AIKBS Hebbal, Bangalore,Karnataka Email : nagesh.v@gmail.com Abstract-The transmission
FP-Growth algorithm in Data Compression frequent patterns Mr. Nagesh V Lecturer, Dept. of CSE Atria Institute of Technology,AIKBS Hebbal, Bangalore,Karnataka Email : nagesh.v@gmail.com Abstract-The transmission
Jarek Szlichta Acknowledgments: Jiawei Han, Micheline Kamber and Jian Pei, Data Mining - Concepts and Techniques
 Jarek Szlichta http://data.science.uoit.ca/ Acknowledgments: Jiawei Han, Micheline Kamber and Jian Pei, Data Mining - Concepts and Techniques Frequent Itemset Mining Methods Apriori Which Patterns Are
Jarek Szlichta http://data.science.uoit.ca/ Acknowledgments: Jiawei Han, Micheline Kamber and Jian Pei, Data Mining - Concepts and Techniques Frequent Itemset Mining Methods Apriori Which Patterns Are
Data Mining Clustering
 Data Mining Clustering Jingpeng Li 1 of 34 Supervised Learning F(x): true function (usually not known) D: training sample (x, F(x)) 57,M,195,0,125,95,39,25,0,1,0,0,0,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,0,0 0
Data Mining Clustering Jingpeng Li 1 of 34 Supervised Learning F(x): true function (usually not known) D: training sample (x, F(x)) 57,M,195,0,125,95,39,25,0,1,0,0,0,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,0,0 0
Data Mining Techniques
 Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 16: Association Rules Jan-Willem van de Meent (credit: Yijun Zhao, Yi Wang, Tan et al., Leskovec et al.) Apriori: Summary All items Count
Data Mining Techniques CS 6220 - Section 3 - Fall 2016 Lecture 16: Association Rules Jan-Willem van de Meent (credit: Yijun Zhao, Yi Wang, Tan et al., Leskovec et al.) Apriori: Summary All items Count
Improved Frequent Pattern Mining Algorithm with Indexing
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 16, Issue 6, Ver. VII (Nov Dec. 2014), PP 73-78 Improved Frequent Pattern Mining Algorithm with Indexing Prof.
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 16, Issue 6, Ver. VII (Nov Dec. 2014), PP 73-78 Improved Frequent Pattern Mining Algorithm with Indexing Prof.
Information Management course
 Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 13: 27/11/2012 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 13: 27/11/2012 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Data Warehousing & Mining. Data integration. OLTP versus OLAP. CPS 116 Introduction to Database Systems
 Data Warehousing & Mining CPS 116 Introduction to Database Systems Data integration 2 Data resides in many distributed, heterogeneous OLTP (On-Line Transaction Processing) sources Sales, inventory, customer,
Data Warehousing & Mining CPS 116 Introduction to Database Systems Data integration 2 Data resides in many distributed, heterogeneous OLTP (On-Line Transaction Processing) sources Sales, inventory, customer,
Data Warehousing and Data Mining. Announcements (December 1) Data integration. CPS 116 Introduction to Database Systems
 Data integration. CPS 116 Introduction to Database Systems") Data Warehousing and Data Mining CPS 116 Introduction to Database Systems Announcements (December 1) 2 Homework #4 due today Sample solution available Thursday Course project demo period has begun! Check
Data Warehousing and Data Mining CPS 116 Introduction to Database Systems Announcements (December 1) 2 Homework #4 due today Sample solution available Thursday Course project demo period has begun! Check
CHAPTER 8. ITEMSET MINING 226
 CHAPTER 8. ITEMSET MINING 226 Chapter 8 Itemset Mining In many applications one is interested in how often two or more objectsofinterest co-occur. For example, consider a popular web site, which logs all
CHAPTER 8. ITEMSET MINING 226 Chapter 8 Itemset Mining In many applications one is interested in how often two or more objectsofinterest co-occur. For example, consider a popular web site, which logs all
Association Rule Mining
 Huiping Cao, FPGrowth, Slide 1/22 Association Rule Mining FPGrowth Huiping Cao Huiping Cao, FPGrowth, Slide 2/22 Issues with Apriori-like approaches Candidate set generation is costly, especially when
Huiping Cao, FPGrowth, Slide 1/22 Association Rule Mining FPGrowth Huiping Cao Huiping Cao, FPGrowth, Slide 2/22 Issues with Apriori-like approaches Candidate set generation is costly, especially when
AN IMPROVISED FREQUENT PATTERN TREE BASED ASSOCIATION RULE MINING TECHNIQUE WITH MINING FREQUENT ITEM SETS ALGORITHM AND A MODIFIED HEADER TABLE
 AN IMPROVISED FREQUENT PATTERN TREE BASED ASSOCIATION RULE MINING TECHNIQUE WITH MINING FREQUENT ITEM SETS ALGORITHM AND A MODIFIED HEADER TABLE Vandit Agarwal 1, Mandhani Kushal 2 and Preetham Kumar 3
AN IMPROVISED FREQUENT PATTERN TREE BASED ASSOCIATION RULE MINING TECHNIQUE WITH MINING FREQUENT ITEM SETS ALGORITHM AND A MODIFIED HEADER TABLE Vandit Agarwal 1, Mandhani Kushal 2 and Preetham Kumar 3
Association Rule Discovery
 Association Rule Discovery Association Rules describe frequent co-occurences in sets an itemset is a subset A of all possible items I Example Problems: Which products are frequently bought together by
Association Rule Discovery Association Rules describe frequent co-occurences in sets an itemset is a subset A of all possible items I Example Problems: Which products are frequently bought together by
Tutorial on Association Rule Mining
 Tutorial on Association Rule Mining Yang Yang yang.yang@itee.uq.edu.au DKE Group, 78-625 August 13, 2010 Outline 1 Quick Review 2 Apriori Algorithm 3 FP-Growth Algorithm 4 Mining Flickr and Tag Recommendation
Tutorial on Association Rule Mining Yang Yang yang.yang@itee.uq.edu.au DKE Group, 78-625 August 13, 2010 Outline 1 Quick Review 2 Apriori Algorithm 3 FP-Growth Algorithm 4 Mining Flickr and Tag Recommendation
Advance Association Analysis
 Advance Association Analysis 1 Minimum Support Threshold 3 Effect of Support Distribution Many real data sets have skewed support distribution Support distribution of a retail data set 4 Effect of Support
Advance Association Analysis 1 Minimum Support Threshold 3 Effect of Support Distribution Many real data sets have skewed support distribution Support distribution of a retail data set 4 Effect of Support
Association Rule Discovery
 Association Rule Discovery Association Rules describe frequent co-occurences in sets an item set is a subset A of all possible items I Example Problems: Which products are frequently bought together by
Association Rule Discovery Association Rules describe frequent co-occurences in sets an item set is a subset A of all possible items I Example Problems: Which products are frequently bought together by
Mining Frequent Patterns without Candidate Generation: A Frequent-Pattern Tree Approach
 Data Mining and Knowledge Discovery, 8, 53 87, 2004 c 2004 Kluwer Academic Publishers. Manufactured in The Netherlands. Mining Frequent Patterns without Candidate Generation: A Frequent-Pattern Tree Approach
Data Mining and Knowledge Discovery, 8, 53 87, 2004 c 2004 Kluwer Academic Publishers. Manufactured in The Netherlands. Mining Frequent Patterns without Candidate Generation: A Frequent-Pattern Tree Approach
An Evolutionary Algorithm for Mining Association Rules Using Boolean Approach
 An Evolutionary Algorithm for Mining Association Rules Using Boolean Approach ABSTRACT G.Ravi Kumar 1 Dr.G.A. Ramachandra 2 G.Sunitha 3 1. Research Scholar, Department of Computer Science &Technology,
An Evolutionary Algorithm for Mining Association Rules Using Boolean Approach ABSTRACT G.Ravi Kumar 1 Dr.G.A. Ramachandra 2 G.Sunitha 3 1. Research Scholar, Department of Computer Science &Technology,
Machine Learning: Symbolische Ansätze
 Machine Learning: Symbolische Ansätze Unsupervised Learning Clustering Association Rules V2.0 WS 10/11 J. Fürnkranz Different Learning Scenarios Supervised Learning A teacher provides the value for the
Machine Learning: Symbolische Ansätze Unsupervised Learning Clustering Association Rules V2.0 WS 10/11 J. Fürnkranz Different Learning Scenarios Supervised Learning A teacher provides the value for the
CMPUT 391 Database Management Systems. Data Mining. Textbook: Chapter (without 17.10)
") CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
Data Mining: Concepts and Techniques. Chapter 5 Mining Frequent Patterns. Slide credits: Jiawei Han and Micheline Kamber George Kollios
 Data Mining: Concepts and Techniques Chapter 5 Mining Frequent Patterns Slide credits: Jiawei Han and Micheline Kamber George Kollios February 7, 2008 Data Mining: Concepts and Techniques 1 Chapter 5:
Data Mining: Concepts and Techniques Chapter 5 Mining Frequent Patterns Slide credits: Jiawei Han and Micheline Kamber George Kollios February 7, 2008 Data Mining: Concepts and Techniques 1 Chapter 5:
Data Mining: Concepts and Techniques
 Data Mining: Concepts and Techniques Chapter 5 100 年 11 月 15 日星期二 Data Mining: Concepts and Techniques 1 Chapter 5: Mining Frequent Patterns, Association and Correlations Basic concepts and a road map
Data Mining: Concepts and Techniques Chapter 5 100 年 11 月 15 日星期二 Data Mining: Concepts and Techniques 1 Chapter 5: Mining Frequent Patterns, Association and Correlations Basic concepts and a road map
CS 6093 Lecture 7 Spring 2011 Basic Data Mining. Cong Yu 03/21/2011
 CS 6093 Lecture 7 Spring 2011 Basic Data Mining Cong Yu 03/21/2011 Announcements No regular office hour next Monday (March 28 th ) Office hour next week will be on Tuesday through Thursday by appointment
CS 6093 Lecture 7 Spring 2011 Basic Data Mining Cong Yu 03/21/2011 Announcements No regular office hour next Monday (March 28 th ) Office hour next week will be on Tuesday through Thursday by appointment
Data Mining: Concepts and Techniques. Chapter 5
 Data Mining: Concepts and Techniques Chapter 5 Jiawei Han Department of Computer Science University of Illinois at Urbana-Champaign www.cs.uiuc.edu/~hanj 2006 Jiawei Han and Micheline Kamber, All rights
Data Mining: Concepts and Techniques Chapter 5 Jiawei Han Department of Computer Science University of Illinois at Urbana-Champaign www.cs.uiuc.edu/~hanj 2006 Jiawei Han and Micheline Kamber, All rights
An Improved Apriori Algorithm for Association Rules
 Research article An Improved Apriori Algorithm for Association Rules Hassan M. Najadat 1, Mohammed Al-Maolegi 2, Bassam Arkok 3 Computer Science, Jordan University of Science and Technology, Irbid, Jordan
Research article An Improved Apriori Algorithm for Association Rules Hassan M. Najadat 1, Mohammed Al-Maolegi 2, Bassam Arkok 3 Computer Science, Jordan University of Science and Technology, Irbid, Jordan
Association Rule Mining. Introduction 46. Study core 46
 Learning Unit 7 Association Rule Mining Introduction 46 Study core 46 1 Association Rule Mining: Motivation and Main Concepts 46 2 Apriori Algorithm 47 3 FP-Growth Algorithm 47 4 Assignment Bundle: Frequent
Learning Unit 7 Association Rule Mining Introduction 46 Study core 46 1 Association Rule Mining: Motivation and Main Concepts 46 2 Apriori Algorithm 47 3 FP-Growth Algorithm 47 4 Assignment Bundle: Frequent
DESIGN AND CONSTRUCTION OF A FREQUENT-PATTERN TREE
 DESIGN AND CONSTRUCTION OF A FREQUENT-PATTERN TREE 1 P.SIVA 2 D.GEETHA 1 Research Scholar, Sree Saraswathi Thyagaraja College, Pollachi. 2 Head & Assistant Professor, Department of Computer Application,
DESIGN AND CONSTRUCTION OF A FREQUENT-PATTERN TREE 1 P.SIVA 2 D.GEETHA 1 Research Scholar, Sree Saraswathi Thyagaraja College, Pollachi. 2 Head & Assistant Professor, Department of Computer Application,
Data Mining: Concepts and Techniques. Why Data Mining? What Is Data Mining? Chapter 5
 Data Mining: Concepts and Techniques Chapter 5 Jiawei Han Department of Computer Science University of Illiis at Urbana-Champaign www.cs.uiuc.edu/~hanj 2006 Jiawei Han and Micheline Kamber, All rights
Data Mining: Concepts and Techniques Chapter 5 Jiawei Han Department of Computer Science University of Illiis at Urbana-Champaign www.cs.uiuc.edu/~hanj 2006 Jiawei Han and Micheline Kamber, All rights
Association Rules Apriori Algorithm
 Association Rules Apriori Algorithm Market basket analysis n Market basket analysis might tell a retailer that customers often purchase shampoo and conditioner n Putting both items on promotion at the
Association Rules Apriori Algorithm Market basket analysis n Market basket analysis might tell a retailer that customers often purchase shampoo and conditioner n Putting both items on promotion at the
Association Analysis: Basic Concepts and Algorithms
 5 Association Analysis: Basic Concepts and Algorithms Many business enterprises accumulate large quantities of data from their dayto-day operations. For example, huge amounts of customer purchase data
5 Association Analysis: Basic Concepts and Algorithms Many business enterprises accumulate large quantities of data from their dayto-day operations. For example, huge amounts of customer purchase data
Association mining rules
 Association mining rules Given a data set, find the items in data that are associated with each other. Association is measured as frequency of occurrence in the same context. Purchasing one product when
Association mining rules Given a data set, find the items in data that are associated with each other. Association is measured as frequency of occurrence in the same context. Purchasing one product when
Chapter 7: Frequent Itemsets and Association Rules
 Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2011/12 VII.1-1 Chapter VII: Frequent Itemsets and Association
Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2011/12 VII.1-1 Chapter VII: Frequent Itemsets and Association
Carnegie Mellon Univ. Dept. of Computer Science /615 DB Applications. Data mining - detailed outline. Problem
 Faloutsos & Pavlo 15415/615 Carnegie Mellon Univ. Dept. of Computer Science 15415/615 DB Applications Lecture # 24: Data Warehousing / Data Mining (R&G, ch 25 and 26) Data mining detailed outline Problem
Faloutsos & Pavlo 15415/615 Carnegie Mellon Univ. Dept. of Computer Science 15415/615 DB Applications Lecture # 24: Data Warehousing / Data Mining (R&G, ch 25 and 26) Data mining detailed outline Problem
CompSci 516 Data Intensive Computing Systems
 CompSci 516 Data Intensive Computing Systems Lecture 20 Data Mining and Mining Association Rules Instructor: Sudeepa Roy CompSci 516: Data Intensive Computing Systems 1 Reading Material Optional Reading:
CompSci 516 Data Intensive Computing Systems Lecture 20 Data Mining and Mining Association Rules Instructor: Sudeepa Roy CompSci 516: Data Intensive Computing Systems 1 Reading Material Optional Reading:
Data mining - detailed outline. Carnegie Mellon Univ. Dept. of Computer Science /615 DB Applications. Problem.
 Faloutsos & Pavlo 15415/615 Carnegie Mellon Univ. Dept. of Computer Science 15415/615 DB Applications Data Warehousing / Data Mining (R&G, ch 25 and 26) C. Faloutsos and A. Pavlo Data mining detailed outline
Faloutsos & Pavlo 15415/615 Carnegie Mellon Univ. Dept. of Computer Science 15415/615 DB Applications Data Warehousing / Data Mining (R&G, ch 25 and 26) C. Faloutsos and A. Pavlo Data mining detailed outline
Introduction to Data Mining
 Introduction to Data Mining 1 Large-scale data is everywhere! There has been enormous data growth in both commercial and scientific databases due to advances in data generation and collection technologies.
Introduction to Data Mining 1 Large-scale data is everywhere! There has been enormous data growth in both commercial and scientific databases due to advances in data generation and collection technologies.
Chapter 6: Mining Association Rules in Large Databases
 Chapter 6: Mining Association Rules in Large Databases Association rule mining Algorithms for scalable mining of (single-dimensional Boolean) association rules in transactional databases Mining various
Chapter 6: Mining Association Rules in Large Databases Association rule mining Algorithms for scalable mining of (single-dimensional Boolean) association rules in transactional databases Mining various
Mining Frequent Patterns with Counting Inference at Multiple Levels
 International Journal of Computer Applications (097 7) Volume 3 No.10, July 010 Mining Frequent Patterns with Counting Inference at Multiple Levels Mittar Vishav Deptt. Of IT M.M.University, Mullana Ruchika
International Journal of Computer Applications (097 7) Volume 3 No.10, July 010 Mining Frequent Patterns with Counting Inference at Multiple Levels Mittar Vishav Deptt. Of IT M.M.University, Mullana Ruchika