UNIT-I MODES OF COMMUNICATION
|
|
|
- Willa Sharlene Armstrong
- 5 years ago
- Views:
Transcription
1 UNIT-I MODES OF COMMUNICATION
2 SYSTEM PROCESS Distributed operating system. A distributed operating system is a software over a collection of independent, networked, communicating, and physically separate computational nodes.... The first is a ubiquitous minimal kernel, or microkernel, that directly controls that node's hardware.

3 INTERRUPT HANDLING

4 INTERRUPT HANDLING

5 INTERRUPT HANDLING

6 INTERRUPT HANDLING

7 INTERRUPT HANDLING

8 HANDLING SYSTEM CALLS

9 HANDLING SYSTEM CALLS

10 HANDLING SYSTEM CALLS

11 HANDLING SYSTEM CALLS

12 HANDLING SYSTEM CALLS

13 HANDLING SYSTEM CALLS

14 HANDLING SYSTEM CALLS

15 HANDLING SYSTEM CALLS

16 HANDLING SYSTEM CALLS

17 PROTECTION OF RESOURCES

18 PROTECTION OF RESOURCES
19

20

21 PROTECTION OF RESOURCES

22 PROTECTION OF RESOURCES
23 RESOURCES MANAGEMENT

24 MICRO- KERNEL

25 MICRO- KERNEL

26 MICRO- KERNEL

27 MICRO- KERNEL

28 MICRO- KERNEL

29 MICRO- KERNEL

30 MICRO- KERNEL
31 UNIT -II REVIEW OF NETWORK OPERATING SYSTEM
32 DISTRIBUTED OS A distributed operating system is a software over a collection of independent, networked, communicating, and physically separate computational nodes. Each individual node holds a specific software subset of the global aggregate operating system. Each subset is a composite of two distinct service provisioners.
33 DISTRIBUTED OS


34 DISTRIBUTED OS
35 DISTRIBUTED OS
36 DISTRIBUTED OS

37 DISTRIBUTED OS

38 DISTRIBUTED OS
39 COMPUTER N/W
40 COMPUTER N/W
41 COMPUTER N/W
42 COMPUTER N/W
43 COMPUTER N/W
44 COMPUTER N/W
45 COMPUTER N/W
46 COMPUTER N/W
47 Interprocess communication Interprocess communication (IPC) is a set of programming interfaces that allow a programmer to coordinate activities among different programprocesses that can run concurrently in an operating system. This allows a program to handle many user requests at the same time.
48 Interprocess communication
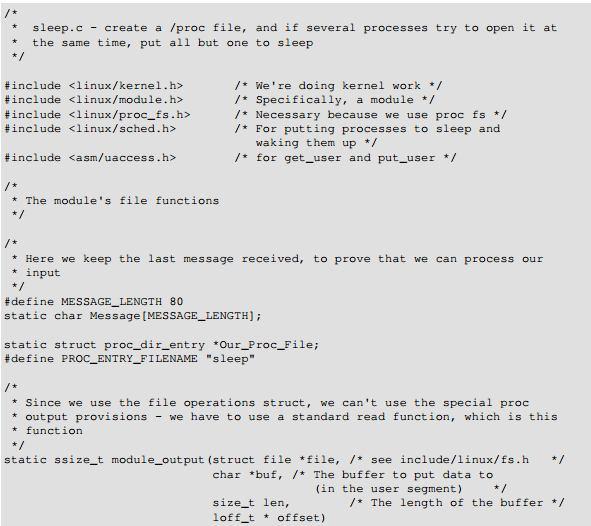
49 LINUX IPC Interprocess CommunicationMechanisms. Processes communicate with each other and with the kernel to coordinate their activities.... Signals and pipes are two of them but Linux also supports the System V IPC mechanisms named after the Unix TM release in which they first appeared.

50 LINUX IPC

51 LINUX IPC
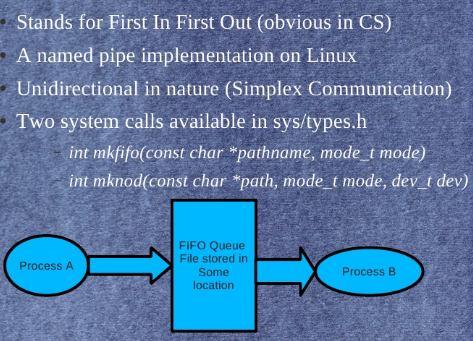
52 LINUX IPC
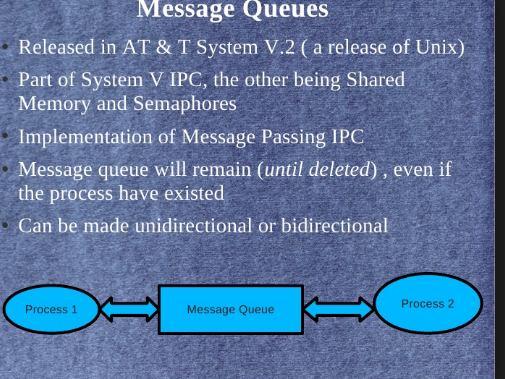
53 LINUX IPC
54 REMOTE PROCEDURE CALLS n distributed computing, a remote procedure call (RPC) is when a computer program causes a procedure(subroutine) to execute in another address space (commonly on another computer on a shared network), which is coded as if it were a normal (local) procedure call, without the programmer explicitly coding the details...
55 REMOTE PROCEDURE CALLS

56 REMOTE PROCEDURE CALLS
57 REMOTE PROCEDURE CALLS
58 REMOTE PROCEDURE CALLS
59 REMOTE PROCEDURE CALLS
60 REMOTE PROCEDURE CALLS
61 REMOTE PROCEDURE CALLS
62 REMOTE PROCEDURE CALLS
63 REMOTE PROCEDURE CALLS
64 REMOTE PROCEDURE CALLS
65 REMOTE PROCEDURE CALLS
66 REMOTE PROCEDURE CALLS
67 REMOTE PROCEDURE CALLS
68 REMOTE PROCEDURE CALLS
69 REMOTE PROCEDURE CALLS
70 REMOTE PROCEDURE CALLS
71 REMOTE PROCEDURE CALLS
72 3. Synchronization in Distributed Systems
73 In a centralized system: all processes reside on the same system utilize the same clock. In a distributed system: like synchronize everyone s watch in the classroom.
74 Global Time Global Time is utilized to provide timestamps for processes and data. time Physical clock: concerned with People Logical clock: concerned with relative time and maintain logical consistency
75 Physical Clocks There are two aspects: Obtaining an accurate value for physical time Synchronizing the concept of physical time throughout the distributed system These can be implemented using centralized algorithms or distributed algorithms
76 Obtaining an Accurate Physical Time A physical time server is needed to access the current time from a universal time coordinator (UTC). Two sources for UTC: WWV shortwave radio station in Ft. Collins, Colorado Geostationary Operational Environmental Satellites (GEOS)
77 Synchronizing Physical Time The difference in time between two clocks due to drifting is defined as clock skew. As long as any and every two clocks differ by a value less than the maximum skew value, the time service is considered to be maintaining synchronization.
78 How to synchronize two clocks in A and B? The information necessary to read the value must be communicated across the network to location B. B s clock value must be read. B s clock value is communicated back to location A. B s clock value is adjusted to reflect the time necessary to travel across the network. B s clock value is compared to A s clock value.
79 Centralized Physical Time Services Broadcast Based Request Driven
80 Broadcast Based first approach The centralized time server s action: The physical time service broadcasts periodically the current time to members of the distributed systems. The participants action: If a given participant s clock is ahead of the time server s clock, the participant slows down its clock so that it will continually move closer to the accurate time. If a participant s clock is behind the time server s clock, the participant moves its clock forward. Alternatives do include gradually speeding up the clock.
81 For example Location A Current time = 720 Current time=740 Delay of 10 Time server Broadcast based Location A Current time=720 Adjusted current time=750 New current time=750
82 Broadcast Based second approach (Berkeley algorithm) Location A Current time=720 Move forward=6 Time Server Location B 1 Current time= Adjusted location A 2 Current time=732 Delay=10 =730 Delay=6 Adjusted location B Slow clock down to 4 =738 5 accommodate 2 Average and the new current time= Current time = My current time = My current time = Adjust forward = 6 5. Adjust slowdown to accommodate 2
83 Request Driven Location A Current time=730 Adjusted time=750 New current time=750 Request for current time Current time=740 Delay=10 Timer Server Current time=740
84 Distributed Physical Time Service Each location broadcasts its current time at predefined set intervals. Once a location has broadcast its time, it starts a timer. It then collects time messages that it receives. Each time message that arrives is stamped with the local current time. This process continues until the timer expires. Upon the expiration of the timer, each message is adjusted to reflect the network delay time estimated for the message source. At this stage, the participant calculates the average time according to one of the following approaches:
85 Calculate the average of all messages Adjusted received times
86 Delete the times that are above the threshold and then average the rest. Adjusted received times 760 X X 723 The numbers besides X are deleted. The rest are averaged.
87 Discard the highest x and the lowest x values and then average Adjusted received times 760 X X X 765 X
88 Logical Clocks Why Logical Clocks? It is difficult to utilize physical clocks to order events uniquely in distributed systems. The essence of logical clocks is based on the happened-before relationship presented by Lamport.
89 Happen-Before Relationship If two events, a and b, occurred at the same process, they occurred in the order of which they were observed. That is, a > b. If a sends a message to b, then a > b. That is, you cannot receive something before it is sent. This relationship holds regardless of where events a and b occur. The happen-before relationship is transitive. If a happens before b and b happens before c, then a happens before c. That is, if a > b and b > c, then a > c.
90 Logical Ordering If T(a) is the timestamp for event a, the following relationships must hold in a distributed system utilizing logical ordering. If two events, a and b, occurred at the same process, they occurred in the order of which they were observed. That is T(a) > T(b). If a sends a message to b, then T(a) > T(b). If a happens before b and b happens before c, T(a) > T(b), T(b) > T(c), and T(a) > T(c).
91 For example Process 3 E F Process 2 C D Process 1 A B A>B>C>D>F E
92 Lamport s Algorithm Each process increments its clock counter between every two consecutive events. If a sends a message to b, then the message must include T(a). Upon receiving a and T(a), the receiving process must set its clock to the greater of [T(a)+d, Current Clock]. That is, if the recipient s clock is behind, it must be advanced to preserve the happenbefore relationship. Usually d=1.
93 For example Process 3 E(1) F(5) Process 2 C(3) D(4) Process 1 A(1) B(2)
94 Total Ordering with Logical Clocks Process 3 E(1.3) F(5.3) Process 2 C(3.2) D(4.2) Process 1 A(1.1) B(2.1) A>E>B>C>D>F
95 Mutual Exclusion In single-processor systems, critical regions are protected using semaphores, monitors, and similar constructs. In distributed systems, since there is no shared memory, these methods cannot be used.
96 A Centralized Algorithm Enter crical section process Request Grant Release coordinator Advantages: It Exit is fair, easy to implement, and requires only three messages per use of a critical region (request, grant, release). Disadvantages: single point of failure.
97 Distributed Algorithm OK REQ OK REQ REQ REQ
98 Token Ring Algorithm
99 A Comparison of the Three Algorithms Algorithm Messages per entry/exit Delay before entry Problems Centralized 3 2 Coordinator crash Distributed 2(n-1) 2(n-1) Crash of any process Token ring 1 to 0 to n-1 Lost token, process crash
100 Election Algorithm The bully algorithm When a process notices that the coordinator is no longer responding to requests, it initiates an election. A process, P, holds an election as follows: P sends an ELECTION message to all processes with higher numbers. If no one responds, P wins the election and becomes coordinator. If one of the higher-ups answers, it takes over. P s job is done.
101 For example Election Ok Election Ok 3 6 Coordinator
102 A Ring Algorithm
103 Atomic Transactions All the synchronization techniques we have studied so far are essentially low level, like semaphores. What we would really like is a much higherlevel abstraction such as atomic transaction.
104 For example Atomic bank transactions: 1. Withdraw(amount, account1) 2. Deposit(amount, account2)
105 Stable Storage Stable storage is designed to survive anything except major calamities such as floods and earthquakes. Stable storage can be implemented with a pair of ordinary disks. Stable storage is well suited to applications that require a high degree of fault tolerance, such as atomic transactions.
106 s a o h t f b w s a t f b w s a o h t f b w s a t f b w s a o h t f b w s a t f b w Stable storage Stable storage Stable storage Drive 1 Drive 2 (a) Stable storage (b) Crash after drive 1 is updated Bad spot
107 Transaction Primitives 1 BEGIN_TRANSACTION: Mark the start of a transaction. 2 END_TRANSACTION: Terminate the transaction and try to commit. 3 ABORT_TRANSACTION: Kill the transaction; restore the old values. 4 READ: Read data from a file (or other object). 5 WRITE: Write data to a file (or other object). For example, BEGIN_TRANSACTION reserve Austin-Houston; reserve Houston-Los Angeles; reserve Los Angeles-Seatle; END_TRANSCATION
108 Properties of Transactions 1 Atomic: To the outside world, the transaction happens indivisibly. 2 Consistent: The transaction does not violate system invariants. 3 Isolated: Concurrent transactions do not interfere with each other. 4 Durable: Once a transaction commits, the changes are permanent.
109 Isolated or serializable Isolated or serializable means that if two or more transactions are running at the same time, to each of them and to other processes, the final result looks as though all transactions ran sequentially in some (system dependent) order.
110 BEGIN_TRANACATION X = 0; X=X+1; END_TRANSACTION (a) BEGIN_TRANSACTION X=0; X= X+2; END_TRANSACTION (b) BEGIN_TRANSACTION X=0; X=X+3; END_TRANSACTION (c ) An example
111 Schedule 1 x=0; x=x+1; x=0; x=x+2; x=0; x=x+3; legal Schedule 2 x=0; x=0; x=x+1; x=x+2; x=0; x=x+3; legal Schedule 3 x=0; x=0; x=x+1; x=0; x=x+2; x=x+3; illegal
112 Nest Transactions Transactions may contain subtransactions, often called nested transactions. If the subtransaction commits and the parent transaction aborts, the permanence applies only to top-level transactions.
113 Implementation Private Workspace Private workspace Index Index Index
114 Writeahead log x=0; y=0; BEGIN_TRANSACTION x=x+1; log: x=0/; y=y+2; log: x=0/1; y=0/2; x=y * y; log: x=0/1; y=0/2; x=1/4; END_TRANSACTION
115 Achieving atomic commit in a distributed system Two-Phase Commit Protocol Phase 1 Coordinator Write Prepare in the log Send Prepare message Collect all replies Subordinates Write Ready in the log Send Ready message Phase 2 Write log record (if all are ready, commit; if not, abort) Send Commit message Write Commit in the log Commit Send Finished message
116 Concurrency Control When multiple transactions are executing simultaneously in different processes, some mechanism is needed to keep them out of each other s way. That mechanism is called a concurrency control algorithm.
117 Concurrency control algorithms Locking In the simplest form, when a process needs to read or write a file (or other object) as part of a transaction, it first locks the file. Distinguishing read locks from write locks. The unit of locking can be an individual record or page, a file, or a larger item.
118 Two-phase locking The process first acquires all the locks it needs during the growing phase, then releases them during the shrinking phase. In many systems, the shrinking phase does not take place until the transaction has finished running and has either committed or aborted. This policy is called strict two-phase locking.
119 Two-phase locking Lock point Number of locks Growing phase Shrinking phase Time
120 Optimistic Concurrency Control A second approach to handling multiple transactions at the same time is optimistic concurrency control. The idea is simple: just go ahead and do whatever you want to, without paying attention to what anybody else is doing. If there is a problem, worry about it later.
121 Timestamps T RD T WR T Do tenative ( ) ( ) ( ) write T WR T RD T Do tentative write ( ) ( ) ( ) Write T ( ) T ( ) T RD T WR ( ) ( ) Abort Abort
122 Read Ok T WR ( ) T ( ) T ( ) T WR ( ) Abort Wait T WR ( ) T TENT ( ) T ( ) T ( ) T TENT ( ) Abort
123 THRASHING If a process does not have enough pages, the page-fault rate is very high low CPU utilization OS thinks it needs increased multiprogramming adds another process to system Thrashing is when a process is busy swapping pages in and out
124 Thrashing CPU utilization degree of muliprogramming
125 Cause of Thrashing Why does paging work? Locality model process migrates from one locality to another localities may overlap Why does thrashing occur? sum of localities > total memory size How do we fix thrashing? Working Set Model Page Fault Frequency
126 HETEROGENOUS DSM The design, implementation, and performance of heterogeneous distributed shared memory (HDSM) are studied. A prototype HDSM system that integrates very different types of hosts has been developed, and a number of applications of this system are reported. Experience shows that despite a number of difficulties in data conversion, HDSM is implementable with minimal loss in functional and performance transparency when compared to homogeneous DSM systems

127 HETEROGENOUS DSM
128 RESOURCE MANAGEMENT In organizational studies, resource management is the efficient and effective development of an organization's resources when they are needed. Such resources may include financial resources, inventory, human skills, production resources, or information technology (IT).
129 RESOURCE MANAGEMENT DIVIDED INTO TWO TECHNIQUES 1.LOAD BALANCING APPROACH 2.LOAD SHARING APPROACH
130 Load-balancing approach Type of dynamic load-balancing algorithms Centralized versus Distributed Centralized approach collects information to server node and makes assignment decision Distributed approach contains entities to make decisions on a predefined set of nodes Centralized algorithms can make efficient decisions, have lower fault-tolerance Distributed algorithms avoid the bottleneck of collecting state information and react faster 130
131 Load-balancing approach Type of distributed load-balancing algorithms Cooperative versus Noncooperative In Noncooperative algorithms entities act as autonomous ones and make scheduling decisions independently from other entities In Cooperative algorithms distributed entities cooperatewith each other Cooperative algorithms are more complex and involve larger overhead Stability of Cooperative algorithms are better 131
132 Load-sharing approach Drawbacks of Load-balancing approach Load balancing technique with attempting equalizing the workload on all the nodes is not an appropriate object since big overhead is generated by gathering exact state information Load balancing is not achievable since number of processes in a node is always fluctuating and temporal unbalance among the nodes exists every moment Basic ideas for Load-sharing approach It is necessary and sufficient to prevent nodes from being idle while some other nodes have more than two processes Load-sharing is much simpler than load-balancing since it only attempts to ensure that no node is idle when heavily node exists Priority assignment policy and migration limiting policy are the same as that for the load-balancing algorithms 132
133 Load estimation policies for Load-sharing algorithms Since load-sharing algorithms simply attempt to avoid idle nodes, it is sufficient to know whether a node is busy or idle Thus these algorithms normally employ the simplest load estimation policy of counting the total number of processes In modern systems where permanent existence of several processes on an idle node is possible, algorithms measure CPU utilization to estimate the load of a node 133
134 Location policies I. for Load-sharing algorithms Location policy decides whether the sender node or the receiver node of the process takes the initiative to search for suitable node in the system, and this policy can be the following: Sender-initiated location policy Sender node decides where to send the process Heavily loaded nodes search for lightly loaded nodes Receiver-initiated location policy Receiver node decides from where to get the process Lightly loaded nodes search for heavily loaded nodes 134
135 PROCESS MANAGEMENT 135
136 PROCESS MANAGEMENT 136
137 PROCESS MANAGEMENT Process Migration refers to the mobility of executing (or suspended) processes in a distributed computing environment. Usually, this term indicates that a processuses a network to migrate to another machine to continue its execution there. 137

138 PROCESS MANAGEMENT 138

139 PROCESS MANAGEMENT 139
140 THREAD Multithreading. Multithreading is mainly found in multitasking operating systems. Multithreading is a widespread programming and execution model that allows multiple threads to exist within the context of one process. These threads share the process's resources, but are able to execute independently. 140

141 THREAD 141
142 THREAD 142
143 THREAD Responsiveness: multithreading can allow an application to remain responsive to input. In a onethread program, if the main execution thread blocks on a long-running task, the entire application can appear to freeze. By moving such long-running tasks to a worker thread that runs concurrently with the main execution thread, it is possible for the application to remain responsive to user input while executing tasks in the background. On the other hand, in most cases multithreading is not the only way to keep a program responsive, with non-blocking I/O and/or UniX signals being available for gaining similar results 143
144 THREAD Faster execution: this advantage of a multithreaded program allows it to operate faster on computer systems that have multiple central processing units (CPUs) or one or more multi-core processors, or across a clusterof machines, because the threads of the program naturally lend themselves to parallel execution, assuming sufficient independence (that they do not need to wait for each other). 144
145 THREAD Parallelization: applications looking to use multicore or multi-cpu systems can use multithreading to split data and tasks into parallel subtasks and let the underlying architecture manage how the threads run, either concurrently on one core or in parallel on multiple cores. GPU computing environments like CUDA and OpenCLuse the multithreading model where dozens to hundreds of threads run in parallel across data on a large number of cores. 145
146 UNIT -IV OVERVIEW OF SHARED MEMORY
147 CONSISTENCY MODEL A memory consistency model only applies to systems that allow multiple copies ofshared data; e.g., through caching... Other aspects include the order in which a processor issues memory operations to the memory system, and whether a write executes atomically.
148 CONSISTENCY MODEL In describing the behavior of these memory models, we are only interested in the shared memory behavior - not anything else related to the programs. We aren't interested in control flow within the programs, data manipulations within the programs, or behavior related to local (in the sense of non-shared) variables. There is a stnadard notation for this, which we'll be using in what follows. In the notation, there will be a line for each processor in the system, and time proceeds from left to right. Each shared-memory operation performed will appear on the processor's line. The two main operations are Read and Write, which are expressed as W(var)value which means "write value to shared variable var", and R(var)value which means "read shared variable var, obtaining value." So, for instance, W(x)1 means "write a 1 to x" and R(y)3 means "read y, and get the value 3." More operations (especially synchronization operations) will be defined as we go on. For simplicity, variables are assumed to be initialized to 0. An important thing to notice about this is that a single high-level language statement (like x = x + 1;) will typically appear as several memory operations. If x previously had a value of 0, then that statement becomes (in the absence of any other processors) P1: R(x)0 W(x) On a RISC-style processor, it's likely that C statement would have turned into three instructions: a load, an add, and a store. Of those three instructions, two affect memory and are shown in the diagram. On a CISC-style processor, the statement would probably have turned into a single, in-memory add instruction. Even so, the processor would have executed the instruction by reading memory, doing the addition, and then writing memory, so it would still appear as two memory operations. Notice that the actual memory operations performed could equally well have been performed by some completely different high level language code; maybe an if-then-else statement that checked and then set a flag. If I ask for memory operations and there is anything in your answer that looks like a transformation or something of the data, then something is wrong!
149 CONSISTENCY MODEL Strict Consistency The intuitive notion of memory consistency is the strict consistency model. In the strict model, any read to a memory location X returns the value stored by the most recent write operation to X. If we have a bunch of processors, with no caches, talking to memory through a bus then we will have strict consistency. The point here is the precise serialization of all memory accesses. We can give an example of what is, and what is not, strict consistency and also show an example of the notation for operations in the memory system. As we said before, we assume that all variables have a value of 0 before we begin. An example of a scenario that would be valid under the strict consistency model is the following: P1: W(x) P2: R(x)1 R(x)1 This says, ``processor P1 writes a value of 1 to variable x; at some later time processor P2 reads x and obtains a value of 1. Then it reads it again and gets the same value'' Here's another scenario which would be valid under strict consistency: P1: W(x) P2: R(x)0 R(x)1 This time, P2 got a little ahead of P1; its first read of x got a value of 0, while its second read got the 1 that was written by P1. Notice that these two scenarios could be obtained in two runs of the same program on the same processors. Here's a scenario which would not be valid under strict consistency: P1: W(x) P2: R(x)0 R(x)1 In this scenario, the new value of x had not been propagated to P2 yet when it did its first read, but it did reach it eventually. I've also seen this model called atomic consistency.
150 CONSISTENCY MODEL Sequential Consistency Sequential consistency is a slightly weaker model than strict consistency. It was defined by Lamport as the result of any execution is the same as if the reads and writes occurred in some order, and the operations of each individual processor appear in this sequence in the order specified by its program. In essence, any ordering that could have been produced by a strict ordering regardless of processor speeds is valid under sequential consistency. The idea is that by expanding from the sets of reads and writes that actually happened to the sets that could have happened, we can reason more effectively about the program (since we can ask the far more useful question, "could the program have broken?"). We can reason about the program itself, with less interference from the details of the hardware on which it is running. It's probably fair to say that if we have a computer system that really uses strict consistency, we'll want to reason about it using sequential consistency
151 CONSISTENCY MODEL
152 CONSISTENCY MODEL
153 SHARED MEMORY In computer science, distributed shared memory(dsm) is a form of memory architecture where physically separated memories can be addressed as one logically shared address space.

154 SHARED MEMORY

155 SHARED MEMORY
156 SHARED MEMORY
157 SHARED MEMORY
158 SHARED MEMORY

159 SHARED MEMORY
160 SHARED MEMORY
161 SHARED MEMORY

162 VARIABLE BASED SHARED MEMORY
163 VARIABLE BASED SHARED MEMORY

164 VARIABLE BASED SHARED MEMORY
165 VARIABLE BASED SHARED MEMORY

166 VARIABLE BASED SHARED MEMORY
167 OBJECT BASED SHARED MEMORY
168 OBJECT BASED SHARED MEMORY

169 OBJECT BASED SHARED MEMORY

170 OBJECT BASED SHARED MEMORY
171 OBJECT BASED SHARED MEMORY
172 UNIT -V FILE MODELS
173 FILE ACCESS

174 FILE ACCESS
175 FILE ACCESS
176 FILE ACCESS
177 FILE SHARING
178 FILE SHARING

179 FILE SHARING
180 FILE SHARING
181 FILE CACHING
182 FILE CACHING
183 FILE CACHING
184 FILE CACHING
185 FILE CACHING

186 FILE CACHING

187 FILE CACHING
188 FILE CACHING
189 FILE REPLICATION There are three basic replication models the master-slave client-server peer-to-peer models.
190 FILE REPLICATION Master-slave model In this model one of the copy is the master replica and all the other copies are slaves. The slaves should always be identical to the master. In this model the functionality of the slaves are very limited, thus the configuration is very simple. The slaves essentially are read-only. Most of the master-slaves services ignore all the updates or modifications performed at the slave, and undo the update during synchronization, making the slave identical to the master [3]. The modifications or the updates can be reliably performed at the master and the slaves must synchronize directly with the master.

191 FILE REPLICATION
192 FILE REPLICATION Peer-to-peer model The Peer-to-peer model is very different from both the master-slave and the client-server models. Here all the replicas or the copies are of equal importance or they are all peers. In this model any replica can synchronize with any other replica, and any file system modification or update can be applied at any replica. Optimistic replication can use a peer-topeer model. Peer-to-peer systems allow any replica to propagate updates to any other replicas [11]. The peer-to-peer model has been implemented in Locus, Rumor and in other distributed environments such as xfs in the NOW project. Peer-to-peer systems can propagate updates faster by making use of any available connectivity. They provide a very rich and robust communication framework. But they are more complex in implementation and in the states they can achieve [11]. One more problem with this model is scalability. Peer models are implemented by storing all necessary replication knowledge at every site thus each replica has full knowledge about everyone else. As synchronization and communication is allowed between any replicas, this results in exceedingly large replicated data structures and clearly does not scale well. Additionally, distributed algorithms that determine global state must, by definition, communicate with or hear about (via gossiping) each replica at least once and often twice. Since all replicas are peers, any single machine could potentially affect the outcome of such distributed algorithms; therefore each must participate before the algorithm can complete, again leading to potential scaling problems [3]. Simulation studies in the file system arena have demonstrated that the peer model increases the speed of update propagation among a set of replicas, decreasing the frequency of using an outdated version of the data
193 FAULT TOLERANCE Fault tolerance is the property that enables a system to continue operating properly in the event of the failure of (or one or more faults within) some of its components.

194 FAULT TOLERANCE

195 FAULT TOLERANCE
196 FAULT TOLERANCE
197 NETWORK FILE SHARING A Network File System (NFS) allows remote hosts to mount file systems over a network and interact with those file systems as though they are mounted locally. This enables system administrators to consolidate resources onto centralized servers on the network. This chapter focuses on fundamental NFS concepts and supplemental information. For specific instructions regarding the configuration and operation of NFS server and client software, refer to the chapter titled Network File System (NFS) in the Red Hat Enterprise Linux System Administration Guide.
198 NETWORK FILE SYSTEM Required Services Red Hat Enterprise Linux uses a combination of kernel-level support and daemon processes to provide NFS file sharing. NFS relies on Remote Procedure Calls (RPC) to route requests between clients and servers. RPC services under Linux are controlled by the portmap service. To share or mount NFS file systems, the following services work together: nfs Starts the appropriate RPC processes to service requests for shared NFS file systems. nfslock An optional service that starts the appropriate RPC processes to allow NFS clients to lock files on the server. portmap The RPC service for Linux; it responds to requests for RPC services and sets up connections to the requested RPC service. The following RPC processes work together behind the scenes to facilitate NFS services: rpc.mountd This process receives mount requests from NFS clients and verifies the requested file system is currently exported. This process is started automatically by the nfs service and does not require user configuration. rpc.nfsd This process is the NFS server. It works with the Linux kernel to meet the dynamic demands of NFS clients, such as providing server threads each time an NFS client connects. This process corresponds to the nfs service. rpc.lockd An optional process that allows NFS clients to lock files on the server. This process corresponds to the nfslock service. rpc.statd This process implements the Network Status Monitor (NSM) RPC protocol which notifies NFS clients when an NFS server is restarted without being gracefully brought down. This process is started automatically by the nfslock service and does not require user configuration. rpc.rquotad This process provides user quota information for remote users. This process is started automatically by the nfs service and does not require user configuration.
199 NETWORK FILE SYSTEM Troubleshooting NFS and portmap Because portmap provides coordination between RPC services and the port numbers used to communicate with them, it is useful to view the status of current RPC services usingportmap when troubleshooting. The rpcinfo command shows each RPC-based service with port numbers, an RPC program number, a version and an IP protocol type (TCP or UDP).
Synchronization. Clock Synchronization
 Synchronization Clock Synchronization Logical clocks Global state Election algorithms Mutual exclusion Distributed transactions 1 Clock Synchronization Time is counted based on tick Time judged by query
Synchronization Clock Synchronization Logical clocks Global state Election algorithms Mutual exclusion Distributed transactions 1 Clock Synchronization Time is counted based on tick Time judged by query
Synchronization. Chapter 5
 Synchronization Chapter 5 Clock Synchronization In a centralized system time is unambiguous. (each computer has its own clock) In a distributed system achieving agreement on time is not trivial. (it is
Synchronization Chapter 5 Clock Synchronization In a centralized system time is unambiguous. (each computer has its own clock) In a distributed system achieving agreement on time is not trivial. (it is
Synchronization Part 2. REK s adaptation of Claypool s adaptation oftanenbaum s Distributed Systems Chapter 5 and Silberschatz Chapter 17
 Synchronization Part 2 REK s adaptation of Claypool s adaptation oftanenbaum s Distributed Systems Chapter 5 and Silberschatz Chapter 17 1 Outline Part 2! Clock Synchronization! Clock Synchronization Algorithms!
Synchronization Part 2 REK s adaptation of Claypool s adaptation oftanenbaum s Distributed Systems Chapter 5 and Silberschatz Chapter 17 1 Outline Part 2! Clock Synchronization! Clock Synchronization Algorithms!
Synchronization Part II. CS403/534 Distributed Systems Erkay Savas Sabanci University
 Synchronization Part II CS403/534 Distributed Systems Erkay Savas Sabanci University 1 Election Algorithms Issue: Many distributed algorithms require that one process act as a coordinator (initiator, etc).
Synchronization Part II CS403/534 Distributed Systems Erkay Savas Sabanci University 1 Election Algorithms Issue: Many distributed algorithms require that one process act as a coordinator (initiator, etc).
Synchronization (contd.)
") Outline Synchronization (contd.) http://net.pku.edu.cn/~course/cs501/2008 Hongfei Yan School of EECS, Peking University 3/17/2008 Mutual Exclusion Permission-based Token-based Election Algorithms The Bully
Outline Synchronization (contd.) http://net.pku.edu.cn/~course/cs501/2008 Hongfei Yan School of EECS, Peking University 3/17/2008 Mutual Exclusion Permission-based Token-based Election Algorithms The Bully
Distributed Systems COMP 212. Revision 2 Othon Michail
 Distributed Systems COMP 212 Revision 2 Othon Michail Synchronisation 2/55 How would Lamport s algorithm synchronise the clocks in the following scenario? 3/55 How would Lamport s algorithm synchronise
Distributed Systems COMP 212 Revision 2 Othon Michail Synchronisation 2/55 How would Lamport s algorithm synchronise the clocks in the following scenario? 3/55 How would Lamport s algorithm synchronise
Atomic Transac1ons. Atomic Transactions. Q1: What if network fails before deposit? Q2: What if sequence is interrupted by another sequence?
 CPSC-4/6: Operang Systems Atomic Transactions The Transaction Model / Primitives Serializability Implementation Serialization Graphs 2-Phase Locking Optimistic Concurrency Control Transactional Memory
CPSC-4/6: Operang Systems Atomic Transactions The Transaction Model / Primitives Serializability Implementation Serialization Graphs 2-Phase Locking Optimistic Concurrency Control Transactional Memory
殷亚凤. Synchronization. Distributed Systems [6]
![殷亚凤. Synchronization. Distributed Systems [6]](/thumbs/88/117193765.jpg "殷亚凤. Synchronization. Distributed Systems [6]") Synchronization Distributed Systems [6] 殷亚凤 Email: yafeng@nju.edu.cn Homepage: http://cs.nju.edu.cn/yafeng/ Room 301, Building of Computer Science and Technology Review Protocols Remote Procedure Call
Synchronization Distributed Systems [6] 殷亚凤 Email: yafeng@nju.edu.cn Homepage: http://cs.nju.edu.cn/yafeng/ Room 301, Building of Computer Science and Technology Review Protocols Remote Procedure Call
Synchronization Part 1. REK s adaptation of Claypool s adaptation of Tanenbaum s Distributed Systems Chapter 5
 Synchronization Part 1 REK s adaptation of Claypool s adaptation of Tanenbaum s Distributed Systems Chapter 5 1 Outline! Clock Synchronization! Clock Synchronization Algorithms! Logical Clocks! Election
Synchronization Part 1 REK s adaptation of Claypool s adaptation of Tanenbaum s Distributed Systems Chapter 5 1 Outline! Clock Synchronization! Clock Synchronization Algorithms! Logical Clocks! Election
Exam 2 Review. Fall 2011
 Exam 2 Review Fall 2011 Question 1 What is a drawback of the token ring election algorithm? Bad question! Token ring mutex vs. Ring election! Ring election: multiple concurrent elections message size grows
Exam 2 Review Fall 2011 Question 1 What is a drawback of the token ring election algorithm? Bad question! Token ring mutex vs. Ring election! Ring election: multiple concurrent elections message size grows
DISTRIBUTED SYSTEMS [COMP9243] Lecture 5: Synchronisation and Coordination (Part 2) TRANSACTION EXAMPLES TRANSACTIONS.
![DISTRIBUTED SYSTEMS [COMP9243] Lecture 5: Synchronisation and Coordination (Part 2) TRANSACTION EXAMPLES TRANSACTIONS.](/thumbs/72/66655861.jpg "DISTRIBUTED SYSTEMS [COMP9243] Lecture 5: Synchronisation and Coordination (Part 2) TRANSACTION EXAMPLES TRANSACTIONS.") TRANSACTIONS Transaction: DISTRIBUTED SYSTEMS [COMP94] Comes from database world Defines a sequence of operations Atomic in presence of multiple clients and failures Slide Lecture 5: Synchronisation and
TRANSACTIONS Transaction: DISTRIBUTED SYSTEMS [COMP94] Comes from database world Defines a sequence of operations Atomic in presence of multiple clients and failures Slide Lecture 5: Synchronisation and
DISTRIBUTED SYSTEMS [COMP9243] Lecture 5: Synchronisation and Coordination (Part 2) TRANSACTION EXAMPLES TRANSACTIONS.
![DISTRIBUTED SYSTEMS [COMP9243] Lecture 5: Synchronisation and Coordination (Part 2) TRANSACTION EXAMPLES TRANSACTIONS.](/thumbs/93/111469359.jpg "DISTRIBUTED SYSTEMS [COMP9243] Lecture 5: Synchronisation and Coordination (Part 2) TRANSACTION EXAMPLES TRANSACTIONS.") TRANSACTIONS Transaction: DISTRIBUTED SYSTEMS [COMP94] Comes from database world Defines a sequence of operations Atomic in presence of multiple clients and failures Slide Lecture 5: Synchronisation and
TRANSACTIONS Transaction: DISTRIBUTED SYSTEMS [COMP94] Comes from database world Defines a sequence of operations Atomic in presence of multiple clients and failures Slide Lecture 5: Synchronisation and
CSE 5306 Distributed Systems. Synchronization
 CSE 5306 Distributed Systems Synchronization 1 Synchronization An important issue in distributed system is how processes cooperate and synchronize with one another Cooperation is partially supported by
CSE 5306 Distributed Systems Synchronization 1 Synchronization An important issue in distributed system is how processes cooperate and synchronize with one another Cooperation is partially supported by
Distributed Operating Systems. Distributed Synchronization
 2 Distributed Operating Systems Distributed Synchronization Steve Goddard goddard@cse.unl.edu http://www.cse.unl.edu/~goddard/courses/csce855 1 Synchronization Coordinating processes to achieve common
2 Distributed Operating Systems Distributed Synchronization Steve Goddard goddard@cse.unl.edu http://www.cse.unl.edu/~goddard/courses/csce855 1 Synchronization Coordinating processes to achieve common
(Pessimistic) Timestamp Ordering. Rules for read and write Operations. Read Operations and Timestamps. Write Operations and Timestamps
 Timestamp Ordering. Rules for read and write Operations. Read Operations and Timestamps. Write Operations and Timestamps") (Pessimistic) stamp Ordering Another approach to concurrency control: Assign a timestamp ts(t) to transaction T at the moment it starts Using Lamport's timestamps: total order is given. In distributed
(Pessimistic) stamp Ordering Another approach to concurrency control: Assign a timestamp ts(t) to transaction T at the moment it starts Using Lamport's timestamps: total order is given. In distributed
Transactions. A Banking Example
 Transactions A transaction is specified by a client as a sequence of operations on objects to be performed as an indivisible unit by the servers managing those objects Goal is to ensure that all objects
Transactions A transaction is specified by a client as a sequence of operations on objects to be performed as an indivisible unit by the servers managing those objects Goal is to ensure that all objects
Distributed Systems Principles and Paradigms
 Distributed Systems Principles and Paradigms Chapter 05 (version 16th May 2006) Maarten van Steen Vrije Universiteit Amsterdam, Faculty of Science Dept. Mathematics and Computer Science Room R4.20. Tel:
Distributed Systems Principles and Paradigms Chapter 05 (version 16th May 2006) Maarten van Steen Vrije Universiteit Amsterdam, Faculty of Science Dept. Mathematics and Computer Science Room R4.20. Tel:
(Pessimistic) Timestamp Ordering
 Timestamp Ordering") (Pessimistic) Timestamp Ordering Another approach to concurrency control: Assign a timestamp ts(t) to transaction T at the moment it starts Using Lamport's timestamps: total order is given. In distributed
(Pessimistic) Timestamp Ordering Another approach to concurrency control: Assign a timestamp ts(t) to transaction T at the moment it starts Using Lamport's timestamps: total order is given. In distributed
Distributed systems. Lecture 6: distributed transactions, elections, consensus and replication. Malte Schwarzkopf
 Distributed systems Lecture 6: distributed transactions, elections, consensus and replication Malte Schwarzkopf Last time Saw how we can build ordered multicast Messages between processes in a group Need
Distributed systems Lecture 6: distributed transactions, elections, consensus and replication Malte Schwarzkopf Last time Saw how we can build ordered multicast Messages between processes in a group Need
Clock Synchronization. Synchronization. Clock Synchronization Algorithms. Physical Clock Synchronization. Tanenbaum Chapter 6 plus additional papers
 Clock Synchronization Synchronization Tanenbaum Chapter 6 plus additional papers Fig 6-1. In a distributed system, each machine has its own clock. When this is the case, an event that occurred after another
Clock Synchronization Synchronization Tanenbaum Chapter 6 plus additional papers Fig 6-1. In a distributed system, each machine has its own clock. When this is the case, an event that occurred after another
PROCESS SYNCHRONIZATION
 DISTRIBUTED COMPUTER SYSTEMS PROCESS SYNCHRONIZATION Dr. Jack Lange Computer Science Department University of Pittsburgh Fall 2015 Process Synchronization Mutual Exclusion Algorithms Permission Based Centralized
DISTRIBUTED COMPUTER SYSTEMS PROCESS SYNCHRONIZATION Dr. Jack Lange Computer Science Department University of Pittsburgh Fall 2015 Process Synchronization Mutual Exclusion Algorithms Permission Based Centralized
Synchronisation and Coordination (Part 2)
") The University of New South Wales School of Computer Science & Engineering COMP9243 Week 5 (18s1) Ihor Kuz, Manuel M. T. Chakravarty & Gernot Heiser Synchronisation and Coordination (Part 2) Transactions
The University of New South Wales School of Computer Science & Engineering COMP9243 Week 5 (18s1) Ihor Kuz, Manuel M. T. Chakravarty & Gernot Heiser Synchronisation and Coordination (Part 2) Transactions
Control. CS432: Distributed Systems Spring 2017
 Transactions and Concurrency Control Reading Chapter 16, 17 (17.2,17.4,17.5 ) [Coulouris 11] Chapter 12 [Ozsu 10] 2 Objectives Learn about the following: Transactions in distributed systems Techniques
Transactions and Concurrency Control Reading Chapter 16, 17 (17.2,17.4,17.5 ) [Coulouris 11] Chapter 12 [Ozsu 10] 2 Objectives Learn about the following: Transactions in distributed systems Techniques
DISTRIBUTED SYSTEMS Principles and Paradigms Second Edition ANDREW S. TANENBAUM MAARTEN VAN STEEN. Chapter 1. Introduction
 DISTRIBUTED SYSTEMS Principles and Paradigms Second Edition ANDREW S. TANENBAUM MAARTEN VAN STEEN Chapter 1 Introduction Modified by: Dr. Ramzi Saifan Definition of a Distributed System (1) A distributed
DISTRIBUTED SYSTEMS Principles and Paradigms Second Edition ANDREW S. TANENBAUM MAARTEN VAN STEEN Chapter 1 Introduction Modified by: Dr. Ramzi Saifan Definition of a Distributed System (1) A distributed
Part III Transactions
 Part III Transactions Transactions Example Transaction: Transfer amount X from A to B debit(account A; Amount X): A = A X; credit(account B; Amount X): B = B + X; Either do the whole thing or nothing ACID
Part III Transactions Transactions Example Transaction: Transfer amount X from A to B debit(account A; Amount X): A = A X; credit(account B; Amount X): B = B + X; Either do the whole thing or nothing ACID
INSTITUTE OF AERONAUTICAL ENGINEERING (Autonomous) Dundigal, Hyderabad
 Dundigal, Hyderabad") Course Name Course Code Class Branch INSTITUTE OF AERONAUTICAL ENGINEERING (Autonomous) Dundigal, Hyderabad -500 043 COMPUTER SCIENCE AND ENGINEERING TUTORIAL QUESTION BANK 2015-2016 : DISTRIBUTED SYSTEMS
Course Name Course Code Class Branch INSTITUTE OF AERONAUTICAL ENGINEERING (Autonomous) Dundigal, Hyderabad -500 043 COMPUTER SCIENCE AND ENGINEERING TUTORIAL QUESTION BANK 2015-2016 : DISTRIBUTED SYSTEMS
Synchronization. Distributed Systems IT332
 Synchronization Distributed Systems IT332 2 Outline Clock synchronization Logical clocks Election algorithms Mutual exclusion Transactions 3 Hardware/Software Clocks Physical clocks in computers are realized
Synchronization Distributed Systems IT332 2 Outline Clock synchronization Logical clocks Election algorithms Mutual exclusion Transactions 3 Hardware/Software Clocks Physical clocks in computers are realized
Topics. File Buffer Cache for Performance. What to Cache? COS 318: Operating Systems. File Performance and Reliability
 Topics COS 318: Operating Systems File Performance and Reliability File buffer cache Disk failure and recovery tools Consistent updates Transactions and logging 2 File Buffer Cache for Performance What
Topics COS 318: Operating Systems File Performance and Reliability File buffer cache Disk failure and recovery tools Consistent updates Transactions and logging 2 File Buffer Cache for Performance What
Distributed Systems COMP 212. Lecture 17 Othon Michail
 Distributed Systems COMP 212 Lecture 17 Othon Michail Synchronisation 2/29 What Can Go Wrong Updating a replicated database: Customer (update 1) adds 100 to an account, bank employee (update 2) adds 1%
Distributed Systems COMP 212 Lecture 17 Othon Michail Synchronisation 2/29 What Can Go Wrong Updating a replicated database: Customer (update 1) adds 100 to an account, bank employee (update 2) adds 1%
Processes and Non-Preemptive Scheduling. Otto J. Anshus
 Processes and Non-Preemptive Scheduling Otto J. Anshus Threads Processes Processes Kernel An aside on concurrency Timing and sequence of events are key concurrency issues We will study classical OS concurrency
Processes and Non-Preemptive Scheduling Otto J. Anshus Threads Processes Processes Kernel An aside on concurrency Timing and sequence of events are key concurrency issues We will study classical OS concurrency
Outline. Definition of a Distributed System Goals of a Distributed System Types of Distributed Systems
 Distributed Systems Outline Definition of a Distributed System Goals of a Distributed System Types of Distributed Systems What Is A Distributed System? A collection of independent computers that appears
Distributed Systems Outline Definition of a Distributed System Goals of a Distributed System Types of Distributed Systems What Is A Distributed System? A collection of independent computers that appears
VALLIAMMAI ENGINEERING COLLEGE
 VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK II SEMESTER CP7204 Advanced Operating Systems Regulation 2013 Academic Year
VALLIAMMAI ENGINEERING COLLEGE SRM Nagar, Kattankulathur 603 203 DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING QUESTION BANK II SEMESTER CP7204 Advanced Operating Systems Regulation 2013 Academic Year
CHAPTER 3 - PROCESS CONCEPT
 CHAPTER 3 - PROCESS CONCEPT 1 OBJECTIVES Introduce a process a program in execution basis of all computation Describe features of processes: scheduling, creation, termination, communication Explore interprocess
CHAPTER 3 - PROCESS CONCEPT 1 OBJECTIVES Introduce a process a program in execution basis of all computation Describe features of processes: scheduling, creation, termination, communication Explore interprocess
Concurrency Control in Distributed Systems. ECE 677 University of Arizona
 Concurrency Control in Distributed Systems ECE 677 University of Arizona Agenda What? Why? Main problems Techniques Two-phase locking Time stamping method Optimistic Concurrency Control 2 Why concurrency
Concurrency Control in Distributed Systems ECE 677 University of Arizona Agenda What? Why? Main problems Techniques Two-phase locking Time stamping method Optimistic Concurrency Control 2 Why concurrency
PART B UNIT II COMMUNICATION IN DISTRIBUTED SYSTEM PART A
 CS6601 DISTRIBUTED SYSTEMS QUESTION BANK UNIT 1 INTRODUCTION 1. What is a distributed system? 2. Mention few examples of distributed systems. 3. Mention the trends in distributed systems. 4. What are backbones
CS6601 DISTRIBUTED SYSTEMS QUESTION BANK UNIT 1 INTRODUCTION 1. What is a distributed system? 2. Mention few examples of distributed systems. 3. Mention the trends in distributed systems. 4. What are backbones
Database systems. Database: a collection of shared data objects (d1, d2, dn) that can be accessed by users
 that can be accessed by users") Database systems Database: a collection of shared data objects (d1, d2, dn) that can be accessed by users every database has some correctness constraints defined on it (called consistency assertions or
Database systems Database: a collection of shared data objects (d1, d2, dn) that can be accessed by users every database has some correctness constraints defined on it (called consistency assertions or
Database Architectures
 Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 11/15/12 Agenda Check-in Centralized and Client-Server Models Parallelism Distributed Databases Homework 6 Check-in
Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 11/15/12 Agenda Check-in Centralized and Client-Server Models Parallelism Distributed Databases Homework 6 Check-in
Distributed Systems. 05. Clock Synchronization. Paul Krzyzanowski. Rutgers University. Fall 2017
 Distributed Systems 05. Clock Synchronization Paul Krzyzanowski Rutgers University Fall 2017 2014-2017 Paul Krzyzanowski 1 Synchronization Synchronization covers interactions among distributed processes
Distributed Systems 05. Clock Synchronization Paul Krzyzanowski Rutgers University Fall 2017 2014-2017 Paul Krzyzanowski 1 Synchronization Synchronization covers interactions among distributed processes
CS5412: TRANSACTIONS (I)
") 1 CS5412: TRANSACTIONS (I) Lecture XVII Ken Birman Transactions 2 A widely used reliability technology, despite the BASE methodology we use in the first tier Goal for this week: in-depth examination of
1 CS5412: TRANSACTIONS (I) Lecture XVII Ken Birman Transactions 2 A widely used reliability technology, despite the BASE methodology we use in the first tier Goal for this week: in-depth examination of
ECE519 Advanced Operating Systems
 IT 540 Operating Systems ECE519 Advanced Operating Systems Prof. Dr. Hasan Hüseyin BALIK (10 th Week) (Advanced) Operating Systems 10. Multiprocessor, Multicore and Real-Time Scheduling 10. Outline Multiprocessor
IT 540 Operating Systems ECE519 Advanced Operating Systems Prof. Dr. Hasan Hüseyin BALIK (10 th Week) (Advanced) Operating Systems 10. Multiprocessor, Multicore and Real-Time Scheduling 10. Outline Multiprocessor
CMPSCI 677 Operating Systems Spring Lecture 14: March 9
 CMPSCI 677 Operating Systems Spring 2014 Lecture 14: March 9 Lecturer: Prashant Shenoy Scribe: Nikita Mehra 14.1 Distributed Snapshot Algorithm A distributed snapshot algorithm captures a consistent global
CMPSCI 677 Operating Systems Spring 2014 Lecture 14: March 9 Lecturer: Prashant Shenoy Scribe: Nikita Mehra 14.1 Distributed Snapshot Algorithm A distributed snapshot algorithm captures a consistent global
Distributed Systems (ICE 601) Transactions & Concurrency Control - Part1
 Transactions & Concurrency Control - Part1") Distributed Systems (ICE 601) Transactions & Concurrency Control - Part1 Dongman Lee ICU Class Overview Transactions Why Concurrency Control Concurrency Control Protocols pessimistic optimistic time-based
Distributed Systems (ICE 601) Transactions & Concurrency Control - Part1 Dongman Lee ICU Class Overview Transactions Why Concurrency Control Concurrency Control Protocols pessimistic optimistic time-based
Distributed Synchronization. EECS 591 Farnam Jahanian University of Michigan
 Distributed Synchronization EECS 591 Farnam Jahanian University of Michigan Reading List Tanenbaum Chapter 5.1, 5.4 and 5.5 Clock Synchronization Distributed Election Mutual Exclusion Clock Synchronization
Distributed Synchronization EECS 591 Farnam Jahanian University of Michigan Reading List Tanenbaum Chapter 5.1, 5.4 and 5.5 Clock Synchronization Distributed Election Mutual Exclusion Clock Synchronization
Integrity in Distributed Databases
 Integrity in Distributed Databases Andreas Farella Free University of Bozen-Bolzano Table of Contents 1 Introduction................................................... 3 2 Different aspects of integrity.....................................
Integrity in Distributed Databases Andreas Farella Free University of Bozen-Bolzano Table of Contents 1 Introduction................................................... 3 2 Different aspects of integrity.....................................
Last time. Distributed systems Lecture 6: Elections, distributed transactions, and replication. DrRobert N. M. Watson
 Distributed systems Lecture 6: Elections, distributed transactions, and replication DrRobert N. M. Watson 1 Last time Saw how we can build ordered multicast Messages between processes in a group Need to
Distributed systems Lecture 6: Elections, distributed transactions, and replication DrRobert N. M. Watson 1 Last time Saw how we can build ordered multicast Messages between processes in a group Need to
Distributed Operating Systems
 2 Distributed Operating Systems System Models, Processor Allocation, Distributed Scheduling, and Fault Tolerance Steve Goddard goddard@cse.unl.edu http://www.cse.unl.edu/~goddard/courses/csce855 System
2 Distributed Operating Systems System Models, Processor Allocation, Distributed Scheduling, and Fault Tolerance Steve Goddard goddard@cse.unl.edu http://www.cse.unl.edu/~goddard/courses/csce855 System
Distributed Systems. Clock Synchronization: Physical Clocks. Paul Krzyzanowski
 Distributed Systems Clock Synchronization: Physical Clocks Paul Krzyzanowski pxk@cs.rutgers.edu Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution
Distributed Systems Clock Synchronization: Physical Clocks Paul Krzyzanowski pxk@cs.rutgers.edu Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution
Operating System. Operating System Overview. Structure of a Computer System. Structure of a Computer System. Structure of a Computer System
 Overview Chapter 1.5 1.9 A program that controls execution of applications The resource manager An interface between applications and hardware The extended machine 1 2 Structure of a Computer System Structure
Overview Chapter 1.5 1.9 A program that controls execution of applications The resource manager An interface between applications and hardware The extended machine 1 2 Structure of a Computer System Structure
Distributed Transaction Management. Distributed Database System
 Distributed Transaction Management Advanced Topics in Database Management (INFSCI 2711) Some materials are from Database Management Systems, Ramakrishnan and Gehrke and Database System Concepts, Siberschatz,
Distributed Transaction Management Advanced Topics in Database Management (INFSCI 2711) Some materials are from Database Management Systems, Ramakrishnan and Gehrke and Database System Concepts, Siberschatz,
Mutual Exclusion. A Centralized Algorithm
 Mutual Exclusion Processes in a distributed system may need to simultaneously access the same resource Mutual exclusion is required to prevent interference and ensure consistency We will study three algorithms
Mutual Exclusion Processes in a distributed system may need to simultaneously access the same resource Mutual exclusion is required to prevent interference and ensure consistency We will study three algorithms
CSE 5306 Distributed Systems
 CSE 5306 Distributed Systems Synchronization Jia Rao http://ranger.uta.edu/~jrao/ 1 Synchronization An important issue in distributed system is how process cooperate and synchronize with one another Cooperation
CSE 5306 Distributed Systems Synchronization Jia Rao http://ranger.uta.edu/~jrao/ 1 Synchronization An important issue in distributed system is how process cooperate and synchronize with one another Cooperation
Operating Systems Overview. Chapter 2
 Operating Systems Overview Chapter 2 Operating System A program that controls the execution of application programs An interface between the user and hardware Masks the details of the hardware Layers and
Operating Systems Overview Chapter 2 Operating System A program that controls the execution of application programs An interface between the user and hardware Masks the details of the hardware Layers and
Process Synchroniztion Mutual Exclusion & Election Algorithms
 Process Synchroniztion Mutual Exclusion & Election Algorithms Paul Krzyzanowski Rutgers University November 2, 2017 1 Introduction Process synchronization is the set of techniques that are used to coordinate
Process Synchroniztion Mutual Exclusion & Election Algorithms Paul Krzyzanowski Rutgers University November 2, 2017 1 Introduction Process synchronization is the set of techniques that are used to coordinate
02 - Distributed Systems
 02 - Distributed Systems Definition Coulouris 1 (Dis)advantages Coulouris 2 Challenges Saltzer_84.pdf Models Physical Architectural Fundamental 2/58 Definition Distributed Systems Distributed System is
02 - Distributed Systems Definition Coulouris 1 (Dis)advantages Coulouris 2 Challenges Saltzer_84.pdf Models Physical Architectural Fundamental 2/58 Definition Distributed Systems Distributed System is
CS /15/16. Paul Krzyzanowski 1. Question 1. Distributed Systems 2016 Exam 2 Review. Question 3. Question 2. Question 5.
 Question 1 What makes a message unstable? How does an unstable message become stable? Distributed Systems 2016 Exam 2 Review Paul Krzyzanowski Rutgers University Fall 2016 In virtual sychrony, a message
Question 1 What makes a message unstable? How does an unstable message become stable? Distributed Systems 2016 Exam 2 Review Paul Krzyzanowski Rutgers University Fall 2016 In virtual sychrony, a message
Distributed Systems. coordination Johan Montelius ID2201. Distributed Systems ID2201
 Distributed Systems ID2201 coordination Johan Montelius 1 Coordination Coordinating several threads in one node is a problem, coordination in a network is of course worse: failure of nodes and networks
Distributed Systems ID2201 coordination Johan Montelius 1 Coordination Coordinating several threads in one node is a problem, coordination in a network is of course worse: failure of nodes and networks
Distributed Systems Synchronization
 Distributed Systems Synchronization Gianpaolo Cugola Dipartimento di Elettronica e Informazione Politecnico, Italy cugola@elet.polimi.it http://home.dei.polimi.it/cugola http://corsi.dei.polimi.it/distsys
Distributed Systems Synchronization Gianpaolo Cugola Dipartimento di Elettronica e Informazione Politecnico, Italy cugola@elet.polimi.it http://home.dei.polimi.it/cugola http://corsi.dei.polimi.it/distsys
Chapter 25: Advanced Transaction Processing
 Chapter 25: Advanced Transaction Processing Transaction-Processing Monitors Transactional Workflows High-Performance Transaction Systems Main memory databases Real-Time Transaction Systems Long-Duration
Chapter 25: Advanced Transaction Processing Transaction-Processing Monitors Transactional Workflows High-Performance Transaction Systems Main memory databases Real-Time Transaction Systems Long-Duration
MODELS OF DISTRIBUTED SYSTEMS
 Distributed Systems Fö 2/3-1 Distributed Systems Fö 2/3-2 MODELS OF DISTRIBUTED SYSTEMS Basic Elements 1. Architectural Models 2. Interaction Models Resources in a distributed system are shared between
Distributed Systems Fö 2/3-1 Distributed Systems Fö 2/3-2 MODELS OF DISTRIBUTED SYSTEMS Basic Elements 1. Architectural Models 2. Interaction Models Resources in a distributed system are shared between
Chapter 17: Distributed Systems (DS)
") Chapter 17: Distributed Systems (DS) Silberschatz, Galvin and Gagne 2013 Chapter 17: Distributed Systems Advantages of Distributed Systems Types of Network-Based Operating Systems Network Structure Communication
Chapter 17: Distributed Systems (DS) Silberschatz, Galvin and Gagne 2013 Chapter 17: Distributed Systems Advantages of Distributed Systems Types of Network-Based Operating Systems Network Structure Communication
Multiprocessor scheduling
 Chapter 10 Multiprocessor scheduling When a computer system contains multiple processors, a few new issues arise. Multiprocessor systems can be categorized into the following: Loosely coupled or distributed.
Chapter 10 Multiprocessor scheduling When a computer system contains multiple processors, a few new issues arise. Multiprocessor systems can be categorized into the following: Loosely coupled or distributed.
Assignment 5. Georgia Koloniari
 Assignment 5 Georgia Koloniari 2. "Peer-to-Peer Computing" 1. What is the definition of a p2p system given by the authors in sec 1? Compare it with at least one of the definitions surveyed in the last
Assignment 5 Georgia Koloniari 2. "Peer-to-Peer Computing" 1. What is the definition of a p2p system given by the authors in sec 1? Compare it with at least one of the definitions surveyed in the last
02 - Distributed Systems
 02 - Distributed Systems Definition Coulouris 1 (Dis)advantages Coulouris 2 Challenges Saltzer_84.pdf Models Physical Architectural Fundamental 2/60 Definition Distributed Systems Distributed System is
02 - Distributed Systems Definition Coulouris 1 (Dis)advantages Coulouris 2 Challenges Saltzer_84.pdf Models Physical Architectural Fundamental 2/60 Definition Distributed Systems Distributed System is
Database Architectures
 Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 4/15/15 Agenda Check-in Parallelism and Distributed Databases Technology Research Project Introduction to NoSQL
Database Architectures CPS352: Database Systems Simon Miner Gordon College Last Revised: 4/15/15 Agenda Check-in Parallelism and Distributed Databases Technology Research Project Introduction to NoSQL
Process Description and Control
 Process Description and Control 1 Process:the concept Process = a program in execution Example processes: OS kernel OS shell Program executing after compilation www-browser Process management by OS : Allocate
Process Description and Control 1 Process:the concept Process = a program in execution Example processes: OS kernel OS shell Program executing after compilation www-browser Process management by OS : Allocate
Multiprocessor and Real-Time Scheduling. Chapter 10
 Multiprocessor and Real-Time Scheduling Chapter 10 1 Roadmap Multiprocessor Scheduling Real-Time Scheduling Linux Scheduling Unix SVR4 Scheduling Windows Scheduling Classifications of Multiprocessor Systems
Multiprocessor and Real-Time Scheduling Chapter 10 1 Roadmap Multiprocessor Scheduling Real-Time Scheduling Linux Scheduling Unix SVR4 Scheduling Windows Scheduling Classifications of Multiprocessor Systems
Chapter 8 Fault Tolerance
 DISTRIBUTED SYSTEMS Principles and Paradigms Second Edition ANDREW S. TANENBAUM MAARTEN VAN STEEN Chapter 8 Fault Tolerance 1 Fault Tolerance Basic Concepts Being fault tolerant is strongly related to
DISTRIBUTED SYSTEMS Principles and Paradigms Second Edition ANDREW S. TANENBAUM MAARTEN VAN STEEN Chapter 8 Fault Tolerance 1 Fault Tolerance Basic Concepts Being fault tolerant is strongly related to
Chapter 18: Database System Architectures.! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems!
 Chapter 18: Database System Architectures! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types 18.1 Centralized Systems! Run on a single computer system and
Chapter 18: Database System Architectures! Centralized Systems! Client--Server Systems! Parallel Systems! Distributed Systems! Network Types 18.1 Centralized Systems! Run on a single computer system and
CprE Fault Tolerance. Dr. Yong Guan. Department of Electrical and Computer Engineering & Information Assurance Center Iowa State University
 Fault Tolerance Dr. Yong Guan Department of Electrical and Computer Engineering & Information Assurance Center Iowa State University Outline for Today s Talk Basic Concepts Process Resilience Reliable
Fault Tolerance Dr. Yong Guan Department of Electrical and Computer Engineering & Information Assurance Center Iowa State University Outline for Today s Talk Basic Concepts Process Resilience Reliable
T ransaction Management 4/23/2018 1
 T ransaction Management 4/23/2018 1 Air-line Reservation 10 available seats vs 15 travel agents. How do you design a robust and fair reservation system? Do not enough resources Fair policy to every body
T ransaction Management 4/23/2018 1 Air-line Reservation 10 available seats vs 15 travel agents. How do you design a robust and fair reservation system? Do not enough resources Fair policy to every body
06-Dec-17. Credits:4. Notes by Pritee Parwekar,ANITS 06-Dec-17 1
 Credits:4 1 Understand the Distributed Systems and the challenges involved in Design of the Distributed Systems. Understand how communication is created and synchronized in Distributed systems Design and
Credits:4 1 Understand the Distributed Systems and the challenges involved in Design of the Distributed Systems. Understand how communication is created and synchronized in Distributed systems Design and
Distributed Scheduling for the Sombrero Single Address Space Distributed Operating System
 Distributed Scheduling for the Sombrero Single Address Space Distributed Operating System Donald S. Miller Department of Computer Science and Engineering Arizona State University Tempe, AZ, USA Alan C.
Distributed Scheduling for the Sombrero Single Address Space Distributed Operating System Donald S. Miller Department of Computer Science and Engineering Arizona State University Tempe, AZ, USA Alan C.
Part V. Process Management. Sadeghi, Cubaleska RUB Course Operating System Security Memory Management and Protection
 Part V Process Management Sadeghi, Cubaleska RUB 2008-09 Course Operating System Security Memory Management and Protection Roadmap of Chapter 5 Notion of Process and Thread Data Structures Used to Manage
Part V Process Management Sadeghi, Cubaleska RUB 2008-09 Course Operating System Security Memory Management and Protection Roadmap of Chapter 5 Notion of Process and Thread Data Structures Used to Manage
Distributed Systems Exam 1 Review. Paul Krzyzanowski. Rutgers University. Fall 2016
 Distributed Systems 2016 Exam 1 Review Paul Krzyzanowski Rutgers University Fall 2016 Question 1 Why does it not make sense to use TCP (Transmission Control Protocol) for the Network Time Protocol (NTP)?
Distributed Systems 2016 Exam 1 Review Paul Krzyzanowski Rutgers University Fall 2016 Question 1 Why does it not make sense to use TCP (Transmission Control Protocol) for the Network Time Protocol (NTP)?
Silberschatz and Galvin Chapter 18
 Silberschatz and Galvin Chapter 18 Distributed Coordination CPSC 410--Richard Furuta 4/21/99 1 Distributed Coordination Synchronization in a distributed environment Ð Event ordering Ð Mutual exclusion
Silberschatz and Galvin Chapter 18 Distributed Coordination CPSC 410--Richard Furuta 4/21/99 1 Distributed Coordination Synchronization in a distributed environment Ð Event ordering Ð Mutual exclusion
Distributed Databases
 Distributed Databases These slides are a modified version of the slides of the book Database System Concepts (Chapter 20 and 22), 5th Ed., McGraw-Hill, by Silberschatz, Korth and Sudarshan. Original slides
Distributed Databases These slides are a modified version of the slides of the book Database System Concepts (Chapter 20 and 22), 5th Ed., McGraw-Hill, by Silberschatz, Korth and Sudarshan. Original slides
SYNCHRONIZATION. DISTRIBUTED SYSTEMS Principles and Paradigms. Second Edition. Chapter 6 ANDREW S. TANENBAUM MAARTEN VAN STEEN
 DISTRIBUTED SYSTEMS Principles and Paradigms Second Edition ANDREW S. TANENBAUM MAARTEN VAN STEEN واحد نجف آباد Chapter 6 SYNCHRONIZATION Dr. Rastegari - Email: rastegari@iaun.ac.ir - Tel: +98331-2291111-2488
DISTRIBUTED SYSTEMS Principles and Paradigms Second Edition ANDREW S. TANENBAUM MAARTEN VAN STEEN واحد نجف آباد Chapter 6 SYNCHRONIZATION Dr. Rastegari - Email: rastegari@iaun.ac.ir - Tel: +98331-2291111-2488
Module 6: Process Synchronization. Operating System Concepts with Java 8 th Edition
 Module 6: Process Synchronization 6.1 Silberschatz, Galvin and Gagne 2009 Module 6: Process Synchronization Background The Critical-Section Problem Peterson s Solution Synchronization Hardware Semaphores
Module 6: Process Synchronization 6.1 Silberschatz, Galvin and Gagne 2009 Module 6: Process Synchronization Background The Critical-Section Problem Peterson s Solution Synchronization Hardware Semaphores
Mobile and Heterogeneous databases Distributed Database System Transaction Management. A.R. Hurson Computer Science Missouri Science & Technology
 Mobile and Heterogeneous databases Distributed Database System Transaction Management A.R. Hurson Computer Science Missouri Science & Technology 1 Distributed Database System Note, this unit will be covered
Mobile and Heterogeneous databases Distributed Database System Transaction Management A.R. Hurson Computer Science Missouri Science & Technology 1 Distributed Database System Note, this unit will be covered
Frequently asked questions from the previous class survey
 CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [DISTRIBUTED COORDINATION/MUTUAL EXCLUSION] Shrideep Pallickara Computer Science Colorado State University L22.1 Frequently asked questions from the previous
CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [DISTRIBUTED COORDINATION/MUTUAL EXCLUSION] Shrideep Pallickara Computer Science Colorado State University L22.1 Frequently asked questions from the previous
* What are the different states for a task in an OS?
 * Kernel, Services, Libraries, Application: define the 4 terms, and their roles. The kernel is a computer program that manages input/output requests from software, and translates them into data processing
* Kernel, Services, Libraries, Application: define the 4 terms, and their roles. The kernel is a computer program that manages input/output requests from software, and translates them into data processing
DEPARTMENT OF INFORMATION TECHNOLOGY QUESTION BANK. UNIT I PART A (2 marks)
") DEPARTMENT OF INFORMATION TECHNOLOGY QUESTION BANK Subject Code : IT1001 Subject Name : Distributed Systems Year / Sem : IV / VII UNIT I 1. Define distributed systems. 2. Give examples of distributed systems
DEPARTMENT OF INFORMATION TECHNOLOGY QUESTION BANK Subject Code : IT1001 Subject Name : Distributed Systems Year / Sem : IV / VII UNIT I 1. Define distributed systems. 2. Give examples of distributed systems
CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University
![CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University](/thumbs/90/101789192.jpg "CS455: Introduction to Distributed Systems [Spring 2018] Dept. Of Computer Science, Colorado State University") Frequently asked questions from the previous class survey CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [DISTRIBUTED COORDINATION/MUTUAL EXCLUSION] Shrideep Pallickara Computer Science Colorado State University
Frequently asked questions from the previous class survey CS 455: INTRODUCTION TO DISTRIBUTED SYSTEMS [DISTRIBUTED COORDINATION/MUTUAL EXCLUSION] Shrideep Pallickara Computer Science Colorado State University
Time in Distributed Systems
 in Distributed Systems There is no common universal time (Einstein) but the speed of light is constant for all observers irrespective of their velocity event e2 at earth time t2 ---- large distances ----
in Distributed Systems There is no common universal time (Einstein) but the speed of light is constant for all observers irrespective of their velocity event e2 at earth time t2 ---- large distances ----
Clock-Synchronisation
 Chapter 2.7 Clock-Synchronisation 1 Content Introduction Physical Clocks - How to measure time? - Synchronisation - Cristian s Algorithm - Berkeley Algorithm - NTP / SNTP - PTP IEEE 1588 Logical Clocks
Chapter 2.7 Clock-Synchronisation 1 Content Introduction Physical Clocks - How to measure time? - Synchronisation - Cristian s Algorithm - Berkeley Algorithm - NTP / SNTP - PTP IEEE 1588 Logical Clocks
CS October 2017
 Atomic Transactions Transaction An operation composed of a number of discrete steps. Distributed Systems 11. Distributed Commit Protocols All the steps must be completed for the transaction to be committed.
Atomic Transactions Transaction An operation composed of a number of discrete steps. Distributed Systems 11. Distributed Commit Protocols All the steps must be completed for the transaction to be committed.
Operating Systems : Overview
 Operating Systems : Overview Bina Ramamurthy CSE421 8/29/2006 B.Ramamurthy 1 Topics for discussion What will you learn in this course? (goals) What is an Operating System (OS)? Evolution of OS Important
Operating Systems : Overview Bina Ramamurthy CSE421 8/29/2006 B.Ramamurthy 1 Topics for discussion What will you learn in this course? (goals) What is an Operating System (OS)? Evolution of OS Important
PRIMARY-BACKUP REPLICATION
 PRIMARY-BACKUP REPLICATION Primary Backup George Porter Nov 14, 2018 ATTRIBUTION These slides are released under an Attribution-NonCommercial-ShareAlike 3.0 Unported (CC BY-NC-SA 3.0) Creative Commons
PRIMARY-BACKUP REPLICATION Primary Backup George Porter Nov 14, 2018 ATTRIBUTION These slides are released under an Attribution-NonCommercial-ShareAlike 3.0 Unported (CC BY-NC-SA 3.0) Creative Commons
3.1 Introduction. Computers perform operations concurrently
 PROCESS CONCEPTS 1 3.1 Introduction Computers perform operations concurrently For example, compiling a program, sending a file to a printer, rendering a Web page, playing music and receiving e-mail Processes
PROCESS CONCEPTS 1 3.1 Introduction Computers perform operations concurrently For example, compiling a program, sending a file to a printer, rendering a Web page, playing music and receiving e-mail Processes
Distributed Systems. Before We Begin. Advantages. What is a Distributed System? CSE 120: Principles of Operating Systems. Lecture 13.
 CSE 120: Principles of Operating Systems Lecture 13 Distributed Systems December 2, 2003 Before We Begin Read Chapters 15, 17 (on Distributed Systems topics) Prof. Joe Pasquale Department of Computer Science
CSE 120: Principles of Operating Systems Lecture 13 Distributed Systems December 2, 2003 Before We Begin Read Chapters 15, 17 (on Distributed Systems topics) Prof. Joe Pasquale Department of Computer Science
 VALLIAMMAI ENGNIEERING COLLEGE SRM Nagar, Kattankulathur 603203. DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III and VI Section : CSE- 1 & 2 Subject Code : CS6601 Subject Name : DISTRIBUTED
VALLIAMMAI ENGNIEERING COLLEGE SRM Nagar, Kattankulathur 603203. DEPARTMENT OF COMPUTER SCIENCE AND ENGINEERING Year & Semester : III and VI Section : CSE- 1 & 2 Subject Code : CS6601 Subject Name : DISTRIBUTED
CSE 5306 Distributed Systems
 CSE 5306 Distributed Systems Consistency and Replication Jia Rao http://ranger.uta.edu/~jrao/ 1 Reasons for Replication Data is replicated for the reliability of the system Servers are replicated for performance
CSE 5306 Distributed Systems Consistency and Replication Jia Rao http://ranger.uta.edu/~jrao/ 1 Reasons for Replication Data is replicated for the reliability of the system Servers are replicated for performance
Transactions. Kathleen Durant PhD Northeastern University CS3200 Lesson 9
 Transactions Kathleen Durant PhD Northeastern University CS3200 Lesson 9 1 Outline for the day The definition of a transaction Benefits provided What they look like in SQL Scheduling Transactions Serializability
Transactions Kathleen Durant PhD Northeastern University CS3200 Lesson 9 1 Outline for the day The definition of a transaction Benefits provided What they look like in SQL Scheduling Transactions Serializability
Distributed Shared Memory
 Distributed Shared Memory History, fundamentals and a few examples Coming up The Purpose of DSM Research Distributed Shared Memory Models Distributed Shared Memory Timeline Three example DSM Systems The
Distributed Shared Memory History, fundamentals and a few examples Coming up The Purpose of DSM Research Distributed Shared Memory Models Distributed Shared Memory Timeline Three example DSM Systems The
Chapter 16: Distributed Synchronization
 Chapter 16: Distributed Synchronization Chapter 16 Distributed Synchronization Event Ordering Mutual Exclusion Atomicity Concurrency Control Deadlock Handling Election Algorithms Reaching Agreement 18.2
Chapter 16: Distributed Synchronization Chapter 16 Distributed Synchronization Event Ordering Mutual Exclusion Atomicity Concurrency Control Deadlock Handling Election Algorithms Reaching Agreement 18.2
Chapter 6 Synchronization
 DISTRIBUTED SYSTEMS Principles and Paradigms Second Edition ANDREW S. TANENBAUM MAARTEN VAN STEEN Chapter 6 Synchronization Clock Synchronization Figure 6-1. When each machine has its own clock, an event
DISTRIBUTED SYSTEMS Principles and Paradigms Second Edition ANDREW S. TANENBAUM MAARTEN VAN STEEN Chapter 6 Synchronization Clock Synchronization Figure 6-1. When each machine has its own clock, an event
Notes based on prof. Morris's lecture on scheduling (6.824, fall'02).
.") Scheduling Required reading: Eliminating receive livelock Notes based on prof. Morris's lecture on scheduling (6.824, fall'02). Overview What is scheduling? The OS policies and mechanisms to allocates
Scheduling Required reading: Eliminating receive livelock Notes based on prof. Morris's lecture on scheduling (6.824, fall'02). Overview What is scheduling? The OS policies and mechanisms to allocates
Chapter 20: Database System Architectures
 Chapter 20: Database System Architectures Chapter 20: Database System Architectures Centralized and Client-Server Systems Server System Architectures Parallel Systems Distributed Systems Network Types
Chapter 20: Database System Architectures Chapter 20: Database System Architectures Centralized and Client-Server Systems Server System Architectures Parallel Systems Distributed Systems Network Types
transaction - (another def) - the execution of a program that accesses or changes the contents of the database
 - the execution of a program that accesses or changes the contents of the database") Chapter 19-21 - Transaction Processing Concepts transaction - logical unit of database processing - becomes interesting only with multiprogramming - multiuser database - more than one transaction executing
Chapter 19-21 - Transaction Processing Concepts transaction - logical unit of database processing - becomes interesting only with multiprogramming - multiuser database - more than one transaction executing
Last Class: Naming. Today: Classical Problems in Distributed Systems. Naming. Time ordering and clock synchronization (today)
") Last Class: Naming Naming Distributed naming DNS LDAP Lecture 12, page 1 Today: Classical Problems in Distributed Systems Time ordering and clock synchronization (today) Next few classes: Leader election
Last Class: Naming Naming Distributed naming DNS LDAP Lecture 12, page 1 Today: Classical Problems in Distributed Systems Time ordering and clock synchronization (today) Next few classes: Leader election