Enterprise Big Data Platforms
|
|
|
- Randolph Franklin
- 5 years ago
- Views:
Transcription
1 Enterprise Big Data Platforms + Big Data Roma Tre Antonio Maccioni maccioni@dia.uniroma3.it 19 April 2017
2 Outline Polystores QUEPA project Data Lakes KAYAK project

3 No one size fits all

4 Polyglot Persistence

5 Typical polyglot persistence scenario


6 Typical polyglot persistence scenario What if I need data spread over several sources?
7 Integration of different database systems Tightly-coupled architectures Multi-model: ArangoDB, OrientDB, BDMS: Apache AsterixDB Loosely-coupled integration (Polystores): Uniform interfaces query language: UnQL primitives: ODBC model: Apache Metamodel Federated databases data mediators: R*, Ingres*, Garlic islands of information: BigDAWG
8 Multi-model: ArangoDB + + KEY-VALUE DOCUMENT GRAPHS pid -> x34 name -> John surname -> Doe AQL { pid : x34 name : John, surname : Doe } pid : x34 name : John surname : Doe

9 BDMS: Apache AsterixDB
10 Polystores A polystore architecture is a loosely coupled integration of heterogeneous data sources that allows the direct access, with the local language, to each specific storage engine to exploit its distinctive features.

11 Apache Metamodel a uniform connector and query API to many very different datastore types
 [The BigDAWG Polystore System, Duggan et al.")
12 BigDAWG Island of informations: a collection of storage engines accessed with a single query language Support conjunct analytics cross-db joins based on copies between back ends (cast) [The BigDAWG Polystore System, Duggan et al., Sigmod Record 2015]
13 QUerying and Exploring a Polystore by Augmentation A user of a database wants to access the polystore but she doesn t know how to query other databases and, sometimes, does not even know their existence [QUerying and Exploring a Polystore by Augmentation, Maccioni, Basili, Torlone, Sigmod 2016]
14 QUerying and Exploring a Polystore by Augmentation SELECT * FROM inventory WHERE name like %wish% Augmentation is a new construct for data access automatic enrichment of data extracted from one database with data stored elsewhere [QUerying and Exploring a Polystore by Augmentation, Maccioni, Basili, Torlone, Sigmod 2016]
15 Query Augmentation SELECT * FROM inventory WHERE name like %wish% < a32, Cure, Wish >
16 Query Augmentation SELECT * FROM inventory WHERE name like %wish% < a32, Cure, Wish > (discounts: 40%) (catalogue: { title: Wish, artist id: a1, artist: The Cure, year: 1992,... } )


17 Architecture of QUEPA
18 Optimizations in QUEPA Network-based optimization: Batch Augmenter; CPU-based optimization: Inner Augmenter; Outer Augmenter; Outer+Inner Augmenter; Outer+Batch Augmenter; Memory-based optimization: Caching objects from Polystore.
19 Batch Augmentation SEQUENTIAL BATCH

20 CPU-based optimization SEQUENTIAL INNER OUTER Polystores are inherently distributed


21 CPU-based optimization INNER BATCH OUTER-INNER OUTER-BATCH OUTER OUTER
22 Query Optimization Adaptive Augmenter Rule-based optimizer for query augmentation; Based on machine learning rules are created with 4 decision/regression trees training based on logs and other parameters (e.g., polystore RTT)






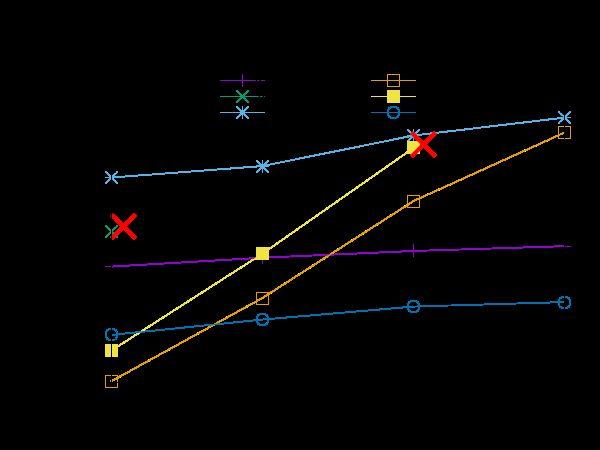

23 Benchmarking SCALABILITY vs COMPETITORS
24 Augmented Exploration Provides an interactive way to access a polystore It is the guided expansion of the result of a local query The user finds her way by just clicking on the links as soon as they are made available similarly to Web surfing
25 How to rank polystore objects?
26 Diversity-Driven PageRank {db1,db3} {db1,db3} {db5,db6, db8}
27 Dynamic adjustment of ranking Loop avoidance Detour
28 Data Lake A data lake is a method of storing data within a system or repository, in its natural format, that facilitates the collocation of data in various schemata and structural forms, usually object blobs or files. -- Wikipedia The idea of data lake is to have a single store of all data in the enterprise ranging from raw data... to transformed data which is used for various tasks including reporting, visualization, analytics and machine learning. -- Wikipedia
29 Data Lake vs Data Warehouse Data warehouse is schema-on-write ETL TIME USER CAN ACCESS DATA SCHEMA READING TIME USER IS ABLE TO ACCESS DATA t Data lake is schema-on-read TIME USER CAN ACCESS DATA DATA PREPARATION TIME USER IS ABLE TO ACCESS DATA t In schema on read, data is applied to a plan or schema as it is pulled out of a stored location, rather than as it goes in -- Techopedia
30 Logical data warehouse A logical data warehouse is a data system that follows the ideas of traditional EDW and includes, in addition to one (or more) core DWs, data from external sources
31 Data preparation Data preparation is the process of gathering, combining, structuring and organizing data so it can be analyzed as part of business intelligence and business analytics programs. The components of data preparation include data discovery, profiling, cleansing, validation and transformation


32 Data preparation


33 Tools supporting data preparation Data/Metadata Catalogs CKAN, GOODS, Data Ground, Apache Atlas, DataHub Help fishing a dataset, not preparing analysis Data Profilers Pandas, Metanome, Constance Involve hard-to-scale algorithms Data Curators Data Civilizer Focus on data cleaning and data transformations
34 Example of Metadata Catalog
35 KAYAK A data management framework for a data lake with the aim of: 1) Reducing the time that a data scientist spends on data preparation 2) Guiding the data scientist to the insights


36 Tasks, Primitives and Pipelines Tasks are atomic operations executed by the system Primitives are operations exposed to users asynchronous synchronous Pipelines are compositions of primitives
37 Time-to-action Time-to-action: time elapsing between the submission of the primitive and when the data scientist is able to take an informed decision on how to move forward to the next step of the pipeline We observe that: Time-to-action is often unnecessarily long approximate results are often enough informative to move forward in the data preparation pipeline
38 15% Tolerance

39 Incremental Execution An approximation of the final result is called a preview A preview is associated to a confidence the uncertainty on the correctness of the result KAYAK produces, incrementally, one or more previews for the primitive within the user s tolerance previews are produced with an increasing confidence We have identified two strategies for incremental execution: GREEDY: produces as many previews as possible BEST-FIT: produces the most accurate preview only

40 Architecture & Workflow
41 Aspects involved in KAYAK Data profiling Data cataloguing Strategies for task generation Task dependencies management Scheduling of tasks Query recommendation Ad-hoc Access Management More aspects to be plugged in (later): cleansing visualization...
42 References Polyglot persistence / Polystores M. Stonebraker, The case for polystores, ( J. Duggan et al., The BigDAWG Polystore System, SIGMOD Record 2015 A. Maccioni, E. Basili, R. Torlone, QUEPA: QUerying and Exploring a Polystore by Augmentation, Sigmod 2016 Y. Papakonstantinou, Polystore Query Rewriting: The Challenges of Variety, EDBT/ICDT Workshops 2016 Apache AsterixDB (paper, tool) Apache Metamodel ( CloudMdsQl: (paper, tool) RHEEM (paper, tools) MuSQLe (paper, tool) Myria (paper, tool) ArangoDB ( OrientDB (
43 References Data Lakes A. Halevy et al., Goods: Organizing Google's Datasets, Sigmod 2016 Z. Abedjan et al., Profiling relational data: a survey. VLDB J D. Deng et al., The Data Civilizer System, CIDR 2017 Data Ground (paper, tool) Apache Atlas ( DataHub (paper, tool) Metanome (paper, tool)
Modern Data Warehouse The New Approach to Azure BI
 Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
Modern Data Warehouse The New Approach to Azure BI History On-Premise SQL Server Big Data Solutions Technical Barriers Modern Analytics Platform On-Premise SQL Server Big Data Solutions Modern Analytics
1 Dulcian, Inc., 2001 All rights reserved. Oracle9i Data Warehouse Review. Agenda
 Agenda Oracle9i Warehouse Review Dulcian, Inc. Oracle9i Server OLAP Server Analytical SQL Mining ETL Infrastructure 9i Warehouse Builder Oracle 9i Server Overview E-Business Intelligence Platform 9i Server:
Agenda Oracle9i Warehouse Review Dulcian, Inc. Oracle9i Server OLAP Server Analytical SQL Mining ETL Infrastructure 9i Warehouse Builder Oracle 9i Server Overview E-Business Intelligence Platform 9i Server:
Data Management Glossary
 Data Management Glossary A Access path: The route through a system by which data is found, accessed and retrieved Agile methodology: An approach to software development which takes incremental, iterative
Data Management Glossary A Access path: The route through a system by which data is found, accessed and retrieved Agile methodology: An approach to software development which takes incremental, iterative
MAPR DATA GOVERNANCE WITHOUT COMPROMISE
 MAPR TECHNOLOGIES, INC. WHITE PAPER JANUARY 2018 MAPR DATA GOVERNANCE TABLE OF CONTENTS EXECUTIVE SUMMARY 3 BACKGROUND 4 MAPR DATA GOVERNANCE 5 CONCLUSION 7 EXECUTIVE SUMMARY The MapR DataOps Governance
MAPR TECHNOLOGIES, INC. WHITE PAPER JANUARY 2018 MAPR DATA GOVERNANCE TABLE OF CONTENTS EXECUTIVE SUMMARY 3 BACKGROUND 4 MAPR DATA GOVERNANCE 5 CONCLUSION 7 EXECUTIVE SUMMARY The MapR DataOps Governance
Streaming Data Integration: Challenges and Opportunities. Nesime Tatbul
 Streaming Data Integration: Challenges and Opportunities Nesime Tatbul Talk Outline Integrated data stream processing An example project: MaxStream Architecture Query model Conclusions ICDE NTII Workshop,
Streaming Data Integration: Challenges and Opportunities Nesime Tatbul Talk Outline Integrated data stream processing An example project: MaxStream Architecture Query model Conclusions ICDE NTII Workshop,
Introduction to Federation Server
 Introduction to Federation Server Alex Lee IBM Information Integration Solutions Manager of Technical Presales Asia Pacific 2006 IBM Corporation WebSphere Federation Server Federation overview Tooling
Introduction to Federation Server Alex Lee IBM Information Integration Solutions Manager of Technical Presales Asia Pacific 2006 IBM Corporation WebSphere Federation Server Federation overview Tooling
HUMIT Interactive Data Integration in a Data Lake System for the Life Sciences
 HUMIT Interactive Data Integration in a Data Lake System for the Life Sciences PD Dr. Christoph Quix Fraunhofer-Institut für Angewandte Informationstechnik FIT Life Science Informatics Abteilungsleiter
HUMIT Interactive Data Integration in a Data Lake System for the Life Sciences PD Dr. Christoph Quix Fraunhofer-Institut für Angewandte Informationstechnik FIT Life Science Informatics Abteilungsleiter
CHAPTER 3 Implementation of Data warehouse in Data Mining
 CHAPTER 3 Implementation of Data warehouse in Data Mining 3.1 Introduction to Data Warehousing A data warehouse is storage of convenient, consistent, complete and consolidated data, which is collected
CHAPTER 3 Implementation of Data warehouse in Data Mining 3.1 Introduction to Data Warehousing A data warehouse is storage of convenient, consistent, complete and consolidated data, which is collected
Agile Data Management Challenges in Enterprise Big Data Landscape
 Agile Data Management Challenges in Enterprise Big Data Landscape Eric Simon, SAP Big Data October, 2017 1 Evolution Towards Enterprise Big Data Landscape administrator Data analyst Athena Redshift #123
Agile Data Management Challenges in Enterprise Big Data Landscape Eric Simon, SAP Big Data October, 2017 1 Evolution Towards Enterprise Big Data Landscape administrator Data analyst Athena Redshift #123
What is Gluent? The Gluent Data Platform
 What is Gluent? The Gluent Data Platform The Gluent Data Platform provides a transparent data virtualization layer between traditional databases and modern data storage platforms, such as Hadoop, in the
What is Gluent? The Gluent Data Platform The Gluent Data Platform provides a transparent data virtualization layer between traditional databases and modern data storage platforms, such as Hadoop, in the
Call: SAS BI Course Content:35-40hours
 SAS BI Course Content:35-40hours Course Outline SAS Data Integration Studio 4.2 Introduction * to SAS DIS Studio Features of SAS DIS Studio Tasks performed by SAS DIS Studio Navigation to SAS DIS Studio
SAS BI Course Content:35-40hours Course Outline SAS Data Integration Studio 4.2 Introduction * to SAS DIS Studio Features of SAS DIS Studio Tasks performed by SAS DIS Studio Navigation to SAS DIS Studio
EUDAT-B2FIND A FAIR and Interdisciplinary Discovery Portal for Research Data
 EUDAT-B2FIND A FAIR and Interdisciplinary Discovery Portal for Research Data Heinrich Widmann, DKRZ Claudia Martens, DKRZ Open Science Days, Berlin, 17 October 2017 www.eudat.eu EUDAT receives funding
EUDAT-B2FIND A FAIR and Interdisciplinary Discovery Portal for Research Data Heinrich Widmann, DKRZ Claudia Martens, DKRZ Open Science Days, Berlin, 17 October 2017 www.eudat.eu EUDAT receives funding
An Information Asset Hub. How to Effectively Share Your Data
 An Information Asset Hub How to Effectively Share Your Data Hello! I am Jack Kennedy Data Architect @ CNO Enterprise Data Management Team Jack.Kennedy@CNOinc.com 1 4 Data Functions Your Data Warehouse
An Information Asset Hub How to Effectively Share Your Data Hello! I am Jack Kennedy Data Architect @ CNO Enterprise Data Management Team Jack.Kennedy@CNOinc.com 1 4 Data Functions Your Data Warehouse
The BigDAWG Polystore. Michael Stonebraker
 The BigDAWG Polystore by Michael Stonebraker Purpose of BigDAWG (Intel ISTC on Big Data) Flatten BDAS (Badass) Outline Why do we need a polystore What exactly is a Polystore The BigDAWG stack The big kahuna
The BigDAWG Polystore by Michael Stonebraker Purpose of BigDAWG (Intel ISTC on Big Data) Flatten BDAS (Badass) Outline Why do we need a polystore What exactly is a Polystore The BigDAWG stack The big kahuna
Overview of Data Services and Streaming Data Solution with Azure
 Overview of Data Services and Streaming Data Solution with Azure Tara Mason Senior Consultant tmason@impactmakers.com Platform as a Service Offerings SQL Server On Premises vs. Azure SQL Server SQL Server
Overview of Data Services and Streaming Data Solution with Azure Tara Mason Senior Consultant tmason@impactmakers.com Platform as a Service Offerings SQL Server On Premises vs. Azure SQL Server SQL Server
Big Data with Hadoop Ecosystem
 Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
Diógenes Pires Big Data with Hadoop Ecosystem Hands-on (HBase, MySql and Hive + Power BI) Internet Live http://www.internetlivestats.com/ Introduction Business Intelligence Business Intelligence Process
IBM DATA VIRTUALIZATION MANAGER FOR z/os
 IBM DATA VIRTUALIZATION MANAGER FOR z/os Any Data to Any App John Casey Senior Solutions Advisor jcasey@rocketsoftware.com IBM z Analytics A New Era of Digital Business To Remain Competitive You must deliver
IBM DATA VIRTUALIZATION MANAGER FOR z/os Any Data to Any App John Casey Senior Solutions Advisor jcasey@rocketsoftware.com IBM z Analytics A New Era of Digital Business To Remain Competitive You must deliver
Microsoft Azure Databricks for data engineering. Building production data pipelines with Apache Spark in the cloud
 Microsoft Azure Databricks for data engineering Building production data pipelines with Apache Spark in the cloud Azure Databricks As companies continue to set their sights on making data-driven decisions
Microsoft Azure Databricks for data engineering Building production data pipelines with Apache Spark in the cloud Azure Databricks As companies continue to set their sights on making data-driven decisions
Microsoft Developer Day
 Microsoft Developer Day Pradeep Menon Microsoft Developer Day Solutions Architect Agenda Microsoft Developer Day Traditional Business Intelligence Architecture Structured Sources Extract Transform Structurize
Microsoft Developer Day Pradeep Menon Microsoft Developer Day Solutions Architect Agenda Microsoft Developer Day Traditional Business Intelligence Architecture Structured Sources Extract Transform Structurize
Migrate from Netezza Workload Migration
 Migrate from Netezza Automated Big Data Open Netezza Source Workload Migration CASE SOLUTION STUDY BRIEF Automated Netezza Workload Migration To achieve greater scalability and tighter integration with
Migrate from Netezza Automated Big Data Open Netezza Source Workload Migration CASE SOLUTION STUDY BRIEF Automated Netezza Workload Migration To achieve greater scalability and tighter integration with
SAP Agile Data Preparation Simplify the Way You Shape Data PUBLIC
 SAP Agile Data Preparation Simplify the Way You Shape Data Introduction SAP Agile Data Preparation Overview Video SAP Agile Data Preparation is a self-service data preparation application providing data
SAP Agile Data Preparation Simplify the Way You Shape Data Introduction SAP Agile Data Preparation Overview Video SAP Agile Data Preparation is a self-service data preparation application providing data
CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED DATA PLATFORM
 CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED PLATFORM Executive Summary Financial institutions have implemented and continue to implement many disparate applications
CONSOLIDATING RISK MANAGEMENT AND REGULATORY COMPLIANCE APPLICATIONS USING A UNIFIED PLATFORM Executive Summary Financial institutions have implemented and continue to implement many disparate applications
Data-Intensive Distributed Computing
 Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 5: Analyzing Relational Data (1/3) February 8, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Data-Intensive Distributed Computing CS 451/651 431/631 (Winter 2018) Part 5: Analyzing Relational Data (1/3) February 8, 2018 Jimmy Lin David R. Cheriton School of Computer Science University of Waterloo
Geospatial Enterprise Search. June
 Geospatial Enterprise Search June 2013 www.voyagersearch.com www.voyagersearch.com/demo The Problem: Data Not Found The National Geospatial-Intelligence Agency is the primary source of geospatial intelligence
Geospatial Enterprise Search June 2013 www.voyagersearch.com www.voyagersearch.com/demo The Problem: Data Not Found The National Geospatial-Intelligence Agency is the primary source of geospatial intelligence
From Single Purpose to Multi Purpose Data Lakes. Thomas Niewel Technical Sales Director DACH Denodo Technologies March, 2019
 From Single Purpose to Multi Purpose Data Lakes Thomas Niewel Technical Sales Director DACH Denodo Technologies March, 2019 Agenda Data Lakes Multiple Purpose Data Lakes Customer Example Demo Takeaways
From Single Purpose to Multi Purpose Data Lakes Thomas Niewel Technical Sales Director DACH Denodo Technologies March, 2019 Agenda Data Lakes Multiple Purpose Data Lakes Customer Example Demo Takeaways
Data Transformation and Migration in Polystores
 Data Transformation and Migration in Polystores Adam Dziedzic, Aaron Elmore & Michael Stonebraker September 15th, 2016 Agenda Data Migration for Polystores: What & Why? How? Acceleration of physical data
Data Transformation and Migration in Polystores Adam Dziedzic, Aaron Elmore & Michael Stonebraker September 15th, 2016 Agenda Data Migration for Polystores: What & Why? How? Acceleration of physical data
Managing Data at Scale: Microservices and Events. Randy linkedin.com/in/randyshoup
 Managing Data at Scale: Microservices and Events Randy Shoup @randyshoup linkedin.com/in/randyshoup Background VP Engineering at Stitch Fix o Combining Art and Science to revolutionize apparel retail Consulting
Managing Data at Scale: Microservices and Events Randy Shoup @randyshoup linkedin.com/in/randyshoup Background VP Engineering at Stitch Fix o Combining Art and Science to revolutionize apparel retail Consulting
Introduction to Data Science
 UNIT I INTRODUCTION TO DATA SCIENCE Syllabus Introduction of Data Science Basic Data Analytics using R R Graphical User Interfaces Data Import and Export Attribute and Data Types Descriptive Statistics
UNIT I INTRODUCTION TO DATA SCIENCE Syllabus Introduction of Data Science Basic Data Analytics using R R Graphical User Interfaces Data Import and Export Attribute and Data Types Descriptive Statistics
Data Warehousing and Decision Support (mostly using Relational Databases) CS634 Class 20
 CS634 Class 20") Data Warehousing and Decision Support (mostly using Relational Databases) CS634 Class 20 Slides based on Database Management Systems 3 rd ed, Ramakrishnan and Gehrke, Chapter 25 Introduction Increasingly,
Data Warehousing and Decision Support (mostly using Relational Databases) CS634 Class 20 Slides based on Database Management Systems 3 rd ed, Ramakrishnan and Gehrke, Chapter 25 Introduction Increasingly,
IBM Data Virtualization Manager for z/os Leverage data virtualization synergy with API economy to evolve the information architecture on IBM Z
 IBM for z/os Leverage data virtualization synergy with API economy to evolve the information architecture on IBM Z IBM z Analytics Agenda Big Data vs. Dark Data Traditional Data Integration Mainframe Data
IBM for z/os Leverage data virtualization synergy with API economy to evolve the information architecture on IBM Z IBM z Analytics Agenda Big Data vs. Dark Data Traditional Data Integration Mainframe Data
Data Analytics at Logitech Snowflake + Tableau = #Winning
 Welcome # T C 1 8 Data Analytics at Logitech Snowflake + Tableau = #Winning Avinash Deshpande I am a futurist, scientist, engineer, designer, data evangelist at heart Find me at Avinash Deshpande Chief
Welcome # T C 1 8 Data Analytics at Logitech Snowflake + Tableau = #Winning Avinash Deshpande I am a futurist, scientist, engineer, designer, data evangelist at heart Find me at Avinash Deshpande Chief
What's New in SAS Data Management
 Paper SAS1390-2015 What's New in SAS Data Management Nancy Rausch, SAS Institute Inc., Cary, NC ABSTRACT The latest releases of SAS Data Integration Studio and DataFlux Data Management Platform provide
Paper SAS1390-2015 What's New in SAS Data Management Nancy Rausch, SAS Institute Inc., Cary, NC ABSTRACT The latest releases of SAS Data Integration Studio and DataFlux Data Management Platform provide
HDInsight > Hadoop. October 12, 2017
 HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
HDInsight > Hadoop October 12, 2017 2 Introduction Mark Hudson >20 years mixing technology with data >10 years with CapTech Microsoft Certified IT Professional Business Intelligence Member of the Richmond
White Paper / Azure Data Platform: Ingest
 White Paper / Azure Data Platform: Ingest Contents White Paper / Azure Data Platform: Ingest... 1 Versioning... 2 Meta Data... 2 Foreword... 3 Prerequisites... 3 Azure Data Platform... 4 Flowchart Guidance...
White Paper / Azure Data Platform: Ingest Contents White Paper / Azure Data Platform: Ingest... 1 Versioning... 2 Meta Data... 2 Foreword... 3 Prerequisites... 3 Azure Data Platform... 4 Flowchart Guidance...
IOTA ARCHITECTURE: DATA VIRTUALIZATION AND PROCESSING MEDIUM DR. KONSTANTIN BOUDNIK DR. ALEXANDRE BOUDNIK
 IOTA ARCHITECTURE: DATA VIRTUALIZATION AND PROCESSING MEDIUM DR. KONSTANTIN BOUDNIK DR. ALEXANDRE BOUDNIK DR. KONSTANTIN BOUDNIK DR.KONSTANTIN BOUDNIK EPAM SYSTEMS CHIEF TECHNOLOGIST BIGDATA, OPEN SOURCE
IOTA ARCHITECTURE: DATA VIRTUALIZATION AND PROCESSING MEDIUM DR. KONSTANTIN BOUDNIK DR. ALEXANDRE BOUDNIK DR. KONSTANTIN BOUDNIK DR.KONSTANTIN BOUDNIK EPAM SYSTEMS CHIEF TECHNOLOGIST BIGDATA, OPEN SOURCE
The Seven Steps to Implement DataOps
 The Seven Steps to Implement Ops ABSTRACT analytics teams challenged by inflexibility and poor quality have found that Ops can address these and many other obstacles. Ops includes tools and process improvements
The Seven Steps to Implement Ops ABSTRACT analytics teams challenged by inflexibility and poor quality have found that Ops can address these and many other obstacles. Ops includes tools and process improvements
Good analytics needs good data and that needs good metadata
 Good analytics needs good data and that needs good metadata 28 th February 2018 Mandy Chessell CBE FREng CEng FBCS Distinguished Engineer, Master Inventor Analytics Chief Data Office mandy_chessell@uk.ibm.com
Good analytics needs good data and that needs good metadata 28 th February 2018 Mandy Chessell CBE FREng CEng FBCS Distinguished Engineer, Master Inventor Analytics Chief Data Office mandy_chessell@uk.ibm.com
Guide Users along Information Pathways and Surf through the Data
 Guide Users along Information Pathways and Surf through the Data Stephen Overton, Overton Technologies, LLC, Raleigh, NC ABSTRACT Business information can be consumed many ways using the SAS Enterprise
Guide Users along Information Pathways and Surf through the Data Stephen Overton, Overton Technologies, LLC, Raleigh, NC ABSTRACT Business information can be consumed many ways using the SAS Enterprise
The Hadoop Paradigm & the Need for Dataset Management
 The Hadoop Paradigm & the Need for Dataset Management 1. Hadoop Adoption Hadoop is being adopted rapidly by many different types of enterprises and government entities and it is an extraordinarily complex
The Hadoop Paradigm & the Need for Dataset Management 1. Hadoop Adoption Hadoop is being adopted rapidly by many different types of enterprises and government entities and it is an extraordinarily complex
Oracle Big Data Discovery
 Oracle Big Data Discovery Turning Data into Business Value Harald Erb Oracle Business Analytics & Big Data 1 Safe Harbor Statement The following is intended to outline our general product direction. It
Oracle Big Data Discovery Turning Data into Business Value Harald Erb Oracle Business Analytics & Big Data 1 Safe Harbor Statement The following is intended to outline our general product direction. It
COMPARISON WHITEPAPER. Snowplow Insights VS SaaS load-your-data warehouse providers. We do data collection right.
 COMPARISON WHITEPAPER Snowplow Insights VS SaaS load-your-data warehouse providers We do data collection right. Background We were the first company to launch a platform that enabled companies to track
COMPARISON WHITEPAPER Snowplow Insights VS SaaS load-your-data warehouse providers We do data collection right. Background We were the first company to launch a platform that enabled companies to track
The Materials Data Facility
 The Materials Data Facility Ben Blaiszik (blaiszik@uchicago.edu), Kyle Chard (chard@uchicago.edu) Ian Foster (foster@uchicago.edu) materialsdatafacility.org What is MDF? We aim to make it simple for materials
The Materials Data Facility Ben Blaiszik (blaiszik@uchicago.edu), Kyle Chard (chard@uchicago.edu) Ian Foster (foster@uchicago.edu) materialsdatafacility.org What is MDF? We aim to make it simple for materials
Top 7 Data API Headaches (and How to Handle Them) Jeff Reser Data Connectivity & Integration Progress Software
 Jeff Reser Data Connectivity & Integration Progress Software") Top 7 Data API Headaches (and How to Handle Them) Jeff Reser Data Connectivity & Integration Progress Software jreser@progress.com Agenda Data Variety (Cloud and Enterprise) ABL ODBC Bridge Using Progress
Top 7 Data API Headaches (and How to Handle Them) Jeff Reser Data Connectivity & Integration Progress Software jreser@progress.com Agenda Data Variety (Cloud and Enterprise) ABL ODBC Bridge Using Progress
Lambda Architecture for Batch and Stream Processing. October 2018
 Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
Lambda Architecture for Batch and Stream Processing October 2018 2018, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only.
ANY Data for ANY Application Exploring IBM Data Virtualization Manager for z/os in the era of API Economy
 ANY Data for ANY Application Exploring IBM for z/os in the era of API Economy Francesco Borrello francesco.borrello@it.ibm.com IBM z Analytics Traditional Data Integration Inadequate No longer Viable to
ANY Data for ANY Application Exploring IBM for z/os in the era of API Economy Francesco Borrello francesco.borrello@it.ibm.com IBM z Analytics Traditional Data Integration Inadequate No longer Viable to
ETL is No Longer King, Long Live SDD
 ETL is No Longer King, Long Live SDD How to Close the Loop from Discovery to Information () to Insights (Analytics) to Outcomes (Business Processes) A presentation by Brian McCalley of DXC Technology,
ETL is No Longer King, Long Live SDD How to Close the Loop from Discovery to Information () to Insights (Analytics) to Outcomes (Business Processes) A presentation by Brian McCalley of DXC Technology,
Best practices for building a Hadoop Data Lake Solution CHARLOTTE HADOOP USER GROUP
 Best practices for building a Hadoop Data Lake Solution CHARLOTTE HADOOP USER GROUP 07.29.2015 LANDING STAGING DW Let s start with something basic Is Data Lake a new concept? What is the closest we can
Best practices for building a Hadoop Data Lake Solution CHARLOTTE HADOOP USER GROUP 07.29.2015 LANDING STAGING DW Let s start with something basic Is Data Lake a new concept? What is the closest we can
Science-as-a-Service
 Science-as-a-Service The iplant Foundation Rion Dooley Edwin Skidmore Dan Stanzione Steve Terry Matthew Vaughn Outline Why, why, why! When duct tape isn t enough Building an API for the web Core services
Science-as-a-Service The iplant Foundation Rion Dooley Edwin Skidmore Dan Stanzione Steve Terry Matthew Vaughn Outline Why, why, why! When duct tape isn t enough Building an API for the web Core services
Introduction to Big-Data
 Introduction to Big-Data Ms.N.D.Sonwane 1, Mr.S.P.Taley 2 1 Assistant Professor, Computer Science & Engineering, DBACER, Maharashtra, India 2 Assistant Professor, Information Technology, DBACER, Maharashtra,
Introduction to Big-Data Ms.N.D.Sonwane 1, Mr.S.P.Taley 2 1 Assistant Professor, Computer Science & Engineering, DBACER, Maharashtra, India 2 Assistant Professor, Information Technology, DBACER, Maharashtra,
A Data warehouse within a Federated database architecture
 Association for Information Systems AIS Electronic Library (AISeL) AMCIS 1997 Proceedings Americas Conference on Information Systems (AMCIS) 8-15-1997 A Data warehouse within a Federated database architecture
Association for Information Systems AIS Electronic Library (AISeL) AMCIS 1997 Proceedings Americas Conference on Information Systems (AMCIS) 8-15-1997 A Data warehouse within a Federated database architecture
Flash Storage Complementing a Data Lake for Real-Time Insight
 Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Flash Storage Complementing a Data Lake for Real-Time Insight Dr. Sanhita Sarkar Global Director, Analytics Software Development August 7, 2018 Agenda 1 2 3 4 5 Delivering insight along the entire spectrum
Extending the Reach of LSA++ Using New SAP BW 7.40 Artifacts Pravin Gupta, TekLink International Inc. Bhanu Gupta, Molex SESSION CODE: BI2241
 Extending the Reach of LSA++ Using New SAP BW 7.40 Artifacts Pravin Gupta, TekLink International Inc. Bhanu Gupta, Molex SESSION CODE: BI2241 Agenda What is Enterprise Data Warehousing (EDW)? Introduction
Extending the Reach of LSA++ Using New SAP BW 7.40 Artifacts Pravin Gupta, TekLink International Inc. Bhanu Gupta, Molex SESSION CODE: BI2241 Agenda What is Enterprise Data Warehousing (EDW)? Introduction
Saving ETL Costs Through Data Virtualization Across The Enterprise
 Saving ETL Costs Through Virtualization Across The Enterprise IBM Virtualization Manager for z/os Marcos Caurim z Analytics Technical Sales Specialist 2017 IBM Corporation What is Wrong with Status Quo?
Saving ETL Costs Through Virtualization Across The Enterprise IBM Virtualization Manager for z/os Marcos Caurim z Analytics Technical Sales Specialist 2017 IBM Corporation What is Wrong with Status Quo?
MetaMatrix Enterprise Data Services Platform
 MetaMatrix Enterprise Data Services Platform MetaMatrix Overview Agenda Background What it does Where it fits How it works Demo Q/A 2 Product Review: Problem Data Challenges Difficult to implement new
MetaMatrix Enterprise Data Services Platform MetaMatrix Overview Agenda Background What it does Where it fits How it works Demo Q/A 2 Product Review: Problem Data Challenges Difficult to implement new
#mstrworld. Analyzing Multiple Data Sources with Multisource Data Federation and In-Memory Data Blending. Presented by: Trishla Maru.
 Analyzing Multiple Data Sources with Multisource Data Federation and In-Memory Data Blending Presented by: Trishla Maru Agenda Overview MultiSource Data Federation Use Cases Design Considerations Data
Analyzing Multiple Data Sources with Multisource Data Federation and In-Memory Data Blending Presented by: Trishla Maru Agenda Overview MultiSource Data Federation Use Cases Design Considerations Data
Datameer for Data Preparation:
 Datameer for Data Preparation: Explore, Profile, Blend, Cleanse, Enrich, Share, Operationalize DATAMEER FOR DATA PREPARATION: EXPLORE, PROFILE, BLEND, CLEANSE, ENRICH, SHARE, OPERATIONALIZE Datameer Datameer
Datameer for Data Preparation: Explore, Profile, Blend, Cleanse, Enrich, Share, Operationalize DATAMEER FOR DATA PREPARATION: EXPLORE, PROFILE, BLEND, CLEANSE, ENRICH, SHARE, OPERATIONALIZE Datameer Datameer
Top Five Reasons for Data Warehouse Modernization Philip Russom
 Top Five Reasons for Data Warehouse Modernization Philip Russom TDWI Research Director for Data Management May 28, 2014 Sponsor Speakers Philip Russom TDWI Research Director, Data Management Steve Sarsfield
Top Five Reasons for Data Warehouse Modernization Philip Russom TDWI Research Director for Data Management May 28, 2014 Sponsor Speakers Philip Russom TDWI Research Director, Data Management Steve Sarsfield
Big Data com Hadoop. VIII Sessão - SQL Bahia. Impala, Hive e Spark. Diógenes Pires 03/03/2018
 Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
Big Data com Hadoop Impala, Hive e Spark VIII Sessão - SQL Bahia 03/03/2018 Diógenes Pires Connect with PASS Sign up for a free membership today at: pass.org #sqlpass Internet Live http://www.internetlivestats.com/
11/04/16. Data Profiling. Helena Galhardas DEI/IST. References
 Data Profiling Helena Galhardas DEI/IST References Slides Data Profiling course, Felix Naumann, Trento, July 2015 Z. Abedjan, L. Golab, F. Naumann, Profiling Relational Data A Survey, VLDBJ 2015 T. Papenbrock
Data Profiling Helena Galhardas DEI/IST References Slides Data Profiling course, Felix Naumann, Trento, July 2015 Z. Abedjan, L. Golab, F. Naumann, Profiling Relational Data A Survey, VLDBJ 2015 T. Papenbrock
Appliances and DW Architecture. John O Brien President and Executive Architect Zukeran Technologies 1
 Appliances and DW Architecture John O Brien President and Executive Architect Zukeran Technologies 1 OBJECTIVES To define an appliance Understand critical components of a DW appliance Learn how DW appliances
Appliances and DW Architecture John O Brien President and Executive Architect Zukeran Technologies 1 OBJECTIVES To define an appliance Understand critical components of a DW appliance Learn how DW appliances
Big Data Hadoop Stack
 Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
Big Data Hadoop Stack Lecture #1 Hadoop Beginnings What is Hadoop? Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware
User Guide. Data Preparation R-1.1
 User Guide Data Preparation R-1.1 Contents 1. About this Guide... 4 1.1. Document History... 4 1.2. Overview... 4 1.3. Target Audience... 4 2. Introduction... 4 2.1. Introducing the Big Data BizViz Data
User Guide Data Preparation R-1.1 Contents 1. About this Guide... 4 1.1. Document History... 4 1.2. Overview... 4 1.3. Target Audience... 4 2. Introduction... 4 2.1. Introducing the Big Data BizViz Data
User Guide. Data Preparation R-1.0
 User Guide Data Preparation R-1.0 Contents 1. About this Guide... 4 1.1. Document History... 4 1.2. Overview... 4 1.3. Target Audience... 4 2. Introduction... 4 2.1. Introducing the Big Data BizViz Data
User Guide Data Preparation R-1.0 Contents 1. About this Guide... 4 1.1. Document History... 4 1.2. Overview... 4 1.3. Target Audience... 4 2. Introduction... 4 2.1. Introducing the Big Data BizViz Data
Data publication and discovery with Globus
 Data publication and discovery with Globus Questions and comments to outreach@globus.org The Globus data publication and discovery services make it easy for institutions and projects to establish collections,
Data publication and discovery with Globus Questions and comments to outreach@globus.org The Globus data publication and discovery services make it easy for institutions and projects to establish collections,
April Copyright 2013 Cloudera Inc. All rights reserved.
 Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Hadoop Beyond Batch: Real-time Workloads, SQL-on- Hadoop, and the Virtual EDW Headline Goes Here Marcel Kornacker marcel@cloudera.com Speaker Name or Subhead Goes Here April 2014 Analytic Workloads on
Data Warehousing. Ritham Vashisht, Sukhdeep Kaur and Shobti Saini
 Advance in Electronic and Electric Engineering. ISSN 2231-1297, Volume 3, Number 6 (2013), pp. 669-674 Research India Publications http://www.ripublication.com/aeee.htm Data Warehousing Ritham Vashisht,
Advance in Electronic and Electric Engineering. ISSN 2231-1297, Volume 3, Number 6 (2013), pp. 669-674 Research India Publications http://www.ripublication.com/aeee.htm Data Warehousing Ritham Vashisht,
Designing your BI Architecture
 IBM Software Group Designing your BI Architecture Data Movement and Transformation David Cope EDW Architect Asia Pacific 2007 IBM Corporation DataStage and DWE SQW Complex Files SQL Scripts ERP ETL Engine
IBM Software Group Designing your BI Architecture Data Movement and Transformation David Cope EDW Architect Asia Pacific 2007 IBM Corporation DataStage and DWE SQW Complex Files SQL Scripts ERP ETL Engine
Copyright 2016 Datalynx Pty Ltd. All rights reserved. Datalynx Enterprise Data Management Solution Catalogue
 Datalynx Enterprise Data Management Solution Catalogue About Datalynx Vendor of the world s most versatile Enterprise Data Management software Licence our software to clients & partners Partner-based sales
Datalynx Enterprise Data Management Solution Catalogue About Datalynx Vendor of the world s most versatile Enterprise Data Management software Licence our software to clients & partners Partner-based sales
Capture Business Opportunities from Systems of Record and Systems of Innovation
 Capture Business Opportunities from Systems of Record and Systems of Innovation Amit Satoor, SAP March Hartz, SAP PUBLIC Big Data transformation powers digital innovation system Relevant nuggets of information
Capture Business Opportunities from Systems of Record and Systems of Innovation Amit Satoor, SAP March Hartz, SAP PUBLIC Big Data transformation powers digital innovation system Relevant nuggets of information
An Introduction to Big Data Formats
 Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Introduction to Big Data Formats 1 An Introduction to Big Data Formats Understanding Avro, Parquet, and ORC WHITE PAPER Introduction to Big Data Formats 2 TABLE OF TABLE OF CONTENTS CONTENTS INTRODUCTION
Evolution of the ATLAS PanDA Workload Management System for Exascale Computational Science
 Evolution of the ATLAS PanDA Workload Management System for Exascale Computational Science T. Maeno, K. De, A. Klimentov, P. Nilsson, D. Oleynik, S. Panitkin, A. Petrosyan, J. Schovancova, A. Vaniachine,
Evolution of the ATLAS PanDA Workload Management System for Exascale Computational Science T. Maeno, K. De, A. Klimentov, P. Nilsson, D. Oleynik, S. Panitkin, A. Petrosyan, J. Schovancova, A. Vaniachine,
Perform scalable data exchange using InfoSphere DataStage DB2 Connector
 Perform scalable data exchange using InfoSphere DataStage Angelia Song (azsong@us.ibm.com) Technical Consultant IBM 13 August 2015 Brian Caufield (bcaufiel@us.ibm.com) Software Architect IBM Fan Ding (fding@us.ibm.com)
Perform scalable data exchange using InfoSphere DataStage Angelia Song (azsong@us.ibm.com) Technical Consultant IBM 13 August 2015 Brian Caufield (bcaufiel@us.ibm.com) Software Architect IBM Fan Ding (fding@us.ibm.com)
Understanding the latent value in all content
 Understanding the latent value in all content John F. Kennedy (JFK) November 22, 1963 INGEST ENRICH EXPLORE Cognitive skills Data in any format, any Azure store Search Annotations Data Cloud Intelligence
Understanding the latent value in all content John F. Kennedy (JFK) November 22, 1963 INGEST ENRICH EXPLORE Cognitive skills Data in any format, any Azure store Search Annotations Data Cloud Intelligence
Optimizing and Modeling SAP Business Analytics for SAP HANA. Iver van de Zand, Business Analytics
 Optimizing and Modeling SAP Business Analytics for SAP HANA Iver van de Zand, Business Analytics Early data warehouse projects LIMITATIONS ISSUES RAISED Data driven by acquisition, not architecture Too
Optimizing and Modeling SAP Business Analytics for SAP HANA Iver van de Zand, Business Analytics Early data warehouse projects LIMITATIONS ISSUES RAISED Data driven by acquisition, not architecture Too
Built for Speed: Comparing Panoply and Amazon Redshift Rendering Performance Utilizing Tableau Visualizations
 Built for Speed: Comparing Panoply and Amazon Redshift Rendering Performance Utilizing Tableau Visualizations Table of contents Faster Visualizations from Data Warehouses 3 The Plan 4 The Criteria 4 Learning
Built for Speed: Comparing Panoply and Amazon Redshift Rendering Performance Utilizing Tableau Visualizations Table of contents Faster Visualizations from Data Warehouses 3 The Plan 4 The Criteria 4 Learning
Shark. Hive on Spark. Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker
 Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Shark Hive on Spark Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Michael Franklin, Ion Stoica, Scott Shenker Agenda Intro to Spark Apache Hive Shark Shark s Improvements over Hive Demo Alpha
Asanka Padmakumara. ETL 2.0: Data Engineering with Azure Databricks
 Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Asanka Padmakumara ETL 2.0: Data Engineering with Azure Databricks Who am I? Asanka Padmakumara Business Intelligence Consultant, More than 8 years in BI and Data Warehousing A regular speaker in data
Sub-Second Response Times with New In-Memory Analytics in MicroStrategy 10. Onur Kahraman
 Sub-Second Response Times with New In-Memory Analytics in MicroStrategy 10 Onur Kahraman High Performance Is No Longer A Nice To Have In Analytical Applications Users expect Google Like performance from
Sub-Second Response Times with New In-Memory Analytics in MicroStrategy 10 Onur Kahraman High Performance Is No Longer A Nice To Have In Analytical Applications Users expect Google Like performance from
Data Acquisition. The reference Big Data stack
 Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Università degli Studi di Roma Tor Vergata Dipartimento di Ingegneria Civile e Ingegneria Informatica Data Acquisition Corso di Sistemi e Architetture per Big Data A.A. 2016/17 Valeria Cardellini The reference
Incremental Updates VS Full Reload
 Incremental Updates VS Full Reload Change Data Capture Minutes VS Hours 1 Table of Contents Executive Summary - 3 Accessing Data from a Variety of Data Sources and Platforms - 4 Approaches to Moving Changed
Incremental Updates VS Full Reload Change Data Capture Minutes VS Hours 1 Table of Contents Executive Summary - 3 Accessing Data from a Variety of Data Sources and Platforms - 4 Approaches to Moving Changed
Processing Unstructured Data. Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd.
 Processing Unstructured Data Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd. http://dinesql.com / Dinesh Priyankara @dinesh_priya Founder/Principal Architect dinesql Pvt Ltd. Microsoft Most
Processing Unstructured Data Dinesh Priyankara Founder/Principal Architect dinesql Pvt Ltd. http://dinesql.com / Dinesh Priyankara @dinesh_priya Founder/Principal Architect dinesql Pvt Ltd. Microsoft Most
Databricks, an Introduction
 Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
Databricks, an Introduction Chuck Connell, Insight Digital Innovation Insight Presentation Speaker Bio Senior Data Architect at Insight Digital Innovation Focus on Azure big data services HDInsight/Hadoop,
Introduction to Grid Computing
 Milestone 2 Include the names of the papers You only have a page be selective about what you include Be specific; summarize the authors contributions, not just what the paper is about. You might be able
Milestone 2 Include the names of the papers You only have a page be selective about what you include Be specific; summarize the authors contributions, not just what the paper is about. You might be able
Lesson 14 SOA with REST (Part I)
") Lesson 14 SOA with REST (Part I) Service Oriented Architectures Security Module 3 - Resource-oriented services Unit 1 REST Ernesto Damiani Università di Milano Web Sites (1992) WS-* Web Services (2000)
Lesson 14 SOA with REST (Part I) Service Oriented Architectures Security Module 3 - Resource-oriented services Unit 1 REST Ernesto Damiani Università di Milano Web Sites (1992) WS-* Web Services (2000)
Delivering a 360 o View in Healthcare and Life Sciences With Agile Data
 Delivering a 360 o View in Healthcare and Life Sciences With Agile Data Imran Chaudhri, @imrantech, Solutions Director, Healthcare & Life Sciences Mark Ferneau, @ferneau, Practice Manager, Healthcare &
Delivering a 360 o View in Healthcare and Life Sciences With Agile Data Imran Chaudhri, @imrantech, Solutions Director, Healthcare & Life Sciences Mark Ferneau, @ferneau, Practice Manager, Healthcare &
Dataspaces: A New Abstraction for Data Management. Mike Franklin, Alon Halevy, David Maier, Jennifer Widom
 Dataspaces: A New Abstraction for Data Management Mike Franklin, Alon Halevy, David Maier, Jennifer Widom Today s Agenda Why databases are great. What problems people really have Why databases are not
Dataspaces: A New Abstraction for Data Management Mike Franklin, Alon Halevy, David Maier, Jennifer Widom Today s Agenda Why databases are great. What problems people really have Why databases are not
An Introduction to Software Architecture. David Garlan & Mary Shaw 94
 An Introduction to Software Architecture David Garlan & Mary Shaw 94 Motivation Motivation An increase in (system) size and complexity structural issues communication (type, protocol) synchronization data
An Introduction to Software Architecture David Garlan & Mary Shaw 94 Motivation Motivation An increase in (system) size and complexity structural issues communication (type, protocol) synchronization data
MCSA SQL SERVER 2012
 MCSA SQL SERVER 2012 1. Course 10774A: Querying Microsoft SQL Server 2012 Course Outline Module 1: Introduction to Microsoft SQL Server 2012 Introducing Microsoft SQL Server 2012 Getting Started with SQL
MCSA SQL SERVER 2012 1. Course 10774A: Querying Microsoft SQL Server 2012 Course Outline Module 1: Introduction to Microsoft SQL Server 2012 Introducing Microsoft SQL Server 2012 Getting Started with SQL
It also performs many parallelization operations like, data loading and query processing.
 Introduction to Parallel Databases Companies need to handle huge amount of data with high data transfer rate. The client server and centralized system is not much efficient. The need to improve the efficiency
Introduction to Parallel Databases Companies need to handle huge amount of data with high data transfer rate. The client server and centralized system is not much efficient. The need to improve the efficiency
End-to-End data mining feature integration, transformation and selection with Datameer Datameer, Inc. All rights reserved.
 End-to-End data mining feature integration, transformation and selection with Datameer Fastest time to Insights Rapid Data Integration Zero coding data integration Wizard-led data integration & No ETL
End-to-End data mining feature integration, transformation and selection with Datameer Fastest time to Insights Rapid Data Integration Zero coding data integration Wizard-led data integration & No ETL
Own change. TECHNICAL WHITE PAPER Data Integration With REST API
 TECHNICAL WHITE PAPER Data Integration With REST API Real-time or near real-time accurate and fast retrieval of key metrics is a critical need for an organization. Many times, valuable data are stored
TECHNICAL WHITE PAPER Data Integration With REST API Real-time or near real-time accurate and fast retrieval of key metrics is a critical need for an organization. Many times, valuable data are stored
C_HANAIMP142
 C_HANAIMP142 Passing Score: 800 Time Limit: 4 min Exam A QUESTION 1 Where does SAP recommend you create calculated measures? A. In a column view B. In a business layer C. In an attribute view D. In an
C_HANAIMP142 Passing Score: 800 Time Limit: 4 min Exam A QUESTION 1 Where does SAP recommend you create calculated measures? A. In a column view B. In a business layer C. In an attribute view D. In an
RDP203 - Enhanced Support for SAP NetWeaver BW Powered by SAP HANA and Mixed Scenarios. October 2013
 RDP203 - Enhanced Support for SAP NetWeaver BW Powered by SAP HANA and Mixed Scenarios October 2013 Disclaimer This presentation outlines our general product direction and should not be relied on in making
RDP203 - Enhanced Support for SAP NetWeaver BW Powered by SAP HANA and Mixed Scenarios October 2013 Disclaimer This presentation outlines our general product direction and should not be relied on in making
Bigtable: A Distributed Storage System for Structured Data. Andrew Hon, Phyllis Lau, Justin Ng
 Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Bigtable: A Distributed Storage System for Structured Data Andrew Hon, Phyllis Lau, Justin Ng What is Bigtable? - A storage system for managing structured data - Used in 60+ Google services - Motivation:
Migrate from Netezza Workload Migration
 Migrate from Netezza Automated Big Data Open Netezza Source Workload Migration CASE SOLUTION STUDY BRIEF Automated Netezza Workload Migration To achieve greater scalability and tighter integration with
Migrate from Netezza Automated Big Data Open Netezza Source Workload Migration CASE SOLUTION STUDY BRIEF Automated Netezza Workload Migration To achieve greater scalability and tighter integration with
Overview. Prerequisites. Course Outline. Course Outline :: Apache Spark Development::
 Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
Title Duration : Apache Spark Development : 4 days Overview Spark is a fast and general cluster computing system for Big Data. It provides high-level APIs in Scala, Java, Python, and R, and an optimized
@unterstein #bedcon. Operating microservices with Apache Mesos and DC/OS
 @unterstein @dcos @bedcon #bedcon Operating microservices with Apache Mesos and DC/OS 1 Johannes Unterstein Software Engineer @Mesosphere @unterstein @unterstein.mesosphere 2017 Mesosphere, Inc. All Rights
@unterstein @dcos @bedcon #bedcon Operating microservices with Apache Mesos and DC/OS 1 Johannes Unterstein Software Engineer @Mesosphere @unterstein @unterstein.mesosphere 2017 Mesosphere, Inc. All Rights
Evolution of Big Data Facebook. Architecture Summit, Shenzhen, August 2012 Ashish Thusoo
 Evolution of Big Data Architectures@ Facebook Architecture Summit, Shenzhen, August 2012 Ashish Thusoo About Me Currently Co-founder/CEO of Qubole Ran the Data Infrastructure Team at Facebook till 2011
Evolution of Big Data Architectures@ Facebook Architecture Summit, Shenzhen, August 2012 Ashish Thusoo About Me Currently Co-founder/CEO of Qubole Ran the Data Infrastructure Team at Facebook till 2011
FastDAWG: Improving Data Migration in the BigDAWG Polystore System
 FastDAWG: Improving Data Migration in the BigDAWG Polystore System Xiangyao Yu 1, Vijay Gadepally 2, Stan Zdonik 3, Tim Kraska 1, and Michael Stonebraker 1 1 Massachusetts Institute of Technology, Computer
FastDAWG: Improving Data Migration in the BigDAWG Polystore System Xiangyao Yu 1, Vijay Gadepally 2, Stan Zdonik 3, Tim Kraska 1, and Michael Stonebraker 1 1 Massachusetts Institute of Technology, Computer
Tamr Technical Whitepaper
 Tamr Technical Whitepaper 1. Executive Summary Tamr was founded to tackle large-scale data management challenges in organizations where extreme data volume and variety require an approach different from
Tamr Technical Whitepaper 1. Executive Summary Tamr was founded to tackle large-scale data management challenges in organizations where extreme data volume and variety require an approach different from