Nesnelerin İnternetinde Veri Analizi
|
|
|
- Marcus Greer
- 5 years ago
- Views:
Transcription
1 Bölüm 4. Frequent Patterns in Data Streams w3.gazi.edu.tr/~suatozdemir
2 What Is Pattern Discovery? What are patterns? Patterns: A set of items, subsequences, or substructures that occur frequently together (or strongly correlated) in a data set Patterns represent intrinsic and important properties of datasets Pattern discovery: Uncovering patterns from massive data sets Motivation examples: What products were often purchased together? What are the subsequent purchases after buying an ipad? What code segments likely contain copy-and-paste bugs? What word sequences likely form phrases in this corpus?
3 Pattern Discovery: Why Is It Important? Finding inherent regularities in a data set Foundation for many essential data mining tasks Association, correlation, and causality analysis Mining sequential, structural (e.g., sub-graph) patterns Pattern analysis in spatiotemporal, multimedia, time-series, and stream data Classification: Discriminative pattern-based analysis Cluster analysis: Pattern-based subspace clustering Broad applications Market basket analysis, cross-marketing, catalog design, sale campaign analysis, Web log analysis, biological sequence analysis
4 Basic Concepts: k-itemsets and Their Supports Itemset: A set of one or more items k-itemset: X = {x 1,, x k } Ex. {Beer, Nuts, Diaper} is a 3- itemset (absolute) support (count) of X, sup{x}: Frequency or the number of occurrences of an itemset X Ex. sup{beer} = 3 Ex. sup{diaper} = 4 Ex. sup{beer, Diaper} = 3 Ex. sup{beer, Eggs} = 1 Tid Items bought 10 Beer, Nuts, Diaper 20 Beer, Coffee, Diaper 30 Beer, Diaper, Eggs 40 Nuts, Eggs, Milk 50 Nuts, Coffee, Diaper, Eggs, Milk (relative) support, s{x}: The fraction of transactions that contains X (i.e., the probability that a transaction contains X) Ex. s{beer} = 3/5 = 60% Ex. s{diaper} = 4/5 = 80% Ex. s{beer, Eggs} = 1/5 = 20%
5 Basic Concepts: Frequent Itemsets (Patterns) An itemset (or a pattern) X is frequent if the support of X is no less than a minsup threshold σ Let σ = 50% (σ: minsup threshold) For the given 5-transaction dataset All the frequent 1-itemsets: Beer: 3/5 (60%); Nuts: 3/5 (60%) Diaper: 4/5 (80%); Eggs: 3/5 (60%) All the frequent 2-itemsets: {Beer, Diaper}: 3/5 (60%) All the frequent 3-itemsets? None Tid Items bought 10 Beer, Nuts, Diaper 20 Beer, Coffee, Diaper 30 Beer, Diaper, Eggs 40 Nuts, Eggs, Milk 50 Nuts, Coffee, Diaper, Eggs, Milk Why do these itemsets (shown on the left) form the complete set of frequent k-itemsets (patterns) for any k? Observation: We may need an efficient method to mine a complete set of frequent patterns
6 From Frequent Itemsets to Association Rules Comparing with itemsets, rules can be more telling Ex. Diaper Beer Buying diapers may likely lead to buying beers How strong is this rule? (support, confidence) Measuring association rules: X Y (s, c) Both X and Y are itemsets Support, s: The probability that a transaction contains X Y Ex. s{diaper, Beer} = 3/5 = 0.6 (i.e., 60%) Confidence, c: The conditional probability that a transaction containing X also contains Y Calculation: c = sup(x Y) / sup(x) Ex. c = sup{diaper, Beer}/sup{Diaper} = ¾ = 0.75 Tid Items bought 10 Beer, Nuts, Diaper 20 Beer, Coffee, Diaper 30 Beer, Diaper, Eggs 40 Nuts, Eggs, Milk 50 Nuts, Coffee, Diaper, Eggs, Milk Beer Containing both {Beer} {Diaper} Diaper Containing diaper Containing beer {Beer} {Diaper} = {Beer, Diaper} Note: X Y: the union of two itemsets The set contains both X and Y
7 Mining Frequent Itemsets and Association Rules Association rule mining Given two thresholds: minsup, minconf Find all of the rules, X Y (s, c) such that, s minsup and c minconf Let minsup = 50% Freq. 1-itemsets: Beer: 3, Nuts: 3, Diaper: 4, Eggs: 3 Freq. 2-itemsets: {Beer, Diaper}: 3 Let minconf = 50% Beer Diaper (60%, 100%) Diaper Beer (60%, 75%) (Q: Are these all rules?) Tid Items bought 10 Beer, Nuts, Diaper 20 Beer, Coffee, Diaper 30 Beer, Diaper, Eggs 40 Nuts, Eggs, Milk 50 Nuts, Coffee, Diaper, Eggs, Milk Observations: Mining association rules and mining frequent patterns are very close problems Scalable methods are needed for mining large datasets
8 Challenge: There Are Too Many Frequent Patterns! A long pattern contains a combinatorial number of sub-patterns How many frequent itemsets does the following TDB 1 contain? TDB 1: T 1 : {a 1,, a 50 }; T 2 : {a 1,, a 100 } Assuming (absolute) minsup = 1 Let s have a try 1-itemsets: {a 1 }: 2, {a 2 }: 2,, {a 50 }: 2, {a 51 }: 1,, {a 100 }: 1, 2-itemsets: {a 1, a 2 }: 2,, {a 1, a 50 }: 2, {a 1, a 51 }: 1,, {a 99, a 100 }: 1,,,, 99-itemsets: {a 1, a 2,, a 99 }: 1,, {a 2, a 3,, a 100 }: itemset: {a 1, a 2,, a 100 }: 1 The total number of frequent itemsets: A too huge set for any one to compute or store!
9 Example: Construct FP-tree from a Transaction DB TID Items in the Transaction Ordered, frequent itemlist 100 {f, a, c, d, g, i, m, p} f, c, a, m, p 200 {a, b, c, f, l, m, o} f, c, a, b, m 300 {b, f, h, j, o, w} f, b 400 {b, c, k, s, p} c, b, p 500 {a, f, c, e, l, p, m, n} f, c, a, m, p Let min_support = 3 1. Scan DB once, find single item frequent pattern: f:4, a:3, c:4, b:3, m:3, p:3 2. Sort frequent items in frequency descending order, f-list F-list = f-c-a-b-m-p 3. Scan DB again, construct FP-tree The frequent itemlist of each transaction is inserted as a branch, with shared subbranches merged, counts accumulated Header Table Item Frequency heade r f 4 c 4 a 3 b 3 m 3 p 3 After inserting the 1 st frequent Itemlist: f, c, a, m, p {} f:1 c:1 a:1 m:1 p:1
10 Example: Construct FP-tree from a Transaction DB TID Items in the Transaction Ordered, frequent itemlist 100 {f, a, c, d, g, i, m, p} f, c, a, m, p 200 {a, b, c, f, l, m, o} f, c, a, b, m 300 {b, f, h, j, o, w} f, b 400 {b, c, k, s, p} c, b, p 500 {a, f, c, e, l, p, m, n} f, c, a, m, p Let min_support = 3 1. Scan DB once, find single item frequent pattern: f:4, a:3, c:4, b:3, m:3, p:3 2. Sort frequent items in frequency descending order, f-list F-list = f-c-a-b-m-p 3. Scan DB again, construct FP-tree The frequent itemlist of each transaction is inserted as a branch, with shared subbranches merged, counts accumulated Header Table Item Frequency heade r f 4 c 4 a 3 b 3 m 3 p 3 After inserting the 2 nd frequent itemlist f, c, a, b, m m:1 { } f:2 c:2 a:2 b:1 p:1 m:1
11 Example: Construct FP-tree from a Transaction DB TID Items in the Transaction Ordered, frequent itemlist 100 {f, a, c, d, g, i, m, p} f, c, a, m, p 200 {a, b, c, f, l, m, o} f, c, a, b, m 300 {b, f, h, j, o, w} f, b 400 {b, c, k, s, p} c, b, p 500 {a, f, c, e, l, p, m, n} f, c, a, m, p Let min_support = 3 1. Scan DB once, find single item frequent pattern: f:4, a:3, c:4, b:3, m:3, p:3 2. Sort frequent items in frequency descending order, f-list F-list = f-c-a-b-m-p 3. Scan DB again, construct FP-tree The frequent itemlist of each transaction is inserted as a branch, with shared subbranches merged, counts accumulated Header Table Item Frequency heade r f 4 c 4 a 3 b 3 m 3 p 3 m:2 After inserting all the frequent itemlists {} c:3 a:3 f:4 c:1 b:1 p:2 m:1 b:1 b:1 p:1
12 Mining FP-Tree: Divide and Conquer Based on Patterns and Data Pattern mining can be partitioned according to current patterns Patterns containing p: p s conditional database: fcam:2, cb:1 p s conditional database (i.e., the database under the condition that p exists): transformed prefix paths of item p Patterns having m but no p: m s conditional database: fca:2, fcab:1 min_support = 3 Item Frequency Header f 4 c 4 a 3 b 3 m 3 p 3 m:2 c:3 a:3 {} f:4 c:1 b:1 p:2 m:1 b:1 b:1 p:1 Item c f:3 a Conditional database fc:3 b fca:1, f:1, c:1 m p Conditional database of each pattern fca:2, fcab:1 fcam:2, cb:1
13 Mine Each Conditional Database Recursively item c f:3 a {} f:3 c:3 a:3 m s FP-tree cond. data base fc:3 b fca:1, f:1, c:1 m p min_support = 3 Conditional Data Bases fca:2, fcab:1 fcam:2, cb:1 {} f:3 c:3 am s FP-tree {} f:3 cm s FP-tree Then, mining m s FPtree: fca:3 For each conditional database {} f:3 cam s FP-tree Mine single-item patterns Construct its FP-tree & mine it p s conditional DB: fcam:2, cb:1 c: 3 m s conditional DB: fca:2, fcab:1 fca: 3 b s conditional DB: fca:1, f:1, c:1 ɸ Actually, for single branch FP-tree, all the frequent patterns can be generated in one shot m: 3 fm: 3, cm: 3, am: 3 fcm: 3, fam:3, cam: 3 fcam: 3
14 Mining Frequent Itemsets from Data Streams The most difficult problem in mining frequent itemsets from data streams is that infrequent itemsets in the past might become frequent, and frequent itemsets in the past might become infrequent. Three main approaches. Approaches that do not distinguish recent items from older ones (using landmark windows); Approaches that give more importance to recent transactions (using sliding windows or decay factors); Approaches for mining at different time granularities.
15 LossyCounting algorithm A onepass algorithm for computing frequency counts exceeding a user-specified threshold over data streams. Although the output is approximate, the error is guaranteed not to exceed a user-specified parameter. LossyCounting accepts two user-specified parameters: a support threshold s [0,1] and an error parameter ε [0,1] such that ε s. At any point of time, the LossyCounting algorithm can produce a list of item(set)s along with their estimated frequencies.

16 LossyCounting algorithm Let N denote the current length of the stream. The answers produced will have the following guarantees:
17 LossyCounting algorithm

18 LossyCounting algorithm Divide the stream into windows
19 LossyCounting algorithm
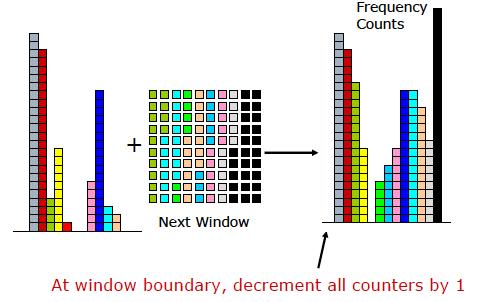
20 LossyCounting algorithm
21 Frequent Itemsets using LossyCounting Depending on the application, the LossyCounting algorithm might treat a tuple as a single item or as a set of items. In the latter case (set of items), the input stream is not processed transaction by transaction. Instead, the available main memory is filled in with as many transactions as possible. After that, they process such a batch of transactions together.

22 Frequent Itemsets using LossyCounting Let β denote the number of buckets in memory.
23 Mining Recent Frequent Itemsets Chang and Lee (2005) propose the estwin algorithm to maintain frequent itemsets over a sliding window. The itemsets generated by estwin are maintained in a prefix tree structure, D. An itemset, X, in D has the following three fields: freq (X), err (X) and tid (X), freq (X) is the frequency of X in the current window since X was inserted into D err (X) is an upper bound for the frequency of X in the current window before X was inserted into D, tid (X) is the ID of the transaction being processed, when X was inserted into D.
24 Mining Recent Frequent Itemsets For each incoming transaction Y with ID = tid t, estwin increments the computed frequency of each subset of Y in D. Let N be the number of transactions in the window and tid 1 be the ID of the first transaction in the current window. We prune an itemset X and all X 's supersets if: Old and not frequent in all stream New but not frequent in the current window
25 The FP-Stream Algorithm For stream mining at different time granularities The FP-Stream Algorithm was designed to maintain frequent patterns under a tilted-time window framework in order to answer time-sensitive queries The frequent patterns are compressed and stored using a tree structure similar to FP-tree and updated incrementally with incoming transactions.
26 The FP-Stream Algorithm Three categories of patterns: Frequent patterns Subfrequent patterns Infrequent patterns The frequency of an itemset I over a period of time T is the number of transactions in T in which I occurs. The support of I is the frequency divided by the total number of transactions observed in T.
27 The FP-Stream Algorithm The FP-stream structure consists of two parts. A global FP-tree held in main memory, and tilted-time windows embedded in this pattern-tree. Incremental updates can be performed on both parts of the FP-stream. Incremental updates occur when some infrequent patterns become (sub)frequent, or vice versa. At any moment, the set of frequent patterns over a period can be obtained from FP-stream.
28 Tilted-time window The design of the tilted-time window is based on the fact that people are often interested in recent changes at a fine granularity, but long term changes at a coarse granularity the most recent 4 quarters of an hour, then the last 24 hours, and 31 days. This model registers only = 59 units of time, with an acceptable trade-off of lower granularity at distant times. For each tilted-time window, a collection of patterns and their frequencies can be maintained.
29 The FP-Stream Algorithm A compact tree representation of the pattern collections, called pattern-tree, can be used. Each node in the pattern tree represents a pattern (from root to this node) and its frequency is recorded in the node. This tree shares a similar structure with an FP-tree The difference is that it stores patterns instead of transactions.
30 The FP-Stream Algorithm The patterns in adjacent time windows will likely be very similar. the tree structure for different tilted-time windows will likely have considerable overlap. Embedding the tilted-time window structure into each node, will likely save considerable space. use only one pattern tree, where at each node, the frequency for each tilted-time window is maintained. FP-Stream
31 The FP-Stream Algorithm Tail Pruning Let t 1 ;.; t n be the tilted-time windows which group the batches seen so far. Denote the number of transactions in t i by w i. The goal is to mine all frequent itemsets with support larger than σ over period T = t k t k+1 t k where 1 k k n The size of T, denoted by W, is the sum of the sizes of all time-windows considered in T. It is not possible to store all possible itemsets in all periods. FP-stream drops the tail sequences when
32 Possible Reading Mining frequent itemsets in a stream Mining frequent itemsets over distributed data streams by continuously maintaining a global synopsis Mining Frequent Itemsets Over Tuple-evolving Data Streams
Chapter 4: Mining Frequent Patterns, Associations and Correlations
 Chapter 4: Mining Frequent Patterns, Associations and Correlations 4.1 Basic Concepts 4.2 Frequent Itemset Mining Methods 4.3 Which Patterns Are Interesting? Pattern Evaluation Methods 4.4 Summary Frequent
Chapter 4: Mining Frequent Patterns, Associations and Correlations 4.1 Basic Concepts 4.2 Frequent Itemset Mining Methods 4.3 Which Patterns Are Interesting? Pattern Evaluation Methods 4.4 Summary Frequent
Chapter 6: Basic Concepts: Association Rules. Basic Concepts: Frequent Patterns. (absolute) support, or, support. (relative) support, s, is the
 support, or, support. (relative) support, s, is the") Chapter 6: What Is Frequent ent Pattern Analysis? Frequent pattern: a pattern (a set of items, subsequences, substructures, etc) that occurs frequently in a data set frequent itemsets and association rule
Chapter 6: What Is Frequent ent Pattern Analysis? Frequent pattern: a pattern (a set of items, subsequences, substructures, etc) that occurs frequently in a data set frequent itemsets and association rule
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University 10/19/2017 Slides adapted from Prof. Jiawei Han @UIUC, Prof.
CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University 10/19/2017 Slides adapted from Prof. Jiawei Han @UIUC, Prof.
Association Rule Mining
 Association Rule Mining Generating assoc. rules from frequent itemsets Assume that we have discovered the frequent itemsets and their support How do we generate association rules? Frequent itemsets: {1}
Association Rule Mining Generating assoc. rules from frequent itemsets Assume that we have discovered the frequent itemsets and their support How do we generate association rules? Frequent itemsets: {1}
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R,
 Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R, statistics foundations 5 Introduction to D3, visual analytics
Lecture Topic Projects 1 Intro, schedule, and logistics 2 Data Science components and tasks 3 Data types Project #1 out 4 Introduction to R, statistics foundations 5 Introduction to D3, visual analytics
Association Rule Mining. Entscheidungsunterstützungssysteme
 Association Rule Mining Entscheidungsunterstützungssysteme Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set
Association Rule Mining Entscheidungsunterstützungssysteme Frequent Pattern Analysis Frequent pattern: a pattern (a set of items, subsequences, substructures, etc.) that occurs frequently in a data set
Association rules. Marco Saerens (UCL), with Christine Decaestecker (ULB)
, with Christine Decaestecker (ULB)") Association rules Marco Saerens (UCL), with Christine Decaestecker (ULB) 1 Slides references Many slides and figures have been adapted from the slides associated to the following books: Alpaydin (2004),
Association rules Marco Saerens (UCL), with Christine Decaestecker (ULB) 1 Slides references Many slides and figures have been adapted from the slides associated to the following books: Alpaydin (2004),
Data Mining for Knowledge Management. Association Rules
 1 Data Mining for Knowledge Management Association Rules Themis Palpanas University of Trento http://disi.unitn.eu/~themis 1 Thanks for slides to: Jiawei Han George Kollios Zhenyu Lu Osmar R. Zaïane Mohammad
1 Data Mining for Knowledge Management Association Rules Themis Palpanas University of Trento http://disi.unitn.eu/~themis 1 Thanks for slides to: Jiawei Han George Kollios Zhenyu Lu Osmar R. Zaïane Mohammad
Mining Frequent Patterns without Candidate Generation
 Mining Frequent Patterns without Candidate Generation Outline of the Presentation Outline Frequent Pattern Mining: Problem statement and an example Review of Apriori like Approaches FP Growth: Overview
Mining Frequent Patterns without Candidate Generation Outline of the Presentation Outline Frequent Pattern Mining: Problem statement and an example Review of Apriori like Approaches FP Growth: Overview
Association Rule Mining
 Huiping Cao, FPGrowth, Slide 1/22 Association Rule Mining FPGrowth Huiping Cao Huiping Cao, FPGrowth, Slide 2/22 Issues with Apriori-like approaches Candidate set generation is costly, especially when
Huiping Cao, FPGrowth, Slide 1/22 Association Rule Mining FPGrowth Huiping Cao Huiping Cao, FPGrowth, Slide 2/22 Issues with Apriori-like approaches Candidate set generation is costly, especially when
Association Rules. A. Bellaachia Page: 1
 Association Rules 1. Objectives... 2 2. Definitions... 2 3. Type of Association Rules... 7 4. Frequent Itemset generation... 9 5. Apriori Algorithm: Mining Single-Dimension Boolean AR 13 5.1. Join Step:...
Association Rules 1. Objectives... 2 2. Definitions... 2 3. Type of Association Rules... 7 4. Frequent Itemset generation... 9 5. Apriori Algorithm: Mining Single-Dimension Boolean AR 13 5.1. Join Step:...
Fundamental Data Mining Algorithms
 2018 EE448, Big Data Mining, Lecture 3 Fundamental Data Mining Algorithms Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html REVIEW What is Data
2018 EE448, Big Data Mining, Lecture 3 Fundamental Data Mining Algorithms Weinan Zhang Shanghai Jiao Tong University http://wnzhang.net http://wnzhang.net/teaching/ee448/index.html REVIEW What is Data
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
CSE 5243 INTRO. TO DATA MINING
 CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
CSE 5243 INTRO. TO DATA MINING Mining Frequent Patterns and Associations: Basic Concepts (Chapter 6) Huan Sun, CSE@The Ohio State University Slides adapted from Prof. Jiawei Han @UIUC, Prof. Srinivasan
Decision Support Systems
 Decision Support Systems 2011/2012 Week 6. Lecture 11 HELLO DATA MINING! THE PLAN: MINING FREQUENT PATTERNS (Classes 11-13) Homework 5 CLUSTER ANALYSIS (Classes 14-16) Homework 6 SUPERVISED LEARNING (Classes
Decision Support Systems 2011/2012 Week 6. Lecture 11 HELLO DATA MINING! THE PLAN: MINING FREQUENT PATTERNS (Classes 11-13) Homework 5 CLUSTER ANALYSIS (Classes 14-16) Homework 6 SUPERVISED LEARNING (Classes
Frequent Pattern Mining
 Frequent Pattern Mining How Many Words Is a Picture Worth? E. Aiden and J-B Michel: Uncharted. Reverhead Books, 2013 Jian Pei: CMPT 741/459 Frequent Pattern Mining (1) 2 Burnt or Burned? E. Aiden and J-B
Frequent Pattern Mining How Many Words Is a Picture Worth? E. Aiden and J-B Michel: Uncharted. Reverhead Books, 2013 Jian Pei: CMPT 741/459 Frequent Pattern Mining (1) 2 Burnt or Burned? E. Aiden and J-B
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 6
 Chapter 6") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2017 Han, Kamber & Pei. All
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2017 Han, Kamber & Pei. All
BCB 713 Module Spring 2011
 Association Rule Mining COMP 790-90 Seminar BCB 713 Module Spring 2011 The UNIVERSITY of NORTH CAROLINA at CHAPEL HILL Outline What is association rule mining? Methods for association rule mining Extensions
Association Rule Mining COMP 790-90 Seminar BCB 713 Module Spring 2011 The UNIVERSITY of NORTH CAROLINA at CHAPEL HILL Outline What is association rule mining? Methods for association rule mining Extensions
Frequent Pattern Mining
 Frequent Pattern Mining...3 Frequent Pattern Mining Frequent Patterns The Apriori Algorithm The FP-growth Algorithm Sequential Pattern Mining Summary 44 / 193 Netflix Prize Frequent Pattern Mining Frequent
Frequent Pattern Mining...3 Frequent Pattern Mining Frequent Patterns The Apriori Algorithm The FP-growth Algorithm Sequential Pattern Mining Summary 44 / 193 Netflix Prize Frequent Pattern Mining Frequent
CS570 Introduction to Data Mining
 CS570 Introduction to Data Mining Frequent Pattern Mining and Association Analysis Cengiz Gunay Partial slide credits: Li Xiong, Jiawei Han and Micheline Kamber George Kollios 1 Mining Frequent Patterns,
CS570 Introduction to Data Mining Frequent Pattern Mining and Association Analysis Cengiz Gunay Partial slide credits: Li Xiong, Jiawei Han and Micheline Kamber George Kollios 1 Mining Frequent Patterns,
Apriori Algorithm. 1 Bread, Milk 2 Bread, Diaper, Beer, Eggs 3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer 5 Bread, Milk, Diaper, Coke
 Apriori Algorithm For a given set of transactions, the main aim of Association Rule Mining is to find rules that will predict the occurrence of an item based on the occurrences of the other items in the
Apriori Algorithm For a given set of transactions, the main aim of Association Rule Mining is to find rules that will predict the occurrence of an item based on the occurrences of the other items in the
Data Mining Part 3. Associations Rules
 Data Mining Part 3. Associations Rules 3.2 Efficient Frequent Itemset Mining Methods Fall 2009 Instructor: Dr. Masoud Yaghini Outline Apriori Algorithm Generating Association Rules from Frequent Itemsets
Data Mining Part 3. Associations Rules 3.2 Efficient Frequent Itemset Mining Methods Fall 2009 Instructor: Dr. Masoud Yaghini Outline Apriori Algorithm Generating Association Rules from Frequent Itemsets
What Is Data Mining? CMPT 354: Database I -- Data Mining 2
 Data Mining What Is Data Mining? Mining data mining knowledge Data mining is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data CMPT
Data Mining What Is Data Mining? Mining data mining knowledge Data mining is the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data CMPT
Data Mining: Concepts and Techniques. Chapter 5. SS Chung. April 5, 2013 Data Mining: Concepts and Techniques 1
 Data Mining: Concepts and Techniques Chapter 5 SS Chung April 5, 2013 Data Mining: Concepts and Techniques 1 Chapter 5: Mining Frequent Patterns, Association and Correlations Basic concepts and a road
Data Mining: Concepts and Techniques Chapter 5 SS Chung April 5, 2013 Data Mining: Concepts and Techniques 1 Chapter 5: Mining Frequent Patterns, Association and Correlations Basic concepts and a road
DESIGN AND CONSTRUCTION OF A FREQUENT-PATTERN TREE
 DESIGN AND CONSTRUCTION OF A FREQUENT-PATTERN TREE 1 P.SIVA 2 D.GEETHA 1 Research Scholar, Sree Saraswathi Thyagaraja College, Pollachi. 2 Head & Assistant Professor, Department of Computer Application,
DESIGN AND CONSTRUCTION OF A FREQUENT-PATTERN TREE 1 P.SIVA 2 D.GEETHA 1 Research Scholar, Sree Saraswathi Thyagaraja College, Pollachi. 2 Head & Assistant Professor, Department of Computer Application,
Frequent Pattern Mining. Based on: Introduction to Data Mining by Tan, Steinbach, Kumar
 Frequent Pattern Mining Based on: Introduction to Data Mining by Tan, Steinbach, Kumar Item sets A New Type of Data Some notation: All possible items: Database: T is a bag of transactions Transaction transaction
Frequent Pattern Mining Based on: Introduction to Data Mining by Tan, Steinbach, Kumar Item sets A New Type of Data Some notation: All possible items: Database: T is a bag of transactions Transaction transaction
Basic Concepts: Association Rules. What Is Frequent Pattern Analysis? COMP 465: Data Mining Mining Frequent Patterns, Associations and Correlations
 What Is Frequent Pattern Analysis? COMP 465: Data Mining Mining Frequent Patterns, Associations and Correlations Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and
What Is Frequent Pattern Analysis? COMP 465: Data Mining Mining Frequent Patterns, Associations and Correlations Slides Adapted From : Jiawei Han, Micheline Kamber & Jian Pei Data Mining: Concepts and
Chapter 4: Association analysis:
 Chapter 4: Association analysis: 4.1 Introduction: Many business enterprises accumulate large quantities of data from their day-to-day operations, huge amounts of customer purchase data are collected daily
Chapter 4: Association analysis: 4.1 Introduction: Many business enterprises accumulate large quantities of data from their day-to-day operations, huge amounts of customer purchase data are collected daily
Frequent Pattern Mining S L I D E S B Y : S H R E E J A S W A L
 Frequent Pattern Mining S L I D E S B Y : S H R E E J A S W A L Topics to be covered Market Basket Analysis, Frequent Itemsets, Closed Itemsets, and Association Rules; Frequent Pattern Mining, Efficient
Frequent Pattern Mining S L I D E S B Y : S H R E E J A S W A L Topics to be covered Market Basket Analysis, Frequent Itemsets, Closed Itemsets, and Association Rules; Frequent Pattern Mining, Efficient
2 CONTENTS
 Contents 5 Mining Frequent Patterns, Associations, and Correlations 3 5.1 Basic Concepts and a Road Map..................................... 3 5.1.1 Market Basket Analysis: A Motivating Example........................
Contents 5 Mining Frequent Patterns, Associations, and Correlations 3 5.1 Basic Concepts and a Road Map..................................... 3 5.1.1 Market Basket Analysis: A Motivating Example........................
Association Rule Mining (ARM) Komate AMPHAWAN
 Komate AMPHAWAN") Association Rule Mining (ARM) Komate AMPHAWAN 1 J-O-K-E???? 2 What can be inferred? I purchase diapers I purchase a new car I purchase OTC cough (ไอ) medicine I purchase a prescription medication (ใบส
Association Rule Mining (ARM) Komate AMPHAWAN 1 J-O-K-E???? 2 What can be inferred? I purchase diapers I purchase a new car I purchase OTC cough (ไอ) medicine I purchase a prescription medication (ใบส
Data Structures. Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali Association Rules: Basic Concepts and Application
 Data Structures Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali 2009-2010 Association Rules: Basic Concepts and Application 1. Association rules: Given a set of transactions, find
Data Structures Notes for Lecture 14 Techniques of Data Mining By Samaher Hussein Ali 2009-2010 Association Rules: Basic Concepts and Application 1. Association rules: Given a set of transactions, find
Pattern Mining. Knowledge Discovery and Data Mining 1. Roman Kern KTI, TU Graz. Roman Kern (KTI, TU Graz) Pattern Mining / 42
 Pattern Mining / 42") Pattern Mining Knowledge Discovery and Data Mining 1 Roman Kern KTI, TU Graz 2016-01-14 Roman Kern (KTI, TU Graz) Pattern Mining 2016-01-14 1 / 42 Outline 1 Introduction 2 Apriori Algorithm 3 FP-Growth
Pattern Mining Knowledge Discovery and Data Mining 1 Roman Kern KTI, TU Graz 2016-01-14 Roman Kern (KTI, TU Graz) Pattern Mining 2016-01-14 1 / 42 Outline 1 Introduction 2 Apriori Algorithm 3 FP-Growth
Association Rules. Berlin Chen References:
 Association Rules Berlin Chen 2005 References: 1. Data Mining: Concepts, Models, Methods and Algorithms, Chapter 8 2. Data Mining: Concepts and Techniques, Chapter 6 Association Rules: Basic Concepts A
Association Rules Berlin Chen 2005 References: 1. Data Mining: Concepts, Models, Methods and Algorithms, Chapter 8 2. Data Mining: Concepts and Techniques, Chapter 6 Association Rules: Basic Concepts A
Scalable Frequent Itemset Mining Methods
 Scalable Frequent Itemset Mining Methods The Downward Closure Property of Frequent Patterns The Apriori Algorithm Extensions or Improvements of Apriori Mining Frequent Patterns by Exploring Vertical Data
Scalable Frequent Itemset Mining Methods The Downward Closure Property of Frequent Patterns The Apriori Algorithm Extensions or Improvements of Apriori Mining Frequent Patterns by Exploring Vertical Data
Mining Frequent Patterns without Candidate Generation: A Frequent-Pattern Tree Approach
 Data Mining and Knowledge Discovery, 8, 53 87, 2004 c 2004 Kluwer Academic Publishers. Manufactured in The Netherlands. Mining Frequent Patterns without Candidate Generation: A Frequent-Pattern Tree Approach
Data Mining and Knowledge Discovery, 8, 53 87, 2004 c 2004 Kluwer Academic Publishers. Manufactured in The Netherlands. Mining Frequent Patterns without Candidate Generation: A Frequent-Pattern Tree Approach
Mining Association Rules in Large Databases
 Mining Association Rules in Large Databases Association rules Given a set of transactions D, find rules that will predict the occurrence of an item (or a set of items) based on the occurrences of other
Mining Association Rules in Large Databases Association rules Given a set of transactions D, find rules that will predict the occurrence of an item (or a set of items) based on the occurrences of other
FP-Growth algorithm in Data Compression frequent patterns
 FP-Growth algorithm in Data Compression frequent patterns Mr. Nagesh V Lecturer, Dept. of CSE Atria Institute of Technology,AIKBS Hebbal, Bangalore,Karnataka Email : nagesh.v@gmail.com Abstract-The transmission
FP-Growth algorithm in Data Compression frequent patterns Mr. Nagesh V Lecturer, Dept. of CSE Atria Institute of Technology,AIKBS Hebbal, Bangalore,Karnataka Email : nagesh.v@gmail.com Abstract-The transmission
Association mining rules
 Association mining rules Given a data set, find the items in data that are associated with each other. Association is measured as frequency of occurrence in the same context. Purchasing one product when
Association mining rules Given a data set, find the items in data that are associated with each other. Association is measured as frequency of occurrence in the same context. Purchasing one product when
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 6
 Chapter 6") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2016 Han, Kamber & Pei. All
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2013-2016 Han, Kamber & Pei. All
Mining Association Rules in Large Databases
 Mining Association Rules in Large Databases Vladimir Estivill-Castro School of Computing and Information Technology With contributions fromj. Han 1 Association Rule Mining A typical example is market basket
Mining Association Rules in Large Databases Vladimir Estivill-Castro School of Computing and Information Technology With contributions fromj. Han 1 Association Rule Mining A typical example is market basket
Market baskets Frequent itemsets FP growth. Data mining. Frequent itemset Association&decision rule mining. University of Szeged.
 Frequent itemset Association&decision rule mining University of Szeged What frequent itemsets could be used for? Features/observations frequently co-occurring in some database can gain us useful insights
Frequent itemset Association&decision rule mining University of Szeged What frequent itemsets could be used for? Features/observations frequently co-occurring in some database can gain us useful insights
This paper proposes: Mining Frequent Patterns without Candidate Generation
 Mining Frequent Patterns without Candidate Generation a paper by Jiawei Han, Jian Pei and Yiwen Yin School of Computing Science Simon Fraser University Presented by Maria Cutumisu Department of Computing
Mining Frequent Patterns without Candidate Generation a paper by Jiawei Han, Jian Pei and Yiwen Yin School of Computing Science Simon Fraser University Presented by Maria Cutumisu Department of Computing
Data Mining Clustering
 Data Mining Clustering Jingpeng Li 1 of 34 Supervised Learning F(x): true function (usually not known) D: training sample (x, F(x)) 57,M,195,0,125,95,39,25,0,1,0,0,0,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,0,0 0
Data Mining Clustering Jingpeng Li 1 of 34 Supervised Learning F(x): true function (usually not known) D: training sample (x, F(x)) 57,M,195,0,125,95,39,25,0,1,0,0,0,1,0,0,0,0,0,0,1,1,0,0,0,0,0,0,0,0 0
Chapter 7: Frequent Itemsets and Association Rules
 Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2013/14 VII.1&2 1 Motivational Example Assume you run an on-line
Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2013/14 VII.1&2 1 Motivational Example Assume you run an on-line
Tutorial on Association Rule Mining
 Tutorial on Association Rule Mining Yang Yang yang.yang@itee.uq.edu.au DKE Group, 78-625 August 13, 2010 Outline 1 Quick Review 2 Apriori Algorithm 3 FP-Growth Algorithm 4 Mining Flickr and Tag Recommendation
Tutorial on Association Rule Mining Yang Yang yang.yang@itee.uq.edu.au DKE Group, 78-625 August 13, 2010 Outline 1 Quick Review 2 Apriori Algorithm 3 FP-Growth Algorithm 4 Mining Flickr and Tag Recommendation
1. Interpret single-dimensional Boolean association rules from transactional databases
 1 STARTSTUDING.COM 1. Interpret single-dimensional Boolean association rules from transactional databases Association rule mining: Finding frequent patterns, associations, correlations, or causal structures
1 STARTSTUDING.COM 1. Interpret single-dimensional Boolean association rules from transactional databases Association rule mining: Finding frequent patterns, associations, correlations, or causal structures
Chapter 7: Frequent Itemsets and Association Rules
 Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2011/12 VII.1-1 Chapter VII: Frequent Itemsets and Association
Chapter 7: Frequent Itemsets and Association Rules Information Retrieval & Data Mining Universität des Saarlandes, Saarbrücken Winter Semester 2011/12 VII.1-1 Chapter VII: Frequent Itemsets and Association
2. Discovery of Association Rules
 2. Discovery of Association Rules Part I Motivation: market basket data Basic notions: association rule, frequency and confidence Problem of association rule mining (Sub)problem of frequent set mining
2. Discovery of Association Rules Part I Motivation: market basket data Basic notions: association rule, frequency and confidence Problem of association rule mining (Sub)problem of frequent set mining
Product presentations can be more intelligently planned
 Association Rules Lecture /DMBI/IKI8303T/MTI/UI Yudho Giri Sucahyo, Ph.D, CISA (yudho@cs.ui.ac.id) Faculty of Computer Science, Objectives Introduction What is Association Mining? Mining Association Rules
Association Rules Lecture /DMBI/IKI8303T/MTI/UI Yudho Giri Sucahyo, Ph.D, CISA (yudho@cs.ui.ac.id) Faculty of Computer Science, Objectives Introduction What is Association Mining? Mining Association Rules
ANU MLSS 2010: Data Mining. Part 2: Association rule mining
 ANU MLSS 2010: Data Mining Part 2: Association rule mining Lecture outline What is association mining? Market basket analysis and association rule examples Basic concepts and formalism Basic rule measurements
ANU MLSS 2010: Data Mining Part 2: Association rule mining Lecture outline What is association mining? Market basket analysis and association rule examples Basic concepts and formalism Basic rule measurements
CS145: INTRODUCTION TO DATA MINING
 CS145: INTRODUCTION TO DATA MINING Set Data: Frequent Pattern Mining Instructor: Yizhou Sun yzsun@cs.ucla.edu November 22, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification
CS145: INTRODUCTION TO DATA MINING Set Data: Frequent Pattern Mining Instructor: Yizhou Sun yzsun@cs.ucla.edu November 22, 2017 Methods to be Learnt Vector Data Set Data Sequence Data Text Data Classification
Information Management course
 Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 18: 01/12/2015 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 18: 01/12/2015 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Thanks to the advances of data processing technologies, a lot of data can be collected and stored in databases efficiently New challenges: with a
 Data Mining and Information Retrieval Introduction to Data Mining Why Data Mining? Thanks to the advances of data processing technologies, a lot of data can be collected and stored in databases efficiently
Data Mining and Information Retrieval Introduction to Data Mining Why Data Mining? Thanks to the advances of data processing technologies, a lot of data can be collected and stored in databases efficiently
Chapter 4 Data Mining A Short Introduction
 Chapter 4 Data Mining A Short Introduction Data Mining - 1 1 Today's Question 1. Data Mining Overview 2. Association Rule Mining 3. Clustering 4. Classification Data Mining - 2 2 1. Data Mining Overview
Chapter 4 Data Mining A Short Introduction Data Mining - 1 1 Today's Question 1. Data Mining Overview 2. Association Rule Mining 3. Clustering 4. Classification Data Mining - 2 2 1. Data Mining Overview
Chapter 6: Association Rules
 Chapter 6: Association Rules Association rule mining Proposed by Agrawal et al in 1993. It is an important data mining model. Transaction data (no time-dependent) Assume all data are categorical. No good
Chapter 6: Association Rules Association rule mining Proposed by Agrawal et al in 1993. It is an important data mining model. Transaction data (no time-dependent) Assume all data are categorical. No good
Association Rules Apriori Algorithm
 Association Rules Apriori Algorithm Market basket analysis n Market basket analysis might tell a retailer that customers often purchase shampoo and conditioner n Putting both items on promotion at the
Association Rules Apriori Algorithm Market basket analysis n Market basket analysis might tell a retailer that customers often purchase shampoo and conditioner n Putting both items on promotion at the
CMPUT 391 Database Management Systems. Data Mining. Textbook: Chapter (without 17.10)
") CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
CMPUT 391 Database Management Systems Data Mining Textbook: Chapter 17.7-17.11 (without 17.10) University of Alberta 1 Overview Motivation KDD and Data Mining Association Rules Clustering Classification
Association Pattern Mining. Lijun Zhang
 Association Pattern Mining Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction The Frequent Pattern Mining Model Association Rule Generation Framework Frequent Itemset Mining Algorithms
Association Pattern Mining Lijun Zhang zlj@nju.edu.cn http://cs.nju.edu.cn/zlj Outline Introduction The Frequent Pattern Mining Model Association Rule Generation Framework Frequent Itemset Mining Algorithms
CS6220: DATA MINING TECHNIQUES
 CS6220: DATA MINING TECHNIQUES Set Data: Frequent Pattern Mining Instructor: Yizhou Sun yzsun@ccs.neu.edu November 1, 2015 Midterm Reminder Next Monday (Nov. 9), 2-hour (6-8pm) in class Closed-book exam,
CS6220: DATA MINING TECHNIQUES Set Data: Frequent Pattern Mining Instructor: Yizhou Sun yzsun@ccs.neu.edu November 1, 2015 Midterm Reminder Next Monday (Nov. 9), 2-hour (6-8pm) in class Closed-book exam,
WIP: mining Weighted Interesting Patterns with a strong weight and/or support affinity
 WIP: mining Weighted Interesting Patterns with a strong weight and/or support affinity Unil Yun and John J. Leggett Department of Computer Science Texas A&M University College Station, Texas 7783, USA
WIP: mining Weighted Interesting Patterns with a strong weight and/or support affinity Unil Yun and John J. Leggett Department of Computer Science Texas A&M University College Station, Texas 7783, USA
Data warehouse and Data Mining
 Data warehouse and Data Mining Lecture No. 14 Data Mining and its techniques Naeem A. Mahoto Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
Data warehouse and Data Mining Lecture No. 14 Data Mining and its techniques Naeem A. Mahoto Email: naeemmahoto@gmail.com Department of Software Engineering Mehran Univeristy of Engineering and Technology
CS246: Mining Massive Datasets Jure Leskovec, Stanford University
 CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 1/8/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 Supermarket shelf
CS246: Mining Massive Datasets Jure Leskovec, Stanford University http://cs246.stanford.edu 1/8/2014 Jure Leskovec, Stanford CS246: Mining Massive Datasets, http://cs246.stanford.edu 2 Supermarket shelf
Knowledge Discovery in Databases
 Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 3: Frequent Itemsets
Ludwig-Maximilians-Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Lecture notes Knowledge Discovery in Databases Summer Semester 2012 Lecture 3: Frequent Itemsets
CLOSET+:Searching for the Best Strategies for Mining Frequent Closed Itemsets
 CLOSET+:Searching for the Best Strategies for Mining Frequent Closed Itemsets Jianyong Wang, Jiawei Han, Jian Pei Presentation by: Nasimeh Asgarian Department of Computing Science University of Alberta
CLOSET+:Searching for the Best Strategies for Mining Frequent Closed Itemsets Jianyong Wang, Jiawei Han, Jian Pei Presentation by: Nasimeh Asgarian Department of Computing Science University of Alberta
High dim. data. Graph data. Infinite data. Machine learning. Apps. Locality sensitive hashing. Filtering data streams.
 http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Network Analysis
http://www.mmds.org High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing PageRank, SimRank Filtering data streams SVM Recommen der systems Clustering Network Analysis
Effectiveness of Freq Pat Mining
 Effectiveness of Freq Pat Mining Too many patterns! A pattern a 1 a 2 a n contains 2 n -1 subpatterns Understanding many patterns is difficult or even impossible for human users Non-focused mining A manager
Effectiveness of Freq Pat Mining Too many patterns! A pattern a 1 a 2 a n contains 2 n -1 subpatterns Understanding many patterns is difficult or even impossible for human users Non-focused mining A manager
Association Rules Apriori Algorithm
 Association Rules Apriori Algorithm Market basket analysis n Market basket analysis might tell a retailer that customers often purchase shampoo and conditioner n Putting both items on promotion at the
Association Rules Apriori Algorithm Market basket analysis n Market basket analysis might tell a retailer that customers often purchase shampoo and conditioner n Putting both items on promotion at the
Improved Frequent Pattern Mining Algorithm with Indexing
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 16, Issue 6, Ver. VII (Nov Dec. 2014), PP 73-78 Improved Frequent Pattern Mining Algorithm with Indexing Prof.
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 16, Issue 6, Ver. VII (Nov Dec. 2014), PP 73-78 Improved Frequent Pattern Mining Algorithm with Indexing Prof.
An Introduction to WEKA Explorer. In part from: Yizhou Sun 2008
 An Introduction to WEKA Explorer In part from: Yizhou Sun 2008 What is WEKA? Waikato Environment for Knowledge Analysis It s a data mining/machine learning tool developed by Department of Computer Science,,
An Introduction to WEKA Explorer In part from: Yizhou Sun 2008 What is WEKA? Waikato Environment for Knowledge Analysis It s a data mining/machine learning tool developed by Department of Computer Science,,
Association Rule Mining: FP-Growth
 Yufei Tao Department of Computer Science and Engineering Chinese University of Hong Kong We have already learned the Apriori algorithm for association rule mining. In this lecture, we will discuss a faster
Yufei Tao Department of Computer Science and Engineering Chinese University of Hong Kong We have already learned the Apriori algorithm for association rule mining. In this lecture, we will discuss a faster
Interestingness Measurements
 Interestingness Measurements Objective measures Two popular measurements: support and confidence Subjective measures [Silberschatz & Tuzhilin, KDD95] A rule (pattern) is interesting if it is unexpected
Interestingness Measurements Objective measures Two popular measurements: support and confidence Subjective measures [Silberschatz & Tuzhilin, KDD95] A rule (pattern) is interesting if it is unexpected
Roadmap DB Sys. Design & Impl. Association rules - outline. Citations. Association rules - idea. Association rules - idea.
 15-721 DB Sys. Design & Impl. Association Rules Christos Faloutsos www.cs.cmu.edu/~christos Roadmap 1) Roots: System R and Ingres... 7) Data Analysis - data mining datacubes and OLAP classifiers association
15-721 DB Sys. Design & Impl. Association Rules Christos Faloutsos www.cs.cmu.edu/~christos Roadmap 1) Roots: System R and Ingres... 7) Data Analysis - data mining datacubes and OLAP classifiers association
CHAPTER 8. ITEMSET MINING 226
 CHAPTER 8. ITEMSET MINING 226 Chapter 8 Itemset Mining In many applications one is interested in how often two or more objectsofinterest co-occur. For example, consider a popular web site, which logs all
CHAPTER 8. ITEMSET MINING 226 Chapter 8 Itemset Mining In many applications one is interested in how often two or more objectsofinterest co-occur. For example, consider a popular web site, which logs all
D Data Mining: Concepts and and Tech Techniques
 Data Mining: Concepts and Techniques (3 rd ed.) Chapter 5 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2009 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 5 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2009 Han, Kamber & Pei. All rights
A Survey on Moving Towards Frequent Pattern Growth for Infrequent Weighted Itemset Mining
 A Survey on Moving Towards Frequent Pattern Growth for Infrequent Weighted Itemset Mining Miss. Rituja M. Zagade Computer Engineering Department,JSPM,NTC RSSOER,Savitribai Phule Pune University Pune,India
A Survey on Moving Towards Frequent Pattern Growth for Infrequent Weighted Itemset Mining Miss. Rituja M. Zagade Computer Engineering Department,JSPM,NTC RSSOER,Savitribai Phule Pune University Pune,India
Data Mining: Concepts and Techniques. (3 rd ed.) Chapter 6
 Chapter 6") Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2011 Han, Kamber & Pei. All rights
Data Mining: Concepts and Techniques (3 rd ed.) Chapter 6 Jiawei Han, Micheline Kamber, and Jian Pei University of Illinois at Urbana-Champaign & Simon Fraser University 2011 Han, Kamber & Pei. All rights
Mining Recent Frequent Itemsets in Data Streams with Optimistic Pruning
 Mining Recent Frequent Itemsets in Data Streams with Optimistic Pruning Kun Li 1,2, Yongyan Wang 1, Manzoor Elahi 1,2, Xin Li 3, and Hongan Wang 1 1 Institute of Software, Chinese Academy of Sciences,
Mining Recent Frequent Itemsets in Data Streams with Optimistic Pruning Kun Li 1,2, Yongyan Wang 1, Manzoor Elahi 1,2, Xin Li 3, and Hongan Wang 1 1 Institute of Software, Chinese Academy of Sciences,
Data Warehousing and Data Mining. Announcements (December 1) Data integration. CPS 116 Introduction to Database Systems
 Data integration. CPS 116 Introduction to Database Systems") Data Warehousing and Data Mining CPS 116 Introduction to Database Systems Announcements (December 1) 2 Homework #4 due today Sample solution available Thursday Course project demo period has begun! Check
Data Warehousing and Data Mining CPS 116 Introduction to Database Systems Announcements (December 1) 2 Homework #4 due today Sample solution available Thursday Course project demo period has begun! Check
INFREQUENT WEIGHTED ITEM SET MINING USING NODE SET BASED ALGORITHM
 INFREQUENT WEIGHTED ITEM SET MINING USING NODE SET BASED ALGORITHM G.Amlu #1 S.Chandralekha #2 and PraveenKumar *1 # B.Tech, Information Technology, Anand Institute of Higher Technology, Chennai, India
INFREQUENT WEIGHTED ITEM SET MINING USING NODE SET BASED ALGORITHM G.Amlu #1 S.Chandralekha #2 and PraveenKumar *1 # B.Tech, Information Technology, Anand Institute of Higher Technology, Chennai, India
Data Mining Algorithms
 Algorithms Fall 2017 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Looking for patterns in data Machine
Algorithms Fall 2017 Big Data Tools and Techniques Basic Data Manipulation and Analysis Performing well-defined computations or asking well-defined questions ( queries ) Looking for patterns in data Machine
Jarek Szlichta Acknowledgments: Jiawei Han, Micheline Kamber and Jian Pei, Data Mining - Concepts and Techniques
 Jarek Szlichta http://data.science.uoit.ca/ Acknowledgments: Jiawei Han, Micheline Kamber and Jian Pei, Data Mining - Concepts and Techniques Frequent Itemset Mining Methods Apriori Which Patterns Are
Jarek Szlichta http://data.science.uoit.ca/ Acknowledgments: Jiawei Han, Micheline Kamber and Jian Pei, Data Mining - Concepts and Techniques Frequent Itemset Mining Methods Apriori Which Patterns Are
An Improved Apriori Algorithm for Association Rules
 Research article An Improved Apriori Algorithm for Association Rules Hassan M. Najadat 1, Mohammed Al-Maolegi 2, Bassam Arkok 3 Computer Science, Jordan University of Science and Technology, Irbid, Jordan
Research article An Improved Apriori Algorithm for Association Rules Hassan M. Najadat 1, Mohammed Al-Maolegi 2, Bassam Arkok 3 Computer Science, Jordan University of Science and Technology, Irbid, Jordan
CompSci 516 Data Intensive Computing Systems
 CompSci 516 Data Intensive Computing Systems Lecture 20 Data Mining and Mining Association Rules Instructor: Sudeepa Roy CompSci 516: Data Intensive Computing Systems 1 Reading Material Optional Reading:
CompSci 516 Data Intensive Computing Systems Lecture 20 Data Mining and Mining Association Rules Instructor: Sudeepa Roy CompSci 516: Data Intensive Computing Systems 1 Reading Material Optional Reading:
Association Rule Mining. Introduction 46. Study core 46
 Learning Unit 7 Association Rule Mining Introduction 46 Study core 46 1 Association Rule Mining: Motivation and Main Concepts 46 2 Apriori Algorithm 47 3 FP-Growth Algorithm 47 4 Assignment Bundle: Frequent
Learning Unit 7 Association Rule Mining Introduction 46 Study core 46 1 Association Rule Mining: Motivation and Main Concepts 46 2 Apriori Algorithm 47 3 FP-Growth Algorithm 47 4 Assignment Bundle: Frequent
ALGORITHM FOR MINING TIME VARYING FREQUENT ITEMSETS
 ALGORITHM FOR MINING TIME VARYING FREQUENT ITEMSETS D.SUJATHA 1, PROF.B.L.DEEKSHATULU 2 1 HOD, Department of IT, Aurora s Technological and Research Institute, Hyderabad 2 Visiting Professor, Department
ALGORITHM FOR MINING TIME VARYING FREQUENT ITEMSETS D.SUJATHA 1, PROF.B.L.DEEKSHATULU 2 1 HOD, Department of IT, Aurora s Technological and Research Institute, Hyderabad 2 Visiting Professor, Department
signicantly higher than it would be if items were placed at random into baskets. For example, we
 2 Association Rules and Frequent Itemsets The market-basket problem assumes we have some large number of items, e.g., \bread," \milk." Customers ll their market baskets with some subset of the items, and
2 Association Rules and Frequent Itemsets The market-basket problem assumes we have some large number of items, e.g., \bread," \milk." Customers ll their market baskets with some subset of the items, and
Maintaining Frequent Itemsets over High-Speed Data Streams
 Maintaining Frequent Itemsets over High-Speed Data Streams James Cheng, Yiping Ke, and Wilfred Ng Department of Computer Science Hong Kong University of Science and Technology Clear Water Bay, Kowloon,
Maintaining Frequent Itemsets over High-Speed Data Streams James Cheng, Yiping Ke, and Wilfred Ng Department of Computer Science Hong Kong University of Science and Technology Clear Water Bay, Kowloon,
A BETTER APPROACH TO MINE FREQUENT ITEMSETS USING APRIORI AND FP-TREE APPROACH
 A BETTER APPROACH TO MINE FREQUENT ITEMSETS USING APRIORI AND FP-TREE APPROACH Thesis submitted in partial fulfillment of the requirements for the award of degree of Master of Engineering in Computer Science
A BETTER APPROACH TO MINE FREQUENT ITEMSETS USING APRIORI AND FP-TREE APPROACH Thesis submitted in partial fulfillment of the requirements for the award of degree of Master of Engineering in Computer Science
Performance Based Study of Association Rule Algorithms On Voter DB
 Performance Based Study of Association Rule Algorithms On Voter DB K.Padmavathi 1, R.Aruna Kirithika 2 1 Department of BCA, St.Joseph s College, Thiruvalluvar University, Cuddalore, Tamil Nadu, India,
Performance Based Study of Association Rule Algorithms On Voter DB K.Padmavathi 1, R.Aruna Kirithika 2 1 Department of BCA, St.Joseph s College, Thiruvalluvar University, Cuddalore, Tamil Nadu, India,
Unsupervised learning: Data Mining. Associa6on rules and frequent itemsets mining
 Unsupervised learning: Data Mining Associa6on rules and frequent itemsets mining Data Mining concepts Is the computa6onal process of discovering pa
Unsupervised learning: Data Mining Associa6on rules and frequent itemsets mining Data Mining concepts Is the computa6onal process of discovering pa
Mining Top-K Strongly Correlated Item Pairs Without Minimum Correlation Threshold
 Mining Top-K Strongly Correlated Item Pairs Without Minimum Correlation Threshold Zengyou He, Xiaofei Xu, Shengchun Deng Department of Computer Science and Engineering, Harbin Institute of Technology,
Mining Top-K Strongly Correlated Item Pairs Without Minimum Correlation Threshold Zengyou He, Xiaofei Xu, Shengchun Deng Department of Computer Science and Engineering, Harbin Institute of Technology,
Association Rules Outline
 Association Rules Outline Goal: Provide an overview of basic Association Rule mining techniques Association Rules Problem Overview Large/Frequent itemsets Association Rules Algorithms Apriori Sampling
Association Rules Outline Goal: Provide an overview of basic Association Rule mining techniques Association Rules Problem Overview Large/Frequent itemsets Association Rules Algorithms Apriori Sampling
Association Rule Discovery
 Association Rule Discovery Association Rules describe frequent co-occurences in sets an item set is a subset A of all possible items I Example Problems: Which products are frequently bought together by
Association Rule Discovery Association Rules describe frequent co-occurences in sets an item set is a subset A of all possible items I Example Problems: Which products are frequently bought together by
APPLICATION OF FP TREE GROWTH ALGORITHM IN TEXT MINING
 APPLICATION OF FP TREE GROWTH ALGORITHM IN TEXT MINING Project Report Submitted In Partial Fulfillment Of The Requirements for the Degree Of Master of Computer Application Of Jadavpur University By Jagdish
APPLICATION OF FP TREE GROWTH ALGORITHM IN TEXT MINING Project Report Submitted In Partial Fulfillment Of The Requirements for the Degree Of Master of Computer Application Of Jadavpur University By Jagdish
Machine Learning: Symbolische Ansätze
 Machine Learning: Symbolische Ansätze Unsupervised Learning Clustering Association Rules V2.0 WS 10/11 J. Fürnkranz Different Learning Scenarios Supervised Learning A teacher provides the value for the
Machine Learning: Symbolische Ansätze Unsupervised Learning Clustering Association Rules V2.0 WS 10/11 J. Fürnkranz Different Learning Scenarios Supervised Learning A teacher provides the value for the
Information Management course
 Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 13: 27/11/2012 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
Università degli Studi di Milano Master Degree in Computer Science Information Management course Teacher: Alberto Ceselli Lecture 13: 27/11/2012 Data Mining: Concepts and Techniques (3 rd ed.) Chapter
CHAPTER 3 ASSOCIATION RULE MINING WITH LEVELWISE AUTOMATIC SUPPORT THRESHOLDS
 23 CHAPTER 3 ASSOCIATION RULE MINING WITH LEVELWISE AUTOMATIC SUPPORT THRESHOLDS This chapter introduces the concepts of association rule mining. It also proposes two algorithms based on, to calculate
23 CHAPTER 3 ASSOCIATION RULE MINING WITH LEVELWISE AUTOMATIC SUPPORT THRESHOLDS This chapter introduces the concepts of association rule mining. It also proposes two algorithms based on, to calculate
Data Warehousing & Mining. Data integration. OLTP versus OLAP. CPS 116 Introduction to Database Systems
 Data Warehousing & Mining CPS 116 Introduction to Database Systems Data integration 2 Data resides in many distributed, heterogeneous OLTP (On-Line Transaction Processing) sources Sales, inventory, customer,
Data Warehousing & Mining CPS 116 Introduction to Database Systems Data integration 2 Data resides in many distributed, heterogeneous OLTP (On-Line Transaction Processing) sources Sales, inventory, customer,
Appropriate Item Partition for Improving the Mining Performance
 Appropriate Item Partition for Improving the Mining Performance Tzung-Pei Hong 1,2, Jheng-Nan Huang 1, Kawuu W. Lin 3 and Wen-Yang Lin 1 1 Department of Computer Science and Information Engineering National
Appropriate Item Partition for Improving the Mining Performance Tzung-Pei Hong 1,2, Jheng-Nan Huang 1, Kawuu W. Lin 3 and Wen-Yang Lin 1 1 Department of Computer Science and Information Engineering National